|
Ministère de l'enseignement supérieur
et de la
recherche scientifique
université des sciences et de la technologie
d'ORAN
- MOHAMMED BOUDIAF-
Faculté de
Génie Electrique
Département
d'électronique
Mémoire de projet de fin
d'étude
Pour l'obtention du diplôme
D'ingénieur en électronique :
Thème :

Présenté par :
· ZAHDOUR HICHAM .
· YOUBI ABDENOUR .
· Option : Communication
Devant le jury :
· président : Mr
OUSSLIM .
· Examinateur : Mr HAMADA . H
.
· Encadreur : Mr SAHARI . M
.


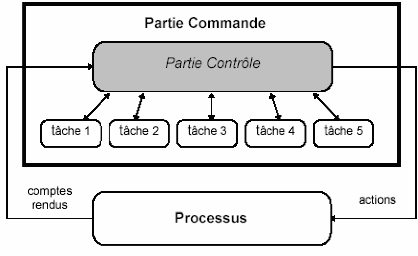
Remerciements
On exprime nos sincères remerciements à
monsieur
DR .SAHARI MOHAMMED, qui nous a
encadré.
Acceptez donc monsieur, l'hommage de ma
gratitude,
qui, si grande qu'elle puisse être, ne sera
jamais à la
hauteur de votre éloquence et de votre
dévouement.
On remercie vivement tout nos chers
enseignants,
dont on leurs adresse nos profondes
reconnaissances,
pour leurs efforts et aides.
Je dédie ce travail modeste, à mes
très chers parents, qui n'ont
jamais cessé à me tendre la main,
à me transmettre la volonté et
l'amour pour les études.
A mes frères et soeurs, et surtout à ma
grand mère.
A tous mes amis, à tout ceux qui m'ont
encouragé pour mes
études.
ZAHDOUR HICHAM
Je dédie ce travail a mes parents , a mes
familles et a tous
mes amis
Youbi Abdenour
Liste des figure
Fig 1-1 système temps réel / l'environnement Fig
1-2 échéance d'une tache
Fig 1-3 système de commande
Fig 1-4 parallélisme
Fig 1-5 principe de programmation en mode bouclé. Fig 2-1
Notion de périodicité
Fig 2-2 Transition d'état entre tache
Fig 3-1 Principe des Systems embarquée
Fig 3-2 Caractérise de PICOS18
Fig 3-3 les états d'une tache OSEK/VDX :basique(a gauche),
étendue (a droite). Fig 3-4 Exemple de synchronisation par
événement.
Fig 3-5 Exemple d'un événement
Fig 3-6 Inversion de priorité
Fig 3-7 Héritage de priorité
Fig 3-8 Fonctionnement des alarmes
Fig 4-1 liste des événements
Fig 4-2 exemple d'un événement
Fig 4-3 tableau des alarmes
Fig 4-4 Montage d'un capteur de température Fig 4-5
affichage de température sur PC.
Fig. 5-1 les codes source d'un objet
Fig 5-2 La chaîne de compilation Microchip
Sommaire
Préambule .01
Chapitre I Le temps réel 02
1-1Introduction : 03
1-2 La notion de temps réel ....03
1- 3 Architecture des Systèmes Temps Réel ...05
1- 4 Système de commande en temps réel ..06
1- 5 Contraintes de temps dans un système ....07
1- 6 Contraintes de temps faibles (tc << Tmax) 08
Chapitre II Multitâche .....09
2-1 Introduction 10
2-2 Notion de Tâche 10
2-3 Caractéristiques des tâches 11
2-3-1 Notion de priorité 11
2-3-2 Notion de périodicité 12
2-3-2-1 Les tâches périodiques 12
2-3-2-2 Les tâches non périodiques 13
2-3-2-3-1 Les tâches sporadiques 13
2-3-2-3-2 Les tâches apériodiques 13
2-4 Tâches matérielles, tâches logicielles
13
2-5 Etats d'une tâche 14
2-5-1 Transition entre tâche 14
Chapitre III Noyau temps réel pour système
Embarqué 17
3-1 Les Systèmes Embarqués
|
.18
|
3-2 Les Systèmes d'Exploitation pour Systèmes
Embarqués
|
18
|
3-3 Noyaux pour systèmes embarqués
|
19
|
3-3-1 Les Caractéristiques d'un noyau temps réel
|
19
|
3-3-2 Le Noyau temps réel PICOS18
|
20
|
3-3-3 Les Caractéristiques de PICos18
|
20
|
3-4 Historique de la proposition OSEK/VDX
|
21
|
3-5 La Gestion des tâches
|
22
|
3-5-1 les tâches basiques
|
22
|
3-5-2 les tâches étendues
|
23
|
3-6 Ordonnancement
|
23
|
3-6-1 Non-préemptif
|
23
|
3-6-2 Préemptif
|
...23
|
3-6-3 Mixte
|
24
|
3-7 La synchronisation des tâches
|
24
|
3-7-1 Les événements
|
24
|
3-7-2 Partage de ressources et exclusion mutuelle
|
27
|
3-7-2-1 l'exclusion mutuelle
|
27
|
3-7-2-2 Héritage de priorité (Priority
Inheritance)
|
28
|
3-7-2-2-1 Inversion de priorité
|
28
|
|
3-7-2-2-2 Remèdes 29
3-7-2-2-3 Héritage par la méthode du plafond de
priorité (PCP) 29
3-8 Les objets Alarme et Compteur 32
3-9 Conclusion .34
Chapitre IV Application Multitâche 35
4-1 introduction 36
4-2 description de systeme 36
4-3 Configuration De L'application 41
4-4 Description Détaillée 41
Chapitre V Les ressource « Software » de
PICOS18 55
5-1 Les sources du projet 56
5-1-1 Include 56
5-1-2 Kernel 57
5-1-3 Linker 57
5-1-4 Project/MyApp 57
5-1-5 Project/Tutorial 58
5-2 La chaîne de compilation Microchip 58
5-3- les fichiers source 60
5-3-1 Le fichier « INT.C » 60
5-3-2 Le fichier MAIN.C 61
5-3-3 Taskdesc.c 62
5-3-4 Les fichiers d'inclusion (Header File * .h) 65
Conclusion Générale 67
Annex 68
Préambule
Pourquoi avons-nous besoin d'un noyau temps réel
?
Les techniques de conception temps réel permettent
à l'ingénieur/concepteur de décomposer un problème
complexe et large en un ensemble de taches ou threads simples. Ces
unités de codes simples à gérer permettent des
réponses rapides à des événements importants,
d'autre part, des priorités peuvent être allouées à
des traitements pour être exécutés d'une manière
structurée et bien testée. Le noyau fait le nécessaire
pour maintenir le temps, une certaine harmonie entre les taches, et aussi le
flux des communications entres les taches... Plusieurs activités peuvent
être réalisées dans le même laps de temps en
autorisant à des taches de travailler pendant que d'autres sont en
attente de l'occurrence de certains évènements. Le code obtenu en
utilisant ces techniques est plus dense et plus petit car l'information est
condensée au niveau des variables d'état et des structures de
code. Si vous voulez un exemple, lisez la description de l'application faite
dans ce mémoire.
Au fait, en quoi consiste le multitâche
?
Ceci est l'apparence d'avoir plusieurs taches
s'exécutant en même temps ou simultanément. Chaque tache
pense qu'elle possède l'unité centrale à elle seule, mais
cette apparence est justement contrôlée par le noyau. Seulement
une seule tache est en exécution à un moment donné, mais
il existe d'autres travaux no encore accomplis qui peuvent
réalisés par des taches qui ne sont pas, justement,
bloqués. Le multitâche est l'orchestration des interruptions, des
événements, des communications, des données
partagées et des synchronisations dans le temps ,pour La programmation
en temps réel est simplement un ensemble d'idées, de concepts, et
de techniques qui nous permettent de diviser des problèmes en
unités de code qui sont basées sur des unités de temps, ou
événements qui conduisent les taches à transiter d'un
état vers un autre état.
Chapitre I
Le temps réel
1-1 Introduction :
L'évolution majeure des systèmes d'exploitation
(standards ou embarquées), concerne le support de l'exécution
concurrente de plusieurs traitements et a donné naissance aux
systèmes dits multitâches. Toutefois, les systèmes
multitâches même s'ils permettent de partager l'accès au
microprocesseur n'offrent que peu de garanties concernant la
disponibilité de cette ressource.
Les systèmes temps réels sont donc une
réponse au problème de disponibilité de la ressource
microprocesseur. Le temps réel est un domaine à part entier de
recherche qui est le sujet de nombreuses études multi-domaines (logique
temporelle, théorie des files d'attente, systèmes d'exploitation
...).
Borner l'exécution d'un traitement permet d'obtenir
des garanties quant aux temps de réponse aux divers ensembles de
données auxquels il pourra être soumis. Plus
précisément cela permet de garantir la terminaison d'un
traitement et aussi de mesurer la quantité de pourcentage du processeur
nécessaire à sa terminaison. Ce contrôle est en particulier
nécessaire dans beaucoup de traitements proches du matériel dans
les système d'exploitations standards et embarquées.
1-2 La notion de temps réel :
On appelle classiquement une application temps réel,
un système de traitement de l'information ayant pour mission de
commander un environnement, en respectant les contraintes de temps (temps de
réponse à un stimulus, taux de perte d'information
toléré en entrée ...) qui sont imposées à
ses interfaces avec cet environnement.
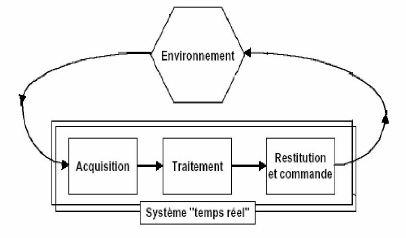
Fig 1.1 système temps réel /
l'environnement
Un système temps réel est un système qui
est étroitement lié à son environnement. La
propriété du temps réel est attribuée si
l'exactitude du système est déterminée par les dates
auxquelles les résultats d'exécution sont disponibles. La notion
d'information valide ne devient vraie que si le résultat est correct et
disponible dans l'intervalle de temps fixé par l'environnement.
« Même la bonne réponse est fausse si
elle arrive trop tard »
Nous pouvons représenter un système temps
réel comme étant composé de :
· L'environnement à contrôler,
· Un système de contrôle qui représente
le système d'exploitation au dessus duquel l'application sera
exécutée.
· l'application
L'interaction entre ces trois composants se traduit par un
échange d'informations entre l'application et l'environnement selon des
contraintes temporelles imposées par ce dernier. Le système
d'exploitation permet de contrôler cette interaction [1].
Un système temps réel pilote un processus
comportant des contraintes de temps aléatoires et
variées. Ce système doit être
déterministe puisqu'il doit savoir avec
précision l'instant de début et de fin d'un
traitement. Dans un système temps réel, les contraintes
temporelles portent essentiellement sur les dates de début et de fin
d'exécution des tâches.
Une tâche temps réel est associée à
des contraintes de temps et de ressources. Selon les contraintes et les
caractéristiques des tâches [2].

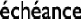
Fig 1-2 échéance d'une tache
1- 3 Architecture des Systèmes Temps
Réel :
Les systèmes temps réel peuvent être
classés selon leur couplage avec des éléments
matériels avec lesquels ils interagissent. Ainsi, l'application
concurrente et le système d'exploitation qui lui est associé
peuvent se trouver :
· soit directement dans le procédé
contrôlé : c'est ce que l'on appelle des systèmes
embarqués (embedded systems). Le procédé est
souvent très spécialisé et fortement dépendant du
calculateur. Les exemples de systèmes embarqués sont nombreux :
contrôle d'injection automobile, stabilisation d'avion,
électroménager, missile. C'est le domaine des systèmes
spécifiques intégrant des logiciels sécurisés
optimisés en encombrement et en temps de réponse.
· soit le calculateur est détaché du
procédé : c'est souvent le cas lorsque le procédé
ne peut être physiquement couplé avec le système ou dans le
cas général des contrôle/commandes de processus
industriels. Dans ce cas, les applications utilisent généralement
des calculateurs industriels munis de systèmes d'exploitation standards
ou des automates programmables industriels comme dans les chaînes de
montage industrielles par exemple [3].
1- 4 Système de commande en temps réel
:
C'est tout d'abord un système de commande, ce qui
implique l'existence d'un système commandé : le
processus. Ce dernier, en général un
procédé industriel, doit d'abord être surveillé :
son état est déterminé à des instants suffisamment
rapprochés par des capteurs (capteur de température comme dans
notre application). A partir de ces états et d'une stratégie
fixée, il sera piloté en envoyant des consignes à des
actionneurs : rôle de la partie commande.
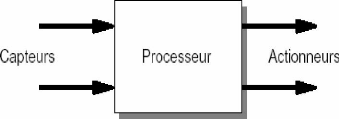
Fig 1-3 systéme de commande
Un système de commande a donc un grand nombre de
tâches à exécuter telles que :
calculer une action, écrire le résultat d'un
calcul sur un écran de visualisation, effectuer une mesure,
détecter l'éventuelle présence d'une panne
latente, signaler des comportements anormaux, ... Nombre de ces
tâches sont indépendantes et peuvent donc être
exécutées simultanément. C'est pourquoi
on dit qu'un système de commande est naturellement
parallèle.
- Fig 1-4 parallélisme
Le séquencement et l'enchaînement de ces
tâches sont assurés, en fonction d'événements
internes ou externes, par la partie contrôle de l'automatisme. Toutes ces
activités simultanées peuvent être réparties
géographiquement. Le système de contrôle devra centraliser
quantité d'informations et réagir en respectant toutes les
contraintes de temps imposées par le processus : ceci définit
l'aspect temps réel de ce système. Cette notion implique que le
temps d'exécution d'une tâche soit négligeable par rapport
à la vitesse d'évolution du système commandé.
La résolution du problème de commande en temps
réel consiste à rechercher une structure d'exécution et
des ordonnancements permettant de satisfaire ces
contraintes de temps
(deadlines), le non-respect
de l'une d'entre elles étant assimilé à une
panne. [2].
1- 5 Contraintes de temps dans un système :
Chaque tâche de l'automatisme (Figure 1.4) est
exécutée en réponse à des sollicitations externes
ou internes avec des contraintes de temps fixées par l'évolution
du processus ou par les dialogues avec l'opérateur. Ce problème
peut être formalisé en écrivant que, pour chaque
événement Ei, il est nécessaire de
calculer un ensemble de fonctions Fn (travaux
à effectuer) dépendant de Ei et de l'état
Q(t) de la commande. Chaque calcul (des fonctions
Fn) est soumis à une échéance
Tmaxn. La durée tc du calcul est fonction
des algorithmes utilisés et de la puissance du processeur, la
présence de l'échéance Tmax
caractérisant l'aspect temps réel. [2].
1- 6 Contraintes de temps faibles (tc << Tmax)
:
Ce type de contrainte autorise une programmation en mode
bouclé (du type « automate Programmable ») appelée
également gestion des entrées/sorties par scrutation.
Les rebouclages en arrière en attente
d'événements sont ici interdits, car ils
allongent la durée du cycle (tcycle) de façon
indéterminée.
Sachant que la durée d'une boucle est, bien
évidemment, plus courte que la période des
événements testés, le programme doit pouvoir
scruter en permanence les entrées avec un temps
tcycle < Tmax. Le principe de programmation est
schématisé figure 1-5.
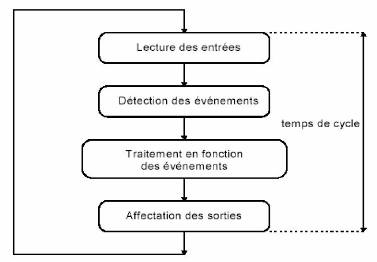
Fig 1-5 principe de programmation en mode bouclé.
Chapitre II
Multitâche
2-1 Introduction :
Un système temps réel interagit avec un
environnement extérieur souvent complexe et en évolution. Dans le
monde réel les périphériques et l'environnement du
système évoluent simultanément (en parallèle ou
concurrence) Si l'on veut réduire la complexité de conception et
calquer fidèlement la réalité il faut s'appuyer sur de la
programmation concurrente :
· utiliser un modèle de tâches.
· utiliser des moyens de communication et de
synchronisation inter tâches ou inter processus (mémoire
partagée, boites aux lettres, files de messages, moniteurs, ...).
Le modèle utilisé en programmation des
systèmes temps réel est un modèle basé sur
la concurrence (applications concurrentes). L'exécution
de ces applications se fait généralement dans un environnement
mono-processeur.? On "simule" l'exécution concurrente des
processus par la mise en oeuvre du pseudo-parallélisme
: le parallélisme est apparent à
l'échelle de l'utiisateur mais le traitement sur le
processeur (unique) est fait séquentiellement en tirant
profit des entrées/sorties réalisées par les processus.
[4]
2-2 Notion de Tâche :
Une tâche est un programme ou une partie de programme
en exécution. Elle possède son propre environnement.
Conceptuellement, chaque tâche est associée à un
processeur virtuel comprenant :
· Son pointeur d'instructions (PC),
· Son pointeur de pile (SP),
· Sa zone de données.
Le processeur réel commute de tâche en
tâche sous le contrôle (et parfois la volonté) d'un module
particulier du NTR : l'ordonnanceur
(scheduler). A chaque commutation, le processeur
réel se retrouve chargé avec le contenu du processeur virtuel de
la nouvelle tâche. Cette opération s'appelle un
changement de contexte.
Les tâches sont des parties de code (fonctions) qui
n'acceptent pas de paramètre et qui ne retournent aucune valeur. Une
tâche doit comporter une boucle infinie
lorsqu'elle n'est jamais sensée se terminer ou
se détruire lorsqu'elle est terminée.
Dans un système multitâche monoprocesseur, les tâches
semblent macroscopiquement s'exécuter simultanément bien qu'en
vérité l'ordonnanceur alloue le contrôle du processeur
d'une manière « entrelacée ». Dans ce modèle,
les tâches ne doivent pas être programmées en faisant des
hypothèses quant à leur durée d'exécution. Le
programmeur n'a plus la maîtrise de l'attribution du processeur à
une tâche, c'est l'ordonnanceur qui s'en acquitte suivant des
règles fixées lors de sa conception. Dans ce cas, toute
temporisation basée sur la notion de boucle doit être exclue.
Par exemple un programme Temps Réel peut être
constitué d'une collection de tâches telles
que :
· des exécutions périodiques de mesures de
différentes grandeurs physiques (pression, température,
accélération etc..). Ces valeurs peuvent être
comparées à des valeurs de consignes liées au cahier des
charges du procédé ;
· des traitements à intervalles réguliers
ou programmés ;
· des traitements en réaction à des
évènements internes ou externes ; dans ce cas les tâches
doivent être capables d'accepter et de traiter en accord avec la
dynamique du système les requêtes associées à ces
évènements. Nous caractérisons ainsi une Application Temps
Réel comme étant une application multitâches [2].
2-3 Caractéristiques des tâches :
Cette section présente d'autres caractéristiques
des tâches, qui peuvent influencer l'ordonnancement : la priorité
utilisateur et la périodicité des tâches.
2-3-1 Notion de priorité :
Toutes les tâches temps réel n'ont pas la
même importance vis à vis du système. On parle alors de
priorité attribuée par le mécanisme d'ordonnancement, afin
de distinguer les tâches entre elles. Cette priorité est
définie par les échéances des tâches. Certaines ont
des échéances très proches, leur exécution est par
conséquent plus urgente, elles sont donc plus prioritaires que d'autres.
Dans un système dynamique, il peut arriver que des tâches ne
soient pas garanties, même si cette éventualité est rare.
Dans ce cas le système doit être capable de choisir entre les
tâches, afin de ne pas écarter des tâches très
importantes. Pour ce faire, des priorités peuvent être
définies par l'utilisateur.
2-3-2 Notion de périodicité :
Les tâches temps réel peuvent ne pas avoir de
priorité utilisateur, auquel cas leurs priorités sont
définies par leurs échéances. Toutefois, la notion de
périodicité que nous introduisons révèle une autre
distinction entre les tâches. Le mécanisme doit donc outre les
priorités des tâches prendre en compte le fait qu'elles peuvent
être : périodiques, apériodiques ou sporadiques.
2-3-2-1 Les tâches périodiques
:
Une tâche Ti est dite périodique de
période Pi si elle est réexécutée chaque
Pi unités de temps. Une telle tâche à ses
paramètres Ri et Di connus. Soit
Tin la niéme exécution de la
tâche Ti, Rin la date au plus tôt est
donnée par le taux d'interarrivée et Din est
déterminé par l'occurrence de la (n+1)iéme
exécution de Ti (comme illustré dans la figure 2.1).
Quand le système doit ordonnancer une tâche périodique, il
doit être capable de garantir toutes les futures occurrences de la
tâche.
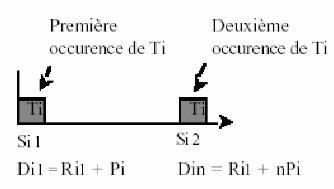
Fig 2.1 Notion de périodicité
Dans la plupart des systèmes, une occurrence de
tâche périodique a son échéance égale
à sa période. Nous précisons toutefois que dans certains
modèles l'échéance peut être inférieure
à la période.
2-3-2-2 Les tâches non périodiques
: Sont réparties en deux catégories :
2-3-2-3-1 Les tâches sporadiques : Pas
d'activation régulière mais il existe un temps minimal entre deux
activations. Elles ont donc des contraintes de temps fortes.
2-3-2-3-2 Les tâches apériodiques
: Pas d'activation régulière mais avec des
échéances plus lâches et sans temps minimal entre deux
activations. C'est le temps de réponse du système qui est
privilégié [2].
2-4 Tâches matérielles, tâches
logicielles :
Un système temps réel comporte en
général des tâches soumises à des fortes contraintes
de temps, et des tâches pouvant être différées, tout
en étant exécutées dans l'intervalle de temps voulu.
Les tâches soumises à de fortes contraintes de
temps sont liées à des interruptions et
sont appelées tâches matérielles.
Les tâches différées ou
tâches logicielles sont programmées,
soit dans une boucle de scrutation soit de façon indépendante
(principe utilisé dans ce document). Elles sont alors
exécutées d'une manière
pseudo-simultanée. Lorsque la programmation
est effectuée par une boucle de scrutation, on parle d'un système
temps réel mono tâche ; dans le cas contraire, de système
temps réel multitâche. Dans tous les cas, un programme temps
réel doit gérer l'occupation du processeur en fonction des
échéances de temps liées au processus, des ressources
disponibles, des synchronisations et des échanges de données.
Dès que l'application devient complexe, les systèmes
temps réels sont programmés selon le mode multitâche
en raison d'une plus grande facilité de conception. On fera donc
attention à la distinction entre application multitâche (de type
temps partagé) et application temps réel (multitâche,
aussi, mais soumis à des contraintes temporelles).
Dans le premier cas, l'application gérera
simultanément, de façon concurrente, plusieurs tâches dont
l'ensemble traduit la globalité du processus modélisé.
Dans le second cas, l'application réagira en fonction
d'événements externes asynchrones dans le respect strict des
contraintes de temps imposées par le processus physique
modélisé.
Un système temps réel doit répondre
rapidement à des événements extérieurs pour
interagir efficacement avec l'environnement extérieur, les tâches
(logicielles) s'exécutent au niveau 0 des
priorités du processeur, alors que les ISR (tâches
matérielles) s'exécutent à des niveaux
supérieurs de priorité. Généralement
les ISR réalisent seulement les actions nécessaires
réclamées par l'interruption. La donnée entrée ou
sortante, l'information de contrôle sont passées au niveau des
tâches logicielles pour un futur traitement [2].
2-5 Etats d'une tâche :
Dans un environnement multitâche, les tâches peuvent
être dans un des quatre états suivants :
- RUNNING (en exécution) : Tache en
possession d'un processeur et en cours d'exécution.
- READY (prête à
l'exécution) : Donc en possession de toutes les ressources
nécessaire a son fonctionnement sauf d'un processeur.
- WAITING (en dormie) : Soit en attente
d'une ressource quelconque indispensable à son exécution
future.
- SUSPENDED (suspendue) : La
tâche est présente dans le projet, mais n'est pas prise en compte
par le noyau.
Les trois premiers états sont considérés
comme des états actifs (les tâches existent et jouent un
rôle dans l'application), le dernier étant un état inactif
(les tâches ne jouent pas, ou plus, un rôle dans l'application). Le
passage d'un état à l'autre se fait grâce à des
appels-système ou sur décision de l'ordonnanceur. Dans la
pratique, un changement d'état (même pour une tâche qui ne
possède pas le processeur) aura souvent pour conséquence une
commutation de contexte.
2-5-1 Transition entre tâche :
Il y a six transition d'états entre tache comme la figure
2.2 indique
· READY -* RUNNING
(START) : Correspond à une allocation
du processeur.
· RUNNING -* READY
(PREEMPT) : Correspond a une préemption du
processeur au profit d'une autre tache cette préemption est
décidée selon l'algorithme d'ordonnancement utilisé.
· RUNNING -* WAIT
(WAIT) : Due à un appel system impliquant
l'attente d'une ressource du system (waitEvent),
· WAIT -*
READY(RELEASE) : Appelé réveil
de la tache
· SUSPENDED -* READY
(ACTIVATE): Activation de la tâche
désignée. Si la tâche ainsi activée est la
tâche prête la plus prioritaire elle prend immédiatement la
main sur la tâche en cours.
· RUNNING -* SYSPENDED
(TERMINATE): Termine la tâche appelante. La
tâche n'est plus alors considérée par le noyau. Pour
l'exécuter de nouveau il est nécessaire de l'activer à
l'aide de la fonction ActivateTask.
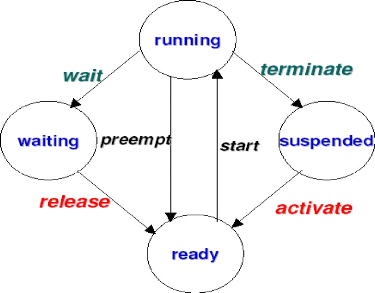
Fig 2-2 Transition d'état entre tache
En environnement multitâche, les taches coopèrent
en vue de la réalisation d'une activité commune, alors On
distingue 02 sortes de coopération :
· Coopération temporelle : Faisant
intervenir les notions de blocage et de déblocage de tache.
· Coopération spatiale : Se rapportant
à l'échange d'information entre tache.
Ces 02 types de coopération caractérisent
respectivement la synchronisation et la communication entre taches car les
taches ont besoin d'échanger des données pour coopérer
durant l'exécution d'une application.
Tous les échanges se feront à l'aide de
mécanismes spéciaux sous le contrôle du système. Ces
mécanismes peuvent revêtir des formes multiples : files d'attente,
événements, ... Cette multiplicité s'explique par le fait
qu'aucun mécanisme n'est vraiment satisfaisant et ne permet de couvrir
l'ensemble des besoins de communication, chacun étant adapté
à un modèle d'échange particulier. On associera la notion
de synchronisation entre tâches à celle de communication; en
effet, pour se synchroniser, les tâches seront obligées de
communiquer entre elles. Cette gestion des taches qui est la synchronisation et
la communication entre taches est assurée par un noyau tempos
réel [5] .
Chapitre III
Noyau temps réel pour système
Embarqué
3-1 Les Systèmes
Embarqués
Les Systèmes Embarqués sont
caractérisés par leur intégration à un
système plus grand. Ils sont composés de un ou plusieurs
processeurs, ainsi que de mémoire de plus ou moins grande taille. On
rencontre des mémoires ROM, pour les programmes à
exécuter, et RAM, pour le stockage temporaire des données. La
figure 3-1 montre le principe de fonctionnement d'un Système
Embarqué. Les informations en entrée viennent de capteurs, En
sortie, ce sont des actionneurs, des écrans d'affichage, ou des signaux
de communication [1].
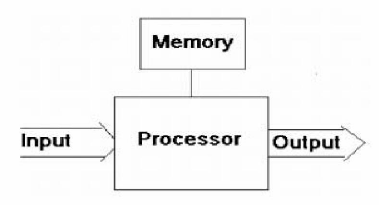
Fig. 3-1 Principe des Systems embarquée
3-2 Les Systèmes d'Exploitation pour
Systèmes Embarqués
Les Systèmes d'Exploitation (SE) servent à
rendre disponible les éléments matériels d'un
système informatique pour les applications. En fonction du contexte
d'exécution, des objectifs du SE, les types de tâches qu'il
supporte, son architecture, peuvent varier, même si son rôle reste
toujours globalement identique.
L'usage de Systèmes d'Exploitation est devenue
nécessaire dans les Systèmes embarqués, du fait de la
complexité croissante de ces systèmes (ex : Systèmes sur
puce), de la présence de fortes contraintes temps réel, de la
limitation des ressources disponibles, tant en mémoire qu'en
énergie disponible et donc en puissance de calcul.
Parmi les Systèmes d'Exploitations pour les
Systèmes Embarqués, on distingue les SE temps-réel (RTOS -
Real Time Operating Systems), qui se caractérisent par la
présence de contrainte temps-réel.
3-3 Noyaux pour systèmes embarqués
Ce sont des noyaux exécutifs de petites tailles, assez
performants et particulièrement appropriés à des
systèmes embarqués simples où les besoins sont
essentiellement une exécution et un temps de réaction aux
événements rapide (alarmes, interruptions...). Ils offrent un
ordonnancement par priorités (généralement un ensemble de
priorités prédéfinies est offert), une horloge globale,
des primitives pour la préemption des tâches, pour le retardement
ainsi que des mécanismes de synchronisation, etc. Toutefois, ces noyaux
sont inefficaces pour des systèmes complexes ou de taille importante. En
effet, dans de pareils systèmes, les contraintes sont plus
compliquées et portent à la fois, sur le temps, les ressources,
la communication et il est extrêmement difficile de prédire avec
de pareils noyaux de base que les contraintes seront vérifiées.
La principale cause est due aux délais introduits pour la gestion de ces
systèmes. Dans le cas où ces noyaux sont utilisés, on se
retrouve aussi avec des phénomènes d'inversion de
priorités (voir 3-7-2-2-1) car les mécanismes
d'ordonnancement utilisés dans ces noyaux sont de très bas
niveau. Egalement, des situations où les ressources ne sont pas
disponibles à temps, où les messages ne sont pas
délivrés à temps, etc.
3-3-1 Les Caractéristiques d'un noyau temps
réel :
C'est en fait un ensemble de fonctionnalités,
regroupées sous le terme de SERVICES pour la plupart,
qui forment le noyau. Une des fonctionnalités les plus connues des
noyaux (sans être pour autant un service) est le
SCHEDULER, responsable de la cohabitation des
différents programmes pendant leur exécution. C'est donc le noyau
qui contrôle les ressources et permet leur utilisation de façon
sûre et efficace au travers de SERVICES. Puisque le
noyau garantit la stabilité du système, plusieurs programmes
indépendants peuvent se tenir prêts à fonctionner, au bon
vouloir du noyau. Cette MULTIPROGRAMMATION permet aux
développeurs de créer des programmes sans se soucier de savoir
s'il existe d'autres programmes dans le système. Chacun a l'impression
que le système lui est dédié. Si le noyau le permet, il
est même possible de faire fonctionner ces programmes en parallèle
tout en donnant l'impression à chacun d'être seul à
fonctionner (au prix d'une perte de vitesse bien entendu). Lorsque le noyau
joue parfaitement son rôle de chef d'orchestre (le fonctionnement en
parallèle des tâches incombent au noyau seul) on dit que le noyau
est MULTITACHES PREEMPTIF. Si le noyau n'est pas capable de faire une telle
chose, alors c'est aux tâches de "rendre la main" au noyau de temps en
temps, on dit que le noyau est MULTI-TACHES COOPERATIF.
Le noyau multitâche peut simplement gérer le
parallélisme en découpant le temps en parts égales pour
chaque tâche en mémoire. Le problème, c'est que les
tâches en fonctionnement ont rarement les mêmes besoins, et
certaines, rarement actives, requièrent toute la puissance du
système lorsqu'elles se réveillent.
Les tâches ont donc des PRIORITES différentes, et
doivent pouvoir répondre à un événement dans
un
temps le plus court possible. Plutôt que d'assurer un temps de
réactivité quasi-nul (ce qui est
impossible), le noyau se doit de garantir un TEMPS DE LATENCE
constant : c'est le DETERMINISME [6].
3-3-2 Le Noyau temps réel PICOS18 :
Après maintes consultations sur le net à la
recherche de noyaux temps réel gratuits pour l'embarqué, notre
choix, qui était limité, a porté sur le NTR PICOS18.
PICOS18 est un produit de la société PRAGMATEC
distribué gratuitement sous la licence GPL (General Public Licence).
Celle-ci garantit la libre circulation des sources de PICOS. PICOS18 est un
noyau temps réel basé sur la norme automobile OSEK/VDX et
destiné aux microcontrôleurs PIC18 de la société
Microchip Technologie Inc [6].
3-3-3 Les Caractéristiques de PICos18 :
Le noyau PICos18 possède les caractéristiques
suivantes :

Fig. 3-2 Caractérise de PICOS18
· Le coeur du noyau (Init + Scheduler + Task
Manager) qui a la responsabilité de gérer les tâches de
l'application et donc de déterminer la prochaine tâche active en
fonction de l'état et la priorité de chaque tâche.
· ?Le gestionnaire d'alarmes et de
compteurs (Alarm Manager). Proche du coeur du noyau, il répond
à l'interruption du TIMER0 afin de mettre à jour
périodiquement les alarmes et compteurs associées aux
tâches.
· Les Hook routines sont proches du coeur du noyau
et permettent à l'utilisateur de dérouter le déroulement
normal du noyau de façon à prendre temporairement le
contrôle du système.
· ?Le gestionnaire de tâches
(Process Manager) est un service du noyau, dont le rôle est d'offrir
à l'application les fonctions nécessaires à la gestion des
états (changer l'état d'une tâche, chaîner des
tâches, activer une tâche...).
· ?Le gestionnaire
d'évènement (Event Manager) est un service du noyau dont le
rôle est d'offrir à l'application les fonctions nécessaires
à la gestion des évènements d'une tâche (mise en
attente sur un évènement, effacer un
évènement...).
?Le gestionnaire d'interruption (INT Manager) offre
à l'application les fonctions nécessaires à l'activation
et la désactivation des interruptions du système [6].
3-4 Historique de la proposition OSEK/VDX
OSEK/VDX est une proposition récente d'exécutif
pour l'électronique embarquée dans les automobiles. Cette
proposition est le fruit des travaux de nombreux constructeurs automobiles et
équipementiers européens depuis septembre 1995. OSEK a
été étudié par les équipes principalement
allemandes et VDX par le GIE PSA-Renault ; OSEK/VDX est le résultat
commun des travaux. L'un des objectifs visés par le consortium est de
standardiser les interfaces du système d'exploitation afin de faciliter
la fourniture de logiciels par de multiples sources, la portabilité,
l'interopérabilité et la réutilisation. Différents
travaux ont été menés dans le cadre d'OSEK/VDX :
- OSEK/VDX OS : les services de base du noyau du
système d'exploitation ;
- OSEK/VDX COM : les services pour la communication
entre des noeuds d'un système réparti ou la communication locale
;
- OSEK/VDX NM (Network Management) : les services de
gestion et de surveillance du réseau
;
- OSEK/VDX OIL (OSEK Implémentation Langage) :
langage de description pour la mise en oeuvre automatisée d'une
application.
La présentation ci-après porte uniquement sur le
noyau du système d'exploitation [7].
3-5 La Gestion des tâches :
La tâche est l'agent actif de l'application. C'est une
portion de code séquentiel correspondant souvent à la notion de
procédure (ou fonction) dans le langage de programmation utilisé
pour coder l'application. La tâche étant un agent actif, il est
naturel de lui associer un diagramme d'état qui représente
l'ensemble de ses états possibles ainsi que les conditions
associées aux transitions d'états (voir figure 3-3).
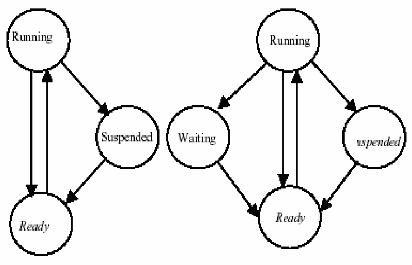
Fig 3-3 les états d'une tache OSEK/VDX :basique(a gauche),
étendue (a droite).
OSEK/VDX utilise deux types de tâches définis
ci-après :
3-5-1 les tâches basiques : Sont
des modules sans point bloquant, c'est à dire sans appel de service
pouvant provoquer une mise en attente de la tâche. La tâche est
activée, elle s'exécute puis elle doit se terminer, les points de
synchronisation sont donc seulement au début et à la fin de la
tâche. Elle ne possède que trois états:
SUSPENDED (inactive), READY (attente du
processeur), RUNNING (elle a le processeur).
3-5-2 les tâches étendues
: Sont composées de un ou plusieurs modules
séparés par des invocations de services éventuellement
bloquants (WaitEvent). Le diagramme d'état
possède donc un état supplémentaire : l'état
waiting.
Voici quelques exemples de services :
a- ActivateTask
(<TaskName>) : activation de la tâche
désignée, Permet de faire passer l'état d'une tâche
de SUSPENDED à READY. Si la tâche ainsi activée est la
tâche prête la plus prioritaire elle prend immédiatement la
main sur la tâche en cours.
b- TerminateTask (void) : termine
la tâche appelante, Permet de faire passer l'état d'une
tâche de RUNNING à SYSPENDED. La tâche n'est plus alors
considérée par le noyau. Pour l'exécuter de nouveau il est
nécessaire de l'activer à l'aide de la fonction ActivateTask.
c- ChainTask
(<TaskName>) : termine la tâche appelante et
active la tâche désignée, Permet de faire passer
l'état de tâche courante de RUNNING à SUSPENDED. La
tâche dont l'ID est TaskID
passe à l `état READY quelque soit son état
actuel. Si la tâche ainsi activée est la tâche prête
la plus prioritaire elle prend immédiatement la main sur la tâche
en cours.
Remarque : Une application temps réel
comporte souvent des tâches périodiques [7].
3-6 Ordonnancement
Les tâches possèdent une priorité
utilisée pour l'ordonnancement. La valeur de priorité est
statique, non modifiable sauf par l'exécutif lorsqu'il met en oeuvre
l'algorithme « Priority Ceiling Protocol » (voir 3-7-2-2-3)
pour la gestion des ressources. L'ordonnancement peut être :
3-6-1 Non-préemptif : La
tâche rend le processeur lorsqu'elle se termine (TerminateTask),
lorsqu'elle active une autre tâche (ChainTask), ou lorsqu'elle entre dans
un état d'attente (WaitEvent). Dans ce cas le contexte à sauver
pour la tâche est minimal .
3-6-2 Préemptif : Toute
tâche réveillée et plus prioritaire que la tâche en
cours prend le processeur. Le module d'ordonnancement étant
considéré comme une ressource occupée ou
relâchée, une tâche peut se l'approprier dans un contexte
préemptif pour passer en mode non-préemptif.
3-6-3 Mixte : Les deux modes
d'ordonnancement sont utilisés en même temps pour des tâches
différentes. Dans ce cas chaque tâche possède un attribut
indiquant son mode d'ordonnancement. La possibilité d'avoir des
tâches ordonnancées selon un mode non préemptif dans un
contexte préemptif est utile lorsque des tâches sont courtes
(temps d'exécution voisin du temps de changement de contexte), si
l'espace mémoire RAM doit être économisé ou encore
si la non-préemption est nécessaire [7].
3-7 La synchronisation des tâches
On distingue en général deux types de
synchronisation entre tâches ou entre les tâches et l'environnement
: la signalisation synchrone et la signalisation
asynchrone. La signalisation asynchrone qui est utilisée, par
exemple dans les exécutifs UNIX temps réel pour traiter certains
types d'exception, n'a pas été retenue dans OSEK/VDX ; elle ne
sera donc pas présentée ici, compte tenu de la place disponible
[7].
Les événements
Pour OSEK/VDX, la synchronisation est basée sur le
mécanisme des événements privés car appartenant au
consommateur. Les services liés aux événements ne peuvent
être utilisés que par les tâches de type étendu. La
synchronisation est de type synchrone, la tâche réceptrice se
mettant explicitement en attente de l'occurrence pour pouvoir être
réveillée. Chaque tâche peut posséder un certain
nombre d'événements pour lesquels des occurrences seront
signalées par d'autres tâches (de type basique ou étendu)
ou des ISRs. Seule la tâche propriétaire peut se mettre en attente
(OU implicite sur la liste des événements nommés),
l'attente n'étant pas automatiquement surveillée temporellement
(pas de délai de garde) et l'effacement de l'occurrence étant
à la charge de la tâche réceptrice [7].
Voici quelques exemples de services utilisables par les
tâches
a- SetEvent (TaskType TaskID,
EventMaskType Mask)
· Description :Permet de poster un
événement à la tâche dont l'identificateur est ID
et
selon le masque d'événements Mask.
· Paramètres : TaskID : ID
de la tâche concernée.
Mask : masque de l'événement
posté.
b- ClearEvent (EventMaskType
Mask)
· Description : Permet de supprimer un
événement reçu par la tâche en cours
selon le
masque d'événements Mask.
· Paramètres : Mask :
masque de l'événement supprimé.
c- WaitEvent (EventMaskType
Mask)
· Description : Fait passer l'état
de la tâche en cours de RUNNING à WAITING. La
valeur Mask
désigne l'ensemble des événements attendus par la
tâche
· Paramètres : Mask :
Ensemble des événements attendus.
d- GetEvent (TaskType
TaskID, EventMaskRefType Event)
· Description : Permet d'obtenir les
événements reçus par une tâche dont l'identificateur
est
taskID. Lorsqu'une tâche attend plusieurs
événements et qu'elle est réveillée par l'un de
ces
événements, elle peut connaître le ou les
événements postés à l'aide de la fonction GetEvent.
La figure 3-4 montre un exemple de signalisation entre tâches et entre
une tâche et l'environnement utilisant des événements
privés [6].
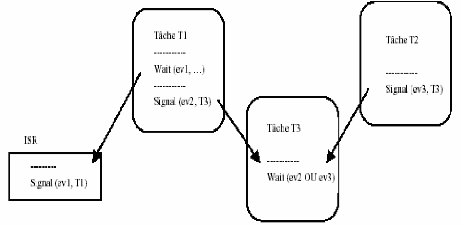
Fig 3-4 Exemple de synchronisation par événement.
Exemple: (De notre application)
Fig 3-5 Exemple de l'événement
En fait cela s'explique par le fait que la tâche 3 est
plus prioritaire que la tâche 5, donc lorsqu'elle aura posté un
événement à la tâche 5, elle continuera à
s'exécuter jusqu'à ce qu'elle soit mise en sommeil (blocage). La
tache 5 elle réveille avec l'arrivée de l'événement
(POTVAL_EVENT) Apres elle va supprimer ce événement avec
ClearEvent(POTVAL_EVENT); et elle va exécuter sont code tant que la
tache 3 est bloquée car elle est plus prioritaire que la tache 5.
Toutefois cette structure ne permet pas à une tâche d'attendre
l'arrivée de plusieurs événements simultanément.
C'est pourquoi les drapeaux événements apparaissent sous forme de
groupes (event flag groups) de 8 bits, suivant le type de microprocesseur,
chaque bit étant un drapeau événement.
Désigne un ensemble d'événements attendus
ou postés d'une tâche. Valeur 8 bits signée (char) comprise
entre 0 et 128 inclus. Cette valeur est un multiple de 2 (0, 1, 2, 4, 8, 16,
32, 64 et 128). Exemple : #define POTVAL_EVENT 0x08
Les drapeaux événements ont l'avantage de
concentrer beaucoup d'information dans très peu de place. Cependant ils
n'indiquent que si l'événement a eu lieu ou non. C'est ensuite
à la tâche avertie d'aller chercher au besoin des informations sur
l'événement. Pour gérer des groupes de drapeaux
événements, il faut apporter d'autres fonctions aux
précédentes (elles aussi à perfectionner). Quelle que soit
la manière dont ils sont gérés, les groupes doivent
être des structures globales si l'on veut qu'ils soient
reconnus par toute l'application [6].
3-7-1 Partage de ressources et exclusion mutuelle
Il est naturel, dans un contexte où plusieurs
tâches coopérants sont en concurrence, d'avoir à
contrôler et obtenir l'accès cohérent à des
ressources partagées par les tâches. Les ressources peuvent
être de natures très diverses, comme par exemple un système
de fichiers accessible en lecture par plusieurs tâches, ou encore une
imprimante accessible en exclusion mutuelle par les tâches, ou encore un
élément physique du procédé contrôlé
qui ne peut être utilisé que par une tâche à la fois,
ou tout simplement des données communes. On se trouve donc
confronté à un problème de synchronisation entre
tâches afin de respecter le protocole d'accès aux ressources, la
politique la plus classique étant celle de l'accès en exclusion
mutuelle pour une ressource non partageable [2].
3-7-2-1 l'exclusion mutuelle :
L'exclusion mutuelle de 02 taches vis-à-vis d'une
ressource partageable Suppose une phase pendant laquelle, une seule des 02
taches est en possession de la ressource. Cette phase appelée section
critique (partie d'un programme qui conduit à un conflit d'accès
au ressource), OSEK/VDX assure la gestion de l'accès concurrent aux
ressources partagées par le protocole PCP (« Priority Ceiling
Protocol »), ce qui garantit la non-inversion de priorité et
l'absence de blocage par usage des services GetResource et ReleaseResource
« encadrant » la section critique, sous réserve d'une gestion
bien ordonnée (LIFO) des prises de ressources multiples. A
l'intérieur de la section critique, les restrictions classiques sur
l'appel des services concernent les services de terminaison ou de blocage de la
tâche [5].
3-7-2-2 Héritage de priorité (Priority
Inheritance) :
3-7-2-2-1 Inversion de priorité
:
L'exemple décrit dans la figure 3 -6 présente
une situation Inversion de priorité alors que la tâche 1 est en
section critique ( procession de la ressource) et la tâche 3 en attente
de la ressource, une tâche 2, de priorité intermédiaire, se
retrouve prête à l'exécution. Le scheduler préemptif
lui attribue le processeur pour une durée qu'il est impossible
d'estimer.
La tâche 3 doit d'abord attendre que la tâche 2
termine son exécution, ensuite que la tâche 1 libère
la
ressource avant de reprendre. On ne peut donc plus déterminer au
bout de quelle durée maximale la
tâche 1 libérera la ressource, il est donc
impossible de savoir si la tâche 3 respectera sa contrainte. C'est donc
un cas de panne logicielle grave [2].
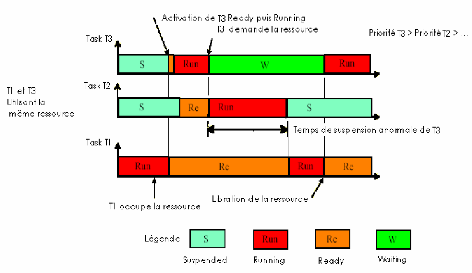
Fig 3-6 Inversion de priorité
On constate que la tâche 3 se trouve « ralentie
» par une tâche de priorité inférieure (la tache 2),
que le temps nécessaire, et indéfini, pour qu'elle finisse son
code, et donc respecte sa contrainte, dépend de cette tâche.
Tout se passe donc comme si les deux tâches de plus forte
priorité avaient inversé leur priorité [2].
3-7-2-2-2 Remèdes :
Pour éviter ceci, en ne permettant pas qu'une tâche
soit préemptée systématiquement si elle est en section
critique, alors le noyau doit autoriser, provisoirement, un
héritage de priorité [2].
3-7-2-2-3 Héritage par la méthode du
plafond de priorité (PCP) :
PICos18 autorise le libre accès à toutes les
ressources du PIC18xxx à toutes les tâches d'une applications.
Ceci permet de vous simplifier l'accès aux périphériques
mais peut engendrer quelques soucis de droit d'accès lorsque ce
même périphérique est utilisé par plusieurs
tâches en même temps. Ceci est résolu par la gestion des
ressources en mode « ceiling protocole >> de la norme OSEK/VDX.
Le principe du « ceiling protocol >> est simple :
Une ressource possède une certaine priorité.
Supposons que 2 tâches cherchent à accéder à
l'EEPROM interne du PIC18. Pour éviter des accès concurrents du
fait que l'application est multitâches, on attribue à la ressource
une priorité supérieure aux 2 autres tâches.
Lorsque l'une des tâches accède à la
ressource, sa priorité est modifiée pour prendre la valeur de
la
priorité de la ressource. Sa priorité est ainsi
assurée d'être la plus élevée d'entre les 2
tâches.
32
Laressource ne pourra donc être prise par la tâche
de moindre priorité car celle-ci n'aura pas la main, du fait du jeux des
priorités.
Toutefois la tâche qui a accès à la
ressource peut aussi être ponctuellement suspendue, en appelant par
exemple le service WaitEvent. Pour éviter que la tâche de moindre
priorité n'en profite pour accéder à la ressource
déjà réservée, un champ « lock » a
été ajouté afin de permettre afin de vérifier si la
ressource n'est pas déjà réservée.
L'héritage de priorité garantit qu'aucune
tâche de priorité intermédiaire ne viendra rallonger la
période de blocage (de la tâche la plus prioritaire)
Lorsqu'une tâche obtienne la ressource et qu'une autre
tache la réclame, la priorité de la tâche qui la
possède est augmentée au niveau de la priorité de la
tâche qui réclame (dans le cas où cette priorité est
supérieure). La tâche qui obtienne la ressource hérite
ainsi de la priorité de la tâche qui la réclame. Ceci
permet de limiter à une seule fois le nombre de situations d'inversion
de priorité. Le prix à payer est le blocage des tâches de
priorité intermédiaire qui ne partagent pas la même
ressource.
Pour la mise en oeuvre du protocole PCP une priorité
plafond est affectée à chaque ressource. Cette priorité
doit être supérieure ou égale à la plus haute
priorité des tâches utilisant la ressource tout en étant
inférieure à la plus basse priorité des tâches
n'utilisant pas la ressource, ces dernières étant
néanmoins de plus forte priorité que les tâches utilisant
la ressource. Ce protocole est également utilisé pour le partage
de ressources entre les tâches et les ISRs ou entre les ISRs ; pour ce
faire une priorité virtuelle est allouée à chaque
interruption. La ressource système prédéfinie permet
à une tâche de s'allouer le processeur, puisque l'ordonnanceur est
traité comme une ressource. Ceci permet donc de passer en mode
non-préemptif.
Deux services permettent de contrôler l'accès aux
ressources :
- GetResource (<Res_Name>) : demande
l'accès à la ressource désignée avant
d'exécuter le code d'utilisation de la ressource. Il est possible
d'utiliser plusieurs ressources (différentes) pour une même
tâche, pourvu que les appels soient convenablement imbriqués
(LIFO) ;
- ReleaseResource (<Res_Name>) :
libère l'accès à la ressource désignée.
[7][2].
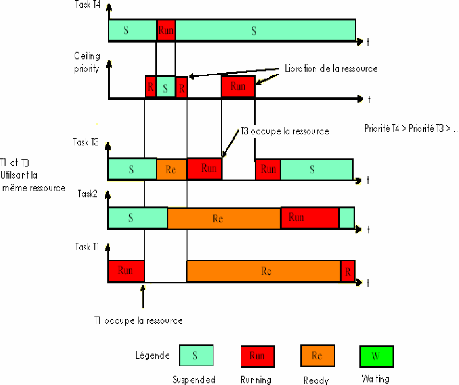
Fig 3-7 Héritage de priorité
· T1 s'exécute puisque les autres taches sont
suspendues.
· T1 demande la ressource et hérite la plus forte
priorité.
· T4 et T3 demande au même temps le uP, T4 prend le
uP car elle est plus prioritaire a T3.
· T4 libère le uP quand elle se termine.
· T1 reprend le uP et T3 reste toujours bloqué
(même chose pour T2) car T1 est plus prioritaire .
· Quand T1 libere la ressource elle va
récupérer sa priorité initiale, mais ne s'exécute
pas car T3 et
T2 son plus prioritaire.
· La T3 est réveillé et s' exécute.
· T3 demande la ressource, alors sa priorité est
augmente(PCP) et T2 reste bloquée.
· T3 libère la ressource, alors sa priorité
revient à sa valeur initiale.
· A ce moment la T2 est activée elle va
exécuter jusqu'à terminaison. l
· T1 elle réveil est récupère le uP
pour terminé son exécution.
3-8 Les objets Alarme et Compteur
Ces objets, propres à la spécification
OSEK/VDX, permettent principalement le traitement de phénomènes
récurrents dans le temps en provenance de l'environnement
extérieur, comme par exemple une horloge ou des signaux en provenance
d'organes mécaniques d'un moteur automobile (arbre à cames,
vilebrequin). Ils constituent des compléments des mécanismes de
signalisation par événement. Ils permettent également la
mise en oeuvre des chiens de garde, par exemple sur l'émission ou la
réception des messages. C'est un mécanisme à deux <<
étages » pour lequel deux objets sont associés : les
compteurs, qui ne font pas partie de l'API OSEK mais du langage OIL, et les
alarmes. Un compteur est un objet destiné à l'enregistrement de
<< ticks » en provenance d'une horloge ou d'un dispositif quelconque
émettant des stimulis. C'est un dispositif de comptage ayant une
certaine dynamique, qui repasse à zéro après avoir atteint
sa valeur maximale (valeur définie à la génération
de l'application). Il compte les ticks après une éventuelle
pré-division (par exemple 10 ticks représentent une unité
pour le compteur). Plusieurs alarmes peuvent être associées
à un même compteur, ce qui permet de constituer facilement, par
exemple, des bases de temps. Une alarme est associée (statiquement
à la génération du système) à un compteur et
une tâche. L'action associée, lors de l'occurrence de l'alarme,
peut être :
- l'activation de la tâche ;
- la signalisation d'une occurrence pour un
événement de la tâche ;
- l'activation d'une routine pour faire un traitement
spécifique. Elle s'exécute avec certaines restrictions puisqu
`elle est dans le contexte de l'exécutif (ce n'est pas une
tâche).
Une alarme peut être unique ou cyclique, absolue ou
relative. Si elle est relative, la valeur spécifiée par un
paramètre du service est un incrément par rapport à la
valeur courante du compteur (expression d'un délai de garde par exemple)
; si elle est absolue, la valeur spécifiée par un
paramètre du service définit la valeur du compteur qui active
l'alarme. Une autre valeur est spécifiée dans le cas d'une alarme
cyclique afin de préciser (en nombre de ticks) la valeur du cycle. Ainsi
on sait simplement, sur un compteur lié à l'horloge temps
réel, définir au travers de plusieurs alarmes, des tâches
périodiques de périodes différentes. La figure 4 montre
des exemples d'alarmes unique ou cyclique à partir d'un compteur de
dynamique 8 ticks.
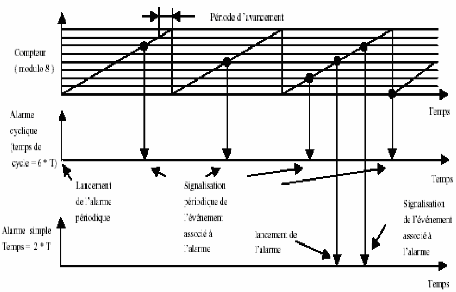
Fig 3-8 Fonctionnement des alarmes Voici des exemples de
services :
-SetRelAlarm (<AlarmName>,
<Increment>, <Cycle>) : arme l'alarme désignée avec
une valeur relative, éventuellement cyclique. Si l'alarme est cyclique
la valeur relative indique alors la « distance » par rapport à
la première occurrence ;
- SetAbsAlarm
(<AlarmName>,<Start>,<Cycle>) : arme l'alarme
désignée avec une valeur absolue (référence
à une valeur particulière du compteur), éventuellement
cyclique. Si l'alarme est cyclique, la valeur relative indique alors la «
distance » par rapport à la première occurrence ;
- GetAlarm (<AlarmName>, <Ticks>) :
permet d'obtenir pour l'alarme désignée le nombre de ticks
restant avant l'occurrence de l'alarme ;
- CancelAlarm (<AlarmName>) :
arrête l'alarme désignée (la désactive) [7].
3-9 Conclusion
Nous avons présenté les concepts de base d'un
exécutif temps réel sans toutefois, compte tenu de la place
disponible, prétendre avoir fait une analyse exhaustive : d'autres
points seraient encore à aborder tels que la gestion de la
mémoire, la gestion des exceptions et erreurs, un approfondissement de
la communication inter-systèmes, ainsi que bien entendu
l'approfondissement des exécutifs Unix temps réel et ceux
académiques. Le noyau d'OSEK/VDX, un exemple d'exécutif statique,
développé dans le contexte de « l'électronique
embarquée » pour l'automobile, a été utilisé
afin d'illustrer la nature des services que peut apporter un exécutif et
donc montrer tout l'intérêt de la conception d'une application
s'exécutant sous le contrôle d'un d'exécutif. C'est
là une démarche naturelle puisque la
programmation d'une application sous forme de tâches
reflète bien le découpage fonctionnel que fait le concepteur lors
de l'analyse du cahier des charges. Les produits commerciaux disponibles sont
nombreux et, si initialement leur emploi était restreint aux produits de
haute technologie, actuellement on peut constater une croissance très
importante des domaines d'application [7].
Chapitre IV
Application Multitâche
4-1 INTRODUCTION
Dans le but d'illustrer les notions relatives au temps
réel, qui ont été décrites dans les chapitres
précédents, nous avons développé une application
utilisant la carte Easypic2 basées sur le PIC18F452.
L'application est écrite en langage C en utilisant le
compilateur MCC18 de Microchip nécessaire à la compilation de
programmes écrits pour le noyau PICOS18. L'IDE MPLAB 7.4 est
utilisé comme environnement intégré de
développement avec le PIC18F452. L'application permet le monitoring de
quatre zones de température, la gestion des entrées de
l'utilisateur et affiche les informations importantes liées à la
température.
4-2 DESCRIPTION DE SYSTÈME
Le matériel du prototype inclut
· Quatre capteurs de température.
· Deux potentiomètres.
· Un port série.
· Quatre afficher 7-segment.
· Clavier numérique de 7 boutons.
· et la gestion d'une alarme sonore.
L'expression « des conditions normales » sera
utilisée fréquemment dans cette note d'application, le
témoin du panneau de démo est en mode de contrôle de
température sans des fonctions d'alarme ou d'utilisateur étant
exécutées.
La base de temps est une interruption périodique de
2ms géré par le Timer1. Il y a un total de six (06) tâches,
dont deux (02) sont dans l'état d'attente dans des conditions normales.
Il y a six événements comme indiquée dans la figure 4-1
.
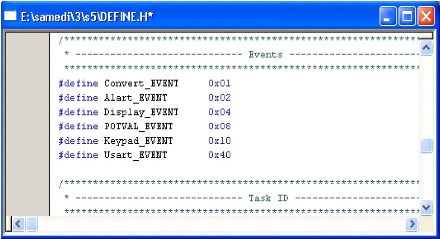
Fig 4-1 liste des événements
- Dont deux dépendent des conditions
extérieures (par exemple, entrée clavier, alarme)
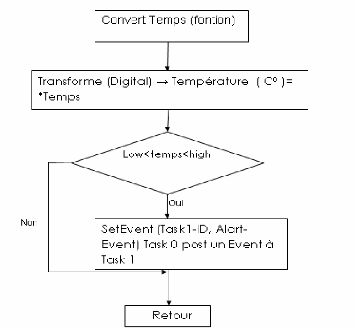
· Alart_EVENT : En cas de
dépassement des limites de température la tache 0 (convert())
poste un événement (Alart_EVENT) à la tache1
(alarme).
· Keypad_EVENT : En cas d'appuyé
sur les touches de potentiomètre la tache3 (keypad) poste un
événement (Keypad_EVENT) à la tache 5 .
- Et les autres événements qui
définition la périodicité des taches.
· Convert_EVENT : un
événement posté périodiquement (40ms) par
alarm(voir tableaux des alarmes dans fichier "taskdesc.c" ).
· Display_EVENT : un
événement posté périodiquement (2ms) par alarm1
· Keypad_EVENT : un
événement posté périodiquement (20ms) par alarm2
· Usart_EVENT : un événement
posté périodiquement (4ms) par alarm3
On prend par exemple l'événement
Convert_EVENT :
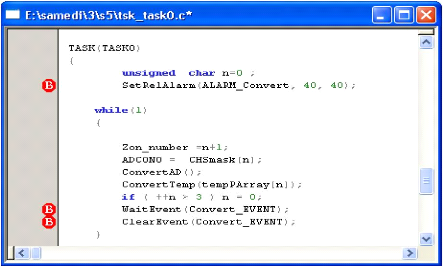
Fig 4-2 exemple d'un événement
L'instruction SetRelAlarm (
ALARM_Convert, 40, 40) est utilisée
pour programmer l'alarme de la tâche 0.Une alarme est un objet TIMER
basé sur une horloge logicielle à 1ms.
La fonction SetRelAlarm possède 3 champs
:
· Alarm ID (ALARM_Convert) : indice de
l'alarme dans le tableau Alarm_list
· TIMER 1 (40 ms): nombre de millisecondes
avant le premier événement posté
· TIMER 2 (40 ms): nombre de millisecondes
entre 2 événements successifs
L'alarme 0 va attendre 40ms avant de poster
l'événement ALARM_Convert à la
tache0, puis le postera périodiquement toutes les 40 ms.
Dans le fichier "taskdesc.c" (tableau des alarmes) l'alarme dont
l'ID vaut 0 (ALARM_Convert) a été associée
à la tâche TASK0.
Avec : #define ALARM_Convert 0 (
L'alarme 0 au tableau des alarmes -voir tableau des
alarmes - ).

Fig 4-3 tableau des alarmes
- Quatre capteurs de température sont divisés en
quatre zones (Z1, Z2, Z3, Z4). Chaque zone sera surveillée pour
contrôler si la température est entre les limites haute et
basse.
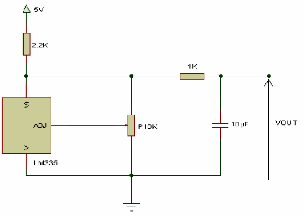
Fig 4-4 Montage d'un capteur de température
Une zone qui n'est pas dans les limites actionnera l'alarme
sonore(en PC) en affichant simultanément le numéro de la zone en
alarme dans le premier digit. Par exemple la zone 3 est on
alarme .

Dans des conditions normales, les afficheurs afficheront
toujours une température de zone sélectionnée au clavier.
La zone particulière sur l'affichage dépendra du bouton de zone
appuyé, par exemple la zone 2 qui est sélectionné par le
bouton 2 affiches la température 23°C
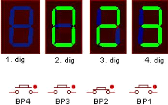
Deux boutons sont utilisés pour le réglage des
potentiomètres utilisés pour simuler la valeur analogique de la
température. Quand un de ces boutons est appuyé la valeur
correspondant à la température est affichée. A ce moment
deux actions peuvent être exécutées ; soit ajuster la
valeur du potentiomètre, soit on presse un autre bouton pour quitter
cette fonction.
- La liaison série, en mode asynchrone, avec un PC est
utilisée pour envoyer un message vers le moniteur du PC, affichant les
différentes zones avec leur température ; cette action est
initiée sur demande au niveau du PC par la touche
`Z'.
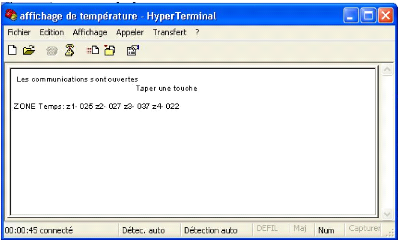
Fig 4-5 affichage de température sur PC.
4-3 Configuration De L'application
Tout d'abord il est nécessaire de créer un
projet sous MPLAB®, qui contient les sources du noyau. Ensuite il faudra
avoir installé le compilateur MCC18 de Microchip, et l'avoir
paramétré (voir
www.picos18.com).
Puis il faut inclure les taches (Source Files.*c) et les
fonctions (Header File * .h) nécessaires à l'application Voir
annexe 1.
4-4 Description Détaillée :
On va dans ce paragraphe expliqué des priorités,
du mode, et des responsabilités de chaque tâche :
1-Tsk-task 0 : (tache de conversion ())
· Priorité : 10
La tâche a une priorité de « 10 » parce
que nous devons déterminer les températures de thermistance pour
décider si des conditions d'alarme existent.
· -Mode : Exécute toutes les 40
millisecondes.
· Responsabilités :
a- Convertit la tension analogique de
thermistance en valeur digitale, puis traduit cette valeur en
température en degrés Celsius.
b. Cette valeur est comparée avec les
températures faibles et élevées de seuil (par
l'intermédiaire de la fonction ConvertTemp () pour déterminer si
une alarme est nécessaire.
c. Si aucune alarme ne s'appelle alors d'autres zones de
thermistance sont converties.
· Organigramme
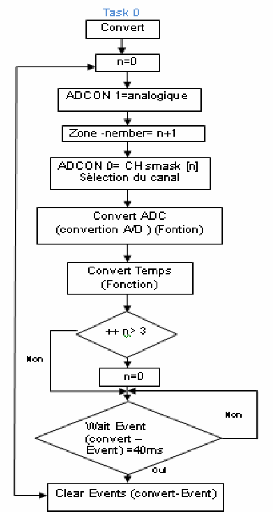
· Programme:
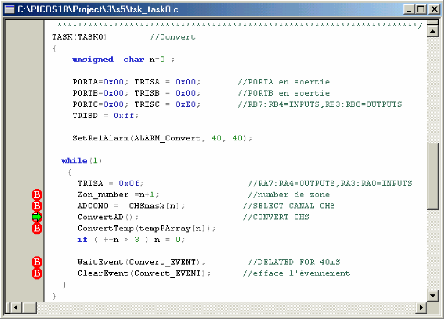
2- Tsk-task 1 : (tache des alarmes ())
· Priorité : 10
Cette tâche a également une priorité de
«10 », mais s'exécute après Tsk-task 0 en mode Round
Robin.
Après détermination de la température, la
vérification des alarmes de zone est la plus importante.
· Mode : Attente sur un
événement.
· Responsabilités :
a. A la même priorité comme Tsk-task 0, et
exécute juste après, Tsk-task 0.
b. Affiche le numéro de zone dans l'alarme.
c. Actionne l'alarme sonore (marche-arrêt).
· Organigramme
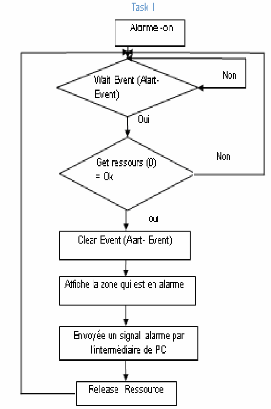
· Programme:
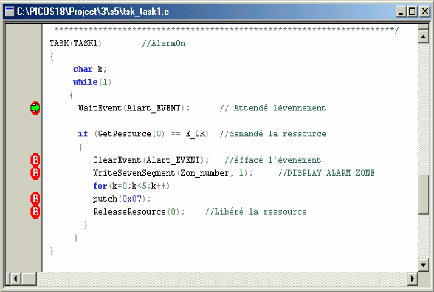
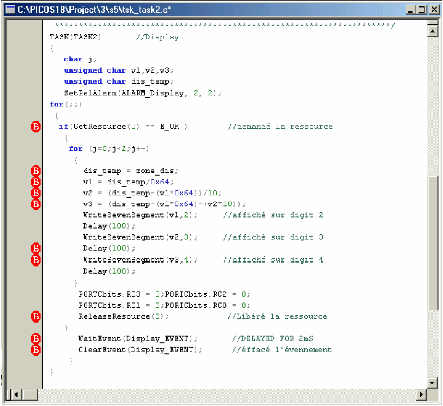
3-Tsk-tas 2 (Tâche d'affichage () )
· -Priorité: 9
Permet aux températures d'être lues pour
affichage.
· Mode : Exécute toutes les 2
millisecondes.
· Responsabilités :
a. Convertit la valeur de la température en format
nécessaire pour
b. Affiche chaque chiffre converti.
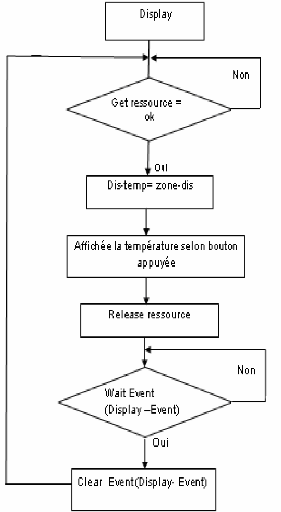
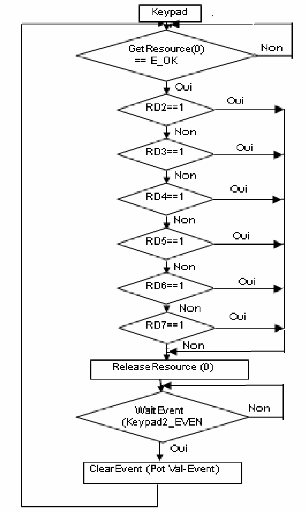
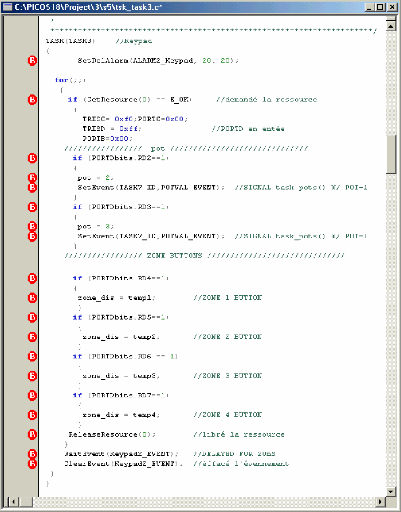
4-Tsk-task 3 (Tache de clavier -boutons -)
· Priorité : 8
L'entrée de clavier numérique est peu
fréquente et ne devrait pas précéder les tâches
antérieures. Mode : Exécute toutes les 20 millisecondes.
· Responsabilités :
a. Scrute pour l'entrée de réglage de
potentiomètre.
b. Scrute pour l'entrée d'affichage de zone
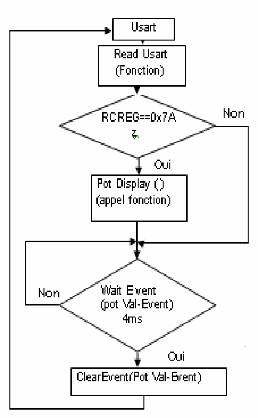
5-Tsk-task 4 (Tache de l'usart)
· Priorité : 7
La surveillance éloignée de PC est seulement
exécutée de temps en temps parce que l'utilisation est faible.
· Mode : Exécute toutes les 800
millisecondes.
· Responsabilités :
1. Scrute pour une entrée de clavier de PC (appuyez
z).
2. Prépare chaque température de zone pour
l'affichage de moniteur de PC.
3. Écrit la chaîne de caractères Z1 vers la
fenêtre Hyper Terminal par l'intermédiaire de l'USART.
· Organigramme
Task 4
Chapitre V
Les ressource « Software » de
PICOS18
1- L'environnement de développement
1-1 Les sources du projet
les fichiers sources du noyau et de l'application sont
représenté comme la figure indique. Voici à quoi
correspond chacun de ces fichiers
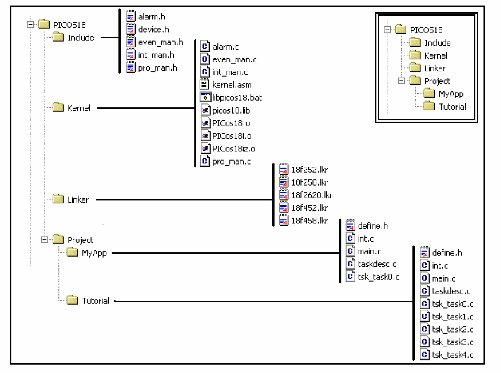
1- 1-1 Include
Comme son nom l'indique ce répertoire contient
l'ensemble des headers du noyau PICos18. Les headers propres à
l'application et aux drivers se trouveront dans les répertoires propres
aux applications (sous Project). Il existe un header spécifique pour
chaque sous-ensemble du noyau : alarmes, événements, interruption
et processus. Le fichier device.h contient les définitions
génériques du noyau comme les définitions des valeurs de
retour des fonctions du noyau.
1-1-2 Kernel
Vous trouverez sous ce répertoire toutes les sources du
noyau. Les fichiers C correspondent aux services du noyau (l'API), et le
fichier kernel.asm, seul fichier assembleur de PICos18, réunit
l'ensemble des fonctions propres au noyau, c'est-à-dire les
algorithmes de scheduler, l'ordonancement des tâches et
le gestionnaire d'erreurs. Les sources sont fournies à titre
d'information ou si vous souhaitez les modifier pour vos besoins propres. Pour
vous permettre d'utiliser PICos18 plus facilement, nous y avons
ajouter le noyau sous forme de librairie
:
picos18.lib. De plus les codes d'amorce du compilateur
(runtime) fournis par Microchip ne sont pas adaptés à PICos18,
nous avons donc choisi de les adapter en conséquence. Ils sont fournis
sous forme de fichier .o (comme PICos18iz.o). Vous n'avez pas à vous
souciez de la librairie picos18.lib et des fichiers d'amorce, ils sont
automatiquement associés à votre projet par PICos18 !
1-1-3 Linker
Lorsque vous construisez votre application avec PICos18, vous
écrivez votre code en language C. Par la suite il convient de compiler
votre application avec C18 (créer chaque fichier .o correspondant
à chaque fichier .c) puis de les lier entre eux à l'aide du
linker. La façon de lier les fichiers .o est paramétrable, et
elle est décrite dans les fichiers .lkr de ce répertoire. Pour
chaque type de processeurs remarquables dans la famille PIC18, il est fourni un
fichier lkr pour vous éviter de gérer cette partie
délicate de l'étape de compilation. Pour chaque nouveau PIC18
géré par un PICos18, un nouveau script de linker se verra ajouter
à ce répertoire au fil du temps.
1-1-4 Project/MyApp
Ce répertoire contient les fichiers nécessaires
à la création de tout projet avec PICos18. Comme vous pouvez le
constater il n'y a que très peu de fichiers : le main.c qui est le
premier fichier applicatif exécuté par PICos18, le fichier int.c
qui rassemble les routines d'interruptions et d'interruptions rapides, le
fichier taskdesc.c qui décrit précisément tous les
éléments de votre application (alarmes, compteurs,
caractéristiques de vos tâches, ...), et un fichier C par
tâche de l'application.
1-1-5 Project/Tutorial
Le tutorial s'appuie sur la réalisation d'une
application type sous PICos18. Tout au long des différents chapitres
vous allez découvrir comment programmer sous PICos18 et comment
construire vos applications. Les fichiers présents sous ce
répertoire sont ceux de l'application finale, une fois terminée.
Ceci apporte un support concrêt à ce tutorial en vous fournissant
le code source de l'application de test.
2- La chaîne de compilation Microchip
Vousavons programmer notre application en C sous PICos18.
Toutefois le noyau luimême composé de fichiers en C pour les
services par exemple et de fichiers écrits en assembleur comme fichier
kernel.asm.
Ces différents fichiers devront être compilés
ou assemblés puis liés afin d'obtenir un seul fichier final : le
fichier HEX qui pourra être chargé dans le PIC18.
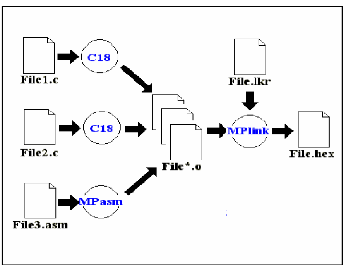
La chaîne de compilation Microchip se décompose en 3
éléments :
l'assembleur MPASM qui permet de transformer un fichier ASM en
fichier O le compilateur MCC18 qui permet de transformer un fichier C en un
fichier O
le linkeur MPLINK qui permet de fusionner tous les fichiers O en
un unique fichierHEX
Le fichier dit «script du linkeur» (File.lkr sur le
schéma ci-dessus) est essentiel pour permettre de générer
le fichier HEX. En effet le contenu des fichiers O ne permet pas encore de
savoir où va être logé le code en mémoire. Par
exemple la fonction main() a été traduite en un langage
compréhensible par le PIC18 mais pas encore positionné à
un endroit précis de la mémoire.
C'est le rôle du script du linkeur que de
préciser les emplacements de chaque portion de code en ROM et chaque
portion de variable en RAM. PICos18 est fourni avec des scripts de linker
pré-établi pour les PIC les plus utilisés de la famille
PICos18. Vous pouvez vous en inspirer pour réaliser votre propre script
ou bien pour l'adapter à un nouveau PIC18.
Il existe d'autres types de fichiers
générés pendant la compilation et l'assemblage des
fichiers du projet (*.map, *.lst, *.cod). Référez vous aux
documents Microchip pour de plus amples informations.
Ce tutorial est destiné à la compréhension
et la prise en main du logiciel PICos18. Pour des raisons
techniques, il a été réalisé sous
MPLABÒ et compilé avec le compilateur C18 pour cible
PIC18F452.
Nous tenons à préciser que ce tutorial a
été entièrement réalisé et testé sous
le système d'exploitation Microsoft WindowsÔ 98/NT/2K/XP, ainsi
qu'avec l'environnement de développement MPLABÒ v7.00 et le
compilateur C18 v2.40 de Microchip (version gratuite).
Ces différents logiciels peuvent être
téléchargés depuis le site web de Microchip Technology
Inc. :
www.microchip.com.
3- les fichiers source :
Les fichiers sources du noyau nécessaires à
l'application sont (Source Files.*c) :
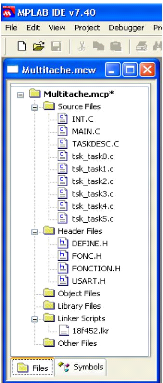
3- 1 Le fichier « INT.C » :
Ce fichier prend en charge la gestion de la totalité
des interruptions. Il faut savoir que le PIC18 gère 2 types
d'interruptions : les interruptions de basses priorités (IT_vector_low)
et celles de hautes priorités (IT_vector_high). A quoi cela peut-il bien
servir....?!
En fait il faut considérer que le noyau PICos18
effectue parfois des opérations délicates sur les tâches et
qu'il n'est pas souhaitable qu'il soit interrompu par une IT pendant son
traitement (par exemple pendant la préemption d'une nouvelle tâche
sur la tâche courante). Du coup pour faire simple on a choisi de rendre
le noyau non-interruptible. Or on a vu que le déterminisme de PICos18
était de 50us (ce qu'on appelle le temps de latence), donc il existe une
zone d'ombre, un black-out de 50 us pendant laquelle une IT ne sera pas
détectée.
Pour éviter cela on utilise les interruptions rapides
("fast interrupts") du PIC18, qui utilise un mécanisme hardware pour la
sauvegarde des registres élémentaires (comme WREG, STATUS, ...).
Hélas pour utiliser les interruptions rapides du PIC18, il faut
écrire un code C excrément léger, presque trivial. Si l'on
a besoin d'un code plus complexe, qui appelle par exemple d'autres fonctions C,
il faut impérativement utiliser les interruptions lentes... avec
toutefois le risque d'être mis en attente pendant 50uS ! . (6)
3- 2 Le fichier MAIN.C :
Selon la norme OSEK ce fichier main ne fait pas partie de l'OS
mais il est bel et bien de la partie applicative, et c'est à lui que
revient le rôle de lancer le noyau (car il est en effet possible de
stopper et de lancer le noyau depuis le fichier main).
Dans le fichier main on trouve une fonction Init () qui va
nous permettre de paramétrer la fréquence de fonctionnement sans
avoir besoin d'ouvrir la datasheet du PIC18 :
Void Init (void) {
FSR0H = 0;
FSR0L = 0;
/* User setting: actual PIC frequency */ Tmr0.lt =
_40MHZ;
/* Timer OFF - Enabled by Kernel */ T0CON =
0x08;
TMR0H = Tmr0.bt [1];
TMR0L = Tmr0.bt [0];
}
La ligne en gras permet de régler la fréquence
INTERNE du PIC18. En effet celui-ci possède une PLL par 4, que nous
pouvons activer ou non. Une utilisation classique des PIC18 consiste à
les équiper d'un quartz externe de 10 MHz et de 2 capacités de 15
pF, puis d'activer la PLL interne afin d'obtenir une fréquence interne
de 40 MHz.
Le pipeline interne du processeur étant de niveau 4, le
pire cas de fonctionnement du
PIC18 est de 10 MIPS, soit 10 millions d'instructions par
secondes (voir la datasheet du composant). Cela en fait un
microcontrôleur 8 bits faible cout puissant et bien armé en
périphérique. (6)
3-3 Taskdesc.c :
Ce fichier contient tout ce qui concerne notre application on
trouve dans ce fichier, comme par exemple : l'identifiant de la tâche, sa
priorité, sa pile logicielle, les alarmes nécessaires au projet,
...
3-3-1 On trouve tout d'abord la liste des alarmes de
l'application:
AlarmObject Alarm_list [ ] = {
* First task
*******************************************************************/
{
|
OFF,
|
/*
|
State
|
*/
|
|
0,
|
/*
|
AlarmValue
|
*/
|
|
0,
|
/*
|
Cycle
|
*/
|
|
&Counter_kernel,
|
/*
|
ptrCounter
|
*/
|
|
TASK0_ID,
|
/*
|
TaskID2Activate
|
*/
|
|
ALARM_EVENT,
|
/*
|
EventToPost
|
*/
|
|
0
|
/*
|
CallBack
|
*/
|
} };
Ce tableau constitue la liste des alarmes, chaque alarme
étant représentée par une structure. Une alarme est une
sorte d'objet TIMER géré de façon logicielle par le noyau.
En fait PICos18 possède une référence de temps de 1ms,
générée de façon hardware et logicielle. De cette
façon il est possible de créer une alarme logicielle basée
sur cette base de temps de 1ms : les alarmes.
Une alarme est associé à un compteur (ici
Counter_kernel qui est la référence de 1ms) et une tâche
(dont l'identifiant est TASK0_ID). Lorsque l'alarme atteint une valeur de seuil
elle peut poster un événement à cette tâche
(ALARM_EVENT dans cet exemple) ou bien appeler une fonction en C.
3-3-2 - On trouve ensuite la liste des ressources de
l'application:
/******************************************************************
* COUNTER & ALARM DEFINITION
******************************************************************/
Resource Resource_list[] =
{
{
10, /* priority */
0, /* Task prio */
0, /* lock */
}
};
Une ressource est un autre objet géré par le
noyau. Une ressource est généralement un
périphérique partagé par plusieurs tâches, par
exemple un port 8 bits du PIC18. Elle possède une priorité
(priority) et peut être verrouillée (lock) par une tâche
(Task- prio). Ainsi lorsqu'une tâche veut avoir accès à la
ressource (e.g un port 8 bits) elle y accède via la ressource
définie et empêche ainsi pendant un cours instant à toute
autre tâche d'y avoir accès. La priorité de la ressource
sera égale à une valeur supérieure à celle de la
tache la plus prioritaire des taches qui utiliseront la ressource. (6)
3-3-3-3 On trouve ensuite la liste des piles logicielles
de l'application:
Il existe 2 types de variables : les variables statiques et
les variables automatiques...de façon plus compréhensible nous
parlerons de variables globales et de variables locales, même si la
correspondance n'est pas tout à fait exacte. Les variables globales
(c'est-à-dire placées en dehors de toutes fonctions C) sont
placées en RAM à une adresse absolue, adresse qui ne change
jamais.
Les variables locales (déclarées au sein de
fonctions C) sont elles compilées par MCC18 de sorte de se retrouver
stockées dans une zone mémoire dite pile logicielle. Une pile
logicielle est une zone mémoire dynamique, vivante en quelques sortes.
Lorsque l'on rentre dans une fonction C, on commence par empiler sur cette zone
les variables locales, et lorsque l'on quitte la fonction C, on dépile
l'espace réservé aux variables locales libérant ainsi de
la mémoire. Ce type de fonctionnement permet de gagner beaucoup de place
mémoire lorsqu'il existe de nombreuses fonctions écrites en C, au
prix d'un surplus de code minimal.
PICos18 est compatible avec la gestion de la pile logicielle
faite par MCC18. Chaque tâche possède alors sa propre pile
logicielle, si bien que chacune des tâches de
l'application peut travailler de façon autonome dans
son propre espace de travail, sans perturber les autres tâches. De plus
PICos18 possède un mécanisme de détection de
débordement mémoire, ce qui arrive lorsqu'une pile logicielle
commence à déborder sur celle d'une autre tâche.
/**********************************************************************
* TASK & STACK DEFINITION
**********************************************************************/
#define DEFAULT_STACK_SIZE 128
DeclareTask (TASK0);
volatile unsigned char
stack0[DEFAULT_STACK_SIZE];
Chaque fois que nous ajoutons une tâche à notre
application, il faut ajouter une pile en copiant la ligne ci-dessus et en
changeant le nom de la nouvelle pile (par stack1 par exemple).
. Une taille de pile minimale sous PICos18 est
64.
. Une taille de pile maximale est 256.
. Une taille de pile raisonnable est 128.
Seules ces 3 valeurs sont possibles, il ne faut pas essayer
d'utiliser une taille de valeur intermédiaire, la compilateur MCC18 ne
pourrait pas la gérer. De plus une pile doit toujours se trouver sur une
même bank, et pas à cheval sur 2 banks. (6)
3-3-4 On trouve ensuite la liste des tâches de
l'application:
/**********************************************************************
* task 0
**********************************************************************/
rom_desc_tsk rom_desc_task0 = {
TASK0_ PRIO, /* prioinit from 0 to 15 */
stack0, /* stack address (16 bits) */
TASK0, /* start address (16 bits) */
READY, /* state at init phase */
TASK0_ ID, /* id_tsk from 1 to 15 */
sizeof(stack0) /* stack size (16 bits) */
};
Nous avons déjà abordé le descripteur de
tâche, voici plus en détail le sens de chaque champ :
prioinit : c'est la priorité de la tâche comprise
entre 1 et 15 inclus. 1 est la priorité la plus faible et 15 la plus
forte. La priorité 0 est réservée au noyau
lui-même.
stack address : c'est la pile logicielle de la tâche.
Chaque tâche possède une pile
logicielle sur laquelle seront stockée les variables
locales au cours de l'exécution, mais aussi tout le contexte du PIC18
(registres, pile hardware) lorsque la tâche n'est pas en cours
d'exécution.
start address : c'est le nom de notre tâche, ou encore
le nom de la fonction d'entrée de notre tâche. Le compilateur le
traduit en une adresse, utilisée par le noyau pour accéder la
première fois à notre tâche.
state init : c'est l'état initial de la tâche. Dans
ce cas il vaut READY ce qui signifie que la tâche est
opérationnelle au démarrage de l'application.
stack size : c'est la taille de la pile logicielle
attribuée. Cela sert au noyau afin de vérifier à tout
moment qu'il n'y a aucun débordement mémoire d'une pile sur
l'autre. (6)
4- Les fichiers d'inclusion (Header File *
.h)
Comme son nom l'indique ce répertoire contient
l'ensemble des headers du noyau PICos18. Les headers propres à
l'application et aux drivers se trouveront dans les répertoires propres
aux applications (sous Project). Il existe un header spécifique pour
chaque sous-ensemble du noyau : alarmes, événements, interruption
et processus.
Les fichiers d'inclusion ou d'en tête *.h (header)
contiennent pour l'essentiel cinq types d'informations :
· Des définitions de nouveau type
· Des définitions de structure
· Des définitions de constantes
· Des déclarations de fonctions
· Des définitions de macro_fonctions. (6)/(9)

6-Tsk-task 5 (Tache pour les
potentiomètres )
· Priorité :
Cette tâche est la moins importante parce qu'elle est
seulement utilisée pour ajuster les potentiomètres, qui
n'affectent aucun mode de la température ou d'alarme.
· Mode : Attente sur
événement.
· Responsabilités :
Selon la valeur reçue pot_val( variable loca)l, le
potentiomètre approprié est sélectionné pour le
réglage tout en affichant la valeur ANALOGIQUE-NUMÉRIQUE du
potentiomètre actuel sur les affichers.
· Organigramme Task 5
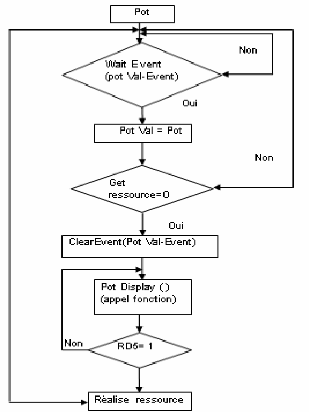
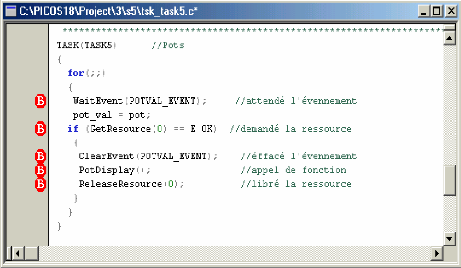
Conclusion Générale
Les noyaux temps réel permettent aux applications temps
réel d'être développées et étudiées
facillement.L'utilisation d'un noyau TR simplifie le processus de conception en
divisant le code de l'application en taches séparées .il nous
permet une meilleure utilisation des ressources d'un système en nous
fournissant des services des grandes valeur tel que la gestion du temps .( time
délais, périodicité , la gestion des ressources : la
communication la synchronisation , l'exclusion mutuelle , boite aux lettres
etc.
Durant les dernières décennies, on a vu la
prévalence des microcontrôleurs et surtout celle de la famille des
pic xxx .Cependant un système embarqué est une combinaison de
hardware et de software .Nous trouvons sur la marché tous les types de
hardware (CAN, USB, RS232, TCP/IP )intégrées dans des
microcontrôleurs . Quoique tous les outils de programmation classiques
avec leur environnement de développement intégré (IDE) Ce
qui est manquant était le noyau temps réel pour cette famille de
microcontrôleurs qui est le PIC xxx, qui ont été
comblé durant les 2 ou 3 dernières décennies.
On peut dire maintenant, que nous disposons de tous les calculs
adéquats pour accélérer la conception d'une application
temps réel , appelé un système embarqué.
Nous travail a consisté en la mise en oeuvre d'un noyau
temps réel (picos18 ) de la société pragmatec aux norme
OSEK/VDX basé sur pic18f452 , nous avons exploité la
majorité des services offerts par ce noyau , d'autres services
définit par la norme OSEK n'ont pas encor être
développé pour ce noyau .
Ce travail nous a permis de nous familiariser avec le domaine du
temps réel et à approfondir nos connaissances de la programmation
en langage C pour les PIC.
Nous tenons à signaler que les problèmes
rencontrés dans le développement des application temps
réel sont très différente de celle de la programmation
mono tache .
Un défaut de synchronisation peut bloquer toute
l'application et il n'ya aucun moyen de déblocage d'où l'exigence
des ateliers de genre logiciel pour le temps réel.
Annexe
ANNEXE
Pour effectuer une mesure de température, il faut donc,
dans un premier temps, convertir la température en tension et ensuite
dans un deuxième temps, convertir cette tension en valeur
numérique. Le schéma synoptique de la figure représente
ces deux étapes de conversion [10].

Schéma synoptique de la conversion analogique
/numérique 1- conversion température -tension analogique
:
La conversion de la température en tension analogique
s'effectue grâce à un capteur de température. ces capteurs
se distinguent selon la gamme des températures où ils peuvent
travailler et aussi selon la vitesse de réaction aux variations de
température. Dans cette expérience, nous avons utilisé le
capteur LM 335. Le LM335 permet de mesurer des températures comprises
entre - 40°C et +100°C.
Comme montre la figure, il est encapsulé dans les
mêmes types de boîtiers que les transistors.
Brochage du LM335 et son symbole graphique
Le circuit d'utilisation du LM335 est comme suite :

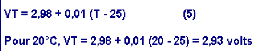
Circuit d'utilisation du LM335
A 25° C et avec un courant de 1 mA circulant dans le capteur
(LM 335), la valeur typique de la tension est de 2,98 volts. La valeur minimum
est de 2,92 volts et la valeur maximum est de 3,04 volts.
La valeur de la résistance R4 doit être
calculée en fonction de + Vcc pour que le capteur soit parcouru par un
courant de 1 mA.
Calcul de R4 :
R4 = (Vcc - 2,98) / 1 mA
Pour Vcc = + 5 volts, R4 = (5 - 2,98) / 10-3 = 2,02 k ohm
On prend R4 = 2,2 k qui est une valeur normalisée proche
de celle calculée.
La tension en sortie est proportionnelle à la
température. Elle augmente de 10 mV par degré Celsius
supplémentaire.
La relation entre la tension et la température est
donnée par la formule suivante :
VT est la tension de sortie, T la température ambiante,
VT0 est la tension de référence pour une température
T0.
Pour T0 = 25°C et VT0 = 2,98 volts, on obtient :
Pour améliorer la précision de la mesure, on
peut effectuer l'étalonnage du capteur à l'aide d'un
thermomètre de précision. Avec ce dernier, on mesure la
température et on reporte la valeur trouvée dans la formule (5),
ce qui permet de calculer VT.
Il ne reste plus qu'à régler la tension de sortie
à la valeur calculée. Pour cela, il faut utiliser un
voltmètre de
précision et agir sur le potentiomètre P de 10 k
ohm (10)
B- conversion analogique - numérique :
Pour la conversion A/D on a utilisé le convertisseur A/D
du pic18f452
Configuration du CAN :[11]
- Configurer les pins analogiques et les tensions de
référence : ADCON1 :

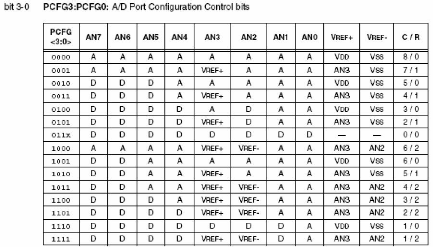
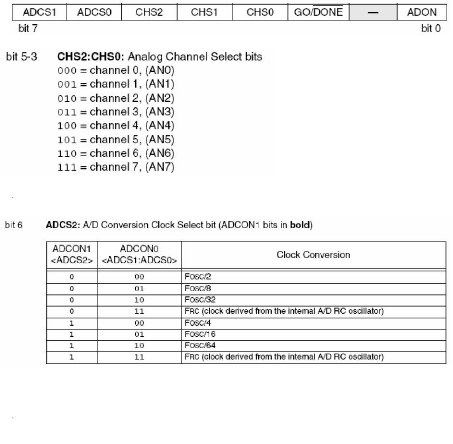
- Déterminer l'horloge du convertisseur
:
- Configure l'interruption du CAN :
- ADIF bit = 0
72
- Choix du canal d'entrer analogique du convertisseur:
ADCON0 :
- ADIE bit = 1 (permet l'interruption)
- GIE bit = 1 (permet les interruptions globales)
- PEIE bit = 1 (permet les interruptions
périphériques)
- démarrer la conversion :
GO/DONE bit (ADCON0) = 1
- Attendre la fin de la conversion :
ADIF < PIR1 > = 1 la
conversion est terminé
ADIF < PIR1 > = 0 la
conversion n'est pas encore terminé
- Lecture du résultat de la conversion (dans
ADRESL OU ADRESH) :
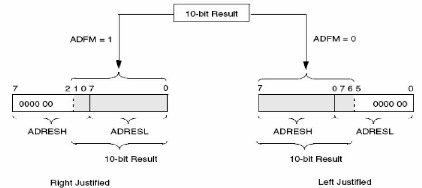
Bibliographie
1- THESE de DOCTORAT
-« Un Mécanisme d'Ordonnancement Distribué de
Tâches Temps Réel » -Leïla Baccouche
-
http://tel.archives-ouvertes.fr/documents/archives0/00/00/49/76/index
fr.html
2- Système temps réel
-Marc rivaletto
-
http://www.univ-
pau.fr/ENSEIGNEMENT/IUPGEII/Index/prof/rivaletto/tpsreel/cours
str.pdf
3- THÈSE de DOCTORAT
-« Analyse Hors Ligne d'Ordonnançabilité d'
Applications Temps Réel comportant Des Tâches Conditionnelles et
Sporadiques »
-stéphane PAILLER
-
www.lisi.ensma.fr/ftp/pub/documents/thesis/2006-thesis-pailler.pdf
4- Informatique industrielle A7-19571Systèmes
temps-réel
- J.F.Peyre
-www.deptinfo.cnam.fr/
5-
www.picos18.com
6-http://etr05.loria.fr/
7-www.comelec.enst.fr/rtpsoc/RTOS/Aussois/amd1.pdf
8-www.microchip.com
9-
http://www.premiumorange.com/daniel.robert9/Digit/Pratique/Digit
14P l
| 

