|

République de Côte d'Ivoire
Union - Discipline - Travail
MÉMOIRE DE FIN DE CYCLE EN VUE DE L'OBTENTION DU
DIPLÔME DE
LA LICENCE PROFESSIONNELLE DES SYSTÈMES
RÉSEAU
INFORMATIQUE ET TÉLÉCOMMUNICATIONS
OPTION : ADMINISTRATION SYSTÈMES ET RÉSEAUX
Année académique : 2012 - 2013
DIRECTEUR DE MÉMOIRE
M. AGBISSI K.
Jean-Paul
Ingénieur des systèmes réseau
et
télécommunications
S/CSI DGTTC / Ministère des
Transports
IMPÉTRANT
N'GUESSAN KÔLOU HYPPOLYTE
UN SYSTÈME DE SAUVEGARDE ET DE
RESTAURATION DE DONNÉES AVEC
TOLÉRANCE DE PANNES EN
ENTREPRISE
CAS DE LA DGTTC
Année académique : 2012 - 2013
MÉMOIRE DE FIN DE CYCLE EN VUE DE L'OBTENTION DU
DIPLÔME DE
LA LICENCE PROFESSIONNELLE DES SYSTÈMES
RÉSEAU
INFORMATIQUE ET TÉLÉCOMMUNICATIONS
OPTION : ADMINISTRATION SYSTÈMES ET RÉSEAUX
UN SYSTÈME DE SAUVEGARDE ET DE
RESTAURATION DE DONNÉES AVEC
TOLÉRANCE DE PANNES EN
ENTREPRISE
CAS DE LA DGTTC
N'GUESSAN K. Hyppolyte 2012 - 2013
III
SOMMAIRE
SOMMAIRE III
TABLE DES FIGURES V
TABLE DES TABLEAUX VI
GLOSSAIRE VII
DEDICACE X
REMERCIEMENTS XI
RESUME XII
ABSTRACT XIII
INTRODUCTION GENERALE 14
1. Contexte et problématique 14
2. Justification du choix du thème 14
3. Objectifs 15
4. Approche méthodologique de la recherche 15
5. Plan 15
CHAPITRE I : CAHIER DE CHARGES FONCTIONNEL 17
I.1. Introduction partielle 17
I.2. L'objet de la demande 17
I.3. Le contexte du projet 17
I.4. La présentation du projet 18
I.5. Analyse de l'existant 19
I.6. La synthèse des éléments importants
24
I.7. La mise en oeuvre 24
I.8. La maintenance 25
I.9. Conclusion partielle 25
CHAPITRE II : LES GENERALITES
SUR LES SYSTEMES DE SAUVEGARDE ET DE
RESTAURATION DE DONNES 27
II.1. Introduction partielle 27
II.2. Les méthodes de sauvegarde les plus courantes 27
II.3. Les architectures de sauvegarde 32
II.4. Les techniques améliorant la disponibilité
41
II.5. Les critères de choix d'un sauvegarde et
restauration de données performant 42
II.6. Conclusion partielle 45
CHAPITRE III : DEPLOIEMENT DE
LA SOLUTION D'AMELIORATION DU SYSTEME DE
SAUVEGARDE ET DE RESTAURATION DE DONNEES 46
III.1.Introduction partielle 46
N'GUESSAN K. Hyppolyte 2012 - 2013
IV
III.2.Présentation de la solution 46
III.3.Le déploiement de la solution 49
III.4.La valorisation du projet d'amélioration du
système de sauvegarde et de restauration des données
63
II.7. Conclusion partielle 64
CONCLUSION GENERALE 65
BIBLIOGRAPHIE 67
ANNEXE 73
LES MISSION, L'ORGANISATION ET LE FONCTIONNEMENT DE LA DGTTC A
N'GUESSAN K. Hyppolyte 2012 - 2013
V
TABLE DES FIGURES
Figure 1:L'architecture réseau de la DGTTC (source :
SINDA) 20
Figure 2: L'architecture de sauvegarde DAS (DASTUGUE, 2008) 32
Figure 3: L'architecture de sauvegarde SAN (DASTUGUE, 2008) 34
Figure 4: Le schéma de principe d'une grappe de disques en
RAID 0 (DASTUGUE, 2008) 35
Figure 5: Schéma de principe d'une grappe de disques en
RAID 1 (DASTUGUE, 2008) 35
Figure 6: Schéma de principe d'une grappe de disques en
RAID 5 (DASTUGUE, 2008) 36
Figure 7: Schéma de principe d'une grappe de disques en
RAID 6 (DASTUGUE, 2008) 36
Figure 8: Schéma de principe d'une grappe de disques en
RAID combiné 0+1 (DASTUGUE, 2008) 37
Figure 9: L'architecture de sauvegarde NAS (DASTUGUE, 2008) 39
Figure 10: La nouvelle architecture réseau de la DGTTC
(Source : Hyppolyte N'GUESSAN) 47
Figure 11: La configuration du mot de passe de BackupPC (Source :
Hyppolyte N'GUESSAN) 49
Figure 12: La page web BackupPC (Source : Hyppolyte N'GUESSAN)
50
Figure 13: L'interface Web de configuration des hôtes
(Source : Hyppolyte N'GUESSAN) 50
Figure 14: La configuration manuelle des hôtes (Source :
Hyppolyte N'GUESSAN) 51
Figure 15: La configuration générale de BackupPC
via l'interface Web (Source : Hyppolyte
N'GUESSAN) 51
Figure 16: L'interface web d'administration (Source : Hyppolyte
N'GUESSAN) 55
Figure 17: Le fichier de configuration pour un hôte linux
(Source : Hyppolyte N'GUESSAN) 55
Figure 18: Le fichier de configuration pour un hôte Windows
(Source : Hyppolyte N'GUESSAN) 56
Figure 19: La synoptique du clustering de serveurs (Source :
Hyppolyte N'GUESSAN) 57
Figure 20: La vérification de l'activation du service de
haute disponibilité (Source : Hyppolyte
N'GUESSAN) 59
Figure 21: Une partie du fichier log (Source : Hyppolyte
N'GUESSAN) 59
Figure 22: L'analyse du fichier log (Source : Hyppolyte
N'GUESSAN) 60
Figure 23: La simulation d'une panne (Source : Hyppolyte
N'GUESSAN) 60
Figure 24: La vérification du fonctionnement du service de
haute disponibilité (Source : Hyppolyte
N'GUESSAN) 60
Figure 25: La reprise de la tête du
cluster par le serveur principal (Source : Hyppolyte N'GUESSAN)
61
Figure 26: Le rajout de disque au serveur principal
Cluster node 1 (Source : Hyppolyte N'GUESSAN)
61
Figure 27: Le fichier de configuration de DRBD (Source :
Hyppolyte N'GUESSAN) 62
Figure 28: La vérification de la synchronisation initiale
(Source : Hyppolyte N'GUESSAN) 63
Figure 29: L'organigramme du SINDA (Source : SINDA) C
N'GUESSAN K. Hyppolyte 2012 - 2013
VI
TABLE DES TABLEAUX
Tableau 1: L'inventaire des ordinateurs et imprimantes de la
DGTTC (Source : SINDA) 21
Tableau 2: L'inventaire des serveurs de la DGTTC (Source :
SINDA) 22
Tableau 3:Le tableau comparatif des différentes
solutions SAN et NAS (DUFRESNES, 2008) 40
Tableau 4: Le tableau récapitulatif du matériel
nécessaire (Source : Hyppolyte N'GUESSAN) 64
N'GUESSAN K. Hyppolyte 2012 - 2013
VII
GLOSSAIRE
CIFS : Common Internet File System est un
protocole permettant le partage de ressources (fichiers et imprimantes) sur des
réseaux locaux avec des PC sous Windows.
CLUSIF : Club de la sécurité de
l'information français est un club professionnel, constitué en
association indépendante, ouvert à toute entreprise ou
collectivité.
CRC : Cyclic Redundancy Check est un code de
détection d'erreur couramment utilisé dans les réseaux
numériques et des périphériques de stockage pour
détecter les modifications accidentelles de données brutes
DAS : Direct Attached Storage
Datacenter ou centre de données en
français est un site physique sur lequel se trouvent regroupés
des équipements constituants du système d'information de
l'entreprise.
Déduplication également
appelée factorisation ou stockage d'instance unique est une technique de
stockage de données, consistant à factoriser des séquences
de données identiques afin d'économiser l'espace
utilisé.
DHCP : Dynamic Host Configuration Protocol
est un protocole réseau dont le rôle est d'assurer la
configuration automatique des paramètres IP d'une station, notamment en
lui affectant automatiquement une adresse IP et un masque de
sous-réseau.
FCP : Fibre Channel Protocol. Ce protocole est
défini par la norme ANSI X3T11.
FTP : File Transfer Protocol (protocole de
transfert de fichiers), ou FTP, est un protocole de communication
destiné à l'échange informatique de fichiers sur un
réseau TCP/IP.
GHOST : General Hardware-Oriented System
Transfer, le mot anglais « ghost » signifie « fantôme
», mais il ne faut pas pour autant parler d'images fantômes : ici,
« ghost» est un jeu de mots
HTTP : HyperText Transfer Protocol est un
protocole de communication client-serveur développé pour le World
Wide Web.
iSCSI : Internet Small Computer Systems
Interconnect ou Internet SCSI. Ce protocole est défini dans les RFC 3720
& RFC 3783.
N'GUESSAN K. Hyppolyte 2012 - 2013
VIII
ITIL : Information Technology Infrastructure
Library (en français Bibliothèque pour l'infrastructure des
technologies de l'information) est un ensemble d'ouvrages recensant les bonnes
pratiques (« best practices ») du management du système
d'information.
LDAP : Lightweight Directory Access Protocol
est à l'origine un protocole permettant l'interrogation et la
modification des services d'annuaire.
LTO : Linear Tape Open est une technique de
stockage sur bande magnétique au format ouvert.
MD5 : Message Digest 5, est une fonction de
hachage cryptographique qui permet d'obtenir l'empreinte numérique d'un
fichier (on parle souvent de message).
NAS : Network Attached Storage est un serveur
de stockage directement attaché au réseau IP fournissant un
service de partage de fichiers aux clients /serveurs d'un environnement
hétérogène (multi-OS).
NFS : Network File System est à
l'origine un protocole développé par Sun Microsystems en 1984 qui
permet à un ordinateur d'accéder à des fichiers via un
réseau.
PRA Plan de reprise d'activité (en
anglais : Disaster Recovery Plan ou DRP) permet d'assurer, en cas de crise
majeure ou importante d'un centre informatique, la reconstruction de son
infrastructure et la remise en route des applications supportant
l'activité d'une organisation.
RAID : Redundant Array of Independent Disks
est un ensemble de techniques de virtualisation du stockage permettant de
répartir des données sur plusieurs disques durs afin
d'améliorer soit les performances, soit la sécurité ou la
tolérance aux pannes de l'ensemble du ou des systèmes.
RSA (nommé par les initiales de ses
trois inventeurs) est un algorithme de cryptographie asymétrique,
très utilisé dans le commerce électronique, et plus
généralement pour échanger des données
confidentielles sur Internet.
SAN : Storage Area Network est un
réseau de stockage sur lequel transitent des blocs de données.
SAS : Serial Attached SCSI est une technique
d'interface pour disques durs, elle constitue une évolution des bus SCSI
en termes de performances, et apporte le mode de transmission en série
de l'interface SATA.
SCSI : Small Computer System Interface en
anglais, est un standard définissant un bus informatique reliant un
ordinateur à des périphériques ou à un autre
ordinateur.
N'GUESSAN K. Hyppolyte 2012 - 2013
IX
SHA-1 : Secure Hash Algorithm 1 est une
fonction de hachage cryptographique conçue par la National Security
Agency des États-Unis (NSA), et publiée par le gouvernement des
États-Unis comme un standard fédéral de traitement de
l'information (Federal Information Processing Standard du National Institute of
Standards and Technology (NIST).
SQUID est un serveur mandataire (proxy) et un
mandataire inverse capable d'utiliser les protocoles FTP, HTTP, Gopher, et
HTTPS.
SSH : Secure Shell (SSH) est à la fois
un programme informatique et un protocole de communication
sécurisé.
USB : Universal Serial Bus (USB, en
français Bus universel en série, dont le sigle, inusité,
est BUS) est une norme relative à un bus informatique en transmission
série qui sert à connecter des périphériques
informatiques à un ordinateur.
DEDICACE
N'GUESSAN K. Hyppolyte 2012 - 2013
X
A Dieu Tout Puissant...
N'GUESSAN K. Hyppolyte 2012 - 2013
XI
REMERCIEMENTS
La réalisation de ce mémoire a été
possible grâce au concours de plusieurs personnes auxquelles nous
voudrions témoigner toute notre reconnaissance.
Nous voudrions tout d'abord adresser toute notre gratitude
à notre directeur de mémoire Monsieur AGBISSI K.
Jean-Paul pour sa patience, sa disponibilité et surtout ses
judicieux conseils, qui ont contribué à alimenter notre
réflexion.
Nous désirons aussi remercier les professeurs du
Groupe École d'Ingénieurs HETEC, qui nous ont
fourni les outils nécessaires à la réussite de nos
études universitaires.
Nous voudrions exprimer notre reconnaissance envers les amis
et collègues qui nous ont apporté leur support moral et
intellectuel tout au long de notre démarche.
Enfin, nous tenons à témoigner toute notre
gratitude à KOUASSI Hermann, LOUA Amandine et MOBIO
Jean-Baptiste pour leur confiance et leur support inestimable.
N'GUESSAN K. Hyppolyte 2012 - 2013
XII
RESUME
Ce mémoire se propose d'être un outil qui guidera
les responsables de la sécurité des systèmes
d'informations dans la mise en place d'un système de sauvegarde et de
restauration de données robuste et disponible à tout moment. Pour
cela, nous avons choisi d'illustrer nos propos en traitant un cas pratique :
celui de la DGTTC (Direction Générale des Transports Terrestres
et de la Circulation) qui dispose actuellement d'un système de
sauvegarde et de restauration de données sensibles aux pannes et aux
incidents de tout genre. Nous nous proposons donc à travers ce
mémoire de proposer à la DGTTC, une solution qui vise à
améliorer son système de sauvegarde.
Dans cette optique, nous étudions d'abord les
systèmes de sauvegarde et de restauration de données dans leur
généralité, afin de mieux les appréhender et
maîtriser leurs forces et surtout leurs faiblesses. Mais aussi pour nous
aider à comprendre les raisons pour lesquelles le système de
sauvegarde et de restauration de données de la DGTTC est si
intolérant aux pannes. Pour résoudre ce problème, nous
optons pour la mise en place d'un clustering de serveurs avec un système
de mirroring des disques durs, c'est-à-dire un RAID de niveau 1 et un
service d'équilibrage de charges visant à garantir une haute
disponibilité et une tolérance aux pannes de types
matériel. La dernière étape de notre solution vise
à garantir la pérennité des données de la DGTTC,
pour cela nous allons les externaliser vers un serveur distant.
N'GUESSAN K. Hyppolyte 2012 - 2013
XIII
ABSTRACT
This report suggests being a tool which will guide the
security officers of information systems in the implementation of a system of
protection and restoration of strong and available data at any time. For that
purpose, we chose to illustrate our words by handling a practical case: that of
the HGTT (Head office of the Ground Transport and the Traffic) which has at
present a system of protection and restoration of critical data in the
breakdowns and in the incidents of any kind. Thus we suggest through this
report proposing in the HGTT, the solution which aims at improving its system
of protection.
From this perspective, we study at first the systems of
protection and restoration of data in their majority, to arrest them better and
master their strengths and especially their weaknesses. But also to help us to
understand reasons why the system of protection and restoration of data of the
HGTT is so intolerant in the breakdowns. To solve this problem, we opt for the
implementation of waiters' clustering with a system of mirroring hard disks,
that is RAID 1 and service of load balancing to guarantee a high availability
and a fault tolerance of types material. The last stage of our solution aims at
guaranteeing the sustainability of the data of the HGTT, for it we are going to
outsource them towards a remote server.
N'GUESSAN K. Hyppolyte 2012 - 2013
14
INTRODUCTION GENERALE
1. Contexte et problématique
Aujourd'hui la pérennité d'une
société repose en grande partie sur ses données
informatiques. Il parait donc inévitable et impératif de
sécuriser sa société avec une bonne sauvegarde. La
sauvegarde des données est la mémoire de l'entreprise, que
deviendra la société sans sa mémoire ? La sauvegarde des
données informatiques a donc pour objectif de minimiser les
conséquences liées aux pertes de données informatiques.
Ces conséquences peuvent avoir un impact (direct ou indirect) non
négligeable sur l'activité de l'entreprise. La sauvegarde des
données permet alors de prévenir une panne naturelle, une erreur
humaine, un virus ou un sinistre.
Cependant, comment choisir efficacement son système de
sauvegarde ; comment le mettre en place et lui permettre de résister aux
pannes ?
2. Justification du choix du thème
Dans la majeure partie des cas, ce sont les maladresses
internes, (volontaires ou non) ou l'absence de sauvegardes fiables qui sont
à l'origine de la perte ou de la destruction d'informations sensibles.
La petite partie restante est imputable à des actes externes mal
intentionnés.
En effet, la sauvegarde de vos données est fondamentale
pour la continuité d'une entreprise. Dans certains cas exceptionnels, le
retour à la normale peut s'avérer extrêmement long et
fastidieux et engager des coûts difficilement supportables par
l'entreprise. Dans ce cas, c'est la pérennité de l'entreprise qui
est mise en jeu. Une autre conséquence est que la durée
nécessaire au retour à la normale peut être mis à
profit par la concurrence pour accroître ses parts de marché. Ce
cas de figure s'est déjà produit et a conduit des entreprises
à la perte de position de leader du marché. Enfin, les aptitudes
de l'entreprise à apporter des réponses adéquates aux
besoins de ses clients peuvent être remises en question : son image en
est altérée ainsi que sa crédibilité... et
probablement sa rentabilité.
Voici, brièvement présentées, les raisons
qui nous ont poussé à choisir comme thème de
mémoire de fin de cycle « La mise en place d'un
système de sauvegarde et de restauration de données avec
tolérance de pannes dans une entreprise : Cas de la DGTTC (Direction
Générale des Transports Terrestres et de la Circulation)
».
N'GUESSAN K. Hyppolyte 2012 - 2013
15
3. Objectifs
L'objectif de ce mémoire est avant tout de proposer une
solution de sauvegarde efficace qui résiste aux pannes pour permettre la
restauration du système informatique dans un état de
fonctionnement à la suite d'un sinistre (inondation, incendie, perte
d'un support de stockage). Mais aussi de restaurer des fichiers qui auraient
été supprimés accidentellement par un utilisateur, ou de
retrouver le fichier d'origine qui aurait subi une modification non
désirée.
3. Approche méthodologique de la recherche
Pour arriver à réaliser ce mémoire, nous
allons utiliser les méthodes suivantes :
-- La méthode de l'Internet, qui nous permet de consulter
certains sites pour avoir
les informations relatives au sujet ;
-- La méthode documentaire, qui nous permet de consulter
les différents ouvrages,
mémoires de fin d'études et cours relatifs au sujet
;
-- La méthode de l'interview auprès des
spécialistes en la matière pour avoir
certaines informations.
4. Plan
Dans le but d'atteindre nos objectifs, nous allons organiser
notre travail en trois (3) grands chapitres.
Dans le premier chapitre intitulé cahier de charges
fonctionnel, nous présentons d'abord l'objet de la demande ; ensuite
nous présentons le contexte du projet ; puis la présentation du
projet ; et enfin, l'étude de l'existant et abordons la mise en oeuvre
et la maintenance.
Le Deuxième chapitre est consacré aux
généralités sur les systèmes de sauvegardes et de
restauration de données, nous présentons tout d'abord les
méthodes de sauvegarde les plus courantes ; ensuite les
différentes architectures de sauvegarde ; et les techniques
améliorant la disponibilité. Enfin, les critères de choix
d'un système de sauvegarde performant.
Le dernier chapitre est consacré à la
réalisation de notre projet. Nous y faisons tout d'abord la
présentation de la solution que nous avons retenue conformément
au cahier de charges qui nous a été fourni. Ensuite, nous passons
au déploiement de cette solution et enfin,
N'GUESSAN K. Hyppolyte 2012 - 2013
16
la valorisation de notre projet d'amélioration du
système de sauvegarde et de restauration des données.
N'GUESSAN K. Hyppolyte 2012 - 2013
17
CHAPITRE I : CAHIER DE CHARGES FONCTIONNEL
I.1. Introduction partielle
Ce chapitre nous permet de faire une étude du projet
qui a été soumis de notre étude.
Nous ne pouvons bien évidemment pas revenir sur les
détails de l'étude complète d'un projet, mais nous
travaillerons sur les parties fondamentales faisant ressortir les points
saillants du travail qui nous a été confié.
I.2. L'objet de la demande
La Direction Générale des Transports Terrestres et
de la Circulation (DGTTC) souhaite améliorer son système de
sauvegarde et de restauration de données, afin d'augmenter sa
disponibilité et le rendre robuste face aux pannes
éventuelles.
I.3. Le contexte du projet
I.3.1. Le demandeur
I.3.1.1. La présentation de la DGTTC
La Direction Générale des Transports Terrestres
et de la Circulation (DGTTC) est créée le 11/08/2006 par
l'arrêté N°0207/MT/CAB. Elle est rattachée au
Ministère des Transports et a pour mission de conduire la politique
nationale en matière de Transport Terrestre et de la circulation
Routière et Ferroviaire sous l'autorité du Ministre des
Transports et de coordonner les activités des directions et services
sous son autorité.
I.3.1.2. La situation géographique de la
DGTTC
La DGTTC est située en Abidjan Plateau, à la
Tour C de la Cité Administrative. Elle occupe précisément
le rez-de-chaussée, les 3ème, 4ème et 5ème
étage.
I.3.2. Les données concernées par le
système de sauvegarde et de restauration
Toutes les données de la DGTTC sont importantes et
méritent d'être sauvegardées. C'est la mémoire et
l'histoire de cette dernière. Il s'agit généralement de la
comptabilité, des documents commerciaux (devis, contrats, factures, bons
de commandes, ...), des messageries ; de la base de clients et de toutes les
données concernant le milieu du transport (cartes grises, permis de
conduire, autorisations d'exercer des auto-écoles, etc...).
Il est donc primordial de mettre en place des
procédures et systèmes de sauvegardes automatiques robustes
visant à assurer la sécurité et la pérennité
de ces informations.
N'GUESSAN K. Hyppolyte 2012 - 2013
18
I.4. La présentation du projet
I.4.1. Les objectifs
Les objectifs de l'amélioration du système de
sauvegarde et de restauration de données sont les suivants :
- Sécuriser les données de l'entreprise ;
- Permettre de reprendre rapidement les activités de
l'entreprise après un incident ;
- Résister aux pannes et augmenter de la
disponibilité des serveurs de sauvegarde et de restauration de
données.
Les répercussions concrètes sur le long terme
seraient de :
- Pouvoir gérer les situations d'urgence ou de crise ;
- Gagner en temps, en performance, en qualité et donc en
coût.
I.4.2. Les principaux besoins
I.4.2.1. Le constat
Les différentes entités de la DGTTC stockent les
différentes informations sur un serveur de sauvegarde et de restauration
de données de type NAS. La panne de celui-ci ou la panne d'un de ses
disques induit les problèmes suivants :
- Perte de toutes les données sauvegardées ;
- Des difficultés dans la reprise d'activités
après des sinistres (incendie, destruction accidentelle d'un support de
stockage, etc...) ;
I.4.2.2. Les besoins
Les principaux problèmes que doit résoudre
l'amélioration du système de sauvegarde et de restauration de
données sont donc les suivants :
- Résoudre les problèmes de pannes
éventuelles et de disponibilité des serveurs ;
- Interfacer la solution avec les outils existants ;
- Stocker et gérer un volume important de fichiers ;
- Externaliser les sauvegardes sur un serveur distant ;
- Gérer les archives de façon électronique
;
- Faciliter la reprise d'activité après sinistre
N'GUESSAN K. Hyppolyte 2012 - 2013
19
I.4.2.3. Les enjeux relatifs à la sauvegarde et
à la restauration des données
En entreprise, les données informatiques ont aujourd'hui
une valeur unique. Toute société a besoin de protéger ses
données, et d'avoir la garantie d'assurer sa continuité de
service en cas de problème.
Aujourd'hui, tout professionnel reconnaît la
nécessité de disposer d'une sauvegarde fiable de ses
données informatiques. Pour autant, il est indispensable de pouvoir
réduire au maximum le temps de restauration des données.
Que ce soit lié à un sinistre total ou partiel (vol
de machine, erreur de manipulation, panne irrécupérable de
serveur), il est indispensable de pouvoir restaurer la totalité, ou une
partie de ses données dans les plus brefs délais.
I.4.2.4. La technique
Pour réaliser ce projet, nous nous sommes
appuyés sur les expériences acquises au cours de notre formation,
sur quelques personnes ressources et quelques recherches sur internet, mais
aussi sur les forums où la plupart de nos difficultés ont
été étayées.
I.5. Analyse de l'existant
I.5.1. La description de l'existant
La figure 1 ci-après nous présente
l'architecture réseau de la Direction Générale des
Transports Terrestres et de la Circulation (DGTTC). C'est une architecture
client-serveur composée de quatre (04) niveaux. Sur chaque niveau, nous
avons un rack contenant deux (02) routeurs de type CISCO Catalyst 2960 ou
Juniper SSG 20 ; deux (02) switches ; deux (02) panneaux de brassages de 24
ports chacun et deux (02) Wibox MTN pour la connexion à Internet. Au
rez-de-chaussée, nous avons la salle d'examen composée d'une
dizaine d'ordinateurs équipés chacun d'un lecteur l'empreinte
digitale. Les ordinateurs des paliers supérieurs sont tous
équipés d'une imprimante. La salle des serveurs située
à la porte 25 du
N'GUESSAN K. Hyppolyte 2012 - 2013
20
4ème étage quant à elle est
équipée d'un serveur Windows, un serveur Linux et un serveur NAS
(Network Attached Storage).

Figure 1:L'architecture réseau de la DGTTC (source :
SINDA)
I.5.2. L'inventaire de l'existant
I.5.2.1. Les ordinateurs et imprimantes
Le tableau 1 suivant, nous présente l'ensemble du
matériel de bureau dont dispose la DGTTC dans son pack informatique. Il
faut noter que parmi les 150 ordinateurs que compte la DGTTC, il y en a une
dizaine d'ordinateurs équipés de lecteur d'empreinte digitale.
N'GUESSAN K. Hyppolyte 2012 - 2013
21
|
Désignation
|
Type
|
Caractéristiques
|
Système
d'exploitation
|
Quantité
|
|
Ordinateur
|
HP Pro
|
Processeur Core I3
Fréquence 3,40
GHz
Disque Dur
500 GB
Mémoire
RAM 4 GB
|
8 / Windows 7 / Windows XP
|
150
|
|
Imprimantes
|
HP
OfficeJet
|
Impression, copie, numérisation, télécopie,
Web
A4 ; A5 ; A6 ; B5 (JIS) ; Enveloppe (DL, C5, C6)
1 port USB 2.0 haut débit ; 1 port USB ; 1 Ethernet ; 1
Wifi 802,11b/g/n 2 ports modem RJ-11
Jusqu'à 30000
pages
|
Compatible
avec tous les systèmes d'exploitation
|
150
|
Tableau 1: L'inventaire des ordinateurs et imprimantes de la
DGTTC (Source : SINDA)
I.5.2.2. Les serveurs
La salle des serveurs de la DGTTC, tel que nous
présente le tableau 2, est équipée de 3 serveurs HP
Proliant. Un de type DL360 et deux de type DL380p Génération 8.
Chaque serveur est équipé de 6 disques durs SATA de 500 Go. Le
serveur HP Proliant DL360 sert de serveur de stockage réseau (NAS).
Quant aux deux autres, il y a un sur lequel est installé un serveur
linux équipé de détecteur d'intrusion logiciel IDS,
notamment SNORT. Sur le deuxième est installé le système
d'exploitation Windows server 2012. On y a aussi installé un serveur
d'antivirus, en occurrence BitDefender et un service d'annuaire LDAP
(Lightweight Directory Access Protocolest) Active directory pour la gestion des
ordinateurs et des utilisateurs.
N'GUESSAN K. Hyppolyte 2012 - 2013
22
|
Désignation
|
Caractéristiques
Techniques
|
Quantité
|
|
HP Proliant
DL 360
|
Processeur Intel®
Xeon® E5-2600 v3 Format 1U
Mémoire, maximale
1,5TB
Contrôleur réseau
Adaptateur Ethernet 1
Go 331i, 4 ports par contrôleur
HDD 6 x 500 Go
|
1
|
|
HP Proliant DL 380p Gen8
|
Format 1U 1 voie
1 x P G2120 / 3.1 GHz RAM 2 Go
SATA - non
remplaçable à chaud 3.5"
HDD 6 x 500 Go
|
2
|
Tableau 2: L'inventaire des serveurs de la DGTTC (Source :
SINDA)
I.5.3. L'étude des méthodes de
sécurisation actuelles des données
I.5.3.1. La sécurité des postes de
travail
En ce qui concerne la sécurité des postes de
travail, une authentification de chaque utilisateur est nécessaire avant
usage. Une sensibilisation des agents sur les méfaits et risques
liés à l'usage des clés USB (Universal Serial Bus)
provenant de l'extérieur est tout le temps organisé. Les postes
de travail sont aussi régulièrement mis à jour par le
serveur d'antivirus. Un serveur proxy SQUID empêche les utilisateurs
d'aller sur des sites dangereux. Les postes de travail sont
régulièrement maintenus pour prévenir les pannes. Mais
aussi pour réparer les machines défectueuses. Du point de vue
électrique, les postes de travail sont branchés à des
onduleurs pour éviter les extinctions brusques.
I.5.3.2. La sécurité des serveurs et des
équipements réseaux
Les serveurs tout comme les postes sont protégés
par un pare-feu et un détecteur d'instruisions logiciel. La salle des
serveurs est équipée d'une porte métallique blindée
qui reste
N'GUESSAN K. Hyppolyte 2012 - 2013
23
fermée en permanence. La salle est climatisée et
maintenue à une température inférieure à 18°C
pour éviter la surchauffe. L'accès est interdit à toute
personne étrangère. On y accède seulement que pour des
travaux de maintenances ne pouvant être exécutés à
distance (remplacement d'un disque défectueux, un câble
endommagé, etc...). Un audit est régulièrement fait pour
évaluer les risques et les problèmes auxquels les serveurs
peuvent être exposés, afin de procéder immédiatement
à sa résolution.
Les équipements réseaux sont rangés dans
des baies vitrés hermétiquement fermés, à l'abri de
la poussière. Les armoires sont installées dans des endroits
frais et secs pour éviter la surchauffe. Les équipements
réseaux sont régulièrement
dépoussiérés et maintenus.
I.5.3.3. La méthode de sauvegarde et de
restauration de données actuelle
Il est mis en place un serveur de sauvegarde réseau
NAS. Il est directement attaché au réseau IP fournissant un
service de partage de fichiers aux clients /serveurs d'un environnement
hétérogène (multi-OS). Ce service de partage de fichiers
est fourni à l'aide d'un protocole de transport de fichiers de haut
niveau (NFS, CIFS, HTTP et FTP). La sauvegarde se fait de manière
régulière. La méthode de sauvegarde retenue est une
sauvegarde incrémentielle.
I.5.4. La critique des méthodes de
sécurisation actuelles du système informatique
Suite à l'étude de l'existant, on peut noter les
observations suivantes :
· La faiblesse du débit de connexion Internet par
rapport au nombre de postes global ;
· Absence de serveur de sauvegarde redondant et de plan de
reprise d'activité ;
· Perte de la totalité des données en cas
de sinistre majeur dans la salle des serveurs ou de panne du serveur de
sauvegarde ;
A la lumière de ce qui précède, les
opérations suivantes s'avèrent nécessaires pour
l'amélioration du réseau :
· Augmentation du débit de connexion Internet ;
· Installation d'un serveur de sauvegarde redondant et
mis en clustering avec l'ancien en vue d'augmenter la disponibilité ;
faciliter la montée en charge ; permettre une répartition de la
charge et faciliter la gestion des ressources (processeur, mémoire vive,
disques dur, bande passante réseau) ;
· Externalisation des sauvegardes vers un serveur
distant ;
· Mise en place d'un plan de reprise d'activité
;
·
N'GUESSAN K. Hyppolyte 2012 - 2013
24
Mise en place d'un système de gestion électronique
des archives ;
I.6. La synthèse des éléments
importants
Suite à la critique des méthodes de
sécurisation actuelles du système informatique, nous pouvons
relever ces quelques éléments importants :
o Pérennité de la solution, assurant la
pérennité et la sécurité des informations,
documents et fichiers contenus dans la solution
o Evolutivité et souplesse de la solution permettant
de paramétrer soi-même de nombreux éléments : la
structuration des informations, la définition des droits et profils
associés, le paramétrage des formulaires
o Ergonomie et simplicité de paramétrage : la
configuration et les modifications doivent être accessibles sans devoir
acquérir de compétences informatiques particulières,
exceptée une formation spécifique à l'outil.
o Compatibilité informatique : avec des environnements
MAC, Windows et Linux.
I.7. La mise en oeuvre
I.7.1. L'installation et la configuration
Deux scenarii de mise en oeuvre sont envisagés selon
le type de licence de la solution proposée :
o Licence libre : code source accessible et partagé,
logiciel librement téléchargeable et configurable
o Licence propriétaire : code propriétaire,
logiciel payant
I.7.1.1. Le scénario A : licence libre
Dans le cas d'un logiciel libre et gratuit, la DGTTC prend en
charge l'installation et la configuration basique de la solution communautaire
(proposée en téléchargement).
La DGTTC requiert cependant l'assistance d'un prestataire pour
le transfert de compétences nécessaires à la
maîtrise complète de la solution afin qu'elle réponde au
mieux au présent cahier des charges.
Le prestataire fournit donc une assistance à la DGTTC
pour la configuration avancée du système de sauvegarde et de
restauration de données. Il apporte une aide ponctuelle pour le
paramétrage complexe de la solution de base (communautaire).
N'GUESSAN K. Hyppolyte 2012 - 2013
25
Par ailleurs, le prestataire assiste au paramétrage des
interfaces avec les systèmes existants à la DGTTC (Base de
données, serveur de fichiers, pare-feu, etc.).
I.7.1.2. Scénario B : licence
propriétaire
Le prestataire devra installer la solution chez le demandeur sur
un serveur dédié.
Le prestataire assistera la DGTTC dans le paramétrage
de la solution. Il aura réalisé la configuration avancée
de la solution et devra configurer des interfaces avec les systèmes
existants à la DGTTC.
I.7.2. La formation
Le prestataire s'engage à effectuer un transfert de
compétences afin de fournir aux administrateurs toutes les informations
nécessaires à leur autonomie pour paramétrer et faire
évoluer la solution. Ces informations doivent pouvoir lui être
accessibles ultérieurement (sur un site web, dans des documents).
La DGTTC doit avoir accès à une documentation,
si possible en français, lui permettant de paramétrer et mettre
à jour l'outil selon le présent cahier des charges. Il doit
également avoir accès à une documentation de base pour
l'utilisation de l'outil, en français si possible.
L'existence d'un forum et d'un club utilisateur serait un
plus.
I.8. La maintenance
Le prestataire s'engage à fournir des prestations de
maintenance de l'outil : assistance en ligne, réponse
personnalisée, interventions directes, mises à jour et correctifs
(fonctionnel et de sécurité).
I.9. Conclusion partielle
Ce premier chapitre nous a permis de présenter dans les
moindres détails notre environnement de travail et les conditions dans
lesquelles nous aurons à travailler pour offrir à la DGTTC une
solution visant à résoudre leur problème et à
garantir la pérennité de leurs données.
Dans le chapitre suivant intitulé les systèmes
de sauvegardes et de restaurations de données d'une manière
générale, nous présentons les différents
systèmes de sauvegarde et restauration de données existant et
nous relevons leurs forces, mais aussi leurs faiblesses. Cela
N'GUESSAN K. Hyppolyte 2012 - 2013
26
devrait nous permettre de comprendre le problème du
système de sauvegarde et de restauration de données de la DGTTC
et de lui proposer une solution efficace et adéquate.
N'GUESSAN K. Hyppolyte 2012 - 2013
27
CHAPITRE II : LES GENERALITES SUR LES SYSTEMES DE
SAUVEGARDE ET DE RESTAURATION DE DONNES
II.1. Introduction partielle
En informatique, la sauvegarde (backup en anglais) est
l'opération qui consiste à dupliquer et à mettre en
sécurité les données contenues dans un système
informatique.
Ce terme est à distinguer de deux notions proches :
· l'enregistrement des données,
qui consiste à écrire des données sur un
périphérique, tel qu'un disque dur, une clé USB, des
bandes magnétiques, où les informations demeureront même
après l'extinction de la machine, contrairement à la
mémoire vive.
· l'archivage, qui consiste à
enregistrer des données de manière à garantir sur le long
terme leur conformité à un état donné, en
général leur état au moment où elles ont
été validées par leurs auteurs.
La sauvegarde passe forcément par un enregistrement des
données, mais pas nécessairement dans un but d'archivage.
L'opération inverse qui consiste à
réutiliser des données sauvegardées s'appelle une
restauration.
II.2. Les méthodes de sauvegarde les plus
courantes
La méthode la plus simple est la sauvegarde
complète ou totale (appelée aussi "full
backup") ; elle consiste à copier toutes les données
à sauvegarder que celles-ci soient récentes, anciennes,
modifiées ou non.
Cette méthode est aussi la plus fiable mais elle est
longue et très coûteuse en termes d'espace disque, ce qui
empêche de l'utiliser en pratique pour toutes les sauvegardes à
effectuer. Afin de gagner en rapidité et en temps de sauvegarde, il
existe des méthodes qui procèdent à la sauvegarde des
seules données modifiées et/ou ajoutées entre deux
sauvegardes totales. On en recense deux :
? La sauvegarde différentielle ? La sauvegarde
incrémentale
La restauration d'un disque avec l'une de ces méthodes
s'avère plus longue et plus fastidieuse puisqu'en plus de la
restauration de la sauvegarde différentielle ou des sauvegardes
N'GUESSAN K. Hyppolyte 2012 - 2013
28
incrémentielles, on doit également restaurer la
dernière sauvegarde complète. Les fichiers supprimés
entre-temps seront restaurés ou non (en fonction des
fonctionnalités du logiciel de sauvegarde utilisé)
Afin de comprendre la différence entre les deux
méthodes, nous prendrons l'exemple d'un plan de sauvegarde selon le
cycle suivant :
? Une sauvegarde complète au jour J (dimanche soir par
exemple)
? Une sauvegarde des fichiers modifiés ou nouveaux du jour
J+1 au jour J+6 (du lundi soir au samedi soir inclus)
? Une sauvegarde complète au jour J+7 (dimanche soir
suivant)
II.2.1. Le mécanisme
Pour pouvoir différencier ces différentes
méthodes de sauvegarde/archivage (complète,
incrémentielle, différentielle), le mécanisme mis en place
est l'utilisation d'un marqueur d'archivage. Chaque fichier possède ce
marqueur d'archivage, qui est positionné à "vrai" lorsque l'on
crée ou modifie un fichier. On peut comprendre cette position comme "Je
viens d'être modifié ou créé : je suis prêt
à être archivé donc je positionne mon marqueur à
vrai". Ce marqueur est appelé aussi attribut d'archivage (ou bit
d'archivage). Sous Windows, cet attribut est modifiable et peut être
visualisé par la commande ATTRIB (attribut A pour archive). Le
système de sauvegarde peut aussi constituer une base de données
contenant les définitions des fichiers et utiliser un marquage
interne.
II.2.2. La sauvegarde complète
Lors d'une sauvegarde complète, on va remettre à
"0" l'attribut du fichier pour mémoriser le fait que le fichier a
été enregistré.
II.2.2.1. Le détail technique
Lors d'une sauvegarde complète, tous les fichiers sont
sauvegardés, indépendamment de la position du marqueur (vrai ou
faux). Une fois le fichier archivé, celui-ci se voit attribuer la
position de son marqueur (le bit d'archive) à "faux" (ou à
"0").
II.2.3. La sauvegarde différentielle
La restauration faite à partir de ce type de sauvegarde
nécessite la recopie sur disque de la dernière sauvegarde
complète et de la sauvegarde différentielle la plus
récente.
N'GUESSAN K. Hyppolyte 2012 - 2013
29
Avec notre exemple, si la restauration porte sur un disque
complet qui a été sauvegardé le jour J+2, on doit alors
recopier sur disque la sauvegarde complète du jour J et la sauvegarde
différentielle du jour J+2 afin d'avoir la dernière version des
données.
Cependant lorsqu'il s'agit de la restauration d'un fichier ou
d'un répertoire qui a été sauvegardé le jour J+2
seule la dernière sauvegarde, ici la différentielle, est
utile.
II.2.3.1. Le détail technique
Lors d'une sauvegarde différentielle, tous les fichiers
dont le marqueur est à "vrai" sont sauvegardés. Une fois le
fichier archivé, celui-ci garde la position de son marqueur tel qu'il
l'avait avant la sauvegarde.
Certains logiciels de sauvegarde donnent la possibilité
d'utiliser non pas le bit d'archive, mais l'heure de modification du fichier
pour déterminer si celui-ci est candidat ou non à la
sauvegarde.
II.2.4. La sauvegarde incrémentielle ou
incrémentale
Exemple : une sauvegarde complète est
réalisée le jour J. Le jour J+1, la sauvegarde
incrémentielle est réalisée par référence au
jour J. Le jour J+2, la sauvegarde incrémentielle est
réalisée par référence au jour J+1. Et ainsi de
suite.
Si la restauration se porte sur un disque complet qui a
été sauvegardé le jour J+4, on doit alors recopier sur
disque la sauvegarde du jour J et les sauvegardes incrémentielles des
jours J+1, J+2, J+3 et J+4 afin d'obtenir la dernière version de la
totalité des données.
Cependant lorsqu'il s'agit de la restauration d'un fichier ou
d'un répertoire qui a été sauvegardé le jour J+3,
seule la dernière sauvegarde, ici l'incrémentielle, est utile.
La sauvegarde incrémentale peut également porter
sur les seuls octets modifiés des fichiers à sauvegarder. On
parle alors de sauvegarde incrémentale octet. Cette méthode est
celle qui permet d'optimiser le plus l'utilisation de la bande passante. Elle
rend possible la sauvegarde de fichiers de plusieurs Giga-octets, puisque seul
un pourcentage minime du volume est transféré à chaque
fois sur la plateforme de sauvegarde.
Lorsqu'un fichier a été supprimé du
système de fichier, une sauvegarde incrémentale doit enregistrer
que ce fichier qui était présent lors de la sauvegarde
précédente devra être supprimé lors de la
restauration de cette sauvegarde incrémentale, afin de restaurer le
système de fichier exactement dans son état d'origine. Ce point
n'est pas toujours pris en compte par les logiciels
N'GUESSAN K. Hyppolyte 2012 - 2013
30
de sauvegardes gérant les sauvegardes
incrémentales. La restauration à partir de sauvegardes
incrémentales avec des logiciels ne gérant pas la suppression des
fichiers conduit alors à reconstituer le système de fichier
original pollué par tous les fichiers qui ont été
supprimés parfois de longue date.
II.2.4.1. Le détail technique
Lors d'une sauvegarde incrémentielle, tous les fichiers
dont le marqueur est à "vrai" sont sauvegardés. Une fois le
fichier archivé, celui-ci se voit attribuer la position de son marqueur
à "faux".
II.2.4.2. La sauvegarde, l'archivage et la
conservation
La conservation permet de faire la différence entre
sauvegarde et archivage.
La durée de conservation est le temps pendant lequel la
donnée sauvegardée est maintenue intacte et accessible. Si elle
est courte, il s'agit d'une sauvegarde classique : la donnée est
protégée contre sa disparition/son altération. Si elle est
longue (une ou plusieurs années), il s'agit d'archivage, dont le but de
retrouver la donnée avec la garantie qu'elle n'a pas été
modifiée ou falsifiée.
Exemple : une conservation de quatre semaines implique que les
données sauvegardées à une date précise seront
toujours disponibles jusqu'à 28 jours après leur sauvegarde.
Après ces 28 jours, d'un point de vue logique, les données
n'existent plus dans le système de sauvegarde et sont
considérées comme introuvables. Physiquement, les pistes
utilisées pour enregistrer cette sauvegarde peuvent être
effacées.
Plus la conservation est longue et plus le nombre d'instances
sauvegardées pour un même objet fichier ou dossier est important,
ce qui nécessite un système de recherche et d'indexation
approprié, et plus l'espace nécessaire pour stocker les
résultats de la sauvegarde sera important.
II.2.4.3. La formule de calcul de l'espace de
sauvegarde nécessaire Cette formule permet de
dimensionner une librairie de sauvegarde.
Dans le cas d'une sauvegarde classique, c'est-à-dire
sauvegarde totale le week-end (vendredi soir) et sauvegardes
incrémentielles les autres jours ouvrés de la semaine, du lundi
au jeudi (pas le vendredi) soit quatre jours :
- soit D l'espace de donnée utile à sauvegarder,
N'GUESSAN K. Hyppolyte 2012 - 2013
31
- soit R la durée de conservation des travaux
souhaitée, exprimée en semaine, - soit T le taux de modification
par jour des fichiers de l'espace à sauvegarder, La formule suivante est
obtenue :
D x R + (D x T %) x 4 = capacité de
sauvegarde.
Exemple chiffré :
100 Go au total à sauvegarder avec une rétention
de 3 semaines et un taux de modification de 20 % par jour donne 100 x 3 + (100
x 20 %) x 4 = 380 Go. 380 Go seront nécessaires pour sauvegarder nos 100
Go de données avec une rétention de 3 semaines et une
modification de 20 % par jour.
Des innovations technologiques telles que les snapshots ou la
déduplication permettent de réduire cette valeur d'une
façon très intéressante.
II.2.5. La sauvegarde
décrémentale
Contrairement à la sauvegarde incrémentale
où la sauvegarde la plus ancienne est complète et les suivantes
différentielles, le principe de la sauvegarde décrémentale
consiste à obtenir une sauvegarde complète comme sauvegarde la
plus récente et des sauvegardes différentielles pour les plus
anciennes.
L'avantage tient au fait que la restauration complète
du système dans son état le plus récent est simple et
rapide, on n'utilise que la dernière sauvegarde, (contrairement à
la méthode incrémentale qui implique la restauration de la plus
ancienne (complète) puis de toutes les suivantes, incrémentales).
Si maintenant on souhaite récupérer le système dans
l'état de l'avant dernière sauvegarde, il faut restaurer la
dernière sauvegarde (complète) puis la précédente
(dite "décrémentale" parce qu'elle donne la différence
à appliquer au système de fichier pour atteindre l'état
N-1 à partir de l'état N). Autre avantage, le recyclage de
l'espace de stockage des sauvegardes est simple car il consiste à
supprimer les sauvegardes les plus anciennes, alors que dans le cas des
sauvegardes incrémentales le recyclage implique usuellement plusieurs
jeux de sauvegarde (complète + incrémentales).
Le désavantage de cette approche est qu'elle
nécessite plus de manipulation de données à chaque
sauvegarde, car il faut construire une sauvegarde complète à
chaque nouvelle sauvegarde et transformer l'ancienne sauvegarde la plus
ancienne (qui était donc une sauvegarde complète) en une
sauvegarde décrémentale.
N'GUESSAN K. Hyppolyte 2012 - 2013
32
II.3. Les architectures de sauvegarde
Les architectures qui seront présentées
répondent aux problématiques suivantes :
o Comment partager des données efficacement à
travers un réseau ?
o Comment faire face à l'explosion des volumes de
données stockés dans les entreprises ?
o Comment assurer les sauvegardes pour des volumes de
données à sauver de plus en plus grand ?
o Comment garantir l'accès aux données 24h/24h
et 7j/7j ?
Pour cela, trois différentes architectures permettent
d'organiser son stockage pour répondre à ces besoins : DAS
(Direct Attached Storage), SAN (Storage Area Network) et NAS.
II.3.1. Le DAS (Direct Attached Storage)
Il ne désigne pas une architecture de stockage en
lui-même. Il désigne tout périphérique de stockage
attaché directement à un serveur. Par exemple, le disque dur
interne d'un serveur est un DAS car celui-ci est relié directement au
serveur sans passer par un réseau quelconque. Dans sa forme la plus
évoluée, le DAS représente un serveur qui possède
une carte SCSI (Small Computer System Interface) ou SAS (Serial Attached SCSI)
externe sur laquelle on va accrocher une cage de disques.
Les solutions de stockage de type DAS (Direct Attached
Storage) consistent à connecter directement un
périphérique au serveur ou à la station de travail. Il
s'agit principalement d'un lecteur de bandes magnétiques mais d'autres
solutions peuvent être envisagées comme le support optique ou les
disques durs externes (voir figure 2).

Figure 2: L'architecture de sauvegarde DAS (DASTUGUE,
2008)
N'GUESSAN K. Hyppolyte 2012 - 2013
33
II.3.1.1. Les avantages et les inconvénients
II.3.1.1.1. Les avantages
· Les supports amovibles peuvent être
externalisés (il s'agit de mettre les sauvegardes à l'abri en
dehors de l'entreprise). Si le lieu de production est très
endommagé, les sauvegardes ne seront pas détruites. Cependant, le
coût du lieu de stockage est à prendre en compte.
· Le coût de l'investissement est abordable
à toutes PME, quelle que soit sa taille.
II.3.1.1.2. Les inconvénients
· La permutation des supports de stockage n'est pas
entièrement automatisée. Il est soumis aux erreurs humaines
(oubli, perte, etc.).
· Les supports sont fragiles. Ils peuvent subir des
chocs et des rayures. Les bandes magnétiques sont plus ou moins fragiles
selon leur vitesse de défilement. Leur durée de vie est
limitée à 200 / 300 passages. Quant aux lecteurs, ils sont
sensibles à la poussière. Afin de faciliter leur remplacement, il
est conseillé d'utiliser un type de bande standard. Les supports
optiques peuvent, dans les cas les plus extrêmes, exploser dans le
lecteur.
· Avec le temps, les supports amovibles peuvent se
détériorer. Les CD-ROM de mauvaise qualité sont les plus
exposés à ce phénomène. La période de
conservation d'un support optique est théoriquement d'un siècle,
estimation difficile à vérifier puisque la technologie existe
depuis seulement une dizaine d'années. Les données
stockées sur des bandes peuvent s'effacer au fil du temps. Pour
éviter toute perte de données, il est important d'effectuer une
réécriture après quelques années.
· Les applications telles que les bases de
données doivent être fermées avant de lancer la sauvegarde.
Pendant ce temps, il est impossible d'y effectuer toute modification. Cependant
certains logiciels permettent de sauvegarder « à chaud »
(c'est-à-dire en cours de fonctionnement) certaines bases de
données.
· Les supports amovibles sont sensibles à
l'environnement (électricité, température,
humidité...). En particulier, les supports optiques sont facilement
rayés et deviennent illisibles.
· La vitesse de transfert que proposent les lecteurs de
bandes et de DVD est relativement faible. Il faut prévoir en moyenne
entre deux à cinq heures pour effectuer
N'GUESSAN K. Hyppolyte 2012 - 2013
34
la sauvegarde ou la restauration de la totalité des
informations d'une bande. Le type LTO (Linear Tape Open) permet d'atteindre un
débit de 80 Mo/s.
II.3.2. Le SAN (Storage Area Network)
Le SAN (Storage Area Network) est un réseau
spécialisé permettant de partager de l'espace de stockage
à une librairie de sauvegarde et à des serveurs. Dans le cas du
SAN, les baies de stockage n'apparaissent pas comme des volumes partagés
sur le réseau. Elles sont directement accessibles en mode bloc par le
système de fichiers des serveurs. En clair, chaque serveur voit l'espace
disque d'une baie SAN auquel il a accès comme son propre disque dur.
L'administrateur doit donc définir très précisément
la zone d'accès que possède un serveur sur le SAN, ceci afin
d'éviter qu'un serveur Unix n'accède aux mêmes ressources
qu'un serveur Windows utilisant un système de fichiers différent,
par exemple.
Cette technologie permet de centraliser les systèmes
d'exploitation sur le SAN, protégeant ainsi les données et les
configurations des défaillances matérielles.
Il est généralement constitué de trois types
d'éléments :
o Des serveurs,
o Des éléments réseaux tels que des
switches ou des routeurs
o Des baies de disques qui vont fournir de l'espace de
stockage.
La figure 3 montre une architecture SAN minimaliste : en
effet, on peut redonder les liens et les switches réseaux pour
répondre à des besoins de haute disponibilité.
Le SAN est conçu pour fournir de l'espace disque rapide
et fiable. La technologie la plus répandue pour y arriver est la fibre
optique. Toutefois, les équipements relatifs à cette
dernière étant très coûteux, deux nouvelles
technologies ont vu le jour :

Figure 3: L'architecture de sauvegarde SAN (DASTUGUE,
2008)
N'GUESSAN K. Hyppolyte 2012 - 2013
35
II.3.2.1. Les baies de disques
Une baie de disques ou disk array contient des disques qui
sont pilotés par un ou des contrôleurs suivant la
disponibilité des données que l'on souhaite. Ces disques sont
regroupés en volume via un système de RAID (Redundant Array of
Independent Disks).
Il existe différents RAID :
II.3.2.1.1. Le RAID 0 (Stripping)
Comme nous le présente la figure 4, ce RAID permet de
stocker les données en les distribuant sur l'ensemble des disques du
volume de RAID. Pour n disques de x Go dans un volume, on dispose alors d'une
capacité disque n*x pour stocker nos données. Cette technique
permet d'améliorer les capacités de transfert mais si un disque
tombe en panne, on ne peut plus accéder à nos données.

Figure 4: Le schéma de principe d'une grappe de
disques en RAID 0 (DASTUGUE, 2008)
II.3.2.1.2. Le RAID 1 (Mirroring)
Sur la figure 5, nous voyons que ce RAID permet de dupliquer
les données sur l'ensemble des disques du volume. Cela agit comme un
miroir, c'est-à-dire que chaque disque est une image

Figure 5: Schéma de principe d'une grappe de disques
en RAID 1 (DASTUGUE, 2008)
|
|
|
Figure 7: Schéma de principe d'une grappe de disques
en RAID 6 (DASTUGUE, 2008)
|
|
|
|
|
N'GUESSAN K. Hyppolyte 2012 - 2013
|
36
|
des autres disques du volume. Pour n disques de x Go dans un
volume, on dispose d'une capacité disque de x Go mais on assure de la
tolérance aux pannes puisque si un disque tombe, les données sont
accessibles à travers un autre disque du volume.
II.3.2.1.3. Le RAID 5 (Stripping + partie distribuée)
Pour fonctionner, ce RAID doit disposer de trois disques
minimums. Si l'on dispose de 4 disques comme illustré sur la figure 6,
on écrit les données sur 3 disques et le 4ème
disque contiendra la parité des blocs de données des 3 disques.
On est dans une configuration à parité distribuée donc le
disque qui reçoit la parité change tout le temps. Le RAID 5
accepte la défaillance d'un disque sans que la disponibilité des
données soit affectée. De plus, il propose de bonnes performances
avec le système de parités distribuées.

Figure 6: Schéma de principe d'une grappe de disques
en RAID 5 (DASTUGUE, 2008)
II.3.2.1.4. Le RAID 6
Même chose que le RAID 5 sauf que comme nous le
présente la figure 7, l'on écrit deux parités à
chaque fois. On perd donc un disque de données utiles au profit d'une
tolérance aux pannes de deux disques en même temps.
N'GUESSAN K. Hyppolyte 2012 - 2013
37
II.3.2.1.5. Le RAID « combiné »
Les Raids combinés permettent de combiner
différents Raids. Par exemple sur la figure 8, on va regrouper deux
volumes Raid 0 en un Raid 1 (Raid 0+1). Cela permet de mixer les avantages
propres à chaque RAID.
Les communications entre un serveur et une baie de disques ou
un disque utilisent le protocole SCSI.

Figure 8: Schéma de principe d'une grappe de
disques en RAID combiné 0+1 (DASTUGUE, 2008)
II.3.2.2. SCSI
SCSI est l'acronyme de Small Computer System Interface. SCSI
est une norme qui permet de relier un ordinateur à un
périphérique en mode bloc (disque, lecteur CDROM...). C'est un
protocole client/serveur. Dans la norme SCSI, on parle d'initiateurs et de
cibles.
Une communication SCSI se résume en trois phases :
? La première phase constitue en l'envoi d'une commande
de l'initiateur (serveur) vers la cible (disque). Cette commande peut
être READ, WRITE ou toutes autres commandes.
? Ensuite vient l'envoi ou réception de données.
Cette phase est optionnelle et n'a lieu qu'en cas de READ ou WRITE. En cas de
READ, la cible envoie les données à l'initiateur. En cas de
WRITE, l'initiateur envoie les données à la cible.
? Pour finir, la cible envoie le résultat de
l'opération à l'initiateur.
SCSI souffre de quelques limitations :
? En termes de performance, le débit maximal atteignable
est de 20-40 MB / seconde.
·
N'GUESSAN K. Hyppolyte 2012 - 2013
38
En termes de distance, la distance maximale entre deux
périphériques est limitée à 1925 m.
SCSI ne permet pas le transport de blocs de données
à travers une grande distance ni à travers un réseau alors
l'architecture SAN s'appuie sur des protocoles réseaux (FCP ou ISCSI)
qui encapsule les commandes SCSI.
II.3.2.3. Les Avantages et les
inconvénients
II.3.2.3.1. Les avantages
· Un SAN fournit de grosses performances disques.
· Un SAN peut fournir une capacité disque
illimitée avec l'ajout sans cesse de nouveaux
périphériques de blocs pour sauvegarder les données.
· Il permet la consolidation des données en
évitant de devoir à chaque fois de rajouter des
périphériques de blocs séparés des autres.
II.3.2.3.2. Les inconvénients
· Il demande des ressources humaines spécifiques
ou une formation du personnel afin de pouvoir l'administrer et le maintenir
correctement.
· Une architecture SAN
II.3.3. Le NAS (Network Attached System)
Le NAS (Network Attached System) est un ensemble de disques
durs, typiquement SCSI, regroupés sous la direction d'un
contrôleur RAID (certaines solutions incluent un second contrôleur
pour assurer la tolérance de pannes). L'unité est directement
connectée au réseau Ethernet de l'entreprise. Le NAS
intègre le support de multiples systèmes de fichiers
réseau, tels que CIFS (Common Internet File System, le protocole de
partage de fichiers de Microsoft), NFS (Network File System, un protocole de
partage de fichiers Unix) ou encore AFP (AppleShare File Protocol, le protocole
de partage de fichiers d'Apple). Une fois connecté au réseau, il
peut jouer le rôle de plusieurs serveurs de fichiers partagés.
Un NAS va donc stocker des données partagées,
un peu comme un serveur de fichiers mais en plus solide, plus rapide et plus
simple à administrer (voir figure 9).
N'GUESSAN K. Hyppolyte 2012 - 2013
39
Un NAS est un serveur classique qui va disposer
d'équipements redondés (alimentations, ventilateurs...) pour
assurer de la tolérance aux pannes. Sur ce serveur, on pourra installer
un OS optimisé pour le stockage de données comme Microsoft
Windows Storage Server 2003.

Figure 9: L'architecture de sauvegarde NAS (DASTUGUE,
2008)
II.3.3.1. Les avantages et les
inconvénients
II.3.3.1.1. Les avantages
· Spécialement adapté au partage de
fichiers.
· Facile à mettre en place (Plug And Play). Il
suffit juste d'intégrer un serveur sur le réseau.
· Partage multi-environnements lié aux
différentes implémentations du protocole (NFS, CIFS...)
disponible sur les OS que l'on utilise.
· Ne demande pas de connaissances spécifiques.
II.3.3.1.2. Inconvénients
· Déconseillé avec des applications
demandant de grosses performances disques comme des bases de données.
· Demande des ressources CPU au niveau de la tête de
NAS. II.3.4. Le tableau comparatif des différentes solutions SAN
et NAS
Le tableau 3 ci-dessous fait l'étude comparative des
différentes solutions SAN et NAS selon différents
critères. Il nous aussi les différences entre l'architecture de
sauvegarde SAN et l'architecture de sauvegarde NAS.
Différences entre le SAN et le NAS
|
SAN
|
NAS
|
Orienté paquets SCSI
|
Orienté fichier
|
|
N'GUESSAN K. Hyppolyte 2012 - 2013
40
Basé sur le protocole Fibre Channel
|
Basé sur le protocole Ethernet
|
Le stockage est isolé et protégé de
l'accès
client général
|
Conçu spécifiquement pour un accès
client
général
|
Support des applications serveur avec haut
niveau de
performances SCSI
|
Support des applications client dans un
environnement
NFS/CIFS hétérogène
|
Le déploiement est souvent complexe
|
Peut être installé rapidement et facilement
|
|
Comparatif SAN et NAS
|
|
SAN
|
NAS
|
Fonction principale
|
Le stockage est accessible à
travers un
réseau qui lui est
spécialement dédié.
Sa
principale fonction est de
fournir aux serveurs un
stockage
consolidé basé sur
le Fibre Channel
|
Serveur spécialisé, qui sert
les fichiers et les données stockées aux postes
clients et aux autres serveurs à travers
le réseau
|
Applications bien adaptées
|
Idéal pour les bases de
données et le
traitement des
transactions en ligne
|
Idéal pour serveur de
fichiers
|
Transfert des données
|
A travers le SAN vers un
serveur vers un LAN ou
un
WAN
|
A travers un LAN ou un
WAN
|
Ressources de stockage et
de sauvegarde
|
Les ressources de stockage
et de sauvegardes
peuvent
être attachées directement au
serveur ou à
travers une
structure Fibre Channel
|
Les sauvegardes peuvent
être attachées
directement à
des Appliance NAS
intermédiaires ou
être
distribuées et attachées à un
LAN ou un
WAN
|
Disponibilité
|
Des composants matériels et
logiciels redondants
donnent
au système une haute
disponibilité. Le
système
peut être configuré sans le
moindre point de
panne
|
Des alimentations et des
ventilateurs redondants
sont
couramment utilisés
|
Scalabilité
|
Le stockage peut être étendu par l'ajout de
switches Fibre Channel et de dispositifs de stockage
|
Plusieurs serveurs NAS
peuvent être ajoutés
au
réseau, et du stockage peut
être ajouté
aux serveurs
NAS intermédiaires
|
|
Tableau 3:Le tableau comparatif des différentes
solutions SAN et NAS (DUFRESNES, 2008)
N'GUESSAN K. Hyppolyte 2012 - 2013
41
II.4. Les techniques améliorant la
disponibilité
La haute disponibilité est un terme souvent
utilisé en informatique, à propos d'architecture de
système ou d'un service pour désigner le fait que cette
architecture ou ce service a un taux de disponibilité convenable. La
disponibilité est aujourd'hui un enjeu important des infrastructures
informatiques.
Deux moyens complémentaires sont utilisés pour
améliorer la haute disponibilité :
· La mise en place d'une infrastructure
matérielle spécialisée, généralement en se
basant sur de la redondance matérielle. Est alors créé un
cluster de haute-disponibilité (par opposition à un cluster de
calcul) : une grappe d'ordinateurs dont le but est d'assurer un service en
évitant au maximum les indisponibilités ;
· La mise en place de processus adaptés
permettant de réduire les erreurs, et d'accélérer la
reprise en cas d'erreur. ITIL contient de nombreux processus de ce type.
De nombreuses techniques sont utilisées pour
améliorer la disponibilité :
· La redondance des matériels et la mise en cluster
;
· La sécurisation des données : RAID,
snapshots, Oracle Data Guard (en), BCV (Business Copy Volume), SRDF (Symmetrix
Remote Data Facility), DRBD ;
· La possibilité de reconfigurer le serveur
« à chaud » (c'est-à-dire lorsque celui-ci fonctionne)
;
· Un mode dégradé ou un mode panique ;
· Un plan de secours ;
· La sécurisation des sauvegardes :
externalisation, centralisation sur site tiers.
La haute disponibilité exige le plus souvent un local
adapté : alimentation stabilisée, climatisation sur plancher,
avec filtre à particules, service de maintenance, service de gardiennage
et de sécurité contre la malveillance et le vol. Attention aussi
au risque d'incendie et de dégât des eaux. Les câbles
d'alimentation et de communication doivent être multiples et
enterrés. Ils ne doivent pas être saillants dans le parking
souterrain de l'immeuble, ce qui est trop souvent vu dans certains immeubles.
Ces critères sont les premiers à entrer en compte lors du choix
d'un prestataire d'hébergement (cas de la location d'un local à
haute disponibilité).
Pour chaque niveau de l'architecture, pour chaque composant,
chaque liaison entre composants, il faut établir :
· Comment détecter une panne ?
Exemples : Tests de vie TCP Health Check
implémenté par un boîtier Alteon4, programme de test
invoqué périodiquement (« heartbeat »), interface de
type « diagnostic » sur les composants...
· Comment le composant est-il
sécurisé, redondé, secouru... ?
Exemples : serveur de secours, cluster système,
clustering Websphere, stockage RAID, sauvegardes, double attachement SAN, mode
dégradé, matériel non utilisé libre prêt
à être réinstallé...
· Comment désire-t-on enclencher la
bascule en mode secours / dégradé. Manuellement après
analyse ? Automatiquement ?
· Comment s'assurer que le système de
secours reparte sur un état stable et connu ?
Exemples : on repart d'une copie de la base et on
réapplique les archives logs, relance des batchs depuis un état
connu, commit à 2 phases pour les transactions mettant à jour
plusieurs gisements de données...
? Comment l'application redémarre sur le
mécanisme de secours ?
Exemples : redémarrage de l'application,
redémarrage des batchs interrompus, activation d'un mode
dégradé, reprise de l'adresse IP du serveur défaillant par
le serveur de secours...
? Comment reprendre éventuellement les
transactions ou sessions en cours ? Exemples : persistance de session
sur le serveur applicatif, mécanisme pour assurer une réponse
à un client pour une transaction qui s'est bien effectuée avant
défaillance mais pour laquelle le client n'a pas eu de
réponse...
? Comment revenir à la situation nominale
?
Exemples : Si un mode dégradé permet en cas de
défaillance d'une base de données de stocker des transactions en
attente dans un fichier, comment les transactions sont-elles
réappliquées quand la base de données redevient active. Si
un composant défaillant a été désactivé,
comment s'effectue sa réintroduction en service actif
(nécessité par exemple de resynchroniser des données, de
retester le composant...)
II.5. Les critères de choix d'un sauvegarde et
restauration de données
performant
Nous avons répertorié les principaux
critères, regroupés selon deux catégories :
fonctionnalité et caractéristique, qui devraient rester en trame
de fond lors du choix d'une solution de sauvegarde.
II.5.1. Les fonctionnalités
II.5.1.1. Multiplateforme
Sauvegarde des informations présentes sur plusieurs
systèmes d'exploitation : Windows, Linux, MAC.
II.5.1.2. Multi jeux de sauvegarde
Création de jeux de sauvegarde différents sur
un même ordinateur. C'est-à-dire ; avoir la possibilité de
sauvegarder de plusieurs façons et en même temps un même
ordinateur. Les données fonctionnelles et actives de votre
système informatique seront sauvegardées
régulièrement alors que la configuration de vos ordinateurs ainsi
que les OS n'entraînent pas les mêmes obligations ni les
mêmes fréquences de sauvegarde.
II.5.1.3. Gestion fichiers ouverts
N'GUESSAN K. Hyppolyte 2012 - 2013
42
Sauvegarde des fichiers en utilisation (ouverts).
II.5.1.4. Gestion de version
Gestion de plusieurs versions sauvegardées d'un
même fichier.
II.5.1.5. Gestion de la bande passante
Limitation paramétrable de l'utilisation de la bande
passante de votre réseau lors des sauvegardes.
II.5.1.6. Administration centralisée
Bénéficier d'une interface de gestion qui
permet l'administration de toutes les sauvegardes, sur tous les ordinateurs, de
façon centralisée. Cette fonctionnalité évite de
travailler sur chacun des ordinateurs pour gérer la sauvegarde.
II.5.1.7. Accès sécurisé
L'accès aux sauvegardes doit être
contrôlé par mot de passe.
II.5.1.8. Fonction de recherche
Permettre la recherche selon plusieurs critères :
date, nom et version parmi les fichiers sauvegardés, afin de retrouver
les données à restaurer rapidement.
II.5.1.9. Cryptage des données
Permettre, sans être obligatoire, le cryptage des
données sauvegardées. Les médias de sauvegarde contenant
les données ne pourront pas être réutilisées par des
personnes non autorisées.
II.5.1.10. Support de différents
médias
Permettre la sauvegarde sur bandes, disques, CD ou DVD.
L'évolution de votre système informatique et l'augmentation de la
volumétrie des données à sauvegarder peut obliger un
changement de média dans l'avenir. Dans le cas de l'utilisation de
disques, il est important de vérifier qu'une sauvegarde sur un disque
réseau est possible.
II.5.1.11. Compression des données
N'GUESSAN K. Hyppolyte 2012 - 2013
43
Permettre, sans être obligatoire, la compression des
données sauvegardées.
N'GUESSAN K. Hyppolyte 2012 - 2013
44
II.5.1.12. Restauration rapide
Le temps nécessaire pour réaliser la
restauration d'un système ou d'un fichier perdu est fortement lié
à la facilité de retrouver rapidement les données à
restaurer. Dans le cas de la restauration d'un système complet, les
utilisateurs accepteront facilement un délai de quelques heures. Par
contre, avertir un utilisateur que la restauration de son fichier de
données `WORD' prendra 4 heures risque de vous mettre dans l'embarras !
La fiabilité et la flexibilité du système de sauvegarde
seront fortement remises en question dans un tel cas.
II.5.2. Caractéristique
II.5.2.1. Autonome et automatique
Le fonctionnement de la sauvegarde ne doit pas exiger
d'opérations manuelles. Les sauvegardes doivent s'effectuer
malgré l'absence du personnel. Il est important de minimiser les
manipulations de média. La gestion des médias de sauvegarde, si
elle est faite de façon manuelle, risque d'entraîner des erreurs
qui seront fatales lors d'une tentative de restauration. De plus, la
manipulation des médias en réduit rapidement l'espérance
de vie utile. La flexibilité d'un système de sauvegarde est
directement liée à l'autonomie et à l'automatisme. Plus un
système de sauvegarde est flexible plus l'autonomie est importante.
II.5.2.2. Planifiable
La réalisation des sauvegardes doit être
planifiable. C'est-à-dire que chaque jeu de sauvegarde peut se
réaliser selon son propre planning et de façon
indépendante des autres jeux. La configuration du serveur pourra
être sauvegardée tous les dimanches à 20h00 alors que la
sauvegarde des données comptables pourrait être faite deux fois
par jour : le midi et le soir. Parallèlement, la sauvegarde des postes
de travail pourrait être réalisée tous les jours à
18h30.
II.5.2.3. Auditable
Permettre la surveillance du système, à la
façon d'un `tableau de bord'. Un système d'alertes en cas de
problème évitera les opérations de vérification
régulières des sauvegardes. Lorsque la sauvegarde a
été correctement complétée : aucun message, par
contre, en cas de problème : le responsable sera notifié. Les
alertes seront suffisamment précises pour identifier rapidement la
source du problème. Un rapport décrivant le déroulement
des sauvegardes doit être disponible sur demande.
N'GUESSAN K. Hyppolyte 2012 - 2013
45
II.5.2.4. Testable
Il est frustrant de mettre en place un système de
sauvegarde et être dans l'incapacité de le tester. Les
opérations de test des sauvegardes doivent être réalisables
simplement et ne pas entraîner des risques pour le système
opérationnel. Le message de bonne fin des sauvegardes, surtout dans le
cas d'utilisation de bandes, n'est pas toujours aussi fiable qu'il n'y
paraît.
II.5.2.5. Sécuritaire
Bien que le système de sauvegarde soit fiable,
flexible et autonome il ne pourra jamais remplacer les mesures de
sécurité essentielles. Mettre en place, de façon
consciencieuse les sauvegardes, n'enlève pas l'obligation de garder en
lieu sûr les médias. Abandonner tous les médias de
sauvegarde dans la même pièce diminue sérieusement la
sécurité. Il existe, aujourd'hui, des systèmes de
sauvegarde qui protègent efficacement des sinistres sans que vous soyez
dans l'obligation de manipuler les médias.
II.5.2.6. Évolutif
Votre système informatique évoluera. La
volumétrie des données risque d'augmenter. On doit s'assurer que
le système de sauvegarde mise en oeuvre permettra la gestion d'une
volumétrie en constante évolution.
II.5.2.7. Résilient
Le système de sauvegarde doit demeurer fonctionnel
malgré une panne de certains éléments ou encore lors de
changements de certains composants matériels.
II.6. Conclusion partielle
Un système de sauvegarde est une couverture
d'assurance contre les pertes monétaires dues à la
défaillance matérielle ou fonctionnelle de votre système
informatique. L'importance de mettre en place un système de sauvegarde
est directement liée à la criticité des données de
votre entreprise et à la rapidité avec laquelle elles seront
remises à disposition pour continuer ou reprendre votre
activité.
N'GUESSAN K. Hyppolyte 2012 - 2013
46
CHAPITRE III : DEPLOIEMENT DE LA SOLUTION
D'AMELIORATION DU SYSTEME DE SAUVEGARDE ET DE RESTAURATION DE DONNEES
III.1. Introduction partielle
Ce chapitre est consacré à la
réalisation de notre projet. Pour commencer, nous présentons tout
d'abord, les différentes améliorations apportées au
système de sauvegarde et de restauration de données de la DGTTC,
en vue d'augmenter sa disponibilité selon le cahier de charges qui nous
a été soumis. Nous procédons ensuite à son
installation et à sa configuration. Pour finir, nous faisons son
estimation financière et présentons son impact sur le
réseau existant de la DGTTC.
III.2. Présentation de la solution
Pour résoudre les problèmes soumis à
notre expertise à travers le cahier de charges qui nous a
été soumis, nous avons décidé d'installer un autre
serveur de sauvegarde et de restauration de données. Nous allons par la
suite créer un clustering de serveur. Ensuite, nous allons mettre en
place un RAID de niveau 1, c'est-à-dire mirroring de partition à
travers une interface réseau. Nous allons pour finir, externaliser les
sauvegardes vers un serveur distant tel que le présente la figure 10.
Pour cela, nous allons choisir comme gestionnaire de
sauvegarde, BackupPC ; pour le service de haute
disponibilité, nous avons choisi Heartbeat ou linux HA (High
Availability) et enfin, pour la mise en place de la solution RAID de
niveau 1, nous avons opté pour Distributed Replicated Block
Device (DRBD).

N'GUESSAN K. Hyppolyte 2012 - 2013
47
Figure 10: La nouvelle architecture réseau de la DGTTC
(Source : Hyppolyte N'GUESSAN)
N'GUESSAN K. Hyppolyte 2012 - 2013
48
III.1.1. BackupPC
BackupPC est un logiciel libre utilisé pour
sauvegarder un ensemble de postes. Il possède une interface Web pour
configurer, lancer des sauvegardes ou restaurer des fichiers. Il est
également possible de sauvegarder des bases de données. BackupPC
permet de sauvegarder automatiquement à des intervalles de temps
réguliers des répertoires situés sur des machines du
réseau. Il permet d'assurer une politique de sauvegardes pour des
clients de différents types (Unix, GNU/Linux, Windows, Mac).
III.1.2. Heartbeat ou linux High Availability
Heartbeat ou linux HA (High Availability) est un
système permettant, sous Linux, la mise en cluster (en groupe) de
plusieurs serveurs. C'est plus clairement un outil de haute
disponibilité qui va permettre à plusieurs serveurs d'effectuer
entre eux un processus de fail-over. Le principe du «fail- over» (ou
«tolérance de panne«) est le fait qu'un serveur appelé
«passif» ou «esclave» soit en attente et puisse prendre le
relais d'un serveur «actif» ou «maitre» si ce dernier
serait amené à tomber en panne ou à ne plus fournir un
service. Le principe d'Heartbeat est donc de mettre nos serveurs dans un
cluster qui détiendra et sera représenté par une IP
«virtuelle» par laquelle lesclients vont passer plutôt que de
passer par l'IP d'un serveur (actif ou passif). Le processus Heartbeat se
chargera de passer les communications aux serveurs actif si celui-ci est vivant
et au serveur passif le cas échéant.
Nous allons donc mettre en place un clustering de serveur qui
partagera une même adresse IP virtuelle. Le but étant qu'il y a
toujours une réponse à un ping vers une IP (qui sera l'IP
virtuelle du cluster).
III.1.3. Distributed Replicated Block Device (DRBD)
DRBD permet de mettre en oeuvre une solution de RAID-1 au
travers du réseau. C'est-à-dire que sur deux serveurs, on a une
partition1 par serveur qui est à tout moment une copie exacte d'une
partition de l'autre serveur. C'est un mirroring (miroir) de partitions
à travers une interface réseau. Cela nous permettra dans notre
système Backup d'avoir un serveur passif qui sera la réplique
exacte du serveur actif. Le but est que le serveur passif n'est pas à
faire de mise à jour volumineuse quand le serveur actif tombe.
N'GUESSAN K. Hyppolyte 2012 - 2013
49
III.3. Le déploiement de la solution
III.3.1. Le système de sauvegarde et de
restauration de données
III.3.1.1. L'installation
La première étape est l'installation et la
configuration du serveur de sauvegardes. BackupPC est disponible dans les
dépôts Ubuntu et Debian. Pour l'installer, il faut simplement
lancer la commande suivante :
apt-get install backuppc
A l'installation, il est créé l'utilisateur
backuppc ainsi que le « password user ». Soit nous la conservons
tel-quel ou nous la changeons à l'aide de la commande (voir figure
11)
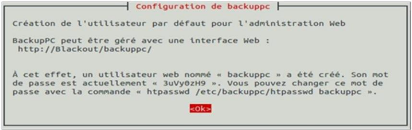
sudo htpasswd /etc/backuppc/htpasswd
backuppc
Figure 11: La configuration du mot de passe de BackupPC
(Source : Hyppolyte N'GUESSAN)
III.3.1.1.1. Ajout de l'utilisateur dans le groupe backuppc
Pour démarrer backuppc, il faut ajouter l'utilisateur de
la session dans le groupe backuppc.
Pour cela, il faut exécuter la ligne de commande suivante
:
sudo adduser [MON_USER] backuppc
III.3.1.1.2. Ajout du fichier apache.conf
Comme l'installation ne copie pas le
/etc/backuppc/apache.conf sur le serveur apache2.
Il faut le faire soit même en copiant le fichier dans le
répertoire /etc/apache2/site-available/ avant de rendre actif le
site:
sudo cp /etc/backuppc/apache.conf /etc/apache2/site-
available/backuppc.conf
puis le rendre actif :
sudo a2ensite backuppc.conf
Un redémarrage du serveur web est nécessaire pour
prendre en compte les modifications.
N'GUESSAN K. Hyppolyte 2012 - 2013
50
sudo /etc/init.d/apache2 restart
La page web de backuppc est ainsi disponible pour toutes les
configurations à l'adresse : localhost/backuppc
(voir figure 12)
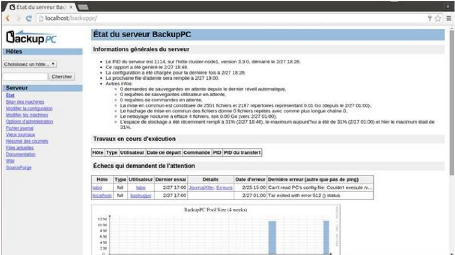
Figure 12: La page web BackupPC (Source : Hyppolyte
N'GUESSAN)
III.3.1.2. La configuration du serveur de sauvegarde
et de restauration de données
III.3.1.2.1. Le fichier hôte
Nous pouvons utiliser l'interface web pour configurer nos
hôtes comme nous le montre le voyons sur la figure 13.

Figure 13: L'interface Web de configuration des hôtes
(Source : Hyppolyte N'GUESSAN)
Nous pouvons également éditer manuellement le
fichier dans notre terminal en utilisant la commande :
vim /etc/BackupPC/conf/hosts
N'GUESSAN K. Hyppolyte 2012 - 2013
51
Sur la figure 14, nous avons une illustration de ce fichier.
Cela nous permey de voir que la première colonne correspond au nom
d'hôte. La seconde spécifie si DHCP (Dynamic Host Configuration
Protocol) doit être activé pour la recherche de l'hôte. La
troisième colonne indique l'utilisateur "propriétaire" de
l'hôte, la quatrième et dernière les utilisateurs
supplémentaires.

Figure 14: La configuration manuelle des hôtes (Source
: Hyppolyte N'GUESSAN)
III.3.1.2.2. Fichier de configuration générale
Il s'agit maintenant de configurer le serveur. Il existe deux
fichiers de configuration : un général et un par hôte. Le
fichier général est /etc/BackupPC/
config.pl,
chacun des fichiers de configuration des hôtes
/etc/BackupPC/pc/{nom_hôte}.pl. Le fichier de
configuration général est créé lors de
l'installation, les fichiers de configuration par hôte via l'ajout d'un
hôte et sa configuration depuis l'interface web d'administration comme
nous le montre la figure 15.
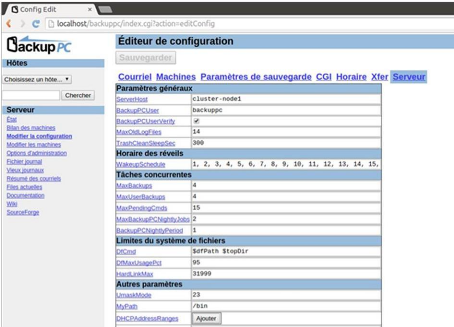
Figure 15: La configuration générale de
BackupPC via l'interface Web (Source : Hyppolyte N'GUESSAN)
Nous pouvons ici aussi choisir de modifier le fichier à
la main. Voici certaines options de configuration du serveur :
N'GUESSAN K. Hyppolyte 2012 - 2013
52
$Conf{ServerHost} = 'localhost'; nom du
serveur de sauvegarde. $Conf{WakeupSchedule} = [1, 2, 3] ; :
heures de réveil du serveur. La valeur
1, 2, 3 (par défaut) signifie que le serveur
s'éveillera toutes les heures sauf minuit. Il est aussi possible de
spécifier une ou plusieurs heures fixes, séparées par des
virgules : 1,2.5,6 (une heure, deux heures trente et six heures).
$Conf{BackupPCUserVerify} = 1 ; la valeur
par défaut (1) force le script à vérifier que le serveur
est lancé par l'utilisateur spécifié dans la directive
$Conf{BackupPCUser}. Cela permet d'éviter que le
script du serveur soit exécuté par un utilisateur non
autorisé (par exemple root). Il est conseillé de laisser cette
valeur à 1.
Suivent ensuite des directives qui peuvent être
remplacées dans le fichier de configuration d'un hôte. Si le
fichier d'hôte ne contient aucune indication, la valeur du fichier
général de configuration sera prise en compte.
$Conf{SmbShareName} = ['C$','D$'] ; nom
du/des partage(s) à sauvegarder pour les sauvegardes via samba
$Conf{SmbShareUserName} = ; utilisateur
samba à utiliser lors des sauvegardes windows
$Conf{SmbSharePasswd} = ; mot de passe de
l'utilisateur samba
$Conf{TarShareName} = ['/', '/home'];
système(s) de fichiers à sauvegarder en utilisant la
méthode tar
$Conf{RsyncShareName} = ['/','/home'] ;
système(s) de fichiers à sauvegarder en utilisant les
méthodes rsync et rsyncd
$Conf{FullPeriod} = 6.97;
périodicité de sauvegarde complète des hôtes
$Conf{IncrPeriod} = 0.97; périodicité de
sauvegarde incrémentielle des hôtes
$Conf{FullKeepCnt} = 2 ; nombre de
sauvegardes complètes à conserver. Cette directive est
très souple, je vous recommande la lecture de cette partie de l'aide en
ligne afin de configurer cette option selon vos besoins
$Conf{BackupFilesOnly} = undef ; liste des
fichiers et répertoires à sauvegarder. Je laisse personnellement
cette valeur à undef car je la défini spécifiquement pour
chaque hôte.
N'GUESSAN K. Hyppolyte 2012 - 2013
53
Dans le cas où cette valeur ne serait pas
définie dans le fichier de configuration de l'hôte, la sauvegarde
s'opérerait sur le partage par défaut (C$ et D$ pour samba, / et
/home pour tar, ...)
$Conf{BackupFilesExclude} = undef; liste des
fichiers et répertoires à ne pas sauvegarder. Identique à
l'option précédente
$Conf{BlackoutPeriods} = [{hourBegin =>
8.0, hourEnd => 23.0, weekDays
=> [1, 2, 3, 4, 5, 6, 7],},] ; : configuration du
blackout. Le blackout correspond aux périodes durant lesquelles le
serveur ne se réveillera pas automatiquement. Ici, la période de
blackout est définie de 8 heures à 23 heures pour tous les jours
de la semaine
$Conf{XferMethod} = 'rsync' ; méthode
de sauvegarde des hôtes (peut être rsync, smb, rsyncd, tar,
archive)
$Conf{XferLogLevel} = 1 ; degré de
verbosité. Plus le degré sera élevé, plus le
fichier de log sera complet. Il peut être utile d'augmenter cette valeur
pour un hôte donné qui pose des problèmes
$Conf{ArchiveComp} = 'bzip2'; méthode
de compression à utiliser pour la sauvegarde. Cette valeur peut
être none, gzip ou bzip2
$Conf{ServerInitdPath} =
'/etc/init.d/backuppc'; chemin vers le script de démarrage. Cette
directive permet le lancement du serveur depuis l'interface CGI
$Conf{ServerInitdStartCmd} = '$sshPath -q -x -l
root $serverHost
$serverInitdPath start < /dev/null >& /dev/null'; :
commande de démarrage du serveur depuis l'interface CGI. Cet exemple est
tiré des commentaires du fichier de configuration
$Conf{CompressLevel} = 3 ; taux de
compression tel que renseigné lors de l'exécution du script
configure.pl. Le taux peut prendre une
valeur de 0 à 9, reportez-vous à la documentation de backuppc et
de zlib pour plus d'informations. La valeur 3 est généralement un
bon choix.
La section suivante dans le fichier de configuration vous
permet de configurer l'envoi des emails en cas d'erreur, d'hôte jamais
sauvegardé, etc...
$Conf{EMailNotifyMinDays} = 2.5;
période minimale durant laquelle un utilisateur ne recevra pas de mails.
La valeur par défaut (2.5) signifie que l'utilisateur ne recevra qu'un
message tous les trois jours au maximum
N'GUESSAN K. Hyppolyte 2012 - 2013
54
$Conf{EMailFromUserName} = 'backuppc';
adresse de l'expéditeur. Les emails envoyés prendront en champ
from la valeur indiquée ici. Il est possible d'indiquer le nom
d'utilisateur ou l'adresse email complète en fonction de la
configuration de votre serveur mail
$Conf{EMailAdminUserName} =
'admin-backup@backup.domain.com'; : adresse email de
l'administrateur du serveur de sauvegarde
$Conf{EMailUserDestDomain} =
'@domain.com'; domaine des
utilisateurs. Les emails seront envoyés à l'adresse {utilisateur}@
domain.com
La dernière section du fichier correspond à la
configuration de l'interface CGI :
$Conf{CgiAdminUserGroup} = ; groupe des
utilisateurs administrateurs. Le groupe doit exister dans le fichier
.htpasswd
$Conf{CgiAdminUsers} = 'admin utilisateur1' ;
utilisateurs administrateurs. Chaque utilisateur doit exister dans le fichier
/etc/BackupPC/apache.users
$Conf{CgiURL} = '
http://localhost/BackupPC' ;
adresse HTTP du script CGI $Conf{Language} = 'fr'; langue de
l'interface CGI
$Conf {CgiDateFormatMMDD} = 0 ; format de
date. 0 pour le format international (JJ/MM) et 1 pour le format US (MM/JJ)
$Conf{CgiNavBarAdminAllHosts} = 1 ; liste de
tous les hôtes pour les administrateurs. Si cette valeur est à 1,
les administrateurs pourront accéder à tous les hôtes,
sinon seuls seront listés les hôtes pour lesquels l'utilisateur
est spécifié en user ou moreUsers dans le fichier de
configuration des hôtes.
III.3.1.2.3. Le fichier de configuration par PC
Il est maintenant nécessaire de configurer les
hôtes à sauvegarder. Les directives des fichiers d'hôtes
(/etc/BackupPC/pc/{hote}.pl) prennent le pas sur
celles du fichier de configuration général. Bien entendu, si vous
planifiez de ne sauvegarder qu'un seul et unique poste, ou que la configuration
est strictement identique sur chacun des postes à sauvegarder, il est
possible d'utiliser uniquement le fichier de configuration
général paramétré avec les bonnes directives. Vous
pouvez utiliser l'interface web d'administration pour cela en
sélectionnant un hôte dans la liste déroulante et en
cliquant sur le lien « Modifier la configuration ».
(Voir figure 16)
|
|
Figure 17: Le fichier de configuration pour un hôte
linux (Source : Hyppolyte N'GUESSAN)
|
|
|
|
N'GUESSAN K. Hyppolyte 2012 - 2013
|
55
|
|
Figure 16: L'interface web d'administration (Source :
Hyppolyte N'GUESSAN)
Cette fois encore, nous pouvons choisir d'éditer le
fichier nous-même. Les directives possibles sont celles situées
dans les parties spécifiées du fichier de configuration
général. Il est intéressant de noter que bon nombre des
directives peuvent être modifiées par hôte, votre fichier de
configuration général peut être configuré pour
utiliser rsync avec SSH (Secure
Shell), et vous pouvez facilement mettre en place une sauvegarde
via SMB pour un hôte donné.
Voici ce à quoi pourrait ressembler un fichier de
configuration pour un hôte linux :
N'GUESSAN K. Hyppolyte 2012 - 2013
56
Un fichier de configuration pour un poste Windows pourrait
ressembler à ceci :
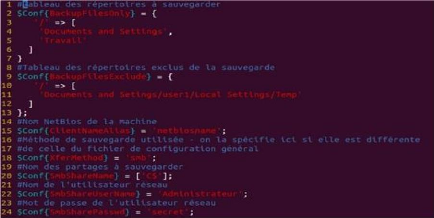
Figure 18: Le fichier de configuration pour un hôte
Windows (Source : Hyppolyte N'GUESSAN)
III.3.1.2.4. La configuration du SSH
Il va falloir configurer nos deux hôtes pour que le
serveur puisse établir une connexion sur le poste à sauvegarder
en SSH mais sans être embêté par la demande de mot de passe.
Pour cela nous allons utiliser l'utilisateur 'backuppc'
(car c'est lui qui instancie la connexion au serveur distant),
puis créer une clef RSA, que nous copierons dans le répertoire
'authorized_keys' de l'utilisateur de la machine
à sauvegarder. Ainsi notre utilisateur 'backuppc' pourra se logger sur
le serveur distant sans mot de passe. Pour réaliser cela, nous utilisons
les commandes suivantes :
su backuppc ssh-keygen -t rsa
Il convient ensuite de copier la clé ainsi
créée sur chaque hôte cible, dans le fichier
~/.ssh/authorized_keys de l'utilisateur
possédant les droits de lecture des répertoires à
sauvegarder. Pour cela, nous utilisons la commande :
ssh-copy-id -i .ssh/id_rsa.pub
utilisateur@dgttc
Pour vérifier simplement que la
précédente manipulation a fonctionné, nous nous connectons
à l'hôte distant. Il ne nous sera pas demandé de mot de
passe.
N'GUESSAN K. Hyppolyte 2012 - 2013
57
III.3.2. Le service de haute disponibilité
III.3.2.1. L'installation
Pour notre cluster, nous suivons le schéma suivant :

Figure 19: La synoptique du clustering de serveurs (Source
: Hyppolyte N'GUESSAN)
Nous aurons donc un serveur actif en 192.168.0.2
et un serveur passif 192.168.0.3 tout deux sous Linux
sur lesquels sera installé le paquet Heartbeat et ses
dépendances. Nous souhaitons que les clients communiquent avec le
serveur via l'IP virtuelle du cluster 192.168.0.50 et non pas
vers 192.168.0.2 ou 192.168.0.3. Ce sera au
cluster de passer les requêtes à tel ou tel serveur suivant la
disponibilité du serveur «maître«.
Après avoir mis en place les serveurs et s'être
assuré de leur inter- connectivité (via un simple ping), nous
allons mettre à jours notre liste de paquet :
apt-get update
Puis installer le paquet Heartbeat
apt-get install Heartbeat
III.3.2.2. La configuration
Les fichiers de configuration devront être les
mêmes sur les deux serveurs membres du cluster et devront se
situés dans «/etc/ha.d»
(ou «/etc/heartbeat» qui est
un lien symbolique
N'GUESSAN K. Hyppolyte 2012 - 2013
58
vers «/etc/ha.d«). Ces
fichiers devront être créés car ils ne le sont pas à
l'installation d'Heartbeat :
vim /etc/heartbeat/
ha.cf
Un «node» est un noeud.
Autrement dit un serveur membre du cluster. L'auto_failback
permet de rebasculer directement sur le serveur maitre quand il
redevient opérationnel après qu'il ait été
déclaré comme «mort» (quand il est configuré
à «yes«. Nous passons maintenant au
fichier «/etc/heartbeat/authkeys«, ce
fichier va définir la clé qui permettra d'authentifier un minimum
les serveurs membres du cluster entre eux :
vim /etc/heartbeat/authkeys
Voici un contenu
Auth1
1sha1 ma clef secrète
Il faut savoir que l'on peut utiliser trois modes de
sécurisation dans ce fichier :
· Sha 1 (Secure Hash Algorithm
1)
· md5 (Message Digest 5)
· crc (Cyclic Redundancy
Check)
Par sécurité, on sécurise ce fichier en lui
mettant des droits plus restreints :
chmod 600 /etc/heartbeat/authkeys
On passe maintenant au fichier
«/etc/heartbeat/haresources» qui va
contenir les actions à mener au moment d'un basculement. Plus
clairement, quand un serveur passera du statut «passif»
à «actif«, il ira lire ce fichier
pour voir ce qu'il doit faire. Dans notre cas nous allons dire à notre
serveur de prendre l'IP virtuelle 192.168.0.50
cluster-node1 192.168.0.50
On rappelle que le contenu du fichier doit être le
même sur les deux serveurs. On indique donc ici le nom du serveur
primaire du cluster (cluster-node1 est pour moi
«192.168.0.2«) puis l'IP virtuelle du cluster :
«192.168.0.50» dans notre cas. Pour information, les
logs de Heartbeat se situent comme indiqué dans le fichier de
configuration dans le fichier
«/var/log/daemon.log«.
N'GUESSAN K. Hyppolyte 2012 - 2013
59
III.3.2.3. Le démarrage du cluster et l'analyse
des logs
Nous allons pourvoir maintenant passer au démarrage de
notre cluster, nous verrons par la même occasion l'attribution et l'IP
virtuelle. Pour avoir une vue en détail de ce qu'il se passe sur nos
serveurs, il est aussi intéressant d'avoir un oeil sur les logs de
ceux-ci qui se situent, selon notre configuration, dans le fichier
«/var/log/heartbeat.log«. Nous saisissons
donc sur nos deux serveurs la commande suivante :
service heartbeat start
Si tout se passe bien, nous aurons une nouvelle interface et
une nouvelle IP lors de la saisie de la commande
«ifconfig» sur le serveur actif
(«maître«) comme sur la figure 20:

Figure 20: La vérification de l'activation du service
de haute disponibilité (Source : Hyppolyte N'GUESSAN)
On voit donc bien ici que c'est une IP virtuelle
(« :0«) qui est basée sur eth0 et qu'elle
à l'IP 192.168.0.50 qui devrait alors être
joignable (par un simple ping). Jetons maintenant un oeil du coté de nos
logs.
D'abord sur le serveur actif
(«maitre«)
On voit sur la figure ci-dessous le début du processus
des statuts. Le but est ici de définir qui est vivant et qui ne l'est
pas pour définir qui se chargera d'être actif. On voit donc que le
serveur commence par joindre la passerelle afin de vérifier la
connectivité de son interface (ici «eth0«).
Il déclare ensuite le statut de cette interface en
«up« (figure 21)

Figure 21: Une partie du fichier log (Source : Hyppolyte
N'GUESSAN)
On voit ici qu'Heartbeat utilise un deuxième de ses
scripts qui permet de vérifier la réponse d'une requête sur
l'IP virtuelle.
N'GUESSAN K. Hyppolyte 2012 - 2013
60
Après avoir effectué cette vérification,
le serveur paramètre donc l'IP virtuelle dans sa configurati on
grâce à son script «IPaddr«

Figure 22: L'analyse du fichier log (Source : Hyppolyte
N'GUESSAN)
III.3.2.4. Simulation d'une panne,
récupération et analyse des logs
Nous allons maintenant simuler un dysfonctionnement dans le
cluster en éteignant notre serveur «actif»
pour voir si la reprise par le serveur «passif» se
fait correctement, nous allons également vérifier les logs pour
voir comment les actions sont reçues et menées. Nous voyons alors
directement dans les logs les informations suivantes :
On voit ici que le serveur passif détecte que le lien
cluster-node1 (serveur maitre«192.168.0.2«) ne
répond plus, il le considère donc comme
«mort» (figure 23) :

Figure 23: La simulation d'une panne (Source : Hyppolyte
N'GUESSAN)
Il lance ensuite la reprise du serveur actif en configurant
l'IP virtuelle sur son interface comme précisé dans le fichier
«/etc/heartbeat/haresources«. A ce moment,
si l'on fait un «ifconfig» sur le serveur
192.168.0.3, nous allons voir qu'il a bien
récupérer l'IP virtuelle sur cluster (figure 24).

Figure 24: La vérification du fonctionnement du
service de haute disponibilité (Source : Hyppolyte N'GUESSAN)
Pour continuer l'exemple d'une production, nous allons
rallumer notre serveur 192.168.0.2 (ancien actif) pour qu'il
récupère l'IP virtuelle et redevienne le serveur principal comme
nous le voulons. Cela est possible grâce à l'option
«auto_failback» qui est à
«yes«.
N'GUESSAN K. Hyppolyte 2012 - 2013
61
Cela indique que dès que le serveur dit comme
«principal» redeviendra
«vivant«, il prendra à nouveau la fonction et
la tête du cluster. L'utilité de ce paramétrage peut
dépendre du service hébergé sur les serveurs en cluster
(figure 25)

Figure 25: La reprise de la tête du cluster par le
serveur principal (Source : Hyppolyte N'GUESSAN)
III.3.3. Le service RAID de niveau 1
III.3.3.1. L'installation
Pour commencer nous rajoutons des disques durs à nos
serveurs, ensuite nous créons une partition sur les seconds disques que
nous avons rajoutés.
Pour cela, nous tapons la commande fdisk «
partition » avec partition correspondant au nom logique de
celle-ci sur chacun des clusters. Nous commençons sur le
Cluster node 1, en tapant fdisk /dev/sbd
comme nous le montre la figure 26. Nous faisons de même
avec le Cluster-node 2

Figure 26: Le rajout de disque au serveur principal Cluster
node 1 (Source : Hyppolyte N'GUESSAN)
Maintenant que nous avons partitionnés les deux
disques nous allons installer les paquets nécessaires à
l'utilisation de DRBD.
Sur les deux machines (node1 et node2) tapez les commandes
suivantes :
apt-get install drbd8-utils
Puis une fois le paquet installé on active le module avec
la commande suivante : modprobe drbd
N'GUESSAN K. Hyppolyte 2012 - 2013
62
III.3.3.2. La configuration
Maintenant que nos disques et DRBD sont mis en place nous allons
configurer la réplication des données entre les deux disques.
Pour ce faire nous allons créer et éditer un
fichier que nous allons appeler drbd1.res dans le
dossier « /etc/drbd.d/ » les commandes et
les configurations suivantes sont à faire sur les deux serveurs.
cd /etc/drbd.d
vim drbd1.res
Puis remplissez le fichier de la façon suivante (figure
28) :

Figure 27: Le fichier de configuration de DRBD (Source :
Hyppolyte N'GUESSAN)
Explications :
Tout d'abord on donne un nom à notre ressource DRBD dans
notre cas nous allons
l'appeler r0.
Dans cette ressource nous allons renseigner nos deux nodes,
cela commence donc par on cluster-node1 (cluster-node1 doit
être le hostname de la machine) on fait la même chose pour
node2.
Une fois ce fichier écrit sur les deux nodes nous
allons enfin pouvoir mettre en place la réplication.
Toujours sur les deux nodes tapons les commandes suivantes :
drbdadm create-md r0
N'GUESSAN K. Hyppolyte 2012 - 2013
63
drbdadm up r0
Notre DRBD est pratiquement mis en place
cependant, étant donné qu'aucun des deux n'est en mode «
Primary », vos nodes se connectent mais que la
réplication n'est pas encore possible.
Pour y remédier nous allons mettre cluster-node1 en
« primary » avec la commande suivante :
drbdadm -- --overwrite-data-of-peer primary
r0
Et node2 en secondary drbdadm secondary
r0
La synchronisation initiale se lance et nous pouvons
vérifier son état avec la commande suivante (figure 29):
cat /proc/drbd

Figure 28: La vérification de la synchronisation
initiale (Source : Hyppolyte N'GUESSAN)
Maintenant que notre raid réseau et fonctionnel nous
allons créer un système de fichier en ext4 pour pouvoir
écrire dessus.
Tapons la commande suivante sur le node primaire.
mkfs.ext4 /dev/drbd0
Maintenant nous pouvons monter le disque DRBD comme n'importe
quel disque dur
mkdir /mnt/r0
mount /dev/drbd0 /mnt/r0/
III.4. La valorisation du projet
d'amélioration du système de sauvegarde et de
restauration des données
III.4.1. Le coût du projet
Le projet d'amélioration du système de
sauvegarde et de restauration de données nécessite au
préalable un deuxième serveur de sauvegarde de données
avec au minimum six (06) disques
N'GUESSAN K. Hyppolyte 2012 - 2013
64
durs de 500 Go chacun. A côté de cela, nous
devons louer un espace de stockage de données dans un Datacenter distant
en vue d'externaliser nos sauvegardes. Le tableau 4 nous permet d'avoir une
idée de l'estimation financière de ce projet.
Désignation
|
Quantité
|
Prix Unitaire (FCFA)
|
Prix Total (FCFA)
|
HP Proliant 380p Gen9 + 6 Disques durs de 500 Go
|
01
|
1.540.000
|
1.540.000
|
Espace de stockage de données de 2 To
|
01
|
1.500.000
|
1.500.000
|
Total
|
3.040.000
|
3.040.000
|
|
Tableau 4: Le tableau récapitulatif du
matériel nécessaire (Source : Hyppolyte N'GUESSAN)
III.4.2. L'impact du projet sur l'environnement de la
DGTTC
L'amélioration du système de sauvegarde et de
restauration de données de la DGTTC offre plutôt de nombreux
avantages quant à la pérennité et à la
l'intégrité ses données. Parmi ses avantages, nous pouvons
citer :
· La résistance du serveur de sauvegarde de
données aux pannes matérielles telles que la défaillance
d'un disque dur ; le bug d'un des serveurs de sauvegarde ; la rupture de la
communication des hôtes avec l'un des serveurs de sauvegarde ;
· La restauration rapide et efficace de la
totalité des données en cas de sinistre ou d'incident majeur ;
· La reprise effective des activités de la DGTTC
après un sinistre ou incident majeur ;
· Une meilleure garantie de la conservation et de
l'intégralité des données des différentes bases de
données de la DGTTC
· Amélioration de la qualité de service du
système de sauvegarde et de restauration de données
II.5. Conclusion partielle
Dans ce chapitre, il a été question de
présenter notre solution pour l'amélioration du système de
sauvegarde et de restauration de données de la DGTTC et de
procéder à son implémentation. Nous avons ensuite
procéder à des tests qui consistaient à simuler des
pannes, en vue de se rassurer que notre solution répond aux exigences du
cahier de charges fonctionnel qui nous a été soumis.
N'GUESSAN K. Hyppolyte 2012 - 2013
65
CONCLUSION GENERALE
Au terme de notre étude, nous conclurons qu'en plus de
la mise en place de pare-feu, de système d'authentification et tout
autre outil de sécurité du système d'information, il est,
de nos jours, nécessaire de mettre en place un système de
sauvegarde et de restauration de données à tolérance de
pannes, qui est l'un des éléments essentiels d'une bonne
politique de de sécurité.
Ce mémoire a donc pour objectif, de guider,
d'accompagner, et d'aider tout responsable de la sécurité du
système d'information, non seulement, dans le choix d'un système
de sauvegarde et de restauration de données avec une haute
disponibilité, mais aussi dans sa mise en place. Pour mieux illustrer
nos propos, nous nous sommes servis du cas pratique de la Direction
Générale des Transports Terrestres et de la Circulation où
nous avons eu à proposer une solution d'amélioration de leur
système de sauvegarde et de restauration de données qui
était sensible aux défaillances d'ordre matériel et
quelques fois logiciel.
La mise en place d'un système de sauvegarde et de
restauration de données avec une haute disponibilité, de
manière générale, se fait en trois grandes
étapes.
Dans première étape, nous avons vu comment se
fait l'installation du logiciel de gestion des différents serveurs de
sauvegarde et de restauration de données, en occurrence BackupPC. Il
faut noter que nous devons disposer d'un serveur de sauvegarde et d'un autre
serveur qui est la copie conforme de notre serveur de sauvegarde.
Après l'installation de nos différents serveurs
et de leur logiciel de gestion, je suis passé dans la deuxième
étape de la mise en place du système de sauvegarde et de
restauration de données avec une haute disponibilité à
l'installation du logiciel de clustering, à savoir HeartBeat. Ce
logiciel se charge du basculement entre le serveur actif et le serveur passif
en cas de panne afin d'assurer la continuité du service. Afin de
s'assurer de son bon fonctionnement, j'ai même procédé
à des tests au cours desquels j'ai simulé la panne du serveur
actif et vérifié que le basculement s'effectue de manière
automatique.
La dernière partie de cette mise en place a
consisté à installer une solution RAID de niveau 1. Pour cela,
j'ai installé le logiciel DRBD qui a en charge la réplication des
données sauvegardées par le serveur actif sur le serveur passif
afin qu'il est les mêmes données en tout temps. Cela permet ainsi
d'optimiser la prise de service par le serveur passif lorsque le serveur actif
sera down.
N'GUESSAN K. Hyppolyte 2012 - 2013
66
Néanmoins, la mise en place d'une architecture
redondante ne permet que de s'assurer de la disponibilité des
données d'un système mais ne permet pas de protéger les
données contre les erreurs de manipulation des utilisateurs ou contre
des catastrophes naturelles telles qu'un incendie, une inondation ou encore un
tremblement de terre.
Il est donc nécessaire de prévoir des
mécanismes de sauvegarde (en anglais backup), idéalement sur des
sites distants, afin de garantir la pérennité des
données.
Par ailleurs, un mécanisme de sauvegarde permet
d'assurer une fonction d'archivage, c'est-à-dire de conserver les
données dans un état correspondant à une date
donnée.
Rappelons enfin que l'importance de mettre en place un
système de sauvegarde est directement liée à la
criticité des données de votre entreprise et à la
rapidité avec laquelle elles seront remises à disposition pour
continuer ou reprendre votre activité.
N'GUESSAN K. Hyppolyte 2012 - 2013
67
BIBLIOGRAPHIE
1. Cédric, L., Laurent, L., & Denis, V. (2006).
Tableau de bord de la sécurité réseau. Paris:
Eyrolles.
2. DASTUGUE, J. (2008). Les architectures de stockage.
Récupéré sur Exposés Informatique &
Réseau 2007-2008; Site Internet
http://www-igm.univ-mlv.fr/~dr/XPOSE2007/jdastugNAS_SAN/index.html
3. DUFRESNES, C. (2008, Août 18). SAN et NAS.
Récupéré sur Notions Informatiques; Site Internet
http://notionsinformatique.free.fr
4. LAURÈS, G. (s.d.). La sauvegarde des
données informatiques. Récupéré sur Conseils
comparatifs réseau informatique; Site Internet
http://reseau-informatique.prestataires.com/sauvegarde-donnees-informatiques
5. Serge, B. (2013). Linux et la sécurité
Version 0.3, Cours, Abidjan: HETEC.
6. SOGEC GROUPE. (2012, Décembre 11).
http://entreprise-conseil-expert.com.
Pourquoi est-il important de sauvegarder de vos données
(numériques) ? Le Mans, 72000, France.
7. Stanislas, B., GNEBA. Mise en place d'un réseau local
sécurisé pour l'Etat-Major Général des FRCI,
Mémoire de fin de cycle, HETEC, Abidjan
N'GUESSAN K. Hyppolyte 2012 - 2013
68
TABLE DES MATIERES
SOMMAIRE III
TABLE DES FIGURES V
TABLE DES TABLEAUX VI
GLOSSAIRE VII
DEDICACE X
REMERCIEMENTS XI
RESUME XII
ABSTRACT XIII
INTRODUCTION GENERALE 14
1. Contexte et problématique 14
2. Justification du choix du thème 14
3. Objectifs 15
4. Approche méthodologique de la recherche
15
5. Plan 15
CHAPITRE I : CAHIER DE CHARGES FONCTIONNEL 17
I.1. Introduction partielle 17
I.2. L'objet de la demande 17
I.3. Le contexte du projet 17
I.3.1. Le demandeur 17
I.3.1.1. La présentation de la DGTTC 17
I.3.1.2. La situation géographique de la DGTTC 17
I.3.2. Les données concernées par le
système de sauvegarde et de restauration 17
I.4. La présentation du projet 18
I.4.1. Les objectifs 18
I.4.2. Les principaux besoins 18
I.4.2.1. Le constat 18
I.4.2.2. Les besoins 18
I.4.2.3. Les enjeux relatifs à la sauvegarde et à
la restauration des données 19
I.4.2.4. La technique 19
I.5. Analyse de l'existant 19
I.5.1. La description de l'existant 19
I.5.2. L'inventaire de l'existant 20
I.5.2.1. Les ordinateurs et imprimantes 20
I.5.2.2. Les serveurs 21
I.5.3. L'étude des méthodes de
sécurisation actuelles des données 22
N'GUESSAN K. Hyppolyte 2012 - 2013
69
I.5.3.1. La sécurité des postes de travail 22
I.5.3.2. La sécurité des serveurs et des
équipements réseaux 22
I.5.3.3. La méthode de sauvegarde et de restauration de
données actuelle 23
I.5.4. La critique des méthodes de
sécurisation actuelles du système informatique 23
I.6. La synthèse des éléments
importants 24
I.7. La mise en oeuvre 24
I.7.1. L'installation et la configuration 24
I.7.1.1. Le scénario A : licence libre 24
I.7.1.2. Scénario B : licence propriétaire 25
I.7.2. La formation 25
I.8. La maintenance 25
I.9. Conclusion partielle 25
CHAPITRE II : LES
GENERALITES SUR LES SYSTEMES DE SAUVEGARDE ET DE
RESTAURATION DE DONNES 27
II.1. Introduction partielle 27
II.2. Les méthodes de sauvegarde les plus
courantes 27
II.2.1. Le mécanisme 28
II.2.2. La sauvegarde complète 28
II.2.2.1. Le détail technique 28
II.2.3. La sauvegarde différentielle
28
II.2.3.1. Le détail technique 29
II.2.4. La sauvegarde incrémentielle ou
incrémentale 29
II.2.4.1. Le détail technique 30
II.2.4.2. La sauvegarde, l'archivage et la conservation 30
II.2.4.3. La formule de calcul de l'espace de sauvegarde
nécessaire 30
II.2.5. La sauvegarde décrémentale
31
II.3. Les architectures de sauvegarde 32
II.3.1. Le DAS (Direct Attached Storage) 32
II.3.1.1. Les avantages et les inconvénients 33
II.3.1.1.1. Les avantages 33
II.3.1.1.2. Les inconvénients 33
II.3.2. Le SAN (Storage Area Network) 34
II.3.2.1. Les baies de disques 35
II.3.2.1.1. Le RAID 0 (Stripping) 35
II.3.2.1.2. Le RAID 1 (Mirroring) 35
II.3.2.1.3. Le RAID 5 (Stripping + partie distribuée)
36
II.3.2.1.4. Le RAID 6 36
N'GUESSAN K. Hyppolyte 2012 - 2013
70
II.3.2.1.5. Le RAID « combiné » 37
II.3.2.2. SCSI 37
II.3.2.3. Les Avantages et les inconvénients 38
II.3.2.3.1. Les avantages 38
II.3.2.3.2. Les inconvénients 38
II.3.3. Le NAS (Network Attached System) 38
II.3.3.1. Les avantages et les inconvénients 39
II.3.3.1.1. Les avantages 39
II.3.3.1.2. Inconvénients 39
II.3.4. Le tableau comparatif des différentes
solutions SAN et NAS 39
II.4. Les techniques améliorant la
disponibilité 41
II.5. Les critères de choix d'un sauvegarde et
restauration de données performant 42
II.5.1. Les fonctionnalités 42
II.5.1.1. Multiplateforme 42
II.5.1.2. Multi jeux de sauvegarde 42
II.5.1.3. Gestion fichiers ouverts 42
II.5.1.4. Gestion de version 43
II.5.1.5. Gestion de la bande passante 43
II.5.1.6. Administration centralisée 43
II.5.1.7. Accès sécurisé 43
II.5.1.8. Fonction de recherche 43
II.5.1.9. Cryptage des données 43
II.5.1.10. Support de différents médias 43
II.5.1.11. Compression des données 43
II.5.1.12. Restauration rapide 44
II.5.2. Caractéristique 44
II.5.2.1. Autonome et automatique 44
II.5.2.2. Planifiable 44
II.5.2.3. Auditable 44
II.5.2.4. Testable 45
II.5.2.5. Sécuritaire 45
II.5.2.6. Évolutif 45
II.5.2.7. Résilient 45
II.6. Conclusion partielle
45
CHAPITRE III : DEPLOIEMENT DE LA SOLUTION D'AMELIORATION
DU SYSTEME
DE SAUVEGARDE ET DE RESTAURATION DE DONNEES
46
III.1. Introduction partielle 46
III.2. Présentation de la solution 46
N'GUESSAN K. Hyppolyte 2012 - 2013
71
III.1.1. BackupPC 48
III.1.2. Heartbeat ou linux High Availability
48
III.1.3. Distributed Replicated Block Device (DRBD)
48
III.3. Le déploiement de la solution
49
III.3.1. Le système de sauvegarde et de
restauration de données 49
III.3.1.1. L'installation 49
III.3.1.1.1. Ajout de l'utilisateur dans le groupe backuppc 49
III.3.1.1.2. Ajout du fichier apache.conf 49
III.3.1.2. La configuration du serveur de sauvegarde et de
restauration de données 50
III.3.1.2.1. Le fichier hôte 50
III.3.1.2.2. Fichier de configuration générale
51
III.3.1.2.3. Le fichier de configuration par PC 54
III.3.1.2.4. La configuration du SSH 56
III.3.2. Le service de haute disponibilité
57
III.3.2.1. L'installation 57
III.3.2.2. La configuration 57
III.3.2.3. Le démarrage du cluster et l'analyse des logs
59
III.3.2.4. Simulation d'une panne, récupération et
analyse des logs 60
III.3.3. Le service RAID de niveau 1 61
III.3.3.1. L'installation 61
III.3.3.2. La configuration 62
III.4. La valorisation du projet d'amélioration du
système de sauvegarde et de restauration
des données 63
III.4.1. Le coût du projet 63
III.4.2. L'impact du projet sur l'environnement de la
DGTTC 64
II.7. Conclusion partielle 64
CONCLUSION GENERALE 65
BIBLIOGRAPHIE 67
73
LES MISSION, L'ORGANISATION ET LE FONCTIONNEMENT DE LA
DGTTC A
1. Les missions de la DGTTC A
2. L'organisation de la DGTTC A
2.1. La Direction des Transports Routiers et Ferroviaires A
2.1.1. La Direction de la Circulation A
2.1.2. La Direction de la Coordination des Transports
Terrestres B
2.1.3. La Direction de la Promotion des Entreprises du
Transport B
N'GUESSAN K. Hyppolyte 2012 - 2013
72
2.1.4. Le Service de l'Informatique, de la Documentation
et des Archives (SINDA). B
2.1.4.1. Les missions du SINDA C
2.1.4.2. L'organigramme du SINDA C
2.1.4.3. Le fonctionnement du SINDA C
N'GUESSAN K. Hyppolyte 2012 - 2013
A
LES MISSION, L'ORGANISATION ET LE
FONCTIONNEMENT DE
LA DGTTC
1. Les missions de la DGTTC
La Direction Générale des Transports Terrestre
et de la Circulation a pour mission principale :
· De conduire la politique nationale en matière
de transport terrestre et de la circulation routière et ferroviaire sous
l'autorité du Ministre des Transports.
· De coordonner les activités des directions et
services sous son autorité.
2. L'organisation de la DGTTC
Le Directeur Général des Transports Terrestre
et de la Circulation, Monsieur KOUAKOU KOUAKOU ROMAIN, a pour mission d'oeuvrer
à la réalisation des attributions définies ci-dessus. A ce
titre, il organise, coordonne, anime et contrôle toutes les
activités de la Direction Générale. Pour son exercice le
Directeur Général dispose de quatre (04) directions et des
services rattachés.
2.1. La Direction des Transports Routiers et
Ferroviaires
Elle est chargée de mettre en oeuvre et suivre la
politique des transports routiers et ferroviaires, d'élaborer, de
suivre, de contrôler la règlementation en matière de
transport routier et ferroviaire, de représenter le ministre des
transports auprès des organismes régionaux et internationaux des
transports terrestres.
Elle comprend deux (02) sous-directions : la sous-direction
des transports des personnes et la sous-direction des transports des
marchandises.
2.1.1. La Direction de la Circulation
Elle est chargée d'étudier, d'élaborer,
de suivre la réglementation en matière de circulation
routière, d'analyser les données sur la circulation
routière, de contrôler la production des permis de conduire et des
cartes grises, de suivre et contrôler l'évolution du parc
automobile par la radiation des véhicules automobiles hors d'usage de la
base de données, de suivre et coordonner les missions de contrôles
routiers.
N'GUESSAN K. Hyppolyte 2012 - 2013
B
Elle comprend deux (02) sous-directions : la sous-direction de
la réglementation de la circulation et, la sous-direction des
études et de la circulation ;
2.1.2. La Direction de la Coordination des Transports
Terrestres
Elle est chargée de suivre les relations avec les
organisations professionnelles, les auxiliaires de transport et les entreprises
de transports terrestres, d'élaborer et mettre en oeuvre les politiques
de formation, de gestion prévisionnelle et la promotion du personnel
ainsi que de la formation des acteurs du secteur des transports terrestres,
d'assurer l'entretien et la gestion des locaux, de suivre et de contrôler
la mise en place du budget de la Direction Générale.
Elle comprend trois (03) sous-directions : la sous-direction
des Organisations Professionnelles et des Entreprise, la sous-direction des
Relations Extérieures et la sous-direction des Moyens
Généraux ;
2.1.3. La Direction de la Promotion des Entreprises du
Transport
Elle est chargée de conduire une politique de
réglementation et de définition des besoins, de promouvoir et
renforcer la capacité des transporteurs, de promouvoir les entreprises
de transport, de promouvoir les actions relatives aux affaires sociales des
acteurs du secteur des transports.
Elle comprend trois (03) sous-directions : la sous-direction
des Entreprises de Transport ; la sous-direction de la Réglementation,
de la Logistique et de la Recherche de financement et la sous-direction des
Affaires sociales ;
2.1.4. Le Service de l'Informatique, de la Documentation
et des Archives (SINDA).
Le Service de l'Informatique, de la Documentation et des
Archives est situé à la tour C de la cité administrative,
elle occupe les portes 20, 23, 24, 25 et 26 du 3ième étage.
Ce service est doté de 4 salles d'archivages et une
salle des serveurs qui sont reparties comme suit :
? 2 salles situées au 3ième étage ;
? 1 salle située au 4ième étage ;
? 1 salle située au 5ième étage
? 1 salle des serveurs située à la porte 25 du
4ème étage
N'GUESSAN K. Hyppolyte 2012 - 2013
C
2.1.4.1. Les missions du SINDA
La direction de l'Informatique, de la Documentation et des
Archives est chargé :
· De gérer la documentation et les archives de la
direction générale ;
· D'archiver les dossiers provenant des structures sous
tutelle du ministère ;
· De mettre en oeuvre et développer un schéma
directeur informatique de la direction générale en liaison avec
les structures sous tutelle ;
· De constituer une banque de données informatiques
des activités de la direction générale et d'en assurer
l'archivage électronique ;
· D'assurer la maintenance des équipements
informatiques de la direction générale.
2.1.4.2. L'organigramme du SINDA

Figure 29: L'organigramme du SINDA (Source : SINDA)
2.1.4.3. Le fonctionnement du SINDA
Le chef de la direction, Monsieur DJODIRO François est
chargé de :
· La coordination des activités des services ;
· La conception de la mise en oeuvre du schéma
directeur informatique ;
· La conception du réseau informatique ;
· La conception des projets et la mise en place de nouveaux
logiciels ;
· La création d'un fonds documentaire ;
· La gestion des statistiques.
| 

