CHAPITRE 0. INTRODUCTION GENERALE
0.1. Introduction
Le monde du travail actuel tend à migrer vers
l'automatisation des tâches par le biais de l'informatisation. Le besoin
de facilité, efficacité et fiabilité dans la
résolution des problèmes et dans la réalisation des
tâches est devenu énorme et pousse les entrepreneurs à
doter de leurs entreprises des systèmes de gestion automatisés.
De ce fait, j'ai préféré, pour mon projet de fin
d'études universitaires, développer un système de gestion
de donneurs de sang pour le CNTS en vue d'améliorer son travail combien
important pour le pays.
0.2. Choix du sujet
Dans le noble souci de voir tous
les services publics et privés jouissant des systèmes de gestion
classiques se trouver un jour munis d'un système de gestion
automatisé, il importe pour un informaticien de songer à mettre
en place des systèmes de gestion automatisés pour stimuler les
décideurs à réaliser les avantages de ces derniers et
même d'en acheter, afin de rendre la production nationale plus
abondante.
C'est alors dans cet optique que
j'ai choisi le sujet intitulé : « Analyse et
Développement d'un logiciel de gestion des donneurs de sang : cas
du CNTS ».
0.3. Intérêt
du sujet
Ce sujet a pour
intérêt de permettre au CNTS de se doter d'un logiciel lui
permettant de mieux gérer ses donneurs de sang qui lui sont sans doute
chers, de pouvoir évaluer de façon rapide et précise
l'état de ces activités en matière de don de sang.
En plus, il lui sera commode de
gérer les autres types de patients entre autres les Ambulants et les
EPC.
0.4. Délimitation du sujet
Le sujet se focalise essentiellement sur le suivi des donneurs
de sang ; leur évolution sanitaire et leur régularité
aux dons.
Toutefois, le sujet s'étend également sur le
suivi des Ambulants qui peuvent devenir donneurs après sensibilisation
et aux EPC qui peuvent provenir des donneurs.
0.5.
Problématique
Le CNTS offre un service important
et indispensable, il est unique dans le pays et devrait
bénéficier d'une attention particulière de la part des
dirigeants de ce pays et cela en lui dotant des outils modernes et suffisants
pour son bon fonctionnement. Mais hélas, le CNTS fonctionne d'une
façon archaïque dans son système de gestion : des
donneurs, de la comptabilité, du personnel, du laboratoire, du charroi
et de la communication.
0.6. Hypothèse
A voir le système de fonctionnement du CNTS, il est
évident de poser l'hypothèse suivant et de l'infirmer ou
l'affirmer:
Hypothèse : Le logiciel de gestion des donneurs de
sang contribuera à l'amélioration de la gestion de ces
derniers.
0.7. Méthodologie de
recherche
La méthodologie
utilisée est mixte, elle comprend ; la consultation des ouvrages,
le questionnement des agents du CNTS et la consultation des sites web.
0.8. Articulation du sujet
Notre sujet s'articule sur quatre chapitres à
savoir :
Ø Le Chapitre 0 : Introduction
générale qui après son introduction, montre le choix,
l'intérêt et la délimitation de ce dernier. Ce chapitre
montre également la problématique, l'hypothèse à
affirmer ou infirmer, la méthodologie utilisée pour recueillir
les données et en fin la conclusion.
Ø Le Chapitre I : Présentation du CNTS qui
est un chapitre après son introduction, destiné à parler
brièvement de ce qu'est le CNTS, son historique, ses activités,
sa mission, ses objectifs et son organigramme. Il cible particulièrement
le champ de travail dan son contenu et parle de la situation informatique en
général au CNTS et se termine par une conclusion.
Ø Le Chapitre II : Méthodes et outils, lui,
après son introduction, il met en évidence la méthode et
les outils adoptés pour la modélisation et la
réalisation du projet et justifie leur choix, il se termine par une
conclusion.
Ø Le Chapitre III : Analyse et conception, il
comporte une introduction et il concerne alors le travail important d'analyse
en spécifiant les besoins, il décrit la méthode choisie
pour la modélisation et montre la modélisation proprement dite et
finit par une conclusion.
Ø Le Chapitre IV : Réalisation, il est le
dernier et après son introduction, il relate le fonctionnement du
logiciel ; ses performances, sa fiabilité et son efficacité.
Il finit par une conclusion.
Ø Ce travail se termine par une conclusion
générale et des recommandations.
0.9. Conclusion
Le travail issu du sujet ci-haut
mentionné vient relever un défi parmi tant d'autres que le CNTS a
et apporter une lueur d'espoir aux autres secteurs du ministère de
tuteur en particulier et du gouvernement en général.
CHAPITRE I. PRESENTATION DU CNTS
I.0. Introduction
Le Centre National de Transfusion Sanguine (CNTS) est un
programme du Ministère de la Santé Publique et de la Lutte contre
le SIDA avec autonomie de gestion et a son siège en mairie de
BUJUMBURA.
Le CNTS sert toute la population Burundaise et oeuvre sur tout
le territoire national.
I.1. Historique1(*)
La gestion de la transfusion sanguine au BURUNDI a
été confiée à la Croix Rouge Burundaise
jusqu'à 1988 tandis que des petites unités intra
hospitalières ont été développées dans les
centres de soins du monde rural particulièrement les centres tenus par
les missionnaires.
De 1988 à 1992, la gestion de la transfusion sanguine
était confiée à un service du Département des soins
de Santé au sein du Ministère de la Santé Publique.
En 1993 était créé un Centre National de
Transfusion Sanguine avec statut d'une administration personnalisée de
l'Etat jouissant d'une certaine autonomie de gestion, autonomie administrative
et compétence technique mais sans compétence administrative sur
les Centres Régionaux de Transfusion Sanguine et les banques de sang.
L'autonomie financière est également relative,
le budget du CNTS émergeant sur le budget des voies de moyens de
l'Etat.
Cette autonomie entre en vigueur en 1996 avec la nomination
d'un Conseil d'Administration.
I.2. Activités
Le CNTS, ses activités sont essentiellement : La
sensibilisation de la population humaine au don de sang, collecte et la
distribution de sang.
I.2.1. La sensibilisation
Elle se fait surtout par des supports
publicitaires, par la conscientisation des ambulants accueillis au CNTS, par
les remerciements publics des donneurs.
1.2.2. La collecte du sang
La collecte du sang se fait normalement au siège du
CNTS, aux bureaux régionaux du CNTS basés surtout dans les
hôpitaux de l'intérieur du pays et dans les milieux de groupement
de gens comme dans les camps militaires ou policiers, dans les écoles et
universités.
1.2.3. La distribution de sang
Elle se fait généralement au siège du
CNTS et ce sont les unités de santé publiques et privées
qui viennent s'approvisionner.
I.2.3.1. La transfusion sanguine2(*)
La transfusion est une pratique qui existe depuis la
1ère guerre mondiale (1914-1918).
C'est dans des situations d'urgence, guerre, catastrophe
naturelle, accident à grande échelle ou conflit humain, que la
nécessité d'un service de transfusion sanguine efficace se fait
sentir.
En présence de tels événements, les
services transfusionnels sont très sollicités, ainsi il importe
d'avoir toujours des stocks de sang pour parer à ces incidents.
La transfusion sanguine consiste au fait qu'une personne
(receveur) reçoive du sang à travers une perfusion. Ce sang
provienne d'une autre personne (donneur) qui est sain, qui a fait un geste
humanitaire de donner du sang.
Une personne en bonne santé peut sans danger donner du
sang 4 à 6 fois par an.
Après chaque don, il faut au moins 36 heures à
l'organisme pour le rétablissement du volume sanguin et 21 jours pour le
retour à la normale de la numération globulaire.
Les donneurs jouent un rôle clé dans les
traitements médicaux et chirurgicaux.
Tout le monde peut avoir besoin du sang à un moment ou
à un autre ; une maladie ou un accident grave peut survenir
n'importe où dans le monde, pendant l'activité quotidienne ou en
voyage, entraînant des pertes de sang si abondantes qu'elles mettent la
vie en danger.
Il est donc dans l'intérêt de tous qu'il existe
des réserves de sang et de produits sanguins dans le monde entier, mais
aussi dans notre pays.
Ainsi, grâce à des personnes qui donnent
anonymement du sang des vies sont sauvées.
Tous les donneurs doivent savoir qu'ils ne peuvent sauver des
vies que si leur sang est exempt de toute infection et ne présente pas
de risque pour le receveur.
De même, il faut comprendre qu'en donnant du sang qui
pourrait être contaminé, on prend le risque de transmettre une
infection potentiellement mortelle.
La transfusion sanguine est donc un acte médical qui
consiste à donner du sang à un malade pour différentes
raisons : Accidents, à la suite d'un accouchement difficile, au
cours d'une opération chirurgicale, dans le cas d'une anémie,
dans le cas des maladies infectieuses ou héréditaires.
La transfusion sanguine n'est possible que s'il y a quelqu'un
qui donne du sang (donneur), c'est-à-dire quand il y' a un majeur bien
portant qui accepte qu'on prélève une partie de son sang à
travers sa veine.
La transfusion sanguine suit
certaines lois c'est-à-dire qu'on transfuse du sang iso groupe, iso
rhésus.
Le sang peut être
donné aux nécessiteux sous différentes formes :
- Le sang total
- Les produits sanguins labiles :
· Les concentrés de globules rouges
· Le plasma
· Les plaquettes
Le sang à transfuser est analysé pour exclure
diverses infections transmissibles par le sang à savoir : le VIH,
le VHB, le VHC et la syphilis.
I.3. Mission et Objectifs
Dans notre pays la sensibilisation au don
bénévole de sang est assurée par le CNTS appuyé par
la CROIX ROUGE du BURUNDI.
Beaucoup de gens ont tendance à confondre la Croix
Rouge et le CNTS, mais la différance entre les deux est que le CNTS a
pour mission de faire la sensibilisation, la collecte du sang jusqu'à sa
distribution, alors que la Croix Rouge intervient seulement dans la
sensibilisation.
Il a dans ses objectifs :
- La sensibilisation et le recrutement au don
bénévole du sang.
- La collecte du sang sur tout le territoire national.
- L'analyse du sang par des tests de dépistage du VIH,
des virus des hépatites B et C, du Tréponème pallidum pour
chaque poche de sang collecté et des tests de groupage sanguin sur
toutes les poches à distribuer.
- La conservation des produits sanguins depuis le
prélèvement jusqu'à la distribution.
- L'approvisionnement des hôpitaux de tout le pays en
produits sanguins.
- L'approvisionnement des CNTS et des banques de sang en
réactifs et en matériels de laboratoires.
I.4. Organigramme général 3(*)
I.5. Présentation du champ d'étude
Le champ d'étude couvre :
· L'accueil et l'archive
Les gens qui se présentent au CNTS ne sont pas tous des
donneurs. Ils peuvent être des Ambulants (des demandeurs des examens de
sang ou autres sans être donneurs), des EPC (des gens atteints du VIH et
qui sont prises en charge au CNTS).
Pour être donneur, il faut qu'un sujet ait au moins
subit un test de sang pour évaluer sa sérologie virale (VIH, VHB,
VHC) et bactérienne (SYPHILIS). C'est après analyse du sang de
résultat négatif qu'avec la volonté du sujet, celui-ci
devient donneur.
L'accueil comprend : l'identification du sujet, le
recueil de l'objet de sa visite, son enregistrement et son orientation suivant
son but.
L'archive consiste à bien conserver les fiches des
donneurs, ambulants et EPC.
· Sélection des donneurs
La sélection des donneurs consiste à faire
certaines mesures (tension artérielle et poids) et à poser une
série de questions relatives à la santé d'un sujet en vue
de déterminer préalablement l'état sérologique de
ce dernier ou s'il a d'autres problèmes de santé pouvant lui
être obstacle au don de sang. Si après ces mesures et questions,
l'infirmier trouve que le sujet est dans les normes de donner son sang, ce
dernier est envoyé chez l'infirmier qui fait le
prélèvement de sang après lui avoir donné une poche
et un tube.
· Prélèvement du sang
On parle généralement de
prélèvement lorsqu'il s'agit d'une petite quantité de sang
destiné uniquement aux tests tandis que pour une quantité de
350ml là, on parle de don. Le sang à tester est mis dans un
tube.
 4(*) 4(*)
Fig. II.1.Tube de sang
Le prélèvement se fait dans une salle
appropriée, avec des outils modernes et la conservation du sang est
assurée.
 5(*) 5(*)
Fig. II .2. Acte de don de sang
· Test du sang
Le test du sang à la CNTS se focalise surtout sur le
test du groupe sanguin, le rhésus, la sérologie virale et
s'ajoute le test de sérologie bactérienne pour la Syphilis.
· Remise des résultats
La remise des résultats intervient
généralement deux semaines après un don de sang ou un
simple prélèvement. Le remettant informe au récepteur de
résultat, parmi les cinq maladies testées laquelle il porte ou
s'il est sain. Et au besoin, le remettant lui informe de son groupe sanguin.
I.6. Situation informatique
La situation informatique à la CNTS se limite seulement
à l'exploitation des logiciels bureautiques, il n'y a rien d'application
informatique spécifique dans tous les services, les machines ne sont pas
en réseau et pas d'Internet.
I.7. Conclusion
Le CNTS, à voir son importance, il devait jouir d'un
soutien matériel, financier et juridique très considérable
car maintenant :
- Matériellement ; il n'est pas très
outillé par exemple en charroi, applications informatiques
spécifiques et en personnel suffisant.
- Financièrement ; il n'arrive pas à
fonctionner 24h sur 24 pour maximiser la collecte de sang et il ne parvient pas
à couvrir tout le territoire national en laboratoires
spécialisés.
- Juridiquement ; il n'est pas protégé par
la loi contre une concurrence éventuelle pouvant le dissoudre et offrir
un service moins contrôlé.
CHAPITRE II. METHODES ET OUTILS
II.1. Introduction
Il est évident que les méthodes et les outils
choisis pour concevoir et développer une application doivent être
en fonction de l'environnement et du domaine d'application de celle-ci.
Dans ce chapitre on va justifier le choix des méthodes
et outils qui seront utilisés dans le chapitre suivant.
II.2. Architecture
L'informatique est une science évolutive. A nos jours
avec l'arrivée des nouvelles technologies de l'information et de la
communication (NTIC), en occurrence l'Internet. L'architecture logicielle ne
peut pas rester indemne, elle doit suivre l'évolution, raison pour
laquelle, on trouve plusieurs architectures sur le marché qu'on peut
subdiviser en deux catégories :
· Architecture utilisant un serveur centré
· Architecture n-tiers
II.2.1 Architecture utilisant un serveur centré
Il s'agit de la première
génération : l'ensemble des traitements et de données
se trouvent dans un serveur et les utilisateurs des applications utilisent des
terminaux pour appeler les fonctions se trouvant dans le serveur. Les terminaux
ont uniquement une fonction d'affichage.
II.2.
2. Architectures n-tiers
Comme son nom l'indique cette architecture est un prototype de
plusieurs architectures. Commençant du 2-tiers (appelée
régulièrement Client/serveur) qui est la base de mon application
allant du 3-tiers voire 4-tiers.
D'une manière générale les architectures
n-tiers suivent les mêmes principes qui sont l'affichage (User
interface), le traitement (Business logic) et la partie accès et
stockage des données (Data Access Object).
On peut regrouper les deux (Client/serveur) ou de les
séparer carrément (3-tiers et plus).
En ce qui me concerne j'ai besoin de développer une
application qui sera utilisé localement.
II.3. Choix des méthodes et outils
Ce choix justifie le pourquoi et les raisons qui sont à
l'origine de l'utilisation de l'une ou de l'autre méthode ou outil.
II.3 .1.Choix de la méthode de
modélisation
Merise et UML sont deux grands principes de « traduction
» ou modélisation d'un système d'information.
Néanmoins, ils ne sont pas aussi proches qu'on pourrait le penser.
Le choix de l'un ou de l'autre se fait selon trois axes à
savoir l'accessibilité, la précision et
l'exploitabilité.
Pour le premier axe (accessibilité) MERISE présente
l'intérêt d'avoir des modèles logiques moins
détaillés facilement compréhensibles.
Tandis qu'UML conçu pour s'adapter à n'importe quel
langage de programmation orientée objet (POO), présente plusieurs
modèles (diagrammes) dont leurs compréhensions nécessitent
une grande attention.
En ce qui concerne le deuxième critère
(précision), MERISE est moins préférable. Malgré sa
clarté, il manque une précision du fait qu'elle est
éloignée du langage donc difficile à implémenter
alors qu'UML intègre les éléments communs des
différents langages, sa volonté est d'être fidèle
à la réalisation finale. Elle est beaucoup plus complète
avec ses différents diagrammes.
Pour en finir avec l'exploitabilité, MERISE est une
méthode plus généraliste. Elle donne une vue globale de la
solution sans autant entrer dans les petits détails. Contrairement
à UML qui est conçu pour l'implémentation objet avec ses
différents détails et sa portabilité (s'adapte à
n'importe quelle plateforme) elle est donc plus exploitable.
L'une ou l'autre présente des avantages et des
inconvénients. Il est réservé au concepteur de choisir la
méthode la mieux adaptée pour son cas. Si on cherche la
précision et l'exploitabilité UML devance MERISE. Tandis que, si
c'est la clarté et l'accessibilité qui sont en question MERISE
est préférable.
Mon application gère des données moins complexes
d'où merise est la mieux recommandée, vue qu'elle rend la
modélisation plus simple à implémenter.
II.3.2. Choix du langage de développement
Le schéma suivant nous fait un bref aperçu
concernant quelques langages. Il montre le domaine principal d'application, de
l'année de l'essor du langage ainsi que l'interdépendance entre
les différents langages.
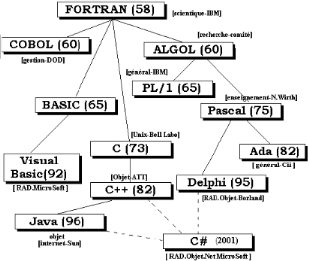
Fig. II. 1.
Relation entre les langages
Comme déjà dit, le schéma ci-dessus donne
une vue globale de l'évolution des langages. La plupart des langages
présents dans ce schéma sont développés par des
sociétés privées et sont donc destinés pour le
marché, ils subissent alors la loi du marché (des hauts et des
bas).
Souvent la sortie d'un nouveau langage n'est pas un fruit du
hasard mais il s'appuie sur les anciens en profitant de leurs qualités
et en essayant de remédier les défauts.
Ici, je vais essayer de faire une étude comparative sur
les langages de programmation orientés objets qui sont en vogue sur le
marché et essayer d'en sélectionner un qui répondra bien
aux besoins d'implémentation de mon application.
On va s'intéresser surtout sur les langages Java, C++
et Visual Basic.
· Java
Java est pourvu d'une grande sécurité, la
richesse de ses bibliothèques, son adaptation à plusieurs
plateformes, la qualité présentée par ses composantes
graphiques (Swing) qui suivent le modèle MVC, sa facilité de
déploiement en réseau (RMI) et le fait qu'on peut avoir plusieurs
« Look And Feel », font de lui un langage redoutable,
puissant et performant. Une grande partie de sa syntaxe est empruntée de
C et C++. La lenteur de sa machine virtuelle (JVM) constitue son principal
défaut.
· Visual Basic (VB)
VB fait parti des langages suivant le concept orienté
objet il a un environnement de développement intégré (EDI)
qui permet de développer facilement des interfaces graphiques.
En appliquant quelques propriétés à ces
dernières et en écrivant quelques petits bouts de codes on
obtient des résultats satisfaisants.
VB est facilement accessible et assimilable.
· C++
Comme je l'ai dit précédemment, Java puise une
grande partie de ses sources dans le C++ ce qui fait que les défauts
rencontrés sur le deuxième sont améliorés, voire
éliminés par le premier.
Les comparaisons faites ci-dessus nous permettent de choisir
VB 6.0 comme langage d'implémentation de notre application vue son
approche orienté objet son environnement de développement
intégré (EDI) qui permet de développer facilement des
interfaces graphiques.
II.3.3. Choix du SGBD
De nombreux SGBD sont disponibles sur le marché,
partant des SGBD gratuits jusqu'aux SGBD destinés spécialement
aux professionnels, comportant de plus nombreuses fonctionnalités, mais
plus coûteux.
Je vais essayer de faire comme d'habitude une étude
comparative d'une sélection de quelques SGBD et choisir un pour mon
application. En guise de cause, on mentionne quelques facteurs subjectifs qui
influent souvent sur le choix du SGBD :
Ø La politique sécuritaire
Ø Le budget à disposition
Ø Les compétences déjà acquises en
terme de développement et d'administration et au besoin du prix de la
formation
Ø Le système d'exploitation hébergeant
Ø Les architectures logicielles et matérielles
Ensuite viendront des points tels que :
Ø La richesse fonctionnelle du SGBDR
Ø Les ressources (disques, mémoire, CPU,
Transactions par secondes, nombre de connexions simultanées)
Ø L'attente que vous avez vis-à-vis du support
technique
Ø Les compétences déjà acquises en
termes de développement et d'administration
Ø Le type d'accès aux données (OLTP,
décisionnelle, reporting, mixte)
Faisons l'étude de quelques uns qui sont connus par un
grand nombre du public :
· Oracle
Database
Oracle n'est pas un SGBDR optimisé pour de petites
bases de données. Sur de petits volumes de traitements (2 Go par
exemple) et peu d'utilisateurs (une trentaine).
· Avantage
· Procédures stockés en PL-SQL (langage
propriétaire Oracle, orienté ADA) ou en JAVA, ce qui peut
s'avérer utile pour les équipes de développement.
· Assistants performants via Oracle Manager Server,
possibilité de gérer en interne des tâches et des alarmes
· Gestion centralisée de plusieurs instances
· Concept unique de retour arrière (Flashback)
· Pérennité de l'éditeur : avec plus
de 40% de part de marché, ce n'est pas demain qu'Oracle
disparaîtra
· Réglages fins : dans la mesure où l'on
connait suffisamment le moteur, presque TOUT est paramétrable.
· Accès aux données système via des
vues, bien plus aisément manipulable que des procédures
stockées.
· Services Web
· Support XML
· Ordonnanceur intégré
· Inconvénients
· Prix exorbitant, tant au point de vue des licences que
des composants matériels (RAM, CPU) à fournir pour de bonnes
performances
· Fort demandeur de ressources, ce qui n'arrange rien au
point précité, Oracle est bien plus gourmand en ressource
mémoire que ses concurrents, ce qui implique un investissement
matériel non négligeable. La connexion utilisateur
nécessite par exemple près de 700 Ko/utilisateur, contre une
petite centaine sur des serveurs MS-SQL ou Sybase ASE. Gourmand aussi en espace
disques puisque la plupart des modules requièrent leur propre
ORACLE_HOME de par le versionning de patches incontrôlés.
· Porosité entre les schémas = difficile de
faire cohabiter de nombreuses applications sans devoir créer plusieurs
instances. Il manque réellement la couche "base de données" au
sens Db2/Microsoft/Sybase du terme.
· Méta modèle propriétaire, loin de
la norme.
· Tables partitionnées, uniquement possible
à l'aide de modules payants complémentaires. Parallélisme
mal géré sur des tables non-partitionnées.
· Gestion des verrous mortels mal conçue
(suppression d'une commande bloquante sans roll back)
· Pauvreté de l'optimiseur (ne distingue pas les
pages en cache ou en disque, n'utilise pas d'index lors de tris
généraux, statistiques régénérées par
saccade...)
· Pas de prise directe sur les tables système
(vues système)
· Une quantité de bugs proportionnels à la
richesse fonctionnelle, surtout sur les dernières versions
· Gestion erratique des rôles et privilèges
(pas possible de donner des droits sur des schémas particuliers sans
passer par leurs objets, désactivation des rôles lors
d'exécution de packages...)
· Nombreuses failles de sécurités
liées à l'architecture elle-même
· Access
Access est aussi bien un outil grand public que professionnel,
selon les besoins qu'on a. Il est assez performant en tant que SGBD
allié à un outil de développement intégré
qui en facilite l'utilisation. Access peut, en tant qu'outil de
développement, être utilisé conjointement avec un
véritable Serveur de base de données SQL pour
bénéficier des avantages du Client/serveur, sous certaines
conditions. Un néophyte peut facilement utiliser Access et se
créer une base de données complète, grâce à
de nombreux assistants pour l'aider à remarquer son intégration
dans Office.
Le problème est qu'Access en tant que format de
données n'est pas un SGBD client/serveur mais seulement un SGBD fichier.
Le trafic qu'il génère sur le réseau en utilisation
réseau multiposte peut fortement perturber ses performances. Les
performances chutent rapidement lorsque plusieurs utilisateurs sont
connectés ou si la base dépasse les 100000 lignes. Cependant,
Access en tant qu'outil de développement peut être utilisé
conjointement avec un véritable Serveur de base de données SQL
pour bénéficier des avantages du Client/serveur.
MS-Access reste un bon choix si vous souhaitez avoir une base
de donnée de petite taille et facilement gérable, ou que vous ne
connaissez pas grand chose aux SGBD.
En se référant du domaine d'application du
logiciel à développer et de l'étude comparative faite
entre les deux SGBD cités ci-dessus on a choisi Access.6(*)
II.4.Conclusion
Ce chapitre vient de passer en revue quelques méthodes
dans les modélisations des données et les outils utilisés
dans la programmation et le stockage des données.
Après avoir analysé leurs avantages et
inconvénients, le chois se dégage et va conduire le chapitre
suivant d'analyse et conception.
CHAPITRE III. ANALYSE ET CONCEPTION
III.1. Introduction
Cette partie est consacrée aux étapes
fondamentales pour le développement de mon système de gestion des
donneurs de sang. Pour la conception et la réalisation de mon
application, j'ai choisi de modéliser avec MERISE.
III.2. Spécification des besoins
C'est une étape primordiale au début de chaque
démarche de développement. Son but est de veiller à
développer un logiciel adéquat, sa finalité est la
description générale des fonctionnalités du
système, en répondant à la question : Quelles sont les
fonctions du système?
Le système doit répondre aux exigences suivantes
:
· Le système doit pouvoir récupérer
des informations de chaque entité à partir de son numéro
pour mettre à jour la base des données de l'application.
· L'insertion des valeurs dans les entités
· Modification des informations contenues dans les
entités.
· La suppression des informations contenues dans les
entités.
· L'impression des documents comme (Listes des donneurs
de sang, Listes des donneurs atteints du VIH, etc....
· Calcul de statistiques : le nombre de donneurs, le
nombre de donneurs atteints de l'hépatite B, etc....
III.3. Modélisation par la méthode
MERISE
III.3.1. Définition
Merise (prononcer « Meurise » et non «
Mérise ») est une méthode d'analyse, de conception et de
gestion de projet intégrée, ce qui en constitue le principal
atout.7(*)
III.3.2. Historique
Issue de l'
analyse
systémique, la méthode MERISE est le résultat des
travaux menés par
Hubert Tardieu
dans les
années
1970 et qui s'inséraient dans le cadre d'une réflexion
internationale, autour notamment du
modèle
relationnel d'
Edgar Frank
Codd. Elle est devenue un projet opérationnel au début
des
années
1980 à la demande du ministère de l'industrie, et a
surtout été utilisée en
France, par les
SSII
de ses membres fondateurs (
Sema-Metra, ainsi
que par la
CGI
Informatique) et principalement pour les projets d'envergure, notamment
des grandes
administrations
publiques ou privées.
Merise, méthode spécifiquement française,
a d'emblée connu la
concurrence
internationale de méthodes anglo-saxonnes telles que
SSADM, SDM/S ou Axial.
Elle a ensuite cherché à s'adapter aux évolutions rapides
des technologies de l'informatique avec Merise/
objet,
puis Merise/2 destinée à s'adapter au
client-serveur.
Merise était un courant majeur des réflexions sur une
« Euro Méthode » qui n'a pas réussi à
percer.
De l'aveu même d'un de ses fondateurs, le nom Merise
vient de l'analogie faite avec le
merisier "qui ne
peut porter de beaux fruits que si on lui greffe une branche de cerisier :
ainsi en va-t-il des méthodes informatiques bien conçues, qui ne
produisent de bons résultats que si la greffe sur l'organisation
réussit", même si beaucoup de gens ont voulu y voir un
acronyme comme par
exemple Méthode d'Étude et de Réalisation Informatique par
les Sous-ensembles ou pour les systèmes d'entreprise. 8(*)
III.3.3. Positionnement de la
méthode
La méthode Merise est une
méthode
d'analyse, de
conception et de
réalisation de
systèmes
d'informations informatisés.
En amont, elle se situait dans le prolongement naturel d'un
schéma
directeur, souvent conduit suivant la
méthode
RACINES, très présente notamment dans le
secteur
public.
Les projets Merise étaient généralement
des
projets de grande
ampleur de refonte d'un existant complexe, dans un environnement
grand
système. La
méthode a
aussi connu des tentatives d'adaptation avec les
SGBD relationnels, les
différentes interfaces homme-machine
IHM, l'
Orienté
objet, le développement micro, les outils
CASE,
la
rétro-ingénierie...
mais qui n'ont pas connu le même succès.
La méthode est essentiellement française. Elle a
des équivalents à l'étranger en ce qui concerne les
modèles de
données (avec des différences, par exemple les
cardinalités
ne sont pas aussi détaillées dans les modèles
anglo-saxons). En revanche la modélisation des traitements est beaucoup
plus complexe que dans les méthodes anglo-saxonnes.
Sa mise en oeuvre peut paraître lourde. On consacre
beaucoup de temps à concevoir et à pré-documenter avant de
commencer à coder, ce qui pouvait sembler nécessaire à une
époque où les moyens informatiques n'étaient pas aussi
diffusés qu'aujourd'hui. Cela dit, elle évite l'écueil
inverse du développement micro, qui souffre du manque de documentation,
et où les erreurs sont finalement très coûteuses à
réparer à posteriori.
Même si les échanges et la consultation entre
concepteurs et utilisateurs sont formellement organisés, on a aussi
reproché à Merise d'utiliser un formalisme jugé complexe
(surtout pour les modèles de données), qu'il faut d'abord
apprendre à manier, mais qui constitue ensuite un véritable
langage commun, puissant et rigoureux pour qui la maîtrise.
L'articulation très codifiée et bien
balisée des différentes étapes, avec un descriptif
très précis des résultats attendus est ce qui reste
aujourd'hui de mieux connu et de plus utilisé.
La méthode Merise est bien adaptée à
l'automatisation de tâches séquentielles de gestion pure. En
revanche, elle est mal adaptée aux environnements distribués,
où de multiples applications externes à un domaine viennent
interagir avec l'application à modéliser. De plus, elle n'est pas
en mesure de modéliser les
informations
à caractère
sémantique
(documents,...).
III.3.4. Méthode
d'analyse et de conception
La méthode MERISE préconise d'analyser
séparément données et traitements, à chaque niveau.
On aura pris soin de vérifier la cohérence entre ces deux
analyses avant la validation et le passage au niveau suivant.
La méthode Merise d'analyse et de conception propose
une démarche articulée simultanément selon 3 axes pour
hiérarchiser les préoccupations et les questions auxquelles il
faut répondre lors de la conduite d'un projet:
· Cycle de vie : phases de conception, de
réalisation, de maintenance puis nouveau cycle de projet.
· Cycle de décision : des grands choix (GO-NO
GO : Étude préalable), la définition du projet
(étude détaillée) jusqu'aux petites décisions des
détails de la réalisation et de la mise en oeuvre du
système d'information. Chaque étape est documentée et
marquée par une prise de décision.
· Cycle d'abstraction : niveaux conceptuels,
logique/organisationnel et physique/opérationnel (du plus abstrait au
plus concret) L'objectif du cycle d'abstraction est de prendre d'abord les
grandes décisions métier, pour les principales activités
(Conceptuel) sans rentrer dans le détail de questions d'ordre
organisationnel ou technique.
La méthode Merise, très analytique (attention
méthode systémique), distingue nettement les données et
les traitements, même si les interactions entre les deux sont profondes
et s'enrichissent mutuellement (validation des données par les
traitements et réciproquement). Certains auteurs (Merise/méga,
puis Merise/2) ont également apporté la notion
complémentaire de communications, vues au sens des messages
échangés. Aujourd'hui, avec les SGBD-R, l'objet, les notions de
données et de traitements sont de plus en plus imbriquées.
III.3.4. 1. Courbe du
soleil
La littérature parle de « courbe du
soleil », établissant une analogie entre la démarche
Merise et le lever puis le coucher du soleil : de même, le projet
doit élaborer une analyse critique de l'existant (en partant du niveau
physique et en s'élevant jusqu'au conceptuel : démarche
bottom-up,
phase ascendante de la courbe), puis décliner la solution retenue (en
partant du niveau conceptuel et revenant au niveau physique :
démarche
top-down,
phase descendante de la courbe).
Le recensement de l'existant est très
décrié en 2008, car il augmente la durée du projet. Sur ce
point, la démarche Merise est à l'opposé des
méthodes itératives de type
RAD,
ou de l'adoption systématique des best practices observées dans
d'autres entreprises du secteur, qui constituent une démarche typique
dans l'implémentation de progiciels.9(*)
III.3.4. 2. Niveau
conceptuel
L'étude conceptuelle Merise s'attache aux invariants de
l'entreprise ou de l'organisme du point de vue du métier : quels
sont les activités, les métiers gérés par
l'entreprise, quels sont les grands
processus
traités, de quoi parle-t-on en matière de données,
quelles notions manipule-t-on ?... et ce indépendamment des choix
techniques (comment fait-on ?) ou organisationnels (qui fait quoi ?)
qui ne seront abordés que dans les niveaux suivants.
Au niveau conceptuel on veut décrire, après
abstraction, le modèle (le système) de l'entreprise ou de
l'organisme :
· le Modèle conceptuel des données (ou
MCD), schéma représentant la structure du
système
d'information, du point de vue des
données,
c'est-à-dire les dépendances ou relations entre les
différentes données du
système
d'information (par exemple : le client, la commande, la ligne de
commande, etc.),
· et le Modèle conceptuel des traitements (ou
MCT), schéma représentant les traitements, en réponse aux
événements à traiter (par exemple : la prise en
compte de la commande d'un client).
Dans l'idéal, le MCD et le MCT d'une entreprise sont
stables, à périmètre fonctionnel constant, et tant que le
métier de l'entreprise ne varie pas. La modélisation ne
dépend pas du choix d'un
progiciel ou d'un
autre, d'une automatisation ou non des tâches à effectuer, d'une
organisation ou d'une autre, etc.
III.3.4. 2.1. Le MCD : modèle conceptuel des
données
Le MCD repose sur les notions d'entité et d'association
et sur les notions de relations. (entity/relationship en anglais).
·
Justification des cardinalités
Pour l'entité Donneur et l'entité DonSang
- Un Donneur doit faire un donsang et peut en faire
plusieurs
- Un donsang ne doit être fait que par un donneur.
Pour l'entité Donneur et l'entité
Prélèvement
- Un donneur peut subir un ou plusieurs
prélèvements
- Un prélèvement ne peut être subi que par
un donneur
Pour l'entité Ambulant et Prélèvement
- Un Ambulant peut subir un ou plusieurs
prélèvements
- Un prélèvement ne peut être subi que par
un Ambulant
Pour l'entité EPC et Prélèvement
- Un EPC peut subir un ou plusieurs
prélèvements
- Un prélèvement ne peut être subi que par
un EPC
Pour l'entité DonSang et Test
- Un donsang doit subir un test et peut en subir plusieurs
- Un Test ne peut être subi que par un donsang
Pour l'entité Prélèvement et Test
- Un prélèvement doit subir un test et peut en
subir plusieurs
- Un Test ne peut être subit que par un
prélèvement
Pour l'entité Employé et Test
- Un employé peut faire un ou plusieurs tests
- Un test doit être fait par un employé
Pour l'entité Employé et RemiseRst
- Un employé peut faire une ou plusieurs remises de
résultats
- Une remise de résultat ne doit être faite que
par un employé
· Vérification du MCD
Il existe des règles de vérification applicables
aux différentes propriétés du MCD.il s'agit des
contraintes d'intégrités et de normalisation.
Contrainte d'intégrité
Les contraintes d'intégrité reflètent la
règle de gestion de l'organisation. Il existe trois contraintes
d'intégrité liées au modèle relationnel.
Il s'agit de
Ø Contrainte d'intégrité de
domaine ;
Ø Contrainte d'intégrité
d'entité ;
Ø Contrainte d'intégrité
référentielle.
L'intégrité de domaine concerne toutes les
propriétés, tandis que l'intégrité d'entité
et l'intégrité référentielle concernent les
identifiants.
ü Contrainte d'intégrité de domaine ;
elle stipule que toute valeur prise par une propriété ou attribut
doit être contrôlé par rapport au domaine au quel il est
associé.
ü Contrainte d'intégrité
d'entité ; elle stipule que toute valeur prise par un identifiant
doit être unique et non nulle.
ü Contrainte d'intégrité
référentielle ; elle stipule que toute valeur prise par une
clé étrangère doit également apparaître parmi
les valeurs prises par la clé primaire correspondante. En d'autres
termes, les composants de d'identifiant d'une relation doivent exister. Lors
que toutes les contraintes d'intégrité sont
vérifiées, le système d'information est dans un
état dit `cohérent'.
· Les règles de normalisation
Les règles de normalisation ont un objectif
d'éliminer les redondances pour prévenir les risques
d'incohérence dans la base de données suite à certains
traitements tels que les mises à jour.
Il existe cinq règles de normalisation [ou forme normale]
dont les trois premières sont couramment utilisées.
ü La première forme normale [1FN]
On dit qu'une relation est en première forme normale si
tous les attributs qui le composent sont atomiques, c'est - à - dire
non décomposables.
ü La deuxième forme normale [2FN]
On dit qu'une relation est en deuxième forme normale
si :
- Elle est en première forme normale
- Toutes les dépendances fonctionnelles entre la
clé et les autres attributs sont élémentaires, c'est -
à - dire toute attribut non clé primaire est dépendant de
la clé primaire entière.
ü La troisièmement forme normale [3FN]
On dit qu'une relation est en troisième forme
normale si :
- Elle est en deuxième forme normale
- Toutes les dépendances fonctionnelles entre la
clé et les autres attributs sont élémentaires et directes,
c'est - à - dire tout attribut non clé ne dépend pas d'un
attribut non clé.
ü Forme normale de Boyce-Codd [ED09] :
- Un objet ou une association est en BCFN s'il est en 3FN et
quand X détermine Y (Y n'est pas inclus dans X) est
vérifié alors X contient un identifiant de l'objet ou de
l'association.
ü Quatrième forme normale [4FN] :
- Une association est en 4FN si elle est en BCFN et si elle
ne possède pas de dépendance multivaluée.
ü Cinquième forme normale [5FN] :
- Une association est en 5FN si elle est en 4FN et si elle ne
possède pas de dépendance de jointure.
En fin, il faut supprimer du modèle des polysémies,
c'est-à-dire les propriétés différentes ayant le
même nom, et les synonymes, c'est-à-dire des
propriétés différentes ayant la même signification.
a) L'entité ou objet
L'entité est définie comme un objet de gestion
considéré d'intérêt pour représenter
l'activité à modéliser (exemple : entité
Donneur) et chaque entité est porteuse d'une ou plusieurs
propriétés simples, dites atomiques (exemples : codeD,
NumcarteD, nomD, PrénomD, AdresseD, LieuND, DateND, SexeD, PoidsD, TAD)
dont l'une, unique et discriminante, est désignée comme
identifiant (exemple : codeD).
L'entité représente le concept qui se
décline, dans le concret en occurrences d'individus.
Exemples :
· (1, KANA, Jean, C13/461, Rohero, Ntunda, 10/4/1975,
Masculin, 64,12/7) et
· (2, BUKURU, Emile, C15/467, Ngagara, Bitare, 15/4/1964,
Masculin, 78, 13/8), sont deux occurrences de l'entité "Donneur" et sont
constituées de n-uplets de propriétés, que le code 1 ou 2,
suffit à identifier sans risque de doublon.
Par construction, le MCD impose que toutes les
propriétés d'une entité aient vocation à être
renseignées (il n'y a pas de propriété
« facultative »).
Le MCD doit, de préférence, ne contenir que le
coeur des informations strictement nécessaires pour réaliser les
traitements conceptuels : les informations calculées (ex: Le nombre de
donneurs Masculins) et a fortiori celles liées aux choix d'organisation
conçus pour effectuer les traitements ne doivent pas y figurer.
b) L'association ou relation
L'association est un lien sémantique entre une ou
plusieurs entités : l'association peut être réflexive,
de préférence binaire (ex : un donneur fait un don), parfois
ternaire, voire de dimension supérieure. Elle peut également
être porteuse d'une ou plusieurs propriétés.
Cette description sémantique est enrichie par la notion
de cardinalité, celle-ci indique le nombre minimum (0 ou 1) et maximum
(1 ou n) de fois où une occurrence quelconque d'une entité peut
participer à une association (ex: un donneur fait un don dans un (card.
min=1) et plusieurs dons (card. Max = n) ; et réciproquement un don
doit être fait par un donneur (card. min=1) et un seul (card .
Max=1).
Le MCT repose sur les notions d'événement et
d'opération, celle de processus en découle.
a) L'événement
Un événement est assimilable à un message
porteur d'informations donc potentiellement de données
mémorisables (par exemple : l'événement don
contient au minimum l'identification du donneur, Quantité du sang et
Lieu de don).
Un événement peut
· déclencher une opération (ex : `don
de sang à tester' déclenche l'opération `test du sang'),
· être le résultat d'une opération
(ex : 'résultat à remettre' suite à
l'opération de 'test du sang'), et à ce titre être,
éventuellement, un événement déclencheur d'une
autre opération.
b) L'opération
Une opération se déclenche uniquement par le
stimulus d'un ou de plusieurs évènements synchronisés
Elle est constituée d'un ensemble d'actions
correspondant à des règles de gestion de niveau conceptuel,
stables pour la durée de vie de la future application (ex: pour remettre
le résultat: vérifier le code du donneur.
Le déroulement d'une opération est non
interruptible : les actions à réaliser en cas d'exceptions,
les évènements résultats correspondants doivent être
formellement décrits (ex : en reprenant l'exemple
précédent, si le code du donneur indiqué est incorrect
prévoir sa recherche à partir du nom ou de l'adresse.
c) Le processus
Un processus est une vue du MCT correspondant à un
enchaînement pertinent d'opérations du point de vue de l'analyse
(ex : l'ensemble des évènements et opérations qui se
déroulent entre le test du sang et la remise du résultat.
III.3.4. 3. Niveau logique
ou organisationnel
A ce niveau de préoccupation, les modèles
conceptuels sont précisés et font l'objet de choix
organisationnels. On construit :
· un Modèle Logique des Données (ou MLD),
qui reprend le contenu du MCD précédent, mais précise la
volumétrie, la structure et l'organisation des
données telles
qu'elles pourront être implémentées. Par exemple, à
ce stade, il est possible de connaître la liste exhaustive des tables qui
seront à créer dans une
base de
données relationnelle
· un Modèle Logique des Traitements (ou MLT), qui
précise les acteurs et les moyens qui seront mis en oeuvre. C'est ici
que les traitements sont découpés en
procédures
fonctionnelles (ou PF).
Comme son nom l'indique, l'étude organisationnelle
s'attache à préciser comment on organise les données de
l'entreprise (MLD) et les tâches ou procédures (MLT). Pour autant,
les choix techniques d'implémentation, tant pour les données
(choix d'un
SGBD) que pour les
traitements (
logiciel,
progiciel), ne
seront effectués qu'au niveau suivant.
La façon dont seront conservés les
historiques
des
données fait
également partie de ce niveau de préoccupation.
III.3.4. 3. 1. Le MLD : modèle logique des
données
Également appelée dérivation du MCD dans
un formalisme adapté à une implémentation
ultérieure, au niveau physique, sous forme de base de données
relationnelle ou réseau, ou autres (ex: simples fichiers).
La transcription d'un MCD en modèle relationnel
s'effectue selon quelques règles simples qui consistent d'abord à
transformer toute entité en table, avec l'identifiant comme
clé
primaire, puis à observer les valeurs prises par les
cardinalités maximum de chaque association pour représenter
celle-ci soit (ex : card. max 1-n ou 0-n) par l'ajout d'une clé
étrangère dans une table existante.
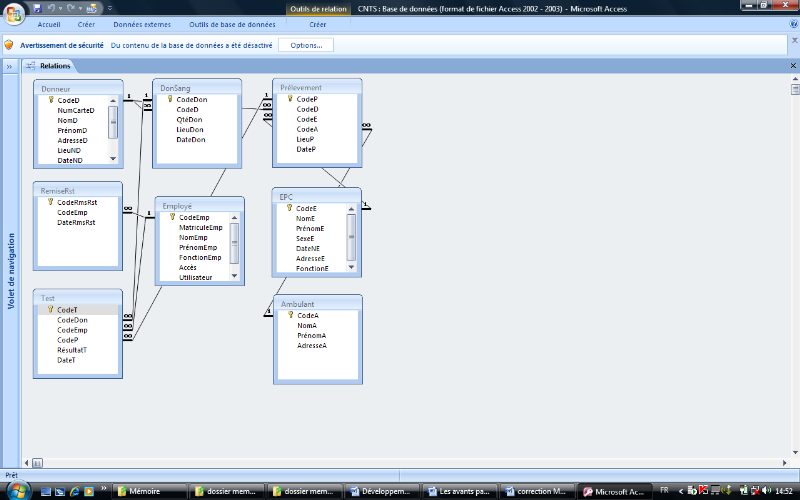
· MLD / Modèle relationnel
Donneur (codeD, numcarteD, NomD, PrénomD,
AdresseD, LieuND, DateND, SexeD, PoidsD, TAD)
DonSang (codeDon, CodeD, QtéDon, LieuDon,
DateDon)
Prélèvement (CodeP, CodeD, CodeE, CodeA,
LieuP, DateP)
EPC (CodeE, NomE, PrénomE, SexeE, DateNE,
AdresseE, FonctionE)
Ambulant (CodeA, NomA, PrénomA, AdresseA)
Test (CodeT, CodeDon, CodeEmp, CodeP, RésultatT,
DateT)
RemiseRst (CodeRmsRst, CodeEmp, DateRmsRst
Employé (CodeEmp, MatriculeEmp, NomEmp,
PrénomEmp, FonctionEmp, Accès, Utilisateur, MotPasse)
Les opérateurs de l'algèbre relationnelle
(projection, sélection, jointure, opérateurs ensemblistes)
peuvent ensuite directement s'appliquer sur le modèle relationnel ainsi
obtenu et normalisé.
Cette démarche algorithmique ne fournit pas à ce
niveau d'élément sur l'optimisation de la durée ou des
ressources nécessaires pour exécuter les traitements dans
l'environnement de production cible.
La transcription du MCD en MLD doit également
être précédée d'une étape de synchronisation
et de validation des modèles de données (MCD) et de traitement
(MCT et MLT), au moyen de vues. Cela afin d'y introduire les informations
d'organisation définies au MLT, d'éliminer les
propriétés conceptuelles non utilisées dans les
traitements ou redondantes et enfin de vérifier que les données
utilisées pour un traitement sont bien atteignables par 'navigation'
entre les entités/relations du MCD.
III.3.4. 3. 2. Le MLT modèle logique des
traitements
Le MLT, appelé aussi MOT pour « modèle
organisationnel des traitements », décrit avec
précision l'organisation à mettre en place pour réaliser
une ou, le cas échéant, plusieurs opérations figurant dans
le MCT. Il répond aux questions suivantes : qui ? Quoi ?
Où ? Quand ? À un MCT correspondent donc
généralement plusieurs MLT.
Les notions introduites à ce niveau sont : le
poste de travail, la phase, la tâche et la procédure.
a) Le poste de travail
Le poste de travail décrit la localisation, les
responsabilités, et les ressources nécessaires pour chaque profil
d'utilisateur du système.
Par exemple, on peut identifier les profils suivants :
chargé de la sélection des donneurs de sang, chargé de la
remise des résultats, etc.
b) La phase
La phase est un ensemble d'actions (cf. la notion
d'opération pour le MCT) réalisées sur un même poste
de travail.
La phase peut être :
· soit manuelle : par exemple, le
prélèvement du sang sur un Ambulant ;
· soit automatisée et interactive : par
exemple, la saisie d'un formulaire EPC;
· soit automatisée et planifiée (on parle
aussi de batch) : par exemple, la production et l'envoi des listes des
donneurs à la Direction.
c) La tâche
La tâche est une description détaillée
d'une phase automatisée interactive.
Par exemple, elle correspond à la spécification
de l'interface et du dialogue humain-machine, à la localisation et la
nature des contrôles à effectuer, etc.
d) La procédure
La procédure est un regroupement de phases. Elle
équivaut sur le plan organisationnel aux notions d'opérations et
d'actions conceptuelles. La différence est que l'on considère ici
ces dernières comme se déroulant sur une période de temps
homogène.
Des procédures d'origines non conceptuelles peuvent
être ajoutées du fait des choix d'organisation effectués.
Par exemple, on peut citer les procédures
d'échanges d'informations liées à l'externalisation de
certaines activités, la prise en compte des questions de
sécurité en cas de choix de solution Web, etc.
III.3.4. 4. Niveau
physique
Les réponses apportées à ce dernier
niveau permettent d'établir la manière concrète dont le
système sera mis en place.
· le Modèle Physique des Données (ou MPD ou
MPhD) permet de préciser les systèmes de stockage employés
(implémentation du MLD dans le
SGBD retenu)
· le Modèle Opérationnel des Traitements
(ou MOT ou MOpT) permet de
spécifier
les fonctions telles qu'elles seront ensuite réalisées par le
programmeur.
III.3.5. Les
différentes phases d'un projet Merise
Un projet élaboré selon la méthode Merise
est composé de différentes phases :
· Les acteurs d'un projet : il s'agit ici
d'identifier les acteurs d'un projet, les personnes qui interviennent dans une
quelconque phase de celui-ci. Ces acteurs apparaitront logiquement dans la
modélisation des flux de données.
· Schéma
directeur : « le schéma directeur définit
le cadre organisationnel et informatique des futurs projets », et
donc doit définir le projet relativement aux objectifs de l'entreprise,
sa stratégie. Il ne s'agira pas ici de donner les détails du
projet, mais plutôt de fournir le cadre, les objectifs, et moyens du
projet.
· L'
étude
préalable : elle décrit les
besoins et les
attentes des
utilisateurs, les
traitements
(
processus
métier) pour la procédure représentative
(modèle conceptuel des traitements, modèle logique des
traitements, ébauche de modèle physique des données), et
les principales
données (
modèle
conceptuel des données,
modèle
logique des données, ébauche de modèle physique
externe des traitements),
· L'
étude
détaillée : elle décrit les besoins,
traitements, et données de façon plus détaillée
pour chaque
procédure
fonctionnelle. L'étude détaillée se
décompose elle-même en :
o
Spécifications fonctionnelles générales (
Tableau
des opérations par processus, TOP), écrites par la
maîtrise
d'ouvrage,
o
Spécifications fonctionnelles détaillées,
écrites par la
maîtrise
d'oeuvre,
· L'
étude
technique : elle décrit les moyens techniques
nécessaires à la réalisation de l'application
(environnement technique,
SGBD,
langages
informatiques, consignes de développement,...).
· Production : elle décrit la mise en
production.
· Maintenance : elle décrit la maintenance du
système, et fournira donc au moins les éléments
suivants :
o les acteurs
o les documentations
o les formations 10(*)
III.4. Conclusion
L'analyse et la conception d'un logiciel exige un travail
délicat en choisissant objectivement les méthodes et les
outils ; de modélisation, de développement et de gestion de
base de données.
En optant pour MERISE comme méthode d'analyse et de
conception, VB 6.0 comme outils de développement et Access comme SGBD,
l'arrivée aux résultats escomptés est sûre.
Ce chapitre montre déjà ce qu'est la structure
de données qui vont être stockées dans la base de
données Access, il reste le codage.
CHAPITRE IV. REALISATION
IV.1. Introduction
Ce chapitre va mettre en exergue l'aspect
général du logiciel ; le fonctionnement et l'apparence. Ce
logiciel est conçu et réalisé pour élucider la
problématique détaillée dans les premières pages et
fera objet une fois utilisé, de thèse à l'hypothèse
de départ.
IV.2. Cycle de Vie
Le « cycle de vie d'un logiciel » (en
anglais software lifecycle), désigne toutes les étapes du
développement d'un logiciel, de sa conception à sa disparition.
L'objectif d'un tel découpage est de permettre de définir des
jalons intermédiaires permettant la validation du développement
logiciel, c'est-à-dire la conformité du logiciel avec les besoins
exprimés, et la vérification du processus de
développement, c'est-à-dire l'adéquation des
méthodes mises en oeuvre.
L'origine de ce découpage provient du constat que les
erreurs ont un coût d'autant plus élevé qu'elles sont
détectées tardivement dans le processus de réalisation. Le
cycle de vie permet de détecter les erreurs au plus tôt et ainsi
de maîtriser la
qualité
du logiciel, les délais de sa réalisation et les coûts
associés.
Le cycle de vie du logiciel comprend
généralement au minima les activités suivantes :
· Définition des objectifs, consistant à
définir la finalité du projet et son inscription dans une
stratégie globale.
· Analyse des besoins et faisabilité,
c'est-à-dire l'expression, le recueil et la formalisation des besoins du
demandeur (le client) et de l'ensemble des contraintes.
· Conception générale. Il s'agit de
l'élaboration des spécifications de l'architecture
générale du logiciel.
· Conception détaillée, consistant à
définir précisément chaque sous-ensemble du logiciel.
· Codage (Implémentation ou programmation), soit
la traduction dans un langage de programmation des fonctionnalités
définies lors de phases de conception.
· Tests unitaires, permettant de vérifier
individuellement que chaque sous-ensemble du logiciel est
implémenté conformément aux spécifications.
· Intégration, dont l'objectif est de s'assurer de
l'interfaçage des différents éléments (modules) du
logiciel. Elle fait l'objet de tests d'intégration consignés dans
un document.
· Qualification (ou recette), c'est-à-dire la
vérification de la conformité du logiciel aux
spécifications initiales.
· Documentation, visant à produire les
informations nécessaires pour l'utilisation du logiciel et pour des
développements ultérieurs.
· Mise en production, démarrage de l'utilisation
du logiciel.
· Maintenance, comprenant toutes les actions correctives
(maintenance corrective) et évolutives (maintenance évolutive)
sur le logiciel.
La séquence et la présence de chacune de ces
activités dans le cycle de vie dépend du choix d'un modèle
de cycle de vie entre le client et l'équipe de développement.
IV.2.1. Modèle de cycle
de vie en cascade
Le modèle de cycle de vie en cascade a
été mis au point dès 1966, puis formalisé aux
alentours de 1970. Dans ce modèle le principe est très simple :
chaque phase se termine à une date précise par la production de
certains documents ou logiciels. Les résultats sont définis sur
la base des interactions entre étapes, ils sont soumis à une
revue approfondie et on ne passe à la phase suivante que s'ils sont
jugés satisfaisants. Le modèle original ne comportait pas de
possibilité de retour en arrière. Celle-ci a été
rajoutée ultérieurement sur la base qu'une étape ne remet
en cause que l'étape précédente, ce qui s'avère
insuffisant dans la pratique.
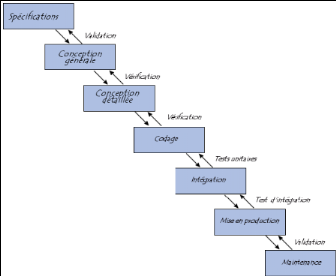
Fig. IV.1 :
Modèle du cycle de vie en cascade
IV.2.2.
Modèle de cycle de vie en V
Le modèle en V demeure actuellement le cycle de vie le
plus connu et certainement le plus utilisé. Le principe de ce
modèle est qu'avec toute décomposition doit être
décrite la recomposition, et que toute description d'un composant doit
être accompagnée de tests qui permettront de s'assurer qu'il
correspond à sa description. Ceci rend explicite la préparation
des dernières phases (validation et vérification) par les
premières (construction du logiciel), et permet ainsi d'éviter un
écueil bien connu de la spécification du logiciel :
énoncer une propriété qu'il est impossible de
vérifier objectivement après la réalisation.
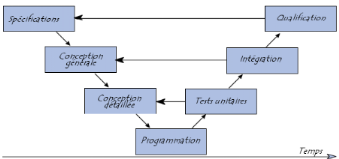
Fig. IV. 2 : Modèle du cycle de vie en
V
IV.2.3. Modèle de cycle de vie en spirale
Proposé par B. Boehm en 1988, ce modèle est
beaucoup plus général que le précédent. Il met
l'accent sur l'activité d'analyse des risques : chaque cycle de la
spirale se déroule en quatre phases :
Ø détermination, à partir des
résultats des cycles précédents, ou de l'analyse
préliminaire des besoins, des objectifs du cycle, des alternatives pour
les atteindre et des contraintes.
Ø Analyse des risques, évaluation des
alternatives et, éventuellement maquettage.
Ø Développement et vérification de la
solution retenue, un modèle « classique » (Cascade ou en V)
peut être utilisé ici ;
Ø Revue des résultats et vérification du
cycle suivant.
L'analyse préliminaire est affinée au cours des
premiers cycles. Le modèle utilise des maquettes exploratoires pour
guider la phase de conception du cycle suivant. Le dernier cycle se termine par
un processus de développement classique.
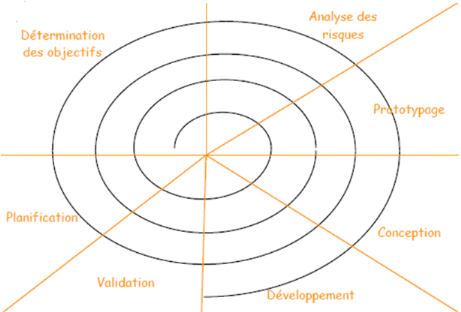
Fig.
IV.3 : Modèle de cycle de vie en spirale
IV.2.4. Modèle par incrément
Dans les modèles précédents un logiciel
est décomposé en composants développés
séparément et intégrés à la fin du
processus.
Dans les modèles par incrément, un seul ensemble
de composants est développé à la fois : des
incréments viennent s'intégrer à un noyau
de logiciel développé au préalable.
Chaque incrément est développé selon l'un des
modèles précédents.
Les avantages de ce type de modèle sont les suivants
:
· Chaque développement est moins complexe.
· Les intégrations sont progressives.
· Il est ainsi possible de livrer et de mettre en service
chaque incrément.
· Il permet un meilleur usage du temps et de l'effort de
développement grâce à la possibilité de recouvrement
(parallélisassions) des différentes phases.
Les risques de ce type de modèle sont les suivants :
· Remettre en cause les incréments
précédents ou pire le noyau.
· Ne pas pouvoir intégrer de nouveaux
incréments.
Les noyaux, les incréments ainsi que leurs interactions
doivent donc être spécifiés globalement, au début du
projet. Les incréments doivent être aussi indépendants que
possibles, fonctionnellement mais aussi sur le plan du calendrier du
développement.
IV.2.5. Modèle de prototypage
Un prototype : Un modèle exécutable d'un
système logiciel, qui souligne des aspects spécifiques.
· Caractéristiques :
Un degré élevé de participation du
client, une représentation tangible des exigences du client, très
utile quand les exigences sont instables ou incertaines.
 11(*) 11(*)
Fig. IV.4. :
Modèle de prototypage
IV.2.6. Choix du modèle de cycle de vie
Le cycle de vie adopté dans notre projet est celui en V
du fait que son principe est qu'avec toute décomposition doit
être décrite la recomposition, et que toute description d'un
composant doit être accompagnée de tests qui permettront de
s'assurer qu'il correspond à sa description. Puisque la vigilance est de
rigueur dans de tels projets, ce modèle évite au plus haut
degré le risque de tout refaire par le fait qu'il permet d'éviter
un écueil bien connu de la spécification du logiciel.
IV.3. Description de l'application
L'application est un logiciel de gestion des donneurs de sang
sur mesure permettant de gérer les donneurs de sang (la gestion des dons
de sang, prélèvements, tests de sang et les remises de
résultats) et d'offrir à l'utilisateur quelques accessoires
à savoir un calendrier. L'outil de programmation est VB 6.0 et
grâce à son mode de programmation graphique, les formulaires
forment l'interface utilisateur qui permet de manipuler la base de
données en Access et sont également le support des informations
liées au CNTS (photo, slogan,...). La couleur de ces formulaires est
rouge pour symboliser le don de sang, ce qui est à la base de ce projet.
Le logiciel permet également la gestion des accès pour les
utilisateurs selon leur champ d'action. Il offre également la
possibilité d'imprimer quelques listes (liste des donneurs, liste des
ambulants,...).
IV.3.1. L'interface utilisateur
a. Liste des formulaires et quelques
illustrations
- Accueil
- Identification d'un utilisateur
- Principal
- Gestion de Donneurs
- Gestion des EPC
- Gestion des Ambulants
- Gestion des Employés (utilisateurs)
- Validation de don de sang
- Validation d'un prélèvement
- Recherche d'un Donneur
- Recherche d'un Ambulant
- Recherche d'une EPC
- Validation de remise de résultat
- Suivi individuel d'un Donneur de sang
- Gestion des tests de sang
· Le formulaire d'accueil
Il est le premier formulaire qui apparaît après
le lancement de l'application, elle dispose de deux boutons, l'un
« entrer » pour accéder au deuxième qui
permet de s'identifier et l'autre « sortir » pour
abandonner l'accès à ce dernier et permet de quitter
l'application.
Une fois accéder au formulaire de l'identification, le
formulaire d'accueil reste en mode d'état de fenêtre maximum
pour permettre à l'utilisateur de voir constamment le slogan
défilant du CNTS, donc ce formulaire d'accueil reste comme
arrière plan de l'écran.

· Le formulaire d'identification
Ce formulaire permet de s'identifier pour accéder au
formulaire principal qui donne accès aux autres formulaires et aux
imprimés suivant le droit d'accès préétabli.
Il donne le choix entre « Oui » pour
continuer, « Non » pour recommencer à entrer
l'utilisateur et le mot de passe et « Annuler » pour
quitter le formulaire.
Si les paramètres entrés sont incorrects, il
renvoie le message qui te dit « Utilisateur ou Mot de Passe
incorrect!!!Cliquez sur OUI pour recommencer ou sur NON pour
Quitter ».
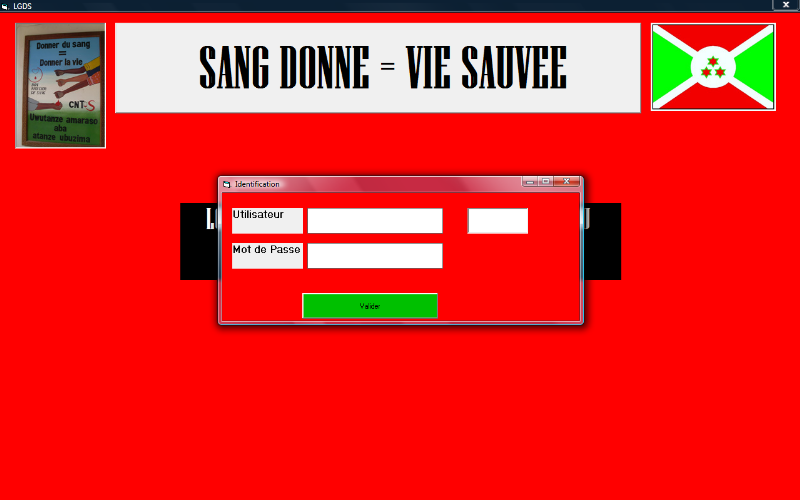
Fig. IV. 6. Le formulaire d'identification
· Formulaire principal
Ce formulaire a comme principale fonction de montrer tous les
formulaires et rapports accessibles par accès. Pour voir la liste des
formulaires, il faut cliquer sur le menu « ouvrir »
puis « formulaires » et après il faut choisir
un des formulaires activés car ceux qui ne le sont pas sont
inaccessibles suite aux droits d'accès.
Cela est également valable pour les rapports et le
chemin suivi est « ouvrir »
puis « rapports » et enfin le choix d'un rapport voulu
et activé.

Fig. IV. 7. Formulaire principal
· Formulaire de gestion de donneurs
Ce formulaire permet la saisie des donneurs de sang par le
bouton « Enregistrer », la modification des attributs
d'un donneur (adresse, poids et la valeur de la tension artérielle) par
le bouton « Modifier » , la recherche d'un donneur par
code (n° de donneur) ou par nom ou encore par numéro de carte du
donneur par le bouton « Recherche » et en faisant le
choix sur l'un des boutons radio(bouton d'option). Il dispose d'un bouton
« Quitter » pour quitter le formulaire.
Puisque généralement, l'enregistrement d'un
donneur précède un don ou un prélèvement, le
formulaire dispose d'un menu « ouvrir » qui,
après avoir cliqué dessus, donne le choix entre l'ouverture du
formulaire « donsang » ou
« prélèvement ».
Lors de la saisie des attributs d'un donneur, arriver sur la
date de naissance, là il faut doubler cliquer dans cette zone de texte
pour voir s'afficher un calendrier afin d'opérer une sélection de
date, mois(en cliquant sur la zone comportant la date ou le mois voulu) et
année(en déroulant la zone comportant l'année par
défaut).
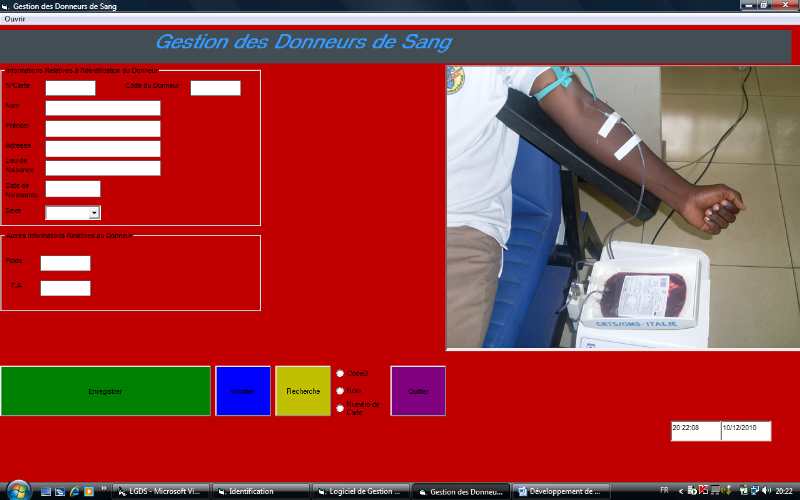
Fig. IV.8. Formulaire de gestion de donneurs
· Formulaire de validation de dons de
sang
Lui, il suit l'enregistrement de l'arrivée d'un
donneur et se contente de valider l'acte de don de sang.
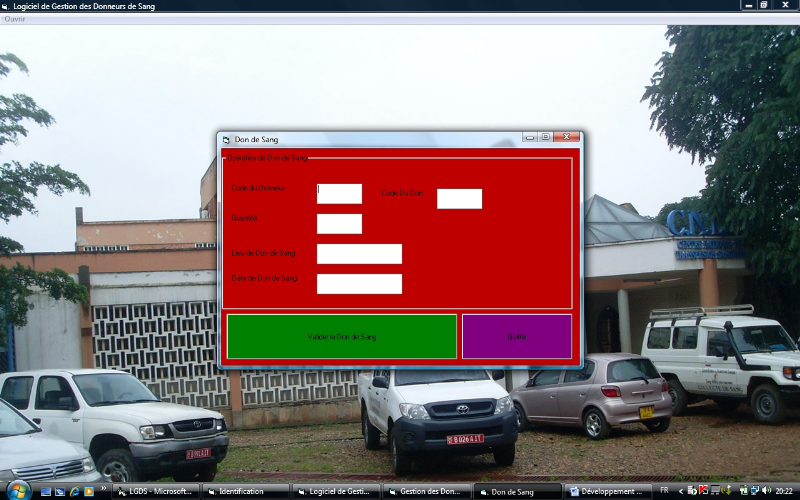
Fig. IV.9. Formulaire de validation de dons de sang
· Formulaire de
prélèvement
Ce formulaire, il est appelé pour valider un
prélèvement sur un Donneur, un Ambulant ou un EPC. Quand il est
appelé après enregistrement de l'arrivée d'un Donneur,
là le Donneur est suspect et doit d'abord être
prélevé pour test une petite quantité de sang avant de
refaire un don de sang.
Le formulaire valide ce prélèvement tout en
précisant le code de celui qui est prélevé selon qu'il est
Donneur, Ambulant ou EPC.
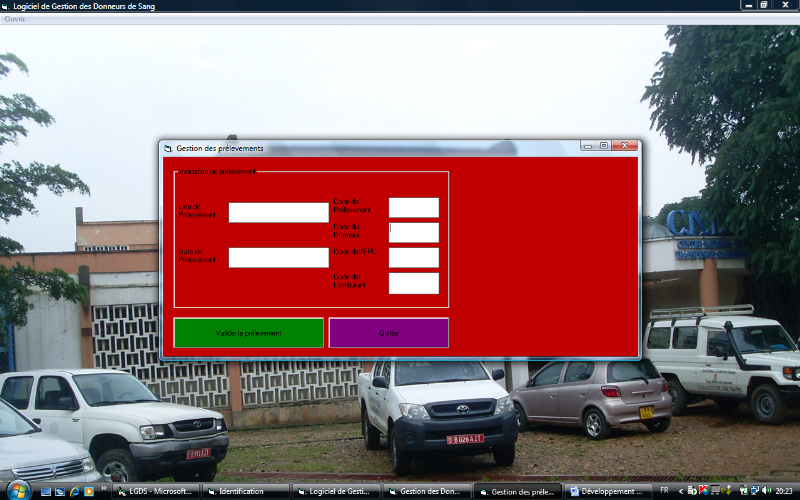
Fig. IV. 10. Formulaire de prélèvement
· Formulaire de Gestion des Ambulants
Le formulaire de gestion des Ambulant fonctionne comme celui
de gestion des Donneurs de sang sauf quelques différences à
savoir la modification d'un Ambulant qui porte uniquement sur l'adresse et la
recherche portant sur le code et le nom seulement. Sinon même
l'accès au formulaire de prélèvement suit le même
chemin que pour ce dernier.
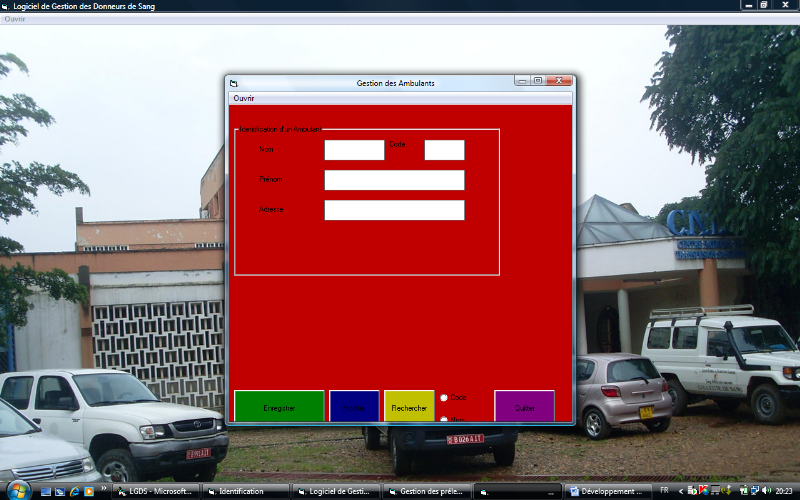
Fig. IV.11. Formulaire de Gestion des Ambulants
IV.4. Les imprimés
Pour permettre à l'utilisateur de mieux visualiser et
classer physiquement certaines informations, le logiciel prévoit un
moyen de pouvoir imprimer des listes.
a) Suite des listes imprimables
- Les Donneurs de sang
- Les Ambulants
- Les EPC
- Les Donneurs atteints du VIH
- Les Donneurs atteints d'Hépatite B
- Les Donneurs atteints d'Hépatite C
- Les Donneurs atteints de Syphilis
- Les Ambulants atteints du VIH
- Les Ambulants atteints d'Hépatite B
- Les Ambulants atteints d'Hépatite C
- Les Ambulants atteints de Syphilis
- Les EPC atteints d'Hépatite B
- Les EPC atteints d'Hépatite C
- Les EPC atteints de Syphilis
- Les Donneurs de Sang, leur Dons et le nombre de fois.
· Liste des Donneurs de Sang
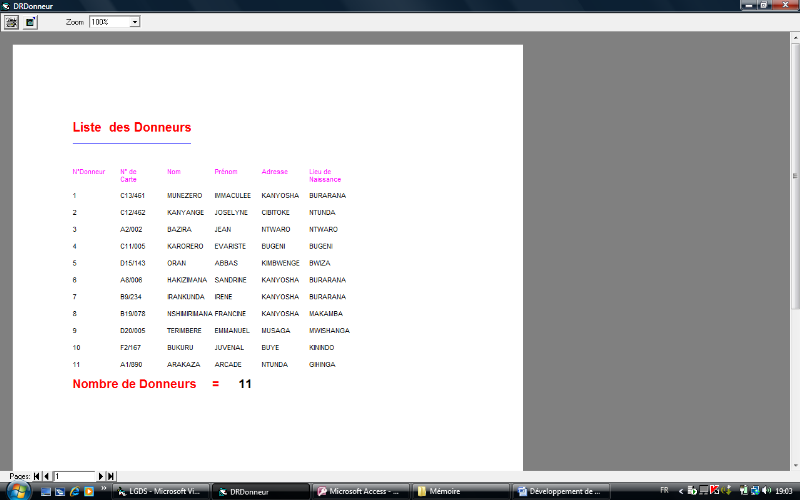
Fig. IV.12. Liste des Donneurs de Sang
· Liste des Donneurs atteints du VIH
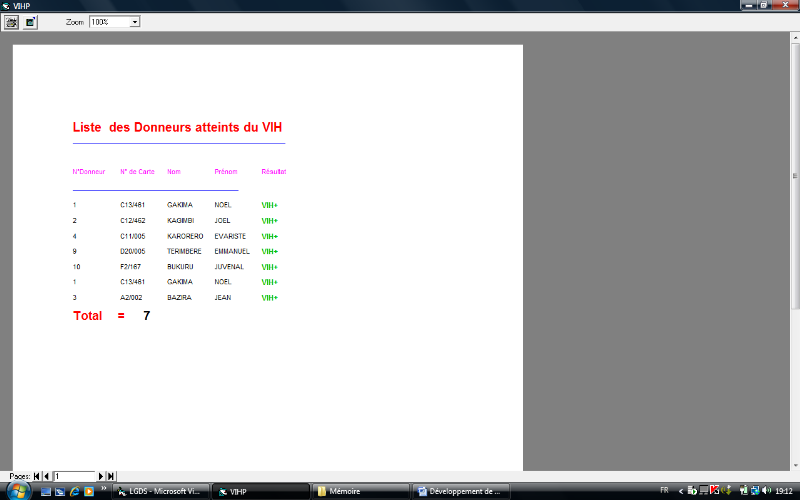
Fig. IV. 12. Liste des Donneurs atteints du VIH
IV.5. Conclusion
La réalisation de ce logiciel qui vient d'être
parcourue laisse pas mal d'autres fonctionnalités qui ne sont pas
décrites au cours de ce chapitre.
Ce logiciel se veut être évolutif et laisse au
développeur la possibilité d'enrichir sa performance et son
efficacité dans son fonctionnement.
CONCLUSION GENERALE ET RECOMMANDATIONS
Le travail qui consiste à analyser et développer
le logiciel de gestion des donneurs de sang qui vient d'être fait en
détails dans ces chapitres ci-haut, vient en premier lieu enrichir mes
connaissances théoriques et surtout pratiques dans l'option de la
programmation qui est un domaine préféré et une passion
pour moi.
En plus, avoir eu la chance de travailler sur la gestion des
donneurs de sang, est une immense joie pour moi d'apporter une contribution au
bon fonctionnement de ce centre dont je suis l'un des partenaires.
Ce travail est articulé en quatre chapitres qui
sont :
v L'Introduction générale : qui parle en
gros du squelette de tout le travail et justifie le choix du sujet, la
problématique et surtout fixe l'hypothèse.
v Présentation du CNTS : Il décrit en
général ce qu'est le CNTS ; son historique, sa mission, ses
objectifs et particulièrement, il se focalise sur le service des
donneurs de sang.
v Méthodes et outils : Ce chapitre met en
évidence la méthode de modélisation MERISE, le SGBD
Access, l'outil de programmation VB 6.0 utilisés dans ce travail et
justifie également le choix de derniers.
v Analyse et conception : Il est le noyau du travail
car, il comporte toutes les démarches d'analyse et de conception du
logiciel. C'est dans ce chapitre qu'on détecte réellement ce que
va être la structure des données dans leur base et surtout tous
les contours du champ d'action du projet.
v Réalisation : Il porte sur la
présentation du logiciel conçu en expliquant son fonctionnement.
Il est le chapitre final.
En guise de recommandations, le CNTS ferait mieux de se doter
d'un système de gestion automatisé dans tous ses services afin de
rendre son travail plus rentable car cela diminuerait le nombre de
salariés et rendrait le travail très rapide et moins fastidieux.
BIBLIOGRAPHIE
Cours vue en classe
Cours Structure de l'information première licence
année 2008; dispensé par Me. Evariste MINANI.
Documents électroniques
http://www.commentcamarche.net/contents/genie-logiciel/cycle-de-vie.php3
http://fr.wikipedia.org/wiki/Fichier:Blut-EDTA.jpg#file
http://fr.wikipedia.org/wiki/Don_de_sang
http://www.memoireonline.com/02/09/2005/m_Conception-et-Developpement-dun-logiciel--de-gestion-commerciale7.html
http://www.google.fr/search?hl=fr&defl=fr&q=define:Merise&sa=X&ei=2fHwTM2BKIK8lQe23LiyDA&ved=0CBoQkAE
http://fr.wikipedia.org/wiki/Merise_(informatique)#Historique
http://fr.wikipedia.org/wiki/Merise_(informatique)#Positionnement_de_la_m.C3.A9thode
Autres documents
consultés
Archives du CNTS
* 1 _ Archives du CNTS
* 2 _ Archives du CNTS
* 3 _ Archives du CNTS
* 4 _
http://fr.wikipedia.org/wiki/Fichier:Blut-EDTA.jpg#file
* 5 _ CNTS
* 6 _
http://www.memoireonline.com/02/09/2005/m_Conception-et-Developpement-dun-logiciel--de-gestion-commerciale7.html
* 7 _
http://www.google.fr/search?hl=fr&defl=fr&q=define:Merise&sa=X&ei=2fHwTM2BKIK8lQe23LiyDA&ved=0CBoQkAE
* 8 _
http://fr.wikipedia.org/wiki/Merise_(informatique)#Historique
* 9 _
http://fr.wikipedia.org/wiki/Merise_(informatique)#Positionnement_de_la_m.C3.A9thode
* 10 _ Cours de la structure de
l'information
* 11 _
http://www.commentcamarche.net/contents/genie-logiciel/cycle-de-vie.php3
| 

