De nombreuses applications fonctionnent selon un
environnement client / serveur, cela signifie que des machines clientes (des
machines faisant partie du réseau) contactent un serveur, une machine
généralement très puissante en terme de capacités
d'entrée-sortie, qui leur fournit des services. Ces services sont des
programmes fournissant des données telles que l'heure, des fichiers, une
connexion, etc.
Les services sont exploités par des programmes,
appelés programmes clients, s'exécutant sur les machines
clientes. On parle ainsi de client FTP, client de messagerie, etc. Le
programme, tournant sur une machine cliente, est capable de traiter des
informations qu'il récupère auprès du serveur (dans le cas
du client FTP il s'agit de fichiers, tandis que pour le client messagerie il
s'agit de courrier électronique).
Dans un environnement purement Client / serveur, les ordinateurs
du réseau (les clients) ne peuvent voir que le serveur, c'est un des
principaux atouts de ce modèle.
II. 1. Fonctionnement d'un système Client /
Serveur
Un système Client / Serveur fonctionne selon le
schéma suivant:
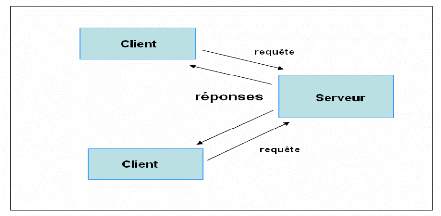
Figure 6 : Système Client / Serveur
Le client émet une requête vers le serveur
grâce à son adresse et le port, et le serveur reçoit la
demande et répond à l'aide de l'adresse de la machine client et
son port.
II. 2. Présentation de l'architecture à
deux niveaux
L'architecture à deux niveaux, appelée aussi
architecture 2-tier (`Tier' est un mot anglais qui signifie étage)
caractérise les systèmes clients / serveurs dans lesquels le
client demande une ressource et le serveur la lui fournit directement. Cela
signifie que le serveur ne fait pas appel à une autre application afin
de fournir le service. En fait, l'interface graphique se situe sur le poste
client et la base de données est localisée sur le serveur. La
logique de traitement pouvant se situer sur l'une ou l'autre des parties. Dans
une architecture client- serveur à deux niveaux, les PC sont
généralement connectés aux serveurs de base de
données via un réseau local.
L'utilisateur final contrôle le poste client qui
réalise une grande partie des traitements de l'application et sollicite
des informations ou des traitements SQL de la part de un ou plusieurs serveurs.
Dans le modèle à deux niveaux, une partie de la logique de
gestion réside sur le serveur sous la forme de procédures
stockées. La caractéristique majeure du serveur est d'être
disponible pour répondre, de préférence de manière
simultanée, aux demandes de
plusieurs clients. Ce type d'architecture est une bonne
solution d'informatique distribuée lorsque le nombre d'utilisateurs ne
dépasse pas une centaine d'utilisateurs, cependant il existe d'une part
une limite tenant au fait que la connexion est maintenue en permanence entre le
client et le serveur, même si aucun travail n'est effectué,
d'autre part les procédures d'accès aux données
étant spécifiques aux moteurs de base de données, la
flexibilité et le choix d'une base de données sont
réduites.
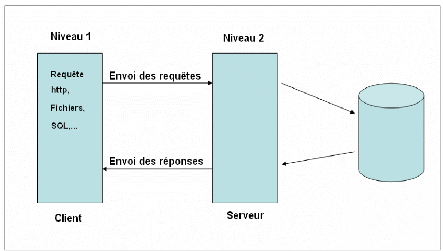
L'architecture à deux niveaux fonctionne selon le
schéma suivant:
Figure 7 : Architecture à deux
niveaux
II. 3. Présentation de l'architecture à
trois niveaux
Dans l'architecture à trois niveaux (appelées
architecture 3-tier), il existe un niveau intermédiaire,
c'est-à-dire que l'on a généralement une architecture
partagée entre :
Le client : le demandeur de ressources.
· Le serveur d'application (appelé aussi middleware)
: le serveur chargé de fournir la ressource mais faisant appel à
un autre serveur.
· Le serveur secondaire (généralement un
serveur de base de données) : fournissant un service au premier
serveur.
La figure suivante montre le fonctionnement de cette
architecture :
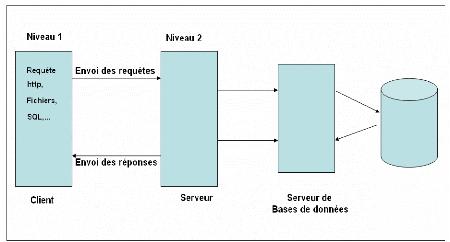
Figure 8 : Architecture à trois
niveaux
Etant donné l'emploi massif du terme d'architecture
à 3 niveaux, celui-ci peut parfois désigner aussi les
architectures suivantes :
· Partage d'application entre client, serveur
intermédiaire et serveur d'entreprise.
· Partage d'application entre client, base de
données intermédiaire et base de données d'entreprise.


