|

Table des matières
Table des matières
I. Introduction
général..................................................................
4
II. Motivation du choix du
thème................................................................
5
III. Objectif
.............................................................................................
5
Chapitre I : généralités sur les
systèmes embarqués
1.
Définitions.............................................................................................
7
2. Historique 8
3. Classe des systèmes
embarqués..................................................................
10
4. Caractéristiques des systèmes
embarqués.................................................................10
5. Contraintes des systèmes
embarqués................................................................
11
6. Architecture des systèmes
embarqués............................................................
12
1. Les systèmes embarqués de première
génération........................... 12
2. Les systèmes embarqués de deuxième
génération.............................................13
3. Les systèmes embarqués de troisième
génération.............................................14
7. Les systèmes embarqués
spécifiques.........................................................
15
Chapitre II : conception des logiciels
embarqués
1.
Introduction..........................................................................................
17
2. Les systèmes pour puces 17
3. La conception des systèmes sur puces 20
4. Les systèmes monopuces (SoC)... 22
5. Conception des systèmes
embarqués......................................................
23
1. Flots classiques de conception des
SE.......................................... 23
2. Flots de conception récents 25
6. Exemple de flot de conception pour
SoC................................................ 26
1. Présentation générale 27
2. Architecture détaillée du flot
...................................................... 31
7. De la compilation au ciblage du logiciel 35
1. Introduction sur la
compilation.....................................................................35
2. Le ciblage logiciel en
général......................................................
37
3. Représentations pour le ciblage logiciel
38
4. Le ciblage logiciel pour les architectures
spécifiques 41
8. Etat de l'art sur les systèmes d'exploitation
OS............................................. 48
1. Introduction sur les systèmes d'exploitation
48
2. Systèmes d'exploitation définitions
48
9. Les systèmes d'exploitation dans les
systèmes embarqués.......................................
50
1. Fonctionnalités requises pour le logiciel dans les
SE........................... 51
2. Contraintes imposées par les SE pour le logiciel
54
3. Les degrés de liberté pour le logiciel dans
les SE 56
4. Exemples de SE généralistes 56
5. Avantages et inconvénients des OS pour les SE
57
10. Conclusion 59

Chapitre III : conception matériel
1. Introduction 61
2. Modéliser et synthétiser à un haut
niveau 61
3. Réutilisation de composants matériels
63
1. Composants
virtuels.................................................................................
63
2. Standardisation 64
4. Un exemple d'environnement orienté composante pour
la conception
d'architecture
numérique..............................................................................
65
5. L'état de lieux de perspectives de
recherche......................................................... 67
6. Architecture
matérielle...........................................................................
68
1. Les capteurs 69
2. Les convertisseurs analogiques numériques
70
3. Effecteurs : influent sur l'environnement 72
4. Interface homme machine 73
5. Interfaces
associées..................................................................
73
6. Les
mémoires....................................................................................
73
7. Circuit logique programmable « FPGA
»............................................. 74
8. Unité centrale de traitement « CPU »
74
7. Conclusion 75
Chapitre IV : sécurité des systèmes
embarqués
1.
Introduction.............................................................................................
77
2.
Cryptologie......................................................................................................
77
1.
Introduction..............................................................................
77
2.
Confidentialité.................................................................................
78
3. Intégrité et authentification 78
3. Les menaces de sécurité
....................................................................................
79
1. Types d'attaques
(menaces)..................................................................
79
2. Objectifs des
attaques...............................................................
79
3. Classement des
attaques............................................. 79
4. Contre mesure 82
5.
Conclusion................................................................................................
83
Conclusiongénéral..................................................................
84
Bibliographie
........................................................................
85
Glossaire...................................................................................................
86

Table des figures
Table Des Figures
Chapitre I
Figure a : Système de régulation de
quantité de
vapeur............................................................ 8
Figure b : Le premier système embarqué
9
Figure c : Le système de contrôle aux LGM-30
Minuteman............................................................ 9
Figure I.1 : Un système embarqué dans son
environnement................................................... 11
Figure I.2 : Architecture embarquée de première
génération
..........................................................12
Figure I.3 : Architecture embarquée de deuxième
génération.............................................
13
Figure I.4 : Architecture embarquée de
troisième génération....................................
14
Chapitre II
Figure II.1 : Architecture logicielle/matérielle d'un
SoC................................................ 19
Figure II.2 : Les métiers de la conception
système
......................................................................20 Figure
II.3 : Le flot de conception
système................................................................................21
Figure II.4a : Les flots de conception classiques pour les
SE..........................................................24 Figure II.4b :
codéveloppement pour les
SE..............................................................................24
Figure II.5 : Les deux méthodes de cosimulation
...................................................... 26 Figure II.6 : La
représentation
intermédiaire.............................................................................28
Figure II.7 : Exemple de description pour chaque niveau
d'abstraction ......... 29
Figure II.8 : représentation simplifiée du flot
de conception pour SoC................................. 30
Figure II.9 : Un module
processeur........................................................................................31
Figure II.10 : Le flot de conception générale
pour les SoC................................................ 32
Figure II.11 : Génération d'interfaces
matérielles et logicielles.......................................
34
Figure II.12 : Enveloppes de
simulation..................................................................
35
Figure II.13 : Les étapes de la compilation d'un
programme en langage C........................................37 Figure II.14 :
Les étapes du ciblage
logiciel..............................................................................40
Figure II.15 : OS en tant qu'abstraction du
matériel................................................... 49
Figure II.16 : OS en tant que gestionnaire de ressources
................................................ 50
Figure II.17 : Communication point à point et
communication multipoint ........................ 52
Figure II.18 : Files d'attentes FIFO pour
désynchroniser deux blocs ................................. 53
Chapitre III
Figure III.1 : Système embarqué typique
..................................................................................68
Figure III.2 : Capteur et transmetteur en situation
......................................................................69 Figure
III.3 : Principe de la pesée successive
............................................................................70
Figure III.4: Principe du convertisseur simple rampe
...................................................................71 Figure
III.5: Architecture du convertisseur double rampe
......................................................... 71 Figure III.6 : Le
convertisseur flash
........................................................................................72
Chapitre IV
Figure IV.1 : Classement des attaques
....................................................................................80
Figure
IV.2 : Modèle de menaces
..........................................................................................81
Figure
IV.3 : Types de
menaces..............................................................................................81
Listes des tableaux
Tableau II.1 : Exemple de description pour chaque niveau
d'abstraction...........................................28

Introduction général
I. Introduction général :
Un système embarqué est un système
électronique et informatique autonome ne possédant pas des
entrées/sorties standards comme un clavier ou un écran
d'ordinateur. Il est piloté dans la majorité des cas par un
logiciel, qui est complètement intégré au système
qu'il contrôle. On peut aussi définir un système
embarqué comme un système électronique soumis à
diverses contraintes. Les concepteurs des systèmes électroniques
sont aujourd'hui confrontés à la complexité croissante des
algorithmes mis en oeuvre et à la variété des cibles
potentielles FPGAs et/ou DSPs. Actuellement, il n'est pas rare que ces
systèmes intègrent plusieurs douzaines voire des centaines de
processeurs. A l'origine, ce sont des systèmes matériels et
logiciels intégrés dans des avions militaires ou des missiles.
Ensuite dans le civil: avions, voitures, machine à laver...! La machine
et le logiciel sont intimement liés et noyés dans le
matériel et ne sont pas aussi facilement discernables comme dans un
environnement de travail classique de type PC. On mentionne les contraintes
physiques fortes: dimensions, poids, taille, autonomie, consommation,
fiabilité, contraintes temporelles (temps réels).
Le premier chapitre est une introduction
générale à ce domaine pluridisciplinaire. Après en
avoir posé les grands principes avec des
généralités, en effet, l'électronique se trouve
maintenant embarquée dans de très nombreux objets usuels : les
téléphones, les agendas électroniques, les voitures. Ce
sont ces systèmes électroniques enfouis dans les objets
usuels.
Le deuxième chapitre est consacré à la
conception des logiciels embarqués, les habitudes de programmation pour
les ordinateurs portent à croire que la compilation et l'édition
de liens sont les seuls traitements à apporter au logiciel pour pouvoir
le faire fonctionner sur une architecture cible. Le but de ce chapitre est de
montrer que dans le cas des systèmes embarqués, une autre
étape est nécessaire avant la compilation : elle adapte le
logiciel à l'architecture cible spécifique et sera nommée
dans ce mémoire le ciblage logiciel.
Dans le troisième chapitre, nous nous
intéresserons aux bases de conception matérielle. En effet, les
systèmes à base de composants apparaissent bien dans une
architecture matérielle qui est vue comme l'interconnexion sur une carte
(PCB pour Printed Circuit Board) de composants sur étagère vendus
dans des boîtiers séparés. Ces composants sont vus comme
des boîtes noires auxquelles les constructeurs associent des documents
(datasheets, notes d'application), pour en préciser les
fonctionnalités, les interfaces et les contraintes d'utilisation. Une
même carte regroupe généralement un processeur, de la
mémoire, des périphériques de taille modeste et des
circuits logiques. Ces derniers sont combinés soit pour construire des
circuits plus complexes, soit sous forme de «glu» pour adapter les
interfaces entre composants.
Le quatrième chapitre traite des problèmes sur
la sécurité des systèmes embarqués. On cite
notamment : La cryptologie qui est la science du secret, elle se divise en deux
branches : La cryptographie : qui étudie les différentes
possibilités de cacher, protéger ou contrôler
l'authenticité d'une information; La cryptanalyse : qui étudie
les moyens de retrouver cette information à partir du texte
chiffré (de l'information cachée) sans connaître les
clés ayant servi à protéger celle-ci, c'est en quelque
sorte l'analyse des méthodes cryptographiques.
Le besoin des entreprises internationales installées en
Algérie, dans les nouvelles technologies de l'information et de la
communication, et spécialement dans le domaine de conception des
systèmes embarqués, c'est dans ce contexte qu'on a
étudié ce thème qui a pour but le transfert de
compétence dans le domaine des systèmes embarqués.
Internationalement, Les multiprocesseurs sur monopuce paraient être une
voie prometteuse, ils introduisent de nouvelles contraintes et de nouveau
défis à soulever, due essentiellement à leurs natures
multi-coeurs.

Motivation et Objectif
Motivation :
Les systèmes embarqués prennent une place de
plus en plus importante dans notre société, ils servent à
contrôler, réguler des dispositifs électroniques
grâce à des capteurs, embarqués dans des robots, des
véhicules spatiaux, etc. Ces systèmes embarqués sont
souvent utilisés par le public dans la vie de tous les jours sans
même qu'on ne s'en rende compte, par exemple dans les systèmes de
freinage d'une voiture, le contrôle de vol d'un avion,... Et grâce
a cette importance des systèmes embarqués on a choisis ce
thème la.
IV. Objectif :
Notre but principal est la conception des systèmes
embarqués en général par l'étude des points
suivants :
- Bien connaitre les systèmes embarqués.
- Les flots de conception existant des systèmes
embarqués.
- Les systèmes d'exploitation dédiés aux
systèmes embarqués. - L'architecture matérielle des
systèmes embarqués.
- La sécurité des systèmes
embarqués.
Chapitre I
Généralités sur les
systèmes
embarqués

Chapitre I
généralités sur les systèmes
embarqués
I.1. DEFINITIONS :
Définition 1 :
Les systèmes électroniques sont de plus en plus
présents dans la vie courante. Les ordinateurs et micro-ordinateurs sont
des systèmes électroniques bien connus. Mais
l'électronique se trouve maintenant embarquée dans de très
nombreux objets usuels : les téléphones, les agendas
électroniques, les voitures. Ce sont ces systèmes
électroniques enfouis dans les objets usuels qui sont appelés
systèmes embarqués.
Définition 2 :
« Embedded system » tout système conçu
pour résoudre un problème ou une tache spécifique mais
n'est pas un ordinateur d'usage général.
-Utilisent généralement un microprocesseur
combiné avec d'autres matériels et logiciel pour résoudre
un problème de calcul spécifique.
-Système électronique et informatique autonome ne
possédant pas des entrées-sorties standards.
-le système matériel et l'application sont
intimement liés et noyés dans le matériel et ne sont
discernables comme dans un environnement de travail classique de type PC.
Définition 3 :
N'est pas visible en tant que tel, mais est
intégré dans un équipement doté d'une autre
fonction ; ou dit aussi que le système est enfoui, ce qui traduit plus
fidèlement le terme anglais « Embedded ».
-Une faible barrière existe entre les systèmes
embarqués et les systèmes temps réel (un logiciel
embarqué n'a pas forcément de contraintes temps réel).
-La conception des ces systèmes est fiable (avions,
système de freinage ABS) à cause de leur utilisations dans des
domaines à fortes contraintes mais également parce que
l'accès au logiciel est souvent difficile une fois le système
fabriqué.
Définition 4 :
Les microprocesseurs s'étendent depuis de simples
microcontrôleurs 8bits aux 64bit le plus rapidement et les plus
sophistiqués.
-le logiciel système inclus s'étend d'un petit
directeur à un grand logiciel d'exploitation en temps réel (RTOS)
avec une interface utilisateur graphique (GUI). Typiquement, le logiciel
système inclus doit répondre aux événements d'une
manière déterministe et devrait toujours être
opérationnel.
Les systèmes embarqués couvrent aussi bien les
commandes de navigation et de commande de trafic aérien qu'un simple
agenda électronique de poche.

I.2. HISTORIQUE :
La plupart des machines qui nous simplifient la vie ont besoin
d'un système de régulation ou de contrôle pour fonctionner
de manière correcte.
Ces systèmes de contrôle existent depuis bien avant
l'invention des ordinateurs. Exemple :
Pour maintenir une locomotive à vapeur à une
vitesse constante, on a besoin d'un système qui régule la
quantité de vapeur envoyée dans les pistons.
Si la locomotive ralentit (pente montante...) il faut injecter
plus de vapeur, si la locomotive accélère, il faut injecter moins
de vapeur On aimerait que cette tâche se fasse de façon
«automatique», c'est-à dire avec un minimum d'intervention de
l'être humain.
Solution : le gouverneur à force centrifuge
valve valve
d'admission d'adminission
de vapeur de vapeur
axe relié aux roues rotation rapide
fermeture
Figure a : Système de régulation de
quantité de vapeur
Ces systèmes de contrôle peuvent donc être
réalisés de manière forte simple. Avec le
développement de la technologie, on a opté pour des
systèmes basés sur l'électronique.
Parallèlement à ce développement des
systèmes de contrôle, les systèmes informatiques se sont
développés. Ceux-ci sont vite sortis du cadre des «machines
de bureau» ou de «machine à calculer» dans lequel ils
avaient initialement été développés, (Ordinateur =
machine à traiter l'information).
Il est donc naturel d'utiliser les possibilités de
calcul de l'ordinateur comme composant d'un système plus large. Pour
remplacer un système de régulation analogique, et pour
réaliser un traitement qui serait trop complexe / impossible en
analogique...
Les Avantages:
· plus grande flexibilité des systèmes
informatiques.
· On peut modifier le programme.
· On peut réutiliser plus facilement ce qui existe
déjà.
· plus de puissance de calcul.
· plus compact.
Sys. Contrôle Informatique
Systèmes embarqués

Un des premiers exemples de système embarqué
date du début des années 1960. Il s'agit de l'ordinateur de bord
des vaisseaux spatiaux du programme Apollo, qui a amené N. Armstrong sur
la lune. Cet ordinateur contrôlait en temps réel les
paramètres de vol et adaptait la trajectoire. Il fonctionnait en mode
interactif.
|
Interface utilisateur
Pas de CPU: plus de 4000 circuits intégrés
contenant chacun 3 portes NOR 32 Ko de RAM
72 Ko de ROM 2MHz
Programme en assembleur (11 instructions)
|
Figure b : Le premier système
embarqué
Le premier système embarqué qui a
été produit en série est vraisemblablement le D-17
d'Autonetics. Il servait de système de contrôle aux missiles
nucléaires américains LGM-30 Minuteman, produit à partir
de 1962.

Disque dur
Figure c : Le système de contrôle aux
LGM-30 Minuteman Le disque était utilisé comme
mémoire primaire !
Depuis les systèmes se sont diversifiés, ils ont
permis l'explosion du marché des «consumer
electronics» où tout est (devenu) numérique (GSM,
électroménager, MP3s, etc.). Ils sont également bien
présents dans le domaine industriel pour Contrôle de processus de
production, etc.
La convergence entre les applications électroniques
pour grand public et les ordinateurs est de plus en plus grande : La console de
jeu XBox de Microsoft n'est qu'un PC «emballé» sous la forme
d'une console. Il est de plus en facile de transformer son PC de bureau en
«media center» qui remplace la chaîne hi-fi et le
lecteur DVD...
Brève histoire des systèmes
embarqués :
1967 : Apollo Guidance Computer, premier système
embarqué. Environ un millier de circuits intégrés
identiques (portes NAND).
1960-1970 : Missile Minuteman, guidé par des circuits
intégrés.
1971 : Intel produit le 4004, premier microprocesseur, à
la demande de Busicom. Premier circuit générique, personnalisable
par logiciel.

Chapitre I généralités sur les
systèmes embarqués
1972 : lancement de l'Intel 8008, premier microprocesseur 8 bits
(48 instructions, 800kHz).
1974 : lancement du 8080, premier microprocesseur largement
diffusé. 8 bits, (64KB d'espace adressable, 2MHz - 3MHz).
1978 : création du Z80, processeur 8 bits.
1979 : création du MC68000, processeur 16/32 bits.
I.3.Classes des systèmes embarqués
: > Calcul normal (limite de
matériels) - Application similaire à une
application de bureau mais empaquetée dans un système
embarqué.
- Les jeux de vidéo, set- top box, et TV Box. >
Les systèmes de contrôle
- Contrôle de systèmes en Temps Réel.
- Moteur d'automobile, traitement chimique, traitement
nucléaire, système de navigation aérien.
> Traitement de signal
- Calcul sur de grosses quantités de données.
- Le radar et sonar, le dispositif de compression
vidéo.
> Télécommunications &
Réseau
- Transmission d'information et commutation. -
Téléphone portable, Dispositifs de l'Internet.
I.4.Caractéristiques des systèmes
embarqués :
La principale caractéristique d'un système
embarqué est qu'il est conçu pour gérer quelques
tâches simples, mais les étapes de la manipulation ou de
l'accomplissement de cette tâche mai être aussi complexe que tout
programme d'ordinateur. Un contrôleur de jeux vidéo, par exemple,
mai être considérés comme ayant des tâches simples,
charge le jeu et permettre au joueur de contrôler par le biais de
commandes entrées par l'intermédiaire du combiné. En
vérité, cependant, un contrôleur de jeu (surtout les
nouveaux jeux conçus pour la X-Box ou PS3) passe par une série de
mesures et d'actions qui nécessitent le plus de puissance de traitement
comme un ordinateur. Parmi les caractéristiques de modernes
systèmes embarqués sont:
Interface utilisateur
L'origine, un système intégré n'a pas
d'interface utilisateur, l'information et des programmes ont déjà
été intégrés dans le système (par exemple,
le système de guidage d'un missile balistique intercontinental ou ICBM)
et il n'y avait pas de nécessité d'intervention humaine ou de
l'intervention, sauf pour installer le dispositif de test.
De nombreux systèmes embarqués modernes ont
toutefois à grande échelle des interfaces utilisateur bien que ce
ne sont que des entrées de données, mais ne sont pas
censés fournir des fonctionnalités supplémentaires pour le
système, par exemple, un clavier QWERTY pour PDA utilisé pour
saisir des noms, adresses, numéros de téléphone et des
notes et même le plein la taille des

documents. Le moment PDA ordinateur de bureau, atteindre le plein
de fonctionnalités, mais ils mai ne sera plus considéré
comme les systèmes embarqués.
Simple Système Limité, qui provient de la
fonctionnalitéL'origine, cette
référence à des systèmes de base tels que les
interrupteurs, les petits
caractères ou des chiffres et les voyants affiche
uniquement pour but de montrer la «santé» du système
embarqué, mais il a également atteint un certain niveau de
complexité. Une caisse enregistreuse ou d'un guichet automatique avec la
technologie d'écran tactile est considéré comme un
système intégré, car il a des usages limités,
même si l'interface utilisateur (l'écran tactile) est un
système complexe.
CPU avec les plates-formes microprocesseurs ou de
microcontrôleurs
Encore une fois, la fonctionnalité limitée est
la clé dans la définition de ce que les systèmes
embarqués. Dans un sens, le BIOS est considéré comme un
système intégré, car il a des fonctions limitées,
et fonctionne automatiquement (quand l'ordinateur est démarré).
Périphériques comme l'USB peuvent aussi être
considérées comme des systèmes embarqués.
Les systèmes embarqués ont pour but de permettre
aux objets usuels de réagir à l'environnement. Ils peuvent aussi
apporter une interface avec l'utilisateur. La structure de base de ces
systèmes est donnée figure I.1 : l'environnement est
mesuré par divers capteurs. L'information des capteurs est
échantillonnée pour être traitée par le coeur du
système embarqué. Puis le résultat du traitement est
converti en signaux analogiques qui génèrent les actions sur
l'environnement (afficheur d'informations pour l'utilisateur, actionneurs,
transmission d'information, etc.).
Capteur
Capteur
Capteur
C
A
N
Environnement
Système
embarqué
Coeur
du
système
embarqué
C
N
A
Afficheur
Actionneurs
etc.
Figure I.1 : Un système embarqué dans
son environnement I.5. Les contraintes des systèmes
embarqués :
Les systèmes embarqués exécutent des
tâches prédéfinies et ont un cahier des charges
contraignant à remplir, qui peut être d'ordre :
De coût. Le prix de revient doit être le plus faible
possible surtout s'il est produit en grande
série.

Chapitre I généralités sur les
systèmes embarqués
D'espace compté, ayant un espace mémoire
limité de l'ordre de quelques Mo maximum. Il convient de concevoir des
systèmes embarqués qui répondent au besoin au plus juste
pour éviter un surcoût.
De puissance de calcul. Il convient d'avoir la puissance de
calcul juste nécessaire pour répondre aux besoins et aux
contraintes temporelles. Les processeurs utilisés dans les
systèmes embarqués sont 2 à 3 décades moins
puissantes qu'un processeur d'un ordinateur PC.
De consommation énergétique la plus faible
possible, due à l'utilisation de batteries et/ou, de panneaux solaires
voir de pile à combustible pour certain prototypes.
Temporel, dont les temps d'exécution et
l'échéance temporel d'une tâches est
déterminé (les délais sont connus ou bornés a
priori). Cette dernière contrainte fait que généralement
de tels systèmes ont des propriétés temps réel.
De sécurité et de sûreté de
fonctionnement. Car s'il arrive que certains de ces systèmes
embarqués subissent une défaillance, ils mettent des vies
humaines en danger ou mettent en périls des investissements importants.
Ils sont alors dits « critiques » et ne doivent jamais faillir. Par
« jamais faillir », il faut comprendre toujours donner des
résultats juste, pertinents et ce dans les délais attendus par
les utilisateurs (machines et/ou humains) desdits résultats.
I.6. Architecture des systèmes embarqués
:
Dans cette section, nous présentons les architectures
supportées par trois générations d'outils de
conception.
I.6.1. Les systèmes embarqués de
première génération :
I.6.1.1. Partie matérielle des systèmes
embarqués de première génération :
Les premiers systèmes embarqués supportés
par des outils tels que COSYMA et Vulcan étaient très simples :
ils étaient constitués d'un processeur qui contrôlait un
nombre restreint de CIAS (circuits intégrés à applications
spécifiques) ou ASIC qui étaient appelés
périphériques. Cette architecture est représentée
figure I.2. Les communications de cette architecture se situent au niveau du
bus du processeur et sont type maître/esclave : le processeur est le
maître et les périphériques sont les esclaves.

Système embarqué
Processeur
Périphérique
d'entrée
Mémoire
Bus du processeur
Périphérique
de sortie
Environnement
Figure I.2 : Architecture embarquée de
première génération

Les périphériques de ces architectures
étaient essentiellement des capteurs et des actionneurs
(contrôleurs magnétiques, sortie, etc.). Le processeur est
dédié au calcul et au contrôle de l'ensemble du
système.
Les microcontrôleurs assemblent sur une même puce le
processeur et les périphériques.
I.6.1.2. Partie logicielle des systèmes
embarqués de première génération :
Ne devant pas exécuter de nombreuses opérations
simultanées (le nombre de périphériques et de fonctions
étant restreint), les parties logicielles étaient
constituées d'un seul programme. La réaction aux
événements était effectuée par le biais de routines
de traitement d'interruptions.
Cette partie logicielle était décrite directement
en langage d'assemblage ce qui permettait d'obtenir un code efficace et de
petite taille.
I.6.2. Les systèmes embarqués de
deuxième génération :
Les premiers systèmes embarqués ne pouvaient
fournir que des fonctions simples ne requérant que peu de puissance de
calcul. Leur architecture ne peut pas supporter les fonctionnalités
requises pour les systèmes embarqués actuels à qui il est
demandé non seulement d'effectuer du contrôle, mais aussi des
calculs complexes tels que ceux requis pour le traitement numérique du
signal. De nouveaux outils tels que N2C (dans ces nouvelles versions)
permettent de traiter des architectures plus complexes.
I.6.2.1. Partie matérielle des systèmes
embarqués de deuxième génération :
L'architecture des systèmes embarqués de
deuxième génération est composée d'un processeur
central, de nombreux périphériques, et souvent de quelques
processeurs annexes contrôlés par le processeur central. Le
processeur central est dédié au contrôle de l'ensemble du
système. Les processeurs annexes sont utilisés pour les calculs ;
il s'agit souvent de processeurs spécialisés comme les DSP. Une
telle architecture est représentée figure I.3. Dans une telle
architecture, plusieurs bus de communication peuvent être
nécessaires : chaque processeur dispose de son bus de communication.

Système embarqué
Processeur central
Périphériques d'entrée
Mémoire centrale
Bus annexe
Pont
Périphériques de sortie
Bus du processeur central
Mémoire annexe
Autres
périphériques
Processeur annexe
Environnement
Figure I.3 : Architecture embarquée de
deuxième génération

Chapitre I généralités sur les
systèmes embarqués
I.6.2.2. Partie logicielle des systèmes
embarqués de deuxième génération :
La partie logicielle des systèmes embarqués de
deuxième génération est répartie sur plusieurs
processeurs (le processeur principal et les processeurs annexes). Les
systèmes actuels sont trop complexes pour pouvoir être
gérés par un unique programme sur le processeur principal. Il est
donc nécessaire d'avoir une gestion multitâche sur ce processeur,
et un système d'exploitation est couramment employé dans ce
but.
Le logiciel du processeur central est souvent décrit
dans un langage de haut niveau tel que le C. le logiciel des processeurs
annexes est souvent trop spécifique pour être entièrement
décrit dans un langage de haut niveau, et l'utilisation des langages
d'assemblage est nécessaire.
I.6.3. Les systèmes embarqués de
troisième génération :
Les progrès de l'intégration permettent
d'envisager des circuits pouvant contenir plusieurs milliers de portes. Il
devient donc techniquement possible de fabriquer des systèmes
embarqués pouvant remplir toutes les fonctionnalités
souhaitées.
I.6.3.1. Parties matérielles des systèmes
embarqués de troisième génération :
Pour pouvoir supporter conjointement les besoins en puissance
et en flexibilité, ces architectures comprennent de plus en plus de
processeurs, qui peuvent chacun se comporter en maître : l'architecture
couramment utilisée, basée sur un processeur central
contrôlant le reste du système, n'est donc plus suffisante.
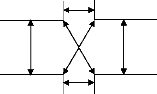
Processeur
ASIC
Processeur
Mémoire
Processeur
Mémoire
ASIC
Processeur
ASIC
Mémoire
Bus
Architecture à base de bus Architecture en barres
croisées
ASIC
ASIC
Mémoire
Processeur
Architecture à base de réseau
commuté
Mémoire
ASIC
Bus
Processeur
ASIC
Mémoire
ASIC
Processeur
Architecture mixte
Figure I.4 : Architectures embarquées de
troisième génération

Alors le goulet d'étranglement était les
ressources en calcul, de nos jours il est situé plutôt au niveau
des communications. Ce sont elles qui définissent désormais
l'architecture, et nos plus les ressources de calcul. La figure I.4 donne des
exemples d'architectures centrées sur les communications. Dans cette
figure, tous les éléments (processeur, ASIC ou mémoires)
sont traités de la même manière. Le premier exemple est
basé sur des communications par bus : ce modèle de communication
consomme peu de surface, mais risque de devenir un goulet
d'étranglement. Le deuxième est basé sur des
communications en barres croisées très performantes mais aussi
très coûteuses en surface. Le troisième exemple donne une
solution intermédiaire, par réseau commuté. Enfin le
dernier exemple montre qu'il est possible de mixer plusieurs modèles de
communication, et d'apporter de la hiérarchie dans l'architecture.
Autour de ce modèle d'architecture centré sur
les communications, se greffent les autres modèles d'architecture :
architectures des éléments de calcul et des mémoires.
L'architecture des éléments de calcul consiste à
définir quels sont les éléments principaux et quels sont
leurs périphériques de manière à les grouper dans
une architecture locale. L'architecture des mémoires sert à
définir quelles sont les mémoires locales à un groupe et
quelles sont celles qui seront partagées.
I.6.3.2. Parties logicielles des systèmes
embarqués de troisième génération :
Les parties logicielles ont beaucoup gagné en
importance dans les systèmes embarqués. Plusieurs systèmes
d'exploitation sont parfois nécessaires pour les divers processeurs de
l'architecture. De plus, la complexité et la diversité des
architectures possibles font qu'il devient de plus en plus nécessaire
d'abstraire les tâches logicielles des détails du matériel.
Toute cette complexité est donc reportée dans les systèmes
d'exploitation, qui deviennent de plus en plus complexes.
Cette complexité logicielle et matérielle
entraîne de nombreuses alternatives. En particulier, l'aspect
multiprocesseur apporte des alternatives pour les systèmes
d'exploitation : il peut y avoir un seul système pour tous les
processeurs (solution difficilement applicable lorsque les processeurs sont
hétérogènes), ou il peut y avoir un système par
processeur (solution qui peut être plus coûteuse).
I.7. Les systèmes embarqués
spécifiques :
Lorsqu'un système est utilisé pour une
tâche bien précise, il est souvent plus efficace et économe
s'il est spécifique à cette fonctionnalité que s'il est
général. Les systèmes embarqués sont très
souvent utilisés dans ces conditions, et il est donc intéressant
qu'ils soient conçus spécifiquement pour les fonctions qu'ils
doivent remplir. Notamment, les contraintes citées dans la section
précédente ne peuvent souvent être respectées que si
le système est conçu dès le départ pour pouvoir les
respecter. Il est donc de par sa conception même spécifique.
Le problème qui se pose alors est que, pour chaque
nouvelle fonctionnalité, il faudra concevoir un système
spécifique différent de ceux déjà existants. Le
flot de conception, présenté dans la section II.6 (chapitre II),
et dont le travail de ce mémoire fait partie, s'intéresse
à ce type de système embarqué, et tout
particulièrement aux systèmes sur une puce,
présentés dans le chapitre suivante.
Chapitre II
Conception des logiciels
embarqués

Chapitre II conception des logiciels
embarqués
II.1.Introduction :
La conjonction de l'évolution des technologies de
fabrication des circuits intégrés et de la nature du
marché des systèmes électroniques fait que l'on est
amené à concevoir des circuits de plus en plus complexes
(plusieurs millions) de transistors en un temps de plus en plus court (quelques
mois). Ce phénomène a entraîné une
métamorphose du processus de conception allant de l'idée au
produit.
Durant les dernières décennies, on est
passé de la conception de circuits composés de quelques milliers
de portes à des systèmes structurés et
intégrés comme un réseau sur une même puce. Les
puces modernes peuvent contenir plusieurs processeurs, de la mémoire et
un réseau de communication complexe. Le principe de la conception reste
le même ; il s'agit de générer une réalisation
physique sous forme d'une puce en partant d'une spécification
système. Par contre, les outils mis en oeuvre et l'organisation du
travail durant le processus de conception ont beaucoup évolué.
Partant d'une conception complètement manuelle où l'on dessinait
les masques du circuit à réaliser sur du papier spécial,
on est passé à une conception quasi automatique en partant d'une
description du comportement du circuit sous forme d'un programme décrit
dans un langage de haut niveau.
Le ciblage de logiciel dans le cas des systèmes
embarqués est traité aussi dans ce chapitre. Dans le domaine de
la conception de logiciel, de très nombreux travaux ont
été et sont effectués sur la compilation de descriptions
de haut niveau vers les langages machines (interprétés par les
processeurs). Les habitudes de programmation pour les ordinateurs portes
à croire que la compilation et l'édition de liens sont les seuls
traitements à apporter au logiciel pour pouvoir le faire fonctionner sur
une architecture cible. Le but de ce chapitre est de montrer que dans le cas
des systèmes embarqués, une autre étape est
nécessaire avant la compilation : elle adapte le logiciel à
l'architecture cible spécifique et sera nommée dans ce
mémoire le ciblage logiciel.
II.2.Les systèmes pour puces :
Les prévisions stratégiques d'ITRS annoncent que
70 % des ASIC comporteront au moins un CPU embarqué à partir de
l'année 2005. Ainsi la plupart des ASIC seront des systèmes
mono-puces (SoC pour System on Chip en anglais). Cette tendance semble
non seulement se confirmer mais se renforcer : les systèmes mono-puces
contiendront des réseaux formés de plusieurs processeurs dans le
cas d'applications telles que les terminaux mobiles, les Set top box, les
processeurs de jeux et les processeurs de réseaux. De plus, ces puces
contiendront des éléments non digitaux (par exemple analogique ou
RF) et des mécanismes de communication très sophistiqués.
Etant donné que tous ces systèmes correspondent à des
marchés de masse, ils ont tous été (ou seront)
intégrés sur une seul puce afin de réduire les coûts
de production. Il est prévu que ces systèmes soient les
principaux vecteurs d'orientation de toute l'industrie des semi-conducteurs. Il
est donc crucial de maîtriser la conception de tels systèmes tout
en respectant les contraintes de mise sur le marché et les objectifs de
qualité.
Tous les acteurs dans le domaine des semi-conducteurs
travaillent déjà sur des produits intégrant des
processeurs multiples (CPU, DSP, ASIC, IP, etc.) et des réseaux de
communication complexes (bus hiérarchiques, bus avec protocole TDMA,
connexion point à point, structure en anneau et même
réseaux de communication par paquets) dans des systèmes
monopuces. Certains commencent même à parler de réseaux de
composants monopuces (network on chip). Il s'agit

d'assembler des composants standards pour en faire un
système comme on le fait pour les cartes. Ainsi, le problème
n'est plus tant de concevoir des composants efficaces mais surtout d'obtenir
une architecture qui respecte les contraintes de performances et de
coûts. Pour les composants, le problème devient plutôt de
s'assurer de leur validité avant de les utiliser. Cette évolution
fait que le goulet d'étranglement du processus de conception devient
maintenant la réalisation du réseau de communication des
composants embarqués sur la puce et la validation globale de l'ensemble
du système avant sa réalisation. Ainsi, nous sommes
déjà passés de l'ASIC au SoC et nous sommes en train de
passer au réseau sur puce.
La conception de ces nouveaux systèmes à l'aide
de méthodes classiques conduit à des coûts et des
délais de réalisation inacceptables. En fait, la conception de
ces systèmes induit plusieurs points de cassures qui rendent difficile
la mise en échelle des méthodes de conception existantes. Les
principaux défis sont les suivants :
1. la conception des systèmes multiprocesseurs
monopuces entraînera inévitablement la réutilisation de
composants existants qui n'ont pas été conçu
spécialement pour être assembler sur la même puce. Il sera
donc nécessaire d'utiliser des méthodes d'assemblage de
composants hétérogènes ;
2. le concepteur d'un système contenant des
processeurs programmables doit obligatoirement fournir, en plus du
matériel, une couche logicielle permettant la programmation de haut
niveau du circuit. Il sera donc nécessaire d'aider les concepteurs de
circuits à concevoir les couches logicielles ;
3. l'assemblage de composants
hétérogènes sur une même puce concevoir des
architectures dédiées à des applications
particulières peut nécessiter des schémas de communication
très sophistiqués mettant en oeuvre des parties
matérielles, des parties logicielles et des parties non
numériques telles que les interfaces de composants optiques ou
micromécaniques. La conception de ces interfaces
hétérogènes sera vraisemblablement le principal goulet
d'étranglement du processus de conception des systèmes
multiprocesseurs monopuces ;
4. la complexité des systèmes est telle qu'il
devient quasi impossible de les spécifier/valider manuellement à
des niveaux bas tels que le RTL où il faut donner/valider des
détails au niveau du cycle d'horloge. Des méthodes de
conception/validation basées sur des concepts de plus haut niveau sont
donc nécessaires. Comme pour le logiciel, des outils de synthèse
de haut niveau seront nécessaires pour le matériel. La
vérification des composants synthétisés sera obligatoire
afin de pouvoir en assurer la qualité.
La grande difficulté sera de maîtriser la
complexité lors de la conception de ces réseaux monopuces. Il
s'agira de réussir la conception rapide de système monopuces
multiprocesseurs, et ce, sous de fortes contraintes de qualité et de
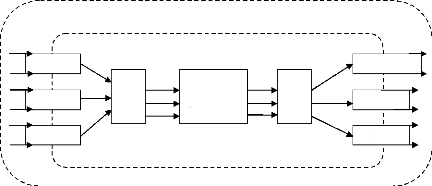
temps de conception. La figure II.1 montre l'architecture d'un système
monopuces. Cette architecture est structurée en couches en vue de
maîtriser la complexité. La partie matérielle est
composée de deux couches :
- la couche basse contient les principaux composants
utilisés par le système. Il s'agit de composants standard tels
que des processeurs (DSP, MCU, IP, mémoires) ;
- la couche de communication matérielle
embarquée sur une puce. Il s'agit des dispositifs nécessaires
à l'interaction complexe allant du simple pont (bridge en
anglais) entre deux processeurs au réseau de communication de paquets.
Bien que le réseau de communication lui-même soit

Chapitre II conception des logiciels embarqués
composé d'élément standard, il est souvent
nécessaire d'ajouter des couches d'adaptation entre le réseau de
communication et les composants de la première couche.
|
Logiciel spécifique à
l'application
|
|
API
|
|
Services du système
d'exploitation
(interruptions, gestion des ressources,
entrées/sorties)
|
|
Pilotes
|
|
Réseau de communication matériel
embarqué
|
|
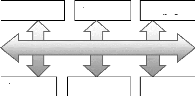
CPU, IP, mémoires
(DSP, MCU) (ASIC, COTS)
|
Compromis
matériel/logiciel
Logiciel
Matériel
Figure II.1. Architecture
logicielle/matérielle d'un système mono-puce Le
logiciel embarqué est aussi découpé en couches :
- la couche de gestion de ressources permet d'adapter
l'application à l'architecture.
Cette couche fournit les fonctions utilitaires nécessaires
à l'application qu'il est indispensable de personnaliser pour
l'architecture et ce pour des raisons d'efficacité.
Cette couche permet d'isoler l'application de l'architecture.
Cette couche est souvent appelé « système d'exploitation
» (OS). Les applications embarquées utilisent souvent des
structures de données particulières avec des accès non
standard (manipulation de champs de bits ou parcours rapides de tableaux) qui
ne sont généralement pas fournis par les OS standard. D'autre
part, les OS standard sont généralement trop volumineux pour
être embarqués. Il sera souvent nécessaire de
réaliser des OS spécifiques dédiés aux
applications. Le lien avec le matériel se fait via les pilotes
d'entrées/sorties et d'autres contrôleurs de bas niveau, qui
permettent de contrôler les composants de l'architecture. Le code
correspondant à ces pilotes est intimement lié au
matériel. Ces pilotes permettent d'isoler le matériel du reste du
logiciel ;
- le code de l'application.
Cette représentation en couches des systèmes
monopuces permet de séparer la conception des composants logiciels
(application) et matériels (composants existants ou
dédiés) des couches de communication. Elle permet aussi de
définir les différents métiers de conception et la
distribution du travail entre les différentes équipes.
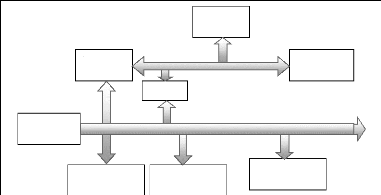
La plupart des méthodes de conception actuelles
essayent de copier le flot de conception des cartes. Ce dernier sépare
la conception en quatre métiers, l'architecture système, la
conception des composants matériels, la conception des composants
logiciels et l'intégration ou la conception système. Les trois
derniers métiers sont montrés dans la figure II.2a. Dans les
schémas traditionnels, le travail de l'architecte consistait à
tailler des composants matériels sur mesure afin de prévoir les
interconnexions de manière efficace et d'obtenir les meilleures
performances. Ainsi tout le matériel est taillé sur mesure, les
composants et le réseau de communication. Le logiciel étant
réalisé à part, le concepteur d'architecture doit juste
fournir une couche mince de logiciel permettant d'accéder aux ressources
matérielles. Le fait que la grande partie des couches de communication
est réalisée par des équipes séparées
(logiciel, matériel) peut entraîner des surcoûts dus aux
précautions et/ou aux sous-

|
Conception
|
Logiciel d'application
|
du API 1
|
logiciel
|
Système d'exploitation sur mesure
|
|
|
Piotes d'entrées/sorties
|
2
|
|
Réseau de communication matériel
|
|
|
intégrateur
|
Conception des composants
|
3
|
|
|
système 1. Concepteur du logiciel
d'application
2. Concepteur des interfaces logicielles/
Matérielles pour système sur puce Concepteur
3. Concepteur de circuit
de circuit
utilisations. La vérification des différentes
parties est aussi réalisée de manière
séparée et chaque équipe utilise des programmes de test
spécifiques.
API
Système d'exploitation standard
Modèle abstrait de l'architecture
Piotes d'entrées/sorties
Réseau de communication
matériel
Modèle des composants matériels
Conception des composants
a) Les métiers pour la conception b) Les
métiers de la conception
des systèmes sur cartes des systèmes sur
puces
Figure II.2 : Les métiers de la conception
système
Ce schéma n'est plus applicable à partir d'un
certain degré de complexité. Ainsi la conception d'architecture
consistera surtout à assembler des composants existants en vue de
respecter des contraintes de performances et de coûts au niveau du
système global et non plus au niveau du seul composant. Ainsi, il
devient crucial de combiner la conception des couches de communication
logicielles et matérielles. Cette évolution permettra la
séparation totale entre la conception des couches de communication et
les composants matériels et logiciels. Une telle séparation est
nécessaire pour introduire un peu de flexibilité et de
modularité dans l'architecture en permettant de charger plus facilement
les modules de base. Ainsi, l'abstraction des interfaces de communication
devient le pivot de la conception des systèmes monopuces.
C'est cette abstraction qui va permettre la conception de
circuits à partir d'un modèle supérieur au niveau RTL
utilisé aujourd'hui. Le fait de pouvoir décrire l'architecture
globale du système et d'abstraire la communication entre les composants
doit permettre de mieux finaliser les interfaces entre les différentes
couches à l'aide de procédure d'interface (API pour
Application Procédure Interface) de haut niveau. Ainsi on
pourra décrire le matériel au niveau comportemental et le
logiciel à un haut niveau ; bien entendu, le but étant de pouvoir
simuler globalement le système à partir de ce modèle
abstrait et de permettre la génération automatique de codes
logiciel et matériel. C'est ce schéma (présenté
figure II.2b) qu'essaient d'atteindre les nouvelles recherches dans le domaine
de la conception système.
II.3. La conception des systèmes sur puces :
Le flot de conception est généralement
découpé en deux parties, la partie frontale et la partie dorsale
du flot (en anglais ces parties sont appelées front-end et
back-end). La première partie consiste à raffiner les
spécifications initiales pour produire une réalisation de haut
niveau. La partie dorsale du flot réalise les étapes de
conception de bas niveau pour aller à la puce. Le point de

Chapitre II conception des logiciels embarqués
rencontre constitue un contrat (en anglais sign-off)
permettant de sous-traiter la partie dorsale du flot. Au cours des
années, la réalisation de haut niveau faisant l'objet du contrat
à évolué du simple dessin des masques aux modèles
de portes et est en passe d'atteindre le niveau transfert de registre. Il est
prévu que cette évolution continue pour atteindre le niveau
micro-architecture puis le niveau architecture de système contenant
à la fois les parties matérielles (composants et interconnexions)
et les parties logicielles (programmes d'applications et systèmes
d'exploitation).
La partie frontale du flot part d'une spécification
système qui permet de fixer les principales contraintes du produit
à réaliser. Ce modèle sera aussi utilisé pour
l'exploration d'architecture afin de fixer la solution architecturale qui sera
réalisée. Suit alors la conception de cette solution. Cette
étape comporte trois types d'actions ; la conception des composants
logiciels, la conception des composants matériels et la conception des
interfaces logicielles/matérielles.
Le résultat de cette partie est actuellement une
micro-architecture de l'ensemble du système. Les parties
matérielles sont détaillées au niveau transfert de
registre (description au niveau du cycle d'horloge). Dans le cas où le
système contient des parties logicielles exécutées sur un
ou plusieurs processeurs embarqués, elles sont décrites au niveau
de l'instruction (assembleur)
La partie dorsale comprend la conception des parties
matérielles en passant par la conception logique et la conception
physique. La figure II.3 montre une vue simplifiée de ce flot. Les
rectangles désignent des modèles de description et les ovales des
outils.
Verification, validation (tome!)
Architecture
Code assembleur
Raffinement du Raffinement de la
Synthèse
Logiciel (tome3) communication (tome3)
comportementale
(tome1)
Spécification des parties logicielles
Exploration d'architecture
(tome1)
Produit (niveau physique)
Spécification système
Conception physique
(tome2)
Interconnexion
Conception logique
(tome2)
Micro-architecture
Ports logiques
Spécification des
parties
matérielles
Test (Tome2)
Figure II.3 : le flot de conception
système

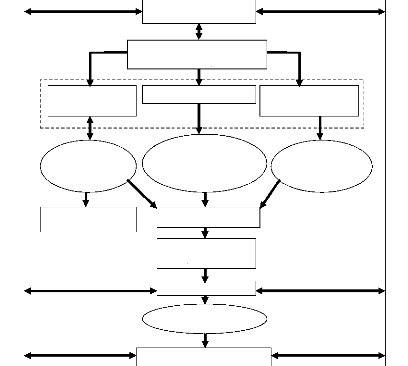
Ce flot considère cinq niveaux d'abstraction : le
niveau système, le niveau architecture et le niveau microarchitecture,
le niveau porte et le niveau physique. Au niveau système le circuit est
spécifié au niveau des transactions entre les
éléments de calcul : un ensemble de modules hiérarchiques
et de processus communiquant par protocoles de communication de haut niveau par
l'intermédiaire de canaux abstraits. Un canal peut cacher des protocoles
de communication de haut niveau et des primitives de communication qui
manipulent des types de données abstrait. A ce niveau, les modules
peuvent être décrits en utilisant différents langages et/ou
en utilisant différents niveaux d'abstraction. La cosimulation est
utilisée pour valider la fonctionnalité du système. Ce
modèle peut être utilisé pour explorer l'espace des
solutions architecturales et fixer les grandes lignes de l'architecture. Cette
étape est généralement réalisée à
l'aide d'outils de simulation et d'estimation de performances.
Le deuxième niveau d'abstraction représente une
architecture abstraite qu'on appelle macroarchitecture, ce modèle est
composé d'un ensemble de modules reliés ensemble par des fils
logiques. Chaque module représente un processeur dans l'architecture
finale. Ceci peut être un processeur logiciel (par exemple : un DSP ou un
microcontrôleur exécutant le logiciel), un processeur
matériel (un composant spécifique) ou un module existant
(mémoire globale, périphérique, contrôleur de bus,
etc.). Les fils logiques sont des canaux abstraits qui transfèrent des
types de données fixes (par exemple : nombre entier ou flottant) et
peuvent cacher des protocoles de bas niveau (par exemple : poignée de
main, transfert en mode rafale). Les différents modules peuvent
être décrits en utilisant un ou plusieurs langages. La
cosimulation peut être utilisée pour valider ce découpage
architectural. Cette macroarchitecture peut être utilisée par
différentes équipes pour réaliser les composants
matériels, les composants logiciels et l'intégration des
différents composants. Le résultat de ce flot est une
macroarchitecture du système décrite au niveau transfert de
registre. Ce modèle contient tout les détails de la communication
entre les composants. Les couches de communication logicielles peuvent
comporter un système d'exploitation spécifique (OS). Les couches
de communication matérielles comportent les bus et autres dispositifs
permettent de router les informations entre les composants. Les blocs
matériels sont raffinés au niveau du cycle d'horloge. Finalement,
les blocs existants (souvent appelés IP de l'anglais Intellectual
Property) sont enveloppés dans des interfaces afin de les adapter
aux bus et réseaux de communication utilisés. La connexion entre
les différents blocs matériels est faite par les fils physiques
qui mettent en application les protocoles choisis. Les composants logiciels
communiquent entre eux et avec l'extérieur via des appels système
à l'OS.
Le niveau porte détaille le système au niveau
des délais élémentaires des transferts entre les portes de
base. Finalement, le niveau physique représente les dessins des
masques.
II.4. Les systèmes monopuces :
Les progrès réalisés par les fondeurs de
circuits permettent maintenant d'envisager l'intégration sur une
même puce d'un système embarqué complet. Ces
systèmes monopuces (SoC : system on chip) apportent des changements
importants dans les flots de conception classique.
Dans les systèmes électroniques classiques, les
grandes dimensions des cartes électroniques entraînaient des
problèmes électriques. Ils limitaient notamment la vitesse de
communication. Cela pouvait conduire à des communications lentes entre
des composants potentiellement très rapides. C'était
particulièrement critique pour la communication entre le processeur et
la mémoire : quelle

Chapitre II conception des logiciels embarqués
que soit la vitesse du processeur, il devait aller lire ses
instructions en mémoire. Pour pallier à ces problèmes, il
était nécessaire d'utiliser des caches. L'inconvénient des
caches est dû à la très grande complexité
d'étude de leur système. Ils induisent en plus de gros facteurs
d'indéterminisme. Avec les systèmes monopuces, la communication
reste toujours un goulet d'étranglement, car elle est très
consommatrice de surface, mais avec un facteur bien moindre. En effet le fait
d'avoir sur la même puce l'ensemble du système raccourcit les
chemins de communication et facilite la construction d'architecture s'accordant
aux localités de calcul de l'application. Ces facilités
permettent ainsi souvent de s'affranchir des caches. Les systèmes
monopuces sont aussi moins encombrants et surtout, ils peuvent consommer moins
: en effet les données doivent transiter par des chemins beaucoup moins
longs, l'énergie nécessaire à cette transmission est donc
plus faible.
Les systèmes monopuces apportent aussi des changements
dans les habitudes de conception. Notamment, la frontière entre le
logiciel et le matériel n'est plus aussi nette : en effet avec les
anciens systèmes le matériel était déjà
conçu lorsqu'il fallait concevoir le logiciel. Avec les systèmes
monopuces, les deux doivent être conçus en même temps. Cela
augmente la complexité de la conception, mais cela offre aussi plus de
liberté : chaque partie peut être réalisée en
logiciel, en matériel, ou de manière mixte.
II.5. Conception des systèmes embarqués :
Les systèmes embarqués de première
génération étaient suffisamment simples pour que leur
conception ne requière pas de méthodologie particulière :
quelques essais-erreurs pouvaient suffire pour satisfaire aux contraintes. Avec
la seconde génération, la complexité est devenue trop
importante pour que la conception puisse être menée à bien
sans méthode. Un premier type de flot de conception a donc
été utilisé, inspiré par les flots de conception
pour les systèmes généralistes. Ce flot est
présenté dans la première section. La troisième
génération remet en question ce type de flot, et de nouvelles
méthodes émergent. Elles sont présentées dans la
section suivante.
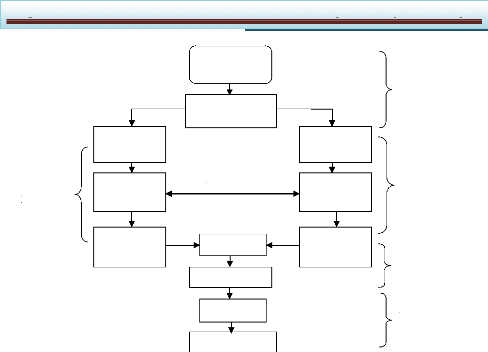
II.5.1. Flots classiques de conception des systèmes
embarqués : II.5.1.1. Le flot :
Le flot classique de conception des systèmes
embarqués est représenté sur les figures II.4a et II.4b.
Ce flot part d'une spécification souvent informelle du système.
Il distingue immédiatement les parties logicielles des parties
matérielles. Ces parties sont développées
indépendamment l'une de l'autre par des équipes
différentes. A la fin, une équipe d'intégration assemble
les parties, ce qui pose souvent des problèmes d'incompatibilité.
Cette intégration donne directement un prototype à tester. En cas
d'erreur, il peut être nécessaire de recommencer
complètement le flot.
Dans un tel flot il peut être difficile de
développer complètement le logiciel sans que le matériel
soit défini. C'est pour cela que son développement devait souvent
attendre que la partie matérielle soit décrite pour être
achevé.
Equipe
logicielle
Spécification
logicielle
Conception
logicielle
Prototype
logiciel
Partitionnement
logiciel
/matériel
Prototype final
Compte-rendu
Spécification
générale
Sur le matériel
Information
Intégration
TEST
Spécification
matérielle
Conception
matérielle
Prototype
matériel
Equipe
test
Equipe
intégration
Equipe
matériell
Equipe
système
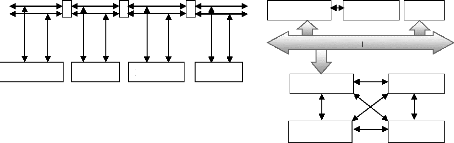
Figure II.4a : Les flots de conception classiques
pour les systèmes
Equipe
intégration
Equipe
test
Equipe
matérielle
Equipe architecture
Equipe
système

TEST final
Compte-rendu
Equipe
logicielle
Spécification
logicielle
Conception
logicielle
Prototype
logiciel
Partitionnement
synthèse
allocations
Architecture
globale
raffinée/annotée
Intégration
Prototype
Spécification
matérielle
Conception
matérielle
Prototype
matériel
Spécification générale
Définition
de
l'architecture
Architecture globale

Figure II.4b :
Codéveloppement pour les systèmes
embarqués

Chapitre II conception des logiciels embarqués
II.5.1.2. Les limitations du flot classique :
Le flot classique de conception de systèmes
embarqués possède de nombreuses faiblesses qui le rendent
inadapté pour supporter la complexité des systèmes
embarqués de troisième génération.
Tout d'abord, il manque une description globale qui
accompagnerait la conception du système (logiciel et matériel) du
début à la fin. Cette description permettrait à toutes les
équipes de conception de bien connaître l'ensemble du
système, ce qui éviterait de nombreuses erreurs. Il devrait
également être possible d'effectuer des vérifications du
système complet à tous les stades de la conception.
La séparation entre le logiciel et le matériel
est effectuée trop tôt dans le flot de conception : au stade
où elle est effectuée il n'est souvent pas possible de savoir
quelle est la meilleure configuration. A l'inverse, l'intégration des
différentes parties est effectuée trop tard dans le flot : il est
souvent trop tard pour lever les incompatibilités.
Les faiblesses de ce type de flot font que les temps de
développement ne sont plus réalistes pour la conception des
systèmes embarqués actuels.
II.5.2. Flots de conception récents :
Si le flot de conception classique pouvait suffire pour les
première et deuxième générations de systèmes
embarqués, la troisième génération, fortement
hétérogène et multimaître, est trop complexe pour
que les limitations précédemment énoncées soient
acceptable telles que le codéveloppement.
II.5.2.1. Codéveloppement :
Le codéveloppement ou codesing a pour but de
développer conjointement les diverses parties d'un système
hétérogène (logiciel, électronique,
mécanique, etc.). C'est pourquoi une description globale du
système est nécessaire.
Deux approches sont possibles pour cette description : la
première consiste à décrire toutes les parties dans un
langage unique. Ce langage doit alors avoir une sémantique pour chacune
des parties. L'avantage est qu'il est plus simple pour les outils et les
utilisateurs de gérer un langage unique. L'inconvénient est qu'il
est difficile, sinon impossible, de définir un langage qui soit vraiment
adapté à toutes les parties du système. La deuxième
approche consiste à utiliser plusieurs langages, chacun étant
adapté à une partie du système. Un langage de coordination
sert à faire le lien entre toutes les descriptions. L'avantage est que,
cette fois, il est possible d'avoir le langage optimal pour chaque partie.
L'inconvénient est que la gestion de tous ces langages est difficile.
Une partie difficile du codéveloppement est le
découpage entre le logiciel et le matériel. De nombreuses
heuristiques ont été développées, etc. cependant
l'approche manuelle prévaut toujours.
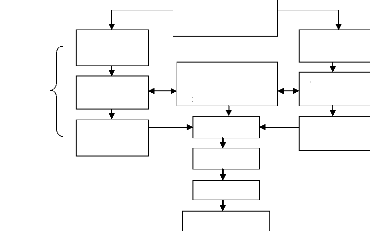
La figure II.4 donne un exemple de flot basé sur le
codévloppement en comparaison avec le flot classique : dans le nouveau
flot, la séparation entre le logiciel et le matériel est
effectuée plus tard, et une nouvelle équipe fait son apparition :
l'équipe d'architecture, qui s'occupe du système global et de la
coordination entre les équipes.



Le codéveloppement repose aussi sur l'utilisation d'une
autre technique permettant la simulation du système aux divers niveaux
d'avancement dans la conception. Ces simulations, appelées
cosimulations, sont décrites dans la section suivante.
II.5.2.2. Cosimulation :
La cosimulation a pour but de simuler conjointement les
diverses parties d'un système hétérogène. Cela
permet d'effectuer la validation d'un système complet avant le
prototype, mais aussi à divers niveaux d'abstraction.
Il existe deux méthodes pour effectuer cette
cosimulation (présentées figure II.5) : la première
consiste à traduire les descriptions des diverses parties dans un unique
langage pour la simulation. Très souvent, il s'agit d'un langage de
programmation tel que le C pour accélérer les simulations. La
difficulté est d'être assuré que la traduction et la
simulation du langage unique ne changent pas la sémantique des
descriptions des diverses parties. La deuxième méthode consiste
à conserver les descriptions spécifiques des diverses parties et
à exécuter en parallèle les divers simulateurs. Un
programme, appelé bus de cosimulation, cette tâche peut
s'avérer difficile à effectuer lorsque les modèles de
simulation sont différents ; de plus les communications entre les
simulateurs peuvent s'avérer coûteuses.
|
Cosimulation avec description
|
Cosimulation multilangage
|
Description
logicielle
Description
matérielle
Description
autre
Description
logicielle
Description
matérielle
Description
autre
Traduction
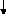
Simulateur
logiciel
Simulateur
matériel
Simulateur
autre
|
Description
unique
|
|
|
|
|
|
|
|
Simulateur
|
Bus de cosimulation
|
Figure II.5 : Les deux
méthodes de cosimulation
II.6. Exemple de flot de conception pour
systèmes monopuces :
La conception du logiciel est très liée aux
autres étapes et modèles utilisés dans le flot de
conception. Cette section présente un flot typique qui peut servir
d'environnement aux méthodes de conception de logiciel décrites
dans ce travail. Le but est de définir une démarche et un
ensemble d'outils permettant de faciliter la conception des systèmes
monopuces.
L'aide à la conception sera obtenue en élevant
le niveau d'abstraction avec lequel les concepteurs travaillent, et en
automatisant au maximum les passages aux niveaux d'abstraction
inférieurs. Ce flot est centré sur les communications car elles
apparaissent comme étant l'épine dorsale de la conception des
systèmes monopuces.

Chapitre II conception des logiciels embarqués
II.6.1. Présentation générale :
II.6.1.1. Domaine d'application :
Le flot a pour but d'aider à la conception des
systèmes embarqués spécifiques, et notamment les
systèmes sur une puce. Les diverses équipes de conception peuvent
utiliser conjointement cet outil (voir le paragraphe II.5.2). Mais il est tout
particulièrement destiné à l'équipe d'architecture.
L'aide consiste d'une part en l'apport d'une représentation multiniveau
et multilangage de l'architecture globale. Cette représentation sert de
référence pour la conception de toutes les parties du
système et aussi pour sa simulation. D'autre part, elle consiste en
l'apport d'outils d'automatisation de diverses opérations telles que la
génération des interfaces matérielles et logicielles.
Il supporte les architectures hétérogènes
multiprocesseur, multimaîtres et multitâches. Dans ce flot, chaque
processeur dispose d'un système d'exploitation et d'un jeu de
tâches qui lui sont propres. Chaque composant matériel est
encapsulé dans une interface qui adapte ses communications locales aux
communications globales de l'architecture.
II.6.1.2. Les restrictions :
La conception d'un système embarqué complet
commence souvent par une spécification informelle et
générale. Il existe des langages tels que UML qui permettent de
représenter de manière formelle ce type de spécification,
avec un niveau d'abstraction très élevé (le niveau service
du paragraphe II.6.1.3). Le flot proposé n'est pas encore capable
d'intégrer ce type de spécification : il débute plus bas
dans l'abstraction, à un niveau où l'architecture globale est
définie (le niveau fonctionnel du paragraphe II.6.1.3).
II.6.1.3. Le modèle de représentation de
base :
II.6.1.3.1. La forme intermédiaire utilisée :
Le flot utilise une forme intermédiaire pour
décrire la spécification quels que soient les niveaux
d'abstraction. Cette forme intermédiaire utilise le langage Colif. Ce
langage permet de décrire la structure d'un système, à
plusieurs niveaux d'abstraction, et en mettant l'accent sur les communications.
Les descriptions comportementales sont supposées issues de la
description initiale de l'application.
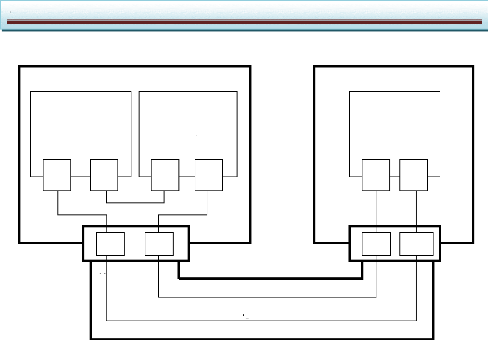
II.6.1.3.2. Les objets de la description :
Quel que soit le niveau d'abstraction, la description est
constituée de modules communicants. Ces modules peuvent
représenter des parties matérielles, des parties logicielles ou
des éléments de mémorisation. Ils communiquent par
l'intermédiaire de ports, au travers de canaux.
Chaque objet (module, port ou canal) est
décomposé en une interface et un contenu. Le contenu de chaque
objet peut être hiérarchique (c'est-à-dire contenir
d'autres objets) ou faire référence à un comportement.
La figure II.6 donne un exemple d'une telle architecture : les
modules, les ports et les canaux sont respectivement nommés M, P et C
lorsqu'ils sont hiérarchiques et m, p et c lorsqu'ils ne le sont pas.
M1
m1
m2
m3
P1
P2
P3
P4
P7
P8
c6
c7
c1
c2
c3
P5
P6
P9
P10
P1
c5
C1
c4 p2
Figure II.6 : La représentation
intermédiaire
|
Niveau
|
service
|
Fonctionnel
|
Macro-
architecture
|
Micro-
architecture
|
|
comportement
|
Objets
concurrents
|
Transactions Partiellement ordonnées
|
Pas de calcul
|
cycles
|
|
communications
|
Requêtes / services
|
Passage de
messages
|
Transmission
de
données
événements
|
Valeurs de bits
|
|
Exemple de
langages
|
CORBA/UML
|
SDL
|
VHDL, systemC
|
VHDL, systemC
|
Tableau II.1 : Exemple de description pour chaque
niveau d'abstraction II.6.1.3.3. Les niveaux d'abstraction utilisés
dans le flot :
Les systèmes est représenté sur quatre
niveaux d'abstraction différents : le niveau service, le niveau
fonctionnel, le niveau macroarchitecture et le niveau microarchitecture. Le
tableau II.1 compare les caractéristiques de ces différents
niveaux, et la figure II.7 donne un exemple pour chaque niveau. Au niveau
service, les objets peuvent interagir anonymement par le biais de
requêtes et de service. Seules les fonctionnalités sont
définies. Au niveau fonctionnel, les connexions entre les objets sont
définies. Au niveau macroarchitecture, les éléments
d'architecture sont définis : les processeurs, les ASIC,
etc. au niveau microarchitecture, tous les
détails de réalisation sont définis, comme les interfaces
de communications des processeurs ou les systèmes d'exploitation.

Chapitre II conception des logiciels embarqués
Niveau service niveau fonctionnel

R S S
F1 F2 F3
Routeur de requêtes /services
R R S R
F4
S
F1 F1
message
F1 F1
message
message
Niveau macroarchitecture
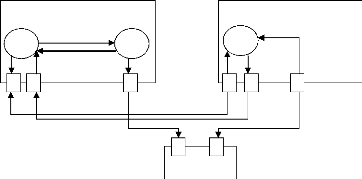
Processeur 1
F1
Données données
Evénement
Evénement
Evénement
Données
F2
F4
ASIC
Processeur 2
F3
Niveau microarchitecture
Système d'exploitation
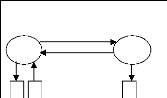
Processeur 1
Evénement
Données
F1
F2
Système d'exploitation
Processeur 2
Evénement
F3
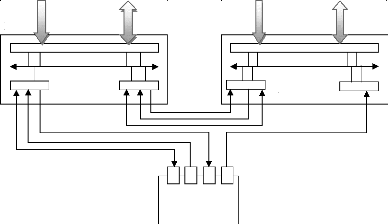
Bus adresses bus données bus adresses bus
données
Interface
F4
ASIC
Interface
Figure II.7 : Exemple de description pour chaque
niveau d'abstraction


Dans l'exemple de la figure II.7, une application est
présentée aux quatre niveaux d'abstraction. Cette application est
composée de quatre fonctions (ou tâches) F1, F2, F3 et F4. Au
niveau service, elles communiquent anonymement grâce au routeur de
requêtes. Au niveau fonctionnel, les connexions entre les tâches
sont explicitées, par exemple F1 envoie et reçoit des messages
avec F2 et F3 mais F4 n'envoie des messages qu'à F3, et n'en
reçoit que de F2. Au niveau macroarchitecture, l'architecture globale a
été décidée : F1 et F2 sont sur le processeur 1, F3
sur le processeur 2 tandis que F4 est un ASIC. Finalement, au niveau
microarchitecture, les détails locaux sont aussi explicités : les
processeurs disposent de leurs interfaces logicielles (systèmes
d'exploitation) et matérielles. Les ports des processeurs et de l'ASIC
sont réels t non plus ceux de la communication entre les tâches
(qui sont cachés dans les interfaces).
Le niveau service n'est pour l'instant pas traité par
le flot. Nous commençons par le niveau fonctionnel, pour arriver
jusqu'au niveau microarchitecture. Ce dernier est souvent appelé niveau
transfert de registres ou RTL (register transfer level).
II.6.1.4. Architecture générale du flot :
La figure II.8 donne une vision simplifiée du flot de
conception. Ce flot débute au niveau fonctionnel, mais après que
le partitionnement logiciel/matériel ait été
décidé. Il se termine au niveau microarchitecture, où une
classique étape de compilation et de synthèse logique permet
d'obtenir la réalisation finale du système. C'est un flot
descendant qui permet cependant de simuler à tous les niveaux et de
revenir en arrière à chaque étape. En entrée, le
flot attend une description de l'application au niveau fonctionnel. Cette
description est traduite dans la forme intermédiaire multi niveau Colif
pour être raffinée au cours de trois étapes :
- La première étape fait passer la description
au niveau macroarchitecture : elle effectue la synthèse de la
communication et les allocations globales de la mémoire ;
- La deuxième étape génère une table
d'allocation (mémoire et protocoles) : elle effectue les affectations de
mémoire et de protocoles, et également les optimisations des
accès ;
Description fonctionnelle
après
partitionnement
logiciel / matériel

Synthèse de la communication
Allocation mémoire globale

Description macroarchitecture
Affectation mémoire et protocoles
Optimisation des accès
Description macroarchitecture
annotée (table
d'allocations)

Génération d'interfaces
matérielles
Génération d'interfaces
logicielles
Figure II.8 : Représentation simplifiée
du flot de conception pour systèmes monopuces

Chapitre II conception des logiciels embarqués
- La dernière étape fait passer la description au
niveau microarchitecture : elle effectue la génération des
interfaces logicielles et matérielles qui permettent l'assemblage des
divers composants ainsi que leurs communications.
II.6.2. Architecture détaillée du flot :
Ce flot global est présenté sur la figure II.10.
Il part d'une spécification architecturale et comportementale du
système à concevoir. La description est alors raffinée de
niveaux d'abstraction en niveaux d'abstraction. En sortie, nous obtenons le
code logiciel et matériel réalisant l'application.
II.6.2.1. L'entrée du flot au niveau fonctionnel
:
En entrée du flot, nous prenons une description dans le
langage systemC. Ce langage permet de décrire la structure et le
comportement d'un système logiciel et matériel. Il est
basé sur le langage C++ étendu avec des bibliothèques
permettant la modélisation et la simulation de systèmes
logiciels/matériels globalement synchrones, ou asynchrones avec un
modèle à événements proches de celui du VHDL.
Cette description peut être effectuée au niveau
fonctionnel ou aux niveaux inférieurs. Il est aussi possible de combiner
les niveaux. Elle donne les informations sur la structure, et
éventuellement le comportement. Si certains composants sont fournis sans
comportement, ils sont considérés comme des boîtes
noires.
Cependant il était préférable que nous
possédions l'entière maîtrise du flot et donc qu'il ne
dépende pas d'un langage d'entrée externe à notre groupe.
C'est pourquoi la première étape du flot consiste à
convertir la description system C en une description Colif.
REMARQUE :
Lorsqu'un module représente un processeur, nous
considérons qu'il est accompagné par une mémoire locale
dans laquelle sont stockés le code et les données locales du
logiciel que le processeur doit exécuter. Tout au long de ce travail,
dès que nous parlerons de processeur, nous supposerons implicitement
l'existence de cette mémoire locale. Dans le cas où le processeur
est un microcontrôleur, les périphériques
intégrés seront eux aussi encapsulés dans l'enveloppe
représentant le processeur. La figure II.9 montre l'architecture
représentée par un module processeur.
Processeur
Périphérique
local
Bus du processeur
Mémoire
local
Périphérique
local
Figure II.9. Un module processeur

Niveau micro-architecture
Niveau fonctionnel
Niveau macroarchitecture
Bibliothèque
d'interfaces
Bibliothèque
de mémoire
Code des interfaces matérielles
Bibliothèque
de
modèles
mémoire
Bibliothèque
de
commun-
ication
Système monopuce
Architecture Colif annotée
macro-
architecture avec mémoire
Génération
d'interfaces
matérielles
Architecture Colif micro-architecture
Allocation mémoire globales
SystemC annoté
Génération
d'architecture
mémoire
Description du comportement
Description de l'architecture
Architecture Colif
fonctionnelle
Architecture Colif
macroarchitecture
Table d'allocations
Affectations
mémoire
Génération
de
systèmes
d'exploitation
(interfaces
logicielles)
Traduction vers Colif
Code systèmes
d'exploitation
raffinement : synthèse de
communication
Optimisations
d'accès
mémoire
Comportement
(ex. C++)
Comportement
(ex. C++)
Comportement
optimisé
Compilation / Synthèse
Bibliothèque
de
système
d'exploitation
Comportement optimisé
Boites
noires
Génération
d'architecture
mémoire
Description
multilangage
multiniveau
simulable
Cosimulation
Bibliothèque
de simulation
Composants
existants
Figure II.10 : Le flot de conception
générale pour les systèmes monopuces

Chapitre II conception des logiciels embarqués
II.6.2.2. Etape de traduction vers Colif :
Cette étape extrait les informations structurelles de
la description d'entrée (systemC), pour les mettre sous le format Colif
qui sera traité tout au long du flot. Les informations comportementales
et les informations «boîte noire » sont conservées.
Cette étape a été automatisée grâce aux
outils développés dans l'équipe par Wander
Cesário.
II.6.2.3. Etape d'allocation mémoire et de
synthèse de la communication :
Cette étape permet de passer d'une description du
niveau fonctionnel au niveau macroarchitecture.
L'allocation mémoire consiste en la définition
des blocs mémoires qui vont contenir les données de
l'application. Il s'agit généralement d'une heuristique
permettant de déterminer automatiquement une configuration optimale pour
réduire le coût en communication mémoire.
La synthèse de la communication consiste à
choisir les protocoles de communication et les éléments de calcul
(processeurs, ASIC, etc.) qui seront utilisés. Dans l'état actuel
du flot, aucun outil ne permet d'effectuer cette synthèse de
communication. Cette opération est donc effectuée à la
main.
Des résultats de simulation au niveau macroarchitecture
(voir le paragraphe II.6.2.9) permettent de guider les choix pour les
protocoles. A l'avenir, il est prévu d'intégrer une
méthodologie et des outils permettant d'automatiser les choix à
l'aide d'une bibliothèque de résultats de simulation.
II.6.2.4. Etape d'affectation et d'optimisation de
mémoire :
Une fois que les blocs mémoire ont été
décidés, il est possible de leur assigner les données.
Cette opération est effectuée au cours de cette étape en
parallèle avec l'optimisation des accès mémoire.
II.6.2.5. Etape de génération
d'architecture mémoire :
Durant cette étape, les types de mémoires, leurs
contrôleurs et leurs interfaces sont générés
à partir d'une bibliothèque. Le principe de cette
génération est celui d'un assemblage de blocs de la
bibliothèque. Cet assemblage est guidé par les choix d'allocation
et de synthèse (voir le paragraphe II.6.2.3).
II.6.2.6 Etape de génération d'interfaces
matérielles :
La génération d'interfaces matérielles
permet d'interconnecter les divers éléments de calcul : en effet
ces éléments ne sont pas tous compatibles entre eux. Ces
interfaces permettent aussi de réaliser de protocoles de communication
non supportés nativement par les éléments.
Cette étape, est basée sur un assemblage de
blocs à partir d'une bibliothèque. Le modèle d'interface
généré au sein du flot est présenté figure
II.11. L'interface est constituée de trois parties. Une première
partie, dépendante de l'élément de calcul (processeur),
fait le pont entre son bus et celui de l'interface. La deuxième partie
est le bus de l'interface, et la dernière est l'ensemble des
contrôleurs de communication qui réalisent les protocoles. Ce
découpage permet de générer aisément des interfaces
pour tout type de processeur et tout type de protocole sans que la
bibliothèque soit trop grande.
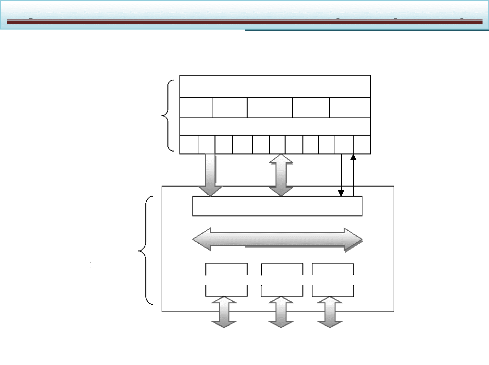
Figure II.11 : Génération d'interfaces
matérielles et logicielles
Interface
matérielle
Processeur
Application
API
Noyau
ES
PILOT
Bus interne
Bus adresse bus données contrôle
Coprocesseurs de communication
Pont vers le bus interne
II.6.2.7. Etape de génération de
systèmes d'exploitation :
Les parties logicielles ne peuvent pas être
exécutées directement sur les processeurs : l'exécution
concurrente de plusieurs tâches sur un même processeur et les
communications entre le logiciel et le matériel doivent être
gérée par une couche logicielle appelée système
d'exploitation. La figure II.11 illustre le modèle de ces interfaces
logicielles.
II.6.2.8. Les étapes de simulation :
II.6.2.8.1. La génération d'enveloppes de
simulation :
Le flot permet d'effectuer des simulations du système
à tout niveau d'abstraction, et même en mélangeant les
niveaux d'abstraction. La technique de base consiste à encapsuler les
divers composants à simuler dans des enveloppes qui adaptent le niveau
de leurs communications à celui de la simulation globale. La figure
II.12 illustre l'utilisation de ces enveloppes : à l'intérieur de
chacune se trouve un composant qui est simulé à un niveau
d'abstraction qui peut être inférieur (module A) égal ou
supérieur (module B) au niveau d'abstraction de la simulation. Ces
enveloppes permettent aussi d'adapter les divers simulateurs entre eux, comme
par exemple un simulateur VHDL (module B) et un simulateur systemC.
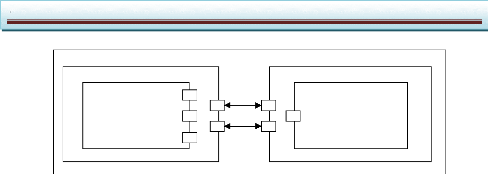
Chapitre II conception des logiciels embarqués
Simulation SystemC
Enveloppe A
Module A
VHDL
Niveau : micro-architecture
Enveloppe B
Module B systemC Niveau : fonctionnel
Figure II.12. Enveloppes de
simulation
Un outil qui permet de générer ces enveloppes
est basé sur le même principe que la génération
d'interface : la bibliothèque contient les trois types de composants
précédemment cités, mais le bus interne devient une API
(application programming interface) de simulation.
II.6.2.8.2. La cosimulation :
Grâce aux enveloppes, il est possible d'effectuer des
validations par cosimulation pour toutes les étapes du flot, ou
même sur des composants situés à des étapes
différentes. Plus le niveau d'abstraction est élevé, plus
la simulation est rapide, et plus le niveau est bas, plus la simulation est
précise. Cette cosimulation est multiniveau, mais elle peut être
aussi multilangage. La raison de telles cosimulations est que très
souvent un langage est adapté pour la simulation de certaines parties
d'un système, mais inadapté pour d'autres. Par exemple les
simulateurs VHDL sont bons pour les circuits mais pas pour la mécanique
qui est mieux modélisée par Matlab.
Pour effectuer une cosimulation, chaque simulateur est
exécuté dans un processus différent. Un processus de
contrôle gère l'ensemble des communications et synchronisations
entre les simulateurs par le biais de mémoires partagées. Le
modèle temporel utilisé est le modèle synchrone : chaque
simulateur exécute un pas de calcul, puis toutes les données sont
échangées grâce au processus de routage. Une fois que les
communications sont achevées, un autre pas de calcul peut être
effectué.
Le processus de contrôle est décrit en systemC.
Cela permet de l'utiliser pour décrire des parties matérielles ou
logicielles au niveau macroarchitecture, sans avoir à utiliser un
simulateur externe. Il est généré en même temps que
les enveloppes à partir de la bibliothèque de simulation.
II.6.2.9. Utilisation des résultats de
simulation :
Les simulations pourront servir de base pour mettre en place
une méthodologie d'évaluation qui permettra dans un premier temps
de guider les choix du concepteur dans l'étape de synthèse, puis
d'automatiser cette synthèse avec recherche d'optimum. Pour ce faire, il
faudra définir des modèles de performance et des heuristiques
permettant de les composer en même temps que l'on compose les divers
modules des systèmes à générer.
II.7. De la compilation au ciblage du logiciel :
II.7.1 Introduction sur la compilation :
La compilation est un sujet récurrent en informatique
comme en électronique : en effet, pour simplifier les descriptions, il
est préférable d'utiliser des langages de haut niveau, proche
d'un langage naturel. Cependant, ces langages ne peuvent en
général pas être utilisés directement : il est

nécessaire de les traduire dans des formes moins
sympathiques, mais correspondant directement à la réalité
(dans le cas de l'électronique), ou directement utilisables par les
outils ou les machines (dans le cas de l'électronique et de
l'informatique). Cette section est une introduction à ce
mécanisme de traduction appelé compilation.
II.7.1.1. Définitions de la compilation :
La compilation est la traduction automatique d'une description
écrite dans un langage vers un autre langage. Très souvent, ce
terme est restreint à la traduction d'un langage de programmation de
haut niveau tel que le C vers le langage machine du processeur qui devra
exécuter le programme.
Le flot de compilation est décomposé en plusieurs
étapes (passes) consécutives :
- L'analyse lexicale qui produit une suite d'identificateurs
correspondant aux instructions du programme d'entrée. Ces
identificateurs sont appelés unités lexicales ou token
;
- L'analyse syntaxique qui produit un arbre dont chaque noeud
décrit une opération élémentaire, et dont les arcs
indiquent les dépendances de contrôle ;
- L'analyse sémantique qui enrichit cet arbre pour obtenir
un arbre dit « décoré ». Il s'agit d'une étape
de synthèse ;
- La génération de code qui parcourt l'arbre «
décoré » en générant le code du langage cible
correspondant à chaque noeud.
Les trois premières étapes ne dépendent
que du langage d'entrée et sont appelées le frontal du
compilateur. La dernière étape ne dépend que du langage
cible et est appelée le dorsal du compilateur.
REMARQUE :
Très souvent, il y a une étape
supplémentaire entre l'analyse sémantique et la
génération de code : l'étape d'optimisation
indépendante du langage cible. Cette étape se rencontre notamment
avec les compilateurs vers les langages d'assemblage.
L'étape de génération de code peut
être très complexe lorsque des optimisations spécifiques au
langage cible sont entreprises.
Un abus de langage souvent commis est d'inclure
l'édition de liens dans le flot de compilation vers le langage machine
d'un processeur. L'édition de liens consiste à associer une
adresse à chaque objet d'un programme en langage machine pour pouvoir le
charger en mémoire et l'utiliser conjointement avec d'autres
programmes.
II.7.1.2. Exemple de la compilation du langage C vers
le langage d'assemblage :
Un flot de compilation typique pour le langage C est
représenté figure II.13. Il s'agit d'un flot séquentiel,
le résultat de chaque étape étant l'entrée de
l'étape suivante. Les trois premières étapes sont le
frontal du compilateur ; elles prennent en entrée le programme C et
restent inchangées quel que soit le processeur cible. La dernière
étape est le dorsal du compilateur qui produit en sortie le programme en
langage d'assemblage. Cette étape dépend du processeur cible.

Chapitre II conception des logiciels embarqués
Programme C
Analyse lexicale
Liste de tokens
Analyse syntaxique

Arbre de compilation
Analyse sémantique
Arbre décoré
Génération de code
Programme assembleur
Figure II.13 : Les étapes de la compilation
d'un programme en langage C
II.7.2. Le ciblage logiciel en général :
Dans ce travail nous présentons un flot de ciblage avec
génération de système d'exploitation. Dans cette section
nous nous intéresserons au ciblage logiciel de manière plus
générale, c'est-à-dire sans se soucier des architectures
spécifiques et sans l'introduction ou non de systèmes
d'exploitation dans le flot. Dans un premier temps nous donnons quelques
définitions concernant le ciblage logiciel et notamment la nuance entre
ciblage et compilation, puis nous nous intéressons aux flots de ciblage
avec les représentations utilisées et les étapes à
suivre.
II.7.2.1. Notion d'exécutable :
Le logiciel peut se présenter sous plusieurs formes,
dans plusieurs langages. Cependant, le processeur sur lequel il
s'exécute ne comprend en général qu'un langage basé
sur des suites de 0 et de 1, on parle de langage machine. Un programme est dit
exécutable lorsqu'il se présente sous cette forme,
c'est-à-dire qu'il est « compris » par le processeur et qu'il
peut donc être exécuté.
On parle parfois de langage exécutable pour les
langages qui peuvent être traduits en un langage exécutable (par
exemple le C), par opposition à ceux qui ne le permettent pas (par
exemple UML).
Il existe de très nombreux processeurs et ils ne sont
en générale pas compatibles entre eux. En particulier, ils ne
« comprennent » pas le même langage machine. Dès lors,
la notion d'exécutable n'est pas générale : un programme
est sous une forme exécutable pour un processeur donné.
De nos jours il existe aussi ce que l'on appelle des machines
virtuelles, qui sont des couches logicielles ajoutées aux processeurs et
comprenant le même langage quel que soit le processeur sur lequel elles
sont installées. L'exemple le plus connu est le langage Java qui
s'exécute sur une machine virtuelle Java. Dans ce cas, un programme
exécutable pour la machine virtuelle, l'est indépendamment du
processeur. L'avantage est qu'un même programme peut fonctionner quel que
soit le processeur. L'inconvénient est que ces machines sont en
général très lentes.

II.7.2.2. Définition du ciblage logiciel :
Le ciblage logiciel consiste à produire une description
exécutable (pour une architecture matérielle donnée) d'une
application logicielle, à partir d'une ou plusieurs descriptions de haut
niveau de cette dernière, ne contenant pas de détails
d'implémentation.
Le ciblage n'est pas exactement une compilation. En effet, une
compilation est simplement la traduction d'un langage vers un autre. Le
compilateur ne doit donc effectuer aucun changement dans la sémantique
de la description. Le compilateur ne réalise donc pas de raffinement
dans la description et n'est pas capable de l'adapter à l'architecture
cible. Pour que la compilation puisse produire un logiciel correct, il est
nécessaire au préalable, d'adapter cette description d'entre
à l'architecture.
Le ciblage logiciel quant à lui effectue cette
adaptation, la compilation étant l'étape finale d'un flot de
ciblage. Un tel flot va tout d'abord raffiné certaines parties de la
description d'entrée pour qu'elle soit compatible et efficace avec
l'architecture cible. Cela veut dire qu'elle change la sémantique de
cette description. Par exemple, dans le cas d'une spécification
système, le ciblage logiciel consiste à traiter les concepts de
haut niveau contenus dans la description (communication, structures
parallèles) pour rendre la spécification exécutable pour
une architecture donnée.
II.7.2.3. Ciblage logiciel idéal :
Le but d'un flot de ciblage est de permettre au programmeur de
développer son application logicielle à haut niveau, sans se
préoccuper des détails d'implémentation spécifiques
à l'architecture. Il est aussi souhaitable que ce flot ne soit pas trop
contraignant quant au codage de l'application. Enfin, il faudrait que le
programmeur puisse remonter assez facilement du code ciblé au code, pour
faciliter le travail de vérification et de correction des erreurs.
Idéalement, un flot de ciblage pourrait cibler
n'importe quelle application (quel que soit son style de programmation), pour
n'importe quelle architecture cible. De plus, le code ciblé par un tel
flot contiendrait sans aucune modification le code initial, c'est-à-dire
que l'opération de ciblage aura consisté uniquement à
ajouter le code nécessaire pour rendre la description initiale
compatible avec l'architecture.
II.7.3. Représentations pour le ciblage logiciel :
II.7.3.1. Représentations initiales pour le
ciblage logiciel :
Comme tout flot dont le but final est la
génération de code, les flots de ciblage utilisent au minimum
deux types de représentations : une représentation d'origine et
une représentation de destination.
II.7.3.1.1. La représentation d'entrée :
La représentation d'entrée est une
spécification du système. Cette spécification peut
contenir des informations structurelles, des informations comportementales,
mais aussi des paramètres qui précisent les détails des
éléments à générer. Ces paramètres
peuvent être présents sous la forme d'annotations associées
aux éléments de la spécification.
La représentation d'entrée n'a pas besoin
d'être exécutable. Au contraire, les informations
nécessaires pour l'exécution ou la simulation peuvent
interférer avec le ciblage. Il peut être par

Chapitre II conception des logiciels embarqués
exemple suffisant pour la description comportementale de
donner des listes de fonctionnalités requises, sans donner leurs
réalisations.
Cette représentation est souvent une forme
intermédiaire, produite par une étape de synthèse. Elle
n'a donc pas forcément de format humainement accessible : elle peut par
exemple être limitée à une structure de données
interne à un outil de ciblage.
II.7.3.1.2. La représentation de sortie :
Le résultat de la génération est
donné dans la représentation de sortie. Etant la cible de la
génération, il n'y a pas de contrainte particulière sur
cette représentation.
Elle décrit le système donné en
entrée, mais avec tous les détails d'implémentation
obtenus par le générateur de code.
II.7.3.1.3. Représentation supplémentaire,
nécessaire pour le fonctionnement du ciblage :
Le ciblage consiste souvent à produire et assembler des
parties de code élémentaires (décrites dans la
représentation de sortie) correspondant à certains
éléments donnés dans la spécification
d'entrée. L'ordre dans lequel les parties de code
élémentaires doivent être assemblées est
déduit de l'ordre dans lequel sont présentés les
éléments du système, c'est-à-dire les informations
structurelles de la spécification (voir le paragraphe II.7.3.1.1). La
production des parties de code élémentaires est dirigée
par les paramètres associés aux éléments de la
spécification.
Le cibleur de code doit donc être capable de produire
les parties élémentaires de code pour chaque type
d'élément de la représentation d'entrée. La
méthode couramment employée est de ranger toutes les parties de
code élémentaire possibles dans une bibliothèque. Le
problème se réduit alors à la recherche dans la
bibliothèque des portions de code correspondant aux
éléments de la spécification. Pour le résoudre il
convient d'avoir une représentation pour décrire le contenue de
cette bibliothèque. Cette représentation doit être
relationnelle pour donner les correspondances entre les éléments
de spécification et les portions de code finales. Elle doit être
aussi comportementale pour la description des portions de code.
Si la représentation de sortie est suffisamment souple
pour pouvoir décrire les parties élémentaires de code,
leur paramétrage et leur assemblage, elle peut être
utilisée également pour la description de la partie
comportementale de la bibliothèque. Si ce n'est pas le cas, il convient
alors d'encapsuler les parties de code final dans une autre
représentation plus flexible.
II.7.3.2. Les étapes du ciblage logiciel :
Nous allons présenter dans cette section les
étapes à suivre lors du ciblage logiciel. Nous procéderons
par ordre chronologique, en partant des descriptions de l'application et de
l'architecture matérielle cible, jusqu'à la production des
exécutables finaux.
Le but de cette section n'est pas de présenter une
méthodologie de ciblage, mais plutôt de montrer le type
d'opérations et la chronologie qu'il sera généralement
nécessaire de suivre. Nous nous contenterons donc ici de
présentations sommaires des étapes du ciblage, sachant que les
détails les concernant varient suivant la méthodologie
employée.
La figure II.14 présente les diverses étapes d'un
flot de ciblage. Ces étapes sont présentées dans les
paragraphes suivants.
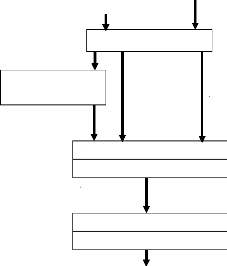
II.7.3.2.1. Analyse des entrées :
application et architecture matérielle :
Cette étape consiste en l'acquisition des informations
nécessaire au ciblage. Nous allons voir les types d'information requis
pour effectuer un ciblage et comment nous pouvons y accéder.
Les informations nécessaires pour le ciblage sont tout
d'abord les services requis : dans cette catégorie se trouvent toutes
les informations concernant les fonctionnalités logicielles à
ajouter. Parmi celles-ci trouvent les fonctionnalités de communication,
les fonctionnalités du système d'exploitation et les
gestionnaires de périphérique
Application Architecture
logicielle Choix des
éléments
logiciels

Analyse des entrées
Requis
Code de
l'application logicielle
Paramètre
Eléments
logiciels
supplémentaires
Mise en place des paramètres
Génération du code ciblé
Code ciblé de l'application logicielle
Compilation
Edition de liens
Code exécutable de l'application
Figure II.14
: Les étapes du ciblage logiciel
D'autres informations requises prennent la forme de
paramètres : dans cette catégorie, se trouvent toutes les valeurs
qui permettront de configurer les éléments logiciels. Ces
paramètres peuvent avoir les origines suivantes :
- les informations sur le matériel : quel type de
processeur, quel type de périphériques, etc. ;
- les allocations, c'est-à-dire les adresses
mémoire des divers éléments (logiciels ou
matériels) ;
- les contraintes imposées par l'environnement. Il peut
s'agir de contraintes temporelles (délais à respecter,
débit, etc.), de contraintes de surface (quantité de
mémoire limitée), de contraintes de consommation ou d'autres
contraintes plus spécifiques (liées par exemple à du
matériel particulier). Ces contraintes peuvent elles aussi avoir une
influence sur le chois des services.
Accès aux informations
Ces informations sont en règle générale
dispersées dans plusieurs endroits, et sous plusieurs formes :
- directement dans la spécification, sous la forme
d'annotations,

Chapitre II conception des logiciels embarqués
- déductibles à partir de la structure de la
spécification,
- déductibles à partir d'autres informations de la
spécification, - données en langage naturel.
Il est préférable de rassembler ces informations
avant de commencer toute opération de ciblage.
II.7.3.2.2. Choix des éléments logiciels
à ajouter :
Dans cette étape sont sélectionnés les
divers éléments logiciels à ajouter pour le ciblage. Ces
éléments sont à choisir en fonction de leurs
fonctionnalités, sachant qu'au final il faut que toutes les
fonctionnalités requises par le système soient fournies (voir le
paragraphe II.7.3.2.1)
Les éléments logiciels peuvent avoir plusieurs
formes. La forme la plus courante consiste en l'ensemble des fonctions
présentes dans le système d'exploitation choisis. Dans ces
conditions, l'étape de choix des éléments logiciels
consiste simplement au choix du système d'exploitation qui fournira le
plus de fonctionnalités requises par l'architecture, les autres devant
être développées. L'inconvénient est
évidemment qu'il y a souvent de très nombreuses
fonctionnalités inutiles apportées par le système choisis.
Certains systèmes d'exploitation peuvent être
paramétrés en fonction des besoins. Dans ce cas, l'étape
de choix consiste au choix du système qui fournira le plus de
fonctionnalités requises par l'architecture et à l'inhibition de
ses fonctionnalités superflues. Il reste toujours nécessaire de
développer les fonctionnalités manquantes. Des flots de ciblage
plus élaborés se basent sur des bibliothèques.
L'étape de choix consiste alors au choix des bons éléments
dans la bibliothèque. S'il manque des fonctionnalités, il faut
les développer, cependant elles peuvent être ajoutées
à la bibliothèque pour pouvoir être
réutilisées dans d'autres conditions.
II.7.3.2.3. Mise en place des paramètres et
production du code logiciel exécutable :
Dans cette étape, le code exécutable est
généré. Pour cela, il faut introduire les
paramètres précédemment définis (voir le paragraphe
II.7.3.2.1) et, éventuellement, adapter le code de l'application
à l'environnement utilisé (système d'exploitation et
architecture). Là encore les méthodes varient suivant le code des
éléments logiciels. Parfois le code est présent sous la
forme d'un simple exécutable. Dans ces conditions, les paramètres
ne peuvent être mis en place qu'au niveau de l'application, qui doit
être réécrite en fonction de l'environnement, avec par
exemple l'utilisation des appels système fournis par le système
d'exploitation. Une autre conséquence est que de nombreux
paramètres (comme les contraintes sur l'ordonnancement) ne peuvent pas
être introduits. Parfois, le code est présent sous la forme de
sources paramétrables.
II.7.3.2.4. Compilation et édition de liens :
La dernière étape consiste en la compilation et en
l'édition de liens pour la production du code final. Avec cette
étape, le flot rejoint les flots standards de conception.
II.7.4. Le ciblage logiciel pour les architectures
spécifiques :
Ce paragraphe présente les difficultés
particulières du ciblage logiciel dans le cas des systèmes
embarqués spécifiques. Pour atténuer ces
difficultés, la faisabilité de flots de ciblage automatiques est
étudiée. Ce paragraphe propose enfin l'intégration des
systèmes d'exploitation dans le flot de ciblage.

II.7.4.1. Difficultés du ciblage logiciel :
Nous présentons dans cette section les difficultés
que présente le ciblage logiciel. Ces difficultés sont de deux
ordres : la variété des domaines et la quantité
d'opérations à effectuer.
II.7.4.1.1. La variété des architectures
cibles :
La variété des processeurs
Il existe de très nombreux processeurs, qui ne sont pas
compatibles entre eux et qui ne comprennent pas le même langage. En
première analyse, il pourrait sembler que seul le compilateur soit
concerné par cette diversité de processeurs, et qu'il suffit de
choisir le compilateur correspondant au processeur pour s'affranchir des
incompatibilités.
En fait, cette première vue est inexacte : le type du
processeur a une influence non négligeable sur le code de haut niveau du
logiciel, et notamment dans le cas des applications embarquées. Pour
voir pourquoi, nous allons montrer quelques caractéristiques d'un
processeur qui peuvent conduire à des adaptations difficiles voire
impossibles à la compilation :
- les types des données : les processeurs
possèdent en général un type de données
privilégié, correspondant à la taille de leurs registres.
Pour qu'une application soit performante, il est préférable
d'utiliser ce type au maximum pour les variables. Evidemment, suivant le
processeur ce type n'est pas le même : cela peut être entier sur 8
bits, 16bits, 32bits, ou d'autres types plus exotiques. Une solution
apportée par le langage C est de nommer ce type privilégié
le type int, auquel cas, c'est bien le compilateur qui décide du type
à prendre. Mais cela pose toujours des problèmes lorsqu'il s'agit
de communiquer ces données : le type doit correspondre à
l'émission et à la réception, et si les deux n'ont pas le
même type de base il faut en choisir un et l'imposer aux deux. On se
retrouve donc toujours dans une situation où il faut changer de type
suivant le processeur et son environnement ;
- la représentation des données : les
données sont représentées en mémoire par des
paquets de bits. Cependant, il existe de nombreuses manières pour
interpréter ces bits (par exemple en complément à deux, en
mantisse et exposant, etc.) et il est aussi possible de les interpréter
en grosboutistes (big-endians) ou en petit-boutistes
(little-endians). Il est important de noter que pour un même
type il peut exister plusieurs représentations possibles ;
- les instructions : chaque type de processeur dispose d'un
jeu d'instructions qui lui est propre. C'est au compilateur de produire le code
compréhensible par le processeur, et en fait n'importe quel programme de
haut niveau doit pouvoir être traduit par ce dernier. Cependant, une
description de haut niveau générale ne prend pas en compte les
spécificités d'un processeur, notamment en termes de performance.
Il est parfois préférable de changer l'algorithme pour un
processeur donné. En outre, un certain nombre d'instructions ne peuvent
pas être représentées à haut niveau : c'est le cas
par exemple des instructions de contrôle de consommation que
possèdent de nombreux processeurs utilisés dans les
systèmes embarqués. Dans ces deux cas le compilateur ne peut pas
agir ;
- les interruptions : la plupart des processeurs disposent
d'un mécanisme d'interruptions qui permet de générer des
événements. Ces mécanismes sont toujours très
spécifiques à chaque à chaque processeur et peuvent
être d'une grande complexité. Cependant, ils sont très
rarement pris en compte

Chapitre II conception des logiciels embarqués
par le compilateur, car ils ne font pas partie du modèle
de programmation classique (séquentiel continu).
Comme on le voit, les différences entre les processeurs
sont de plusieurs ordres et ne peuvent être prises en compte par les
seuls compilateurs.
La variété des communications
Suivant l'architecture cible, des modes de communication
très différents peuvent être utilisés. Il peut y
avoir des différences d'un point de vue topologique : communications
point à point ou non, hiérarchique ou non, à base de
barres croisées ou non, etc. Les différences peuvent être
d'un point de vue protocolaire : avec ou sans connexion, avec ou sans
poignée de main, avec ou sans rafale, etc. Enfin, elles peuvent
être d'un point de vue matériel : avec ou sans mémoire,
avec ou sans accès direct à la mémoire (DMA), etc.
Toutes ces caractéristiques peuvent se combiner, ce qui
fait un très grand nombre de cas possibles, pour chacun desquels un
ciblage différent sera nécessaire.
La variété des circuits connectés au
processeur
Suivant l'architecture cible, des circuits différents
peuvent être utilisés, et même s'ils peuvent avoir des
fonctionnalités identiques, ils risquent d'avoir des modes de
fonctionnement et de communication différents. Cela implique que chaque
circuit induit des détails logiciels différents et change donc
les opérations de ciblage à effectuer.
Logiciel abstrait
Le but de ciblage est d'adapter le logiciel aux architectures
cibles. Ce logiciel est donc très général et utilise des
primitives abstraites pour interagir avec l'extérieur. Nous avons vu
dans les sections précédentes que les éléments
d'architecture étaient très variés. Pour pouvoir les
relier avec le logiciel, il convient de fournir au concepteur du logiciel les
primitives abstraites correspondantes.
Pour simplifier et clarifier la programmation, il convient que
le nombre de primitives soit le plus faible possible. Dès lors, une
partie du travail de ciblage sera d'adapter ces quelques primitives à la
diversité des architectures cibles.
Conséquences sur la variété des
architectures cibles
Comme nous venons de le voir, le nombre d'architectures cibles
possibles pour une même application au départ est énorme.
Evidemment de très nombreuses configurations ne sont pas valables, mais
il est souvent difficile a priori de savoir si une architecture sera valable ou
non (notamment du point de vue temporel). Dès lors, il arrive souvent
que le choix d'une architecture soit effectué au terme d'une suite
d'essais sur différentes architectures.
Dans ces conditions, il apparaît important que le
ciblage soit le plus rapide possible et demande le moins d'efforts possible.
Ainsi, il sera possible d'obtenir plus rapidement une réalisation finale
valide, il sera aussi possible de tester un plus grand nombre d'architecture,
ce qui donne plus de chances pour atteindre un optimum.

II.7.4.1.2. La diversité des connaissances
liées au ciblage logiciel :
Le ciblage requiert des domaines de compétence très
divers ; nous allons ici en donner une liste des principaux et explique en quoi
ils sont nécessaires.
Connaissances sur les processeurs
Il est important de bien connaître le processeur cible
lorsque l'on veut adapter le logiciel qui doit être exécuté
dessus. Il faut notamment connaître :
- les « dimensions » du processeur : la taille de ses
registres, la taille de ses bus adresse et donnée, pour savoir quels
types de données utiliser ;
- les modes de communication du processeur : utilise-t-il une
mémoire commune données/programme (von Neumann) ou distincte
(Harvard), quels protocoles utilise-t-il pour lire/écrire les
données (exemple : programmation particulière de certains
protocoles du 8051 [HOA]), quel est son système d'interruption ? Chaque
système se programme de manière différente et la plupart
du temps en langage d'assemblage uniquement ;
- le langage d'assemblage du processeur : pour pouvoir
écrire toutes les parties du code spécifiques au processeur,
comme la gestion des interruptions ou le changement de contexte ;
- les performances du processeur suivant les cas (vitesse
d'exécution, temps de réaction aux interruptions, etc.) pour
choisir les meilleurs algorithmes et réalisations ;
- l'architecture du processeur (pipeline, RISC ou CISC, etc.)
cela aidera aussi au choix des algorithmes et des réalisations.
Connaissances sur les communications
Une partie du ciblage consiste en la réalisation des
communications entre le logiciel à cibler et le reste. Pour ce travail,
il est nécessaire d'avoir des connaissances en communication, et plus
précisément :
- protocole : il faut connaître leurs
caractéristiques ;
- langage de description de communication : très souvent
les communications sont décrites dans un langage qui leur est propre
(par exemple SDL), qu'il faut donc savoir interpréter ;
- méthode de réalisation des communications : il
existe un certain nombre de méthodes pour réaliser des
communications, certaines complètement logicielles, certaines faisant
appel à du matériel (par exemple un DMA).
Connaissances en description d'application
Connaître l'application permet de faire de meilleurs choix
lors du ciblage. Cela implique de connaître également :
- le langage dans lequel l'application est décrite :
très souvent c'est du C ou du C++, cependant d'autres langages peuvent
être utilisés comme Ada, SDL, etc. ;
- les algorithmes habituellement utilisés dans une
application donnée, pour savoir quelles sont les implémentations
optimales ;
- les paramètres de ces applications : nombre de
données à traiter, nombre de tâche possibles,
etc.
Connaissances en architecture
Le ciblage sur une architecture implique la compréhension
de cette dernière, il est donc nécessaire de connaître ;
- les langages de description d'architectures (VHDL, System C,
etc.) ;
- les principes utilisés dans les architectures comme la
modularité, l'instanciation, etc. ; - les différents types
d'architectures et les conséquences sur l'implémentation
[ARM].
Connaissances en électronique
Bien qu'il s'agisse de ciblage logiciel, la cible est une
architecture matérielle comprenant des éléments
électroniques. Si de vastes connaissances en électronique ne sont
pas nécessaires, il est important d'avoir des notions sur :
- les bases de l'électronique numérique (portes),
sachant que le processeur cible peut être
connecté à un peu de logique ;
- quelques circuits électroniques comme les DMA, les
arbitres de bus, et autres contrôleurs ;
- les bases de l'électronique analogique pour être
capable de prendre en compte les problèmes liés à la
consommation.
Connaissances sur les systèmes
d'exploitation
Une bonne part du ciblage consiste dans le choix et
l'adaptation du ou des systèmes d'exploitation qui seront
utilisés. Il est donc important de bien connaître les principes
liés aux systèmes d'exploitation.
II.7.4.1.3. Nombreuses opérations et nombreuses
erreurs :
Une bonne part du ciblage consiste en une fastidieuse suite
d'opérations élémentaires (construire de nombreuses tables
de correspondances, choisir et assembler de nombreux composants logiciels,
etc.). Toutes ces opérations sont sources de nombreuses erreurs de
frappe difficiles à détecter. De plus, elles sont à
recommencer complètement à chaque fois que l'architecture cible
change.
II.7.4.2. Faisabilité de l'automatisation du
ciblage logiciel :
Dans ce paragraphe, nous allons voir dans quelle mesure il est
possible d'automatiser certaines opérations dans le ciblage logiciel. Le
but est d'accélérer le processus de ciblage et de limiter les
erreurs, ce qui permettra une exploration plus large des diverses solutions
possibles pour réaliser une application.
Pour ce faire nous allons essayer de localiser la redondance
dans les opérations de ciblage, puis nous allons analyserons les types
de choix à effectuer et nous déterminerons ce qui est
systématique dans les flots de ciblage. Enfin, nous conclurons en
précisant ce qu'il serait possible d'automatiser.
II.7.4.2.1. La redondance des opérations de ciblage
:
Il y a redondance dans les informations : très souvent
une même information se trouve présente dans plusieurs endroits
dans les entrées du flot de ciblage ; par exemple le format de
données dans un protocole de communication peut se trouve dans la
description de l'architecture et

Chapitre II conception des logiciels embarqués
dans les spécifications ou même le code de
l'application à cibler. Il y a aussi redondance dans les
fonctionnalités des éléments logiciels : il est
fréquent que deux éléments logiciels aient des
fonctionnalités communes, ce qui fait que s'ils sont tous les deux
sélectionnés pour le ciblage, il y aura du code inutile.
Cette redondance est source de conception lors d'un ciblage
manuel, mais elle peut être un avantage pour l'automatisation, car elle
peut permettre certaines factorisations.
II.7.4.2.2. Le problème des choix à effectuer
lors d'un ciblage :
Nous avons vu précédemment qu'il fallait faire
un certain nombre de choix lors du ciblage : il faut par exemple choisir des
éléments logiciels en fonction des fonctionnalités
requises, des contraintes et des performances. Il faut aussi choisir les
valeurs de paramètres de configuration des éléments
logiciels (par exemple la taille des mémoires tampons), en fonction des
contraintes et des performances.
Si le choix en fonction des fonctionnalités requises
peut être effectué automatiquement par simple gestion de
dépendances (comme par exemple dans Tornado de Windriver), le choix de
fonctions de contrainte et de critères de performance (vitesse, taille,
ou consommation) est plus délicat. Dans ce dernier cas, il est
nécessaire d'avoir une évaluation des conséquences des
choix sue les performances, ce qui peut être d'autant plus difficile
à obtenir si les éléments logiciels possèdent de
nombreux paramètres. Dans tous les cas le résultat est rarement
certain, et il est donc préférable de laisser à
l'utilisateur la possibilité d'influencer ces choix.
II.7.4.2.3. Ce qui est systématique dans le flot de
ciblage :
Pour automatiser le flot de ciblage, il est intéressant de
repérer les actions systématiques, c'est-à-dire les
actions qui ne demandent pas d'intelligence.
Dans le cas du ciblage, les actions suivantes sont directement
systématiques :
- l'acquisition des informations : cette action consiste juste
en la lecture des entrées du flot avec extraction des informations. A
partir du moment où les entrées sont bien définies (par
exemple des fichiers sous un format connu), les techniques de base d'analyse
syntaxique peuvent être utilisées ;
- la mise en place des paramètres : en supposant que
les divers éléments logiciels pour le ciblage sont décrits
suivant un formalisme connu et que les paramètres sont directement
accessibles, cela revient à effectuer des opérations d'expansion
de macro ;
- la compilation et l'édition de liens : les
compilations et éditeurs de liens existent déjà et sont
automatiques, il suffit juste d'automatiser leur appel dans le bon ordre.
Il existe aussi d'autres actions qui peuvent devenir en partie
systématiques :
- le choix des éléments logiciels
nécessaires : si tous les choix ne sont pas systématiques, un
certain nombre peut l'être, comme la détection de tous les
éléments ayant une certaine fonctionnalité, et le choix
des éléments compatibles avec une certaine architecture
matérielle. Cela suppose que le flot de ciblage dispose de descriptions
des fonctionnalités de ces éléments ainsi que de leur
compatibilités ;

- l'adaptation du code de l'application peut elle aussi
être en partie systématique : cela concerne notamment les appels
de communications qui peuvent être remplacés par les bons appels
au système d'exploitation.
II.7.4.2.4. Conclusion sur l'automatisation du ciblage
logiciel :
Nous avons vu dans ce paragraphe que si l'automatisation
complète du ciblage n'est pas encore réaliste, une bonne part du
flot peut l'être avec seulement quelques interventions humaines lorsqu'il
s'agit d'effectuer les choix concernant les performances.
Avec une automatisation partielle, il y aura gain de temps :
il est toujours plus rapide de générer et d'adapter du code
automatiquement plutôt qu'à la main (hors des
considérations d'optimisation qui reste un problème NP-complet).
Il y aura aussi un gain au niveau des erreurs : toutes les opérations
répétitives et sources d'erreurs pour un homme peuvent être
prises en charge par l'outil de ciblage automatique. Il peut être aussi
possible de prouver des équivalences entre l'entrée et la sortie
du flot de ciblage, auquel cas nous avons la certitude de la validité du
résultat. Enfin, même s'il est toujours recommandé d'avoir
une bonne compréhension des concepts liés au ciblage, il n'est
plus nécessaire pour le concepteur de connaître tous les
détails d'implémentation.
II.7.4.3. Les systèmes d'exploitation dans le
ciblage logiciel :
II.7.4.3.1. Système d'exploitation : cible et source
logicielle pour le ciblage :
Les systèmes d'exploitation ont un statu particulier
dans les flots de ciblage car ils peuvent être à la fois vus comme
une partie logicielle à cibler pour une architecture matérielle
et comme paramètre d'un ciblage pour faire fonctionner une application
pour cette architecture.
Un flot de ciblage complet devrait être capable de
prendre en comte ces deux vues du système d'exploitation : il devrait
être capable de générer ou de choisir le système
d'exploitation avec les bons paramètres pour faire fonctionner
l'application, et il devrait être capable de cibler ce même
système d'exploitation pour l'architecture matérielle.
II.7.4.3.2. Apport de l'utilisation d'un système
d'exploitation pour le ciblage logiciel :
Nous verrons dans le paragraphe II.8.1.1 qu'un système
d'exploitation peut être vu comme une abstraction du matériel qui
soulage le programmeur de la programmation des détails
spécifiques à l'architecture cible. L'utilisation d'un
système d'exploitation peut donc grandement simplifier le ciblage
logiciel. Il faut par contre que, pour chaque architecture, il existe un
système d'exploitation capable de la gérer. Nous avons vu que ce
n'était pas le cas : il est très souvent nécessaire
d'adapter un système d'exploitation plus ou moins
générique à une architecture donnée.
Chaque système d'exploitation fournit une API pour
l'application logicielle. C'est cette API qui représente les contraintes
pour la programmation de l'application. L'avantage est qu'une API ne fournit
pas de contraintes pour le style de programmation, comme cela peut être
le cas pour les logiciels de synthèse de haut niveau, mais seulement des
contraintes pour les points de communication et de synchronisation qui doivent
être des fonctions du système d'exploitation.
Ces fonctions système peuvent être très
générales, mais elles manquent alors d'efficacité, ou
elles peuvent être plus spécifiques à l'architecture cible
ou au système d'exploitation. Dès lors, si

Chapitre II conception des logiciels embarqués
l'application logicielle doit être ciblée pour une
autre architecture ou si un autre système d'exploitation doit être
utilisé, il faut changer son code. Ce dernier point n'est pas
souhaitable.
II.8. Etat de l'art sur les systèmes
d'exploitation :
Il est courant d'utiliser un système d'exploitation
pour gérer plusieurs tâches concurrentes sur un même
processeur. C'est une méthode aussi couramment employée dans les
systèmes embarqués spécifiques, même s'il existe des
solutions alternatives comme nous le verront au cours de cette section,
Cependant, le terme système d'exploitation est un terme très
vaste et cette section va commencer par une introduction générale
à ce sujet. Enfin, la dernière section sera consacrée
à leur intégration dans les flots de conceptions pour
systèmes embarqués.
II.8.1. Introduction sur les systèmes d'exploitation
:
Dans le monde de l'informatique et de l'électronique le
terme de système d'exploitation peut être employé avec des
sens différents : il peut par exemple être un ordonnanceur de
tâche ou, à l'extrême opposé, un environnement
complet pour faire fonctionner des programmes (sans forcément fournir
d'ordonnancement). Il est très souvent logiciel, mais il peut aussi
être matériel.
Dans cette section, nous présenterons dans un premier
temps quelques définitions pour les systèmes d'exploitation, et
nous présenterons quelques inconvénients liés à
l'emploi des systèmes d'exploitation dans les systèmes
embarqués ainsi que des alternatives à leur emploi.
II.8.2. Systèmes d'exploitation : définitions
Dans cette section, nous allons tenter de définir le
terme système d'exploitation. Cette section n'a pas pour but de
définir de manière absolue les systèmes d'exploitation,
mais plutôt d'éviter les confusions avec d'autres
définitions relatives au même sujet.
II.8.2.1. Un système d'exploitation en tant
qu'abstraction du matériel :
II.8.2.1.1. Le matériel idéal et le
matériel réel :
Pour un programme, le matériel idéal aurait des
ressources infinies (mémoire, calcul, etc.) et immédiatement
disponibles. Tous ses composants disposeraient aussi de la même interface
simple.
Le matériel réel n'a hélas pas ces
propriétés : aucun composant matériel ne peut
réagir instantanément. Les ressources matérielles
étant onéreuses, il est souvent nécessaire de les partager
entre plusieurs tâches logicielles (c'est notamment le cas pour le
processeur et la mémoire). Enfin les différents composants
matériels peuvent proposer une très grande variété
d'interfaces (pour des raisons de performance, ou tout simplement du fait de
leurs fonctionnalités).
II.8.2.1.2 Solution apportée par le système
d'exploitation :
Un système d'exploitation peut être vu comme un
matériel abstrait idéal. Il s'agit en fait d'une couche
logicielle qui encapsule le matériel et dont le but est de simplifier la
conception des applications logicielles. Il peut alors se placer comme unique
interlocuteur avec les programmes car il présente les
caractéristiques suivantes.
- Il peut cacher aux tâches logicielles les
indisponibilités du matériel ;

- Il peut offrir des fonctions de gestion de ressources, qui,
même si elles ne permettent pas de les rendre infinies, soulagent le
programme de cette gestion. Par exemple, un ordonnanceur permettra à
plusieurs tâches logicielles de partager le processeur ;
- Il peut fournir une interface simple identique quel que soit le
composant matériel (par exemple UNIX encapsule les accès
matériels dans des accès fichiers).
La figure II.15 représente une application
complète allant des programmes logiciels (Tâche 1, Tâche 2
et Tâche 3) à l'architecture matérielle permettant son
fonctionnement. Chaque couche ne peut communiquer qu'avec ses voisines, ainsi
les tâches logicielles ne peuvent communiquer qu'avec le système
d'exploitation.
|
Tâche 1
|
Tâche 2
|
Tâche 3
|
|
Système d'exploitation
|
|
Processeur
|
|
Périph.1
|
Périph.2
|
Périph.3
|
|
Logiciel
Matériel
|
Figure II.15 : Système d'exploitation en tant
qu'abstraction du matériel
II.8.2.2. Un système d'exploitation en tant que
gestionnaire de ressource :
II.8.2.2.1. Les ressources matérielles
:
Les programmes peuvent être vus comme des entités
consommatrices de ressources, ces ressources représentant le
matériel.
Parmi les ressources matérielles, les premières
sont le processeur sur lequel les programmes sont exécutés et la
mémoire dans laquelle ils stockent leurs données.
Les autres peuvent être des éléments de
calcul, de communication, etc. II.8.2.2.2. La gestion des
ressources : le système d'exploitation
Les ressources matérielles ne sont pas toujours
directement accessibles. De plus dans les applications complexes, elles sont
souvent partagées entre plusieurs programmes : il arrive par exemple
souvent que plusieurs programmes doivent se partager le même processeur.
Il est donc nécessaire de pouvoir gérer ces ressources.
Le système d'exploitation peut être
considéré comme ce gestionnaire de ressources matérielles
pour l'application, il peut gérer la ressource processeur grâce
aux algorithmes d'ordonnancement de tâches, la ressource mémoire
grâce aux fonctions d'allocation et de libération de la
mémoire, ainsi que toutes les autres ressources grâce à des
gestionnaires de périphériques.
La gestion de ces ressources peut être plus ou moins
équitable suivant les besoins de l'application : l'ordonnancement peut
avoir des tâches prioritaires, certaines zones mémoire peuvent
être réservées pour certaines tâches. Une telle
vision du système d'exploitation est illustrée par la figure
II.16 : dans cette figure, le système d'exploitation, associé au
matériel, est considéré comme un serveur de ressources et
les tâches logicielles sont considérées comme des
clients.
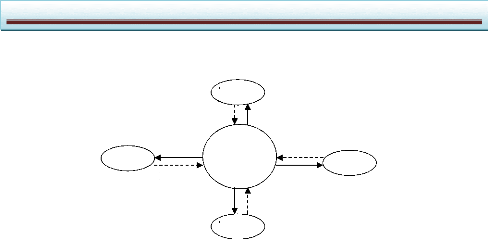
Chapitre II conception des logiciels embarqués
Tâche 1
R S
Tâche 2
Tâche 4
S R
Tâche 3
Système
Service d'exploitation requête
+
Requête Matériel service
Figure II.16 : Système d'exploitation en tant
que gestionnaire de ressources
II.8.2.3. Elargissement du terme système
d'exploitation :
II.8.2.3.1. Système d'exploitation : uniquement
logiciel ?
La plupart des systèmes d'exploitation sont logiciels.
Toutefois, une partie du système d'exploitation peut être
réalisée en matériel. Dans cette section, nous nous
intéressons principalement aux parties logicielles d'un système
d'exploitation, mais la méthode présentée est compatible
avec la mise en place d'éléments matériels pour le
système d'exploitation.
II.8.2.3.2. Les interpréteurs de langages
évolués :
Les processeurs sont des interpréteurs de langage machine.
Il existe aussi des interpréteurs de langages plus évolués
comme le LISP ou le Java .
Certains de ces interpréteurs fournissent toutes les
fonctionnalités d'un système d'exploitation. C'est le cas des
machines virtuelles Java. Ils peuvent donc être considérés
comme des ensembles système d'exploitation/processeur.
II.9. Les systèmes d'exploitation dans les
systèmes embarqués :
Dans la section précédente, nous avons
présenté les systèmes d'exploitation en
général, et notamment pour les ordinateurs. Dans le monde des
systèmes embarqués, le logiciel a une part de plus en plus
importante ; les systèmes d'exploitation deviennent donc essentiels dans
ce domaine.
Cette section présente les systèmes
d'exploitation dans le cas particulier des systèmes embarqués.
Dans une première sous-section nous présenterons les
fonctionnalités requises pour le logiciel dans les systèmes
embarqués, puis dans la deuxième sous-section les contraintes et
les degrés de libertés. Enfin, nous résumerons les
avantages et inconvénients de l'utilisation de systèmes
d'exploitation dans les systèmes embarqués et nous
présenterons quelques solutions alternatives.

II.9.1. Fonctionnalités requises pour le logiciel
dans les systèmes embarqués :
Dans ce paragraphe nous allons présenter les
fonctionnalités requises pour les systèmes embarqués. Nous
verrons d'abord les fonctionnalités communes avec les systèmes
d'exploitation généraux, puis nous verrons les
fonctionnalités spécifiques aux systèmes embarqués
: pour les communications, pour le temps, et pour les pilotes de
périphériques.
II.9.1.1. Fonctionnalités communes avec les
systèmes d'exploitation généraux :
Les systèmes d'exploitation embarqués
possèdent de nombreuses fonctionnalités communes avec les
systèmes d'exploitation généraux. Ils doivent par exemple
pouvoir gérer une ou plusieurs tâches et les ressources
matérielles.
Ces fonctionnalités sont cependant à moduler les
besoins spécifiques d'un système embarqué : par exemple
une gestion multitâche n'est pas nécessaire si une seule
tâche est exécutée par le processeur. De plus, elles
doivent respecter des contraintes particulières pour les systèmes
embarqués qui peuvent notablement changer leur implémentation
comme nous le verrons dans le paragraphe II.9.2.
II.9.1.2. Fonctionnalités de communication
spécifique :
Dans les systèmes embarqués spécifiques,
et notamment dans les systèmes monopuces, l'architecture est
dédiée à l'application pour optimiser les performances et
le coût. Cela implique que les architectures de tels systèmes sont
très variées. Cette variété se répercute
directement sur les communications : tout d'abord parce qu'elles aussi sont
optimisées pour l'application, mais aussi parce que les divers
composants n'utilisent que rarement les mêmes types de communications.
Ainsi les communications peuvent être point à
point ou multipoints comme le montre la figure II.17. Cette figure
présente les deux types de communications, le premier requiert plus de
connexions et donc plus de surface, tandis que le deuxième peut
être un goulet d'étranglement et donc un facteur ralentissant.
Elles peuvent être implémentées avec ou sans
mémorisation intermédiaire. La mémorisation
intermédiaire permet de désynchroniser deux blocs, sans pour
autant forcer les blocs à s'attendre mutuellement pour échanger
des données. Cette mémorisation intermédiaire peut
elle-même être gérer de plusieurs manières
différentes : par exemple cela peut être un système de
mémoire partagée ou un système FIFO, illustré
à la figure II.18, qui montre aussi les avantages de la
mémorisation intermédiaire pour désynchroniser deux
blocs.
Une caractéristique importante des communications est
la définition des protocoles : ils sont très nombreux suivant les
architectures, les données à transiter et les contraintes
associées (par exemple : CAN ou même TCP/IP). Ces communications
peuvent être réalisées en faisant plus ou moins intervenir
le logiciel ou le matériel, suivant les compromis choisis entre la
performance et la souplesse. De plus, au cours de la conception, ou même
après la réalisation, la frontière entre le logiciel et le
matériel n'est pas fixe.
Ces divers cas se retrouvent souvent combinés dans la
même architecture.

Chapitre II conception des logiciels embarqués
Communication point a point
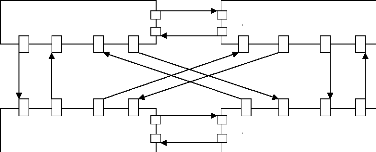
Module 1
(processeur,
matériel...)
Module 3
(processeur,
matériel...)
Module 2
(processeur,
matériel...)
Module 4
(processeur,
matériel...)
Communication multipoint
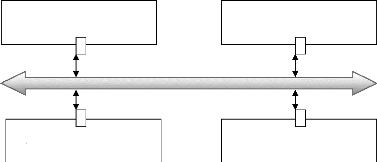
Module 1
(processeur,
matériel...)
Module 3
(processeur,
matériel...)
Module 2
(processeur,
matériel...)
Module 4
(processeur,
matériel...)
Figure II.17 : Communication point à point et
communication multipoint

p p g q
Chapitre II conception des logiciels embarqués

Communication asynchrone (par poignée de
main)
Module 1
(processeur,
matériel...)
Module 2 (processeur, matériel...)

Module 1 écrit Module 2 lit
|
Module 1 : requête donnée
Module 2 :
acquittement
|
|
|
Module 1 doit attendre
|
Communication par FIFO (et poignée de
main)
Module 1
(processeur,
matériel...)


Module 2
(processeur,
matériel...)
Module 1 écrit Module 2 lit


Module 1 : peut effectuer une autre
tâche
Module 1 : requête donnée
FIFO
acquittement
Module 2 : requête
acquittement
FIFO donnée
Figure II.18 : Files d'attentes FIFO pour
désynchroniser deux blocs sans les forcer à
s'attendre
mutuellement
II.9.1.3. Fonctionnalités temporelles :
Tout comme les systèmes d'exploitation
multiutilisateurs tels qu'UNIX, les systèmes embarqué ont des
contraintes temporelles fortes. Cependant, ces contraintes n'ont pas la
même nature:
- pour les systèmes multiutilisateurs il est important
de ne pas bloquer longtemps une tâche. Le modèle temporel
employé est celui du temps partagé, le but étant d'assurer
une certaine équité entre les tâches ;

Chapitre II conception des logiciels embarqués
- pour les systèmes d'exploitation embarqués, il
est important de respecter des délais, même s'il est
nécessaire de bloquer des tâches pendant une longue durée.
Le modèle temporel employé est le modèle
temps-réel.
II.9.1.4. Pilotes de périphériques :
Avec les systèmes embarqués spécifiques
il faut souvent trouver des compromis entre le respect des contraintes
temporelles, les performances, la consommation et la surface. Les pilotes de
périphériques ne sont pas les même suivant les compromis
choisis, ce qui augmente d'autant leur nombre.
Enfin les systèmes embarqués devenant
très complexes, il est fréquent que plusieurs processeurs
fonctionnent en concurrence. Cette concurrence doit elle aussi être
gérée par des pilotes.
II.9.1.5 conséquences des
fonctionnalités requises sur les systèmes d'exploitation
embarqués :
Nous avons vu que les fonctionnalités requises pour les
systèmes d'exploitation embarqués étaient d'une grande
variété, notamment pour les communications. Cette
variété peut se retrouver sur une même puce, voire pour un
même système d'exploitation. Il est donc nécessaire que ce
dernier puisse supporter cette variété, et il doit donc disposer
de très nombreuses parties spécifiques. C'est un obstacle
à l'idée de standardisation générale des
systèmes d'exploitation embarqués : en effet, à moins
d'avoir un jeu de fonctionnalités disproportionné capable de
fournir des fonctions optimales pour chaque cas, il est souvent
nécessaire d'ajouter des fonctions spécifiques au système
pour qu'il puisse fonctionner avec une architecture particulière.
II.9.2. Contraintes imposées par les
systèmes embarqués pour le logiciel :
Dans ce paragraphe, nous allons présenter les
contraintes spécifiques liées aux systèmes
embarqués. Nous verrons dans un premier temps les contraintes purement
matérielles (surface et consommation). Ensuite nous verrons les
contraintes temporelles, en mémoire et en vitesse d'exécution.
II.9.2.1. Contraintes en surface et consommation :
Deux contraintes spécifiques aux systèmes
embarqués sont la surface et la consommation. Le logiciel influe aussi
sur ces paramètres, et il peut être par exemple intéressant
de savoir s'il vaut mieux implémenter une fonctionnalité en
logiciel plutôt qu'en matériel pour la consommation ou la
surface.
Il est possible de dégager du logiciel quelques
paramètres influençant la taille et la consommation :
- La surface pour le logiciel est celle de la mémoire
nécessaire pour le stocker et l'exécuter. Ainsi, plus le code du
logiciel est important ou plus les besoins en mémoire à
l'exécution seront importants, plus la surface nécessaire sera
importante ;
- La consommation dépend du taux d'activité des
processeurs : plus ils effectuent de calculs, plus ils consomment. De meilleurs
algorithmes peuvent réduire les calculs, et donc réduire la
consommation ;
La consommation dépend aussi du nombre d'accès
mémoire. Or les mémoires qui utilisent le moins de surface sont
les mémoires dynamiques qui doivent être fréquemment
rafraîchies, ce qui

provoque une grande consommation. Il y a donc un compromis
à trouver entre surface et consommation dans le cas de la
mémoire.
II.9.2.2. Contraintes temporelles : II.9.2.2.1. Les
performances :
Lorsqu'il est question de contraintes temporelles, il est
souvent sous-entendu performances. Pourtant, la notion de performance
diffère entre les systèmes d'exploitation généraux
et les systèmes d'exploitation embarqués :
- Les performances des systèmes d'exploitation
généraux sont en général évaluées en
moyenne car les écarts momentanés importent peu ;
- Les performances des systèmes d'exploitation
embarqués sont évaluées pour les pires cas des parties
citriques : quand le système doit réagir vite, il doit le faire
dans tous les cas de figures ; par contre dans les cas où il n'a pas de
délai à respecter, le temps qu'il met n'a pas d'importance.
Ces contraintes temporelles peuvent devenir vitales comme par
exemple dans le cas d'un système de freinage ABS.
II.9.2.2.2. Contraintes temps-réel :
Nous avons vu dans le paragraphe précédent,
qu'il y a des cas où les contraintes temporelles pour les
systèmes embarqués prennent la forme de délais qu'il est
impératif de respecter : elles sont appelées contraintes
temps-réel, et, pour pouvoir y répondre, des systèmes dits
« temps-réel » sont nécessaire.
II.9.2.3. Contraintes en mémoire :
Nous avons vu dans le paragraphe II.9.2.1, que dans les
systèmes embarqués, la mémoire disponible pour le code et
pour les données pouvait être limitée. Cette contrainte se
répercute sur le système d'exploitation puisque son code ses
données ajoutés à ceux de l'application doivent pouvoir
tenir dans la mémoire disponible. Il est de plus
préférable de disposer d'un maximum de mémoire pour
l'application ; le système d'exploitation doit donc être le plus
petit possible.
Cette contrainte en mémoire est si forte dans le
domaine des systèmes embarqués, qu'il est fréquent de ne
pouvoir disposer que de quelques kilo-octets de mémoire pour le
système d'exploitation.
II.9.2.4. Les erreurs :
Les systèmes embarqués occupant des fonctions
critiques disposent d'une dernière contrainte : ils ne peuvent pas
être en panne, même en cas d'erreur.
Cette dernière contrainte conduit à des
validations beaucoup plus strictes et donc beaucoup plus longues des
applications embarquées, et aussi des systèmes d'exploitation
embarqués. Des mécanismes de tolérance aux fautes peuvent
aussi être ajoutés au système, ou à l'application,
pour pouvoir continuer à fonctionner malgré les erreurs.
II.9.2.5. L'aspect multiprocesseur
hétérogène :
Les architectures embarquées récentes contiennent
souvent plusieurs processeurs différents, chacun étant
spécialisé pour un domaine : par exemple un processeur
générale pour le contrôle et un

Chapitre II conception des logiciels embarqués
processeur de traitement du signal pour certains calculs. Avec
de telles architectures, l'utilisation d'un système d'exploitation
unique pour gérer l'ensemble des processeurs est problématique :
en effet, une fois compilé pour un processeur, le logiciel ne peut pas
être exécuté sur un autre. Une solution possible est
d'utiliser une machine virtuelle au-dessus des processeurs pour pouvoir
exécuter tout le logiciel dans un langage d'assemblage unique. Cette
solution est peu performante et il est préférable d'envisager une
autre méthode : utiliser un système d'exploitation par
processeur. Cette seconde méthode apporte cependant des contraintes
supplémentaires : tout d'abord les contraintes en surface deviennent
plus fortes, car plusieurs systèmes d'exploitation sont susceptibles de
consommer plus de mémoire qu'un seul ; ensuite il est peut-être
difficile de maintenir une cohérence globale avec plusieurs
systèmes. Enfin, avec une telle architecture, les tâches ne
peuvent pas passer d'un processeur à un autre : il faut décider
avant la compilation de la conception à quel processeur chacune est
allouée.
II.9.3. Les degrés de liberté pour le
logiciel dans les systèmes embarqués :
Jusqu'à présent nous avons vu les
difficultés supplémentaires liées aux systèmes
d'exploitation embarqués par rapport aux systèmes d'exploitation
généraux. Dans ce paragraphe nous allons voir les points qui sont
plus simples à traiter pour les évolutions du logiciel.
II.9.3.1. Gestion utilisateurs simple :
En général, les systèmes embarqués
n'ont pas à gérer plusieurs utilisateurs en même temps. Il
n'est donc plus nécessaire de gérer la sécurité ni
le temps partagé entre les utilisateurs.
II.9.3.2. Evolution du logiciel lente :
Nous entendons par évolution du logiciel lente le fait
que les programmes sont plus rarement chargés ou déchargés
dans les systèmes embarqués que dans les systèmes
généraux : en général les systèmes
embarqués disposent d'un nombre restreint de programme, soit disponibles
en ROM, soit chargés au démarrage du système. Au
contraire, les systèmes d'exploitation généraux (pour
station de travail) peuvent à tout moment charger ou décharger
une multitude de programmes présents sur leurs disques.
Cette évolution logicielle lente limite le risque du
chargement d'un programme « indésirable » qui pourrait
provoquer des erreurs, ou déséquilibrer l'accès aux
ressources. Le nombre d'allocations et de libérations en mémoire
est aussi réduit, ce qui donne plus de liberté dans les
mécanismes de gestion de la mémoire.
II.9.4. Exemples de systèmes embarqués
généralistes :
Il existe un très grand nombre de systèmes
embarqués. Nous allons ici présenter rapidement deux
catégories de systèmes d'exploitation
généralistes.
II.9.4.1. Les systèmes d'exploitation
embarqués propriétaires :
Les systèmes de cette catégorie les plus connus
sont : VxWorks, Nucleus PLUS, QNX, pSOS et Windows CE.
Ce sont des systèmes d'exploitation
généralistes qui présentent souvent de bonnes
caractéristiques temps-réel et en mémoire. Ils manquent
cependant souvent de fonctionnalités

spécifiques. Il est aussi difficile de les adapter
à de nouvelles architectures du fait de leur nature propriétaire
qui empêche leur modification.
II.9.4.2. Les extensions temps-réel :
Cette catégorie comprend les systèmes
d'exploitation obtenus après adaptations aux contraintes
temps-réel de systèmes d'exploitation ouverts existants. Il
existe ainsi Linux temps-réel (dont le plus connu est eCos) ou mach
temps-réel.
Ces systèmes, n'étant pas initialement
prévus pour l'embarqués, ont souvent de moins bonnes
caractéristiques que les systèmes d'exploitation embarqués
propriétaires. Notamment, ils sont souvent non déterministes et
plus lents. Ils disposent par contre de beaucoup plus de fonctionnalités
spécifiques que les précédents, et ils sont simples
à étendre du fait de leur nature ouverte.
II.9.5. Avantages et inconvénients des
systèmes d'exploitation pour les systèmes embarqués :
Tout au long de ces sections, nous avons
présenté les systèmes d'exploitation en
général puis dans le cas particulier des systèmes
embarqués. Dans ce paragraphe nous allons essayer de donner les
avantages et inconvénients de l'utilisation d'un système
d'exploitation pour les systèmes embarqués.
II.9.5.1. Avantages des systèmes d'exploitation
pour les systèmes embarqués : II.9.5.1.1. Programmation
simplifiée des applications :
Le système d'exploitation gère lui-même le
matériel et propose aux applications des fonctions d'accès de
haut niveau. Le travail du programmeur d'applications est donc soulagé
de la programmation des accès au matériel, travail difficile,
fastidieux et source de nombreuses erreurs.
Cet avantage serait encore plus important si tous les
systèmes d'exploitation offraient une même interface très
simple. Ce n'est malheureusement pas le cas : les impératifs de
performance empêchent souvent l'utilisation d'interfaces
génériques abstraites, et la multitude des systèmes
d'exploitation et des architectures sont des freins à
l'uniformité des interfaces.
II.9.5.1.2. Utilisation des spécificités des
processeurs :
Les systèmes d'exploitation, spécialement
programmés pour le processeur sur lequel ils vont s'exécuter,
peuvent tirer partie de ses spécificités :
- Le mécanisme d'interruption permet d'interrompre le
fonctionnement séquentiel du programme suite à un
événement extérieur. Ces interruptions ne sont en
général pas prises en compte dans les modèles logiciels,
de plus elles sont très variables d'un processeur à un autre. Un
système d'exploitation est capable de les gérer;
- Des instructions de réduction de consommation sont
proposées par de nombreux processeurs pour systèmes
embarqués. Il y a par exemple des fonctions de mise en veille du
processeur jusqu'au prochain événement ;
- Des instructions de synchronisation ou d'exclusion mutuelle
(par exemple l'instruction Test AND Set) servent pour l'utilisation de
mémoire partagées entre plusieurs processeurs ;

Chapitre II conception des logiciels embarqués
- Des instructions permettent de contrôler le
fonctionnement du processeur, comme les instructions de gestion de cache, qui
permettent aussi des optimisations de performances ou de consommation.
II.9.5.2. Inconvénients des systèmes
d'exploitation pour les systèmes embarqués :
II.9.5.2.1. Les systèmes d'exploitation consomment
de la mémoire :
Les systèmes d'exploitation sont spécifiques au
processeur sur lequel ils s'exécutent. Par contre, ils restent
très généraux pour l'application qu'ils doivent
gérer. En effet, ils sont prévus pour exécuter n'importe
quel type d'application et ils doivent donc proposer des services suffisamment
généraux pour être utilisables par toutes.
La généralité du système
d'exploitation vis-à-vis de l'application fait qu'il est souvent plus
volumineux que nécessaire. C'est un défaut important dans le
monde des systèmes embarqués où la mémoire est
limitée.
Les systèmes d'exploitation modulaires tentent de
résoudre ce problème en mettant leurs fonctionnalités sous
la forme de modules optionnels, qui ne seront effectivement chargés dans
la mémoire que s'ils sont utilisés. Cependant, ces modules
restent eux-mêmes généraux, à moins d'avoir une
bibliothèque de modules contenant tous les types de modules
spécifiques possibles, ce qui n'est guère réaliste.
II.9.5.2.2. Les systèmes d'exploitation consomment
des ressources processeur :
Comme nous l'avons vu dans le paragraphe
précédent, les systèmes d'exploitation sont très
généraux pour les applications qu'ils doivent exécuter.
Cette généralité se paye en termes de mémoire
consommée, mais elle peut se payer aussi en termes de vitesse
d'exécution : par exemple les synchronisations utiliseront toujours des
mécanismes de sémaphores complets, alors que dans de nombreux cas
un simple verrou suffit.
La vitesse du système d'exploitation est aussi
limitée par l'ordonnancement dynamique des tâches qui demande du
temps aussi bien pour la décision que pour le passage d'une tâche
à l'autre.
II.9.5.2.3. Les systèmes d'exploitation peuvent
être non déterministes :
Nous avons vu que dans les systèmes embarqués,
des contraintes temps-réel pouvaient imposer que le fonctionnement soit
déterministe. Ce déterminisme n'est pas toujours aisé
à obtenir avec les systèmes d'exploitation qui sont des
programmes à exécution complexe. En fait, il est souvent
impossible de savoir avant utilisation si une application basée sur un
système d'exploitation va respecter des délais ou non.
II.9.5.3. Solutions alternatives aux systèmes
d'exploitation :
Nous avons vu précédemment les avantages et
inconvénients de l'utilisation des systèmes d'exploitation pour
les applications embarquées. Il existe aussi des solutions sans
système d'exploitation. Nous allons ici présenter les deux grands
types de solutions alternatives.
II.9.5.3.1. Utilisation d'un programme unique par
processeur :
La solution la plus simple consiste à écrire un
seul programme qui fonctionnera directement pour le processeur. Elle
présente l'avantage de pouvoir prendre en compte les
spécificités du

processeur et de l'application ; elle n'est pas contre
utilisable que si l'application et le processeur sont simples. Il est notamment
difficile d'utiliser cette méthode dans le cas d'applications
multitâches.
Cette méthode a été la première
employée dans la conception des systèmes embarqués et elle
est encore couramment utilisée dans le cas des processeurs de traitement
du signal par exemple.
II.10. Conclusion :
Dans ce chapitre, nous avons précisé le cadre du
travail de cette mémoire : il s'agit des systèmes
embarqués électroniques et informatiques spécifiques, et
notamment les systèmes sur une puce (SoC). Si la conception de la
première génération était suffisamment simple pour
ne pas requérir de méthode ni d'outils particuliers, la
dernière génération, hétérogène,
multiprocesseur et multimaître est trop complexe pour être
conçu sans de nouvelles approches.
Les méthodes récentes de conception de basent
sur le codéveloppement et la cosimulation, c'est-à-dire le
développement et la simulation conjoints de toutes les parties d'un
système. Un exemple de flot de conception basé sur ces principes
a été présenté. Ce flot démarre au niveau
fonctionnel, c'est-à-dire lorsque les divers composants de
l'architecture ont été définis. Il raffine cette
description jusqu'au niveau transfert de registres (appelé
micro-architecture). Ce chapitre est consacré à l'étape de
la génération d'interfaces logicielles et au ciblage logiciel. La
principale action de cette étape est de générer un
ensemble logiciel appelé système d'exploitation. Ce logiciel
particulier est complexe et recouvre un domaine très vaste, il est
présenté aussi dans ce chapitre.
Dans la deuxième partie de ce chapitre, le concept de
ciblage logiciel a été introduit : il s'agit de l'adaptation du
logiciel à l'architecture cible. C'est une étape obligatoire dans
les flots de conception, mais elle est souvent négligée par
rapport à la seule compilation. Pourtant, le ciblage logiciel est
difficile, fastidieux et sujet à de nombreuses erreurs.
Cette étape peut être grandement
automatisée et l'inclusion du système d'exploitation simplifie ce
travail. Dès lors le concepteur du logiciel n'a plus qu'à se
concentrer sur les fonctionnalités, les détails
d'implémentation étant en grande partie automatiquement
résolus par le flot de ciblage.
Chapitre III
Conception matériel

Chapitre III conception matériel
III.1. Introduction :
La conception de systèmes à base de composants
apparaît bien établie dans le monde de l'électronique
où les ingénieurs ont toujours travaillé ainsi. Dans les
années 1980, une architecture matérielle est vue comme
l'interconnexion sur une carte (PCB pour Printed Circuit Board) de composants
sur étagère vendus dans des boîtiers séparés.
Ces composants sont vus comme des boîtes noires auxquelles les
constructeurs associent des documents (datasheets, notes d'application) pour en
préciser les fonctionnalités, les interfaces et les contraintes
d'utilisation. Une même carte regroupe généralement un
processeur, de la mémoire, des périphériques de taille
modeste et des circuits logiques. Ces derniers sont combinés soit pour
construire des circuits plus complexes, soit sous forme de «glu» pour
adapter les interfaces entre composants.
Dans les années 1990, les microcontrôleurs
intègrent dans un même boîtier un coeur de processeur, ses
périphériques et de la mémoire. La capacité
croissante des ASICs (Application Specific Integrated Circuits) autorise
l'implantation directement en matériel de fonctions complexes tandis que
les circuits logiques programmables (PLD) permettent de regrouper la
«glu» sur une même puce pour en réduire
l'encombrement.
A partir de 2000, un simple ASIC ou FPGA (Field-Programmable
Gate Array) peut contenir l'équivalent de plusieurs millions de portes
logiques, ce qui permet d'intégrer dans le même boîtier un
ou plusieurs coeurs de processeurs, des bus, de la mémoire et des
périphériques. L'ordre de complexité de ces
périphériques va d'un simple timer à un décodeur
vidéo complet.
Aussi, un effort important est fourni pour la
vérification des SoC en utilisant des représentations abstraites
du système et de ses composants. Compte tenu de la complexité en
nombre de portes des composants, cette vérification ne peut être
exhaustive et s'avère à son tour très coûteuse en
temps de développement. Les concepteurs de circuits combinent plusieurs
approches :
- l'optimisation et la génération automatique de
matériel à partir d'une modélisation de haut niveau du
système,
- la réutilisation de composants pour éviter de la
redondance dans la conception,
- l'utilisation de techniques de simulation et de
vérification formelle afin de s'assurer que les modèles sont
consistants par rapport aux spécifications.
III.2 Modéliser et synthétiser à
un haut niveau d'abstraction :
Un flot typique de conception de matériel suit une
progression descendante faite d'une succession d'étapes qui enrichissent
la vision abstraite du système. Le diagramme en Y, proposé par
Gajski et Kuhn, donne une vision synthétique des domaines de conception
et des niveaux d'abstraction sous lesquels un circuit peut se présenter
au cours de son développement. Les trois domaines proposés sont
le domaine comportemental, dans lequel on s'intéresse aux
propriétés dynamiques du fonctionnement d'un système ; le
domaine structurel dans lequel un système est vu comme une
interconnexion de composants ; le domaine géométrique, ou
physique dans lequel on s'intéresse aux relations spatiales entre ces
composants sur le support cible (carte ou circuit intégré). Les
différents niveaux d'abstraction identifiés dans chacun de ces
domaines sont :

- le niveau architectural décrit les
fonctionnalités d'un système au niveau spécifications,
donne sa décomposition en sous-systèmes ainsi que ses contraintes
d'implantation physique ;
- le niveau algorithmique exprime des comportements de type
flot de données et/ou de contrôle en utilisant des modèles
hauts niveaux. La structure représente l'affectation des fonctions aux
ressources. Des informations géométriques sont exprimées
en terme de partitionnement en blocs sur un circuit intégré ou
une carte ;
- le niveau transfert de registres (RTL) exprime
l'ordonnancement au cycle d'horloge près des opérations et des
transferts de données. Pour l'aspect structurel, ces opérations
sont projetées sur des ressources matérielles
élémentaires (registres, opérateurs arithmétiques,
etc.) ;
- le niveau logique décrit le comportement sous forme
d'équations booléennes, qui peuvent elles mêmes se traduire
sous la forme d'une interconnexion de portes logiques d'une part, et d'autre
part de cellules élémentaires placées et routées
d'une bibliothèque technologique de type ASIC ;
- le niveau circuit modélise le comportement
électrique sous forme d'équations différentielles ou de
fonctions de transfert ; une représentation structurelle
décompose le circuit en une interconnexion de transistors et une
représentation géométrique détaille le placement et
le routage de ces transistors sur le substrat de silicium.
Cette décomposition en domaines et niveaux
d'abstraction conduit à une représentation commune des formes
sous lesquelles un système peut se présenter et des
transformations réalisables pour passer d'une représentation
à une autre. Les langages de description de matériel comme VHDL
ou Verilog autorisent des représentations combinant différents
niveaux et domaines, représentations sur lesquelles des outils
automatiques peuvent travailler à des fins d'analyse et de
synthèse. Les outils de synthèse matérielle
réalisent en fait l'équivalent de la «compilation», au
sens logiciel, en automatisant le raffinement d'une description de «haut
niveau» (par exemple une description comportementale au niveau RTL) en une
description de plus bas niveau (par exemple une description structurelle au
niveau logique).
Trois étapes de synthèse sont aujourd'hui
couramment utilisées dans l'industrie : synthèse RTL (du niveau
RTL comportemental vers le niveau logique structurel) ; synthèse logique
(optimisation au niveau logique structurel) et synthèse physique, ou
placement/routage (du niveau logique structurel vers le niveau logique ou
circuit dans le domaine géométrique). Ces étapes
s'enchaînent et les interventions du concepteur se limitent à
l'écriture de scripts qui précisent notamment les contraintes
à respecter. En amont de ces trois étapes, la synthèse de
haut niveau promet la génération automatique d'une description
RTL à partir d'une description du comportement au niveau algorithmique :
ces nouveaux outils qui émergent depuis quelques années sur le
marché de la CAO reposent sur l'ordonnancement automatique des
opérations et la synthèse d'un contrôleur adapté aux
performances souhaitées pour l'architecture matérielle de
sortie.

Chapitre III conception
matériel
III.3 Réutilisation de composants
matériels :
Les systèmes électroniques embarqués
actuels sont un mélange de technologies hétérogènes
(numérique /analogique, matériel/logiciel, orientation
contrôle/données) et de fonctionnalités complexes dont
certaines sont communes pour une famille de produits. La réutilisation
devient alors nécessaire pour éviter de multiples
implémentations de fonctionnalités identiques.
La réutilisation de composants matériels sur
étagère (composants en boîtiers) est une pratique courante
dans le domaine de la conception de systèmes sur cartes. Un composant
est une boîte noire conditionnée et interfacée de
manière standard. La documentation constructeur en détaille les
fonctionnalités et les conditions d'utilisation (chronogrammes des
entrées/sorties). Elle fournit également des notes d'application
avec des exemples de réalisation et des circuits de
référence.
III.3.1 Composants virtuels :
La notion de système sur circuit intégré
amène des changements majeurs sur cette définition du composant :
un composant ne recouvre plus un objet physique palpable mais se
présente sous la forme d'une unité de structuration abstraite
dont il n'est pas sûr qu'elle corresponde à une entité
physique distincte après fonderie. L'utilisation de langages de
description de matériel et d'outils de synthèse automatiques
devient ici incontournable. Rapidement, se pose le problématique de
concevoir, échanger et réutiliser de tels composants
(appelés composants virtuels ou IP cores pour Intellectual Property),
problématique nouvelle dans le monde du matériel mais
déjà rencontrée dans le monde du génie logiciel.
Comparée à la réutilisation de composants en
boîtiers, l'intégration d'un composant virtuel dans un
système introduit de nouveaux problèmes :
- Les standards d'interface (bus de communication) qui
régissaient la conception de cartes sont remis en question. Un composant
virtuel n'étant plus limité par les contraintes de packaging peut
être muni d'interfaces spécifiques, optimisées en fonction
du fonctionnement interne du composant. Pour permettre à deux composants
de collaborer le concepteur d'un système doit leur ajouter des couches
d'adaptation qui introduisent un surcoût en temps de développement
et une possible dégradation des performances.
- Les composants manipulés dans les flots de conception
sont des modèles fournis sous forme de fichiers sources (code
synthétisable écrit dans un langage de description de
matériel) ou ayant déjà subi les étapes de
synthèse logique et physique (netlists, masques prêt à
fondre). Les formats d'échange et la nature des informations
échangées entre concepteur et utilisateur d'un composant
conditionnent l'interopérabilité de leurs outils de conception
respectifs.
- La modélisation des composants à un haut
niveau d'abstraction permet une certaine flexibilité dans leur
conception. Il devient possible de les «personnaliser» à
différents niveaux (paramètres algorithmiques comme les nombres
de points d'une FFT, paramètres de performances comme le nombre
d'étages de pipeline, paramètres technologiques comme la
fréquence d'horloge). En revanche, les caractéristiques physiques
d'un composant (encombrement, consommation) sont d'autant moins
prédictibles qu'il est décrit à un haut niveau.

Chapitre III conception matériel
- Un dernier aspect des composants virtuels concerne la
protection de la propriété intellectuelle dans la mesure
où, selon le niveau d'abstraction de sa description, l'utilisateur
dispose d'une vue en boîte grise voire en boîte blanche qui
facilite la rétro-conception. A la différence des composants en
boîtiers dont il faut acheter autant d'exemplaires que de produits
à fabriquer, un composant virtuel peut être reproduit à
l'infini en toute illégalité. Une notion de licence d'utilisation
similaire à celles des produits logiciels s'applique aujourd'hui
également au matériel.
III.3.2 Standardisation :
VSIA (Virtual Socket Interface Alliance) est une organisation
qui regroupe des vendeurs de CAO et des sociétés qui
développent des systèmes. Elle propose des recommandations sur
les points suivants :
- les standards permettant de définir, ce qu'est un
composant virtuel ;
- les méthodologies pour la conception et la
réutilisation d'IP ;
- les techniques de vérification et de test de ces IP ;
- la protection de la propriété intellectuelle pour
ces IP ;
- les méthodes de transfert de composants.
VSIA définit trois niveaux d'abstraction sous lesquels
un composant peut être délivré :
- Les composants virtuels durs (hard) sont livrés sous
forme de masques prêts à fondre. Ses performances et ses
propriétés physiques sont pleinement caractérisées.
En revanche, un jeu de masques est spécifique à une technologie
donnée et peut difficilement être porté d'une technologie
à une autre. Un tel composant n'est pas paramétrable et ne peut
pas être optimisé pour une application donnée.
- Un composant virtuel ferme (firm) se présente sous la
forme d'une netlist structurelle aux niveaux portes logiques. Elle est
généralement optimisée en vue d'une cible technologique
donnée, mais autorise des optimisations supplémentaires lors du
placement et du routage sur le support physique. La fonction
réalisée et les performances sont figées.
- Un composant virtuel mou (soft) est délivré
sous la forme d'une description de niveau transfert de registres dans un
langage de description de matériel. Cette description est portable d'une
technologie à une autre et pourra traverser différentes
étapes d'optimisation en lien étroit avec les besoins de
l'utilisateur. Elle peut également supporter un paramétrage au
niveau micro-architectural (par exemple de la largeur des bus).
Les composants soft sont plus facilement sujets aux violations
de la propriété intellectuelle. Généralement, un
composant annoncé comme soft est délivré sous forme firm,
le constructeur préférant réaliser la synthèse chez
lui en fonction des contraintes de l'utilisateur plutôt que de lui
délivrer son code source.
Les travaux du groupe VSIA visent également à
standardiser la notion de plate forme d'intégration qui fournit un cadre
de développement de SoC dont le coeur est réutilisable pour une
famille d'architectures donnée. Le terme plate-forme, assez vague,
regroupe en fait quatre niveaux :

- Les plates-formes «de niveau zéro» font
simplement référence à un ensemble de blocs de base utiles
pour une large famille d'applications.
- Les plates-formes «de niveau un» sont
constituées d'une architecture minimale basée sur un ou un
ensemble de processeurs, choisi pour une famille d'applications précises
(ex. ARM7/9 + RISC pour un produit utilisant la technologie sans-fil), et dont
l'utilisation est maîtrisée. Ces architectures font en
général apparaître un certains nombre de
différenciateurs qui permettent de particulariser la plate-forme pour un
produit spécifique (ex. DECT ou GSM).
- Les plates-formes «de niveau deux»,
appelées également «plates-formes d'intégration
système», visent un taux de réutilisation de l'ordre de 95
pourcent. Ce taux de réutilisation peut seulement être atteint car
la majorité de la plate forme est déjà
pré-validée, souvent cette validation a été
'prouvée' par la réalisation d'un ou plusieurs produits. Avec ce
type de plate-forme, le degré de liberté est très
réduit (i.e. on peut seulement choisir un certain nombre de
périphériques parmi un ensemble proposé, changer le
contenu des composants programmables ou rajouter des parties analogiques
spécifiques). Il est toutefois indispensable de valider les nouveaux
composants selon des critères fonctionnels, temporels et
matériels (encombrement, contraintes
électromagnétiques).
- Enfin le «niveau trois» représente les
«plates-formes de production» ou les aspects matériels sont
fixes et pré-validés ; seuls les composants programmables ou les
aspects logiciels peuvent être modifiés. Dans ce dernier type de
plate forme, la validation et la mise au point des applications et/ou du
système d'exploitation devient l'étape qui fait la
différence au niveau du produit final.
Cette approche par plates-formes d'IP fait partie des
avancées dans le domaine du matériel qui pourraient être
adaptées à la conception d'architecture embarquées.
III.4. Un exemple d'environnement orienté
composants pour la conception d'architectures numériques :
Dans ce paragraphe, nous présentons une étude
qui utilise les techniques orientées objets et l'approche par composant
pour concevoir et simuler des architectures numériques. Il s'agit
là d'un exemple d'environnement de modélisation et
d'évaluation de performance d'architecture : SEP (Simulation et
Evaluation de Performance). Initialement SEP a été
étudié pour répondre à des besoins d'industriels
qui souhaitaient pouvoir réutiliser leurs modèles existants et
les enrichir afin qu'ils réalisent les nouvelles fonctions. Les langages
objets ont été choisis dans SEP afin d'enrichir les
modèles bien conçus en utilisant les mécanismes
d'héritage et de composition. Les composants pour leur part, permettent
d'encapsuler par une interface de communication une ou plusieurs
fonctionnalités. Ils communiquent par l'intermédiaire de
connecteurs qui ont l'avantage indiscutable sur les objets de faire
apparaître sur un pied d'égalité l'émetteur et le
récepteur. De ce point de vue, le composant est un modèle mieux
adapté que les objets pour représenter cette
caractéristique des échanges dans le matériel. Ces
approches doivent être combinées et adaptées aux outils et
modèles existants pour la conception de circuits.
Les langages de description du matériel (VHDL ou
Verilog) sont orientés composants. Ils permettent la description de
l'interface de communication ou entité, ainsi que de plusieurs
implémentations différentes (composant) et enfin de la
configuration. Ils manquent néanmoins de mécanismes
d'enrichissement des composants existants. SEP se base donc sur deux approches
pour la modélisation et la simulation d'architecture numérique
à savoir :

Chapitre III conception matériel
- utiliser des langages orientés objets tels que Java
ou C++ pour décrire les fonctions (services) élémentaires
réalisés par les architectures matérielles. Ces
modèles peuvent alors être enrichis et adaptés à de
nouvelles spécifications ;
- utiliser un langage de description d'architecture pour
décrire les entités elles-mêmes et les mécanismes de
communication et de synchronisation. Cette description matérielle
utilise les modèles objets définis précédemment
pour réaliser le comportement. Alors qu'avec des langages tels que VHDL
et Verilog, le comportement est indissociable de l'interface du composant, dans
l'outil SEP, ce comportement est délégué par un
mécanisme d'interposition vers le monde des objets. Cela permet d'avoir
une approche 'top-down' dans la conception et ainsi de vérifier les
aspects fonctionnels avant de vérifier les aspects temporels de VHDL ou
Verilog.
Le composant SEP L'entité de base de
modélisation dans SEP est le composant. On distingue deux
catégories de composants :
- les composants "élémentaires"
représentés par la classe "Active Component" et dont le
comportement est modélisé par un ensemble de services. Le
comportement des composants est complètement autonome, il ne
dépend pas de la configuration dans laquelle ils sont placés ce
qui assure la modularité et la réutilisation ;
- les composants "Material Container" appelés aussi
modules dont le comportement est représenté par une description
structurelle, c'est-à-dire par composition d'autres composants.
Interface des composants SEP Les composants
communiquent avec l'extérieur au travers de leur interface. Cette
interface est constituée d'un ensemble de ports munis d'une
sensibilité qui définit les conditions sous lesquelles les
composants réagissent. Cette notion de sensibilité est
caractéristique du matériel.
Les ports sont reliés entre eux par des signaux. Ils
communiquent avec le composant dont ils dépendent en utilisant le ou les
"event Listener" qui leur est associés. Les composants utilisent les
ports pour échanger des données à travers des signaux de
communication. Une donnée émise sur un port de sortie PS d'un
composant est diffusée vers le ou les ports connectés au port PS
par un signal. Cette autonomie rend possible la définition de nouvelles
configurations qui modifient l'interconnexion des composants. En effet, une
connexion directe entre deux composants, c'est-àdire un composant
invoquant explicitement un service d'un autre composant sans connecteur, ne
permet ni une modification aisée de la configuration, ni une
réutilisation aisée des composants. La modélisation avec
des composants et des connecteurs permet plus de souplesse que la simple
utilisation d'objets.
Les services d'un composant La description du
comportement d'un composant (Active Component) commence par la
définition des services fournis par le composant. Ces services sont
décrits par les méthodes d'une classe appelée "Service
Provider" associée à ce composant. Ensuite, chaque service est
encapsulé dans un composant SEP afin de réaliser un comportement.
En effet, le service constitue seulement une partie du comportement. Il est
exécuté en concurrence avec d'autres services du même
composant ou d'autres composants. Il existe deux catégories
élémentaires de composant dans SEP. Les composants combinatoires
dont les sorties ne dépendent que des entrées : "Level
Component", et les composants séquentiels qui peuvent être
modélisés par des machines à

états et dont les sorties dépendent de
l'état courant du composant et de ses entrées (modèle de
Mealy): "Edge Component". L'état suivant est calculé en fonction
de l'état courant et des entrées.
La composition de composants Dans SEP, il est
possible de construire un comportement complexe par composition du comportement
de composants plus simples. La définition d'une configuration de
composants et de connecteurs permet de construire ce comportement. Les
connecteurs élémentaires de SEP sont les signaux de
contrôle et les bus de données. L'introduction de la notion de
module permet de réutiliser des parties de modèles existants et
permet une approche incrémentale. La notion de service est donc aussi
présente au niveau des modules, c'est pourquoi un mécanisme qui
la fait apparaître explicitement a été mis en oeuvre. Ce
mécanisme permet la définition de services dans un module,
améliore la lisibilité et donc la possibilité de
réutilisation.
Héritage de comportements et de services
Que la description du comportement des composants soit logicielle ou
structurelle, tous les composants sont potentiellement constitués d'un
ensemble de services.
On définit une relation d'héritage du
comportement d'un composant fils vers son composant père comme d'une
part, l'héritage par le fils de l'interface du composant père et
d'autre part, l'héritage des services définis par le père.
C'est-à-dire que le composant fils possède dans son interface au
minimum les mêmes ports que son père ; bien évidemment, il
peut en déclarer de nouveaux ; de plus, il hérite des services
définis par son père et peut les redéfinir. Une
deuxième notion d'héritage a été définie,
c'est l'héritage des services d'un composant fils par son composant
père, c'est-à-dire par le module auquel il appartient.
Les services du fils peuvent être directement
invoqués sur le père comme s'il les avait définis
lui-même.
III.5 L'état des lieux et les perspectives de
recherche :
La conception de systèmes à base de composants
est devenue une pratique courante depuis déjà plusieurs
années. Face aux difficultés mentionnées plus haut et
à l'impossibilité pour les grands groupes d'obtenir un consensus
sur des standards, la notion de composant IP Plug-and-Play - c'està-dire
implantable directement sans effort de la part de l'utilisateur et sans
intervention du concepteur - est perçue aujourd'hui comme un objectif
irréaliste et des solutions industrielles ont été mises en
place pour résoudre les problèmes sans attendre. La notion de
Platform IP résout la question de l'interopérabilité des
composants provenant de sources variées en fournissant une architecture
SoC prête à l'emploi et configurable de manière
limitée (choix des périphériques dans une
bibliothèque de composants sélectionnés pour la
compatibilité de leurs interfaces).
Une partie des résultats obtenus par les industriels
dans la construction et la mise au point de ces plates-formes pourraient
être exploités pour leur adaptation à la notion de
composant temps réel. En particulier, la gestion des interfaces et
l'interopérabilité des composants est un problème bien
cerné pour les IP. La caractérisation temporelle des IP fait
également partie des contraintes qu'il faudrait attacher aux composants
temps réel. Il faudrait étendre ces travaux afin de les adapter
à des matériels de plus haut niveau que les SoC.
A l'inverse, il semble maintenant acquis que les techniques
employées dans la conception du logiciel (méthodologie, outil de
développement, outil de vérification) doivent être
appliquées à la

Chapitre III conception matériel
conception de systèmes matériels. Cela suppose une
adaptions de ces méthodes et outils logiciels pour la prise en compte,
au niveau de ces modèles, de caractéristiques inhérentes
au matériel.
III.6. Architecture matérielle d'un
système embarqué :
La figure III.1 présente les caractéristiques
principales d'un système embarqué typique.
FPGA/ ASIC
LOGICIELLE
MEMOIRES
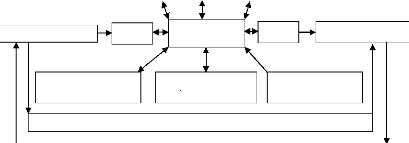
CNA
CAN
CAPTEURS
CPU
INTERFACE
UTILISATEUR
SECURITE ELECTROMECANIQUE
PORT
ENTREES
ALIMENTATION
AUXILIAIRE
ACTIONNEURS
ENVIRONNEMENT EXTERIEURE
Figure.III.1 : Système embarqué
typique
On retrouve en entrée des capteurs
généralement analogiques couplés à des
convertisseurs A/N. On retrouve en sortie des actionneurs
généralement analogiques couplés à des
convertisseurs N/A. Au milieu, on trouve le calculateur mettant en oeuvre un
processeur embarqué et ses périphériques d'E/S. Il est
à noter qu'il est complété généralement d'un
circuit FPGA jouant le rôle de coprocesseur afin de proposer des
accélérations matérielles au processeur.
On retrouve en fait un beau système d'asservissement
entre les entrées et les sorties ! Il est à noter que
l'expression la plus simple de cette figure est de considérer, comme
capteurs, des interrupteurs et, comme actionneurs, des LED
Sur ce schéma théorique se greffe un
paramètre important : le rôle de l'environnement extérieur.
Contrairement au PC ronronnant bien au chaud dans un bureau, un système
embarqué doit faire face à des environnements plus hostiles. Il
doit faire face à un ensemble de paramètres agressifs :
· Variations de la température ;
· Vibrations, chocs ;
· Variations des alimentations ;
· Interférences RF ;
· Corrosion ;
· Eau, feu, radiations ;
L'environnement dans lequel opère le système
embarqué n'est pas contrôlé ou contrôlable. Cela
suppose donc de prendre en compte ce paramètre lors de sa conception. On
doit par exemple

prendre en compte les évolutions des
caractéristiques électriques des composants en fonction de la
température, des radiations... Pense-t-on à tout cela lorsque
l'on conçoit une carte mère de PC ? Enfin pour terminer cette
partie, les systèmes embarqués sont aujourd'hui fortement
communicants. Cela est possible grâce aux puissances de calcul offertes
par les processeurs pour l'embarqué (32 bits en particulier) et
grâce aussi à l'explosion de l'usage de la connectivité
Internet ou connectivité IP. La connectivité IP permet
fondamentalement de contrôler à distance un système
embarqué par Internet. Ce n'est en fait que l'aboutissement du
contrôle à distance d'un système électronique par
des liaisons de tout type : liaisons RS.232, RS.485, bus de terrain...
Cela permet l'emploi des technologies modernes du web pour ce
contrôle à distance par l'utilisateur : il suffit d'embarquer un
serveur web dans son équipement électronique pour pouvoir le
contrôler ensuite à distance, de n'importe où, à
l'aide d'un simple navigateur. Il n'y a plus d'IHM spécifique à
concevoir pour cela, ce rôle étant rempli par le navigateur web.
Cela est une réalité : les chauffagistes proposent maintenant des
chaudières pouvant être pilotées par le web ! Il faut aussi
noter la montée en puissance des communications sans fil dans
l'embarqué au détriment des communications filaires pour limiter
le câblage et faciliter la mise en place du système
embarqué. Le wifi et toutes les normes de réseaux sans fil IEEE
802.15 comme Zigbee ont le vent en poupe dans l'embarqué et surtout en
domotique (réseaux de capteurs sans fil par exemple).Mais ne nous
méprenons pas sur ces facilités et commodités, cela a bien
sûr un revers : la sécurité du système
embarqué, puisque connecté à Internet.
III.6.1. Les capteurs : III.6.1.1. Définition
:
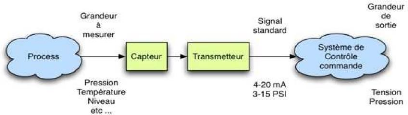
Figure .III.2 : Capteur et transmetteur en
situation
Un capteur est un organe de prélèvement
d'information qui élabore à partir d'une grandeur physique, une
autre grandeur physique de nature différente (très souvent
électrique). Cette grandeur représentative de la grandeur
prélevée est utilisable à des fins de mesure ou de
commande.
-virtuellement, tous les stimuli physiques peuvent être
captés (température, lumière, couleur, son,
vélocité, accélération (linéaire,
angulaire), pression, champ magnétique, tension, courant,
capacité...).
-Interfaces pour ces capteurs (alimentation, isolation et
amplification, filtrage, multiplexage, conversion A/N, FPAA).

Chapitre III conception matériel
III.6.2. Les Convertisseurs Analogiques Numériques
:
Le but du CAN est de convertir un signal analogique continu en
un signal discret et cela de manière régulière (à
la fréquence d'échantillonnage).
Il existe différents types de convertisseur qui va se
différencier par leur temps de conversion et leur coût (Surface de
silicium).
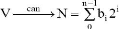
III.6.2.1. Les convertisseurs à
intégration :
III.6.2.1.1. Convertisseur à approximations
successives :
Principe : On
détermine les valeurs des différents bits l'un après
l'autre en commençant par le MSB, un peu à la manière
d'une marchande de marché :
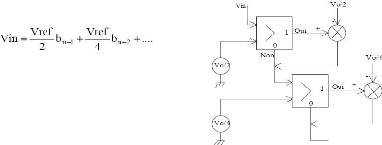
Figure .III.3 : Principe de la pesée
successive
Le signal est comparé à une tension de
référence: Vo/2. S'il est supérieur, on lui retranche
cette valeur et on met le bit de comparaison à '1', sinon on met le bit
de comparaison à '0' et on le compare à la tension suivante.
On effectue ainsi un encadrement progressif de plus en plus fin.
Ainsi pour un CAN N bits, en N coups on obtient la conversion.
Il est plus lent que le Flash. Ainsi pour 16 bits, il lui faut
en moyenne un temps de conversion de 10jts. Il est très adapté
à des signaux audio.
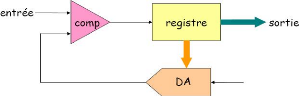

III.6.2.1.2. Simple rampe / tracking :
Principe : A la valeur de la
tension d'entrée on fait correspondre une impulsion dont la largeur est
proportionnelle à cette tension. Cette impulsion vient contrôler
l'autorisation à s'incrémenter d'un compteur. On
génère ainsi le code binaire de sortie en comptant plus ou moins
longtemps en fonction de l'amplitude du signal à convertir.
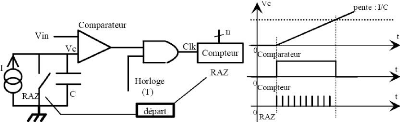
Figure .III.4 : Principe du convertisseur simple
rampe
Caractéristiques :
> Les Avantages :
· Simple et peu coûteux.
· Inconvénients :
· N dépend de C donc de la tolérance sur
C.
· Lent car nécessite 2N cycles d'horloges
pour effectuer une conversion.
· Comme il n'y a pas de synchronisme entre l'horloge et le
RAZ, cela induit une imprécision
de 1 période au début
et à la fin de la conversion soit une erreur moyenne de 1,5 quantum.
III.6.2.1.3. Double rampe (intégrateur) :
Principe : On effectue une
double intégration de manière à faire s'annuler les
erreurs dues aux composants :
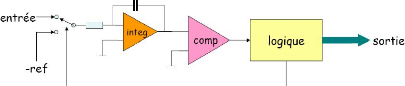
Figure .III.5 : Architecture du convertisseur
double rampe
- phase 1 : intégration de l'entrée pendant un
temps T1
- phase 2 : décharge de l'intégrateur vers 0
à vitesse constante.
- Le temps T2 mis à décharger l'intégrateur
donne la valeur d'entrée
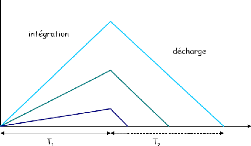

Chapitre III conception matériel
III.6.2.1.4. Parallèle (flash) : Principe :
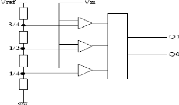
Figure .III.6 : le convertisseur
Flash
C'est un réseau de comparateur mis en parallèle.
Un codage sur n bits nécessite 2n-1 comparateurs et
résistances.
Facteurs clefs : temps de
conversion, résolution, précision, linéarité, codes
manquants, fenêtre d'acquisition, impédance d'entrée,
bruit
III.6.3. Effecteurs : influent sur l'environnement :
moteurs, servomoteurs, valves, restitution de son
(haut-parleurs, buzzers, ...), relais, afficheurs, Contrôleurs
d'effecteurs, conversion N/A, amplification, interrupteurs de puissance (IGBT,
MOS,...),relais, générateurs PWM ,FPAA
III.6.3.1. Les Convertisseurs Numériques
Analogiques :
Définition : On souhaite
à partir d'une information numérique, codée sur n bits,
récupérer un signal analogique, image du numérique.
Principe : Chaque bit va
être associé à un interrupteur qui connectera (1) ou non
(0) une source (de courant) sur la sortie.
- sortie quantifiée et échantillonnée -
filtrage souvent nécessaire !
Facteurs clefs :
résolution, linéarité, temps de conversion, glitches :
échantillonneur, bloqueur en sortie, bruit...

III.6.4. Interface homme machine :
> entrées de données (clavier, boutons
poussoirs, interrupteurs à main, à pied) > dispositifs de
pointage (souris, touchpad, stylos optiques)
> afficheurs (LED, afficheurs LCD, écrans CRT, sortie
télévision)
III.6.5. Interfaces associées :
> multiplexage du clavier
> protection / isolation de l'environnement > alimentation
des afficheurs
III.6.6. Les mémoires :
III.6.6.1. Mémoire non volatiles :
Une mémoire non volatile est une mémoire qui
conserve ses données en l'absence d'alimentation électrique. On
distingue les mémoires mortes (ROM), et les mémoires de type RAM
non volatiles (NVRAM pour non-volatile RAM).
· stockage
- du programme (firmware)
- de données de calibration ou de configuration
· encore peu de disques durs, ou bien disques amovibles
· horloges temps réel (RTC) sauvegardées par
batteries
- Il y'a plusieurs types (mask-ROM / OTP-ROM, EPROM, EEPROM,
Flash, RAM sauvegardées par batteries).
III.6.6.2. Mémoire vive :
La mémoire vive, mémoire système ou
mémoire volatile, aussi appelée RAM de l'anglais Random Access
Memory (que l'on traduit en français par 'mémoire à
accès direct'), est la mémoire informatique dans laquelle un
ordinateur place les données lors de leur traitement. Les
caractéristiques de cette mémoire sont :
Sa rapidité d'accès (cette rapidité est
essentielle pour fournir rapidement les données au processeur) ;
Sa volatilité (cette volatilité implique que les
données sont perdues dès que l'ordinateur cesse d'être
alimenté en électricité).
Les Types :
> Statique: SRAM, SSRAM, ZBT-RAM, NoBL-RAM, > Dynamique :
DRAM, SDRAM, DDRAM, ...
Les Fonction :
Fonctionnement du CPU
Acquisition / restitution de données à haut
débit (tampons)
Le choix du type de RAM est souvent dicté par le type
d'interface disponible sur le processeur

Chapitre III conception matériel
III.6.7. Circuit logique programmable « FPGA » :
Un circuit logique programmable, ou réseau logique
programmable, est un circuit intégré logique qui peut être
reprogrammé après sa fabrication.
Il est composé de nombreuses cellules logiques
élémentaires librement assemblables.
La plupart des grands FPGA modernes sont basés sur des
cellules SRAM aussi bien pour le routage du circuit que pour les blocs logiques
à interconnecter.
FPGA jouant le rôle de coprocesseur afin de proposer des
accélérations matérielles au processeur.
Quelques fonctionnalités particulières disponibles
sur certains composants :
· blocs de mémoire supplémentaires (hors des
LUT), souvent double-port, parfois avec mécanisme de FIFO,
· multiplieurs câblés (coûteux à
implémenter en LUT),
· coeur de microprocesseur enfoui (dit hard core),
· blocs PLL pour synthétiser ou resynchroniser les
horloges,
· reconfiguration partielle, même en cours de
fonctionnement,
· cryptage des données de configuration,
· Sérialiseurs / désérialiseurs
dans les entrées-sorties, permettant des liaisons série
haut-débit, impédance contrôlée numériquement
dans les entrées-sorties, évitant de nombreux composants passifs
sur la carte.
III.6.8. Unité centrale de traitement (Central
processing unit « CPU ») :
Le processeur, (ou CPU, Central Processing Unit, «
Unité centrale de traitement » en français) est le composant
essentiel d'un ordinateur qui interprète les instructions et traite les
données d'un programme.
La vitesse de traitement d'un processeur est encore parfois
exprimée en MIPS (million d'instructions par seconde) ou en
Mégaflops (millions de floating-point operations per second) pour la
partie virgule flottante, dite FPU (Floating Point Unit). Pourtant,
aujourd'hui, les processeurs sont basés sur différentes
architectures et techniques de parallélisation des traitements qui ne
permettent plus de déterminer simplement leurs performances. Des
programmes spécifiques d'évaluation des performances (benchmarks)
ont été mis au point pour obtenir des comparatifs des temps
d'exécution de programmes réels.
C'est le processeur qui apporte aux ordinateurs leur
capacité fondamentale à être programmés, c'est un
des composants nécessaires au fonctionnement de tous les types
d'ordinateurs, associés aux mémoires primaires et aux dispositifs
d'entrée/sortie. Un processeur construit en un seul circuit
intégré est communément nommé microprocesseur,
à l'inverse, certains fabricants ont développé des
processeurs en tranches, dans ce cas les fonctions élémentaires
(ALU, FPU, séquenceur, etc.) sont réparties dans plusieurs
circuits intégrés spécialisés.
L'invention du transistor en 1947 a ouvert la voie de la
miniaturisation des composants électroniques et le terme d'unité
centrale (CPU) est utilisé dans l'industrie électronique
dès le début des années 1960 (Weik 1961). Depuis le milieu
des années 1970, la complexité et la puissance des

microprocesseurs n'a cessé d'augmenter au-delà
de tous les autres types de processeurs au point qu'aujourd'hui les termes de
processeur, microprocesseur ou CPU, s'utilisent de manière
indifférenciée pour tous les types de processeurs.
Les processeurs des débuts étaient conçus
spécifiquement pour un ordinateur d'un type donné. Cette
méthode coûteuse de conception des processeurs pour une
application spécifique a conduit au développement de la
production de masse de processeurs qui conviennent pour un ou plusieurs usages.
Cette tendance à la standardisation qui débuta dans le domaine
des ordinateurs centraux (mainframes à transistors discrets et
mini-ordinateurs) a connu une accélération rapide avec
l'avènement des circuits intégrés. Les circuits
intégrés ont permis la miniaturisation des processeurs dont les
dimensions sont réduites à l'ordre de grandeur du
millimètre. La miniaturisation et la standardisation des processeurs ont
conduit à leur diffusion dans la vie moderne bien au-delà des
usages des machines programmables dédiées. On trouve les
microprocesseurs modernes partout, de l'automobile aux téléphones
portables, en passant par les jouets pour enfants.
III.7. Conclusion :
L'évolution de la conception matérielle des
systèmes embarqués présente l'avantage d'une
intégration plus poussée qui va dans le sens des besoins en
miniaturisation de ces systèmes mobiles. En revanche, le
développement de ces systèmes fortement intégrés
présente de nouvelles difficultés : à la différence
des systèmes sur cartes où un prototype de chaque sous
système pouvait être réalisé et testé
séparément au fur et à mesure du développement, un
SoC destiné à une cible ASIC doit avoir été
développé entièrement avant de pouvoir être mis sur
silicium. Le coût de fonderie d'un ASIC en faible quantité est en
effet trop élevé pour qu'un prototype de chaque sous
système soit réalisé.
Chapitre IV
Sécurité des systèmes
embarqués

Chapitre IV sécurité des
systèmes embarqués
IV.1.Introduction :
Les réseaux et systèmes informatiques prennent
un rôle et une place chaque jour plus importants dans tous les aspects
des activités humaines. Les situations multiples dans lesquelles il est
indispensable de savoir définir et garantir leur sécurité
concernent aussi bien les activités professionnelles qu'associatives ou
personnelles. La sécurité se décline alors de nombreuses
manières, par exemple dans le cadre des transactions
électroniques mais également dans la protection des
données, des informations, des personnes et des biens. Dans ce contexte,
la sécurité comprend en particulier celle des systèmes,
des logiciels, des protocoles, des architectures globales, des composants
matériels, des réseaux tant filaires ou optiques que radios, des
équipements d'extrémités, des moyens de stockage de
l'information. Par ailleurs, le caractère distribué, ouvert,
mobile, ubiquitaire, de beaucoup de systèmes complexifie grandement le
problème et la recherche de solutions.
Par ailleurs, la sécurisation des systèmes
d'information repose sur de nouvelles techniques de sécurisation
algorithmique, mais aussi sur des principes physiques comme la cryptographie
quantique ou la cryptographie par chaos.
L'informatique a un rôle crucial dans la
sûreté de fonctionnement des systèmes technologiques
critiques et/ou complexes, tels que les centrales nucléaires, les avions
et engins spatiaux, les systèmes industriels de production continue
(électricité, pétrole, chimie, métallurgie,
sidérurgie), les grands ouvrages de génie civil (barrages, ponts,
plateformes pétrolières), les véhicules et les
infrastructures des systèmes de transport routiers et ferroviaires. En
raison de la diffusion massive de capteurs de toutes natures, ces
systèmes bénéficient à l'heure actuelle d'une
instrumentation conséquente, et leur sûreté de
fonctionnement passe par la conception d'algorithmes de traitement in-situ des
données numériques ainsi disponibles. Sur la base des
informations et connaissances disponibles (instrumentation, modèles), il
s'agit alors en particulier d'opérer une véritable perception
(détection, localisation, diagnostic) et réaction (correction,
tolérance, maintenance) par rapport aux événements
imprévus ou d'évolutions ou de déviations par rapport
à un état ou un comportement de référence normal,
souhaitable ou nominal. Les événements et déviations en
question concernent aussi bien le système proprement dit que son
environnement humain et technique, en particulier les infrastructures
informatiques.
IV.2.Cryptologie :
IV.2.1 Introduction :
La cryptologie est la science du secret, elle se divise en deux
branches :
> La cryptographie : qui étudie les différentes
possibilités de cacher, protéger ou contrôler
l'authenticité d'une information;
> La cryptanalyse : qui étudie les moyens de
retrouver cette information à partir du texte chiffré (de
l'information cachée) sans connaître les clés ayant servi
à protéger celle-ci, c'est en quelque sorte l'analyse des
méthodes cryptographiques.
La cryptographie doit garantir certains principes qualifiant la
bonne sécurité d'un système:
1.

Confidentialité : grâce à un
chiffrement pour que les données soient illisibles par une personne
tierce et ainsi garantir que l'information est restée secrète de
bout en bout.
2. Authentification : afin que personne ne
puisse se faire passer pour la source de l'information, que la provenance des
données soit garantie.
3. Intégrité : pour que les
données ne puissent pas être modifiées sans qu'on ne s'en
rende compte.
IV.2.2 Confidentialité :
La confidentialité est historiquement le premier but des
études en cryptographie : rendre secrètes des informations.
Cela se réalise par un chiffrement mathématique
des données qui utilise comme paramètre une clé. Le
chiffrement consiste à appliquer une suite d'opérations sur un
texte clair, pour obtenir un texte chiffré, aussi appelé
cryptogramme, ne pouvant être déchiffré que par
l'entité qui possède la clé adéquate.
Il existe deux catégories de chiffrements:
· Le chiffrement symétrique également
appelé le chiffrement à clé secrète:
· Le principe est de chiffrer le texte clair avec une
clé et de le déchiffrer avec la même clé ou une
clé dérivée de celle-ci. La clé n'est connue que
par les deux entités s'échangeant des informations.
Le chiffrement asymétrique également
appelé le chiffrement à clé publique: Les clés
utilisées pour le chiffrement et le déchiffrement sont
différentes et ne peuvent être déduites l'une de l'autre
par un observateur extérieur sans la connaissance des informations
nécessaires. Une des clés peut être connue de tous tandis
que l'autre doit rester secrète. Le but étant que tout le monde
puisse à l'aide d'une clé publique chiffrer des données
que seule l'entité possédant la clé secrète puisse
déchiffrer. La vision d'un ensemble de textes chiffrés ne doit
apporter aucune information sur le texte clair, c'est ce qu'on appelle la
notion de sécurité sémantique (propre au chiffrement
asymétrique).
Dans le cadre de la sécurité dans les
systèmes temps réel qui doivent respecter des contraintes de
temps, nous nous intéresserons plus particulièrement au
chiffrement symétrique qu'il est préférable d'utiliser car
le chiffrement asymétrique a été montré comme plus
complexe au niveau du temps de calcul.
IV.2.3. Intégrité et authentification :
Le réseau reliant les entités n'étant
pas toujours sûr, il est important de contrôler la provenance des
informations et de s'assurer qu'elles n'ont pas été
modifiées en chemin, ce sont respectivement les principes
d'authentification et d'intégrité des données.
Afin de garantir ces deux principes, on utilise des codes
d'authentification de message (MAC: Message Authentication Code). Un MAC est un
code envoyé avec le message, il est aussi appelé hachage
ou empreinte du message. Le hachage correspond au message et
permet de garantir la validité de celui-ci. Il est obtenu à
partir d'un algorithme MAC qui prend deux paramètres en entrée:
le message dont on désire garantir l'intégrité et une
clé secrète connue des deux entités s'échangeant ce
message.

Chapitre IV sécurité des systèmes
embarqués
La probabilité que des données
différentes possèdent le même hachage est très
faible, c'est ce qu'on appelle une « collision ». La
probabilité de trouver une collision et que le message possédant
le même hachage soit compréhensible par le récepteur est
quasi nulle. Une modification même très légère des
données provoque un changement radical au niveau du hachage obtenu. Si
une modification a lieu entre la source et la destination, le hachage ne
correspondra plus aux données et celles-ci seront rejetées par le
récepteur.
Le fait d'utiliser une clé secrète
partagée entre les deux entités en plus de la fonction de hachage
garantit l'authenticité des données étant donné
qu'un attaquant ne connaissant pas la clé ne peut envoyer des
informations accompagnées d'un hachage correct de celles-ci.
Différentes méthodes existent pour créer
une empreinte du message:
· une fonction de hachage utilisant une clé en
paramètre en plus du message (ex : HMAC);
· un chiffrement par blocs (comme les méthodes
CBC-MAC).
IV.3. Les menace de sécurités :
IV.3.1. Types d'attaquants (menaces) :
· Terroristes (but : destruction) ;
· Ennemis (but : causer des désagréments)
;
· Espions, services de renseignement (gouvernementaux,
industriels) (but : informations) ;
· Concurrents industriels (but : prise de part de
marché) ;
· Pirates (but : vol) ;
· Hackers (but : défi, jeux).
IV.3.2. Objectifs des attaques :
· Accéder aux données privées et
secrètes pour accéder à un niveau supérieur
d'information (exemple: clé de cryptage pour décoder un message
crypté) ;
· Accéder aux données privées pour les
modifier ou les détruire ;
· Copier les données de conception pour reconstruire
ou améliorer un système ;
· Prendre en main un système pour le
détourner de sa fonction ou pour le détruire.
IV. 3.3. Classement des attaques :
Il y'a des différentes manières pour classer ces
attaques, et on peut les classés en deux catégories comme le
montre la figure IV.1.
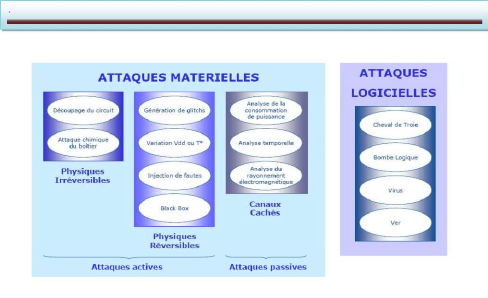
Figure .IV.1 : Classement des
attaques
IV.3.3.1. Les attaques logicielles :
IV.3.3.1.1. Infections informatiques, codes malveillants :
Programmes simples qui exécutent un programme en
tâche de fond (dans le cas de la bombe logique le départ du
programme est retardé). Ils ne peuvent pas se reproduire, ils servent
souvent à ouvrir une brèche cachée dans le système
pour y faire pénétrer un pirate, par exemple : Cheval de Troie et
Bombe Logique.
Programmes autoreproducteurs par exemple : Un ver est un virus
très virulent qui se diffuse de façon planétaire.
IV.3.3.1.2. Vulnérabilités logicielles :
La plus part des systèmes embarqués ont une zone
mémoire extérieure au SoC principal. Des données et des
instructions sont échangés entre le processeur et la
mémoire sur un ou plusieurs bus (adresse, instruction, donnée)
Menaces (logicielle ou matérielle) : Lecture non
autorisée de données, Injection de code, Modification des
données.

bus de donné
SoC
(sécurisé)
bus d'adresse
Mémoire
externe
IV.3.3.1.3. Modèle de menaces :
Hypothèse de départ
: le SoC est dans un environnement sécurisé
à contraire de la mémoire externe qui n'est pas dans un
environnement sécurisé (voir la figure IV.2)
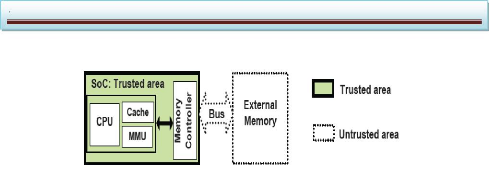
Chapitre IV sécurité des systèmes
embarqués
Figure IV.2 : modèle de
menaces
Dans ce cas il y'a deux modèles d'attaques :
1. Attaques passives : écoute du bus (bus
probing) et l'objectifs de l'attaque par analyse horsligne du code est la
reconstitution d'une clé de chiffrement, reconstitution de message,
matière première pour préparer une attaque active.
2. Attaques actives : modification du contenu de la
mémoire (memory tampering). Il y'a trois types d'attaques actives sont
définies en fonction du choix fait par l'attaquant : 1' Spoofing:
injection aléatoire de données.
1' Splicing: permutation spatial de données.
1' Replay (rejeu): permutation temporelle de données.
Les objectifs de ces attaques : détournement du code,
réduire l'espace de recherche pour la reconstruction d'une clé ou
d'un message.
IV.3.3.2. Les attaques matérielles :
IV.3.3.2.1. Vulnérabilités
matérielles :
Plusieurs types de menaces peut être
considérés en fonction de l'environnement et de la
possibilité d'accès ou non à l'intérieure du
système (voir la figure IV.3)
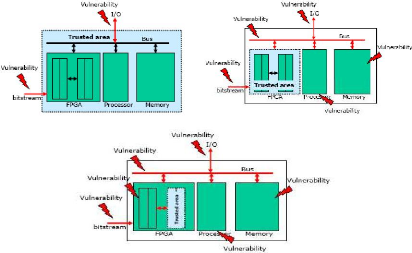
Figure IV.3 : types de menaces


Chapitre IV sécurité des systèmes
embarqués
IV.3.3.2.2. Attaques physiques irréversibles
(Invasive attacks, tampering) :
> Découpage du circuit intégré >
Attaque chimique de la puce > Découpage du layout
> Analyse microscopique
> Reconstruction du layout
IV.3.3.2.3. Attaques physiques réversibles:
> Décapsulage : cette attaque utilisée dans les
systèmes matériels portables, légers, peuvent être
facilement substitué puis attaqués matériellement.
> Injection de fautes (non-invasive ou semi-invasive
attacks) : les attaques par perturbation sont extrêmement puissantes et
permettent à un attaquant de casser un système non
protégé plus rapidement que n'importe quelle autre attaque par
canaux auxiliaires. Par conséquent, ces attaques sont largement
utilisées pour valider la sécurité des applications
sensibles s'exécutant dans un environnement carte à puce. Et
cette attaque est faite par :
> Glitch (power, clock) qui altéré le
fonctionnement du système.
> Flash lumineux qui agit sur les technologies
EPROM/E2PROM/Flash pour modifier une partie du système.
> Ionisation locales qui se fait par l'utilisation du Laser
pour les mémoires CMOS SRAM.
IV.3.3.2.4. Les canaux cachés :
Les attaques par canaux cachés (auxiliaires) dans
l'environnement de la carte à puce sont composées des quatre
catégories présentées ci-dessus :
- analyse de temps d'exécution ;
- analyse de courant/de fréquences radio ;
- analyse du rayonnement électromagnétique ;
- attaques par perturbation (Bien que ce dernier type
d'attaque n'utilise pas directement les informations disponibles par canaux
auxiliaires, il est très souvent classé comme tel dans la
littérature).
IV.4. Contres mesures :
1' Symptôme Gratuit (Symptom Free) : ne fournir aucune
information par fuite pour éviter les attaques passives.
v' Consciente de sécurité (Security Aware) :
être toujours conscient de son état et notamment de sa
vulnérabilité dans le but d'être réactif.
v' Conscient d'activité (Activity Aware) : Analyser son
environnement pour détecter une
activité irrégulière en embarquant des
capteurs et des systèmes de surveillance.
1' Système agile (Agile System) : Etre flexible pour
pouvoir rapidement répondre à une attaque
ou alors anticiper l'attaque.
v' Mise à jour du logiciel et de matériel (Software
or Hardware update) : Remettre à jour facilement les mécanismes
de sécurité en fonction de l'évolution des attaques.
v' Resistance contre les erreurs : Etre résistant aux
sabotages et attaques physiques.
v' Efficacité (Efficient) : Rester performant : ressources
limités des systèmes embarqués plus contraintes fortes
(consommation de puissance et d'énergie, débit, latence,
surface).
IV.5. Conclusion :
La sécurité des systèmes et des
données est un problème critique pour nos sociétés
développées a cause des : Coûts de plus en plus important,
le nombre d'attaques logicielles explose, de plus en plus de systèmes
embarqués mobiles et communicants, menaces fortes des attaques
matérielles. Et pour aborder la sécurité des
systèmes et des données qui subissent des attaques sont soft ou
hard impliquant des protections soft ou hard, il faut envisager des solutions
à tous les niveaux, du système au transistor, définir des
politiques de sécurité (sécurisé suffisante au bon
moment), définir des méthodes de conception
sécurisée assurant les performances des systèmes, ne rien
négliger (aspect humain, légal, logicielle, matérielle,
extérieur, intérieur).
La sécurité sa concerne qui : l'informatique,
l'électronique (embarquée en particulier), les
télécommunications, les individus, les entreprises, la
Société...
La sécurité des systèmes embarqués
est donc cruciale aujourd'hui et doit être prise en compte dès
leur conception sous peine de voir apparaître une armée de
crackers prompts à venir planter votre belle chaudière high tech
!

Conclusion général
Conclusion général :
L'évolution des technologies des systèmes sur
puce « SoCs » offre aujourd'hui des perspectives d'intégration
importante. Désormais, des systèmes complexes peuvent être
intégrés dans des processeurs sur le même circuit SoC.
D'autre part, les applications de compression vidéo sous contrainte
d'exécution temps réel présentent des complexités
énormes. C'est pourquoi, les architectures multiprocesseurs sur puce
implémentant ces applications doivent être capables de supporter
plusieurs fonctionnalités et de les mettre en oeuvre dynamiquement. Dans
ce contexte, les méthodologies de conception doivent évoluer pour
faciliter le développement, la validation et le prototypage de ces
systèmes complexes.
Les concepteurs des systèmes électroniques sont
confrontés à la complexité croissante des algorithmes mis
en oeuvre et à la variété des cibles potentielles FPGAs
et/ou DSPs.
Les concepteurs sont forcés de migrer, d'une part,
à un niveau d'abstraction plus élevé pour le prototypage
rapide de leurs applications sur des plateformes reconfigurables et d'autre
part d'envisager la conception de systèmes MPSoC (Multiprocessor System
on Chip) basés sur les NoC (Network on Chip). On a étudié
un système embarqué dans son environnement, où les
tâches prédéfinies ont un cahier des charges contraignant
à remplir, qui peut être d'ordre :
1. Coût; prix de revient doit être le plus faible
possible surtout s'il est produit en grande série.
2. Espace compté, ayant un espace mémoire
limité de l'ordre de quelques Mo maximum. Il convient de concevoir des
systèmes embarqués qui répondent au besoin au plus juste
pour éviter un surcoût.
3. Puissance de calcul. Il convient d'avoir la puissance de
calcul juste nécessaire pour répondre aux besoins et aux
contraintes temporelles.
On a évoqué les systèmes embarqués de
la première à la dernière génération en
mentionnant les métiers pour la conception des systèmes sur puces
et la conception des systèmes sur cartes.
L'utilisation d'un système embarqué dans la
réception d'images satellites permet d'en apprendre beaucoup dans des
domaines variés et sera comme la première thématique de
recherche dans le futur proche. Enfin, en étudiant les systèmes
embarqués, j'ai pu faire une percée dans ce domaine vaste,
important et utile dans notre vie quotidienne ainsi que dans des domaines
spécifiques.

Bibliographie
Bibliographie
INTERNET :
>
http://richard.grisel.free.fr/Master_OSM/2_Introduction_Embedded_systems.pdf
>
http://www.rfc1149.net/download/documents/12-os.pdf
>
http://sen.enst.fr/ue/elec344/cours_architecture
>
http://www.univ-valenciennes.fr/ROI/niar/Master1/Inem/ch2.ppt
>
http://www.univ-valenciennes.fr/ROI/niar/Master1/Inem/ch3.ppt
>
http://perso.citi.insa-lyon.fr/trisset/cours/MasterWeb/index.html
>
http://pficheux.free.fr/articles/lmf/embedded/
>
http://cllfst.tuxfamily.org/index.php?option=com_jotloader§ion=files&task=download&
cid=2_59926e273ae6768c4ce63de3d2735231&Itemid=78
>
http://www-valoria.univ-ubs.fr/jp-ifsic/2006/pdf/exposes/IntroSystemesEnfouisFB.ppt
>
http://www.unixgarden.com/index.php/embarque/les-systemes-embarques%%A0-uneintroduction
>
ftp://ftp-developpez.com/kadionik/systeme/linux-embarque.pdf
>
http://www.enseirb.fr/~kadionik/embedded/linux_SoC/linux_SoC.pdf
>
http://deptinfo.cnam.fr/new/spip.php?pdoc3929
>
http://www.ecole.ensicaen.fr/~lefebvre/cours/rse.pdf
>
http://users-tima.imag.fr/vds/lpierre/M2Archi/B7.html
>
http://www.electroniciens.aquitainelimousin.cnrs.fr/IMG/pdf/securite_materielle_des_systemes_et_des_donnees.pdf
>
http://www.irit.fr/~Iulian.Ober/str/STR-1.1.IntroSTR.pdf
>
http://fr.wikipedia.org/wiki/Syst%C3%A8me_embarqu%C3%A9
>
http://www1.ifi.auf.org/rapports/tpe-promo10/tipe-pham_viet_hung.pdf
>
http://tic.rcso.ch/Portals/0/docs/uml_for_embedded30.pdf
LIVRES :
> Conception des logiciels embarqués pour les
systèmes monopuces, sous la direction de Lovic Gauthier, Lavoisier
2003
Mémoires de fin
d'étude :
> Proposition d'une architecture mixte
logiciel/matériel pour les algorithmes du traitement d'image
2007/2008
> La régulation d'une serre agricole à l'aide
d'un contrôleur PID en logique floue 2006/2007

Glossaire
Glossaire :
A
Ada Est un langage de programmation
orienté objet dont les premières versions remontent au
début des années 1980.
API Application Program Interface
Ensemble de routines standards destinées à
faciliter au programmeur le développement d'applications.
ASIC Application Specific Integrated Circuit
Circuit intégré développé
Spécifiquement pour une Application
B
BIOS Basic Input Output System
Système élémentaire
d'entrée/sortie.
C
COLIF COdesign language independent format
Langage de représentation de la composition de
systèmes hétérogènes embarqués en niveaux
d'abstraction, en protocoles de communication et en langages de description.
CORBA Common Object Request Broker
Architecture
Architecture commune de courtier d'objets de requête :
une norme établie par l'Object Management Group (OMG) (groupe de gestion
des objets), destinée à la communication entre objets
répartis.
COSYMA Système digital de gestion des
communications.
CPU Central Processor Unit
Partie principale d'un système, réservée aux
traitements.
D
DSP Digital Signal Processor
Processeur spécialisé pour le calcul d'algorithmes
de traitement de signal. DMA Direct Memory Access
L'accès direct à la mémoire.
E
eCos Système d'exploitation temps
réel. Il permet de réaliser des applications temps
réel.
F
FIFO First In First Out
Classe ou protocole de communication qui assure que les
premières données envoyées sont les premières
reçues.
FPGA Field Programmable Gate Array
Réseau prédiffusé programmable par
l'utilisateur : Réseau prédiffusé de portes logiques qui
est destiné à être programmé sur place, avant
d'être utilisé pour une fonction particulière.
G
GSM Global System for Mobile Communications
I
IP Intellectual Property
Élément (logiciel ou matériel) dont le
fonctionnement est connu et documenté, mais dont la structure interne
est inconnue.

ITRS International Technology Roadmap for
Semiconductors.
Organisation ayant pour but le développement des
semi-conducteurs.
M
MCU Micro-Controller Unit
Puce constituée d'éléments
intégrés lui permettant de fonctionner comme une unité
autonome, et conçue spécifiquement pour contrôler un
dispositif donné.
N
N2C Napkin-to-Chip
Extension de C utilisée dans l'environnement de conception
CoWare pour la description des systèmes.
Nucleus RTOS Système d'exploitation temps
réel.
O
OS Operating System
Un operating system ou système d'exploitation, est une
couche logicielle permettant d'abstraire une architecture matérielle
à la vue de l'application logicielle afin de gérer implicitement
l'utilisation partagée des ressources, mais aussi de garantir la
portabilité de l'application sur des architectures diverses.
P
PDA Personal Digital Assistant
Un assistant personnel ou ordinateur de poche est un appareil
numérique portable, souvent appelé par son sigle anglais pour.
pSOS Système d'exploitation temps
réel.
PC Personal Computer
Q
QNX (prononcé Q-N-X ou Q-nix)
est un système d'exploitation UNIX commercial temps réel
compatible POSIX, conçu principalement pour le
marché des systèmes embarqués. Il utilise un
micro-noyau.
R
RAM Random Access Memory
Mémoire à accès direct.
ROM Read Only Memory
Mémoire morte.
RTL Register Transfer Level
Niveau d'abstraction pour la spécification des
systèmes.
RTOS Real Time Operating System
Logiciel d'exploitation en temps reel.
S
SDL Specification and Design Language
Langage de haut niveau pour la spécification
non-ambiguë des systèmes comportant des processus
parallèles.
SoC System on Chip
Système monopuce - circuit intégrant sur une
même puce différents composants fonctionnels (ex. mémoires,
processeurs).
STB Set-top box
Adjoint de poste de télévision (ou
littéralement boîte de dessus de poste).

Glossaire
SEP Simulation et Evaluation de Performance
T
TDMA Temporal Division Multiple Access
Accès multiple à répartition dans le
temps, multiplexage temporel qui consiste à diviser le temps en petits
intervalles. Les utilisateurs émettent alors sur des intervalles de
temps différents.
U
UML Unified Modelling Language
Langage de modélisation, permettant de déterminer
et de présenter les composants d'un système lors de son
développement, ainsi que d'en générer la documentation.
V
VHDL Very high-scale integrated Hardware Description
Language
Langage de description de système électronique
numérique, basé sur une extension d'Ada.
W
Windows CE Windows Embedded Compact
Parfois abrégé WinCE, est une variation de
Windows pour les systèmes embarqués et autres systèmes
minimalistes, utilisée notamment dans les PC de poche ou Handheld. Il
utilise un noyau distinct des autres Windows plutôt qu'une version
allégée et supporte les architectures processeur Intel x86 et
similaires, MIPS (jusqu'à CE 3.0), ARM et aussi Hitachi SH.
| 

