PREMIER CHAPITRE
REVUE DE LITTERATURE
Les bases de données réparties et la
réplication des données sont reconnues aujourd'hui comme
étant des moyens efficaces pour augmenter la disponibilité et la
fiabilité des bases de données. La réplication offre aux
utilisateurs de meilleures performances et une plus grande disponibilité
des données. (Lambert SONNA MOMO, 2001). De nombreuses recherches ont
mené à cette conclusion étant donné que la question
de la haute disponibilité des données ne date pas d'aujourd'hui,
et beaucoup d'auteurs se sont exprimés à propos.
Dans cette partie de notre recherche, nous souhaitons passer
en revue les théories, les méthodes et les résultats
obtenus par d'autres Auteurs au cours de leurs investigations. Cette revue
cherche donc à trouver une solution à la question de savoir quel
modèle informatique permettrait de s'assurer de la disponibilité
des informations découlant des opérations en cours entre les
bases de données afin de répondre, en temps réel, aux
différentes requêtes que les utilisateurs peuvent
exécuter.
I.1. Base de Données Reparties ou
Distribuées
En décembre 2007, Mathieu EXBRAYAT a
désigné par base de donnée répartie (ou
distribuée), une base de données logique dont les données
sont distribuées sur plusieurs SGBD et visibles comme un tout. Quoi
qu'Il s'est limité à expliquer les concepts liés à
la notion des bases de données reparties et leurs techniques de mise en
place. Ses recherches sont d'une importance capitale dans la mesure où
elles aident à bien comprendre différents concepts
utilisés dans la mise en place des bases de données
distribuées quand bien même qu'il n'offre aucun algorithme de
réplication des données capable de répondre à notre
question de recherche.
Pour J. Akoka et I. Wattiau (2011), une base de données
distribuée permet la création, l'accès et la manipulation
des données inter reliées sur différents sites d'un
réseau informatique. Ils ont listé quelques
éléments à retrouver dans une architecture
distribuée :
· Chaque site a une capacité de traitement local
autonome
· L'accessibilité, le partage, la performance et la
disponibilité sont améliorés
· l'optimisation globale des traitements, dans le but de
préserver les avantages de la base de données
centralisée.
~ 6 ~
Ils ajoutent quelques facteurs dont dépend la base de
données centralisée:
- Du coût de communication
- Du coût des traitements locaux
- De la stratégie d'allocation des données et
- De la stratégie d'exécution de traitements
MATHIEU EXBRAYAT présente deux approches de la
Conception répartie ; il s'agit de la Conception ascendante
c'est à dire qui intègre les bases locales dans un
schéma global (Décomposition) et la
conception descendante qui part du schéma global et le
scinde en schémas locaux (Intégration).
Graphiquement, sa conception produit la figure suivante :
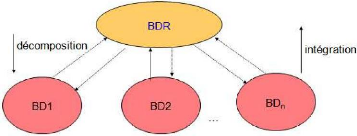
Figure 1 : Conception BD Répartie par
Décomposition et par Intégration (Mathieu
EXBRAYAT, 2007)
Ces notions sont d'une importance capitale dans la mesure
où elles facilitent la compréhension des concepts de bases de
données réparties étant des structures favorisant la
réplication préventive des données, c'est-à-dire
qui prévoit la tolérance aux pannes.
~ 7 ~
| 

