I. Résumé
Mon stage de fin d'étude effectué au sein de
CAPGEMINI durant environ quatre mois s'inscrit dans le cadre d'un projet de
recherche & développement et veille technologique portant sur les
tendances et concepts technologiques Big Data. Les Big Data sont des
méthodes et des technologies pour des environnements évolutifs,
pour l'intégration, le stockage et l'analyse des données
multi-structurées (structurées, semi structurées et non
structurées). L'objectif de ce stage a consisté à monter
en compétence sur les technologies Big Data afin d'élaborer une
présentation commerciale des ces technologies, puis de faire des tests
techniques des composants de l'écosystème Hadoop (
framework
Java
libre, destiné
à faciliter la création d'applications
distribuées et
scalables) et
réaliser un démonstrateur Big Data illustrant des cas
d'utilisation du Big Data.
Ce rapport a pour but de donner un aperçu du stage que
j'ai effectué au sein de CAPGEMINI. On y trouve, dans une
première partie, une présentation de l'entreprise permettant de
dégager des informations sur l'environnement du travail au sein de cette
société. Dans la seconde partie, avant de présenter les
travaux effectués, la mission du stage et l'environnement technique de
travail sont présentés. Enfin la dernière partie est
consacrée au bilan du stage et la conclusion.
Remerciements
Ce rapport est le résultat d'une période
d'immersion dans le milieu professionnel. En préambule, je souhaite
adresser mes remerciements aux personnes que j'ai côtoyées durant
cette période et qui ont ainsi contribué à
l'élaboration de ce rapport.
Tout d'abord de grands remerciements à Monsieur Didier
CHEVRERE, mon tuteur d'entreprise, pour son aide et pour le temps qu'il a bien
voulu me consacrer.
Je remercie également Monsieur Pascal ESPINOUS et
Monsieur Olivier FIQUET qui ont su m'aiguiller vers leurs collègues
spécialisés dans certaines technologies que je devais utiliser
dans le cadre de mon travail ; je les remercie également pour leur
réactivité. Je tiens aussi à exprimer ma reconnaissance
à Kévin DEVAUX pour le support technique qu'il m'a apporté
durant ce stage.
J'aimerais également remercier toutes les personnes de
l'open space que j'ai rencontrées lors de la période de stage et
plus particulièrement à Monsieur Patrick GUYARD pour ses
connaissances de ma structure d'accueil et ses conseils.
Je remercie Ameline Bermond, la stagiaire qui m'a
précédé sur ce sujet de stage, pour sa
disponibilité et sa gentillesse.
J'exprime ma gratitude à toutes les personnes
rencontrées au sein de CAPGEMINI, qui ont accepté de m'apporter
un support et de répondre à mes questions avec gentillesse
malgré leur emploi de temps chargé.
J'adresse également mes remerciements à Monsieur
Jean Marie PINON, mon tuteur académique et tout le corps administratif
du mastère spécialisé informatique à l'INSA de
Lyon. Je remercie CAPGEMINI qui a m'a accordé cette opportunité
d'effectuer un stage en son sein.
Enfin, j'adresse mes sincères remerciements à
mes parents, ma fratrie et à tous mes proches et amis, qui m'ont
encouragé, aidé et soutenu durant cette année de
formation.
Que ceux-ci et ceux dont les noms n'y figurent pas, puissent
trouver l'expression de leur encouragement dans ce travail.
Sommaire
Résumé
I
Remerciements
II
Sommaire
III
Liste des abréviations
6
Introduction générale
7
I.
Présentation de l'entreprise et du contexte de stage
8
I.1 Présentation de L'entreprise
8
I.1.1 Historique et secteur
d'activité
8
I.1.2 Valeurs
9
I.1.3 Mission
10
I.1.4 Métiers et secteurs
d'activité
10
I.1.5 Partenariats et concurrence
11
I.1.6 Organisation
11
I.2 Contexte du stage
12
II.
Présentation de la mission lors du stage
14
II.1 Collecte et analyse de la
documentation
14
II.2 Tests techniques et montée en
compétence opérationnel
15
II.3 Réalisation de la plateforme de
démonstration
15
III. Les Big
Data
16
III.1 Présentation
16
III.2 Caractéristiques des Big
Data
16
III.3 Les Big Data en chiffres
16
III.4 Intérêts des Big Data
17
III.5 Enjeux des Big Data
17
III.5.1 Enjeux techniques
17
III.5.2 Enjeux économiques
17
III.5.3 Enjeux juridiques
18
III.6 Limites des Big Data
18
III.7 Paysage technologique des Big Data
19
III.7.1 Intégration
19
III.7.2 Stockage
20
III.7.3 Analyse
20
III.7.4 Restitution
21
III.8 Ecosystème Hadoop
21
III.8.1 Hadoop kernel
22
III.8.2 Composants Apache Hadoop
25
III.9 Solutions Big Data sur le
marché
27
IV. Solution mise
en place
29
IV.1 Choix de la solution et tests
techniques réalisés
29
IV.1.1 Architecture du cluster mise en
place
29
IV.1.2 Architectures des composants des
machines
30
IV.1.3 Déploiement de la
plateforme
32
IV.1.4 Tests techniques
réalisés
32
IV.2 Démonstrateur Big Data
38
IV.2.1 Création des jeux de
donnée de test
39
IV.2.2 Scénario d'exécution
des cas d'utilisation
40
IV.2.3 Création des programmes
MapReduce
42
IV.2.4 Restitution des données via
Hive
42
IV.2.5 Restitution des données via
QlikView
43
IV.3 Outils utilisés
46
V. Futur du Big
Data
48
VI. Bilan du
stage
49
VI.1 Planning prévisionnel
49
VI.2 Planning de réalisation
50
VI.3 Livrables
52
VI.4 Difficultés
rencontrées
52
VI.5 Solutions
53
VI.6 Projet big data
53
VI.7 Apport du stage
53
Conclusion
55
Références
bibliographiques
56
Liste des figures
57
Liste des tableaux
58
Liste des
abréviations
SOGETI : Société pour la
Gestion de l'Entreprise et Traitement de l'Information
ESN : Entreprise de Services du
Numérique
SSII : Société de Services
en Ingénierie Informatique
BPO : Business Process Outsourcing
(externalisation de processus métiers)
ALM : Application Lifecycle Management
CSD : Custom Software Development
PBS : Package Business Solution
ERP : Enterprise Resource Planning
(planification des ressources de l'entreprise)
CXP : Centre d'expertise des
logiciels
RFID : Radio Frequency Identification
(radio identification)
ETL : Extract, Transform and Load
EAI : Enterprise Application Integration
(Intégration d'applications d'entreprise)
EII : Enterprise Information
Integration
CRM : Customer Relationship Management
(gestion des relations avec les clients)
IDC :
International
Data Conseil
DSI :
Direction des Systèmes
d'Information
SQL : Structured Query Language
HDFS : Hadoop Distributed File System
SPOF : Single Point Of Failure
UDF : User Defined Function
UDAF : User Defined Aggregate Function
UDTF : User Defined Table Function
JDBC : Java DataBase Connectivity
ODBC : Open Database
Connectivity
CDH : Cloudera's Distribution including
apache Hadoop
SI : Système d'Information
POC : Proof Of Concept
API : Application Programming
Interface
R&D : Recherche et
Développement
II. Introduction
générale
Depuis les débuts d'internet jusqu'à 2003,
5 Exaoctets (1 exaoctet (Eo) =
1018 octets = 1 000 Po = 1 000 000 000 000 000 000 octets) de
données ont été générées. Avec la
venue du Web 2.0, la prolifération des réseaux sociaux, ...,
cette quantité de donnée était
générée en 2 jours. Actuellement, il
suffit de 10 minutes pour en produire autant. D'après
les prévisions, d'ici 2020 cette croissance sera supérieure
à 40 Zettaoctets
(1 zettaoctet (Zo) = 1021 octets =
1 000 Eo =
1 000 000 000 000 000 000 000 octets) et le
volume des données produites, diffusées et consommées en
l`espace d`une année, doublera tous les 2 ans.
Face à cette croissance exponentielle du volume de
données, les entreprises sont confrontées à certaines
problématiques qui sont celles de savoir comment collecter, stocker,
analyser et exploiter ces grands volumes de données pour créer de
la valeur ajoutée. Tout l'enjeu, pour les entreprises et les
administrations, consiste à ne pas passer à côté
d'informations précieuses noyées dans la masse. C'est là
qu'intervient la technologie du "Big Data", qui repose sur une
analyse très fine de masses de données.
Aujourd'hui, un fossé se creuse entre le potentiel
d'utilisation des données et l'utilisation actuelle. D'après
certaines sources, 23 % des données existantes
pourraient être valorisées, seulement 0,5% le
sont.
A l'heure où des technologies du Big Data sont en
gestation afin de répondre aux problématiques citées
ci-dessus, il est important pour les ESN qui veulent en tirer profit au moyen
de leur expertise, de faire d'ores et déjà de la veille
technologique. C'est dans ce contexte que ma mission dans le cadre du stage a
consisté à la réalisation d'un travail de Recherche &
Développement et de veille technologique des tendances et concepts
technologiques Big Data.
L'objectif était premièrement de monter en
compétence sur les technologies du Big Data afin de compléter la
documentation détaillée réutilisable à des fins de
présentation pour un client ou de formation interne. Le second objectif
était de réaliser une plateforme de démonstration en
exploitant les connaissances théoriques acquises afin de mettre en
oeuvre un cas d'utilisation du Big Data.
Ce travail permettra à CAPGEMINI de présenter
à ses clients des solutions (mises en oeuvre et expérimentions)
répondant à leurs besoins et donc il a la maîtrise de mise
en oeuvre de bout en bout et l'exploitation.
III. Présentation de l'entreprise et du contexte de
stage
III.1 Présentation de L'entreprise
III.1.1 Historique et
secteur d'activité
Crée en 1967 à Grenoble par Serge KAMPF sous le
nom SOGETI, CAPGEMINI est une ESN ex SSII. Depuis sa création, la
société à évolué à travers de
multiples acquisitions dans tous les secteurs d'activités liés
aux services informatiques comme la plupart de ses concurrents. Le groupe ne
cesse de se constituer, c'est ainsi qu'Euriware, filiale informatique du groupe
Areva sera probablement acquis par le groupe d'ici la fin de l'année
2013.
CAPGEMINI est la deuxième ESN en France. Ce classement
est réalisé sur la base du chiffre d'affaire (VISION IT
GROUP, 2013).
Le groupe Capgemini est divisé en trois
marques :
§ Capgemini Consulting : pour les
services de conseils.
§ Capgemini : pour les
intégrations de système et l'infogérance.
§ Sogeti : pour les services
informatiques de proximité.
Fort d'environ 125 000 collaborateurs et présent dans
44 pays, le Groupe a réalisé en 2012 un chiffre d'affaires de
10,264 milliards d'euros.

Figure 1 : Implantation de Capgemini dans le
monde
L'inde est le pays comptabilisant le plus grand nombre de
collaborateurs, devant la France qui vient en deuxième position.
III.1.2 Valeurs
Pour une culture de l'entreprise qui favorise un soutien
individuel et mutuel des collaborateurs et une véritable collaboration,
CAPGEMINI s'appui sur sept valeurs :
§ L'honnêteté, le refus de
toutes pratiques déloyales dans la conduite des affaires en vue
d'obtenir un contrat ou un avantage particulier
§ L'audace, le goût
d'entreprendre, de l'envie de prendre des risques et de s'engager, dans le
respect d'un principe général de prudence et de lucidité
sans lequel le manager audacieux peut se révéler dangereux
§ La confiance, elle implique la
volonté de responsabiliser les hommes et les équipes, et de
confronter les responsables aux effets de leurs actions et décisions. La
confiance implique également l'ouverture d'esprit et une grande
transparence dans la circulation de l'information
§ La liberté, ou encore la
créativité, l'innovation, l'indépendance d'esprit et le
respect des autres dans leurs cultures, leurs habitudes et leurs
différences, ce qui est indispensable dans un Groupe présent dans
plus d'une trentaine de pays et comptant plus d'une centaine de
nationalités différentes
§ La solidarité, la
capacité à partager solidairement les bons et les mauvais
moments
§ La simplicité, c'est la
discrétion, la modestie réelle, le bon sens, l'attention
portée aux autres et le soin mis à se faire comprendre d'eux,
c'est la franchise des relations dans le travail, la décontraction, le
sens de l'humour
§ Le plaisir, sans lequel tout projet
d'entreprise est difficile, voire impossible à réaliser.
III.1.3 Mission
Avec ses clients, CAPGEMINI conçoit et met en oeuvre
les solutions business et technologiques qui correspondent à leurs
besoins et leur apporte les résultats auxquels ils aspirent, c'est la
mission principale du groupe. CAPGEMINI permet à ses clients de
transformer leur organisation et d'améliorer leur performance dans
l'objectif de leur donner les moyens de réagir plus rapidement et plus
intuitivement aux évolutions du marché. Profondément
multiculturel, CAPGEMINI revendique un style de travail qui lui est propre, la
« Collaborative Business ExperienceTM »,
et s'appuie sur un mode de production mondialisé, le «
Rightshore® ». Ce style de travail consiste à
instaurer une collaboration au coeur l'exercice de ses activités, ainsi
les experts CAPGEMINI associent leurs forces à celles leurs
collaborateurs (clients) pour former une seule et même équipe.
III.1.4 Métiers
et secteurs d'activité
CAPGEMINI propose une large gamme de solutions et produits
liés à ses métiers et ses activités. Il
définit ses métiers en quatre grandes catégories :
§ Le consulting (conseil en management)
à travers CAPGEMINI Consulting : son rôle est d'aider les
chefs d'entreprise à identifier, structurer et mettre en oeuvre les
transformations qui amélioreront durablement leurs résultats et
leur compétitivité.
§ L'intégration des systèmes
: il s'agit de concevoir, développer et mettre en oeuvre tous
types de projets techniques comportant l'intégration de systèmes
complexes et le développement d'applications informatiques.
§ Les Services informatiques de
proximité à travers SOGETI : cette entité a pour
mission la fourniture de services informatiques répondant à des
besoins locaux en matière d'infrastructures, d'applications,
d'ingénierie, de tests et d'exploitation.
§ L'infogérance : il s'agit
de la prise en charge totale ou partielle du système d'information d'un
client (ou d'un regroupement de plusieurs clients) et des activités
métiers s'y rattachant (BPO) pour une durée moyenne de cinq ans,
mais qui peut aller jusqu'à dix ans, voire davantage.
Le portefeuille client de CAPGEMINI est reparti en en
différentes divisions opérationnelles qui couvrent les
différents secteurs d'activité, lesquels englobent le secteur
public, l'industrie, les services financiers, le commerce, la distribution et
le transport, l'énergie, la chimie, les
télécommunications, les médias et le divertissement.
III.1.5 Partenariats
et concurrence
Le groupe Capgemini a créé au cours de son
histoire des partenariats et des alliances stratégiques avec plusieurs
acteurs majeurs de l'informatique comme EMC², HP, IBM, Microsoft, Oracle,
Salesforce, SAP. Ces partenariats permettent à l'entreprise de placer
l'innovation au coeur de son activité avec pour objectif de stisfaire
ses clients.
Les concurrents du groupe Capgemini peuvent être
classés en trois catégories :
§ Les acteurs mondiaux qui comprennent
deux géants informatiques IBM et HP mais également des purs
acteurs de services informatiques tels que Accenture, CSC, Fujitsu ou NTT
Data.
§ Les acteurs offshore, essentiellement
d'origine indienne, qui sont des acteurs émergents des services
informatiques comme TCS, Infosys, Wipro, Cognizant ou HCL. Capgemini a
développé sa présence en Inde afin de contrer cette
concurrence et améliorer sa compétitivité.
§ Les acteurs régionaux qui sont
très nombreux mais qui n'ont généralement pas la
couverture géographique ou la profondeur de l'offre de Capgemini. En
Europe les plus importants sont Atos Origin, T-Systems, Siemens IT Services,
Indra et Steria, tandis qu'en Amérique du Nord, il s'agit de Lockheed
Martin, SAIC, CGI, Deloitte, Xerox.
III.1.6
Organisation
Le groupe Capgemini est constitué de cinq grandes
unités opérationnelles (Strategic Business Unit ou
« SBU ») différentes :
· Capgemini Consulting qui
délivre des services de conseil.
· Application Services qui se charge de
l'intégration de systèmes et la maintenance applicative et est
subdivisée en deux autres unités opérationnelles suivant
les régions géographiques :
o Application Services 1 (APPS1) pour l'Amérique du
Nord, le Royaume Uni et l'Asie/Pacifique (hors la Chine). Cette unité a
également la responsabilité mondiale du secteur des Services
Financiers.
o Application Services 2 (APPS2) pour la France, le Benelux,
les pays nordiques, l'Allemagne et l'Europe Centrale, l'Europe du Sud et
l'Amérique latine (hors Brésil).
· Infrastructure Services qui optimise
les infrastructures informatiques des entreprises clientes.
· Business Process Outsourcing (BPO) qui
propose une externalisation des services des entreprises clientes dans le
domaine de la finance/comptabilité, de la gestion de la chaîne
logistique (supply chain), de l'approvisionnement, de la gestion des
opérations clients, des services financiers et des ressources
humaines.
· Sogeti qui fournit des services de
proximité.
Figure 2 :
Organigramme des unités opérationnelles du groupe
Capgemini
Dans l'unité opérationnelle
« Application Services », il existe 4 divisions :
§ Services
§ Industries et Distribution
§ Télécom et Média
§ Aérospatiale et Défense
La division Industries et Distribution est elle-même
divisée en lignes de service ou Services Lines :
§ Application Lifecycle Management (ALM) : en charge
de la maintenance des solutions déployées chez les clients.
§ Custom Software Development (CSD) : en charge du
développement d'applications spécifiques adaptées aux
clients.
§ Package Business Solution (PBS) : en charge des ERP au
niveau fonctionnel et technique.
Durant mon stage, j'ai intégré la
société Capgemini au sein de l'unité opérationnelle
Application Services 2, dans la division Industries et Distribution et plus
précisément dans la partie Digital Industry de la ligne de
service Custom Software Development.
III.2 Contexte du stage
Dans un monde où la performance des entreprises devient
davantage synonyme de la maturité digitale, il faut prendre de l'avance
afin d'élaborer les solutions innovantes pouvant répondre aux
besoins sans cesse croissants de la clientèle, dans sa quête
perpétuelle de la performance. CAPGEMINI, en tant qu'un des leaders
nationaux et mondiaux des le domaine de services du numérique, anticipe
sur les éventuelles besoins clients en mettant en oeuvre des
technologies innovantes. C'est ainsi que les nouvelles solutions passent par
une étape de veille technologique où on s'informe sur les
technologies les plus récentes et la mise en oeuvre commerciale. Les Big
Data font donc partie des technologies récentes en cours de
gestation.
IV.
Présentation de la mission lors du stage
La mission du stage a débuté le 18 Juin 2013
pour prendre fin le 27 Septembre 2013. Au sein de l'équipe Digital
Industry rattaché au skil CSD de la division Industrie et distribution
de Lyon, ma mission consistait à :
§ Réaliser un travail de R&D et veille
technologique des tendances et concepts technologiques Big Data
§ Mettre en place les processus métiers Marketing
permettant la collecte, l'agrégation et l'exploitation des gros volumes
de données issus des usages digitaux
§ Mettre en place les processus métiers permettant
la collecte, l'agrégation et l'exploitation des gros volumes de
données issus de briques fondatrices du Legacy d'entreprise (ERP, CRM,
Supply Chain)
En intégrant le projet, une partie de la documentation
et des tests techniques avait déjà été
réalisée par la précédente stagiaire qui m'a
transmis ses compétences. Ma mission se résumait à prendre
connaissance du contexte du projet, des tâches déjà
effectuées ou non et de finaliser ces dernières. Les principaux
livrables étaient :
§ La documentation détaillée de
présentation des technologies Big Data
§ Les documents techniques des composants
déployés et des tests techniques réalisés
§ La réalisation d'une plateforme de
démonstration, mettant en oeuvre des cas d'utilisation du Big Data
La recherche et développement est un ensemble
d'activités entreprises de façon systématique dans
l'optique d'accroître des connaissances et l'utilisation de ces
connaissances pour de nouvelles applications, donc la réalisation
d'une initiative, d'un projet. Au sein de la R&D, on a plusieurs
tâches transversales dont la veille technologique, le
développement des technologies spécifiques et la protection des
innovations à l'aide des brevets. Les deux premières tâches
ont celles qui sont utilisées dans le cadre de ce projet. La veille
technologique consiste à s'informer systématiquement sur les
techniques les plus récentes et surtout sur leur mise en disposition
commerciale. Autrement dit, elle consiste à trouver les sources
d'informations pertinentes, puis analyser ces informations afin de mieux les
utiliser.
Pour parvenir à la réalisation de
différents livrables, il a fallut passer par différentes
étapes présentées ci-après.
IV.1 Collecte et analyse de la documentation
Aujourd'hui, ce ne sont pas des sources d'information qui
manquent, dans le monde virtuel, on peut penser aux sites des fournisseurs de
solutions, aux sites informatifs, aux divers blogs spécialisés,
aux livres blancs, etc. Cette étape a consisté à collecter
des informations sur internet et à parcourir de fond en comble toute la
documentation précédemment collectée, celle en cours de
production et celle que je devais rajouter. Je devrais également
m'intéresser aux solutions qui existent sur le marché et qui
répondent déjà aux problématiques des Big Data,
plus précisément la solution qui avait été
adopté pour la réalisation des tests techniques. Compte tenu du
fait que le monde du Big Data évolue sans cesse, il fallait aussi que je
me pencher sur les évolutions des versions des composants
précédemment utilisés. Après le parcours de la
documentation, a suivi l'analyse des informations afin d'extraire celles qui
était utiles pour la suite de mon travail.
IV.2 Tests techniques et montée en compétence
opérationnel
Après la collecte et l'analyse des informations, il
fallait passer à l'utilisation des informations extraites. Compte tenu
du fait qu'on ne dispose pas d'un temps infini pour monter en
compétence, il fallait être opérationnel le plus rapidement
possible pour avancer dans ma mission.
Ici, il fallait réaliser les tests des
fonctionnalités précédemment testées dans un nouvel
environnement (nouvelle version) tout en tenant compte des évolutions
apportées à l'ancienne version ; faire des tests techniques
qui n'avaient pas encore été faits et explorer les nouvelles
fonctionnalités.
IV.3 Réalisation de la plateforme de
démonstration
Cette étape devait s'appuyer sur les
précédentes. Elle devait me permettre de consolider les
connaissances acquises en mettant en oeuvre une plateforme de
démonstration.
V. Les Big Data
V.1
Présentation
Après le très en vogue "cloud computing", un
nouveau concept émerge dans le secteur informatique, celui du "Big
data". A l'origine du concept de "Big data" se trouve l'explosion du volume de
données informatiques, conséquence de la flambée de
l'usage d'Internet, au travers des réseaux sociaux, des appareils
mobiles, des objets connectés, etc.
Selon le CXP, les Big Data désignent des
méthodes et des technologies (pas seulement des outils) pour des
environnements évolutifs (augmentation du volume de données,
augmentation du nombre d'utilisateurs, augmentation de la complexité des
analyses, disponibilité rapide des données) pour
l'intégration, le stockage et l'analyse des données
multi-structurées (structurées, semi structurées et non
structurées).
V.2
Caractéristiques des Big Data
Le Big Data se caractérise par la problématique des
3V :
§ Volume, c'est le poids des
données à collecter. Confrontées à des contraintes
de stockage, les entreprises doivent aussi gérer le tsunami des
réseaux sociaux. La montée en puissance des réseaux
sociaux a accentué cette production de données.
§ Variété, l'origine
variée des sources de données qui sont
générées. premièrement, l'époque où
les entreprises s'appuyaient uniquement sur les informations qu'elles
détenaient dans leurs archives et leurs ordinateurs est révolue.
De plus en plus de données nécessaires à une parfaite
compréhension du marché sont produites par des tiers.
Deuxièmement, les sources se sont multipliées : banques de
données, sites, blogs, réseaux sociaux, terminaux
connectés comme les smartphones, puces RFID, capteurs, caméras...
Les appareils produisant et transmettant des données par l'Internet ou
d'autres réseaux sont partout, y compris dans des boîtiers aux
apparences anodines comme les compteurs électriques.
§ Vélocité, la vitesse
à laquelle les données sont traitées simultanément.
à l'ère d'internet et de l'information quasi instantanée,
les prises de décision doivent être rapides pour que l'entreprise
ne soit pas dépassée par ses concurrents. La
vélocité va du batch au temps réel.
A ces « 3V », les uns rajoutent la
visualisation des données qui permet d'analyser les
tendances ; les autres rajoutent la variabilité
pour exprimer le fait que l'on ne sait pas prévoir l'évolution
des types de données.
V.3 Les Big Data en
chiffres
Après le siècle du pétrole, nous entrons
dans l'ère de la donnée. Les chiffres ci-dessous permettent de
présenter la quantité de données
générées jusqu'ici et la croissance dans les prochaines
années.
« 12 zettaoctets de
données ont été créés dans le monde
en 2011
118 milliards
d'emails sont envoyés chaque
jour
235 téraoctets de
données ont été collectés
par The Library of Congress en avril
2011
30 fois plus de données seront
générées
d'ici 2020
Le télescope "Square
kilometers away" produira plus d'1 téraoctet de
données par minute en
2024
Twitter génère 7
téraoctets de données par
jour
Facebook génère 10
téraoctets de données par jour
Facebook traite 50 milliards
de photos
30 milliards de contenus sont
échangés chaque mois sur Facebook »
(Saulem, Définition de Big Data trois V variété,
volume, vélocité - Le big data.htm, 2013)
Nous pouvons bien constater que nous nageons dans un
océan de donnée où le niveau de la mer augmente
rapidement.
V.4
Intérêts des Big Data
L'utilisation des Big Data pourrait impacter fortement le
monde de l'entreprise et ce de façon méliorative, ainsi les
entreprises pourront :
§ Améliorer la prise de décision
§ Réduire les coûts d'infrastructures
informatiques via l'utilisation des serveurs standards et des logiciels open
source
§ Développer la réactivité et
l'interactivité à l'égard des clients
§ Améliorer les performances
opérationnelles
Tout ce ci orientera les entreprises vers une économie
centrée sur la donnée.
V.5 Enjeux des Big
Data
Le Big Data apparaît comme le challenge technologique
des années 2010-2020. Dépassant les domaines techniques et
informatiques, le Big Data suscite un vif intérêt auprès
des politiciens, des scientifiques et des entreprises. Les enjeux du Big Data
touchent plusieurs secteurs d'activités.
V.5.1 Enjeux techniques
Les enjeux techniques s'articulent autour de
l'intégration, le stockage, l'analyse, l'archivage, l'organisation et la
protection des données.
V.5.2 Enjeux
économiques
D'après le cabinet de conseil dans le marketing IDC,
« le marché du Big Data représentera 24 milliards de
dollars e 2016, avec une part de stockage estimée à 1/3 de ce
montant » (Saulem, Enjeux économiques du Big Data
à l'échelle mondiale - Le big data.htm, 2013). Il va sans
dire que la « donnée » est le nouvel or noir du
siècle présent, les spécialistes s'accordent
déjà sur le fait que le Big Data sera l'arme économique
de demain pour les entreprises et se présentera comme un levier qui fera
la différence.
Les entreprises collectent de plus en plus d'information en
relation avec leurs activités (production, stockage, logistique, ventes,
clients, fournisseurs, partenaires, etc), toutes ces informations peuvent
être stockées et exploitées pour stimuler leur croissance.
Les Big Data permettent :
§ D'améliorer les stratégies marketing et
commerciale
§ D'améliorer et entretenir la relation client
§ De fidéliser la clientèle
§ De gagner de nouvelles parts de marché
§ De réduire les coûts logistiques
§ De favoriser la veille concurrentielle
Le client est un acteur majeur dans ce contexte.
Jusqu'à présent, la vente consistait à se
demander « J'ai un produit, à qui vais-je pouvoir le
vendre? ». A l'ère du Big Data, nous devons changer le
paradigme pour dire « J'ai un client, de quoi a-t-il besoin
aujourd'hui ? ». En connaissant mieux son public, à
travers ses achats, ses activités sur Internet, son environnement, les
commerçants peuvent améliorer l'expérience-client,
exploiter la recommandation, imaginer le marketing prédictif (le
marketing prédictif regroupe les techniques de traitement et de
modélisation des comportements clients qui permettent d'anticiper leurs
actions futures à partir du comportement présent).
V.5.3 Enjeux juridiques
Le principal enjeu juridique dans un contexte où les
utilisateurs sont souvent des « produits », reste la
protection de la vie privée.
V.6 Limites des Big
Data
Si le terrain de jeu du Big Data est loin d'être
restreint, il n'est pas sans limites. Elles tiennent, en premier lieu, à
la nature des données et aux traitements envisagés, et lorsqu'il
est question des données personnelles, la vigilance est
nécessaire. Dans certains pays, le traitement des données
à caractère personnel est régi par des dispositions
particulières, ce qui n'est pas le cas dans la majorité des
pays.
Nous sommes arrivés à un point où la
protection des données personnelles, portée à la
défense des libertés fondamentales de l'individu, est en train de
devenir un argument économique. L'enjeu étant dorénavant,
d'élaborer le cadre normatif le plus attractif pour le
développement de l'économie numérique et des
échanges de données, ceci nécessite d'être vigilent
dans un contexte de forte concurrence entre les puissances économiques.
L'autre préoccupation provient de la
sécurité : une faille minuscule peut menacer des quantités
de données considérables. Si les
utilisateurs perdent confiance dans l'utilisation de leurs informations, c'est
donc tout l'édifice du big data qui risque de s'écrouler. Pour
éviter cela, par exemple en Europe, la commission européenne a
présenté, en début 2012, un règlement qui vise
à protéger davantage les utilisateurs. Ce texte devrait
être voté en 2014 pour une application en 2016, il obligera les
entreprises à demander le consentement explicite de l'utilisateur avant
de collecter ses données. (Haas, 2013)
V.7 Paysage
technologique des Big Data
Après la présentation des Big Data, il est aussi
important de voir le paysage technologique qui constitue cette technologie. Les
données quelque soit leur structure passent par plusieurs étapes
avant que leur valeur ne soit perceptible. Ci-dessus, nous avons un
aperçu global de différentes technologies présentes dans
le paysage Big Data.
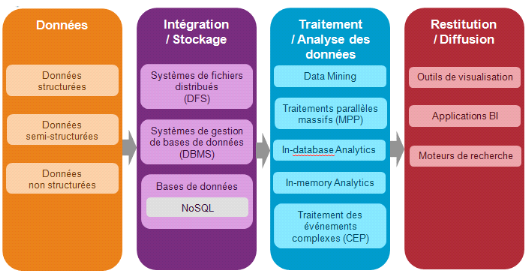
Figure 3 : Paysage technologique Big Data,
(Bermond, 2013)
Le Big Data repose sur plusieurs technologies, qui sont
utilisées pour exploiter les gigantesques masses de données.
V.7.1 Intégration
Dans le contexte Big Data, l'intégration des
données s'est étendue à des données non
structurées (données des capteurs, journaux Web, réseaux
sociaux, documents). Hadoop utilise le scripting via MapReduce ; Sqoop et
Flume participent également à l'intégration des
donnés non structurées. Ainsi, certains outils
d'intégration comprenant un adaptateur Big Data existe
déjà sur le marché ; c'est le cas de Talend
Enterprise Data Integration - Big Data Edition. Pour intégrer des gros
volumes de données issus de briques fondatrices du système
d'information des entreprises (ERP, CRM, Supply Chain (gestion de la
chaîne logistique)), les ETL, les EAI, les EII sont toujours
utilisés.
V.7.2 Stockage
Le premier élément structurant dans le contexte
Big Data est le socle de stockage des données. Anciennement, la solution
était les DatawareHouse (entrepôts de données), qui ont
évolué pour supporter de plus grandes quantités de
données et faire porter par le stockage, une capacité de
traitement étendue. Les solutions de DatawareHouse ont toutes en commun
un modèle de données profondément structuré
(schéma, base de données, tables, types, vues, etc) et un langage
de requête SQL.
Le Big Data vient rompre cette approche ; l'approche du
Big Data consiste en 2 grands principes.
Premièrement, le principe de la scalabilité
(horizontale) des clusters de traitement. Puis deuxièmement, on peut
s'affranchir de certaines contraintes inhérentes aux bases de
données relationnelles traditionnelles et qui ne sont pas
forcément nécessaires pour le Big Data. C'est le cas de
l'ACIDité (Atomicité, Cohérence, Isolation et
Durabilité). (Mathieu Millet, 2013)
Pour mettre en oeuvre cette approche avec une infrastructure
simple, scalable (mot utilisé pour indiquer à quel point un
système matériel ou logiciel parvient à répondre
à une demande grandissante de la part des
utilisateurs,
il traduit aussi la capacité de montée en charge), du
matériel à bas coût, le framework Hadoop est utilisé
pour la gestion du cluster, l'organisation et la manière de
développer. La solution la plus emblématique de cette approche
est Hadoop et son écosystème.
V.7.3 Analyse
C'est bien de pouvoir stocker les données, mais faut-il
pouvoir également les rechercher, les retrouver et les exploiter :
c'est l'analyse des données. Elle est naturellement l'autre volet
majeur du paysage technologique du Big Data. En la matière, une
technologie qui s'impose, Hadoop. Ce projet applicatif fait l'unanimité
même s'il est loin d'être stable et mature dans ses
développements. Hadoop utilise MapReduce pour le traitement
distribué.
MapReduce est un patron d'architecture de développement
informatique introduit par Google qui permet de réaliser des calculs
parallèles de données volumineuses (supérieures à 1
téraoctet). Les calculs peuvent être distribués sur
plusieurs machines ce qui permet de répartir les charges de travail et
d'ajuster facilement le nombre de serveurs suivant les besoins.
Plusieurs implémentations de MapReduce existent dont
les plus connues sont l'implémentation réalisée par Google
nommée Google MapReduce et l'implémentation Apache MapReduce.
L'implémentation de Google est propriétaire alors qu'Apache
MapReduce est open source.
Apache MapReduce est un des deux composants majeurs du
framework open source Apache Hadoop qui permet la gestion des Big Data.
V.7.4 Restitution
Le Big data met aussi l'accent sur l'importance de restituer
efficacement les résultats d'analyse et d'accroître
l'interactivité entre utilisateurs et données. Ainsi, des
produits comme QlikView, Tableau (de Tableau Software), PowerView, SpotFire
proposent des visualisations graphiques innovantes.
V.8
Ecosystème Hadoop
Pour certains, l'avenir appartiendra à ceux qui seront
capable d'analyser les vastes volumes de données qu'ils ont
collectés.
En écologie, un écosystème est l'ensemble
formé par une association ou communauté d'êtres vivants et
son environnement biologique, géologique, édaphique,
hydrologique, climatique, etc. l'écosystème Hadoop est l'ensemble
des projets Apache ou non, liés à Hadoop et qui sont
appelés à se cohabiter.
Hadoop désigne un framework Java libre ou un
environnement d'exécution distribuée, performant et scalable,
dont la vocation est de traiter des volumes des données
considérables. Il est le socle d'un vaste écosystème
constitué d'autres projets spécialisés dans un domaine
particulier parmi lesquels on compte les entrepôts de données, le
suivi applicatif (monitorring) ou la persistance de données.
Le schéma ci-après présente les
différents éléments de l'écosystème Hadoop
en fonction du type d'opération.
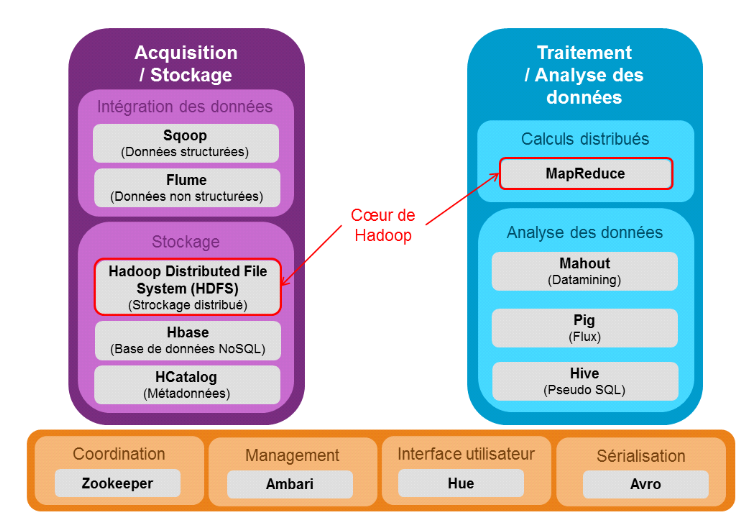
Figure 4 : Ecosystème Hadoop
V.8.1 Hadoop kernel
Hadoop Kernel est le coeur de l'écosystème
Hadoop. Ce framework est actuellement le plus utilisé pour faire du Big
Data. Hadoop est écrit en Java et a été crée par
Doug Cuttting et Michael Cafarella en 2005, (Le framework Apache
Hadoop). Le noyau est composé de 2 composants. Hadoop
présente l'avantage d'être issu de la communauté open
source, de ce fait un porte un message exprimant une opportunité
économique. En revanche, il affiche une complexité qui est loin
de rendre accessible au commun des DSI.
Nous continuerons par une présentation de quelques
grands concepts d'Hadoop.
V.8.1.1
Architecture Hadoop
Le schéma ci-dessous présente l'architecture
distribué dans le contexte Hadoop.
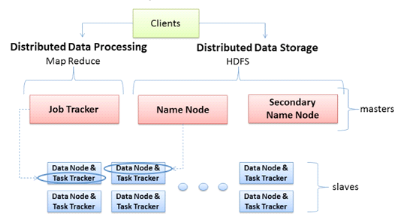
Figure 5 : Architecture Hadoop avec les
principaux rôles des machines, (Le framework Apache Hadoop)
Il est primordial de savoir qu'une architecture Hadoop est
basée sur le principe maître/esclave, représentant les deux
principaux rôles des machines. Les sous rôles relatifs au
système de fichiers et à l'exécution des tâches
distribuées sont associés à chaque machine de
l'architecture.
Les machines maîtres ont trois principaux rôles
qui leur sont associées :
§ JobTracker : c'est le rôle
qui permet à la machine maître de lancer des tâches
distribuées, en coordonnant les esclaves. Il planifie les
exécutions, gère l'état des machines esclaves et
agrège les résultats des calculs.
§ NameNode : ce rôle assure
la répartition des données sur les machines esclaves et la
gestion de l'espace de nom du cluster. La machine qui joue ce rôle
contient des métadonnées qui lui permettent de savoir sur quelle
machine chaque fichier est hébergé.
§ SecondaryNameNode : ce rôle
intervient pour la redondance du NameNode. Normalement, il doit être
assuré par une autre machine physique autre que le NameNode car il
permet en cas de panne de ce dernier, d'assurer la continuité de
fonctionnement du cluster.
Deux rôles sont associés aux machines
esclaves :
§ TaskTracker : ce rôle permet à un
esclave d'exécuter une tâche MapReduce sur les données
qu'elle héberge. Le TaskTracker est piloté par JobTracker d'une
machine maître qui lui envoie la tâche à exécuter.
§ DataNode : dans le cluster, c'est une machine qui
héberge une partie des données. Les noeuds de données sont
généralement répliqués dans le cadre d'une
architecture Hadoop dans l'optique d'assurer la haute disponibilité des
données.
Lorsqu'un client veut accéder aux données ou
exécuter une tâche distribuée, il fait appel à la
machine maître qui joue le rôle de JobTracker et de Namenode.
Maintenant que nous avons vu globalement l'articulation d'une
architecture Hadoop, nous allons voir deux principaux concepts inhérents
aux différents rôles que nous avons présentes.
V.8.1.2 HDFS
HDFS est le système de fichiers Java, permettant de
gérer le stockage des données sur des machines d'une architecture
Hadoop. Il s'appuie sur le système de fichier natif de l'OS (unix) pour
présenter un système de stockage unifié reposant sur un
ensemble de disques et de systèmes de fichiers.
La consistance des données réside sur la
redondance ; une donnée est stockée sur au moins n volumes
différents.
Le NameNode rendrait le cluster inaccessible s'il venait
à tomber en panne, il représente le SPOF (maillon faible) du
cluster Hadoop. Actuellement, la version 2.0 introduit le failover
automatisé (capacité d'un équipement à basculer
automatiquement vers un équipement alternatif, en cas de panne). Bien
qu'il y ait plusieurs NameNodes, la promotion d'un NameNode se fait
manuellement sur la version 1.0.
Dans un cluster les données sont
découpées et distribuées en blocks selon la taille
unitaire de stockage (généralement 64 ou 128 Mo) et le facteur
de réplication (nombre de copie d'une donnée, qui est de 3 par
défaut).
Un principe important de HDFS est que les fichiers sont de
type « write-one » ; ce ci est lié au fait que
lors des opérations analytiques, la lecture des données est
beaucoup plus utilisée que l'écriture.
V.8.1.3
MapReduce
Mapreduce qui est le deuxième composant du noyau Hadoop
permet d'effectuer des traitements distribués sur les noeuds du cluster.
Il décompose un job (unité de traitement mettant en oeuvre un jeu
de données en entrée, un programme MapReduce
(packagé dans un JAR (Java Archive : fichier d'archive,
utilisé pour distribuer un ensemble de classes
Java)) et
des éléments de configuration) en un ensemble de tâche
plus petites qui vont produire chacune un sous ensemble du résultat
final ; ce au moyen de la fonction Map.
L'ensemble des résultats intermédiaires est
traité (par agrégation, filtrage), ce au moyen de la fonction
Reduce.
Le schéma ci-dessous présente le processus d'un
traitement MapReduce.
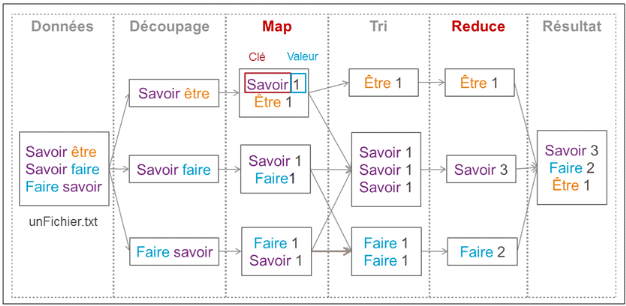
Figure 6 : Processus d'un traitement MapReduce,
(Bermond, 2013)
Le MapReduce présenté sur le schéma
permet de trouver le nombre d'occurrence des mots d'un fichier nommé ici
« unFichier.txt ».
Durant la phase de « Découpage »,
les lignes du fichier sont découpées en blocs.
Puis lors de la phase « Map », des
clés sont créées avec une valeur associée. Dans cet
exemple une clé est un mot et la valeur est 1 pour signifier que le mot
est présent une fois.
Lors du « Tri », toutes les clés
identiques sont regroupées, ici ce sont tous les mots identiques.
Ensuite lors de la phase « Reduce » un
traitement est réalisé sur toutes les valeurs d'une même
clé. Dans cet exemple on additionne les valeurs ce qui permet d'obtenir
le nombre d'occurrence des mots.
V.8.1.4 Modes
d'utilisation
Hadoop peut être sous trois modes
différents :
§ Mode Standalone : ce mode
à pour objectif de tester le fonctionnement d'une tâche MapReduce.
Ici, la tâche est exécutée sur le poste client dans la
seule machine virtuelle Java (JVM), pas besoin d'une configuration
particulière car c'est la mode de fonctionnement de base de Hadoop.
§ Mode Pseudo distributed : ce mode
permettra de tester l'exécution d'une tâche MapReduce sur une
seule machine tout en simulant le fonctionnement d'un cluster Hadoop. Je job
est exécuté sur la machine et les opérations de stockage
et de traitement du job seront gérées par des processus Java
différents. L'objectif de ce mode est de tester le bon fonctionnement
d'un job sans besoin de mobiliser toutes les ressources du cluster.
§ Mode Fully distributed : c'est le mode
réel d'exécution d'Hadoop. Il permet de mobiliser le
système de fichier distribué et les jobs MapReduce sur un
ensemble de machines ; ceci nécessite de disposer de plusieurs
postes pour héberger les données et exécuter les
tâches.
Dans la suite, d'autres composants qui entrent dans
l'écosystème Hahoop sont présentés.
V.8.2 Composants Apache
Hadoop
V.8.2.1 Hbase
Hbase est un système de gestion de bases de
données non relationnelles distribuées, écrit en Java,
disposant d'un stockage structuré pour les grandes tables. C'est une
base de données NoSQL, orientée colonnes. Utilisé
conjointement avec HDFS, ce dernier facilite la distribution des données
de Hbase sur plusieurs noeuds. Contrairement à HDFS, HBase permet de
gérer les accès aléatoires read/write pour des
applications de type temps réel.
V.8.2.2
HaCatalog
HCatalog permet l'interopérabilité d'un cluster
de données Hadoop avec d'autres systèmes (Hive, Pig, ...). C'est
un service de gestion de tables et de schéma Hadoop. Il permet :
§ D'attaquer les données HDFS via des
schémas de type tables de données en lecture/écriture.
§ D'opérer sur des données issues de
MapReduce, Pig ou Hive.
V.8.2.3 Hive
Hive est un outil de requêtage des données, il
permet l'exécution de requêtes SQL sur le cluster Hadoop en vue
d'analyser et d'agréger les données. Le langage utilisé
par Hive est nommé HiveQL. C'est un langage de visualisation uniquement,
raison pour laquelle seules les instructions de type
« Select » sont supportées pour la manipulation des
données.
Hive proposent des fonctions prédéfinies (calcul
de la somme, du maximum, de la moyenne), il permet également à
l'utilisateur de définir ses propres fonctions qui peuvent
être de 3 types :
§ UDF (User Defined Function) : qui prennent une ligne en
entrée et retournent une ligne en sortie. Exemple : mettre une
chaîne de caractère en minuscule et inversement
§ UDAF (User Defined Aggregate Function) : qui prennent
plusieurs lignes en entrée et retournent une ligne en sortie.
Exemple : somme, moyenne, max....
§ UDTF (User Defined Table Function) : qui prennent une
ligne en entrée et retournent plusieurs lignes en sortie. Exemple :
découper une chaîne de caractère en plusieurs mots.
Hive utilise un connecteur jdbc/odbc, ce qui permet de le
connecter à des outils de création de rapport comme QlikView.
V.8.2.4 Pig
Pig est une brique qui permet le requêtage des
données Hadoop à partir d'un langage de script (langage qui
interprète le code ligne par ligne au lieu de faire une compilation).
Pig est basé sur un langage de haut niveau appelé PigLatin. Il
transforme étape par étape des flux de données en
exécutant des programmes MapReduce successivement ou en utilisant des
méthodes prédéfinies du type calcul de la moyenne, de la
valeur minimale, ou en permettant à l'utilisateur de définir ses
propres méthode appelées User Defined Functions (UDF).
V.8.2.5 Sqoop
Sqoop est une brique pour l'intégration des
données. Il permet le transfert des données entre un cluster et
une base de données relationnelles.
V.8.2.6 Flume
Flume permet la collecte et l'agrégation des fichiers
logs, destinés à être stockés et traités par
Hadoop. Il s'interface directement avec HDFS au moyen d'une API native.
V.8.2.7 Oozie
Oozie est utilisé pour gérer et coordonner les
tâches de traitement de données à destination de Hadoop. Il
supporte des jobs Mapreduce, Pig, Hive, Sqoop, etc.
V.8.2.8
Zookeeper
Zookeeper est une solution de gestion de cluster Hadoop. Il
permet de coordonner les tâches des services d'un cluster Hadoop. Il
fournit au composants Hadoop les fonctionnalités de distribution.
V.8.2.9 Ambari
Ambari est une solution de supervision et d'administration de
clusters Hadoop. Il propose un tableau de bord qui permet de visualiser
rapidement l'état d'un cluster. Ambari inclut un système de
gestion de configuration permettant de déployer des services d'Hadoop ou
de son écosystème sur des clusters de machines. Il ne se limite
pas à Hadoop mais permet de gérer également tous les
outils de l'écosystème.
V.8.2.10 Mahout
Mahout est un projet de la fondation
Apache visant à créer des implémentations
d'algorithmes d'apprentissage automatique et de datamining.
V.8.2.11 Avro
Avro est un format utilisé pour la sérialisation
des données.
Le caractère open source de Hadoop a permis à
des entreprises de développer leur propre distribution en ajoutant des
spécificités.
V.9 Solutions Big
Data sur le marché
Sur le marché, on retrouve une panoplie de solutions,
chacune avec ses particularités.
Figure 7 : Solutions
Big Data sur le marché, (Bermond, 2013)
Parmi cette panoplie, trois se distinguent par le
développement d'une distribution Hadoop :
§ Cloudera : c'est le leader, ce
qui lui donne une légitimité avec un nombre de clients
supérieur à celui de ses concurrents. Le fait de disposer du
créateur du framework Hadoop dans ces rangs est un grand avantage.
§ MapR : cette distribution offre
une solution un peu éloignée d'Apache Hadoop car elle
intègre sa propre vision de MapReduce et HDFS. Elle vient juste
après Cloudera.
§ Hortonworks : cette distribution
est l'unique plateforme entièrement Hadoop. Sa stratégie est de
se baser sur les versions stables de Hadoop plutôt que sur les
dernières versions.
Cloudera est la solution qui a été retenue pour
la réalisation des tests.
VI. Solution mise
en place
VI.1 Choix de la solution et tests techniques
réalisés
La distribution Cloudera a été utilisée
pour plusieurs raisons. Tout d'abord le fait que Cloudera propose une version
open source qui utilise les principaux composants de Hadoop. Ensuite, la
distribution de Cloudera est la plus mature sur le marché avec
déjà la quatrième version nommée CDH4. Mais
surtout, la distribution de Cloudera est la plus utilisée en entreprise.
En effet, selon le livre blanc « Où en est l'adoption du Big
Data ? » publié par Talend en 2013, 12% des personnes ont
répondues qu'elles considéraient pour l'avenir ou utilisaient
déjà la distribution de Cloudera contre 4% pour la distribution
de MapR et 3% pour la distribution d'Hortonworks. Le reste des réponses
concernant d'autres solutions. (Talend, 2013)
Cloudera existe en trois versions : Free
Edition, Standard et Enterprise.
J'ai décidé d'utiliser la version Enterprise (car elle
était gratuite pour une période de 60 jours et passait en version
Standard si l'on arrivait au terme de la période d'essai sans
s'être procuré d'une licence) afin d'explorer les
fonctionnalités qu'elle offre vu que celles-ci sont adaptées pour
un contexte d'entreprise. Cloudera propose un outil pour superviser et
automatiser le déploiement des clusters Hadoop nommé Cloudera
Manager. C'est ce composant que j'ai utilisé pour installer le cluster
Hadoop.
Les fonctionnalités clés de Cloudera sont les
suivantes :
§ Gestion du cluster : elle permet de
déployer, configurer et exploiter facilement des clusters de
façon centralisée, avec une administration intuitive pour tous
les services, les hôtes et les workflows.
§ Monitoring du cluster : elle permet de maintenir
une vue centralisée de toutes les activités de la grappe (noeuds
du cluster), ses contrôles proactifs et des alertes.
§ Diagnostique du cluster : cette
fonctionnalité permet de diagnostiquer et résoudre facilement les
problèmes avec l'aide des rapports opérationnels et des tableaux
de bord, des événements, de l'affichage des journaux, des pistes
d'audit.
§ Intégration : cette fonctionnalité
permet d'intégrer les outils de surveillance existants (SNMP, SMTP) avec
Cloudera Manager.
Cloudera Manager permet de choisir entre la version 1.0 et 2.0
du framework Hadoop. J'ai opté pour la version 1.0 puisque la version
2.0 était en version alpha et n'était pas encore tout à
fait stable.
VI.1.1 Architecture
du cluster mise en place
Le schéma ci-dessous présente l'architecture du
cluster hadoop que j'ai mis en place dans le cadre de ce mon travail.
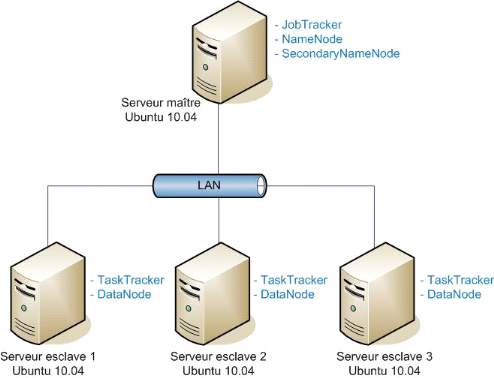
Figure 8 : Architecture du cluster Hadoop mis en
place
Ce cluster est constitué de postes standards
équipés de système d'exploitation Ubuntu (version 10.04).
Cette architecture est hébergée dans un environnement virtuel, ce
qui nous a permis de tester la virtualisation d'un cluster Hadoop, solution
incontournable pour faire du Big Data sur le cloud. Ce schéma
présente les différentes machines (maître et esclave) du
cluster et les rôles qui leurs sont associés dans le cadre d'une
architecture Hadoop.
VI.1.2
Architectures des composants des machines
Ces architectures présentent les composants qui sont
déployés sur chaque machine. Sur les machines, plusieurs
composants de l'écosystème Hadoop sont installés, à
savoir les composants du kernel Hadoop, les composants Apache Hadoop et des
composants spécifiques à Cloudera.
Les composants propres à Cloudera sont les
suivants :
§ Cloudera Manager : il permet
l'installation automatisée des composants de la plateforme sur une
machine. Il permet également de centraliser la configuration des
composants du cluster, d'effectuer un contrôle d'intégrité
des composants à la fin de l'installation.
§ Hue : c'est un outil qui fournit
des interfaces utilisateur pour les applications Hadoop.
§ Impala : c'est moteur temps
réel de requêtage SQL parallélisé de données
stockées dans HDFS ou HBase. Il n'utilise pas MapReduce qui exige
le stockage des résultats dans HDFS, ce qui lui permet d'une part
d'optimiser le temps d'exécution des requêtes et d'autre part, une
consultation des données de façon interactive.
§ Solr (Cloudera search), c'est un outil
qui n'est pas propre à Cloudera mais qu'il intègre pour effectuer
la recherche sur les données du cluster.
VI.1.2.1 Serveur maître
Ce schéma présente les composants
déployé sur le serveur maître.
Figure 9 : Architecture des composants sur un
serveur maître
VI.1.2.2 Serveur esclave
Ce schéma présente l'architecture des composants
sur un serveur esclave.
VI.1.3
Déploiement de la plateforme
Le déploiement du cluster peut se faire soit
manuellement (utilisation des packages), soit automatique avec Cloudera
Manager. J'ai fait une installation automatique pour limiter des
éventuelles erreurs d'installation et aussi compte tenu du temps donc je
disposais pour mon stage.
La figure ci-dessous présente la page d'accueil de la
console web de Cloudera Manager après l'installation du cluster, listant
les différents composants installés sur le cluster Hadoop.
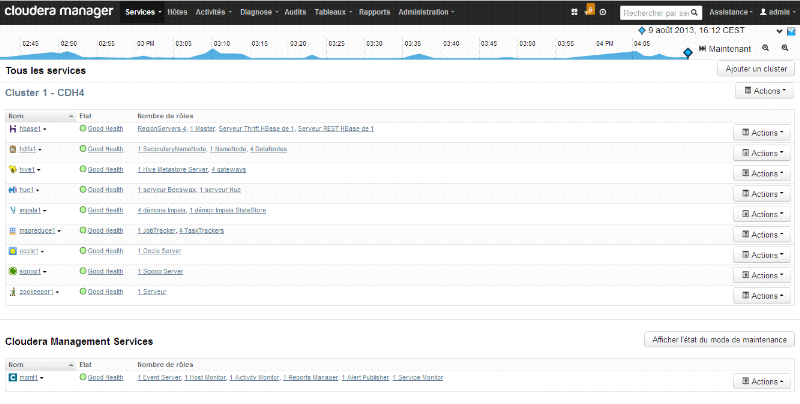
Figure 10 : Page
d'accueil de Cloudera Manager après l'installation du
cluster
VI.1.4 Tests techniques réalisés
VI.1.4.1 But des tests
Lorsqu'on réalise un test, il est important de
d'utiliser une démarche précise et de définir les
objectifs à atteindre à la fin du test, ce qui permettra de faire
un contrôle à la fin, par rapport aux résultats obtenus
pour savoir si le test à été satisfaisant ou non.
La démarche a consisté à tester les
composants séparément ou conjointement, à identifier les
fonctionnalités de chacun.
Les objectifs des différents tests
étaient :
§ D'acquérir une meilleure connaissance de chaque
composant
§ Pouvoir présenter le fonctionnement de chaque
composant
§ Faire des recommandations par rapport à
l'utilisation d'un composant
§ Montrer la mise en oeuvre de certains concepts
VI.1.4.2 Test de l'environnement existant
Avant de compléter les tests, il fallait que je refasse
des tests précédemment réalisées pour mieux
appréhender l'environnement. Ainsi j'ai redéployé le
précédent environnement, puis j'ai testé les composants
HDFS, Mapreduce, Flume, Hbase, Hive, Hue et Coudera Manager.
VI.1.4.3 Test sur le nouvel environnement
VI.1.4.3.1
Traitement de données avec Mapreduce et HDFS
Lorsque les données sont collectées sans un
outil spécifique, elles sont d'abord stockées sur le
système de fichier local, puis l'utilisateur les déplace sur le
système de fichier HDFS. HDFS repartit et réplique les
données sur les différents noeuds du cluster en tenant compte du
facteur de réplication pour assurer une certaine tolérance
à d'éventuelles pannes. Lors du traitement, toutes les
données concernées sont mobilisées quelque soit leur
emplacement.
La problématique sous-jacente est celle de savoir
comment les traitements sont réalisés sur des données
dispersées dans le cluster.
Ce sont les composants du noyau Hadoop qui participent au
traitement : MapReduce et HDFS. Pour réaliser le traitement, il
faut développer un programma java composé de deux fonctions
principales : map et reduce.
Pour le test, j'ai crée un programme dans une classe
java nommée « Election », je me suis procurée
des open data sur les élections françaises et européennes.
Le programme devait parcourir le répertoire sur HDFS, contenant les
différents fichiers relatifs aux élections et pour chaque
scrutin, il devait retourner le libellé du scrutin et le nombre
d'inscrit à ce scrutin.
Par la suite j'ai compilé le programme et crée
un fichier JAR exécuté via cette commande :
Nombre de fichier en entrée (input)
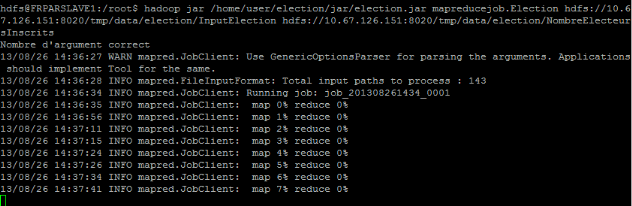
Hadoop jar : c'est la commande
permettant de lancer un programme MapReduce
/home/user/election/jar/election.jar :
c'est le chemin d'accès au fichier JAR qui s'appelle
« election.jar »
mapreducejob.Election : c'est le nom de
la classe java contenant l'entrée du programme (méthode main)
précédé du nom du package qui le contient
hdfs://10.67.126.151 :8020/tmp/data/election/InputElection :
c'est le chemin d'accès aux données sur lesquelles le traitement
s'effectue
hdfs://10.67.126.151 :8020/tmp/data/election/NombreElecteursInscrits
: c'est le chemin d'accès au répertoire qui stocke le
résultat du traitement
L'exécution du fichier jar a bien fonctionné et
le résultat est bien en registré dans HDFS, dans le
répertoire indiqué lors de l'exécution, ce qui est
perceptible via le commande ci-dessous

VI.1.4.3.2
Restitution des données
La restitution des résultats des traitements dans
Hadoop n'est pas conviviale à cause des propriétés
intrinsèques de HDFS qui est un système de fichier et non outil
de présentation de données. De plus, les résultats de
traitement ne sont pas assez structurés pour faciliter leur
lisibilité.
La problématique qui se pose est de savoir comment
faciliter la lisibilité des résultats des traitements
stockés dans HDFS.
Dans l'écosystème Hadoop, plusieurs solution
sont possibles (utilisation de Sqoop, Pig), j'ai opté pour l'utilisation
de Hive car elle offre déjà la possibilité de connexion
à un outil de visualisation de données.
Requêtage des données via Hive
Le composant Hive permet de créer une structure des
données à partir des données stockées dans HDFS.
L'objectif était donc d'appréhender concrètement comment
Hive améliore la restitution des informations provenant de HDFS.
Les requêtes étant réalisées avec
HiveQL, langage similaire au langage SQL, l'appropriation du langage est plus
rapide.
J'ai testé des requêtes sur des données
stockées dans HDFS et visualisé les résultats depuis la
console Hive et l'interface web. Les données sont stockées sous
forme de tables. Les exemples sont présentés dans la suite du
document.
Hive se base sur des traitements MapReduce pour
réaliser les requêtes ce qui suscite des temps de réponse
assez long. Pour pallier ce problème, il est possible de partitionner
les tables pour réaliser les requêtes sur certaines parties de la
table au lieu de la table entière. Cela permet également de ne
recharger qu'une partie des données en cas de modification ou de
suppression ce qui est important dans le cas de grands volumes de
données.
VI.1.4.3.3 Test de
scalabilité et traitements distribués
Hadoop permet le stockage des données dans le
système de fichier HDFS et la réalisation des traitements
distribués sur ces données. L'infrastructure matérielle
contribue largement au traitement des données. Le traitement sur de gros
volumes de données qui augmentent continuellement suppose de disposer
d'une infrastructure qui supporte la montée en charge.
La scalabilité est considérée comme la
capacité d'un produit à s'adapter à un changement d'ordre
de grandeur de la demande ; elle est également
considérée comme la capacité d'un système à
accroître sa capacité de calcul sous une charge accrue quand des
ressources (généralement du matériel) sont
ajoutées.
La problématique est de savoir comment un cluster
Hadoop répond au besoin de scalabilité et la distribution des
traitements avec une scalabilité horizontale.
Dans un premier temps, j'ai testé un programme
MapReduce sur un échantillon de 100 Mo de données, dans un
cluster à 4 noeuds où j'avais mis un noeud hors service.
Figure 11 : Capacité de stockage initiale
du cluster
Le schéma ci-dessus présente la capacité de
stockage sur les trois noeuds actifs du cluster sur lequel le job MapReduce est
lancé. A partir de cette fenêtre de la console, on
peut accéder :
§ A l'interface utilisateur du NameNode
§ Aux évènements générés
par le service hdfs1
§ Aux différents rapports sur le système de
fichiers
§ Aux différentes instances du service
§ Aux commandes en cours d'exécution, utilisant ce
service
§ A la configuration du service
§ Etc
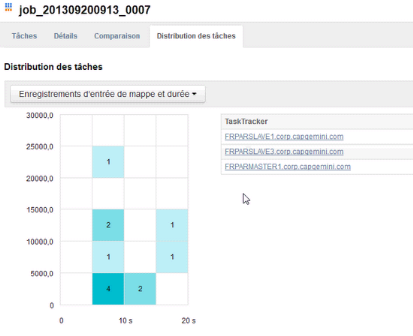
Figure 12 : Distribution des tâches du job
sur les 3 noeuds actifs
Sur ce schéma, on voit les TaskTrackers qui ont
participé au job. En cliquant sur chaque cellule colorée, on
observe le ou les TaskTracker(s) qui ont été sollicités
durant un intervalle de temps précis.
Dans un deuxième temps, j'ai testé le même
programme sur un échantillon de 5 Go de, dans un cluster à 4
noeuds dont un noeud hors service.
 Figure 13 : Etat
d'avancement du job Figure 13 : Etat
d'avancement du job
Mis à part la durée du job qui est un peu plus
longue, les tâches sont également distribuées sur les 3
noeuds actifs du cluster.
Dans un troisième temps, j'ai testé le
même programme sur un échantillon de 5Go de données, dans
un cluster à 4 noeuds avec tous les noeuds actifs.

Figure 14 : Capacité de stockage du
cluster après la remise en service du quatrième noeud
Lorsqu'on remet en service un noeud qui était inactif,
la capacité de stockage du cluster augmente.
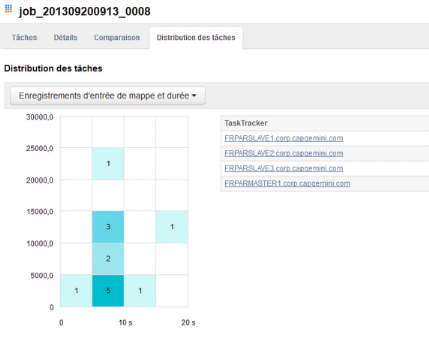
Figure 15 : Distribution des tâches sur les
4 noeuds actifs
Compte tenu de la capacité du poste physique et de
celle des machines virtuelles, je n'ai pas pu achever ce test ; par contre
avec un échantillon plus réduit
Les différents tests ci-dessus ont permis de montrer
que la scalabilité (horizontale) et la distribution de traitement sont
des concepts bien réels dans un cluster Hadoop, ceci me permet de dire
que l'extension de la capacité de stockage et de traitement est moins
coûteux sur un cluster Hadoop que sur des systèmes de gestions de
base de données traditionnelles.
VI.2 Démonstrateur Big Data
Le démonstrateur Big Data est le livrable qui
présente la mise en oeuvre des cas d'utilisation du Big data. C'est un
livrable qui pourra être utilisé à des fin de
présentation à un client. Le démonstrateur déroule
les cas d'utilisation de la création des jeux de données pour les
tests à la restitution des données via QlikView (outil de
visualisation de données), en passant par les traitements et la
structuration des données.
En terme d'architecture réseau et architecture des
composants, j'ai utilisé las architecture présentées plus
haut dans ce document.
Les différents cas d'utilisations traités sont
les suivantes :
§ Cas d'utilisation 1 : Les différents types
d'utilisateurs sur les réseaux sociaux
§ Cas d'utilisation 2 : Les taux d'adolescents et
d'adultes sur quelques réseaux sociaux
§ Cas d'utilisation 3 : Les taux d'utilisation de
certaines activités sur internet via PC et Mobile
La suite présente la création des données
des tests.
VI.2.1
Création des jeux de donnée de test
Pour la mise en oeuvre des cas d'utilisation de test, à
défaut de disposer des données réels, j'ai crée des
scripts xml pour générer des données semblables aux
données qu'on peut avoir dans un contexte de production. Les scripts xml
étaient exécutés via le générateur de
données Benerator.
Les tableaux ci-dessous présentent les fichiers de
données que j'ai générés pour chaque cas
d'utilisation. Ces différents fichiers xml (tous nommés
benerator.xml et stockés dans des répertoires différents)
sont exécutés sur l'invite de commande à partir des
répertoires qui les contiennent.
VI.2.1.1 Cas d'utilisation 1
Benerator utilise le même nom
« benerator.xml » pour tous les fichiers descripteurs,
raisons pour laquelle ils doivent être dans des répertoires
différents.
|
Fichier descripteur
|
Effectif
|
Fichier en sortie
|
|
benerator.xml
|
400
|
TypesUtilisateurs.csv
|
Format d'une ligne du fichier
TypesUtilisateurs.csv
id,nom_profil,nom,prenom,age,sexe,email,ville,pays,numero_de_rue,rue,code_postal,duree_connexion_par_sem,support_acces,nombre_inscription,nombre_amis,communaute_appartenance,interet_utilisation,frequence_utilisation_par_jour,activite_sociale,marque_preferee
Exemple de ligne du fichier TypesUtilisateurs.csv
9,POBHKCRUKAWFUNEHGOJVHQ,Lefebvre,Daniel,44,F,daniellefebvre@tradeshop.com,WALNUT,United
States,26,11th
Street,38683,2,Mobile,3,486,Musulmane,Professionnel,3,the_dansant,Nike
VI.2.1.2 Cas d'utilisation 2
|
Fichier descripteur
|
Réseau social / Tranche
|
Effectif
|
Fichier en sortie
|
|
benerator.xml
|
Facebook /Adolescent
|
164
|
TauxAdoFacebook.csv
|
|
benerator.xml
|
Facebook / Adulte
|
164
|
TauxAdultesFacebook.csv
|
|
benerator.xml
|
Twitter /Adolescent
|
395
|
TauxAdoTwitter.csv
|
|
benerator.xml
|
Twitter / Adulte
|
542
|
TauxAdultesTwitter.csv
|
|
benerator.xml
|
Pinterest /Adolescent
|
319
|
TauxAdoPinterest.csv
|
|
benerator.xml
|
Pinterest / Adulte
|
542
|
TauxAdultesPinterest.csv
|
|
benerator.xml
|
Instagram /Adolescent
|
318
|
TauxAdoPinterest.csv
|
|
benerator.xml
|
Instagram / Adulte
|
532
|
TauxAdultesPinterest.csv
|
|
benerator.xml
|
Tumblr / Adulte
|
318
|
TauxAdoTumblr.csv
|
|
benerator.xml
|
Tumblr / Adulte
|
542
|
TauxAdultesTumblr.csv
|
Format d'une ligne d'un fichier
id,nom_profil,nom,prenom,age,sexe,email,ville,pays,numero_de_rue,rue,code_postal,taux_Ado_facebook
Exemple de ligne d'un fichier
1,TRNSEGBTOUXIWZV,Bernard,Andre,16,F,andre_bernard@gmail.com,GRAND
CHENIER,United States,34,Spring Street,70643,Oui
VI.2.1.3 Cas d'utilisation 3
|
Fichier descripteur
|
Effectif
|
Fichier en sortie
|
|
benerator.xml
|
1000
|
TempsPCMobileSurInternet.csv
|
Format d'une ligne du fichier TempsPCMobileSurInternet.csv
id,maps,weather,music,social_network,sport,retail,newspaper,game,email,portal
Exemple de ligne du fichier TempsPCMobileSurInternet.csv (chaque
mot correspond à une activité, par exemples méto,
musique)
16,Mobile,Mobile,Mobile,PC,PC,Mobile,Mobile,Mobile,PC,PC
VI.2.2
Scénario d'exécution des cas d'utilisation
Le schéma ci-dessous présente les
enchaînements à suivre pour dérouler complètement un
cas d'utilisation.
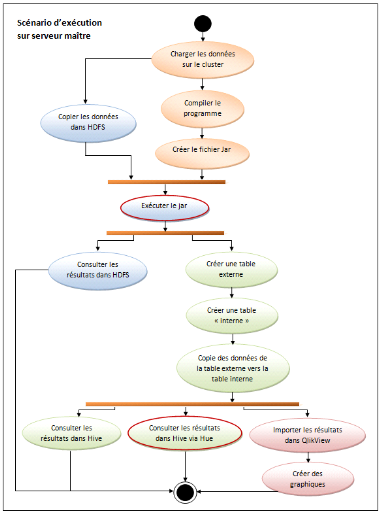
Figure 16 :
Scénario d'exécution des cas d'utilisation
VI.2.3
Création des programmes MapReduce
Pour chacun des fichiers csv présent dans les tableaux
précédents, j'ai crée un programme java qui
sélectionne pour chaque ligne du fichier, les champs utiles et les
formate afin de faciliter leur intégration dans Hive.
Exemple de résultat des programmes
exécutés :
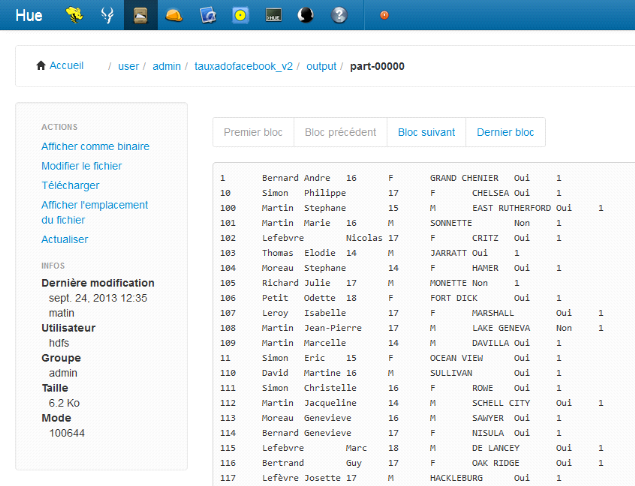
Figure 17 : Résultat d'un job MapReduce
via l'interface Hue
VI.2.4 Restitution
des données via Hive
Comme mentionnée un peu plus haut dans ce document, pour
améliorer la lisibilité des données dans HDFS, j'ai
importé les résultats des traitements dans Hive.
Dans hive, lorsqu'une table est crée avec des
données stockées dans HDFS, les données sont
déplacées de HDFS vers Hive, il n'y plus les données
aucune copie sur HDFS pour d'éventuelles utilisation. Pour éviter
que les données ne soient supprimer de HDFS, il faut créer une
table externe qui pointer vers les données présentes sur HDFS et
une table simple ; copier les données de la table externe vers la
table simple, ceci permettra de pouvoir réutiliser les données
présentes sur HDFS. Ainsi pour chaque résultat de traitement j'ai
crée une table externe, une table simple et j'ai copié les
données la table externe vers la table simple.
Exemple du cas d'utilisation 1
§ Création de la table externe
CREATE EXTERNAL TABLE types_utilisateurs_ex (id int, age int,
genre string, amis int, nombre_inscription int, duree_connexion_par_sem double,
frequence_utilisation_par_jour int, mapreduce int) ROW FORMAT DELIMITED FIELDS
TERMINATED BY '\t' LOCATION
'hdfs://Master.corp.capgemini.com:8020/user/admin/typesutilisateurs_rs/output/';
§ Création de la table simple
CREATE TABLE types_utilisateurs_in (id int, age int, genre
string, amis int, nombre_inscription int, duree_connexion_par_sem double,
frequence_utilisation_par_jour int);
§ Copie des données de la table externe vers la
table simple
FROM types_utilisateurs_ex ue INSERT OVERWRITE TABLE
types_utilisateurs_in SELECT ue.id, ue. age, ue.genre, ue.amis,
ue.nombre_inscription, ue. duree_connexion_par_sem,
ue.frequence_utilisation_par_jour ;
Avec Hive, il est possible de visualiser les contenus des
tables soit en sur la console, soit sur l'interface graphique. Le schéma
ci-dessous présente un extrait du résultat de la requête
« select * from utilisateurs_in; » sur l'invite de commande.
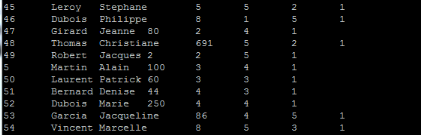
Figure 18 : Résultat de requête sur
l'invite de commande de Hive
J'ai traité tous les résultats présents
dans HDFS de la même façon pour améliorer leur
visualisation dans Hive.
Les données ainsi structurées, sont
importées dans un outil de visualisation qui va faciliter leur analyse
et la prise de décision.
VI.2.5 Restitution
des données via QlikView
QlikView est un outil du monde de la Business Intelligence
(BI), utilisé dans le cadre de la visualisation des données. Il
dispose d'une interface utilisateur conviviale et utilise la technologie
in-memory (technologie permettant d'effectuer des traitements en mémoire
vive sur de grandes quantités de données) pour une interaction
plus rapide avec les données. La plateforme Big Data mise en place avec
cluster Hadoop est indépendante des plateformes de Business Intelligence
des entreprises. Néanmoins, ces deux mondes partagent un même
objectif qui est d'extraire de la valeur des données dont disposent les
entreprises afin de faciliter la prise de décision. (Bermond,
2013)
A la différence de la BI qui est plus mature et qui
fournit des outils efficaces et ergonomiques, les plateformes Big Data ne
permettent pas encore une restitution de données conviviale.
Pour répondre à la problématique de
visualisation, le monde du Big Data s'appui actuellement sur les outils du
monde de la BI. Il est donc judicieux d'utiliser les outils de la BI
déjà connus et adoptés par les utilisateurs.
Pour exploiter cet outil, premièrement, j'ai
installé un connecteur ODBC pour connecter Hive à QlikView et
tester la connexion à Hive à partir de la machine physique.
Dans un second temps, j'ai réalisé une
application QlikView qui m'a permis de créer le script permettant de
créer et d'importer les données. A partir des données
importées dans QlikView, j'ai créés des graphiques pour
les différents cas d'utilisation.
Les schémas ci-dessous présentent les
résultats des différents Cas d'utilisation s via des graphiques
crées sur QlikView.
VI.2.5.1 Cas d'utilisation 1
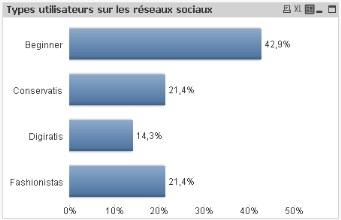
Figure 19 : Les types d'utilisateur sur les
réseaux sociaux
Cette classification est faite en fonction du nombre de
réseau social auquel l'utilisateur est inscrit et du temps moyen de
connexion par semaine. Sur un échantillon de 400 utilisateurs, QlikView
m'a permis de créer des dimensions en fonction des certaines attributs
de l'utilisateur, ainsi :
§ Ceux qui sont inscrits sur moins de trois réseaux
sociaux et qui passent moins de 3 heures par semaine sur ces réseaux
sociaux sont des « Biginners »
§ Ceux qui sont inscrits sur moins de trois réseaux
sociaux et qui passent 3 heures ou plus par semaine sur ces réseaux
sociaux sont des « Conservatis »
§ Ceux qui sont inscrits sur trois réseaux sociaux ou
plus et qui passent moins de 3 heures par semaine sur ces réseaux
sociaux sont des « Fashionitas »
§ Ceux qui sont inscrits sur trois réseaux sociaux ou
plus et qui passent 3 heures ou plus par semaine sur ces réseaux sociaux
sont des « Digiratis »
VI.2.5.2 Cas d'utilisation 2
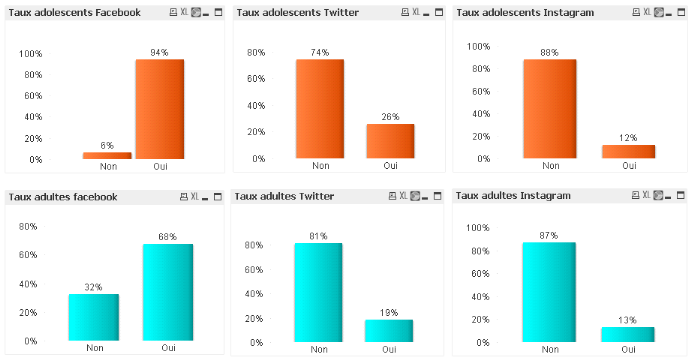
Figure 20 : Taux d'adolescents et d'adulte sur
les réseaux sociaux
VI.2.5.3 Cas d'utilisation 3
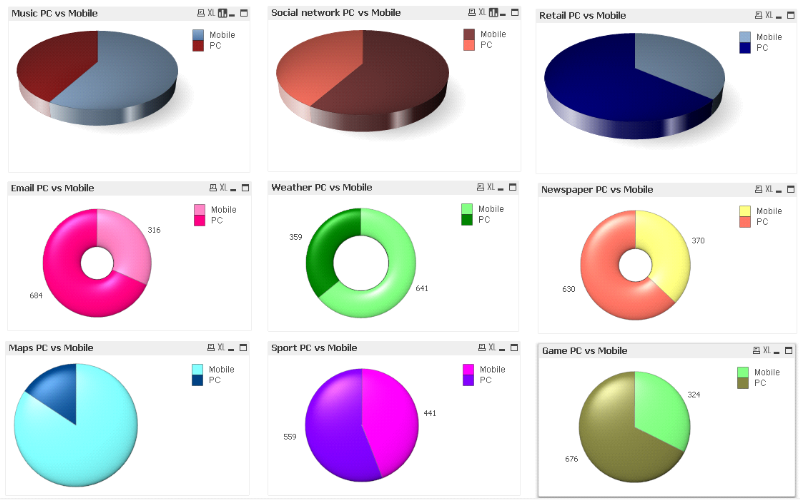
Figure 21 : Activités sur internet PC vs
Mobile
QlikView permet également de d'agréger des
données à travers des fonctions d'agrégation, mais ceci
n'est judicieux que pour des petites quantités des données. Il
propose une visualisation plus agréable et performante des
données pour faciliter la prise de décision.
Lorsque les données sont importées dans
QlikView, pour représenter des graphiques, les champs passés dans
l'expression sont agrégés. Il faut donc faire attention dans le
traitement au niveau de Hadoop, à ne pas agréger toutes les
données dans le Reduce.
Il faut faire des agrégations utiles à la
récupération des données (qu'on veut exploiter) dans
Hadoop et effectuer des agrégations utiles à la
représentation des graphiques dans QlikView.
VI.3 Outils utilisés
En dehors des composants de l'écosystème et des
composants propres à Cloudera, j'ai utilisé :
§ Vritual box pour la virtualisation des
machines,
§ Winscp pour le transfert des fichiers de
la machine physique aux machines virtuelles et inversement,
§ Putty pour l'accès aux machines
via ssh,
§ Dropbox pour le partage des fichiers,
§ NodePad++ et Eclipse pour le
développement des programmes
§ Benerator pour la
génération des données de test,
§ Photosphop pour la préparation des
contenus de la vidéo de démonstration,
§ Powtoon, Movie Maker, HyperCam et
VirtualDubMod pour la réalisation de la vidéo
§ QlikView pour la réalisation de
graphiques.
VII. Futur du Big Data
Les technologies du Big Data s'inscrivent dans une
évolution continue compte tenu du fait qu'elles sont jeunes et pas
encore stables, ce qui leur vaut la réticence des certaines entreprises.
Actuellement, le virage technologique est d'ores et déjà
annoncé. Le Big Data s'impose tout doucement, mais certains aspects ne
sont pas encore à la hauteur des attentes, certaines pistes sont
à explorer profondément avant l'intégration dans les
systèmes d'information :
§ La sécurité : elle est
encore balbutiante malgré quelques initiatives comme Apache Knox
(système qui fournit un point unique d'authentification et
d'accès pour les services Apache Hadoop dans un cluster. Le but est
de simplifier la sécurité Hadoop pour les utilisateurs (qui ont
accès aux données du cluster et exécutent des jobs) et les
opérateurs (qui contrôlent les accès et de gèrent le
cluster).
§ L'intégration avec le système
d'information (SI), une plate forme Hadoop isolée et non
intégrée au système d'information ne sera plus possible
dans le futur (en tout cas certains besoins exigeront une interaction plus
grande). Cette intégration entraînera une modification des
processus et par conséquent des besoins de formation des ressources
humaines.
§ Les ressources
compétentes : actuellement les compétences ne sont
pas encore assez poussées dans le domaine
§ Protection de la vie
privée : la manipulation à grande échelle de
des données pose aussi le problème de la
vie privée.
Trouver l'équilibre
entre le respect de son intimité et les bénéfices
tirés du big data n'est pas simple. Les utilisateurs des
réseaux sociaux ignorent souvent que leurs données privées
sont accessibles par un grand public, beaucoup reste à faire afin de
garantir la protection des utilisateurs.
« L'avenir appartiendra à ceux qui seront
capable d'analyser les vastes volumes de données qu'ils ont
collectés ».
VIII. Bilan du stage
VIII.1 Planning
prévisionnel
Au début du stage, j'ai élaboré un
planning qui couvrait toute ma période de stage.
TT : test technique
VM : virtual machine
|
Activités
|
Tâches
|
Durée prévue (en jours)
|
|
Contexte du stage, structure d'accueil
|
Présentation CAPGEMINI, sujets de stages
|
1
|
|
Documentation (Support)
|
Présentation de la documentation
|
1
|
|
Présentation des outils
|
0,25
|
|
Installation des outils (Putty, virtual box, dropbox)
|
0,25
|
|
Présentation de la vidéo (stockage, traitement,
restitution des données)
|
0,25
|
|
Récupération et importation des machines
virtuelles
|
0,15
|
|
Parcourir la documentation
|
5
|
|
Récupération et exploitation de la documentation
sur les "usages et apports des technologies Big Data"
|
2
|
|
Identification des cas d'utilisation (permettant de
définir les besoins fonctionnels)
|
0,15
|
|
Recherche algorithme de recommandation
|
1
|
|
Documentation installation du cluster (Cloudera installation
manuelle)
|
1
|
|
Documentation collecte des données via l'API Flume
|
1
|
|
Documentation et compréhension fonctionnement de REST
|
0,5
|
|
Divers
|
Réunion avec Ameline (questionnaire)
|
0,1
|
|
Relecture du powerpoint
|
1
|
|
Récupération des codes sources
|
0,1
|
|
Réunion avec Ameline (questionnaire)
|
1
|
|
Test des VM (démarrage, connexion, configuration
réseau)
|
1
|
|
Faire une sauvegarde (image) des VM
|
0,25
|
|
Mise à jour du powerpoint
|
5
|
|
Compréhension des langages utilisés par les
différentes briques
|
2
|
|
Suivi de projet
|
Réalisation du planning
|
0,5
|
|
Mise à jour du planning
|
0,5
|
|
Réunion de suivi
|
1
|
|
Installation du cluster (Production)
|
Installation et configuration des VMs
|
1
|
|
Installation de Cloudera Manager et CDH4 (HDFS, Mapreduce, Hbase,
Hive, Oozie, Zookeer, Hcatalog)
|
2
|
|
Déploiement des services sur des VM
|
2
|
|
Installation d'Impala et Solr
|
2
|
|
Test des briques (Production)
|
Test des VM reçu de Itics / demande de
réinstallation
|
0,5
|
|
Récupération des données de test
|
1
|
|
TF Flume : collecte des données (log) et stockage dans
HDFS
|
3
|
|
TF MapReduce : traitement des données
(développement et test)
|
2
|
|
TF Pig : traitement des données
|
2
|
|
TF Hive : traitement des données
|
2
|
|
TF Hcatalog : traitement des données
|
2
|
|
TF restitution : Réalisation d'une recherche de
données sur HDFS (Cloudera Search Solr)
|
4
|
|
TF Impala : traitement en temps réel
|
2
|
|
TF Solr : recherche des données
|
2
|
|
TF Mahout (Data mining)
|
2
|
|
TF Ambari (gestionnaire de cluster)
|
2
|
|
Utilisation d'une source de données mongoDB
|
1
|
|
Utilisation d'une source de données cassandra
|
|
|
Réalisation du POC (Production)
|
Définition de l'infrastructure matérielle
|
0,5
|
|
Elaboration du scénario d'exécution du POC
(enchainement des fonctionnalités)
|
2
|
|
Création et installation des machines virtuelles
|
1
|
|
Fabrication des données de test
|
5
|
|
Installation des briques retenues (Acquisition, stockage,
traitement, restitution)
|
0,5
|
|
Test des briques retenues
|
5
|
|
Finalisation de la documentation du déploiement et du test
de chaque brique
|
1
|
|
Finalisation de la documentation du POC
|
1
|
|
Réalisation de la vidéo (scénario
d'exécution)
|
1
|
|
Documentation des points importants en vu d'une
préconisation
|
2
|
|
Mise en forme des différents documents
|
1
|
|
Restitution
|
Rédaction de la présentation
|
1
|
|
Présentation du POC
|
1
|
|
|
Rédaction du rapport de stage
|
10
|
|
Total
|
90,5
|
Tableau 1 : Planning
prévisionnel
VIII.2 Planning de
réalisation
Le planning élaboré au début du stage a
été adapté au fil de l'avance du stage, compte de la
priorité de certains livrables, ce qui a donné lieu au planning
de réalisation ci-dessous.
|
Activités
|
Tâches
|
Durée prévue (en jours)
|
Durée réalisée (en
jour)
|
Ecart (en jour)
|
|
Contexte du stage, structure d'acceuil
|
Présentation CAPGEMINI, sujets de stages
|
1
|
1
|
0
|
|
Documentation (Support)
|
Présentation de la documentation
|
1
|
1
|
0
|
|
Présentation des outils
|
0,25
|
0,25
|
0
|
|
Installation des outils (Putty, virtual box, dropbox)
|
0,25
|
0,25
|
0
|
|
Présentation de la vidéo (stockage, traitement,
restitution des données)
|
0,25
|
0,25
|
0
|
|
Récupération et importation des machines
virtuelles
|
0,15
|
0,15
|
0
|
|
Parcourir la documentation
|
5
|
5
|
0
|
|
Récupération et exploitation de la documentation
sur les "usages et apports des technologies Big Data"
|
2
|
4
|
2
|
|
Identification des cas d'utilisation (permettant de
définir les besoins fonctionnels)
|
0,15
|
0,2
|
0,05
|
|
Recherche algorithme de recommandation
|
1
|
1
|
0
|
|
Documentation installation du cluster (Cloudera installation
manuelle)
|
1
|
1
|
0
|
|
Documentation collecte des données via l'API Flume
|
1
|
1
|
0
|
|
|
|
|
|
|
Documentation et compréhension fonctionnement de REST
|
0,5
|
0,5
|
0
|
|
Divers
|
Réunion avec Ameline (questionnaire)
|
0,1
|
0,1
|
0
|
|
Relecture du powerpoint
|
1
|
1
|
0
|
|
Récupération des codes sources
|
0,1
|
0,1
|
0
|
|
Réunion avec Ameline (questionnaire)
|
1
|
1
|
0
|
|
Test des VM (démarrage, connexion, configuration
réseau)
|
1
|
1
|
0
|
|
Faire une sauvegarde (image) des VM
|
0,25
|
0,25
|
0
|
|
Mise à jour du powerpoint
|
5
|
3
|
-2
|
|
Compréhension des langages utilisés par les
différentes briques
|
2
|
3
|
1
|
|
Suivi de projet
|
Réalisation du planning
|
0,5
|
0,5
|
0
|
|
Mise à jour du planning
|
0,5
|
0,5
|
0
|
|
Réunion de suivi
|
1
|
0,5
|
-0,5
|
|
Installation du cluster (Production)
|
Installation et configuration des VMs
|
1
|
8
|
7
|
|
Installation de Cloudera Manager et CDH4 (HDFS, Mapreduce, Hbase,
Hive, Oozie, Zookeer, Hcatalog, Impala, Solr)
|
6
|
5
|
-1
|
|
Test de l'installation et exploration de la console
|
0,5
|
1
|
0,5
|
|
Test des briques (Production)
|
Test des VM reçu de Itics / demande de
réinstallation
|
0,5
|
0,5
|
0
|
|
Récupération des données de test
|
1
|
1
|
0
|
|
TT Flume : collecte des données (log) et stockage dans
HDFS
|
3
|
0
|
-3
|
|
TT MapReduce : traitement des données
(développement et test)
|
2
|
0
|
-2
|
|
TT Pig : traitement des données
|
2
|
0
|
-2
|
|
TT Hive : traitement des données
|
2
|
0
|
-2
|
|
TT Hcatalog : traitement des données
|
2
|
0
|
-2
|
|
TT Impala : traitement en temps réel
|
2
|
0
|
-2
|
|
TT Solr : recherche des données
|
2
|
0
|
-2
|
|
TT Mahout (Data mining)
|
2
|
0
|
-2
|
|
TT Ambari (gestionnaire de cluster)
|
2
|
0
|
-2
|
|
Utilisation d'une source de données mongoDB
|
1
|
0
|
-1
|
|
Utilisation d'une source de données cassandra
|
1
|
0
|
-1
|
|
|
Test technique scalabilité et traitements
distribués
|
2
|
2
|
0
|
|
Réalisation du
démonstrateur(Production)
|
Définition de l'infrastructure matérielle
|
0,5
|
0,5
|
0
|
|
Identification de Cas d'utilisation s (UC)
|
0,5
|
0,5
|
0
|
|
Elaboration du scénario d'exécution des UC
|
2
|
1
|
-1
|
|
Création et installation des machines virtuelles
|
1
|
0,3
|
-0,7
|
|
Fabrication des données de test
|
5
|
5
|
0
|
|
Installation des briques retenues (Acquisition, stockage,
traitement, restitution)
|
0,5
|
1
|
0,5
|
|
Test des briques retenues et réalisation des UC
|
3
|
10
|
7
|
|
Finalisation de la documentation des tests techniques
|
1
|
3
|
2
|
|
Restitution sur QlikView
|
2
|
2
|
0
|
|
Réalisation de la vidéo (scénario
d'exécution)
|
7
|
8
|
1
|
|
Documentation des points importants en vu d'une
préconisation
|
2
|
2
|
0
|
|
Mise en forme des différents documents
|
1
|
1
|
0
|
|
Restitution
|
Rédaction de la présentation et du discours
|
1
|
1
|
0
|
|
|
Rédaction du rapport de stage
|
10
|
10
|
0
|
|
Total
|
94,5
|
79,35
|
-5,15
|
Tableau 2 : Planning
prévisionnel
VIII.3
Livrables

Tableau 3 : Liste des
livrables et taux de réalisation
L'ensemble des livrables que la stagiaire
précédente et moi avons réalisé servira à
des fin de support pour la présentation des solutions Big Data aux
potentiels clients. La plateforme de démonstration (vidéo) que
j'ai réalisée devait servir pour l'évènement
« architecture week » que CAPGEMINI a organisé au
sein de ses locaux le 4 Octobre dernier. Pendant cet événement,
les architectes solution de CAPGEMINI présentent à leurs clients
l'expertise de CAPGEMINI dans certaines nouvelles technologies ; le Big
Data devait faire partie des technologies présentées.
VIII.4
Difficultés rencontrées
La fonction de R&D en général
nécessite de mobiliser des moyens financiers, matériels, du temps
et des personnes. Or les résultats de recherches sont souvent
aléatoires. La question du financement de ces activités se pose
logiquement. Dans le cadre ce mon stage, j'ai été
confrontée à des difficultés d'ordre
matériel ; les ressources matériels à disposition
n'étaient pas adaptées pour un environnement de test. Il
était plus judicieux d'utiliser des machines physiques avec des
caractéristiques optimales ou des machines virtuelles
équivalentes pour les tests. Etant donné que les résultats
ne devaient pas être directement rentables pour l'entreprise, il
n'était pas évident de disposer des ressources matériels
adaptées.
D'autres difficultés sont celles rencontrées
lors des tests techniques, liées parfois aux matériels ou aux
logiciels ou à la configuration.
VIII.5 Solutions
Pour palier aux problèmes rencontrés, j'ai
utilisé plusieurs solutions, chacune adaptée à un
problème. Les solutions envisagées ont été
celles-ci :
§ Demander de l'aide aux bons interlocuteurs : me
rapprocher des personnes ayant déjà travaillées sur une
telle mission tout en évitant de les interrompre dans mes
interrogations, me rapprocher des personnes ayant une bonne connaissance du
fonctionnement interne de l'entreprise
§ Elaborer des questionnaires pour plus
d'efficacité
§ Recherches sur Internet, échanges sur des forums
VIII.6 Projet big
data
Actuellement, il y'a trop de buzz autour des technologies Big
Data. Avant de s'y lancer, il est important d'adopter une stratégie qui
s'appui sur le coeur de métier de l'entreprise, car il n'y a pas de
solution clé en main pour les Big Data.
Pour tirer le meilleur parti d'un projet Big Data, il faut
intégrer des connaissances approfondies dans des processus et
applications métiers afin d'accroître la réactivité
de l'entreprise et de prendre des décisions avisées plus
rapidement tout en misant sur l'innovation.
L'exploitation des Big data permet à une entreprise de
bénéficier d'un avantage concurrentiel indéniable dans son
secteur d'activité. « Le Big Data est à nos portes,
nous devons réfléchir à ses usages, pas à ses
technologies ! »
VIII.7 Apport du
stage
Au début du stage, j'étais dans un état
de panique car je n'avais aucune connaissance des technologies du Big Data. Je
partais en terrain inconnu.
A l'issu de mon stage, la montée en compétence
était bien perceptible au travers du travail
réalisé :
§ J'ai acquis une compréhension des enjeux
digitaux et des solutions adaptées pour le tissu industriel
§ Je me suis approprié les concepts du Big Data et
j'ai découvert les solutions qui existe sur le marché en
réponse à la problématique des Big Data
§ J'ai développé des connaissances sur des
outils décisionnels, des bases de données NoSQL.
IX. Conclusion
L'informatique à la base était le traitement de
grande quantité de données, mais ce qui a changé avec la
venue du Big Data, c'est la formalisation de l'évolution des volumes, de
la vitesse et de la variété des données, qui crée
de la valeur ajoutée.
Jusqu'ici, il n'existe pas encore sur le marché un
logiciel Big Data prêt à l'emploi que l'on puisse installer dans
une entreprise. Le Big Data est avant tout une démarche
stratégique, il faut se poser la question : comment est-ce
qu'à partir des données que j'ai ou que je peux collecter dans
mon entreprise, je peux créer de la valeur ? Autrement dit, qu'est
ce que je peux créer à partir de mes données. C'est
ça la stratégie, donner de la valeur à vos données,
transformer les données en euros ou en dollars. C'est grâce
à cette stratégie que le Big Data fonctionnera à
l'intérieur d'une entreprise.
L'écosystème Hadoop est constitué de
plusieurs briques, qui pour certaines sont similaires en terme de
fonctionnalités. Les tests techniques effectués m'ont permit de
comprendre que toutes les briques ne sont pas forcément
nécessaires pour faire fonctionner le cluster, celui-ci est
modulable ; il revient à l'utilisateur de choisir les briques qui
lui sont utiles en fonction de ses besoins. L'installation des briques
séparément est possible mais il est plus judicieux d'utiliser un
gestionnaire de cluster tel que Cloudera Manager pour centraliser toutes les
tâches de déploiement, d'administration et de supervision du
cluster.
Déployer une infrastructure Big Data demande de mettre
les mains dans le cambouis et de programmer. L'on peut faire ce qu'il veut
des données, à condition de rentrer dans le code pour obtenir ce
qu'il souhaite.
Le bilan de ce stage est dans l'ensemble positif, les
principaux buts du projet étant accomplis. La plus grande partie du
travail qui m'a été demandée a été
réalisée.
Pour conclure, je dirais que ce stage m'a été
d'un apport indéniable en matière de connaissances acquises sur
les technologies Big Data. C'est une expérience enrichissante qui m'a
permit de comprendre les enjeux d'un projet de Recherche &
Développement et de veille technologique, fort de plus dans un domaine
porteur ; pour capitaliser davantage sur cette expérience, je
continue à faire de la veille technologique sur concepts et technologies
Big Data.
Références
bibliographiques
Bermond, A. (2013). Big Data.
Haas, G. (2013, Septembre 17). Big data enjeux & risques
juridiques. Consulté le Octobre 2, 2013, sur site web
journaldunet.com:
http://www.journaldunet.com/ebusiness/expert/55180/big-data---enjeux---risques-juridiques.shtml
Le framework Apache Hadoop. (s.d.). Consulté le
Octobre 2013, sur Site web http://www-igm.univ-mlv.fr:
http://www-igm.univ-mlv.fr/~dr/XPOSE2012/Le%20framework%20Apache%20Hadoop/histoire.html
Le framework Apache Hadoop. (s.d.). Consulté le
Octobre 2013, sur site web www-igm.univ-mlv.fr:
http://www-igm.univ-mlv.fr/~dr/XPOSE2012/Le%20framework%20Apache%20Hadoop/architecture.html
Mathieu Millet, L. G. (2013, Février 3). Quel est le
paysage technologique du Big Data. Consulté le Septembre 30, 2013,
sur site web www.solucominsight.fr:
http://www.solucominsight.fr/2012/02/quest-ce-que-le-paysage-technologique-du-big-data/
Saulem, B. (2013, Mai). Définition de Big Data trois V
variété, volume, vélocité - Le big data.htm.
Consulté le Octobre 2013, sur site web daf-mag.fr:
http://www.daf-mag.fr/Fondamentaux/Le-Big-Data-255/Definition-de-Big-Data-trois-V-variete-volume-velocite-1076.htm
Saulem, B. (2013, Mai). Enjeux économiques du Big Data
à l'échelle mondiale - Le big data.htm. Consulté le
Octobre 2013, sur site web daf-mag.fr:
http://www.daf-mag.fr/Fondamentaux/Le-Big-Data-255/Enjeux-economiques-du-Big-Data-a-l-echelle-mondiale-1077.htm
Talend. (2013). Où en est l'adoption du BIG DATA.
Consulté le Juin 23, 2013, sur
http://info.talend.com/rs/talend/images/WP_FR_BD_Talend_SurveyResults_BigDataAdoption.pdf.
VISION IT GROUP. (2013). LE LIVRE D'OR 2013 DES ESN.
IPRESSE.NET.
Liste des figures
Figure 1 : Implantation de Capgemini dans le
monde
9
Figure 2 : Organigramme des unités
opérationnelles du groupe Capgemini
12
Figure 3 : Paysage technologique Big Data,
(Bermond, 2013)
19
Figure 4 : Ecosystème Hadoop
21
Figure 5 : Architecture Hadoop avec les
principaux rôles des machines, (Le framework Apache Hadoop)
22
Figure 6 : Processus d'un traitement MapReduce,
(Bermond, 2013)
24
Figure 7 : Solutions Big Data sur le
marché, (Bermond, 2013)
27
Figure 8 : Architecture du cluster Hadoop mis
en place
30
Figure 9 : Architecture des composants sur un
serveur maître
31
Figure 10 : Page d'accueil de Cloudera Manager
après l'installation du cluster
32
Figure 11 : Capacité de stockage
initiale du cluster
35
Figure 12 : Distribution des tâches du
job sur les 3 noeuds actifs
36
Figure 13 : Etat d'avancement du job
36
Figure 14 : Capacité de stockage du
cluster après la remise en service du quatrième noeud
37
Figure 15 : Distribution des tâches sur
les 4 noeuds actifs
38
Figure 16 : Scénario d'exécution
des cas d'utilisation
41
Figure 17 : Résultat d'un job MapReduce
via l'interface Hue
42
Figure 18 : Résultat de requête
sur l'invite de commande de Hive
43
Figure 19 : Les types d'utilisateur sur les
réseaux sociaux
44
Figure 20 : Taux d'adolescents et d'adulte sur
les réseaux sociaux
45
Figure 21 : Activités sur internet PC vs
Mobile
46
Liste des tableaux
Tableau 1 : Planning prévisionnel
50
Tableau 2 : Planning prévisionnel
52
Tableau 3 : Liste des livrables et taux de
réalisation
52
| 

