Big data (rapport de stage)( Télécharger le fichier original )par Angeline KONE INSA Lyon - Mastère spécialisé SI 2013 |

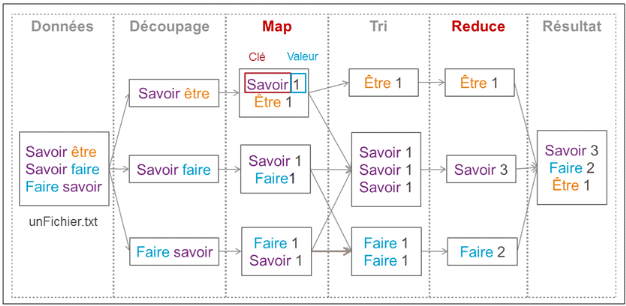
V.8.1.2 HDFSHDFS est le système de fichiers Java, permettant de gérer le stockage des données sur des machines d'une architecture Hadoop. Il s'appuie sur le système de fichier natif de l'OS (unix) pour présenter un système de stockage unifié reposant sur un ensemble de disques et de systèmes de fichiers. La consistance des données réside sur la redondance ; une donnée est stockée sur au moins n volumes différents. Le NameNode rendrait le cluster inaccessible s'il venait à tomber en panne, il représente le SPOF (maillon faible) du cluster Hadoop. Actuellement, la version 2.0 introduit le failover automatisé (capacité d'un équipement à basculer automatiquement vers un équipement alternatif, en cas de panne). Bien qu'il y ait plusieurs NameNodes, la promotion d'un NameNode se fait manuellement sur la version 1.0. Dans un cluster les données sont découpées et distribuées en blocks selon la taille unitaire de stockage (généralement 64 ou 128 Mo) et le facteur de réplication (nombre de copie d'une donnée, qui est de 3 par défaut). Un principe important de HDFS est que les fichiers sont de type « write-one » ; ce ci est lié au fait que lors des opérations analytiques, la lecture des données est beaucoup plus utilisée que l'écriture. V.8.1.3 MapReduceMapreduce qui est le deuxième composant du noyau Hadoop permet d'effectuer des traitements distribués sur les noeuds du cluster. Il décompose un job (unité de traitement mettant en oeuvre un jeu de données en entrée, un programme MapReduce (packagé dans un JAR (Java Archive : fichier d'archive, utilisé pour distribuer un ensemble de classes Java)) et des éléments de configuration) en un ensemble de tâche plus petites qui vont produire chacune un sous ensemble du résultat final ; ce au moyen de la fonction Map. L'ensemble des résultats intermédiaires est traité (par agrégation, filtrage), ce au moyen de la fonction Reduce. Le schéma ci-dessous présente le processus d'un traitement MapReduce.
Figure 6 : Processus d'un traitement MapReduce, (Bermond, 2013) Le MapReduce présenté sur le schéma permet de trouver le nombre d'occurrence des mots d'un fichier nommé ici « unFichier.txt ». Durant la phase de « Découpage », les lignes du fichier sont découpées en blocs. Puis lors de la phase « Map », des clés sont créées avec une valeur associée. Dans cet exemple une clé est un mot et la valeur est 1 pour signifier que le mot est présent une fois. Lors du « Tri », toutes les clés identiques sont regroupées, ici ce sont tous les mots identiques. Ensuite lors de la phase « Reduce » un traitement est réalisé sur toutes les valeurs d'une même clé. Dans cet exemple on additionne les valeurs ce qui permet d'obtenir le nombre d'occurrence des mots. |
|