INTRODUCTION GENERALE
A l'heure actuelle, les problèmes du
développement de la République Démocratique du Congo, RDC
en sigle sont étroitement liés à la maîtrise
respectivement de la conception, l'implémentation et l'administration
Réseau à distance sur base des outils libres. Qui prennent une
importance croissante sans cesse pendant que le monde informatique est devenu
un petit village planétaire1(*). Ceux-ci constituent la préoccupation majeure
des organismes tant nationaux qu'internationaux, touchés directement ou
indirectement par des difficultés créées par ce
paramètre.
Actuellement, l'Administration de Réseau Informatique
et la gestion de base de données à l'instar d'autres ressources
informatiques occupent une place prépondérante parmi ces
ressources. Sans une bonne maîtrise de ces dernières, aucune
entreprise ne peut espérer un avenir, un développement dynamique,
surtout que les équilibres dans ces domaines sont fragiles.
Ainsi, l'Administration de Réseau Informatique
apparaît comme l'une des préoccupations de maîtrise pour
tout Informaticien qui se respecte dans ce 21e siècle car
elle permet à l'entrepreneur de suivre l'évolution des cinq axes
importants cernés par International Standard Organisation, ISO, en sigle
que nous aurons l'occasion de décrire par la suite dans ce travail.
0. PRESENTATION DU PROJET
D'abord, un projet est un regroupement d'acteurs et de
ressources en vue de réaliser des objectifs identifiés dans un
délai et par les moyens prévus en faisant appel ou non à
des moyens extérieurs.
Un projet consiste à réaliser une idée
ayant un caractère nouveau. Dans le cadre de notre travail, pour
sanctionner la fin du second cycle en informatique, notre projet est
intitulé « CONCEPTION, IMPLEMENTATION D' UNE BASE DE DONNEES
POUR LA GESTION D' UN ORGANISME ET L'ADMINISTRATION RESEAU A DISTANCE SUR BASE
D' OUTILS LIBRES » .
I. PROBLEMATIQUE ET HYPOTHESE
I.1. Problématique
D'abord, la problématique est un ensemble de questions
précises que l'on se pose au sujet d'une étude ou recherche
spécifique2(*).
A l'heure actuelle, l'administration réseau dans sa
globalité á déjà réussi son pari et s'impose
dans tous les secteurs de la vie active d'un informaticien.
A cet effet, le Projet Limete Université Cardinal
Malula, PLUCM, en sigle cherche aussi à profiter les avantages offerts
par la Conception, l'Implémentation d'une base de données et
l'administration de Réseaux à distance sur base des outils
libres.
En ce qui concerne notre travail, nous nous sommes
posés les questions ci-après :
· Qu'est-ce que l'administration de réseau
à distance ?
· Comment cette administration à distance
sera-t-elle réalisée au site ciblé dans le cadre
de Projet Limeté/Université Cardinal Malula?
· Quel serait l'apport de notre travail au sein de cet
organisme ?
· Par quelle voie peut-t-on retrouver le reçu d'un
étudiant à distance en temps réel afin de rendre inutile
son déplacement physique?
· Les administratifs, les partenaires de la Commune de
Watermael Bois Fort et de l'Ecole Internationale de Bruxelles, sont-ils
capables de connaître la situation générale ,
financière et autre de Projet Limeté/Université Cardinal
Malula en entrant directement dans la base de données se trouvant
à distance ?
· Quels sont les mécanismes que cette application
doit utiliser pour permettre les apprenants, les formateurs, les
administratifs, les partenaires à accéder dans la base de
données d'une façon sécurisée ?
· Quel sera le coût global d'Implantation du
nouveau système ?
Toutes ces questions sous-tendent notre problématique
et ne manquent pas d'intérêt.
I.2. Hypothèse
L'hypothèse est une réponse qui permet de
prédire la vérité vraisemblable au regard des questions
soulevés par la problématique et dont la recherche vérifie
le bien fondé ou le mauvais côté de cette recherche3(*).
En vue de remédier aux inquiétudes
soulevées au travers des questions posées ci haut, nous pensons
que les systèmes actuels de gestion des apprenants, élèves
, de la bibliothèque , recettes du cyber café a besoin d'un
réaménagement.
Nous pensons que l'informatisation de Projet Limete
Université Cardinal Malula et la gestion de leur Réseau
Informatique à distance sur base de logiciel Libre serait
idéale.
II. CHOIX ET INTERET DU SUJET
Notre travail présente un intérêt à
la fois théorique et pratique.
Sur le plan théorique : ce
travail veut faire bénéficier au Projet Limete Université
Cardinal Malula les avantages de notre savoir faire accumulé durant
notre formation au second cycle à l' ECOLE SUPERIEURE DES METIERS D'
INFORMATIQUE ET DE COMMERCE, ESMICOM en sigle. En plus cette étude nous
permet d'élever le niveau de connaissance sur la gestion informatique,
les bases de données et l'administration de Réseau par les
diverses documentations mises à notre possession afin de suppléer
la carence de cours théoriques.
Sur le plan pratique : cette
étude est une contribution capitale et inoubliable car elle permet au
apprenant, gestionnaire et/ou partenaire de Projet Limete Université
Cardinal Malula d'obtenir de notre part, une proposition optimale pour mieux
administrer le réseau et gérer toutes leurs activités.
Car nous sommes convaincus que ce système qui sera mis
en application apportera des innovations pour la gestion des activités
et l'administration de leur réseau d'une façon distante. En plus,
il diminuera les erreurs dans l'administration de leur réseau
informatique, le suivi, la gestion des recettes, la gestion des apprenants
ainsi que le gestion de la bibliothèque.
Il sera ici question de se rendre de l'application
réelle des principes ou formules relatives à l'administration de
réseau informatique et la gestion de base de donnée
particulièrement au sein du Projet Limeté/Université
Cardinal Malula à Limete/Kingabwa à Kinshasa et se fera d'une
façon sécurisée.
Un autre intérêt important est que, les corps
administratifs qui sont à Kinshasa et ceux qui sont à
l'étranger (les partenaires de la commune de watermael bois fort et de
l'école Internationale de Bruxelles) tous vont commencer à suivre
l'évolution du projet au même moment. Au lieu d'attendre les
gérants de Kinshasa puissent leurs envoyer le rapport au format Excel ou
Word comme toujours. Ainsi pour bien analyser cette étude, il nous faut
un plan cohérant.
III. DELIMITATION DU SUJET
Il est affirmé qu'un travail scientifique pour
être bien précis, doit être délimité. Raison
pour laquelle, nous n'allons pas aborder toutes les questions liées
à l'administration de réseau à distance et la Conception
de base de données car elles paraient une matière très
complexe. Ainsi, nous avons pensé limiter notre étude dans le
temps et dans l'espace.
Dans le temps, nous avons considéré les
données allant de décembre 2007 jusqu'à juin
2008 ;
Dans l'espace, notre étude est limitée à
la Conception, Implémentation d'une base de donnée pour la
gestion d'un organisme et l'administration de réseau à distance
sur base des outils libres au sein du Projet Limeté/Université
Cardinal Malula.
IV. METHODES ET TECHNIQUES
UTILISEES
IV.1. Méthodes
Est un ensemble d'opération mise en oeuvre pour
atteindre un ou plusieurs objectifs4(*).
En d'autres termes, une méthode est un ensemble des
normes permettant de sélectionner et coordonner les recherches.
Quatre méthodes ont été utilisées
pour l'élaboration de notre projet :
IV.1.1. Méthode historique
Elle nous a permis de remonter dans le temps pour avoir un
aperçu général de notre terrain de recherche qui est le
Projet Limete Université Cardinal Malula.
IV.1.2. Méthode analytique
Au moyen de cette méthode, nous sommes parvenus
à décomposer les différents éléments du
système dans le but de définir et d'en dégager les
spécifiés.
IV.1.3. Méthode structuro
fonctionnelle
Basée sur la structure, elle nous a facilité la
tâche de comprendre les difficultés actuelles en analysant la
structure et les fonctions actuelles du système.
IV.1.4. Méthode MERISE
Est une méthode de conception, de développement
et de réalisation des projets informatiques ou système
d'informations5(*).
La méthode est basée sur la séparation
des données et des traitements à effectuer en plusieurs
modèles. La dénomination MERISE est une abréviation qui
signifie Méthode d'Etude de Réalisation Informatique par Sous
Ensemble.
IV.1.5. Méthode PERT (Program
Evaluation and Review Technic)
Est une représentation axée sur la logique
d'enchaînement des t?ches laquelle nous a beaucoup servi pour
l'évaluation de notre projet.
IV.2. Techniques
Est définie comme étant comme un processus
concret qui permet à un chercheur de récolter les informations
nécessaires, les analyser afin de tirer une conclusion6(*).
Trois techniques ont été utilisées pour
l'élaboration de notre mémoire :
IV.2.1. Techniques d'interview
L'interview consistant en un jeu de question - réponse,
cette technique nous a permis de poser des questions auprès de personnel
de Projet Limete Université Cardinal Malula. Afin d'avoir les
réponses concernant notre étude.
IV.2.2. Techniques documentaires
Elle nous a facilité la collecte et la consultation des
différents documents et ouvrages relatifs à notre
étude.
IV.2.3. Techniques d'observation
Elle nous a permis de s'approcher du terrain de recherche pour
appréhender ce qui se fait et comment cela se fait.
V. CAHIER DE CHARGE
Le cahier des charges comporte quatre volets encadrant et
orientant le travail : Administrer et centraliser toutes les informations
concernant le réseau informatique de Projet
Limeté/Université Cardinal Malula à distance, les
recommandations portant sur l'interface graphique, les fonctionnalités
attendues et les spécifications concernant l'architecture de
l'application.
V.1. Administration et Centralisation de
Réseau
L'objectif de ce travail est d'administrer et centraliser
toutes les informations concernant le réseau informatique à
distance :
o Services (vérifier que les services sont bien
fonctionnels) ;
o Sécurité (contrôle de firewall,
détection d'intrusions...) ;
o Machine (état du système de fichiers,
chargement mémoire et CPU, ...) ;
o Réseau (engorgement du réseau, bande passante,
table de routage, ...) ;
V.2. Architecture de l'application
Aucune installation côté client ne doit
être nécessaire pour accéder dans la base de
donnée.
Deux entrées doivent être prévues :
l'une publique, l'autre protégée par login et mot de passe
donnant accès en plus des données accessibles à partir de
l'entrée publique, aux informations relatives à la finance du
projet Limeté/UCM, au nombre d'apprenant et élève des
écoles de Kingabwa en formation en cours ou historique, au module de
recherche et à l'interface de gestion de la base de données.
La gestion des données doit être
centralisée et facilitée par une application
dédiée.
La gestion de date historique de la bibliothèque est
obligatoire pour faciliter les administratifs et partenaires de voir quels sont
les livres préférés dans la bibliothèque.
Le serveur d'application doit être accessible via une
page d'accueil.
V.3 Fonctionnalités
L'ensemble des fonctionnalités standard d'un viewer
doit être disponible (zoom, déplacement, interrogation d'objet,
module de recherche, calcul de salaire de personnel, affichage à
échelle souhaitée, sortie image et impression).
La gestion des couches doit être simple et facilement
accessible.
Possibilité d'effectuer des requêtes par
attribut.
La navigation et l'utilisation des fonctionnalités
doivent être intuitives et améliorées par rapport à
celles d'un viewer.
V.4. Interface graphique
L'interface graphique doit être simple et ergonomique.
Optimisation pour Microsoft Internet explorer 6.0 (résolution 1024*768
pixels).
L'application doit enfin être livrée avec un
guide de maintenance et d'utilisation détaillant la distribution et
l'architecture du serveur, les étapes de son installation ainsi que les
manipulations fréquentes (comme l'ajout de nouveau apprenant ou
élève ou le paramétrage de l'affichage).
VI. SUBDIVISION DU TRAVAIL
Notre travail comprendra quatre parties dont la
première sera consacré à l'évaluation de notre
projet cette partie comporte 2 chapitres à savoir :
La deuxième portera sur l'administration de
réseau à distance au Projet Limete/ Université Cardinal
Malula. Cette seconde partie comprend 7 chapitres.
Tandis que la troisième parlera de la conception de la
base de donnée au Projet Limete Université Cardinal, cette
troisième partie comprend 3 chapitres.
En fin la quatrième partie clôturera sur la
programmation de l'application et son implémentation.
Toutes ces parties seront passés en revu.
VII. PLANNING PREVISIONNEL DU
PROJET
VII.1. PLANIFICATION
VII.1.1. Planification
VII.1.2. Découpage du projet
VII.2. PLANNING PREVISIONNEL DE REALISATION DU PROJET
VII.3.MODELE D' ORDONNANCEMENT
VII.4. TECHNIQUE PERT
VII.4.1. Recensement et Déroulement des
Tâches
VII.4.2. Estimation des durées et des
coûts
VII.4.3. Elaboration du Graphe
VII.4.4. Graphe du Projet
VII.4.5. Graphe Pert avec niveau
VII.4.6. Recherche de Chemin Critique
VII.4.6.1. Calcul du Chemin Critique
VII.4.7. Chemin Critique
VII.4.8. Calcul des dates au plus Tôt et au plus
Tard
VII.4.9. Calcul des Marges.
VII.4.9.1. Marges Total (MT)
VII.4.9.2. Marges. Libre (ML)
VII.4.10. Graphe d'ordonnancement
VII.5. TABLEAU DES SYNTHESES
VII.6. ELABORATION DU CALENDRIER
VII.7. CONCLUSION SUR LA TECHNIQUE PERT
VII.8. LES REGLE DE L'ART.
Formule du taux de capacité réseau*(*).
TC=N x 100 / N+
N : Nombre d'ordinateurs existant
N+ : Nombre d'ordinateurs à
ajouter
TC : Taux de Croissance exprimé en
%
VIII. PLAN DU TRAVAIL
PREMIERE PARTIE : EVOLUTION DU PROJET ET ETUDE
PREALABLE.
DEUXIEME PARTIE : ADMINISTRATION DE RESEAU A DISTANCE
AU PLUCM.
TROISIEME PARTIE : CONCEPTION DE BASE DE DONNEE AU
PLUCM.
QUATRIEME PARTIE : PROGRAMMATION ET IMPLEMENTATION.
Chapitre 1. ORGANISATION DU TRAVAIL
Pour la réalisation de ce projet, nous avons
disposé d'une totale liberté d'organisation et d'une large marge
de manoeuvre dans le choix de la solution, les éléments de
cadrage étant définis en amont, dans le cahier des charges.
Après la phase assez rapide de diagnostic portant sur
le matériel et les données, nous avons dû travailler en
tant que prestataire externe. En effet, aucun poste adapté
n'était disponible et aucune compétence à la gestion de
base de données et développement orienté web (notamment
php) susceptible de nous aider n'existaient en interne.
Comme il a été dit, cette mission était
encadrée par le responsable informatique du Projet Limeté
Université Cardinal Malula, lequel a aussi des responsabilités au
sein du service financier et technique. Il ne s'agissait donc pas de coordonner
cette mission avec le travail d'un service ou d'un agent en particulier, mais
de produire un outil conforme aux attentes en termes de fonctionnalités
et aux prescriptions techniques détaillées dans le cahier des
charges. De notre côté, notre démarche avait une forte
dimension technique.
Connaissant déjà le monde de l'entreprise, cette
organisation devait nous permettre de nous adapter à une autre
façon de travailler caractérisée par une plus grande
responsabilisation.
Entre la phase d'inventaire (matériels et
données) et celle du déploiement du serveur sur le site,
l'essentiel de la mission a donc consisté en un travail de
développement en local sur notre poste personnel.
La liste des activités de notre projet est reprise dans le
tableau ci-dessous :
|
Code Activité
|
LIBELLET ACTIVITE
|
Activité Antérieure
|
Durée/ Jour
|
Coût/Dollar
|
|
a
|
Enquête et entretien
|
_
|
6
|
55
|
|
b
|
conception du système d'information
|
a
|
18
|
35
|
|
c
|
Prép. des données/choix solution
|
b
|
22
|
60
|
|
d
|
Inventaire du matériel
|
c
|
23
|
20
|
|
e
|
commande du mat, et logiciel
|
d
|
12
|
3500
|
|
f
|
Développement
|
e
|
6
|
2600
|
|
g
|
Configuration serveur/nouveau système
|
e, f
|
15
|
50
|
|
h
|
Contrôle/Ajustement
|
g
|
30
|
75
|
|
i
|
Formation
|
h
|
12
|
220
|
a) Graphe Bruit
1
2
3
4
5
6
7
8
9
10
e(12) g (15)
d(23)
H(30)
F(6)
c(22)
i(12)
f ` 0
b(18)
a(6)
Sommet ou étape
b) Calculs des Rangs
Rn est le nombre d'étape maximal
Rn-1 = [10] = R9
Rn-2 = [9] = R8
Rn-3 = [8] = R7
Rn-4 = [7] = R6
Rn-5 = [6] = R5
Rn-6 = [5] = R4
Rn-7 = [4] = R3
Rn-8 = [3] = R2
Rn-9 = [2] = R1
Rn-10 = [1] = R0
c) Graphe ordonné
g
1
2
3
4
5
6
7
8
9
10
d
e
h
c
f f ` i
b
a
R0 R1 R2 R3 R4 R5 R6
R7 R8 R9
d. Matrices Booléenne
Cette matrice booléenne nous aidera à
contrôle notre graphe, la présence d'un arc est symbolisée
par le chiffre un (1), tandis que l'absence d'un arc est symbolisée par
le chiffre zéro (0).mais le chiffre un (1) peut être
remplacé par la valeur réelle de l'arc pour obtenir ainsi une
matrice valuée (qui a de valeur réelle)
|
MATRICE BOOLEEN
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
|
1
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
2
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
3
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
|
4
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
|
5
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
|
6
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
|
7
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
|
8
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
|
9
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
|
10
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
e) Matrice valuée
Le chiffre un (1) peut être remplacé par la
valeur réelle de l'arc pour obtenir ainsi une matrice valuée (qui
a de valeur réelle), comme ceci.
|
MATRICE VALUEE
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
|
1
|
0
|
6
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
2
|
0
|
0
|
18
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
3
|
0
|
0
|
0
|
22
|
0
|
0
|
0
|
0
|
0
|
0
|
|
4
|
0
|
0
|
0
|
0
|
23
|
0
|
0
|
0
|
0
|
0
|
|
5
|
0
|
0
|
0
|
0
|
0
|
6
|
0
|
0
|
0
|
0
|
|
6
|
0
|
0
|
0
|
0
|
0
|
0
|
12
|
0
|
0
|
0
|
|
7
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
15
|
0
|
0
|
|
8
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
30
|
0
|
|
9
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
12
|
|
10
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
F) Recherche De T?ches de la Date Au Plus Tôt Et
Date Au Plus Tard
F.1 Date Au Plus Tôt (dto)
La date au plus tôt (dto) est la date la plus
rapprochée à laquelle il est possible de réaliser une
étape2(*) sa formule
est dto(x) = Max {dto (y) + d (i)}. dto (x) est considéré comme
2e étape, dto (y) est considéré comme
1e étape et i comme une tâche.
f.i.1 calcul
Dto (1) = 0
Dto (2) = Dto (1) + d(a) = 0 + 6 = 6
Dto (3) = Dto (2) + d(b) = 6 + 18 = 24
Dto (4) = Dto (3) + d(c) = 24 + 22 = 46
Dto (5) = Dto (4) + d(d) = 46 + 23 = 69
Dto (6) = Dto (5) + d(e) = 69 + 6 = 75
Dto (7) = Max Dto (5) + d(e) = Max 69 +12 = 81 (qui est la
valeur maximum)
Dto(6) + d(f `) 75 + 0
Dto (8) = Dto (7) + d(g) = 81 + 15 = 96
Dto (9) = Dto (8) + d(h) = 96 + 30 = 126
Dto (10) = Dto (9) + d(i) = 126 +12 = 138
f.2 Date Au Plus Tard (Dta)
La date au plus tard (dta) est la date à laquelle il faut
absolument commencer une tâche afin de la réaliser3(*). Sa formule est dta(y) = Min
dta (x) - d (i)
Dta (10) = 138
Dta (9) = Dta (10) - d(i) = 138 - 12 = 126
Dta (8) = Dta (9) - d(h) = 126 - 30 = 96
Dta (7) = Dta (8) - d(g) = 96 - 15 = 81
Dta (6) = Dta (7) - d(f `) = 81 - 0 = 81
Dta (5) = Max Dta (6) + d(f) = Max 81 +6 =69
Dta(7) + d(e) 81+ 12
Dta (4) = Dta (5) - d(d) = 69 - 23 = 46
Dta (3) = Dta (4) - d(c) = 46 - 22 = 24
Dta (2) = Dta (3) - d(b) = 24 +18 = 6
Dta (1) = Dta (2) - d(a) = 6 + 6 = 0
G(15) h(30)
0 0
1
6 6 2
24 24 3
46 46 4
69 69 5
75 81 6
81 81 7
96 96 8
126 126 9
138 138 10
E(12)
D(23)
C(22) f ` 0
12
B(18) f(6)
a(6)
g. Marge Libre
La marge libre d'une tâche ML (i) est le délai de
la mise en route de la tâche (i) sans compromettre la dto de
l'étape(y). Sa formule est ML (i) = Dto (x) -d (i), sur base de cette
formule que nous allons chercher les marges libre des nos tâches.
g.1 Calcul
ML (a) =dto (2) - dto (1) -d(a) = 6- 0 -6 = 0 tâche
critique
ML (b) = dto (3) - dto (2) - d(b) = 24 - 6 - 18 = 0
tâche critique
ML ( c) = dto (4) - dto (3) - d( c) = 46 - 24 -22 = 0
tâche critique
ML ( d) = dto (5) - dto (4) - d( d) = 69 - 46 23 = 0
tâche critique
ML (e ) = dto (6) - dto (5) - d ( e ) = 75 - 69 -12 = - 6
tâche non critique
ML (f ) = dto (7) - dto (6) - d ( f ) = 81 - 75 -6= 0
tâche critique
ML (f `) = dto (7) - dto (6) - d (f ` ) = 81 - 75 - 0 = 6
tâche non critique
ML (g ) = dto (8) - dto (7) - d ( g ) = 96 - 81 -15 = 0
tâche critique
ML (h ) = dto (9) - dto (8) - d ( h ) = 126 - 96 -30 = 0
tâche critique
ML (i ) = dto (10) - dto (9) - d ( i ) = 138 - 126 -12 = 0
tâche critique
Pour que nous puisons déterminer les chemins critiques,
lesquelles sont les chemins que nous allons suivre, il nous faut utiliser cette
formule (dta - dto).
h. Marge Total
La marge total MT(i) qui est la tâche (i) le
délai que nous avons disposer pour la mise en route de la tâche
(i) sans modifier la dta de l'étape (y) ( x étant le sommet
initial de la tâche (i) et y son sommet terminal. Sa formule est MT(i) =
dta (y) - dto(x) - d(i). dta (y) est le sommet terminal, dto (x) est le sommet
initial
h.1 Calcul
Mt(a) = dta(2) - dto(1) - d(a) = 6 - 0 - 6 = 0
Mt(b) = dta(3) - dto(2) - d(b) = 24 - 6 - 18 = 0
Mt(c) = dta(4) - dto(2) - d(c) = 46 - 24 - 22 = 0
Mt(d) = dta(5) - dto(3) - d(d) = 69 - 46 - 23 = 0
Mt(e) = dta(7) - dto(4) - d(e) = 81 - 69 - 12 = 6
Mt(f) = dta(6) - dto(5) - d(f) = 81 - 69 - 6 = 6
Mt(g) = dta(7) - dto(6) - d(f') = 81 - 75 - 0 = 6
Mt(h) = dta(8) - dto(7) - d(g) = 96 - 81 - 15 = 0
Mt(i) = dta(9) - dto(8) - d(h) = 126 - 96 - 30 = 0
Mt(j) = dta(10) - dto(9) - d(i) = 138 - 126 - 12 = 0
NB: - si dto et dta c'est à dire si dto = dta alors
l'étape est critique
- lorsque la ml (i) marge libre est égale marge totale
mt(i) alors la tâche est critique
i. Interprétation de Résultat de Date Et
Marge
i.1 les étapes (dto et dta)
|
Code étape
|
Dto
|
Dta
|
Observation
|
|
1
2
3
4
5
6
7
8
9
10
|
0
6
24
46
69
75
81
96
126
138
|
0
6
24
46
69
81
81
96
126
138
|
Etape critique
Etape critique
Etape critique
Etape critique
Etape critique
Etape non critique
Etape critique
Etape critique
Etape critique
Etape critique
|
|
i.2.les tâches ml (i) et mt(i)
|
Code activité
|
Ml (i)
|
Mt (i)
|
Observation
|
|
A
B
C
D
E
F
F'
G
H
I
|
|
0
0
0
0
-6
0
6
0
0
0
|
0
0
0
0
0
6
6
0
0
0
|
Tâche critique
Tâche critique
Tâche critique
Tâche critique
Tâche non critique
Tâche critique
Tâche critique
Tâche critique
Tâche critique
Tâche critique
|
j. Chemin Critique
Le chemin critique est celui qui relie toute les tâches
dont la marge totale (mt) est nul c'est-à-dire a, b, c, d, e, g, h, i
k. Présentation de Résultat
k.a. durée global de notre
projet : est égale à 138 jours qui est dta(10) et dto(10)
k.b. coût total du projet :
Formule : 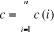
Application :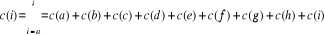
= 55 + 35 + 60 + 20 + 3.500 + 2.600 + 50 + 75 + 220 = 6615$
Chapitre 2. ETUDE
PREALABLE
2.0. DEFINTION ET BUT
2.0.1. Définition
L'étude d'opportunité, est aussi appelée
étude préalable, est l'étude qui permet à un
informaticien de préparer la décision relative à la
nécessité d'informatiser ou de n'est pas informatiser le
traitement de l'information, le changement d'ordinateurs ou encore l'achat des
nouveaux matériels7(*).
Cette étude fournira les informations
nécessaires aux responsables de Projet Limete/UCM pour la prise des
décisions concernant les modifications des objets, des nouvelles
méthodes du système afin d'améliorer les performances et
en déduire les coûts.
L'étude d'opportunité est une étude
menée afin de déterminer s'il y a nécessité
d'automatiser ou pas l'application ou l'entreprise sous l'étude.
Cette étude d'opportunité se divise en 4
parties :
- L'analyse de l'existant ;
- Le critique de l'existant ;
- La proposition des solutions nouvelles ;
- Le choix de la nouvelle solution.
2.0.2. But
Le but de cette étude est de recueillir les
données qui vont servir à l'élaboration du diagnostic en
vue de la recherche et de choix de solution pour améliorer les
performances, les qualités ainsi que la capacité8(*).
Elle permet de prendre une connaissance générale
et suffisante de l'entreprise afin d'en faire la synthèse et de
concevoir la solution.
Dans notre cas, nous allons analyser les activités du
système de gestion de recette, apprenant, bibliothèque et
administration de réseau informatique au Projet Limete Université
Cardinal Malula dans la commune de LIMETE, à Kinshasa,
République Démocratique du Congo.
2.1. PRESENTATION DE PL/UCM
2.1.1. Situation Géographique
PROJET LIMETE UNIVERSITE CARDINAL MALULA, PL/UCM en sigle, est
situé sur l'avenue Kingabwa dans la commune de LIMETE, à
Kinshasa capitale de la République Démocratique du Congo.
2.1.2 Historique
Après avoir constaté les difficultés des
étudiants dans le cours d'informatique, difficultés liées
au manque de matériel informatique (ordinateurs), l'Université
Cardinal Malula, par son Comité de gestion, a formulé le
présent Projet qui a été conçu dans sa phase
préliminaire par Monsieur Anastase Nzeza et Madame Anne Louise Flynn au
mois de février 2003. L'idée a été
présentée auprès des responsables de l'Ecole
Internationale de Bruxelles, de la Vénerie (centre culturel de la
communauté française de Belgique) et de la Commune de
Watermael-Boitsfort afin d'aboutir à un partenariat.
La démarche a permis d'obtenir 12 ordinateurs + une
imprimante, 5 onduleurs, un lot d'environ 1700 livres dont une centaine
d'ouvrages d'informatique ainsi que l'appui pour le transport vers Kinshasa.
Grâce à l'équipement technologique et aux
ouvrages acquis et à acquérir, le Secrétaire
Général de l'UCM, nommé Coordinateur du projet a
recruté une petite équipe pour démarrer les
activités de la première phase du projet (2004-2007).
2.1.3. Personnel
Le Projet Limete Université Cardinal Malula est
dirigé par :
1. le Recteur d' Université Cardinal Malula :
Professeur Charles MAZINGA pour la Représentation et promotion du
projet.
2. le Secrétaire Général de
l'Université Cardinal Malula : Monsieur Anastase NZEZA, qui assure
la Coordination du Projet.
3. Monsieur Thierry MUNGEMA pour l'animation et la Gestion
quotidienne du Projet.
4. une équipe de formateurs en Technologie
Informatique et Internet, la même équipe assure la maintenance des
ordinateurs et de réseaux informatique.
2.1.4 Domaines d'Intervention
Le Projet Limete/Université Cardinal Malula s'est
spécialisé dans le domaine de la formation des
élèves des écoles partenaires et les jeunes de la Commune
de Limeté en particulière et de Kinshasa en
général.
Le projet Limete/Université Cardinal Malula
maîtrise aussi les protocoles tels que :
HTTP : le protocole utilisé pour les communications web
;
SOAP : le protocole d'échanges utilisé pour la
communication avec un service Web ;
DAP : le protocole de communication avec des annuaires ;
SMTP/POP/IMAP : les protocoles utilisés pour le
transfert du courrier électronique ; ...
Le projet Limete/Université Cardinal oriente ses
activités en trois branches qui sont :
q le centre informatique pour la formation des jeunes et
élèves de plusieurs écoles de la Commune de Limete, lequel
est opérationnel depuis 2004.
q Le cybercafé pour la population de la Commune de
Limete et d'autres, ce cybercafé est opérationnel depuis mars
2005.
q Une bibliothèque pour la jeunesse de la Commune de
Limete, qui est opérationnelles depuis août 2005.
2.2. ANALYSE DE L'EXISTANT
2.2.1 Définition et But
L'analyse de l'existant est une étape qui consiste
à décortiquer l'organisme concerné ainsi que la
manière où il fonctionne à ce moment précis9(*).
L'analyse de l'existant revêt une importance
indéniable dans la mesure où elle permet de reproduire le
système existant sous ses différents aspects.
Elle consiste notamment ici à étudier :
- les activités de Projet Limete Université
Cardinal Malula ;
- les structures et les postes concernés ;
- les documents et les fichiers ;
- les moyens de traitements de l'information ;
- les moyens de circulations des informations ainsi que la
manière où les informations circulent.
2.2.2. Etude des activités du
Service Concerné
2.2.2.1. But
Le but de cette étude est d'analyser les
activités et le fonctionnement de l'organisme concerné.
Pour notre cas, nous voudrions analyser le système de
paie de personnel, la recette de cyber café et autre au Projet Limete
Université Cardinal Malula dans la commune de LIMETE, ville de Kinshasa,
République Démocratique du Congo.
2.2.2.2. Organigramme du service
concerné
COORDINATEUR
ANIMATEUR ET GESTIONNAIRE
Cyber Café
Bibliothécaire
Service de la formation
REPRESENTATEUR
2.2.2.3. Description et présentation
de la structure
Après une première approche, nous avons
constaté que les activités au sein du Projet Limete
Université Cardinal Malula se déroulent comme suit :
LE REPRESENTATEUR : il s'occupe de la
Représentation et promotion du projet Limete Université Cardinal
Malula.
LE COORDONATEUR : s'occupe de la gestion
générale du Projet Limete Université Cardinal Malula
à savoir :
- La gestion financière du PL/UCM ;
- Edicter les directives ;
- Convoquer et présider les réunions au
PLUCM ;
- Vérifier les documents.
L'ANIMATEUR ET GESTIONNAIRE : il est rattaché au
COORDONATEUR et s'occupe de :
- La réception et l'expédition de la
correspondance ;
- L'encaissement et décaissement des recettes ;
- la paie des Agents de PLUCM ;
- Exécute quelques taches administratives chaque
mois.
LE CHEF DE SERVICE IT : il présente le rapport
chaque moi d'abord auprès de L' ANIMATEUR, ensuite au TECHNICIEN
(Responsable de service IT) de l'école internationale de Bruxelles (Mr.
Dante Dianoli) il s'occupe de :
- contrôle de matériel informatique.
2.2.2.4. Etude de poste
Après avoir analysé la structure de structure
concernée, on peut alors passer à l'étude de poste de
travail. Cette étude doit être réalisée afin de
faciliter la collecte des informations par l'établissement d'une liste
de poste de travail ainsi qu'une fiche d'étude de poste.
2.2.2.4.1. Liste de poste de
travail
|
N°
|
Intitulé du poste
|
Titulaire
|
Fonction
|
|
0.
|
Représentant
|
Charles MAZINGA
|
REPRESENTANT
|
|
1.
|
Gestionnaire
|
Anastase NZEZA
|
COORDINATEUR
|
|
2
|
Animation
|
Thierry MONGEMA
|
ANIMATEUR
|
|
3.
|
Responsable de service
|
Médard BATANASWE
|
RESPONSABLE SERVICE IT
|
2.2.2.4.2. Description des fiches
d'études de poste
2.2.2.4.2.0 Fiche
d'étude de poste 0
|
|
Code :
0HJK5
|
|
Désignation du poste :
REPRESENTANT
Service auquel est attaché le
poste : la représentation
Responsable du poste : Prof. Charles
MAZINGA
|
|
Taches à accomplir :
Faire la promotion du Projet Limete Université Cardinal
Malula
|
|
Taches
|
Fréquence
|
Délais
|
Remarques
|
|
prévus
|
réel
|
|
Représentation
|
Quotidienne
|
----
|
----
|
|
|
|
----
|
----
|
|
|
Promotion
|
Mensuelle et annuelle
|
----
|
----
|
|
2.2.2.4.2.1 Fiche
d'étude de poste 1
|
Code :
0HJK5
|
|
Désignation du poste :
COORDINATEUR
Service auquel est attaché le
poste : Gestionnaire
Responsable du poste : Mr. Anastase
NZEZA
|
|
Taches à accomplir :
gère les activités du Projet Limete
Université Cardinal Malula
|
|
Taches
|
Fréquence
|
Délais
|
Remarques
|
|
prévus
|
réel
|
|
Gestion des activités
|
Quotidienne
|
----
|
----
|
|
|
|
----
|
----
|
|
|
Vérification de documents de gestion
|
Hebdomadaire
|
----
|
----
|
|
|
Préside les réunions
|
Mensuelle et annuelle
|
----
|
----
|
|
2.2.3.4.2.2 Fiche
d'étude de poste 2
|
Code : OlJHGH
|
|
Désignation du poste :
Animateur
Service auquel est attaché le
poste : Animation des activités quotidiennes
Responsable du poste : Mr. Thierry
MONGEMA
|
|
Taches à accomplir : Animation
des activités de Projet limeté Université Cardinal
Malula
|
|
Taches
|
Fréquence
|
Délais
|
Remarques
|
|
prévus
|
réel
|
|
Gestion de correspondance
|
Quotidienne
|
----
|
----
|
|
|
Encaissement et décaissement
|
Quotidienne
|
----
|
----
|
|
|
Paie des employés
|
Mensuel
|
----
|
----
|
|
2.2.3.4.2.3. Fiche
d'étude de poste 3
|
Code : OlJHG5
|
|
Désignation du poste :
Responsable service IT
Service auquel est attaché le
poste : Contrôle de Matériel Informatique
Responsable du poste : Mr. Médard
BATANASWE
|
|
Taches à accomplir :
Contrôler le matériel Informatique et faire son rapport
auprès de Responsable de service IT de l'école Internationale de
Bruxelles
|
|
Taches
|
Fréquence
|
Délais
|
Remarques
|
|
prévus
|
réel
|
|
Contrôle de Matériel
|
Quotidienne
|
----
|
----
|
|
|
|
|
|
|
|
Rapport de Matériel au coordinateur et au Responsable de
service IT (ISB)
|
Mensuel
|
----
|
----
|
|
2.2.2.4.3. Etude de circuit de
l'information
2.2.2.4.3.1.
Narration
Pour ce qui est de la manière où les
informations circulent au sein de service concerné, il est à
signaler que, lors de l'arriver d'un internaute, celui-ci se présentera
au Cyber Café pour acheter un code chez le moniteur Internet, lequel
lui donnera l'accès aux machines du cyber une fois ce code est fini, la
machine s'arrête automatiquement.
À la fin de service (jour ou soir), le moniteur doit
présenter son rapport auprès de l'animateur gestionnaire.
à la fin du moi l'animateur gestionnaire fera un
rapport global d'abord auprès de coordonnateur en suite le
téléchargé dans le fichier EXCEL pour l'envoyer à
l'école International de Bruxelles et la commune de watermael Boistfort.
La même chose avec le Responsable de service IT pour le
rapport de matériel.
Une fois le matériel informatique tombe en panne le
responsable de service IT est chargé de réparer si possible ou
demander aux autres techniciens de PLUCM de réparer en suite, il va
faire un rapport auprès de Responsable de service IT de l'école
Internationale de Bruxelles.
2.2.2.5. Etudes de Réseau
utilisés
2.2.2.5.1. Définition de
Concepts
Un réseau permet de partage des ressources entre
plusieurs ordinateurs10(*).
Par ces ressources, nous entendons des données ou des
périphériques (imprimante, scanner, ...)
Le réseau permet aux ordinateurs de l'entreprise de
partager des ressources matérielles et logicielles : des
périphériques, des programmes et des données ainsi qu'aux
hommes d'échanger : des messages et des fichiers
Un réseau est un ensemble
d'équipements informatiques interconnectés entre eux en vue de se
changer de données.
En effet, le PLUCM possède du Wan pour se servir de
communication entre la commune de Watermael Boistfort, Ecole Internationale de
Bruxelles, la commune de limeté en RDC. Il utilise la topologie en
étoiles.
2.2.3.5.2. Description de matériels
utilisés
Hub


Connecteur
RJ45
Client

2.2.3.5.3. Présentation de Réseau
utilisé
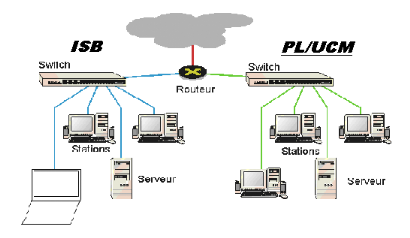
2.2.3.6. Etudes de documents
utilisés
2.2.3.6.1. Inventaires des documents
existants
|
N°
|
Désignation du document
|
|
D01
|
Fiche de Rapport Internet
|
|
D02
|
Fiche de Rapport Formation (élèves des
écoles partenaires, adulte de la commune, Etudiant de UCM, Professeur
UCM)
|
|
D03
|
Journal de caisse
|
|
D04
|
Reçu ou preuve de paiement
|
2.2.2.6.2. Description des documents
existants
Ici nous allons essayer de décrire quelques documents
utilisés au Projet Limeté Université Cardinal Malula.
2.2.2.6.2.1 Fiche de Rapport
Journalière
|
|
|
|
|
|
|
|
|
RAPPORT JOURNALIER INTERNET & IT
|
|
Date:
|
|
Moniteur:
|
|
|
Jour ou Soir
|
|
|
A: RAPPORT FINANCIER
|
|
|
|
CODES INTERNET VENDUS
|
Signature du Moniteur qui reçoit les
codes
|
CODES IT VENDUS
|
|
|
|
|
|
|
|
|
|
CODES INTERNET RESTANT
|
Signature de Justin ou de l'agent de
sécurité
|
CODES IT RESTANT
|
|
|
|
|
|
|
|
|
|
CODES COMPLEMENTAIRE INTERNET
|
Nom & Signature du Bénéficier et
explication
|
CODES COMPLEMENTAIRE IT
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
CODES INTERNET SERVIS
|
100 FC / 20 min
|
|
150 / heure
|
CODES IT SERVIS
|
|
|
|
|
|
|
|
|
|
|
|
|
Recettes Internet
|
PHOTO
|
IMPRESSION
|
PHOTOCOPIES
|
AUTRES
|
Recettes IT
|
TOTAL RECETTES
|
|
FC
|
FC
|
FC
|
FC
|
FC
|
FC
|
FC
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
USD
|
USD
|
USD
|
USD
|
USD
|
USD
|
|
USD
|
|
|
|
|
|
|
|
|
|
Moins Dépenses
|
Pièces Justifictives
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Bénéficiaire
|
Motifs
|
Montant FC
|
Montant USD
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
TOTAL DEPENSES
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
SOLDE
|
|
|
|
|
|
|
|
|
|
|
|
B: RAPPORT TECHNIQUE
|
|
Groupe Electrogène
|
Coupure du Connexion
|
Coupure du Courant Electrique
|
Commentaires
|
|
De
|
A
|
De
|
A
|
De
|
A
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2.2.2.6.3 Etude des fichiers
existants
2.2.2.6.3.1 Description des fichiers
existants
1.2.2.6.3.1.1. Fichier « Fiche Rapport
Internet »
|
Désignation
|
Code
|
Support
|
Localisation
|
Nbre d'exemplaire.
|
|
Fiche Rapport Internet
|
25ljg5
|
Fichier Excel dans l'ordinateur n°1
|
Bureau de l'animateur
|
1
|
2.2.2.6.1.2 Fichier « Journal de Caisse
en franc Congolais »
|
Désignation
|
Code
|
Support
|
Localisation
|
Nbre d'exemplaire.
|
|
Fiche Journal de Caisse en franc Congolais
|
JHGDF
|
Papier
|
Classeur
|
10
|
2.2.2.6.4. Etude des moyens
utilisés
On appelle moyens utilisés, ensemble de matériel
et ressources humaines utilisés pour le traitement des informations au
cours de l'analyse.
Il est nécessaire de recenser tous les moyens de
traitement utilisés au cours cette étude sur les moyens
utilisés, notre objectif primordial sera de faire ressortir tous les
moyens humains au sein de Projet Limete Université Cardinal Malula d'une
part et tous les moyens matériels existant d'autre part.
L'étude des moyens utilisés sera
subdivisée en 2 parties :
- Etude des moyens humains ;
- Etude des moyens matériels.
2.2.2.6.4.1. Etude des moyens
matériels
Cette étude consistera à recenser les
différents matériels au sein de Projet Limete Université
Cardinal Malula, pour traiter les informations de l'application sous
étude.
|
MATERIEL
|
DESCRIPTION
|
QTE
|
LOCATION
|
ETAT
|
|
Clavier
|
Qwerty
|
6
|
Salle IT
|
Bon
|
|
0
|
Cybercafé
|
-
|
|
8
|
Park salle IT
|
Bon
|
|
Azerty
|
1
|
Salle IT
|
Bon
|
|
11
|
Cybercafé
|
Bon
|
|
Souris
|
|
11
|
Salle IT
|
Bon
|
|
3
|
Salle IT
|
Mauvais
|
|
11
|
Cybercafé
|
Bon
|
|
|
|
|
|
|
|
PC
|
Compaq PIII 933
|
4
|
Salle IT
|
Bon
|
|
2
|
Salle IT
|
Mauvais
|
|
7
|
Cybercafé
|
Bon
|
|
4
|
Park salle IT
|
Mauvais
|
|
Compaq PIII 650
|
10
|
Salle IT
|
Bon
|
|
4
|
Cybercafé
|
Bon
|
|
|
2
|
Park salle IT
|
Mauvais
|
|
|
|
|
|
|
|
Ecran
|
Compaq 15 pouces
|
12
|
Salle IT
|
Bon
|
|
Mauvais
|
|
5
|
Cybercafé
|
Bon
|
|
Mauvais
|
|
Compaq 17 pouces
|
8
|
Salle IT
|
Bon
|
|
Mauvais
|
|
8
|
Cybercafé
|
Bon
|
|
Mauvais
|
|
|
|
|
|
|
|
Imprimante
|
HP Laser Jet 5N
|
1
|
Park salle IT
|
Mauvais
|
|
Imprimante
|
HP Deskjet 3840
|
1
|
Park salle IT
|
Bon
|
|
Onduleur
|
MGE 1100 VA
|
4
|
Cybercafé
|
Bon
|
|
Onduleur
|
MGE 1100 VA
|
1
|
Salle IT
|
Bon
|
|
Projecteur
|
Pro screen 4600
|
1
|
Salle IT
|
Mauvais
|
|
Stabilisateur
|
Semtoni 3000W
|
1
|
Salle IT
|
Bon
|
|
Stabilisateur
|
EMKAY 3000W
|
1
|
Salle IT
|
Bon
|
|
Stabilisateur
|
Jacob's
|
1
|
Cybercafé
|
Bon
|
|
Appareil photo Num
|
Sony
|
5
|
Coffre
|
Bon
|
2.2.2.6.4.2. Etude des moyens
humains
Cette étude des moyens humains est toujours
nécessaire pour mieux comprendre les qualifications du personnel
|
N°
|
Poste
|
Nbre de Personne
|
Fonction
|
Qualification
|
Ancienneté
|
Salaire net
|
|
0
|
Représentant
|
1
|
Représentant
|
Recteur à l' UCM
|
-----------
|
----------
|
|
1
|
Gestionnaire
|
1
|
Coordonnateur
|
Sec.Gén. à UCM.
|
----------
|
----------
|
|
2
|
Animateur
|
1
|
Animateur Gestionnaire
|
Etudiant L2 Droit
|
-----------
|
------------
|
|
3
|
Responsable IT
|
1
|
Chef IT
|
Gradué à ISC
|
------------
|
-----------
|
2.3. CRITIQUE DE L'EXISTANT
La critique de l'existant, appelée aussi bilan de
l'existant, va nous aider à l'évaluation du système
existant par rapport à l'analyse faite au Projet Limete
Université Cardinal Malula sous étude tout en établissant
un diagnostic.
Ce diagnostic est établit dans le but de rechercher des
solutions futures à des problèmes posés.
Le but de la critique de l'existant est d'établir un
diagnostic précis sur les procédures utilisées, relever
les anomalies, les qualités et les défauts du système
existant.
Par ailleurs, deux aspects sont toujours dégagés
lors de cette critique dont l'un est positif et l'autre positif.
Ces deux aspects méritent d'être soulevés
étant donné que le besoin de la perfection sera toujours
souhaité par les utilisateurs en vue de bon fonctionnement.
2.3.1. Aspects positifs
Au terme de l'analyse de l'existant, il convient d'avouer que
le Projet Limete Université Cardinal Malula a au moins un système
d'organisation bien défini du point fonctionnel et organisationnel.
Cependant, le Projet Limete Université Cardinal Malula
ne pourra renforcer l'efficience de ses services s'il arrive à surmonter
les insuffisances constatées.
Le Projet Limete Université Cardinal Malula ainsi que
son personnel offre :
- un bon contrôle de matériel ;
- des matériels informatique bien protégé
par les onduleurs et stabilisateurs ;
- une bonne circulation des informations et transparence des
documents entre les partenaires ;
- une bonne collaboration et transmissions des informations
entre eux.
2.3.2. Aspects négatifs
- Les documents étant conservés dans les
classeurs à papiers, l'accès est difficile étant
donné il faut toujours une recherche sérieuse pour retrouver un
document tel que : un reçu d'un étudiant et tant
d'autres ;
- pour que le coordonnateur puisse voir le recette produit
pendant la journée, il faut qu'il se déplace, venir
obligatoirement au Projet limeté/UCM.
- Le lenteur considérable dans le traitement de
l'information ;
- Le suivi de document est très fatiguant à
cause de volume élevé des informations ;
- Le Projet Limete Université Cardinal Malula ne
possède que deux stabilisateurs, cinq onduleurs pour toutes les salles
dont 4 pour les machines connectées à l'Internet plus ou moins 12
ordinateurs et un stabilisateur, un onduleur et un stabilisateur pour le
service IT plus ou moins 15 machines. Cependant, ces derniers sont vieillis.
Pour cette insuffisance des onduleurs et stabilisateurs, les matériels
informatiques tombent toujours en panne (soit bloc d'alimentation
brûlé soit système d'exploitation endommagé...);
- Le Projet Limete Université Cardinal Malula n'a pas
de logiciel approprié pour gérer toutes les données en
local ou à distance.
- Le Projet Limete Université Cardinal Malula n'a pas
un moyen d'administrer leur réseau à distance.
2.4. PROPOSITION DE SOLUTION
A la lumière des anomalies qui viennent d'être
reprises dans le système existant, nous pouvons proposer deux solutions,
l'une manuelle et l'autre automatique, dans le but d'améliorer la
performance et le bon fonctionnement du système existant.
2.4.1. Solution manuelle
La solution manuelle consiste en une simple
réorganisation du système en reconduisant les qualités
tout en conservant le traitement manuel.
Cette proposition qui ne garantit en rien la rapidité
dans l'exécution des tâches, occasionnera des erreurs de
manipulation et fatiguera le personnel dans le traitement des informations.
2.4.1.1. Les Avantages
- L'achat de nouvel équipement du bureau ;
- Modification de l'organigramme et une nouvelle conception
des fichiers et des documents ;
- Solution moins coûteuse et facile à implanter
car elle prendra moins de l'espace.
2.4.1.2. Les
Inconvénients
- Les procédures des traitements des informations
restent toujours manuelles et la fatigue humaine peut faire commettre les
erreurs de temps à autre ;
- Il n'y a pas une grande sécurité des
informations car les supports utilisés restent les papiers ;
- Encombrement du bureau par les documents ;
- Accès facile aux informations par des personnes non
autorisées.
2.4.1.3. Solution informatique
La solution informatique a l'avantage de traiter des
informations avec la rapidité et précision, de rendre fiable la
gestion de l'information.
Elle présente aussi l'inconvénient d'engager des
grosses dépenses pour son installation, le coût à la
formation des agents et autres.
2.4.1.3.1. les
Avantages
L'introduction d'une part de l'administration réseau
à distance va améliorer :
- la rapidité de détection des erreurs dans le
réseau et les ordinateurs ;
- la capacité de modifier le paramètre d'une
machine même à distance sans que l'administrateur réseau se
déplacer.
D'autre part la conception, l'implémentation d'une base
de donnée au Projet Limete Université Cardinal Malula va
encore améliorer :
- la sécurité des informations ;
- la bonne circulation des informations entre les
partenaires externes ou internes par exemple en temps réel;
La réduction des certaines t?ches et éviter
l'encombrement des fichiers ;
- la conservation des informations avec une longue
durée grâce à des supports informatiques ;
- la réduction de l'espace ainsi que le volume en ce
qui concerne le support de stockage des informations ;
- l'impression des informations en cas de besoin et à
temps réel même à distance.
2.4.1.3.2. Les
Inconvénients
- Le coût de maintenance des machines est quasiment
élevé ;
- L'achat des consommables informatiques tels que ajoute des
onduleurs et stabilisateurs.
- La formation des utilisateurs afin de maîtriser
l'outil et les logiciels nécessaires ;
- Interruption du travail lors d'une coupure brusque du
courant électrique et surtout que les onduleurs et les stabilisateurs
sont insuffisants ainsi que le groupe électrogène est
déjà vieilli.
2.5. CHOIX DE SOLUTION
Compte tenu des inconvénients cités ci haut et
dans le souci de produire des meilleures applications, nous pensons mettre un
système automatique où la machine serait vraiment importante pour
alléger certaines taches.
En comparant les avantages de deux solutions proposées
précédemment, nous opterons pour la solution automatiquement ou
informatique pour des raisons suivantes :
- la prise en charge par la machine (ordinateur) tous les
traitements afin d'éviter les erreurs et fournir les résultats
fiables dans un bref délai à l'intérieur du pays comme
à l'extérieur du pays ;
- administrer les machines du réseau à
l'intérieur du pays ou à l'extérieur du pays ;
- les énormes avantages et procédures beaucoup
plus satisfaisants.
Chapitre 1. EXAMEN GENERAL DE LA THEORIE DES LOGICIELS
LIBRES
1.0. DEFINTION ET APERÇU
DE LOGICIEL LIBRE
1.0.1 Définition
Pour être qualifié de logiciel libre, un
logiciel doit être disponible sous des conditions répondant
à des critères stricts. La
Free
Software Foundation et le projet
Debian étudient avec
soin chaque licence de logiciel pour déterminer si le logiciel est libre
(selon leurs critères respectifs0(*)).
La FSF
maintient une définition du logiciel libre basée sur quatre
libertés1(*) :
· Liberté 0 : La liberté
d'exécuter le programme, pour tous les
usages.
· Liberté 1 : La liberté
d'étudier le fonctionnement du programme.
o Ceci suppose l'accès au
code source.
· Liberté 2 : La liberté de
redistribuer des copies.
o Ceci comprend la liberté de vendre des copies.
· Liberté 3 : La liberté
d'améliorer le programme et de publier ses améliorations.
o Ceci suppose l'accès au
code source.
La liberté 3 encourage la création d'une
communauté de développeurs améliorant le logiciel et
permet la création d'une branche de développement
dérivée concurrente, notamment en cas de désaccord entre
développeurs.
La FSF insiste sur le fait que «libre» ne doit pas
être compris comme «gratuit». Cette confusion est
particulièrement possible en
anglais, où
«libre» et «gratuit» se traduisent par
«free», et «logiciel libre» s'écrit
«free software». Pour lever cette confusion, la phrase
«Free as in "free speech", not as in "free beer"»
(«Libre comme dans liberté d'expression, pas comme dans
bière gratuite») est souvent répétée
par les promoteurs des logiciels libres. Concernant l'aspect financier, notons
que les logiciels libres se trouvent gratuitement sur
Internet et qu'il existe en
parallèle des entreprises spécialisées dans la vente et le
soutien de logiciels libres, une des plus connues dans ce domaine étant
Red Hat. Chacun a bien
sûr le droit de redistribuer gratuitement ou non un logiciel libre, quel
que soit le moyen par lequel il l'a acquis.
La FSF précise la définition: ces
libertés doivent être irrévocables; on doit pouvoir en
jouir sans devoir prévenir un tiers; on doit pouvoir redistribuer le
programme sous toute forme, notamment
compilée, et le
code source doit
être accessible pour jouir des libertés d'étude et
d'amélioration; on doit pouvoir fusionner des logiciels libres dont on
n'est pas soi-même l'auteur. La FSF accepte des restrictions mineures
quant à la façon dont un logiciel modifié doit être
présenté lorsqu'il est redistribué.
En tant que
distribution
Linux rassemblant des milliers de logiciels libres de toutes provenances,
le projet
Debian est confronté
à des problèmes un peu différents, la FSF se concentrant
plus sur le développement de logiciels.
Debian a
développé Les principes du logiciel libre selon
Debian2(*)
également connus sous l'acronyme DFSG (pour Debian Free Software
Guidelines). Ils comprennent la non-discrimination des utilisateurs et des
usages.
Ils précisent les restrictions acceptables en
matière de préservation du code source de l'auteur original.
Debian accepte explicitement l'exigence que la distribution d'une forme
modifiée d'un logiciel libre se fasse sous un autre nom que le logiciel
original. On peut noter à ce propos que les noms de plusieurs logiciels
libres sont des
marques
déposées: par exemple
Linux
,
Mozilla et
Apache.
1.0.2.
Bref aperçu sur les logiciels libres
Un logiciel libre est un
logiciel dont la
licence dite
libre donne à
chacun le droit d'utiliser, d'étudier, de modifier, de dupliquer, de
donner et de vendre le logiciel.
Richard Stallman a
formalisé la notion de logiciel libre dans la première
moitié des
années 1980
puis l'a popularisée avec le
projet GNU et la
Free
Software Foundation (FSF).
Depuis la fin des
années 1990,
le succès des logiciels libres, notamment de
Linux, suscite un vif
intérêt dans l'industrie informatique et les médias
1. Les
logiciels libres constituent une option face à ceux qui ne le sont pas,
qualifiés de «
propriétaires».
La notion de logiciel libre ne se confond ni avec celle de
logiciel
gratuit (
freewares), ni
avec celle de
sharewares, ni
avec celle de
domaine
public. De même, les libertés définies par un logiciel
libre sont beaucoup plus étendues que le simple accès au code
source, ce qu'on appelle souvent logiciel Open Source ou
«à sources ouvertes». Toutefois, la notion formelle de
logiciel
Open Source telle
qu'elle est définie par l'
Open Source
Initiative est reconnue comme techniquement comparable au logiciel
libre.
  Voici le Logo
copyleft
(« gauche d'auteurs ») symbolise l'obligation de conserver
le droit de copier Voici le Logo
copyleft
(« gauche d'auteurs ») symbolise l'obligation de conserver
le droit de copier
1.0.3. Quelques logiciels libres
Parmi les logiciels libres les plus connus du grand public
figurent :
· le
noyau
de système d'exploitation
Linux
· le
navigateur web
Mozilla Firefox
(Quoique ce statut soit contesté dans les dernières versions)
· le
serveur HTTP
Apache
· le logiciel de
retouche d'image,
The Gimp
Les gestionnaires de base de données
MySQL et
PostgreSQL
Ce chapitre nous a aidé de procéder à
l'étude minutieuse des logiciels libres afin de mieux les
appréhender et déblayer le terrain pour le chapitre suivant.
Chapitre 2. LA METHODE APPLICABLE
POUR L'ADMINISTRATION DE RESEAU
Dans ce chapitre, nous allons axer notre étude sur la
méthode d'administration de réseau à distance applicable
dans notre travail en vue d'administrer et centraliser d'une façon
distante le réseau de Projet Limete/Université Cardinal Malula.
Nous pouvons d'abord, présenter les concepts dans un premier temps. Le
protocole SNMP qui est le standard de fait dans ce domaine sera ensuite
passé en revue.
La mise en pratique de SNMP est présentée au
travers la mise en oeuvre du package NET-SNMP.
2.0. GENERALITES SUR
L'ADMINISTRATION DE RESEAU
On peut se poser à quoi correspond le concept
d'administration de réseau. L'ISO (International Standard
Organization) a cerné 5 axes :
· La gestion des anomalies (Fault Management).
L'objectif de l'administration réseau est d'avoir un réseau
opérationnel sans rupture de service (taux de disponibilité
à 99,999 % par exemple soit quelques secondes d'indisponibilité
par an), ce qui définit une certaine Qualité de Service (QoS)
offerte par l'opérateur à l'abonné. On doit être en
mesure de localiser le plus rapidement possible toute panne ou
défaillance. Pour cela, on surveille les alarmes émises par le
réseau, on localise un incident par un diagnostic des alarmes, on
journalise les problèmes...
· La gestion de la configuration réseau
(Configuration Management). Il convient de gérer la
configuration matérielle et logicielle du réseau pour en
optimiser l'utilisation. Il est important que chaque équipement, chaque
compteur... soit parfaitement identifié de façon unique à
l'aide d'un nom ou identificateur d'objet OID (Object Identifier).
· La gestion des performances (Performance
Management). Il convient de contrôler à tout moment le
réseau pour voir s'il est en mesure d'écouler le trafic pour
lequel il a été conçu.
· La gestion de la sécurité (Security
Management). On gère ici les contrôles d'accès au
réseau, la confidentialité des données qui y transitent,
leur intégrité et leur authentification.
· La gestion de la comptabilité (Accounting
Management). L'objectif est de gérer la consommation réseau
par abonner en vue d'établir une facture.
En fait, on s'aperçoit qu'un administrateur
système d'un réseau local d'une entreprise, d'un campus, d'une
école administre aussi son réseau. Il le fait sans trop de
problèmes mais les difficultés s'amoncellent dès que la
taille du réseau devient importante. La solution est alors de
rationaliser, de normaliser les choses et l'on a proposé des normes
d'administration de réseau.
L'ISO a proposé dans les années 80 la norme
CMIS/CMIP (Common Management Information Service ISO 9595, Common
Management Information Protocol ISO 9596) comme protocole d'administration
de réseau et définit un cadre général au niveau
architecture (ISO 7498).
En parallèle, l'IAB (Internet Activities
Board) approuve le protocole SNMP (Simple Network Management
Protocol) comme solution à cours terme et CMOT (CMIP Over
TCP) à plus long terme. Au début des années 90, SNMP,
plus simple, devient alors standard de fait et est adopté par de
nombreux constructeurs. C'est le protocole d'administration de
réseau des réseaux IP mais aussi des réseaux des
opérateurs comme pour les réseaux ATM !
2.1. LES CONCEPTS DE SNMP
2.1.1. Introduction
Bien qu'issu du monde IP, le protocole SNMP (Simple
Network Management Protocol) développé dans les
années 80 reprend beaucoup des idées du protocole CMIS/CMIP de
l'ISO.
SNMP est défini dans la RFC 1157 (Request For
Comments). Il utilise le concept d'application Client/Serveur bien connu
dans le monde IP :
· Sur chaque équipement administrable
s'exécute un programme serveur : l'agent SNMP. Cet agent
gère les informations relatives à l'équipement et sont
stockées dans une base de données propre : la MIB
(Management Information Base).
· On retrouve une station d'administration
côté client qui interagit avec un ou plusieurs agents SNMP :
le manager SNMP. Le manager est généralement une application
possédant une interface graphique élaborée pour plus de
convivialité. On peut citer comme exemple de manager le produit
commercial Openview de HP.
On retrouve donc 3 éléments importants
dans SNMP :
· Une base de donnée (MIB) gérée par
chaque agent SNMP et modifiable éventuellement par un manager SNMP. Les
RFC 1156 et 1213 définissent la MIB-I (version 1) puis la MIB-II qui
remplace la précédente, c'est à dire les objets que doit
gérer tout agent SNMP.
· Une structure commune et un système de
représentation des objets de la MIB : le SMI (Structure of
Management Information, RFC 1155).
· Un protocole d'échange entre manager et
agent : le protocole SNMP (RFC 1157). Le protocole SNMP a
évolué pour intégrer les aspects de confidentialité
et d'authentification. Seule la version 1 de SNMP est décrite ici. C'est
d'ailleurs la seule version adoptée et utilisé par tous.
Chapitre 3. MISE EN OEUVRE DE
NET-SNMP SOUS LINUX
Ce chapitre nous montre comment mettre en oeuvre le NET-SNMP
SOUS LINUX étant donné que celui-ci est un système
d'exploitation que nous utilisons pour l'administration de réseau
à distance dans notre travail. Sachant que la mise en oeuvre de SNMP
sous Linux se fera en utilisant le standard de fait dans le logiciel
libre : le package NET-SNMP.
Le projet NET-SNMP appelé anciennement UCD-SNMP a
été historiquement développé par
l'université américaine Carnegie Mellon University (CMU)
puis amélioré et maintenu maintenant par l'université
américaine University of California Davis (UCD).
NET-SNMP est en fait Net-SNMP est un ensemble d'applications
utilisées pour implémenter le protocole SNMP (v1, v2c & v3)
utilisant ã la fois l'IPv4 & IPv6. Et un ensemble d'outils et de
fonctionnalités :
· Une API (Application Programming Interface)
d'accès à SNMP.
· Un agent SNMP extensible.
· Des commandes en ligne pour interroger des agents SNMP.
· Des commandes en ligne pour gérer et
générer des TRAPs SNMP.
· Une version de la commande UNIX netstat utilisant SNMP.
Un browser de MIB SNMP (tkmib) écrit en Tk
NET-SNMP est porté sur différents
systèmes et en particulier sur :
· Linux (noyaux 2.4 à 1.3).
· HP-UX (10.20 à 9.01 et 11.0).
· Ultrix (4.5 à 4.2).
· Solaris (2.8 à 2.3) et SunOS (4.1.4 à
4.1.2).
· NetBSD (1.5alpha à 1.0).
· FreeBSD (4.1 à 2.2).
· Win32.
· ...
NET-SNMP supporte SNMPv1, SNMPv2 et SNMPv3 que ce soit
côté agent SNMP comme du côté manager SNMP via les
commandes en ligne NET-SNMP.
3.1. INSTALLATION DE
NET-SNMP
L'installation de NET-SNMP est des plus traditionnels sous
Linux :
Décompression :
# cd
# tar xvzf net-snmp-5.0.2.tar.gz
# ln -s net-snmp-5.0.2 net-snmp
Configuration. On choisira d'utiliser par défaut
SNMPv1 :
# cd ~/net-snmp
# ./configure
Compilation :
# make
Installation :
# make install
Les commandes Linux NET-SNMP sont recopiées dans le
répertoire /usr/local/bin et /usr/local/sbin qu'il faudra rajouter
à sa variable d'environnement PATH.
Les fichiers correspondants aux MIBs exploités
côté manager SNMP par les commandes en ligne NET-SNMP sont sous
/usr/local/share/snmp/mibs.
3.1.1. Configuration et lancement
de l'agent SNMP NET-SNMP
L'agent SNMP NET-SNMP est l'exécutable snmpd sous
/usr/local/sbin. Il possède un fichier de configuration
général s'appelant snmpd.conf à copier sous
/usr/local/share/snmp. Un exemple de fichier qu'il faudra bien sûr
modifier en fonction de ce que l'on veut faire est fourni. C'est le fichier
EXAMPLE.conf sous ~/net-snmp.
On pourra consulter l'aide en ligne sur la structure de ce
fichier (# man snmpd.conf).
Les champs les plus importants sont :
Déclaration d'une machine et d'un réseau IP
ayant accès à l'agent SNMP, local et mynetwork de
communauté tst :
# sec.name source community
com2sec local localhost tst
com2sec mynetwork 192.9.201.0/24 tst
Déclaration de groupes d'accès aux objets de la
MIB de l'agent SNMP pour local et mynetwork :
####
# Second, map the security names into group names:
# sec.model sec.name
group MyRWGroup v1 local
group MyRWGroup v2c local
group MyROGroup v1 mynetwork
group MyROGroup v2c mynetwork
Accès en lecture/écriture aux objets de la MIB
de l'agent pour l'accès local et lecture seulement pour l'accès
mynetwork :
####
# Finally, grant the 2 groups access to the 1 view with
different
# write permissions:
# context sec.model sec.level match read write notif
access MyROGroup "" any noauth exact all none none
access MyRWGroup "" any noauth exact all all none
Autorisation de la génération de TRAPs
SNMP en direction d'un manager SNMP de la machine localhost de
communauté tst :
####
# Traps and v2 traps enabled and sent to localhost
#
# command host manager community
trapsink localhost tst
trap2sink localhost tst
Renseignement de l'objet sysLocation de la branche
system :
syslocation ENSEIRB, Bordeaux, France
Renseignement de l'objet sysContact de la branche system
:
syscontact Kadionik <kadionik@enseirb.fr>
L'utilitaire snmpconf permet de créer le fichier
snmpd.conf de façon interactive et conviviale sans en connaître
exactement sa structure.
Création rapide du fichier snmpd.conf à la
première utilisation :
# snmpconf -g basic_setup
Mode interactif :
# snmpconf
Après création du fichier snmpd.conf avec les
valeur décrites précédemment et recopie sous
/usr/local/share/snmp, il ne reste plus qu'à lancer l'agent
snmpd :
# snmpd
On pourra lancer dans une autre fenêtre un sniffer
réseau comme tcpdump pour voir les échanges agent SNMP/manager
SNMP :
# tcpdump -vv -i lo
3.1.2. Tests de l'agent SNMP
NET-SNMP
Le test de l'agent SNMP NET-SNMP se fait en utilisant un
manager SNMP. Dans le cas du package NET-SNMP, on a accès à des
commandes en ligne sous /usr/local/bin permettant d'émettre des
requêtes SNMP.
Il convient d'abord de configurer son environnement Linux.
Pour accéder aux objets de la MIB d'un agent sous forme symbolique et
non sous forme décimale OID, il faut aller lire l'ensemble des fichiers
MIB sous /usr/local/share/snmp/mibs :
#
# PATH
#
PATH=$PATH:/usr/local/bin:/usr/local/sbin
#
# MIBS : forces to read all MIB files under
/usr/local/share/snmp/mibs
#
MIBS=ALL
#
# exporting all variables
#
export PATH MIBS
Les principales commandes utiles notées
globalement snmpxxx sont :
· snmpget : envoi d'une requête SNMP GET pour
obtenir une information sur un objet de la MIB d'un agent SNMP distant.
· snmpset : envoi d'une requête SNMP SET pour
mettre à jour la valeur d'un objet de la MIB d'un agent SNMP distant.
· snmpgetnext : envoi d'une requête SNMP
GETNEXT et donne aussi la valeur de l'objet suivant de la MIB d'un agent SNMP
distant si toutefois il en existe un.
· snmpwalk : cette commande fonctionne comme
snmpgetnext mais permet de balayer complètement une branche de la MIB
d'un agent SNMP distant.
· snmptranslate : permet de convertir un objet d'une
MIB représenté sous sa forme décimale OID en sa forme
symbolique et réciproquement.
L'utilitaire snmpconf permet de créer le fichier
snmp.conf de façon interactive et conviviale sans en connaître sa
structure pour configurer par défaut l'usage des commandes snmpxxx
précédentes (choix de la version du protocole SNMP par
défaut, communauté...). Le fichier ainsi créé sera
à recopier sous /usr/local/share/snmp.
Une fois l'agent SNMP lancé sur sa machine comme
précédemment, il est ensuite possible de le tester avec les
commandes snmpxxx.
Correspondance OID et nom symbolique :
# snmptranslate 1.3.6.1.2.1.1.3.0
SNMPv2-MIB::sysUpTime.0
Représentation sous forme graphique de la branche
system de la MIB par analyse de l'ensemble des fichiers MIB sous
/usr/local/share/snmp/mibs :
# snmptranslate -Tp -IR system
+--system(1)
|
+-- -R-- String sysDescr(1)
| Textual Convention: DisplayString
| Size: 0..255
. . .
Récupération par SNMPv1 de la valeur
courante de l'objet sysUpTime géré par l'agent SNMP de la machine
localhost :
# snmpget -v 1 -c tst localhost system.sysUpTime.0
SNMPv2-MIB::sysUpTime.0 = Timeticks: (12908) 0:02:09.08
Récupération de la valeur courante de l'objet
sysUpTime avec SNMPv2c :
# snmpget -v 2c -c tst localhost system.sysUpTime.0
SNMPv2-MIB::sysUpTime.0 = Timeticks: (13966) 0:02:19.66
Récupération de la valeur courante des objets
sysLocation et sysContact (renseignés dans le fichier snmpd.conf)
:
# snmpget -v 1 -c tst localhost system.sysLocation.0
SNMPv2-MIB::sysLocation.0 = STRING: ENSEIRB, Bordeaux,
France
# snmpget -v 1 -c tst localhost system.sysContact.0
SNMPv2-MIB::sysContact.0 = STRING: lusikila
<blaise_apakumu@yahoo.fr>
Parcours de la branche system de la MIB de l'agent
SNMP :
# snmpwalk -v 1 -c tst localhost system
SNMPv2-MIB::sysDescr.0 = STRING: Linux poire1 2.4.18-3 #1 Thu
Apr 18 07:31:07 EDT 2002 i586
SNMPv2-MIB::sysObjectID.0 = OID:
NET-SNMP-MIB::netSnmpAgentOIDs
SNMPv2-MIB::sysUpTime.0 = Timeticks: (28119) 0:04:41.19
SNMPv2-MIB::sysContact.0 = STRING: lusikila
<blaise_apakumu@yahoo.fr>
SNMPv2-MIB::sysName.0 = STRING: poire1
SNMPv2-MIB::sysLocation.0 = STRING: ENSEIRB, Bordeaux,
France
. . .
Affection d'une nouvelle valeur à l'objet sysLocation
de la MIB de l'agent avec SNMPv1 :
# snmpset -v 1 -c tst localhost system.sysLocation.0 s
"coucou"
Error in packet.
Reason: (noSuchName) There is no such variable name in this
MIB.
Failed object: SNMPv2-MIB::sysLocation.0
Affection d'une nouvelle valeur à l'objet sysLocation.0
de la MIB de l'agent avec SNMPv2c :
# snmpset -v 2c -c tst localhost system.sysLocation.0 s
"coucou"
Error in packet.
Reason: notWritable (that object does not support
modification)
Failed object: SNMPv2-MIB::sysLocation.0
En comparant le résultat des 2 dernières
commandes, on voit que SNMPv1 ne définit pas en retour de code d'erreur,
ce que corrige SNMPv2c. Dans notre cas, on essaye de modifier un objet de la
MIB de l'agent SNMP distant accessible en lecture seulement !
La trace tcpdump générée par
l'exécution de la commande :
# snmpget -v 1 -c tst localhost sysUpTime.0
est la suivante :
# tcpdump -vv -i lo
tcpdump: listening on lo
15:17:54.733310 poire1.1092 > poire1.snmp: [udp sum ok]
|30|26|02|01{ SNMPv1 |04|03C=tst |a0|1c{ GetRequest(28) |02|04R=691700679
|02|01|02|01|30|0e |30|0c|06|08system.sysUpTime.0|05|00} } (DF) (ttl 64, id 0,
len 68)
15:17:54.734564 poire1.snmp > poire1.1092: [udp sum ok]
|30|29|02|01{ SNMPv1 |04|03C=tst |a2|1f{ GetResponse(31) |02|04R=691700679
|02|01|02|01|30|11 |30|0f|06|08system.sysUpTime.0=|43|03127125} } (DF) (ttl 64,
id 0, len 71)
On voit que la communauté (ici tst) qu'il faut
considérer comme un mot de passe circule en clair sur le
réseau avec SNMPv1 !
Il est à noter que l'on peut aussi
générer des TRAPs SNMP en direction d'un manager SNMP d'une
machine en utilisant la commande snmptrap. Le démon snmptrapd (sous
/usr/local/sbin) peut être utilisé comme collecteur pour traiter
les TRAPs SNMP. Il utilise le fichier de configuration snmptrapd.conf à
recopier sous /usr/local/share/snmp. Ce fichier de configuration peut
être généré en utilisant l'outil snmpconf comme
précédemment. On verra l'utilisation des TRAPs SNMP lors du
contrôle à distance par SNMP d'un système
électronique.
3.1.3. Présentation du
protocole SNMP
Le système de gestion de réseau est basé
sur trois éléments principaux: un superviseur, des noeuds (ou
nodes) et des agents. Dans la terminologie SNMP, le synonyme manager est plus
souvent employé que superviseur. Le superviseur est la console qui
permet à l'administrateur réseau d'exécuter des
requêtes de management. Les agents sont des entités qui se
trouvent au niveau de chaque interface, connectant l'équipement
managé (noeud) au réseau et permettant de
récupérer des informations sur différents objets.
Switchs, hubs, routeurs et serveurs sont des exemples
d'équipements contenant des objets manageables. Ces objets manageables
peuvent être des informations matérielles, des paramètres
de configuration, des statistiques de performance et autres objets qui sont
directement liés au comportement en cours de l'équipement en
question. Ces objets sont classés dans une sorte de base de
données appelée MIB (« Management Information Base
»). SNMP permet le dialogue entre le superviseur et les agents afin
de recueillir les objets souhaités dans la MIB.
L'architecture de gestion du réseau proposée par
le protocole SNMP est donc fondée sur trois principaux
éléments :
Les équipements managés (managed devices)
sont des éléments du réseau (ponts, hubs,
routeurs ou serveurs), contenant des « objets de gestion »
(managed objects) pouvant être des informations sur le
matériel, des éléments de configuration ou des
informations statistiques ;
Les agents, c'est-à-dire une application de gestion de
réseau résidant dans un périphérique et
chargé de transmettre les données locales de gestion du
périphérique au format SNMP ; Les systèmes de management
de réseau (network management systems notés NMS),
c'està-dire une console à travers laquelle les
administrateurs peuvent réaliser des tâches d'administration.
Concrètement, dans le cadre d'un réseau, SNMP
est utilisé:
- pour administrer les équipement de réseau
(Ordinateur, Onduleur, Hub, Routeur, Serveur.... ) au Projet Limete
Université Cardinal Malula.
- pour surveiller le comportement des équipement du
PL/UCM...
Une requête SNMP est un datagramme UDP habituellement
à destination du port 161. Les schémas de sécurité
dépendent des versions de SNMP (v1, v2 ou v3). Dans les
versions 1 et 2, une requête SNMP contient un nom appelé
communauté, utilisé comme un mot de passe. Il y a un nom de
communauté différent pour obtenir les droits en lecture et pour
obtenir les droits en écriture. Dans bien des cas, les colossales
lacunes de sécurité que comportent les versions 1 et 2 de SNMP
limitent l'utilisation de SNMP à la lecture des informations car la
communauté circule sans chiffrement avec ces deux protocoles. Un grand
nombre de logiciels libres et payants utilisent SNMP pour interroger
régulièrement les équipements et produire des graphes
rendant compte de l'évolution des réseaux ou des systèmes
informatiques (MRTG, Cacti, Nagios,...).
Le protocole SNMP définit aussi un concept de Trap. Une
fois défini, si un certain évènement se produit, comme par
exemple le dépassement d'un seuil, l'agent envoie un paquet UDP à
un serveur. Ce processus d'alerte est utilisé dans les cas où il
est possible de définir simplement un seuil d'alerte. Dans nombre de
cas, hélas, un alerte réseau ne devrait être
déclenchée qu'en corrélant plusieurs
événements.
3.1.3.1. Les Trames
La trame SNMPv1 est complètement encodée en
ASN.1 [ISO 87]. Les requêtes et les réponses ont le même
format :
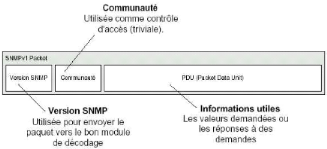
3.1.3.2. Les Paquet SNMP
La version la plus utilisée est encore la version 1.
Plusieurs versions 2 ont été proposées par des documents
de travail, mais malheureusement, aucune d'entre elles n'a jamais
été adoptée comme standard. La version 3 est actuellement
en voie d'être adoptée. On place la valeur zéro dans le
champ version pour SNMPv1, et la valeur 3 pour SNMPv3.
La communauté permet de créer des domaines
d'administration. La communauté est décrite par une chaîne
de caractères. Par défaut, la communauté est « PUBLIC
».
3.1.3.3. Le PDU sa 3e Version
Cette nouvelle version du protocole SNMP vise essentiellement
à inclure la sécurité des transactions. La
sécurité comprend l'identification des parties qui communiquent
et l'assurance que la conversation soit privée, même si elle passe
par un réseau public.
Cette sécurité est basée sur 2 concepts
:
- USM (User-based Security Model)
- VACM (View - Based Access Control Model)
3.1.3.3.1. USM - User-based Security Model
Trois mécanismes sont utilisés. Chacun de ces
mécanismes a pour but d'empêcher un type d'attaque.
3.1.3.3.1.1. L'authentification
L'authentification empêche un intrus
vienne changer le paquet SNMPv3 en cours de route et de valider le mot de passe
de la personne qui transmet la requête.
3.1.3.3.1.1.1. Schéma d'authentification du
SNMPv3
1. Le transmetteur groupe des informations à
transmettre avec le mot de passe.
2. On passe ensuite ce groupe dans la fonction de hachage
à une direction.
3. Les données et le code de hachage sont ensuite
transmis sur le réseau.
4. Le receveur prend le bloc des données, et y ajoute
le mot de passe.
5. On passe ce groupe dans la fonction de hachage à une
direction.
6. Si le code de hachage est identique à celui
transmis, le transmetteur est authentifié.
3.1.3.3.1.2. Le Cryptage
Le cryptage empêche quiconque de lire
les informations de gestions contenues dans un paquet SNMPv3.
Avec SNMPv3, le cryptage de base se fait sur un mot de passe
« partagé » entre le manager et l'agent. Ce mot de passe ne
doit être connu par personne d'autre. Pour des raisons de
sécurité, SNMPv3 utilise deux mots de passe : un pour
l'authentification et un pour le cryptage. Ceci permet au système
d'authentification et au système de cryptage d'être
indépendants. Un de ces systèmes ne peut pas compromettre
l'autre.
SNMPv3 se base sur DES (Data Encryption Standard)
pour effectuer le cryptage.
1.3.4.1.2.1. Cryptage des données du SNMPv3
On utilise une clé de 64 bits (8 des 64 bits sont des
parités, la clé réelle est donc longue de 56 bits) et DES
encrypte 64 bits à la fois. Comme les informations que l'on doit
encrypter sont plus longues que 8 octets, on utilise du chaînage de blocs
DES de 64 bits.
Une combinaison du mot de passe, d'une chaîne
aléatoire et d'autres informations forme le « Vecteur
d'initialisation ». Chacun des blocs de 64 bits est passé par
DES et est chaîné avec le bloc précédent avec un
XOR. Le premier bloc est chaîné par un XOR au vecteur
d'initialisation. Le vecteur d'initialisation est transmis avec chaque paquet
dans les « Paramètres de sécurité », un
champ qui fait partie du paquet SNMPv3.
Contrairement à l'authentification qui est
appliquée à tout le paquet, le cryptage est seulement
appliqué sur le PDU.
1.3.4.1.3. L'estampillage du temps
L'estampillage du temps empêche la réutilisation
d'un paquet SNMPv3 valide déjà transmis par quelqu'un.
Par exemple, si l'administrateur effectue l'opération
de remise à jours d'un équipement, quelqu'un peut saisir ce
paquet et tenter de le retransmettre à l'équipement à
chaque fois que cette personne désire faire une mise à jour
illicite de l'équipement. Même si la personne n'a pas
l'autorisation nécessaire, elle envoie un paquet, authentifié et
encrypté correctement pour l'administration de l'équipement.
On appelle ce type d'attaques le « Replay Attack
». Pour éviter ceci, le temps est estampillé sur chaque
paquet. Quand on reçoit un paquet SNMPv3, on compare le temps actuel
avec le temps dans le paquet. Si la différence est plus que
supérieur à 150 secondes, le paquet est ignoré.
SNMPv3 n'utilise pas l'heure normale. On utilise plutôt
une horloge différente dans chaque agent. Ceux-ci gardent en
mémoire le nombre de secondes écoulées depuis que l'agent
a été mis en circuit.
Ils gardent également un compteur pour connaître
le nombre de fois où l'équipement a été mis en
fonctionnement. On appelle ces compteurs BOOTS (Nombre de fois ou
l'équipement a été allumé) et TIME (Nombre
de secondes depuis la dernière fois que l'équipement a
été mis en fonctionnement).
La combinaison du BOOTS et du TIME donne une valeur qui
augmente toujours, et qui peut être utilisée pour l'estampillage.
Comme chaque agent a sa propre valeur du BOOTS/TIME, la plate-forme de gestion
doit garder une horloge qui doit être synchronisée pour chaque
agent qu'elle contacte. Au moment du contact initial, la plateforme obtient la
valeur du BOOTS/TIME de l'agent et synchronise une horloge distincte.
3.1.3.3.2. VACM - View- based Access Control Model
Permet le contrôle d'accès au MIB. Ainsi on a la
possibilité de restreindre l'accès en lecture et/ou
écriture pour un groupe ou par utilisateur.
3.1.3.3.2.1. La trame SNMPv3
Le format de la trame SNMPv3 est très différent
du format de SNMPv1. Ils sont toutefois codés tous deux dans le format
ASN.1 [ISO 87]. Ceci assure la compatibilité des types de données
entres les ordinateurs d'architectures différentes.
Pour rendre plus facile la distinction entre les versions, le
numéro de la version SNMP est placée tout au début du
paquet.
Ce schéma montre clairement les différents
champs du paquet SNMPv3. Toutefois, le contenu de chaque champ varie selon la
situation. Selon que l'on envoie une requête, une réponse, ou un
message d'erreur, les informations placées dans le paquet respectent des
règles bien définies dans le standard.
Chapitre 4. UTILISATION DE SNMP AU
PL/UCM
Pour administrer les différents équipements,
nous utilisons le protocole SNMP. Pour ce faire, il faut installer sur les
machines Net-SNMP. Net-SNMP est une collection d'applications utilisées
pour implémenter SNMP v1, SNMP v2c, SNMP v3 en utilisant à la
fois IPv4 et IPv6.
Nous avons rapatrié les packages Net-SNMP suivant via
les dépôts de Red Hat :


Net-snmp
o Snmpd (daemon) : agent qui répondra aux
requêtes SNMP
o Snmptrapd (daemon) : application qui recevra les
notifications SNMP Net-snmp-utils : contient les divers outils (snmpwalk,
snmpget, ?)
Une fois les packages installés, il suffit de lancer le
daemon snmpd et on peut déjà interroger l'agent avec des petits
utilitaires du genre de Getif.
4.1.
CONFIGURATION
4.1.1. Création d'un
utilisateur v3
Pour créer un utilisateur v3 (snmpd doit être
arrêté). Il suffit d'ajouter les lignes suivantes au tout
début du fichier /etc/snmp/snmpd.conf
createUser MonUtilisateur MD5 "MonMot2passe" DES
MonMot2PasseDES rouser MonUtilisateur.
MonUtilisateur : nom d'utilisateur
MonMot2passe : authentication protocol pass phrase (qui se
transformera en MD5)
MonMot2PasseDES : privacy protocol pass phrase (qui
servira pour le cryptage des données en DES)
4.1.2. Le fichier snmpd.conf
Ensuite, modifier le fichier comme suit :
####
# First, map the community name "public" into a "security
name"
# sec.name source community
com2sec Local monserveur.domain.tld
ma_communaute_ro
####
# Second, map the security name into a group name:
# groupName securityModel securityName
group LocalGroup usm Local
####
# Third, create a view for us to let the group have rights
to:
# Make at least snmpwalk -v 1 localhost -c public system
fast again.
# name incl/excl subtree mask(optional)
view allview included .1.3.6
view systemview included
.1.3.6.1.2.1.1
view systemview included
.1.3.6.1.2.1.25.1.1
29 Net-SNMP3(*) :
30 Getif4(*) :
####
# Finally, grant the group read-only access to the
systemview view.
# group context sec.model sec.level prefix read write
notif
access LocalGroup "" usm authPriv exact allview
none none
chercher les mots : syslocation et
syscontact et les modifier en conséquence :
syslocation Rack 6, Armoire 9, Societe, Ville, Province,
Pays
syscontact Departement Informatique
<adresse-mail@domain.cd> lancer le service snmpd (
# /etc/init.d/snmpd start )
rééditer le fichier précédent et
supprimer la ligne « create user? »
Chapitre 5. ADMINSTRATION DE
MATERIELS
5.1. LES CONTROLES DES UPS
Les UPS sont un des éléments
importants dans une infrastructure de serveurs. Lors d'une coupure de courant,
ils prennent instantanément le relais le temps que le courant revienne
ou au pire des cas peuvent arrêter les serveurs de manière «
propre ». Il est important dès lors, de vérifier leur
état de fonctionnement.
Nous souhaitons qu'au Projet Limete/Université Cardinal
Malula, le serveur soient protégé par un UPS de marque
MGE UPS SYSTEMS et le modèle
Pulsar Evolution.
5.1.1. La Connectique
Les UPS peuvent être reliés par câble
séries ou USB. Dans cas de Projet Limete Université Cardinal
Malula, le serveur dispose d'une prise USB et d'un connecteur série
à l'arrière. Suite à quelques problèmes avec le
câble série, nous allons relier le UPS en USB.
5.1.2. Les Logiciels
Pour administrer les UPS nous avons besoin de deux logiciels,
lesquels sont nécessaires : UPSmon et Drivers Nut.5(*)
5.1.2.1. UPSmon
Upsmon est un processus client qui a la responsabilité
de la partie la plus importante d'administration couper correctement le
système quand le courant est épuisé. Il peut faire appel
à d'autres programmes dans le but de notifier des
évènements de l'alimentation.
5.1.2.2. Drivers Nut
Le driver libre NUT (Network UPS Tools) est un
logiciel libre largement soutenu par le fabricant MGE qui y
contribue beaucoup, dont les deux atouts principaux sont :
Universalité : fonctionne avec la
plupart des UPS du marché, quelque soit leur connectique (liaison
série, USB, ...)
Client/serveur : un serveur tourne sur la
machine à laquelle est branchée l'UPS, ce qui permet ã
tout le réseau de connaître ã tout moment l'état du
système, et éventuellement d'envisager les actions
nécessaires le cas échéant (batterie faible
?).
5.1.3. Nagios dans tout
cela
L'administration de l'UPS est très simple ã
mettre en oeuvre avec Nagios.
5.1.3.1. Présentation du plugin
Il existe un plugin officiel du coté de Nagios qui
permet d'administrer les UPS ã l'aide de Nut. Ce plugin essaye de
déterminer le statut de l'UPS sur une machine locale ou distante. Si
l'UPS est en ligne ou en calibrage, le plugin retournera un état OK. Si
la batterie est en fonctionnement, il retournera un état Warning.
Si l'UPS est coupé ou a une batterie faible, le plugin retournera
un état Critical.
La définition du service approprié est aussi
simple que pour le reste. Cependant, il faut bien entendu définir la
commande.
5.1.3.1.1. Définition de la commande
Voici la définition de la commande :
define command(
command_name check_ups
command_line $USER1$/check_ups -H $HOSTADDRESS$ -u
$ARG1$
I
Le plugin prend comme argument l'adresse de l'hôte et le
nom de l'UPS. Voyons ensuite la définition du service.
5.1.3.1.2 Définition du service
Rien de bien compliqué :
define service(
use local-service
host _name HOST A
service_description UPS
check_command check_ups!myups
I
Un service local, sur le serveur HOST A. Une courte
description du service et enfin la ligne de commande.
Nous pouvons constater que le plugin contrôle la charge
utile, le pourcentage de charge et l'utilisation de celle-ci.
Chapitre 6. UTILISATION D'UN
SCRIPT A DISTANCE VIA SNMP
Le protocole SNMP permet d'obtenir un nombre incroyable
d'informations sur l'hôte distant.
Malheureusement, on ne peut pas obtenir toutes les
informations que l'on souhaite... Cela peut s'arranger en ajoutant des
informations simplement dans la MIB.
6.1. DES PLUGINS
SUPPLEMENTAIRES
Au Projet Limete Université Cardinal Malula, nous
utiliserons deux PlugIns. Il serait nécessaire de placer soi-même
sur les hôtes distants.
Le premier Plugin est check_connections.pl.
Il fait partie des PlugIns officiels de Nagios. Il permet d'obtenir le
nombre de connections TCP ouverts pour un processus et/ou un utilisateur.
Le deuxième Plugin est check_diskio.
Il est téléchargeable6(*). Il permet de connaître le nombre de secteurs
lus par seconde. Les PlugIns peuvent être placés où on le
souhaite sur l'hôte. Dans notre cas, nous les ai placé dans
/usr/lib(64)/nagios/plugins.
6.2. LA CONFIGURATION DE
L'AGENT SNMP
On peut placer les lignes suivantes où on le souhaite.
Mais par rapport aux commentaires déjà présents dans le
fichier, nous avons préféré mettre les lignes qui suivent
après les commentaires sur :
# Executables/scripts
exec1.3.6.1.4.1.17259.100ldaptcpconn-check
/usr/lib64/nagios/plugins/check_connections.pl -C ns-slapd -w 500 -c
800
exec 1.3.6.1.4.1.17259.101 DiskIOsda
/usr/lib64/nagios/plugins/check_diskio -w 100 -c 200 -d sda
6.2.1. Définition de la
commande et des services sur le serveur
Bien entendu, il faut définir la commande et le service
respectif aux lignes précédentes.
|
define command(
command_name check_snmp
command_line $USER1$/check_snmp -H $HOSTADDRESS$
-o $ARG1$ -r "OK" $USER4$ }
define service(
use ldap-service
host _name mxisrv1
service_description LDAP
Connections
check_command check_snmp!1.3.6.1 .4.1 .1
7259.100.1 01 .1 }
define service{
use host-service
host _name
mx1srv1,mx1srv2,mx1srv3,mx1srv7,mx1srv9,mxisrv1,mxisrv2 service_description
DiskIOsda
check_command check_snmp!1.3.6.1 .4.1 .1
7259.101.1 01 .1
I
|
|
Certaines informations que l'on souhaite obtenir de la machine
nécessitent donc le lancement d'un Plugin à distance. Seulement,
il serait absurde que le Plugin tourne 24h/7j.
Le protocole SNMP permet d'exécuter à distance
des scripts notamment. Ce qui est notre cas avec les deux PlugIns plus haut.
Lorsque Nagios fera une requête SNMP sur l'OID
1.3.6.1.4.1.17259.100.101.1 sur mxisrv1 (par exemple),
le daemon snmpd va interpréter ce message, va se renseigner dans sa
MIB pour obtenir les informations demandées. Pour les obtenir, il va
exécuter le Plugin adéquat. Ce Plugin va renvoyer des
informations que le daemon va capturer et renvoyer au serveur de contrôle
qui lui les analysera et réagira en fonction.
Chapitre 7. LES TRAPS
7.1 UTILISATION DES TRAPS AVEC
NAGIOS
Le protocole SNMP définit aussi un concept de trap.
Une fois défini, si un certain évènement se produit,
comme par exemple le dépassement d'un seuil, l'agent envoie un paquet
UDP (port 162) à un serveur. Ce processus d'alerte est
utilisé dans les cas où il est possible de définir
simplement un seuil d'alerte. Dans nombres de cas, hélas, un alerte
réseau ne devrait être déclenchée qu'en unissant
plusieurs événements.
7.2 CONFIGURATIONS
Une petite configuration est nécessaire coté
serveur et coté client pour que les traps puissent fonctionner. Au
projet Limete/Université Cardinal Malula nous Commencerons par le
client.
7.2.1 Coté client
(l'agent)
Tout d'abord, il faut éditer le fichier
/etc/snmp/snmpd.conf et ajouter les lignes suivantes à
la fin du fichier. Pour nos tests, nous utiliserons la communauté «
public ».
# Définit la communauté par défaut
à utiliser quand les traps seront envoyées. trapcommunity
public
# Envois des traps de version 1 - HOTE où se trouve
le daemon snmptrad [Community [Port]] trapsink 192.1 68.88.129 public
162
# Envois des traps de version 2
trap2sink 192.1 68.88.129 public
162
#Utilisé lors d'envois d'inform ã la place
des traps
informsink 192.1 68.88.129 public
162
# Envois de traps lors d'authentification
ratée
authtrapenable 1
# Permet d'envoyer des traps lors du changement
d'état (Down/Up) des interfaces réseaux
linkUpDownNotifications yes
# Envois des traps pour une liste de problèmes
généraux defaultMonitors yes
7.2.2 Coté serveur
Premièrement, il faut créer (ou
éditer) le fichier /etc/snmp/snmptrapd.conf et
ajouter les lignes suivantes à la fin du fichier.
# On traite de la même façon toutes les
interruptions : avec SNMPTT
traphandle default
/usr/sbin/snmptt
# On accepte toutes les interruptions
disableAuthorization yes
#on ne journalise pas les interruptions reçues
(c'est SNMPTT qui s 'en chargera). On aura quand même une trace de
snmptrapd dans syslog, grâce à l'option -Lsd du lanceur (voir
ci-dessous). donotlogtraps yes
Pour la petite histoire, snmptrad passe à SNMPTT les
éléments de l'interruption qu'il a reçus via les
paramètres de la ligne de commande.
Le lanceur du service snmptrapd doit être modifié
pour ne pas traduire les OID, mais les laisser sous forme numérique.
C'est SNMPTT qui fera la traduction. Il faut modifier
/etc/init.d/snmptrapd :
OPTIONS="-On -Lsd -p /var/run/snmptrapd.pid"
# Il faut rajouter le -On
Après modification, il suffit de redémarrer le
daemon snmptrapd.
7.3 NAGIOS DOIT COMPRENDRE, SNMPTT
L'AIDE.
SNMPTT6(*) (SNMP Trap Translator v1.2beta2) est un handler de
trap écrit en Perl pour être utilisé avec le programme
snmptrapd de Net-SNMP.
7.3.1 Fonctionnement général
1. Un hôte sur le réseau (ou plutôt une
application de cet hôte) envoie une interruption SNMP au serveur qui
héberge Nagios. Celui-ci la reçoit via le service
snmptrapd (qui est en écoute sur le port UDP
162).
2. Snmptrapd la passe ensuite à
SNMPTT, dont le rôle est de rendre intelligible l'interruption.
Pour cela, il se base sur la MIB de l'application
émettrice, que l'on aura bien sûr récupérée
et transformée au préalable pour en nourrir SNMPTT.
3. SNMPTT envoie enfin l'interruption
interprétée à Nagios, via le fichier de commandes externes
de celui-ci. Il utilise pour cela la commande Nagios
submit_check_result.
Dans notre configuration de Nagios, il n'y a qu'un service par
hôte qui reçoit les traps SNMP. Cela signifie que si plusieurs
traps sont reçus en provenance d'un même hôte, seul le
dernier sera affiché.
Par contre, chaque trap reçu générera
bien une notification. Pour acquitter une interruption dans Nagios, il faut
soit forcer un check immédiat du service (qui fera un ping et remettra
l'état à OK), soit soumettre manuellement un check passif, avec
l'intitulé "Init", ou "RAZ", par exemple.
7.3.2 Configuration
Nous allons faire fonctionner SNMPTT en mode "stand-alone" ;
il sera appelé chaque fois que nécessaire par le gestionnaire
d'interruptions snmptrapd. L'initialisation est plus longue dans ce cas, mais
le paramétrage plus simple.
Le fichier de configuration /etc/snmp/snmptt.ini
doit contenir : [General]
mode = standalone
multiple_event = 1
dns_enable = 1
strip_domain = 1
strip_domain_list = <<END
mon.domaine
END
resolve_value_ip_addresses = 0
net_snmp_perl_enable = 1
net_snmp_perl_best_guess = 0 translate_log_trap_oid = 0
translate_value_oids = 1
translate_enterprise_oid_format = 1 translate_trap_oid_format
= 1 translate_varname_oid_format = 1 translate_integers = 1
wildca rd_expansion_separator = " " allow_unsafe_regex = 0
remove_backslash_from_quotes = 0 dynamic_nodes = 0
description_mode = 0
description_clean = 1
[Logging]
stdout_enable = 0
log_enable = 1
log_file = /var/log/snmptt.log
unknown_trap_log_enable = 1
unknown_trap_log_file = /var/log/snmpttunknown.log
statistics_interval = 0
syslog_enable = 1
syslog_facility = local0
syslog_level_debug = <<END
END
syslog_level_info = <<END
END
syslog_level_notice = <<END
END
syslog_level_warning = <<END
END
syslog_level_err = <<END
END
syslog_level_crit = <<END END
syslog_level_alert = <<END END
syslog_level = info
syslog_system_enable = 1 syslog_system_facility = local0
syslog_system_level = warning
[Exec]
exec_enable = 1
pre_exec_enable = 0 unknown_trap_exec =
[Debugging]
DEBUGGING = 0
DEBUGGING_FILE =
DEBUGGING_FILE_HANDLER =
[TrapFiles]
snmptt_conf_files = <<END /etc/snmp/snmptt.conf END
7.3.3 A noter :
Le nom de domaine à supprimer pour ne garder que le nom
d'hôte, qui devra être adapté ã l'environnement on
travaille, et le fait que le module Perl net-snmp est activé. Il permet
l'interprétation étendue des OID.
7.3.4 Compilation des mibs
Il faut maintenant récupérer le ou les fichiers
MIB des équipements à superviser, pour les convertir au format
SNMPTT. Le but est d'extraire ce qui dans le fichier MIB est un commentaire,
pour que SNMPTT le mette en correspondance avec l'OID qui sera reçu.
snmpttconvertmib --in=<fichier MIB>
--out=/etc/snmp/snmptt.conf.<equipement> \ --
exec='/usr/local/nagios/libexec/eventhandlers/submit_check_result
$r TRAP 1'
Dans le cas où on aurait trop de MIB, on peut
exécuter le petit script suivant en tenant compte que toutes les mibs se
trouvent dans /usr/share/snmp/mibs/ :
for i in /usr/share/snmp/mibs/
*.txt
> do
> /usr/sbin/snmpttconvertmib --in=$i
--out=/etc/snmp/snmptt.conf \
--exec='/usr/lib/nagios/plugins/eventhandlers/submit_check_result $r TRAP
1
> done
Ce qui va donc permettre de prendre en compte toutes les mibs
dans le répertoire précédemment cité et les ajouter
dans le fichier snmptt.conf. On aura quelques lignes dans le
genre :
EVENT coldStart .1.3.6.1.6.3.1.1.5.1 "Status
Events" Normal
FORMAT A coldStart trap signifies that the SNMP
entity, $*
EXEC
/usr/lib/nagios/plugins/eventhandlers/submit_check_result $r TRAP 1 "A
coldStart trap signifies that the SNMP entity, $*"
SDESC
A coldStart trap signifies that the SNMP
entity,
supporting a notification originator application,
is
reinitializing itself and that its configuration
may
have been altered.
Variables:
EDESC
7.3.5 Dans Nagios
Le principe est d'utiliser, pour recevoir les interruptions
SNMP, des services passifs mais aussi volatiles, car si nous recevons une
deuxième interruption pour le même hôte avant que la
première ait été remise à OK, nous voulons
être notifié à nouveau.
Pour cela, il faut (par exemple) définir un
service générique pour les traps SNMP, dérivé de
mon service générique général :
define service{
name snmptrap-service
use generic-service
register 0
service_description TRAP
is_volatile 1
check_command check-host-alive
max_check_attempts 1
normal_check_interval 1
retry_check_interval 1
passive_checks_enabled 1
check_period none
notification_interval 31536000
contact_groups admins
}
Et le dériver pour chaque machine supervisée,
par exemple :
define service{
host _name Ubuntu
use snmptrap-service
contact_ groups admins
}
Tout d'abord, il y a la commande check-host-alive
(un simple ping) qui permet de remettre à OK
l'état du service en forçant un contrôle actif. D'autre
part, l'intervalle de notification est artificiellement long : un an ici. Il
permet d'éviter de recevoir régulièrement des
notifications pour la même interruption (tant que le service n'est
pas ramené à l'état OK), laissant penser qu'une
nouvelle interruption, identique à la précédente, a
été reçue. Le problème est qu'il faut
redémarrer Nagios au moins une fois par an.
7.3.6Quelques Tests
Coté client (agent), il suffit de
redémarrer simplement le daemon SNMPD pour qu'un évènement
se produise dans les logs du serveur (manager) :
# tail -f /var/lo g/snmptt.log
Tue May 29 14:20:38 2007 .1.3.6.1.4.1.8072.4.0.2
Normal "Status Events" 192.1 68.88.1 28 - An indication that the agent is in
the process of being shut down.
Tue May 29 14:20:40 2007 .1.3.6.1.6.3.1.1.5.1
Normal "Status Events" 192.1 68.88.128 - A coldStart trap signifies that the
SNMP entity,
Chapitre 1. CONCEPTION DES BASES
DE DONNEES
I.0.INTRODUCTION
Cette présentation n'est pas une partie complète
sur la conception de Bases de données, mais une première approche
destinée à préciser la démarche et les concepts
nécessaires que nous allons utilisé pour construire une base de
donnée cohérente dans notre projet.
Les démarches que nous allons présentés
dans ces pages est un cas de Projet Limete Université Cardinal Malula et
permettent de construire et d'utiliser des bases de données
"réelles" à usage professionnel.
Aussi longtemps que nous venons de bâtir une bonne
fondation dans la partie précédente laquelle, le travail
était de mettre tous les mécanismes permettant d'administrer le
Réseau de Projet Limete Université Cardinal Malula. Maintenant
nous allons procédé à :
1. Utilisation pratique de la démarche de conception de
bases de données
2. Conception et utilisation de bases de données
relationnelles.
I.1. ETUDE CONCEPTIELLE
I.1.1. Définition
- L'étude conceptuelle nous permet d'établir un
schéma conceptuel des données de traitement lesquelles,
constituent une base de référence stable indépendante de
tout matériel ou logiciel de base.
- L'étude conceptuelle est aussi un processus qui
consiste à définir des principes de gestion, aboutissant à
des modèles conceptuels de données et de traitements.
- L'étude conceptuelle se définit
généralement comme une étude de premier niveau et
d'évaluation préliminaire d'un projet. Le niveau de confiance
dans les estimations est d'environ +/- 30%. Les études conceptuelles ne
sont pas suffisamment précises pour permettre un engagement
définitif sur la viabilité économique d'un projet.
Après identification d'un projet potentiel, une étude
conceptuelle peut être entreprise sur plusieurs variantes d'un projet
pour identifier les scénarios potentiels et le temps requis pour
entreprendre des études plus poussées3(*).
I.1.2. But
L'étude conceptuelle a pour but de :
- développer les caractéristiques essentielles
de la solution à émerger ;
- grossir la solution retenue lors de l'étude
d'opportunité ;
- décrire les principes des solutions
indépendamment de moyens utilisés.
2.0 GENERALITES
2.0.1 Notions de base de
données
Une base de données est un ensemble
structuré d'informations non redondantes dont
l'organisation est régie par un modèle de
données.
Les deux mots clefs qui nous interviennent dans la
définition d'une base de données sont :
Structuration (à l'aide du modèle de
données) et non répétition (non redondance ou
redondance minimale) des données.
Construire une base de
données consiste à regrouper les données en paquets
"homogènes", les (entités, tables), chaque entité (table)
étant composée d'un nombre fini de données
élémentaires, les Attributs ou Champs, la
répétition (redondance) des attributs devant être minimale.
Le modèle de données que nous avons utilisée dans ce
travail est le modèle "entités-associations".
2.0.2. Quelques définitions
relatives aux bases de données
La base de données peut être definit de plusieurs
façons, pour cette raison nous nous ciblons quelques définitions
qui sont :
- Une base de données est une collection de
données d'un domaine déterminé ;
- Une base de données est un ensemble d'informations
bien ordonnées qui sont en relation les uns des autres ;
- Une base de données est un ensemble d'informations
exhaustives et non redondants nécessaires à une série
d'application automatisée et qui en assure la gestion ;
- Une base de données est un ensemble d'informations
normalisées en liaison logique les unes des autres qui après
avoir été saisies une seule fois permet de fournir aux
différents échelons de la hiérarchie les informations
actualisées pour agir à temps réel.
2.0.3. Caractéristiques
d'une base de données
- Elle n'accepte pas la redondance, c'est-à-dire aucune
donnée ne sera répétée dans la base de
données ;
- Elle n'accepte pas l'incohérence des
données ;
- Les données doivent être structurées
dans la base de données ;
- Elle assure la sécurité des
informations ;
- Elle doit être indépendante des programmes et
des données, elle doit permettre la prise en compte facile de nouvelles
applications.
2.0.4. Objectifs d'une base de
données
La base de donnée a beaucoup d'abjectifs parmi lesquels
nous pouvons citer :
- Eviter les redondances et les incohérences des
données qui entraînaient fatalement une approche où les
données seraient reparties dans des différents fichiers sans
connexion entre eux.
- Offrir un langage de haut niveau pour la définition
et la manipulation des données ;
- Contrôler l'intégrité entre plusieurs
utilisateurs et la confidentialité des données ;
- Assurer l'indépendance entre les données et
les traitements.
2.0.5. Quelques définitions
de concepts
- Une classe d'entité ou d'objet est un ensemble
composé d'entités ou objets de même type,
c'est-à-dire dont la définition est la même ;
- Une propriété
peut être définie comme étant une information
élémentaire permettant l'identification d'un objet ou d'une
entité5(*) ;
- Un identifiant ou une propriété
clé est une propriété
particulière permettant de caractériser de façon univoque
une entité ou un objet6(*). Une propriété clé ou
identifiant peut être primaire ou secondaire
(étrangère) ;
· Elle est primaire lorsqu'elle répond aux
critères d'univocité et de non nullité.
· Elle est secondaire lorsqu'elle est utilisée
dans une autre entité pour référence à une
entité où elle est définie comme clé
primaire.
- Une Propriété
signalétique est la propriété faisant
référence aux autres propriétés de la classe
d'entités ;
- Une propriété de situation est la
propriété définissant une situation ou un
événement dans un objet ou une entité ;
- Une association est un lien
sémantique qui peut exister entre deux entités
c'est-à-dire c'est le lien qui permet de mettre en relation deux
entités en donnant l'ensemble de caractéristique du
système7(*).
- Une cardinalité est
une modélisation des participations minimum et maximum d'une
entité ou d'un objet8(*). Une cardinalité permet de caractériser
le lien qui existe entre une entité et l'association à laquelle
elle est située.
La cardinalité nous permet de caractériser le
lien qui existe entre une entité et la relation à laquelle elle
est reliée.
La cardinalité d'une relation est composée d'un
couple comportant une borne maximale (1 ou n : décrit le nombre
maximum de fois qu'une quantité peut participer à une relation)
et une borne minimale (0 ou 1 : décrit le nombre minimum de fois
qu'une entité peut participer à une relation).
- Le Formalisme reconnu par MERISE exige que :
· L'objet soit représenté par un rectangle
dans lequel on indique le nom de l'entité ainsi que ses
propriétés ;
· La relation soit représentée par une
ellipse ou hexagone dans laquelle on indique son nom ainsi que ses
propriétés.
3.0 CONCEPTION DE BASE DE DONNEES
DANS NOTRE CAS
Pour la conception de notre Base de données, nous avons
impliqué 3 étapes fondamentales :
1.
Analyse des documents : construction du dictionnaire des données.
2.
Structuration du dictionnaire des données : détermination des
entités et associations.
3. Mise
en relation des entités : Schéma des données.
A 1.Analyse des documents
La première étape, dans la construction d'une
base de données, consiste à réunir tous les documents
représentatifs des données que l'on souhaite modéliser.
Le terme "documents" doit être ici pris dans un sens
large. Il peut s'agir en effet soit de documents papier, soit de documents
magnétiques (enregistrement d'entretiens, disque ou disquette
informatique)... soit de tout autre support utilisable pour conserver des
informations.
A.2. Documents de travail
Pour notre cas, nous allons illustré les
différentes étapes de conception d'une base de données en
utilisant, la gestion tout entière de Projet Limete Université
Cardinal suivent les différents domaines du travail notamment, la
formation des élèves, étudiants, professeur de
l'Université Cardinal Malula, les Recette de Cybercafé, la
Gestion de la Bibliothèque...
A savoir que nous avons déjà
énuméré une bonne partie de ces documents dans notre
première partie du travail.
Nous pouvons aussi ajouter les documents suivants :
|
LISTE DES APPRENANTS DU PLCUM
|
|
N° apprenant
|
Nom Apprenant
|
Post Nom Apprenant
|
Prénom Apprenant
|
Titre Apprenant
|
Catégorie Apprenant
|
|
1
|
Balegnela
|
Ntosule
|
Nancy
|
Mademoiselle
|
élève
|
|
2
|
Mulumba
|
Katoto
|
Fiston
|
Monsieur
|
Etudant
|
|
3
|
Mwamba
|
Tumba
|
Fifi
|
Madame
|
Apprenante
|
|
4
|
Likofo
|
kazadi
|
Tresseur
|
Monsieur
|
Professeur UCM
|
|
5
|
Lilomba
|
Mukuma
|
Franc
|
Monsieur
|
Professeur UCM
|
|
6
|
lokombo
|
talaka
|
Bijoux
|
Mademoiselle
|
élève
|
|
FICHE DE PAYE PAR APPRENANT
|
|
N° APPRENANT : 1 BALENGELA NTOSULE
|
|
N°MODULE
|
LIBELLE MODULE
|
MONTANT PAYE
|
MONNAIE
|
|
1
|
INITIATION
|
10
|
DOLLARS
|
|
2
|
WORD
|
10
|
DOLLARS
|
|
TOTAL PAYE
|
20
|
DOLLARS
|
|
FICHE DE PAYE PAR APPRENANT
|
|
N° APPRENANT : 1 BALENGELA NTOSULE
|
|
N°MODULE
|
LIBELLE MODULE
|
MONTANT PAYE
|
MONNAIE
|
|
1
|
INITIATION
|
5500
|
Franc
|
|
2
|
WORD
|
5500
|
Franc
|
|
TOTAL PAYE
|
11.000
|
Franc
|
|
FICHE DES AGENTS
|
|
N° personnel
|
Nom
|
Post Nom
|
Prénom
|
Catégorie
|
TITRE
|
|
1
|
Lusikila
|
Luambasu
|
BLAISE
|
administrateur
|
Monsieur
|
|
2
|
Batanaswe
|
|
Médard
|
utilisateur
|
Monsieur
|
|
...
|
...
|
|
...
|
...
|
...
|
|
15
|
Tinda
|
|
Laurant
|
utilisateur
|
Monsieur
|
|
FICHE DES APPRENANTS
|
|
N° Apprenant
|
Nom
|
Post Nom
|
Prénom
|
Catégorie
|
TITRE
|
|
1
|
Luaka
|
Lubuma
|
Joel
|
élève
|
Monsieur
|
|
2
|
Gumbo
|
Sitina
|
Fiston
|
Apprenant
|
Monsieur
|
|
...
|
...
|
|
...
|
...
|
...
|
|
14
|
Lomami
|
Titumba
|
Titina
|
Prof.ucm
|
Madame
|
|
15
|
Longo
|
Matina
|
trésor
|
Etudiant
|
Monsieur
|
A.3. Règles de gestion :
o Un livre concerne un et un seul emprunt historique.
o Un emprunt historique peut concerner zéro ou
plusieurs livres.
o Un apprenant peut avoir effectuer Zéro ou plusieurs
emprunt historiques.
o Un emprunt historique est effectué par un et un seul
apprenant.
A.4. Dictionnaire des données
Partant des documents, la phase d'analyse consiste à en
extraire les informations élémentaires (non décomposables)
qui vont constituer la future base de données.
La réunion de l'ensemble des données
élémentaires, que l'on appelle des attributs ou
des champs, constitue le dictionnaire des données.
Chaque attribut (champ) du dictionnaire de données peut être
caractérisé par les propriétés suivantes :
|
Propriété
|
Signification
|
|
Mnémonique
|
Abréviation du nom de l'attribut.
|
|
Libellé
|
Libellé contenant la signification précise et le
rôle de l'attribut.
|
|
Type de donnée
|
Type de l'attribut : entier, réel, chaîne de
caractères, date...
|
|
Contraintes d'intégrité
|
Liste des contraintes sur les valeurs possibles de
l'attribut
|
|
Règle de calcul
|
Règle de calcul (d'obtention) de l'attribut
correspondant.
|
Le dictionnaire des données relatives aux documents que
le Projet Limete Université Cardinal Malula nous a
présenté est le suivant :
|
DICTIONNAIRE DE DONNEES PL/UCM
|
|
agent
|
|
|
|
|
|
|
|
|
|
|
|
Champ
|
Signification
|
Type
|
Null
|
Défaut
|
|
idagent
|
Identification de l'agent
|
int(11)
|
Non
|
|
|
prenom
|
prenom
|
varchar(20)
|
Non
|
|
|
nom_agent
|
nom_agent
|
varchar(20)
|
Non
|
|
|
postnom
|
postnom
|
varchar(20)
|
Non
|
|
|
telephone
|
telephone
|
varchar(20)
|
Non
|
|
|
email
|
email
|
varchar(20)
|
Non
|
|
|
login
|
login
|
varchar(20)
|
Non
|
|
|
mot_de_passe
|
Mot de passe de l'agent
|
varchar(20)
|
Non
|
|
|
site
|
site
|
varchar(20)
|
Oui
|
NULL
|
|
adresse
|
adresse
|
varchar(30)
|
Non
|
|
|
idsexe
|
Identification de sexe
|
int(11)
|
Non
|
0
|
|
idcategorie
|
Identification de catégories
|
int(11)
|
Non
|
0
|
|
date_engag
|
date d'engagement de l'agent
|
varchar(30)
|
Non
|
|
|
|
|
|
|
|
|
apprenants
|
|
|
|
|
|
|
|
|
|
|
|
Champ
|
Signification
|
Type
|
Null
|
Défaut
|
|
idapprenant
|
identification de l'apprenant
|
int(11)
|
Non
|
|
|
prenom
|
prenom
|
varchar(20)
|
Non
|
|
|
nom
|
nom
|
varchar(20)
|
Non
|
|
|
postnom
|
postnom
|
varchar(20)
|
Non
|
|
|
telephone
|
telephone
|
varchar(30)
|
Non
|
|
|
email
|
email
|
varchar(20)
|
Non
|
|
|
login
|
login
|
varchar(30)
|
Non
|
|
|
mot_de_passe
|
mot_de_passe
|
varchar(20)
|
Non
|
|
|
site
|
site
|
varchar(20)
|
Non
|
|
|
adresse
|
adresse
|
varchar(20)
|
Non
|
0000-00-00
|
|
idsexe
|
identification de sexe
|
int(11)
|
Non
|
0
|
|
idcategorie_ap
|
identification de catégories apprenants
|
int(11)
|
Non
|
0
|
|
date_inscription
|
date d'inscription de l'apprenant
|
varchar(20)
|
Non
|
|
|
idformation
|
identification de formation
|
int(11)
|
Non
|
0
|
|
idecole
|
identification de l'école
|
int(11)
|
Non
|
0
|
|
id_etatcivil
|
identification de l'état civil
|
int(11)
|
Non
|
0
|
|
profession
|
profession
|
varchar(50)
|
Non
|
|
|
organisme
|
organisme
|
varchar(50)
|
Non
|
|
|
employeur
|
employeur
|
varchar(20)
|
Non
|
|
|
activite
|
activite
|
varchar(50)
|
Non
|
|
|
occupation
|
occupation
|
varchar(50)
|
Non
|
|
|
choisirplucm
|
la raison qui a pousé à choisir plucm
|
varchar(50)
|
Non
|
|
|
|
|
|
|
|
|
auteur
|
|
|
|
|
|
|
|
|
|
|
|
Champ
|
Signification
|
Type
|
Null
|
Défaut
|
|
idauteur
|
identification d'auteur
|
int(11)
|
Non
|
|
|
nom
|
nom
|
varchar(30)
|
Non
|
|
|
nationalite
|
nationalite
|
varchar(30)
|
Non
|
|
|
|
|
|
|
|
|
categories
|
|
|
|
|
|
|
|
|
|
|
|
Champ
|
Signification
|
Type
|
Null
|
Défaut
|
|
idcategorie
|
identification de catégories dans la table
catégories
|
int(11)
|
Non
|
|
|
categorie
|
catégories d'agent
|
varchar(20)
|
Non
|
|
|
|
|
|
|
|
|
categoriesap
|
|
|
|
|
|
|
|
|
|
|
|
Champ
|
Signification
|
Type
|
Null
|
Défaut
|
|
idcategorie_ap
|
identification de catégories dans la table
catégories ap
|
int(11)
|
Non
|
|
|
categorie_ap
|
catégories de l'apprenant
|
varchar(20)
|
Non
|
|
|
|
|
|
|
|
|
charges
|
|
|
|
|
|
|
|
|
|
|
|
Champ
|
Signification
|
Type
|
Null
|
Défaut
|
|
idcharge
|
identification de charge
|
int(11)
|
Non
|
|
|
datedepense
|
date de dépense
|
varchar(20)
|
Non
|
|
|
libdepense
|
libellé de dépense
|
varchar(20)
|
Non
|
|
|
montantcha
|
montant de la charge
|
float
|
Non
|
0
|
|
idmonnaie
|
identification de la monnaie
|
int(11)
|
Non
|
0
|
|
idagent
|
identification de l'agent
|
int(11)
|
Non
|
0
|
|
idmoment
|
identification de moment de la dépense
|
int(11)
|
Non
|
0
|
|
|
|
|
|
|
|
chat
|
|
|
|
|
|
|
|
|
|
|
|
Champ
|
Signification
|
Type
|
Null
|
Défaut
|
|
id
|
identification
|
int(11)
|
Non
|
|
|
pseudo
|
pseudo de l'utilisateur
|
varchar(20)
|
Non
|
|
|
message
|
message qu'il envoie
|
varchar(200)
|
Non
|
|
|
|
|
|
|
|
|
|
|
|
|
|
B.1.Structuration des données
Les informations contenues dans le dictionnaire de
données doivent être étudié avec soin en fin
qu'elles soient très bien structurées en "paquets"
homogènes (entités, tables) dans lesquels la
répétition (redondance) d'informations doit être
minimale.
Les attributs qui sont calculés (qui ont une
règle de calcul) ne doivent pas être pris en compte dans
la phase de structuration des données. Ils sont en effet obtenus
à partir d'autres attributs, et les inclure dans la phase de
structuration introduirait une forme de redondance et donc des
possibilités d'incohérence. Dans notre exemple, l'attribut
"Moyenne" appartient à cette catégorie.
On dira qu'un ensemble d'attributs est homogène si tous
les attributs qui le composent ont un lien "direct".
La redondance à l'intérieur d'un ensemble doit
être minimale car la redondance est source d'incohérence. En
effet, si la même information est répétée plusieurs
fois, cela signifie :
· Qu'elle devra être saisie plusieurs fois, ce qui
multiplie les risques d'erreurs de frappe.
· Que lorsqu'elle devra être mise à jour,
les modifications devront intervenir à plusieurs endroits d'où
des risques de mise à jour partielle.
Pour regrouper les attributs du dictionnaire de données
on utilise un élément structurant qui s'appelle la
dépendance fonctionnelle (DF).
B.2 Notion de dépendance fonctionnelle (DF)
Pour établir efficacement un modèle
entités- associations bien normalisé, on peut étudier au
préalable les dépendances fonctionnelles entre les attribues
puis, les organiser en graphe de couverture minimale. Cette technique est
traditionnellement employée pour normaliser les schémas
relationnels, mais elle s'applique très en amont, au niveau des
modèles conceptuels.
B.2.1 Dépendance Fonctionnelle dans notre
cas
Dans notre base de données
plucm, connaissant un numéro d'apprenant, on connaît de
manière unique le nom de cet apprenant et, entre autres, sa
catégorie.
B.2.2 Définition et Propriétés
Un attribut Y dépend fonctionnellement d'un attribut X
si et seulement si une valeur de X induit une unique valeur de Y on note une
dépendance fonctionnelle par une flèche simple : XY.
Pour notre cas : si X est le Id_donateur et Y le nom de
donateur, alors on a bien XY par contre on pas YX, car plusieurs donateurs de
id_donatuer différents peuvent porter le même nom.
B.2.3. Transitivité
Si X Y et Y Z alors X Z
Pour notre cas, on as id_recu id_apprenant nom_apprenant,
donc on a aussi id_recu nom_apprenant. Mais la dépendance fonctionnelle
id_recu nom_apprenant est dite transitive, car il faut passer par le
id_apprenant pour l'obtenir.
Au contraire, la dépendance fonctionnelle id_apprenant
nom_apprenant est directe, seules les dépendances fonctionnelle
directes nous intéressent, d'autres exemples sont données dans le
tableau suivant :
|
DEPENDANCES FONCTIONNELLES
|
DIRECTE ?
|
|
id_auteur nom_auteur
id_livre titre livre
id_agent nom_agent
id_charge moment
id_moment moment
id_emprunt titre_livre
id_emprunt date_emprunt
id_recu date_paye
id_recu titre_formation
id_formation lib_formation
|
Oui
Oui
Oui
Non
Oui
Nom
Oui
Oui
Non
oui
|
Un attribut Y peut avoir une dépendance fonctionnelle
qui repose sur la conjonction de plusieurs attributs auquel cas la
dépendance fonctionnelle est dite non élémentaire1(*).les dépendances
fonctionnelles non élémentaires sont notées par une
flèche unique mais comportant plusieurs points d'entrée (
regroupés autour d'un cercle).
Pour notre cas, la quantité de livre donné par
un donateur dans la bibliothèque. Dépend de deux attributs :
id_livre et id_donateur. Notons que cett'e dépendance fonctionnelle
Id_livre + id_donateur quantité donnée est à la fois nom
élémentaire et directe.
Id_livre
Quantité donnée
Id_donateur
Nous avons dans notre le cas une dépendance
fonctionnelle non élémentaire, mais directe.
B.3. Graphe de Couverture Minimale
En présentant tous les attributs et toutes les
dépendances fonctionnelles directes entre eux, nous obtenons un
réseau appelé graphe de couverture minimale de la manière
suivante :
Id_livre id_donateur
Titre_livre
nom_don
Quantite_donne
adresse
Nb_paeges
Téléphone
La technique de traduction en un schéma entités
associations qui sont, supposé qu'aucun attribut n'a été
oublié sur le graphe de couverture minimale et notamment, aucun
identifiant. Si ce n'est pas le cas, c'est qu'un identifiant a
été omis.
B.3.1 Association sans atributs
La lacune majeure de cette méthode reste tant de
même le fait que les associations dont toutes les cardinalités
maximales sont n mais qui sont sans attributs ne figurent pas sur le graphe de
couverture minimale.
Il faut alors, sont leur inventer temporairement un attribut
(comme pour la normalisation des attributs des associations), soit introduire
une notation spéciale (par exemple, une dépendance no
élémentaire qui ne débouche sur aucun attribut).
Pour rappeler ce cas, nous revenons sur la relation du livres
et auteurs il y a pas d'attributs qui dépende à la fois du
id_livre et id_auteur (à moins d'imaginer le temps d'apparition à
l'écran) et pourtant, les deux non élémentaire et sans
enfant, on peut rendre compte de cette situation sur le graphe de couverture
minimale et faire ainsi apparaître l'association sur le schéma
entités - associations.
Id_auteur id_livre
nationalite nb_pages titre_livre
Nom_auteur
B.3.3 Traduction
Id_auteur
Nom
nationalité
Auteur
ecrire
Id_livre
Titre
nb_pages
livre
1, n 1, n
B.3.4. Union de deux Graphes
Nous pouvons unir ces deux graphes pour faire sortir une seule
traduction en entités - Associations.
Id_auteur id_livre id_donateur
Nationalité nb_pages
nom_don téléphone
nom_auteur titre_livre
adresse quantité
B.3.5 Traduction vers un schéma entités -
associations
A partir du graphe de couverture minimale, le schéma,
le schéma entités - associations normalisé correspondant
apparaît naturellement en suivant quelques étapes très
simples.
Id_livre
Titre_livre
Nb_pages
Id_donateur
Adresse
Nom
Quantité
Id_auteur
Nom_aut
Nationalité
Nous avons essayé d'identifier les entités et
les associations sur le graphe de couverture minimale ainsi, nous avions eu
quelques étapes à suivre de près telles que :
1. Repérer et souligner les identifiants.
2. Puis tous les attributs non identifiant qui
dépendent directement d'un identifiant et d'un seul, forment une
entité (avec l'identifiant bien sur).
3. Ensuite, les dépendece élémentaires
entre les identifiants forment les associations binaires dont les
cardinalité maximales sont 1 au départ de la dépendance
fonctionnelle et n à l'arrivée.
4. Sauf si entre deux identifiants se trouvent deux
dépendances fonctionnelles élémentaires
réflexives, auquel cas l'association binaire à deux
cardinalités maximales valant 1.
Il faut noter qu'à cause de cette point 4 qu'il est
préférable de ne pas traduire directement le graphe de couverture
minimale en un schéma relationnel.
5. Enfin, les attributs (non identifiants) qui
dépendent de plusieurs identifiant sont les attributs d'une association
supplémentaire dont les cardinalités sont toutes n.
La traduction du graphe du couverture minimale en un
schéma entités - associations normalisé est donné
comme suit:
livres
donateur
Id_livre
Tire_livre
Id_donateur
Nom_donateur
Adresse...
1, n
Écrire
Donner
Quantité
auteur
Id_auteur
Nom_auteur
Nationalité
1, n
0, n 1, n
Nous avons trouvé le schéma entités -
associations normalisé obtenu à partir du graphe de couverture
minimale.
Dans ce genre de traductions, il faut donner un nom aux
entités et aux associations, car ce n'est pas le cas pour le graphe de
couverture minimale et il reste les cardinalités minimales à
établir.
Remarquons également qu'en réalité il
faut déjà connaître les entités en présence
pour établir correctement, cette technique n'est une aide pour
établir les associations entre les entités et pour normaliser les
entités et leurs associations jusqu'en troisième forme normale de
Boyce-codd).
B.3.6 Gestion des dates et du Caractère
historique
Dans la bibliothèque du Projet Limete Cardinal Malula,
on peut vouloir stocker les emprunts en cours et / ou les emprunts historiques.
Pour les emprunts en cours, la date de retour prévu est un attribut de
l'entité livre, car un livre ne peut faire l'objet que d'un seul emprunt
en cours, dans ce cas, l'établissement du graphe de couverture minimale
ne pose aucun problème.
Par là, nous avons un sérieux problème,
car un livre peut faire l'objet de plusieurs emprunts historiques et dans ces
conditions, la date d'emprunt est déterminante pour une
dépendance fonctionnelle ne peut partir que d'un ou plusieurs
identifiants. Ces le signe qu'il manque un identifiants :
Le numéro d'emprunt
Id_livre date_emprunt
Titre_livre
date date
retour retour
Prévu
effectif id_apprenant
Nom_appre adresse
Nous devons corrigé ce graphe car une date n'est pas
être un identifiant.
Id_livre date_d'emprunt
Tire_livre numéro d'emprunt
Date date id_apprenant
retour retour
prévu effectif
nom_appre
adresse
À présent nous avons la facilité de le
traduire en un modèle entités- associations.
Id_livre
Tire_livre
livres
Numéro_emprunt
date_emprunt
date_retour_prevu
date_retour_effectif
Emprunt historique
Id_appre
Nom_appre
Postnom_appre
Prenom_appre
Téléphone
E-mail
Login
Password
...
Apprenant
Concerner
Avoir effectué
0, n 1,1
1,1 0,n
Nous avons évité même pour une
entité historique, il vaut mieux éviter que la date n'entre dans
l'identifiant. Notons que l'entité emprunts historiques
supplémentaires qui apparaît après tradition ne peut pas
être transformé en une association comme on pourrait le croire au
simple examen des cardinalités qui l'entourent, en effet, les attributs
de l'association qui en resulterait ne verififieraient pas la normalisation des
attributs des associations. Notamment, la date de retour effectif ne
dépend pas du numéro de livre et du id_apprenant, mais du
id_livre et la date d'emprunt.
La normalisation des entités ne s'applique donc pas aux
entités qui ont un caractère historique2(*) . à moins que les
dates ne soient regroupées dans une entité séparée,
ce qui n'est pas conseillé tant qu'aucune information liée aux
dates telles que : caractère férié, par exemple n'est
nécessaire.
B.3.7 Méthodologie de base utilisé
Face à notre situation bien définie, nous
n'avons pas présenté l'ensemble de démarche pour tous
entités ou associations, puis que nous puissions aussi procéder
sans établir le graphe de couverture minimale, en procédant par
les méthodologies de base qui sont :
1. Identifier les entités en présence ;
2. Lister leurs attributs ;
3. Ajouter les identifiants (nous avons beaucoup plus utiliser
les auto incrémentes).
4. Lister leurs attributs ;
5. Calculer les cardinalités ;
6. Vérifier les règles de normalisation et en
particulier, la normalisation des entités (c'est à ce stade
qu'apparaissent les association non binaires), des associations et leurs
attributs ainsi que la troisième forme normale de Boyece-codd ;
7. Effectuer les corrections nécessaires ;
Mais il est parfois plus intuitif d'en passer par
l'étude de la dépendance fonctionnelle directe ;
8. Identifier les entités en présence et leurs
donner un identifiant (numéro arbitraire ou auto
incrémente) ;
9. Ajouter l'ensemble des attributs et leurs
dépendances fonctionnelles directes avec les identifiant (en
commençant par les dépendances
élémentaires) ;
10. Traduire le graphe de couverture minimale obtenu en un
schéma entités - associations ;
11. Ajouter les cardinalités minimales et ;
12. A ce stade, la majorité des règles de
normalisations devraient être vérifiées, il reste tout de
même la normalisation de noms, la présence d'attributs en
plusieurs exemplaires et d'associations redondantes ou en plusieurs exemplaires
à corriger.
Nous avons gardé également en l'esprit que le
modèle doit être exhaustif ( c'est -à - dire contenir
toutes les informations nécessaires) et éviter toute redondance
que nous ne dirions pas assez, constitué une perte d'espace3(*),une démultiplication du
travail de maintenance et un risque d'incohérence.
Il va de soi que cette méthodologie ne doit pas
être suivie pas à pas une bonne fois pour toute. Au contraire, il
faut itérer plusieurs fois les étapes successives, pour
espérer converger vers une modélisation pertinente de la
situation de notre travail.
C.1. Construction du schéma des
données
La dernière étape consiste à mettre en
relation les entités et associations trouvées dans l'étape
précédente afin de construire la structure générale
des données : le schéma des données.
C.2. Mise en relation des entités
Les entités sont mises en relation par
l'intermédiaire des attributs qu'elles possèdent en commun. Les
types de relations autorisées pour relier deux entités
(associations) appartiennent aux deux catégories suivantes :
· Relation de type 1-1 : à un
élément de l'ensemble départ on ne peut faire correspondre
qu'un seul élément de l'ensemble d'arrivée et
réciproquement.
· Relation de type 1-n : à un
élément de l'ensemble de départ on peut faire correspondre
plusieurs éléments de l'ensemble d'arrivée. Par
application de la méthode, les seules relations possibles entres
entités et associations sont des relations de type n-1, soient des
dépendances fonctionnelles. Cette étape vise donc à
déterminer les dépendances fonctionnelles entre entités et
associations : construction du graphe des index.
Pour déterminer les
relations entre entités (associations), il faut donc examiner le
cardinal de chacune des entités qui interviennent dans la relation.
Dans notre cas, nous avons des relations suivantes :
|
Entité source
|
Entité but
|
Relation sur l'attribut
|
Type de relation
|
|
SEXE
|
APPRENANT
|
Id_sexe
|
1-n
|
|
MONNAIES
|
FORMATION
|
Id_monnaie
|
1-n
|
|
SEXE
|
AGENT
|
idsexe
|
1-n
|
|
LIVRE
|
DONNER
|
Id_livre
|
1-n
|
|
DONATEUR
|
DONNER
|
Id_donateur
|
1-n
|
Si l'on examine la première ligne du tableau, nous
avons précisé que la relation entre SEXE et APPRENANT
était de type 1-n.
En effet, dans l'entité SEXE, une valeur
particulière de l'attribut Idsexe (H ou F) ne sera présente
qu'une seule fois (1). En revanche, dans l'entité APPRENANT, la
même valeur de l'attribut Idsexe pourra être présente
plusieurs fois (n), autant de fois qu'il y a d'apprenants de ce sexe.
C.3. Représentation graphique du schéma
des données
Pour avoir une vision synthétique de la structure de la
base de données (le schéma des données) on utilise une
représentation graphique du type suivant laquelle va prendre toutes les
tables qu'on a montrées et celles qu'on n'a pas montrées:
C.3.1.base de donnees pour la gestion de projet limete
universite cadinal malula
PAIES
id_paye
# id_agent
Prime
dettes
salbase
saltot
datepaye
RECUS
id_recu
# id_agent
# id_monnaie
# id_apprenant
# id_formation
# id_categorie_ap
datepaye
montantpaye
DONNER
#id_livre
#id_donnateur
quantité
DONATEURS
id_donateur
nom
adresse
AGENTS
id_agent
# id_categorie
# id_sexe
#idetat
nomagent
postnomagent
APPRENANTS
id_apprenant
#id_categorie ap
# id_ sexe
#id_formation
#id_ecole
#idetat
nomappre
postnomappre
CATEGORIESAP
id_categorie ap
categorie ap.
CATEGORIES
id_categorie
categorie
id_categorie
categorie
SEXES
id_sexe
sexe
FORMATIONS
id_formation
lib_formation
prix
# id_monnais
CHARGES
id_charge
date depense
id_agent
#id_moment
#id_monnais
MONNAIS
id_monnais
monnais
MOMENTS
id_moments
id_moments
LIVRES
id_livre
-titre
-editeur
-prix
#id_monnais
PRODUITS
id_produits
datepro
montant pro
#id_agent
id_monnais
#id_source
#id_moment
ECRIRES
#id_livre
#id_auteur
SOURCES
id_source
lib_source
AUTEURS
id_auteur
Nom
EMPRUNT HISTORI
idemprunt
#idlivre
#idaprenant
Dateemprunt
Dateretourpreuvu
dateretoureffective
ECOLE
id_ecole
NomEcole
Adresse...
Etat Civil
idetat
libetat
4.0. QUELQUES ETATS EN
SORTIES
A partir de ce Modèle Organisationnel de
Données, on peut alors établir la conception de quelques
états qui seront établis lors de l'étude
opérationnelle ou de l'exploitation.
Lors de la conception des états de sorties, il faut
étudier successivement les parties ci-dessous :
- L'entête : rubrique qui ne se
répète pas ;
- Le corps ou le détail : rubrique pouvant se
répéter ;
- Le pied : rubrique de totalisation.
Pour faciliter ce travail de la conception de quelques
états, tous les états de sortie doivent être
répertoriés dans une fiche descriptive des sorties.
4.0.1. Fiche Descriptive des
sorties
|
Caractéristiques
1. Mode de sortie
- papier
- écran
2. Volume
- nombre de page : 1 ou n
- nombre de ligne par page : n
- nombre d'exemplaire : 1 ou n
3. Périodicité
|
Contenus : rubriques
|
|
Nombre de rubrique
|
Nature de rubriques
|
Liste des états en sortie
|
Longueur de rubriques
|
|
Plusieurs
|
Etats de sortie
|
Liste01
Liste02
Liste03
Liste04
Liste05
...
|
A déterminer
|
4.0.1.1. Liste de apprenants (liste01)
1. But : permet d'établir la liste de
tous les apprenants
2. Source : Adminstration
3. Modèle
Page Kinshasa, le xx/xx/xxxx
PROJET LIMETE UNIVERSITE CARDINAL MALULA
PL/UCM
Liste de tous les apprenants
N° Numéro fiche Nom &
Post-Nom sexe Profession Adresse
Module
xx xxxxxxxxxxx xxxxx xxxxxxxx xxx xxxxxxxxx xxxxxxx
xxxxxx
4.0.1.2. Liste de apprenants de sexe masculin
(liste02)
But : permet d'établir la liste de
tous les apprenants de sexe masculin
Source : Administration
Modèle
Page Kinshasa, le xx/xx/xxxx
PROJET LIMETE UNIVERSITE CARDINAL MALULA
PL/UCM
Liste de tous les patients de sexe
masculin
N° Numéro fiche Nom &
Post-Nom Profession Adresse Module
xx xxxxxxxxxxx xxxxx xxxxxxxx xxxxxxxxx xxxxxxx
xxxxxxx
4.0.1.3. Liste de apprenants de sexe féminin
(liste03)
1. But : permet d'établir la liste de
tous les patients de sexe féminin
2. Source : Administration
3. Modèle
Page Kinshasa, le xx/xx/xxxx
PROJET LIMETE UNIVERSITE CARDINAL MALULA
PL/UCM
Liste de tous les patients de sexe
féminin
N° Numéro fiche Nom &
Post-Nom Profession Adresse Module
xx xxxxxxxxxxx xxxxx xxxxxxxx xxxxxxxxx xxxxxxx
xxxxxxx
4.0.1.4. Liste de Reçu (liste04)
1. But : permet d'établir la liste de
tous les Reçus
2. Source : Admininstration
3. Modèle
Page Kinshasa, le xx/xx/xxxx
PROJET LIMETE UNIVERSITE CARDINAL MALULA
PL/UCM
Liste de tous les patients de sexe
masculin
N° Numéro fiche Numéro
reçu Montant à payer Montant payé
xx xxxxxxxxxxx xxxxx xxxxxxxx xxxxxxxxx xxxxxxx
4.0.1.5. Reçu (liste05)
1. But : permet d'établir le
reçu des apprenants après paiement
2. Source : Administration
3. Modèle
Page Kinshasa, le xx/xx/xxxx
PROJET LIMETE UNIVERSITE CARDINAL MALULA
PL/UCM
reçu de l'apprenant
N° Numéro fiche Nom de module
Date formation Montant payé
xx xxxxxxxxxxx xxxxx xxxxxxxx xxxxxxxxx
xxxxxxxxxx
Chapitre 2. ETUDE
OPERATIONNELLE
2.1. GENERALITES
C'est au cours de cette partie, appelée aussi
réalisation, dont il sera question de détailler suffisamment la
solution qui sera retenue pour l'étape de la programmation.
C'est une analyse détaillée de grand module de
traitement conçut lors de l'étude conceptuelle en vue de donner
une ouverture aux travaux de la programmation afin de pouvoir rendre
l'exploitation possible et aisée pour que la programmation soit aussi
possible.
2.2. DESCRIPTION DE
MATERIELS
Cette étape nous aide à faire le choix
technique c'est-à-dire de présenter les contraintes
matérielles (hardware) et du logiciel (software) à utiliser. Afin
de permettre l'implémentation de la base de données, nous
décrirons deux aspects matériels qui permettront
l'évolution synthétique de l'étude
opérationnelle.
Ces deux aspects peuvent être soit hardware ou
software.
2.2.1. Aspect Hardware
L'hardware est l'ensemble des ressources visibles qui
constituent l'architecture palpable de l'ordinateur.
Notre option est fait sur des ordinateurs qui seront
utilisés soit comme serveur ou soit comme clients. En ce qui concerne le
serveur, notre choix est porté sur l'ordinateur de marque Compaq
ProLiant ML310 - P4 2 GHz, par ailleurs, pour les machines clients, nous avons
préféré utiliser les matériels de marque Compaq
DeskPro EN.
2.2.1.1. Caractéristiques de Compaq ProLiant
ML310 - P4 2 GHz
Il comprend la prise en charge de la technologie RAID en
option.
- Processeur : INTEL® PENTIUM® 4, 2 GHz
- Mémoire cache : L2 Cache - Advanced Transfer
Cache
Installed Size: 512 KB
- RAM : 512 MB / 4 GB (max)
- Carte graphique : 5 au total (2 PCI Express - 3 PCI)
- Disque dur : 180 GB x 6 SATA avec contrôleur
RAID
- RAID Level: RAID 0, RAID 1, RAID 10
- Port USB : USB 2.0 (8 ports - 3 avant et 5
arrières)
- Lecteur CD : CD - RW/DVD
CD - R/DVD
- Lecteur disquette : 3.5 pouces de 1.44 MB
2.2.1.2 Caractéristique de Compaq DeskPro
EN
- Processeur : INTEL® PENTIUM® III 647
647MHz
- Mémoire cache : L2 - Pipeline Burst, 128 Ko
(installé) / 128 Ko (maximum)
- RAM : 64 Mo / 512 Mo (maximum) , DIMM 168 broches
- Carte graphique : AGP 2x - intégré,
- Résolution maxi (externe) : 1280 x 1024 / 24
bits (16,7 millions de couleurs)
- Affichages graphiques pris en charge : VGA (640x480),
XGA (1024x768), SVGA (800x600), SXGA (1280x1024)
- Sortie vidéo prise en charge : RGB
- Reseaux :Adaptateur réseau - PCI -
intégré
- Protocole de liaison de données : Ethernet, Fast
Ethernet
- Protocole réseau / transport : TCP/IP, IPX/SPX,
NetBEUI/NetBIOS
- Normes : IEEE 802.3, IEEE 802.3U
- Disque dur : 20 GB
- Port USB : USB 2.0 2ports
- Lecteur CD : CD - RW/DVD
CD - R/DVD
- Lecteur disquette : 3.5 pouces de 1.44 MB
- Ecran : TFT MONITOR 17 pouces
- Souris : PS2 Standard
- Imprimantes : Laser : HP Laser Jet 1010
séries
2.2.3. Aspect Software
Pour définir le software, plusieurs définitions
peuvent être utilisées :
Le Software Par opposition à hardware, matériel,
un software est un logiciel1(*)1.
Le software peut être considéré comme
l'ensemble de programmes, procédés, règles et
éventuellement la documentation en relation ou fonctionnement d'un
ensemble de données.
Le software est l'ensemble des programmes écrit ou non
par les constructeurs d'ordinateurs en vue de permettre un bon fonctionnement
aisé.
C'est la partie qui touche l'intelligence artificielle de
l'ordinateur, c'est que l'on appelle en français Logiciel.
Pour ce faire, nous utiliserons les logiciels de base et
d'applications ci-dessous :
- Pour le serveur : Compaq ProLiant
ML310 - P4 2 GHz
· Système d'exploitation : LUNIX
DISTRIBUTION RED HAT
· Système de gestion de base données
: MYSQL
· Langage de programmation : PHP
· Antivirus : NORTON 2007 ANTIVIRUS
· Logiciel d'archivage : WINZIP 9
- Pour les clients : Compaq Despro EN
· Système d'exploitation : Windows XP ou
Linix
· Antivirus : NORTON 2007 ANTIVIRUS
· Logiciel d'archivage : WINZIP 9
· Navigateur : Internet Explorer, ou autres
Chapitre 3. SYSTEME DE GESTION DE
BASE DE DONNEES (SGBD) UTILISE.
3.1. INTRODUCTION
Un SGBD est un logiciel qui joue le rôle d'interface
entre les utilisateurs et la Base de Données.
Un SGBD permet de décrire, manipuler et interroger les
données d'une Base de Données. Il est chargé de tous les
problèmes liés aux accès concurrents, à la
sauvegarde et la restauration des données. Il doit de plus veiller au
contrôle, à l'intégrité et la sécurité
des données.
Nous avons porté notre choix sur MySQL.
Car,MySQL est un
système
de gestion de base de données (SGDB). Selon le type
d'application, sa licence est
libre ou
propriétaire.
Il fait partie des logiciels de gestion de base de données les plus
utilisés au monde, autant par le grand public (applications web
principalement) que par des professionnels, au même titre que
Oracle
ou
Microsoft SQL
Server.MySQL AB a été acheté le
16
janvier
2008 par
Sun
Microsystems pour un milliard de dollars US1(*).
3.2.  CARACTERISTIQUES CARACTERISTIQUES
MySQL est un serveur de
bases
de données relationnelles
SQL
développé dans un souci de performances élevées en
lecture, ce qui signifie qu'il est davantage orienté vers le service de
données déjà en place que vers celui de mises à
jour fréquentes et fortement sécurisées. Il est
multi-thread
et multi-utilisateurs.
C'est un
logiciel libre
développé sous double licence en fonction de l'utilisation qui en
est faite : dans un
produit libre
ou dans un produit propriétaire. Dans ce dernier cas, la licence est
payante, sinon c'est
LGPL
qui s'applique. Ce type de licence double est utilisé par d'autres
produits.
3.3. SYSTEMES D'EXPLOITATION
SUPPORTES
MySQL fonctionne sur de nombreux
systèmes
d'exploitation différents, incluant
AIX,
BSDi,
FreeBSD,
HP-UX,
Linux,
Mac OS X,
NetWare,
NetBSD,
OpenBSD,
OS/2 Warp,
SGI
Irix,
Solaris,
SunOS,
SCO
OpenServer,
SCO
UnixWare,
Tru64 Unix,
Windows 95,
98, NT, 2000, XP et Vista.
Les bases de données sont accessibles en utilisant les
langages de
programmation
C,
C++,
C#,
Delphi /
Kylix,
Eiffel,
Java,
Perl,
PHP,
Python,
Ruby et
Tcl ;
une
API
spécifique est disponible pour chacun d'entre eux. Une interface
ODBC appelée
MyODBC
est aussi disponible. En Java, MySQL peut être utilisé de
façon transparente avec le standard
JDO.
Depuis le rachat de MySQL AB par
Sun, MySQL est devenu
officieusement la base de données à utiliser conjointement avec
le language de programmation
Java, ce qui donne une
notoriété supplémentaire au SGDB auprès des
entreprises utilisant Java.
3.4.
UTILISATION
MySQL fait partie du quatuor
LAMP :
Linux,
Apache, MySQL,
PHP.
Le couple PHP/MySQL est très utilisé par les
sites web et proposé
par la majorité des hébergeurs. Plus de la moitié des
sites web fonctionennt sous Apache2(*), qui est le plus souvent utilisé conjointement
avec PHP et MySQL.
Wikipédia
ainsi que de nombreuses autres entreprises et services utilisent MySQL, tels
que
Google,
Yahoo!,
YouTube,
Adobe,
Airbus,
Alstom,
Crédit
agricole, Linden Lab (
Second Life),
RATP,
URSSAF,
AFP,
Reuters,
BBC News,
Leader Price,
Système U,
Cap Gemini,
Ernst & Young,
Alcatel-
Lucent et d'autres11(*).
MySQL étant récent, il grossit au fil de ses
versions. Depuis la version 5, il est possible d'utiliser le PL/SQL
originairement développé par Oracle afin d'utiliser des
procédures et fonctions stockées ainsi que des
déclencheurs.
Par ailleurs, MySQL supporte la norme SQL2 (utilisation des JOIN), ce qui fait
de lui un SGBD sûr puisque la conformité à cette norme
garantira sa compatibilité avec les requêtes
normalisées.
Son absence de support des transactions et d'une gestion de
l'intégrité des tables automatique (sauf en utilisant certains
moteurs comme InnoBD) ne lui permet pas d'être utilisée dans des
applications à données particulièrement sensible comme,
par exemple, dans les sociétés banquaires, cependant, ses
performances étant généralement plus importantes que la
majorité des autres systèmes concurrents, et son prix
d'implantation nettement inférieur, lui permet d'obtenir un certain
succès auprès des entreprises ayants besoin d'une base de
données peu onéreuse et/ou performante.
Nous avons essayé de faire une vision sur quelques
Systèmes de gestion de base de données les plus utilisées
au monde, tout est classé sur le tableau ci-dessou :
|
Relationnel
propriétaire
|
4D - DB2 - dBase - Informix - MaxDB - Oracle - SQL Server
|
|
Relationnel
libre
|
Derby - Firebird - Ingres - MySQL -
PostgreSQL
|
|
Embarqué
|
Berkeley DB - SQLite
|
|
Autre
|
Access - FileMaker - HyperFile - OpenOffice.org Base -
Paradox
|
|
API
|
JDBC - ODBC - OLE DB - SQL
|
3.8. SECURITE DE LA BASE DE
DONNEES
La sécurité de la base de données
consiste à protéger les systèmes contre les
éventuels accidents physiques et/ou logiques qui peuvent l'endommage ou
l'anéantir.
Pour ne pas être surpris par ces accidents, nous
proposons les mesures de sécurités ou mesures préventives
telles que :
- Le BACK UP ;
- La duplication de la base de données ;
- Le verrouillage (interdiction d'écriture) sur la base
de données pour les utilisateurs non autorisées ;
- Pas de suppression sans duplication ;
- Le stockage de tous les BACK UP en dehors des installations
informatiques et de l'entreprise.
Pour notre cas, nous avons choisi la méthode de
Backup automatique dans le logiciel, la méthode verrouillage automatique
(avec interdiction d'écriture) sur la base de données pour les
utilisateurs non autorisés.
3.9. CREATION DES BASES DE
DONNEES ET DES TABLES POUR LE PLUCM
-- phpMyAdmin SQL Dump
-- version 2.6.1
-- http://www.phpmyadmin.net
--
-- Serveur: localhost
-- Généré le : Mercredi 20 Août 2008
à 11:59
-- Version du serveur: 4.1.9
-- Version de PHP: 4.3.10
--
-- Base de données: `plucm`
--
-- --------------------------------------------------------
--
-- Structure de la table `agent`
--
CREATE TABLE `agent` (
`idagent` int(11) NOT NULL auto_increment,
`prenom` varchar(20) NOT NULL default '',
`nom_agent` varchar(20) NOT NULL default '',
`postnom` varchar(20) NOT NULL default '',
`telephone` varchar(20) NOT NULL default '',
`email` varchar(20) NOT NULL default '',
`login` varchar(20) NOT NULL default '',
`mot_de_passe` varchar(20) NOT NULL default '',
`site` varchar(20) default NULL,
`adresse` varchar(30) NOT NULL default '',
`idsexe` int(11) NOT NULL default '0',
`idcategorie` int(11) NOT NULL default '0',
`date_engag` varchar(30) NOT NULL default '',
PRIMARY KEY (`idagent`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1 AUTO_INCREMENT=46 ;
--
-- Contenu de la table `agent`
--
-- --------------------------------------------------------
--
-- Structure de la table `apprenants`
--
CREATE TABLE `apprenants` (
`idapprenant` int(11) NOT NULL auto_increment,
`prenom` varchar(20) NOT NULL default '',
`nom` varchar(20) NOT NULL default '',
`postnom` varchar(20) NOT NULL default '',
`telephone` varchar(30) NOT NULL default '',
`email` varchar(20) NOT NULL default '',
`login` varchar(30) NOT NULL default '',
`mot_de_passe` varchar(20) NOT NULL default '',
`site` varchar(20) NOT NULL default '',
`adresse` varchar(20) NOT NULL default '0000-00-00',
`idsexe` int(11) NOT NULL default '0',
`idcategorie_ap` int(11) NOT NULL default '0',
`date_inscription` varchar(20) NOT NULL default '',
`idformation` int(11) NOT NULL default '0',
`idecole` int(11) NOT NULL default '0',
`id_etatcivil` int(11) NOT NULL default '0',
`profession` varchar(50) NOT NULL default '',
`organisme` varchar(50) NOT NULL default '',
`employeur` varchar(20) NOT NULL default '',
`activite` varchar(50) NOT NULL default '',
`occupation` varchar(50) NOT NULL default '',
`choisirplucm` varchar(50) NOT NULL default '',
PRIMARY KEY (`idapprenant`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1 AUTO_INCREMENT=72 ;
--
-- Contenu de la table `apprenants`
--
-- ---------------------------------------------------------
-- Structure de la table `auteur`
--
CREATE TABLE `auteur` (
`idauteur` int(11) NOT NULL auto_increment,
`nom` varchar(30) NOT NULL default '',
`nationalite` varchar(30) NOT NULL default '',
PRIMARY KEY (`idauteur`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1 AUTO_INCREMENT=4 ;
--
-- Contenu de la table `auteur`
--
INSERT INTO `auteur` VALUES (2, 'walt Desney Productions',
'Francais');
INSERT INTO `auteur` VALUES (3, 'blaise pascal', 'Francais');
-- --------------------------------------------------------
--
-- Structure de la table `categories`
--
CREATE TABLE `categories` (
`idcategorie` int(11) NOT NULL auto_increment,
`categorie` varchar(20) NOT NULL default '',
PRIMARY KEY (`idcategorie`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1 AUTO_INCREMENT=4 ;
--
-- Contenu de la table `categories`
--
INSERT INTO `categories` VALUES (1, 'Choisir
catégorie');
INSERT INTO `categories` VALUES (2, 'Administrateur');
INSERT INTO `categories` VALUES (3, 'Utilisateur');
-- --------------------------------------------------------
--
-- Structure de la table `categoriesap`
--
CREATE TABLE `categoriesap` (
`idcategorie_ap` int(11) NOT NULL auto_increment,
`categorie_ap` varchar(20) NOT NULL default '',
PRIMARY KEY (`idcategorie_ap`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1 AUTO_INCREMENT=6 ;
--
-- Contenu de la table `categoriesap`
Toutes ces instructions SQL nous ont permit
de créer notre base de données et les tables, étant
donné qu'une base de données est toujours composée de une
ou plusieurs tables. Cela nous permettra alors d'exploiter cette base de
données créée lors de la programmation ou
développement dans le cas de Projet Limete Université Cardinal
Malula.
3.10. MODELE LOGIQUE DE
TRAITEMENT
3.10.1. Definition
Le Modèle Logique de traitement est une vue qui
reflète la vision de l'utilisateur pour les données à
travers la procédure algorithmique.
Le Modèle Logique de Traitement est un dialogue qui
s'effectue entre l'homme et la machine.
Le Modèle Logique de Traitement comprend la partie
visible, la spécification externe de transaction clavier, le cheminement
possible d'un écran à un autre après le menu
d'accueil.
Certes, l'affichage à l'écran de menu permettra
à l'utilisateur de choisir le traitement qu'il désire
effectuer.
3.10.2. Présentation de
menus
Un menu est un écran physique qui permet à
l'utilisateur de porter un choix sur les différentes options
correspondantes aux différents types de traitements d'une application ou
logiciel que l'on désire c'est-à-dire c'est un répertoire
de possibilités offertes à l'opérateur ou l'utilisateur en
vue de faire le choix correspondant au traitement désiré.
ACCEUIL
GESTION GENERAL DE PROJET LIMETE UNIVERSITE CARDINAL
MALULA
Menu principal
· Agents
· Apprenants
· Productions
· Charges
· Reçus
· Bibliothèque
· Discussion
· Rapport Journalier
· Déconnexion
Agents
- Ajouter Agents
- Afficher Agents
- Update
Apprenants
- Ajouter Apprenants
- Afficher Apprenants
- Update
- Productions
- Ajouter Production
- Afficher Production
- Update
- Charges
- Ajouter Charge
- Afficher Charge
- Update
- Reçus
- Ajouter Reçu
- Afficher Reçu
- Update
- Bordereau
Bibliothèque
- Ajouter livre
- Afficher livre
- Ajouter Auteur
- Afficher Auteur
- Update
- Discussion
- Ajouter Question
- Rechercher Question
- Update
- Rapport journalier
- Faire le Rapport
- Afficher le Rapport
- Update
Déconnexion
- Déconnexion nous aide à fermer la base de
données
3.11.
INTERFACE DE L'UTILISATEUR
Ici nous allons présenter quelques Interfaces,
lesquelles vont permettre aux utilisateurs d'éfectuer quelques
opérations telles que : l'ajout de nouveau apprenant, remise d'un
reçu de minerval et autres...
3.11.1. Saisie des apprenants
Numéro
Nom Apprenant
Postnom Apprenant
Prenom de l'Apprenant
Adresse de l'Apprenant
Sexe
Age
Date d'inscription
Heure d'entrée
login
mot de passe
Valider
Numéro
Nom Agent
Postnom Agent
Prenom de l'Agent
Adresse de l'Agent
Sexe
Age
Date d'engagement
Heure d'entrée
login
mot de passe
Valider
3.11.2. Saisie des Agent
3.11.3. Saisies des auteurs
Numéro
Nom auteur :
Postnom auteur :
Nationalit de l'auteur
Valider
|
DateHeure:
|
|
Montant Produit:
|
|
Commentaire Produit:
|
|
Production en:
|
|
Produit par:
|
|
Choisir Moment:
|
Valider
|
Date payé:
|
|
Montant Payé
|
|
Nom Apprenant:
|
|
Nom Agent:
|
|
Module:
|
|
Catégories apprenants:
|
Valider
3.11.4. Saisie des Produits
3.11.5. Saisie des
reçus
4. MODELE PHYSIQUE DE
DONNEES
4.1. Définition
Un modèle Physique de Données est une
étape de définition des données à
l'intérieur de la structure physique de l'ordinateur c'est-à-dire
le résultat de la décision technique qui a été
prise en fonction des objets et des contraintes techniques11(*).
Un Modèle Physique de Données est un formalisme
qui permet de préciser le système de stockage employé pour
un système de gestion de base de données.
4.2. Règle de passage du
Modèle logique de données au Modèle Physique de
données
Le passage du Modèle Logique de Données au
Modèle Physique de Données exige que les tables qui jusque
là sont externe à la base de données se traduisent en
fichiers faisant partie intégrante de la base de données.
Ainsi
- les tables décrites au niveau du schéma
logique deviennent des fichiers de données appelées
« tables » ;
- les propriétés des deviennent des champs de
tables ;
- les identifiants deviennent des clés primaires
- les clés héritées deviennent des
clés secondaires
4.3. Présentation du
Modèle Physique de Données
|
Table
|
Code rubrique
|
Désignation
|
Nature
|
Taille
|
Décimal
|
Clé
|
|
AGENT
|
idagent
|
Identification de l'agent
|
+
|
+
|
Oui
|
Oui
|
|
prenom
|
prenom
|
Texte
|
35
|
Non
|
Non
|
|
nom_agent
|
nom_agent
|
Texte
|
35
|
Non
|
Non
|
|
postnom
|
postnom
|
Texte
|
35
|
Non
|
Non
|
|
telephone
|
telephone
|
Texte
|
35
|
Non
|
Non
|
|
email
|
email
|
Texte
|
10
|
Non
|
Non
|
|
login
|
login
|
texte
|
8
|
Non
|
Non
|
|
mot_de_passe
|
Mot de passe de l'agent
|
texte
|
8
|
Non
|
Non
|
|
site
|
site
|
Texte
|
35
|
Non
|
Non
|
|
adresse
|
adresse
|
Texte
|
3
|
Non
|
Non
|
|
idsexe
|
Identification de sexe
|
Num
|
10
|
Oui
|
Oui
|
|
APPRENANT
|
|
|
|
|
|
|
|
idapprenant
|
identification de l'apprenant
|
+
|
+
|
Non
|
Oui
|
|
prenom
|
prenom
|
Texte
|
35
|
Non
|
Non
|
|
nom
|
nom
|
Texte
|
35
|
Non
|
Non
|
|
postnom
|
postnom
|
Texte
|
35
|
Non
|
Non
|
|
telephone
|
telephone
|
Texte
|
35
|
Non
|
Non
|
|
email
|
email
|
Texte
|
10
|
Non
|
Non
|
|
login
|
login
|
texte
|
8
|
Non
|
Non
|
|
mot_de_passe
|
mot_de_passe
|
texte
|
8
|
Non
|
Non
|
|
site
|
site
|
Texte
|
35
|
Non
|
Non
|
|
adresse
|
adresse
|
Texte
|
3
|
Non
|
Non
|
|
idsexe
|
identification de sexe
|
Num
|
10
|
Oui
|
Oui
|
|
idcategorie_ap
|
identification de catégories apprenants
|
Num
|
10
|
Oui
|
oui
|
|
date_inscription
|
date d'inscription de l'apprenant
|
date
|
|
Non
|
Non
|
|
idformation
|
identification de formation
|
Num
|
10
|
Oui
|
Oui
|
|
idecole
|
identification de l'école
|
Num
|
10
|
Oui
|
Oui
|
|
id_etatcivil
|
identification de l'état civil
|
num
|
10
|
oui
|
Oui
|
|
profession
|
profession
|
texte
|
12
|
non
|
nom
|
|
organisme
|
organisme
|
Date
|
8
|
Non
|
Non
|
|
employeur
|
employeur
|
texte
|
35
|
Non
|
Non
|
|
activite
|
activite
|
Texte
|
35
|
Non
|
Non
|
|
occupation
|
occupation
|
Texte
|
40
|
Non
|
Non
|
|
choisirplucm
|
la raison qui a pousé à choisir plucm
|
texte
|
30
|
Non
|
Non
|
|
DONATEUR
|
id_donnateur
|
identification de donateur
|
+
|
+
|
Non
|
oui
|
|
nom
|
nom
|
texte
|
30
|
non
|
non
|
|
adresse
|
adresse
|
texte
|
30
|
Non
|
Non
|
|
telephone
|
telephone
|
Date
|
8
|
Non
|
Non
|
|
email
|
email
|
Texte
|
30
|
Non
|
Non
|
|
mot_de_passe
|
mot de passe de donateur
|
texte
|
30
|
Non
|
nom
|
Chapitre 1. PROGRAMMATION DE
L'APPLICATION
1.1. DEFINITION
Une programmation est un ensemble des activités qui
consiste à transformer les données entrant en données
sortant suivant la logique de traitement bien déterminée
appelée Logique de programmation12(*).
Un programme est un ensemble d'instruction logique que l'on
soumet à l'ordinateur pour résoudre un problème bien
déterminé13(*).
1.1.1. Choix de méthode de
programmation
La mise sur pied d'un programme a toujours exigé le
respect d'énormes règles informatiques, appelée aussi
méthode de programmation informatique, qui ne sont d'autres que des
méthodes utilisées par un informaticien et d'autre part le
langage lié à cette méthode.
Parmi les méthodes de programmation, nous
distinguons :
- La programmation classique ;
- La programmation structurée et modulaire ;
- La programmation orientée objet.
1.1.2. La programmation classique
C'est une programmation empirique c'est-à-dire caduque
et obsolète dans laquelle on utilise le système de renvoie
(Goto) souvent dans le système d'exploitation DOS ou MS-DOS et qui
présente comme conséquence :
- Le non respect de séquence dans le traitement des
instructions (à cause de goto)
- La non fiabilité
- La non efficacité
1.1.3. La programmation
structurée et modulaire
La programmation modulaire et structurée consiste
à décomposé logiquement un problème en sous
problèmes faciles à résoudre et à respecter les
principes d'utilisation des concepts (la séquence, les structures
d'alternatives et les structures d'itérations qui permettent
d'éviter l'utilisation de renvoie avec Goto)
Lorsque tous les sous problèmes sont résolus
alors le problème est résolu.
Les différentes étapes utilisées
sont :
· La conception et l'analyse
- définir les objectifs généraux :
c'est le problème que le client pose et les besoins d ce
dernier ;
- définition des objectifs fonctionnels : sont les
grandes lignes ou idées à suivre dans la mise sur pieds de
l'application
- définition des objectifs de système :
étude détaillée de grande lignes conçues dans
l'étape fonctionnelle
- définir les interfaces utilisateurs :
prévoir le masque de saisie pour les informations à saisir (les
fiches)
- définir les bases de données : structures
des différents tables qui regrouperont les données les
données à traiter ou à saisir ou éditer (selon
définis).
- Définir les test : ce que les programmes doivent
faire et ne doivent pas faire. Vérification du résultat par
rapport aux besoins des utilisateurs.
· La programmation structurée et modulaire
- faire la logique du problème dans un langage pseudo
code
- conversion des instructions en langage informatique
· Le test
- faire le test individuel (par objet) entre les
différents modules pour voir leur fiabilité ;
- faire le test collectif (ensemble par le système)
1.1.4. La programmation
orientée objet
La Programmation Orientée Objet (POO) est une extension
de la programmation structurée qui intensifie la réutilisation du
code et l'encapsulation de données avec des
fonctionnalités.
La Programmation Orientée Objet (POO) est un
modèle de programmation qui se démarque des modèles
classiques en cherchant à décomposer de manière
structurelles les programmes en entités, appelées objets, qui
possèdent un état (variable) et un comportement (fonction ou
méthode).
la Programmation Orientée Objet est
caractérisée par l'héritage (permet
à un objet de récupérer les caractéristiques d'un
autre objet (attributs et méthodes) et de celui ajouter de nouvelle
caractéristique) et le polymorphisme
(permet d'attribuer à différents objets une
méthode portant le même nom afin d'exprimer la même action,
même si l'implémentation de la méthode diffère
complètement)
Avant la programmation orientée objet, les
données et les opérations (les fonctions) constituaient des
éléments distincts.
Vous pouvez comprendre les objets comme si vous comprenez
les enregistrements (constitués de champs qui contiennent des
données, chaque champ ayant son propre type).
Les enregistrements sont un moyen commode de désigner
une collection d'éléments de données variées. Mais
Les objets sont également des collections d'éléments de
données, à la différence des enregistrements, contiennent
des procédures et fonctions (Ces procédures et fonctions
sont appelées des méthodes) portant sur leurs
données. Les éléments de données d'un objet sont
accessibles via des propriétés.
Les propriétés des objets de la Programmation
Orienté Objet ont une valeur qu'il est possible de modifier à la
conception sans écrire de codes sources.
Pour la création de notre logiciel, notre choix sera
porté sur la Programmation Orientée Objet.
1.1.5. Choix de langage de
programmation
Notre choix est fait : nous allons nous mettre au PHP pour la
conception de notre Application.
Nous allons d'abord commencer à nous faire
découvrir PHP dans cette première partie, et nous veillerons
à ce que tout ce que nous disons soit le plus clair possible. Si vous me
suivez bien.
Nous présentons aussi l'éléPHPant. C'est
la mascotte du PHP, C'est un signe de reconnaissance en quelque sorte.
Comme nous savons ce que c'est PHP, mais nous savons que
c'est un univers tellement riche et varié qu'on ne peut pas
prétendre le connaître entièrement. Il y a toujours quelque
chose à découvrir.
1.1.5. Qu'est-ce que c'est
PHP ?
Un site c'est l'ensemble de pages web1(*) ou l'ensemble d'informations
présentées sous forme de pages, le lien par exemple. Pour aller
sur un site web, on tape son adresse, par exemple
http://www.plucm.org En tapant l'adresse
d'un site web, le navigateur (Firefox par exemple), nous amènera visiter
ce site web.
On peut faire beaucoup de choses sur un site web : jouer,
discuter, échanger, s'informer etc...
Le langage XHTML est le nouveau nom du langage HTML. Que nous
voyions écrit l'un ou l'autre, nous savons que c'est la même
chose : c'est le langage qui permet de créer une page web à
la base, nous 'écrirons le plus souvent "HTML" (une vieille habitude)
pour désigner ce fameux langage qui permet de créer des pages
web.
Si nous ne le connaissons pas, nous ne pourrons pas utiliser le
PHP.
Pour nous rappeler, le (X) HTML c'est un langage qui nous
permet de créer des pages web. En tapant un code spécial (les
"tags", ou "balises"), on peut mettre du texte en gras, insérer une
image etc...
Et PHP dans tout ça ? C'est un autre langage qui vient
se mettre au milieu de ce code HTML.
Il y a toujours du langage HTML autour, mais on trouve au
milieu des instructions PHP. Ce que nous allons signaler c'est
à savoir manier des lignes de ce type. Oui, ça fait
peut-être un peu peur ces caractères bizarres au milieu ($ ; ?
> ). Comme nous le voyons, une page qui ne contient que du HTML
possède l'extension ".html". Une page qui contient du code PHP, elle a
l'extension ".php".
Comme il y a eu plusieurs versions de PHP, il n'est pas
rare de rencontrer des extensions .php3 ou .php5. La version actuelle de PHP
est la v5.
Ce qu'il faut noter qu'il n'existe pas des pages qui ne
contiennent que du PHP ? On a quand même toujours besoin du HTML pour
faire une page web.
On ne peut pas y échapper !
En résumé : le HTML est pratique un moment, mais
il est limité. A l'aide de PHP, nous allons réaliser bien plus de
choses pour la réalisation de notre Travail telles que :
· Un forum, où tout le partenaire de Projet Limete
Université Cardinal Malula peut discuter, échanger, s'entraider
s'il y a un problème.
· Un Chat, pour ils puissent discuter entre eux en temps
réel ou avec leurs apprenants !
· Un livre d'or : pour voire si notre application
plaît aux travailleurs, partenaires et apprenants, ils peuvent laisser un
message disant que votre application est super, et tout le monde pourra le
lire !
· Une newsletter : c'est très facile à
mettre en place. Nous rédigons notre newsletter, nous cliquez sur un
bouton, et là le mail s'envoit automatiquement à toutes les
personnes inscrites à votre newsletter !
· Un compteur de visiteurs, visible ou caché,
c'est nous qui voyons ce que nous préférons. Et comme c'est nous
qui allons le créer, il n'y aura pas de pub (ceux qui utilisent un
compteur avec une pub se font arnaquer nous le dirons de suite.
· Un système de news automatisé : nous
allons sur une page, nous tapons le texte de la nouvelle news, et
immédiatement après la page d'accueil de notre application
s'actualise et tous nos partenaires, apprenants, travailleurs... voient cette
news !
· On peut imaginer alors qu'ils réagissent
à cette news : ils donnent leur avis, se proposent pour nous aider
etc...
PHP peut faire encore beaucoup
plus que ça, mais c'était ce que nous avons prévu pour
notre application. Ce qu'il faut bien retenir donc, c'est que PHP nous permet
de créer des pages web dynamiques, qui se mettent à jour toutes
seules sans que nous ayons à passer par là.
En clair, nous pouvons être
en vacances aux Bahamas, et notre site continuera à évoluer tout
seul !
Autre gros avantage, nous allons
nous en rendre compte, PHP inaugure l'ère du Webmaster Fainéant:
une fois que nous avons mis notre site en place, il se met à jour tout
seul, se transforme, sans que nous ayons à lever le petit doigt.
1.1.6. Différences entre
HTML et PHP
Ce que nous allons signaler maintenant, ce n'est pas
très compliqué, et pourtant beaucoup de gens se lancent dans le
PHP sans le savoir ! Nous faisons l'effort de comprendre comment ça
marche (ça nous prendra beaucoup de temps), non seulement nous allons
gagner beaucoup de temps ensuite, mais en plus nous comprendrons ce
que nous ferons.
De quoi nous allons parler ? Nous allons expliquer ce qui se
passe exactement quand un visiteur veut aller sur notre site web. Il tape
l'adresse, mais ensuite La page s'affiche, d'accord, mais entre-temps que
s'est-il passé ?
Ca c'est vraiment important, parce qu'en HTML et en PHP
ça ne fonctionne pas vraiment pareil.
Il y a une notion fondamentale à connaître : les
relations entre le client et le serveur.
· Le client : celui qu'on appelle "le client",
c'est la machine qui demande le service ou la page à distance. qui
êtes tranquille pépère installé devant son
ordinateur, et qui demandez à voir une page web. Tous les visiteurs d'un
site web sont des clients. nous va représenter l'ordinateur du client
par cette machine :

· Le serveur : il n'y en a qu'un seul. Le serveur,
c'est une sorte de gros ordinateur tout le temps connecté à
Internet (avec une connexion très rapide). Cet ordinateur est
installé quelque part dans le monde ou à Kinshasa au PLUCM, il
est tout le temps allumé, et personne n'y touche. Il travaille 24h/24,
et ne s'occupe que de distribuer notre application. En d'autres termes,
personne ne joue dessus
Sa fonction, il contient notre application sur son
disque dur, et dès qu'un client demande à voir une information,
il la lui envoie. Pour représenter le serveur, nous allons utiliser
cette machine (notez qu'en général le serveur n'a pas
d'écran : ça ne sert à rien puisque personne ne travaille
dessus) :

Eh bien: le serveur est un ordinateur qui envoie des reponse
aux clients qui le lui demandent. Et il travaille sans arrêt comme un
forcené.
Bien, maintenant nous allons montrer le petit plus qui fait
toute la différence entre une page HTML et une page PHP.
a)Avant : en HTML
nous rappellons qu'une page HTML possède l'extension
.html, comme exemple.html
nous n'allons pas entrer dans les détails,
mais en gros voici comment ça fonctionne pour une page HTML :
Il y a 2 étapes :
1. Le client (c'est un travailleur par exemple) demande
à voir une information. Il va donc faire une demande au serveur : "S'il
te plaît, envoie-moi la page affichierlivre.html".
2. Le serveur lui répond en lui envoyant la page
affichierlivre.html: "Tiens, voici la page que tu m'as demandée".
Tout ça se passe très poliment bien entendu le
client voulait consulter la page affichierlivre.html sur notre application :
il l'a demandée au serveur qui gère cette
application, et le serveur lui a envoyé la page que le client voulait.
La page s'affiche alors sur l'écran du client, sous ses yeux.
Cela se passe à chaque fois que vous consultez une page
HTML. Mais qu'est-ce qui peut bien changer avec PHP ?
b) Maintenant : en PHP
Il y a une étape qui vient s'ajouter entre les deux :
la page PHP est générée par le serveur avant l'envoi.
Schématiquement ça donne ça :
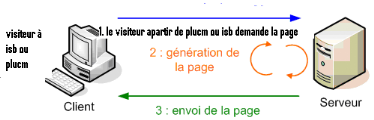
Voyons à nouveau les étapes :
1. Le client demande à voir une page PHP. Pour lui il
n'y a aucune différence. Il demande la page au serveur, toujours aussi
poliment : "S'il te plaît, envoie-moi la page affichierlivre.php".
2. Mais là, il y a une étape très
importante, qui fait toute la différence en PHP. Le serveur n'envoie pas
de suite la page au client. Il la génère. En
effet, le client n'est pas capable de lire une page PHP (seul le serveur sait
faire ça). Le client ne peut lire que des pages HTML.
Ce que fait le
serveur est simple : il va transformer la page PHP en page HTML, pour que le
client puisse la lire.
3. Enfin, une fois que la page est
générée, elle ne contient plus que du code HTML. Le
serveur peut l'envoyer au client : "Tiens, voici la page que tu as
demandée".
Nous allons en dire un peu plus sur cette deuxième
étape : celle de la génération de la page. Il est
important de bien comprendre ce qui s'y passe. Que veut dire
"génération de la page PHP" ? Nous montrons un bout de code PHP
au début.
Code : PHP
|
1
|
<?php echo("Vous êtes le travailleur n°" .
$nbre_visiteurs);?>
|
Les ordinateurs des clients ne savent pas lire ce code PHP :
ils ne connaissent que le HTML. C'est donc au serveur de transformer le code
PHP en HTML. Le code PHP contient des instructions. Il
demande au serveur d'effectuer des actions : donner l'heure, le nombre de
personnes connectées sur le site etc... Bref, le PHP donne des ordres au
serveur.
Ce genre de choses était impossible en HTML. Avec PHP,
c'est possible, et nous verrons que ça change tout.
Nous n'oublions pas qu'une page PHP contient aussi du code
HTML.
Tant qu'il y a du code HTML, le serveur n'y touche pas.
Dès qu'il tombe sur du code PHP, il le lit, il l'exécute (il fait
ce que le code lui demande), et il transforme ça en HTML.
En fin de compte, la page générée ne
contient plus que du HTML :
Le client peut alors la lire.
Ce qui est particulier ici, c'est que cette page
générée est destinée à un seul client. Quand
un nouveau client se présente, le serveur recommence à
générer une page HTML.
Ca veut dire qu'en fait la page
générée peut être à chaque fois unique.
C'est bien ça qui est génial par rapport au HTML : en HTML la
page envoyée était toujours la même, le serveur envoyait
juste le fichier. En PHP, le serveur travaille pour le client et lui offre une
page personnalisée.
Notons que la génération de la page peut prendre
du temps (quelques millisecondes en fonction de la taille de la page).
Cela veut dire que le serveur doit être plus puissant
pour pouvoir traiter du PHP qu'un serveur HTML normal... comme le cas dans
notre application , ce n'est pas un personnel, partenaire ou apprenant qui va
demander une page PHP, mais plutôt plusieurs en même temps !
Chapitre 2. UTILISATION DE PHP
POUR NOTRE APPLICATION
2.1. INTRODUCTION
Comme le chapitre précèdent l'a indiqué
et balayé le chemin, c'est maintenant que nous allons faire nos premiers
pas en PHP. Nous avons créé un dossier dans lequel tout nos
fichiers seront logés.
Mais pour se connecter nous avons
tenu compte des attaques qui arrivent souvent lors de la transmission de
message et de mot de passe.
1. Attaque « Man in the
middle »
L'attaque « Man in the middle » consiste
pour le pirate à se brancher sur la ligne entre nous et le serveur,
à écouter ce qui transite, puis, au bon moment, à essayer
de prendre notre place.
Dans l'exemple suivant, blaise est le pseudonyme d'un
administrateur se connectant au site, pascal est l'identifiant de session.
Schématisation d'une attaque Man in the middle
Cette technique est très facile à mettre en
place dans les entreprises ou les universités, car il y a souvent une
seule passerelle entre internet et le reste du réseau. Cela signifie que
toute donnée envoyée sur internet par un ordinateur du
réseau sera susceptible d'être « entendue ».
Le pire scénario se produit lorsque le matériel est un peu vieux
ou que l'installation a été réalisée à
moindre coût et que les boîtiers permettant la mise en
réseau sont des hubs et non des switchs.
Le hub, lorsqu'il reçoit un message provenant d'un
ordinateur, se contente de l'amplifier et de l'envoyer à tout le monde,
alors que le switch n'envoie qu'à la bonne machine. Ce qui veut dire
qu'avec un logiciel comme Ethereal sur un réseau constitué de
hubs (il y en a encore beaucoup), un hacker pourrait prendre la place de
n'importe quel membre sur n'importe quel site ouvert depuis le réseau.
1.1. Les vols
Nous avons vu comment il est possible pour un hacker
d'écouter le réseau. Mais que peut-il voler exactement ?
1.2. Session
Pour voler une session, il suffit de récupérer
l'identifiant de session. Cet identifiant est unique et propre à une et
une seule session à un instant donné. L'identifiant de session en
PHP peut être transmit par deux moyens, cookie ou url.
Le passage par URL est une faille de sécurité.
Imaginons ce cas de figure : nous naviguons sur un site qui transmet
l'identifiant de session par URL, par exemple un forum comme phpBB. Un visiteur
(mal intentionné) que nous nommerons Mr X, poste un message avec un lien
sur son site perso, avec en général beaucoup de pipo pour attirer
les gens. Sur ce site, Mr X a écrit un script qui récupère
la variable globale $_SERVER['HTTP_REFERER'] qui contient la dernière
adresse visitée, c'est-à-dire celle du forum avec l'identifiant
de session dedans. Le script de Mr X va repérer cet identifiant et Mr X
pourra alors l'utiliser pour voler la session.
Que ce soit par URL ou par cookie, l'attaque du "Man in the
middle" permet de récupérer l'identifiant de session.
.3. Mot de passe
Le pire scénario, le vol du mot de passe. Ce vol est
aussi le plus dur, car le hacker n'a souvent qu'un seul essai, lors de la phase
d'identification (ou d'inscription). Dans un espace membre classique, autant
lors de l'inscription que de la connexion, le mot de passe circule en clair.
1.4. Cookie
Il existe 2 types de cookie permettant l'identification : le
cookie de session, tel qu'on l'a vu précédemment, ne contenant en
général que l'identifiant de session, et un cookie dit
« d'autologin » qui permet à un visiteur de ne pas
saisir de nouveau son login et son mot de passe lors d'une visite
ultérieure. Le vol peut, comme on l'a vu, se faire par l'attaque du "Man
in the middle", mais peut aussi se faire par un vol physique (pour les cookies
d'autologin en général). Une personne utilise votre PC, fouille
dans vos cookies et copie par exemple sur une clé USB les cookies
d'autologin qui l'intéressent. Elle les copie chez elle, et se connecte
ensuite directement sur votre compte sur le site concerné. La seule
solution pour éviter ceci est de ne pas faire de cookie d'autologin et
de forcer le visiteur à se reconnecter manuellement à chaque
fois.
2. chiffrement et hash en php
contre l'attaque man in the middle
2.1. Protection contre le vol de mot de passe
Pour éviter le vol du mot de passe, il faut limiter,
voire proscrire, sa transmission et son stockage en clair. À la place,
on va manipuler un hash, beaucoup sécurisé car il est
(théoriquement) impossible à inverser. En pratique, c'est
"réversible". Le hacker utilisera par exemple des dictionnaires pour
obtenir le mot de passe en clair. Nous verrons comment lui compliquer la vie
avec la technique du grain de sel.
2.1.1. Utilité du hash
Le hash est un procédé de chiffrement
irréversible. Ceci implique qu'on ne peut appliquer la transformation
inverse, et qu'on ne peut donc que comparer les hashs entre eux. L'avantage est
que personne, y compris le webmaster, n'a accès aux mots de passe des
membres.
Il existe deux principaux algorithmes de hash, le MD5 et le
SHA1
Le MD5 est déprécié et NE DOIT PLUS ETRE UTILISE.
En effet, une faille dans l'algorithme a été trouvée,
permettant de diminuer considérablement le nombre d'opérations
nécessaires à un inversement par rapport à une attaque
force brute. De plus, et c'est le plus inquiétant, il a
été montré qu'il était possible de créer
volontairement des collisions avec un document donné. En effet, les
hashs MD5 sont constitués de 32 caractères
alphanumériques, soit 3632= 6.3349 combinaisons
possibles. Ainsi, le nombre de hashs possibles est limité. Or, nous
réalisons des hashs de chaîne de caractères (strings,
fichiers...) de taille indeterminée et pour la plupart bien plus grandes
que 32 caractères. Par exemple, nous pouvons constituer 21556
chaînes de 1000 caractères alphanumériques.
Nous avons donc une infinité de chaîne de
caractères pouvant donner un hash précis et il est maintenant
possible de déterminer instantanément les autres chaînes de
caractères à partir d'une des chaînes et du hash.
Il est donc recommandé d'utiliser des algorithmes plus
robustes, comme le SHA1 ou le SHA-256. Mais il faut bien garder en tête
qu'un algorithme est reconnu comme fiable uniquement car il n'a pas
encore été craqué. Ainsi, le SHA1 est
déjà sur la pente descendante.
Maintenant que nous avons présenté le principe
du hash et les principaux algorithmes, nous allons voir un exemple pratique de
mise en place côté serveur et côté client.
|
nous pouvons tester un code de ce type sur notre serveur pour
avoir la liste des hashs supportés par notre installation de PHP.
|
|
Afficher la liste des hashs supportés
|
|
print_r(hash_algos());
|
|
Résultat
|
|
Array
(
[0] => md4
[1] =>
md5
[2] =>
sha1
[3] => sha256
[4] => sha384
[5] => sha512
[6] => ripemd128
[7] => ripemd160
...
);
|
2.1.2. Mise en place
2.1..2-a. Coté serveur
Le hash coté serveur empêche, en cas de vol de la
base de donnée par intrusion sur le serveur, de fournir au hacker tous
les mots de passe en clair des membres du site. Il faut savoir que la plupart
des membres ne possèdent que 2 ou 3 mots de passe qu'ils utilisent sur
presque tous les sites. Nous devons donc nous assurer de notre
côté de l'intégrité des mots de passe de ses
visiteurs. Pour effectuer un hash coté serveur, il existe la fonction
SHA1 incorporée à PHP.
On l'appelle lors de l'inscription du membre puis, à
chaque connexion, on compare les 2 hashs.
2.1. 1. Présentation des
interfaces de l'application
Quand l'utilisateur lance l'application, une page d'accueil
s'ouvre pour lui donner l'accès de choisir s'il est apprenant ou agent
de PLUCM.
2.2.1.1. Interface d'accueil
2.2.2. Interface d'Inscription
des Apprenants
Dès l'inscription des apprenants :
élèves des écoles de Kingabwa, Abutant adule de la commune
de Limete/Kingabwa..., son mot de passe doit déjà être
hasher avant d'aller dans la base de données.
2.2.3. Interface d'Identification
Les utilisateurs doivent s'identifier avant d'entrer dans la
base de données à l'aide d'un login et mot de passe, or le mot de
passe nous l'avons hasher lors de l'inscription. En effet, l'utilisateur lors
de la connexion doit comparer son mot de passe hasher avec celui qui ce trouve
dans le serveur distant.
// L'utilisateur peut maintenant se connecter avec
sécurité.
2.2.4. Interface de menu
Après la connexion, l'utilisateur entre dans
l'application où il trouvera tout le menu possible pour son travail. Ce
même menu qui va nous guider partout dans l'application sans reprendre
les codes. Cela se fait à l'aide de la fonction include de php.
2.2.4. Fenetre de recherche
à distance
Cette interface de recherche de reçu permet à
l'étudiant qui est à distance, après avoir se connecter
avec son login et mot de passe tels que : le login
« cyna » et le mot de passe « 123456 »
pour l'apprenante Nancy Balegnela. Il peut
voire ou imprimer tout ce qu'elle a payé comme frais sans se
déplacer pour venir au plucm connaître sa solde.
Ceci est le resulta de recherche faite par l'apprenante
Nancy d'une façon distante.
2.2.5. Calcule de paie de parsonnel
Cettre fenetre nous aide à calculer le salaire de
personnel de PLUCM ici, le salaire est considé comme prime.
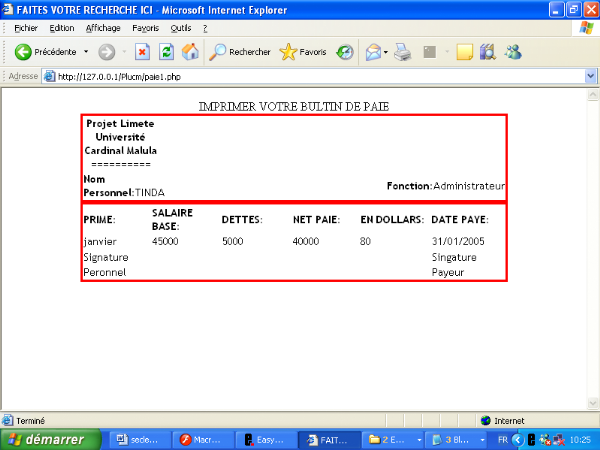
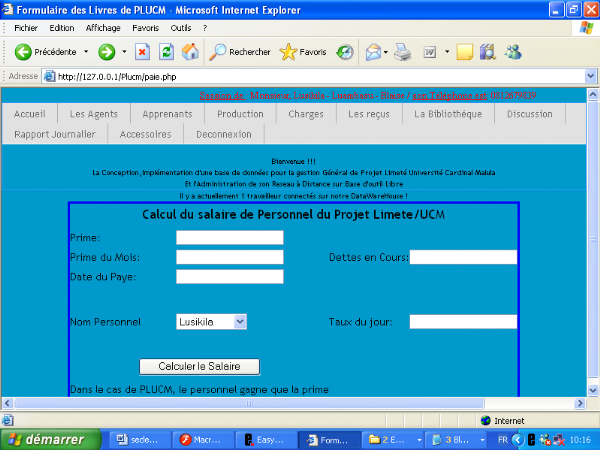
Ceci est la fiche de paie de l'agent TINDA
après le calcule par l'animateur de Projet Limete
Université Cardinal Malula.CONCLUSION
GENERALE
Nous voici à la fin de notre Travail qui
s'intitule : CONCEPTION, IMPLEMENTATION D'UNE BASE DE DONNEES POUR LA
GESTION D'UN ORGANISME ET ADMINISTRATION DE RESEAU A DISTANCE SUR BASE D'OUTIL
LIBRE. Nous avons pris le cas de PROJET LIMETE UNIVERSITE CARDINAL MALULA.
Pour franchir la fin de notre second cycle de licence.
Alors qu'en plein 21ème siècle,
l'informatique est un critère de l'alphabétisation, la
conception et l'implémentation d'une base de données pour la
gestion générale d'une entreprise ou organisme et
l'administration de réseau à distance sur base d'outil libre dans
notre pays, la République Démocratique du Congo n'a pas encore
évolué.
Raison pour laquelle nous nous sommes assignés le
devoir ainsi l'objectif de concevoir et implémenter une base de
données qui sera partagée en réseau pour la gestion
générale de Projet Limete Université Cardinal Malula.
De ce qui précède, il est difficile de
prétendre avoir eu une solution idéal, toutefois nous
espérons avoir répondu tant soi peu à notre
problématique et confirmé nos hypothèses.
En effet, ce travail étant une oeuvre humaine, n'est
pas un modèle unique et parfait, c'est pourquoi nous restons ouvert
à toutes les critiques et sommes prêts à recevoir toutes
les suggestions et remarques tendant à améliorer d'avantage cette
étude seront les bienvenus. Etant donné que tout travail
informatique a été toujours l'oeuvre d'une équipe.
En ce qui concerne la présentation de notre
application, nous singalons d'avance que nous n'avons pas
présenté toutes les interfaces, ceux qui aurons les desirs de les
voir toutes, nous les recommandons dans le site web de Projet Limete
Université Cardinala Malula :
www.plucm.org
Bientôt sur le web.
PAGE D'ACCUEIL
<html>
<title>Projet Limete Université Cardinal
Malula</title>
<body>
<div align="center">
<table border="0" width="100%">
<tr>
<td width="100%" align="center">
<?php
include('includes/corps.php');
?>
</td>
</tr>
</table>
</div>
</html>
</body>
<?php
include('includes/footer.php');
?>
<?php
include('includes/footer2.php');
?>
INSCRIPTION DES APPRENANTS BIEN HASHER
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="fr"
lang="fr">
<head>
<title>Formulaire des agents de
PLUCM</title>
<meta http-equiv="Content-Type" content="text/html;
charset=iso-8859-1"/>
</head>
<body>
<?php include("menu.php");?>
<p><center>Ceci est le formulaire dans lequel tout le
livre de Projet Limete Université Cardinal Malula se
trouve!</center></p>
<style type="text/css">
.contenu
{
border-width:3px;/*Epaisseur de la bordure */
border-color:blue;/*Couleur de la bordure */
border-collapse: collapse; /* Colle les bordures entre elles
*/
border-style:solid;/*Type de bordure */
font-size:14px; font-family:Trebuchet MS, Verdana, Arial,
Helvetica, sans-serif;
text-align:justify;
}
.contenu2
{
font-size:17px; font-family:Trebuchet MS, Verdana, Arial,
Helvetica, sans-serif;
}
</style>
</head>
<body>
<div align="center">
<table class="contenu">
<tr><td colspan="6" height="30"><span
class="contenu2"><center>Incription des agents de Projet Limete/UCM
dans la base de
données</center></span></td></tr>
<form name="" method="post" action="insertagent.php">
<tr><td width="100"
height="30">Prénom:</td><td><input type="text"
name="prenom" value=""
/></td><td></td><td></td></tr>
<tr><td width="100">Nom
:</td><td><input type="text" name="nom" value=""
/></td><td>Postnom:</td><td><input type="text"
name="postnom" value=""/></td></tr>
<tr><td width="100"
height="30">telephone:</td><td><input type="text"
name="telephone" value="" /></td><td>Adresse
E-mail:</td><td><input type="text" name="email" value=""
/></td></tr>
<tr><td width="100" height="30">Mot de
Passe:</td><td><input type="password" name="mot_de_passe"
value=""/></td><td>login:</td><td><input
type="text" name="login" value="" /></td></tr>
<tr><td width="100"
height="30">Confirmer:</td><td><input type="password"
name="mot_de_passe2"
value=""/></td><td></td><td></td></tr>
<tr><td width="100"
height="30">adresse:</td><td><input type="text"
name="adresse" value="" /></td><td>Site
Internet:</td><td><input type="text" name="site" value=""
/></td></tr>
<tr><td width="100" height="30">Votre
sexe:</td><td><select name="sexe" size="1"/>
<?php
mysql_connect("localhost","root","");
mysql_select_db("plucm");
$query=mysql_query("SELECT* FROM sexe");
mysql_close();
while($query1=mysql_fetch_array($query))
{
echo"<option
value=".$query1['idsexe'].">".$query1['libsexe']."</option>";
}
?>
</select></td><td></td><td></td></tr>
<tr><td width="100" height="30">Votre
Catégorie:</td><td><select name="categorie"
size="1"/>
<?php
mysql_connect("localhost","root","");
mysql_select_db("plucm");
$query=mysql_query("SELECT* FROM categories");
mysql_close();
while($query2=mysql_fetch_array($query))
{
echo"<option
value=".$query2['idcategorie'].">".$query2['categorie']."</option>";
}
?>
</select></td><td></td><td></td></tr>
<tr><td width="100" height="30">Date
Engagement:</td><td><input type="text" name="date_engag"
value=""
/></td><td></td><td></td></tr>
<tr><td colspan="2" height="30"><div
align="center"><input type="submit" value="valider" name=""
/></div></td></tr>
</form>
<?php
mysql_connect("localhost", "root", "");
mysql_select_db("plucm");
if (isset($_POST['prenom'])AND isset($_POST['nom'])AND
isset($_POST['postnom']) AND isset($_POST['telephone'])AND
isset($_POST['email'])AND isset($_POST['mot_de_passe'])AND
isset($_POST['mot_de_passe'])AND isset($_POST['mot_de_passe2']) AND
isset($_POST['login'])AND isset($_POST['site'])AND isset($_POST['adresse'])AND
isset($_POST['date_engag']))
{
$prenom=
mysql_real_escape_string(htmlspecialchars($_POST['prenom'])); // On utilise
mysql_real_escape_string et htmlspecialchars par mesure de
sécurité
$nom= mysql_real_escape_string(htmlspecialchars($_POST['nom']));
// On utilise mysql_real_escape_string et htmlspecialchars par mesure de
sécurité
$postnom=
mysql_real_escape_string(htmlspecialchars($_POST['postnom']));
$telephone=
mysql_real_escape_string(htmlspecialchars($_POST['telephone']));
$email=
mysql_real_escape_string(htmlspecialchars($_POST['email']));
$mot_de_passe=
mysql_real_escape_string(htmlspecialchars(sha1($_POST['mot_de_passe'])));
$login=
mysql_real_escape_string(htmlspecialchars($_POST['login']));
$adresse=
mysql_real_escape_string(htmlspecialchars($_POST['adresse']));
$site=
mysql_real_escape_string(htmlspecialchars($_POST['site']));
$sexe=
mysql_real_escape_string(htmlspecialchars($_POST['sexe']));
$categorie=
mysql_real_escape_string(htmlspecialchars($_POST['categorie']));
$date_engag=
mysql_real_escape_string(htmlspecialchars($_POST['date_engag']));
//nous pouvons maitenant enregistrer
mysql_query("INSERT INTO agent
VALUES('','$prenom','$nom','$postnom','$telephone','$email','$login','$mot_de_passe','$site','$adresse','$sexe','$categorie','$date_engag')");
}
mysql_close();
?>
</table>
</div>
</body>
</html>
IDENTIFICATION
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html;
charset=iso-8859-1" />
<title>Identification de l' agent</title>
<style type="text/css">
.contenu
{
border-width:3px;/*Epaisseur de la bordure */
border-color:red;/*Couleur de la bordure */
border-collapse: collapse; /* Colle les bordures entre elles
*/
border-style:solid;/*Type de bordure */
font-size:14px; font-family:Trebuchet MS, Verdana, Arial,
Helvetica, sans-serif;
text-align:justify;
}
.contenu2
{
font-size:17px; font-family:Trebuchet MS, Verdana, Arial,
Helvetica, sans-serif;
}
</style>
</head>
<body>
<div align="center">
<table border="0">
<td>
<p align="center"><img
border="1"src="logomalula.png"width="750"height="150"></td>
</tr>
</table>
</div>
<div align="center">
<table class="contenu">
<tr><td colspan="2" height="30"><span
class="contenu2"><center>Paramètres de
connexion</center></span></td></tr>
<form name="" method="post" action="connexion.php">
<tr><td width="100">Votre
Nom:</td><td><input type="text" name="login" value=""
/></td></tr>
<tr><td width="100" height="30">Mot de
passe:</td><td><input type="password" name="pass" value=""
/></td></tr>
<tr><td colspan="2" height="30"><div
align="center"><input type="submit" value="valider" name=""
/></div></td></tr>
</form>
</table>
</div>
</body>
</html>
Pour que la connexion soit réelement établit, il
faut entrer dans le dexième fichier connxion.php.
<?php
session_start();//demarre la session
$_SESSION = array();//detruit toutes les variables de session
session_destroy();//ferme la session
session_start();
?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html;
charset=iso-8859-1" />
<title>connexion</title>
</head>
<body>
<?php
mysql_connect("localhost","root","");
mysql_select_db("plucm");
if (isset($_POST['login']) AND isset($_POST['pass']))
{
if ($_POST['login']!=NULL AND $_POST['pass']!=NULL)
{
$log=mysql_real_escape_string(htmlspecialchars($_POST['login']));
$pass=mysql_real_escape_string(htmlspecialchars($_POST['pass']));
$agent=mysql_query("SELECT* FROM agent,sexe, categories WHERE
agent.login='$log' AND agent.idsexe=sexe.idsexe AND
agent.idcategorie=categories.idcategorie");
mysql_close();
$agent1=mysql_fetch_array($agent);
if($agent1['login']!=$log){}
if($agent1['mot_de_passe']!=sha1("$pass"))
{
?>
<div align="center"><font color="#FF0000"
face="Trebuchet MS" size="2">**le Gestionnaire de cette base de
donnée a constaté que, votre Identifiant ou le mot de passe est
invalide. Veuillez les corriger SVP!!!**<br
/></font></div>
<?php include("login.php");?>
<?php
}
else//si identifiant correct
{
$_SESSION['log1']=$log;
$_SESSION['pass1']=$pass;
$_SESSION['log']=$agent1['login'];
$_SESSION['pass']=$agent1['mot_de_passe'];
$_SESSION['nom']=$agent1['nom_agent'];
$_SESSION['postnom']=$agent1['postnom'];
$_SESSION['prenom']=$agent1['prenom'];
$_SESSION['libcategorie']=$agent1['categorie'];
$_SESSION['telephone']=$agent1['telephone'];
$_SESSION['sexe']=$agent1['libsexe'];
?>
<?php include("menu.php");?>
<?php
}
}
else
{
?>
<div align="center"><font color="#FF0000"
face="Trebuchet MS" size="2">**Champs vide**<br
/></font></div>
<?php include("login.php");?>
<?php
}
}
else//si le champs n'existe pas
{
?>
<div align="center"><font color="#FF0000"
face="Trebuchet MS" size="2">**Accès securisé !!!**<br
/></font></div>
<?php include("login.php");?>
<?php
}
?>
</body>
</html>
Menu
<?php
session_start();//demarre la session
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html;
charset=iso-8859-1" />
<title>Analyse des activités de
PL/UCM</title>
<style type="text/css">
*{padding:0; margin:0;}
body{font-size:62.5%; font-family:Trebuchet MS, Verdana, Arial,
Helvetica, sans-serif;}
.menu{white-space:nowrap /*IE hact*/; float:left; width:100%;
background:rgb(225,225,225); color:rgb(0,0,0); font-size:130%;
text-align:left}
.menu ul{list-style-type:none;}
.menu ul li{float:left; z-index:auto !important/*Non-IE6*/;
z-index:1000/*IE6*/; border-right:solid 1px rgb(175,175,175);}
.menu ul li a{ float:none !important/*Non-IE6*/;
float:left/*IE-6*/; display:block; height:2.1em; line-height:2.1em; padding:0
16px 0 16px; text-decoration:none; font-weight: normal;
color:rgb(100,100,100)}
.menu ul li ul{display:none; border:none;}
/*Non-IE6 hovering*/
.menu ul li:hover{position:relative;}
.menu ul li:hover a{background-color:rgb(210,210,210);
text-decoration: none; color:#0000FF}
.menu ul li:hover ul{display:block; width:10.0em;
position:absolute; z-index:999; top:2.0em; margin-top:0.1em; left:0;}
.menu ul li:hover ul li a{white-space:normal; display:block;
width:10.0em; height:auto; line-height:1.3em; margin-left:-1px; padding:4px
16px 4px 16px; border-left:solid 1px rgb(175,175,175);border-bottom:solid 1px
rgb(175,175,175); background-color:rgb(237,237,237); font-weight:normal;
color:rgb(50,50,50);}
.menu ul li:hover ul li
a:hover{background-color:rgb(210,210,210); text-decoration:none;
color:#0000FF;}
/*IE6 hovering*/
.menu table{position:absolute; top:0; left:0;
border-collapse:collapse;}
.menu ul li a:hover{position:relative /*IE hack*/;
z-index:1000/*IE hack*/; background-color:rgb(210,210,210);
text-decoration:none; color:#0000FF;}
.menu ul li a:hover ul{display:block; width:10.0em;
position:absolute; z-index:999; top:2.0em; left:0; margin-top:0.1em;}
.menu ul li a:hover ul li a{white-space:normal; display:block;
width:10.0em; height:1px; line-height:1.3em; padding:4px 16px 4px 16px;
border-left:solid 1px rgb(175,175,157); border-bottom:solid 1px
rgb(175,175,175); background-color:rgb(237,237,237); font-weight:normal;
color:rgb(50,50,50);}
.menu ul li a:hover ul li
a:hover{background-color:rgb(210,210,210); text-decoration:none;
color:#0000FF;}
@media print{.menu{float:left; width:900px; border:none;
background:rgb(240,240,240); color:rgb(75,75,75); font-size:1.0em;
font-size:130%;}}
.presentation
{
border-width:1px;/*Epaisseur de la bordure */
border-color:#3399FF;/*Couleur de la bordure */
border-collapse: collapse; /* Colle les bordures entre elles
*/
border-style:solid;/*Type de bordure */
}
</style>
<!--2e style commence la programmation en Java Script pour
l'annimation de notre adresse URL.-->
<style>
.spanstyle {
position:absolute;
visibility:visible;
top:-50px;
font-size:10pt;
font-family:Arial;
font-weight:bold;
color:white;
}
body {
background-color: #0099CC;
}
.style10 {
color: #0033FF;
font-weight: bold;
}
</style>
<script>
/*
Ce script se nomme :
Texte qui suit la souris :-)
*/
var x,y
var step=10
var flag=0
var message='www.plucm.org '
message=message.split("")
var xpos=new Array()
for (i=0;i<=message.length-1;i++) {
xpos[i]=-50
}
var ypos=new Array()
for (i=0;i<=message.length-1;i++) {
ypos[i]=-50
}
function handlerMM(e){
x = (document.layers) ? e.pageX :
document.body.scrollLeft+event.clientX
y = (document.layers) ? e.pageY :
document.body.scrollTop+event.clientY
flag=1
}
function makesnake() {
if (flag==1 && document.all) {
for (i=message.length-1; i>=1; i--) {
xpos[i]=xpos[i-1]+step
ypos[i]=ypos[i-1]
}
xpos[0]=x+step
ypos[0]=y
for (i=0; i<message.length-1; i++) {
var thisspan = eval("span"+(i)+".style")
thisspan.posLeft=xpos[i]
thisspan.posTop=ypos[i]
}
}
else if (flag==1 && document.layers) {
for (i=message.length-1; i>=1; i--) {
xpos[i]=xpos[i-1]+step
ypos[i]=ypos[i-1]
}
xpos[0]=x+step
ypos[0]=y
for (i=0; i<message.length-1; i++) {
var thisspan = eval("document.span"+i)
thisspan.left=xpos[i]
thisspan.top=ypos[i]
}
}
var timer=setTimeout("makesnake()",30)
}
</script>
</head>
<script>
for (i=0;i<=message.length-1;i++) {
document.write("<span id='span"+i+"'
class='spanstyle'>")
document.write(message[i])
document.write("</span>")
}
if (document.layers){
document.captureEvents(Event.MOUSEMOVE);
}
document.onmousemove = handlerMM;
makesnake()
</script>
<!-- Copyright 2005 Macromedia, Inc. All rights reserved.
-->
<title>Entertainment - Calendar</title>
<meta http-equiv="Content-Type" content="text/html;
charset=iso-8859-1" />
<link rel="stylesheet" href="file:///C|/Program
Files/EasyPHP1-8/www/mm_entertainment.css" type="text/css" />
<style type="text/css">
<!--
.style2 {color: #333333}
.style3 {font-weight: bold}
.style4 {color: #FF0000}
.style5 {
color: #FF0000;
font-family: Arial;
font-size: 12px;
}
.style7 {font-size: large}
.style9 {color: #FF0000; font-weight: bold; }
.style11 {
color: #FF0000;
font-style: italic;
font-weight: bold;
}
.style12 {font-size: 18px; color: #FF0000;}
-->
</style>
</head>
<body>
<body>
<?php if($_SESSION['log']!=$_SESSION['log1'])
{
}
if($_SESSION['pass']!=$_SESSION['pass1'])
{?>
<div align="center">
<font face="Times New Roman, Times, serif" size="2"
color="red"><table width="650"><tr><td><div
align="right"><u>Session de </u>:
<?php echo $_SESSION['sexe'];?>,
<?php echo $_SESSION['nom'];?> -
<?php echo $_SESSION['postnom'];?> -
<?php echo $_SESSION['prenom'];?> /
<u>son Téléphone est</u>: <?php echo
$_SESSION['telephone'];?></div></td></tr></table></font>
<table class="presentation" border="2">
<tr>
<td>
<div class="menu">
<!--un menu de navigation-->
<ul>
<li><a
href="login.php">Accueil</a></li>
</ul>
<!--un menu de navigation avec sous-menus-->
<ul>
<li><a href="#">Les Agents<!--[if IE
7]><!--></a><!--<![endif]-->
<!--[if lte IE
6]><table><tr><td><![endif]-->
<ul>
<li><a
href="insertagent.php">Ajouter</a></li>
<li><a href="affichieragent.php">Affichier
Agents</a></li>
<li><a
href="lien.html">Update</a></li>
</ul>
<!--[if lte IE
6]></td></tr></table></a><![endif]-->
</li>
</ul>
<!--un menu de navigation avec sous-menus-->
<ul>
<li><a href="#">Apprenants<!--[if IE
7]><!--></a><!--<![endif]-->
<!--[if lte IE
6]><table><tr><td><![endif]-->
<ul>
<li><a
href="apprenant.php">Ajouter</a></li>
<li><a href="affichierapprenants.php">Affichier
Etudiants</a></li>
<li><a
href="lien.html">Update</a></li>
</ul>
<!--[if lte IE
6]></td></tr></table></a><![endif]-->
</li>
</ul>
<!--un menu de navigation avec sous-menus-->
<ul>
<li><a href="#">Production<!--[if IE
7]><!--></a><!--<![endif]-->
<!--[if lte IE
6]><table><tr><td><![endif]-->
<ul>
<li><a
href="produitsseule.php">Ajouter</a></li>
<li><a href="affichierlesproduits.php">Affichier
les Produitions</a></li>
<li><a
href="lien.html">Update</a></li>
</ul>
<!--[if lte IE
6]></td></tr></table></a><![endif]-->
</li>
</ul>
<!--un menu de navigation avec sous-menus-->
<ul>
<li><a href="#">Charges<!--[if IE
7]><!--></a><!--<![endif]-->
<!--[if lte IE
6]><table><tr><td><![endif]-->
<ul>
<li><a
href="charge.php">Ajouter</a></li>
<li><a href="affichiercharges.php">Affichier
Charges</a></li>
<li><a
href="lien.html">Update</a></li>
</ul>
<!--[if lte IE
6]></td></tr></table></a><![endif]-->
</li>
</ul>
<!--un menu de navigation avec sous-menus-->
<ul>
<li><a href="#">Les reçus<!--[if IE
7]><!--></a><!--<![endif]-->
<!--[if lte IE
6]><table><tr><td><![endif]-->
<ul>
<li><a
href="recu.php">Ajouter</a></li>
<li><a
href="affichierrecu.php">Affichier</a></li>
<li><a href="rechercherrecu.php">Recherche
Reçu</a></li>
<li><a
href="lien.html">Bordereau</a></li>
</ul>
<!--[if lte IE
6]></td></tr></table></a><![endif]-->
</li>
</ul>
<!--un menu de navigation avec sous-menus-->
<ul>
<li><a href="#">La Bibliothéque<!--[if
IE 7]><!--></a><!--<![endif]-->
<!--[if lte IE
6]><table><tr><td><![endif]-->
<ul>
<li><a href="livre.php">Ajouter
Livre</a></li>
<li><a href="affichierauteur.php">Affichier les
Auteurs</a></li>
<li><a href="emprunt.php">Ajouter emprunts
histo</a></li>
<li><a href="affichierlesemprunts.php">Affichier
emprunts historiques</a></li>
<li><a
href="lien.html">Update</a></li>
</ul>
<!--[if lte IE
6]></td></tr></table></a><![endif]-->
</li>
</ul>
<!--un menu de navigation avec sous-menus-->
<ul>
<li><a href="#">Discussion<!--[if IE
7]><!--></a><!--<![endif]-->
<!--[if lte IE
6]><table><tr><td><![endif]-->
<ul>
<li><a href="accueil.php">Une
Question</a></li>
<li><a
href="lien.html">Rechercher</a></li>
<li><a
href="lien.html">Update</a></li>
</ul>
<!--[if lte IE
6]></td></tr></table></a><![endif]-->
</li>
</ul>
<!--un menu de navigation avec sous-menus-->
<ul>
<li><a href="#">Rapport Journalier<!--[if IE
7]><!--></a><!--<![endif]-->
<!--[if lte IE
6]><table><tr><td><![endif]-->
<ul>
<li><a href="produits.php">faire le
Rapport</a></li>
<li><a href="affichierrapport.php">Affihier
Rapports</a></li>
<li><a
href="lien.html">Update</a></li>
</ul>
<!--[if lte IE
6]></td></tr></table></a><![endif]-->
</li>
</ul>
<!--un menu de navigation avec sous-menus-->
<ul>
<li><a href="#">Accessoires<!--[if IE
7]><!--></a><!--<![endif]-->
<!--[if lte IE
6]><table><tr><td><![endif]-->
<ul>
<li><a href="calculatrice3.php">Calcule
Simple</a></li>
<li><a
href="lien.html">Update</a></li>
</ul>
<!--[if lte IE
6]></td></tr></table></a><![endif]-->
</li>
</ul>
<ul>
<li><a
href="connexion.php">Deconnexion</a></li>
</ul>
</div>
</td>
</tr>
<tr>
<td><br />
<div align="center">Bienvenue !!!<br />
La Conception,Implémentation d'une base de
données pour la gestion Général de Projet Limeté
Université Cardinal Malula<br />
Et l'Administration de son Reseau à Distance sur Base
d'outil Libre</div>
</td>
</tr>
</table>
<?php
}
else
{
include("connexion.php");
}
?>
<?php include("connecter.php");?>
</body>
</html>
Recherche
rechercherecu.php
<?php
session_start();//demarre la session
?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="fr"
lang="fr">
<head>
<title>FAITES VOTRE RECHERCHE ICI</title>
<?php include("menu.php");?>
<meta http-equiv="Content-Type" content="text/html;
charset=iso-8859-1"/>
<meta http-equiv="Content-Type" content="text/html;
charset=iso-8859-1" />
</head>
<body>
<p><center>FAITES VOTRE RECHERCHE
ICI!</center></p>
<center>
<style type="text/css">
.contenu
{
border-width:3px;/*Epaisseur de la bordure */
border-color:red;/*Couleur de la bordure */
border-collapse: collapse; /* Colle les bordures entre elles
*/
border-style:solid;/*Type de bordure */
font-size:14px; font-family:Trebuchet MS, Verdana, Arial,
Helvetica, sans-serif;
text-align:justify;
}
.contenu2
{
font-size:17px; font-family:Trebuchet MS, Verdana, Arial,
Helvetica, sans-serif;
}
</style>
</head>
<html>
<head>
</head>
<body>
<form name="" method="post"
action="rechercherrecu1.php">
<tr><td width="100" height="60">Récherche
par nom:</td><td><input type="text" name="nom" value=""
/></td><td>Postnom:</td><td><input type="text"
name="postnom" value="" /></td><td></td></tr>
<tr><td colspan="3" height="30"><div
align="center"><input type="submit" value="RECHERCHE DE REÇU"
name="" /></div></td></tr>
</form>
</head>
</body>
</html>rechercherrecu1.php
Résultat de la recherche
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="fr"
lang="fr">
<head>
<meta http-equiv="Content-Type" content="text/html;
charset=iso-8859-1" />
</head>
<body>
<p><center><b>VOTRE PREUVE DE
PAIEMANT!</b></center></p>
<p><center><h>=============================</h></center></p>
<center>
<style type="text/css">
.contenu
{
border-width:3px;/*Epaisseur de la bordure */
border-color:red;/*Couleur de la bordure */
border-collapse: collapse; /* Colle les bordures entre elles
*/
border-style:solid;/*Type de bordure */
font-size:14px; font-family:Trebuchet MS, Verdana, Arial,
Helvetica, sans-serif;
text-align:justify;
}
.contenu2
{
font-size:17px; font-family:Trebuchet MS, Verdana, Arial,
Helvetica, sans-serif;
}
</style>
<html>
<head>
<body>
<?php
If ($_POST['nom']!=NULL AND $_POST['postnom']!=NULL)
{
$nom= $_POST['nom'];
$postnom= $_POST['postnom'];
?>
<?php
echo'<table class="contenu" width ="70%">';
echo'<tr>';
echo'<td width="100" colspan ="5">';
echo'<b><center>Projet Limete Université
Cardinal Malula</center></b>';
echo'<b><center>==========</center></b>';
echo'</td width="100" colspan="5">';
echo'<td width="100%" colspan ="5">';
echo'</td width="100" colspan="5">';
echo'</tr>';
echo'<tr>';
echo'<td colspan ="7">';
echo'<center><b>Imprimez votre preuve de
paiement</b></center>';
echo'<center><b>===============================</b></center>';
echo'</td colspan="5">';
echo'</tr>';
mysql_connect("localhost","root","");
mysql_select_db("plucm");
$query5=mysql_query("SELECT* FROM
recu,agent,apprenants,formations,categoriesap,monnaies WHERE
apprenants.nom='$nom'AND apprenants.postnom='$postnom' AND
recu.idagent=agent.idagent AND recu.idapprenant=apprenants.idapprenant AND
recu.idformation=formations.idformation AND
recu.idcategorie_ap=categoriesap.idcategorie_ap AND
recu.idmonnaie=monnaies.idmonnaie");
mysql_close();
while($query6=mysql_fetch_array($query5))
{
echo'<tr>';
echo'<td colspan ="5">';
echo'<b>Nom Apprenant:</b>';
echo $nom;
echo'</td >';
echo'<td>';
echo'<b><center>Categorie:</center></b>';
echo '<center>';
echo $query6['categorie_ap'];
echo'</center>';
echo'</td>';
echo'</tr>';
echo'<table class="contenu" width ="70%">';
echo'<tr>';
echo'<td width="100" colspan ="5">';
echo'</td width="100" colspan="5">';
echo'</tr>';
echo'<tr>';
echo'<td width="100">';
echo'<b>DATE PAYE:</b>';
echo'</td>';
echo'</td>';
echo'<td width="100"colspan="2">';
echo'<b>MONTANT:</b>';
echo'</td>';
echo'<td width="100">';
echo'<b>FORMATION:</b>';
echo'</td>';
echo'<td width="100">';
echo'<center>Signature Percepteur</center>';
echo'</td>';
echo'</tr>';
echo'<tr>';
echo'<td>'.$query6['datepaye'].'</td>';
echo'<td>'.$query6['montantpaye'].'</td>';
echo'<td>'.$query6['monnaie'].'</td>';
echo'<td>'.$query6['lib_formation'].'</td>';
echo'</tr>';
echo'</table>';
}
}
else
echo"Veuillez entrer votre NOM ET POSTNOM CORRECT,si vous
êtes apprenant au Projet Limete Université Cardinal Malula";
?>
</head>
</body>
</html>
L'affichage de toute la production
affichierlesproduits.php
<?php
session_start();//demarre la session
?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="fr"
lang="fr">
<head>
<title>Formulaire des Apprenants de
PLUCM</title>
<meta http-equiv="Content-Type" content="text/html;
charset=iso-8859-1" />
</head>
<body>
<?php include("menu.php");?>
<p><center>Ceci est la liste des auteurs
!</center></p>
<center>
<style type="text/css">
.contenu
{
border-width:3px;/*Epaisseur de la bordure */
border-color:red;/*Couleur de la bordure */
border-collapse: collapse; /* Colle les bordures entre elles
*/
border-style:solid;/*Type de bordure */
font-size:14px; font-family:Trebuchet MS, Verdana, Arial,
Helvetica, sans-serif;
text-align:justify;
}
.contenu2
{
font-size:17px; font-family:Trebuchet MS, Verdana, Arial,
Helvetica, sans-serif;
}
</style>
</head>
<html>
<head>
<title>voici tous les produits</title>
</head>
<body>
<?php
echo'<table border="2" width ="100%">';
echo'<tr>';
echo'<td width="100">';
echo'<b>Date:</b>';
echo'</td>';
echo'<td width="100">';
echo'<b>Moniteur:</b>';
echo'</td>';
echo'</td>';
echo'<td width="100">';
echo'<b>Code Vendus:</b>';
echo'</td>';
echo'<td width="100">';
echo'<b>Codes Restants:</b>';
echo'</td>';
echo'<td width="100">';
echo'<b>Codes Servis:</b>';
echo'</td>';
echo'<td width="100">';
echo'<b>Codes Perdus:</b>';
echo'</td>';
echo'<td width="100"colspan="2">';
echo'<b>Recette:</b>';
echo'</td>';
echo'<td width="100">';
echo'<b>Sources:</b>';
echo'</td>';
echo'<td width="100">';
echo'<b>Service:</b>';
echo'</td>';
echo'<td width="100">';
echo'<b>Commentaires:</b>';
echo'</td>';
echo'<td width="100"colspan="2">';
echo'<center><b>Action</b></center>';
echo'</td>';
echo'</tr>';
mysql_connect("localhost","root","");
mysql_select_db("plucm");
// --------------- Etape 1-----------------
// nous allons chercher à créer des pages et
écrit les liens vers chacune des pages
// -----------------------------------------
// On met dans une variable le nombre de messages qu'on veut
par page
$nombreDeMessagesParPage = 20; // Essayez de changer ce nombre
pour voir :o)
// On récupère le nombre total de messages
$retour = mysql_query('SELECT COUNT(*) AS nb_messages FROM
produits');
$donnees = mysql_fetch_array($retour);$totalDesMessages =
$donnees['nb_messages'];
// On calcule le nombre de pages à créer
$nombreDePages = ceil($totalDesMessages /
$nombreDeMessagesParPage);
// Puis on fait une boucle pour écrire les liens vers
chacune des pages
echo 'Page : ';
for ($i = 1 ; $i <= $nombreDePages ; $i++)
{
echo '<a href="affichierlesproduits.php?page=' . $i .
'">' . $i . '</a> ';
}
mysql_connect("localhost","root","");
mysql_select_db("plucm");
// --------------- Etape 2 ---------------
// Maintenant, on va afficher les messages
// ---------------------------------------
if (isset($_GET['page']))
{
$page = intval($_GET['page']); // On
récupère le numéro de la page indiqué dans
l'adresse (affichierlesproduits.php?page=4)
}
else // La variable n'existe pas, c'est la première
fois qu'on charge la page
{
$page = 1; // On se met sur la page 1 (par
défaut)
}
// On calcule le numéro du premier message qu'on prend
pour le LIMIT de MySQL
$premierMessageAafficher = ($page - 1) *
$nombreDeMessagesParPage;
$reponse = mysql_query('SELECT * FROM produits ORDER BY
idproduit DESC LIMIT ' . $premierMessageAafficher . ', ' .
$nombreDeMessagesParPage);
while ($donnees = mysql_fetch_array($reponse))
{
}
mysql_close(); // On n'oublie pas de fermer la connexion
à MySQL ;o)
mysql_connect("localhost","root","");
mysql_select_db("plucm");
$query5=mysql_query("SELECT* FROM
produits,agent,monnaies,sources,moments WHERE
produits.idagent=agent.idagent AND
produits.idsource=sources.idsource AND produits.idmonnaie=monnaies.idmonnaie
AND produits.idmoment=moments.idmoment");
mysql_close();
while($query6=mysql_fetch_array($query5))
{
echo'<tr>';
echo'<td>'.$query6['datepro'].'</td>';
echo'<td>'.$query6['nom_agent'].'</td>';
echo'<td>'.$query6['codevendu'].'</td>';
echo'<td>'.$query6['coderestant'].'</td>';
echo'<td>'.$query6['coderecu'].'</td>';
echo'<td>'.$query6['codeperdu'].'</td>';
echo'<td>'.$query6['montantpro'].'</td>';
echo'<td>'.$query6['monnaie'].'</td>';
echo'<td>'.$query6['libsource'].'</td>';
echo'<td>'.$query6['libmoment'].'</td>';
echo'<td>'.$query6['commentaire'].'</td>';
echo'<td width="25">';
echo'<center><a href="modifier"><img
src="../Plucm/fag.jpg"title="Modifier"/></a></center>';
echo'</td>';
echo'<td width="25">';
echo'<center><a href="modifier"><img
src="../Plucm/fag.jpg"title="Supprimé"/></a></center>';
echo'</td>';
echo'</tr>';
}
echo'</table>';
?>
</p>
</head>
</body>
</html>
BIBLIOGRAPHIE
1. Ouvrages
·
Frédéric Couchet et
Benoît
Sibaud,
Enjeux
des logiciels libres face à la privatisation de la
connaissance,2005, éditions Charles Léopold Mayer
· Florent
Latrive,
Du
bon usage de la piraterie : culture libre, sciences ouvertes . 2004,
éditions Exils.
· Harvard University Press. The
success of open source
Steven Weber,
2006
· Jean-Paul Smets-Solanes et
Benoît Faucon. Logiciels libres. Liberté,
égalité, business., 1999, éditions Edispher.
· Linus
Torvalds, David Diamond, Il était une
fois
Linux.
L'extraordinaire histoire d'une révolution accidentelle.. 2001,
éditions Osman Eyrolles Multimédia.
· Michael Kofler (
2005), MySQL
5 : Guide de l'administrateur et du développeur (
ISBN
2212116330
· Perline, Thierry Noisette, La
bataille du logiciel libre - Dix clés pour comprendre.. 2004,
réédition augmentée 2006, éditions La
Découverte.
· Philippe
Aigrain, Cause commune de, 2005, éditions Fayard.
· Paul Dubois, Stefan Hinz, Carsten
Pedersen (
2004), MySQL - Guide
officiel (
ISBN
2-7440-1782-5)
· Tribune Libre - Ténors de
l'Informatique Libre. Sous la direction de Chris DiBona. 1999,
Éditions O'Reilly.
2. Note de cours
Dido MBUYAMBA : Méthode d'Analyse
Informatique, 2ème Graduat ARGBD, ESMICOM 2006 - 2007
MAVINGA: comception de systèmes
d'informations, Cours 2ème Licence,
ESMICOM 2007 - 2008
MANIONGA: Methode de Conduite de Projet
Informatique, ESMICOM, année 2007-2008
MANIONGA: Initiation de Projet
Informatique, 2ème Licence, ESMICOM 2007- 2008.
NTUMBA: Méthode de Recherche
Scientifique, 2ème Licence, ESMICOM 2007 - 2008
OKIT'OLEKO: Technologie de l'Internet,
L1info, ESMICOM 2006 - 2007
OKIT'OLEKO:
Télématique, Ecole Supérieur de
Métier le l'Informatique et de Commerce, 2005.-2006.
OKIT'OLEKO: Conception d'architecture de
réseau, Ecole Supérieur de Métier le
l'Informatique et de Commerce, 2006.-2007.
3. WEBIOGRAPHIE
http://fr.wikipedia.org/wiki/logiciel_libre
http://www.net-snmp.org
http://www.networkupstools.org
http://linux.developpez.com/cours/upsusb/
http://eu1.networkupstools.org/compat/stable.html
http://www.id.ethz.ch/people/allid
list/corti/gnu software
http://www.snmptt.org
http://fr.wikipedia.org/wiki/logicil_libre
http://www.wtcs.org/snmp4tpc/getif.htm
http://www.met-chem.com/fr/services/
http://dictionnaire.phpmyvisites.net/definition-Software-13015.htm
Sun
acquires MySQL, blogs.mysql.com
http://fr.wikipedia.org/wiki/Apache_HTTP_Server#Historique
http://fr.wikipedia.org/wiki/Apache_HTTP_Server#HistoriqueTABLE
DE MATIERE
Chapitre 0. INTRODUCTION GENERALE
1
0. PRESENTATION DU PROJET
1
I. PROBLEMATIQUE ET HYPOTHESE
2
I.1. Problématique
2
I.2. Hypothèse
3
II. CHOIX ET INTERET DU SUJET
3
III. DELIMITATION DU SUJET
4
IV. METHODES ET TECHNIQUES UTILISEES
5
IV.2. Techniques
6
V. CAHIER DE CHARGE 6
VI. SUBDIVISION DU TRAVAIL
8
VII. PLANNING PREVISIONNEL DU PROJET
8
VIII. PLAN DU TRAVAIL
10
Chapitre 1. ORGANISATION DU TRAVAIL
11
I. TABLEAU DES ACTIVITES
13
Chapitre 2. ETUDE PREALABLE
19
PRESENTATION DE
PL/UCM....................................................................20
ANALYSE DE L'
EXISTANT........................................................................21
Présentation de Réseau utilisé
au PLUCM......................................... 27
CRITIQUE DE
L'EXISTANT.................................................................................32
PROPOSITION DE
SOLUTION.............................................................................33
2.5. CHOIX DE SOLUTION
35
Chapitre 1. EXAMEN GENERAL DE LA THEORIE DES
LOGICIELS LIBRES
37
1.0. DEFINTION ET APERCU DE LOGICILE
LIBRE
37
1.0.1 Définition
37
1.0.2. Bref aperçu sur les logiciels
libres
38
Chapitre 2. LE METHODE APPLICABLES POUR
L'ADMINISTRATION DE RESEAUX
40
2.0. GENERALITE SUR L'ADMNISTRATION DE
RESEAU
40
2.1. LES CONCEPTS DE SNMP
41
2.1.1. Introduction
41
Chapitre 3. MISE EN OEUVRE DE NET-SNMP SOUS
LINUX
43
3.1. INSTALLATION DE NET-SNMP
44
3.1.1. Configuration et lancement de l'agent SNMP
NET-SNMP
44
3.1.2. Tests de l'agent SNMP NET-SNMP
46
3.1.3. Présentation du protocole SNMP
50
Chapitre 4. UTILISATION DE SNMP AU
PL/UCM
55
4.1. CONFIGURATION
55
4.1.1. Création d'un utilisateur v3
55
4.1.2. Le fichier snmpd.conf 55
Chapitre 5. ADMINSTRATION DE MATERIELS
57
5.1. LES CONTROLES DES UPS
57
5.1.1. La Connectique
57
5.1.2. Les Logiciels
58
5.1.3. Nagios dans tout cela
58
Chapitre 6. UTILISATION D'UN SCRIPT A DISTANCE
VIA SNMP
60
6.1. DES PLUGINS SUPPLEMENTAIRES
60
6.2. LA CONFIGURATION DE L'AGENT
SNMP
60
6.2.1. Définition de la commande et des
services sur le serveur
60
Chapitre 7. LES TRAPS
62
7.1 UTILISATION DES TRAPS AVEC NAGIOS
62
7.2 CONFIGURATIONS
62
7.2.1 Coté client (l'agent)
62
7.2.2 Coté serveur
63
7.3 NAGIOS DOIT COMPRENDRE, SNMPTT L'AIDE.
63
Chapitre 1. CONCEPTION DES BASES DE
DONNEES
69
I.0.INTRODUCTION
69
I.1. ETUDE CONCEPTIELLE
69
I.1.1.
Définition
69
I.1.2. But
70
2.0 GENERALITES
70
2.0.1 Notions de base de données
70
2.0.2. Quelques définitions relatives aux
bases de données
71
2.0.3. Caractéristiques d'une base de
données 71
2.0.4. Objectifs d'une base de données
71
2.0.5. Quelques définitions de concepts
72
3.0.3. Conception de Base de données dans
notre cas 73
4.0. QUELQUES ETATS EN SORTIES
89
4.0.1. Fiche Descriptive des sorties 89
Chapitre 2. ETUDE OPERATIONNELLE
92
2.1. GENERALITES
92
2.2. DESCRIPTION DE MATERIELS
92
2.2.1. Aspect Hardware
92
2.2.3. Aspect Software 92
Chapitre 3. SYSTEME DE GESTION DE BASE DE
DONNEES (SGBD) UTILISE.
195
3.1. INTRODUCTION 95
3.2. CARACTERISTIQUES 95
3.3. SYSTEMES D'EXPLOITATION SUPPORTES
96
3.4. UTILISATION
196
3.7. QUELQUE SYSTEMES DE
GESTION DE BASE DE DONNEES 97
3.8. SECURITE DE LA BASE DE DONNEES
97
3.9. CREATION DES BASES DE DONNEES ET DES
TABLES POUR LE PLUCM
98
3.10. MODELE LOGIQUE DE TRAITEMENT
102
3.10.1. Definition
102
3.10.2. Présentation de menus
102
3.11. INTERFACE DE L'UTILISATEUR
103
4. MODELE PHYSIQUE DE DONNEES
106
4.1. Définition
106
4.2. Règle de passage du
Modèle logique de données au Modèle Physique de
données
106
4.3. Présentation du Modèle Physique
de Données
107
Chapitre 1. PROGRAMMATION DE
L'APPLICATION
109
1.1. DEFINITION
109
1.1.1. Choix de méthode de programmation
109
1.1.2. La programmation classique
109
Chapitre 2. UTILISATION DE PHP POUR NOTRE
APPLICATION
118
2.1. INTRODUCTION
118
2.1. 1. Présentation des codes
sources et des interfaces de l'application
122
CONCLUSION
GENERALE............................................................
...... .. 127
BIBLIOGRAPHIE
148
![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]()
* 1 OKIT'OLEKO,
note de cours de technologie de l'Internet,
L1info, ESMICOM 2006 - 2007 p.32
* 2 NTUMBA,
note de cours de Méthode de Recherche Scientifique,
2ème Licence, ESMICOM 2007 - 2008, P. 22
* 3 NTUMBA, Op.
Cit, P. 23
* 4 NTUMBA, Op.
Cit, P. 24
* 5 MAVINGA,
Cours conception de systèmes d'informations, ,
2ème Licence , ESMICOM 2007 - 2008, P. 12
* 6 NTUMBA,
Op. Cit, P. 25
* * OKIT'OLEKO, Note de
cours, Conception d'architecture de réseau informatique, ESMICOM,
2e Licence ARGBD, .2007-2008
* 2 MANIONGA,
Note de Cours, Méthode de Conduite de Projet Informatique, ESMICOM,
année 2007-2008
* 32 MANIONGA,
Op. Cit., P. 13
* 7 MANIONGA,
Cours de Initiation de Projet Informatique, 2ème
Licence, ESMICOM 2007- 2008, P. 20
* 8 idem
* 9 MAVINGA,
Op. Cit., P. 12
* 10
OKIT'OLEKO, Cours de
Télématique, Ecole Supérieure de Métier le
l'Informatique et de Commerce, 2005.-2006, P.12
* 0
http://fr.wikipedia.org/wiki/logicil_libre
* 1 idem
* 2
http://fr.wikipedia.org/wiki/logicil_libre
* 3
http://www.net-snmp.org
* 4
http://www.wtcs.org/snmp4tpc/getif.htm
* 5
http://www.networkupstools.org
* 6
http://www.id.ethz.ch/people/allid
list/corti/gnu software
* 6
http://www.snmptt.org
* 3
http://www.met-chem.com/fr/services/
* 5
DONKING, Note de cours de base de données, ESMICOM,
2007-2008
* 6 idem
* 7 DONKING,
Op. Cit, P. 149
* 8 DONKING,
Op. Cit, P. 150
* 1 DONKING, note de cours Base
de Données, année 2007-2008, ESMICOM
*
2LUFUNGULA, cours conception de
base de donnée, année 2003-2004, UCM
* 3DONKING, Op. Cit., P.49
* 11
http://dictionnaire.phpmyvisites.net/definition-Software-13015.htm
* 1.
Sun
acquires MySQL, blogs.mysql.com
*
2.
http://fr.wikipedia.org/wiki/Apache_HTTP_Server#Historique
* 11 Dido MBUYAMBA, Op. Cit.,
P.49
* 12 Pierre
MORVAN, Dictionnaire Informatique, LAROUSSE, Paris
1991, P. 243
* 13 Dido
MBUYAMBA, cours Programmation Orientée Objet sous DELPHI et
INTERBASE, 1ER Licence ARGBD - RTM, ESMICOM 2006 -2007, P.
17
* 1
OKIT'OLEKO, cours Initiation à la Technologie de
L'Internet L1, ESMICO,2006-2007
| 

