|


j4 S7vtj4
qj4S7vtIJiJiE
AVANT PROPOS
Au cours des deux dernières années, nous avons
étudié à l'Ecole Supérieure Sup'Management à
Fès au Maroc, précisément dans la filière
ingénierie informatique.
Au terme de ce cycle, il nous est demandé de traiter
d'un sujet de recherche, pour l'obtention du diplôme bac+4
d'ingénieur en informatique. C'est à ce titre que vous est
rédigé le présent rapport qui essaye d'une façon
précise et concise, de souligner les principaux points que nous avons
abordés. Aussi, afin de joindre la pratique à la théorie,
nous avons réalisé notre travail dans un cadre professionnel au
cours du stage académique effectué de juillet à septembre
2008 à la société Call In Out de Fès !
Nous espérons que le contenu ci-après
présenté comblera vos attentes et posera à sa
manière, une pierre solide à l'édification du monde
informatique.
REMERCIEMENTS
Je souhaite remercier toutes les personnes et organes qui
m'ont aidé d'une façon directe ou indirecte à la
réalisation de ce rapport. Entre autres je peux citer :
> La société Call In Out à travers son
directeur général M Khalid Cohen qui nous accepté en
stage,
> Le directeur de production de la société M
Andre Mbeka,
> La cellule Informatique, dont certains membres devenus des
amis,
m'ont particulièrement marqués : M Alain NGOKO,
Thierry
MUKENDI, Ouakor SIDI MOHAMED et Hind LAZRAK,
> L'école Sup'Management à travers son
président fondateur
M Abdesselam Erkik
> Mon encadreur académique M Khalid El FAZAZY
> Tous mes enseignants,
> Tous mes camarades de classe et amis,
> Mes colocataires et amis Seraphin ESSONO et Eustache ANTALI
> Mes frères et soeurs de l'Eglise de FES,
> Sans oublier le Maroc tout entier, qui est mon pays
d'accueil !
Aussi, de chaleureux remerciements à ma famille
restée dans mon pays le Cameroun, et toujours soucieuse de mon bien
être et, une reconnaissance particulière à Monsieur
Jérémie et Madame Julienne YIKAM, qui en plus d'être mes
parents géniteurs, sont de véritables amis, conseillés et
appuis.
Enfin, je tiens à rendre grâce à Dieu, qui
est pour moi un soutien et un refuge. A lui soit la Gloire et l'Adoration pour
toujours !
TABLE DES MATIÈRES
Introduction 9
PARTIE I. Bases de données réparties 10
I. Problématique et Avantages 11
I.1. Problematique 11
I.2. Avantages 11
II. Les différentes architectures 12
II.1. L'architecture Client-Serveur 12
II.2. L'architecture serveur-serveur 12
III. Conception d'une base de données reparties 14
III.1. La conception ascendante ou bottum up design
14
III.2. La conception descendante ou top down design
14
III.3. La fragmentation 14
III.3.A. La fragmentation horizontale 14
III.3.B. La fragmentation verticale 15
III.3.C. Les trois regles de la fragmentation 15
III.4. L'allocation 15
IV. Les transactions réparties 16
IV.1. Definitions 16
IV.2. Contrôle de concurrence 17
IV.3. Mecanismes utilisés 17
IV.3.A. Verrouillage 17
IV.3.B. Estampilles 17
IV.4. Interblocages 17
IV.5. Transactions reparties 18
V. La replication 19
VI. Les requetes reparties 20
VI.1. Definition 20
VI.2. Optimisation 20
VI.2.A. Decomposition de la requete 20
VI.2.B. Repartition de la requete 22
VI.2.C. Schema general de l'optimisation 23
VII. Les objectifs d'une base de données répartie
24
VII. 1. L'autonomie locale 24
VII.2. Ne pas se reposer sur un site unique 25
VII.3. Opération en continu 25
VII.4. Transparence vis à vis de la localisation 25
VII.5. Independance vis à vis de la fragmentation 25
VII.6. Indépendance vis à vis de la
réplication 25
VII.7. Traitement des requêtes distribuées 25
VII.8. Gestion répartie des transactions 26
VII.9. Une indépendance vis à vis du
matériel 26
VII. 10. Une indépendance vis à vis du
système d'exploitation 26
VII. 11. Une indépendance vis à vis du
réseau 26
VII.12. Une indépendance vis à vis du type de la
base de données relationnelle 26
PARTIE II. Bases de donnees reparties sous oracle 27
I. Presentation de oracle net 28
I.1. Architectures 29
I.1 .A. Architecture monoposte 29
I.1 .B. Architecture client - serveur (A) 29
I.1 .C. Architecture client - serveur (B) 30
I.1.D. Architecture serveur - serveur 30
I.2. Installation et configuration 31
I.2.A. Parametres de configuration 31
I.2.B. Outils de configuration 32
I.2.C. Fichiers de configuration 34
II. Referencement dans un systeme distribue 35
II.1. Nom global 35
II.2. Les data base links 35
II.3. Les synonymes 36
III. Le mecanisme de replication 37
III.1. La commande copy 37
III.2. Les snapshots 37
III.2.A. Types de snapshots 38
III.2.B. Raffraichissements 39
III.3. Vues materialisees 40
III.4. La replication avancee 40
IV. Optimisation des requetes reparties 41
PARTIE III. Le cas pratique de la societe call in out 42
I. Presentation de la societe call in out 43
II. Analyse du besoin 44
II.1. Fonctionnement de la societe 44
II.2. Presentation de la campagne X 45
II.3. Specification du besoin 45
II.4. Solution proposee 46
III. Conception de la solution 46
III.1. Diagramme de cas d'utilisation 47
III.1 .A. Les cas d'utilisation 47
III.1.B. Les acteurs 47
III.1.C. Diagramme 48
III.2. Diagrammes de sequences 48
III.2.A. Diagramme de sequence « saisir
donnees» 49
III.2.B. Diagramme de sequence « superviser
» 50
III.2.C. Diagramme de sequence « gerer compte
» 51
III.3. Diagramme de classes 52
III.3.A. Differentes classes ou tables 52
III.3.B. Diagramme 53
IV. Repartition de la base de donnees 54
IV. 1. Fragmentation et localisation 54
IV.2. Replication 55
V. Implementation 55
V. 1. Installation de oracle et creation de la base de donnees
55
V.2. Migration de la base access à la base oracle 56
V.3. Configuration de oracle net 57
V.4. Creation des data links 57
V.5. Mise en place de la replication 58
V.5.A. Replication
des données des tables operateurs et datacode 58
V.5.B. Replication de la table rdv 60
V.5.C. Création des vues 61
V.6. Modification de l'application de l'entreprise 61
V.7. Mise en service 62
Conclusion 64
Annexes 65
Annexe 1 : Table des illustrations 66
Annexe 2 : Références 67
Annexe 3 : quelques Vues utilisées par l'administration
oracle 68
INTRODUCTION
Les Bases de données désignent des ensembles
structurés de données. Elles ont pour principal but de recevoir,
conserver et restituer les données d'une application. Ceci dit, elles
sont d'une importance capitale pour le développement d'un logiciel car
celle-ci divisée en 2 grandes parties : La partie traitements et la
partie données.
Les bases de données réparties quant à
elles, insistent en plus sur l'aspect réparti d'une base de
données. C'est-à-dire sur la distribution des données de
l'application sur plusieurs sites.
Dans le cadre de notre travail de fin d'étude
effectué au cours de notre stage académique à la
société CALLINOUT, nous avons tenu à étudier en
profondeur ce concept. Ainsi, tour à tour dans ce rapport, nous
présenterons le concept de base de données réparties, sa
modélisation dans le SGBD réparti ORACLE, et le cas pratique
réalisée à CALLINOUT.
PARTIE I. BASES DE DONNEES REPARTIES
I. PROBLEMATIQUE ET AVANTAGES
I.1. PROBLEMATIQUE
Comme nous l'avons mentionné à l'introduction,
les BDR (Bases de données réparties) sont d'abords des bases de
données normales. En fait, elles sont issues de l'évolution de
ces dernières.
En effet, la gestion de bases de données avec le temps,
s'est confrontée à divers problèmes qui sont :
> L'augmentation du volume de
données
> l'augmentation du volume de traitements
> l'augmentation du volume de
transactions
> etc.
Cela a entraîné la lenteur des applications, car
les périphériques de stockage submergés, ne
répondant pas assez vite. Aussi, il a été noté que
les débits des liaisons réseaux évoluaient beaucoup plus
vite que les capacités des périphériques de stockage.
Ainsi, l'idée est venue de multiplier les sources de
données et les faire communiquer par réseau, afin de
bénéficier de traitements parallèles, minimisant ainsi les
temps de réponses. Aujourd'hui, les BDRs sont de plus en plus
répandus, et comblent largement les lacunes des bases de données
classiques.
I.2. AVANTAGES
Les avantages d'une base de données sont nombreux. On peut
citer comme principaux :
> Le gain en performances : les traitements se font en
parallèles
> La fiabilité : Si un site a une panne, un
autre peut le remplacer valablement.
> La transparence des données : les
développeurs et les utilisateurs n'ont pas à se préoccuper
de la localisation des données qu'ils utilisent.
II. LES DIFFERENTES ARCHITECTURES
Dans un environnement de bases de données
réparties, il existe 2 principaux types d'architectures :
II.1. L'ARCHITECTURE CLIENT-SERVEUR

Figure 1: Architecture Client-Serveur
Dans cette architecture, l'application client se connecte au
serveur de base de données (ici Oracle). Ce dernier à son tour,
leur renvoie des réponses en fonction de leurs requêtes.
II.2. L'ARCHITECTURE SERVEUR-SERVEUR
Dans un système de bases de données
réparties, il existe en général plusieurs serveurs de
données qui fonctionnent selon l'architecture suivante :

Figure 2 :Architecture serveur-serveur
Chaque serveur gère sa base de données et
échange les informations avec les autres. Le tout est vu comme une seule
base de données logique.
De façon globale voici comment fonctionne un
système de base de données réparties :

Figure 3 Architecture générale
Les clients se connectent à leurs serveurs respectifs, et
ces derniers s'échangent les informations si nécessaires.
III. CONCEPTION D'UNE BASE DE DONNEES REPARTIES
Comme dans tous les mécanismes, la phase de conception
est la plus importante et déterminante dans la mise en place d'une base
de données reparties. Le rôle du concepteur est de définir
les différents fragments de la base et, leurs localisations ;
d'évaluer les différents coûts de stockage et de transfert,
et les priorités à respecter. On distingue deux principaux types
de conception : la conception ascendante et la conception descendante.
III.1. LA CONCEPTION ASCENDANTE OU BOTTUM UP
DESIGN
Dans ce cas de figure, il existe plusieurs bases de
données disjointes qu'il faut réunir en une seule base de
données reparties et cohérente avec un schéma de
conception global.
III.2. LA CONCEPTION DESCENDANTE OU TOP DOWN
DESIGN
Ici, on a au départ une seule base de données
qu'il faut fragmenter et allouer les fragments aux différents sites. On
va donc d'un schéma global de conception a des sous schémas
locaux.
III.3. LA FRAGMENTATION
La fragmentation désigne le découpage de la base
globale en sous bases selon les critères d'analyse. Le concepteur choisi
entre un découpage horizontal, vertical ou mixte.
III.3.A. LA FRAGMENTATION HORIZONTALE
Cette fragmentation consiste à faire une
séparation selon les enregistrements. On définit le
critère de sélection suivant les valeurs d'un ou plusieurs champs
et la division est faite. Par exemple dans le cas d'une gestion de contrats, on
peut séparer les contrats signés à Rabat de ceux
signés à Casablanca.
III.3.B. LA FRAGMENTATION VERTICALE
Ici, la division est faite non au niveau des données,
mais de la structure même de la base. Certains champs sont envoyés
dans un fragments et d'autres ailleurs. En continuant avec l'exemple des
contrats, on peut avoir d'une part le numéro du client , son nom et
prénom, et d'autre part le numéro du client, le lieu
d'habitation, et lieu du contrat.
La fragmentation mixte consiste à utiliser conjointement
les deux méthodes citées ci-dessus.
III.3.C. LES TROIS REGLES DE LA FRAGMENTATION
La fragmentation doit respecter trois principales
règles.
· Pour toute donnée de la relation originale R il
doit avoir une sous relation Ri la contenant.
· Pour toute fragmentation de la relation R en plusieurs
sous relations Ri il doit avoir un procédé inverse de
reconstitution de la relation principale R.
· Aucune donnée ne doit se trouver dans plus d'un
fragment sauf dans le cas d'une fragmentation verticale ou la clé
primaire doit être présente partout.
III.4. L'ALLOCATION
Lorsque le concepteur a fini de fragmenter sa base, il lui
faut ensuite allouer chaque fragment sur son site correspondant. Cette phase
est appelée Allocation. L'allocation peut être faite de plusieurs
façons :
> La réplication totale des
données
Pour des raisons de fiabilité on peut décider de
répliquer toutes les données sur tous les sites. Ainsi, si un
site est temporairement ou définitivement défaillant, on utilise
simplement un autre. Mais cette méthode n'est pas très efficace
lorsque les données sont régulièrement mises à jour
car il se pose le problème de cohérence de données
Rapport de fin de cycle Ingénierie Informatique
> L'absence de réplication
On peut aussi choisir de ne rien répliquer afin
d'assurer une meilleur cohérence de données. Ici, chaque
donnée est mise à jour sur un seul site. Cette méthode est
plus efficace quand les données sont beaucoup plus modifiées que
lues.
> La méthode hybride
Afin de bénéficier des deux méthodes
citées à la fois, celle hybride peut être utilisé.
Ainsi les données en Read Only peuvent être
répliquées et les données en Read Write pas du tout.
IV. LES TRANSACTIONS REPARTIES
IV.1. DEFINITIONS
Une transaction désigne un ensemble d'opérations
effectuées de manière indivisible sur une base de
données.
Elle est soit validée par un Commit, soit
annulé par un rollback soit interrompue par un abort.
Afin de garantir la stabilité du système, une transaction
doit validée quatre propriétés indispensables :
> L'Atomicité
Cette propriété signifie que toutes les
opérations d'une transaction sont menées de façon
indivisible ; toutes le opérations doivent être validées,
si non tout est annulé.
> La cohérence
La transaction doit amener le système d'un état
cohérent vers un état cohérent, telles que toutes les
contraintes d'intégrités soient respectées.
> L'isolation
Une transaction en cours ne peut révéler ses
résultats à d'autres transactions si toutes ces opérations
n'ont pas été validées.
> La durabilité
Tout résultat produit par une transaction doit être
permanent et ne doit souffrir d'aucune altération, quelques soient les
pannes du système.
IV.2. CONTROLE DE CONCURRENCE
Afin d'améliorer les performances dans les traitements
de bases de données, il est utile de mener en parallèles
plusieurs transactions. Dans ce cas, des mécanismes sont mis en place
pour gérer leurs accès concurrents aux données.
IV.3. MECANISMES UTILISES
IV.3 .A. VERROUILLAGE
La méthode la plus utilisée pour gérer
des accès concurrents est bien sûr celle des verrouillages. Elle
consiste pour chaque transaction avant de débuter de s'assurer de la
disponibilité des données requises en y plaçant des
verrous : c'est la phase de croissance. Si un objet est déjà
verrouillé, la transaction ne peut débuter. Dans la phase de
diminution, les verrous sont enlevés. Cette méthode est
appelée verrouillage à 2 phases.
IV.3 .B. ESTAMPILLES
L'autre méthode de contrôle de concurrence est
la méthode des estampilles. Ici, à chaque transaction est
attribuée un numéro par un compteur. Les transactions
s'exécutent par ordre croissant. Dans le cas de systèmes
distribués, l'ordre global est partiel, mais total sur chaque site. En
effet chaque site a son compteur. L'ordre global peut devenir total si à
chaque site est attribué aussi un numéro.
IV.4. INTERBLOCAGES
Lorsqu'on applique un système de verrouillage, on doit
toujours penser au problème d'interblocage. En effet supposons qu'une
transaction a mi un verrou sur un objet A et attend un objet B
verrouillé par un autre qui a son tour
attends de verrouiller l'objet A. Dans ce cas de figure, il est
clair que les deux transactions vont s'attendrent indéfiniment : c'est
l'interblocage.
Afin de gérer les interblocages trois principales actions
peuvent être effectuées :
· Détecter les interblocages et les
résoudre
· Prévenir les interblocages avant qu'ils
n'apparaissent !
· Eviter les interblocages, par la façon d'allouer
les ressources.
La méthode la plus utilisée est la
première, qui consiste à attendre que les interblocages arrivent,
les détecter, et décanter la situation. Pour cela, il est
utilisé un graphe qui représente l'état d'attente des
transactions : c'est le WFG (Wait For Graph) (voir fig 4). Chaque
noeud représente une transaction en cours. Et les arcs entre les noeuds
sont les attentes d'une transaction par rapport à l'autre. Lorsque un
cycle est détecté, on a un interblocage. La solution consiste
à retirer (abort) une transaction, afin de libérer ses
ressources. Encore faudrait-il faire le meilleur choix, qui
génère moins de coûts.

Figure 4 : Graphe d'attentes
IV.5. TRANSACTIONS REPARTIES
Dans le cadre de systèmes répartis, les
algorithmes cités ci-dessus sont aussi valables. La différence
est qu'ici, une transaction peut être en attente pas seulement para
rapport à une transaction locale, mais située sur autre site. La
gestion en est donc un peu plus compliquée. Aussi, on peut avoir le cas
de
transaction répartie ; c'est-à-dire une
transaction constituée de plusieurs transactions locales. Dans ce cas,
on utilise un protocole de validation à 2 phases. Dans la
première phase dite phase de préparation, le site coordonnateur
demande aux sites participants de se préparer à la validation.
Lorsqu'il reçoit les notifications positives il lance alors la phase de
validation en donnant l'ordre correspondant aux sites. Dans le cas contraire il
donne l'ordre d'interrompre les transactions.

Figure 5 : Validation à deux phases
V. LA REPLICATION
La réplication désigne la reproduction identique
de données d'un site à un autre. Elle a pour but d'assurer la
fiabilité du système et diminuer les trafics réseaux, dans
le cadre de systèmes distribués. Ainsi, si un site est
momentanément inaccessible, un autre peut valablement le remplacer sans
que les utilisateurs ne s'en aperçoivent. Aussi, au lieu de faire des
requêtes réparties, qui occupent la bande passante, les
requêtes se font au niveau local.
Le mode le plus courant de la réplication dans les bases
de données est la notion de clichés en anglais
snapshots.
Un cliché est une photo de la base de données
partiellement ou totalement à un instant donné. Afin de garder
une certaine cohérence de la base, les clichés
doivent régulièrement êtres mis à
jour. Ainsi, plus le cliché est récent, plus il est fiable.
VI. LES REQUETES REPARTIES
VI.1. DEFINITION
Une requête répartie est une requête
s'effectuant sur une base de données répartie. Comme une
requête normale, elle se base sur les relations de la base et leurs
champs, en utilisant l'algèbre relationnel. Mais elle doit tenir compte
en plus de certains paramètres essentiels de fragmentation, de
localisation afin d'optimiser le temps de réponse global de la
requête.
Dans le cadre d'une base de données locale, 2
principaux paramètres sont considérés pour l'optimisation
des résultats à savoir : les coûts d'accès aux
entrées sorties et les capacités de traitement du CPU. Pour une
base de donnée distribuée, en plus de ces indices, il faut aussi
tenir compte des coûts de communication réseaux.
VI.2. OPTIMISATION
Optimisation consiste à choisir parmi de nombreuses
possibles, une stratégie d'exécution de requête tant
efficace que efficiente. En effet, lorsque l'utilisateur soumet une
requête au SGBD, le composant appelé le Query Processor
entre en action pour récrire la requête sous une forme plus
simple, et optimale.
L'optimisation d'une requête intervient à deux
principaux niveaux :
VI.2.A. DECOMPOSITION DE LA REQUETE
VI.2.A.a. Normalisation
La normalisation consiste à écrire la partie
critère (contenu dans la clause WHERE) sous forme d'une conjonction de
coordination ou disjonction de conjonction de prédicats.
WHERE (a et b) ou (c et d).
Ceci afin de simplifier la clause et faciliter ainsi l'analyse et
l'optimisation.
VI.2.A.b. Analyse
Après la normalisation, il est question d'analyser la
requête afin de détecter et éliminer les erreurs. Parmi
elles on peut citer, la présence de champs ou relations inexistants,
l'incohérence des valeurs données avec les types réels des
champs, etc.
VI.2.A.c. Elimination des redondances
Ensuite, la requête est simplifiée en
éliminant les redondances. En effet dans certains cas, plusieurs
formules identiques peuvent se retrouver au sein de la même
requête.
Exemple : NON (NON A) == A
A ET A == A
A OU A ==A
Ainsi lorsque de tels cas sont détectés, le
Query processor les simplifie et obtient une formule finale plus
claire.
VI.2.A.d. Réécriture
La dernière phase de cette première partie
consiste à réécrire la requête en une forme qui
améliore ou optimise le temps de traitement global. En effet, les
opérations de l'algèbre relationnel à savoir : l'Union, la
Sélection, la Projection, la Différence, la jointure, le Produit
cartésien n'ont pas les mêmes complexités (voir
tableau1). Alors il est plus avantageux d'exécuter de les
exécuter dans l'ordre de complexités croissantes.
|
Opérations
|
Complexité en nombre de
données
|
|
Sélection
Projection (sans élimination des doublons)
|
O (n)
|
|
Opérations
|
Complexité en nombre de
données
|
|
Projection (avec élimination
des doublons) Union
Jointure
Semi-j ointure Quotient
Opérations de mises à jour
|
O (n*log n)
|
|
Produit Cartésien
|
O (n2)
|
Tableau 1 :Tableau des complexités des
opérations
Ainsi, le Query Processor reformule la requête
dans ce sens, en appliquant les règles logiques de commutativité,
associativités, distributions, idem potence, etc ...
VI.2.B. REPARTITION DE LA REQUETE
Après la première partie citée ci-dessus,
il faut tenir compte de la répartition des données :
c'est-à-dire de la fragmentation et de la localisation. En effet, il
faut décomposer la requête globale en requêtes sur les
fragments. Ainsi des reconstructions sont encore faites afin d'annuler les
formules dont les conditions ne respectent pas les restrictions des fragments
aux quelles elles font référence. Dans certains cas aussi, on
peut remplacer certaines opérations par d'autres, comme la jointure par
la sémi - jointure car moins coûteuse.
Selon la localisation de chaque fragment et l'existence ou non
de relations répliquées, une stratégie d'exécution
est mise en place afin de minimiser au maximum les trafics réseaux et
bénéficier de rapides accès aux données et
traitements du CPU. Ainsi, en fonction de la topologie du réseau et de
son
architecture il peut être plus avantageux
d'exécuter tel fragment de requête sur tel site et pas sur un
autre. Par exemple dans le cas d'une architecture client Serveur, il faut
choisir quels fragments s'exécutera sur le client et quel autres sur le
serveur. Aussi les coûts de communication n'étant pas les
mêmes sur un LAN que sur un WAN, les stratégies utilisées
dans ces cas peuvent être différentes.
VI.2.C. SCHEMA GENERAL DE L'OPTIMISATION
Maintenant, nous allons récapituler tout ce qui a
été dit pus haut dans un schéma général
d'optimisation. Tout d'abord, il est important de mentionner que dans un
système distribué, l'optimisation peut se faire de trois
manières principales :
· Une optimisation centralisée où un site
central détermine la stratégie d'exécution sur tous les
autres sites. Dans ce cas, l'optimisation est plus facile mais souvent peu
efficace car il faudrait connaître exactement les indices de chaque site,
ce qui n'est pas évident.
· Une optimisation distribuée où chaque site
a sa propre stratégie d'optimisation
· Enfin on peut joindre les deux première
méthodes pour en faire une hybride. Ainsi, dans un premier temps, un
site décide de l'optimisation globale et ensuite chaque site optimise
à son tour, à son niveau. C'est cette dernière
possibilité que nous illustrons dans le schéma suivant.

Figure 6 : Schéma général de
l`optimisation
VII. LES OBJECTIFS D'UNE BASE DE DONNEES REPARTIE
En conclusion de cette première partie sur la notion
de base de donnée répartie, nous allons donner les principaux
objectifs à respecter par un système réparti, suivant les
12 points définis par C.J Date.
VII.1. L'AUTONOMIE LOCALE
L'autonomie locale implique que chaque site doit fonctionner
indépendamment des autres, même si ces derniers venaient à
avoir des pannes.
Aussi, chaque site est responsable de l'intégrité,
la sécurité et la gestion de sa base de données.
VII.2. NE PAS SE REPOSER SUR UN SITE UNIQUE
Cet objectif vise à éviter des arrêts de
production lorsqu'un site tombe en panne. Pour cela on peut soit penser
à ce que Oracle appelle la réplication avancée ou les
données sont entièrement répliquées d'un site
à l'autre.
On peut aussi utiliser Oracle Parallele Server qui
est une architecture composée de plusieurs SGBD utilisant une même
base de données. Ainsi, si le SGBD d'un site tombe en panne, celui de
l'autre prend la relève.
VII.3. OPERATION EN CONTINU
Ici, il est question d'assurer le fonctionnement continu du
système réparti par des mises à jour et maintenances
effectuées.
VII.4. TRANSPARENCE VIS A VIS DE LA LOCALISATION
Cet objectif a pour but de rendre l'accès aux
données transparentes sur tout le réseau. En effet, ni les
applications, ni les utilisateurs ne doivent savoir la localisation des
informations qu'ils utilisent. Pour cela on peut utiliser les liens de base de
données et les synonymes dont nous parlerons plus amplement dans la
deuxième partie.
VII.5. INDEPENDANCE VIS A VIS DE LA FRAGMENTATION
La fragmentation doit être réelle et
respectée sur chaque site, indépendamment.
VII.6. INDEPENDANCE VIS A VIS DE LA REPLICATION
De même chaque site doit bien gérer ses
réplications.
VII.7. TRAITEMENT DES REQUETES DISTRIBUEES Chaque site
doit avoir des outils et stratégies d'optimisation.
VII.8. GESTION REPARTIE DES TRANSACTIONS
Généralement les SGBD utilisent des protocoles de
validation à 2 phases.
VII.9. UNE INDEPENDANCE VIS A VIS DU MATERIEL
Le SGBD ne doit dépendre du matériel
VII.10. UNE INDEPENDANCE VIS A VIS DU SYSTEME D'EXPLOITATION
Il est important que les SGBD utilisés soient utilisables
sur plusieurs systèmes d'Exploitation.
VII. 11. UNE INDEPENDANCE VIS A VIS DU RES EAU
L'idéal serait que chaque SGBD réparti est son
propre protocole réseau comme Oracle, pour faire communiquer les
différentes instances.
VII.12. UNE INDEPENDANCE VIS A VIS DU TYPE DE LA BASE DE
DONNEES RELATIONNELLE
De plus en plus, il est possible d'interconnecter des SGBD de
types différents, au moyen des standards tels que ODBC, JDBC et des
middlewares fournis par les constructeurs eux-mêmes.
Ainsi se termine cette première partie basée
sur la présentation générale de la notion de base de
données répartie et ses principales caractéristiques. Dans
la suite, nous parlerons du cas particulier de Oracle qui est le SGBD le plus
utilisé au monde dans la répartition et de loin le plus
efficace.
PARTIE II. BASES DE DONNEES REPARTIES
SOUS ORACLE
Dans le cadre de notre travail, nous avons utilisé le
SGBD réparti Oracle 10 g (grid). Comme tout SGBD, il a pour rôle
de gérer l'accès au bases de données qu'il stocke et
restitue à volonté. Oracle 10 g se démarque des autres
gestionnaires de bases de données par son côté
administration très développé (Gestion des utilisateurs,
des profils, des rôles et privilèges, des tablespaces) et aussi de
part son architecture complexe qui repose sur la notion d'instance et qui
assure un traitement rapide, sécurisé, efficace des
données. Aussi, Oracle possède son propre langage de
définition de procédures SQL (Structured Query Langage), le
PL/SQL qui est assez simple a utilisé.
Dans la suite, nous parlerons des caractéristiques
d'Oracle 10 g dans la répartition des données, qui sont
légèrement évoluées par rapport aux versions
précédentes (9i,8i)
I. PRESENTATION DE ORACLE NET
Afin de communiquer avec une base de donnée Oracle
10g, plusieurs logiciels ou middleware peuvent être utilisés,
selon les besoins. Pour ce qui est de la connexion à une base de
donnée distante, l'outil Oracle Net est employé pour
gérer différents modes d'accès aux serveurs. Ses
prédécesseurs sont respectivement Net8, Sql *Net pour les
versions antérieures à la 10g.
Oracle Net permet de spécifier pour le
client, une liste de services oracle qu'il peut atteindre, et pour chaque
serveur, la liste des services oracle qu'il gère et les clients qui
peuvent s'y connecter. Bref il est utilisé comme middleware ou
passerelle entre le client et le serveur, selon les différentes
architectures ci- dessous présentées.
I.1. ARCHITECTURES
I.1.A. ARCHITECTURE MONOPOSTE

Figure 7 : Architecture Monoposte
I.1.B. ARCHITECTURE CLIENT - SERVEUR (A)

Figure 8 : Architecture Client - Serveur A
I.1.C. ARCHITECTURE CLIENT - SERVEUR (B)

Figure 9 : Architecture Client - Serveur B
I.1.D. ARCHITECTURE SERVEUR - SERVEUR

Figure 10 : Architecture Serveur- Serveur
I.2. INSTALLATION ET CONFIGURATION
I.2.A. PARAMETRES DE CONFIGURATION
Pour se connecter à Oracle, il faut fournir trois
paramètres :
· Le nom d'utilisateur
· Le mot de passe
· L'alias
L'Alias renseigne sur plusieurs données à la fois
:
· le protocole réseau utilisé pour
accéder à la machine cible (TCP/IP),
· le nom ou l'adresse de la machine cible sur laquelle se
situe le serveur,
· le SID cible (la machine distante peut héberger
plusieurs bases) ou le nom global de la base,
· le port d'écoute du serveur
· d'autres paramètres dépendants du protocole
réseau utilisé. Afin d'accéder à un serveur
distant, l'application cliente doit pouvoir déterminer ses 3
indications, et pour cela il utilise Oracle Net. En effet, ce dernier
permet de définir 3 principaux paramètres utilisés pour la
connexion à distance :
> Le listener
Le Listener est le processus d'écoute qui
s'exécute sur le serveur. Il faut le configurer en indiquant par exemple
le port d'écoute (par défaut le 1521)
> Les méthodes de résolution de
nom
Pour se connecter à un serveur Oracle, on peut utiliser
plusieurs méthodes :
· La résolution locale de noms
Cette méthode consiste à indiquer que des noms
locaux ou Alias seront utilisés pour désigner des services Oracle
distants.
Connexion : Nom _utilisateur/mot_de_passe@alias
· La résolution de noms Easy connect
Encore appelée méthode Basic, elle permet
d'indiquer qu'à la place d'alias, on aura une nomination complète
sous la forme
Nom _utilisateur/m ot _de_passe@nom_du _serveur:port
_ecoute/nom _du _service
· La résolution de noms d'annuaire (LDAP)
Ici, on précise qu'on utilisera un service d'annuaire
pour identifier le service Oracle à joindre. Le service d'annuaire peut
être Oracle Internet Directory ou Active Directory.
Connexion : Nom _utilisateur/mot_de_passe@alias
· Etc.
> Les noms de services locaux
Un nom de service local est un Alias, défini plus haut.
Il permet de réunir plusieurs paramètres de connexion en une
seule appellation unique.
> Les noms d'annuaire
Si on prévoit utiliser la méthode de
résolution de nom d'annuaire, il faut créer des noms d'annuaire
sur un serveur LDAP.
Voilà les principaux paramètres à
configurer pour Oracle Net.
I.2.B. OUTILS DE CONFIGURATION
Oracle met à la disposition des DBA (Data Base
Administrators) deux outils principaux JAVA pour faire la configuration de
Oracle Net, afin d'indiquer les paramètres cités plus
haut Il s'agit de :
· netca (Oracle Net
Configuration Assistant) : simple, l'utilisateur est guidé pas
à pas pour entrer les paramètres nécessaires à une
configuration,

Figure 11 : netca
· netmgr (Oracle Net
Manager) : plus complet, il permet d'accéder à l'ensemble
des paramètres qui peuvent figurer dans les fichiers de configuration
Oracle Net.

Figure 12: netmgr
I.2.C. FICHIERS DE CONFIGURATION
Oracle Net utilise 3 principaux fichiers de
configuration se trouvant dans $ORA CLE_HOME/network/admin :
> Listener.ora
Ce fichier détermine les paramètres du Listener sur
le serveur

Figure 13: listener.ora
> Sqlnet.ora
Ici est précisé l'ordre des méthodes de
résolution de noms à utiliser

Figure 14: sqlnet.ora

> Tnsnames.ora
Ce dernier contient tous les noms locaux de services ou alias
avec leurs paramètres.
Figure 15 : tnsnames.ora
II. REFERENCEMENT DANS UN SYSTEME DISTRIBUE
II.1. NOM GLOBAL
Dans une architecture distribuée, un système
d'identification unique des bases doit exister ; car, si plusieurs bases ont le
même nom le référencement sera ambigu et donc impossible.
Oracle utilise donc le concept de nom global
(global_name) constitué de :
> Le nom de domaine : domain_
name
> Le nom de la base (SID):
db_name
Pour le définir, on peut le faire à la
création de la base avec l'utilitaire de création de base de
données dbca, ou modifier le fichier d'initialisation de la
base init.ora de la façon suivante :
global_names = true
domain_name = nom_domaine
db_name = nom_base
Ainsi Oracle considèrera comme nom global de la base
nom_base.nom_domaine
II.2. LES DATA BASE LINKS
Pour interroger une BD distante, il faut créer un lien
de base de données. Un lien de base de données est un chemin
unidirectionnel d'un serveur à un autre. En effet, un client
connecté à une BD A, peut utiliser un lien stocké
dans la BD A pour accéder à la BD distante B et vice
versa.
Lorsqu'un lien est référencé par une
instruction SQL, Oracle ouvre une session dans la base distante et y
exécute l'instruction. La session demeure ouverte au cas où elle
serait de nouveau nécessaire.
En créant un lien de BD, on doit indiquer le nom du
compte auquel on se connecte, le mot de passe de ce compte, et le nom de
service associé à la base distante. En l'absence d'un nom de
compte, Oracle utilise le nom et le mot de passe du compte local pour la
connexion à la base distante.
Un lien est soit privé ou public. Seul l'utilisateur
qui a crée un lien privé peut l'utiliser, alors qu'un lien public
est utilisé par tous les utilisateurs de la base de données.
Instruction SQL :
CREATE [SHARED|PUBLIC|PRIVATE] DATABASE LINK NomLien CONNECT
TO
CURRENT_USER
User IDENTIFIED BY password
USING connect_string
CURRENT_USER : Oracle utilise l'utilisateur courant pour
ouvrir la session distante
SHARED : Lien partagé
connect_string: le nom du service représentant la
base à laquelle on veut se connecter
Si on utilise l'option connect to user identified by
password, l'utilisateur doit exister sur la base distante.
Exemple d'utilisation de Data Base Link :
Select * from scott.employe@db~link
Employe = objet de la base de données
référencée par db_link
N.B : Les Data Base Link peuvent fonctionner
sans système de nom global, mais si ce dernier existe, alors, les deux
doivent être identiques, si non une erreur sera
générée.
II.3. LES SYNONYMES
Pour référencer une base de données dans
un système distribué, on utilise le nom global ou le lien de base
de données. Pour référencer un objet (table, trigger,
procédure, etc) on ajoute y ajoute le nom de l'objet comme
mentionné dans l'exemple précédent. Mais afin de converger
plus vers l'un des objectifs de la répartition des bases de
données (voir IV-4) qui est la transparence vis-à-vis
de la localisation, Oracle utilise des synonymes qui masquent le
nom du lien de base de données. Exemple : nom_synonyme
=====scott.employe@db link Instruction SQL : create synonym for
scott.employe@db_link
III. LE MECANISME DE REPLICATION
III.1. LA COMMANDE COPY
La première option consiste à répliquer
régulièrement les données sur le serveur local au moyen de
la commande COPY de SQL*Plus.
Exemple:
COPY FROM user1/password1@db_link1 TO user2/password2@db_link2
CREATE table _2
USING
SELECT * FROM table_1
WHERE `condition' ;
Ici, la copie est faite du site référencé
par db_link1 à db_link2
La clause FROM ou TO peut être émise si l'origine ou
la destination est le site courant.
Aussi, en plus de la clause CREATE, on peut utiliser les clauses
REPLACE (remplacer une table existante), INSERT INTO (ajout de tuples).
III.2. LES SNAPSHOTS
Afin de répliquer les données d'une table à
l'autre, Oracle utilise le concept de SNAPSHOT ou clichés.
Un snapshot est une copie conforme d'une table située
sur une base de donnée du système distribué. Il permet de
diminuer les coûts réseau, en rendant local les données
situées à distance. Afin d'assurer la cohérence de
données, une mise à jour régulière et automatique
est effectuée à partir du site d'origine ou MASTER.
III.2.A. TYPES DE SNAPSHOTS
On distingue deux principaux types de snapshots :
> Les read-only snapshots
Ce sont les snapshots non modifiables à partir du site
esclave, ils ne sont accessibles qu'en lecture.
Création de read only snapshots :
CREA TE SNAPSHOT nom_snapshot REFRESH FAST
STAR T with SysDate
NEXT SysDate+ 7
AS SELECT * FROM Employes@db_link;
Cette instruction crée un snapshot appelé
nom_snapshot pour la table Employes avec un système de
rafraîchissement rapide qui commence au moment courant et se reproduira
chaque 7 jours.
> Les updateable snapshots
Les updateables snapshots ou snapshots de mise à jour
peuvent être directement modifiés. Dans ce cas, les données
mises à jour à leur niveau sont répliquées vers le
site Master lors du processus de rafraîchissement.
Création de updateable snapshot
CREA TE SNAPSHOT nom_snapshot REFRESH FAST
START with SysDate
NEXT SysDate+ 7
FOR update query rewrite
AS SELECT * FROM Employes@db_link;
Deux types de snapshots peuvent également
être considérés : simples et complexes. Un snapshot
simple ne contient pas de clause distinct, group by, connect by, de
jointure multitables ou d'opérations set.
III.2.B. RAFFRAICHISSEMENTS
III.2.B.a. Mode de rafraîchissements
On distingue trois principaux modes de rafraîchissement
pour un snapshot :
> Rapide
Le mode rapide indiqué par la clause FAST permet de
faire un rafraîchissement en tenant compte seulement des mises à
jour effectuées sur le site Maître. Dans ce cas, un SNAPSHOT LOG
doit être crée pour la table Maître afin de noter les
différents changements subvenus qui seront répercutés sur
le snaphot.
> Complet
Ici, à chaque rafraîchissement, toute la table est
transférée. Ce mode est obligatoire pour les snapshots complexes
et est indiqué par COMPLETE
> Forcé
Dans le mode FORCE, un rafraîchissement rapide est d'abords
tenté ; s'il ne marche pas le rafraîchissement complet est
effectué.
III.2.B.b. Temps de rafraîchissements
Le rafraîchissement peut se déclencher de plusieurs
manières : > Sur demande : ON DEMAND
> Sur validation : ON COMMIT
> De façon périodique :
START WITH sysdate NEXT sysdate+n
III.3. VUES MATERIALISEES
Une vue matérialisée est comme son nom
l'indique, une vue réelle d'une ou de plusieurs tables.
C'est-à-dire Oracle crée une représentation physique de la
vue. Ce terme est aussi utilisé dans la réplication, comme
cliché et possède toutes les spécifications citées
plus haut pour les snapshots. Mais il est beaucoup plus souple et permet
à l'optimiseur de requête de travailler de façon plus
performante. Aussi, à l'avenir le concept de snapshot va
disparaître et lui laisser la place.
Création d'une vue matérialisée :
CREA TE MA TERIALIZED VIE W nom_vue_m aterialisée
REFRESH FAST
START WITH sysdate
NEXT sysdate+ 1
AS SELECT * from Employes@db_link
III.4. LA REPLICATION AVANCEE
Oracle utilise le concept de réplication avancée
pour désigner une réplication qui se fait dans les deux sens
entre deux ou plusieurs serveurs de bases de données. Elle est encore
appelée réplication multi-maitre (Replication Multi Master). Dans
une telle implémentation, il faut aussi définir un système
de gestion de conflits afin de respecter la cohérence des données
sur tout le système.
Oracle a mis en place tout un ensemble de concepts permettant
de mettre sur pieds une réplication avancée appelée
replication advanced tools dont nous parlerons à une prochaine
occasion
IV. OPTIMISATION DES REQUETES REPARTIES
L'optimisation des requêtes distribuées est un
outil par défaut d'Oracle. Son principe de fonctionnement est de
réduire le volume des données transférées entre les
sites, lorsqu'on récupère des données distantes.
Oracle utilise une méthode basée sur le calcul
de coût pour trouver et générer la requête SQL qui
extrait uniquement les données nécessaires des tables distantes.
Les données subissent un premier traitement sur le site distant, puis le
site distant envoie le résultat au site local (qui a lancé la
requête) pour le traitement final. Les tables complètes ne sont
donc pas transférées.
Pour l'optimisation des requêtes, Oracle utilise des
« Collocated Inline Views », c'est à dire des vues de
plusieurs tables distantes et « en lignes » (en direct) afin de
forcer les restrictions sur les sites distants.
Oracle permet également, pour améliorer
l'optimisation, de collecter des statistiques sur les différentes tables
du système. Oracle peut ainsi faire une optimisation par calcul de
coût par trois méthodes différentes :
· Réaliser des estimations sur des jeux de
données pris au hasard
· Faire les calculs exacts
· Utiliser des méthodes statistiques définies
par les utilisateurs. Oracle permet de régler l'optimisation en fonction
des objectifs que l'on veut atteindre :
· Des débits importants (utiles par exemple pour des
applications de type reporting, Business Intelligence).
· Un temps de réponse performant (utile pour
toutes les applications utilisateurs pour lesquelles l'apparition des
premières lignes est importante).
PARTIE III. LE CAS PRATIQUE DE LA SOCIETE
CALL IN OUT
I. PRESENTATION DE LA SOCIETE CALL IN OUT
CALL IN OUT est un centre d'appel, qui assure
la mise en place d'un point d'entrée dédié à
l'ensemble des contacts clients :
· Emission et réception d'appels
· Web
· Fax
· Chatting
· Mailing
· E-mailing
· SMS
· Etc.
La cellule Pan-Européan et Middle East accueille les
clients dans leur langue d'origine.
CALL IN OUT couvre le spectre linguistique suivant :
· Français
· Anglais
· Néerlandais
· Allemand
· Espagnol
· Italien
· Portugais
· Arabe
La société est constitué de :
· Un centre de formation
· Un centre de qualité
· Un centre de saisie
· Des métiers
· Plateaux de production
La société est également divisée en
deux établissements : > CALL IN OUT (la
principale)
> LIGHT CLICK (la secondaire)
Les deux sont réparties sur les deux étages que
comporte la société. Site web :
www.callinout.com
II. ANALYSE DU BESOIN
II.1. FONCTIONNEMENT DE LA SOCIETE
La société CALL IN OUT reçoit des projets
ou des campagnes de ses clients. Les différents projets qui peuvent lui
être confiés sont par exemple :
· La vente d'un produit ou service par
téléphone
· Le marketing par téléphone
· Des enquêtes d'opinions,
· Etc.
Le projet lorsqu'il est reçu, passe par plusieurs
phases avant d'être lancé. En effet, il est d'abords modelé
par les superviseurs de campagnes, ensuite informatisé par la cellule
informatique afin d'avoir de meilleurs performances, puis validé par les
superviseurs, et enfin attribué à des agents qui se chargerons
des appels ou réceptions.
Lorsque le projet ou campagne est en production
(lancée), tous les évènements le concernant (tous les
appels, conversations, résultats, heures de production) sont
enregistrées par des programmes informatiques sur des serveurs de base
de données et de fichiers. Ces données servent plus tard à
effectuer des statistiques, des contrôles, garder des traces, et à
des exigences d'ordre commercial et juridique.
Les programmes informatiques qui sont utilisés pour la
production proviennent conjointement d'internationaux producteurs de Solution
pour
Centres d'appel comme VOCALCOM, AXTERIX et de la cellule
informatique de l'entreprise qui dispose également d'un pôle de
développement d'applications internes.
Dans la suite nous parlerons d'une campagne spéciale
sur laquelle nous avons travaillé et dont pour des raisons de
confidentialité nous appèlerons la campagne X.
II.2. PRESENTATION DE LA CAMPAGNE X
La campagne X est une campagne très rentable pour
l'entreprise. Elle a été confiée par un client
fidèle de la boîte et nécessite donc toute l'attention
possible. Elle a pour but de vendre des services par téléphone
aux différents usagers. A cette fin, la société lui a
alloué d'énormes ressources tant humaines, matérielles,
qu'informatiques. En effet, en plus du logiciel d'appel qui est utilisé,
il a été développé en interne, une application qui
se charge de la gérer de façon différente des autres
campagnes. Il s'agit d'une application (vb6 -access) qui permet à chaque
agent de noter sa vente après l'avoir effectuée. En fait le
logiciel d'appel le fait aussi mais il y'a des paramètres et traitements
qui n'y sont pas pris en compte. Aussi, vue la valeur de la campagne comme
précisée plus haut, elle est effectuée aussi bien sur le
site du haut (CALL IN OUT) que sur le site du bas (LIGHT CLICK). Elle est la
seule dans ce cas.
II.3. SPECIFICATION DU BESOIN
Venons en à la problématique du sujet. En fait
comme nous l'avons dit plus haut, après chaque vente, l'agent doit la
saisir. Or il se trouve que les deux sites ne communiquent pas car ayant chacun
son réseau local. Ainsi, afin de garder une cohérence des
données, un seul site est utilisée pour la saisie de
données : le site LIGH CLICK. Alors lorsqu'un agent du site du haut fait
une vente, il est obligé de descendre d'un étage pour faire la
saisie et remonter ensuite. Ce qui génère une perte de temps
grandiose.
Aussi, l'application utilise la même base de
données qu'une autre application interne qui se charge de faire les
statistiques de production de chaque site. En fin de mois, pour le calcul de
primes, cette base de données est utilisée. L'informaticien
chargé des primes copie sur une clé les résultats de
ventes du réseau de LIGHT CLICK et insère les résultats de
la clé sur le site principal CALL IN OUT. C'est juste après
ça qu'il peut faire le calcul de primes de chaque agent ; car un agent
peut être à volonté muté d'un site à l'autre.
A ce niveau donc aussi il y'a un problème d'utilisation de support
intermédiaire. L'idéal serait que les deux bases de
données communiquent directement sans avoir besoin de support
intermédiaire ou de traitement particulier au niveau de
l'application.
Ainsi, nous avons deux problèmes à résoudre
:
· Le déplacement des
téléopérateurs
· L'utilisation de clés pour faire communiquer les
bases.
II.4. SOLUTION PROPOSEE
La solution adoptée pour palier à ces
problèmes est la mise en place d'une base de données reparties
sur les deux sites à travers internet, afin de les faire communiquer
sans problèmes. Ainsi chaque site aura sa base de donnée
indépendante et toute donnée enregistrée sur un site
pourra être connu de l'autre sans aucun déplacement ou
manipulation humaine.
III. CONCEPTION DE LA SOLUTION
Dans le but d'agir avec efficacité et rapidité,
sans oublier concision et précision, nous avons pris une grande partie
de notre temps pour la conception de la solution. Cette partie est
présentée ci-après par des modèles du langage UML
dans sa version 2.
III.1. DIAGRAMME DE CAS D'UTILISATION
Le diagramme de cas d'utilisations nous présente les
principales fonctions ou cas d'utilisation du système, ainsi que les
acteurs qui y interviennent.
III.1.A. LES CAS D'UTILISATION
Un cas d'utilisation est une fonctionnalité du
système. Dans notre travail, nous en avons répertorié
trois principales :
> Saisir données
Action de saisir les ventes effectuées dans le
système
> Superviser
Action d'interroger le système pour savoir l'état
des vantes
> Gérer comptes
Action de créer, supprimer ou modifier les comptes
d'opérateurs. III.1.B. LES ACTEURS
Nous avons trois principaux acteurs :
> L'opérateur
C'est lui qui se charge d'effectuer les ventes
> Le superviseur
Il a pour rôle de contrôler l'activité des
téléopérateurs
> L'administrateur
Il se charge de créer des comptes
Etant donné que certaines tâches peuvent être
effectuées par tous les Utilisateurs, un utilisateur
générique englobant tous les autres a été
crée sous le nom de Utilisateur.
III.1.C. DIAGRAMME
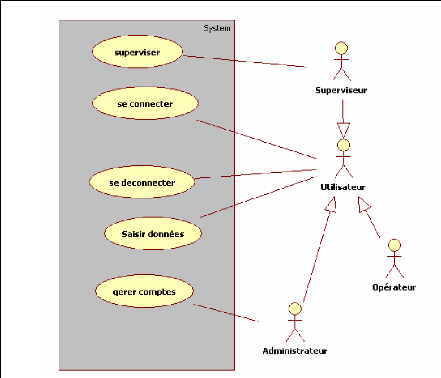
Figure 16 : diagramme de cas d'utilisation
Les acteurs Administrateur, Opérateur, et Superviseur
héritent de l'acteur Utilisateur.
III.2. DIAGRAMMES DE SEQUENCES
Les diagrammes de séquences permettent de
détailler le processus d'exécution d'un cas d'utilisation. Nous
en avons définis 3 pour les principaux cas d'utilisation que nous avons.
Une classe est utilisée : la classe SYSTEM qui
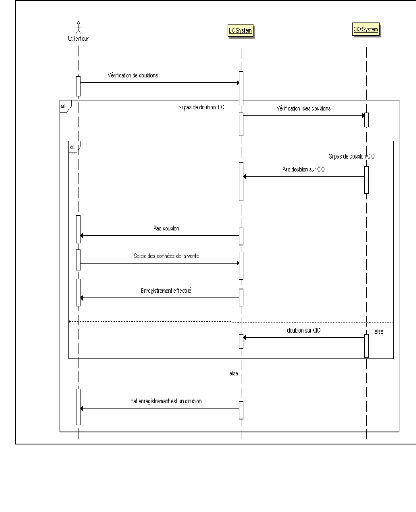
Figure 17 : SD Saisir Données
représente l'un des deux sites de la
société. Elle a dons deux objets : LC (LIGHT CLICK) et CIO (Call
In Out).
III.2.A. DIAGRAMME DE SEQUENCE « SAISIR
DONNEES»
III.2.B. DIAGRAMME DE SEQUENCE «
SUPERVISER »
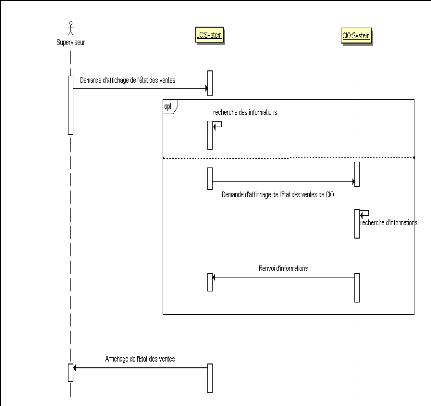
Figure 18 : SD Superviser
III.2.C. DIAGRAMME DE SEQUENCE « GERER
COMPTE »
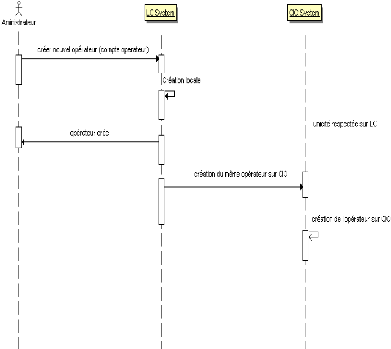
Figure 19 : SD Gérer comptes
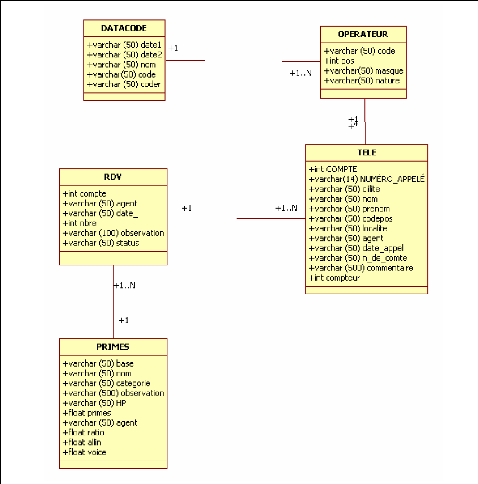
III.3. DIAGRAMME DE CLASSES
Le diagramme de classes représente la
modélisation des données utilisée dans le système,
avec les liens qui existent entre eux. L'application que nous avons
trouvée sur place a une grande base de données de plusieurs
tables. Nous allons nous intéresser seulement aux tables qui
interviennent dans le mécanisme de répartition de la base de
données et dont les noms suivent.
III.3.A. DIFFERENTES CLASSES OU TABLES
> OPERATEUR
Cette table contient les comptes de toutes les personnes
autorisées à se connecter au système, principalement les
téléopérateurs.
> DATACODE
Cette table contient les comptes et mots de passe des
utilisateurs, ainsi que les temps de connexion.
> TELE
Cette table contient toutes les ventes effectuées par les
téléopérateurs de la campagne X.
> RDV
Cette table contient toutes les statistiques de ventes pour
toutes les campagnes du site.
> PRIMES
Elle contient les données relatives aux primes des
utilisateurs
III.3.B. DIAGRAMME
Figure 20 : Diagramme de classes
IV. REPARTITION DE LA BASE DE DONNEES
IV.1. FRAGMENTATION ET LOCALISATION
Comme nous l'avons dit dans la première partie du
document, la fragmentation et la localisation constituent la principale phase
de la conception d'une base de données répartie. Dans notre cas,
il est question de dire quelles sont les tables et données qui seront
logées sur le site Call In Out (site du haut) et lesquelles seront sur
le site LIGHT CLICK (site du bas). Pour cela, tout d'abords nous rappellerons
les contraintes à respecter, puis nous donnerons l'architecture de
répartition choisie.
Les contraintes à respecter pour la répartition
sont les suivantes :
· Chaque site doit être indépendant et avoir
ses propres données
· Chaque site doit pouvoir accéder aux
données de l'autre
· Chaque opérateur doit pouvoir se connecter sur un
site comme sur l'autre.
· Les données de la table RDV qui est très
importante du fait qu'elle gère les ventes et permet de calculer les
primes des opérateurs, doivent être régulièrement
copiées sur le site Call in out , pour une meilleure
sécurité.
· Les primes des opérateurs sont calculées
sur le site Call In Out.
Face à ces contraintes, nous avons adopté
l'architecture suivante :
· Chaque site aura toutes les tables sauf la table PRIME du
système
· La table PRIME sera uniquement sur le site Call In Out
!
· Certaines données seront répliquées
d'un site à l'autre
IV.2. REPLICATION
La réplication nous permettra de transférer
certaines données d'un site à l'autre selon la description
ci-après :
· Tout d'abords, la gestion des opérateurs est
contrôlée par le site LC. Tout nouvel enregistrement ou
modification effectué sur un opérateur du site LC (le site
Maitre), sera automatiquement propagé sur l'autre site ;
c'est-à-dire un nouvel opérateur crée sur ce site, sera
automatiquement crée sur l'autre site. Cette réplication concerne
les tables OPERATEUR (comptes opérateurs) et DATACODE (mots de passe
opérateurs)
· La table RDV du site LIGHT CLICK sera automatiquement
répliquée sur le site Call In Out en fin de journée.
Les données qui ne seront pas répliquées
pourront être consultées à distance au moyen de
requêtes réparties.
V. IMPLEMENTATION
Dans cette nouvelle phase, il est question de réaliser
la solution proprement dite. Toutes les indications de la conception seront
prises en compte en veillant aussi bien sur à la bonne migration de
l'ancien système au nouveau.
Aussi n'oublions pas de mentionner que les deux sites : CIO
(Call In Out) et LC (LIGHT CLICK) seront accessibles à travers
Internet.
V.1. INSTALLATION DE ORACLE ET CREATION DE LA BASE DE DONNEES
La première phase de l'implémentation a
consisté à installer Oracle 10g R 1.5 sur les deux serveurs de
l'entreprise.
Ensuite, nous avons crée la base de donnée
BTELE sur chaque site, utilisant l'utilitaire Assistant de configuration de
base de données, fourni avec ORACLE 10g.
V.2. MIGRATION DE LA BASE ACCESS A LA BASE ORACLE
Etant donné que la base était
gérée par le SGBD ACCESS, il a fallu faire une migration de
ACCESS vers ORACLE. Ce dernier fourni un utilitaire très efficace de
manipulations de bases de données ACCESS, SQL SERVER et ORACLE, ainsi
que de migration d'une plate forme à l'autre. Cet outil qui fait
vaillamment concurrence à TOAD et pourtant gratuit se
nomme SQL DEVELOPPER et à été notre
principal outil de travail. La migration s'est faite en 6 principales phases
:
· Le choix de la base ACCESS et celle de ORACLE
· L'extraction de la structure de la table ACCESS
· Le mappage des types des deux SGBD
· La génération du code ORACLE de
création de ladite structure.
· La création de la structure dans ORACLE (tables,
utilisateurs, procédures, triggers,etc)
· L'importation des données
La migration de données s'est bien effectuée, bien
qu'ayant rencontré quelques difficultés à savoir :
· Certains champs avaient pour nom des mots
réservés de ORACLE comme DATE par exemple. Ces champs ont
été renommés automatiquement durant le processus de
migration en y ajoutant à la fin le caractère `_'. Donc DATE a
donné DATE_
· Le caractère ° n'était pas pris en
charge et devait être remplacé avant la migration
· Etc.
A la fin de la migration, toute la base est désormais
présente sur ORACLE l'utilisateur BTELE est crée.
V.3. CONFIGURATION DE ORACLE NET
Oracle Net a été configuré selon les
critères définis dans la partie II, en utilisant l'outil
netca (Oracle Net Configuration
Assistant).
· Le processus d'écoute est le Listener avec comme
port d'écoute le 5560, port par défaut.
· Les méthodes de résolutions de noms sont
dans l'ordre : la
résolution par noms locaux de services, la
méthode Easy Connect.
· Deux noms locaux de services ont été
crées : BTELE_LC (représentant la base BTELE du site LIGHT CLICK)
et BTELE_CIO pour le site Call In Out.
Aussi, pour que les processus d'écoutes soient
accessibles à travers Internet, il a fallut :
· Créer des exceptions pour le port 5560 dans les
firewalls
· Faire la redirection des ports au niveau des routeurs
V.4. CREATION DES DATA LINKS
Afin d'accéder grâce à une requête
à une base à partir d'une autre, nous avons crée les liens
de base de données ou data links. Les requètes suivants
présentent leurs codes de créations.
Sur le site CIO :
Create data base link dbl_lc
Connect to current user
Using btele_lc
Sur le site LC
Create data base link dbl_lc Connect to current user Using
btele_lc
V.5. MISE EN PLACE DE LA REPLICATION
La réplication nous permettra de rendre les tables
liées aux opérateurs (table Opérateur et table
datacode), identiques, afin qu'un opérateur puisse se connecter
indépendamment sur un site ou sur un autre. Elle nous permettra
également de répliquer les statistiques de ventes
régulièrement sur le site principal.
V.5.A. REPLICATION DES DONNEES DES TABLES
OPERATEURS ET DATACODE
Pour la réplication de ces deux tables, nous avons
utilisé des vues matérialisées Le principe est le suivant
: chaque fois qu'il y'a une modification sur la table operateur ou
datacode (insertion, mise à jour ou suppression) sur le site
maître, la modification est directement transmise sur le site esclave.
Ainsi pas besoin de déplacement pour la mise à jour. Pour la
gestion des opérateurs, le site LC considéré comme
maître (dans ce cas) est le seul a faire des changements qui sont donc
ensuite répercutés sur le site CIO.
Nous avons utilisé à cet effet, des vues
matérialisées simples, avec rafraîchissement rapide et
synchrone, sur validation. Les instructions suivantes décrivent les vues
matérialisées définies pour les tables operateur
et datacode.
V.5.A.a. Table operateur
> Première étape, création du
fichier log de la vue materialisée (car le mode de
rafraîchissement est rapide) sur le site LC
CREATE MATERIALIZED VIE W LOG ON OPERATEUR WITH PRIMAR Y KEY
;
|
|
> Deuxième étape, définition de
la vue matérialisée proprement dite sur le site CIO
CREA TE MA TERIALIZED VIEW OPERATEUR REFRESH FAST
WITH PRIMARY KEY
ON COMMIT
as SELECT * FROM OPERATEUR@dbl_lc;
|
|
V.5.A.b. Table datacode
> Première étape, création du
fichier log de la vue materialisée (car le mode de
rafraîchissement est rapide) sur le site LC
CREATE MA TERIALIZED VIE W LOG ON DA TA CODE WITH PRIMAR Y
KEY ;
|
|
> Deuxième étape, définition de
la vue matérialisée proprement dite sur le site CIO
CREA TE MA TERIALIZED VIE W DA TA CODE REFRESH FAST
WITH PRIMARY KEY
ON COMMIT
as SELECT * FROM DATACODE@dbl_lc;
|
|
V.5.B. REPLICATION DE LA TABLE RDV
Comme nous l'avons dit plus haut, la table RDV
très importante pour l'entreprise, doit être
répliquée régulièrement, sur le site CIO sur lequel
les prîmes mensuelles sont calculées. Pour cela, nous avons
utilisé le concept de JOB.
Un Job Oracle est une procédure spéciale
programmée pour s'exécuter au cours d'un temps défini et
selon une régularité aussi définie. C'est
l'équivalent de tâche planifiée dans Windows et
crontab sur UNIX.
Ainsi, dans notre cas, nous allons définir un job qui
copie grâce à l'instruction « insert select » (joue le
même rôle que copy) tous les enregistrements journaliers
effectués sur la table RD V de LC sur la table RD V de
CIO, chaque jour à 23h00. En voici le code :
DECLARE jobno number;
begin
dbmsjob.submit(jobno, 'insert into btele.rdv@dbl _cio select
* from btele.rdv where date_ = to_date(sysdate);Çtrunc(sysdate) +1+
23/24, 'trunc(sysdate) + 1 + 23/24');
commit ;
dbmsjob. run(jobno);
end;
|
|
Le package utilisé pour cela est dbmsjob appartenant
à l'utilisateur SYS. Les trois procédures les plus
utilisées pour ce package sont :
> Dbmsjob.submit(Entier numerojob, chaine
code_a_excecuter, date date_prochaine_execution, chaine
temps_interval)
Cette procedure permet de definer le job !
> Dbms_run(entier numerojob)
Celle-ci permet de declencher un job.
Rapport de fin de cycle Ingénierie Informatique
> Dbms_remove(entier numerojob)
Cette dernière permet de retirer un job
programmé.
V.5.C. CREATION DES VUES
Dans un environnement reparti, il est important d'avoir des
vues générales sur certaines tables ayant subi des fragmentations
horizontales. Cela facilite la consultation desdites données. Dans notre
cas, on a crée une vue des 2 tables tele des deux sites.
> Sur le site CIO
CREATE VIEW VIE W_TELE
AS SELECT * FROM TELE@dbl_lc
UNION SELECT * FROM
TELE
|
|
> Sur le site LC
CREATE VIEW VIE W_TELE
AS SELECT * FROM TELE
UNION SELECT * FROM TELE@dbl_cio
|
|
Ainsi, chacune de ses vues nous donne l'ensemble des ventes des
deux
sites.
V.6. MODIFICATION DE L'APPLICATION DE L'ENTREPRISE
L'architecture répartie est donc mise en place. La
communication serveur à serveur est assurée par les data base
links et les différents mécanismes de réplication. Il ne
reste plus qu'à implémenter la communication client-serveur. Cela
revient à :
· Définir les outils ou API qui serviront
à l'application de l'entreprise de se connecter au serveur. La
société Call In Out utilise un programme VB 6 pour gérer
la campagne X avec la méthode d'accès aux données ADODB.
Ainsi, le driver à utiliser doit servir de middleware entre Visual Basic
et Oracle. Il s'agit de :
« Microsoft ODBC for Oracle »,
fournit par Microsoft et présente par défaut dans les machines
Windows. Ce driver permet d'indiquer la chaîne de connexion de l'objet
ADODB.connection qui permettra de se connecter à la base de
données, comme indiqué ci-dessous :
.ConnectionString = "UID= " & uid & ";PWD=" &
pwd &
";DRI VER = {Microsoft ODBC For Oracle}; "SER VER=" &
dBase & ";"
· Modifier certaines requêtes : les requêtes
d'insertion, modification, suppression des tables operateur et
datacode ; on y ajoute l'instruction `commit ;' pour la
validation du rafraîchissement des vues matérialisées.
· Ajouter des options pour faire de la supervision
locale, à distance, ou générale du système, en
utilisant les vues créées et les data base links.
· Renommer les noms d'objets et d'attributs changés
au cours de la migration de MS Access vers oracle.
V.7. MISE EN SERVICE
La mise en service a consisté à installer le
client oracle windows sur tous les postes ou s'exécutent l'application.
Pour cela on a utilisé l'outil 10g_win32_client.zip
fourni par oracle et téléchargeable sur son site à
l'adresse :
http://www.oracle.com/technology/software/products/database/oracle10g/index.
html. , après s'être enregistré. Il contient les
composants ORACLE NET, ODBC, OLEDB,
ODP.NET, NET MANAGER, SQLPlus ,etc.
Le programme client est indispensable pour la connexion
à la base de données. La capture d'écran suivante nous
présente une étape de son installation :
Figure 21 : Client Oracle 10 g
Après l'installation de Oracle Client, il faut faire la
configuration de Oracle Net grâce à Oracle Net Configuration
Assistant, et au cours de laquelle on précise pour chaque poste le
service (BTELE_LC ou BTLE_CIO) auquel il va se connecter.
Et le tour est joué !!
CONCLUSION
Ainsi s'achève notre travail à la
société Call In Out ! En résumé, il a
été question pour nous d'implémenter un système de
bases de données reparties Oracle sur les deux sites que possède
l'entreprise, en dotant chacun d'une base de données indépendante
mais qui communique avec l'autre. Les concepts de Oracle Net, vues
matérialisées, lien de base de données, requêtes
réparties, jobs ont été au centre de la mise en place de
cette architecture à la fois client-serveur et serveur-serveur.
Comme intérêt pour l'entreprise, elle se passera
désormais avec joie de déplacements inutiles qui lui faisaient
perdre beaucoup de temps, et donc d'argent. Aussi grâce aux
réplications mises en place, le système a gagné en
fiabilité, car au cas ou surviendraient des accidents sur un site, les
données ne seraient perdues.
En ce qui nous concerne, le travail a été pour
nous à la fois, un sujet de recherche, et d'affirmation dans le monde
professionnel. En effet cette double dimension nous a permis de joindre l'utile
à l'agréable en scrutant aussi bien les profondeurs
théoriques que pratiques de ce vaste et passionnant domaine qu'est celui
des bases de données reparties sous Oracle. C'est pourquoi comme il est
de coutume dans ce beau pays d'accueil qu'est le Maroc, nous nous permettons de
dire « Hamdoullah ! » Comprenez « Gloire à Dieu !
»./.
ANNEXES
ANNEXE I : TABLE DES ILLUSTRATIONS
Figure 1: Architecture Client-Serveur 12
Figure 2:Architecture serveur-serveur 13
Figure 3 Architecture générale 13
Figure 4 : Graphe d'attentes 18
Figure 5 : Validation à deux phases 19
Tableau 1 :Tableau des complexités des opérations
22
Figure 6 : Schéma général de l`optimisation
24
Figure 7 : Architecture Monoposte 29
Figure 8 : Architecture Client - Serveur A 29
Figure 9 : Architecture Client - Serveur B 30
Figure 10 : Architecture Serveur- Serveur 30
Figure 11 : netca 33
Figure 12: netmgr 33
Figure 13: listener.ora 34
Figure 14: sqlnet.ora 34
Figure 15 : tnsnames.ora 34
Figure 16 : diagramme de cas d'utilisation 48
Figure 17 : SD Saisir Données 49
Figure 18 : SD Superviser 50
Figure 19 : SD Gérer comptes 51
Figure 20 : Diagramme de classes 53
Figure 21 : Client Oracle 10 g 63
ANNEXE 2: RtIFtRENCES
Bibliographie
> Sql pour oracle livre, Application avec java,php et
xml de Christian Soutou Edition Eyrolles
> Oracle 10 g Administration livre de Razvan
Bizoi Edition Eyrolles > Oracle, partage et protection des
données, livre de Frank Giraud, collection Epsilon
> Bases de données, livre de Georges Gardarin,
Edition Eyrolles
Webographie
>
www.oracle.com
>
www.dbasupport.com/oracle
>
www.dba-oracle.com
>
download.oracle.com
>
http://rangiroa.essi.fr/cours/systeme-information/01-bd-
reparties .pdf
>
http://ceria.dauphine.fr/Rim/Teaching
fichiers/BDR/Lab BDR 06. pdf
>
http://libd.isnetne.ch/cours/DistributionReplication/Ferrara/BDII
m od II.htm
ANNEXE 3 : QUELQUES VUES UTILISÉES
PAR L'ADMINISTRATION ORACLE
|
NOM
|
DESCRIPTION
|
|
DICT
|
Contient toutes les vues statiques du dictionnaire de
données
|
|
DBA CONSTRAINTS _
|
Définition des contraintes de toutes les tables
|
|
DBA DB LINKS
_ _
|
Liens de bases de données de la base
|
|
DBA JOBS
_
|
Tous les jobs de la base
|
|
DBA JOBS RUNNING
_ _
|
Tous les jobs en exécution
|
|
DBA MVIEWS
_
|
Toutes les vues matérialisées de la
base
|
|
DBA MVIEW LOGS
_ _
|
Tous les fichiers logs de vue
matérialisées
|
|
DBA OBJECTS _
|
Tous les objects
|
|
DBA PROCEDURES _
|
Toutes les procédures
|
|
DBA PROFILES
_
|
Tous les profiles
|
|
DBA ROLES _
|
Tous les rôles de la base
|
|
DBA ROLE PRIVS
_ _
|
Les privilèges affectés aux rôles de la
base
|
|
DBA_SEQUENCES
|
Description de toutes les séquences de la base
|
|
DBA SNAPSHOTS
_
|
Description de tous les snapshots de la base
|
|
DBA_SNAPSHOT_LOGS
|
Tous les fichiers logs des snapshots de la base
|
|
DBA_SYNONYMS
|
Tous les synonymes
|
|
DBA_SYS_PRIVS
|
Tous les privilèges systèmes attribués aux
utilisateurs
|
|
DBA _TABLES
|
Toutes les tables de la base
|
|
DBA_TABLESPACES
|
Tous les tablespaces de la base
|
|
DBA_TAB_PRIVS
|
Tous les privilèges attribués aux
utilisateurs
|
|
DBA_TRIGGERS
|
Tous les triggers
|
|
DBA_USERS
|
Tous les utilisateurs de la base
|
|
DBA_VIEWS
|
Toutes les vues de la base
|
| 

