IV.2. EXPERIMENTATION ET SIMULATION
L'objectif principal étant la conception d'un
algorithme de réplication adapté à la
réalité vécue dans les pays du sud, plus exactement en
RDC, nous ne nous sommes pas limiter à présenter ces algorithmes
sans pour autant présenter également les résultats obtenus
après nos tests d'expérimentation.
IV.2.1. PROTOCOLE D'EXPÉRIMENTATION
Après la configuration de l'environnement de travail
tel qu'expliqué au début de ce chapitre, nous sommes
passés à la configuration des ordinateurs à utiliser pour
les tests. Les données des tests ont été
exécutées sur deux ordinateurs de propriétés
suivantes :
- Modèle : Inspiron 3521 ;
- BIOS : InsydeH20 Version 03.72.24A05 ;
- Processeur : Intel(R) Celeron(R) CPU 1007U @1.50GHZ (2 CPUS),
~1.5GHZ ;
- Memory : 2048 MB RAM,
- Operating System : Windows Server Enterprise 2008
- Configurations de Réseau : - Ordinateur I : IP :
192.168.100.2/255.255.255.0
- Ordinateur II : IP : 192.168.100.3/ 255.255.255.0
4.2.2. RESULTATS DES TESTS
Pour tester nos algorithmes, nous sommes partis des
critères principaux de sélection d'une technologie de
réplication :
> la cohérence des données
répliquées ;
> l'autonomie des sites ;
> le partitionnement des données pour éviter les
conflits.
Il ne nous a pas été possible d'optimiser les trois
critères simultanément. Ainsi une
solution qui favoriserait la cohérence des
données devrait laisser une faible autonomie aux sites afin de
connaître à chaque instant l'ensemble des modifications qui ont
lieu sur les données. Ainsi, nous avons testé nos algorithmes
sous deux dimensions : la méthode transactionnelle et la méthode
par fusion.
~ 45 ~
IV.2.3. PROCEDURES DE MISE EN PLACE DE LA REPLICATION
- Réplication de Fusion
Il s'agissait, dans cette méthode, de surveiller les
modifications de la base de données source et de synchroniser les
valeurs entre l'éditeur et les abonnés, es derniers pouvant tous
effectuer des opérations de mise à jour sur les données
distribuées. Si l'éditeur conserve la maîtrise de la
publication, ce n'est pas toujours les opérations effectuées sur
l'éditeur qui prennent le pas sur celles effectuées sur
l'abonné. Toutes les modifications apportées à la base
cible étaient reportées dans la base source.
Nous n'avons pas eu beaucoup du mal à configurer la
synchronisation des données à partir de SQL Server Management
Studio car il propose différents assistants graphiques pour mettre en
place, surveiller et paramétrer l'environnement de réplication.
Tous les éléments de configurations sont accessibles depuis le
noeud Réplication de l'explorateur d'objets.
Les algorithmes suivants décrivent les procédures
de la mise en place de la réplication entre les serveurs de base de
données :
~ 46 ~
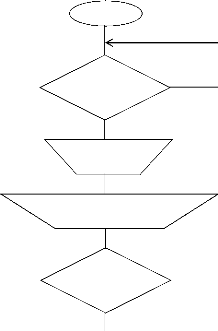
Début
Choix BD Cible
Choix type de publication
Choix
Réplication
Choix
Réplication
Fin
Sélection des Tables
Création
Création de la Publication
Echec de Création
Annulation
Création réussie
Continuer
Figure 23 : Algorithme de sélection du Noeud
réplication pour commencer les configurations de mise en place
~ 47 ~
Début
Choix de la Publicité
Affichage des éléments du Menu
Contextuel
Liste
Affichage Statut de l'Agent de
Publication
Navigation
(Start, Stop, Monitor)

Fin
Figure 24 : Vérification du Statut de l'Agent de
Publication
~ 48 ~

Début
Affichage état de l'Agent de
publication
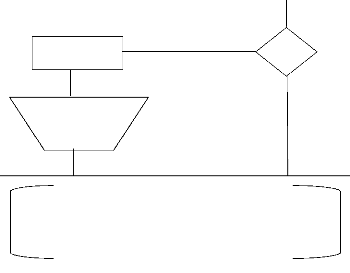
Démarrer
Arrêté
État
Démarré
Démarrage en Cours
Affichage à l'écran de l'état de l'Agent de
la BD Source + le nombre des Données Répliquées
Moniteur de Réplication

Fin
Figure 25 : Fonctionnement de l'Agent de Publication
~ 49 ~

Fin
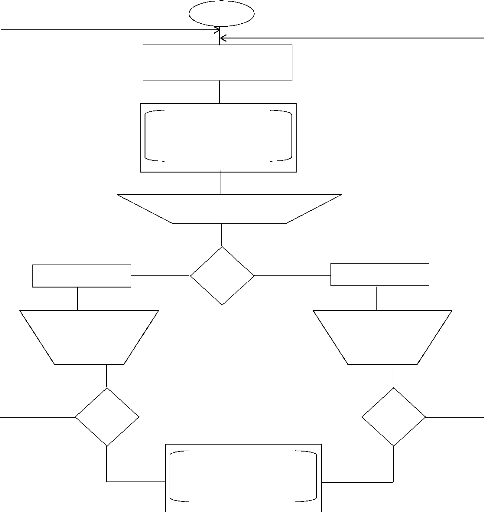
Echec
Configurer Esclave
Choisir Serveurs Cibles
Altern ative
Liste d'éléments Menu Contextuel
Multi Server Administration
SQL Agent
Début
Altern ative
Succès
Configurer Esclave
Choisir Serveur Cible
Altern ative
Echec
Figure 26: Etapes de Configuration du Serveur Maitre et du
Serveur Esclave
Figure 27: Filtrage de connexions des utilisateurs selon leur
poste de travail
~ 50 ~
- Réplication Transactionnelle
Après nos tests par la méthode transactionnelle,
nous avons constaté que cette méthode est facile à mettre
en place parce qu'elle ne nécessite pas de passer à des
configurations au niveau de l'agent de publication et de l'agent de
souscription ; c'est-à-dire que une fois qu'une opération est
effectuée sur la base maitre, les changements s'appliquent en temps
réel sur les bases esclaves.
| 

