Machine learning for big data in galactic archaeologypar Loana Ramuz Université de Strasbourg - Master 2 Astrophysique 2020 |

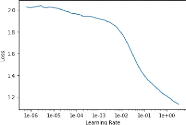
2.3 Training and getting predictionsThis net is ready to be trained, but first a learning rate has to be chosen. This rate has to be adjusted during learning depending on the smoothness and speed of convergence of the losses. For this, fast.ai developed the lr_find() function, which makes forward passes on the training dataset with different learning rates and gets the associated losses. Then the curve can be plotted using the recorder_plot() function, as shown on Figure 5a. It is recommended to choose at first a learning rate which corresponds to the steepest slope. For example on Figure 5a, the recommended learning rate would be 0.03. To train the net we can use the fit() function which allows one to train the net with a given learning rate for a given number of epochs. This function shows the evolution of the training and test losses and a metric to be chosen, like accuracy or root mean square 10
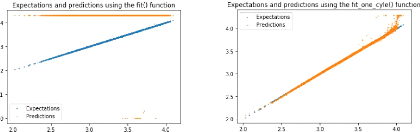
Figure 5: fast.ai tools for choosing the learning rate and training the net. error. There is also a special fitting loop called fit_one_cycle(), which fits a given net following the one cycle policy defined by Leslie Smith [6]. This sets a special schedule for the learning rate which changes all along the training given a maximum value of the learning rate. It helps the net to converge quicker, as shown later in Figure 6. Those two functions allow one to follow up the training epoch by epoch, printing for each epoch the value of the training loss, the validation loss, the metric(s) requested when the net was created and the time the training and validation sessions took. Figure 5b shows the display of those two fitting loop functions. It is also possible to print the evolution of the losses at the end of the fitting loop. Those losses are useful to evaluate the net tendency to overfit or underfit. It is also an indicator as to when the learning rate must be adapted: if the validation loss is unsteady, it may mean that the weights changing step is too big and the net fails to get better precision so it could be a good idea to lower the learning rate. The evolution of the training and validation losses gives a first idea of the precision of the net, but a visual check is more convincing. After the training session, it is possible to get the predictions using the test set, with the get_preds() function. Then they can be visualised using the matlplotlib.pyplot module, as shown in Figure 6. There we can see clearly the efficiency of the one cycle policy: for the same number of epochs, the scheduled learning rate cycle (Fig 6b) gives a really convincing result whereas the fixed learning rate of 0.03 barely begins to converge (Fig 6a). To quantify the precision of the net, we get the difference between the predictions and the expectations, we create a histogram and fit a Gaussian to it. This is shown in Figure 7 with a cut between -1 and 1 for Figure 7a and a cut between -0.1 and 0.1 for Figure 7b. These plots also list the values for the amplitude of the Gaussian, its mean and its standard deviation. The standard deviation ó corresponds to the precision of our net and depends on the cut we choose to apply, since bad values on the edge of the histogram can easily be spotted and not taken into account. Here for the [-1,1] cut, we get ó 0.012 and for the [-0.1,0.1] cut, we get ó 0.007.
(a) Expectations and predictions using a net trained for 10 epochs and for a fixed learning rate of 0.03. (b) Expectations and predictions using a net trained for 10 epochs and for a scheduled learning rate with maximum of 0.03. 11 Figure 6: Visualisation of the expectations and the predictions from the net with the normal fitting loop and the one cycle policy fitting loop, for 10 epochs and a given learning rate of 0.03.
(a) Histogram and fitted Gaussian with a [-1,1] cut. (b) Histogram and fitted Gaussian with a [-0.1,0.1] cut. Figure 7: Histogram of the difference between predictions and expectations and fitted Gaussian, with values of amplitude, mean and standard deviation at the top respectively from left to right.
13 3 Regression neural network for estimating metallicity The aim of this net is to estimate metallicities from training on photometric data. So to get our network started, we need spectrometric ground-truth data as well as photometric data. We have at disposition data from various surveys:
3.1 Input data: photometry Our input data is based on the photometric information we have about our stars, meaning their magnitude in different bands and their uncertainties. The bands we have at disposition are shown on Table1 hereafter.
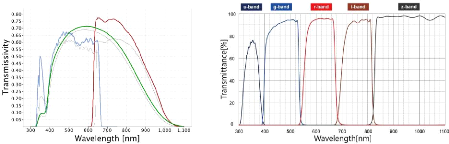
Table 1: Description of the bands used as input data, the filters mean wavelengths were taken from the SVO Filter Profile Service, and are given for SDSS and PS1 respectively. By their number and diversity, they manage to cover a large part of the spectrum, as can be seen on Figure 8: Figure 8a shows Gaia DR2 photometric coverage and Figure 8b gives SDSS coverage and an idea of Pan-STARRS and CFIS coverage. In fact, the values of the mean wavelength for u,g,r,i,z filters can vary a little depending on the survey. The Ca H & K filter by Pristine is a much narrower band between the u and g bands, focused on the Balmer bumps in stars spectra, an area displaying many metal absorption rays. It is thus useful to measure metallicity with high accuracy. The choice of the inputs to be kept for training is a compromise between number of bands available and the number of objects we have information about. In fact, Gaia covers the full sky, Pan-STARRS is three fourths of the sky, SDSS is one fourth of the sky and CFIS is one eighth of the sky. Pristine coverage is even smaller. It means that the more catalogs we keep, the less objects we keep (as the area in common diminishes) but the more information we have on those objects. Our raw photometric data is a combination of all those surveys, in (at first) three catalogs. All three contain at least Gaia DR2, PS1 and SDSS data, then one has the u band only, another one has the CaH&K band only, and the last one has
14 (a) Gaia DR2 passbands, in green the G filter, blue the Bp (b) SDSS passbands, in dark blue the u filer, blue the g filter, red the filter and red the Rp filter, and in thin lines DR1 passbands. r filter, brown the i filter and black the z filter. Figure 8: Illustration of Gaia and SDSS photometric data coverage in wavelength. all bands. We proceed this way because of the differences in survey coverage. Adding CFIS limits the training catalog to about 140,000 objects and Pristine narrows it down to 90,000. With all data, the number of objects goes down to 49,000. We train our algorithm on colors, i.e. differences between two bands. The net precision highly depends on the input and output data, so the amount of data we keep has to be optimized by trial and error. For example, Thomas et al. 2019 [3] choose to keep (u -g), (g - r), (r - i), (i - z) and (u -G). Keeping all the colors would provide redundant information to the network, so we choose to keep only n - 1 colours for n available bands. At first, we keep only colours using the G-band as a reference, since the G-band uncertainty is the lowest so the error propagation should be optimized: the net is to train on (G - Bp), (G - Rp), (G - g), (G - r), (G - i), (G - z), (G - u) and (G -CaHK), and once it gives satisfactory results, other colors are to be tested. 3.2 Output data: stellar parameter predictions Spectroscopic studies have different physical parameters to offer. Table 2 shows the three different spectrometric measurements coming from the SEGUE survey. Those physical parameters are measured and presented in different ways in SEGUE. We choose to work with the same data as Thomas et al. 2019 [3] which are the adopted metallicity fe-hadop, the adopted surface gravity loggadop and the adopted effective temperature tef-fadop.
Table 2: Description of available outputs from the SEGUE survey 15 Of course metallicity is mandatory since the aim is to predict it, but to add surface gravity and/or effective temperature can help the network to converge. This is what is called multi-tasking. In fact, the more links the network can find between inputs and outputs, the better and the quicker the results converge. The dataset we use to train our model has within it the inputs i.e. the colors we defined from the bands, and the outputs. 3.3 Data selection It is obvious that the precision of the network depends on the quality of input data, that's why an initial selection is done on the catalog to obtain a clean input dataset. For this we use topcat, a software which comes in handy when one has to manipulate this kind of catalog. We thus put a limit on the signal to noise ration (SNR) and the uncertainties on all of the data used. We can also put limits on the values of the bands and/or colors and on the outputs. For example, limiting log(g) to values above 3 allows one to delete most of the giant stars that are in the catalog and to focus on the dwarf stars which are way more represented. It is also possible to make color cuts to focus on the bluer stars, as done in the work of Iveziéet al. 2008 [2] and as we need to do to be able to use their photometric distance formulae. The selection we make for our first attempt is as follows: LOGG_ADOP> 3 & SNR>25 & g0-r0>0.2 & g0-r0<0.6 & u0-g0>0.6 & u0-g0<1.35 & FEH_ADOP>-3 & FEH_ADOP<0 & FEH_ADOP_UNC<0.1 & du<0.03 & dg<0.03 & dr<0.03 & di<0.03 & dz<0.05 & eGmag<0.03 & eBpmag<0.03 & eRpmag<0.03 & Gmag0<18 & g0<18.5 & abs(g0-i0-0.45)<0.5 & abs(g0-z0-0.45)<0.5 & abs(g0-Gmag0-0.35)<0.2 topcat also allows one to shuffle the data, a useful tool for machine learning as it ensures that each row is independent from its neighbours in the initial dataset. For example if stars in the initial dataset are sorted according to their metallicity, then there is a risk for the network to train only on low metallicities and then to test on higher metallicities which he won't recognize as well as low ones. With selection on the catalog containing Pristine data and not CFIS, we can't do the color cuts on the u band. With all bands, the number of available data goes from 49,000 down to 14,000, which may not be enough, and with all bands but CaHK, a catalog initially containing more than 140,000 objects, only 41,000 are left. We choose to keep going with those are the data to train our net. |
|