FPGA and Traffic Network Analysis( Télécharger le fichier original )par Jerry TEKOBON Ecole Nationale Supérieure Polytechnique de Yaounde Cameroun - Ingénieur de Conception en Génie Electrique et Télécommunication 2007 |

4.2.5 UCircuits arithmétiques U
En base 2, avec n bits, on dispose d'un maximum de 2Pn Pcombinaisons. Un nombre non signé peut être exprimé par bBn-1B2Pn-1 P+bBn-2B2Pn-2 P+... +bB0B+bB-1B2P-1P+bB-2B2P-2 P+...+bB-mB2P-m Pavec n bits de partie entière et m bits de partie fractionnaire. Cette représentation est appelée Uvirgule fixeU. La virgule est quelque chose de totalement fictif d'un point de vue circuit et un tel nombre peut toujours être vu comme un entier à condition de le multiplier par 2PmP. La suite 0101 sur 4 bits représente aussi bien 5 que 2.5 ou 1 .25. 4.2.5.1.2 UNombres signés : complément à 2 A l'origine, on cherche une représentation pour des nombres signés la plus simple possible au niveau des circuits devant les traiter. En l'occurrence l'addition. Quel est le nombre que je dois rajouter à A pour avoir 0 ? Je déciderais qu'un tel nombre est une représentation de .A. Par exemple sur 4 bits, A = (a3 a2 a1 a0)  = (/a3 /a2 /a1 /a0) A +  = (1 1 1 1) A +  + 1 = (1 0 0 0 0) La somme sur n + 1 bits vaut 2n mais 0 sur n bits. Privilégiant ce derniers cas, on admet alors que  + 1 est une représentation possible de -A. Il en découle alors que sur n bits, un entier signé sera représenté de -2n-1 à +2n-1-1. On peut aussi plus généralement exprimer un nombre signé par la relation : -bn-12n-1 + bn-22n-2 +. + b121 + b0 4.2.5.2 UAdditionneurs, soustracteurs, décalages, comparateursU Les opérateurs de base arithmétiques ou logiques +, -, NOT, *, AND, >, >, =, shift_left, shift_right sont des fonctions courantes disponibles dans des paquetages standards tels que IEEE.NUMERIC_STD. Le synthétiseur les accepte tel quel avec des types integer, signed ou unsigned. D'autres fonctions particulières pourraient enrichir le catalogue de primitives Il n'y a aucun problème pour décrire une quelconque opération mais attention à l'éventuel dimensionnement des mots traités qui pourrait s'avérer incorrect surtout lorsqu'on utilise des conversions de type. Exemple: S <= a + b ; S doit comporter le même nombre de bits que a ou b. 4.2.5.3 UMultiplication ou division par une puissance de 2U D'après ce qui précède, nous déduisons une première règle en terme de circuit : Une division ou une multiplication par une puissance de 2 ne coûte rien sinon en nombres de bits significatifs. Diviser ou multiplier un nombre par une puissance de 2 revient à un simple câblage. S <= `0' & e (7 DOWNTO 1); -- S est égal à e/2 4.2.5 .4 UMultiplication par une constante U Cela sera le plus souvent très facilement réalisé par un nombre limité d'additions ou encore mieux, par un nombre minimal d'additions et de soustractions. Supposons la multiplication 7 * A en binaire. Elle sera décomposée en A + 2*A + 4 *A. Comme les multiplications par 2 et 4 ne coûtent rien, la multiplication par 7 ne nécessite que 2 additionneurs. On remarque cependant que 7*A peut s'écrire 8*A-A, on peut donc réaliser cette même multiplication par un seul soustracteur. De façon générale, l'optimisation du circuit se ferra en cherchant la représentation ternaire (1, 0, -1) des bits qui minimise le nombre d'opérations à effectuer (et maximise le nombre de bits à zéro). Mais attention, une telle représentation d'un nombre n'est pas unique. 6 = 4 + 2 = 8 -2. 4.2.5.5 UMultiplication d'entiersU A priori, la multiplication est une opération purement combinatoire. Elle peut d'ailleurs être implantée de cette façon. Disons simplement que cela conduit à un circuit très volumineux et qui a besoin d'être optimisé en surface et en nombre de couches traversées. De telles optimisations existent assez nombreuses. Citons simplement le multiplieur disponible en synthèse avec Leonardo, c'est le multiplieur de Baugh-Wooley . S <= a * b ; -- multiplieur combinatoire L'autre méthode beaucoup plus économique mais plus lente car demandant n itérations pour n bits est la méthode par additions et décalages. On peut en donner deux formes algorithmique, une dite sans restauration et l'autre plus anticipative dite avec restauration.
Le diviseur le plus simple procède à l'inverse de la multiplication par addition et décalage et produit un bit de quotient par itération. On peut en donner une forme algorithmique dite « sans restauration ». Le dividende n bits est mis dans un registre 2n + 1 bit qui va construire le reste et le quotient. Le diviseur est place dans un registre n + 1 bits. INIT : P = 0, A = dividende, B = diviseur REPETER n fois SI P est négatif ALORS décaler les registres (P,A) d'une position à gauche Ajouter le contenu de B à P SINON décaler les registres (P,A) d'une position à gauche soustraire de P le contenu de B FIN_SI SI P est négatif mettre le bit de poids faible de A à 0 SINON Le mettre à 1 FIN_SI FIN_REPETER On constate très facilement que cet algorithme implique pour un circuit de division : · Un additionneur/soustracteur 2n + 1 bits · Un registre à décalage 2n + 1 bits avec chargement parallèle · Un registre parallèle n + 1 bits Maintenant nous allons parler de la modélisation des circuits en VHDL.
Un modèle est une description valide pour la simulation. En modélisation tout le langage VHDL est donc utilisable. Une description synthétisable reste donc aussi un modèle. Modélisation et synthèse sont tout à fait complémentaires. En effet, lors de la conception d'un circuit, il faut être capable de le tester dans un environnement aussi complet que possible. On a donc besoin pour cela de modèles comportementaux comportant des aspects fonctionnel et temporel. Tel est le cas pour les générateurs de stimuli, les comparateurs de sorties, les modèles de mémoires RAM ou ROM ou tout autre circuit décrit au niveau comportemental. 4.3.1 Modélisation des retards U 4.3.1.1 U Les moyens de pris en compte U · Affectation de signal: s <= a AFTER Tp; · Instruction FOR: WAIT FOR delay1; -- affecte tous les signaux du Processus · Fonction NOW: retourne l'heure actuelle de simulation. Limitée au contexte séquentiel · Attributs définis fonctions du temps: S'delayed [(T)], S'Stable [(T)], S'Quiet [(T)]. · Bibliothèques VITAL 4.3.1.2 UTransport ou inertiel ?U Deux types de retards sont à considérer : Retard inertiel (par défaut) ou retard Transport. Toute sortie affectée d'un retard inertiel filtre toute impulsion de largeur inférieure à ce retard tandis qu'un retard de type transport est un retard pur pour le signal auquel il est appliqué. 4.3.2 UModèle de RAMU [12] -- Fichier : cy7c150.vhd -- Date de creation : Sep 98 -- Contenu : RAM CYPRESS avec e/s separees -- Synthetisable ? : Non -------------------------------------------------------------------------------- LIBRARY IEEE; USE IEEE.STD_LOGIC_1164.ALL; USE ieee.numeric_std.ALL; ENTITY cy7c150 IS PORT ( a : IN unsigned( 9 DOWNTO 0); d : IN unsigned( 3 DOWNTO 0); o : OUT unsigned( 3 DOWNTO 0); rs_l, cs_l, oe_l, we_l : IN std_logic); END cy7c150; -- modèle sans-retard d'après catalogue CYPRESS ARCHITECTURE sans_retard OF cy7c150 IS TYPE matrice IS ARRAY (0 TO 1023 ) OF unsigned( 3 DOWNTO 0); SIGNAL craz , csort, cecri : BOOLEAN; SIGNAL contenu : matrice; BEGIN craz <= ( rs_l = '0' AND cs_l = '0'); csort <= ( cs_l = '0' AND rs_l = '1' AND oe_l = '0' AND we_l = '1'); cecri <= ( cs_l = '0' AND we_l = '0'); ecriture:PROCESS BEGIN WAIT ON craz, cecri; IF craz THEN FOR i IN matrice'RANGE LOOP contenu (i) <= "0000"; END LOOP; ELSIF cecri THEN contenu(to_integer('0'& a)) <= d ; ELSE o <= unsigned(contenu(to_integer('0'& a))); END IF; END PROCESS; -- attention, il faut rajouter '0' en bit de signe de a afin que l'entier correspondant soit positif END; 4.3.3 ULecture de FichierU On doit fournir à un circuit de traitement d'images des pixels extraits d'un fichier image noir et blanc au format PGM. Le format de ce fichier est défini ainsi : P2 #CREATOR XV 512 512 255 155 155 154 154 150. P2 est l'indicateur du format. La ligne suivante est une ligne de commentaire, 512 est le nombre de points par ligne, 512 est le nombre de lignes d'une image et 255 est la valeur maximale du pixel dans l'échelle de gis (codé sur 8 bits). Viennent ensuite la succession des 262144 pixels. C'est un exemple de création de stimuli complexes par lecture de données dans un fichier. On se sert du package Textio et en particulier des procédures READLINE ET READ permettant de parcourir séquentiellement un fichier ASCII. LIBRARY ieee; USE ieee.std_logic_1164.ALL; USE ieee.numeric_std.ALL; LIBRARY std; USE std.textio.ALL; ENTITY camerapgm IS GENERIC (nom_fichier : string := "lena.pgm"; en_tete : IN string := "P2"; largeur : IN natural := 512; hauteur : IN natural := 512 ; couleur_max : IN natural := 255); PORT ( pixel : OUT unsigned( 7 DOWNTO 0 ) ; -- pixels h : IN std_logic); -- horloge pour appeller la sortie END camerapgm ; ARCHITECTURE sans_tableau OF camerapgm IS BEGIN -- sans_tableau lecture : PROCESS FILE fichier : text IS IN nom_fichier; VARIABLE index : natural := 0; VARIABLE ligne : line; VARIABLE donnee : natural; VARIABLE entete : string (1 TO 2); -- on attend P3 ou P2 VARIABLE nx : natural := 15; -- nombre de caracteres par ligne VARIABLE ny : natural; -- nombre de lignes; VARIABLE max : natural; -- intensite max VARIABLE bon : boolean; CONSTANT nbr_pixels : natural := largeur * hauteur ; -- 512 * 512 = 262144 BEGIN -- PROCESS charger ASSERT false REPORT "debut de lecture du fichier " SEVERITY note; readline(fichier, ligne); -- ouverture du fichier image read(ligne,entete,bon); ASSERT bon REPORT "l'en-tete n'est pas trouvee" SEVERITY error; ASSERT entete = en_tete REPORT "en-tete incorrecte" SEVERITY error ; readline(fichier, ligne); -- 1 ligne de commentaire readline(fichier, ligne); read(ligne,nx,bon); ASSERT bon REPORT "erreur de format sur nx" SEVERITY error; ASSERT nx = largeur REPORT "Dimension de ligne incorrect" SEVERITY error; read(ligne,ny,bon); ASSERT bon REPORT "erreur de format sur ny" SEVERITY error; ASSERT ny = hauteur REPORT "Nombre de lignes incorrect" SEVERITY error; readline(fichier, ligne); read(ligne,max,bon); ASSERT bon REPORT "erreur de format sur max" SEVERITY error; ASSERT max = couleur_max REPORT "niveau max de couleur incorrect" SEVERITY error; index := 0; l1: WHILE NOT ENDFILE(fichier) LOOP readline(fichier, ligne); read(ligne,donnee, bon); WHILE bon LOOP WAIT UNTIL rising_edge(h); -- pour synchroniser index := index + 1; pixel <= to_unsigned(donnee,8); IF index = nbr_pixels /4 THEN ASSERT false REPORT "Patience ... plus que 75%" SEVERITY note; END IF; IF index = nbr_pixels /2 THEN ASSERT false REPORT "Patience ... plus que 50%" SEVERITY note; END IF; IF index = nbr_pixels *3 /4 THEN ASSERT false REPORT "Patience ... plus que 25%" SEVERITY note; END IF; read(ligne,donnee, bon); END LOOP; END LOOP; ASSERT false REPORT "Ouf !!, c'est fini" SEVERITY note; ASSERT index = nbr_pixels REPORT "Nombre de pixels incorrect" SEVERITY error; WAIT; END PROCESS; END sans_tableau; 4.3.4 ULes bibliothèques VITALU VITAL (VHDL Initiative Towards ASIC Libraries) est un organisme regroupant des industriels qui s'est donné pour objectif d'accélérer le développement de bibliothèques de modèles de cellules pour la simulation dans un environnement VHDL (depuis 1992). La spécification du standard de modélisation fixe les types, les méthodes, le style d'écriture efficace pour implémenter les problèmes de retards liés à la technologie. L'efficacité est jauchée selon la hiérarchie suivante : · Précision des relations temporelles · Maintenabilité du modèle · Performance de la simulation La plupart des outils de CAO utilisent les bibliothèques VITAL au niveau technologique. 4.3.4.1 UNiveaux de modélisation et conformitéU Une cellule est représentée par un couple entity/architecture VHDL. La spécification définie trois niveaux de modélisation correspondant à des règles précises. · Vital Level 0 · Vital Level 1 · Vital Level 1 Memory
Il définie les types de données et les sous-programmes de modélisation des relations temporelles. Sélection des retards, pilotage des sorties, violation de timing (ex: Setup, Hold) et messages associés. 4.3.4.2.2 UVital_PrimitivesU Il définie un jeu de primitives combinatoires d'usage courant et des tables de vérité 4.3.4.2.3 UVital_MemoryU Spécifique pour modélisation des mémoires. Maintenant dans la partie qui suit nous allons concrètement parler de l'algorithme de Dijkstra. 4.4 UDIJKSTRAU Suivant de près Bellman, DIJKSTRA fut le second, en 1959, à proposer un algorithme cité par tous. Il y propose une manière de trouver le chemin de poids le plus faible entre deux points d'un graphe non-orienté pondéré dont les arêtes ont un poids positif ou nul. Peu de temps après, en 1960, Whiting et Hillier on présenté le même algorithme, en suggérant que la méthode pouvait aisément être appliquée aux graphes orientés. Le temps d'exécution de l'algorithme est de Ï(|V|P2P), et peut être réduit à Ï(|E|log|V|) suivant l'implémentation. 4.4.1 UDescription Soient les considérations suivantes : V : l'ensemble des sommets du graphe; E : l'ensemble des arcs (ou arêtes) du graphe; T : un ensemble temporaire de sommets d'un graphe; S : l'ensemble des sommets traités par l'algorithme; y : un tableau de coût de longueur |V| (le nombre de sommet du graphe); a : l'indice du noeud de départ; c(u, v) : permet d'obtenir le coût d'un arc du sommet u au sommet v appartenant à E. 4.4.2 UAlgorithmeU POUR début
fin yBaB S T TANT QUE T début Sélectionner le sommet j de T de plus petite Valeur yBjB T S POUR début yBkB fin fin
UFigure4.1 : UOrganigramme de l'algorithme de DIJKSTRA
Considérons un réseau informatique défini par le graphe valué = (X, A) et dont la représentation est faite ci-dessous : 0 56 56 56 56 56 56 2 13 7 18 9 2 1 3 1 a c f b e d g
UFigure4.2U : UGraphe1 UEtapes de l'exécutionU : 1) On attribue au sommet choisi (ici a) la marque 0, et à tous les autres sommets une marque initiale infinie. En pratique, les ordinateurs ne connaissant pas les ensembles infinis, il suffit de donner à chaque sommet une marque initiale égale à la somme des valuations de tous les arcs du graphe, soit ici 56 (voir figure ci-dessus). 2) a conserve sa marque 0. On remplace la marque des successeurs k de 1 par la valeur de l'arc (a ; k) :
3) Dans l'ensemble des sommets X - {a} on choisit un (car il peut ne pas être unique) sommet de plus petite marque (ici e, de marque yBeB = 7) et on attribue à tous ses successeurs k la marque Inf {yBkB, yBeB + cekB}. On obtient donc :
Figure4.4U : UGraphe3 4) Dans l'ensemble des sommets X - {a, e} on choisit un sommet de plus petite marque (ici f, de marque yBfB = 8) et on attribue à tous ses successeurs k la marque Inf { yBkB, yBfB + cfkB}. On obtient donc :
5) On itère le procédé : dans l'ensemble des sommets X - {a, e, f} on choisit un sommet de plus petite marque (ici d, de marque yd = 9) et on attribue à tous ses successeurs k la marque Inf {yBkB, yd + cBdkB}
Figure4.6 : UGraphe5U 6) Dans l'ensemble des sommets X - {a, e, f, d} on choisit un sommet de plus petite marque (ici g, de marque yBgB = 6) et on attribue à tous ses successeurs k la marque Inf {yBkB, yBgB + cgkB}. On constate que cette opération ne change aucune marque :
Figure4.7U : UGraphe6U 7) Dans l'ensemble des sommets X - {a, e, f, d, g} on choisit le sommet plus petite marque (ici b, de marque yBbB = 11). Ce sommet n'a pas de successeur. On constate donc également que cette opération ne change aucune marque. Figure4.8U : UGraphe7U 0
8) Enfin dans l'ensemble des sommets X - {a, e, f, d, g, b} on choisit le dernier sommet (ici c, de marque yBcB = 17). Ce sommet n'a pas de successeur. On constate donc également que cette opération ne change aucune marque. Tous les sommets du graphe ayant été choisis, l'algorithme est terminé et on obtient les longueurs des plus courts chemins de a aux autres sommets (voir figure4.4.4i).
Figure4.4.9 : UGraphe8 Les chemins les plus courts par rapport à `'a'' sont : a: a ; 0 c: c b: b g: g UFigure4.10U : UGraphe9U
Rappelons pour commencer quel est le problème que nous voulons résoudre ; bien pour un paquet de données venant d'un poste (voir figure4.11) et arrivant à l'entrée d'un réseau (WAN par exemple) selon la métrique spécifiée, la passerelle doit lui assigner le chemin optimale afin d'éviter le phénomène de congestion. Le problème n'est de réaliser ce processus mais c'est de l'accélérer car il existe déjà (en l'occurrence l'algorithme de dijkstra)). C'est pourquoi on utilise des circuits FPGA. Notre travail fut donc d'implémenter cet algorithme sur FPGA. ligne 5 ligne 2 ligne 4 ligne 3 ligne 1
Passerelle d'entrée Figure 4.11 : Modélisation du problème
Notre environnement intégré de développement est l'outil ISE 8.1 dont nous nous servirons pour l'implémentation sur FPGA de la compagnie Xilinx et notre outil de simulation est ModelSim toujours de Xilinx Edition- III et par ISE. Pour mieux comprendre notre approche, examinons l'architecture ci-dessous :
UFigure 4.12: Uarchitecture du programme d'implémentation sur FPGA Dans notre architecture, nous n'avons pas séparé les bus d'adresses et de données pour besoin de clarté du schéma, signalons seulement que lorsque deux blocks sont reliés par un bus, alors il sont en relation et la description de cette relation sera faite dans la suite. Nous avons subdivisé l'algorithme en block de description, c'est-à-dire par exemple que notre réseau exemple est sauvegardé (sa description) dans une ROM qui elle, est codée sous forme de package. Ainsi qui est notre réseau (voir 4.4.4 exemple) sera stocké dans une ROM. En faite cette ROM contiendra la valeur du coût des liens entre les différents noeuds de notre réseau. Elle est programmée sous forme de package et nous l'appellerons dans le programme principal en mode lecture unique pour lire la description du réseau car nous ne pourrons pas changer son contenu. Signalons que si du point vue hardware nous accédons au contenu de cette ROM par des lignes d'adresses, cependant dans son code, le traitement de son contenu se fait de manière software ; en faite pour être claire cette une matrice d'ordre 2 dont les indices sont des noeuds et l'élément est le coût du lien entre ces deux noeuds (exemple lien (a, b)=1). Pour accéder à un élément de la ROM, nous utilisons des lignes d'adresses qui sont des variables de type signal (voir chapitre précédent), en faite ces lignes d'adresse représentent un vecteur signal et dont le contenu est l'adresse d'un élément de notre matrice. La RAM1 contient la valeur courante des indices de chaque noeud du réseau, au début du programme elle est initialisée à 0 pour le noeud `a' et à infinie (c.a.d. un nombre très grand) pour tous les autres noeuds (signalons que le noeud `a' représente le noeud du réseau physique où se trouve le paquet de données). La RAM2 quant à elle contient la liste des noeuds n'ayant pas été traités par le programme, c'est pourquoi elle est initialisée à la liste de tous les noeuds. Les blocks en V sont juste à titre représentatives, ils n'ont aucune fonction opératoire ou conservatoire, mais elles servent juste à préciser de type de données il s'agit. Le block opérateur est celui qui permet la mise à jour des différents indices de chaque noeud. Le block comparateur comme son nom l'indique, compare les différents indices de chaque noeud et retient le plus petit. Enfin, le block commande est celui d'où partent les noeuds pour le lancement du programme. 4.5.2 UFonctionnement de l'architectureU Au lancement du programme, la ROM contient comme nous l'avons
déjà dis la description du réseau, la RAM1 est
initialisée à 0 pour `a' et à l'infini pour le reste des
noeuds. La RAM2 quant à elle contient la liste de tous les noeuds
(sauf Le block de commande lit la liste des noeuds non traités dans la RAM2 et les transmet avec le noeud de traitement courant aux blocks RAM1 et ROM. Cette transmission est faite sous forme d'adresse, le block RAM1 recevant donc ces adresses renvois non au block commande mais plutôt au block opérateur les indices des noeuds qui lui sont transmises, de même la ROM quant à elle renvoie également au block opérateur non pas les indices de noeuds du réseau, mais le coût de leurs liens. Le block opérateur réalise le calcul attendu, et effectue ensuite une mise à jour des indices des noeuds du réseau contenues dans la RAM1, et enfin bloque l'espace contenant les données concernant le noeud traité (qui est ici `a' à la première boucle du programme), c'est afin que le block comparateur ne puisse pas y avoir accès. Le block comparateur compare ensuite toutes les valeurs des indices des noeuds qui lui sont visibles, et renvois le noeud d'indice minimal au block commande. Celui-ci effectue une mise à jour de liste des noeuds dans la RAM2 en effaçant de cette liste le noeud d'indice minimal qui est maintenant devenu le noeud traité, et le cycle recommence. Le programme s'arrêtera lorsque la RAM2 sera vide. Lorsque le programme est terminé, il y a encore un petit programme dont on ne s'étendra pas ici mais qui permet de débloquer les données de la RAM1 et à partir de ces données, de générer un fichier contenant les différents chemins détaillés du noeud sur lequel se trouve le paquet de données, vers tous les autres noeuds du réseau physique (c'est en faite la table de routage). UN.B.U : Tous ces différents blocks de notre programme ne sont pas physiques, il s'agit là juste d'une illustration des différents processus de notre programme. Cependant, tous ces processus forme un tout et sont décris au sein d'un ensemble commun qui est le programme principal (main program).
Comme nous l'avons déjà dis, la ROM est un package que nous allons définir dans la librairie work et ensuite nous allons juste l'appeler dans le programme principal. Signalons que d'un point de vue physique, pour changer de configuration du réseau, il est nécessaire d'avoir une autre ROM (d'un point de vue physique nous répétons). Les données de la ROM sont des vecteurs de 16 bits. Pourquoi 16 bits, et bien parce que les 4 premiers bits codent une extrémité du lien, les 4 suivants l'autre extrémité et les 8 derniers sont pour représenter la valeur du coût du lien entre ces deux extrémités. Par conséquent son bus de données aura 16 lignes (souvenons nous que cela est une vue de l'esprit). Son bus d'adresse contient 5 lignes pour pouvoir adresser tous les couples de noeuds. En ce qui concerne comment accéder à la ROM, cela a déjà été dis, et son initialisation se fait de manière interne au package. Voila tout en ce qui concerne la ROM.
La RAM1 contient la valeur des indices des noeuds du réseau son bus de données est constitués de 12 lignes dont les 4 premiers sont pour coder le noeud et les 8 autres pour l'indice de ce noeud. Son bus d'adresse possède 4 lignes pour représenter tous les noeuds du réseau. La RAM1 est un composant interne du programme principal.
La RAM2 contient la liste des noeuds du réseau non encore traités. Son bus de données est constitué de 4 lignes pour coder le noeud non traité. Son bus d'adresse possède 4 lignes pour représenter tous les noeuds du réseau. La RAM2 est aussi un composant interne du programme principal. En faite on peut concevoir le block opérateur comme un processeur à part entière et la RAM1 est l'un de ses registres internes, de même on regarder le block commande aussi comme un processeur avec son registre interne comme RAM2. Les blocks commande et opérateur sont eux aussi des composant internes du programme principal. |
|


 sommets de i de V
FAIRE
sommets de i de V
FAIRE yBiB
yBiB  +8
+8 0
0 Ø
Ø
 V
V Ø
FAIRE
Ø
FAIRE T \ j
T \ j S
S j
j
 sommets k de T adjacents
à j FAIRE
sommets k de T adjacents
à j FAIRE min(yBkB ,
yBjB +c(j, k)) {c(j, k) est le coût de j à k}dd
min(yBkB ,
yBjB +c(j, k)) {c(j, k) est le coût de j à k}dd 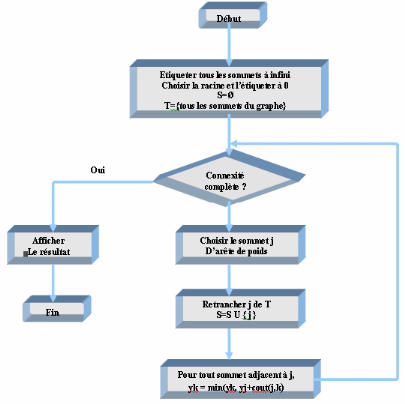
 f
f e
e a ; 17
e: e
a ; 17
e: e a ;
7
a ;
7 d
d e
e a ; 119 d: d
a ; 119 d: d e
e a ; 9
f: f
a ; 9
f: f e
e a ;
8
a ;
8 d
d e
e  a ; 10
a ; 10 Données
Données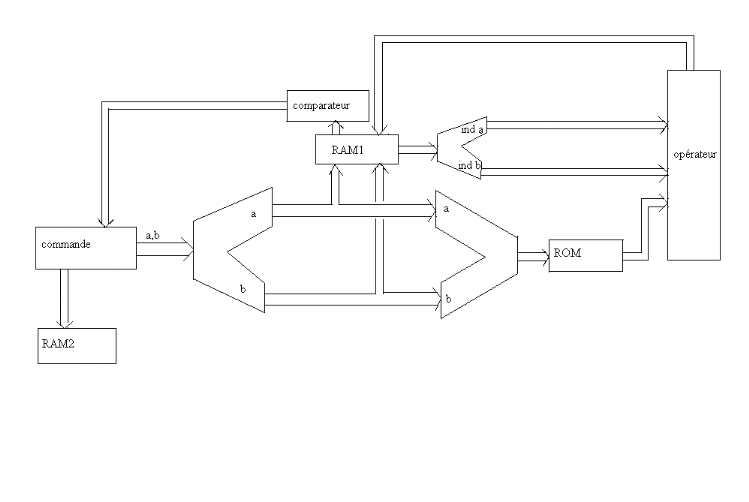
 `a') car
ceux-ci n'ont pas encore été traités par le programme.
`a') car
ceux-ci n'ont pas encore été traités par le programme.