|
UNIVERSITE DE KINSHASA

FACULTE DES SCIENCES
Département des Mathématiques et
Informatique
B.P. 190 KINSHASA XI
Mémoire de fin
d'études
DEPLOIEMENT D'UN COEUR DE RESEAU IP/MPLS
« Cas de la Banque Centrale du Congo »

NDWO MAYELE Jacob
Travail de fin d'étude présenté et
défendu en vue de l'obtention du titre de Licencié en
Sciences
Groupe : Informatique
Option : Génie Informatique
Directeur : Prof. MBUYI MUKENDI
Professeur Ordinaire
Docteur d'Etat ès Sciences
Année Académique :
2016-2017
EPIGRAPHE
La preuve de la valeur d'un système informatique
est son existence.
Alan Jay Perlis
DEDICACE
Je dédie ce travail :
A toute la famille NDWO et
particulièrement à Papa Jean Ndwo,
Hilaire Ndwo, Jean Kayolo, Maman
Martine Batubenga. Vous m'avez inculqué le sens de
responsabilité, d'optimisme et de confiance ; vos conseils ont
guidé mes pas vers la réussite et vos encouragements ont
été pour moi un soutien indispensable ;
A mes oncles, tantes, frères et
soeurs :Evariste Kabisa, Samuel Diangitukulu, Patience Ndwo,
Clarisse Lumesa, Françoise Ndwo, Brigitte Lufungula Kifuka, Masse
Lufungula, Polycarp Batubenga, Depril Ndwo et Jeanne d'arc Nome.
A mes proches :David Katuma, Nicolas Katembwe,
Grâce Idaya, Papy Kasambi, Abed Tomisa, Beatrice Bintu, Israël
Matamba, Thethe Lufutuainsi que Prince Messa;
A nos compagnons de lutte : David Ilunga
Tubilandu, Emmanuel Kongo, Harmonie Bazayakana, Arnold Bisidi
Bulala et tant d'autres.
A papa Jean-Louis Kayembe pour son soutiens financier et
moral
A tous ceux qui de quelques manières que ce soit, ont
contribué à l'élaboration de ce travail. C'est à
vous que je dédie ce travail.
REMERCIEMENTS
Nous exprimons nos profonds remerciements à celui qui
garde l'âme et protège le corps ; Le Seigneur
Jésus-Christ pour nous avoir gardéen bonne santé
tout au long de notre second cycle. Et qui a bien voulu que nous achevions le
présent travail avec son soutien précieux.
Notre profonde et inoubliable reconnaissance s'adresse
également au Professeur Eugène MBUYI
MUKENDIet à l'Assistant Alain TSHIKOLO
KABAMBA, respectivement Directeur et Encadreur de ce travail, qui en
dépit de leurs multiples fonctions et engagements, ont bien voulu
diriger notre mémoire de fin d'études. Leurs avis éclairs,
leurs critiques et remarques pertinentes nous ont été d'une
utilité indispensable, nous ont permis de réaliser notre
pensée et ont donné à notre étude sa structuration
définitive.
Nous exprimons nos remerciements à coeur de joie
à tous nos Professeurs, Chefs de travaux et aux Assistants de la
Faculté des Sciences de l'université de Kinshasa pour tous les
enseignements biens riches et l'encadrement adéquat qu'ils nous ont
fournis tout au long de notre formation.
Nous nous faisons l'agréable devoir d'exprimer nos vifs
remerciements à Monsieur Jean-Louis KAYEMBE WA
KAYEMBE, Directeur Général de la Politique
Monétaire et Opérations Bancaires de la Banque Centrale du
Congo pour son soutien tant moral que financier.
NdwoMayele Jacob
Que ce travail soit l'accomplissement de vos voeux tant
allégués, et le fruit de votre soutien indéfectible.
LISTE DE FIGURES
|
Figure I.1
|
:
|
Couches du modèle OSI
|
|
Figure I.2
|
:
|
Communication des couches du modèle OSI
|
|
Figure I.3
|
:
|
Transmission des données à travers le
modèle OSI
|
|
Figure I.4
|
:
|
Représentation du modèle TCP/IP
|
|
Figure I.5
|
:
|
Comparaison du modèle OSI à TCP/IP
|
|
Figure I.6
|
:
|
Architecture point à point simple
|
|
Figure I.7
|
:
|
Architecture point à point centralisée
|
|
Figure I.8
|
:
|
Architecture point à point hiérarchique
|
|
Figure I.9
|
:
|
Architecture Client/Serveur
|
|
Figure I.10
|
:
|
Architecture générale du triple play
|
|
Figure I.11
|
:
|
Connexion d'un abonné vers sa STB
|
|
Figure I.12
|
:
|
Connexion entre la STB et Internet
|
|
Figure I.13
|
:
|
Architecture logique de réseau NGN
|
|
Figure I.14
|
:
|
Architecture physique de réseau NGN
|
|
Figure II.1
|
:
|
Architecture physique d'un réseau IP
|
|
Figure II.2
|
:
|
Fonctionnement du protocole ARP
|
|
Figure II.3
|
:
|
Format des messages ICMP
|
|
Figure II.4
|
:
|
Format du message RSVP
|
|
Figure II.5
|
:
|
Segmentation d'un réseau logique IP en plusieurs
sous-réseaux
|
|
Figure II.6
|
:
|
Adresse IPv6
|
|
Figure II.7
|
:
|
Format d'un datagramme IPv6
|
|
Figure II.8
|
:
|
Architecture Internet
|
|
Figure II.9
|
:
|
Architecture physique du réseau MPLS
|
|
Figure II.10
|
:
|
Architecture logique du réseau MPLS
|
|
Figure II.11
|
:
|
Routage implicite des labels
|
|
Figure II.12
|
:
|
Routage explicite des labels
|
|
Figure II.13
|
:
|
Principe de fonctionnement d'un LDP
|
|
Figure II.14
|
:
|
MPLS au niveau des couches
|
|
Figure II.15
|
:
|
Flux MPLS
|
|
Figure II.16
|
:
|
Détails d'un label MPLS
|
|
Figure II.17
|
:
|
Encapsulation pour ATM, Frame Relay
|
|
Figure II.18
|
:
|
Format de mise à jour BGP
|
|
Figure II.19
|
:
|
Architecture indiquant la place de BGP et OSPF
|
|
Figure II.20
|
:
|
Architecture indiquant la place des protocoles EBGP, IBGP et
IGP
|
|
Figure II.21
|
:
|
Architecture générale d'un VPN
|
|
Figure II.22
|
:
|
Architecture d'un VPN d'accès
|
|
Figure II.23
|
:
|
Architecture d'un VPN Intranet
|
|
Figure II.24
|
:
|
Architecture d'un VPN Extranet
|
|
Figure II.25
|
:
|
Structure de la trame PPP
|
|
Figure II.26
|
:
|
Format des paquets IPsec
|
|
Figure II.27
|
:
|
Tunnel IPsec
|
|
Figure II.28
|
:
|
Architecture SSL
|
|
Figure II.29
|
:
|
Architecture du protocole SSLv3
|
|
Figure III.1
|
:
|
Organigramme de la Banque Centrale du Congo
|
|
Figure III.2
|
:
|
Organigramme de la Direction de l'Informatique de la BCC
|
|
Figure III.3
|
:
|
Architecture Réseau de la B.C.C
|
|
Figure III.4
|
:
|
Architecture Backbone de la BCC
|
|
Figure III.5
|
:
|
Architecture VPN de la B.C.C
|
|
Figure IV.1
|
:
|
Schéma physique du coeur IP/MPLS
|
|
Figure IV.2
|
:
|
Schéma physique VPN/MPLS
|
|
Figure IV.3
|
:
|
Schéma fonctionnel du coeur de réseau IP/MPLS
|
|
Figure IV.4
|
:
|
Plan d'adressage du réseau
|
LISTE DES ABREVIATIONS
|
ADSL
|
:
|
Asymetric Digital Subscriber Line
|
|
APDU
|
:
|
Application Protocol Data Unit
|
|
ARP
|
:
|
Address Resolution Protocol
|
|
ARPANET
|
:
|
Advanced Research Projects Agency Network
|
|
AS
|
:
|
Autonomous Systems
|
|
ATM
|
:
|
Asynchronous Transfer Mode
|
|
BAS
|
:
|
Broadband Access Server
|
|
BCC
|
:
|
Banque Centrale du Congo
|
|
BE
|
:
|
Best Effort
|
|
BGP
|
:
|
Border Gateway Protocol
|
|
BRAS
|
:
|
Broadband Remote Access Server
|
|
CAC
|
:
|
Cali Acceptance Control
|
|
CE
|
:
|
Customer Edge
|
|
DARPA
|
:
|
Defense Advanced ResearchProjects Agency
|
|
DHCP
|
:
|
DynamicHost Configuration Protocol
|
|
DIRO
|
:
|
Direction d'Informatique et de Recherche
Opérationnelle
|
|
DNS
|
:
|
Domaine Name Service
|
|
DSLAM
|
:
|
Digital Subscriber Line Access Multiplexer
|
|
DWDM
|
:
|
Dense Wavelength Division Multiplexing
|
|
EAS
|
:
|
Équipement d'Accès au Service
|
|
EBGP
|
:
|
Exterior Border Gateway Protocol
|
|
EGP
|
:
|
Exterior Gateway Protocol
|
|
ELSR
|
:
|
Edge Label Switch Router
|
|
ENUM
|
:
|
Electronic NUMbering
|
|
FAI
|
:
|
Fournisseur d'Accès Internet
|
|
FDDI
|
:
|
Fiber Distributed Data Interface
|
|
FEC
|
:
|
Forwarding Equivalent Class
|
|
FIB
|
:
|
Forwarding Information Base
|
|
HDLC
|
:
|
High-level Data Link Control
|
|
HTTP
|
:
|
HyperText Transfer Protocol
|
|
HTTPs
|
:
|
HypeText Transfer Protocol Secure
|
|
IBGP
|
:
|
Interior Border Gateway Protocol
|
|
ICMP
|
:
|
Intemet Control Message Protocol
|
|
IETF
|
:
|
Internet Engineering Task Force
|
|
IGP
|
:
|
Interior Gateway Protocol
|
|
IP
|
:
|
Internet Protocol
|
|
IPS
|
:
|
Intrusion Preventing System
|
|
IPsec
|
:
|
Internet Protocol Security
|
|
IPv4
|
:
|
Internet Protocol version 4
|
|
IPv6
|
:
|
Internet Protocol version 6
|
|
IS-IS
|
:
|
Intermediate System to Intermediate System
|
|
ISP
|
:
|
Internet Service Provider
|
|
L2F
|
:
|
Layer 2 Forwarding
|
|
L2TP
|
:
|
Layer 2 Tunneling Protocol
|
|
LDP
|
:
|
Label Switch Path
|
|
LER
|
:
|
Label Edge Router
|
|
LFIB
|
:
|
Label Forwarding Information Base
|
|
LIB
|
:
|
Label Information Base
|
|
LSP
|
:
|
Label Switched Path
|
|
LSR
|
:
|
Label Switching Router
|
|
MAC
|
:
|
Media Access Control
|
|
MEGACO
|
:
|
Media Gateway Control
|
|
MGC
|
:
|
Media Gateway Controller
|
|
MGW
|
:
|
Media Gateway
|
|
MPLS
|
:
|
Multi Protocol Label Switching
|
|
MPLS/VPN
|
:
|
Multi Protocol Label Switching/Virtual Private Network
|
|
MPLS-TE
|
:
|
Multi Protocol Label Switching - Trafic Engineering
|
|
MRT
|
:
|
Multiplexage à Répartition dans le Temps
|
|
NAC
|
:
|
N
etwork Access
Control
|
|
NAS
|
:
|
Network Access Server
|
|
NAT
|
:
|
Network Address Translation
|
|
NGN
|
:
|
Next Génération Network
|
|
OIPC
|
:
|
Organisation Internationale de Police Criminelle
|
|
OSI
|
:
|
Open System Interconnexion
|
|
OSPF
|
:
|
Open Shortest Path First
|
|
P
|
:
|
Provider Router
|
|
PE
|
:
|
Provider Edge
|
|
PoP
|
:
|
Point of Presence
|
|
POP
|
:
|
Post Office Protocol
|
|
PPDU
|
:
|
Presentation Protocol Data Unit
|
|
PPP
|
:
|
Point to Point protocol
|
|
PPTP
|
:
|
Point to Point Tunneling Protocol
|
|
QdS
|
:
|
Qualité de Service
|
|
RARP
|
:
|
Reverse Address Resolution Protocol)
|
|
RIP
|
:
|
Routing Information Protocol
|
|
RSVP
|
:
|
Resource reSerVation Protocol
|
|
RSVP-TE
|
:
|
Resource reSerVation Protocol - Trafic Engineering
|
|
RTCP
|
:
|
Real-time Transport Protocol
|
|
RTP
|
:
|
Real-time Transport Protocol
|
|
SDH
|
:
|
Synchronous Data Hierarchy
|
|
SG
|
:
|
Signalling Gateway
|
|
SIP
|
:
|
Session Initiation Protocol
|
|
SMTP
|
:
|
Simple Mail Transfer Protocol
|
|
SNMP
|
:
|
Simple Network Management Protocol
|
|
SONET
|
:
|
Synchronous Optical Network
|
|
SPDU
|
:
|
Session Protocol Data Unit
|
|
SS7
|
:
|
Signaling System 7
|
|
SSH
|
:
|
Secure Shell
|
|
SSL
|
:
|
Secure Socket Layer
|
|
STB
|
:
|
Set-Top-Box
|
|
TCP
|
:
|
Transmission Control Protocol
|
|
TDM
|
:
|
Time Division Multiplexing
|
|
TFTP
|
:
|
Trivial File Transfer Protocol
|
|
TPDU
|
:
|
Transport Protocol Data Unit
|
|
TTL
|
:
|
Time To Live
|
|
UIT
|
:
|
Union Internationale des Télécommunications
|
|
UMTS
|
:
|
Universal Mobile Telecommunications System
|
|
URL
|
:
|
Uniform
Resource Locator
|
|
VLAN
|
:
|
Virtual Local Area Network
|
|
VPI/VCI
|
:
|
Virtual Path Identifier / Virtual Chanel Identifier
|
|
VPN
|
:
|
Virtual Private Network
|
|
VSAT
|
:
|
Very Smarl Aperture Terminal
|
|
WiFi
|
:
|
Wireless Fidelity
|
|
WiMAX
|
:
|
Worldwide Interoperability for Microwave Access
|
0. INTRODUCTION GENERALE
L'évolution rapide des technologies d'Internet a permis
l'émergence des réseaux dynamiques utilisant des architectures
fortement décentralisées et dont les services sont
organisés de manière autonome provoquant ainsi la croissance de
la taille d'entreprises, des systèmes d'informations et la
diversification des besoins des applications lors de la transmission de
données et rend la gestion des multiservices de plus en plus
contraignante.
Ces spécificités ont un réel
avantage : le déploiement et la mise en place rapide et peu
coûteux de ce type de réseaux. Mais en contrepartie, elles ont
engendré de nouveaux besoins en termes de Qualité de Service afin
de faire face aux contraintes d'applications novatrices et aux attentes des
utilisateurs finaux. Certes, le développement de l'Internet et la
simplicité du protocole IP ont permis à ce dernier de devenir un
protocole quasi universel, mais son aspect non connecté implique une
difficulté d'intégration de service temps réel qui
exigentun certain degré de la qualité de service (QdS).
En effet, les technologies réseaux qui ont suivi IP ont
essayé de trouver une panacée face à ce problème,
principalement les réseaux ATM au travers du lancement de la
transmission des données en temps réel en gérant les
classes de trafic. Mais au fil du temps, ils sont devenus vulnérables. A
cet effet, il s'avère impérieuxdebasculer vers une technologie de
commutation multi protocole permettant d'optimiserla qualité de service,
la souplesse et la possibilité d'intégration sur
différents types de réseaux (Ethernet,ATM...) ; d'où
l'apparition de la technologie de commutation par étiquettes ou MPLS
(Multi Protocol Label Switching).
Cette technologie représente une solution prometteuse
dans les réseaux de transit où plusieurs millions de flux de
données sont acheminés au travers des routeurs et permet
d'intégrer facilement de nouvelles technologies dans un coeur de
réseau existant, basé sur le principe de commutation de circuits
il est donc un remède face au problème de gaspillage des
ressources à travers la gestion des priorités dans le trafic
à faire circuler.
0.1 Annonce du sujet
Dans le cadre de notre travail, nous avons pris comme cas
d'étude les réseaux coeurs.Nous y avons ciblé un
problème très récurrent que nous formulons de la
manière suivante, « Déploiement d'un coeur de
réseau IP/MPLS ».
0.2 Problématique
La problématique peut être
appréhendée comme un ensemble de questions que se pose le
chercheur dans un domaine d'étude en vue d'y apporter des solutions.
Cependant, l'échange de flux, l'acheminement des
paquets entre les composants réseaux déployés dans les
différents sites équidistants d'une entreprise s'avère
très impérieux au regard de l'accroissement fulgurant d'une part,
des performances des équipements réseaux et de l'autre, des
technologies et protocoles de routage implémentés en vue
d'optimiser l'efficacité, la performance et la sécurité du
réseau de manière générale et
particulièrement des réseaux coeurs.
Au regard de la transmission des informations, l'utilisation
de plusieurs infrastructures sans filposebeaucoup de problème d'ordre
Sécuritaires, Qualité de Services, Interférences,
Disponibilités etc.
A cet effet, le choix de la technique de routage pouvant
remédier à la problématique précitée devient
très pertinent surtout quand il faut évaluer les
paramètres du choix du meilleur chemin que doivent emprunter les paquets
afin d'être acheminer à bon escient.
Quelques questions telles qu'énumérées
ci-dessous, traduisent et reflètent nos préoccupations.
- Quelle infrastructure réseau à mettre en place
pour répondre au mieux les préoccupations évoquées
dans le paragraphe précédent ?
- Comment les succursales d'une entreprise d'envergure nationale
pourraient-elles être interconnectées de manière plus
sécurisées ?
- Quel serait l'impact de ce nouveau
système d'information ?
0.3 Hypothèses
L'hypothèse étant définie comme une
réponse provisoire à une question posée, elle permet de se
rassurer de la véracité de la question posée pour un
problème en étude.
Nous pouvons envisager de mettre sur pied un coeur de
réseau utilisant la technologie IP/MPLS qui estle moyen le plus
évident pour assurer le contrôle, la simplicité et la
gérabilité des transferts de données avec une
qualité de service garantie. Elle nous permettra de combiner la gestion
de la qualité de service (QdS) et l'acheminement rapide de flux
d'informations afin de réduire le temps de propagation aller-retour,
assurant une transmission fiable. Nous entamerons initialement l'étude
du trafic afin de mesurer le débit nécessaire pour les
différents sites et ensuite, nous présenterons une nouvelle
architecture à l'aide des résultats de la dernière en vue
de dégager les avantages de cette architecture par rapport à
l'existante.
En outre, l'impact du nouveau système que nous pensons
déployer sera sublime dans la mesure où il permettra à
cette entreprise de migrer vers une infrastructure réseau innovante,
sécurisée et fiable et optimisera la qualité de service de
son réseau informatique face aux contraintes que posait le
système existant.
0.4 Intérêt du
Sujet
Le but du présent travail est de faire
bénéficier à la Banque Centrale du Congo les avantages
qu'offre la technologie IP/MPLS, dans la mesure où elle
contribueraà la fiabilisation, à l'optimisation de la
qualité de service ainsi qu'à la disponibilité de son
réseau de transport, en vue de la rendre plus performant qu'avant et
servira de même aux futurs chercheurs oeuvrant dans le domaine de
réseaux coeurs de documentation adéquate en vue de parfaire leurs
études.
0.5Délimitation du
travail
Du point de vue spatial, notre travail se limite au
déploiement d'un coeur de réseau IP/MPLS de la Banque Centrale du
Congo. Et du point de vue temporel, nos investigations ont été
menées de la période allant d'Avril 2016 en Mai 2017.
0.6 Méthodes &
Techniques utilisées
L'élaboration d'un travail scientifique exige un
certain nombre des méthodes et techniques universellement admises afin
de recueillir le plus objectivement possible les données
nécessaires à sa bonne réalisation et dans le souci de
bien cerner tous les aspects du problème de recherche il nous est utile
de recourir aux méthodes et techniques de recherche.
0.6.1. Méthodes
utilisées
Une méthode peut être appréhendée
comme étant l'ensemble de démarches intellectuelles par
lesquelles une discipline cherche à atteindre les vérités
qu'elle poursuit, les démontre, les vérifie.Pour ce qui
nous concerne, nous avons utilisé les méthodes
ci-dessous :
· La méthode analytique
C'est une méthode qui nous a permis
d'interpréter et analyser profondémentles données
recueillies afin d'en dégager les spécificités auxquelles
le nouveau système fait face. Durant notre étude, elle nous a
facilité de faire des analyses des données et informations
recueillies au cours de différentes années.
· La méthode historique
La méthode historique est celle qui s'efforce de
reconstituer les événements jusqu'au fait
générateur ou fait initial en essayant de rassembler, d'ordonner
et de hiérarchiser autour d'un phénomène singulier ou une
pluralité des faits afin de déceler celui qui exerce le plus
d'influences sur le phénomène étudié.
0.6.2 Techniques
utilisées
Une technique est un ensemble d'instruments ou d'outils
qu'utilise la méthode afin d'aboutir à la réalisation d'un
travail scientifique.
· La technique d'interview
Elle nous a permis d'interroger les différents
employés du service réseau de ladite entreprise afin
d'acquérir des informations pertinentes sur l'étude de l'existant
au travers d'un jeu des questions / réponses.
· La technique documentaire
Elle nous a permis de consulter divers documents afin de mieux
appréhender les activités qui se déroulent au sein de la
Direction informatique de manière générale et du service
réseau en particulier.
0.7 Subdivision du
travail
En vue d'élucider à bon escient notre
étude, hormis l'introduction générale et la conclusion
générale, nous avons jugé bon de subdiviser notre travail
en trois grandes parties dont la première sera les concepts
théoriques de base.Et, elle est divisée en deux chapitres
respectivement : les architectures des réseaux et Conception de
réseau IP/MPLS. La seconde effectue une étude préalable
avec l'unique chapitre l'étude du site : Cas de la Banque Centrale
du Congo. Et, la troisième c'est une implémentation ; nous
avons montré comment concevoir et déployer un coeur de
réseau IP/MPLS.
CHAPITRE I :
ARCHITECTURES DES RESEAUX
[1], [2], [3], [5], [6], [7], [9], [10], [11], [12], [14],
[19], [20]
Ce chapitre consacré aux différents types
d'architectures réseaux, nous pousse à stipuler qu'une
architecture de communication formalise l'empilement de couches de protocoles
et des services offerts afin d'assurer l'interconnexion des systèmes. A
cet effet, le modèle OSI appréhendé comme l'architecture
de référence facilitant la mise en relation des différents
systèmes hétérogènes a été
évoqué en premier lieu. En second lieu, nous avons abordé
l'architecture TCP/IP qui permet de résoudre les problèmes
d'interconnexion en milieu hétérogène. Cependant, pour une
bonne clarté des modèles précédemment cités,
nous avons mené une étude comparative déduisant les
caractères divergents et convergents de ces derniers afin de
l'expliciter davantage. Enfin, nous avons succinctement décrit la
structure, le fonctionnement, les failles et la portée des autres
architectures telles que le point à point, le Client/Serveur, le
Triple-play ainsi que celle des réseaux convergents dans l'optique de
déceler leurs apports pour la disponibilité des informations
ainsi que l'épanouissement, la qualité et
l'interopérabilité de réseaux informatiques.
I.1MODELE OSI
I.1.1
Généralités
Au début des années 70, chaque constructeur
avait développé sa propre solution réseau autour
d'architectures et protocoles privés tels que SNA d'IBM, DECnet de Bull
etc. Ainsi, il s'est vite avéré qu'il serait impossible
d'interconnecter des différents réseaux
« propriétaires » si une norme internationale
n'était pas établie. Cette norme établie par
l'International Standard Organisation (ISO) ou « Organisation de
Standardisation International (OSI) est la norme « Open System
Interconnexion », (OSI) ou « Interconnexion des
Systèmes Ouverts » (ISO).
I.1.2
Définition
Le modèle OSI (Open System Interconnexion) est un
modèle générique et standard d'architecture d'un
réseau en sept couches, élaboré par l'Organisme
International de Standardisation en 1984 tel que décrit dans la norme
X.200 de l'Union Internationale des Télécommunications (UIT).
I.1.3
Découpage en couches
Le modèle OSI se découpe en 7 couches comme
constaté sur la figure I.1. Toutes ces couches peuvent être
classifiées en deux classes dont les couches basses et les couches
hautes. Les couches basses, commençant de la 1ère
couche jusqu'à la 4ème, s'intéressent au
transfert de l'information par les différents services de transport. Et
les couches hautes, commençant de la 5ème couche
jusqu'à la 7ème couche, s'occupent du traitement de
l'information par les différents services applicatifs.
Application
Présentation
Session
Transport
Réseau
Liaison de données
Physique
La figure ci-dessous, illustre les couches du modèle
OSI.
Figure I.1 : Couches du modèle OSI [1]
I.1.4
Description des couches du modèle OSI
I.1.4.1 Couche physique
La couche physique fournit les moyens mécaniques,
électriques, fonctionnels et procéduraux nécessaires au
maintien et à l'activation des connexions physiques destinées
à la transmission de bits entre deux entités de liaison de
données. Les normes et standards de la couche physique
définissent le type de signaux émis (modulation, puissance,
etc.), la nature et les caractéristiques des supports (câble,
fibre optique, etc.), le sens de transmission, etc.
Cette couche s'occupe de :
· La transmission de bits sur un canal de
communication ;
· L'initialisation de la connexion et son
relâchement à la fin de la communication entre l'émetteur
et le récepteur ;
· L'interface physique de transmission de
données ;
· La résolution de possibilités de
transmission dans les deux sens (Half et Full duplex).
I.1.4.2 Couche liaison de données
La couche de liaison de données a pour rôle de
fournir les moyens fonctionnels et procéduraux nécessaires
à l'établissement, au maintien et à la libération
des connexions de liaison de données entre entités du
réseau. Elle détecte et corrige, si possible, les erreurs
irrécupérables. Elle supervise en même temps, le
fonctionnement de la transmission et définit la structure syntaxique des
messages, la manière d'enchainer les échanges selon un protocole
normalisé ou non.
Elle s'occupe aussi :
- En tant que récepteur,de constituer des trames
à partir des séquences de bits reçus ;
- En tant qu'émetteur,de constituer des trames à
partir des paquets reçus et les envoyer en séquence. C'est elle
qui gère les trames d'acquittement renvoyées par le
récepteur ;
- La correction d'erreur et le contrôle de
flux ;
Une connexion de liaison de données est
réalisée à l'aide d'une ou plusieurs liaisons physiques
entre deux machines adjacentes dans le réseau, donc sans noeuds
intermédiaires entre elles.
I.1.4.3 Couche réseau
Cette couche assure toutes les fonctionnalités de
relais et de l'amélioration de services entre entités de
réseau, à savoir : l'adressage, le routage des paquets, le
contrôle de flux, la détection et la correction d'erreurs non
réglées par la couche 2.
Elle permet aussi de gérer le sous-réseau, la
façon dont les paquets sont acheminés de la source à la
destination ; de la route que prendront les paquets pour arriver à
la destination. Ces routes peuvent être fondées sur des tables
statiques ou dynamiques de routage. Elle renferme les fonctions de
comptabilité, c'est-à-dire le comptage du nombre de paquets
traversant le sous-réseau en vue d'une éventuelle facturation.
Elle doit aussi résoudre les problèmes de l'interconnexion de
réseaux hétérogènes à savoir :
- L'adressage différent des réseaux de
communication (sous-réseaux) ;
- La taille des différents paquets ;
- Les protocoles incompatibles.
A ce stade de l'architecture OSI, il s'agit de transiter une
information complète (un fichier par exemple) d'une machine à une
autre à travers un réseau de plusieurs ordinateurs. Il existe
deux grandes possibilités pour établir un protocole de niveau
réseau : le mode avec connexion qui s'établit lors
du transfert de données entre deux entités homologues, passant
par la phase d'établissement de la connexion, le transfert de
données ainsi que la libération de la connexion et le mode
sans connexionquise repose sur la transmission de données dans
laquelle chaque paquet est préfixé par un en-tête contenant
une adresse de destination, suffisante permettant une livraison autonome du
paquet sans recourir à d'autres informations.
I.1.4.4 La couche transport
Cette couche a pour rôle d'assurer un transport de
données transparent entre les entités de session et en les
déchargeant des détails d'exécution. Elle a pour
rôle d'optimiser l'utilisation des services de réseau disponibles
afin d'assurer à moindre coût les performances requises par la
couche session.
C'est la première couche à résider sur
les systèmes d'extrémité. Elle permet aux applications de
chaque extrémité de dialoguer directement et
indépendamment de la nature des sous-réseaux traversés et
comme si le réseau n'existait pas. Au niveau inférieur de la
couche réseau, seule la phase établissement de la liaison logique
s'effectue de bout en bout, alors que les transferts d'informations se font de
proche en proche.
Un des rôles les plus importants de la couche transport
est l'administration de la communication fiable de bout en bout, entre
l'émetteur et le récepteur, qui agissent entre machines
d'extrémité, alors que les protocoles des couches basses agissent
entre machines voisines. La connexion de transport la plus courante consiste en
un canal point à point exempt d'erreur, délivrant les messages ou
les octets dans l'ordre d'émission. Cela suppose un contrôle
d'erreur et de flux entre hôtes, l'assemblage et le désassemblage
des données.
I.1.4.5 Couche session
La couche session fournit aux entités de la couche
présentation les moyens d'organiser et de synchroniser les dialogues et
les échanges de données ; permet aux utilisateurs
travaillant sur différentes machines d'établir entre eux un type
de connexion appelée « session ». Un utilisateur
peut établir une session pour se connecter à un système
temps partagé ou transférer un fichier entre deux machines.
Elle a pour rôle l'administration du dialogue. Les
sessions peuvent utiliser le mode unidirectionnel ou bidirectionnel du trafic.
Quand on travaille en mode bidirectionnel alterné, ou Half duplex
logique, la couche session détermine qui a le contrôle. Ce type de
service est appelé « administration du jeton ». La
couche session permet aussi de gérer la synchronisation en
insérant des points de reprise dans le flot des données de
façon à reprendre le transfert des données en cas
d'interruption accidentelle.
I.1.4.6 Couche présentation
La présente couche s'occupe de la syntaxe et de la
sémantique des informations transportées en se chargeant
notamment de la représentation des données. Pour ce faire, l'ISO
a défini une norme appelée syntaxe abstraite numéro un qui
permet de définir une sorte de langage commun (une syntaxe de transfert)
dans lequel toutes les applications représentent leurs données
avant de les transmettre. C'est à ce niveau de la couche
présentation que peuvent être implémentées des
techniques de compression (Code Huffman par exemple) et de chiffrement de
données (RSA, DES, etc.)
I.1.4.7 Couche application
La couche application donne au processus d'application le
moyen d'accéder à l'environnement OSI et fournit tous les
services directement utilisables par application, à savoir :
- Le transfert d'informations ;
- L'allocation des ressources ;
- L'intégrité et la cohérence des
données accédées ;
- La synchronisation des applications coopérantes.
La couche application gère les programmes de
l'utilisateur et définit des standards pour que les différents
logiciels commercialisés adoptent les mêmes principes comme
l'illustre la figure ci-dessous :


Figure I.2 : Communication des couches du
modèle OSI [19]
Cependant, il existe pour chaque couche du modèle OSI,
une unité de données ou de mesure des informations
échangées dans un réseau informatique. La couche
application du modèle précité a comme unité de
données, l'APDU qui est un message électronique
utilisé pour la communication avec une carte à puce, pour la
couche présentation, son unité de données est le
PPDU, la couche session a pour unité de données
le SPDU, la couche transport a pour unité de
données le TPDU, pour la couche réseau,
l'unité de données est le Paquet, la couche
liaisons de données a comme unité principale de données le
Trame et le Bit en est l'unité de
données de la couche physique, qui est la dernière couche du
modèle OSI.
I.1.5
Transmission des données à travers le modèle OSI
Pour ce qui est de la transmission des données, le
modèle OSI utilise le principe de communication virtuelle en utilisant
des interfaces inter-couches. Nous dirons qu'il y a encapsulation successive de
données à chaque interface (H : header, T : Trailer ou
bande annonce), tel qu'explicité dans la figure ci-dessous :

Figure I.3 : Transmission des données à
travers le modèle OSI [19]
AH : en-tête d'application ;
PH : en-tête de
présentation ;
SH : en-tête de session ;
TH : en-tête de transport ;
NH : en-tête de réseau ;
DH : en-tête de liaison de
données ;
DT : Délimiteur de fin de
trame.
Il sied de préciser que ce dernier reste, comme
l'indique son nom, un modèle qui n'est pas scrupuleusement
respecté, mais vers lequel, on tente généralement de se
rapprocher dans une optique de standardisation.
I.2
MODELE TCP/IP
I.2.1
Généralités
L'architecture TCP/IP (Transmission Control Protocol/ Internet
Protocol) désigne communément une architecture réseau,
résultant de la jonction de deux protocoles dont celui de transport, TCP
(Transmission Control Protocol) et celui du réseau, IP (Internet
Protocol).
L'origine de TCP/IP remonte au réseau APARNET qui
était un réseau de télécommunication conçu
par l'ARPA (Avanced Research Projects Agency), l'Agence de Recherche du
Ministère Américain de la Défense. Ce modèle
présente la possibilité de connecter des différents
réseaux dits hétérogènes.
Il a alors été convenu qu'APARNET utiliserait la
technologie de commutation des paquets (mode datagramme), une technologie
émergente et promettante. C'est donc dans cet objectif et à ce
choix technique que les protocoles TCP et IP furent inventés en 1974.
I.2.2
Présentation de l'architecture TCP/IP
Application
Transport
Internet
Accès réseau
L'architecture TCP/IP compte quatre couches, comme le montre
la figure I.4 : La couche Accès-réseau, la couche internet,
la couche transport et la couche application.
Figure I.4 : Représentation du modèle
TCP/IP [18]
I.2.3
Description des couches du modèle TCP/IP
I.2.3.1 Couche Accès-réseau
Cette couche a pour rôle d'assurer la communication
entre les réseaux grâce au protocole IP (Internet Protocol). Il
utilise la commutation de paquets de types datagramme afin d'acheminer des
données entre les systèmes d'extrémité, quelle que
soit la technologie réseau qu'ils emploient. Ainsi, le protocole IP
gère les datagrammes : il les achemine jusqu'à leur
destinataire, se charge du routage et de l'adaptation de la taille des
données au réseau sous-jacent. Il définit enfin un service
minimal par l'acheminement des datagrammes à travers l'interconnexion de
réseaux. Parmi les services y attachés, nous citons le service
Ethernet, PPP (Point to Point Protocol), ATM (Asynchronous Transfer Mode), FDDI
(Fiber Distributed Data Interface), Token Ring etc.
I.2.3.2 Couche internet
La présente couche est la clé de voute de cette
architecture, du fait qu'elle réalise l'interconnexion des
réseaux dits hétérogènes distants sans connexion.
Elle permet l'injection de paquets dans n'importe quel réseau et
l'acheminement de ces paquets indépendamment, les uns des autres
jusqu'à la destination. Les paquets peuvent tout de même arriver
en désordre s'il y a aucune connexion établie au
préalable ; le contrôle de remise sera éventuellement
la tâche des couches supérieures. Ainsi, nous y trouvons plusieurs
protocoles entre autres : IP (Internet Protocol), ICMP (Intemet Control
Message Protocol), ARP (Address Resolution Protocol), RARP (ReverseAddress
Resolution Protocol) etc.
I.2.3.3 Couche transport
Le rôle de cette couche est de permettre à des
entités paires de soutenir une conversation. Précisons à
cet effet, qu'elle regorge deux implémentations dont le protocole TCP et
le protocole UDP. Le premier est fiable, orienté connexion et permet
l'acheminement sans erreur de paquets issus d'une machine, à une autre
machine du même réseau. Il a pour rôle de fragmenter le
message à transmettre de manière à pouvoir le faire passer
sur la couche internet. Pour ce qui concerne la machine de destination, le
protocole TCP replace dans l'ordre des fragments transmis sur la couche
internet afin de reconstituer le message initial. En revanche, le second est
non fiable et sans connexion. Son utilisation présuppose que l'on n'a
besoin ni du contrôle de flux, ni de la conservation de l'ordre de remise
de paquets.
I.2.3.4 Couche application
Cette couche se greffe directement au-dessus de la couche de
transport et contient tous les protocoles de haut niveau que tout utilisateur
souhaiterait avoir entre autres : Telnet, TFTP (Trivial File Transfer
Protocol), SMTP (Simple Mail Transfer Protocol), HTTP (HyperText Transfer
Protocol), POP (Post Office Protocol), SNMP (Simple Network Management
Protocol), DHCP (Dynamic Host Configuration Protocol), HTTPs (HyperText
Transfer Protocol Secure) et elle est aussi indispensable sur le choix du
protocole de transport à utiliser partant du principe que les liaisons
physiques sont suffisamment fiables et les temps de transmission suffisamment
courts pour qu'il n'y ait pas d'inversion de paquets à
l'arrivée.
I.3
OSI COMPARE A TCP/IP
Les modèles OSI et TCP/IP sont tous les deux
modèles fondés sur le concept de pile de protocoles
indépendants. Ensuite, les fonctionnalités des couches sont
globalement les mêmes.
Cependant, au niveau des différences, le modèle
OSI faisant clairement la différence entre concepts principaux dont les
services, interfaces et protocoles alors que TCP/IP fait peu la distinction
entre ces concepts malgré les efforts des concepteurs stipulant de le
rapprocher du modèle TCP/IP, ce sont les protocoles qui sont apparus
premièrement. Le modèle n'a fait que donner une justification
théorique aux protocoles finalement. Sans le rendre véritablement
indépendants les uns des autres.
En outre, la dernière grande différence est
liée au mode de connexion. Certes ces modes orienté connexion et
sans connexion sont disponibles dans les deux modèles mais pas à
la même couche : pour le modèle OSI, s'ils ne sont
disponibles qu'au niveau de la couche transport pour le modèle TCP/IP
(la couche internet n'offre que le mode sans connexion). Le modèle
TCP/IP a donc cet avantage par rapport au modèle OSI : les
applications (qui utilisent directement la couche transport) ont
véritablement le choix entre les deux modes de connexion.
Enfin, comme évoqué ci-haut, l'architecture
TCP/IP compte 4 couches alors que le modèle OSI en compte 7. C'est ainsi
qu'à travers la figure ci-dessous nous essayons d'illustrer la
structuration de ces deux modèles.
En nous référant au modèle OSI, le TCP/IP
est amputé de la couche Présentation et Session, mais cela ne
peut pas handicaper ce dernier aux manques de fonctionnalités que
regorge chacune de ces couches auxquelles nous faisons allusion.
Application
Présentation
Application
Session
Transport
Transport
Internet
Réseau
Hôte-réseau
Physique
Liaison de données
Figure I.5 : Comparaison du modèle OSI à
TCP/IP [18]
I.4
ARCHITECTURE POINT A POINT
I.4.1
Généralités
La présente architecture se définit comme
étant une architecture partageant des ressources et des services par
échange direct entre différents systèmes. Ces
échanges peuvent porter sur les informations, les cycles de traitement,
la mémoire cache, ou encore le stockage sur disque des fichiers.
Cependant, dans l'architecture point à point, les
ordinateurs personnels ont le droit de faire partie du réseau. Ainsi, il
désigne une classe d'applications qui tient partie des ressources
matérielles ou humaines qui sont disponibles sur le réseau
Internet.
I.4.2
Caractéristiques du point à point
Les ressources ayant une connectivité instable ou des
adresses IP variables, elles fonctionnent de manière autonome,
indépendamment de systèmes centraux comme les DNS (Domaine Name
Service). A cet effet, le système point à point authentique se
reconnait donc par ces deux caractéristiques principales :
- Le système doit permettre à chaque point de se
connecter de manière intermittente avec des adresses IP
variables ;
- Le système doit donner à chaque point une
autonomie significative.
I.4.3
Fonctionnement de l'architecture point à point
L'architecture point à point fonctionne à
travers une connexion communicante entre deux noeuds. Il existe plusieurs types
d'architecture point à point, mais nous épinglerons
particulièrement le point à point simple, centralisé et
hiérarchique.
I.4.3.1 Architecture point à point simple
Théoriquement, cette architecture représente la
solution la plus confortable pour les échanges et partages des
ressources. Mais dans l'aspect pratique, elle exige plus de ressources que les
servicesde bonne qualité (lenteur, disponibilité, ...) soit elle
est saturée ou limitéeau cas où elle s'étend
à plusieurs utilisateurs.

Figure I.6 : Architecture point à point simple
[5]
Limites
En termes de sécurité, une telle architecture
s'avère vulnérable par le fait qu'elle ne propose qu'une et une
seule porte d'entrée d'où, il suffirait qu'un poste tombe en
panne, l'autre utilisateur ne saura plus inter opérer avec celui-ci et
cela arrête le bon fonctionnement du réseau.
I.4.3.2 Architecture point à point
centralisé
Cette architecture résultede l'amélioration de
l'architecture point à point simple en vue de résoudre les
problèmes de robustesse, de la qualité de connexion et
éviter la chute du réseau en cas d'une panne au niveau d'un
serveurafin de mieux répartir les demandes de connexions et aussi de
limiter la diminution de la bande passante.
Ci-dessous, nous présentons l'architecture point
à point centralisée.

Figure I.7 : Architecture point à point
centralisée [5]
I.4.3.3 Architecturepoint à
pointhiérarchique
Contrairement à l'architecture point à point
centralisée, cette architecture présente plusieurs avantages. Du
point de vue évolutivité,elle peut être aisément
étendue parce que la modularité de la conception permet de
reproduire des éléments de la conception au fur et à
mesure que l'évolution du réseau est effective et rend la gestion
du réseau facile,comme l'illustre la figure ci-dessous :

Figure I.8 : Architecture point à point
hiérarchique [5]
I.4.3
Avantages de l'architecture point à point
L'architecture point à point présente de
manière globale plusieurs avantages parmi lesquelles nous citons :
- La rapidité dans les échanges
d'informations ;
- L'optimisation de l'utilisation de la bande passante pour un
équilibrage de la charge du réseau ;
- La facilitation lors de la maintenance ;
- Laréduction des coûts des logiciels à
installer par le moyen de partage de ressources ;
- La résistance aux pannes à travers la
réplication des ressources etc.
I.4.4
Inconvénients de l'architecture point à point
Comme toute autre architecture, le point à point
présente aussi quelques failles que nous pouvons énumérer
ci-dessous :
- L'inefficacité de fonctionner correctement en cas de
manque de participation active de ses composants ;
- Le freeloading, phénomène nuisible au bon
fonctionnement de ce type de réseaux qui bénéficie des
ressources partagées sans pour autant en partager les leurs ;
- L'anarchie dans les systèmes d'échange de
fichier ;
- Le manque minimum de contrôle des activités
occasionnant la diffusion de virus, l'atteinte à la vie privée,
l'envahissement des bannières publicitaires etc...
I.5
ARCHITECTURE CLIENT/SERVEUR
I.5.1
Généralités
L'architecture client/serveur étant indispensable pour
l'utilisation de nombreuses applications fonctionnant dans un environnement
client/serveur, elle regorge à la fois les machines clientes (des
machines faisant partie du réseau) contactent un serveur (machine
puissante en termes de capacités d'entrées/sorties) qui leur
fournit des services. Ces services sont des programmes qui fournissent des
données telles que l'heure, les fichiers, une connexion, etc...Ces
services sont exploités par des programmes, appelés programmes
clients, s'exécutant sur les machines clientes.
Un client peut être
appréhendé comme un processus effectuant une demande de service
ou l'exécution d'une opération à un autre processus par
envoi de message contenant le descriptif de l'opération à
exécuter et attendant la réponse de cette opération par un
message en retour.
Un serveurpeut être définicomme
étant un processus qui est à l'écoute des requêtes
clientes, il offre des services sur demande d'un client en lui transmettant le
résultat.
Dans cette architecture, le client a pour rôle
d'établir la connexion au serveur à destination d'un ou plusieurs
ports réseaux lorsque la connexion est acceptée par le serveur.
En effet, le serveur joue le rôle d'un site à accès
permanent parce qu'il lui revient la lourde tâche d'accepter, traiter et
renvoyer les résultats voulus par le client qui en est le demandeuret
nous l'avons illustré dans la figure ci-dessous :
Figure I.9 : Architecture Client/serveur [11]

I.5.2
Avantages de l'architecture Client/Serveur
Le modèle Client/Serveur est particulièrement
recommandé pour des réseaux nécessitant un grand niveau de
fiabilité, ses principaux atouts sont :
- Des ressources centralisées :
étant donné que le serveur est au centre du réseau, il
peut gérer des ressources communes à tous les
utilisateurs ;
- Une meilleure sécurité :
car le nombre de points d'entrée permettant l'accès aux
données est moins important ;
- Une administration au niveau serveur :
les clients ayant peu d'importance dans ce modèle, ils ont moins besoin
d'être administrés ;
- Un réseau évolutif :
grâce à cette architecture, il est très facile de rajouter
ou supprimer des clients ou serveurs sans perturber le fonctionnement du
réseau et sans modification majeure.
I.5.3
Inconvénients du modèle Client/Serveur
Cette architecture est loin d'être parfaite comme toutes
les autres architectures, elle présente quelques lacunes parmi
lesquelles :
- Un coût d'exploitation
élevé dû à la technicité du serveur,
bande passante, câbles, ordinateurs surpuissants etc...
- Un maillon faible : le serveur est le
seul maillon faible du réseau Client/Serveur, étant donné
que tout le réseau est architecturé autour de lui.
I.5.4
Fonctionnement du modèle Client/serveur
L'idée essentielle du fonctionnement de l'architecture
Client/Serveur réside sur le fait que dans cette architecture, le client
émet desrequêtes vers le Serveur grâce à son adresse
IP et le serveur reçoit à son tour les demandes et répond
au client à l'aide de l'adresse de la machine cliente et son port.
Cependant, cette interaction forme un système coopératif donnant
à un serveur le moyen de répondre à plusieurs clients de
manière simultanée.
I.6
ARCHITECTURE TRIPLE-PLAY
I.6.1
Généralités
Depuis belle lurette, les Fournisseurs d'Accès Internet
(FAI) proposent à leurs abonnés des nouvelles offres permettant
à ces derniers de bénéficier d'un accès internet
haut débit, de la téléphonie et de la
télévision à travers l'Internet. A cet effet, nous
aborderons les différentes technologiques sur lesquelles se base l'offre
triple play tout en spécifiant son contexte historique ; l'analyse
des changements apportés par ce dernier dans le secteur de
télécoms ainsi que les perspectives d'évolution.
I.6.2
Architecture générale du triple play
Architecture triple play est celle qui permet une adjonction
de la valeur ajoutée aux services Internet standards, comme l'indique
son nom, l'architecture triple play propose trois catégories de services
dont le service d'accès à l'Internet, l'accès à la
Téléphonie via IP, l'accès à la
Télévision via IP et tous ces services via une seule et unique
prise téléphonique comme le décrit la figure
ci-dessous :

Figure I.10 : Architecture générale du
triple play [18]
I.6.3
Triple play par ADSL
L'ADSL (Asymetric Digital Subscriber Line) est la technologie
la plus utilisée actuellement pour l'accès à l'internet
par les particuliers. Bien que cela ne fût pas historiquement sur ce type
de technologie que les offres triple-play ont été
développées, c'est aujourd'hui le premier fournisseur de ce genre
d'offres. A cet effet, nous tenterons par la suite expliciter le fonctionnement
de ces offres via ADSL en abordant brièvement la description de ladite
technologie.
I.6.3.1 Technologie ADSL
La présente technologie a été
développée dans l'optique de transiter les données
informatiques au travers des lignes téléphoniques (cela permet de
réutiliser un réseau de câble existant déjà).
Elle utilise les bandes de hautes fréquences, non utilisées pour
la téléphonie (300 - 400 Hz), en utilisant des techniques de
multiplexage et de modulation adaptées aux lignes
téléphoniques. Le fait d'utiliser les fréquences hautes de
la ligne téléphonique implique cependant l'utilisation d'un
filtre de part et d'autre de la ligne téléphonique afin que les
signaux de téléphonie ne viennent pas perpétuer les
signaux ADSL (et vice-versa).
I.6.3.2 Set-Top-Box
La Set-Top-Box (STB) est un appareil que les fournisseurs
d'accès Internet ASDL fournissent (parfois gratuitement) à leurs
abonnés afin qu'ils bénéficient des offres triple-play. Il
s'agit d'un boitier qui se connecte sur la ligne téléphonique, et
qui dispose au minimum d'une sortie télévision (prise
péritel ou RCA), d'un connecteur téléphonique (R) 11 ou
prise téléphonique), et d'un connecteur internet (RJ45, wifi
etc.)
I.6.3.3 Accès à Internet
L'accès à Internet est le premier type de
service qui a été proposé à travers l'ADSL. Les
autres services d'une offre Triple Play par ADSL étant dépendant
de celui-là, nous allons nous intéresser au fonctionnement de ce
service dans un premier temps.
· Connexion à
l'abonné
La connexion entre l'utilisateur et la STB peut
généralement s'effectuer de trois façons
différentes :
Connexion USB
Il s'agit d'une liaison série permettant à
l'utilisateur de connecter directement son ordinateur à la STB. Elle ne
spécifie aucun protocole de communication particulier à utiliser.
Cependant, la communication avec la STB se fait, la plupart du temps, en
utilisant soit le protocole ATM, soit le protocole Ethernet. Il se peut aussi
que la STB ne fonctionne que comme un modem ADSL classique en utilisant ce type
de connexion, obligeant alors l'utilisation du protocole PPP au-dessus d'ATM
(PPPoA) ou d'Ethernet (PPPoE) dans ce cas.
Connexion Ethernet
Il s'agit d'une connexion Fast Ethernet (100 Mbit/s) qui
permet à l'utilisateur de se connecter à la STB au moyen d'une
carte réseau.
Connexion WiFi
La plupart du temps, il s'agit d'un module optionnel payant
qui permet à l'utilisateur de se connecter à la STB au moyen
d'une connexion sans fil, type 802.11b/g, tel qu'illustré dans la figure
ci-dessous :
Figure I.11 : Connexion d'un abonné vers sa STB
[10]
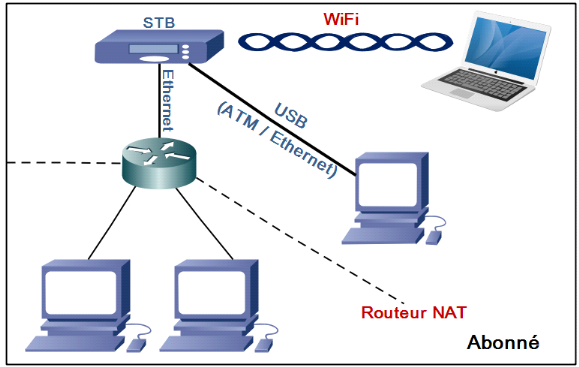
· Connexion à la
Set-Top-Box
La STB est connectée à la ligne
téléphonique de l'utilisateur. A l'autre bout de la ligne
téléphonique se trouve le DSLAM ayant pour tâche
d'établir une passerelle entre les équipements des utilisateurs
(via la STB) et le réseau du FAI. Le DSLAM se situe au niveau du central
téléphonique local appelé autrement le Noeud de
Raccordement Abonné, et peut être un
équipement appartenant au FAI tout en dépendant du niveau de
dégroupage de l'abonné. Un même DSLAM est connecté
à un ensemble d'abonnés (du même FAI). Le nombre
d'abonnés par DSLAM varie en fonction du fabricant, comme nous l'avons
illustré dans la figure ci-dessous :
Figure I.12 : Connexion entre la STB et Internet
[10]
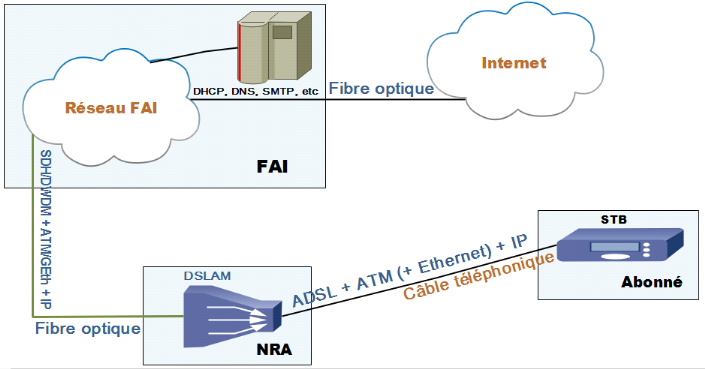
I.6.4
Télévision par ADSL
Actuellement, on trouve des chaînes de
télévision en ligne qui transmettent leurs programmes en temps
réel. C'est ce que l'on appelle du streaming accessible grâce
à des logiciels particuliers (le plus souvent Windows Media Player). Il
s'agit alors d'un simple flux disponible sur son écran d'ordinateur.
Avec ce système, il faut disposer d'un débit constant pour
assurer une bonne réception. La télévision par l'ADSL
permet quant à elle d'accéder à un bouquet de
chaînes télévisés directement sur son poste de
télévision.
I.6.4.1 Fonctionnement
Avec la télévision par ASDL, le câble et
le satellite de toutes les chaînes sont transmis aux abonnés et
c'est au décodeur de faire le tri. Le débit sur la boucle locale
étant limité, le DSLAM ne transmet qu'une seule chaîne au
domicile de l'abonné. Il n'est pas possible de regarder deux
chaînes de manière simultanée, ou d'enregistrer une
chaîne sur son magnétoscope pendant que vous en regardez une
autre. Lorsque l'utilisateur veut changer de chaîne, la set-top-box
transmet la demande au DSLAM et celui-ci a la charge de sélectionner le
bon flux mêmes'il ne reçoit pas toutes les chaînes. Il ne
reçoit que les chaînes qu'il transmet à ce moment à
ces abonnés, et cela pour ne pas saturer le réseau. Quand un
abonné zappe, le DSLAM vérifie s'il ne reçoit pas
déjà la chaîne désirée. Ce serait le cas s'il
la transmet à un autre abonné. Si c'est le cas, il duplique le
flux pour l'envoyer aux différents abonnés. Dans le cas
contraire, il doit aller le rechercher à la tête du réseau
pour entraîner un délai lors du changement de chaîne.
I.6.4.2 Bande passante et encodage
La télévision est le service le plus critique en
matière de bande passante pour les offres Triple play de l'ADSL et
requiert un débit garanti pour une bonne visualisation. La bande
passante allouée à la télévision sur ADSL d'obtenir
une qualité d'images très correcte avec le type d'encodage.
I.7
ARCHITECTURE DU RESEAU CONVERGENT
La convergence des technologies des réseaux, des
services et des équipements terminaux a été à la
base de l'évolution des offres novatrices et des nouveaux modèles
économiques dans le secteur de la communication. En effet, cette
convergence se traduit par le passage de l'architecture traditionnelle en une
situation dans laquelle les différents services assurés par des
réseaux distincts (réseaux mobiles, réseaux de lignes
fixes, télévision par câble,etc) à une situation
dans laquelle l'accès et l'utilisation des services de communication se
feront de façon intégrée sur différents
réseaux. Ces services étant dispensés de façon
interactive à travers des plates-formes multiples. Certes, nous
précisons qu'il existe de nombreuses architectures de réseaux
convergents. Mais pour ce qui nous concerne, nous évoquerons
l'architecture NGN (Next Génération Networks).
I.7.1
Généralités sur le NGN (Next Generation Network)
NGN, Réseau de Nouvelle Génération est un
réseau s'appuyant sur la technologie du transport IP émulant le
réseau de commutation de circuit avec l'ensemble de ses services de
téléphonie ; elle s'appuie sur une architecture
constituée de deux entités principales : Media Gateway (MGW)
et Media Gateway Controller (MGC). Le premier introduit à la couche
application et le second appartient à la couche contrôle.
Ce réseau repose sur une architecture répartie,
exploitant pleinement la technologie de pointe et offre des nouveaux services
sophistiqués et augmenter les recettes des opérateurs tout en
réduisant leurs dépenses d'investissement et leurs coûts
d'exploitation. Il est de même à la base progressive vers le
« tout IP » et sont normalisés en couche
indépendante dialoguant via des interfaces ouvertes et
normalisées, il offre aux fournisseurs de service une plate-forme
évolutive pour créer, déployer et gérer des
services multimédias innovants et accessibles indépendants des
réseaux d'accès.
I.7.2
Les exigences de tourner vers NGN
La nouvelle architecture réseau, le NGN a amené
plusieurs laboratoires de constructeurs et les multiples organismes de
standardisation de s'y pencher afin de répondre à certaines
exigences telles qu'énumérées ci-dessous :
o Les réseaux de télécoms sont
spécialisés et structurés avant tout pour la
téléphonie fixe ;
o Le développement de nouveaux services,
évolution des usages du réseau d'accès fixe et
l'arrivée du haut débit ;
o Difficulté à gérer des technologies
multiples (SONET, ATM, TDM, IP) seul un vrai système
intégré peut maîtriser toutes ces technologies reposant sur
la voix ou le monde des données ;
o Prévision d'une progression lente du trafic voix et
au contraire une progression exponentielle du volume de données, ce qui
provoque la baisse de la rentabilité des opérateurs.
I.7.3
Caractéristiques du réseau NGN
I.7.3.1 Une nouvelle génération de
commutation
Les solutions de commutation de nouvelle
génération fournissent une gamme complète de la
catégorie de commutation, voix over IP adaptée aux besoins des
abonnés complétés par des applications convergées
de voix/données pour établir un réseau de NGN (une
commutation par paquets).
I.7.3.2 Une nouvelle génération de
réseaux optiques
Les solutions de système optique de nouvelle
génération rassemblent les deux réseaux optiques existants
y compris celui du multiplexage DWDM et les réseaux optiques SDH avec la
nouvelle génération de systèmes optiques, des
réseaux IP optimisés peuvent être déployés.
Les fonctions de données et Ethernet sont ajoutées aux
dispositifs classiques de transport.
I.7.3.3 Une nouvelle génération de type
d'accès
Les nouvelles technologies d'accès sont une composante
très importante car elles influencent la rapidité d'introduction
et les modalités techniques de mise en oeuvre des coeurs de
réseaux NGN. Elles ont chacune un rôle à jouer dans le
développement des services IP multimédia de NGN et sont
caractérisées par :
§ Leur niveau de maturité (existence de
produits) ;
§ La commutation utilisée (interface vers le coeur
de réseau) et les débits.
La multitude et la montée en puissance de ses
technologies devenant ingérable en matière de Qualité de
Service sur le mode de perfectionnement actuel, l'intégration du
protocole MPLS s'est avérée urgente dans la couche transport en
vue d'y faire face.
I.7.4
Architecture logique de réseau NGN
Les réseaux NGN reposent sur une architecture en
couches indépendantes (transport, contrôle, services) communiquant
via des interfaces ouvertes et normalisées. Les services doivent
être évolutifs et accessibles indépendamment du
réseau d'accès utilisé comme illustrée dans la
figure ci-dessous :

Figure I.13 : Architecture logique de réseau
NGN [12]
I.7.4.1 Couche transport
C'est la partie responsable de l'acheminement du trafic voix
ou données dans le coeur de réseau, selon le protocole
utilisé. De ce fait, elle se subdivise en deux sous-couches
différentes dont la couche d'accès et la couche coeur de
réseau.
1°) Couche d'accès
Elle regroupe les fonctions et les équipements
permettant de gérer l'accès des équipements utilisateurs
au réseau, selon la technologie d'accès (téléphonie
commutée, DSL, câble). Cette couche inclut par exemple les
équipements DSLAM (DSL Access Multiplexer) fournissant l'accès
DSL.
2°) Couche coeur de
réseau
Cette couche gère l'ensemble des fonctions de
contrôle des services en général, et de contrôle
d'appel en particulier pour le service voix. L'équipement important
à ce niveau dans une architecture NGN est le « Media
Gateway » (MGW) qui est responsable de l'adaptation des protocoles de
transport aux différents types de réseaux physiques disponible
(TDM, IP, ATM, SDH, DWDM).
I.7.4.2 Couche contrôle
Cette couche gère l'ensemble des fonctions de
contrôle des services en général, et de contrôle
d'appel en particulier pour le service voix. L'équipement important
à ce niveau dans une architecture NGN est le serveur d'appel, plus
communément appelé « Softswitch », qui
fournit, dans le cas de services vocaux, l'équivalent de la fonction de
commutation.
I.7.4.3 Couche service
L'ensemble de fonctions permettant la fourniture de services
dans un réseau NGN. En termes d'équipements, cette couche
regroupe deux types d'équipements les serveurs d'application (ou
applications serveurs) et les « essablers » qui sont des
fonctionnalités, comme la gestion de l'information de présence de
l'utilisateur, susceptibles d'être utilisées par plusieurs
applications ; elle inclut d'une manière générale des
serveurs d'application SIP (Session Initiation Protocol), car il est
utilisé dans une architecture NGN pour gérer des sessions
multimédias générales, et des services de voix sur IP en
particulier.
I.7.5
Architecture physique de réseau NGN
L'architecture physique de réseau NGN se résume
dans la figure ci-dessous :

Figure I.14 : Architecture physique de réseau
NGN [12]
I.7.5.1 Eléments de réseau NGN
?Réseaux en mode paquets
- La tendance est d'utiliser les réseaux IP sur
diverses technologies de transport (ATM, SDH, WDM...)
- Les réseaux IP doivent offrir des garanties de
qualité de service (QdS) concernant les caractéristiques de temps
réel de la transmission vocale, vidéo et multimédia.
?Passerelles d'accès
- Permettent de raccorder les lignes d'abonné au
réseau en mode paquet
- Convertissement en paquets les flux de trafic provenant de
dispositifs d'accès analogiques (service téléphonique
ordinaire) ou de dispositifs d'accès à 2 Mbit/s
- Assurent l'accès des abonnés au réseau
NGN et à ses services.
?Passerelles de jonction
- Assurent l'interfonctionnement entre le réseau
téléphonique MRT classique et les réseaux NGN en mode
paquet
- Convertissent les flux provenant des circuits MRT (64
kbits/s) en paquets de données et inversement.
? Plate-forme de commutation logicielle
/MGC
- Appelé agent d'appel ou contrôleur de
passerelle média (MGC)
- Assure le "contrôle de fourniture des services" dans
le réseau
- Assure la commande d'appel et de la commande des passerelles
média (accès et/ou jonction) via le protocole H.248
- Remplit la fonctionnalité de passerelle de
signalisation ou utilise une passerelle de signalisation pour
l'interfonctionnement avant le système de signalisation N7 du RTPC
- Assure la connexion au réseau intelligent / aux
serveurs d'application pour offrir les mêmes services que ceux qui sont
mis à la disposition des abonnés MRT.
? Serveur d'application (AS)
- Elément qui sert d'appui à l'exécution
des services. Pour mieux élucider ce qui précède, nous
illustrons un exemple par un serveur qui contrôle les appels et les
ressources spéciales de réseau NGN (Serveur média, serveur
de messages).
? Protocole H.248
- Egalement appelé MEGACO : protocole
normalisé pour la signalisation et la gestion de session
nécessaires pendant une communication entre une passerelle média
et le contrôleur de passerelle média qui la gère ;
- H.248/MEGACO permet d'établir, de maintenir et de
terminer les appels entre plusieurs points d'extrémité, par
exemple entre des abonnés téléphoniques utilisant la
technologie MRT (Multiplexage à Répartition dans le Temps).
? SIP (Session Initiation
Protocol)
Protocole d'ouverture de session utilisé pour
l'établissement, le maintien et la terminaison d'appel à partir
de terminaux en mode paquet.
? Passerelle de signalisation (SG, Signalling
Gateway)
Elément assurant la conversion de signalisation entre
le réseau NGN et les autres réseaux (par exemple point STP dans
le système SS7).
? ENUM (Electronic
NUMbering)
Numérotage électrique: protocole permettant
d'établir une correspondance entre les numéros de
téléphone traditionnels (E.164) et les adresses de réseau
liées aux réseaux en mode paquet.
? MPLS (Multi Protocol Label
Switching)
Commutation multiprotocole par étiquette: est un
protocole qui assigne des étiquettes aux paquets d'information afin de
permettre aux routeurs nodaux de traiter les flux dans le réseau en
fonction de la priorité établie pour chaque catégorie.
? CAC (Cali Acceptance Control)
Fonction de commande d'acceptation d'appel, qui permet
d'accepter ou de rejeter le trafic dans le réseau afin de garantir la
qualité de service pour les services faisant l'objet d'un accord sur le
niveau de service.
? BGP(Border Gateway Protocol)
Protocole de passerelle frontière permettant de
négocier les procédures et les capacités de routage de
flux entre différents domaines de réseau NGN.
I.7.6
Principaux équipements du réseau NGN
I.7.6.1 MGC (Media Gateway Controller)
Le serveur d'appel autrement appelé sofswitch n'est
autre qu'un serveur informatiques doté d'un logiciel de traitement des
appels vocaux, gérant d'une part les mécanismes de contrôle
d'appel (pilotage de la couche transport, gestion des adresses) et d'autre part
l'accès aux services (profils d'abonnés, accès aux
plates-formes de services à valeur ajoutée). Dans un
réseau NGN, c'est le MGC qui possède
« l'intelligence ». Il gère :
- L'échange des messages de signalisation transmise de
part et d'autre avec les passerelles de signalisation, et
l'interprétation de cette signalisation ;
- Le traitement des appels : dialogue avec les terminaux
H.323, SIP voire MGCP, communication avec les serveurs d'application pour la
fourniture des services ;
- Le choix du MG de sortie selon l'adresse du destinataire, le
type d'appel, la change du réseau, etc ;
- La réservation des ressources dans le MG et le
contrôle des connexions internes au MG (Commande des Média
Gateways).
I.7.6.2 Media Gateway (MGW)
Les Gateways ont un rôle essentiel : elles assurent non
seulement l'acheminement du trafic, mais aussi l'interfonctionnement avec les
réseaux externes et avec les divers réseaux d'accès. La
Media Gateway est située au niveau du transport des flux média
entre le réseau RTC et les réseaux en mode paquet, ou entre le
coeur de réseau NGN et les réseaux d'accès. Elle a pour
rôle le codage et la mise en paquets du flux média reçu du
RTC et vice-versa (conversion du trafic TDM IP). Et aussi la transmission,
suivant les instructions du Media Gateway Controller, des flux média
reçus de part et d'autre.
I.7.6.3 Signalling Gateway (SG)
La fonction Signalling Gateway a pour rôle de convertir
la signalisation échangée entre le réseau NGN et le
réseau externe interconnecté selon un format
compréhensible par les équipements chargés de la traiter,
mais sans l'interpréter (ce rôle étant dévolu au
Media Gateway Controller). Notamment, elle assure l'adaptation de la
signalisation par rapport au protocole de transport utilisé. Cette
fonction est souvent implémentée physiquement dans le même
équipement que la Media Gateway, d'où le fait que ce dernier
terme est parfois employé abusivement pour recouvrir les deux fonctions
MG + SG.
I.7.7
Services offerts par les NGN
Les NGN offrent les capacités, en termes
d'infrastructure, de protocole et de gestion, de créer et de
déployer de nouveaux services multimédia sur des réseaux
en mode paquet. La grande diversité des services est due aux multiples
possibilités offertes par les réseaux NGN en termes de :
· Support multimédia (données, texte,
audio, visuel).
· Mode de communication, Unicast (communication point
à point), Multicast (Communication point-multipoint), Broadcast
(diffusion)
· Mobilité (services disponibles partout et tout
le temps).
· Portabilité sur les différents
terminaux
Parmi ces services offerts, nous citons : La voix sur IP, La
diffusion de contenus multimédia, La messagerie unifiée, Le
stockage de données, La messagerie instantanée, Services
associés à la géolocalisation etc ...
CHAPITRE II : CONCEPTION DE RESEAU IP/MPLS
[1], [2], [3], [4], [6], [8], [15], [17], [18], [19], [21],
[22], [23], [24], [25]
Ce chapitre consacré à la conception de
réseau IP/MPLS,s'attèlera sur les différents moyens et
techniques de mise en oeuvre de réseau IP avec le protocole MPLS. Nous
avons décrit en premier lieu, les réseaux IP tout en
spécifiant les protocoles qu'ils utilisent ensuite, les
différents types d'adressage sans lequel, la transmission de
données entre les hôtes du réseau serait pratiquement
impossible. L'Internet et son service de meilleur qualité
« best effort » ont été évoqué
par la suite et allonsparlerdu routage dans les réseaux IP dont la
prérogative consiste à décider sur quelle interface de
sortie les paquets doivent emprunter pour être transmis, les
réseaux privés virtuels ont été
évoqué par la suite ainsi que les protocoles de tunnelisation qui
permettent d'encapsuler dans leurs datagrammes des paquets afin d'être
transmis.
II.1
RESEAUX IP
Les Réseaux IP sont à la base de la
genèse du protocole IP qui a pour tâche de faciliter la
réalisation des réseaux privés d'entreprises, tels que les
réseaux intranets et extranets ou encore les réseaux mis en place
pour la domotique. Ces réseaux IP présentent de nombreuses
propriétés communes que nous allons examiner succinctement tout
en décrivant le fonctionnement et en détaillant les principaux
protocoles mis en oeuvre pour l'acquisition d'un réseau plus
performant.
II.1.1
Architecture physique d'un réseau IP
Au niveau physique, le réseau IP est constitué
d'un ensemble d'équipements interconnectés, commutateurs (ou
switches) et routeurs, sous le contrôle de différentes
entités indépendantes appelées Systèmes Autonomes
(ou AS, AutonomousSystems) : ce sont généralement des
fournisseurs d'accès, de contenu, des universités, des
entreprises comme illustrée dans la figure ci-dessous :

Figure II.1 : Architecture physique d'un
réseauIP [23]
Cependant, dans un réseau d'opérateur, nous
pouvons distinguer trois composantes structurellement différentes, en
termes de technologies, de débits des liens ou encore de nombre
d'utilisateurs simultanées. Leur étude est
généralement spécifique et met en jeu des modèles
théoriques distincts.
- Le réseau d'accès est la
partie en bordure de réseau reliant le client à
l'opérateur. C'est le cas du réseau ADSL par exemple, qui relie
la passerelle domestique à un DSLAM, ou des réseaux sans fil et
mobiles. Sa capacité est aujourd'hui plutôt limitée et il
est souvent un goulot d'étranglement pour le trafic (les connexions
peuvent facilement atteindre le débit d'accès).
- Le réseau de collecte centralise le
trafic de plusieurs DSLAM et le connecte au réseau de l'opérateur
par l'intermédiaire des équipements d'accès au service.
Typiquement le réseau de collecte est en ATM ou Ethernet Gigabit, et
peut potentiellement être un point de saturation en fonction des nouveaux
services consommateurs de bande passante comme la vidéo à la
demande par exemple.
- Le réseau coeur est la partie
centrale qui offre la connectivité entre les utilisateurs et les
différents services. La capacité des liens est
généralement grande comparée à celle des
réseaux d'accès (plusieurs dizaines de gigabits par seconde),
puisque les liens de coeur transportent le trafic d'un très grand nombre
d'utilisateurs.
II.1.2
Quelques protocoles utilisés par les réseaux IP
Les réseaux IP utilisent plusieurs protocoles mais pour
le cas de notre travail, nous aborderons particulièrement le protocole
ARP, DNS, ICMP, RSVP et RTP.
II.1.2.1 Le protocole ARP (Address Resolution Protocol)
Ce protocole joue un rôle prépondérant
parmi les protocoles de la couche Internet de la suite TCP/IP, il permet de
connaitre l'adresse physique d'une carte réseau correspondant à
une adresse IP, raison pour laquelle il est appelé protocole de
résolution d'adresse. Ci-dessous, la figure II.2 illustre le
fonctionnement du protocole ARP.

Figure II.2 : Fonctionnement du protocole ARP
[6]
De manière opposée, une station qui se connecte
au réseau peut connaître sa propre adresse physique sans avoir
d'adresse IP. Au moment de son initialisation
(bootstrap), cette machine
doit contacter son serveur afin de déterminer son adresse IP et ainsi de
pouvoir utiliser les services TCP/IP.
II.1.2.2 DNS (Domain Name Service)
Le DNS « Domain Name Service ou Système de
Nom de Domaine », il peut être appréhendé comme
un protocole indispensable au fonctionnement d'Internet, du point de vue de son
utilisation, car il permet la mise en correspondance des adresses physiques et
des adresses logiques.
L'utilisation de ce protocole est fréquente quand un
utilisateur désire se connecter à l'Internet. Il joue le
rôle d'un annuaire pour l'ordinateur qui veut échanger avec un
autre sur le réseau. Le premier ordinateur doit interroger le serveur
DNS pour récupérer l'adresse de l'ordinateur qu'il désire
joindre, une fois que la récupération est effective, il pourra le
joindre directement avec son adresse IP. Ce dernier (Serveur DNS) va permettre
d'établir la relation entre nom d'ordinateur et adresse IP, et à
ce stade, vous pouvez maintenant communiquer avec la machine destinateur.
II.1.2.3 ICMP (Internet Control Message Protocol)
Le protocole ICMP est un protocole de signalisation des
problèmes utilisé par le protocole IP dont le but est d'une part,
de tester la connectivité réseau et de l'autre, d'apporter une
aide au diagnostic en cas de problèmes ou de défaillances.
Ci-dessous, la figure II.3 illustre le format des messages qu'utilise le
protocole ICMP.

Figure II.3 : Format des message ICMP [21]
II.1.2.4 RSVP (Resource reSerVationProtocol)
RSVP est un protocole permettant de réserver des
ressources dans un réseau informatique. Il effectue la signalisation
(avec ou sans réservation) à partir du récepteur, ou des
récepteurs dans le cas d'un multipoint et a pour fonction d'avertir les
noeuds intermédiaires de l'arrivée d'un flot correspondant
à des qualités de service déterminées. Cette
signalisation s'effectue sur un flot (flow) envoyé vers un ou plusieurs
récepteurs. Ce flot est identifié par une adresse IP. Lorsqu'un
nouveau point s'ajoute au multipoint, celui-ci peut réaliser
l'adjonction de réservations d'une façon plus simple que ne
pourrait le faire l'émetteur. Les paquets RSVP sont transportés
dans la zone de données des paquets IP. Ci-dessous, nous
présentons le format de message du protocoleRSVP.

Figure II.4 : Format du message RSVP [6]
II.1.2.5 RTP (Real-time Transport Protocol)
L'existence d'applications temps réel, comme la parole
numérique ou la visioconférence, est un problème pour
l'Internet. Ces applications demandent une excellente qualité de service
(QdS) que les protocoles classiques d'Internet ne peuvent offrir. C'est ainsi
que le RTP (Real-time Transport Protocol) a été conçu pour
résoudre ce problème, qui plus est directement dans un
environnement multipoint. RTP a à sa charge aussi bien la gestion du
temps réel que l'administration de la session multipoint.
Les fonctions de RTP sont les suivantes :
§ Le séquencement des paquets par
une numérotation permettant de détecter les paquets perdus
essentiel en vue de la recomposition de la parole.Il est impérieux de
repérer qu'un paquet a été perdu de façon à
en tenir compte et à le remplacer éventuellement par une
synthèse déterminée en fonction des paquets
précédents et suivants.
§ L'identification de ce qui est
transporté dans le message pour permettre, par exemple, une compensation
en cas de perte, la synchronisation entre médias, grâce à
des estampilles.
§ L'indication de tramage : les
applications audio et vidéo sont transportées dans des trames,
dont la dimension dépend des codecs effectuant la numérisation.
Ces trames sont incluses dans les paquets afin d'être
transportées. Elles doivent être récupérées
facilement au moment de la dépaquétisation pour que l'application
soit décodée simplement.
§ L'identification de la source :
la synchronisation supplémentaire entre médias,
l'Identification ainsi que le Contrôle de la session.
II.1.3
La qualité de service dans IP
La qualité de service (QdS) est la capacité
à véhiculer dans de bonnes conditions un type de trafic
donné, en termes de disponibilité, débit, délais de
transmission, gigue, taux de perte de paquets, latence.
ü La disponibilité : est une
mesure de performance ou le rapport entre la durée de fonctionnement et
la durée disponible pour le fonctionnement.
ü Le débit : est le nombre
de données qui peuvent être transmises d'un point à un
autre en un laps de temps déterminé.
ü Le délai de
transmission:est le temps de transfert des paquets (le codage de
données ; passage en file d'attente, propagation dans le
réseau).
ü Gigue : est le délai de
transmission de bout en bout entre des paquets choisis dans un même flux
de paquets, sans prendre en comptes les paquets perdus.
ü Taux de perte de paquets : est le
pourcentage de paquets perdus lors de leur transition dans le réseau par
rapport aux paquets émis.
ü Latence : désigne le temps
nécessaire que prend un paquet de données pour passer de la
source à la destination à travers un réseau.
A cet effet, lebut de la qualité de service dans IP est
d'optimiser les ressources d'un réseau ou d'un processus et de garantir
de bonnes performances aux applications primordiales d'une organisation.
Cependant, dans le réseau IP, la qualité de service permet de
hiérarchiser, de contrôler et de recueillir les statistiques
comptables et de fournir des niveaux de services homogènes, aux
utilisateurs du réseau en gérant le trafic pour éviter la
congestion du réseau.
II.2
ADRESSAGE IP (IPv4 et IPv6)
L'adressage est l'une des premières fonctions des
protocoles de la couche réseau, il permet de mettre en oeuvre la
transmission de données entre des hôtes situés sur un
même réseau ou sur des réseaux différents.
D'après ce qui précède, une adresse IP peut être
appréhendé comme étant un identifiant unique
attribué à chaque interface (ordinateur ou
périphérique) avec le réseau utilisant le protocole IP et
associé à une machine (routeur, ordinateur, etc.). C'est une
adresse unicast utilisable comme adresse source ou comme destination.
II.2.1
Les types d'adressage IP et leurs affectations
Nous distinguons deux types d'adressages IP dont la version 4
et 6.
II.2.1.1 Adressage IPv4
II.2.1.1.1 Décomposition des adresses IPv4
L'adresse IP d'un hôte se divise en deux parties
distinctes dont la première se situant à gauche de l'adresse
indique l'adresse du réseau logique permettant
d'identifier l'adresse de sous-réseau et la seconde indique
l'adresse de l'hôtepermettant d'identifier la machine.
Un hôte désigne un équipement du réseau
possédant une adresse comme un ordinateur, routeur ou imprimante
réseau.

Pour illustrer ce qui précède, prenons l'exemple
de cette adresse : 192.168.52.85 avec le masque 255.255.255.0 :
Pour déterminer la partie réseau (netid) auquel
appartient un équipement, l'opération suivante est
réalisée :
net-id ? adresse IP ET bit à bit
Masque
Exemple : 192.168.52.0
? 192.168.52.85 & 255.255.255.0
Pour déterminer le numéro de l'hôte
(hostid) dans le réseau, l'opération suivante est
réalisée :
host-id ?adresse IP ET bit à bit Masque
Pour expliciter ce qui précède, prenons
l'exemple suivant :
0.0.0.85 ? 192.168.52.85
&0.0.0.255
L'utilisation du masque 255.255.255.255 donnera
l'adresse IP complète assignée à une machine.
II.2.1.1.2 Taille d'un réseau IPv4
On entend par taille d'un réseau, le masque qui
définit la taille d'un réseau IP : c'est-à-dire la plage
d'adresses assignables aux machines du réseau.
Prenons l'exemple d'un réseau 176.16.0.0 avec un masque
de 255.255.0.0. Quel est le nombre d'adresses machine de ce réseau ?
La réponse à la question
précédemment évoquée nous amène à
suggérer que : le masque 255.255.0.0 possède 16 bits
à 1 et découpe donc une adresse IP de la manière suivante
:
§ le netid fera donc 16 bits (valeur
fixée par le masque)
§ nombre de bits restant pour le hostid
: 32 - 16 = 16 bits.
Le nombre d'adresses machines de ce réseau sera donc :
216 - 2 = 65536 -2 = 65534 adresse machines. Et le nombre de bits
à 1 dans le masque de la manière suivante : 176.16.0.0/16.
II.2.1.1.3Types de réseaux adressable en IP
En ce qui concerne les types des réseaux adressables en
IP, nous en distinguons deux types :
o Une adresse IP dite
« Privée » est une adresse qui
n'est pas unique au niveau mondial et n'est utilisé qu'au sein d'un
réseau local. Elle se retrouve dans chacune de classe A, B et C comme
suit :
- Classe A : 10.0.0.0 à
10.255.255.255
- Classe B : 172.16.0.0à
172.31.255.255
- Classe C : 192.168.0.0 à
192.168.255.255
o Une adresse IP dite
« Publique » est une adresse unique au
niveau mondial et qui est attribué à des ordinateurs afin qu'ils
puissent trouver l'autre sur Internet. Elles permettent à ces derniers
de communiquer entre eux sur Internet tel que :
· Le réseau 127.0.0.0 est réservé
pour les tests de boucle locale avec notamment l'adresse IP 127.0.0.1 qui est
l'adresse « localhost », c'est-à-dire de boucle
locale de votre PC.
· Le réseau 0.0.0.0 est celui aussi
réservé et utilisé notamment pour définir une route
par défaut sur un routeur.
II.2.1.1.4 Adressage IPv4 des sous-réseaux
Pour segmenter un réseau en sous-réseaux, il
faut alors décomposer la partie hostid de l'adresse IP en deux parties :
une adresse de sous-réseau (subnetid) et une adresse machine (hostid)
comme l'illustre la figure ci-dessous :
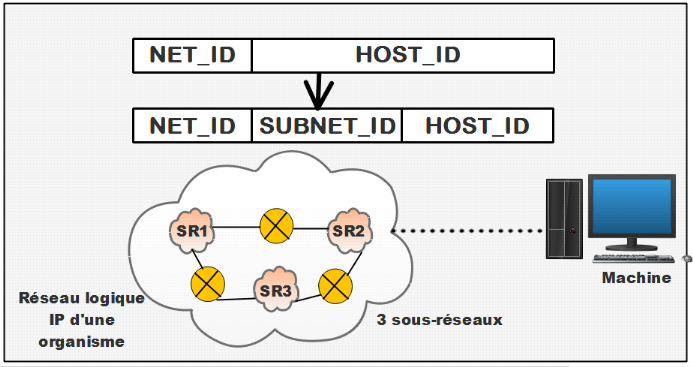
Figure II.5 : Segmentation d'un réseau logique
IP en plusieurs sous-réseaux [20]
Masque de sous-réseaux
Le masque de départ change et doit maintenant englober
la partie netid et la partie subnetid. Ce nouveau masque se nomme masque de
sous-réseaux.
Avantages des sous-réseaux
Maîtriser l'adressage et la segmentation du
réseau, l'utilisation des masques de sous-réseaux permet
d'optimiser le fonctionnement du réseau en segmentant de la façon
la plus correcte l'adressage du réseau (séparation des machines
sensibles du réseau, limitation des congestions, prévision de
l'évolution du réseau, etc ...)
Inconvénientsdes
sous-réseaux
Gérer des tables de routages plus complexes.
Malheureusement, la séparation d'un réseau en plusieurs
sous-réseaux n'a pas que des avantages. L'inconvénient majeur est
notamment la complexification des tables de routage, étant donné
le plus grand nombre de réseaux à «router».
II.2.1.2 Adressage IPv6
IPv6 est conçu pour remédier aux limitations
d'IPv4 et en même temps répondre à de nouvelles exigences
techniques apparues au niveau des réseaux ou des applications. Les
travaux principaux concernant IPv6 sont maintenant terminés. Voici une
explication synthétique des fonctionnalités principales du
protocole IPv6.
Les adresses IPv6 ont pour mission d'apporter un plus grand
nombre d'adresses. Une adresse IPv6 est composée de 128 bits contre 32
bits pour IPv4. Le nombre d'adresses IPv6 disponibles a été
estimé entre 1 564 et 3 911 873 538 269 506 102 adresses par
mètre carré (océans compris). On peut considérer le
nombre d'adresse IPv6 comme illimité. La représentation textuelle
d'une adresse IPv6 s'opère en découpant le mot de 128 bits de
l'adresse en 8 mots de 16 bits séparés par le caractère
":", chacun d'eux étant représenté en hexadécimal.
Pour illustrer ce qui précède,
prenons l'exemple de l'adresse ci-après :
fedc:0000:0000:0000:0400:a987:6543:210f
Dans un champ, il n'est pas nécessaire d'écrire
les 0 placés en tête et plusieurs champs nuls consécutifs
peuvent être abrégés par "::". Ce symbole ne peut
apparaître qu'une seule fois dans une adresse. L'adresse
précédente s'écrit donc en fait :
fedc::400:a987:6543:210f.
II.2.1.2.1 Architectures des adresses IPv6
Le grand nombre d'adresse IPv6 a permis de hiérarchiser
les adresses pour permettre de plus grands agrégats et une
réduction de la taille des tables de routage des routeurs de backbone
(coeurs de réseau).
Ci-dessous, la figure II.6 illustre le schéma d'une
adresse IPv6 unicast global:
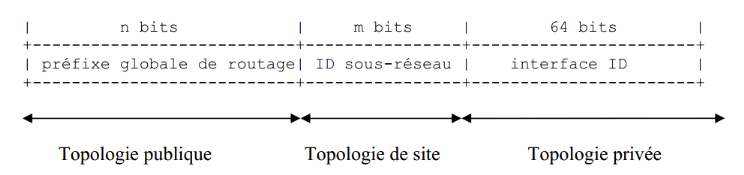
Figure II.6 : Adresse IPv6 [8]
Chaque partie est réservée à un usage
précis. Il est à noter que la partie publique de l'adresse peut
être encore amenée à certaines modifications. La partie
privée quant à elle gardera définitivement cette
structure.
II.2.1.2.2 Format d'un datagramme IPv6
Le format d'un datagramme IPv6 peut être décrit
de la manière ci-dessous :

Figure II.7 : Format d'un datagramme IPv6 [8]
Signification des différents champs :
- Version (4 bits) :Til s'agit de la version
du protocole IP que l'on utilise (ici la valeur de version est 6) afin de
vérifier la validité du datagramme.
- Classe du Trafic, en anglais Traffic Class (8 bits)
:T champ relatif à la classe de trafic au sens DiffServ
(Mécanisme qui permet de garantir la qualité de service).
- Label du Flux, en anglais Flow Label (20 bits)
:T champ relatif au flux d'information. Ce champ contient un
numéro unique choisi par la source, qui a pour but de faciliter le
travail des routeurs et la mise en oeuvre des fonctions de qualité de
service.
- Longueur de la "Charge Utile», en anglais
Payload Length (entier non-signé
sur 16 bits)
:T Longueur en octets de la charge utile, c'est-à-dire le reste
du paquet qui suit cet en-tête IPv6. (Il faut noter que tous les
en-têtes d'extension présents sont considérés comme
faisant partie de la charge utile, c'est-à-dire inclus dans le
décompte de la longueur).
- En-tête suivant, en anglais Next Header (8
bits) : Identifie le type de l'en-tête suivant
immédiatement l'en-tête IPv6. Utilise les mêmes valeurs que
le champ " protocole " d'IPv4.
- Nombre de Sauts Maximum, en anglais Hop Limit
(entier non-signé sur
8
bits) :décrémenté de 1
pour chaque noeud que le paquet traverse. Le paquet est éliminé
si le Nombre de Sauts Maximum arrive à zéro.
- Adresse Source, en anglais Source Address (128
bits) : adresse de l'expéditeur initial du paquet.
- Adresse Destination, en anglais Destination Address
(128 bits) : adresse du destinataire projeté du paquet
(qui peut ne pas être le destinataire ultime, si un en-tête de
routage est présent).
II.2.1.2.3 Les différents types d'adresses
IPv6
IPv6 reconnaît trois types d'adresses dont l'unicast,
multicast et anycast.
o Unicast : c'est le plus simple de
types d'adresses, elledésigne une interface unique c'est-à-dire
un paquet envoyé à une telle adresse, sera donc remis à
l'interface ainsi identifiée.
o Multicast : l'adresse de type
multicast désigne un groupe d'interfaces qui en général
appartiennent à des noeuds différents pouvant être
situés n'importe où dans l'Internet.
o Anycast : désigne un ensemble
de machines dans un domaine bien défini permettant de désigner un
service par une adresse bien connue.
II.2.1.2.4 Auto configuration des stations
Un autre objectif a été de supprimer les
commandes manuelles à fournir en IPv4 (adresse IP, passerelle par
défaut) pour que la connexion au réseau devienne "plug-and-play"
sans avoir à configurer de serveurs supplémentaires comme les
serveurs DHCP. Les 64 bits de poids fort de l'adresse IPv6 correspondent
à un identifiant de réseau et les 64 bits restants peuvent
être calculés en fonction de l'adresse physique de l'interface.
L'autoconfiguration est réalisée par la découverte des
voisins (« neighbor discovery ».
II.3
RESEAU INTERNET ET SON SERVICE BEST-EFFORT
Nous évoquerons ci-dessous le réseau Internet
qui n'est rien d'autres que l'interconnexion d'une multitude de réseaux
de diverses formes ainsi que son service de meilleur qualité
appelé « best-effort » qui permet de maintenir la
qualité de service de manière continuelle.
II.3.1
Réseau Internet
Le réseau Internet peut être
appréhendé comme étant un réseau informatique
mondial accessible au public, parfois appelé réseau des
réseaux, à commutation de paquets, sans centre
névralgique, composé de millions de réseaux
interconnectés capables d'échanger du trafic de données
à l'aide du protocole IP.
Cependant, chacun de ces réseaux ont une autonomie
technique et de fonctionnement nommé « domaine ».
Les domaines sont interconnectés les uns les autres par des liaisons
inter domaines au niveau de points d'interconnexion, les « peering
point ». Pour obtenir un accès à l'Internet, un domaine
a besoin d'un point d'interconnexion avec un autre domaine déjà
connecté à l'Internet.
II.3.2 Architecture de l'Internet
L'architecture Internet se fonde sur une idée simple :
demander à tous les réseaux qui veulent en faire partie de
transporter un type unique de paquet, d'un format déterminé par
le protocole IP. De plus, ce paquet IP doit transporter une adresse
définie avec suffisamment de généralité pour
pouvoir identifier chacun des ordinateurs et des terminaux dispersés
à travers le monde.
L'architecture précitée est illustrée
dans la figure ci-dessous :

Figure II.8 : Architecture Internet [24]
II.3.3 Service best-effort dans Internet
Le principe fondateur de l'Internet est d'offrir un
réseau fondé sur la brique IP offrant à cet effet, une
connectivité de bout en bout sans aucune garantie de service. Cette
technologie simple associée aux réseaux IP est parfaitement
adaptée aux services de type «Best Effort (BE)» ou service de
meilleur qualité fournis initialement dans Internet. A cet effet,
ce service s'avère important car il épargne les applications
d'expédier des requêtes avant de commencer à envoyer leurs
trafics et au cas où ces dernières n'arrivent pas à faire
acheminer leur trafic à cause du manque de capacité du
réseau. Il leur permet d'adapter leurs trafics en fonction de la
capacité disponible de manière permanente.
II.4
TECHNOLOGIE MPLS
II.4.1 Définition
MPLS est une technologie nouvelle qui utilise des
mécanismes de commutation de labels destinés à
réduire les coûts du routage. Son intérêt n'est
actuellement plus la rapidité de commutation par rapport au routage
d'adresse IP mais les services offerts. Un domaine MPLS est composé de
deux sortes de routeurs : les LSR et les ELSR. Les LSR sont les routeurs de
coeur capables de supporter le MPLS et les ELSR sont des routeurs permettant de
faire la transition entre le domaine MPLS et les autres réseaux par
exemple les clients IP.
II.4.2 Architecture physique
du réseau MPLS
Ci-dessous, nous présentons l'architecture physique du
réseau MPLS.

Figure II.9 : Architecture physique du réseau MPLS
[16]
II.4.3 Architecture logique
MPLS
L'architecture logique MPLS est composée de deux plans
principaux pour la commutation dans le réseau backbone :
- Plan de contrôle : Il permet de
créer et de distribuer les routes et les labels. Ainsi, il
contrôle des informations de routage, de commutation et de distribution
des labels entre les périphériques adjacents ;
- Plan de données : Il est connu
également sous le nom de « Forwarding Plane » et permet de
contrôler la transmission des données en se basant sur la
commutation des labels
Les différents composants MPLS sont dans la figure
ci-dessous :

Figure II.10 : Architecture logique du réseau MPLS
[17]
II.4.3.1 Plan de contrôle
Il est composé d'un ensemble des protocoles de routage
classique et de signalisation. Il est chargé de la construction, du
maintien et de la distribution des tables de routage et de commutation. Pour ce
faire, le plan de contrôle utilise des protocoles de routage classique
tels qu'IS-IS ou OSPF afin de créer la topologie des noeuds du
réseau MPLS et des protocoles de signalisation spécialement
développés pour le réseau MPLS comme LDP, MP-BGP
(utilisé par MPLS-VPN) ou RSVP (utilisé par MPLS-TE).
Dans un réseau MPLS, il existe deux méthodes
pour créer et distribuer les labels : « Implicitrouting » et
« Explicit routing ». Ces deux méthodes sont celles
utilisées pour définir les chemins LSP dans le réseau
MPLS.
II.4.3.1.1 La méthode « ImplicitRouting
»
Cette méthode est un modèle
orienté-contrôle fondé sur la topologie du réseau
où les labels sont créés à l'issue de
l'exécution des protocoles de routage classique. Il existe
également la distribution implicite des labels aux routeurs LSR.
Cette distribution est réalisée grâce au
protocole LDP où les labels sont spécifiés selon le chemin
« Hop By Hop » défini par le protocole de routage interne
classique IGP dans le réseau. Chaque routeur LSR doit donc mettre en
oeuvre un protocole de routage interne de niveau 3 et les décisions de
routage sont prises indépendamment les unes des autres comme l'illustre
la figure ci-dessous :
Figure II.11 : Routage implicite des labels [16]

II.4.3.1.2 La méthode « Explicit Routing
»
La méthode explicite est fondée sur les
requêtes (REQUEST-BASED) et consiste à ne construire une route que
lorsqu'un flux de données est susceptible de l'utiliser. Avec cette
méthode, le routeur Ingress ELSR choisit le chemin de bout en bout au
sein du réseau MPLS. Dans ce cas, la création des labels est
déclenchée lors de l'exécution d'une requête de
signalisation comme RSVP par exemple. Comme illustré dans la figure
ci-dessous.Cette méthode est utilisée pour CR-LDP (CR-LDP=LDP+TE)
et RSVP-TE. Et, le LSP n'est plus déterminé à chaque bond
contrairement au routage implicite.
Ce qui permet MPLS de faire du « Trafic Engineering
» afin d'utiliser efficacement les ressources du réseau et
d'éviter les points de forte congestion en répartissant le trafic
sur l'ensemble du réseau. Ainsi, des routes, autres que le plus court
chemin, peuvent être utilisées tel que décrit dans la
figure ci-dessous :

Figure II.12 : Routage explicite des labels [16]
II.4.3.1.3 Protocole de distribution des labels
LDP est un ensemble de procédures par lesquelles un
routeur LSR en informe un autre des affectations faites des labels. Ce
protocole LDP est bidirectionnel utilisé dans l'épine dorsale
MPLS. Les routeurs LSR se basent sur l'information de label pour commuter les
paquets labellisés et l'utilisent pour déterminer l'interface et
le label de sortie. Il définit de même un ensemble de
procédures et de messages permettant l'échange des labels et la
découverte dynamique des noeuds adjacents grâce aux messages
échangés par UDP tel qu'illustré dans la figure
ci-dessous :
Figure II.13 : Principe de fonctionnement d'un LDP
[17]

II.4.3.2 Plan de données
Le plan de données permet de transporter les paquets
labélisés à travers leréseau MPLSen se basant sur
les tables de commutations. Il correspond à l'acheminement des
données enaccolant l'en-tête SHIM aux paquetsarrivant dansle
domaine MPLS. Il est indépendant des algorithmes de routages et
d'échanges deslabels etutilise une table decommutation appelée
LFIBpour transférer les paquets labélisés avec les bons
labels.
Cette table est remplie par les protocoles d'échange de
label comme le protocole LDP.Apartir des informations de labels apprises par
LDP, les routeurs LSR construisent deux tablesla LIB et la LFIB. La
première contient tous les labels appris des voisins LSR et la seconde
est utilisée pour la commutation proprement dite des paquets
labélisés ainsi, la table LFIB est un sous ensemble de la base
LIB.
II.4.3.2.1 Table LIB (Label Information
Base)
Elle est la première table construire par le routeur
MPLS, elle contient pour chaque sous-réseau IP la liste des labels
affectés par les LSR voisins. Il est de même possible de connaitre
les labels affectés à un sous-réseau par chaque LSR voisin
et donc elle contient tous les chemins possibles pour atteindre la
destination.
II.4.3.2.2Table FIB (Forwarding Information Base)
Cette table est la base de données utilisé pour
acheminer les paquets non labélisés.
II.4.3.2.2 Table LFIB (Label Forwarding Information
Base)
La table LFIB est construit à partir de la table LIB et
de la table de routage IP du réseau interne au Backbone par chaque
routeur LSR afin d'être utilisée afin de commuter les paquets
labélisés. C'est ainsi que dans le réseau MPLS, chaque
sous-réseau IPest appris par un protocole IGPqui détermine le
prochain saut (NextHop) pour atteindre le sous-réseau.
II.4.4 Composants du réseau MPLS
Les composants du réseau Multi Protocol Label Switching
sont au nombre de 4 dont : le LSR, le LSP, le FEC et le LDP.
II.4.4.1 LSR (Label Switching Router)
C'est un routeur de coeur du réseau MPLS qui effectue
la commutation sur les labels et qui participe à la mise en place du
chemin par lequel les paquets sont acheminés. Lorsque le routeur LSR
reçoit un paquet labélisé, il le permute avec un autre de
sortie et expédie le nouveau paquet labélisé sur
l'interface de sortie appropriée. Le routeur LSR, selon son emplacement
dans le réseau MPLS, peut jouer plusieurs rôles à savoir :
exécuter la disposition du label (appelé déplacement),
marquer l'imposition (appelée poussée) ou marquer la permutation
en remplaçant le label supérieur dans une pile de labels avec une
nouvelle valeur sortante de label.
II.4.4.2. LSP (Label Switched Path)
C'est un chemin pour un paquet de données dans un
réseau basé sur MPLS ou une séquence de labels à
chaque noeud du chemin allant de la source à la destination. Les LSP
sont établis avant la transmission des données ou à la
détection d'un flot qui souhaite traverser le réseau. Il est
unidirectionnel et le trafic de retour doit donc prendre un autre LSP.
II.4.4.3 FEC (Forwarding Equivalent Class)
Il représente un groupe de paquets ayant les
mêmes propriétés. Tous les paquets d'un tel groupe
reçoivent le même traitement au cours de leur acheminement. Dans
le réseau MPLS, la transmission de paquets s'effectue par
l'intermédiaire de classes d'équivalence FEC. Contrairement aux
transmissions IP classiques, un paquet est assigné à une FEC une
seule fois lors de son entrée sur le réseau. Les FEC sont
basés sur les besoins en termes de service pour certains groupes de
paquets ou même un certain préfixe d'adresses.
II.4.4.4 LDP (Label Switch Path)
C'est un protocole permettant d'apporter aux LSR les
informations d'association des labels dans un réseau MPLS. Il est
utilisé pour associer les labels aux FEC pour créer des LSP. Les
sessions LDP sont établies entre deux éléments du
réseau MPLS qui ne sont pas nécessairement adjacents. Il
construit la table de commutation des labels sur chaque routeur et se base sur
le protocole IGP pour le routage.
Upstream and Downstream : Ce sont les deux modes de
distribution des labels utilisés par le protocole LDP dans un
réseau MPLS : Upstream pour le mode ascendant et Downstream pour le mode
descendant.
II.4.5 Principes MPLS
Le principe de base de MPLS est la commutation des labels qui
rend le concept de commutation générique car il peut fonctionner
sur tout type de protocole de niveau 2 comme illustré dans la figure
ci-dessous :

Figure II.14 : MPLS au niveau des couches [16]
Les routeurs MPLS, à l'intérieur de coeur du
réseau, permutent les labels tout au long du réseau
jusqu'à destination sans consultation de l'en-tête IP et la table
de routage. La commutation MPLS est une technique orientée connexion.
Une transmission des données s'effectue sur un chemin LSP et chaque
routeur MPLS, LSR possède une table de commutation associant un label
d'entrée à un label de sortie. La table de commutation est rapide
à parcourir dans le but d'accroître la rapidité de
commutation sur label par rapport à la table de routage du réseau
IP.
Le résumé du mécanisme se présente
comme suit : le « Ingress ELSR » reçoit les paquets IP,
réalise une classification des paquets dans un FEC en fonction du
réseau de destination, y assigne un label VPN et un label MPLS puis
transmet les paquets labélisés au réseau MPLS. En se
basant uniquement sur les labels, les routeurs LSR du réseau MPLS
commutent les paquets labélisés jusqu'au routeur de sortie «
Egress LSR » qui supprime les labels et remet les paquets à leur
destination finale comme l'illustre la figure ci-dessous :
Figure II.15 : Flux MPLS [17]

II.4.5.1 Label
Les labels sont des simples nombres entiers de 4 octets (32
bits) insérés entre les en-têtes des couches 2 et 3 du
modèle OSI. Un label a une signification locale entre deux routeurs LSR
adjacents et mappe le flux de trafic entre le LSR amont et le LSR aval. A
chaque bond, le long du chemin LSP, un label est utilisé pour chercher
les informations de routage (Next Hop, interface de sortie). Les actions
à réaliser sur le label sont les suivantes: insérer,
permuter et retirer. Un label MPLS se présente sous la forme telle
qu'illustrée dans la figure ci-dessous :

Figure II.16 : Détails d'un label MPLS [16]
La signification des différents champs est
donnée comme suit :
· Label (20 bits) : Valeur du label.
· Exp (3 bits) : Classe du service du
paquet.
· BS (1 bit) : Indicateur de fin de pile
(égal à 1 s'il s'agit du dernier label).
· TTL (8 bits) : Durée de vie du
paquet (évite les doublons).
Un label peut être mis en oeuvre dans les
différentes technologies ATM, Frame Relay, PPP et Ethernet
(Encapsulation). Pour les réseaux Ethernet, un nouveau champ
appelé « SHIM » a été introduit entre les
couches 2 et 3 comme l'indique la figureci-dessous :

Figure II.17 : Encapsulation pour ATM, Frame Relay
[16]
La technologie MPLS repose sur la technique de la commutation
de label, chaque paquet qui traverse le réseau doit donc être
capable de transporter un label. A cet effet, Il existe deux façons de
réaliser le transport des labels dans un réseau MPLS :
- La première solution de transport de labels est celle
appliquée aux protocoles de la couche 2 qui, transporte des labels
à l'intérieur même de leur en-tête (ATM, Frame
Relay). Dans le cas du protocole ATM, le label sera transporté dans le
champ « VPI/VCI » de l'en-tête et dans le cas du Frame Relay,
c'est le champ « DLCI » qui sera affecté à cette
tâche ;
- Pour la seconde solution, le label sera transporté
dans le champ « SHIM » qui sera inséré entre
l'en-tête de la couche liaison et l'en-tête de la couche
réseau. Cette technique permet de supporter la technique de commutation
de label sur n'importe quel protocole de la couche de liaison de
données
II.4.6 Sécurisation des réseaux MPLS
L'intérêt croissant des opérateurs
réseaux pour l'ingénierie de trafic et les nouveaux services
proposés par le protocole MPLS ont soulevé tout naturellement le
problème de sécurisation des réseaux dans le sens de la
tolérance de pannes.
Ainsi, nous pouvons le scinder en deux catégories dont
la restauration correspond aux solutions
réactives dont les LSR jouent un rôle important, car ils activent
les protocoles de re-routage dynamique afin de déterminer de nouveaux
chemins permettant de transférer le flux et la
protection correspond aux solutions proactives. C'est pourquoi
elles agissent en prévision de pannes en déterminant
anticipativement les chemins de re-routage appelé LSP de backup
ou chemin de protection. Ces LSP de backup doivent être
alloués comme les LSP principaux et prêts à accueillir le
trafic re-routé qui leur est dédié.
II.5
ROUTAGE DANS LE RESEAU IP/MPLS
Le routage est une fonctionnalité de la couche
réseau ayant pour responsabilité de décider sur quelle
interface de sortie, un paquet entrant doit être retransmis. Cependant,
nousdistinguons deux types de transfert de datagrammes entre autre la remise
directe qui s'opère entre les hôtes du même réseau et
la remise indirecte qui s'opère quand un routeur sépare
l'expéditeur initial à l'expéditeur final. Ainsi, nous
aborderons en ce point les protocoles de routage utilisé dans le
réseau IP/MPLS, à l'instar du protocole BGP, OSPF, IGP, IS-IS,
RIP.
II.5.1 BGP(Border Gateway Protocol)
BGP (Border Gateway Protocol) est un protocole de routage
utilisé pour l'échange d'informations de routage entre AS de
l'Internet. Les informations de routage se présentent sous la forme de
la suite des numéros d'AS à traverser pour atteindre la
destination.
Dans ce protocole, il existe trois grandes procédures
fonctionnelles définies de la manière ci-dessous :
- L'acquisition des noeuds voisins ;
- La possibilité d'atteindre le voisin ;
- La possibilité d'atteindre des réseaux.
Ci-dessous, la figure II.18 illustre le format du paquet de
mise à jour BGP.

Figure II.18 : Format du paquet de mise à jour BGP
[3]
II.5.2 OSPF(Open Shortest Path First)
OSPF (Open Shortest Path First : Chemin le plus court
d'abord) est un protocole d'état de liaison qui utilise une base de
données distribuées afin de garder en mémoire
l'état des liens. Ces informations forment une description de la
topologie du réseau et de l'état des noeuds permettant ainsi de
définir l'algorithme de routage par un calcul des chemins les plus
courts.
Cependant, avec les protocoles à état des liens,
chaque noeud est capable de détecter l'état du lien avec ses
voisins et le coût de ce lien. Il suffit de donner à chaque noeud
suffisamment d'informations, cela lui permettra de trouver la route la moins
chère vers toutes les destinations. Chaque noeud doit donc avoir la
connaissance de ses voisins. Si chaque noeud a la connaissance des autres
noeuds, une carte complète du réseau peut être
dressée. La dissémination fiable des
informations sur l'état des liens et le calcul des
routes par sommation des connaissances accumulées sur
l'état des liens et ajoute les propriétés
supplémentaires suivantes :
Authentification des messages de routage :
pour un noeud qui, à la suite de la réception de
messages erronés, volontairement ou non, ou de messages d'un attaquant
modifiant sa table de routage, calcule une table de routage dans laquelle tous
les noeuds peuvent être atteints à un coût nul reçoit
automatiquement tous les paquets du réseau. Ces dysfonctionnements
peuvent être évités en authentifiant les émetteurs
des messages.
Nouvelle hiérarchie : ce
mécanisme permet de partitionnerles domaines en ères (area), cela
signifie qu'un routeur à l'intérieur d'un domaine n'a pas besoin
de savoir comment atteindre tous les réseaux du domaine ; Il suffit
qu'il sache comment atteindre la bonne aire et entraine la réduction des
informations à stocker ou à transmettre. Ci-dessous, nous
présentons une architecture indiquant la place de BGP et OSPF.
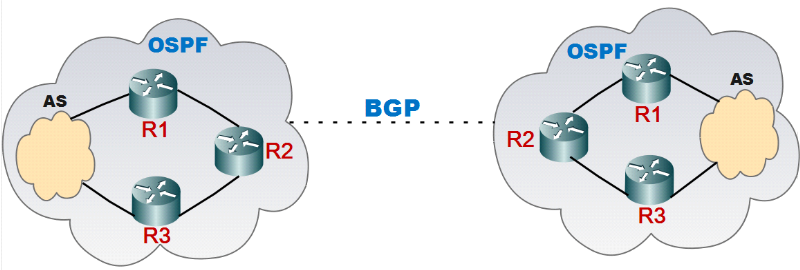
Figure II.19 : Architecture indiquant la place de BGP
et OSPF [21]
II.5.3 EBGP (Exterior Border
Gateway Protocol)
EBGP (Exterior Border Gateway Protocol) est le protocole de
routage utilisé entre deux systèmes autonomes dont les connexions
sont établies sur des connexions point-à-point ou sur des
réseaux locaux (un Internet Exchange Point par exemple),
le TTL des paquets de la session BGP est alors fixé à
1. Si la liaison physique est rompue, la session eBGP l'est également,
et tous les préfixes appris par celle-ci sont annoncés comme
supprimés et retirés de la table de routage.
II.5.4 I-BGP (InteriorBorder
Gateway Protocol)
I-BGP (InteriorBorder Gateway Protocol) est le protocole de
routage utilisé à l'intérieur d'un système autonome
dont les connexions sont établies entre des adresses logiques, non
associées à une interface physique particulière. Ceci
permet, en cas de rupture d'un lien physique, de conserver la session iBGP
active si un lien alternatif existe et si un protocole de routage interne
dynamique (IGP) est employé (en général OSPF et IS-IS).
Une fois la connexion entre deux routeurs établie,
ceux-ci s'échangent des informations sur les réseaux qu'ils
connaissent et pour lesquels ils proposent du transit, ainsi qu'un certain
nombre d'attributs associés à ces réseaux qui vont
permettre d'éviter des boucles (comme AS Path) et de
choisir avec finesse la meilleure route.
II.5.5 IGP (Interior Gateway
Protocol)
IGP (Interior Gateway Protocol) : est un
protocoleutilisé pour le routage au sein d'un système autonome.Il
est également appelé « Routage Intra-S.A » et
est utilisé par les entreprises (organisations) et même les
fournisseurs de services sur leurs réseaux internes.
Le protocole IGP permet :
o D'établir les routes optimales entre un point de
réseaux et toutes les destinations disponibles d'un système
autonome ;
o D'éviter les boucles ;
o En cas de modification de topologie (déconnexion d'un
lien physique, arrêt d'un routeur), d'assurer le rétablissement de
la connectivité optimale sans boucle dans les plus brefs
délais).
Nous présentons ci-dessous, une architecture dans
laquelle nous montronsla place des protocoles EBGP, IBGP et IGP.

Figure II.20: Architecture indiquant la place des
protocoles EBGP, IBGP et IGP [21]
II.5.6 EGP(Exterior Gateway
Protocol)
(Exterior Gateway Protocol) est un protocole de routage
permettant d'échanger les informations d'acheminement avec les
passerelles appartenant à d'autres systèmes autonomes.
Il présente trois caractéristiques
principales dont la première comporte un mécanisme d'acquisition
de voisinage permettant à un routeur de demander l'autorisation à
un autre d'échanger des informations d'accessibilité. La seconde
est la vérification performante par un routeur que ses voisins EGP
répondent et enfin, les routeurs voisins EGP échangent
périodiquement des messages de mise à jour de routage.
II.5.7 IS-IS(Intermediate
System to Intermediate System)
IS-IS(Intermediate System to Intermediate System) est un
protocole de routage interne multi-protocoles à état de lien. Il
utilise la taille de masque de réseau variable et utilise le multicast
pour découvrir les routeurs voisins en utilisant des paquets
« héllo ».
II.5.8 RIP (Routing
Information Protocol),
RIP (Routing Information Protocol), est un protocole de
routage IP de type à vecteur de distance. Il s'appuie sur l'algorithme
de détermination des routes décentralisées de Bellman-Ford
et permet à chaque routeur de communiquer aux routeurs voisins la
distance qui les sépare d'un réseau IP déterminé
quant au nombre de sauts.
Cependant, il existe deux versions de RIP, la première
s'avère très limitée et ne prend pas en charge les masques
de sous-réseaux de longueur variable ni l'authentification des routeurs
et la seconde améliore la précédente et répond aux
contraintes des réseaux actuels (découpages des réseaux IP
en sous-réseau, authentification en mot de passe).
Toutefois, ce protocole est limité et ne prend en
compte que la distance entre deux machines en ce qui concerne le saut, mais il
ne considère pas l'état de la liaison afin de choisir la
meilleure bande passante possible.
II.6
RESEAU PRIVE VIRTUEL
II.6.1 Définition
Le réseau privé virtuel est une liaison
permanente, distante et sécurisée entre deux sites d'une
organisation qui permet de transmettre de données cryptées par le
biais d'un réseau non sécurisé comme Internet. En d'autres
termes, Un VPN est l'extension d'un réseau privé englobant les
liaisons sur des réseaux partagés ou publics, permettant
d'échanger des données entre deux ordinateurs sur un
réseau partagé en utilisant une liaison privée point
à point comme l'illustre la figure II.21.

Figure II.21 : Architecture générale
d'un VPN [22]
II.6.2 Fonctionnement d'un réseau privé
virtuel
Le fonctionnement du VPN repose sur les protocoles de
tunnelisation (tunneling) permettant le passage de données
cryptées d'une extrémité du VPN à l'autre
grâce à des algorithmes. Le tunnel symbolise le fait que les
données soient cryptées et de ce fait incompréhensible
pour tous les autres utilisateurs du réseau public.
A cet effet, si le VPN est établi entre deux machines,
on appelle client VPN l'élément permettant de chiffrer et de
déchiffrer les données du côté utilisateur (client)
et serveur VPN ou d'accès distant l'élément chiffrant et
déchiffrant les données du côté de l'organisation.
Ainsi, lorsqu'un utilisateur désire accéder au VPN, sa
requête sera transmise en clair au système passerelle, qui se
connectera au réseau distant par l'intermédiaire d'une
infrastructure du réseau public, puis va transmettre la requête de
manière chiffrée. L'ordinateur distant va alors fournir les
données au serveur VPN de son niveau local et transmettre la
réponse de façon chiffrée. La réception sur le
client VPN de l'utilisateur, les données seront
déchiffrées.
II.6.3 Types de VPN
En ce qui concerne les types de VPN, nous en distinguons trois
dont le VPN d'accès, le VPN intranet ainsi que le VPN extranet.
II.6.3.1 Le VPN d'accès
Le VPN d'accès est utilisé pour permettre
à unutilisateur itinérant ou isolé de se connecter dans un
réseau local interne par exemple, de son entreprise. L'utilisateur se
sert d'une connexion Internet pour établir la connexion VPN. A cet
effet, cette connexion pourrait être établie de deux
manières distinctes :
· L'utilisateur demande au fournisseur d'accès de
lui établir une connexion cryptée vers le serveur distant :
il communique à cet effet avec le NAS (Network Access Server) du
fournisseur d'accès et ce dernier établit la connexion
cryptée.
· L'utilisateur possède son propre logiciel client
pour le VPN auquel il établit directement la communication de
manière cryptée vers le réseau d'entreprise.
Dans ce cas, il peut avoir son propre client VPN afin de se
connecter directement au réseau. Si non, il doit demander à son
FAI de lui fournir un serveur isolé et le serveur d'accès n'est
pas crypté tel qu'illustré dans la figure ci-dessous :

Figure II.22 : Architecture d'un VPN d'accès
[21]
II.6.3.2 L'Intranet VPN
L'intranet VPN est utilisé pour relier au moins deux
intranets entre eux. Ce type de réseau est particulièrement utile
au sein d'une entreprise possédant plusieurs sites distants. Le plus
important dans ce type de réseau est de garantir la
sécurité et l'intégrité de données. Une
entreprise peut utiliser ce type de VPN pour communiquer avec ses clients et
ses partenaires comme l'illustre la figure ci-dessous :
Figure II.23 : Architecture d'un VPN
Intranet [21]

II.6.3.3 VPN Extranet
Une entreprise peut utiliser le VPN extranet pour communiquer
avec ses clients, les fournisseurs et les partenaires au moyen d'un intranet
d'entreprise reposant sur une infrastructure partagée à l'aide de
connexions dédiées. Dans ce cas, il est fondamental que
l'administrateur du VPN puisse tracer les clients sur le réseau et
gérer les droits de chacun sur celui-ci.
Ci-dessous, la figure II.24 décrit l'architecture d'un
VPN Extranet.
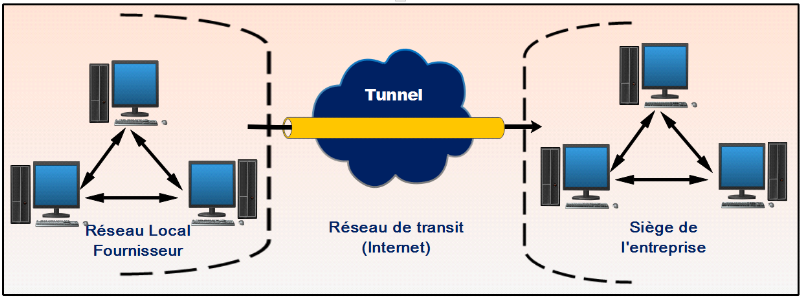
Figure II.24 : Architecture d'un VPN
Extranet [22]
II.6.4 Intérêt d'un VPN
Le réseau privé virtuel a pour tâche de
permettre de connecter de façon sécurisée des ordinateurs
distants au travers d'une liaison non fiable (Internet), comme s'ils
étaient sur le même réseau local. C'est dans cette optique
que de nombreuses entreprises l'utilisent afin de permettre à leurs
utilisateurs de se connecter au réseau d'entreprise hors de leur lieu de
travail.
II.7
PROTOCOLES DE TUNNELISATION
La tunnelisation peut être appréhendée
comme étant une technique permettant aux protocoles d'encapsuler dans
son datagramme un autre paquet de données complet utilisant un protocole
de communication différent. Un tunnel est ainsi créé entre
deux points sur un réseau afin de transmettre en toute
sécurité les données de l'un à l'autre. Cependant,
il existe plusieurs protocoles de tunnelisation dont chacun entre eux est
adapté à un objectif de tunnelisation spécifique comme le
protocole PPP, PPTP, L2F, L2TP, IPsec, MPLS et SSL.
II.7.1 Le protocole PPP
Le protocole PPP (Point-to-Point Protocol) est utilisé
dans les liaisons d'accès au réseau Internet ou sur une liaison
entre deux routeurs. Son rôle est d'encapsuler un paquet IP pour le
transporter vers le noeud suivant et sa fonction consiste à indiquer le
type des informations transportées dans le champ de données de la
trame. Le réseau Internet étant multiprotocole, il est important
de savoir détecter, par un champ spécifique de niveau trame,
l'application qui est transportée de façon à pouvoir
l'envoyer vers la bonne porte de sortie.
La trame du protocole PPP ressemble à celle de HDLC. Un
champ déterminant le protocole de niveau supérieur vient
s'ajouter juste derrière le champ de supervision comme illustrée
dans la figure II.25 ci-dessous :

Figure II.25 : Structure de la trame PPP
[3]
II.7.2 Le protocole PPTP
Le protocole PPTP (Point to Point Tunneling Protocol), est un
protocole qui utilise une connexion Point to Point Protocol à travers un
réseau IP en créant un réseau privé virtuel (VPN).
Il est en même temps une solution très employée dans les
produits VPN commerciaux à cause de son intégration au sein des
systèmes d'exploitation tels que Windows. Tout en étant un
protocole de niveau 2, Le PPTP permet aussi l'encryptage des données
ainsi que leur compression.
Le principe du protocole PPTP est de créer des paquets
sous le protocole PPP et de les encapsuler dans les datagrammes IP.
Le tunnel PPTP se caractérise par une initialisation du
client, une connexion de contrôle entre le client et le serveur ainsi que
la clôture du tunnel par le serveur. Lors de l'établissement
de la connexion, le client effectue premièrement une connexion avec son
Fournisseur d'Accès Internet. Cette première connexion
établira une connexion de type PPP et permettra la bonne circulation des
données sur Internet. Par la suite, quand la seconde connexion est
établie, les paquets PPP seront encapsulés dans des datagrammes
IP et formera ainsi le tunnel PPTP.
II.7.3 Le protocole L2F
Le protocole L2F, Layer 2
Forwarding, d'origine Cisco est un tunnel dit opérateur, il est
initialisé par le fournisseur d'accès (ISP,
Internet Service Provider) et se termine chez le client par un
équipement spécifique. Le protocole L2F n'assure
l'authentification de l'utilisateur qu'à la connexion. Le tunnel L2F ne
garantit pas la confidentialité des données (pas de chiffrement).
Cependant, un chiffrement utilisateur de bout en bout peut être mis en
oeuvre.
II.7.4 Le protocole L2TP
Le protocole L2TP (Layer 2 Tunneling
Protocol), est un protocole de tunnel opérateur (ouvert par le
provider), il autorise les appels outbounds (appels
initiés depuis l'intranet destination), il peut être
utilisé conjointement à IPSec pour chiffrer les données,
en-tête IP d'origine comprise, il tire son origine de l'IETF.
Pour réaliser les communications entre les BAS
(Broadband Access Server) et les serveurs, un protocole de tunneling doit
être mis en place puisque ce chemin peut être
considéré comme devant être emprunté par tous les
paquets ou trames provenant des différents DSLAM (Digital Subscriber
Line Access Multiplexer) et allant vers le même serveur. Le tunneling est
une technique courante, qui ressemble à un circuit virtuel. Les trois
protocoles utilisés pour cela sont PPTP (Point-to-Point Tunneling
Protocol), L2F (Layer 2 Forwarding) et L2TP (Layer 2 Tunneling Protocol). Ces
protocoles permettent l'authentification de l'utilisateur, l'affectation
dynamique d'adresse, le chiffrement des données et éventuellement
leur compression.
Le protocole le plus récent, L2TP, supporte
difficilement le passage à l'échelle, ou scalabilité, et
n'arrive pas à traiter correctement et suffisamment vite un nombre de
flots dépassant les valeurs moyennes.
II.7.5 Le protocole IPsec (IP sécurity)
Ce protocole introduit des mécanismes de
sécurité au niveau du protocole IP, de telle sorte qu'il y ait
indépendance des fonctions introduites pour la sécurité
dans IPsec vis-à-vis du protocole de transport. Le rôle de ce
protocole est de garantir l'intégrité, l'authentification, la
confidentialité et la protection contre les techniques rejouant des
séquences précédentes. L'utilisation des
propriétés d'IPsec est optionnelle dans IPv4 et obligatoire dans
IPv6. L'authentification, l'intégrité des données et la
confidentialité sont les principales fonctions de sécurité
apportées par IPsec. Pour cela, une signature électronique est
ajoutée au paquet IP. La confidentialité est garantie pour les
données et éventuellement pour leur origine et leur destination.
Ci-dessous, la Figure II.26 illustre le format des paquets IPsec.
Figure II.26 : Format des paquets IPsec
[3]

Dans un tunnel IPsec, tous les paquets IP d'un flot sont
transportés de façon totalement chiffrée. Il est de la
sorte impossible de voir les adresses IP ni même les valeurs du champ de
supervision du paquet IP encapsulé. La figure II.27 illustre un tunnel
IPsec.
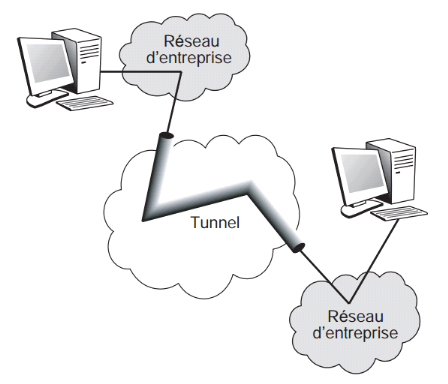
Figure II.27 : Tunnel IPsec [3]
II.7.6 Le protocole MPLS (Multi Protocol Label Switching)
Multi Protocol Label Switching est un protocole de routage
dont le rôle principal est de combiner les concepts de routage IP de
niveau 3, et les mécanismes de la commutation de niveau 2 telles
qu'implémentée dans ATM. Il doit permettre d'améliorer le
rapport entre la performance et le prix des équipements de routage,
d'améliorer l'efficacité du routage et d'enrichir les services de
routage.
Le principe premier de la commutation de labels est de
remplacer les traitements longs et complexes associés au relayage de
paquets IP par un traitement plus simple. Ainsi, cette commutation permet de
réduire fortement le cout de cette recherche dans la mesure où
elle n'est plus effectuée dans les équipements du coeur de
réseau. En fait, chaque équipement interne au coeur de
réseau effectue une seule fois la recherche au moment de la
création du chemin. Pour cela, un label est ajouté dans chaque
paquet par les routeurs en frontière du domaine. Ceux-ci peuvent choisir
le label en fonction de différents critères parmi lesquels on
retrouve généralement l'adresse de destination du paquet.
II.7.7 Le protocole SSL (Secure Sockets Layer)
SSL est un logiciel permettant de sécuriser les
communications sous http ou FTP. Ce logiciel a été
développé par Netscape pour son navigateur et les serveurs Web.
Le rôle de SSL est de chiffrer les messages entre un navigateur et le
serveur Web interrogé. Le niveau d'architecture où se place SSL
est illustré à la figure II.28 Il s'agit d'un niveau compris
entre TCP et les applicatifs.

Figure II.28 : Architecture SSL
[3]
Les signatures électroniques sont utilisées pour
l'authentification des deuxextrémitésdela communication et
l'intégrité des données. Et cette communication continue
par une négociation du niveau de sécurité à
mettreenoeuvre et peut se dérouler avec un chiffrement associé au
niveau négocié à la phase précédente.
Ci-dessous, la figure II.29 illustre une architecture plus
évoluée du protocole SSLv3.

Figure II.29 : Architecture du protocole SSLv3
[3]
CHAPITRE III : ETUDE DU SITE
[4], [13], [15], [22], [23], [25], [26], [27], [28]
Le troisième chapitre de notre travail porte sur
l'étude du site pouvant être appréhendé comme le
centre d'intérêt de nos investigations. Cependant, cette
étude est envisageable dans l'optique de recueillir des informations
nécessaires et relatives à la structuration, au fonctionnement et
à l'organisation d'une entreprise spécifique. A cet effet,
l'objet de ladite étude est surtout de nous permettre de faire une
analyse fine, émettre des critiques objectives et suggérer
quelques recommandations et propositions adéquates dans le but de
maximiser la qualité de service et de réduire des failles dans
les mécanismes de sécurité au sein de l'entreprise.
III.1
ANALYSE PREALABLE
L'analyse préalable peut être
appréhendée comme une analyse permettant de vérifier la
viabilité technique, économique et architecturale d'une
entreprise dont l'objectif primordial consiste à recenser les solutions
informatiques existantesainsi que les besoins en termes de nouvelles
fonctionnalités.
III.1.1 Présentation de l'entreprise
La Banque Centrale du Congoest un organisme
public doté d'une autonomie de gestion ayant pour mission principale de
maintenirla stabilité monétaire en République
Démocratique du Congo. Une stabilité qui ne peut être
effective qu'à travers l'application d'une politique monétaire
adéquate et conduisant à bon escient cette institution en vue de
l'obtention des résultats escomptés.
Outre ce qui précède, la Banque Centrale du
Congo a d'autres missions à accomplir telles que décrites
ci-dessous :
- Déterminer et gérer les réserves
officielles de l'Etat ; promouvoir le bon fonctionnement des
systèmes de compensation et de paiement ;
- Elaborer la réglementation et contrôler les
établissements de crédit, les institutions bancaires, de micro
finances et les autres intermédiaires financiers du pays ;
- Editer les normes et règlements des opérations
sur les devises étrangères ;
- Participer à la négociation de tout accord
international comportant des modalités de paiement et en assurer
l'exécution ;
- Promouvoir le développement des marchés
monétaires des capitaux ;
III.1.2 Situation géographique
La Banque Centrale du Congo est installée dans son
siège social sise n° 563, Boulevard Colonel Tshatshi dans la
commune de la Gombe. Elle est entourée, par le Ministère de la
Fonction Publique, le Palais de la nation, l'ISP Gombe et la Nonciature
Apostolique et son adresse postale est logée à la B.P 2697
à Kinshasa Gombe.
III.1.3 Organigramme et Directions

Ci-dessous, nous présentons l'organigramme
général ainsi que toutes les Directions de la Banque Centrale du
Congo.
Figure III.1 : Organigramme de la Banque
Centrale du Congo [15]
III.1.4 Direction de l'informatique
III.1.4.1 Evolution historique
Jadis, au sein de la Banque Centrale du Congo existait un
service dénommé « Service d'Organisation »,
rattaché à la Direction du Secrétariat
Général et un Service Informatique qui, détaché du
Secrétariat Général, dépendait de la Direction
Générale de la Banque. Mais au fil du temps, cette
dernière mettra sur pied une Direction de l'Informatique à part
entière dont la genèse date du 05 mars 1971 par l'ordre de
service numéro 201.
Cependant, cette genèse a amené à la
fusion de deux services précités ainsi, la nouvelle Direction a
été définie et arrêtée par l'ordre de service
numéro 206 du 07 mai 1971 dontla mission principale consistait à
étudier les problèmes de gestion qui se posait au sein de la
Banque afin de les éradiquer de manière adéquate. A cet
effet, cette restructuration nécessitera l'application des nouvelles
techniques du traitement de l'information dans le souci d'interconnecter toutes
les autres directions de la Banque pour une collaboration plus large ainsi
qu'une migration vers des structures meilleures et plus économiques.
Mais arrivé le 30 décembre 2000, la Direction
de l'Informatique et de la Recherche Opérationnelle (DIRO) sera
effectivement mise en place par l'ordre de service numéro 0072
même si cette configuration sera restructurée pour l'ultime fois
par l'ordre de Service n° 00202/05 du 24 novembre 2005 auquel elle lui a
été conférée les nouveaux organes et attributions
dans l'optique de la rendre plus dynamique et rationnelle.
III.1.4.2 Services de la Direction d'Informatique et
Organigramme
Au vue de la complexité de tâches que doit
accomplir cette direction, elle a été scindée en deux
Sous-directions,entre autre la Sous-direction Infrastructures et la
Sous-direction Développement. En dehors des Sous-directions
précitées, il existe trois services directement rattaché
à la Direction entre autre :
- Le service de secrétariat
administratif, qui a pour mission d'assurer à l'ensemble des
organes de la Direction les services administratifs et de la Logistique et de
gérer aussi de manière conséquente les ressources
matérielles ainsi que les indices budgétaires de la Direction.
- Le service d'infocentrea pour mission
d'assurer le suivi de la qualité des services rendus aux utilisateurs et
une assistance de premier niveau ; de proposer le planning et assurer
leurs formations sur les applications de bureautique et métier ;
développer, maintenir l'entrepôt des données pour le mettre
à la disposition des utilisateurs les outils d'aide à la
décision.
- - Service de Planification, Sécurité
et Changement a pour mission d'Edicter, contrôler et
assurer le suivi des mesures de sécurité informatique au sein de
la banque ; Elaborer et assurer le suivi du plan opérationnel de la
Direction de l'Informatique ainsi que le schéma directeur
informatique de la banque ;
III.1.4.2.1 La Sous-direction Infrastructures
Cette Sous-direction a pour mission d'assurer l'exploitation
des applications, d'évaluer, en collaboration avec les organes de la
Banque centrale, les besoins en équipements ; gérer les
équipements informatiques, de réseau, de sécurité,
de téléphonie et de télécommunication ainsi
que l'énergie, la climatisation dans les locaux techniques et l'espace
informatique et aussi de Coordonner la maintenance des infrastructures
informatiques et de télécommunication.
Cette sous-direction comprend quatre services :
· Le Service
Système conçoit et met en oeuvre l'infrastructure
système et les bases de données ; assure l'administration
technique des systèmes et logiciels ainsi que la gestion de messagerie,
la sauvegarde et le stockage des données informatiques
· Le Service
Exploitation réceptionne, installe, maintient et
entretient les postes clients ; crée et gère les comptes
clients dans le système ; assure l'exploitation des applications
informatiques et applique les règles de sécurité
informatique sur les équipements sous sa responsabilité.
· Le Service
Réseau installe, configure les fonctions réseaux du
système informatique et de télécommunication ainsi
que les dispositifs connectant la banque aux réseaux externes ;
assure la maintenance et l'administration des réseaux informatiques de
la Banque Centrale du Congo ;
· Le Service
Technique conçoit, gère et met en oeuvre les
systèmes intelligents de gestion d'énergie, de climatisation et
de téléphonie des locaux techniques ;assure la maintenance
des équipements de sécurité, de
télésurveillance et d'anti-incendie des locaux techniques et de
l'espace informatique ;
III.1.4.2.2 La Sous-direction Développement
La Sous-direction Développement a pour mission
d'évaluer en collaboration avec les utilisateurs, les besoins
d'informatisation des organes de la Banque ; analyser en collaboration
avec les partenaires concernés les besoins d'intégration des
logiciels et proposer le développement ou l'acquisition de nouveaux
logiciels.
Cette sous-direction comprend trois services :
· Le Service des applications des Systèmes
Comptables, Financiers et de Gestion est chargé de
développer et / ou de proposer l'acquisition des logiciels de
gestion des activités du domaine comptable et financier de la Banque
· Le Service Applications Economiques et
Monétaires est chargé de développer ou de
proposer l'acquisition des logiciels de gestion.
· Le Service Gestion Technique du Système
de Paiements : ce service est exclusivement dédié
à la gestion technique de l'organe chargé du système de
paiement.
DIRECTION
PLANIFICATION, SECURITE ET CHANGEMENT
INFOCENTRE
SECRETARIAT ADMINISTRATIF
SOUS-DIRECTION
DEVELOPPEMENT
SOUS-DIRECTION
INFRASTRUCTURES
SERVICE RESEAUX
SERVICE TECHNIQUE
SERVICE DE GESTION TECHNIQUE DU SYSTEME DE PAIEMENT
SERVICE DES APPLICATIONS ÉCONOMIQUES ET MONETAIRES
SERVICE EXPLOITATION
SERVICE SYSTEME
SERVICE DES APPLICATIONS DES SYSTEMES COMPTABLE, FINANCIER ET
DE GESTION
Ci-dessous, nous présentons l'organigramme de la
direction de l'informatique de la Banque Centrale du Congo.
Figure III.2 : Organigramme de la Direction de
l'informatique de la BCC [15]
III.1.4.3 Réseaux informatiques et
Interconnexion
La croissance des systèmes d'information, l'acquisition
des applications fiables de transmission de données, la gestion des
multiservices et le partage de ressources s'avèrent indispensables pour
une entreprise en vue d'optimiser la qualité de ses services. Soucieuse
de répondre à cesexigences, la BCC a mis sur pied un
réseau d'entreprise étendue (WAN) afin d'assurer le traitement,
l'échange et partage de ses ressources ; et pour ce qui est de
l'interopérabilité entre son siège principal avec toutes
ses représentations sur l'étendue du pays et à
l'étranger, elle se fait aux moyens des liens VSATafin de garantir
à ses utilisateurs l'accès sécurisé, le partage et
échange de ressources ainsi que la traçabilité de fonds,
moyens matériels et logistiques leurs alloués.
III.1.4.3.1 Type de matériels
Pour le déploiement de son architecture réseau,
le Banque Centrale a disposé des matériels
énumérés ci-dessous :
- Antennes VSAT avec Modem
- Switch fédérateur (Switch Cisco CATALYST 4506)
- Firewall et Routeur
- Switch Cisco Catalyst (2900)
- Fibres optiques câblage UTP et STP.
- Des ordinateurs clients, serveurs en fonction sur le
réseau actuellement.
- Serveur de vidéoconférence.
- Vidéos phones IP.
- Téléphones IP Cisco
III.1.4.3.2 Protocoles coeur
Comme protocole coeur, la Banque Centrale du Congo utilise le
PBB-TE (Provider Backbone Bridge - Traffic Engineering) afin de rendre plus
fiable, extensible et déterministe son réseau de grande
dimension.
III.1.4.3.3 Protocoles d'accès
La Banque centrale du Congo utilise la technologie NAP
(Network Access Protection) qui permet de contrôler l'accès
réseau hôte à partir de la conformité du
système hôte en question.
III.1.4.3.4 Topologie
L'architecture réseau de la BCC utilise une topologie
étoilée qui relie le point central qui est son siège,
aux directions provinciaux etcentre hospitalier.
III.1.4.3.5 Architecture

Ci-dessous, nous présentons l'architecture de la
B.C.C.
Figure III.3 : Architecture Réseau de
la B.C.C [25]
III.1.4.4 Le Backbone de la Banque
La Banque Centrale utilise les protocoles de routage dynamique
intra-domaine OSPF afin d'acheminer paisiblement les informations au sein de
son système et BGP pour l'échange d'informations entre les
différents sites. Il s'appuie sur la qualité et les performances
du média de communication touten employant une base de données
distribuée permettant de garder en mémoire l'état des
liaisons. En outre, elleprésente aussi quelques failles contraignantes
d'une part, par la complexité de sa configuration au cas où il
est segmenté en aires, et de l'autre, il est sensible au
phénomène de bagottement ou flapping.
Ci-dessous, nous illustrons l'architecture backbone de la
Banque Centrale du Congo.

Figure III.4 : Architecture Backbone de la BCC
[15]
III.1.4.5 Mécanismes de sécurité
Les mécanismes de sécurité
s'avèrent indispensables pour toute entreprise de manière globale
et bancaire de manière particulière, car la sauvegarde des
informations vitales, la restriction des accès malveillants aux
ressources matérielles ou logicielles et la perte des infrastructures
déployées dans une entreprise demeure une préoccupation
majeure. Au vue de ce qui précède, la Banque Centrale du Congo a
mis sur pied une politique de sécurité physique et logicielle
afin de sécuriser au maximum ses infrastructures réseaux et
maintenir ainsi, la qualité de service en son sein.
· La politique de sécurité
physique
Elle consiste essentiellement à se protéger
contre les vols, fuites d'eau, incendies, coupures d'électricité,
etc. Les règles génériques à considérer sont
les suivantes :
- Une salle contenant des équipements réseau ne
doit pas être vue de l'extérieur afin de ne pas attirer ou
susciter des idées de vol ou de vandalisme
- Des périmètres de sécurité
physique à accès restreint doivent être définis, et
équipés de caméras de surveillance
- Des procédures doivent autoriser et révoquer
l'accès aux périmètres de sécurité.
- Des équipements de protection contre le feu, l'eau,
l'humidité, les pannes de courant, le survoltage, etc., doivent
être installés.
- Des procédures de supervision des
éléments de protection doivent être mises en place.
- Les ressources critiques doivent être placées
dans le périmètre le plus sécurisé.
· La politique de sécurité
administrative et logique
Les contrôles d'accès constitués
de filtrages de paquets(pare-feu) et de relais applicatifs (proxy) est
l'un de mécanismes de sécurité appliqué à la
Banque Centrale du Congo afin d'autoriser un certain nombre de flux
réseau sortants (HTTP, FTP, SMTP, etc.) appliqués à
l'ensemble du réseau interne ou à certaines adresses. Elles
interdisent tout trafic non autorisé vers le réseau interne. Les
contrôles d'accès s'accompagnent d'une politique
définissant les règles suivantes à respecter :
§ Obligation est faite d'installer et de mettre à
jour le logiciel antivirus choisi par l'entreprise.
§ Interdiction d'utiliser tout outil permettant d'obtenir
des informations sur un autre système de l'entreprise.
§ Concernant les communications entre le réseau de
l'entreprise et un autre réseau, une politique spécifique de
contrôle d'accès précise les points suivants :
Définition des services réseau accessibles sur
Internet.
§ Définition des contrôles associés
aux flux autorisés à transiter par le périmètre de
sécurité pour vérifier, par exemple, que les flux SMTP,
HTTP et FTP ne véhiculent pas de virus. Ces contrôles peuvent
aussi concerner des solutions de filtrage d'URL pour empêcher les
employés de visiter des sites non autorisés par l'entreprise,
réprimés par la loi, ou simplement choquants (pédophiles,
pornographiques, de distribution de logiciels ou de morceaux de musique
piratés, etc.).
§ Définition des mécanismes de surveillance
qui doivent être appliqués au périmètre de
sécurité. Ces mécanismes concernent la collecte et le
stockage des traces (logs), les solutions d'analyse d'attaque, comme les sondes
d'intrusion, ou IDS (Intrusion Detection System), et les solutions d'analyse de
trafic ou de prévention d'intrusion IPS (Intrusion Preventing
System).
Les contrôles d'authentification des
utilisateurs s'effectuent à plusieurs passages, au niveau de la
sortie Internet, où chaque utilisateur doit s'authentifier pour avoir
accès à Internet, mais aussi au niveau de chaque serveur pour
accéder au réseau interne (serveurs de fichiers, serveurs
d'impression, etc.).
Chaque fois qu'un utilisateur s'authentifie, un ticket est
créé sur un système chargé de stocker les traces
(logs) afin que le parcours de l'utilisateur soit connu à tout moment de
manière précise.
Cette logique peut être généralisée
et entraîne la création d'une trace pour chaque action de
l'utilisateur sur chaque serveur (création, consultation, modification,
destruction de fichier, impression de document, URL visitée par
l'utilisateur, etc.).
Le mécanisme de Contrôle de
l'accès au réseau
Il permet de vérifier un certain nombre de points de
sécurité avant d'autoriser un système à se
connecter au réseau local. L'objectif est ainsi de contrôler les
accès au plus près de leurs sources.
Dans ce stade, le système qui désire se
connecter et le commutateur (ou le routeur) attaché au LAN doivent
intégrer la fonctionnalité NAC. Du point de vue de la
sécurité, il est toujours recommandé de choisir la
fonctionnalité NAC intégrée dans un commutateur mettant en
oeuvre les mécanismes de sécurité de VLAN (Virtual Local
Area Network), de contrôle des adresses MAC (Media Access Control), etc.,
qui sont moins permissifs que ceux d'un routeur, qui ne voit passer que des
trames IP.
Avant de se connecter au réseau, un dialogue
s'établit entre le système et le commutateur (ou routeur)
d'accès au réseau. Le commutateur (ou routeur) communique alors
avec un serveur de politiques de sécurité pour valider ou refuser
la demande d'accès du système au réseau. Et au cas
où l'un de ces contrôles n'est pas validé, le
système n'est pas autorisé à se connecter au
réseau.
III.1.4.6 Réseau virtuel privé de la Banque
Centrale du Congo
La Banque Centrale du Congodispose bel et bien d'une
infrastructure réseau mais l'utilise uniquement pour interopérer
avec l'Interpol (Organisation Internationale de Police Criminelle) pour
prévenir tout acte criminel pouvant être entrepris en son sein.
Partant par l'identification, la localisation des individus recherchés
sur la base de n'importe quel contrôle pour des fins d'extractions.
III.1.4.6.1 Architecture VPN de la BCC
L'architecture VPN de la BCC est celle d'un VPN Extranet le
reliant à l'Interpol qui est un des partenaires stratégiques de
la Banque par le moyen de l'Internet Public comme l'illustre la figure
ci-dessous :

Figure III.5 : Architecture VPN de la B.C.C
[25]
III.1.4.6.2 Topologie VPN
Le VPN de la BCC utilise une topologie étoilée
dont la caractéristique fondamentale est l'existence d'un point central
qui se comporte comme un hub concentrateur du trafic réseau et
dans le cas qui nous concerne, c'est le réseau Internet Public.
III.1.4.6.3 Protocole VPN
Au niveau protocolaire, le réseau privé virtuel
de la BCC utilise principale le protocole IPsec (Internet
Protocol Security) afin de sécuriser les communications par Internet sur
un réseau IP par le moyen d'un tunnel déployé pour
permettre à l'Interpol d'accéder à son intranet. Il
sécurise de même le protocole communication Internet et
vérifie chaque session avec un cryptage individuel des paquets de
données pendant toute la connexion.
III.2
CRITIQUE DE L'EXISTANT
La critique du système existant constitue une phase
trèscontraignante pour tout travail scientifique. Elle recherche de
manière objective à exhiber les performances et les failles qui
handicapent le bon déroulement et fonctionnement des processus d'un
système en vue de proposer un autre plus fiable et rationnel que le
système existant.
III.2.1 Critique sur les moyens humains
Les ressources humaines étant au coeur de tout
système, elles nécessitent qu'elles soient de hautes factures
pour une entreprise généralement et en particulier sur celle
axée dans le domaine bancaire d'envergure nationale. A cet effet, le
service de réseau de la BCC dispose bel et biend'un personnel
qualifié, laborieux, expérimenté et ingénieux
à la hauteur des missions lui conférées.
Cependant, cette entité devra être
restructurée au vue de la couverture du réseau, les
équipements réseaux déployés en son siège
principal et dans toutes les succursales, nécessitant parfois des
déplacements physiques des agents commis à ce service dans les
différents coins du pays. Ainsi, compte tenu de la multitude des
matériels, d'utilisateurs et la couverture réseau mise à
leur disposition, les contraintes précitées sont plausibles de
porter préjudice au bon fonctionnement de l'entreprise.
III.2.2 Critique sur les moyens matériels
Les moyens matériels sont indispensables pour toute
entreprise qui désire utiliser les nouvelles technologies de
l'information et de la télécommunication de manière
générale et de manière particulière les
technologies de réseau. Ainsi, la BCC utilise principalement les
matériels réseaux CISCO et Microsoft.Concernant l'état de
matériels, ceux déployés en son siège sont en bon
état dans l'ensemble, mais ceux des directions provinciales sont dans un
état préoccupant en raison des moyens logistiques, de
maintenabilité permanente et quelques contraintes qui s'imposent pendant
la migration des systèmes existants vers d'autres.
III.3
PROPOSITIONS DE SOLUTION ET RECOMMANDATION
Nous présentons premièrement
quelquespropositions de solution pouvant servircomme cahier de charge aux
décideurs afin qu'ils participent à l'évolution
technologique et architecturale de l'entreprise et ensuite nous formulerons
quelques recommandations.
III.3.1 Proposition de solution
L'entreprise étant un système complexe dans
lequel transitent de très nombreux flux d'information, sans un
dispositif de maîtrise de ces flux, elle peut très vite être
dépassée et ne plus fonctionner avec une qualité de
service satisfaisante. De ce fait, pour apporter la lumière aux
anomalies du système existant, nous pouvons proposer quelques solutions
nécessaires, dans le but d'améliorer la performance du coeur de
réseau de la Banque Centrale du Congo.
Préparations pour l'évolution du coeur
réseau
Pour préparer une bonne évolution du coeur
réseau, nous proposons dans un premier temps la création d'une
épine dorsale IP/MPLS permettant aux équipements coeur
réseaudistants de dialoguer entre eux. Ce Backbone IP sera un
réseau convergent capable de transporter tout type de trafic. Il sied de
préciser que le réseau IP traditionnel n'incorpore pas de
fonctionnalités de qualité de service en natif. Il fonctionne sur
le principe du « best-effort » et ne peut garantir la fourniture de
services à fortes contraintes comme les applications temps réel,
parmi lesquelles la voix.
A ce titre, nous proposons que pour maximiser les
mécanismes de la qualité de service de ce coeur de réseau,
il est impérieux d'utiliser le protocole MPLS qui est le mieux
adaptable
Mise en place d'un dorsal IP avec la qualité de
service (QdS) requise
Dans un réseau qui tend vers « TOUT IP », la
qualité de service est vraiment requise, d'où la mise en place
d'un dorsal IP/MPLS est la solution idéale. L'intérêt de
MPLS n'est pas seulement pour des fins de rapidité mais plutôt
l'offre de services qu'il permet, avec notamment les réseaux
privés virtuels (VPN) et le Trafic Engineering (TE), qui ne sont pas
réalisables sur des infrastructures IP traditionnelles. Avec ce type de
dorsal, la Banque Centrale du Congopourra promptement basculer tous ses
utilisateurs LS sur le dorsal IP/MPLS en leur offrant plus de débit et
d'autres services.
Proposition d'une topologie backbone IP/MPLS
Selon la localisation des sites abritant les
équipements du coeur réseau, nous proposons une topologie du
réseau IP/MPLS avec les différents points de présences
(PoP) arbitraires. Les routeurs utilisés sur un Backbone IP/MPLS sont en
général des routeurs modulaires compatibles avec l'IP/MPLS avec
des routeurs CISCO séries 7609 et 7200 ainsi des Switchs CISCO Catalys
séries 6500/3560.
Installation d'un centre de supervision du Core network
Dans le cadre de bien entretenir l'ensemble du réseau
particulièrement les coeurs de réseaux, il est nécessaire
de mettre en oeuvre une ingénierie de trafic efficace afin de suivre en
temps utile le fonctionnement des équipements du réseau. Comme la
plupart des opérateurs téléphoniques respectent l'approche
de la gestion de réseaux (RGT) préconisée et
normalisée par l'ISO, nous recommandons également la
création d'un centre (une grande salle équipée des
moniteurs) réservé uniquement pour la supervision des
équipements coeur réseau afin de pouvoir, non seulement
intervenir dans l'urgence en cas de problème, mais aussi anticiper
l'évolution du réseau, planifier l'introduction de nouvelles
applications et améliorer les performances pour les utilisateurs.
La
mise en place d'un VPN/MPLS
La mise sur pied d'un VPN/MPLS permettra à la Banque
d'interconnecter l'ensemble de ses sites distants de manière plus
sécuriséeparce qu'il garantitdes communications privées
contrairement au réseau IPsec et les données seront
achéminés entre les différents sites de l'entrepriseau
travers d'une connexion directe via un réseau opérateur.
Cependant, cette approche apporte premièrement une
facilité d'évolution, en réduisant les coûts et
temps de mise en oeuvre d'un nouveau site, qui peut être vu comme
extension du réseau local contrairement à un réseau IPsec
où les données transitent via Internet Public. Il sécurise
les données et garantie la qualité de service dans la mesure
où elle identifie les flux prioritaires et les acheminent intelligemment
et efficacement comme les paquets sensibles de type VoIP pouvant être
prioritaire que d'autres (messagerie instantanée, P2P etc.).
III.3.2 Recommandation
Notre recommandations'articule en deux volets. Le premier
s'adresse principalement aux décideurs de la Banque Centrale du Congo et
le second au manageren charge du service de réseau et
télécommunication de ladite entreprise.
Aux décideurs de la Banque Centrale du Congo, nous leur
recommandons de mettre leurs expertises enplace afin d'amorcer le processus de
recrutement des nouveaux ingénieurs et experts en la matière, non
seulement pour accroître la main d'oeuvre au sein dudit service, mais
également la qualité de service de l'entreprise. Cependant, nous
les exhortons en plus de disponibiliser les moyens financiers et logistiques
pour que ces ingénieurs et experts participent à des formations
et ateliers pertinents afin d'étudier profondément les
propositions leur suggérées et conduisent à bon escient la
migration vers un coeur de réseau plus dynamique.
Au responsable dudit service, nous lui recommandons de mettre
sur pied une structure engineering et de planification des réseaux
(coeur réseau). Celle-ci devra être composéedes experts
aguerris dans leurs spécialités respectives et permettre ainsi
aux planificateurs des réseaux de dimensionner les capacités, les
noeuds et des liens existantspour la prise des décisions judicieusessur
les caractéristiques des nouveaux équipements réseaux
à acheter.Ils assureront également la prévision du trafic
qui consiste à identifier les caractéristiques du trafic et les
besoins en bande passante des différentes applications qui devront
être supportées par les réseaux multiservices. Il s'agit
d'estimer le trafic de départ et d'arrivée pour chaque
catégorie d'abonnés et les indicateurs clés pour la
performance (KPI) devraient à cet effet, être le centre
d'intérêt des études engineering que devra effectuer cette
structure,car ce sont des paramètres clé qu'un administrateur
ougestionnaire du trafic utilise pour prévenir à une
éventuelle extension du système ou dimensionner les composants du
réseau.
CHAPITRE IV :
CONCEPTION ET DEPLOIEMENT DU NOUVEAU SYSTEME
[17], [18], [21], [23], [25], [28]
Tout au long de ce chapitre, nous nous sommes attelé
sur la conception et déploiement du nouveau coeur de réseau
basé sur la plateforme IP/MPLS. Partant de l'adressage des
équipements réseau qu'abritera cette infrastructure, nous avons
ensuite établi le routage avec des protocoles divers entre autre l'OSPF
pour établir la connectivité entre les différents routeurs
hébergés dans le réseau de l'opérateur, ensuite le
RIP pour l'interconnexion entre ces derniers et les routeurs du client
placés dans différents sites, le MPLS afin d'acheminer les
informations avec la technique de commutation de labels entre les routeurs
clients et enfin le BGP pour l'échange des informations de routage et
avons enfin appliqué la redistribution des routes.
IV.1 PRESENTATION DU
PROBLEME
Dans une entreprise disposant d'un réseau volumineux et
de contraintes de communications particulières, la disponibilité
d'un réseau de transport de données modulaires s'avère
incontournable vu les difficultés de transmission des paquets IP que
peut rencontrer ce réseau de transport. A cet effet, l'application de la
méthode de routage unicast par saut (de l'émetteur vers le
récepteur) opéré par ce type de réseau
s'avère manqué de flexibilité par le fait que certaines
restrictions inhérentes à sa structure sont
opérées.
Cependant, vu que dans ce type de réseau,
l'évolution matérielle est indéniable, il est
nécessaire de trouver les voies et moyens afin de mettre sur pied, une
infrastructure réseau devant assurer l'interconnexion absolue et
sécurisée entre plusieurs sites distants.
IV.2 CONCEPTION DU NOUVEAU
SYSTEME
La conception du nouveau système étant une phase
très capitale, sera axée sur trois (3) points essentiels entre
autre, le Schéma physique du coeur de réseau IP/MPLS, le
Schéma physique VPN/MPLS, Schéma fonctionnel du coeur IP/MPLS.
IV.2.1 Schéma physique
du coeur de réseau IP/MPLS
Le schéma physique du coeur de réseau IP/MPLS
est illustré dans la figure ci-dessous :
Figure IV.1 : Schéma physique du coeur
IP/MPLS

IV.2.2 Schéma physique
VPN/MPLS
Le schéma physique VPN/MPLS de la Banque Centrale du
Congo est présenté dans la figure ci-dessous :

Figure IV.2 : Le schéma physique
VPN/MPLS
IV.2.3 Schéma
Fonctionnel du coeur IP/MPLS
Ci-dessous, nous présentons le schéma
fonctionnel du coeur de réseau IP/MPLS.
Figure IV.3 : Le schéma fonctionnel du
coeur IP/MPLS

IV.3 PLAN D'ADRESSAGE
Un plan d'adressage sert à déterminer l'adresse
IP du réseau, du sous-réseau et donc des équipements
(ordinateur, imprimante, etc..) qui composent le réseau d'entreprise
afin de réduire les possibilités de connexion.
A cet effet, le tableau suivant montre le plan d'adressage de
notre réseau.
|
Routeurs
|
Interface
|
Adresse IP
|
Adresse Loopback
|
|
P1 (Provider router 1)
|
e0/0
|
192.168.15.12
|
1.1.1.1
|
|
e1/0
|
192.168.16.13
|
|
e2/0
|
192.168.16.15
|
|
P2 (Provider router 2)
|
e0/0
|
192.168.8.12
|
2.2.2.2
|
|
e1/0
|
192.168.9.13
|
|
e2/0
|
192.168.15.12
|
|
e3/0
|
192.168.9.15
|
|
PE1 (Provider Edge 1)
|
e0/0
|
192.168.11.12
|
3.3.3.3
|
|
e1/0
|
192.168.8.13
|
|
e2/0
|
192.168.13.14
|
|
e3/0
|
192.168.14.15
|
|
PE2 (Provider Edge 2)
|
e0/0
|
192.168.11.12
|
4.4.4.4
|
|
e1/0
|
192.168.9.13
|
|
e2/0
|
192.168.3.14
|
|
e3/0
|
192.168.16.15
|
|
PE3 (Provider Edge 3)
|
e0/0
|
192.168.3.14
|
5.5.5.5
|
|
e1/0
|
192.168.16.13
|
|
e2/0
|
192.168.6.14
|
|
e3/0
|
192.168.7.15
|
|
e4/0
|
192.168.9.15
|
Figure IV.4 : Plan d'adressage du
réseau
IV.5 DEPLOIEMENT (CONFIGURATION)
Le déploiement de notre coeur de réseau a
été réalisé grâce aux protocoles de routage
nous décrirons dans les lignes qui suivent.
IV.5.1 Présentation de protocole
Pour déployer notre coeur de réseau IP/MPLS nous
avons premièrement attribué des adresses aux routeurs et par le
moyen du protocole OSPF nous avons su appliqué le routage entre les
différents routeurs hébergés chez l'opérateur entre
autres le routeurs P1, P2, PE1, PE2 et PE3. Ensuite, nous nous sommes servi du
protocole RIP afin de dirigé le trafic vers les routeurs clients
déployés dans des sites distants et après le protocole
MPLS afin d'interconnecter tous les routeurs hébergés chez
l'opérateur afin de permettre l'acheminement de données au
travers de la technique de commutation de labels aux routeurs clients.
IV.5.2 Routage
Pour arriver à appliquer à bon escient le
routage nous avons parcouru les plusieurs étapes, que nous
décrirons succinctement ci-dessous :
IV.5.2.1 Routage avec le protocole OSPF
ü Routeur P1

ü Routeur P2

ü Routeur PE1

ü Routeur PE2

ü Routeur PE3

IV.5.2.2 Routage avec le protocole RIP
ü Routeur PE1

ü Routeur CE1

ü Routeur CE2

ü Routeur PE3

ü Routeur CE3

ü Routeur CE4

IV.5.2.3 Routage avec le protocole MPLS
ü Routeur P1

ü Routeur P2

ü Routeur PE1

ü Routeur PE2
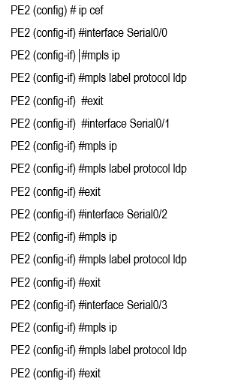
ü Routeur PE3

IV.5.2.4 Routage avec le protocole BGP
ü Routeur PE1
PE1 (config) #router bgp 500
PE1 (config-router) #neighbor 5.5.5.5 remote-as 500
PE1 (config-router) #neighbor 5.5.5.5 update-source loopback
0
PE1 (config-router) #address-family vpnv4
PE1 (config-router-af) #neighbor 5.5.5.5 activate
PE1 (config-router) #exit
PE1 (config) #exit
ü Routeur PE2
PE2 (config) #router bgp 500
PE2 (config-router) #neighbor 3.3.3.3 remote-as 500
PE2 (config-router) #neighbor 3.3.3.3 update-source loopback
0
PE2 (config-router) #address-family vpnv4
PE2 (config-router-af) #neighbor 3.3.3.3 activate
PE2 (config-router) #exit
PE2 (config) #exit
ü Routeur PE3
PE3 (config) #router bgp 500
PE3 (config-router) #neighbor 4.4.4.4 remote-as 500
PE3 (config-router) #neighbor 4.4.4.4 update-source loopback
0
PE3 (config-router) #address-family vpnv4
PE3 (config-router-af) #neighbor 4.4.4.4 activate
PE3 (config-router) #exit
PE3 (config) #exit
IV.5.2.4.1 Activation de la Vrf
ü Routeur PE1
PE1 (config) #ip vrf ce1
PE1 (config) #interface Serial0/3
PE1 (config-if) #no ip address
PE1 (config-if) #exit
PE1 (config-if) #interface Serial0/3
PE1 (config-if) #ip vrf forwarding ce1
PE1 (config-if) #ip address 192.168.14.15 255.255.255.0
PE1 (config-if) #no shutdown
PE1 (config) #ip vrf ce2
PE1 (config-if) #interface Serial0/2
PE1 (config-if) #no ip address
PE1 (config-if) #interface Serial0/2
PE1 (config-if) #ip vrf forwarding ce2
PE1 (config-if) #ip address 192.168.13.14 255.255.255.0
PE1 (config-if) #no shutdown
PE1 (config-if) #exit
PE1 (config) #router rip
PE1 (config-router) #no network 192.168.14.15
PE1 (config-router) #address-family ipv4 vrf ce1
PE1 (config-router-af) #network 192.168.14.15
PE1 (config-router) #no shutdown
PE1 (config-router) #no network 192.168.13.14
PE1 (config-router) #address-family ipv4 vrf ce2
PE1 (config-router-af) #network 192.168.13.14
PE1 (config-router-af) #exit
PE1 (config-router) #exit
PE1 (config) # exit
ü Routeur PE3
PE3 (config) #ip vrf ce3
PE3 (config) #interface Serial0/3
PE3 (config-if) #no ip address
PE3 (config-if) #exit
PE3 (config-if) #interface Serial0/3
PE3 (config-if) #ip vrf forwarding ce3
PE3 (config-if) #ip address 192.168.7.15 255.255.255.0
PE3 (config-if) #no shutdown
PE3 (config) #ip vrf ce4
PE3 (config-if) #interface Serial0/2
PE3 (config-if) #no ip address
PE3 (config-if) #interface Serial0/2
PE3 (config-if) #ip vrf forwarding ce4
PE3 (config-if) #ip address 192.168.6.14 255.255.255.0
PE3 (config-if) #no shutdown
PE3 (config-if) #exit
PE3 (config) #router rip
PE3 (config-router) #no network 192.168.7.15
PE3 (config-router) #address-family ipv4 vrf ce3
PE3 (config-router-af) #network 192.168.7.15
PE3 (config-router) #no shutdown
PE3 (config-router) #no network 192.168.6.14
PE3 (config-router) #address-family ipv4 vrf ce4
PE3 (config-router-af) #network 192.168.6.14
PE3 (config-router-af) #exit
PE3 (config-router) #exit
PE3 (config) # exit
IV.5.2.4.2 Activation du protocole rip dans la Vrf
ü Routeur PE1
PE1 (config) #router rip
PE1 (config-router) #no network 192.168.14.15
PE1 (config-router) #address-family ipv4 vrf ce1
PE1 (config-router-af) #network 192.168.14.15
PE1 (config-router-af) #exit
PE1 (config-router) #no network 192.168.13.14
PE1 (config-router) #address-family ipv4 vrf ce2
PE1 (config-router-af) #network 192.168.13.14
PE1 (config-router-af) #exit
PE1 (config-router) #exit
PE1 (config) #exit
ü Routeur PE3
PE3 (config) #router rip
PE3 (config-router) #no network 192.168.7.15
PE3 (config-router) #address-family ipv4 vrf ce3
PE3 (config-router-af) #network 192.168.7.15
PE3 (config-router-af) #exit
PE3 (config-router) #no network 192.168.6.14
PE3 (config-router) #address-family ipv4 vrf ce4
PE3 (config-router-af) #network 192.168.6.14
PE3 (config-router-af) #exit
PE3 (config-router) #exit
PE3 (config) #exit
IV.5.2.5 Redistribution des routes de bgp-rip et
rip-bgp
ü Routeur PE1
PE1 (config) #ip vrf ce1
PE1 (config-vrf) #rd 500 :1
PE1 (config-vrf) #route-target both 500 :1
PE1 (config-vrf) #exit
PE1 (config) #router rip
PE1 (config-router) #address-family ipv4 vrf ce1
PE1 (config-router-af) #redistribute bgp 500 metric
transparent
PE1 (config-router-af) #exit
PE1 (config-router) #exit
PE1 (config) #router bgp 500
PE1 (config) #redistribute rip
PE1 (config-router-af) #address-family ipv4 vrf ce1
PE1 (config-router-af) #redistribute rip
PE1 (config-router-af) #exit
PE1 (config-router) #exit
PE1 (config) #ip vrf ce2
PE1 (config-vrf) #rd 500 :1
PE1 (config-vrf) #route-target both 500 :1
PE1 (config-vrf) #exit
PE1 (config) #router rip
PE1 (config-router) #address-family ipv4 vrf ce2
PE1 (config-router-af) #redistribute bgp 500 metric
transparent
PE1 (config-router-af) #exit
PE1 (config-router) #exit
PE1 (config) #router bgp 500
PE1 (config) #redistribute rip
PE1 (config-router-af) #address-family ipv4 vrf ce2
PE1 (config-router-af) #redistribute rip
PE1 (config-router-af) #exit
PE1 (config-router) #exit
PE1 (config) #exit
ü Routeur PE3
PE3 (config) #ip vrf ce3
PE3 (config-vrf) #rd 500 :1
PE3 (config-vrf) #route-target both 500 :1
PE3 (config-vrf) #exit
PE3 (config) #router rip
PE3 (config-router) #address-family ipv4 vrf ce3
PE3 (config-router-af) #redistribute bgp 500 metric
transparent
PE3 (config-router-af) #exit
PE3 (config-router) #exit
PE3 (config) #router bgp 500
PE3 (config) #redistribute rip
PE3 (config-router-af) #address-family ipv4 vrf ce3
PE3 (config-router-af) #redistribute rip
PE3 (config-router-af) #exit
PE3 (config-router) #exit
PE3 (config) #ip vrf ce4
PE3 (config-vrf) #rd 500 :1
PE3 (config-vrf) #route-target both 500 :1
PE3 (config-vrf) #exit
PE3 (config) #router rip
PE3 (config-router) #address-family ipv4 vrf ce4
PE3 (config-router-af) #redistribute bgp 500 metric
transparent
PE3 (config-router-af) #exit
PE3 (config-router) #exit
PE3 (config) #router bgp 500
PE3 (config) #redistribute rip
PE3 (config-router-af) #address-family ipv4 vrf ce4
PE3 (config-router-af) #redistribute rip
PE3 (config-router-af) #exit
PE3 (config-router) #exit
PE3 (config) #exit
IV.5.3 Configuration
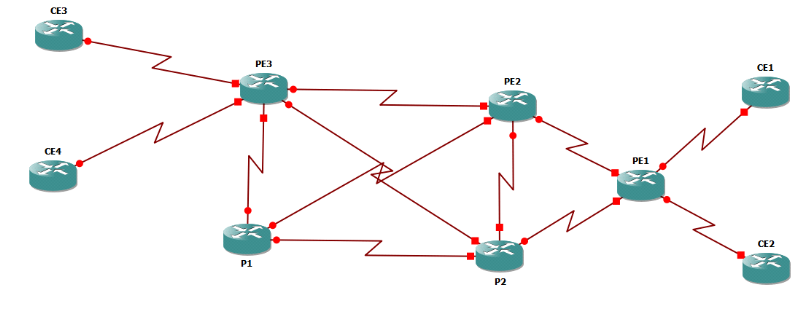
Nous présentons la configuration de notre coeur de
réseau IP/MPLS de la manière suivante :
IV.6 TEST
Après avoir réalisé notre coeur de
réseau IP/MPLS, nous allons tenter de tester nos différentes
routes de transit d'informations afin de nous assurer de l'effectivité
du fonctionnement de notre coeur de réseau.
IV.6.1 Test pour l'attribution
d'adresses aux routeurs
· Routeur P1
P1 (config) #do sh ip int brief
|
Interface
|
IP-Adress
|
Ok ?
|
Method
|
Status
|
Protocol
|
|
Interface FastEthernet 0/0
|
Unassigned
|
YES
|
Unset
|
Administratively down
|
down up
|
|
Serial0/0
|
192.168.15.12
|
YES
|
Manual
|
up
|
Up
|
|
Interface FastEthernet 0/1
|
unassigned
|
YES
|
Unset
|
Administratively down
|
down up
|
|
Serial0/1
|
192.168.16.13
|
YES
|
Manual
|
up
|
Up
|
|
Serial0/2
|
192.168.16.15
|
YES
|
Manual
|
up
|
Up
|
|
Serial0/3
|
unassigned
|
YES
|
Unset
|
Administratively down
|
down up
|
|
Serial0/4
|
unassigned
|
YES
|
Unset
|
Administratively down
|
down up
|
· Routeur P2
P2 (config) #do sh ip int brief
|
Interface
|
IP-Adress
|
Ok ?
|
Method
|
Status
|
Protocol
|
|
Interface FastEthernet 0/0
|
Unassigned
|
YES
|
Unset
|
Administratively down
|
down up
|
|
Serial0/0
|
192.168.15.12
|
YES
|
Manual
|
up
|
Up
|
|
Interface FastEthernet 0/1
|
unassigned
|
YES
|
Unset
|
Administratively down
|
down up
|
|
Serial0/1
|
192.168.16.13
|
YES
|
Manual
|
up
|
Up
|
|
Serial0/2
|
192.168.16.15
|
YES
|
Manual
|
up
|
Up
|
|
Serial0/3
|
unassigned
|
YES
|
Unset
|
Administratively down
|
down up
|
|
Serial0/4
|
unassigned
|
YES
|
Unset
|
Administratively down
|
down up
|
|
|
|
|
|
|
IV.6.2 Test pour le routage
avec le protocole OSPF
· Routeur P1
P1(config) #do sh ip rout
Codes : C - connected, S - static, R - RIP, M - mobile, B
- BGP
D - EIGRP, EX - EIGRP external, 0 - OSPF, IA -
OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF
external type 2
E1 - OSPF external type 1, E2 - OSPF external
type 2
i - IS - IS, su - IS - IS summary, L1 - IS
level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U
- per-user static route
Gateway of last resort is not set
C 192.168.15.0/24 is directly connected, Serial0/0
C 192.168.16.0/24 is directly connected Serial0/1
· Routeur P2
P2(config) #do sh ip rout
Codes : C - connected, S - static, R - RIP, M - mobile, B
- BGP
D - EIGRP, EX - EIGRP external, 0 - OSPF, IA -
OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF
external type 2
E1 - OSPF external type 1, E2 - OSPF external
type 2
i - IS - IS, su - IS - IS summary, L1 - IS
level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U
- per-user static route
Gateway of last resort is not set
C 192.168.15.0/24 is directly connected, Serial0/2
C 192.168.9.0/24 is directly connected Serial0/3
is directly connected Serial0/1
C 192.168.11.0/24 is directly connected Serial0/0
IV.6.3 Test pour le routage
avec le protocole RIP
· Routeur P3
P3(config) #do sh ip rout
Codes : C - connected, S - static, R - RIP, M - mobile, B
- BGP
D - EIGRP, EX - EIGRP external, 0 - OSPF, IA -
OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF
external type 2
E1 - OSPF external type 1, E2 - OSPF external
type 2
i - IS - IS, su - IS - IS summary, L1 - IS
level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U
- per-user static route
Gateway of last resort is not set
C 192.168.6.0/24 is directly connected, Serial0/2
C 192.168.7.0/24 is directly connected Serial0/3
is directly connected Serial0/4
C 192.168.16.0/24 is directly connected Serial0/1
C 192.168.3.0/24 is directly connected Serial0/0
· Routeur CE1
P3(config) #do sh ip rout
Codes : C - connected, S - static, R - RIP, M - mobile, B
- BGP
D - EIGRP, EX - EIGRP external, 0 - OSPF, IA -
OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF
external type 2
E1 - OSPF external type 1, E2 - OSPF external
type 2
i - IS - IS, su - IS - IS summary, L1 - IS
level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U
- per-user static route
Gateway of last resort is not set
C 192.168.14.0/24 is directly connected, Serial0/0
IV.6.4 Test pour le routage
avec le protocole MPLS
· Routeur PE1
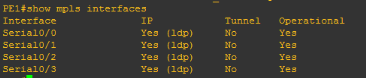
· Routeur P2

IV.6.5 Test pour le routage
avec le protocole BGP
· Routeur PE1
PE1# show ip bgp vpnv4 all summary
BGP router identifier 3.3.3.3, local AS number 500
BGP table version is 1, main routing table version 1
|
neighbor
|
V
|
AS
|
MsgRcvd
|
MsgSent
|
TblVer
|
InQ
|
OutQ
|
Up/Down
|
State/PfxRcd
|
|
5.5.5.5
|
4
|
500
|
6
|
6
|
1
|
0
|
0
|
00 :01 :20
|
0
|
· Routeur PE2
PE2# show ip bgp vpnv4 all summary
BGP router identifier 4.4.4.4, local AS number 500
BGP table version is 1, main routing table version 1
|
neighbor
|
V
|
AS
|
MsgRcvd
|
MsgSent
|
TblVer
|
InQ
|
OutQ
|
Up/Down
|
State/PfxRcd
|
|
3.3.3.3
|
4
|
500
|
6
|
6
|
1
|
0
|
0
|
00 :01 :20
|
0
|
|
|
|
|
|
|
|
|
|
|
· Routeur PE3
PE3# show ip bgp vpnv4 all summary
BGP router identifier 5.5.5.5, local AS number 500
BGP table version is 1, main routing table version 1
|
neighbor
|
V
|
AS
|
MsgRcvd
|
MsgSent
|
TblVer
|
InQ
|
OutQ
|
Up/Down
|
State/PfxRcd
|
|
4.4.4.4
|
4
|
500
|
6
|
6
|
1
|
0
|
0
|
00 :00 :33
|
0
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
IV.6.5.1 Test pour l'activation de la vrf
· Routeur PE1
ü Route allant vers le CE1
PE1 (config-router) #sh ip rout vrf ce1
Codes : C - connected, S - static, R - RIP, M - mobile, B
- BGP
D - EIGRP, EX - EIGRP external, 0 - OSPF, IA -
OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF
external type 2
E1 - OSPF external type 1, E2 - OSPF external
type 2
i - IS - IS, su - IS - IS summary, L1 - IS
level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U
- per-user static route
o - OOR, P - periodic download static route
Gateway of last resort is not set
192.168.14.15/30is subnetted, 1 subnets
C 192.168.14.15 is directly connected Serial0/3
ü Route allant vers le CE2
PE1 (config-router) #sh ip rout vrf ce2
Codes : C - connected, S - static, R - RIP, M - mobile, B
- BGP
D - EIGRP, EX - EIGRP external, 0 - OSPF, IA -
OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF
external type 2
E1 - OSPF external type 1, E2 - OSPF external
type 2
i - IS - IS, su - IS - IS summary, L1 - IS
level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U
- per-user static route
o - OOR, P - periodic download static route
Gateway of last resort is not set
192.168.13.14/30 is subnetted, 1 subnets
C 192.168. 13.14 is directly connected Serial0/2
ü Routeur PE3
· Route allant vers le CE3
PE1 (config-router) #sh ip rout vrf ce3
Codes : C - connected, S - static, R - RIP, M - mobile, B
- BGP
D - EIGRP, EX - EIGRP external, 0 - OSPF, IA -
OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF
external type 2
E1 - OSPF external type 1, E2 - OSPF external
type 2
i - IS - IS, su - IS - IS summary, L1 - IS
level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U
- per-user static route
o - OOR, P - periodic download static route
Gateway of last resort is not set
192.168.7.15/30is subnetted, 1 subnets
C 192.168.7.15 is directly connected Serial0/3
· Route allant vers le CE4
PE1 (config-router) #sh ip rout vrf ce4
Codes : C - connected, S - static, R - RIP, M - mobile, B
- BGP
D - EIGRP, EX - EIGRP external, 0 - OSPF, IA -
OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF
external type 2
E1 - OSPF external type 1, E2 - OSPF external
type 2
i - IS - IS, su - IS - IS summary, L1 - IS
level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U
- per-user static route
o - OOR, P - periodic download static route
Gateway of last resort is not set
192.168.6.14/30is subnetted, 1 subnets
C 192.168.6.14 is directly connected Serial0/2
Conclusion
générale
Au regard de ce qui précède, nous sommes
parvenus à mettre en place un coeur de réseau basé sur la
plateforme IP/MPLS offrant des mécanismes de routage et de transport de
données de manière sécurisée.
Certes, un réseau de transit s'avère être
la partie centrale offrant la connectivité entre les utilisateurs et les
différents services est indéniablement confronté aux
contraintes de communications et transport de trafic d'un très grand
nombre d'utilisateurs d'où, la nécessité d'y employer les
outils plus robustes et efficaces afin de pallier à ces
problèmes. C'est dans cette optique que nous nous sommes servis du
protocole MPLS (Multi Protocol Label Switching) afin de déployer un
réseau de transit robuste, utilisant les mécanismes de
commutation de labels en vue de réduire le coût de routage et
accroître la rapidité lors du trafic de données pour
l'optimisation effective de la qualité de service du réseau
informatique de la Banque Centrale du Congo.
Le système IP/MPLS que nous avons illustré,
permet un bon routage des données d'une façon
sécurisée, assurant la disponibilité des données,
une bonne qualité de service, minimiser les interférences etc.
Cependant, pour y parvenir nous avons utilisés Edraw
Max 8.0 comme logiciel de visualisation afin de concevoir nos
différentes architectures réseaux informatiques et organigrammes
et GNS3 (Graphical Network Simulator) qui est un simulateur de réseau
graphique. Il nous a permis de structurer et de simuler le fonctionnement de
notre coeur de réseau qui constituera le nouveau système que nous
proposons afin de répondre aux différentes préoccupations
que nous nous sommes posées dans la problématique.
En définitive, comme tout travail scientifique, nous
n'avons pas la prétention de réaliser un travail sans critique et
suggestion de la part de tout lecteur afin de le rendre meilleur.
Bibliographie
I. OUVRAGES
[1] A. Tanebaum : Réseaux et
Télécoms, Paris, Eyrolles, 2013
[2] C. Llorens, L. Levier, D. Valois :
Tableaux de bord de la sécurité
réseau, Paris, Eyrolles, 2008
[3] C. Servin : Réseaux et
Télécoms : Cours et Exercices Corrigés,
Paris,Dunod, 2003
[4] DG. Mutombo : Rapport Annuel de la Banque
Centrale du Congo, Kinshasa, BCC, 2015
[5] F. Lefessant : Point à Point :
Architectures et Services, INRIA Saclay, 2008
[6] G. Pujolle : Les
réseaux, Paris, Eyrolles, 2008
[7] G. Pujolle, O. Salvatori : Réseaux
et Télécoms : Cours et Exercices
Corrigés, Paris,Eyrolles, 2008
[8] JP. Lips : Réseaux : Protocole
IPv6, Nice, 2010
[9] L. Michel : Applications Client/Serveur et
Web,Paris, Licence Pro SIL, 2017
[10] M. Razzaghi, B. Rouvio, M. Santel :
Nouvelles Technologies Réseaux : Triple
Play, 2010
[11] O. Gluck : Architecture et communication
client/serveur, Lyon, 2016
[12] O. González : Architecture des
réseaux NGN, Johannesburg, ITU, 2005
II. NOTES DE COURS ET TRAVAUX DE FIN
D'ETUDES
[13] A. Musesa, Initiation à la Recherche
Scientifique ; Cours inédit, Faculté de
Sciences/UNIKIN, G2 Info, 2014
[14] D. Donsez, P2P
(Peer-To-Peer) ;Cours, Faculté de Sciences /
Université Joseph Fourier, 2002
[15] E. Mbuyi :
Télématique ; Cours inédit,
Faculté des Sciences / UNIKIN, G3 Info, 2015
[16] J. Ndwo, Rapport de stage
réalisé à la Banque Centrale du Congo ;
Stage, BCC, L2 Génie info, 2017.
[17] J. Vallet : Optimisation dynamique de
réseaux IP/MPLS ; Thèse en informatique,
Faculté des Sciences/ UNITOU-PS, 2015
[18] N. Saâda, Etude et optimisation d'un
backbone IP/MPLS ; TFE, Faculté des Sciences, UVITU,
2014
[19] P. Kasengedia : Architectures des
Systèmes Téléinformatique ; Cours
inédit, Faculté des Sciences / UNIKIN, L1
Génie Info,2016
[20] P. NKENDA, Phishing : mode de financement et
de propagation des groupes térroriste; TFE, Faculté
des Sciences, UNIKIN, 2006
[21] T. Vaira, Réseaux - Adressage IP ;
Cours, Ecoles Chrétiennes SJBS / Avignon, 2012.
[22] Z. Hamouda : Conception et optimisation
robuste des réseaux de
télécommunications ; Thèse en
Informatique, Faculté des Math., Info et Gestion / UNITOU-PS, 2010
III. WEBOGRAPHIE
[23] http://fr.zapmeta.com/réseau privé
virtuel visité en Septembre 2017
[24]
http://ram-0000.développez.com/tutoriels/réseau/ICMP
visité en février 2017
[25]
http://frameip.com/Vpn/visité
en février 2017
[26]
http://guide.boum.org/tomes/2visité
en février 2017
[27]
http://www.gsara.tv/neutralite/visité
en février 2017
[28]
http://www.hexanet.fr/telecoms/mpls-vpn-interconnexion-sites/visité
en janvier 2017
Table des
matières
Epigraphie
..........................................................................................i
Dédicace
...........................................................................................ii
Remerciements
...................................................................................iii
Liste de figures
...................................................................................iv
Liste d'abréviations
..............................................................................vi
0. INTRODUCTION GENERALE
1
0.1 Annonce du sujet
1
0.2 Problématique
2
0.3 Hypothèses
2
0.4 Intérêt du Sujet
3
0.5 Délimitation du travail
3
0.6 Méthodes & Techniques
utilisées
3
0.6.1. Méthodes utilisées
3
0.6.2 Techniques utilisées
4
0.7 Subdivision du travail
4
CHAPITRE I : ARCHITECTURES DES RESEAUX
5
I.1 MODELE OSI
5
I.1.1 Généralités
5
I.1.2 Définition
5
I.1.3 Découpage en couches
5
I.1.4 Description des couches du modèle
OSI
6
I.1.5 Transmission des données à
travers le modèle OSI
10
I.2 MODELE TCP/IP
11
I.2.1 Généralités
11
I.2.2 Présentation de l'architecture
TCP/IP
11
I.2.3 Description des couches du modèle
TCP/IP
11
I.3 OSI COMPARE A TCP/IP
12
I.4 ARCHITECTURE POINT A POINT
13
I.4.1 Généralités
13
I.4.2 Caractéristiques du point à
point
14
I.4.3 Fonctionnement de l'architecture point
à point
14
I.4.3 Avantages de l'architecture point à
point
16
I.4.4 Inconvénients de l'architecture point
à point
16
I.5 ARCHITECTURE CLIENT/SERVEUR
16
I.5.1 Généralités
16
I.5.2 Avantages de l'architecture
Client/Serveur
17
I.5.3 Inconvénients du modèle
Client/Serveur
17
I.5.4 Fonctionnement du modèle
Client/serveur
18
I.6 ARCHITECTURE TRIPLE-PLAY
18
I.6.1 Généralités
18
I.6.2 Architecture générale du triple
play
18
I.6.3 Triple play par ADSL
19
I.6.4 Télévision par ADSL
21
I.7 ARCHITECTURE DU RESEAU CONVERGENT
22
I.7.1 Généralités sur le NGN
(Next Generation Network)
22
I.7.2 Les exigences de tourner vers NGN
22
I.7.3 Caractéristiques du réseau
NGN
23
I.7.4 Architecture logique de réseau NGN
23
I.7.5 Architecture physique de réseau
NGN
25
I.7.6 Principaux équipements du
réseau NGN
28
I.7.7 Services offerts par les NGN
28
CHAPITRE II : CONCEPTION DE
RESEAU IP/MPLS
30
II.1 RESEAUX IP
30
II.1.1 Architecture physique d'un réseau
IP
30
II.1.2 Quelques protocoles utilisés par les
réseaux IP
31
II.1.3 La qualité de service dans IP
34
II.2 ADRESSAGE IP (IPv4 et IPv6)
34
II.2.1 Les types d'adressage IP et leurs
affectations
35
II.3 RESEAU INTERNET ET SON SERVICE BEST-EFFORT
40
II.3.1 Réseau Internet
40
II.3.2 Architecture de l'Internet
40
II.3.3 Service best-effort dans Internet
41
II.4 TECHNOLOGIE MPLS
41
II.4.1 Définition
41
II.4.2 Architecture physique du réseau
MPLS
42
II.4.3 Architecture logique MPLS
42
II.4.4 Composants du réseau MPLS
45
II.4.5 Principes MPLS
46
II.4.6 Sécurisation des réseaux
MPLS
48
II.5 ROUTAGE DANS LE RESEAU IP/MPLS
49
II.5.1 BGP (Border Gateway Protocol)
49
II.5.2 OSPF (Open Shortest Path First)
49
II.5.3 EBGP (Exterior Border Gateway Protocol)
50
II.5.4 I-BGP (Interior Border Gateway Protocol)
51
II.5.5 IGP (Interior Gateway Protocol)
51
II.5.6 EGP (Exterior Gateway Protocol)
52
II.5.7 IS-IS (Intermediate System to Intermediate
System)
52
II.5.8 RIP (Routing Information Protocol),
52
II.6 RESEAU PRIVE VIRTUEL
52
II.6.1 Définition
52
II.6.2 Fonctionnement d'un réseau
privé virtuel
53
II.6.3 Types de VPN
53
II.6.4 Intérêt d'un VPN
55
II.7 PROTOCOLES DE TUNNELISATION
55
II.7.1 Le protocole PPP
55
II.7.2 Le protocole PPTP
56
II.7.3 Le protocole L2F
56
II.7.4 Le protocole L2TP
57
II.7.5 Le protocole IPsec (IP sécurity)
57
II.7.6 Le protocole MPLS (Multi Protocol Label
Switching)
58
II.7.7 Le protocole SSL (Secure Sockets Layer)
58
CHAPITRE III : ETUDE DU SITE
60
III.1 ANALYSE PREALABLE
60
III.1.1 Présentation de l'entreprise
60
III.1.2 Situation géographique
60
III.1.3 Organigramme et Directions
61
III.1.4 Direction de l'informatique
62
III.2 CRITIQUE DE L'EXISTANT
69
II.2.1 Critique sur les moyens humains
69
II.2.2 Critique sur les moyens matériels
70
III.3 PROPOSITIONS DE SOLUTION ET
RECOMMANDATION
70
III.3.1 Proposition de solution
70
Préparations pour l'évolution du
coeur réseau
70
Installation d'un centre de supervision du Core
network
71
La mise en place d'un VPN/MPLS
71
III.3.2 Recommandation
72
CHAPITRE IV : CONCEPTION ET DEPLOIEMENT DU
NOUVEAU SYSTEME
73
IV.1 PRESENTATION DU PROBLEME
73
IV.2 CONCEPTION DU NOUVEAU SYSTEME
73
IV.2.1 Schéma physique du coeur de
réseau IP/MPLS
73
IV.2.2 Schéma physique VPN/MPLS
74
IV.2.3 Schéma Fonctionnel du coeur
IP/MPLS
75
IV.3 PLAN D'ADRESSAGE
75
IV.5 DEPLOIEMENT (CONFIGURATION)
76
IV.5.1 Présentation de protocole
76
IV.5.2 Routage
76
IV.5.3 Configuration
85
IV.6 TEST
85
IV.6.1 Test pour l'attribution d'adresses aux
routeurs
85
IV.6.2 Test pour le routage avec le protocole
OSPF
86
IV.6.3 Test pour le routage avec le protocole
RIP
87
IV.6.4 Test pour le routage avec le protocole
MPLS
87
IV.6.5 Test pour le routage avec le protocole
BGP
88
Conclusion générale
91
Bibliographie
92
Table des matières
94

| 

