II.2.7.7. Répartition
(sharding)
La montée en charge horizontale est
réalisée par répartition (sharding). MongoDB peut aussi
bien s'exécuter en tant que moteur individuel sur une seule machine ou
être converti en un cluster de données éclatées
géré automatiquement et comportant un nombre de noeuds pouvant
théoriquement aller jusqu'à mille. Le sharding de MongoDB impose
quelques limitations légères à ses fonctionnalités,
notamment une immutabilité de la clé (primaire) du document. Le
choix de
la répartition est fait par collection. C'est une
collection, et non pas une base de données, qu'on répartit. Les
documents de cette collection seront distribués aussi
équitablement que possible entre les différents noeuds, afin
d'équilibrer les traitements.
À chaque opération, il faut bien entendu
identifier le noeud qui contient ou doit contenir les données. Ce
rôle est assuré par un processus nommé mongos, qui
reçoit les requêtes et les redoute, et qui agit donc comme un
répartiteur de charge. Pour assurer une continuité de service,
cette répartition peut être accompagnée de
réplication : chaque noeud peut avoir son propre groupe de
réplicas avec basculement automatique.
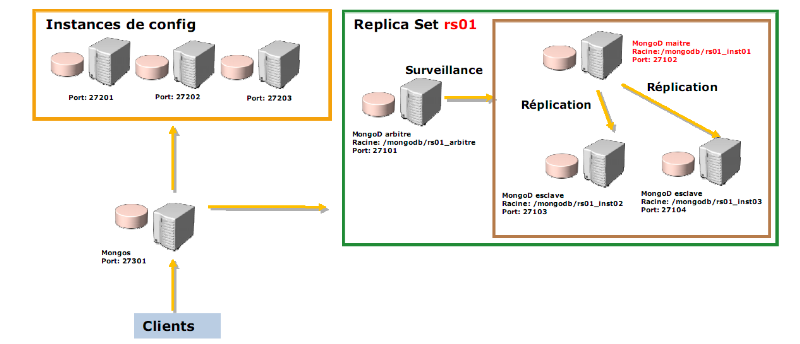
Figure 2.13: Le modèle
de répartition de MongoDB [Noureddine DRISSI, MongoDB,
Administration].
| 

