V-
SOURCE ET DESCRIPTION DES DONNEES
1- Source des
données
Les données exploitées dans le cadre de ce
travail proviennent essentiellement de trois sources. Les séries
climatiques ont été extraites du fichier de l'ANAC (Agence
Nationale de l'Aviation Civile), de l'Institut National de la Statistique
(Congo) et de la Banque Mondiale sur la période de 1986 à 2020,
soit 35 observations. Le choix de cette période est essentiellement
dicté par la disponibilité de données.
2- Description des données
Le Tableau 1, présente un récapitulatif de
l'ensemble des variables introduites dans le modèle et signes
attendus.
Tableau 1 : Récapitulatif des
variables du modèle et signes attendus
|
Variables
|
Intitulé
|
Nature de la variable
|
Source de données
|
signes
|
|
Indice de prix des produits Agricoles
|
Iprix
|
Quantitative
|
l'Institut National de la Statistique (Congo)
|
+/-
|
|
Valeur Ajoutée Agricole
|
VAAg
|
Quantitative
|
La Banque Mondiale
|
-
|
|
Les précipitations
|
Precip
|
Quantitative
|
Direction de la Météorologie Nationale (DMN) de
l'ANAC (Agence Nationale de l'Aviation Civile).
|
-
|
|
La température
|
Temp
|
Quantitative
|
Source : Résultats de recherches documentaires
(2022)
Le tableau ci-dessousdonne les résultats des
statistiques descriptives des variables de l'étude, pour une
période de 1986 à 2020. Ces résultats retracent ce qu'ont
été la moyenne, le maximum et le minimum de chacune des
variables, compte tenu de la période d'observation. Ils renseignent
également sur la situation de la distribution (normalité) de
chaque variable. S'agissant des moyennes des différentes variables,
elles ont été de 111,3971 FCFA, 6,994545%, 781,5453 mm et
25,52970 C°, respectivement pour l'indice de prix, la valeur
ajoutée agricole, les précipitations et la température.
Dans ce même ordre, les maximas représentaient 138,4 FCFA, 13%,
941,5249 mm, 26,70 C°, respectivement pour l'indice de prix, la valeur
ajoutée, les précipitations et la température.
Tableau 2 : Statistiques descriptives
|
Iprix
|
Vaag
|
Precip
|
Temp
|
|
Moyenne
|
111,3971
|
6,994545
|
781,5453
|
25,52970
|
|
Maximum
|
138,4000
|
13,00000
|
941,5200
|
26,70000
|
|
Minimum
|
85,80000
|
2,464525
|
553,5000
|
24,60000
|
|
Ecart-type
|
13,61189
|
3,448466
|
83,53725
|
0,508447
|
|
Jarque-Bera
|
0,724724
|
4,200233
|
0,607599
|
0,109725
|
|
Probabilité
|
0,696031
|
0,122442
|
0,738009
|
0,946615
|
|
Observations
|
35
|
35
|
35
|
35
|
Source : Auteur à partir des résultats
extraits d'Eviews
3- Procédure d'estimation et validation du
modèle
Pour déterminer les paramètres de notre
modèle, nous utilisons le modèle VAR (vector autoRegression).
L'utilisation d'un modèle VAR est méthodiquement
justifiée, car les modèles VAR autorisent les simulations qui
permettent de saisir les modifications des variables objectives, suite à
un choc sur les variables instruments.
Ø Tests de stationnarité et de
cointégration
Avant tout traitement en économétrie, il
convient de s'assurer de la stationnarité des variables retenues, car la
stationnarité représente une condition nécessaire pour
éviter les relations artificielles. Les tests de racine unitaire
permettent de mettre en évidence le caractère stationnaire ou non
d'une chronique par la détermination d'une tendance déterministe
ou stochastique (ou aléatoire). Un processus 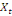  est dit stationnaire si tous ces moments sont invariants pour tout
changement de l'origine du temps. Il existe deux types de processus non
stationnaires. Les processusTS (trend stationnary process) qui constituent une
non stationnarité de type déterministe et le processus DS
(difference stationnary process) pour lesquels la stationnarité est de
type stochastique ou aléatoire. Les processus sont respectivement
stationnarisés par écart à la tendance et par un filtre
à la différence première permettant de déterminer
l'ordre d'intégration de la variable. Pour établir entre les deux
types de processus et d'appliquer la méthode de stationnarité
adéquate, nous utilisons les tests de Dickey-Fuller Augmented (ADF) et
de Phillips-Perron (PP). Ces tests permettent de déterminer l'ordre de
différenciation d'une série macroéconomique suivant son
évolution au cours du temps. Ces tests sont menés sous
hypothèses suivantes : est dit stationnaire si tous ces moments sont invariants pour tout
changement de l'origine du temps. Il existe deux types de processus non
stationnaires. Les processusTS (trend stationnary process) qui constituent une
non stationnarité de type déterministe et le processus DS
(difference stationnary process) pour lesquels la stationnarité est de
type stochastique ou aléatoire. Les processus sont respectivement
stationnarisés par écart à la tendance et par un filtre
à la différence première permettant de déterminer
l'ordre d'intégration de la variable. Pour établir entre les deux
types de processus et d'appliquer la méthode de stationnarité
adéquate, nous utilisons les tests de Dickey-Fuller Augmented (ADF) et
de Phillips-Perron (PP). Ces tests permettent de déterminer l'ordre de
différenciation d'une série macroéconomique suivant son
évolution au cours du temps. Ces tests sont menés sous
hypothèses suivantes :
- absence d'une constante (modèle 1) ;
- présence d'une constante (modèle 2) ;
- présence d'une constante et d'une tendance
(modèle 3).
Nous débuterons par déterminer le nombre de
retards optimal pour chacun des trois modèles suivants :
- Modèle (1) sans constante :  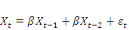 ; ;
- Modèle (2) avec constante :  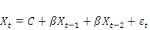 ; ;
- Modèle (3) avec constante et trend : 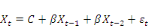  . .
Il s'agit de l'hypothèse nulle de non
stationnarité  . Si cette dernière est acceptée, le processus admet une
racine unitaire. Sinon, le processus est stationnaire. Nous allons
déterminer respectivement la présence d'une constante, d'une
tendance et d'une racine unitaire. Pour chaque variable, nous commençons
par le test d'ADF en niveau, nous déterminons le nombre de retards, nous
étudions la significativité de la tendance et si la variable est
non stationnaire, nous passons au test d'ADF en première
différence. . Si cette dernière est acceptée, le processus admet une
racine unitaire. Sinon, le processus est stationnaire. Nous allons
déterminer respectivement la présence d'une constante, d'une
tendance et d'une racine unitaire. Pour chaque variable, nous commençons
par le test d'ADF en niveau, nous déterminons le nombre de retards, nous
étudions la significativité de la tendance et si la variable est
non stationnaire, nous passons au test d'ADF en première
différence.
|
|


