|
[I]
Epigraphie
« Confie-toi en l'Eternel de tout
ton coeur, de toute ton âme et de toutes tes forces. Ne t'appuie pas sur
ton propre intelligence, dans toutes tes voies tiens compte de lui et il rendra
droit tes sentiers, ne deviens pas sage à tes propres yeux, crains DIEU
et détourne- toi du mal, cela est santé pour ton âme et
rafraichissement pour tes os.»
Proverbe 3 : 5-8
[II]
DEDICACE
Nous rendons grâce à Dieu pour le courage et la
force qu'il nous a donnée tout au long de notre parcours à
l'Université de Kinshasa.
A nos parents NGYAMA MABILA Ephrem et MINZENZE PUNGU Victorine
pour tant des sacrifices et de souffrance consentie pour nos études.
A nos frères Dieudonné MUNDADI, Yannick NGYAMA,
Cédric KAPOKOTO, et nos soeurs Farida KIMBANDA, Divine MAMENGA, Patricia
MINZENZE pour leur encouragement et soutien moral.
A notre neveu Glody MUYEKE
Nous dédions ce travail
Richard KANGIAMA LWANGI
[III]
AVANT PROPOS
Au terme de ce travail, nous tenons à adresser nos vifs
remerciements aux personnes dont le concours nous a été
précieux pour sa réalisation.
Nous remercions particulièrement le professeur MANYA
DJADI LEONARD, qui a accepté volontiers de diriger ce mémoire,
malgré ses multiples occupations.
Notre profonde reconnaissance s'adresse à tout le corps
professoral du Département de Mathématiques et Informatique de
l'Université de Kinshasa pour avoir participé à notre
formation.
Aux chefs de travaux BATUBENGA, BUKANGA et les autres
Assistants pour leur soutien scientifique ; sans oublier le chef de travaux
Pierre KAFUNDA KATALAY pour son encadrement par des sages conseils.
A nos compagnons de la promotion et amis : Felly MANDA,
Jean-Jacques KATSHITSHI, Bijoux TOBO , Trésor
EBONDO, Billy MATIABA, Minion KITOKO ,Arnold
MANZO ,Freddy
KEREDJIM, KALOMBO KALO, Tito LUFUNGULA, Hendrik MITI ,Frémy MAKANGA, Ben
KANZOKA Laetitia LUSIMBA, ya ANNIE ODIMBA, Orchidée KINKO, Patience
LUFUNGULA, Kiki NDESHO ,Youyou MAYOKO, Trésor ALOMA, A toutes les mamans
du Secrétariat Général Académique et autres .
Nous remercions également les familles KINKO,
LUFUNGULA, FUNDJI et les BYM NODASA pour leur assistance morale et
spirituelle.
[IV]
LISTE DES FIGURES
FIG I. 1:ARCHITECTURE GENERALE D'UN SYSTEME DECISIONNEL 7
FIG II. 1:ARCHITECTURE D'UN ENTREPOT DE DONNEES 19
FIG II. 2:ARCHITECTURE D'UN DATAMART 25
FIG II. 3:EXEMPLE DE MODELISATION EN ETOILE 29
FIG II. 4:EXEMPLE DE MODELISATION EN FLOCON DE NEIGE 31
FIG II. 5:EXEMPLE DE MODELISATION EN CONSTELLATION 32
FIG II. 6:EXEMPLE DE SCHEMA MULTIDIMENSIONNEL 33
FIG II. 7: ARCHITECTURE ROLAP 36
FIG II. 8:ARCHITECTURE MOLAP 37
FIG II. 9:ARCHITECTURE HOLAP 38
FIG III 1:ARBRE DE DECISION CONSTRUIT A PARTIR DE L'ATTRIBUT
AGE 54
FIG III 2:ARBRE DE DECISION FINALE 55
FIG IV 1:ORGANIGRAMME 63
FIG IV 2:MODELE CONCEPTUEL DES DONNEES 67
FIG IV 3:MODELE LOGIQUE DE DONNEES 68
FIG IV 4:SCHEMA EN ETOILE DES ACCOUCHEMENTS 72
FIG IV 5:VUE DE L'ENSEMBLE DES DONNEES AVEC SPAD 74
FIG IV 6:ARBRE DE DECISION 77
FIG IV 7:GRAPHIQUE 78
FIG IV 8:DIAGRAMME DE CLASSE 83
FIG IV 9:DIAGRAMME DE CAS D'UTILISATION 84
FIG IV 10:DIAGRAMME DE SEQUENCE 84
FIG IV 11:DIAGRAMME DE SEQUENCE ANALYSE OLAP 85
FIG IV 12:FORMULAIRE DE SECURITE 85
FIG IV 13:FORMULAIRE DE MENU PRINCIPALE 86
FIG IV 14:FORMULAIRE ACCOUCHEMENT 86
[V]
LISTE DES TABLEAUX
TABLEAU II 1:DIFFERENCE ENTRE SGBD ET ENTREPOTS DE DONNEES
22
TABLEAU II 2:COMPARE LES CARACTERISTIQUES DES SYSTEMES 23
TABLEAU III 1:LA METHODOLOGIE A NEUF ETAPES DE KIMBALL 28
TABLEAU III 2:LE TACHES ET TECHNIQUE DU DATAMINING. 45
TABLEAU III 3:EXEMPLES PRATIQUES 52
TABLEAU IV 1:REPARTITION DE MODULE DE SQL SERVEUR 2008 PAR
COMPOSANTE. 66
[VI]
LISTE DES ABREVIATIONS
SID : Système d'informatique décisionnel
OLAP : Online analytical processing
OLTP : Online transactonal processing
ETL : Extract transform and load
SGBD : Système de gestion de base des données
MDO : Magasin des données opérationnelles
ODS : Operational data store
ROLAP : Relational olap
MOLAP : Multidimensional olap
HOLAP :Hybrid olap
BD :Base de données
DW :Datawerahouse
[1]
INTRODUCTION
La prise de décision est un problème essentiel
qui préoccupe les gestionnaires des entreprises. Cette prise de
décision passe par la modélisation des différents
problèmes qu'ils rencontrent dans la gestion, d'où la
nécessité d'un modèle basé sur l'arbre de
décision.
L'entrepôt de données étant une vision
centralisée et universelle de toutes les informations de l'entreprise,
C'est une structure qui a pour but, contrairement aux bases de données,
de regrouper les données de l'entreprise pour des fins analytiques et
pour aider le manager à la prise de décision
stratégique.
Une décision stratégique est une action
entreprise par les décideurs de l'entreprise qui vise à
améliorer, quantitativement ou qualitativement, la performance de
l'entreprise.
Un problème d'extraction de connaissances consiste
à extraire les connaissances à partir d'un entrepôt de
données ou d'une autre source de données en utilisant les
techniques du Datamining (arbre de décision, réseaux bayesien,
réseaux de neurones, etc.).
0 .PROBLEMATIQUE
Vu la capacité d'accueil de l'Hôpital Saint
Joseph , vu le nombre de consultations et des accouchements au sein de cet
hôpital, le décideur qui est le médecin directeur se
présente devant une grande quantité des données
éparpillées dans des différents fichiers Excel .
Le décideur a besoin d'avoir les informations sur
toutes les données éparpillées.
C'est pourquoi nous avons réalisé notre
système d'aides à la prise de décision qui permettra de
réunir toutes les données afin d'en faire des analyses.
[2]
1 .INTERET DU TRAVAIL
Le choix de ce sujet porte sur un double aspect, d'abord il
est question de répondre au schéma de nos inspirations qui est
d'approfondir la notion d'informatique décisionnelle pour essayer de les
appliquer dans la vie courante et professionnelle et ensuite de réaliser
un outil de travail pour la maternité de l'Hôpital Saint Joseph de
Kinshasa Limete.
2 .METHODOLOGIE
Dans le cadre de notre travail, nous allons mettre en place
une application informatique qui permettra au décideur de prendre une
décision et anticiper les événements sur les
accouchements.
Pour notre système nous aurons un fichier Excel que
nous allons intégrer dans une base de données
opérationnelles qui est comme base de données transactionnelles
.Nous allons utiliser les datamining pour explorer les données de notre
DataMart en vue de faire l'extraction.
Pour la construction de notre DataMart nous allons utiliser la
méthodologie de Raph Kimball.
Elle nous a présenté la faveur d'aller sur terrain,
de récolter les
données ; et nous avons utilisé la technique
d'interview, questionnaire et la documentation pour la récolte des
données.
3. DELIMITATION DU TRAVAIL
Pour parler de la délimitation du travail qui consiste
à évoquer sa précision dans le temps et dans l'espace.
Ainsi, nous sommes limité à concevoir un système
décisionnel pour la maternité et nous avons réalisé
une application opérationnelle pour la maternité qui permettra
aux agents de la maternité de saisir les informations sur les
accouchements.
Ensuite nous avons utilisé l'arbre de décision
comme outil de datamining pour l'extraction de données dans notre
DataMart pour la prise de décision. Notre travail a été
réalisé pour la
[3]
maternité de l'Hôpital Saint Joseph de Kinshasa
Limete pendant l'année 2010.
4. PLAN DU TRAVAIL
Outre l'introduction et la conclusion, notre travail comprend
quatre chapitres.
Le premier chapitre reprend les concepts sur
les systèmes décisionnels, nous définissons les
systèmes décisionnels et ses enjeux.
Le deuxième chapitre traite des
entrepôts des données où nous expliquons les
différents concepts relatifs aux entrepôts de données et
ses différents serveurs.
Le troisième chapitre porte sur le
datamining et l'arbre de décision.
Le quatrième chapitre est
consacré à l'implémentation qui est notre contribution
personnelle.
[4]

CHAPITRE I : LES SYSTEMES DECISIONNELS
[17], [18], [7], [19]
I .1 INTRODUCTION
Dans ce chapitre nous allons définir le système
décisionnel et donner quelques concepts relatifs au business intelligent
avec des applications pour boucler par une conclusion.
Notons qu'un nombre plus important d'acteurs des entreprises
éprouvent des difficultés dans le processus de la prise de
décision notamment dans la conception et les choix des outils à
implanter.
Le marche du décisionnel ne cesse d'exploser surtout
avec l'investissement de plusieurs grandes sociétés qui
souhaitent instaurer un système de business intelligence dans leur
organisation. Sa mise en oeuvre demande des expertises et nécessite une
maitrise d'ouvrage de la part des informaticiens concepteurs.
I.1.0 L'INFORMATIQUE DECISIONNELLE [18]
l'informatique décisionnelle désigne les moyens,
les outils et les méthodes qui permettent de collecter, consolider,
modéliser et restituer les données, matérielles ou
immatérielles d'une entreprise en vue d'offrir une aide a la
décision et de permettre aux responsables de prendre des
stratégie pour l'entreprise et d'avoir une vue d'ensemble de
l'activité traitée au sein de l'entreprise.
En générale, ce type d'application utilise un
entrepôt de données pour stocker des données transverses
provenant de plusieurs sources hétérogènes et fait appel a
des traitements par lots pour la collecte de ces informations.
L'informatique décisionnelle s'insère dans
l'architecture plus large d'un système d'information.
[5]
Néanmoins l'informatique décisionnelle n'est pas
un concept concurrent du management du système d'information.
Au même titre que le management relève de la
sociologie et de l'économie, la gestion par l'informatique est
constitutive de deux domaines radicalement différents que sont le
management et l'informatique.
Afin d'enrichir le concept avec ces deux modes de
pesées, il est possible d'envisager un versant oriente ingénierie
de l'informatique portant le nom d'informatique décisionnelle, et un
autre versant servant plus particulièrement les approches de gestion
appelé management du système d'information.
Pour expliciter ce concept, nous posons ces deux questions :
pourquoi le décisionnel et qui a besoin du décisionnel ?
1.1.1 POURQUOI LE DECISIONNEL [19]
Le décisionnel ne concerne souvent que les entreprises
qui gèrent un historique des événements passés
(faits, transactions etc.). Les entreprises qui viennent de naitre n'ont
souvent pas besoin de faire du décisionnel car elles n'ont pas encore
besoin de catégoriser ou de fidéliser leurs clients.
Le souci majeur pour elles serait plutôt d'avoir le
maximum de clients. Et c'est âpres en avoir récupère un
grand nombre qu'elles penseront certainement à les fidéliser et
leur proposer d'autres produits susceptibles de les intéresser. C'est ce
que l'on appelle Customer Relationship management.
Finalement, le troisième processus correspond à
l'interrogation qui se place entre l'entrepôt et les
[6]
1.1.2 QUI A BESOIN DU DECISIONNEL [19J
Comme cela peut se deviner, les décideurs sont les
principaux utilisateurs des systèmes décisionnels. Les
décideurs sont généralement des analystes. Ces derniers
établissent des plans qui leur permettent de mieux cibler leurs clients,
de les fidéliser.
Et pour cela, ils ont besoin d'indicateurs et des
données résumées de leur activités (ils n'ont
souvent besoin de détail que pour des cas spécifiques).
Par exemple, contrairement aux systèmes relationnels
(ou base gestion) ou les utilisateurs chercheront à connaitre leurs
transactions pour faire un bilan, les systèmes décisionnels eux
cherchent plutôt à donner un aperçu global pour connaitre
les tendances des clients d'où l'opposition des deux modes quantitatif
pour le système relationnel par contre qualitatif pour le système
décisionnel.
1.1.3 ARCHITECTURE DE SYSTEME DECISIONNEL [7]
L'architecture générale d'un système
décisionnel qui se décompose en trois processus : extraction et
intégration, organisation et interrogation.
Nous trouvons le processus d'extraction intégration
entre les sources de données et l'entrepôt.
Ce processus est responsable de l'indentification des
données dans les diverses sources internes et externes ;
De l'extraction de l'information qui nous intéresse et
de la préparation et de la transformation (nettoyage, filtrage, etc..)
des données à l'intérieur de l'entrepôt, nous
trouvons le processus d'organisation, il est responsable de structurer les
données par rapport à leur niveau de granularité
(agrégats).
[7]
différents outils pour arriver à l'analyse des
données, pour les différents utilisateurs de l'entreprise.

FIG I. 1:Architecture Générale d'un système
décisionnel
I.2 LES DIFFERENTS ELEMENTS CONSTITUTIFS DU SYSTEME
DECISIONNEL [19]
1.2.1 .1 LES SOURCES DE DONNEES
Les sources de données sont souvent diverses et
variées et le but est de trouver des outils et afin de les extraire, de
les nettoyer, de les transformer et de les mettre dans l'entrepôt de
données .Ces sources de données peuvent être de fichier du
type Excel, base de données opérationnelle d'une entreprise ou
fichier plat.
I.2.1 L'ENTREPOT DE DONNEES
Il est le coeur du système décisionnel et
demande une analyse profonde de la part de la maitre d'ouvrage. La conception
d'un DataWarehouse diffère de la conception d'une base de données
relationnelle.
En effet, alors que les bases de données relationnelles
tendent le plus souvent à être normalisées, les bases de
données multidimensionnelles, elles, sont de normalisées
respectant le modèle en étoile ou le modèle en flocon.
[8]
1.2.3 LE SERVEUR OLAP OU SERVEUR D'ANALYSE
Le serveur OLAP est opposé à OLTP et a pour but
d'organiser les données à analyser par domaine ou par
thème et d'en ressortir des résultats pertinents pour le
décideur. Les résultats sont donc des résumés et
peuvent être obtenus par différents algorithmes de datamining
(fouille de données) du serveur d'analyse.
Ces résultats peuvent amener l'organisation à
prendre des très bonnes décisions en vue d'améliorer le
rendement de leurs entreprises.
1.2.4 LE GENERATEUR D'ETATS
Le générateur d'état permet seulement de
mieux appréhender le résultat de l'analyse. L'utilisateur final
n'étant pas forcement un informaticien, il aura plus de facilité
dans des états business objets (ou même dans des feuilles de
données Excel) avec des diagrammes et courbes statistiques que d'aller
directement requêter dans le serveur d'analyse. Les états
permettent également de faire de l'exploration ou la navigation sur de
données.
I.3 LES ENJEUX DE L'INFORMATIQUE DECISIONNELLE [18]
De nos jours, les données applicatives métier
sont stockées dans une ou plusieurs bases de données
relationnelles ou non relationnelles. Ces données sont extraites,
transformées et chargées dans un entrepôt de données
généralement par un outil de type ETL.
Un entrepôt de données peut prendre la forme d'un
DataWarehouse ou d'un DataMart. en règle générale, le
DataWarehouse globalise toutes les données applicatives de l'entreprise,
tandis que les DataMarts généralement alimentes depuis les
données du DataWarehouse sont des sous-ensembles
[9]
d'informations concernant un métier particulier de
l'entreprise assurance ,marketing, risque, contrôle de gestion ,sante
etc.
Les entrepôts de données permettent de produire
des rapports qui répondent à la question « que s'est-il
passé ? », mais ils peuvent être également
conçus pour répondre à la question analytique «
pourquoi est-ce que cela s'est passé ? » et à la question
pronostique « que va-t-il se passer ? ». Dans un contexte
opérationnel, ils répondent également à la question
« que se passe-t-il en ce moment ? », voire dans le cas d'une
solution d'entrepôt de données actif « que devrait-il se
passer ? ».
I .4 METHODES D'ANALYSE DECISIONNELLE
A. DU TABLEAU A L'HYPER CUBE
L'informatique décisionnelle s'attache à mesurer
:
Un certain nombre d'indicateurs ou de mesures (que l'on
appelle
aussi les faits ou les métriques), Restitues selon les
axes
d'analyse (que l'on appelle aussi les dimensions).
LE TABLEAU
A titre d'exemple considérons les données sur les
naissances des
enfants à l'hôpital saint joseph de LIMETE.
On peut vouloir mesurer :
Trois indicateurs : les recettes totales des accouchements, le
nombre de naissances, le montant de taxes pour chaque accouchement,
Le premier axe, représente l'axe temps : par
année, par trimestre, par mois,
Et le un second, l'axe par catégorie : naissance
normale, naissance césarienne, cas complique. On obtient ainsi un
tableau à deux entrées :
Par exemple en lignes : la nomenclature des naissances a 3
niveaux (naissance normale, naissance par césarienne,
naissance par cas compliqué), et en colonnes : les années,
décomposées en trimestres, puis en mois, avec au croisement des
lignes et colonnes, pour chaque cellule : les recettes totales des
accouchements, le nombre de naissance et le montant de taxe par
accouchement.
[10]
B. LE CUBE
Si l'on s'intéresse à un troisième axe
d'analyse :
Par exemple, la répartition géographique : par
district, par commune, par localité, on obtient une dimension de plus et
on passe ainsi au cube. Avec les tableaux croises dynamiques d'Excel permet
aussi de représenter ce type de cube avec le champ "page".
C. L'HYPER CUBE
Si l'on s'intéresse à un axe d'analyse
supplémentaire :
Par exemple, la segmentation des responsables : par
catégorie, par profession, on obtient alors un cube à plus de
trois dimensions, appelé hyper cube.
Le terme cube est souvent utilise en lieu et place d'
hyper cube.
D. LA NAVIGATION DANS UN HYPER CUBE
Les outils du monde décisionnel offrent des
possibilités de navigation dans les différentes dimensions du
cube ou de l'hyper cube avec ses différentes opération drill down
(la forage avant), slice and dice (le forage arrière), slice and dice et
le drill throuth dans les lignes qui suivent nous allons expliquer en claire
ces différentes possibilité de navigue dans un cube.
Le forage avant ou le drill down:
est la possibilité de zoomer sur une dimension (par
exemple d'éclater les années en quatre trimestres pour avoir une
vision plus fine, ou de passer du district aux différentes communes),
Le forage arrière ou le drill up
appelé aussi roll-up : représente une
l'opération inverse qui permet d' agréger les composantes de l'un
des axes ,par exemple de regrouper les mois en trimestre, ou de totaliser les
résultats des analyses différentes communes pour avoir le total
par districts.
Le slice and dice, aussi
appelé dice down: est une opération
plus complexe qui entraine une permutation des axes d'analyse, par exemple, on
peut vouloir remplacer une vue par district/commune par une nouvelle vue par
les naissances normale et naissances césarienne.
Le drill through : lorsqu'on ne
dispose que de données agrégées (indicateurs totalises),
le drill through permet d'accéder au détail
élémentaire des informations.
[11]
I.5 FONCTIONS ESSENTIELLES DE L'INFORMATIQUE
DECISIONNELLE
Un système d'information décisionnel assure
quatre fonctions fondamentales, à savoir la collecte,
l'intégration, la diffusion et la présentation des
données. à ces quatre fonctions s'ajoute une fonction de
contrôle du système d'information décisionnelle
lui-même, l'administration.
I.5.1COLLECTE
La collecte est l'ensemble des taches consistant à
détecter, à sélectionner, à extraire et a filtrer
les données brutes issues des environnements pertinents compte tenu du
périmètre du SID.
Les sources de données internes ou externes
étant souvent hétérogènes tant sur le plan
technique que sur le plan sémantique, cette fonction est la plus
délicate à mettre en place dans un système
décisionnel complexe. Elle s'appuie notamment sur des outils d'ETL.
Cette alimentation utilise les données sources issues
des systèmes transactionnels de production, le plus souvent sous forme
de :
Compte-rendu d'événement ou compte-rendu
d'opération : c'est le constat au fil du temps des opérations
(achats, ventes, écritures comptables), le film de l'activité de
l'entreprise.
Compte-rendu d'inventaire ou compte-rendu de stock : c'est
l'image photo prise à un instant donné (à une fin de
période : mois, trimestre) de l'ensemble du stock (les clients, les
contrats, les commandes, les encours).
La fonction de collecte joue également, au besoin, un
rôle de recodage.
Une donnée représentée
différemment d'une source à une autre impose le choix d'une
représentation unique pour les futures analyses.
[12]
I.5.2 INTEGRATION
L'intégration consiste à concentrer les
données collectées dans un espace unifié, dont le socle
informatique essentiel est l'entrepôt.
Élément central du dispositif, il permet
aux applications décisionnelles de
bénéficier d'une source d'information commune, homogène,
normalisée et fiable, susceptible de masquer la diversité de
l'origine des données.
Au passage les données sont épurées ou
transformées par :
un filtrage et une validation des données en vue du
maintien de la cohérence d'ensemble (les valeurs acceptées par
les filtres de la fonction de collecte mais susceptibles d'introduire des
incohérences de référentiel par rapport aux autres
données doivent être soit rejetées, soit
intégrées avec un statut spécial) .
Une synchronisation (d'intégrer en même temps ou
à la même date de valeur des événements reçus
ou constates de manière décalée ou
déphasée).
Une certification (pour rapprocher les données de
l'entrepôt des autres systèmes légaux de l'entreprise comme
la comptabilité ou les déclarations réglementaires).
C'est également dans cette fonction que sont effectues
éventuellement les calculs et les agrégations (cumuls) communs
à l'ensemble du projet.
La fonction d'intégration
est
généralement assurée par la gestion de
métadonnées, pour l'interopérabilité entre toutes
les ressources informatiques, des données structurées (bases de
données accédées par des progiciels ou applications), ou
des données non structurées .
[13]
I.5.3 DIFFUSION OU LA DISTRIBUTION
La diffusion met les données à la disposition
des utilisateurs, selon des schémas correspondant au profil ou au
métier de chacun, sachant que l'accès direct à
l'entrepôt ne correspondrait généralement pas aux besoins
d'un décideur ou d'un analyste.
L'objectif prioritaire est de segmenter les données en
contextes informationnels fortement cohérents, simples à utiliser
et correspondant à une activité décisionnelle
particulière.
Alors qu'un entrepôt de données peut
héberger des centaines ou des milliers de variables ou indicateurs, un
contexte de diffusion raisonnable n'en présente que quelques dizaines au
maximum.
Chaque contexte peut correspondre à un DataMart, bien
qu'il n'y ait pas de règles générales concernant le
stockage physique.
Très souvent, un contexte de diffusion est
multidimensionnel, c'est-à-dire modélisable sous la forme d'un
hyper cube , il peut alors être mis à disposition à l'aide
d'un outil OLAP.
Les différents contextes d'un même système
décisionnel n'ont pas tous besoin du même niveau de
détail.
De nombreux agrégats ou cumuls, n'intéressant
que certaines applications et n'ayant donc pas lieu d'être gères
en tant qu'agrégats communs par la fonction d'intégration,
relèvent donc de la diffusion.
Ces agrégats peuvent être, au choix, stockes de
manière persistante ou calcules dynamiquement a la demande.
On peut distinguer trois questions à élucider
pour concevoir un système de reporting :
À qui s'adresse le rapport spécialise ? (choix
des indicateurs a présenter, choix de la mise en page)
Par quel trajet ? (circuit de diffusion type workflow pour les
personnes, circuits de transmission télécoms pour les moyens)
[14]
Selon quel agenda ? (diffusion routinière ou sur
événement prédéfini)
I.5.4 PRESENTATION
Cette quatrième fonction, la plus visible pour
l'utilisateur, régit les conditions d'accès de l'utilisateur aux
informations. Elle assure le fonctionnement du poste de travail, le
contrôle d'accès, la prise en charge des requêtes, la
visualisation des résultats sous une forme ou une autre.
Elle utilise toutes les techniques de communication possibles
comme les outils bureautiques, raquetteurs et générateurs
d'états spécialises, infrastructure web,
télécommunications mobiles, etc.
I.5.5 ADMINISTRATION
C'est la fonction transversale qui supervise la bonne
exécution de toutes les autres. elle pilote le processus de mise
à jour des données, la documentation sur les données et
sur les métadonnées, la sécurité, les sauvegardes,
la gestion des incidents.
I.5.6 LES PHASES DU PROCESSUS DECISIONNEL
? Phase de recueil des exigences
Trois domaines doivent être particulièrement
documentes :
Le type d'information dont l'utilisateur des rapports a
besoin.
Le type de restitution (ergonomie, fréquence, vitesse
de
restitution) .
Le système technique existant : technologies
utilisées
? Phase de conception et de choix technique :
En fonction des exigences recueillies, quels sont les
éléments de
la chaine de la valeur décisionnelle qui doivent
être
implémentes ?
Doit-on seulement créer un rapport sur un cube OLAP
existant ?
[15]
Construire toute la chaine ?
Quelles sont précisément les données que
l'on doit manipuler ? Cela conduit au choix de technologies précises et
a un modèle particulier.
[16]
I.6 CONCLUSION
Dans ce chapitre, nous avons traite le sujet de système
décisionnel, nous avons définit l'informatique
décisionnel, l'architecture de système décisionnel, ses
différents enjeux avec leurs fonction y compris les phases du processus
dans un système décisionnel.
[17]

CHAPITRE II : LES ENTREPOTS DE DONNEES
[8], [1], [16], [5], [7]
II.1 INTRODUCTION
Les entrepôts des données intègrent les
informations en provenance de différentes sources, souvent reparties et
hétérogènes ayant pour objectif de fournir une vue globale
de l'information aux analystes et aux décideurs.
La construction et la mise en oeuvre d'un entrepôt de
données représentent une tache complexe qui se compose de
plusieurs étapes.
La première à l'analyse des sources de
données et à l'identification des besoins des
utilisateurs, la deuxième correspond à l'organisation des
données à l'intérieur de l'entrepôt. Finalement, la
troisième sert à établir divers outils d'interrogation,
analyse, de fouille de données.
Chaque étape présente
des
problématiques spécifiques. Ainsi, par exemple, lors de la
première étape, la difficulté principale consiste en
l'intégration des données, de manière a qu'elles soient de
qualité pour leur stockage .pour l'organisation, il existe plusieurs
problèmes comme : la sélection des vues a matérialiser, le
rafraichissement de l'entrepôt, la gestion de l'ensemble de
données courantes et historisées.
En ce qui concerne le processus d'interrogation, nous avons
besoin des outils performants et conviviaux pour l'accès et l'analyse de
l'information.
Notre travail se focalise principalement
sur une étape du processus décisionnel, avec une
proposition de la définition d'un modèle multidimensionnel, pour
boucle par une conclusion.
[18]
II.2.1 DEFINITION CLASSIQUE D'UN ENTREPOT DES DONNEES
(5J , (7J
Un entrepôt de données est une collection de
données orientées sujet, intégrées, non volatiles
et historisées, organisées pour le support d'un processus d'aide
a la décision. Nous détaillons ces caractéristiques
Orientées sujet : les données
des entrepôts sont organises par sujet plutôt que par application :
par exemple, une chaine de magasins d'alimentation organise les données
de son entrepôt par rapport aux ventes qui ont été
réalisées par produit et par magasin, au cours d'un certain
temps.
Intégrées : les données
provenant des différentes sources doivent être
intégrées, avant leur stockage dans l'entrepôt de
données. L'intégration c'est à dire la mise en
correspondance des formats, permet d'avoir une cohérence de
l'information.
Non volatiles : a la différence des
données opérationnelles, celles de l'entrepôt sont
permanentes et ne peuvent pas être modifiées .le rafraichissement
de l'entrepôt consiste à ajouter de nouvelles données, sans
modifier ou perdre celles qui existent. historisées :la
prise en compte de l'évolution des données est essentielle pour
la prise de décision qui, par exemple, utilise des techniques de
prédication en s'appuyant sur les évolutions passées pour
prévoir les évolutions futures.
II.2.2 ARCHITECTURE D'UN ENTREPOT DE DONNEES (5J
L'architecture des entrepôts de données repose
souvent sur un SGBD séparé du système de production de
l'entreprise qui contient les données de l'entrepôt.
Le processus d'extraction des données permet
d'alimenter périodiquement ce SGBD. Néanmoins avant
d'exécuter ce processus, une phase de transformation est
appliquée aux données opérationnelles.
Celle-ci consiste à les préparer (mise en
correspondance des formats de données), les nettoyer, les filtrer,...,
pour finalement aboutir a leur stockage dans l'entrepôt.
[19]
Dans cette figure II.1, nous présentons une
architecture simplifiée d'un entrepôt selon Doucet et Gangarski.
Les différents composants ont été intègres dans
trois parties : les sources de données, l'entrepôt et les outils
existants dans le marche.
Données de production (SGBD ,ODS, système
légués)
O U T I L S

Données externes
E T
L

Données légèrement résumées
Données fortement résumées
Entrepôt de données
Données anciennes Archivées
Données de détail
Métadonnées
FIG II. 1:Architecture d'un entrepôt de données
a) les sources : les données de l'entrepôt sont
extraites de diverses sources souvent reparties et
hétérogènes, et qui doivent être transformées
avant leur stockage dans l'entrepôt.
Nous avons deux types de sources des donnes : internes et
externes a l'organisation :
Internes : la plupart des données sont saisies
à partir des différents systèmes de production qui
rassemblent les divers SGBD opérationnels, ainsi que des anciens
systèmes de production qui contiennent des données encore
exploitées par l'entreprise.
Externes : ils représentent des données
externes à l'entreprise et qui sont souvent achetées.
Magasin des données opérationnel (ODS
operational data store) : c'est un mini annuaire des données
opérationnelles actualisées et
[20]
intégrées aux analyses pour un
département spécifique au sein de l'entreprise.
b) Les types de données de l'entrepôt de
données : il existe plusieurs types de données dans un
entrepôt, qui correspondent a diverses utilisations, comme :
Données de détail courantes : ce sont
l'ensemble des données quotidiennes et plus couramment utilisées.
Ces données sont généralement stockées sur le
disque pour avoir un accès rapide. Par exemple, le détail des
ventes de l'année en cours, dans les différents magasins.
Données de détail anciennes : ce sont
des données quotidiennes concernant des événements
passés, comme par exemple le détail des ventes des deux
dernières années. Nous les utilisons pour arriver à
l'analyse des tendances ou des requêtes prévisionnelles.
Néanmoins ces données sont plus rarement utilisées que les
précédentes, et elles sont souvent stockes sur des
mémoires d'archives.
Donnes résumées ou agrégées :
ce sont des données moins détaillées que les deux
premières et elles permettent de réduire le volume des
données a stocker. Le type de données, en fonction de leur niveau
de détail, permet de les classifier commandes données
légèrement ou fortement résumées.
Les métadonnées : ce sont des
données essentielles pour parvenir a une exploitation efficace du
contenu d'un entrepôt. Elles représentent des informations
nécessaires a l'accès et l'exploitation des données dans
l'entrepôt comme : la sémantique (leur signification), l'origine
(leur provenance), les règles d'agrégation (leur
périmètre), le stockage (leur format, par exemple : francs,
euro,...) et finalement l'utilisation (par quels programmes sont-elles
utilisées).
Données archives et sauvegarder : cette partie
de l'entrepôt emmagasine les données détaillées
résumées pour le besoins d'archivage et de sauvegarde.les
données sont transférées dans des stockages d'archivage
tel que des bandes magnétiques ou disques optiques.
d) outils : il existe sur le marché différents
outils pour l'aide à la décision, comme les outils de fouille de
données ou datamining
[21]
(pour découvrir des liens sémantiques), outils
d'analyse en ligne (pour la synthèse et l'analyse des données
multidimensionnelles), outils d'interrogation (pour faciliter l'accès
aux données en fournissant une interface conviviale au langage de
requêtes).
II.2.3 ENTREPOTS ET LES BASES DE DONNEES [7]
Dans l'environnement des entrepôts de données,
les opérations, l'organisation des données, les critères
de performance, la gestion des métadonnées, la gestion des
transactions et le processus de requêtes sont très
différents des systèmes de bases de données
opérationnels.
Par conséquent, les SGBD relationnels orientes vers
l'environnement opérationnel, ne peuvent pas être directement
transplantes dans un système d'entrepôt de données.
Les SGBD ont été crées pour les
applications de gestion de systèmes transactionnels.
Par contre, les entrepôts de données ont été
conçus pour l'aide a la prise de décision. Ils intègrent
les informations qui ont pour objectif de fournir une vue globale de
l'information aux analystes et aux décideurs.
[22]
Le tableau II.1 résume ces différences entre les
systèmes de gestion de bases de données et les entrepôts de
données.
|
SGBD
|
entrepôts de données
|
|
Objectifs
|
gestion et
production
|
consultation et
analyse
|
|
Utilisateurs
|
gestionnaires de
production
|
décideurs, analystes
|
|
taille de la base
|
plusieurs giga-octets
|
plusieurs téraoctets
|
|
organisation des
données
|
par traitement
|
par métier
|
|
type de données
|
données de gestion (courantes)
|
données d'analyse
(résumées, historisées )
|
|
Requêtes
|
simples,
prédéterminées ,données
détaillées
|
complexes ,spécifiques, agrégations et group
by
|
|
Transactions
|
courtes et
nombreuses, temps réel
|
longues ,peu
nombreuses
|
Tableau II 1:Différence entre SGBD et entrepôts de
données
II.2.4 SYSTEMES TRANSACTIONNELS ET SYSTEMES DECISIONNELS
:
Les SGBD ont été crées pour gérer
de grands volumes d'information contenus dans les différents
systèmes opérationnels qui appartiennent a l'entreprise.
Ces données sont manipulées en utilisant des
processus transactionnels en ligne .parallèlement à
l'exploitation de l'information contenue dans ces systèmes
opérationnels, les dirigeants des entreprises ont besoin d'avoir une
vision globale concernant toute cette information pour faire des calculs
prévisionnels, des statistiques ou pour établir des
stratégies de développement et d'analyses des tendances.
[23]
|
système transactionnel
|
système décisionnel
|
|
Données
|
Exhaustives courantes dynamiques
|
Résumées historiques statiques
|
|
orientées applications
|
orientées sujets
|
|
|
(d'analyse)
|
|
utilisateurs
|
Nombreux
|
peu nombreux
|
|
varies (employés,
directeurs)
|
uniquement les
décideurs
|
|
concurrentes
|
non concurrents
|
|
mises à jour et
|
interrogations
|
|
interrogations
|
requêtes imprévisibles et
|
|
requêtes prédéfinies réponses
immédiates
|
complexes
réponses moins rapides
accès a de nombreuses
|
|
accès a peu d'information
|
informations
|
Tableau II 2:compare les caractéristiques des
systèmes
II.2.5 DATAMART OU MINI - ENTREPOT DES
DONNEES [16]
II.2.5.1 INTRODUCTION
Un DataMart est un sous-ensemble d'un entrepôt de
données; il est généralement exploité dans les
entreprise pour restituer des informations ciblées sur un métier
spécifique, constituant pour ce dernier un ensemble d'indicateurs
à vocation de pilotage de l'activité et d'aide à la
décision. Un DataMart, selon les définitions, est issu ou fait
partie d'un DataWarehouse, et en reprend par conséquent la plupart des
caractéristiques.
[24]
II.2.5.2 LES DEFINITIONS
Le DataMart est un ensemble de données ciblées,
organisées, regroupées et agrégées pour
répondre à un besoin spécifique à un métier
ou un domaine
donné. il est donc destine à
être interrogé sur un panel de données restreint à
son domaine fonctionnel, selon des paramètres qui auront
été définis à l'avance lors de sa conception.
De façon plus technique, le DataMart peut être
considère de deux manières différentes, attribuées
aux deux principaux théoriciens de l'informatique décisionnelle,
bill inmon et Ralph Kimball :
Définition d'inmon : le DataMart est
issu d'un flux de données provenant du DataWarehouse. Contrairement a ce
dernier qui présente le détail des données pour toute
l'entreprise, il a vocation à présenter la donnée de
manière spécialisée, agrégée et
regroupée fonctionnellement.
Définition de Kimball : le DataMart
est un sous-ensemble du DataWarehouse, constitue de tables au niveau
détail et à des niveaux plus agrèges, permettant de
restituer tout le spectre d'une activité métier. L'ensemble des
DataMarts de l'entreprise constitue le DataWarehouse.
II.2.5.3 STRUCTURE PHYSIQUE ET THEORIQUE
Au même titre que les autres parties de la base de
données globale de l'entreprise, les DataMarts sont stockes physiquement
sur disque dur par un système de gestion de bases de données
relationnelle héberge sur un serveur.
Le DataMart est souvent confondu avec la notion d'hyper cube ;
il peut de fait être représente par un modèle en
étoile ou en flocon dans une base de données relationnelle
notamment lorsqu'il s'agit de données élémentaires ou
unitaires non agrégées.
[25]
II.5.2.3 DATAWAREHOUSE ET DATAMART
La première étape d'un projet busines
intelligent est de créer un entrepôt central pour avoir une vision
globale des données de chaque service. Cet entrepôt porte le nom
de DataWarehouse.
On peut également parler de DataMart, si seulement une
catégorie de services ou métiers est concernée pour notre
travail nous parlerons de DataMart des suivie de traitement médicale de
la consultation jusqu'a la fin.
Par définition, un DataMart peut être contenu
dans un DataWarehouse, ou il peut être seulement issu de celui-ci.
II.5.2.4 ARCHITECTURE D'UN DATAMART [16]

Système transactionnel
Système transactionnel
Système transactionnel
Data Mart
Data Mart
Système transactionnel
Entrepôt
Des données
II II II II
FIG II. 2:Architecture d'un DataMart
[26]
II.5.2.5 LA PLACE DU DATAMART DANS L'ENTREPRISE
Le DataMart se trouve en toute fin de la chaine de traitement
de l'information. En règle générale, il se situe en aval
d'un DataWarehouse plus global à partir duquel il est alimenté,
dont il constitue en quelque sorte un extrait.
Un DataMart forme la principale
interaction entre les utilisateurs et les systèmes
informatiques qui gèrent la production de l'entreprise (souvent des
ERP).
Dans un DataMart, l'information est préparée
pour être exploitée brute par les personnes du métier
auquel il se rapporte. Pour ce faire, il est appelé a être utilise
via des logiciels d'interrogation de bases de données (notamment des
outils de reporting) afin de renseigner ses utilisateurs sur l'état de
l'entreprise à un moment donné (stock) ou sur son activité
(flux).
La préparation de la donnée pour une utilisation
directe, inhérente au DataMart, peut revêtir plusieurs formes. Il
faut noter que toutes représentent une simplification par rapport au
niveau de données inferieur ; on peut citer pour exemple :
L'agrégation de données : le
DataMart ne contient pas le détail de toutes les opérations qui
ont eu lieu, mais seulement des totaux, repartis par groupements.
Le retrait de données inutiles : le
DataMart ne contient que les données qui sont strictement utiles aux
utilisateurs.
l'historisation des données : le
DataMart contient seulement la période de temps qui intéresse les
utilisateurs.
II.2.6. CONCEPTION D'UN ENTREPOT DE DONNEES [5]
La conception d'un entrepôt de données se fait de
deux façon ,la première consiste à construire d'abord
plusieurs mini-entrepôts selon les directions ou le départements
ensuite les intègres dans un seul entrepôt pour l'entreprise ;la
deuxième consiste à construire un entrepôt pour
l'entreprise
[27]
ensuite mettre en place un ou plusieurs mini-entrepôts
pour chaque direction ou départements que compte l'entreprise.
La conception d'un entrepôt de données peut se
faire en utilisant la modélisation relationnelle classique (pour les
bases de données transactionnelles) ou en utilisant la
modélisation dimensionnelle.
Dans un entrepôt de données les requêtes
pour l'interrogation des données utilisent beaucoup des jointures qui
demandent trop de temps ce qui constitue un problème pour le
système transactionnel. c'est pour quoi il est préférable
de utiliser l'approche multidimensionnelle.
II.2.6.1 MODELISATION MULTIDIMENSIONNELLE (8J, (5J
Pour arriver à construire un modèle approprie
pour un entrepôt de données ou un DataMart, nous pouvons choisir,
soit un schéma relationnel (le schéma en étoile, en flocon
de neige ou en constellation) ; soit un schéma multidimensionnel.
Avant de décrire les différents schémas,
nous commençons par quelques concepts de base. La modélisation
multidimensionnelle consiste à considérer un sujet analyse comme
un point dans un espace a plusieurs dimensions.
Les données sont organisées de manière
à mettre en évidence le sujet (le fait) et les différentes
perspectives de l'analyse(les dimensions).
Le fait représente le sujet d'analyse. Il est compose
d'un ensemble de mesures qui représentent les différentes valeurs
de l'activité analysée.
Par exemple, dans le fait ventes, nous pouvons avoir la mesure
"quantité de produits vendus par magasin". Les mesures doivent
être valorisées de manière continue et elles peuvent
être additives (pour résumer une grande quantité
d'enregistrements) ; semi-additives (si elles peuvent seulement être
additionnées pour certaines dimensions) et non additives.
[28]
Une dimension modélise une perspective de l'analyse.
Elle se compose de paramètres(ou attributs) qui servent à
enregistrer les descriptions textuelles.
A. Méthodologie de design de la base de données
pour l'entrepôt des données
:
Dans cette section nous décrivons une
méthodologie par étapes pour construire la base de données
d'un entrepôt de données cette méthode a été
initialement proposées par Kimball et s'appelle méthodologie a
neuf étape dans la modélisation d'un entrepôt des
données :
|
étape
|
Activité
|
|
1
|
choisir la procédure
|
|
2
|
choisir le grain
|
|
3
|
identifier les dimensions et s'y conformer
|
|
4
|
choisir les faits
|
|
5
|
emmagasiner les calculs préliminaires dans la table des
faits
|
|
6
|
finaliser les tables de dimensions
|
|
7
|
choisir la durée de la base de données
|
|
8
|
suivre les dimensions a modification lente
|
|
9
|
Les décideurs doits décidé des
priorités de requêtes et des modes de requêtes
|
Tableau III 1:La méthodologie a neuf étapes de
Kimball
Que nous allons utiliser pour concevoir notre DataMart dans le
chapitre quatre.
II.2.6.2 SCHEMAS RELATIONNELS
Dans les schémas relationnels nous trouvons deux types
de schémas. Les premiers sont des schémas qui répondent
fort bien aux processus de type OLTP qui ont été décrits
précédemment, alors que les deuxièmes, que nous appelons
des schémas pour le décisionnel, ont pour but de proposer des
schémas adaptes pour des applications de type OLAP.
[29]
Nous décrivons les différents types des
schémas relationnels pour le décisionnel.
II.6.2.3 LE SCHEMA EN ETOILE
Il se compose du fait central et de leurs dimensions. Dans ce
schéma il existe une relation pour les faits et plusieurs pour les
différentes dimensions autour de la relation centrale. La relation de
faits contient les différentes mesures et une clé
étrangère pour faire référence à chacune de
leurs dimensions.
La figure 2.2 montre le schéma en étoile en
décrivant les ventes réalisées dans.
Les différents magasins de l'entreprise au cours d'un
jour. Dans ce cas, nous avons une étoile centrale avec une table de
faits appelée ventes et autour leurs diverses dimensions : temps,
produit et magasin.
Produits

Cle_P Description Type Catégorie
Magasin
Cle_M
Raison_soc Adresse Commune Département
Région Pays
Temps
Cle_T Jour Mois Année
Ventes
Cle_P
Cle_T
Cle_M
Quantité
FIG II. 3:Exemple de Modélisation en étoile
[30]
II.6.2.3 LE SCHEMA EN FLOCON DE NEIGE
Il dérivé du schéma
précédent avec une relation centrale et autour d'elle les
différentes dimensions, qui sont éclatées ou
décomposées en sous hiérarchies.
L'avantage du schéma en flocon de neige est de
formaliser une hiérarchie au sein d'une dimension, ce qui peut faciliter
l'analyse. Un autre avantage est représente par la normalisation des
dimensions, car nous réduisons leur taille.
Néanmoins dans, l'auteur démontre que c'est une
perte de temps de normaliser les relations des dimensions dans le but
d'économiser l'espace disque.
Par contre, cette normalisation rend plus complexe la
lisibilité et la gestion dans ce type de schémas. En effet, ce
type de schéma augmente le nombre de jointures à réaliser
dans l'exécution d'une requête.
Les hiérarchies pour le schéma en flocon de
neige de l'exemple de la figure 3 sont :
Dimension temps = jour ? mois ? année
Dimension magasin = commune ? département ?
région? pays La figure 4 montre le schéma en flocon
de neige avec les dimensionnes temps et magasin éclatées en
sous hiérarchies.


Ventes
Cle_P
Cle_T
Cle_M
Quantité

Temps
Cle_T
Jour
Mois
T_Mois
Mois Année
Cle_P Description Type Catégorie
Magasin
Cle_M
Raison_soc Adresse Commune Département
T_Département
|
|
Département Région
|
|
T_Région
|
|
Région Pays
Produits
[31]
FIG II. 4:Exemple de modélisation en flocon de neige
Dans l'exemple ci-dessus, la dimension temps a
été éclatée en deux, temps et T_mois. La
deuxième dimension magasin, a été décomposée
en trois : magasin, m_departement et m_region.
II.6.2.4 LE SCHEMA EN CONSTELLATION
Le schéma en constellation représente plusieurs
relations de faits qui partagent des dimensions communes. Ces
différentes relations de faits composent une famille qui partage les
dimensions mais ou chaque relation de faits a ses propres dimensions.
La figure 2.4 montre le schéma en constellation qui est
compose de deux relations de faits.
La première s'appelle ventes et enregistre les
quantités de produits qui ont été vendus dans les
différents magasins pendant un certain jour. La deuxième relation
gère les différents produits achètes aux fournisseurs
pendant un certain temps.
Produits
[32]
Cle_P Description Type Catégorie

Magasin Cle_M
Ventes
Cle_P Cle_T Cle_M Quantité
Raison_soc Adresse Commune Département
Temps
T_Fournisseur
Cle_F Raison_soc Adresse Code_postal Commune Pays
Cle_T Jour Mois Année
Achats
Cle_P Cle_F Cle_T Quantité
FIG II. 5:Exemple de Modélisation en constellation
La relation de faits ventes partage leurs dimensions temps et
produits avec la table achats. Néanmoins, la dimension magasin
appartient seulement a ventes. Également, la dimension fournisseur est
liée seulement à la relation achats.
II.6.2.5 SCHEMA MULTIDIMENSIONNEL (CUBE) [7]
Dans le modèle multidimensionnel, le concept central
est le cube, lequel est constitue des éléments appelés
cellules qui peuvent contenir une ou plusieurs mesures. La localisation de la
cellule est faite a travers les axes, qui correspondent chacun a une
dimension.
La dimension est composée de membres qui
représentent les différentes valeurs. En reprenant une partie du
schéma en étoile, nous pouvons construire le schéma
multidimensionnel suivant.
[33]

FIG II. 6:Exemple de schéma multidimensionnel
La figure 6, présente un schéma
multidimensionnel pour les ventes qui ont été
réalisées dans les magasins pour les différents produits
au cours d'un temps donne (jour).
II.3 MANIPULATION DES DONNEES MULTIDIMENSIONNELLES
Pour visualise les données
multidimensionnelles, nous pouvons utiliser la
représentation sous forme d'une table de données, qui est la plus
courante. Dans une table, nous représentons les différentes
combinaisons des valeurs choisies pour constituer les noms de lignes et de
colonnes.
Néanmoins, quand le nombre de dimensions est
supérieur à deux, l'utilisateur a des problèmes pour
visualiser simultanément l'ensemble de l'information. Pour
résoudre ce problème, nous devons disposer d'opérations
pour manipuler les données et rendre possible la visualisation.
Nous présentons les opérations pour la
manipulation des données multidimensionnelles, en les divisant selon
leur impact sur la façon de présenter les différentes vues
des données analysées.
[34]
II.3.1 OPERATIONS CLASSIQUES
Ces opérations correspondent aux opérations
relationnelles de manipulation des données :
La sélection :
résulte en un sous-ensemble de données qui respecte
certaines conditions d'appartenance.
La projection :
résulte en un sous-ensemble des attributs d'une relation, qui sont
soit des dimensions, soit des niveaux de granularité. Dans les
systèmes décisionnels, les opérations de sélection
et de projection sont appelées souvent "slice-and-dice". La
jointure : permet d'associer les données de
relations différentes.
A. Les opérations ensemblistes :
D'union, d'intersection et de différence sont des
opérations qui agissent sur des relations qui ont le même
schéma. Par exemple, les opérations agissant sur la structure
visent à présenter une vue (face du cube) différente en
fonction de leur analyse, citons : La rotation (rotate)
: consiste à pivoter ou a effectuer une rotation
du cube, de manière à présenter une vue différente
des données à analyser.
La permutation (switch) :
consiste à inverser des membres d'une dimension, de manière
à permuter deux tranches du cube. La division (split)
: consiste à présenter chaque tranche du
cube en passant d'une représentation tridimensionnelle à une
présentation tabulaire.
L'emboitement (nest) :
permet d'imbriquer les membres d'une dimension. En utilisant cette
opération, nous représentons dans une table bidimensionnelle
toutes les données d'un cube quel que soit le nombre de dimensions.
L'enfoncement (push) :
consiste à combiner les membres d'une dimension aux mesures du cube
et donc de représenter un membre comme une mesure.
L'opération inverse de retrait (pull)
: permet de changer le statut de certaines mesures, pour
transformer une mesure en membre d'une dimension.
La factualisation (fold) :
consiste à transformer une dimension en mesure(s) ; cette
opération permet de transformer en mesure l'ensemble des
paramètres d'une dimension.
[35]
Le para métrisation (unfold) :
permet de transformer une mesure en paramètre dans une
nouvelle dimension.
L'opération cube : permet de
calculer des sous-totaux et un total final.
B. Opérations agissant sur la
granularité :
Les opérations agissant sur la granularité des
données analysées, permettent de hiérarchiser la
navigation entre les différents niveaux de détail d'une
dimension.
Dans la suite nous traitons les deux opérations de ce
type :
Le forage vers le haut (drill-up ou roll-up) :
permet de représenter les données du cube à
un niveau plus haut de granularité en respectant la hiérarchie de
la dimension. Nous utilisons une fonction d'agrégation (somme,
moyenne,...), qui est paramétrée, pour indiquer la façon
de calculer les données du niveau supérieur à partir de
celles du niveau inferieur.
Le forage vers le bas (drill-down ou roll-down ou
scale-down) : consiste à représenter les
données du cube à un niveau de granularité inferieur, donc
sous une forme plus détaillée. Ces types d'opérations ont
besoin d'informations non représentées dans un cube, pour
augmenter ou affiner des données, à partir d'une
représentation initiale vers une représentation de
granularité différente. Le forage vers le haut à besoin de
connaitre la fonction d'agrégation utilisée tandis que le forage
vers le bas nécessite de connaitre les données au niveau
inferieur.
II.4 LES SERVEURS OLAP (ON-LINE ANALYTICAL
PROCESSING)
Les données opérationnelles constituent la
source principale d'un système d'information décisionnel. Les
systèmes décisionnels complets reposent sur la technologie OLAP,
conçue pour répondre aux besoins d'analyse des applications de
gestion.
Nous exposons dans la suite les divers types de stockage des
informations dans les systèmes décisionnels.
[36]
II.4.1 LES SERVEUR ROLAP (RELATIONAL OLAP) [7]
Dans les systèmes relationnels OLAP, l'entrepôt
de données utilise une base de données relationnelle. Le stockage
et la gestion de données sont relationnels. Le moteur ROLAP traduit
dynamiquement le modèle logique de données multidimensionnel
m en modèle de stockage relationnel r ,la plupart des
outils requièrent que la donnée soit structurée en
utilisant un schéma en étoile ou un schéma en flocon de
neige.

FIG II. 7: Architecture ROLAP
La technologie ROLAP a deux avantages principaux :
(1) elle permet la définition de données
complexes et multidimensionnelles en utilisant un modèle relativement
simple.
(2) elle réduit le nombre de jointures à
réaliser dans l'exécution d'une requête.
Le désavantage est que le langage de requêtes tel
qu'il existe, n'est pas assez puisant ou n'est pas assez flexible pour
supporter de vraies capacités d'OLAP.
II.4.2 LES SERVEUR MOLAP (MULTIDIMENSIONAL OLAP)
Les systèmes multidimensionnels OLAP utilisent une base
de données multidimensionnelle pour stocker les données de
l'entrepôt et les applications analytiques sont construites directement
sur elle. Dans cette architecture, le système de base de données
multidimensionnel sert tant au
[37]
niveau de stockage qu'au niveau de gestion des données.
Les données des sources sont conformes au modèle
multidimensionnel, et dans toutes les dimensions, les différentes
agrégations sont pour le calculées pour des raisons de
performance.

FIG II. 8:Architecture MOLAP
Les systèmes MOLAP doivent gérer le
problème de données clairsemées, quand seulement un nombre
réduit de cellules d'un cube contiennent une valeur de mesure
associée.
Les avantages des systèmes MOLAP sont bases sur les
désavantages des systèmes ROLAP et elles représentent la
raison de leur création. D'un cote, les requêtes MOLAP sont
très puissantes et flexibles en termes du processus OLAP, tandis que,
d'un autre cote, le modèle physique correspond plus étroitement
au modèle multidimensionnel. Néanmoins, il existe des
désavantages au modèle physique MOLAP. Le plus important, a notre
avis, c'est qu'il n'existe pas de standard du modèle physique.
II.4.3 LES SERVEUR HOLAP (HYBRID OLAP)
Un système HOLAP est un système qui supporte et
intègre un stockage des données multidimensionnel et relationnel
d'une manière équivalente pour profiter des
caractéristiques de correspondance et des techniques
[38]
d'optimisation donc c'est l'ensemble des deux serveurs MOLAP
et ROLAP.
Dans la figure 9, nous montrons une architecture en utilisant
les types de serveurs ROLAP et MOLAP pour le stockage de données.

FIG II. 9:Architecture HOLAP
Ci-dessous, nous traitons une liste des
caractéristiques principales qu'un système HOLAP doit fournir
:
La transparence du système : Pour la
localisation et l'accès aux données, sans connaître si
elles sont stockées dans un SGBD relationnel ou dimensionnel. Pour la
transparence de la fragmentation.
Un modèle de données
général et un schéma multidimensionnel global
:
Pour aboutir à la transparence du premier point, tant
le modèle de données général que le langage de
requête uniforme doivent être fournis. Etant donné qu'il
n'existe pas un modèle standard, cette condition est difficile à
réaliser.
Une allocation optimale dans le système de
stockage : Le système HOLAP
Doit bénéficier des stratégies
d'allocation qui existent dans les systèmes distribués tels que :
le profil de requêtes, le temps d'accès, l'équilibrage de
chargement.
Une réallocation automatique : Toutes les
caractéristiques traitées ci-dessus
Changent dans le temps. Ces changements peuvent provoquer la
réorganisation de la distribution des données dans le
système de stockage multidimensionnel et relationnel, pour assurer des
performances optimales.
[39]
Actuellement, la plupart des systèmes commerciaux
utilisent une approche hybride. Cette approche permet de manipuler des
informations de l'entrepôt de données avec un moteur ROLAP, tandis
que pour la gestion des DataMarts, ils utilisent l'approche
multidimensionnelle.
[40]
II.5 CONCLUSION
Dans ce chapitre, nous avons traité le sujet des
entrepôts de données nous avons données l'architecture d'un
entrepôt de données, nous avons expliqué les
différents composants qu'il intègre, comme les diverses sources,
les types de données et les différents outils pour arriver
à la visualisation de l'information.
Nous avons décrit les différents modèles
multidimensionnels pour la construction d'un entrepôt de données,
ainsi que les différentes opérations pour la manipulation des
données multidimensionnelles et une aperçu sur le DataMart, le
parallélisme entre le deux et présenter l'apport de DataMart dans
les entreprise.
La dernière partie a été consacrée
aux types de serveurs décisionnels.
Dans un premier temps, nous avons décrit le serveur
ROLAP qui utilise une base de données relationnelle, tant au niveau du
stockage qu'au niveau de la gestion de données.
Le serveur MOLAP a été la deuxième
architecture que nous avons traitée.
Ces types de systèmes utilisent une base de
données multidimensionnelle pour le stockage des données. Les
systèmes MOLAP doivent gérer le problème de données
clairsemées, quand seulement un nombre réduit des cellules d'un
cube et aspects temporels une valeur de mesure associée.
La troisième architecture que nous avons décrite
est le serveur HOLAP et quelque caractéristique de ce types serveur.
[41]

CHAPITRE III : LE DATA MINING ET ARBRE DE DECISION
[6], [14], [3],[16],[4],[12],[10] ,[11]
III .1 LE DATAMANING
III.1 .1 PRESENTATION
Le terme datamining est souvent employé pour
désigner l'ensemble des outils permettant à l'utilisateur
d'accéder aux données de l'entreprise, de les analyser .
Nous retiendrons ici le terme de data mining aux outils ayant
pour objet de générer des informations riches à partir des
données de l'entreprise, notamment des données historiques, de
découvrir des modèles implicites dans les données.
Ces outils peuvent permettre par exemple à un magasin
de dégager des profils de client et des achats types et de
prévoir ainsi les ventes futures. Ils permettent d'augmenter la valeur
des données contenues dans le DataWarehouse.
Les outils d'aides à la décision, qu'ils
soient relationnels ou OLAP ,laissent l'initiative à
l'utilisateur, de choisir les éléments qu'il veut observer ou
analyser .Au contraire ,dans le cas du datamining ,le système a
l'initiative et découvre lui-même les associations entre
données ,sans que l'utilisateur ait à lui dire de rechercher
plutôt dans telle ou telle direction ou à poser des
hypothèses .
Il est alors possible de prédire l'avenir ,par le
comportement d'un client, et de détecter ,dans le passé ,les
données inusuelles ,exceptionnelles.
Ces outils ne sont plus destinés aux seuls experts
statisticiens mais doivent pouvoir être employés par des
utilisateurs connaissant leur métier et voulant l'analyser,
l'explorer.
[42]
Seul un utilisateur connaissant le métier peut
déterminer si les modèles, les règles, les tendances
trouvées par l'outil sont pertinentes, intéressantes et utiles
à l'entreprise .
Ces utilisateurs n'ont donc pas obligatoirement un bagage
statistique important .L'outil doit être soit ergonomique, facile
à utiliser, soit permettre de construire une application clé en
main, pour la transparence de toutes les techniques utilisées par
l'utilisateur.
Nous pourrions définir le data mining comme une
démarche ayant pour objet de découvrir des relations et des
faits, à la fois nouveaux et significatifs, sur de grands ensembles de
données.
Le terme datamining signifie
littéralement forage de
données dont le but est de pouvoir extraire un élément :
la connaissance.
Ces concepts s'appuient sur le constat qu'il existe au sein de
chaque entreprise des informations cachées dans le gisement de
données . Nous appellerons datamining l'ensemble des techniques qui
permettent de transformer les données en connaissances.
L'exploration se fait sur l'initiative du système, par un
utilisateur métier, et son but est de remplir l'une des tâches
suivantes :Classification, estimation, prédiction, regroupement par
similitudes, segmentation
(cautérisation) ,description et ,dans une moindre mesure,
l'optimisation.
III.1 .2 SATATISTIQUE ET DATAMINING [14J
Nous pourrions croire que les techniques du datamining viennent
en remplacement des statistiques .En fait, il n'en est rien et elles sont
omniprésentes .On les utilise : Pour faire une analyse
préalable,
Pour estimer ou alimenter les valeurs manquantes,
Pendant le processus pour évaluer la qualité des
estimations,
Après le processus pour mesurer les actions entreprises et
faire un bilan.
[43]
Ainsi la statistique et datamining sont tout à fait
complémentaires.
III.1 .3 PROCESSUS DU DATAMINING (14J , (8J
Le datamining est un processus méthodique : une suite
ordonnée d'opérations aboutissant à un résultat.
Le data ming est décrit comme un processus itératif
complet constitué de quartes divisées en six phases.
|
PROCESSUS DU DATA MINING
|
|
Acteur
|
Etapes
|
Phases
|
|
Maitre d'oeuvre
|
Objectifs
|
1. Compréhension du métier :
|
|
2. Compréhension des données
|
|
|
|
Traitements
|
4 .Modélisation
|
|
5.Evaluation de la modélisation
|
|
Maître d'ouvrage
|
Déploiement
|
6. Déploiement des résultats de
l'étude
|
Tableau III 1:le processuce du datamining.
A. Compréhension du Métier :
Cette phase consisté à :
Enoncer clairement les objectifs globaux du projet et les
contraintes de l'entreprise.
Traduire ses objectifs et ses contraintes en un problème
de data mining
Préparer une stratégie initiale pour atteindre ces
objectifs.
B. Compréhension des données
Cette phase consiste à :
Recueillir les données
Utiliser l'analyse exploratoire pour se familiariser avec les
données, commencer à les comprendre et imaginer ce qu'on pourrait
en tirer comme connaissance. Evaluer la qualité des données
[44]
Eventuellement, sélectionner des sous ensembles
intéressants
C. Préparation des données
Cette phase aide à préparer, à partir
des données brutes, l'ensemble final des données qui va
être utilisé pour toutes les phases suivantes :
Sélectionner les cas et les variables à
analyser
Réaliser si nécessaire les transformations de
certaines données,
Réaliser si nécessaire la suppression de
certaines données.
D. Modélisation
La phase de la modélisation consiste à :
Sélectionner les techniques de modélisation
appropriées (pouvant être utilisées pour le même
problème)
Calibrer les paramètres des techniques de
modélisation choisies pour optimiser les résultats ;
Eventuellement revoir la préparation des données
pour l'adapter aux techniques utilisées.
E. Evaluation de la modélisation
Cette résume le rapport final :
Pour chaque technique de modélisation utilisée,
évaluer la qualité (la pertinence la signification) des
résultats obtenus ;
Déterminer si les résultats obtenus atteignent
les objectifs globaux identifiés pendant la phase de
compréhension du métier ;
Décider si on passe à la phase suivante (le
déploiement) ou si on souhaite reprendre l'étude en
complétant le jeu de données.
F. Déploiement des résultats obtenus
Cette phase est externe à l'analyse du datamining .Elle
concerne le maître d'ouvrage.
Prendre les décisions en conséquence des
résultats de l'étude de data mining
[45]
Préparer la collecte des informations futures pour
permettre de vérifier la pertinence des décisions effectivement
mis en oeuvre.
III.1 .4 LES TACHES DU DATA MING
Contrairement aux idées reçues, le Data Mining
n'est pas le remède miracle capable de résoudre toutes les
difficultés ou besoins de l'entreprise .Cependant, une multitude de
problèmes d'ordre intellectuel ,médical ,économique
peuvent être regroupés ,dans leurs formalisation ,dans l'une des
tâches suivantes :
1. Classification
2. Estimation
3. Prédiction
4. Discrimination
5. Segmentation
|
TACHES
|
TECHNIQUE
|
|
Classification
|
L'arbre de décision
|
|
Le raisonnement par cas
|
|
L'analyse de lien
|
|
Estimation
|
Le réseau de neurones
|
|
Prédiction
|
L'analyse du panier de la
ménagère
|
|
Le raisonnement base sur le mémoire
|
|
L'arbre de décision
|
|
Les réseaux de neurones
|
|
Extraction de connaissance
|
L'arbre de décision
|
Tableau III 2:le taches et technique du datamining.
En outre, hormis ces quelques techniques et tâches du
datamining, nous signalons qu'il existe d'autres que nous n'avons pas
énumérez dans notre travail.
[46]
III .2 ARBRE DE DECISION (12J , (10J, (11J
III.2 .0 CONCEPTS THEORIQUES SUR LE GRAPHE [12]
Graphe :
Définition :
Un graphe G est un couple G=(X,U) ,X
est un ensemble non vide et au plus dénombrable .
Nota :X est un ensemble fini ,les éléments de x?X
sont appelés les
sommets ou noeuds ,u = une famille d'éléments du
produit
cartésiens XxX .
Les éléments de U=(x,y) ,x,y?X, sont appelés
:
Soit des arcs lorsqu'on tient compte de l'orientation.
Soit les arêtes lorsqu'on ne tient pas compte de
l'orientation.
Graphe connexe :
Définition :
Un graphe est connexe si l'on peut atteindre n'importe quel
sommet à partir d'un sommet quelconque en parcourant les
différentes arêtes.
Exemple : soit G=(X,U)

U8
U7
U9
U1
U3 U4
U5
U6
U2
G=(X,U) est un graphe connexe .
[47]
Arbres et arborescence
1. Arbres :
Définition :
Un arbre est un graphe connexe sans cycle. C'est-à-dire
dont on peut atteindre n'importe quel sommet à partir d'un sommet quel-
conque en parcourant différents arêtes et ses arêtes ne
coïncide pas.
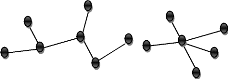
Exemple :
Les notions de branches et de cordes :
Soit G=(X,U) un graphe et notons par T=(X,u') un arbre qui est
un graphe partiel de G ,alors :
Les arêtes appartenant à u' sont appelées
les branches de T (ou relativement T )
Les arêtes de u?u' (c'est-à-dire ? (u /u') sont
appelées cordes relativement T.
Exemple : soit G=(X ,U) un graphe connexe ,on peut en

U4
U10
extraire un arbre.
U1
U8
U9
U6
U2 U3
U11
U5
U12
U7
T=(X ,U') ou u'=(U1,U5,U6,U11,U7) : ce sont les branches
tandis que (U2,U3,U4,U12,U11,U9) : ce sont des cordes.
Chaque réponse possible est prise en compte et permet
de se diriger vers un des fils du noeud. De
[48]

a
c
b
f
e
d
Est un arbre extrait du graphe G=(X ,U)
précédent.
2. Arborescence :
Définition :
Soit G=(X,U),on dit que le sommet r?X
est une racine de G si V x?X,(avec x?r)? un chemin de rà x
.c'est -
à -dire un arbre ayant une racine.
Exemple :

c
b
f
e
d
a
C'est une arborescence de racine a.
Nota : un sommet pendant est un sommet sans successeur . En
informatique on les appelle des feuilles ou feuillets.
III .2.1 INTRODUCTION A L'ARBRE DE DECISION [6J
Un arbre de décision est une structure qui permet de
déduire un résultat à partir de décisions
successives. Pour parcourir un arbre de décision et trouver une
solution, il faut partir de la racine. Chaque noeud est une décision
atomique.
[49]
proche en proche, on descend dans l'arbre jusqu'à
tomber sur une feuille. La feuille représente la réponse
qu'apporte l'arbre au cas ou l'on vient de tester.
? Début à la racine de l'arbre
? Descendre dans l'arbre en passant par les noeuds de test
? La feuille atteinte à la fin permet de classer
l'instance testée. Très souvent on considère qu'un noeud
pose une question sur une variable, la valeur de cette variable permet de
savoir sur quels fils descendre. Pour les variables
énumérées, il est parfois possible d'avoir un fils par
valeurs, on peut aussi décider que plusieurs variables
différentes mènent au même sous arbre.
Pour les variables continues, il n'est pas imaginable de
créer un noeud qui aurait potentiellement un nombre de fils infini, on
doit discrétiser le domaine continu (arrondis, approximation), donc
décider de segmenter le domaine en sous ensembles. Plus l'arbre est
simple, et plus il semble techniquement rapide à utiliser.
En fait, il est plus intéressant d'obtenir un arbre qui
est adapté aux probabilités des variables à tester. La
plupart du temps un arbre équilibré sera un bon résultat.
Si un sous arbre ne peut mener qu'à une solution unique, alors tout ce
sous-arbre peut être réduit à sa simple conclusion, cela
simplifie le traitement et ne change rien au résultat final.
III .2.2 DEFINITION
Un arbre de décision est un outil d'aide à la
décision et à l'exploration de données. Il permet de
modéliser simplement, graphiquement et rapidement un
phénomène mesuré plus ou moins complexe. Sa
lisibilité, sa rapidité d'exécution et le peu
d'hypothèses nécessaires a priori expliquent sa popularité
actuelle.
[50]
III .2.3 CARACTERISTIQUES ET AVANTAGES :
Le caractéristique principale est la lisibilité
du modèle de prédiction que l'arbre de décision fourni, et
de faire faire comprendre ses résultats afin d'emporter
l'adhésion des décideurs.
Cet arbre de décision à également la
capacité de sélectionner automatiquement les variables
discriminantes dans un fichier de données contenant un très grand
nombre de variables potentiellement intéressantes. En ce sens, constitue
aussi une technique exploratoire privilégiée pour
appréhender de gros fichiers de données.
III .2.4 ALGORITHME ID3
L'algorithme ID3 à été
développé à l'origine par ROSS QUINLAN. C'est un
algorithme de classification supervise. C'est-a-dire il se base sur des
exemples déjà classés dans un ensemble de classes pour
déterminer un modèle de classification.
Le modèle que produit ID3 est un arbre de
décision. Cet arbre servira à classer de nouveaux
échantillons. Permet aussi de générer des arbres de
décisions à partir de données. Imaginons que nous ayons
à notre disposition un ensemble d'enregistrements ayant la même
structure, à savoir un certain nombre de paires attribut ou valeur.
L'un de ses attributs représente la catégorie de
l'enregistrement. Le problème consiste à construire un arbre de
décision qui sur la base de réponses à des questions
posées sur des attributs non cible peut prédire correctement la
valeur de l'attribut cible. Souvent l'attribut cible pend seulement les valeurs
vrai, faux ou échec, succès.
[51]
III .2.5 PRINCIPES
Les principales idées sur lesquels repose ID3 sont les
suivantes : ? Dans l'arbre de décision chaque noeud correspond à
un attribut non cible et chaque arc a une valeur possible de cet attribut. Une
feuille de l'arbre donne la valeur escomptée de l'attribut cible pour
l'enregistrement testé décrit par le chemin de la racine de
l'arbre de décision jusqu'à la feuille. (Définition d'un
arbre de décision).
? Dans l'arbre de décision, à chaque noeud doit
être associé l'attribut non cible qui apporte le plus
d'information par rapport aux autres attributs non encore utilisés dans
le chemin depuis la racine.(Critère d'un bon arbre de décision)
.
? L'entropie est utilisée pour mesurer la
quantité d'information apportée par un noeud.( cette notion a
été introduite par Claude Shannon lors de ses recherches
concernant la théorie de l'information qui sert de base à
énormément de méthodes du datamining.
Algorithme
Entrées : ensemble d'attributs A; échantillon E;
classe c
Début
Initialiser à l'arbre vide;
Si tous les exemples de E ont la même classe c
Alors étiqueter la racine par c;
Sinon si l'ensemble des attributs A est vide
Alors étiqueter la racine par la classe majoritaire dans
E;
Si non soit a le meilleur attribut choisi dans A;
Étiqueter la racine par a;
Pour toute valeur v de a
Construire une branche étiquetée par v;
Soit Eav l'ensemble des exemples tels que e(a) = v;
ajouter l'arbre construit par ID3(A-{a}, Eav, c);
[52]
Fin pour Fin sinon
Fin sinon
Retourner racine;
Fin
III .2.2 EXEMPLE PRATIQUE [k], [11]
Pour introduire et exécuter "à la main"
l'algorithme ID3 nous allons tout d'abord considérer l'exemple
ci-dessous: Une entreprise possède les informations suivantes sur ses
clients et souhaite pouvoir prédire à l'avenir si un client
donné effectue des consultations de compte sur Internet.
|
client
|
Moyenne des
montants
|
Age
|
Lieu de
Résidence
|
Etudes supérieures
|
Consultation par internet
|
|
1
|
Moyen
|
Moyen
|
Village
|
Oui
|
oui
|
|
2
|
Elevé
|
Moyen
|
Bourg
|
non
|
non
|
|
3
|
Faible
|
Age
|
Bourg
|
non
|
non
|
|
4
|
Faible
|
Moyen
|
Bourg
|
oui
|
oui
|
|
5
|
Moyen
|
Jeune
|
Ville
|
oui
|
Oui
|
|
6
|
Elevé
|
Agé
|
Ville
|
oui
|
non
|
|
7
|
Moyen
|
Agé
|
Ville
|
oui
|
non
|
|
8
|
Faible
|
Moyen
|
Village
|
non
|
non
|
Tableau III 3:exemples pratiques
Ici, on voit bien que la procédure de classification
à trouver qui à partir de la description d'un client, nous
indique si le client effectue la consultation de ses comptes par Internet,
c'est-à-dire la classe associée au client.
- le premier client est décrit par (M : moyen, Age :
moyen, Résidence : village, Etudes : oui) et a pour classe Oui.
- le deuxième client est décrit par (M :
élevé, Age : moyen, Résidence : bourg, Etudes : non) et a
pour classe Non.
Pour cela, nous allons construire un arbre de décision
qui classifie les clients. Les arbres sont construits de façon
H(C|Lieu) = -P (bourg).(P (C|bourg) log(P (C|bourg)) + P (C
|bourg)
[53]
descendante. Lorsqu'un test est choisi, on divise l'ensemble
d'apprentissage pour chacune des branches et on
réapplique récursivement l'algorithme.
Choix du meilleur attribut : Pour cet
algorithme deux mesures existent pour choisir le meilleur attribut : la mesure
d'entropie et la mesure de fréquence:
L'entropie : Le gain (avec pour fonction i
l'entropie) est également appelé l'entropie de Shannon et
peut se réécrire de la manière suivante :
Pour déterminer le premier attribut test (racine de
l'arbre), on recherche l'attribut d'entropie la plus faible. On doit donc
calculer H(C|Solde), H(C|Age), H(C|Lieu), H(C|Etudes), où la classe C
correspond aux personnes qui consultent leurs comptes sur Internet.
H(C|Solde) = -P (faible).(P (C|faible) log(P (C|faible)) + P
(C |faible) log(P (C|faible)))-P (moyen).(P (C|moyen) log(P (C|moyen)) + P
(C|moyen) log(P (C|moyen)))-P (eleve).(P (C|eleve) log(P (C|eleve)) + P
(C|eleve) log(P(C|eleve)))H(C|Solde)
H(C|Solde) = -3/8(1/3.log(1/3) + 2/3.log(2/3)-3/8(2/3.log(2/3)
+ 1/3.log(1/3)
-2/8(0.log(0) + 1.log(1)
H(C|Solde) = 0.20725
H(C|Age) = -P (jeune).(P (C|jeune) log(P (C|jeune)) + P (C
|jeune) log(P (C|jeune)))-P (moyen).(P (C|moyen) log(P (C|moyen)) + P (C
|moyen) log(P (C|moyen)))-P (age).(P (C|age) log(P (C|age)) + P (C|age) log(P
(C|age)))
H(C|Age) = 0.15051
[54]
log(P (C|bourg)))-P (village).(P (C|village) log(P (C|village)) +
P (C |village) log(P (C|village)))-P (ville).(P (C|ville) log(P (C|ville)) + P
(C|ville)
log(P (C|ville)))
H(C|Lieu) = 0.2825
H(C|Etudes) = -P (oui).(P (C|oui) log(P (C|oui)) + P (C |oui)
log(P (C|oui)))
-P (non).(P (C|non) log(P (C|non)) + P (C|non) log(P (C|non)))
H(C|Etudes) = 0.18275
Le premier attribut est donc l'âge (attribut dont
l'entropie est minimale). On obtient l'arbre suivant :

FIG III 1:Arbre de décision construit à partir de
l'attribut àge
Pour la branche correspondant à un âge moyen, on
ne peut pas conclure, on doit donc recalculer l'entropie sur la partition
correspondante.
H(C|Solde) = -P (faible).(P (C|faible) log(P (C|faible)) + P
(C |faible) log(P (C|faible)))-P (moyen).(P (C|moyen) log(P (C|moyen)) + P
(C|moyen)
log(P (C|moyen)))-P (eleve).(P (C|eleve) log(P (C|eleve)) + P
(C|eleve) log(P (C|eleve)))
H(C|Solde) = -2/4(1/2.log(1/2) + 1/2.log(1/2)-1/4(1.log(1) +
0.log(0)
-1/4(0.log(0) + 1.log(1)
H(C|Solde) = 0.15051
H(C|Lieu) = -P (bourg).(P (C|bourg) log(P (C|bourg)) + P (C
|bourg) log(P (C|bourg)))-P (village).(P (C|village) log(P (C|village)) + P (C
|village) log(P (C|village)))-P (ville).(P (C|ville) log(P (C|ville)) + P
(C|ville) log(P (C|ville)))
[55]
H(C|Lieu) = 0.30103
H(C|Etudes) = -P (oui).(P (C|oui) log(P (C|oui)) + P (C |oui)
log(P (C|oui)))
-P (non).(P (C|non) log(P (C|non)) + P (C|non) log(P (C|non)))
H(C|Etudes) = 0
L'attribut qui a l'entropie la plus faible est « Etudes
».
L'arbre devient alors :

FIG III 2:Arbre de décision finale
L'ensemble des exemples est classé et on constate que
sur cet ensemble d'apprentissage, seuls deux attributs sur les quatre sont
discriminants.
[56]
II .2.3 CONCLUSION
Dans ce chapitre nous avons présenté le
datamining avec ses différentes méthodes, tâches,
techniques et nous introduit quelque notion relatifs à la théorie
de graphe avant de parlé de l'arbre de décision qui répond
à un problème de discrimination.
[57]

CHAPITRE IV : IMPLEMENTATION
[15], [2],[10],[9]
IV .0 INTRODUCTION
Ce chapitre est consacré à la réalisation
de notre système décisionnel ainsi que à
l'interprétation des résultats obtenue à près
construction de notre arbre de décision et pour finir à la
réalisation de l'application opérationnelle qui permettra aux
agents de l'hôpital de saisir les informations concernant les
accouchements.
Ces applications sont réalisées pour le service
de la maternité de l'hôpital Saint Joseph de LIMETE qui constitue
le champ d'application de notre travail.
Ainsi, nous parlerons de l'aperçu historique, la
situation géographique, suivie de la structure organisationnelle pour
terminer par une conception de notre système décisionnel.
Par ailleurs, nous tenons à signaler que notre
étude porte sur la réalisation d'un système
décisionnel qui permettra de faire des analyses sur les accouchements
à l'hôpital saint joseph.
IV.1 ANALYSE DE L'EXISTANT [15]
IV.1.1 BREF APERÇU HISTORIQUE
Cette institution médicale dénommée
Hôpital Saint Joseph fut un couvent des soeurs de Sainte
Thérèse de l'Enfant jésus qui sont des soeurs
diocésaines de Kinshasa. Conformément au projet du feu cardinal
Joseph MALULA ,alors archevêque de Kinshasa, ledit couvent qui fut
transformé ensuite en facultés catholiques ,devrait devenir une
université catholique abritant entre autres facultés ,celle de
médecine.
Un hôpital serait alors construit dans cette
concession.
A l'occasion de son jubilé de vie épiscopale ,
le cardinal reçut un don présidentiel d'un montant de 27 .676
dollars .Ceci va provoquer le déplacement des facultés
à
[58]
leurs emplacement actuel. Les bâtiments
préexistants qui abritaient les facultés connaîtront une
modification et constitueront avec le don présidentiel le fonds de
départ de l'actuel hôpital Saint Joseph.
En 1987,l'inauguration de cet hôpital aura lieu avec un
dispensaire comme premier service comptant deux médecins et quelques
infirmiers.
Ensuite le service de la maternité verra le jour.
Ce n'est qu'après la mort de son initiateur ,le
cardinal MALULA, que la gestion de l'hôpital, fut confiée entre
les mains de religieux dont le père Lietard Edouard . Au fur et à
mesure ,les différents services verront le jour les uns après les
autres et l'hôpital dispensera les soins de santé primaires
à caractère chrétien.
Présentement , l'Hôpital Saint Joseph constitue
une unité hospitalière de référence du bureau
diocésain des oeuvres médicales (B.D.O .M) de
l'archidiocèse de Kinshasa.
IV .1.2 SITUATION GEOGRAPHIQUE
L'hôpital saint joseph est une institution
d'utilité publique située dans la commune de LIMETE
résidentiel
entre la quatorzième et quinzième rue en allant
vers le centre
ville.
Il est borné:
Au nord, par le couvent des pères Dominicains
Au sud, par le quartier MOTEL FIKIN
A l'est, par le boulevard Lumumba
A l'ouest, par le quartier Masiala ,dans le quartier
résidentiel ,de
la commune de Limete.
IV.1.3 MISSION DE L'HOPITAL
Comme tout hôpital digne de ce nom, l'Hôpital
Saint Joseph a comme tâche principale, celle d'assurer les soins de
santé aux malades .Outre cette mission de routine, il a en effet une
triple mission :
? Répondre aux besoins de santé de la population
.
[59]
+ Réduire les distances à parcourir par les
malades en quête des soins médicaux.
+ Procéder à la formation et à
l'éducation du personnel soignant administratif et des stagiaires.
IV.1.4 STRUCTURE DE L'ENTREPRISE
Il est important d'identifier d'abord les différents
services qu'elle organise en son sein.
SERVICES EXISTANTS:
L'hôpital saint joseph dispose des services
ci-après:
a. services Médicaux:
+ Le Dispensaire doté d'un lit,
+ le service d'urgences avec 34 lits dont 17 pour la
pédiatrie
+ le service de la réanimation avec 6 lits
+ La maternité post-partum avec 29 lits
+ La gynécologie avec 66lits ;
+ La chirurgie avec 50 lits ;
+ La pédiatrie avec 24 lits ;
+ La néonatalogie avec 14 lits ;
+ L'ophtalmologie avec 23 lits ;
+ Le pavillon privé avec 19 lits
+ L'oto-rhino-laryngologie avec 10 lits,
+ La dentisterie ;
+ La dermatologie
+ La stérilisation
+ Le bloc opératoire ;
+ L'Anesthésie ;
+ La diabétologie ;
+ La consultation prénatale.
b. services Médico techniques:
+ Le laboratoire d'analyse et banque du sang,
+ La pharmacie
+ la physio kinésithérapie,
+ l'imagerie Médicale et Le service de morgue.
c. services Administratifs:
[60]
· . Les archives, documentation et statistiques,
· . La comptabilité,
· . La facturation,
· . Le recouvrement,
· . Les caisses,
· . L'audit interne,
· . Les ressources humaines,
· . Le service social,
· . La sécurité,
· . Le service technique,
· . Le secrétariat
· . L'informatique,
· . Le mess ,
· . Les achats,
· . La buanderie,
· . La trésorerie,
· . Le mouvement des malades.
IV .1.5 ORGANISATION ET FONCTIONNEMENT
A. Organisation :
Dans son évolution actuelle, l'Hôpital Saint
Joseph
comprend :
50 médecins dont 19 spécialistes (8 à temps
partiel)
2chirurgiens dentistes
194 personnels soignants .
58 paramédicaux, dont 2 à temps partiel
62 administratif et
81 autres agents
Notons que l'effectif du personnel dans son ensemble est de
444
agents dont 428 travaillant à temps plein et 16à
temps partiel .
L'hôpital dispose de quatre directions suivantes :
· . La direction administrative
· . La direction financière
· . La direction médicale
· . La direction de nursing
[61]
B.la direction administrative
Cette direction a pour tâches :
+ Tenir l'administration de l'hôpital
+ Représenter l'hôpital chez les différents
partenaires
+ Engager l'hôpital en cas de besoin
C .La direction financière
Les attributions dévolues à cette direction sont
les suivantes :
+ Assurer la gestion de la trésorerie
+ Planifier les recettes et les dépenses de l'exercice
+ Contrôler les coûts
+ Déterminer les tarifs.
E. La direction Médicale
Cette direction est chargée principalement de
l'organisation des
soins et collabore avec les médecins chefs des services et
les
pharmaciens. Elle regroupe tout le corps médical et
coordonne
l'action de cette dernière .Elle organise le roulement
des
médecins.
La direction médicale est subdivisée en services
suivantes :
+ Dispensaire
+ Urgences,
+ Réanimation,
+ Médecine interne,
+ Maternité post-partum
+ Chirugie,
+ Gynécologie,
+ Ophtalmologie,
+ Pédiatrie,
+ Néonatologie,
+ Pavillon privé,
+ Oto-rhino-laryngologie ,
+ Dentisterie, kinésithérapie,
+ Dermatologie,
+ Stérilisation,
+ Pharmacie,
+ Salle d'opération
+ Anesthésie
[62]
+ Diabétologie
+ Consultation prénatale
F .La direction nursing
Cette dernière direction s'occupe de la dispensation
des
soins infirmiers .Elle joue les rôles ci-après :
+ Regrouper les infirmiers et techniciens chefs des
services para médicaux,
+ Organiser le roulement des infirmiers,
+ Etudier l'organisation matérielle, la planification et
la
dotation humaine .
IV.1.6 FONCTIONNEMENT
C'est le Bureau Diocésain des oeuvres Médicales
,en tant que organe de conception technique et de coordination de l'action des
structures
Sanitaires de l'archidiocèse de Kinshasa, qui
détermine la politique de gestion de l'Hôpital Saint Joseph.
IV.1.7 AUTRES ASPECTS
L'Hôpital Saint Joseph est doté d'un service social
ayant pour
compétences :
+ D'assurer les charges sociales de son personnel
+ De contribuer à la politique générale de
la santé
DIRECTION MEDICALE
PHARMACIE
SERVICES MEDICAUX
REANIMATION
ANESTESIE
DIRECTION DE NURSING
PRIVE
DISPENSAIRE
+
BANQUE DE SANG
REANIMATION
IMAGERIE MEDICALE
GYNECOLOGIE
CHIRUGIE
MEDECINE INTERNE
MATERNITE
STOMATOLOGIE
STERLISATION
[63]
BUREAU DIOCESAIN DES OEUVRES
|
ORGANIGRAM HOPITAL SAINT JOSEPH
DE KINSHSA LIMETE
|
CONSEIL D'ADMINISTRATION
|
|
|
COMITE DIRECTEUR
|
|
AUDIT INTERNE
|
|
|
DIRECTION GENERALE
|
DIRECTION ADMINISTRATIVE
REP MD en cas d'absence
|
RESOURCE HUMAINE
SECRETARIAT
SOCIAL ET PASTORAL
INTENDANCE
SECURITE
MAGASIN
BIBLIOTHEQUE ET ARCHIVES
DIRECTION FINANCIERE
|
COMPTABILITE et
SERVICE DES ARCHIVES
|
FACTURATION
CAISSE
RECOUVREMENT
TRESORERIE
BUDGET
CHARROI
FIG IV 1:Organigramme
[64]
IV.2. PROBLEME RENCONTRE
Lors de nos recherches à l'hôpital saint Joseph
de Limete, on nous a données les données sur les statistiques
globales sur le mouvement des malades en général dans tout
l'hôpital qui été de fichier en format Excel , pour
constituer notre source des données ,nous avons eu à mettre du
temps pour saisir les registres dans une ficher Excel .
IV.2.1 LA PROBELMATIQUE ET MOTIVATION
La problématique de ce travail est de mettre en place
un DataMart pour la maternité en vu de faire l'extraction de
connaissance ,le sujet de ce DataMart est les accouchements pour permettre aux
décideurs d'avoir une vue d'ensemble sur les données au sein de
la maternité, dont voici la liste de raison ou requête qui nous a
poussé à créer cette DataMart :
La première préoccupation est :
D'énumérer les femmes qui ont accouchés au premier
trimestre d'une année dont les poids de bébé est compris
dans un intervalle et la majorité des ces mamans ont avorté
déjà plus de deux fois ?
De déterminer si le poids des enfants à la
naissance est proportionnel à l'âge de la mère et enfin de
savoir si la majorité des femmes qui accouchent par césarienne ne
suivent la CPN à l'hôpital, et savoir aussi les fréquences
des décès des mamans dans la maternité ?
Notons que l'originalité de cet outil est d'une part
qu'il stocke des données médicales complexes sur les
accouchements issues de différents champs de la médecine et de la
biologie, et d'autre part qu'il est conçu pour permettre deux types
d'analyses innovants et sensiblement différents l'un de l'autre, afin de
devenir un support à la maternité pour des patients bien
identifiés ;et de faire des analyses statistiques à large spectre
sur les populations de patients .
[65]
Notre DataMart est également conçu pour être
évolutif et prendre en compte les futures avancées de la
médecine concernant les accouchements .
IV.2.2 OUTIL UITILISE [2J
Nous présentons succinctement les outils ainsi que les
nouvelles méthodes de développement de processus
décisionnels qui en découlent.
1. Microsoft Visual Studio team système
1. SQL serveur 2008 (business intelligence)
Ici nous allons énumérer les modules et composantes
de SQL serveur 2008.
Répartition des modules SQL serveur 2008 par
composantes.
|
Composant
|
Module SQL Serveur 2008
|
Destination dans l'entreprise
|
|
Workflow+Flux de données (ETL)
|
Intégration de services (SSIS)
|
Administrateur de base des données
|
|
Entrepôt de données relationnel et
multidimensionnel
|
Base de donnée relationnelle SQL serveur 2005
|
Administrateur et développeurs
|
|
Base de données multidimensionnelle analytique
|
Analysis services
|
Développeur et utilisateur ayant des connaissances
métier
|
|
Exploration des données
|
Data mining intégré à Analysis services
designer
|
Statistien ou développeur utilisateur
|
|
Création de rapports et de modèles
sémantiques métier
|
Reporting services designer
|
Développeurs
|
|
Requêtes et analyses spécifiques
|
Report builder 1 .0 Excel,proclarity
|
Analystes métier
|
|
Développement d'application BI
|
SQL serveurBusiness Intelligence Devellopment Studio(BIDS)=Visual
Studio
|
Développeur
|
[66]
|
Outils de gestion de
|
SQl Server
|
Administrateur et
|
|
base de données
|
Management
|
développeurs
|
|
Studio
|
|
|
Services de
|
SQL serveur
|
Alertes envoyées
|
|
notification
|
Notification services
|
aux managers sur des événements métier
|
Tableau IV 1:répartition de module de SQL serveur 2008
par composante.
Parmi ces composantes de SQL serveur 2008 nous avons
utilisé l'intégration des services (SSIS) pour transformer notre
source de données en Excel que nous avons d'abord transforme en Access,
nous avons aussi et utiliser l'analysis service(SSAS) pour réaliser
notre entrepôt des données ainsi pour bien faire le datamining.
IV.2.3 MODELISATION MULTIDIMENSIONNEL LE DE
DATAMART
Pour construire un entrepôt global de l'hôpital ou
d'une entreprise il ya des méthodes :
Top down : c'est la méthode la plus
lourde ,la plus contraignante et la plus complète en même temps
elle consiste en la conception de tout l'entrepôt ,puis la
réalisation de ce dernier.
Bottom-up : c'est l'approche inverse, elle consiste à
créer les étoiles ,puis les regrouper par des niveaux
intermédiaires jusqu'à l'obtention d'un véritable
entrepôt pyramidal avec une vision d'entreprise .
Middle-Out :c'est l'approche hybride, et
conseillée par le professionnels du business intelligence. Cette
méthodes consiste en la conception totale de l'entrepôt des
données c-à-dire concevoir toutes dimensions, tous les faits,
toutes les relations, puis créer des divisions plus petites et plus
gérables et les mettre en oeuvre.
Pour notre étude nous avons construit un DataMart
représentant
une étoile pour l'hôpital qui est un DataMart sur
les accouchements au service de la maternité.
[67]
1. MODELISATION DE L'APPLICATION
OPERATIONNELLE
Nous avons modélisé la base de données
opération avec la méthode merise qui est la source de
données alimentant notre entrepôt des données.
A. MODELE logique de données
A prés analyse préalable, nous avons
dégagé les tables suivantes pour le modèle logique de
notre base de données opérationnelles.
|
TABLE
|
ATTRIBUTS
|
|
ACCOUCHEMENT
|
NUM ORDRE
,NA ,NF,NT,ETAT SER,SEXE ,POIDS ,AP GAR,DIAGNOSTIQUE
|
|
FICHE
|
NF,NOMPOSTNOM,AGE,ETA
CIVIL,NATIONALITE,ADRESSE,NIVEAU D'ETUDES,CPN
|
|
ANT OBSTRI
|
NA,
GRAVIDA ,PARITE,AVORTEMENT,DECES
|
SCHEMA DU MODELE CONCEPTUEL DES
DONNEES
|
|
|
|
PK
|
FICHE
NF
|
|
|
|
|
|
PK
|
Accouchement
NUM ORDRE
|

1,0
Attacher à
NA
GRAVIDA PARITE AVORTEMENT
DECES
1,n

1,n
NOM POSTNOM
ETATCIVIL NATIONALITE ADRESSE
NIVEAU D'ETUDES
conserne
1,0
AGE
ETAT SEROLOGIQUE SEXE POIDS
AP GAR DIAGNOSTIQUE DATE PROVENANCE
(CPN)
FIG IV 2:Modèle conceptuel des données
[68]
SCHEMA DU MODELE LOGIQUE DES DONNEES
FICHE
PK
NF
NOM POSTNOM
AGE
ETATCIVIL
NATIONALITE
ADRESSE
NIVEAU D'ETUDES
Accouchement
PK
NUM ORDRE
NA
NF
PROVENANCE
ETAT SEROLOGIQUE
SEXE
POIDS
AP GAR
DIAGNOSTIQUE
DATE
ANT OBSTRI
PK
NA
GRAVIDA
PARITE
AVORTEMENT
DECES
FIG IV 3:Modèle logique de données
SCHEMA DU MODELE PHYSIQUE DE DONNEES
A. TABLES FICHE
|
N°
|
LIBELLE
|
TYPE
|
TAILLE
|
OBSERVATION
|
|
1
|
NF
|
INTEGER
|
23
|
Numéro fiche
|
|
2
|
NOM
POSTNOM
|
STRING
|
50
|
Nom et post nom
|
|
3
|
AGE
|
INTEGER
|
4
|
Age
|
|
4
|
ETAT CIVIL
|
STRING
|
56
|
Etat civil
|
|
5
|
NATIONALITE
|
STRING
|
26
|
Nationalité
|
|
6
|
ADRESSE
|
VARCHAR
|
50
|
Adresse de la maman
|
|
7
|
NIVEAU ETUDES
|
STING
|
7
|
Niveau d'études de la maman
|
[69]
B .TABLE ACCOUCHEMENT
|
N
°
|
LIBELLE
|
TYPE
|
TAILL E
|
OBSERVATION
|
|
1
|
NUMERO ORDRE
|
INTEGER
|
23
|
Numéro d'ordre
(primary key)
|
|
2
|
NA
|
INTEGER
|
50
|
Numéro ANT OBSTRI
|
|
3
|
NF
|
INTEGER
|
4
|
Numéro fiche
|
|
4
|
ETAT SER
|
STRING
|
26
|
Etat sérologique
|
|
5
|
SEXE
|
STRING
|
50
|
Sexe de l'enfant
|
|
6
|
NIVEAU ETUDES
|
STING
|
7
|
Niveau d'études de la maman
|
|
7
|
POIDS
|
INTEGER
|
6
|
Poids de l'enfant à la naissance
|
|
8
|
AP GAR
|
INTEGER
|
4
|
Apparence=peau colorante ,P=cris
Grimace ou geste,
Activité=réactivité
Respiration
|
|
9
|
DIAGNOSTI QUE
|
STRING
|
123
|
Diagnostique
|
|
8
|
PROVENAN CE (CPN)
|
STRING
|
56
|
Lieu de provenance
|
A.TABLE ANT OBSTRI
|
N
°
|
LIBELLE
|
TYPE
|
TAILL E
|
OBSERVATION
|
|
2
|
NA
|
INTEGE R
|
4
|
Numéro ANT OBSTRI
|
|
3
|
GRAVIDA
|
INTEGE R
|
4
|
Nombre des grossesses déjà attrapées
|
|
4
|
PARITE
|
INTEGE R
|
4
|
Nombre ,des fois que la
femme a accouche
|
|
5
|
AVORTEM ENTS
|
INTEGE R
|
4
|
Nombre de fois que la femme
a avorté (spontané ou
provoqué)
|
|
6
|
DECES
|
INTEGE R
|
4
|
Nombre d'enfant né vivant
décédé y compris les morts né
|
[70]
2 .CONCEPTION D'UN DATA MART Etape 1 : Définir le
processus à analyser
La procédure ou fonction fait référence
au sujet de notre mini entrepôt des données
Nous déterminons le processus métier de
l'hôpital saint joseph concerne par notre étude :
Les accouchements. dont voici la modélisation de la base
de données de l'entrepôt de données
Etape 2 : Déterminer le niveau de granularité des
données
Choisir le grain signifie décider exactement de ce que
représente un enregistrement d'une table de faits.par exemple
l'entité accouchement représente les faits relatifs à
chaque accouchement et devient la table de faits du schéma en
étoile des accouchements.
Par conséquent, le grain de la table de faits
accouchement est un accouchement réalisé à la
maternité.
A prés avoir choisi le grain de la table de faits nous
allons commencer à identifier les dimensions de la tables de faits .
A titre d'illustration, les entités fiche et ant
obstetrie serviront de références aux données concernant
les accouchements et deviendront les tables de dimensions du schéma en
étoile des accouchements.
Nous ajoutons aussi le Temps comme dimension principale, car
il est toujours présent dans le schéma en étoile.
Etape 3 : choisir les dimensions
Les dimensions déterminent le contexte dans lequel nous
pourrons poser des questions à propos des faits établis dans la
table de faits .Un ensemble de dimensions de dimensions bien constitué
rend le mini entrepôt de données compréhensible et en
simplifie l'utilisation.
Nous identifions les dimensions avec suffisance de
détails, pour décrire des choses telles que les clients et les
propriétés avec granularité correcte.
Par exemple, toute personne de la dimension fiche est
décrit par
les attributs
:NF,NOMPOSTNOM,AGE,ETAT
CIVIL,NATIONALITE,ADRESSE,NIVEAUETUDES ;
[71]
la dimension ant obstetri est décrit par les attributs
suivants : NA, GRAVIDA ,PARITE,AVORTEMENT,DECES
,la dimension temps est décrit par les attributs
suivants : HEURE ,JOURS ,MOIS et ANNEE .
Etape 4 : identifier les
métriques(faits)
Pou notre cas le fait est accouchement. les métrique
sont les données numériques PROVENANCE(CPN), ETATSER,POIDS ,AP
GAR.
Notons que les autres étapes qui suivent exclusivement
pour la construction d'un entrepôt des données mais pour notre
travail nous construisons un DataMart donc un sous ensemble d'un entrepôt
des données donc nous estimons que nous pouvons nous arrêter ace
points.
Mesures
Dans l'exemple présenté ci-haut ,les mesures
sont définies par la table ACCOUCHEMENT et sont les suivantes :
PROVENANCE ;
ETATSER ; POIDS ;
AP GAR.
Dimensions
Notre veut effectuer des analyses selon divers axes
d'observation.
Axe temps
Année
Mois
Jours
Axe fiche
Numéro fiche, Nom post nom, Age,
Etat civil,
Nationalité,
Adresse,
Niveau études ; Axe anti obstreti
Gravida ,
[72]
Parité,
Avortement, Décès
3.SCHEMA EN ETOILE DE L'ENTREPOT SOUS SQL serveur
2008

FIG IV 4:Schéma en étoile des accouchements
Etant donné que nous construisons un datamart nous
souhaitons nous arrêter à ce étape .pour expliciter,
justifiée notre études de cas.
4.MODULE DE DATAMINING[10],
Ce module de datamining réalisé avec le logiciel
SPAD pour nous facilite l'interprétation .Nous avons importé vers
un fichier Excel le résultat d'une requête sur notre DataMart
à partir de la nous avons importé ces données vers SPAD
pour faire l'ACP.
[73]
Les Analyses Factorielles
Les méthodes factorielles établissent des
représentations synthétiques de vastes tableaux de
données, en général sous forme de représentations
graphiques.
Ces méthodes ont pour objet de réduire les
dimensions des tableaux de données de façon à
représenter les associations entre individus et entre variables dans des
espaces de faibles dimensions.
Les méthodes d'analyse factorielle consistent à
rechercher des sous-espaces de faibles dimensions qui ajustent au mieux le
nuage de points des individus et le nuage de points des variables.
Les proximités mesurées dans ces sous-espaces
doivent refléter au mieux les
Proximités réelles. L'espace de
représentation obtenu est appelé espace factoriel. Les
méthodes diffèrent selon la nature des variables analysées
: il peut s'agir de variables continues, de variables nominales ou de
catégories dans le cas des tableaux de contingences. Les lignes peuvent
être des individus ou des catégories. Pour plus de
précisions
Analyse en composantes principales
L'Analyse en Composantes Principales est une technique de
description statistique conduisant à des représentations
graphiques approchées (mais en un certain sens optimales) du contenu
d'un tableau de données: description simultanée des liaisons
entre variables et des similitudes entre individus.
C'est aussi un outil de réduction de la
dimensionnalité d'un ensemble de variables continues, utilisable comme
intermédiaire de calcul en vue d'analyses ultérieures.
Dans ce chapitre, nous verrons que l'ACP est un outil
exploratoire qui permet de visualiser et de découvrir les
phénomènes tels qu'ils sont décrits par les
données.
[74]
TABLEAU DE CONTINGENCE SYNTHETIQUE :


FIG IV 5:Vue de l'ensemble des données avec SPAD
Description des tranches d'âge par intervalle :
Tranche d'âge 1 : de 19 à 21 ans Tranche
d'âge 2 : de 21 à 2 3 ans Tranche d'âge 3 : de 23 à
25 ans Tranche d'âge 4 : de 25 à 27 ans Tranche d'âge 5 : de
27 à 29 ans Tranche d'âge 6 : de 29 à 31 ans Tranche
d'âge 7 : de 31à 33 ans Tranche d'âge 8:de 33 à 35
ans
[75]
Tranche d'âge 9 : de 35 à 37 ans Tranche d'âge
10 : de 37 à plus
[76]
ANALYSE DES DONNEES AVEC SPAD : ANALYSE FACTORIEL DE
CORRESPONDANCE
|
ANALYSE DES CORRESPONDANCES BINAIRES VALEURS PROPRES
APERCU DE LA PRECISION DES CALCULS : TRACE AVANT DIAGONALISATION
.. 0.0397
SOMME DES VALEURS PROPRES .... 0.0397
HISTOGRAMME DES 4 PREMIERES VALEURS PROPRES
+ + + + + +
| NUMERO | VALEUR | POURCENT.| POURCENT.| |
|
|
|
|
|
|
PROPRE |
|
| CUMULE
|
|
|
|
|
|
+
|
+
|
+
|
+
|
+
|
+
|
|
| 1
|
|
|
0.0360 |
|
90.79 | 90.79
|
|
|
********************************************************************************
|
|
|
| 2
|
|
|
0.0035 |
|
8.73 | 99.52
|
|
|
******** |
|
|
| 3
|
|
|
0.0002 |
|
0.47 | 100.00
|
|
|
* |
|
|
| 4
|
|
|
0.0000 |
|
0.00 | 100.00
|
|
|
* |
|
|
+
|
+
|
+
|
+
|
+
|
+
|
|
COORDONNEES,
|
CONTRIBUTIONS
|
DES FREQUENCES
|
SUR
|
LES AXES 1 A 4
|
FREQUENCES ACTIVES
|
+
|
|
|
FREQUENCES
|
|
+ |
+
|
|
COORDONNEES
|
|
+ |
+
|
|
CONTRIBUTIONS
|
|
+ |
+
|
|
COSINUS CARRES
|
+
|
|
|
|
| IDEN - LIBELLE COURT
|
P.REL
|
DISTO |
|
1
|
2
|
3
|
4
|
0
|
|
|
1
|
2
|
3
|
4
|
0
|
|
|
1
|
2
|
3
|
4
|
0 |
|
|
+
|
|
|
+
|
|
|
|
|
|
+
|
|
|
|
|
|
+
|
|
|
|
|
+
|
|
| CPN - provenance CPN
|
2.90
|
0.26 |
|
-0.47
|
0.19
|
-0.06
|
0.00
|
0.00
|
|
|
18.0
|
31.1
|
48.0
|
0.0
|
0.0
|
|
|
0.85
|
0.14
|
0.01
|
0.00
|
0.00 |
|
|
| GEST - la
|
gestation de la m
|
0.07
|
0.01 |
|
0.05
|
-0.03
|
0.01
|
-0.05
|
0.00
|
|
|
0.0
|
0.0
|
0.0
|
99.9
|
0.0
|
|
|
0.41
|
0.14
|
0.01
|
0.44
|
0.00 |
|
|
| PAR - la
|
parite de la mere
|
5.83
|
0.43 |
|
-0.64
|
-0.12
|
0.01
|
0.00
|
0.00
|
|
|
66.6
|
25.1
|
2.4
|
0.0
|
0.0
|
|
|
0.96
|
0.03
|
0.00
|
0.00
|
0.00 |
|
|
| AVOR - le
|
nombre de fois av
|
1.02
|
0.36 |
|
-0.45
|
0.38
|
0.10
|
0.00
|
0.00
|
|
|
5.8
|
43.6
|
49.6
|
0.0
|
0.0
|
|
|
0.57
|
0.41
|
0.03
|
0.00
|
0.00 |
|
|
| POID - le
|
poids de l'enfant
|
90.17
|
0.00 |
|
0.06
|
0.00
|
0.00
|
0.00
|
0.00
|
|
|
9.6
|
0.2
|
0.0
|
0.1
|
0.0
|
|
|
1.00
|
0.00
|
0.00
|
0.00
|
0.00 |
|
|
+
|
|
|
+
|
|
|
|
|
|
+
|
|
|
|
|
|
+
|
|
|
|
|
+
|
|
COORDONNEES,
|
CONTRIBUTIONS ET
|
COSINUS
|
CARRES
|
DES INDIVIDUS
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
AXES 1 A 4
|
|
|
|
|
|
|
|
|
|
|
+
|
|
|
+
|
|
+
|
|
+
|
|
+
|
|
|
|
INDIVIDUS
|
|
|
|
COORDONNEES
|
|
|
CONTRIBUTIONS
|
|
|
COSINUS CARRES
|
|
|
|
|
|
|
|
+
|
|
+
|
|
+
|
|
|
|
|
| IDENTIFICATEUR
|
|
P.REL
|
DISTO | 1
|
2 3 4
|
0 | 1
|
2 3 4
|
0 | 1
|
2 3 4
|
0 |
|
|
+
|
|
|
+
|
|
+
|
|
+
|
|
+
|
|
| Tr1
|
|
9.53
|
0.03
|
| 0.16
|
0.08 0.01 0.00
|
0.00
|
| 6.8
|
16.1 10.8 8.0
|
0.0
|
| 0.81
|
0.18 0.01 0.00
|
0.00 |
|
|
| Tr2
|
|
9.94
|
0.02
|
| 0.05
|
0.12 -0.02 0.00
|
0.00
|
| 0.6
|
40.5 17.0 12.7
|
0.0
|
| 0.13
|
0.85 0.02 0.00
|
0.00 |
|
|
| Tr3
|
|
9.47
|
0.04
|
| 0.21
|
0.01 0.01 0.00
|
0.00
|
| 11.4
|
0.3 6.5 5.3
|
0.0
|
| 0.99
|
0.00 0.00 0.00
|
0.00 |
|
|
| Tr4
|
|
10.17
|
0.01
|
| -0.12
|
0.03 -0.01 0.00
|
0.00
|
| 3.8
|
3.4 3.2 6.9
|
0.0
|
| 0.92
|
0.08 0.00 0.00
|
0.00 |
|
|
| Tr5
|
|
9.31
|
0.02
|
| 0.13
|
-0.04 -0.01 0.00
|
0.00
|
| 4.6
|
4.2 8.7 6.7
|
0.0
|
| 0.91
|
0.08 0.01 0.00
|
0.00 |
|
|
| Tr6
|
|
11.65
|
0.18
|
| -0.43
|
0.01 0.01 0.00
|
0.00
|
| 59.4
|
0.4 4.1 1.7
|
0.0
|
| 1.00
|
0.00 0.00 0.00
|
0.00 |
|
|
| Tr7
|
|
9.06
|
0.03
|
| 0.16
|
-0.04 0.02 0.00
|
0.00
|
| 6.6
|
3.5 27.0 5.5
|
0.0
|
| 0.93
|
0.05 0.02 0.00
|
0.00 |
|
|
| Tr8
|
|
10.02
|
0.00
|
| 0.01
|
-0.04 0.00 0.00
|
0.00
|
| 0.0
|
5.1 0.8 8.2
|
0.0
|
| 0.07
|
0.92 0.01 0.00
|
0.00 |
|
|
| Tr9
|
|
10.51
|
0.02
|
| -0.13
|
-0.05 0.01 0.00
|
0.00
|
| 5.1
|
8.1 1.8 55.6
|
0.0
|
| 0.87
|
0.13 0.00 0.00
|
0.00 |
|
|
| Tr10
|
|
10.34
|
0.01
|
| 0.07
|
-0.08 -0.02 0.00
|
0.00
|
| 1.6
|
18.4 20.0 3.5
|
0.0
|
| 0.45
|
0.51 0.03 0.00
|
0.00 |
|
|
+
|
|
|
+
|
|
+
|
|
+
|
|
+
|
[77]
ARBRE DE DECISION
FIG IV 6:Arbre de décision
[78]
5.GRAPHIQUE

FIG IV 7:Graphique
Pour l'axe 2 :
[79]
6. INTERPRETATION DES RESULTATS 1. Détermination
des axes
? pour les variables (25%) Pour l'axe 1
La parité de la mère à contribué
à 66% à la création de l'axe 1 elle est de
coordonnées négative.
Pour l'axe 2
La parité de la mère à contribué de
25% à la création de l'axe 2 elle est de coordonnées
négative.
Le nombre de fois que la maman à accoucher à
contribué de 43,6% à la création de l'axe 2 elle est de
coordonnées positive.
La consultation pré natale à contribué de
31, 1% à la création de l'axe 2 elle est de coordonnées
négative.
Pour l'axe 3
La consultation pré natale à contribué de
48% à la création de l'axe 3 elle est de coordonnées
positive.
Le nombre de fois que la maman à accoucher à
contribué de 49,6% à la création de l'axe 3 elle est de
coordonnées positive.
Pour l'axe 4
La gestite a contribué de 99% à la création
de l'axe 3 elle est de coordonnées négative.
? pour les individus (10%) Pour l'axe 1 :
La tranche d'âge 3 à contribué de 11,4%
à la création de l'axe1 elle est de coordonnées
positive.
La tranche d'âge 6 à contribué de 59,4%
à la création de l'axe1 elle est de coordonnées
négative.
Dans cette tranche 2, d'âge que les mamans ont beaucoup
avorté.
[80]
La tranche d'âge 1 à contribué de 16 ,1%
à la création de l'axe 2 elle est de coordonnées
positive.
La tranche d'âge 2 à contribué de 40,5%
à la création de l'axe2 elle est de coordonnées
positive.
La tranche d'âge 10 à contribué de 18,4%
à la création de l'axe2 elle est de coordonnées
négative
Pour l'axe 3 :
La tranche d'âge 1 à contribué de 10,8%
à la création de l'axe 3 elle est de coordonnées
positive.
La tranche d'âge 2 à contribué de 17%
à la création de l'axe 3 elle est de coordonnées
négative.
La tranche d'âge 7 à contribué de 27%
à la création de l'axe 3 elle est de coordonnées
positive
La tranche d'âge 10 à contribué de 20%
à la création de l'axe 3 elle est de coordonnées
négative
Pour l'axe 4 :
La tranche d'âge 2 à contribué de 12,7%
à la création de l'axe 4 elle est de coordonnées
négative.
La tranche d'âge 9 à contribué de 55,6%
à la création de l'axe 4 elle est de coordonnées
positive.
2. Interprétation :
La tranche d'âge allant de 29 à 31 est
associée à la parité de la mère ou nous pouvons
encore dire que la parité explique mieux cette tranche d'âge.
La tranche d'âge allant de 29 à 31 est la tranche
d'âge dont les femmes ont accouché beaucoup.
La tranche d'âge 10 est associe à la CPN, nous
pouvons ainsi dire que la majorité de ce femme on fait la CPN.
[81]
Nous pouvons encore dire dans la tranche d'âge allant de
21à 23 ans ; les jeunes filles sont souvent poussées à
faire l'avortement.
Dans cette tranche 7, d'âge que la majorité des
mamans n'ont pas suivi la
CPN.la plupart de ces femmes se croient
déjà adulte et négligent la CPN.
Dans cette tranche 9, d'âge c'est la tranche d'âge
que la majorité de femme on déjà accouche plus d'une
fois.
[82]
IV.2.4 DEVELOPPEMENT DE L'APPLICATION [9] A qui
l'application est-elle destinée
Notre application est destinée à la direction de la
maternité et au service informatique de l'hôpital.
Quels sont les problèmes de l'application
résoudra-t-elle ?
L'application résoudra le problème de la gestion
des informations notamment l'archivage et permettra aussi d'automatiser le
processus manuel.
Comment l'application fonctionnera -t- elle ?
Nous adopterons une architecture à trois niveaux pour
séparer l'interface utilisateur de la logique de programmation, et la
logique de programmation de la base de données.
[83]
IV.2.4.1 CONCEPTION DE L'APPLICATION DE GESTION DES
ACCOUCHEMENTS :
1. Diagramme de classe de l'application
Les Classe : accouchement ,fiche et antécédent
obstétrical (c'est-à-dire le passe de la maman concernant la
gestation, parité, avortement et décède)
|
|
|
|
ANT OBSTRI
-NA : int
-GRAVIDA : int -PARITE :
int -AVORTEMENT : int -DECES :
int
+enregistre() +rechercher()
+suprimer() +afficher()
|
|
Fiche
|
|
ACCOUCHEMENT
|
|
|
-NF : int
-NOMPOSTNOM : char -AGE :
int
-ETA CIVIL : char -NATIONALITE :
char -ADRESSE : char -NIVEAU
D'ETUDES : char
|
|
-NUM ORDRE : int -NA :
int
-NF : int
-NT : int -PROVENANCE :
int -ETAT SER : int -SEXE :
char
-POIDS : double -AP GAR :
int
-DIAGNOSTIQUE : char
+enregistre() +recherche()
+suprimer() +afficher()
|
|
|
|
|
+enregistre() +recherche()
+suprimer() +afficher()
|
|
|
|
|
|
FIG IV 8:Diagramme de classe
2.Diagramme de cas d'utilisation du système en
Général Les acteurs : décideur, administrateur,
agent
[84]

utilisateur
Décideur
Visualisation des
données dimensionnelles
Appliquer les Data
mining
Saisie des
information d'un malade
Appliquer les
opérations OLAP
Système
Authentification
au système
« Include »
Administrateur
FIG IV 9:Diagramme de cas d'utilisation
3.Diagramme de séquencé Authentification
système
Afficher interface authentification
Saisie des données
Afficher formulaire menu
FIG IV 10:Diagramme de séquence
Opération datamining
FIG IV 12:Formulaire de sécurité
[85]
Afficher les données
Application algorithme
Afficher le résultat
Fig. IV 9.diagramme de séquence « Opération
de datamining». Analyse OLAP
Rafraichir les données
Analyse les données
Sauvegarder et archivage de données
Afficher rapport
FIG IV 11:Diagramme de séquence analyse OLAP
IV.2.4.2 FORMULAIRE DE L'APPLICATION REALISE EN VISUAL
C SHARP
Formulaire de sécurité :

FIG IV 14:Formulaire accouchement
[86]
Formulaire de Menu général :

FIG IV 13:Formulaire de menu principale Formulaire
accouchement

}
[87]
IV.2.4.3 CODES SOURCES :
Code source pour la connexion à l'application :
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Configuration;
namespace MemoireK
{
public partial class Frmconnex : Form
{
public Frmconnex()
{
InitializeComponent();
}
private void btnValider_Click(object sender, EventArgs e)
{
Cursor.Current = Cursors.WaitCursor;
try
{
bd.chaineDeConnexion =
"Provider=Microsoft.Jet.OLEDB.4.0;Data
Source=c:\\memoirefin.mdb";
if (txbCompte.Text == "kangiama" ||
txbMotDePasse.Text=="kangiama") {
Principal t = new Principal();
t.Show();
}
}
catch (Exception ex)
{
MessageBox.Show(ex.Message,
Application.ProductName);
txbMotDePasse.Text = "";
txbMotDePasse.Focus();
}
[88]
Cursor.Current = Cursors.Default;
}
private void Frmconnex_Load(object sender, EventArgs e)
{
}
private void txbCompte_TextChanged(object sender,
EventArgs e)
{
}
}
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Data;
using GSS;
namespace MemoireK
{
class Accouchement
{
string num;
public string Num
{
get { return num; }
set { num = value; }
}
string nf;
public string Nf
{
get { return nf; }
set { nf = value; }
}
string na;
public string Na {
get { return na; } set { na = value; }
[89]
string nt;
public string Nt {
get { return nt; }
set { nt = value; }
}
int prov;
public int Prov
{
get { return prov; }
set { prov = value; }
}
int etat;
public int Etat
{
get { return etat; } set { etat = value; }
}
string sexe;
public string Sexe {
get { return sexe; } set { sexe = value; }
}
float poid;
public float Poid
{
get { return poid; } set { poid = value; }
}
int ap;
public int Ap
{
get { return ap; } set { ap = value; }
}
string diag;
}
}
[90]
public string Diag
{
get { return diag; }
set { diag = value; }
}
#region Accouchement
public DataSet rechercheuneecole(string id)
{
return AccouchementDAO.recherche(id).DataSet;
}
public DataSet rechercheecol()
{
return AccouchementDAO.recherche().DataSet;
}
public void ajoute()
{
new AccouchementDAO(this).ajoute();
}
public void modifierecole(string id)
{
new AccouchementDAO(this).modifier(id);
}
public void supprimerecole(string id)
{
new AccouchementDAO(this).Supprimer(id);
}
#endregion
public static void
Afficheraccou(CrystalDecisions.Windows.Forms.CrystalReportVie
wer crv)
{
Interface.Rapport.listeaccouchement rapport = new
MemoireK.Interface.Rapport.listeaccouchement();
ReportManager report = new ReportManager(rapport, crv);
report.Afficher(AccouchementDAO.recherche());
}
[91]
IV.3 CONCLUSION
Dans ce chapitre nous avons commencé par
présenter l'hôpital saint joseph de Kinshasa Limete qui est notre
champs d'application .en suite nous avons cité les outils utilises pour
la réalisation de ce travail.
Et enfin nous avons présenté les interfaces
graphiques de notre DataMart ainsi que l'arbre de décision obtenue pour
boucler par une interprétation de ces résultats.
[92]
CONCLUSION GENERALE
Nous voici arrivés au terme de notre travail de fin
d'études qui a porté sur l'extraction de connaissances à
partir d'un DataMart à l'aide de l'arbre de décision.
Dans notre travail, nous avons parlé d'abord du
système décisionnel qui présente l'ensemble des processus
qui permet de collecter, d'intégrer , de modéliser et de
présenter les données .
Nous avons également parlé des entrepôts
des données qui constituent le coeur du système
décisionnel jouant un rôle référentiel pour
l'entreprise puisqu'il permet de fédérer des données
souvent éparpillées dans le différentes base de
données.
Ensuite nous avons traité du data mining qui permet de
faire des recherches approfondies sur les données de l'entrepôt,
avec un arbre de décision pour faire la l'extraction de
connaissances.
Nous avons réalisé le datamart avec SQL serveur
2008 avec un modèle de l'arbre de décisions pour nous permettre
de prendre une décision sur nos données.
De ce qui précède, nous sommes persuadé
que l'ensemble des préoccupations répond à la
problématique de notre travail .
Notre contribution dans notre étude de cas était
de réaliser un DataMart sur les accouchements et à partir de ce
DataMart nous avons pu construire un arbre de décision que nous avons
interprété à la fin et pour finir le travail vu que la
maternité utilise le registre qui est un méthode manuel nous
avons implémenté une application en C Sharp pour faciliter le
travail aux agents de la maternité .
[93]
BIBLIOGRAPHIE
OUVRAGES
1. ADIBA .M, Entrepôts de données et fouille de
données, Paris 2002.
2. Bertrand Burquier, Business intelligence avec 2008,
Mise en oeuvre d'un projet décisionnel, Dunod, 2009.
3. DANIEL T. LAROSE, Des données à la
connaissance une introduction au Datamining,
Vuibert, 2005.
4. GUIJARRO Vincent, Les Arbres de Décisions L'
algorithme ID3, lile ,2006.
5. KIMBALL .R and m. ross, Entrepôts de données,
guide pratique de Modélisation dimensionnelle,
vuibert, paris, 2003.
6.RAKOTOMALALA.R : Graphes d'induction apprentissage et data
mining, hermès, 2000.
THESE
7.SERNA ENCINAS MARIA, Entrepôts de données pour
l'aide à la prise de décision médicale, conception et
expérimentation,
UNIVERSITE JOSEPH FOURRIER ,France 2005
NOTES DE COURS
8. DJUNGU SJ, Entrepôts des données, L2
informatique option Gestion, cours inédit, UNIKIN 2009-2010.
9. DJUNGU SJ, Génie logiciel et construction de
programme, L1informatique option Gestion, cours inédit, UNIKIN
2009-2010.
10 .KASORO, Analyse des données, L2 informatique
option Gestion, cours inédit, UNIKIN 2009-2010.
11 .MANYA NDJADI, statistique II, G2 informatique,
cours inédit, UNIKIN 2006-2007.
[94]
12. MANYA NDJADI, Recherche opérationnelle, G3
informatique, cours inédit, UNIKIN 2007-2008.
13. MBUYI MUKENDI, Base des données,
G3informatique, cours inédit, UNIKIN 2007-2008.
MEMOIRES et TFC
14. ALBINI MIANGO Christian, Application de la
programmation mathématique dans le data mining,
UNIKIN 2008-2009.
15. KANGIAMA LWANGI Richard, Conception et
réalisation d'une base de données pour la consultation
médicale au sein d'une institution médicale
« Cas de la service de consultation du personnel de
l'hôpital saint joseph de Kinshasa limete »,
UNIKIN 2007-2008.
16. KALULAMBI KABASELE Didier, Extraction des
connaissances a partir d'un entrepôt des données à l'aide
de l'arbre de décision application a la fouille des données
bancaires, UNIKIN 2008-2009.
INTERNET
17.
www.creatis.insa-lyon.fr,
le 3 octobre 2010.
18.
www.wilkipedia.org , le 23 mars
2010.
19.
www.devellopez.com , le 12
Septembre 2010.
[95]
TABLE DES MATIERES
EPIGRAPHIE I
DEDICACE II
AVANT PROPOS III
LISTE DES FIGURES IV
LISTE DES TABLEAUX V
LISTE DES ABREVIATIONS VI
INTRODUCTION 1
0 .PROBLEMATIQUE 1
1 .INTERET DU TRAVAIL 2
2 .METHODOLOGIE 2
3. DELIMITATION DU TRAVAIL 2
4. PLAN DU TRAVAIL 3
CHAPITRE I : LES SYSTEMES DECISIONNELS
4
I .1 INTRODUCTION 4
I.1.0 L'INFORMATIQUE DECISIONNELLE 4
1.1.1 POURQUOI LE DECISIONNEL 5
1.1.2 QUI A BESOIN DU DECISIONNEL 6
I.2 LES DIFFERENTS ELEMENTS CONSTITUTIFS DU SYSTEME
DECISIONNEL 7
I.3 LES ENJEUX DE L'INFORMATIQUE DECISIONNELLE 8
I .4 METHODES D'ANALYSE DECISIONNELLE 9
I.5 FONCTIONS ESSENTIELLES DE L'INFORMATIQUE DECISIONNELLE .
11
I.5.1COLLECTE 11
I.5.2 INTEGRATION 12
I.5.3 DIFFUSION OU LA DISTRIBUTION 13
I.5.4 PRESENTATION 14
I.5.5 ADMINISTRATION 14
I.5.6 LES PHASES DU PROCESSUS DECISIONNEL 14
I.6 CONCLUSION 16
CHAPITRE II : LES ENTREPOTS DE DONNEES
17
II.1 INTRODUCTION 17
II.2.1 DEFINITION CLASSIQUE D'UN ENTREPOT DES DONNEES 18
II.2.2 ARCHITECTURE D'UN ENTREPOT DE DONNEES 18
[96]
II.2.3 ENTREPOTS ET LES BASES DE DONNEES 21
II.2.4 SYSTEMES TRANSACTIONNELS ET SYSTEMES DECISIONNELS :
22
II.2.5 DATAMART OU MINI - ENTREPOT DES DONNEES 23
II.2.5.1 INTRODUCTION 23
II.2.5.2 LES DEFINITIONS 24
II.2.5.3 STRUCTURE PHYSIQUE ET THEORIQUE 24
II.5.2.3 DATAWAREHOUSE ET DATAMART 25
II.5.2.4 ARCHITECTURE D'UN DATAMART 25
II.5.2.5 LA PLACE DU DATAMART DANS L'ENTREPRISE 26
II.2.6. CONCEPTION D'UN ENTREPOT DE DONNEES 26
II.2.6.1 MODELISATION MULTIDIMENSIONNELLE 27
II.2.6.2 SCHEMAS RELATIONNELS 28
II.6.2.3 LE SCHEMA EN ETOILE 29
II.6.2.3 LE SCHEMA EN FLOCON DE NEIGE 30
II.6.2.4 LE SCHEMA EN CONSTELLATION 31
II.6.2.5 SCHEMA MULTIDIMENSIONNEL (CUBE) 32
II.3 MANIPULATION DES DONNEES MULTIDIMENSIONNELLES 33
II.3.1 OPERATIONS CLASSIQUES 34
II.4 LES SERVEURS OLAP (ON-LINE ANALYTICAL PROCESSING) 35
II.4.1 LES SERVEUR ROLAP (RELATIONAL OLAP) 36
II.4.2 LES SERVEUR MOLAP (MULTIDIMENSIONAL OLAP)
36
II.4.3 LES SERVEUR HOLAP (HYBRID OLAP) 37
II.5 CONCLUSION 40
CHAPITRE III : LE DATA MINING ET ARBRE
DE DECISION 41
III.1 .1 PRESENTATION 41
III.1 .2 SATATISTIQUE ET DATAMINING 42
III.1 .3 PROCESSUS DU DATAMINING 43
III.1 .4 LES TACHES DU DATA MING 45
III .2 ARBRE DE DECISION 46
III.2 .0 CONCEPTS THEORIQUES SUR LE GRAPHE 46
III .2.1 INTRODUCTION A L'ARBRE DE DECISION 48
III .2.2 EXEMPLE PRATIQUE 52
II .2.3 CONCLUSION 56
CHAPITRE IV : IMPLEMENTATION
57
IV .0 INTRODUCTION 57
IV.1 ANALYSE DE L'EXISTANT 57
IV.1.1 BREF APERÇU HISTORIQUE 57
IV .1.2 SITUATION GEOGRAPHIQUE 58
IV.1.3 MISSION DE L'HOPITAL 58
[97]
IV.1.4 STRUCTURE DE L'ENTREPRISE 59
IV .1.5 ORGANISATION ET FONCTIONNEMENT 60
IV.1.6 FONCTIONNEMENT 62
IV.1.7 AUTRES ASPECTS 62
IV.2. PROBLEME RENCONTRE 64
IV.2.1 LA PROBELMATIQUE ET MOTIVATION 64
IV.2.2 OUTIL UITILISE 65
IV.2.3 MODELISATION MULTIDIMENSIONNEL LE DE DATAMART 66
1. MODELISATION DE L'APPLICATION OPERATIONNELLE 67
2 .CONCEPTION D'UN DATA MART 70
3.SCHEMA EN ETOILE DE L'ENTREPOT SOUS SQL serveur 2008
72
4.MODULE DE DATAMINING 72
5.GRAPHIQUE 78
6. INTERPRETATION DES RESULTATS 79
IV.2.4 DEVELOPPEMENT DE L'APPLICATION 82
IV.2.4.1 CONCEPTION DE L'APPLICATION DE GESTION DES
ACCOUCHEMENTS : 83
IV.2.4.2 FORMULAIRE DE
L'APPLICATION REALISE EN VISUAL C SHARP 85
IV.2.4.3 CODES SOURCES : 87
IV.3 CONCLUSION 91
CONCLUSION GENERALE 92
BIBLIOGRAPHIE 93
TABLE DES MATIERES 95
| 

