|
IN MEMORIAM
En mémoire de mon défunt oncle et parrain
académique, MASUMBUKO BUNYAS W.J., pour l'orientation efficace
et mon bien-être ; j'en suis reconnaissant de tous ses biens
faits.
Paix à ton âme.
ÉPIGRAPHE
«Most of the knowledge in the world in the future is
going to be extracted by machines and will reside in machines»1(*)
Yann LeCun
DÉDICACE
À mes parents
Je vous suis reconnaissant pour les sages conseils prodigieux
et les directives insistantes. Je vous sais gré de votre bienveillance,
de vos attentions, de vos scrupules et des principes tant moral et spirituel
que vous m'avez insinués. À vous je dédie cet humble
travail, preuve de mon éternelle gratitude.
REMERCIEMENTS
C'est pour nous un honneur et un réel plaisir de
réaliser un tel travail. Son élaboration traduit, à sa
juste valeur, le dévouement le plus soutenu et l'intérêt
que nous lui avons accordé.
Avant tout, nous adressons nos sincères remerciements
au père céleste, créateur de tout, source d'intelligence
et sagesse.
Nous remercions nos très chers parents pour nous avoir
donné non seulement la vie mais aussi pour leurs sacrifices consentis
pour nous faire arriver au stade actuel de notre formation, que toute la
famille trouve un sentiment de profonde reconnaissance à travers ce
travail.
Au terme de nos études universitaires
sanctionnées par ce travail, nous tenons loyalement à remercier
nos professeurs pour leur formation des plus précieuses ainsi que
l'ensemble du corps académique de notre université.
Nos remerciements s'adressent àMonsieur le Professeur
DocteurKAFUNDA KATALAY Pierre,Professeur
attaché à l'Université de Kinshasa, le directeur de ce
mémoire, les assistantsGradi KAMINGU LUBWELE etCamile LIKOTELO
BINENE. ; pour nous avoir dirigé malgré leurs multiples
tâches. N'eut été votre soutien, ce travail ne
s'appellerait pas mémoire. C'est pour nous une meilleure occasion de
vous exprimer nos sentiments de reconnaissance et de profonde gratitude.
Nos remerciements s'adressent à tout le corps
académique et scientifique de la faculté des sciences
précisément ceux du département de Mathématique et
informatique, à la personne du professeur KAPENGA KAZADI, et tant
d'autres pour leur formation durant notre cursus universitaire.
Nos reconnaissances s'adressent non seulementaux ami(e)s et
ainé(e)s scientifiques mais aussi à nos encadreurs
telques :Serge DISUNDA,Hyppolite KABANGO, Glad MAMPUYA, Huguette LUSAMBA.,
Joe BALANGA, Basile MUAMBA, Arnold MWAMBAYI dit MK, Jerry LOMAYE, Ticky KISUBI,
Jean Denis ZOMBINA, Samuel MATONDO, Ignace AWEKWE, Patrick BANYANGA et Carmi
NDEKE.
Sans pourtant oublier nos compagnons de lutte à
l'instar de :Junior ZAKO, Carlos KALALA, Elysé TSHINAWEJ, Victor
KAINDA, Martin MATANDA, Modeste TANGELO, Éric BASA, Benjamin et Odia
TSHIKANGU, Apphia DISASHI, Mireille NGALULA, Alice MABILO, Blanche KAFUTI,
Déborah MOBUTSHI, Dorcas INYANGI, Gloria KANIONIO, Nora MISENGA, Eloi
KINGUEZE, Joe BONGO, Nadège YAHOBU, Brigitte KENGE, Samuel BIGA et
Steave MAYIRA.
Nos remerciements s'adressent aux famillesMASUMBUKOBunyas W.,
KATAGONDWA, Nathalis MUJANGA, Liévin AMISI,Eddy ELUMBA,Albert
VUNINGOMA, BAGAYA, MUDERHWA et MULENGABYUMA.
Nos remerciements s'adressent également à tous
les héros dans l'ombre qui ont contribués pour notre
bien-être physique, intellectuel et spirituel.
Nous dédions ce travail à Extrem Informations
Technology, notre chère entreprise.
AVANT-PROPOS
Le présent mémoire est le résultat de
cinq années d'études universitaires. En plus de son
témoignage de nos cinq longues années, il nous couronne du titre
de deuxième cycle. Ce travail devrait être lu avec un grand
intérêt, non seulement par les scientifiques, mais aussi par les
professionnels.
Le Big Data est une notion très récente dont
l'analyse s'articule plus sur l'administration des de base des données,
généralement rattachée à l'Informatique (surtout
pour son importance en support de stockage et d'analyse, ses applications
continuent à se multiplier du jour le jour.
Cependant, dans ce travail, nous présentons comment
faire l'administration et l'analyse des bases de données NoSQL, du type
document. Ces bases de données sont généralement
destinées aux applications qui gèrent des documents. La nature
souple, semi-structurée et hiérarchique des documents et des
bases de données de documents leur permet d'évoluer avec les
besoins des applications. Le modèle de document fonctionne bien avec les
cas d'utilisation, comme des catalogues, des profils d'utilisateurs et des
systèmes de gestion de contenu où chaque document est unique et
évolue au fil du temps. Les bases de données de documents
permettent une indexation flexible, des requêtes ad hoc efficaces et des
analyses sur des recueils de documents.
Nous remercions d'avance tous les utilisateurs qui voudront
bien nous faire parvenir leurs remarques, suggestions pour
l'amélioration tant syntaxique que sémantique de cet humble
travail.
LISTE DES ABRÉVIATIONS
UTILISÉES
|
Abréviation
|
Signification
|
|
ACID
|
Acide, Cohérence,Isolation et Durablité
|
|
AGPL
|
Affero General Public Licence
|
|
API
|
Application Programming Interface
|
|
BASE
|
Basically Available, Soft state, Eventually
|
|
BCDC
|
Banque Commerciale Du Congo
|
|
BD / BDD
|
Base de données
|
|
BI
|
Business Intelligence
|
|
CAH
|
Classification Ascendante Hiérarchique
|
|
CAP
|
Consistency, Availability, Partition Tolerance
|
|
CDH
|
Classification Descendante Hiérarchique
|
|
DB
|
Database
|
|
DBTG
|
Data Base Task Group
|
|
EA
|
Entité-Association
|
|
GPL
|
GNU General Public Licence
|
|
HA
|
High availability
|
|
HDFS
|
Hadoop Distributed File System
|
|
http
|
Hypertext transfer protocol
|
|
IBM
|
International Business Machine
|
|
IS - IS
|
Intermediate system to intermediate system
|
|
JDK
|
Java Development Kit
|
|
JVM
|
Java Virtual Machine
|
|
MCD
|
Modèle conceptuel des données
|
|
MERISE
|
Méthode de recherche en informatique pour les
systèmes d'entreprise
|
|
ML
|
Machine Learning
|
|
MongoDB
|
Mongo DataBase
|
|
MPD
|
Modèle physique des données
|
|
NASA
|
National Aeronautics and Space Administration
|
|
NoSQL
|
Not only SQL
|
|
OLAP
|
Online Analytical Processing
|
|
OLTP
|
Online Transaction Processing
|
|
OMT
|
Object Modeling Technique
|
|
ORM
|
Object-Relational Mapping
|
|
OSPF
|
Open Shortest Path Protocol
|
|
RN
|
Réseaux de Neurones
|
|
RPG
|
Retro Propagation de Gradient
|
|
SGBD
|
Système de gestion de base de données
|
|
SGBDR
|
Système de gestion de base de données
relationnelle
|
|
SQL
|
Structured Query Language
|
LISTE DES FIGURES
Figure 1.1: Graphique historique du Big Data
[developpez.com-big data-evolution]
3
Figure 1.2: Les 5V du Big Data.[Évolution
du Big Data]
10
Figure 1.3: Les données du Big Data.[Big
Data et ses données]
11
Figure 1.4: les solutions sur le cloud
computing.
14
Figure 1.5: Guide visuelle au
théorème du CAP.
18
Figure
1.6: Illustration d'une base de données orientées document. [MS
Office Word 2016].
19
Figure 1.7: Illustration d'une donnée
orientées-colonne.
20
Figure 1.8: Illustration d'une base de
données orientées-graphe. [KAMINGU Gradi L, Mémoire
2014].
21
Figure
1.9: Illustration d'une base de données
orientées-clé-valeur [Outil de modélisation
Win'Design].
21
Figure
1.10: Illustration du Cloud Computing.[Du Big Data au Business]
25
Figure 2.11:Présentation logo du SGBD
MongoDB.
32
Figure 2.12:Présentation de Stockage en
GridFS.
34
Figure 2.13: Le modèle de
répartition de MongoDB [Noureddine DRISSI, MongoDB,
Administration].
38
Figure 14: Déroulement de l'algorithme de
centre mobile.
47
Figure 3.15: Hypothèse biologique de
génération d'un comportement intelligent.
50
Figure 3.16: Neurone biologique avec son
arborisation dendritique.
51
Figure 3.17: Description schématique des
divers types structuraux de neurones présents dans le cortex
cérébelleux.
52
Figure
3.18: Mise en correspondance du neurone biologique/neurone artificiel.
53
Figure 3.19: le fonctionnement d'un
RNA.
54
Figure 3.20: Neurone formel.
55
Figure 3.21: réseau de neurones
bouclé.
58
Figure 3.22: Comportement en phase de
reconnaissance d'un réseau de neurone multicouche lors d'une tâche
d'auto-association.
59
Figure 3.23: Réseaux de neurones
interconnectés.
59
Figure 4.24: Architecture Big Data
intégrant les technologies utilisées.
66
Figure 4.25:Logo de la
BCDC.[www.bcdc.cd]
69
Figure 4.26: Organigramme de la Banque
Commerciale Du Congo.[Département Informatique et DSI]
69
Figure 4.27: Logo du langage de programmation
python.
73
Figure 4.28: Installation Python.[Nous
même]
74
Figure 29: Configuration Python.
74
Figure 4.30: Quelques IDE dédiés
au langage de programmation Python.
76
Figure 4.31: Logo de l'environnement de
développement intégré Jupyter-IDE.
76
Figure 4.32: Logo de l'EDI RStudio.
77
Figure 4.33: Espace de travail pour
l'environnement de développement intégré Rstudio version
3.4.
78
Figure 4.34: Préparation de
l'installation du serveur MongoDB.
79
Figure 4.35: Lancement de l'installation du
serveur MongoDB.
79
Figure 4.36: Configuration du Serveur
MongoDB.
79
Figure 4.37: Démarrage du Serveur MongoDB
avec la commande mongod.exe [Serveur MongoDB]
80
Figure 4.38: Création de la base de
données.
80
Figure 4.39: Statut churn selon les types de
compte.
82
Figure 4.40: Statut churn selon le
sexe.
82
Figure 4.41:Statut churn selon l'âge des
clients.
83
Figure 4.42: Statut churn selon
l'ancienneté des clients dans l'institution.
83
Figure 4.43: Statut churn selon les
réclamations des clients.
84
Figure 4.44: Statut churn selon la profession
des clients.
84
Figure 4.45: Extrait de données
d'apprentissage depuis MongoDB. Vue n°1 [Client Navicat
Premium-MongoDB].
83
Figure 4.46: Extrait de données
d'apprentissage depuis MongoDB. Vue n°2 [Client Navicat
Premium-MongoDB].
84
Figure 4.47: Visualisation des données
d'apprentissage.[RStudio]
85
Figure 4.48: Phase d'apprentissage pour le
classement d'un nouveau client (individu). [RStudio]
85
Figure 4.49: Nouvel individu à
prédire cas 1. [RStudio]
86
Figure 4.50: Classement du nouvel individu
premier cas (1). [RStudio]
87
Figure 4.51: Nouvel individu à
prédire deuxième cas (2). [RStudio].
88
Figure 4.52: Classement du deuxième
nouvel individu deuxième cas 2. [RStudio]
89
LISTE DES TABLEAUX
Tableau 1.1: Les sociétés
utilisant la technologie de NoSQL.[ Enjeux et usages du Big Data technologies,
méthodes et mise en oeuvre]
3
Tableau 2.2: Comparaison de système de
Base des données NoSQL.
30
Tableau 3.3: Méthodes de Fouille de
données.
42
Tableau 4.4: Dictionnaire des variables
descriptives utilisées.
81
INTRODUCTION GENERALE
1. CONTEXTE
Au cours de dix dernières années, grâce
à l'internet et des autres objets connectés, les informations
sont devenues non seulement disponibles mais aussi très subtiles et
facilement manipulables. Cette explosion des données est une aubaine
pour les entreprises mais en même temps une responsabilité, parce
qu'elles nécessitent une gestion adéquate et minutieuse afin
d'orienter leurs certaines décisions.
En effet, ces informations qui proviennent de sources
hétérogènes imposent aux entreprises surtout du secteur
bancaire à utiliser des techniques de pointe afin de les gérer et
stocker. Désormais, il a été remarqué que les
entreprises enregistrent plusieurs données des clients surtout lors des
ouvertures des comptes et au cours de la période où ils sont
comme membres, clients.
Ces données peuvent être recueillies de diverses
manières notamment à travers les réseaux sociaux, les
plateformes téléphoniques, les courriers électroniques. Ce
genre d'informations constituent une masse de données souvent non
structurées et posent un problème de gestion (analyse,
traitement, stockage, etc.) avec des outils classiques.
A ces jours, il existe des outils qui permettent de traiter et
de stocker ces gigantesques volumes d'informations grâce à une
technologie appelée le Big Data. L'une de ses plus grandes promesses est
de permettre le développement des entreprises par l'analyse et la
transformation de ces informations, c'est-à-dire l'évaluation du
volume de ces données provenant de diverses sources avec une certaine
rapidité.
Au-delà de leur inopérabilité (formes et
quantités) aux technologies traditionnelles, le Big Data permet
l'exploration de très grands ensembles de données pour obtenir
des informations utilisables.
Le Big Data fait référence à des
technologies qui permettent aux entreprises d'analyser rapidement un grand
volume de données et d'obtenir une vue synoptique. En combinant
l'intégration de stockage, analyse prédictive et applications, le
Big Data permet d'économiser du temps et facilite une
interprétation de qualité des données. Aussi, la
croissance exponentielle des données, la prise en compte des
données faiblement structurées et les avancées
technologiques sont tous des arguments qui poussent les entreprises
principalement les géants du web à faire une migration de leur
système d'information des systèmes de gestion de base de
données traditionnelle (SGBD) aux nouveaux systèmes de gestion de
base de données du type NoSQL, c'est-à-dire aux moteurs de base
de données utilisant non seulement le standard SQL.
Ces nouveaux systèmes de gestion de base de
données dit NoSQL offrent une meilleure disponibilité des
données et des capacités de stockage gigantesques en
libérant les contraintes des propriétés ACID
(Atomicité, Cohérence, Isolation et Durabilité). Ce
mouvement de SGBD de type NoSQL a trouvé une place importante dans les
infrastructures de NTIC (Nouvelle technologie de l'information et de la
communication) et est devenu largement utilisé.
De ce fait, les entreprises en général et les
banques en particulier retardent encore les pas pour s'approprier et d'utiliser
cette technologie pouvant leurs permettre d'analyser, traiter et stocker
facilement les données.
Dans le cadre de ce travail, nous nous sommes appesantie sur
le cas de la Banque Commerciale Du Congo (BCDC) qui accumule une foison des
données avec la croissance sans précédente de ses clients.
Cette banque qui cherche le jour le jour à convaincre des clients
potentiels, les convertir et les fidéliser, utilise jusqu'à ce
jour, malgré les migrations technologiques,des systèmes de
stockage tels que SQL Serveur, Oracle DataBase, Informix et Accès et
Excel comme outils d'analyse. Il se pose donc un problème d'analyse des
comportements des clients (analyse de churn) au sein de cette institution
bancaire en vue d'anticiper au départ brusque des clients. Alors que
l'orientation de certaines stratégies marketing axées sur la
promotion des nouveaux produits et offres se réfère le plus
souvent aux données fidèlement analysées et
stockées dans les bases des données du type NoSQL
orientées document.
L'utilisation de cette technologie NoSQL permettrait à
la BCDC non seulement de mieux analyser les comportements ou des transactions
(dépôts, retraits, transferts, virements bancaires, emprunts etc.)
de ses clients mais aussi et surtout prédire des nouvelles connaissances
ou tendances grâce aux données existantes sur les clients pour
permettre au décideur de prendre une décision afin de maximiser
ses recettes.
2. PROBLEMATIQUE
Partant de cette observation, nous résumons notre
problématique autour des questions suivantes :
· Est-il important de connaître les offres ou
produits qu'aiment les clients au sein de la BCDC ?
· Est-il important de prédire les nouvelles
connaissances sur les clients ?
· La prédiction des nouvelles connaissances
aidera-t-elle la BCDC à fidéliser ses clients aussi longtemps
quepossible ?
· Quelle est la place et la valeur ajoutée
d'une technologie NoSQL orientée document au sein de la
BCDC ?
3. HYPOTHESE
Nous formulons notre hypothèse de la manière
suivante : la mise en place d'un système prédictif
basé sur l'administration d'un Big Data sous le SGBD MongoDB et
l'extraction des connaissances par l'algorithme de data mining, réseaux
de neurones, au sein de la Banque Commerciale Du Congoafin d'avoir une vision
exhaustive de l'ensemble des comportements de ses clients et prendre des
décisions optimales synchrones y afférentesserait la meilleure
solution.
4. CHOIX ET INTERET DU SUJET
4.1.
Choix du sujet
Le sujet que nous avons choisi est intitulé :
« Administration d'un Big Data sous MonogoDB et extraction de
connaissance par réseaux de neurones : Application de
l'analyse de churn dans une institution bancaire » cas de la
BCDC.
4.2.
Intérêt du sujet
Ce travail subdivise son intérêt en trois niveaux
à savoir :
· Au niveau de l'entreprise : ce travail permettra
à l'entreprise de pouvoir gérer et extraire les différents
comportements de ses clients. Cela permettra aux autorités d'analyser le
comportement des clients, c'est-à-dire leurs préférences,
afin de répondre à leurs besoins ou de proposer des offres plus
agréables pour fidéliser leurs clients ;
· Au niveau personnelle :ce travail me permet de
concilier les différentes théories que nous avions apprises
depuis le début de nos études universitaires jusqu'à nos
jours à la pratique ;
· Au niveau scientifique : ce travail est un document
permettant de comprendre les différentes étapes de la conception
d'une base de données NoSQL orientée-document et la mise en
oeuvre d'un système décisionnel utilisant des outils de data
mining.
5. METHODES ET TECHNIQUES UTILISEES
5.1.
Méthodes
Quant à notre travail, nous avons eu à utiliser
des méthodes scientifiques analytiques qui nous ont permis de faire une
analyse profonde par rapport aux données colletées.
5.2.
Techniques
Pour l'élaboration du présent travail, nous
avons fait recours aux techniques ci-après :
ü Documentaire : par laquelle nous nous
sommes servis pour la récolte des diverses informations à partir
de notre cours, livre, syllabus, mémoire, etc.
ü Navigation par internet : par laquelle
nous avons plus utilisé pour consulter quelques sites internet pour la
récolte des informations ayant trait à notre travail.
ü Interview : cette technique nous a
également permis d'entretenir librement avec certains agents de notre
entité.
6. SUBDIVISION DU TRAVAIL
Hormis l'introduction et la conclusion générale,
notre travail comprend 4 chapitres à savoir :
· Le chapitre premier intitulé « Big
Data » contient des généralités sur la notion de
Big Data ;
· Le second chapitre intitulé « SGBD
orienté document et MongoDB » dans lequel nous avons
décrit les différents SGBD orientés documents tout en nous
concentrant sur le SGBD MongoDB,
· Le troisième chapitre, « Fouille de
données et Réseaux de Neurones », dans lequel nous
parlons en détail des différents algorithmes d'analyse que nous
utiliserons dans la mise en oeuvre ;
· Le dernier chapitre, qui concerne
l'« Implémentation et interprétation des
résultats ».
CHAPITRE I: BIG DATA[1],
[6], [12], [16], [19]
I.1. INTRODUCTION
Au cours des dix dernières années, le monde a
connu une augmentation exponentielle des informations disponibles via Internet
et le nombre d'objets connectés augmente constamment. Les entreprises
ont également accumulé des informations utilisées ou non
sur leurs clients.
Les taux de croissance de volume attendus des données
traitées dépassent les limites des technologies traditionnelles.
Parfois, on parle de pétaoctets (ou billard d'octets) ou même de
zettaoctet (trilliard d'octets) et à la longue, on parle de yottaoctet
(1012 octets). Il est rapidement devenu indispensable de mettre
à niveau les baies de stockage traditionnelles pour leur permettre
d'absorber le nombre croissant et la diversité des sources de ces
données. Ces données collectées sur le Web (réseaux
sociaux, plate-forme téléphonique, courrier électronique,
commerce électronique, open data (données en accès libre),
géolocalisation des personnes ouvrent des possibilités de
personnalisation de produits. Les entreprises voient dans ce
phénomène l'occasion de cibler très
précisément les attentes du client.
Les données sont donc le carburant de l'économie
numérique. Tous les secteurs de l'économie, du commerce à
l'automobile en passant par le secteur de l'énergie, tous les domaines
de la vie quotidienne (santé, éducation, etc.) sont
concernés. Le Big Data combine à la fois le traitement de ces
grandes masses de données, leur collecte, leur stockage, leur
visualisation et leur analyse. Comment relier toutes ces données ?
Comment les faire parler ?
Comment faire face à l'explosion du volume de
données, un nouveau domaine technologique est apparu : le Big Data.
Inventé par les géants du Web, outil très important et en
pleine expansion, tant pour la prise de décision que pour l'optimisation
de la compétitivité (au sein des entreprises), les entreprises
ont su dépasser tous les problèmes de multi-structuration et
d'hétérogénéité des sources de ces
données. Ainsi, le Big Data peut être défini sous de
nombreuses formes, en fonction du domaine appliqué, et peut être
considéré comme un outil permettant d'explorer de très
grands ensembles de données pour obtenir des informations
exploitables.
La démarche du Big Data et sa capacité à
traiter rapidement des données non structurées et
structurées provenant d'un grand nombre de sources ouvrent des
perspectives dans un grand nombre de secteurs de la vie tels que: le commerce
et la gestion des relations clients, la défense et le renseignement
(cybersécurité, biométrie), etc. et dans un grand nombre
d'activités humaines telles que: la détection de fraude, la
maintenance prédictive, etc., leur mise en valeur au service des
consommateurs, de nos concitoyens.
I.2. APERÇU HISTORIQUE
Le Big Data a une histoire récente et en partie
cachée, en tant qu'outil des technologies de l'information et en tant
qu'espace virtuel d'importance croissante dans le cyberespace.
SH. Lazare et F. Barthélemy (www.axiodis.com), dans
leur document intitulé « Introduction aux Big Data »,
présentent l'historique suivant, représenté graphiquement
de la manière suivante :

Figure 1.1:Graphique historique
du Big Data [developpez.com-big data-evolution]
Selon le document « Big-Data et Data-Marketing », le
terme « Big Data » est apparu pour la première fois
en 2000 lors d'un congrès d'économétrie, puis a repris en
2008 et 2010 sous la couverture de revues Nature et Sciences, et s'est
établi dans les entreprises suite à un rapport de MC Kinsey en
2011.
Le répertoire de référence pour les
utilisateurs intitulé « GUIDE DU BIG DATA 2013-2014 » indique
que le Big Data est apparu il y a seulement trois ans dans le domaine de la
prise de décision et se positionne comme l'innovation numéro un
de la première décennie et à la frontière entre
technologie et management.
Selon V. Tréguier (2014) et selon la « très
courte histoire du Big Data » publiée par Gil Press en 2013 pour la
période 1944-2012, sa naissance est liée à
l'évolution des systèmes de stockage, de fouille et d'analyse de
l'information numérisée, qui ont permis une sorte de big bang
d'informations stockées, puis une croissance inflationniste dans le
monde des données numérisées. Mais ses prémisses se
situent au confluent de la cybernétique et des courants de pensée
nés pendant la Seconde Guerre mondiale, selon lesquels l'homme et le
monde peuvent être représentés comme des
« ensembles d'informations, dont la seule différence avec la
machine est leur niveau de complexité. La vie deviendrait alors une
séquence de 0 et de 1, « programmable et
prévisible » », ajoute V. Tréguier.
Les risques d'abus par des gouvernements ou des entreprises
ont été décrits pour la première fois par Orwell
à la fin de la dernière guerre mondiale, et souvent par la
science-fiction. Avec l'apparition de grandes banques de données dans
les années 1970 (et tout au long de la guerre froide), de nombreux
auteurs s'inquiètent des risques d'atteinte à la vie
privée, notamment le professeur A. Miller, qui cite l'exemple de la
croissance des données stockées relatives à la
santé physique et mentale des individus.
I.3. PRESENTATION DE
L'ASPECTS BIG DATA2(*)
Au-delà des aspects purement quantitatifs, ces
données sont présentées de telle manière qu'elles
ne sont guère supportées par les SGBD traditionnels :
v Elles ne sont pas nécessairement organisées en
tables et leurs structures peuvent varier ;
v Elles sont produites en
temps rée
l
;
v Elles arrivent mondialement en flots continus ;
v Elles sont
méta taguée
s
mais de façon
disparate (localisation, heure, jour, etc.) ;
v Elles proviennent de sources très disparates
(téléphone mobile, capteurs, téléviseurs
connectés, tablettes, PC fixes, PC portables, objets, machines), de
façon désordonnée et non prédictible.
Depuis quelque temps, le mot Big Data est apparu et est
largement utilisé par les journalistes, les analystes, les consultants
et certains éditeurs ou fabricants occidentaux qu'orientaux
intéressés par le monde de la prise de décision. Mais il
est clair qu'aucune définition n'a été imposée et
que les mots des uns et des autres mélangent avec bonheur beaucoup de
choses, le volume global de données à traiter, le volume de la
base de données (web log, texte, photo, vidéo, etc.), types de
données (structuré, non structuré,
multi-structuré), ambitions analytiques (aller au-delà de la BI),
etc.
Il est difficile de dire si le mot Big Data est adapté
et durera (continuera à l'être), mais il est certain que le
domaine de la prise de décision connaît un développement
important lié à l'émergence simultanée de
« nouvelles demandes » et de « nouvelles solutions
technologiques » aboutissant au traitement de plus en plus de
données, à la fois en termes de volumes et de
variétés. La quantité de données
générées quotidiennement dans les systèmes
d'information augmente de manière exponentielle et, par
conséquent, la volumétrie explose aussi dans le monde de la prise
de décision.
Le traitement du Big Data n'entraîne pas une
révolution dans le monde de la prise de décision mais
élargit le champ de travail des experts de ce domaine, conduit à
modifier les infrastructures en place pour répondre aux nouvelles
exigences de volume, de variété et de vitesse données,
pour changer la façon dont les données sont
préparées pour une analyse avancée, et comme souvent
lorsque le marché aborde un nouveau sujet, les solutions occupent une
place centrale, même si elles ne sont pas une panacée
(remèdes, solutions, moyens) universelles.
Le Big Data permet sans aucun doute de mieux connaître
les clients3(*), par exemple
en traitant automatiquement ce qu'ils disent, pour mieux les servir via des
solutions de commerce électronique et de Cloud Computing, qui sont
à la fois de plus en plus sophistiquées et de plus en plus facile
à mettre en place.
Mais au finish, le Big Data n'est qu'une extension de ce qui a
été fait pendant des années et présente les
mêmes avantages, inconvénients ou risques: information,
propagande, désinformation et mystification.
I.4. OBJECTIFS
Le Big Data est une nouvelle technologie qui poursuit
plusieurs objectifs, parmi lesquels:
v L'objectif de ces solutions d'intégration et de
traitement de données est de gérer un très grand volume de
données structurées et non structurées sur une
variété de terminaux (PC, smartphones, tablettes, objets
communicants, etc.), produits ou non en temps réel depuis n'importe
quelle zone géographique du monde ;
v Un autre objectif réside dans la capacité de
gérer en temps réel un volume de données de plus en plus
important et en constante évolution.
v Le Big Data vise à améliorer les services
existants, c'est-à-dire que leur apparence ne signifie pas la fin des
entrepôts de données, mais vise à les compléter en
fonction de besoins spécifiques de l'entreprise en proposant des
alternatives pour adapter le fonctionnement des bases de données
relationnelles à des besoins spécifiques ;
v Cette solution est conçue pour offrir
également un accès en temps réel aux bases de
données géantes.
I.5. CARACTERISTIQUES
À l'origine, le Big Data était
caractérisé par la problématique du 3V4(*), à savoir Volume,
Vitesse, Variété. Alors que le concept et la technologie se
répandaient rapidement dans de nombreux secteurs industriels et
économiques et occupaient une place prépondérante, les
chercheurs dans ce domaine ont encore poussé plus loin les
caractéristiques du Big Data en valorisant les données pour
obtenir un 4ème V puis rechercher leur véracité
pour constituer son 5ème V.
Vous êtes confronté à un problème
de gestion de données correspondant à ces trois critères,
à savoir Volume, Vitesse et Variété ou plus simplement,
vous ne savez pas comment gérer ces données avec les
architectures traditionnelles, vous avez alors un problème de type Big
Data.
Il faut en effet penser à collecter les données,
les stocker puis les analyser de manière à ne plus pouvoir
être traitées par une approche traditionnelle permettant de
satisfaire les 4ème et 5ème V qui sont la
Valorisation et la Véracité des données.
Ces 5 V du Big Data peuvent se définir ou s'expliquer
de la manière suivante :
· Volume (Volume) :
représente la quantité de données
générées, stockées et utilisées dans le SI.
L'augmentation du volume dans le SI s'explique par l'augmentation de la
quantité de données générées et
stockées, mais aussi et surtout par la nécessité
d'exploiter des données qui, jusqu'à présent, ne
l'étaient pas. L'unité principal pour mesurer le volume de
données étant l'octet.
Pour rappel, 1 mégaoctet = 106 octets ; 1
gigaoctet = 109 octets ; 1 téraoctet =
1012 octets ; 1 pétaocte = 1015
octets ; 1 exaoctet = 1018 octets ; 1 zettaoctet =
1021 octets ; 1 yottaoctet = 1024 octets.
En effet, aujourd'hui, les données sont d'ordre de zetta
ou même yottaoctets.
· Varieté (Variety) :
représente la démultiplication des types de données
gérés par un SI, nous parlons ici de type de données au
sens fonctionnel du terme et pas seulement au sens technique. En fait, les
données traitées sont des tweets, des vidéos, des photos,
des textes, des audios, etc. La démultiplication implique
également la complexification5(*) des liens et des types de lien entre ces
données.
· Vélocité
(Velocity) : représente la fréquence à laquelle
les données sont générées, capturées et
partagées. Les données arrivent par flux et doivent être
analysées en temps réel pour répondre aux besoins des
processus chrono-sensibles, donc urgents.
· Valeur (Value) : représente la
capacité de disséminer rapidement des informations au sein de
l'organisation pour leur permettre d'être reflétées dans
les processus métier.
· Véracité
(Veracity) : représente la résistance à laquelle
se heurte l'organisation pour explorer, exploiter les données
disponibles au sein des processus métier.
Ainsi, aux trois V de base, à savoir Volume,
Variété, Vélocité, les acteurs du marché ont
également ajouté d'autres V, qui sont la Valeur des
données pour ce qu'ils sont susceptibles de contenir sous forme de
signaux ou en référence au fait qu'ils sont commercialisables, et
Véracité d'insister sur la qualité nécessaire des
données.
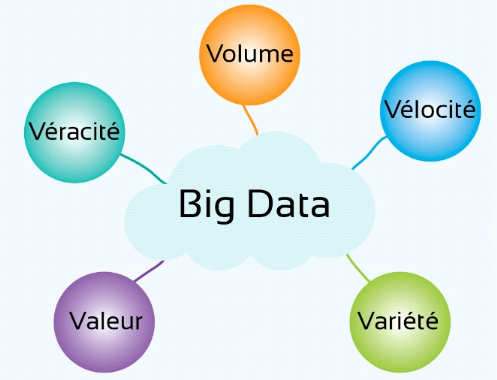
Figure 1.2:Les 5V du Big
Data.[Évolution du Big Data]
I.6. DEFINITION DU BIG
DATA
Eu égard aux concepts définis ci-haut, on peut
redéfinir le Big Data comme suit :
I.6.1. Première
définition de Big Data
Le Big Data désigne des ensembles des
données de nature variée, et se générant à
très grande vitesse, devenus si volumineux qu'ils vont au-delà de
l'intuition et des compétences analytiques humaines, mais
également de celles des outils informatiques de gestion de base de
données (ou de gestion l'information) traditionnels.
I.6.2. Deuxième
définition de Big Data
Le Big Data désigne des ensembles des
données caractérisées par les 3 (ou 5) V.
I.7. TYPES6(*) DES
DONNEES DU BIG DATA
Comme nous l'avons vu, le Big Data réside dans la
capacité de gérer en temps réel un volume de
données de plus en plus important et en constante évolution. Afin
d'approfondir les solutions répondant à ce besoin, il convient de
distinguer les différents cas d'utilisation que l'on refusera en
fonction du type de données manipulées et de l'utilisation que
l'on souhaite en faire. Le Big Data comprend deux types principaux de
données : les données structurées et les données
non structurées.

Figure 1.3:Les données du
Big Data.[Big Data et ses données]
I.7.1. Données structurées
Elles sont définies par le fait qu'elles sont
conçues pour être traitées automatiquement et efficacement
par un logiciel, mais pas nécessairement par un humain. Les
données structurées nous amènent dans un virage qui
s'appelle Big Data Analytics (ou Big Analytics).
Le Big Data Analytic désigne un ensemble des
technologies de pointes mise en place pour fonctionner de manière
efficace sur les grandes masses de données
hétérogènes. Dans cette approche, l'analyse des
données structurées évolue de par la variété
et la vélocité des données manipulées. On ne peut
donc plus se contenter d'analyser des données et de produire des
rapports, la grande variété des données fait que les
systèmes en place doivent être capables d'aider à l'analyse
des données.
L'analyse consiste à déterminer automatiquement,
au sein d'une variété de données en évolution
rapide, les corrélations entre les données afin de contribuer
à leur exploitation.
I.7.2. Données non structurées
Au contraire, elles sont définies comme des
données disponibles mais non directement exploitables. En fait, ce sont
les données qui peuvent être extraites de tous les types de
documents électroniques (courrier électronique, document Word,
vidéo, image, SMS, courrier électronique, page Web, réseau
social). Les données non structurées nous amènent dans un
autre virage celui, du Text Mining.
Le Text Mining (fouille de textes) permet à un ensemble
de documents d'analyser leur contenu par le biais d'une recherche
sémantique basée sur l'analyse du langage naturel (le
français par exemple) et la gestion d'ontologies
spécialisées (pour un secteur d'activité, un
métier). Cette fouille peut permettre de déterminer le contenu
d'un document, mais aussi aller jusqu'à analyser le ressenti par des
tournures de phrases pour savoir par exemple si un client se plaint ou fait une
simple demande d'informations.
À l'issue de cette fouille, on produit la liste des
« concepts et relations » 2 abordés dans un document afin de
pouvoir alimenter une base de connaissances qui permet :
? Soit d'effectuer des recherches au sein de ce fond
documentaire ;
? Soit d'extraire des données qui serviront à
alimenter d'autres systèmes.
La différence entre une analyse sémantique et
une indexation classique de document est que l'indexation se contente de
référencer les mots présents dans un document sans
s'intéresser au sens, à l'usage fait de celui-ci.
I.8. TECHNIQUES D'ANALYSE ET DE VISUALISATION DU BIG DATA
Pour donner un sens à cette masse de données, il
existe des modèles mathématiques qui répondent aux
principes des méthodes prédictives. Vous voulez obtenir des
résultats plus pertinents et dégager des nouvelles tendances,
certains de ces modèles nécessitent des ajustements et des
réglages. Ce détail important fait partie intégrante de
l'analyse des données et plus encore lorsqu'elles sont volumineuses.
Il est concevable que Big Data soit une solution d'aide aux
entreprises qui leur permette non seulement de réduire leurs risques,
mais également de faciliter la prise de décision, et l'aide de
l'analyse prédictive d'avoir une « expérience client »
plus personnalisée et contextualisée (marketing
personnalisé).
Les techniques de « Data Mining » sont
adaptées à cette masse de données dans laquelle il faut
explorer, faire parler et interpréter ces volumes d'informations.
L'apprentissage automatique a d'énormes progrès. La combinaison
de ces algorithmes avec les capacités de stockage disponibles, sans
parler de la puissance de calcul des machines et des outils devenus disponibles
aujourd'hui, nous offre la possibilité de rechercher et de faire parler
les données.
I.8.1. Visualisation
Pour une bonne prise de décision, la
présentation des résultats doit être lisible. La prise de
décision est difficile avec les données présentées
avec toutes leurs complexités. Le Big Data présente d'autres
représentations des données plus lisibles que des graphiques
classiques, histogrammes, courbes, camemberts, tels que nous les connaissons.
La visualisation peut jouer un rôle crucial en rendant
les composants analytiques individuels compréhensibles et en les
regroupant dans une image globale intelligible. De plus, la visualisation peut
être utilisée de différentes manières pour aider
à contrôler le volume et la complexité des données
et ainsi simplifier leur interprétation. Pour comprendre comment, vous
pouvez commencer avec un seul ensemble de données client et ajouter des
vues client, y compris celles de Big Data.
I.9. DIFFERENCES AVEC L'INFORMATIQUE TRADITIONNELLE
OUDECISIONNELLE
Les principales différences entre les données
traditionnelles et les données massives ne concernent donc presque pas
le volume, même s'il a explosé, mais le type de données et
la façon dont elles sont stockées.
v Du point de vue modèle, les données
traditionnelles stockées ou géré avec un modèle
déjà préalablement défini d'avance dans de bases de
données ou entrepôts. À contrario, les données du
Big Data sont stockées sans construction d'un modèle
préalable de rangement.
v Du point de vue type des
données, Les données traditionnelles ont un type
bien définies à l'avance suivant un certain modèle
préalable autrement dit que les données traditionnelles sont des
données de type structurées. En revanche quand on parle du Big
Data, il s'agit donc des données de types divers dont au moins une
partie est constituées de données non structurées ou multi
structurées.
v Du point de vue langage, souvent,
c'est le langage SQL qui est utilisé pour formuler des requêtes
avec des données traditionnelles, cela est supposé d'avoir
défini par avance les types d'informations (ou des données) qui
doivent être stockées et établi un modèle permettant
de relier ses informations entre elles. Avec le Big Data, on parle des
données NoSQL car les normes du langage SQL ne permettent plus de les
traiter.
v Du point de vue stockage et
technologique, les données traditionnelles sont
stockées au sein des bases de données relationnelles ou
entrepôts de données internes au sein des entreprises. Le stockage
des données du type Big Data ou données massives se fait
généralement dans le Cloud au sein d'un DataCenter.
I.10. BIG DATA ET SES TECHNOLOGIES
Si aujourd'hui leBig Data est possible, c'est grâce aux
évolutions technologiques (logicielle ou hardware) qui permettent de
répondre au 5Vs et aux usages nouveaux que l'on souhaite faire des
données. Nous pouvons les subdiviser en 3, à savoir:
· Les solutions de stockage( cloud computing
(LaaS7(*))) ;
· Les solutions logicielles ;
· Les solutions matérielles et/ou architecturales.
I.10.1. Solutions de stockage
Pour les solutions de stockage dans le domaine du Big Data,
nous pouvons citer entre autre : Les Bases NoSQL, que nous utilisons pour notre
travail, et les Outils MapReduce et Hadoop.
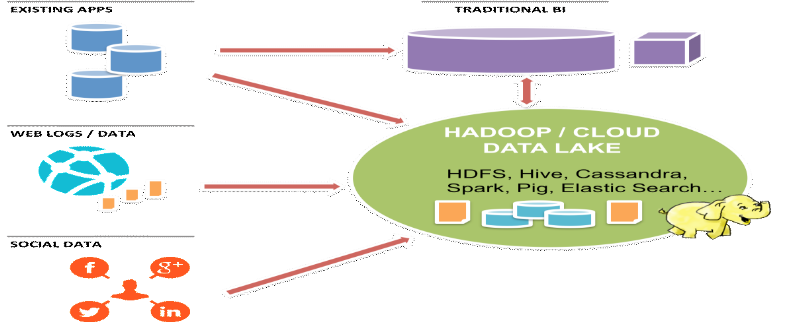
Figure 1.4: les solutions sur le
cloud computing8(*).
I.10.1.1. Bases des Données NoSQL
Le terme NoSQL9(*) (de l'anglais Not only SQL) est apparu en 1989. C'est
à cette année-là que Carlo Stozzi le prononça pour
la première fois en public ; c'était lors de la
présentation de son système de gestion de base des données
relationnelles open source. Il l'a appelé ainsi à cause de
l'absence de l'interface SQL pour communiquer.
Plus tard en 2009, le mot réapparait lorsqu'Eric Evans
l'utilisa pour spécifier le nombre grandissant des bases de
données distribuées open source.
NoSQL est une catégorie de systèmes de gestion
de base de données (SGBD) qui ne repose plus sur l'architecture de base
de données relationnelle classique. L'unité logique n'est plus la
table et les données ne sont généralement pas
manipulées avec le langage de requête SQL.
1) Théorème du CAP (d'Eric
Brewer)10(*)
À l'heure actuelle, il est important de savoir que le
mouvement des bases de données NoSQL contient plusieurs approches qui
ont leur propre architecture et traitent des cas d'utilisation bien
définis. Il est donc nécessaire de choisir l'outil qui
répond le mieux au problème posé, à la fois en
termes de modélisation mais également de diffusion des
données.
Le théorème énonce donc de la
manière suivante :
Il est impossible pour un système distribué
de fournir les trois propriétés suivantes à la fois :
v Cohérence (Consistency) : Tous les
noeuds du système voient les mêmes données au même
moment quelques soient les modifications ;
v Disponibilité (Availability) : Les
requêtes d'écriture et de lecture sont toujours satisfaites, donc
il y a disponibilité pour la lecture et l'écriture ;
v Tolérance au partitionnement(Partition
tolerance) : La seule raison qui pousse un système à
l'arrêt est la coupure totale du réseau. Autrement dit si une
partie du réseau n'est pas opérationnelle, cela n'empêche
pas le système de répondre. Le système tolère
même une partie du réseau.
Afin de créer une architecture distribuée on
doit donc choisir deux de ces propriétés, laissant ainsi trois
conceptions possibles :
· CP : Les données sont consistantes entre tous
les noeuds et le système possède une tolérance aux pannes,
mais il peut aussi subir des problèmes de latence ou plus
généralement, de disponibilité ;
· AP : Le système répond de façon
performante en plus d'être tolérant aux pannes. Cependant rien ne
garantit la consistance des données entre les noeuds ;
· CA : Les données sont consistantes entre tous
les noeuds (tant que les noeuds sont onlines). Toutes les
lectures/écritures des noeuds concernent les mêmes données.
Mais si un problème de réseau apparait, certains noeuds seront
désynchronisés au niveau des données (et perdront donc la
consistance).
2)
Principes ACID et BASE
Hormis le théorème CAP ci-haut
énoncé, nous pouvons aussi parler de deux principes qui sont
alors liés à la répartition des données et qui sont
à la base des architectures actuelles des systèmes de gestion de
bases de données, notamment les systèmes du type NoSQL.
ACID et BASE représentent deux principes de conception
aux extrémités opposées du spectre
cohérence-disponibilité. Les propriétés ACID se
concentrent sur la cohérence et sont l'approche traditionnelle des bases
de données. Le principe BASE était créé à la
fin des années 90 pour saisir les concepts émergents de la haute
disponibilité et rendre explicite à la fois le choix et le
spectre. Les systèmes étendus modernes et à grande
échelle, y compris le Cloud, utilisent une combinaison des deux
approches.
Bien que les deux acronymes soient plus mnémoniques que
précis, l'acronyme BASE (étant le second apparu) est un peu plus
délicat : BasicallyAvailable, Soft state, Eventuallyconsistent
(Simplement disponible, état souple, finalement consistant). Soft state
et Eventualconsistency sont des techniques qui fonctionnent bien en
présence de partitions réseau et donc améliorent la
disponibilité.
La relation entre CAP et ACID est plus complexe et souvent
incomprise, en partie parce que les C et A d'ACID représentent des
concepts différents des mêmes lettres dans CAP et en partie parce
que choisir la disponibilité affecte seulement certaines des garanties
ACID. Les quatre propriétés ACID sont :
· Atomicité : Tout système
bénéficie d'opérations atomiques.
· Cohérence : Dans ACID, le C signifie qu'une
transaction préserve toutes les règles des bases de
données, telles que les clés uniques
· Isolation : L'isolation est au coeur du
théorème CAP : si un système nécessite l'isolation
ACID, il peut opérer sur au plus une partie durant une partition
réseau.
· Durabilité : La propriété
durabilité assure que lorsqu'une transaction a été
confirmée, elle demeure enregistrée même à la suite
d'une panne d'électricité, d'une panne de l'ordinateur ou d'un
autre problème.
Il est à noter que le principe BASE abandonne donc la
consistance au profit de ces nouvelles propriétés :
· Fondamentalement disponible
(BasicallyAvailable) : Le système garantie bien la
disponibilité dans le même sens que celle du
théorème de CAP ;
· Etat souple (Soft-State) : Indique que
l'état du système peut changer à mesure que le temps
passe, et c'est sans action utilisateur. C'est dû à la
propriété suivante ;
· Eventuellement Cohérent (Eventually)
consistent : Spécifie que le système sera consistant à
mesure que le temps passe, à condition qu'il ne reçoive pas une
action utilisateur entre temps.
ACID est nécessaire si :
· Beaucoup d'utilisateurs ou processus qui travaillent
sur une même donnée au même moment ;
· L'ordre des transactions est très important ;
· L'affichage de données dépassées
n'est pas une option ;
· Il y a un impact significatif lorsqu'une transaction
n'aboutit pas (dans des systèmes financiers en temps réel par
exemple).
BASE est possible si :
· Les utilisateurs ou processus ont surtout tendances
à faire des mises à jour ou travailler sur leurs propres
données ;
· L'ordre des transactions n'est pas un problème
;
· L'utilisateur sera sur le même écran
pendant un moment et regardera de toute façon des données
dépassées ;
· Aucun impact grave lors de l'abandon d'une transaction.
Il est ainsi à remarquer que s'agissant des
systèmes AC, il s'agit des bases des données relationnelles
implémentant les propriétés de Cohérence et de
Disponibilité. Ce qui signifie que les bases des données NoSQL
sont généralement des systèmes CP et AP.
C
A
P
Les systèmes CP sont
du groupe NoSQL
Les systèmes AC renferment
tous les systèmes qui
obéissent au principe ACID
Les systèmes AP sont du groupe NoSQL
Figure 1.5:Guide visuelle au
théorème du CAP.
3)
Critères de Migration vers le principe CAP NoSQL
C'est une évidence de dire qu'il convient de choisir la
bonne technologie en fonction du besoin. Il existe cependant certains
critères déterminants pour basculer au NoSQL notamment :
· Taille : Nous sommes dans un monde où il y a des
données ayant une masse considérable (qu'on appelle
infobésité). Il sied d'avoir alors un système pouvant
supporter un nombre important des opérations, d'utilisateurs, des
données, etc. de manière optimale.
· Performance en écriture : Des données qui
augmentent chaque année.
· Performance en lecture clé-valeur : Certaines
solutions NoSQL ne possèdent pas cet avantage mais comme il s'agit d'un
point clé, la plupart d'entre elles en sont dotées.
· Type de données flexibles : Les solutions NoSQL
supportent de nouveaux types de données et c'est une innovation majeure.
· ACID : Bien que ce ne soit pas le but premier du NoSQL,
il existe des solutions permettant de conserver certains (voire tous) aspects
des propriétés ACID. Se référer au
théorème CAP plus haut et aux propriétés BASE.
· Simplicité de développement :
L'accès aux données est simple.
· ParallelComputing : Les solutions NoSQL
améliorent les calculs parallèles.
I.11. TYPES DE BASE DE DONNEES NoSQL
Les bases de données NoSQL ou Bases sans schéma
fait référence à une diversité d'approches
classées en quatre catégories, qui implémentent des
systèmes de stockage considérés comme plus performants que
le traditionnel SQL pour l'analyse de données massives. Il s'agit de :
I.11.1. Bases de données
orientées-document
11(*)Les
bases de données orientées-document sont une extension des bases
orientées clé-valeur, à la place de stocker une valeur,
nous stockons un document. Un document peut contenir plusieurs valeurs et
d'autres documents, qui peuvent à leur tour en contenir d'autres et
ainsi de suite. Un document peut donc posséder plusieurs niveaux de
profondeur. Tous les documents de niveau 0 sont identifiés par une
clé et sont regroupés dans une collection.
Elles s'adaptent aux données non planes (type profil
utilisateur).
Document
|
Champ1
|
Valeur
|
|
Champ2
|
valeur
|
Document
|
Champ1
|
Valeur
|
|
Champ2
|
valeur
|
|
Champ3
|
Valeur
|
Document
Document
|
Champ1
|
Valeur
|
|
Champ2
|
Valeur
|
|
Champ3
|
Valeur
|
|
Champ4
|
Valeur
|
|
Champ5
|
Champ5.1
|
Valeur
|
|
Champ5.2
|
valeur
|
|
Clé
|
|
CLE2016
|
|
CLE2017
|
|
CLE2018
|
|
CLE2019
|
|
CLE...
|
Figure 1.6:Illustration d'une
base de données orientées document. [MS Office Word
2016].
Quelques SGBD orientées-document :
ï MongoDB : Développé en
C++. Les API officielles pour beaucoup de langages.
Protocole personnalisé BSON. Réplication
master/slave. Licence AGPL
(Commercial et libre) ;
ï CouchDB : Développé en
Erlang. Protocol http. Réplication master/master. Licence Apache.
I.11.2. Bases de données
orientées-colonne
Elles s'adaptent mieux au stockage des listes (messages,
postes, commentaires, ...).
Figure 1.7:Illustration d'une
donnée orientées-colonne.
Quelques SGBD orientées-colonnes :
· HBase : Utilise un API Java. Adopte un
design CA. Présence de quelques SPOF.
· Cassandra : Beaucoup d'API
disponibles. Adopte un design AP avec consistance éventuelle. Aucun SPOF
car réplication master/master. Moins performant que HBase sur les
insertions de données.
I.11.3. Bases de données
orientées-graphe
12(*)Elles gèrent les relations multiples entre
objets (comme des relations dans un réseau social). Les bases de
données orientées-graphe sont celles qui stockent les
enregistrements dans les noeuds et les relations entre les enregistrements par
les arêtes. Elles sont modélisées à l'aide de la
théorie des graphes.
C'est ainsi, une base de données
orientées-graphe stocke les informations d'une manière
très optimisée sous forme de graphe. Les liens entre
différentes informations sont aussi faits de manière
optimisée.
Ce type de base de données est très performant
surtout dans des domaines où les données sont très
nombreuses.
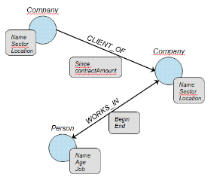
Figure 1.8: Illustration d'une
base de données orientées-graphe. [KAMINGU Gradi L,
Mémoire 2014].
Quelques SGBD orientées-graphe :
· Neo4J : Développé en
Java. Supporte beaucoup de langages. Réplication master/slave.
Propriétés ACID possibles. Langage de requêtes
personnalisé «Cypher».
· Titan : Haute disponibilité
avec réplication master/master. Prise en compte d'ACID avec consistance
éventuelle. Intégration native avec le frameworkTinkerPop.
I.11.4. Bases de données
orientées-clé-valeur
Les bases de données orientées-clé-valeur
permettent de stocker une valeur, cette valeur peut être de tout type
(entier, chaine de caractères, flux binaire, etc.). En revanche les
requêtes ne portent que sur la clé associée à cette
valeur. Ce système de base de données est conçu pour
être très fortement répliqué de manière
à augmenter la disponibilité et les performances. La
réplication de données est plus ou moins partielle pour trouver
un bon compromis entre nombre de serveurs, disponibilité et espace
disque.
Elles permettent d'accéder rapidement aux informations
pour la gestion des caches.
Clé
251657216
Clé2018
Valeur 2019
Valeur2018
Valeur 2017
Clé2019
Clé2017
251655168
Clé...
Figure 1.9:Illustration d'une
base de données orientées-clé-valeur [Outil de
modélisation Win'Design].
Quelques SGBD orientées-clé-valeur :
· DynamoDB : Solution d'Amazon à
l'origine de ce type de base. Design de type AP selon le théorème
de CAP mais peut aussi fournir une consistance éventuelle.
· Voldemort : Implémentation
open-source de Dynamo. Il y a possibilité d'en faire une base
embarquée.
Voici quelques sociétés qui utilisent les bases
des données NoSQL et leur type de technologie :
Tableau 1.1: Les
sociétés utilisant la technologie de NoSQL.[ Enjeux et usages du
Big Data technologies, méthodes et mise en oeuvre]
|
Société
|
Technologie
Développée
|
Type de Technologie
|
|
|
Système de base de données propriétaire
reposant sur GFS (Google File System).
Technologie non open source, mais qui a inspiré HBase qui
est open source.
|
|
Plate-forme de développement pour traitements
distribués.
|
|
|
Plate-forme Java destinée aux applications
distribuées et à la gestion intensive des données. Issue
à l'origine de Google Big Table, MapReduce et Google File System.
|
|
|
Plate-forme de développement dédiée aux
applications de traitement continu des flux de données.
|
|
|
Base de donnée de type NoSQL et distribuée.
|
|
Logiciel d'analyse de données utilisant Hadoop.
|
|
|
Plate-forme de traitement de données massives.
|
|
Base de données distribuées de type graphe.
|
|
|
Système distribué de gestion de messages
|
|
Base de données temps réel distribuée et
semi structurée.
|
|
Base de données distribuée destinée aux
très grosses volumétries.
|
4)
Outils MapReduce et Hadoop
a) MapReduce
MapReduce est un modèle de développement
informatique, popularisé (et non inventé) par Google, dans lequel
sont effectués des calculs parallèles, et souvent
distribués, de très grandes volumes de données
(généralement supérieures à un
téraoctet).
Il s'agit donc d'une technique de programmation
distribuée largement utilisée dans l'environnement NoSQL et qui
vise à produire des requêtes distribuées. C'est
également un modèle de programmation permettant de gérer
de grandes quantités de données qui ne sont pas
nécessairement structurées.
b) Hadoop
Créé par Doug Cutting en 2009 et employé
par Yahoo, Hadoop est la plateforme de développement d'applications
utilisant le modèle MapReduce.
Hadoop est un framework13(*) Java
libre pour les applications
distribuées et la gestion intensive de données. Il permet aux
applications de travailler avec des milliers de noeuds et de pétaoctets
de données. Hadoop a été inspiré par la publication
de Google MapReduce, GoogleFS et BigTable
Il s'agit également d'un framework open source
conçu pour traiter des volumes massifs de données. En d'autres
termes, une technologie open source permettant d'effectuer des requêtes
dans des puits de données distribués, dont les informations sont
localisées sur des serveurs distants.
Le framework Hadoop de base se compose des modules suivants :
· Hadoop Common ;
· Hadoop Distributed File System (HDFS) : le
système de fichiers ;
· Hadoop YARN ;
· Hadoop
MapReduce ;
Le terme Hadoop fait référence non seulement aux
modules de base ci-dessus, mais également à son
écosystème et à tous les logiciels qui y sont
attachés, tels
Apache Pig,
Apache Hive,
Apache HBase, Apache Phoenix,
Apache Spark,
Apache ZooKeeper,
Cloudera Impala,
Apache Flume, Apache Sqoop,
Apache oozie, Apache Storm.
I.12. SOLUTIONS LOGICIELLES
I.12.1. Moteurs Sémantiques (Text Mining)
Généralement associés à un moteur
de recherche, ils permettent une analyse sémantique des documents afin
de comprendre le contenu et permettent ainsi de retrouver, dans une base de
données de documents, le ou les documents traitant d'un sujet, parlant
d'une personne. Parmi les solutions les plus connues : Fise, Zemanta, iKnow
(InterSystems), Noopsis, Luxid (Temis), LingWay.
I.12.2. Solutions d'Analytiques
Ce sont des solutions qui permettent de gérer la
variété des données exploitées par une
visualisation nouvelle de celles-ci avec une première analyse qui les
contextualise, compartimente, corrèle. Pour cela, ces nouvelles
solutions cherchent à aller au-delà d'une analyse statistique des
données pour aller vers une analyse prédictive et la prise en
compte de la temporalité des données.
Parmi les solutions les plus connues : QlickView, PowerPivot,
Tableau. Ainsi que, pour la manipulation des données : Aster, Datameer,
SPSS, SAS ou Kxen pour le DataMining.
Il y a aussi moyen d'écrire ces propres programmes
(scripts) pour exploiter les données d'un Big Data, nous pouvons citer
ces langages par excellence comme : Python, Langage R, Java.... Mais on peut
tout de même adaptée un autre langage dans certain cas.
I.12.3. Solutions matérielles et/ou architecturales
Une des innovations permettant de stocker et de partager de
grandes quantités de données. Le Cloud est un modèle qui
permet d'accéder à des ressources informatiques partagées
telles que des réseaux, des serveurs, de grandes capacités de
stockage, des applications et des services15(*). Le Cloud permet également un accès
réseau, des services à la demande et en libre-service sur des
ressources informatiques partagées et configurables.
Les services les plus connus sont ceux de Google BigQuery, Big
Data sur
Amazon Web
Services
et Microsoft
Windows Azure
.
Le Cloud Computing signifie donc que les applications en ligne
sont utilisées comme si elles étaient situées dans
l'éther, dans un espace sans réalité physique.
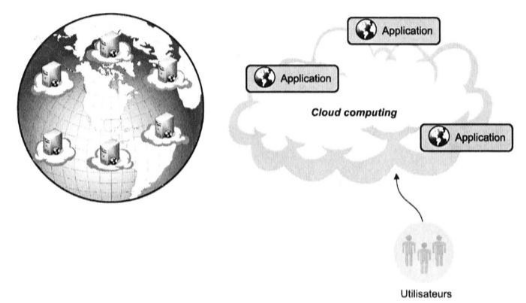
Figure 1.10: Illustration du
Cloud Computing.[Du Big Data au Business]
Sont des machines de haute performance utilisées pour
le traitement des données massives, telles que
IDRIS
,
CINES
,
CEA
ou
HPC-LR qu'on trouve en France dans les Centres Nationaux de Calculs
Universitaire (CNCU).
I.12.3.3. Stockage des Données en Mémoire :
Cette technique permet d'accélérer les temps de
traitement des requêtes.
I.12.3.4. Serveurs des Traitements Distribués :
Cette technique de traitement distribué permet
d'effectuer plusieurs traitements simultanés sur plusieurs noeuds. C'est
ce qu'on appelle un traitement massivement parallèle. Le framework
Hadoop est probablement le plus connu d'entre eux. Il combine le système
de fichiers distribué HDFS, la base de données NoSQL et
l'algorithme MapReduce.
I.13. CHOIX DU BIG DATA [1]
La mise oeuvre (ou soit la migration vers) un système
d'informations du type Big Data se fait pour des raisons :
· Stratégiques : qui permettent d'obtenir des
informations plus riches et approfondies sur les clients et les partenaires
voire même le marché et au bout du compte de
bénéficier d'un avantage concurrentiel. En bref, c'est de
créer un avantage concurrentiel ;
· Organisationnelles : qui permettent de travailler avec
des ensembles de données dont la taille et la diversité
dépassent les capacités classiques. Elles permettent
également le traitement en temps réel d'un flux continu de
données afin de prendre plus rapidement des décisions urgentes.
Les processus d'analyse se dirigent, là où sont les
données pour plus de rapidité et d'efficacité. Elles
permettre ainsi aux personnels dirigeants de prendre de meilleures
décisions, plus rapidement et en temps réel. En bref, c'est
piloter en temps réel pour prendre plus rapidement des décisions
urgentes qui implique les collaborateurs.
I.13.1. Big Data et recrutement
Le Big Data permet de traiter un grand nombre d'applications
et de profils beaucoup plus rapidement, voire simultanément, par rapport
à un recruteur. En fait, pour les questionnaires, le programme commence
l'analyse lorsque la personne a fini de répondre aux questions. De plus,
l'algorithme peut fonctionner en continu et à tout moment.
Néanmoins, si les algorithmes sont efficaces pour
établir un profil et estimer une correspondance entre un individu et un
poste, les recruteurs auront toujours une place prépondérante
à occuper dans les années à venir. En effet, certains
aspects resteront irremplaçables pour les machines, aussi complexes
soient-elles. En effet, l'intelligence artificielle soulève le doute
quant au remplacement de la fonction par de simples algorithmes, et rejoindrait
ainsi les emplois victimes du processus d'automatisation des tâches.
I.13.2. Métiers du Big Data
Les métiers du Big Data sont :
Ø Data Scientist: Il est chargé
de modéliser des problématiques commerciales complexes, d'ouvrir
des perspectives commerciales, et d'identifier les opportunités. Il a :
· Connaissance des logiciels & langages Big Data ;
· Connaissance en modélisations ;
· Connaissances métiers.
Ø Architecte Big Data:
· Connaissance infrastructures et logiciels Big Data ;
· Connaissances en modélisations.
Ø Data Analyst :
· Connaissance des logiciels & langages Big Data ;
· Connaissance en modélisations.
Ø Chief-Data-Officer (Directeur des
données) :
· Responsable des données et de leur gouvernance
(collecte, traitement, sauvegarde, accès) ;
· Responsable de l'analyse des données et aide
à la décision.
CONCLUSION PARTIELLE
La rapidité technologique a mis les données
à la disposition des entreprises à partir de sources multiples,
souvent structurées ou non. Pour faire face à ce type de
données, une technologie Big Data permet l'exploration de grands volumes
de données provenant des sources les plus variées.
Cette technologie Big Data utilise plusieurs autres techniques
pour le traitement de ces données non structurées ou
structurées, leur gestion et leur stockage avec des outils de traitement
et un SGBD (Système de gestion de base de données) très
spécifiques à ces types de données. Dans ce chapitre il a
été question de parler de ladite technologie dans ses multiples
aspects.
CHAPITRE II :
SYSTÈME DE GESTION DE BASE DE DONNEES ORIENTE DOCUMENT ET
MONGODB[7], [9]
II.1. SGBD ORIENTE
DOCUMENT
II.1.1. Introduction
Les systèmes de gestion de bases de données
constituent une grande problématique de nos jours. Ce sont des
systèmes qui enregistrent et classent les données pour permettre
une recherche et un stockage rapides et faciles des informations. Dans un
programme, les bases de données sont utilisées pour de stocker
à long terme ce que les variables enregistrent à court terme.
Pendant des années, ces systèmes de gestion
relationnelle ont constitué la base du stockage de documents. Cela a
entraîné d'importants problèmes de gestion, notamment le
volume, la vitesse et la variabilité des composants de la base de
données. En effet, on ne pouvait pas stocker beaucoup d'enregistrements
et les traitements étaient très lourds, car les informations
disposées sur plusieurs tables nécessitaient l'utilisation de
plusieurs jointures pour être extraites.
II.1.2.Définition
Une base de données orientée
documents est un type de base de données NoSQL conçu pour
stocker et interroger des données sous forme de documents. Elle est donc
destinée aux applications qui gèrent des documents.
Cette catégorie de produits fait le compromis
d'abandonner certaines fonctionnalités classiques des
SGBD relationnels au profit de la
simplicité, la performance et une montée en charge (
scalabilité)
élevée. Ce type de base de données peut être une
superposition d'une base de données relationnelle ou non.
L'avantage des bases de données orientées
documents réside dans l'unité de l'information et l'adaptation
à la distribution. En effet, d'une part, tout étant inclus dans
la structure, cela évite de faire des jointures pour reconstruire
l'information car elle n'est plus dispersée dans plusieurs tables.
Aucune transaction n'est nécessaire car l'écriture est suffisante
pour créer des données sur un document afin de modifier un objet.
Une seule lecture suffit pour reconstruire un document. Par contre, les
documents étant autonomes, ils peuvent être déplacés
facilement, ils sont indépendants les uns des autres.
II.1.3. Types de modèle
de SGBD NoSQL[7]
Bien que plusieurs caractéristiques
générales aient été soulignées
précédemment, il convient de noter qu'il existe plusieurs
familles de systèmes de base de données NoSQL, étant
donné qu'elles sont apparues progressivement, à des fins
différentes et conçus par différents auteurs. Chacune de
ces familles peut parfois s'écarter des définitions
générales.
II.1.4. Comparaison des outils
de gestion des BD NoSQL
Dans cette partie, nous allons lister les
caractéristiques des principales bases de données NoSQL. CouchDB
présente de nombreuses similitudes avec MongoDB, à la
différence que CouchDB est moins adapté à des
données très variables [Oussous et al., 2015].
CouchDB assurera la disponibilité et la
tolérance à la partition là où MongoDB assurera la
disponibilité et la cohérence. Le choix de l'importance de ces
caractéristiques est à effectuer selon les besoins
del'application. De prime à bord, dans les conditions de création
du prototype dans ce travail, ni la disponibilité ni la cohérence
semble avoir plus d'importances l'une que l'autre. Par contre MongoDB
semble
supporter des requêtes plus complexes et a l'avantage de supporter
nativement le partitionnement [Lourenço et al., 2015].
Tableau 2.2: Comparaison de
système de Base des données NoSQL.
|
CouchDB
|
MongoDB
|
Neo4j
|
Big Table
|
|
Basic Concepts
|
Document-Oriented
|
Document-Oriented
|
Network-Oriented
|
Column-Oriented
|
|
Indexing
|
R-Tree Only2D
|
2D 2Dsphere
|
R-Tree 2Dand partially 3D
|
B-Tree Only2D
|
|
Vector Data Types
|
Fully
|
Fully
|
Fully Basic Types and Limited MultiGeometry Types
|
Fully Basic Types
|
|
Topologycal functions
|
Only Within() Contains()
|
Only Wiyhin() Contains(Point)
|
Almost fully
|
Not supported
|
|
Analysis and metric functions
|
Only Distance()
|
Only Distance(Point)
|
FullyMultiGeometry
|
Only Distance()
|
|
Set functions
|
Not support
|
Only Intersection(Point)
|
Fully
|
Not supported
|
MongoDB semble donc être plus approprié pour la
gestion de nos données. L'utilisation de CouchDB n'est pas pour autant
inintéressante, au contraire, elle offre bon nombre d'avantages
simplement par ses objectifs différents (disponibilité au lieu de
cohérence).
II. 2. MongoDB
II.2.1.Présentation
MongoDB est l'un des systèmes de gestion de
données NoSQL les plus populaires. Développé par la
société new-yorkaise MongoDB Inc., il est disponible depuis 2009.
À l'heure actuelle, la dernière version disponible est la
4.6.8.
MongoDB vient du mot anglais humongous qui signifie «
énorme ». Il est un SGBD faisant partie de la mouvance NoSQL qui
n'est plus fondée sur l'architecture classique des bases relationnelles
où l'unité logique n'y est plus la table, et les données
ne sont en général pas manipulées avec le SQL.
MongoDB est un système de gestion de documents
orienté document, répartissables sur un nombre quelconque
d'ordinateurs de scalabilité (extensibilité ou
évolubilité) ou scalability en anglais, avec des performances
raisonnables et ne nécessitant aucun schéma de données
prédéfini. Il est écrit en C ++ et distribué sous
licence AGPL. Son objectif est de fournir des fonctionnalités
avancées.
Avant de fonder 10gen (renommée depuis en MongoDB
Inc.), Kevin Ryan et Dwight Herriman avaient déjà
créé Double Click, une entreprise bien connue de publicité
en ligne. Frustrés par l'impossibilité de monter en charge comme
ils le souhaitaient, ils décidèrent de développer une
plate-forme applicative distribuée conçue pour le cloud,
composée d'un moteur applicatif et d'une base de données, qu'ils
développèrent d'abord en JavaScript. Cette idée de
plate-forme applicative (un App Engine tel que celui de Google)
n'intéressait pas grand monde, mais la base de données
éveillait la curiosité, si bien qu'après un an, ils
décidèrent de libérer son code. Ce fut à ce moment
qu'un net intérêt commença à se manifester. Cet
engouement se traduisit par une activité importante de
développement par la communauté et un investissement grandissant
de la part de 10gen, notamment par le recrutement d'ingénieurs
spécialisés en SGBD.MongoDB est identifié par le logo
ci-dessous :

Figure 2.11:Présentation
logo du SGBD MongoDB.
II.2.2. Schéma
La conception du schéma doit prendre en compte les
particularités de l'application elle-même. Il faut regarder le
nombre de lectures et l'importance de chacune. Les requêtes et la
fréquence des mises à jour doivent également être
étudiées bien avant la conception du modèle.
II.2.2.1. Document
Le modèle de données MongoDB est
entièrement basé sur des documents. Le document est
représenté par un fichier BSON. Les caractéristiques de
ces fichiers permettent d'introduire des documents intégrés, ce
qui permet d'éviter les jointures et les transactions lourdes. Les
documents peuvent donc être comparés à plusieurs lignes
d'une table d'une base de données relationnelle.
MongoDB garantit la conformité ACID (atomicité,
cohérence, isolation et durabilité) au niveau du document. En
effet, toutes les données incluses dans un document peuvent être
collectées en une seule opération. Ainsi, toutes les
données peuvent être stockées dans un seul document pour
appliquer les caractéristiques ACID à l'ensemble de la base de
données [Abraham, 2016].
II.2.2.2. Collection
Une collection est l'ensemble des documents de la
même famille. Il n'y a pas de structure imposée pour les documents
d'une même collection, ils peuvent tous varier entre eux.
Il existe des collections typiques appelées «
collections limitées », créées à l'avance avec
une limite de taille. Quand l'ajout de documents provoque le dépassement
de la taille limite, ce sont les plus vieux documents qui vont être
supprimés [Chodorow, 2013].
II.2.2.3. Documents
intégrés
Les relations un à un ou un à plusieurs
correspondent parfaitement au type de document intégré.Les
documents ne doivent pas être intégrés dans trois cas :
§ Si le document à intégrer demande
beaucoup moins de lecture que le document principal. Cela ne ferait
qu'augmenter la mémoire nécessaire pour les opérations
fréquentes.
§ Si une partie du document est fréquemment mise
à jour contrairement au reste du document.
§ Si la taille totale du document dépasse la
limite des 16 Mo imposée par MongoDB
Il apparait clairement que son utilisation diminuerait les
performances, mais MongoDB offre la possibilité d'un joint contrairement
à la plupart des bases de données NoSQL. Le
référencement est le plus souvent appliqué sur le champ
_id (par la commande $lookup) dans le document de référence.
L'usage du référencement est conseillé dans plusieurs cas
(MongoDB, 2015) :
ü Si l'intégration n'a vraiment pas l'avantage sur le
référencement ;
ü Si l'objet est référencé de plusieurs
sources ;
ü Pour les relations plusieurs à plusieurs ;
ü Pour les jeux de données volumineux et
hiérarchiques.
II.2.3.
Caractéristiques
MongoDB est l'un des rares systèmes de gestion de
données NoSQL codés avec un langage qui offre de grandes
performances : le C++. Les autres moteurs NoSQL populaires sont souvent
codés en Java ou dans des langages particuliers comme Erlang.
MongoDB Inc. le définit comme un SGBD orienté
documents. Le terme « documents » ne signifie pas des documents
binaires (image ou fichier son, par exemple), mais une représentation
structurée, compréhensible par MongoDB, d'une donnée
complexe. Plus simplement, on stocke la représentation des
données comprise par MongoDB.
II.2.4. Structure des
données
Un document BSON représente donc l'unité
stockée par MongoDB, qui équivaut à une ligne dans une
table relationnelle. Il est composé d'une hiérarchie de paires
clé-valeur, sans contrainte de présence ou de quantité.
Les documents sont contenus dans des collections, qui
correspondent plus ou moins aux tables des SGBDR. Même s'il n'y a aucune
obligation pour les membres d'une collection de partager une structure
identique, il est tout de même plus logique et plus efficace, parce que
cela permettra l'indexation de s'assurer de cette cohérence.
MongoDB n'a pas de concept de contraintes comme dans le
modèle relationnel. Il n'y a pas de vérification de
cohérence effectuée par le serveur, toute la
responsabilité est endossée à ce niveau par le code
client.
MongoDB stocke les documents tels
qu'il les reçoit.
De plus, il est inutile de créer explicitement une collection avant d'y
insérer des documents, car MongoDB en crée une dès que le
code client la mentionne.
II.2.5. Stockage des objets
larges
MongoDB peutégalement stocker des documents binaires ou
des objets larges, soit directement dans sa structure BSON, soit à
l'aide de GridFS, spécification destinée à optimiser la
manipulation et la sérialisation de fichiers de taille importante. En
interne, MongoDB découpe les fichiers en plus petits segments qui seront
autant de documents contenus dans une collection nommée chunks. Les
métadonnées des fichiers sont conservées dans une autre
collection, nommée nies. Vous pouvez ajouter des attributs aux documents
de nies pour qualifier vos fichiers.
Lacollection chunks contiendra des documents qui auront un
files_id identifiant le document de la collection nies, unattribut n quiest le
numéro du segment, et un attribut data quicorrespond ausegment, de type
binaire. C'est une façon optimale de conserver des fichiers par rapport
à unstockage sur un système de fichiers avec des URL. Un outil en
ligne de commande, mongoles, permet d'importer ou d'extraire des documents.
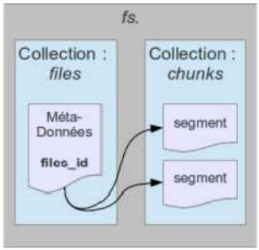
Figure 2.12:Présentation
de Stockage en GridFS.
II.2.6. Traitement des
données
Du point de vue transactionnel, MongoDB supporte
l'atomicité seulement lors de la mise à jour d'un document. En
d'autres termes, il y a bien un verrouillage à l'écriture sur un
document, mais il ne s'étend pas par défaut sur une mise
àjour de plusieurs documents. En ce quiconcerne la durabilité des
transactions, elleest assurée par une journalisation de forme WAl.
write-ahead log. Les instructions de
création-modification-suppression de données sont en premier
lieuécrites dans unjournal. Si le moteurest arrêté
proprement, les écritures sont inscrites sur le disque et le journal est
supprimé.
Donc si MongoDB démarre et constate l'existence
d'un
journal, c'est que le moteur n'a pas été
arrêté correctement. Il exécute alors une phase de
récupération qui rejoue le journal. La journalisation est
activée par défaut dans les versions récentes et 64 bits
de MongoDB, elle peut être désactivée au démarra.ge
par l'option de la ligne de commande --nojournal. Vous perdezen
sécurité et gagnez un peuen performances lors des
écritures.
II.2.7. Mise en oeuvre
II.2.7.1. Installation
Les exécutables MongoDB sont disponibles à
l'adresse suivante :http://www.mongodb.org/downloads. L'installation sur
Windows ou Mac OS X est très simple. Étant donné que nous
disposons d'une distribution Ubuntu Server pour nos exemples, nous pouvons
utiliser le paquet mongodb de la distribution officielle (MongoDB est
disponible sur la plupart des dépôts officiels des distributions
Linux).
Le dépôt porte toujours le nom de 10gen, mais
depuis quelques versions, le paquet s'appelle mongodb-org. Auparavant,
son nom était mongodb-10gen.
Le dépôt
ubuntu-upstart installe une version du démon mongodb
qui se lance grâce au système upstart d'Ubuntu, un système
de lancement de services remplaçant le traditionnel démon
init issu de System-V.
II.2.7.2. Invite
interactive
L'accès à une invite de commandes interactive
pour manipuler les données de MongoDB est possible grâce au shell
mongo (Windows et Ubuntu). Il s'agit d'une invite JavaScript (qui utilise
l'interpréteur V8 depuis la version 2.4 de MongoDB, SpiderMonkey
auparavant) grâce à laquelle vous pouvez interagir avec MongoDB.
Pour l'ouvrir, tapez simplement mongo dans votre terminal, l'exécutable
devrait se trouver dans le chemin. Si vous voulez accéder au serveur
local qui écoute sur le port par défaut 27017, cela suffira.
Sinon, vous pouvez indiquer l'adresse sous la forme suivante
:<serveur>:<port>/<base de données>.
Nous avons vu quelques commandes simples de l'invite. Vous
trouverez une description complète du shell sur le site de MongoDB Inc.
à l'adresse :
http:lldocs.mongodb.org/manualladministration/scripting/. La plupart
du temps, l'administration complète s'effectue , à partir
d'un
code client pour plus d'optimisation des requêtes. Quittons ce
shell en tapant exit, ou à l'aide de la combinaison de touches
Ctrl + D, et voyons comment accéder à MongoDB depuis notre code
Python.
II.2.7.3. Programmation
cliente
MongoDB Inc. développe des bibliothèques pour de
nombreux langages, appelés pilotes (driver). Celui pour Python
se nomme PyMongo, il s'agit d'un pilote officiel.
Nous avons ici effectué notre écriture avec
l'instruction db.articles.insert (article. safe=True) , ce qui signifie: dans
la base de données db ouverte, dans la collection articles,
insérer le dictionnaire article. L'objet sera automatiquement
transformé en document JSON par PyMongo. Si la collection articles
n'existe pas, elle sera créée.
II.2.7.4.Administration
L'interface web d'administration est disponible à
l'adresse http://localhost:27017. Vous pouvez appeler cette page
depuis une machine cliente à condition que la configuration de MongoDB
le permette. Dans le fichier /etc/mongodb.conf, vous pouvez indiquer
sur quelle interface le serveur
Ya écouter avec l'option b1nd_1p.
Pour autoriser un accès à partir de toutes les interfaces,
enlevez ou commentez cette ligne de configuration. Vous devez bien entendu
redémarrer le démon pour que le changement soit pris en
compte.
Les opérations d'administration peuvent être
exécutées grâce à l'invite interactive ou par
l'intermédiaire d'un pilote. À l'intérieur d'une base de
données, un espace de noms spécial, $cmd, permet de passer des
commandes à travers sa méthode find0ne(), qui retourne son
résultat sous forme de document. Beaucoup de ces commandes ont des
fonctions clairement nommées qui les encapsulent. Par exemple, l'invite
interactive dispose d'une fonction générique
db.RunCommand()
et de fonctions spécifiques.
II.2.7.5.
Sécurité
Qu'en est-il de la sécurité dans MongoDB, dans
le sens où on l'entend pour tout type de serveur : authentification et
protection des données ? Pour l'authentification, la configuration
recommandée par MongoDB Inc. est de n'en avoir aucune et
d'exécuter le ou les noeuds MongoDB dans un environnement sûr.
C'est par la configuration réseau que vous vous assurez que les ports
TCP permettant d'accéder à MongoDB ne sont accessibles que depuis
des machines de confiance. Ces clients peuvent accéder et manipuler les
données comme bon leur semble.
II.2.7.6.Réplication
Un démon (processus) MongoDB est appelé un
noeud. Dans les situations de production, il y a en général un
noeud par serveur. Il peut être utile de monter une machine multi noeud
pour le développement et les tests. Ces noeuds peuventêtre
liés dans un ensemble de réplication. C'est-à-dire une
topologie de réplication de type maître-esclave telle qu'on la
trouve dans les SGBDR, à des fins de duplication de données, et
pour assurer une continuité de service, car la réplication inclut
également un basculement automatique du maître.
À un moment donné, un noeud est choisi comme
maître par MongoDB et reçoit donc toutes les écritures,
qu'il distribue aux esclaves. En cas de défaillance du noeud
maître, MongoDB bascule automatiquement et promeut un autre noeud
maître. Les applications clientes sont averties de ce fait et redirigent
toujours les écritures vers le bon maître dans un jeu de
réplicas. Conceptuellement, cette réplication est
effectuée en mode asynchrone ou synchrone selon la demande du client.
Une opération de modification de données peut indiquer le
nombrede réplication sur lesquels l'écriture doit avoir
été effectuée avec succès avant de rendre la main,
comme nous l'avons vu dans les exemples de code précédents.
II.2.7.7. Répartition
(sharding)
La montée en charge horizontale est
réalisée par répartition (sharding). MongoDB peut aussi
bien s'exécuter en tant que moteur individuel sur une seule machine ou
être converti en un cluster de données éclatées
géré automatiquement et comportant un nombre de noeuds pouvant
théoriquement aller jusqu'à mille. Le sharding de MongoDB impose
quelques limitations légères à ses fonctionnalités,
notamment une immutabilité de la clé (primaire) du document. Le
choix de
la répartition est fait par collection. C'est une
collection, et non pas une base de données, qu'on répartit. Les
documents de cette collection seront distribués aussi
équitablement que possible entre les différents noeuds, afin
d'équilibrer les traitements.
À chaque opération, il faut bien entendu
identifier le noeud qui contient ou doit contenir les données. Ce
rôle est assuré par un processus nommé mongos, qui
reçoit les requêtes et les redoute, et qui agit donc comme un
répartiteur de charge. Pour assurer une continuité de service,
cette répartition peut être accompagnée de
réplication : chaque noeud peut avoir son propre groupe de
réplicas avec basculement automatique.
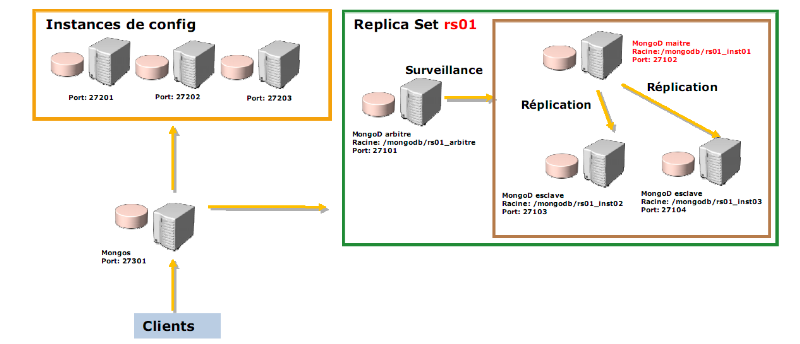
Figure 2.13: Le modèle
de répartition de MongoDB [Noureddine DRISSI, MongoDB,
Administration].
CONCLUSION PARTIELLE
Dans ce chapitre, nous avons mené une étude
approfondie des opérations requises pour manipuler une base de
données orientée document avec le SGBD MongoDB.
Cette étude montre que la solution MongoDB est
très bénéfique et offre de meilleures performances parmi
les autres bases de données NoSQL, en temps de réponse pour
l'équilibrage de la charge entre les noeuds.
Nous pouvons donc en conclure que MongoDB est une base de
données NoSQL légère, rapide et facile à
maîtriser. La force et l'efficacité de MongoDB dans des
environnements à grande échelle ou le temps de réponse et
la disponibilité des informations sont plus importants que leur
intégrité.
CHAPITRE III :
FOUILLE DE DONNEES ET RESEAUX DE NEURONES[13],
[14], [18]
III. 1. FOUILLE DE
DONNEES
III.1.1. Présentation
La Fouille de données (en anglais Data Mining)
est un ensemble de techniques d'exploration et d'analyse, par des moyens
automatiques ou semi-automatiques, d'une masse importante de données
dans le but de découvrir des tendances cachées ou des
règles significatives (non triviales, implicites et potentiellement
utiles).
Dans la littérature, la Fouille de données est
appelée de différente manière, entre autres Exploration de
données, Forage de données, Prospection de données,
Extraction de connaissance à partir de données ou
encore Analyse intelligente de données.
Elle se propose d'utiliser un ensemble
d'algorithmes issus de disciplines scientifiques diverses telles que
les statistiques, l'intelligence artificielle ou l'informatique, pour
construire des modèles à partir des données,
c'est-à-dire trouver des structures intéressantes ou des motifs
selon des critères fixés au préalable, et d'en extraire un
maximum de connaissances.
Nous retiendrons que le terme Fouille de données fait
allusion aux outils ayant pour objet de générer des informations
riches à partir des données de l'entreprise, notamment des
données historiques, de découvrir des modèles implicites
dans les données. Ces outils peuvent permettre par exemple à un
magasin de dégager des profils de client et des achats types et de
prévoir ainsi les ventes futures. Ils permettent d'augmenter la valeur
des données contenues dans l'Entrepôt de données.
Les outils d'aides à la décision, qu'ils soient
relationnels, NoSQL ou OLAP, laissent l'initiative à l'utilisateur, de
choisir les éléments qu'il veut observer ou analyser. Au
contraire, dans le cas de la Fouille de données, le système a
l'initiative et découvre lui-même les associations entre
données, sans que l'utilisateur ait à lui dire de rechercher
plutôt dans telle ou telle direction ou à poser des
hypothèses.
III.1.2. Objectifs de la
Fouille de données
Les objectifs du Data Mining peuvent être
regroupés dans trois axes importants :
(1) Prédiction (What-if) : consiste
à prédire les conséquences d'un événement
(ou d'une décision), se basant sur le passé.
(2) Découverte de règles cachées
: découvrir des règles associatives, entre différents
événements (Exemple : corrélation entre les ventes de deux
produits).
(3) Confirmation d'hypothèses : confirmer des
hypothèses proposées par les analystes et décideurs, et
les doter d'un degré de confiance.
En considérant le serveur de base
données ou le serveur d'entrepôt de données, la Fouille de
données est considéré comme un client riche de ces deux
serveurs. Notons que le client serveur est un mode de dialogue entre deux
processus, l'un appelé client qui sollicite des services auprès
de l'autre appelé serveur, par envoie des requêtes (send request
en anglais). Après avoir lancé une requête par rapport au
fait à analyser, le client data ming applique des méthodes ou
procédures sur les données obtenues, afin d'obtenir les
informations nécessaires pour la prise de décision. Ces
procédures ou méthodes, sont classées en deux
catégories : les méthodes descriptives et les
méthodes prédictives.
III.1.3. Méthodes
(Algorithmes) de Fouille de données
Résoudre un problème par un processus
d'exploration de données impose généralement l'utilisation
d'un grand nombre de méthodes et d'algorithmes différents plus ou
moins faciles à comprendre et à employer. Il existe deux grandes
familles d'algorithmes : les méthodes descriptives et les
méthodes prédictives.
III.1.3.1. Méthodes descriptives
Les méthodes descriptives consistent à mettre en
évidence les informations cachées par le grand volume de
données, en vue de détecter dans ces données des tendances
cachées. Cela signifie identifier des régularités qui
permettent d'un certain de comprimer l'information présente dans les
données et de les décrire de manière synthétique.
Il s'agit donc à simplifier et à aider
à comprendre l'information sous-jacente d'un ensemble important de
données. Il s'agit essentiellement de synthétiser, de
résumer et de structurer l'information contenue dans les données.
Il existe ainsi deux sous-catégories des
méthodes descriptives, à savoir :
· Lesméthodes factorielles, qui ont pour
but de réduire le nombre des variables statistiques en les
résumant en petit nombre des composantes statiques qu'on appelle axe
factoriel. Les techniques utilisées sont l'Analyse en Composante
Principale (A.C.P), l'Analyse Factorielle des Correspondances (A.F.C),
l'Analyse de Correspondances Multiples (ACM), etc. ;
· Lesméthodes de classification ou de
segmentation (en anglais clustering), qui ont pour but de
regrouper en sous-groupes homogènes les individus d'une
population hétérogène de telle manière que les
individus d'une même classe se ressemblent de plus en plus et celles des
classes différentes se diffèrent de plus en plus. Ces
méthodes sont de deux types :
- Lesméthodes hiérarchiques : ce
sont des méthodes qui utilisent des hiérarchies pour former ses
groupes. On a des méthodes comme : la Classification Ascendante
Hiérarchique (C.A.H) et la Classification Descendante
Hiérarchique (C.D.H) et
- Lesméthodes de partitionnement : ce
sont des méthodes qui utilisent des partitions pour former ses groupes.
On a des méthodes comme : le k-means (Centres mobiles),
les nués dynamiques, le modèle de mélange gaussien, etc.
III.1.3.2. Méthodes prédictives
Les méthodes prédictives consistent à
partir d'une collection des données, produit une prédiction d'une
valeur quelconque.Un prédicateur est une procédure, une
fonction mathématique ou un algorithme qui, à partir d'un
ensemble d'exemples, produit une prédiction d'une valeur quelconque.
Mathématiquement, la base d'apprentissage est un
doublet 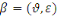 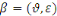 où où   est l'ensemble des observations définies sur est l'ensemble des observations définies sur 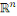 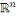 décrivant les formes et : décrivant les formes et :
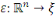
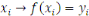
Est la fonction de prédiction. Les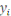 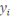 sont les sorties et sont les sorties et   est appelé prédicteur. est appelé prédicteur.
§ Si   est une fonction continue, on parle alors de
régression. Dans ce cas, la fonction de prédiction (ou
le prédicteur) est alors appelée un régresseur.
Un régresseur est donc une fonction mathématique ou un algorithme
qui réalise les tâches de régression. est une fonction continue, on parle alors de
régression. Dans ce cas, la fonction de prédiction (ou
le prédicteur) est alors appelée un régresseur.
Un régresseur est donc une fonction mathématique ou un algorithme
qui réalise les tâches de régression.
En clair, le problème de prédiction est dit de
régression si la valeur à sortie est numérique, par
exemple la température qu'il fera le mois prochain, etc.
Il existe plusieurs modèles de régression
actuellement, à savoir : la régression linéaire, la
régression non-linéaire, qui peuvent être simple ou
multiple, la régression logistique, etc.
§ Si 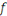  est une fonction discontinue, on parle alors de classement.
Dans ce cas, le prédicteur est appelé classifieur. Un
classifieur est donc une fonction mathématique ou un algorithme qui
réalise les tâches d'affectation. est une fonction discontinue, on parle alors de classement.
Dans ce cas, le prédicteur est appelé classifieur. Un
classifieur est donc une fonction mathématique ou un algorithme qui
réalise les tâches d'affectation.
Ce qui veut dire, le problème de prédiction est
dit de classement si la valeur de sortie est catégorielle ou une
étiquette, par exemple lors de l'analyse des données fiscales, la
valeur, la valeur « frauduleux » ou « non frauduleux ».
Plusieurs modèles sont utilisés pour résoudre le
problème de classement, à savoir : Réseaux de
neurones, l'Arbre de décision, le Séparateur à Vaste Marge
(SVM) ou les Réseaux de Bayes, etc.
On peut alors synthétiser les méthodes de
Fouille de données sous forme de tableau suivant :
Tableau 3.3: Méthodes de
Fouille de données.
|
Méthodes (Algorithmes)
|
Types de methodes
|
Exemples
|
|
Méthodes Descriptives
|
Méthodes factorielles
|
Analyse en Composante Principale (A.C.P), Analyse Factorielle
des Correspondances (A.F.C), Analyse Factorielle Discriminante (A.F.D), Analyse
de Correspondances Multiples (ACM).
|
|
Méthodes de classification (ou segmentation)
|
Méthodes de partitionnement :
La méthode de k-means (Centres mobiles), la
méthode de nués dynamiques, le modèle de mélange
gaussien, les réseaux de Kohonen.
|
|
Méthodes hiérarchiques :
La Classification Ascendante Hiérarchique (C.A.H) et la
Classification Descendante Hiérarchique (C.D.H)
|
|
Méthodes Prédictives
|
Méthodes de régression
|
Modèle de régression linéaire, Modèle
de régression non linéaire, Modèle de régression
logistique, Modèle log-linéaire, Réseaux de neurones,
l'Arbre de décision, le Séparateur à Vaste Marge (SVM),
les Réseaux de Bayes, Méthode de   -plus proche voisin. -plus proche voisin.
|
|
Méthodes de classement
|
Analyse Discriminante Prédictive, Réseaux de
neurones, l'Arbre de décision, le Séparateur à Vaste Marge
(SVM), les Réseaux de Bayes, Méthode de   -plus proche voisin. -plus proche voisin.
|
III.1.4. Concepts de base
de Fouille de données
III.1.4.1. Matrice des données - Individu -
Variable
Nous représentons les données sous la forme
d'une matrice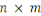 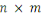 , avec , avec   lignes et lignes et   colonnes, les lignes correspondant aux entités de l'ensemble de
données (entrepôt de données, base de données,
tableur, etc.)) et des colonnes représentant des attributs ou
propriétés appelées variables. Chaque ligne de la matrice
de données enregistre les valeurs d'attribut observées pour une
entité donnée qu'on appelle individu ou instance ou encore
exemple. Cette matrice est donnée par : colonnes, les lignes correspondant aux entités de l'ensemble de
données (entrepôt de données, base de données,
tableur, etc.)) et des colonnes représentant des attributs ou
propriétés appelées variables. Chaque ligne de la matrice
de données enregistre les valeurs d'attribut observées pour une
entité donnée qu'on appelle individu ou instance ou encore
exemple. Cette matrice est donnée par :
|
  , ,
|
|
où   désigne la désigne la   -ème ligne, qui est un n-tuple donné par -ème ligne, qui est un n-tuple donné par
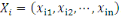
Le nombre d'individus   est appelé la taille des données, alors que le
nombre de variables est appelé la taille des données, alors que le
nombre de variables  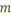 est appelé la dimension des données. est appelé la dimension des données.
Une variable qualitative est une variable pour laquelle la
valeur mesurée sur chaque individu ne représente pas une
quantité. Les différentes valeurs que peut prendre cette variable
sont appelées les catégories, modalités ou niveaux.
Une variable est quantitative si elle reflète une
notion de grandeur, c'est-à-dire si les valeurs qu'elle peut prendre
sont des nombres pouvant être classés en utilisant la relation
=.
III.1.4.2. Ressemblance
Une ressemblance (ou proximité) est un
opérateur capable d'évaluer précisément les
ressemblances ou les dissemblances qui existent entre ces données. Cet
opérateur permet alors de mesurer le lien entre les individus d'un
même ensemble.
III.1.4.3. Dissimilarité
Un opérateur de ressemblance 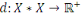  défini sur l'ensemble d'individus défini sur l'ensemble d'individus
 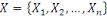 est dit indice de dissimilarité (ou dissimilarité),
si et seulement vérifie les propriétés
suivantes : est dit indice de dissimilarité (ou dissimilarité),
si et seulement vérifie les propriétés
suivantes :
|
(P1)
|
|
(Symétrie)
|
|
(P2)
|
|
(Positivité)
|
III.1.4.4. Distance
Un opérateur de ressemblance 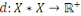 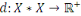 défini sur l'ensemble d'individus défini sur l'ensemble d'individus
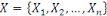 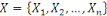 est dit distance ou métrique, si et seulement, en plus de
propriétés (P1) et (P2), il vérifie les
propriétés suivantes : est dit distance ou métrique, si et seulement, en plus de
propriétés (P1) et (P2), il vérifie les
propriétés suivantes :
|
(P3)
|
|
(Identité)
|
|
(P4)
|
|
(Positivité)
|
La distance la plus utilisée pour les données de
type quantitatives continues ou discrètes est la distance de Minkowski
d'ordre á définie dans 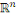  par : par :
où  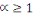 . .
En particulier si :
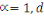 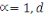 est la distance de city-block ou Manhattan. est la distance de city-block ou Manhattan.
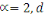 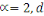 est la distance Euclidienne classique. est la distance Euclidienne classique.
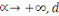 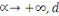 est la distance de Tchebychev définie comme suit : est la distance de Tchebychev définie comme suit :
NOTA
Dans la pratique, c'est la distance euclidienne qui est le
plus souvent utilisée, mais la distance de Manhattan est aussi parfois
utilisée, notamment pour l'atténuement de l'effet de larges
différences dues aux points atypiques ou aberrants pour la simple raison
que puisque leurs coordonnées ne sont pas élevées au
carré.
III.1.4.5. Similarité
Un opérateur de ressemblance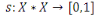 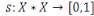 défini sur l'ensemble d'individus défini sur l'ensemble d'individus 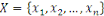 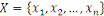 est dit indice de similarité (ou similarité), si et
seulement si, en plus de la propriété (P1), il vérifie les
deux propriétés suivantes : est dit indice de similarité (ou similarité), si et
seulement si, en plus de la propriété (P1), il vérifie les
deux propriétés suivantes :
|
(P5)
|
|
(Positivité)
|
|
(P6)
|
|
(Maximisation)
|
III.2. ALGORITHME DE   -MEANS [2], [15] -MEANS [2], [15]
III.2.1. Introduction
Les algorithmes des centres mobilesvisent à
diviser un ensemble de données en différents
« paquets » homogènes, en ce sens que les
données de chaque sous-ensemble partagent des
caractéristiques communes, qui correspondent le plus souvent à
des critères de proximité (ou similarité) que l'on
définit en introduisant des mesures et classes de distance entre
individus.
Étant donnés des points et un
entier   , le problème est de diviser l'ensemble de , le problème est de diviser l'ensemble de   individus du nuage des points individus du nuage des points  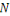 en en   groupes, souvent appelés clusters ou classes, de
façon à minimiser une certaine fonction. On considère la
distance d'un individu à la moyenne des individus de sa classe ; la
fonction à minimiser est la somme des carrés de ces distances. groupes, souvent appelés clusters ou classes, de
façon à minimiser une certaine fonction. On considère la
distance d'un individu à la moyenne des individus de sa classe ; la
fonction à minimiser est la somme des carrés de ces distances.
Ainsi, la similarité à l'intérieur d'un
même groupe est élevée mais faible entre les
différentes classes. Pour ce faire ces algorithmes itèrent en
deux étapes, d'abord ils calculent les centres des groupes,
deuxièmement, ils assignent chaque objet au centre le plus proche.
Chaque classe est caractérisée par le centre ou prototype et par
ses éléments. Le prototype des classes est le point de l'espace
de dimension   ( (  correspond au nombre de descripteurs) où la somme des distances
à tous les objets d'un même groupe est minimale. Avec la
méthode de centre mobile classique, lors d'une itération
donnée, le calcul des centres se fait après l'affectation des
individus dans leurs classes respectives. Mais avec correspond au nombre de descripteurs) où la somme des distances
à tous les objets d'un même groupe est minimale. Avec la
méthode de centre mobile classique, lors d'une itération
donnée, le calcul des centres se fait après l'affectation des
individus dans leurs classes respectives. Mais avec   -means qui est une variante de centre mobile, dès qu'on affecte
un individu dans une classe, on recalcule directement le centre, ce qui
accélère convergence de l'algorithme. -means qui est une variante de centre mobile, dès qu'on affecte
un individu dans une classe, on recalcule directement le centre, ce qui
accélère convergence de l'algorithme.
Le   -means repose généralement sur des algorithmes
simples, et permet de traiter rapidement des ensembles d'effectif assez
élevé en optimisant localement un critère. Il consiste
à minimiser le critère suivant : -means repose généralement sur des algorithmes
simples, et permet de traiter rapidement des ensembles d'effectif assez
élevé en optimisant localement un critère. Il consiste
à minimiser le critère suivant :
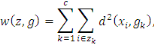
Où 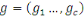 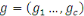 , ,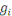  est le centre de la classe zk. Rappelons que le
critère W(z,g), qui est simplement la somme des inerties des c classes,
est appelé inertieintra classe. La méthode des centres mobiles
consiste à chercher la partition telle que le W soit minimal pour avoir
en moyenne des classes bien homogènes, ce qui revient à chercher
le maximum de l'inertie interclasse, est le centre de la classe zk. Rappelons que le
critère W(z,g), qui est simplement la somme des inerties des c classes,
est appelé inertieintra classe. La méthode des centres mobiles
consiste à chercher la partition telle que le W soit minimal pour avoir
en moyenne des classes bien homogènes, ce qui revient à chercher
le maximum de l'inertie interclasse,
Avec   le centre de gravité du nuage et le centre de gravité du nuage et  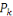 est le poids de la classe zk. est le poids de la classe zk.
In fine, l'inertie intraclasse est la mesure de la dispersion
d'individus dans la même classe, tandis que l'inertie interclasse est la
mesure de la dispersion de centres de classes différentes.
III.2.2. Théorème
de Hyugens
On appelle inertie totale 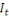 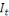 d'un nuage d'un nuage 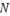 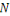 la somme pondérée des carrés des distances de ses
points au centre de gravité du nuage. Donc, si la somme pondérée des carrés des distances de ses
points au centre de gravité du nuage. Donc, si   est le centre de la classe zk, l'inertie totale de est le centre de la classe zk, l'inertie totale de 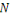 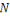 est donnée par : est donnée par :
L'idée de l'algorithme de   -means est de partitionner les données de -means est de partitionner les données de  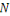 afin de: afin de:
· Minimiser l'inertie interclasse pour obtenir
des classes (cluster en anglais) les plus homogènes
possibles ;
· Maximiser l'inertie interclasse afin d'obtenir des
sous-ensembles bien différenciés.
III.2.3. Principe
général des méthodes des centres mobiles
La méthode des centres mobiles due à Forgy
[Forgy, 1965] est la plus classique et très utilisée. Elle
procède comme suit : dans une première étape, elle
consiste à tirer aléatoirement   individus de la population. Ces individus représentent les
centres provisoires des individus de la population. Ces individus représentent les
centres provisoires des   classes qui formeront la partition initiale. Ensuite, les autres
individus sont regroupés autour de ces classes qui formeront la partition initiale. Ensuite, les autres
individus sont regroupés autour de ces   centres en affectant chacun d'eux au centre le plus proche. centres en affectant chacun d'eux au centre le plus proche.
L'étape suivante consiste à recalculer les   nouveaux centres (dites aussi centroïdes ou centres de
gravité) des nouveaux centres (dites aussi centroïdes ou centres de
gravité) des   classes, sachant qu'un centre n'est pas nécessairement un
individu de la population. Le processus est répété
plusieurs fois jusqu'à stabilité des centres des classes (les
centres ne bougent plus). Comme tout les algorithmes de partitionnement, la
méthode des centres mobiles cherche à minimiser l'inertie
intraclasse définie par la somme des écarts des centroïdes
aux points de leurs classes et donc à maximiser aussi l'inertie
interclasse de la partition donnée par la somme des écarts entre
les centres des classes et le centre de la population totale (d'après le
théorème de Huygens : inertie totale = inertie intraclasse +
inertie interclasse). En minimisant l'inertie intraclasse, la méthode
des centres mobiles a tendance à chercher des classes sphériques,
d'égal volume et de faible inertie. classes, sachant qu'un centre n'est pas nécessairement un
individu de la population. Le processus est répété
plusieurs fois jusqu'à stabilité des centres des classes (les
centres ne bougent plus). Comme tout les algorithmes de partitionnement, la
méthode des centres mobiles cherche à minimiser l'inertie
intraclasse définie par la somme des écarts des centroïdes
aux points de leurs classes et donc à maximiser aussi l'inertie
interclasse de la partition donnée par la somme des écarts entre
les centres des classes et le centre de la population totale (d'après le
théorème de Huygens : inertie totale = inertie intraclasse +
inertie interclasse). En minimisant l'inertie intraclasse, la méthode
des centres mobiles a tendance à chercher des classes sphériques,
d'égal volume et de faible inertie.
Cette méthode a connu des améliorations comme la
méthode des   -moyennes ( -moyennes (  -means) de Mac Queen. Avec l'approche -means) de Mac Queen. Avec l'approche   -means, les centres sont recalculés après chaque
affectation d'un individu dans une classe, plutôt que d'attendre
l'affectation de tous les individus avant de mettre à jour les centres.
Cette approche conduit généralement à de meilleurs
résultats que la méthode des centres mobiles et la convergence
est également plus rapide. -means, les centres sont recalculés après chaque
affectation d'un individu dans une classe, plutôt que d'attendre
l'affectation de tous les individus avant de mettre à jour les centres.
Cette approche conduit généralement à de meilleurs
résultats que la méthode des centres mobiles et la convergence
est également plus rapide.
III.2.4. Déroulement de l'algorithme
Figure 14: Déroulement de
l'algorithme de centre mobile.
Cet algorithme se déroule de la façon suivante
:
1. Initialisation :   points tirés au hasard pour les centres de gravités
(ou centroïdes) points tirés au hasard pour les centres de gravités
(ou centroïdes)
de chaque classe ;
2. Affectation : On affecte les points à la classe
la plus proche ;
3. Représentation : On recalcule les nouveaux
centres de gravités,
4. Itération : On répète les
étapes d'affectation et de représentation jusqu'à
la
convergence de l'algorithme (i.e. plus de changement de
partition).
Les expériences montrant que le nombre
d'itérations nécessaires à l'algorithme pour converger est
assez fiable. Cet algorithme est adapté à des tableaux des
grandes tailles, sa complexité étant linéaire.
III.3. RESEAUX DE
NEURONES
III.3.1.Historique
Depuis plusieurs années, certains scientifiques ont
cherché à comprendre le rôle du cerveau humain et le
comportement de l'homme. On croyait jadis communément que
l'activité mentale avait son siège au centre du corps humain,
dans le coeur. Aristote défendait ce point de vue contre Hippocrate, par
exemple, pour qui déjà pensées, sentiments et
émotions étaient gouvernés par le cerveau. Après
les travaux expérimentaux de Galien, il n'était
déjà plus possible de douter que le siège de l'âme
dirigeante était le cerveau.
Une étape cruciale fut franchie avec la mise en
évidence des cellules du système nerveux que l'on appellera
neurones par Golgi et Cajal, Grâce à une nouvelle technique de
coloration qui permit également des études successives sur la
forme, les propriétés, les fonctions et les connections des
neurones. Sherrington décrit le fonctionnement des systèmes
réflexes, Sperry montre que les parties droite et gauche du cerveau sont
impliquées différemment dans ses fonctions et Penfield
établit une carte des localisations de sensibilité somatique dans
le cortex cérébral.
Grâce aux avancés de la science (médecine,
psychologie, informatique, physique, etc...), que le réseau des neurones
artificiels a vu le jour. L'histoire des réseaux de neurones est donc
tissée à travers des découvertes conceptuelles et des
développements technologiques survenus à diverses
époques.
Brièvement, les premières recherches remontent
à la fin du 19ième et au début du
20ième siècle. Elles consistent en de travaux
multidisciplinaires en physique, en psychologie et en neurophysiologie par des
scientifiques tels Hermann Von Helmholtz, Ernst Mach et Ivan Pavlov. À
cette époque, il s'agissait de théories plutôt
générales sans modèle mathématique précis
d'un neurone. On s'entend pour dire que la naissance du domaine des
réseaux de neurones artificiels remonte aux années 1940 avec les
travaux de Warren McCulloch et Walter Pitts qui ont montré qu'avec de
tels réseaux, on pouvait, en principe, calculer n'importe quelle
fonction arithmétique ou logique. Vers la fin des années 1940,
Donald Hebb a ensuite propose une théorie fondamentale pour
l'apprentissage.
La première application concrète des
réseaux de neurones artificiels est survenue vers la fin des
années 1950 avec l'invention du réseau dit « perceptron
» par un dénommé Frank Rosenblatt. Rosenblatt et ses
collègues ont construit un réseau et démontré ses
habilités à reconnaître des formes. Malheureusement, il a
été démontrépar la suite que ce perceptron simple
ne pouvait résoudre qu'une classe limitée de problème.
Environ au même moment, Bernard Widrow et Ted Hoff ont proposé un
nouvel algorithme d'apprentissage pour entraýner un réseau
adaptatif de neurones linéaires, dont la structure et les
capacités sont similaires au perceptron.
Vers la fin des années 1960, un livre publié par
Marvin Minsky et Seymour Papert est venu jeter beaucoup d'ombre sur le domaine
des réseaux de neurones. Entre autres choses, ces deux auteurs ont
démontré les limitations des réseaux
développés par Rosenblatt et Widrow-Hoff. Beaucoup de gens ont
été influencés par cette démonstration qu'ils ont
généralement mal interprétée. Ils ont conclu
à tort que le domaine des réseaux de neurones était un cul
de sac et qu'il fallait cesser de s'y intéresser (et de financer la
recherche dans ce domaine), d'autant plus qu'on ne disposait pas à
l'époque d'ordinateurs suffisamment puissants pour effectuer des calculs
complexes.
Heureusement, certains chercheurs ont
persévéré en développant de nouvelles architectures
et de nouveaux algorithmes plus puissants. En 1972, TeuvoKohonen et James
Anderson ont développé dépendamment et
simultanément de nouveaux réseaux pouvant servir de
mémoires associatives. Egalement, Stephen Grossberg a investigué
ce qu'on appelle les réseaux' auto-organises.
Dans les années 1980, une pierre d'achoppement a
été levée par l'invention de l'algorithme de
retro-propagation des erreurs. Cet algorithme est la réponse aux
critiques de Minsky et Papert, formulées à la fin des
années 1960. C'est ce nouveau développement,
généralement attribué à David Rumelhart et James
McClelland, mais aussi découvert plus ou moins en même temps par
Paul Werbos et par Yann LeCun, qui a littéralement ressuscité le
domaine des réseaux de neurones. Depuis ce temps, c'est un domaine ou
bouillonne constamment de nouvelles théories, de nouvelles structures et
de nouveaux algorithmes.
III.3.2. Présentation des réseaux de
neurones
Les méthodes neuronales se sont
développées depuis ces trente dernières années
simultanément au paradigme de l'apprentissage (machine learning). Selon
ce paradigme, les machines ne sont pas programmées à l'avance
pour une taches donnée (par exemple, la reconnaissance d'une forme),
mais « apprennent » à effectuer cette tâche à
partir d'exemples.
Un problème typique d'apprentissage consiste à
apprendre à prédire une variable Y, appelée réponse
ou variable de sortie, à partir d'une variable X (appelée
variable d'entrée ou vecteur de caractéristiques). En
général, la relation entre Y et X est stochastique. Le couple (X,
Y) obéit à une certaine loi de probabilité, notée
p, et on dispose d'un ensemble d'apprentissage (x1,y1),
..., (xn, yn) constitué de données
indépendantes observées à partir de la loi p. dans cet
échantillon, yi est la réponse correspondant à
l'entrée xi.
Le problème d'apprentissage consiste à
construire une fonction f (ou machine) à partir des données
(x1, y1), ..., (xn, yn) de sorte
que f(X) soit une bonne approximation de la réponse souhaitée Y.
souvent, on choisit f de manière à minimiser un critère
fonctionnel.
Les réseaux de neurones sont utilisés comme
outils de modélisation par apprentissage, qui permettent d'ajuster des
fonctions non linéaires très générales à des
ensembles de points ; comme toute méthode qui s'appuie sur des
techniques statistiques, l'utilisation de réseaux de neurones
nécessite que l'on dispose de données suffisamment nombreuses et
représentatives. Le neurone artificiel est calqué sur le
modèle biologique. Nous allons donc commencer par donner un petit
aperçu sur le neurone biologique. Ces données nous sont
nécessaires pour aborder la suite de notre chapitre sur le réseau
de neurones artificiels.
III.3.3. Neurone biologique
Le cerveau se compose d'environ 1012 neurones
(mille milliards), avec 1000 à 10000 synapses (connexions) par neurone.
Le neurone est une cellule composée d'un corps cellulaire et d'un noyau.
Le corps cellulaire se ramifie pour former ce que l'on nomme les dendrites.
Celles-ci sont parfois si nombreuses que l'on parle alors de chevelure
dendritique ou d'arborisation dendritique. La figure ci-dessous reprend
l'hypothèse proposée par de nombreux biologistes pour
recréer le comportement intelligent du cerveau.
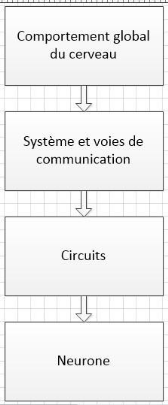
Figure 3.15: Hypothèse
biologique de génération d'un comportement intelligent.
C'est par les dendrites que l'information est acheminée
de l'extérieur vers le soma, corps du neurone. L'information
traitée par le neurone chemine ensuite le long de l'axone (unique) pour
être transmise aux neurones. La transmission entre deux neurones n'est
pas directe. En fait, il existe un espace intercellulaire de quelques dizaines
d'Angstrom (10-9m) entre l'axone du neurone afférent et les
dendrites (on dit une dendrite) du neurone efférent. La jonction entre
deux neurones est appelée la synapse.
III.2.4. Structure du réseau de neurones
Cependant, dans le système nerveux central,
essentiellement tous les neurones sont construits suivant le même
modèle. Ainsi un neurone standard possède un corps cellulaire, le
soma, des ramifications afférentes, les dendrites, et une terminaison
efférente qu'on appelle axone.
Le neurone est une cellule composée d'un corps
cellulaire et d'un noyau. Le corps cellulaire se ramifie pour former ce que
l'on nomme les dendrites. Celles-ci sont parfois si nombreuses que l'on parle
alors de chevelure dendritique ou d'arborisation dendritique. C'est par les
dendrites que l'information est acheminée de l'extérieur vers le
soma, corps du neurone.
L'information traitée par le neurone chemine ensuite le
long de l'axone (unique) pour être transmise aux autres neurones. La
transmission entre deux neurones n'est pas directe. En fait, il existe un
espace intercellulaire de quelques dizaines d'Angströms (10-9 m) entre
l'axone du neurone afférent et les dendrites (on dit une dendrite) du
neurone efférent. La jonction entre deux neurones est appelée la
synapse.
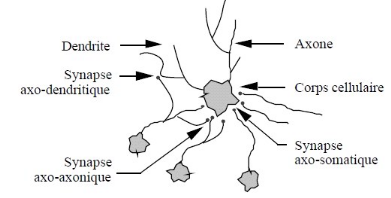
Figure 3.16: Neurone biologique
avec son arborisation dendritique.
Selon le type du neurone, la longueur de l'axone peut varier
de quelques microns à 1.50 mètres pour un motoneurone. De
même les dendrites mesurent de quelques micros à 1.50
mètres pour un neurone sensoriel de la moelle épinière.
Le nombre de synapse par neurone varie considérablement
de plusieurs centaines à une dizaine de milliers.
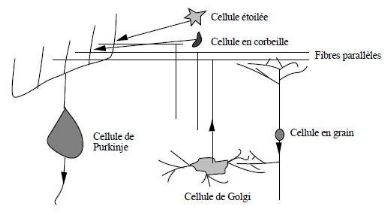
Figure 3.17: Description
schématique des divers types structuraux de neurones présents
dans le cortex cérébelleux.
Les axones ont été repérés par une
fiche.
Les réseaux de neurones biologiques réalisent
facilement un certain nombre d'applications telles que la reconnaissance de
formes, le traitement du signal, l'apprentissage par l'exemple, la
mémorisation, la généralisation. Ces applications sont
pourtant, malgré tous les efforts déployés en
algorithmique et en intelligence artificielle, à la limite des
possibilités actuelles. C'est à partir de l'hypothèse que
le comportement intelligent émerge de la structure et du comportement
des éléments de base du cerveau que les réseaux de
neurones artificiels se sont développés. Telle est la
quintessence du point suivant.
III.3.5. Réseaux de neurones artificiels16(*)(RNA)
III.3.5.1. Quelques définitions sur le RNA
Définition 1
Les réseaux de neurones artificiels sont des
modèles, à ce titre ils peuvent être décrits par
leurs composants, leurs variables descriptives et les interactions des
composants.
Nous avons retenu les définitions suivantes :
Définition 2
Un RNA est un ensemble des processeurs (ou neurones, ou
unité de calcul) interconnectés fonctionnant en parallèle,
chaque processeur calcul le potentiel (ou somme pondérée) sur
base des données qu'il reçoit, et applique ensuite la fonction
d'activation sur le potentiel, le résultat obtenu est transmis aux
processeurs se trouvant en aval.
Définition 3
Un RNA est un graphe pondéré 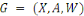 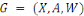 , où , où 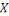 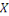 est un ensemble non vide et au plus dénombrable dont les
éléments sont appelés « neurone, ou processeur, ou
unité de calcul » du réseau.A est une famille
d'éléments du produit cartésien est un ensemble non vide et au plus dénombrable dont les
éléments sont appelés « neurone, ou processeur, ou
unité de calcul » du réseau.A est une famille
d'éléments du produit cartésien   = les éléments de = les éléments de   sont appelés : synapse et sur chaque synapse et
associé un poids w. La matrice est appelée « la matrice de
pondération, ou la matrices des poids synaptiques, sont appelés : synapse et sur chaque synapse et
associé un poids w. La matrice est appelée « la matrice de
pondération, ou la matrices des poids synaptiques,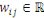 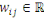 ». ».
La figure 3.17 montre la structure d'un neurone
artificiel17(*). Chaque
neurone artificiel est un processeur élémentaire. Il
reçoit un nombre variable d'entrées en provenance de neurones
amont. À chacune de ces entrées est associé un poids w
abréviation de weight (poids en anglais) représentatif de la
force de la connexion. Chaque processeur élémentaire est
doté d'une sortie unique, qui se ramifie ensuite pour alimenter un
nombre variable de neurones avals. À chaque connexion est associé
un poids.
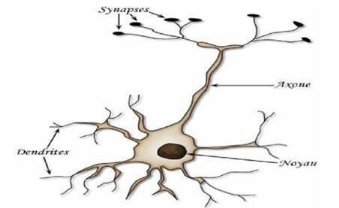
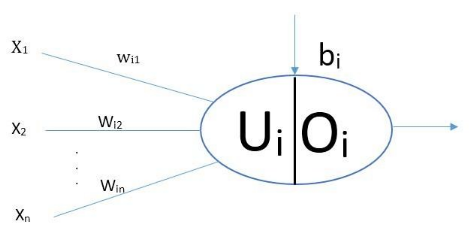
Figure 3.18: Mise en
correspondance du neurone biologique/neurone artificiel.
251664384
Où les synapses, axones, dendrite et noyau
correspondent respectivement au poids de connexion (poids synaptique), signal
de sortie, signal d'entrée et la fonction d'activation.
Définition 4
Un RNA est une fonction paramétrée qui est
la composition d'opérateurs mathématiques simples appelés
neurones formels (ou plus simplement neurones). Un neurone est une fonction
algébrique non linéaire, paramétrée, a valeurs
bornées, de variables réelles appelées entrées.
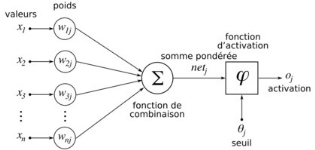
Figure 3.19: le fonctionnement
d'un RNA.
L'argument de la fonction f est une combinaison
linéaire des entrées du neurone (à laquelle on ajoute un
terme constant, le « biais »). La combinaison
linéaire est appelée potentiel ; les coefficients de
pondération {wi} sont fréquemment appelés
"poids synaptiques" (ou plus simplement poids) en référence
à l'origine "biologique" des réseaux de neurones.
Le potentiel d'un neurone est donc calculé de la
façon suivante :
V=wo 
Le biais wo peut être envisagé comme
le coefficient de pondération de l'entrée n°0, qui prend
toujours la valeur 1 :
V =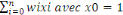 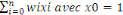
La valeur de la sortie du neurone est donc :
Y = f(v) = f (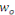 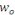 + + 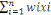 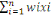 ) : sortie du neurone ) : sortie du neurone
La fonction f est appelée « fonction d'activation
».
III.3.5.2. Comportement du neurone artificiel
On distingue la deuxième phase consiste à
appliquer la fonction d'activation sur la valeur v obtenue lors de la
deuxième phase, et la valeur f(v) est transmise aux neurones avals. On
remarquera qu'à la différence des neurones biologiques dont
l'état est binaire, la plupart des fonctions de transfert sont
continués, offrant une infinité de valeurs possibles comprises
dans l'intervalle [0, +1] (ou [-1, +1]).
Il existe de nombreuses formes possibles pour la fonction de
transfert :
1. Fonction à Seuil
2. Fonction par morceaux
3. Fonction sigmoïde
a : fonction à seuil (S, la valeur du seuil)
f(x) = 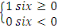 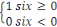 si 01 = si 01 =  
f(x) = 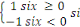 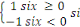 0i 0i 
b : linéaire par morceaux
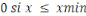
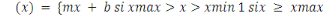
c : Sigmoïde
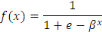
III.3.6. Neurone formel
Un neurone formel est un automate très simple imitant
grossièrement la structure et le fonctionnement d'un neurone biologique.
La première version de ce dernier est celle de Mc Culloch et W. Pitts et
date de 1943. S'inspirant de leurs travaux sur les neurones biologiques, ils
ont proposé le modèle du neurone formel qui se voit comme un
opérateur effectuant une somme pondérée de ses
entrées suivie d'une fonction d'activation (ou de transfert) comme
indiqué par la figure suivante.
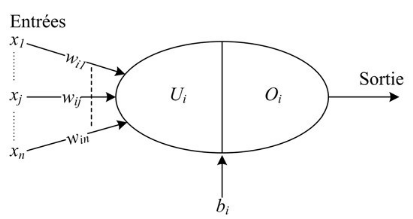
Figure 3.20: Neurone
formel.
Y=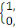 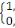 si si   ixi ixi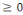 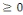
Si non Ui
Représente la somme pondérée des
entrées du neurone
???? = ? ?????????? + ????
Où :
????????????é????????????'????????é??????o??????????é????????????????????????????????????????????????????????????????????????
????????é??????????????????????????????????????????????????????????????????'????????é????????????????????????
????= ??(????)
????????????????????????????????????????????????????????????????????'????????????????????
III.3.7. Sortes de réseau de neurones
Les types de réseau de neurones différent par
plusieurs paramètres :
· La topologie des connexions entre les neurones, on
distingue deux types de réseau neuronaux : le réseau de neurone
bouclé et non bouclé
· La fonction d'agrégation utilisée (somme
pondérée, distance pseudo euclidienne, indice d'agrégation
de Ward,)
· La fonction de seuillage utilisée
(sigmoïde, échelon, fonction gaussienne, ...)
· L'algorithme d'apprentissage (rétro
propagation du gradient, cascade corrélation...)
· Méthodes de dégradation des
pondérations (weightdecay), permettant d'éviter les effets de
bord et de neutraliser le sur-apprentissage.
· Types d'apprentissage : apprentissage supervisé,
non supervisé ou apprentissage par renforcement.
III.3.8. Topologie d'un réseau de neurones
III.3.8.1. Perceptron et son fonctionnement
Avant d'aborder le comportement collectif d'un ensemble de
neurones, nous allons présenter le perceptron (un seul neurone) en phase
d'utilisation. L'apprentissage ayant été réalisé,
les poids sont fixes. Le neurone de la figure 1.12 réalise une simple
somme pondérée de ces entrées, compare une valeur de
seuil, et fourni une réponse binaire en sortie.
Les connexions des deux entrées e1 et e2 au neurone
sont pondérées par les poids w1 et w2. La valeur de sortie du
neurone est notée x. Elle est obtenue après somme
pondérée des entrées (a) et comparaison à une
valeur de seuil S.
Dans le cadre de ce travail, nous pouvons interpréter
le résultat de la manière suivante :
· La transaction sera frauduleuse si la valeur de x est 0
· La transaction sera normale si la valeur de x est +1.
III.3.8.2. Réseau multicouche en phase
d'association
Les connexions entre les neurones qui composent le
réseau décrivent la topologie du modèle. Un réseau
de neurones (RN) est un système informatique, constitué de
plusieurs unités (neurones) organisées sous forme de niveaux
différents appelés couches du réseau. Les neurones
appartenant à la même couche possèdent les mêmes
caractéristiques et utilisent le même type de fonction
d'activation. Entre deux couches voisines les connexions se font par
l'intermédiaire de poids qui jouent le rôle des synapses.
L'information est portée par la valeur de ses poids,
tandis que la structure du réseau de neurones ne sert qu'à
traiter l'information et l'acheminer vers la sortie. La structure ou la
topologie d'un réseau de neurones est la manière dont les
neurones sont connectés. Les structures résultantes peuvent
être très variées mais elles sont souvent réparties
en deux grandes familles à savoir : les réseaux de neurones non
bouclés et les réseaux de neurones bouclés.
Un réseau de neurone est non bouclé lorsque sont
graphe d'interconnexion ne contient pas des circuits tandis qu'un réseau
de neurone est bouclé lorsque sont graphe d'interconnexion contient des
circuits.
III.3.8.3. Réseaux non bouclés
Dans ce type de structure dite feedforward, la propagation de
l'information se fait uniquement de l'entrée vers la sortie. Les
neurones de la même couche peuvent se connecter uniquement avec les
neurones de la couche suivante. L'architecture la plus utilisée est le
Perceptron multicouches. Les neurones composant ce réseau s'organisent
en N couches successives (N°=3). Dans la figure ci-dessous, nous
présentons un perceptron à trois couches. Les neurones de la
première couche, nommée couche d'entrée, voient leur
activation forcée à la valeur d'entrée. La dernière
couche est appelée couche de sortie.
Elle regroupe les neurones dont les fonctions d'activation
sont généralement de type linéaire. Les couches
intermédiaires sont appelées couches cachées. Elles
constituent le coeur du réseau. Les fonctions d'activation
utilisées sont de type sigmoïde.
Les réseaux de neurones disposés suivant cette
architecture sont aussi appelés "perceptrons multicouche" (ou MLP pour
Multi-Layer Perceptrons). Où la fonction d'activation des neurones peut
s'écrire les équations ci - dessus sous forme matricielle comme
suit :
Le perceptron multicouche présente une alternative
prometteuse pour la modélisation des systèmes complexes. Avec une
seule couche cachée, il constitue une approximation universelle.
Les études menées dans (Hornik et al., 1989 ;
Cybenko, 1989) montrent qu'il peut être entrainé de manière
à approximer n'importe quelle fonction sous réserve de mettre
suffisamment de neurones dans la couche cachée et d'utiliser des
sigmoïdes comme fonctions d'activation.
III.3.8.4. Réseaux bouclés
Un réseau dynamique ou récurrent possède
la même structure qu'un réseau multicouche munie de
rétroactions. Les connexions rétroactives peuvent exister entre
tous les neurones du réseau sans distinction, ou seulement entre
certains neurones (les neurones de la couche de sortie et les neurones de la
couche d'entrée ou les neurones de la même couche par exemple).
Les figures suivantes montrent deux exemples de réseaux
récurrents. Le premier est un simple multicouche qui utilise un vecteur
d'entrée qui contient les copies des activations de la couche de sortie
du réseau et le deuxième est un réseau à
mémoire se distingue du premier par la présence des unités
mémoires.
Figure 3.21: réseau de
neurones bouclé.
Le comportement collectif d'un ensemble de neurones permet
l'émergence de fonctions d'ordre supérieure par rapport à
la fonction élémentaire du neurone. Imaginer de prime abord un
tel comportement n'est pas facile, nous nous appuyons sur un exemple
illustratif et donc réductionniste.
Soit un réseau multicouche composé de 361 (19 x
19), 25 et 361 neurones. Ce réseau a appris à associer à
la lettre « a » présentée en entrée la
même lettre en sortie. Présentons au réseau cette lettre
avec quelques erreurs : un certain nombre de pixels ont été
inversé (ils sont passés de blanc à noir ou inversement).
L'image est composée de 19 x 19 pixels, chacun de ces pixels est
associé à un neurone de la couche d'entrée. Chacun des 25
neurones de la couche cachée reçoit 361 connexions (une pour
chaque neurone d'entrée) et envoie sa sortie à chacun des
neurones de la couche de sortie (au nombre de 361). Dans notre exemple, la
couche cachée se compose de 25 neurones, mais ce nombre, à la
différence des couches d'entrée et de sortie, n'est pas
impératif. Il y a donc 2* 361*25= 18050 connexions dans le
réseau.
Figure 3.22: Comportement en
phase de reconnaissance d'un réseau de neurone multicouche lors d'une
tâche d'auto-association.
Les neurones sont binaires. La valeur d'activation de chaque
neurone est indiquée par la hauteur de la colonne. Les neurones sont
rangés par couche, tous les neurones d'une couche sont connexités
à tous les neurones de la couche suivante (avale). La topologie de deux
réseaux directement connectés :
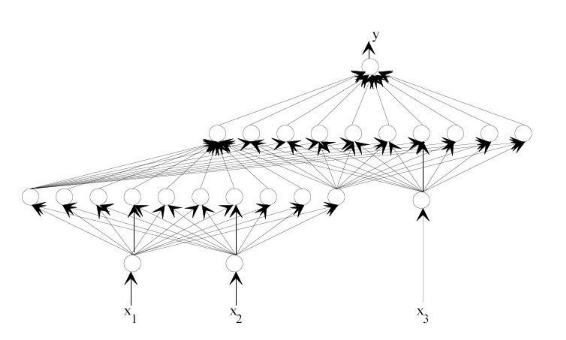
Figure 3.23: Réseaux de
neurones interconnectés.
III.4. APPRENTISSAGE DES RESEAUX DE NEURONES
L'apprentissage est une phase du développement d'un
réseau de neurones durant laquelle le comportement du réseau est
modifié jusqu'à l'obtention du comportement désiré.
L'apprentissage neuronal fait appel à des exemples de comportement.
L'apprentissage est dit supervisé lorsque le
réseau est forcé à converger vers un état final
précis, en même temps qu'un motif lui est présenté.
A l'inverse lors d'un apprentissage non supervisé, le réseau est
laissé libre de converge vers n'importe quel état final lorsqu'un
motif lui est présenté. Il arrive souvent que les exemples de la
base d'apprentissage comportent des valeurs approximatives ou bruitées.
Si on oblige le réseau à répondre de façon quasi
parfaite relativement à ses exemples, on peut obtenir un réseau
qui est biaisé par des valeurs erronées, et là on parle de
sur apprentissage.
III.4.1. Définition
L'apprentissage dans le contexte des réseaux de
neurones, est le processus de modification des poids de connexions (y compris
les biais) ou plus rarement du nombre de couches et de neurones (Man et Halang,
1997), afin d'adapter le traitement effectué par le réseau
à une tache particulière.
III.4.2. Apprentissage par minimisation de l'erreur
Soit E l'ensemble d'apprentissage. On considère un
réseau dont la couche de sortie comporte P cellules. Soit ( ) Les poids de la kè cellule à un instant
donné. L'erreur commise par cette cellule sur l'ensemble E, (( ) Les poids de la kè cellule à un instant
donné. L'erreur commise par cette cellule sur l'ensemble E, (( )) est définie comme étant la moyenne des erreurs
quadratique commise sur chaque forme. )) est définie comme étant la moyenne des erreurs
quadratique commise sur chaque forme.
Xi , ci (wk(t)) :,
C(wk(t)) =   Ci (wk(t)) = Ci (wk(t)) =  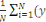 k (Xi't) - Yik)2 k (Xi't) - Yik)2
Où (????, ??) est la sortie de la
Kè cellules au temps t en fonction de l'entrée Xi.
L'apprentissage consiste donc simplement à rechercher
un vecteur 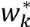 qui minimise C. La méthode proposée par Widrow et Hoff
pour résoudre ce problème consiste à adapter une
méthode d'optimisation bien connue : La minimisation par descente en
gradient. Le principe en est simple l'opposé du gradient C par rapport qui minimise C. La méthode proposée par Widrow et Hoff
pour résoudre ce problème consiste à adapter une
méthode d'optimisation bien connue : La minimisation par descente en
gradient. Le principe en est simple l'opposé du gradient C par rapport
au poids enW(t)k , -   wC (w(t)k) pointe dans la direction
dans laquelle la diminution de (????) est maximale ; en modifiant
le vecteur poids, par itération successives, dans la direction
opposée au gradient, on peut espérer aboutir à un minimum
de (????). wC (w(t)k) pointe dans la direction
dans laquelle la diminution de (????) est maximale ; en modifiant
le vecteur poids, par itération successives, dans la direction
opposée au gradient, on peut espérer aboutir à un minimum
de (????).
Le gradient de la fonction coût par rapport à
????se calcul aisément par :
C (wk(t)) = 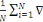 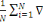 wCi (wk(t)) = wCi (wk(t)) = 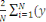 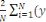 k (Xi't) - Yik).Xi k (Xi't) - Yik).Xi
Et l'algorithme d'apprentissage par descente en gradient est
donc le suivant :
Etape 0 : t=0
Initialiser aléatoirement les poids (??)
Etape 1 : Pour chaque automate sur l'ensemble d'apprentissage
E :
??(????(??))
Etape 2 : Pour chaque automate K, modifier les poids par :
(?? + 1) = ????(??)-?. ???(????(??))
Etape 3 : t = t+1
Si la condition d'arrêt non remplie, aller à
l'étape 2.
Avec ? Taux d'apprentissage.
En résumé soit
E(  ) = ) = 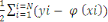 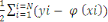 2 2
L'erreur d'apprentissage due aux poids. Si la fonction
d'activation est linéaire, cette erreur E s'écrit :
E(  ) = ) = 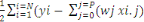 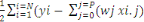 2 2
On voit donc que l'erreur E est un parabolique dans l'espace
des poids. Donc, E possède un seul minimum et il s'agit de trouver la
valeur des poids correspondant à ce minimum. Pour cela, la technique
classique consiste à utiliser un algorithme de descente de gradient.
Pour cela, on part d'un point (dans l'espace des poids, espace de dimension
P+1)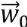 : ensuite, itérativement, on corrige ce point pour se rapprocher
du minimum de E. Pour cela, on corrige chaque poids d'une quantité
proportionnelle au gradient de E en ce point, cela dans chaque direction, donc
par rapport à chacun des poids. Ce gradient est donc la
dérivée (partielle) de E par rapport à chacun des points.
Reste à déterminer le coefficient à appliquer à
cette correction. : ensuite, itérativement, on corrige ce point pour se rapprocher
du minimum de E. Pour cela, on corrige chaque poids d'une quantité
proportionnelle au gradient de E en ce point, cela dans chaque direction, donc
par rapport à chacun des poids. Ce gradient est donc la
dérivée (partielle) de E par rapport à chacun des points.
Reste à déterminer le coefficient à appliquer à
cette correction.
?? ? ?? - ?????(?? ) ?(?? )
Il nous reste à calculer ce terme général
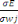 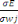 : :
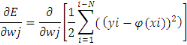
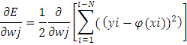
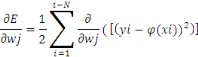
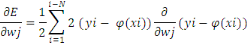
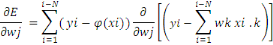
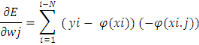
D'où :
??=??
?????= ???(????-
??(????))????.????=1
III.4.1.Algorithmes d'apprentissage
L'apprentissage avec des réseaux de neurones
multicouches se fait principalement suivant deux approches :
· Approche par retro propagation de gradient (RPG) La
retro propagation de gradient détermine les poids de minimisation d'un
cout. Cet algorithme nécessite l'introduction de l'architecture de
réseau.
· Approche constructive Avec cette approche, on apprend
en même temps le nombre d'unités et les poids, commençant
généralement avec une seule unité. Voici quelques
exemples des algorithmes d'apprentissage des réseaux de
neurones :
III.4.1.1. Algorithme de
HEBB
Cet algorithme se déroule en 5 étapes de la
manière suivante :
Etape 1 : initialisation des poids
Etape 2 : présentation d'une entrée ?? =
(??1,2, ...) de la base d'apprentissage.
Etape 3 : calcul de la sortie x pour l'entrée E telle
que :
?? = ? (????*????) - ??
?? = ??????????(??)
??????> 0 ???????????? = +1 ???????????? = -1
Etape 4 : si la sortie calculée x est différente
de la sortie désirée alors il y a modification des poids.
Etape 5 : Retour à l'étape 2.
III.4.1.2. Algorithme
d'apprentissage du perceptron
Cet algorithme nécessite :
ï Les exemples d'apprentissage ??.
ï Chaque exemple xi possède P attributs
dont les valeurs sont notées????.
ï Pour chaque donnée, ????,0 est un
attribut virtuel, toujours égal à 1. La classe de l'exemple
???? est ????
Nécessite :
Taux d'apprentissage ????]0,1]
Nécessite :
ï Un seuil ??
Initialiser les ???? aléatoirement
Répéter
// E mesure l'erreur courante
?? ? 0
Mélanger les exemples
Pour tous les exemples du jeu d'apprentissage?? faire
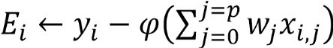
?? ? ?? + |????|
Pour tous les poids ????, ??? {0,1, ... ??} faire
???? ? ???? + ????i??i, ??
Fin pour fin pour jusque ??<??
III.4.1.3. Algorithme de
propagation de gradient pour un perceptron
Nécessite : les ?? instances d'apprentissage ??
Nécessite : taux d'apprentissage ????]0,1]
Nécessite : un seuil ??
Initialiser les ????,{0, ... ??}
aléatoirement Répéter
//E mesure de l'erreur courante
?? ? ??
Pour tous les poids ????,{0,...??} faire
(????) ? 0
fin pour mélanger les exemples pour tous les exemples
du jeu d'apprentissage ????,{1,??} faire
?? ? ?? + (???? - (????))2
Pour tous les poids ????,{0,...??}
faire
??(????) ? ??(????) +
??(????- ??(????)????,??
fin pour tous les poids
????,{0,...??} faire
????? ????+ (????) Avec
:?(??) = -???(??) fin pour jusque ??<??
Fin pour Fin tant que
Le choix de l'algorithme à utiliser dépend de
l'architecture du réseau des neurones. Si, les données sont
linéairement séparables, un perceptron suffit pour faire la
prédiction et dans ce cas, l'algorithme de Hebb ou perceptron peuvent
s'utiliser mais quand les données ne sont pas linéairement
séparables, c'est prouvé par Hornick (1991) que pour la tache de
classification, un réseau de neurones avec une seule couche
cachée de perceptron Sigmoïdes et une couche de sortie peut
résoudre tout problème de classification et dans ce cas , on peut
utiliser l'algorithme de retro-propagation du gradient.
CONCLUSION PARTIELLE
Les réseaux de neurones étant un algorithme
puissant, il était question pour nous de le souligné dans ce
chapitre tout en présentant non seulement quelques définitions
mais aussi son fonctionnement. Dans notre étude ce dernier fait le
fondement de notre implémentation grâce à ses
différentes fonctions mathématiques, partant des analyses a
opérées dans le dernier chapitre, il sied de mener une
étude sur la structure et le comportement de réseaux de neurones
artificiel en vue de ressortir une prédiction quasi réelle.
CHAPITRE IV :
IMPLEMENTATION ET INTERPRETATION DE RESULTATS [3], [4], [5], [6]
IV.1. INTRODUCTION
Ce chapitre est spécialement consacré à
l'implémentation et interprétation de résultats de notre
nouveau système (système prédictif). Il sera question
à la suite celui-ci de construire et implémenter notre algorithme
qui permettra de classifier d'une manière automatique non seulement les
clients éligibles au crédit mais aussi ceux qui ne le sont pas en
temps réel grâce aux technologies Big Data qui sera basé
sur le réseau de neurones qui est l'un des algorithmes du Data Mining.
IV. 1.1. Langages de programmation, SGBD et
Éditeurs utilisés
Pour écrire les différents scripts et lignes de
codes de notre application, nous avons fait recours aux différents
outils suivants :
· Python et Jupyter
Notebook (respectivement le langage de programmation et
l'éditeur utilisés pour l'analyse et la prédiction) ;
· R et RStudio
(respectivement le langage de programmation et l'éditeur utilisés
pour l'intégration des données (ETL), mais aussi pour l'analyse
et la prédiction) ;
· MongoDB (pour la partie Stockage de
données (Serveur) ;
· Navicat Premium (pour la Visualisation
de données du Dataset).
IV. 1.2. Bibliothèques (Modules (Python) ou
packages (R) utilisés)
ü PyMongo, qui est une distribution
Python contenant des outils permettant de travailler avec MongoDB. Il est
recommandé de travailler avec MongoDB à partir de Python.
ü Pandas, qui est un module du langage
de programmation Python permettant la manipulation et l'analyse des
données. Cette bibliothèque propose en particulier des structures
de données et des opérations de manipulation de tableaux
numériques et de séries temporelles.
ü NumPy, qui est une extension du
langage de programmation Python, destinée à manipuler des
matrices ou tableaux multidimensionnels ainsi que des fonctions
mathématiques opérant sur ces tableaux.
ü nnet, qui est un package de langage de
programmation R pour les réseaux de neurones avec une seule couche
cachée et pour les modèles log-linéaires multinomiaux.
ü readxl, qui est un package permettant
de lire un fichier Excel, de type .xls ou .xlsx dans un data frame R; il
fournit une interface à la fonction read_excel dans le package
readxl.
IV.1.3. Architecture Big Data intégrant les
technologies utilisées
En terme d'architecture18(*) Big Data, pour notre projet ci-dessous nous montrons
comment est-ce que les données sont récupérées
depuis les différente plateformes via le protocole pour être mis
dans une zone temporelle, par laquelle elles seront envoyées vers un
espace de stockage des données non structuré où seront
effectués les différentes analyses enfin de pouvoir visualiser
les résultatsdes analyses pour faciliter la compréhension et le
traitement.
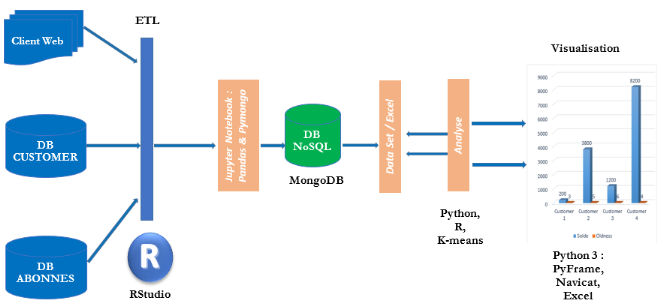
Figure 4.24: Architecture Big
Data intégrant les technologies utilisées.
IV.2. ANALYSE
PREALABLE : PRESENTATION DE LA BANQUE COMMERCIALE DU CONGO
IV.2.1. Brève
aperçue historique de la BCDC19(*)
À l'initiative des dirigeants de la banque d'outre-mer,
institution Belge créée en 1899 en vue de développer des
entreprises à l'étranger, nait en 1908 le projet de créer
une banque au Congo.
Il n'existait aucune banque sur place lors de la cession
à l'État belge des territoires de l'État
indépendant du Congo, jusqu'alors propriétés du roi
Léopold II.
ü L'année 1909 :
Le 11 janvier 1909, la banque du Congo belge voit le jour, son
capital de 2 millions est entièrement souscrit par les principaux
actionnaires suivants : la Banque d'outre-mer, la compagnie du Congo pour
le commerce et l'industrie, le Baron Léon Lambert, la Banque de paris et
de pays bas, FM Philip son et Cie. De nouveaux actionnaires font leur
entrée au capital de 1 million de francs parmi lesquels la
société Générale de Belgique et la
société commerciale et financière.
ü L'année 1910 :
Quasi simultanément, la banque lance ses
activités au Katanga pour ouvrir en 1910, une agence à
Elisabethville (l'actuelle Lubumbashi), le 1er Août de la même
année, l'agence de Léopold ville (aujourd'hui Kinshasa) ouvre ses
guichets.
ü L'année 1911 :
En juillet 1911, la banque obtient une période de 25
ans le privilège d'émission qu'elle plus de 40 ans. Ce qui a
occasionné la modification des statuts de la banque dont le champ
d'activité de banque commerciale se fait réduit. Voit alors le
jour la Banque Commerciale du Congo qui reprend les activités auxquelles
la BCB doit renoncer.
ü Les années 1919-1928
Dans cette période d'après-guerre, la banque a
connu un important essor que son capital est porté à 20 millions,
soit 18 millions de plus comparativement à celui du démarrage en
1909.
En 1960 le Congo devient un État souverain. La Banque
du Congo belge fait apport de ses activités européennes à
la banque belgo Congolaise constituée le 14 avril à Bruxelles.
Les deux établissements agissent dorénavant en qualité de
correspondants et développent une collaboration étroite. Le 24
avril 1960 la banque du Congo belge prend officiellement la dénomination
de la Banque du Congo.
ü Les années 70
La Banque du Congo change de dénomination sociale en
novembre 1971 et devient Banque Commerciale du Zaïre. Dans le même
temps, elle propose au gouvernement Zaïrois de porter la participation de
l'État dans son capital social à celui que détient le
groupe bancaire belge de la société Générale de
Banque. Et ce 1975 que la banque commerciale du zaïre inaugure son
siège au boulevard du 30 juin, après 5 ans de travaux, cela a
apporté une nette amélioration du travail.
ü Depuis 2004...
Profitant de l'amélioration du climat sociopolitique et
de l'embellie économique consécutive, la BCDC redéploye
son réseau sur l'ensemble du territoire et adapte son organisation
commerciale aux besoins de sa clientèle de particuliers, de PME/PMI, des
grandes entreprises et institutionnels. Comme on peut le constater, la BCDC
aujourd'hui est une banque de référence en RDC et active sur
l'ensemble du territoire national, a maintenu le cap contre vents et
marées. Elle a subsisté malgré les différentes
situations sociale, politique et économique tragique qui ont
émaillé l'histoire du pays.
IV.2.2. Objectifs &
Missions de la BCDC20(*)
Comme établissement de crédit, la BCDC a pour
mission principale d'effectuer les opérations de banque,
c'est-à-dire la réception des fonds du public, les
opérations de crédit ainsi que la gestion des moyens de
payement.
Elle a pour mission secondaire :
ï Les opérations de change, l'achat et la vente
des matières premières ;
La représentation, à titre de commissionnaire ou
d'agent, de tout particulier, sociétés, administrations et
établissement privés ou publics ; tous les actes et
opérations pour compte des commettants.
Vue la situation socio-économique de la RDC, la BCDC
s'est fixée plusieurs objectifs dont :
Ø Augmenter les opérations avec la
clientèle, optimiser des possibilités du réseau et une
politique très active de recouvrement des créances
compromises,
Ø Renforcer sa position de banque de
référence des opérations en monnaies
étrangères dans le cadre de la relance de l'économie,
notamment avec les organismes internationaux et de coopération ainsi
qu'avec les entreprises,
Ø Développer et mettre en oeuvre les moyens
techniques, humains et administratifs performant permettant
l'amélioration des services,
Ø Respecter les normes de gestion prudentielles et la
croissance des résultats,
Procéder à la
restructuration des agences des territoires sortant de la guerre et
réhabiliter celles à maintenir dans le réseau.
IV.2.3. Quelques directions de
la BCDC21(*)
|
ü Direction des crédits
|
|
ü Direction de Kinshasa
|
|
ü Direction organisation et informatique
|
|
ü Direction des agences
|
|
ü Direction du sud
|
|
ü Direction commerciale
|
|
ü Direction private et retail banking
|
|
ü Direction finances et contrôle
|
|
ü Direction des risques
|
IV.2.4. Siège22(*)
Le siège social de la Banque Commerciale Du Congo est
à Kinshasa en RDC, sur 856 Boulevard Du 30 Juin, 2798, dans la commune
de la Gombe.

Figure 4.25:Logo de la
BCDC.[www.bcdc.cd]
IV.2.5. Organigramme de la
BCDC23(*)
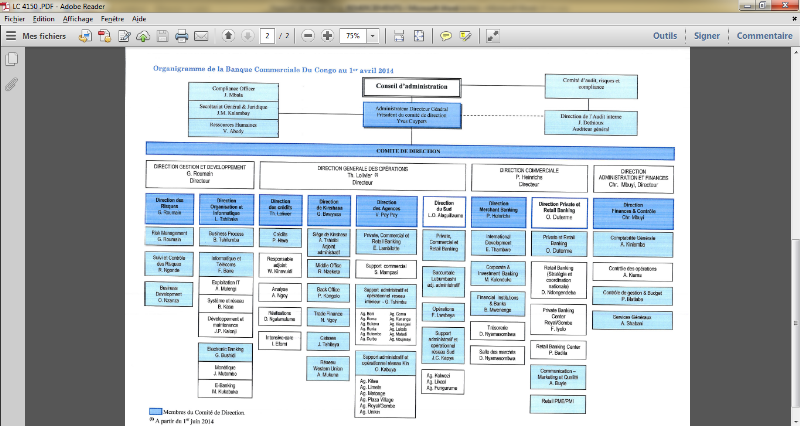
Figure 4.26: Organigramme de la
Banque Commerciale Du Congo.[Département Informatique et DSI]
IV.3. LE CHURN [3],
[17]
IV.3.1. Notions
Le churn est un terme anglais24(*) qui désigne la perte de clientèle ou
d'abonnés. Le terme équivalent au churn est celui d'attrition
désignant également la perte de client, de substance ou d'autres
éléments non forcément matériels. L'attrition est
le contraire de la fidélisation ou de la rétention.
Le churn (de l'anglais to churn up, agiter) se traduit en
français par attrition, exprime le taux de déperdition de clients
pour une entreprise ou un produit.
Le phénomène est généralement
mesuré par le taux d'attrition ou le churn rate. Ce taux d'attrition ou
le churn rate est un indicateur qui permet de mesurer le
phénomène de perte de clientèle ou d'abonnés. Il
est le ratio (nombre de clients perdus/nombre de clients total) mesuré
sur une période donnée qui est le plus souvent
l'année25(*).
L'observation du taux d'attrition est une donnée
très importante quand on connait l'impact de la fidélisation sur
la rentabilité26(*).
A n'est pas confondre le churn avec le turn-over (La rotation
de l'emploi en français ou renouvellement du personnel) qui est
également un indicateur décrivant le rythme de renouvellement des
effectifs dans une organisation27(*).
Le taux de churn représente donc le pourcentage de
clients perdus, sur une période donnée (en général
une année) par rapport au nombre total de clients au début de
cette période.
À ce titre, le taux de churn est un indicateur majeur
dans tous les secteurs où un contrat au long cours engage le client et
le fournisseur. La banque aussi doit surveiller son taux de churn.
On parle également de mesures anti-churn ou de plan
d'actions anti-churn, dont l'objectif est de réduire le taux de
résiliation (est le fait de rompre les effets d'un contrat de prestation
de service à partir d'une date donnée sans annuler ce qui a
déjà été exécuté. Contrairement
à la résolution qui efface les effets du contrat à son
origine.). On y inclut les actions de fidélisation, de
prévention, et de rétention :
ü Actions de fidélisation28(*) : elle vise à
satisfaire le client, et lui donner envie de rester, sans pour autant qu'il
soit lié contractuellement par une durée d'engagement.
ü Actions de prévention :
réengager le client pour une nouvelle période, avant que sa
période d'engagement en cours n'expire.
ü Actions de rétention : tenter de
conserver un client qui souhaite résilier en lui proposant
généralement des avantages qu'il n'aurait pas eu en temps
normal.
En Churn, on dit que conquérir un prospect (est un client
ou un fournisseur potentiel ou acquis) coûte beaucoup plus cher que de
fidéliser un client.
IV.3.2. Définitions
Le phénomène churn peut se définir du
pont vue les domainesd'applications tels que :
1. Du point de vue général
L'attrition29(*) désigne la perte30(*) de client, de substance ou
d'autres éléments non forcément matériels.
2. Du point de vue quantitatif
L'attrition est la diminution naturelle d'une quantité
de choses ou de personnes.
3. Du point de vue bancaire
L'attrition ou le churn est le fait qu'un client n'effectue
plus les activités génératrices pendant un certain temps
telles que le dépôt, retrait et transfert d'argent, utilisation de
monnaie électronique, carte de débit etc. On parle souvent du
candidat au churn c'est-à-dire le client voulait arriver au seuil du
temps fixer pour être déclarer churner.
IV.4. Présentation
des Outils utilisés[10], [11]
IV.4.1. Langages de
programmation : Python et R[10]
a) Langage de programmationPython31(*)
Python est développé depuis 1989 par Guido van
Rossum à Amsterdam et de nombreux contributeurs bénévoles.
Sa première version fut publiée le 20 février 1991 et sa
dernière version date du 18 mars 2019.
Python est un langage de programmation
interprété. Son origine est le langage de script du
système d'exploitation Amoeba. Donc Python est un langage de
script de haut niveau portable et gratuit, doté d'un typage dynamique
fort, d'une gestion automatique de la mémoire et d'un système de
gestion des exceptions.
Depuis, Python est devenu un langage de programmation
généraliste (comp.lang.python est créé en 1994). Il
offre un environnement complet de développement comprenant un
interpréteur performant et de nombreux modules. Un atout
indéniable est sa disponibilité sur la grande majorité des
plates-formes courantes (BeOS, Mac OS X, Unix, Windows). Python est un langage
open source supporté, développé et utilisé par une
large communauté : 300 000 utilisateurs et plus de 500 000
téléchargements par an.
v Caractéristiques32(*) du langage Python
Détaillons un peu les principales
caractéristiques de Python, plus précisément, du
langage.
· Python est portable, non seulement sur les
différentes variantes d'UNiX, mais aussi sur les OS propriétaires
: MacOS, BeOS, NeXTStep, MS-DOS et les différentes variantes de Windows.
Un nouveau compilateur, baptisé JPython, est écrit en Java et
génère du byte code Java.
· Python est gratuit, mais on peut l'utiliser sans
restriction dans des projets commerciaux.
· Python convient aussi bien à des scripts d'une
dizaine de lignes qu'à des projets complexes de plusieurs dizaines de
milliers de lignes.
· La syntaxe de Python est très simple et,
combinée à des types de données évolués
(listes, dictionnaires,), conduit à des programmes à la fois
très compacts et très lisibles. A fonctionnalités
égales, un programme Python (abondamment commenté et
présenté selon les canons standards) est souvent de 3 à 5
fois plus court qu'un programme C ou C++ (ou même Java)
équivalent, ce qui représente en général un temps
de développement de 5 à 10 fois plus court et une facilité
de maintenance largement accrue.
· Python gère ses ressources (mémoire,
descripteurs de fichiers...) sans intervention du programmeur, par un
mécanisme de comptage de références (proche, mais
différent, d'un garbage collector).
· Il n'y a pas de pointeurs explicites en Python.
· Python est (optionnellement) multi-threadé.
· Python est orienté-objet. Il supporte
l'héritage multiple et la surcharge des opérateurs. Dans son
modèle objets, et en reprenant la terminologie de C++, toutes les
méthodes sont virtuelles.
· Python intègre, comme Java ou les versions
récentes de C++, un système d'exceptions, qui permettent de
simplifier considérablement la gestion des erreurs.
· Python est dynamique (l'interpréteur peut
évaluer des chaînes de caractères représentant des
expressions ou des instructions Python), orthogonal (un petit nombre de
concepts suffit à engendrer des constructions très riches),
réflectif (il supporte la méta programmation, par exemple la
capacité pour un objet de se rajouter ou de s'enlever des attributs ou
des méthodes, ou même de changer de classe en cours
d'exécution) et introspectif (un grand nombre d'outils de
développement, comme le debugger ou le profiler, sont implantés
en Python lui-même).
· Comme Scheme ou SmallTalk, Python est dynamiquement
typé. Tout objet manipulable par le programmeur possède un type
bien définit à l'exécution, qui n'a pas besoin
d'être déclaré à l'avance.
· Python possède actuellement deux
implémentations. L'une, interprétée, dans laquelle les
programmes Python sont compilés en instructions portables, puis
exécutés par une machine virtuelle (comme pour Java, avec une
différence importante : Java étant statiquement typé, il
est beaucoup plus facile d'accélérer l'exécution d'un
programme Java que d'un programme Python). L'autre, génère
directement du bytecode Java.
· Python est extensible : comme Tcl ou Guile, on peut
facilement l'interfacer avec des librairies C existantes. On peut aussi s'en
servir comme d'un langage d'extension pour des systèmes logiciels
complexes.
· La librairie standard de Python, et les paquetages
contribués, donnent accès à une grande
variété de services : chaînes de caractères et
expressions régulières, services UNIX standard (fichiers, pipes,
signaux, sockets, threads...), protocoles Internet (Web, News, FTP, CGI,
HTML...), persistance et bases de données, interfaces graphiques.
· Python est un langage qui continue à
évoluer, soutenu par une communauté d'utilisateurs enthousiastes
et responsables, dont la plupart sont des supporters du logiciel libre.
Parallèlement à l'interpréteur principal, écrit en
C et maintenu par le créateur du langage, un deuxième
interpréteur, écrit en Java, est en cours de
développement.
Le langage de programmation python comme tout autre langage a
un logo, on reconnait ce dernier par son logo ci-dessous :

Figure 4.27: Logo du langage de
programmation python.
Figure 4.28: Installation
Python.[Nous même]
Figure 29: Configuration
Python.
b) Langage de programmation R33(*)
R est un logiciel libre permettant de traiter les
données. Ce logiciel est un interpréteur permettant de programmer
avec le langage de programmation S (On parle communément du langage R).
Ce logiciel fait partie de projet GNU conçu dans les laboratoires Bell
par John Chambers, un statisticien de l'université de Harvard avec
l'aide de ses collègues.
Grâce à son panoplie des paquets (packages en
anglais), le langage R est aujourd'hui un outil puissant pour aider dans
plusieurs types d'applications, notamment la statistique multivariée
(analyse des données), l'économétrie, la biométrie,
l'épidémiologie, la modélisation, le traitement d'image,
l'analyse des graphes, l'analyse numérique, le Data mining, le Big Data,
et tant d'autres. De plus, il permet le graphisme de haute qualité.
Il sied de signaler que ces différents packages
permettent aussi d'interagir directement R avec des systèmes de gestion
de bases de données (cas de PostgreSQL via le langage PL/R et MySQL),
avec des systèmes d'information géographique (cas de GRASS), ou
ceux qui permettent d'exporter ses résultats en LATEX ou
OpenDocument.
v Caractéristiques du langage R
L'utilisation de R est aussi motivée par les
caractéristiques qu'il renferme. On peut citer quelques-unes d'entre
elles :
· R est un logiciel libre.
· R est un langage de programmation multi-paradigme. Il
est orientée-objet, impératif, fonctionnel et
procédural.
· R est un langage de programmation multi plate-forme. Il
est disponible sous GNU/Linux, Windows, NetBSD, FreeBSD et MacOS.
· R est un langage de programmation comportant en
standard de très nombreuses fonctionnalités de calcul statistique
ainsi que de représentation graphique.
· R est un langage de programmation comportant un bon
nombre des librairies (open-source).
IV.4.2. Environnement de
développement intégré (EDI)
Un environnement de développement «
Intégré » (abrégé EDI en français ou en
anglaisintegrated development environment (IDE34(*))), est un ensemble d'outils qui permet d'augmenter la
productivité des programmeurs qui développent des logiciels. Il
comporte un éditeur de texte destiné à la programmation,
des fonctions qui permettent, par pression sur un bouton, de démarrer le
compilateur ou l'éditeur de liens ainsi qu'un débogueur en ligne,
qui permet d'exécuter ligne par ligne le programme en cours de
construction. Certains environnements sont dédiés à un
langage de programmation en particulier.
Dans le cadre de notre travail nous avons adopté pour
les EDI Jupyter et RStudio.

Figure 4.30: Quelques IDE
dédiés au langage de programmation Python.
IV.4.2.1.Jupyter[10]
Jupyter est une application web utilisée pour
programmer dans plus de 40 langages de programmation, dont Python, Julia, Ruby,
R, ou encore Scala.
Jupyter est une évolution du projet IPython. Jupyter
permet de réaliser des calepins ou
notebooks , c'est-à-dire
des programmes contenant à la fois du texte en markdown et du code en
Julia, Python, R...
Ces notebooks sont utilisés en science des
données pour explorer et analyser des données.
Jupyter s'appuie sur un noyau IPython pour Python 2, un noyau
IPython pour Python 3, IRkernel, un noyau pour le langage R et un noyau pour le
langage Julia, IPyLua, noyau pour le langage Lua, IRuby, noyau pour le langage
Ruby, etc. Seuls les noyaux pour les langages Julia, Python, R et Scala sont
maintenus par les développeurs principaux du projet, les autres sont
développés par différentes communautés de
développeurs. Jupyter peut être installé sur un ordinateur
personnel. JupyterHub peut être installé sur un serveur et permet
de définir des comptes utilisateurs.

Figure 4.31: Logo de
l'environnement de développement intégré
Jupyter-IDE.
IV.4.2.2. RStudio[11]
RStudio est un
environnement
de développement gratuit, libre et multiplateforme pour
R35(*), un
langage de
programmation utilisé pour le traitement de données et
l'analyse statistique. Il est disponible sous la
licence libre
AGPLv3,
ou bien sous une licence commerciale, soumise à un abonnement annuel.
RStudio est disponible en deux versions : RStudio Desktop,
pour une exécution locale du logiciel comme tout autre application, et
RStudio Server qui, lancé sur un serveur Linux, permet d'accéder
à RStudio par un
navigateur web. Des
distributions de RStudio Desktop sont disponibles pour
Microsoft
Windows,
OS X et
GNU/Linux.
RStudio a été écrit en langage
C++, et son interface
graphique utilise l'interface de programmation
Qt36(*).
Depuis la version 1.0 sorti en novembre 2016 , RStudio
intègre la possibilité d'écrire des
notebooks
combinant de manière interactive du code R, du texte mis en forme en
markdown et des appels à du code
Python37(*) ou
Bash. Ci-dessous
l'image de l'environnement de développement intégré dit
Rstudio.

Figure 4.32: Logo de l'EDI
RStudio.
Figure 4.33: Espace de travail
pour l'environnement de développement intégré Rstudio
version 3.4.
IV.4.3. Système de
gestion de base de données : MongoDB[8], [9]
MongoDB vient du mot anglais humongous qui signifie «
énorme ». Il est un SGBD faisant partie de la mouvance NoSQL qui
n'est plus fondée sur l'architecture classique des bases relationnelles
où l'unité logique n'y est plus la table, et les données
ne sont en général pas manipulées avec SQL.
MongoDB est un Système de Gestion de Bases de
Données orientées documents, répartissables sur un nombre
quelconque d'ordinateurs (Scalabilité ou Scalability en anglais),
à performance raisonnable et ne nécessitant pas de schéma
prédéfini des données. Il est écrit en C++ et
distribué sous licence AGPL et vise à fournir des
fonctionnalités avancées.
IV. 4.3.1. Administration
de Big Data sous le SGBD MongoDB38(*)
Selon Julian Browne, « Lead IT architect » au sein
de la célèbre compagnie de télécommunications
britannique O2, « Pour des raisons évidentes, il ne vaut
vraiment pas la peine d'entreprendre un projet avec n'importe quel produit
NoSQL, sauf si vous en avez besoin pour résoudre un problème
».
La technologie NoSQL répond à de nombreux
problèmes, mais généralement elle répond à
deux besoins c'est la gestion de gros volumes de données etla
montée en charge. Si aucun de ces deux problèmes n'est
identifié dans un domaine d'exploitation, il serait erroné
d'adopter une solution NoSQL.
Le serveur MongoDB deviens plus facile à installer une
fois télécharger depuis le site officiel, comme vous pouvez le
constaté ci-dessous dans quelques étapes voici comment progresse
l'installation du serveur MongoDB sous Windows :

Figure 4.34: Préparation
de l'installation du serveur MongoDB.
Figure 4.35: Lancement de
l'installation du serveur MongoDB.
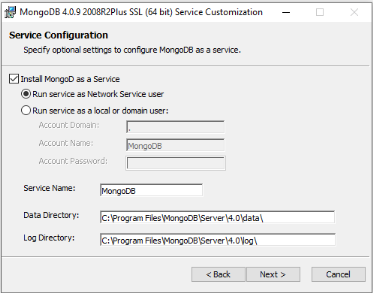
Figure 4.36: Configuration du
Serveur MongoDB.
À l'issue de la configuration du serveur nous
commençons ici par l'alimentation de notre serveur. Pour ce faire, nous
allons d'abord démarrer le serveur pour permettre aux modules clients de
bien fonctionner. La figure ci-dessous, présente le démarrage du
serveur MongoDB, qui écoute au port 27017 sur la machine locale,
grâce à la commande « mongod.exe ».
Figure 4.37: Démarrage du
Serveur MongoDB avec la commande mongod.exe [Serveur MongoDB]
Après avoir démarré le serveur, celui-ci
est à l'attente d'une connexion cliente. Nous allons à
présent nous connecter au serveur entant qu'un client grâce
à la commande mongo.exe et créer une Base de données
nommée « DB_ABONNES » qui va récupérer les
données (documents) d'analyse provenant des sources variées, ces
derniers (documents) seront stockés dans la collection
« Customer ».

Figure 4.38: Création de
la base de données.
IV.5. Présentation
des données
L'ensemble de données exploitées pour
l'implémentation et interprétation de résultats de notre
modèle prédictif sont issues d'un environnement bancaire en se
basant sur la réalité existante au sein de la Banque Commerciale
Du Congo, sur la politique de gestion des clients précisément
ceux qui souscrivent au crédit (un emprunt, ...). Eu égard
à la réalité, nous avons donc constitué un ensemble
de données servant à la simulation du dit modèle.
Reste à signaler que cet ensemble de données
à simuler contiennent des enregistrements décrivant chacun les
comportements des clients provenant desdifférentes sources des
données. En fin dans cet ensemble de données, nous avons retenus
quelques variables descriptives que nous synthétisons dans le tableau
ci-dessous :
|
N°
|
NOM VARIABLE
|
DESCRIPTION VARIABLE
|
TYPE
|
CHOIX
|
|
1
|
CUSTOMER_ID
|
Identifiant du client
|
Numérique
|
-
|
|
2
|
OLDNESS
|
Ancienneté client
|
Numérique
|
-
|
|
3
|
AVG_TRANSACT_MONTH
|
Transaction moyenne par mois du client
|
Numérique
|
-
|
|
4
|
AVG_TRANSACT_YEAR
|
Transaction moyenne par AN du client
|
Numérique
|
-
|
|
5
|
BALANCE_USD
|
Solde actuel du client en USD
|
Money
|
-
|
|
6
|
BALANCE_CDF
|
Solde actuel du client en CDF
|
Money
|
-
|
|
7
|
GENDER
|
Genre du client
|
Boolean
|
Homme or Femme
|
|
8
|
AGE
|
Age du client
|
Numérique
|
-
|
|
9
|
TYPE_COUNT
|
Type du compte client
|
Text
|
-
|
|
10
|
JOB
|
Profession du client
|
Text
|
-
|
|
11
|
OLDNESS_JOB
|
Ancienneté dans la profession
|
Numérique
|
-
|
|
12
|
ESTIMATED_SALARY_USD
|
Estimation Salaire en USD
|
Money
|
-
|
|
13
|
CLAIMS
|
Plaintes
|
Text
|
-
|
|
14
|
STATUT_CHURN
|
Statut churn du client
|
Text
|
|
Tableau 4.4: Dictionnaire des
variables descriptives utilisées.
IV.5.1. Présentation des
données existantes d'analyse
Étant donné que l'algorithme doit prédire
sur base des données existantes, nous présentons quelques
graphiques qui expriment les comportements des clients dans les
différents cas c'est-à-dire les clients non actifs (churner) et
les clients actifs (non churner). Autrement dit, nous présentons le deux
classes (Churner et Non Churner) d'appartenance à laquelle seront
classifier les nouveaux clients. Pour le statut d'un churner nous
utiliserons1 « Oui »,
quant au statut du Non churner nous utiliserons tout simplement
0« Non ».
a) Présentation du statut churn selon les types
de compte
Ci-dessous nous représentons en histogramme rouge, les
clients qui ont churner ou perdus par rapport au compte ouvert au sein de la
BCDC et en vert, les clients non churner (clients actifs)
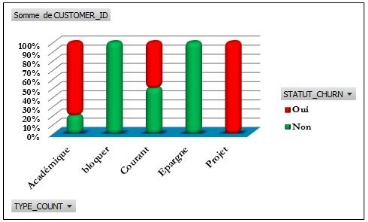
Figure 4.39: Statut churn selon
les types de compte.
b) Présentation du statut churn selon le
sexe
Nous représentons dans le graphique ci-dessous en
histogramme rouge, les clients churner et non churner selon le sexe, du coup le
statut churn peut etre interprété par rapport aux couleurs :
rouge pour les clients perdus et vert pour les clients actifs.
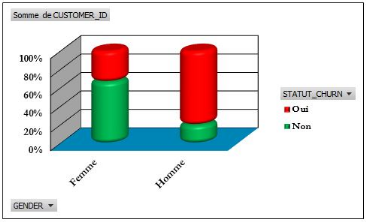
Figure 4.40: Statut churn selon
le sexe.
c) Présentation du statut churn selon
l'âge
Selon l'âge des clients, les clients actifs sont
représentés en histogramme vert et en histogramme rouge les
clients perdus.
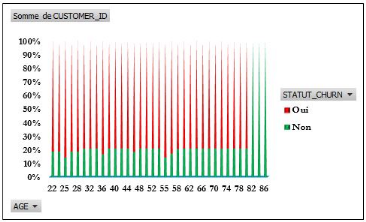
Figure 4.41:Statut churn selon
l'âge des clients.
d) Présentation du statut churn selon
l'ancienneté
Selon l'ancienneté, les clients actifs sont
représentés en histogramme vert et en histogramme rouge les
clients perdus. Il sied de signaler que le graphique ci-dessous est
réparti sur une période allant de 1 - 5 ans.
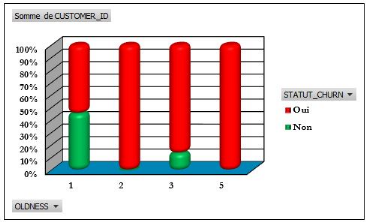
Figure 4.42: Statut churn selon
l'ancienneté des clients dans l'institution.
e) Présentation du statut churn selon les
réclamations ou plaintes
Plusieurs clients affichent un statut de churn d'où le
churner. Par rapport aux plaintes nos résolues, la BCDC court un risque
de perte de ses clients d'autant plus que la boite à suggestion ainsi
que celle de réclamations ne sont pas régulièrement mise
à jours. Ci-dessous voici le graphique reprenant en histogramme rouge
les clients perdus quant à ce.
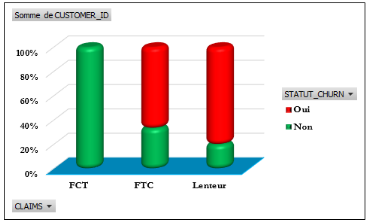
Figure 4.43: Statut churn selon
les réclamations des clients.
f) Présentation du statut churn selon la
profession
Selon la profession, l'institution peut également
perdre ses clients, la BCDC n'est pas exclue. Ci-dessous voici le graphique
reprenant les clients perdus en histogramme rouge, en histogramme vert, les
clients fidélisés malgré leurs professions.
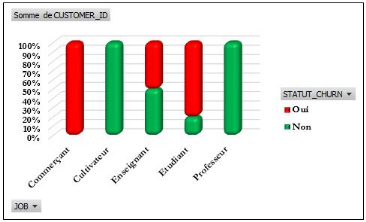
Figure 4.44: Statut churn selon
la profession des clients.
g) Extrait de données d'apprentissage
Ci-dessous nous présentons l'extrait des données
que nous allons s'en servir pour notre système prédictif.
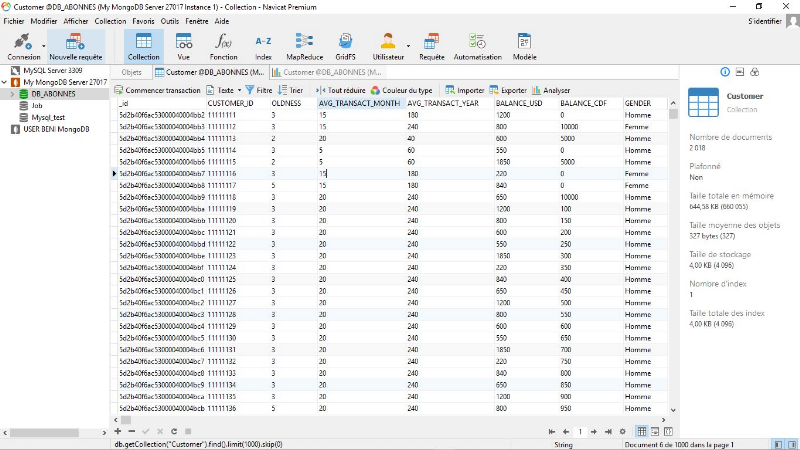
Figure 4.45: Extrait de
données d'apprentissage depuis MongoDB. Vue n°1 [Client Navicat
Premium-MongoDB].
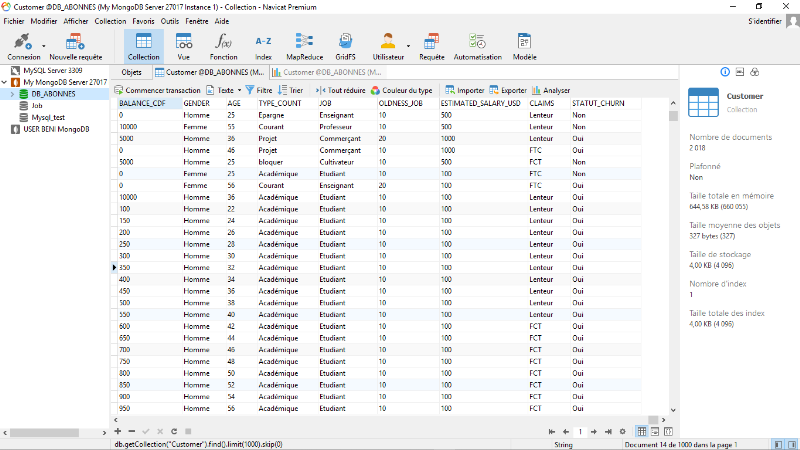
Figure 4.46: Extrait de
données d'apprentissage depuis MongoDB. Vue n°2 [Client Navicat
Premium-MongoDB].
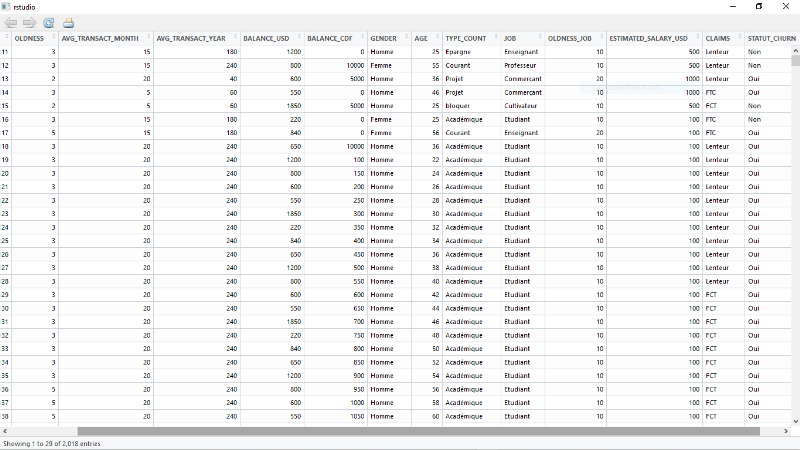
Figure 4.47: Visualisation des
données d'apprentissage.[RStudio]
IV.6. Implémentation
et Analyse des résultats
1. Phase d'apprentissage
Notre problème étant l'analyse de churn, nous
voulons ici évaluer le risque de départ d'un client en
implémentant un modèle d'apprentissage en vue d'etablir un
classement par rapport à un nouveau client s'il est churner ou pas.
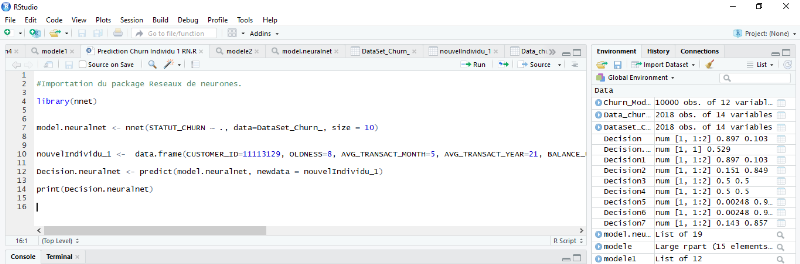
Figure 4.48:Phase
d'apprentissage pour le classement d'un nouveau client
(individu).[RStudio]
À travers la figure ci-dessus figure nous avons
importé le package « nnet » qui est
une bibliothèque puissante pour la prédiction avec le
réseau de neurones. Cette bibliothèque marche de pair avec la
fonction « size » : ce dernier
représente le nombre de la couche cachée.
Nota : La convergence et le temps
d'exécution sont très rapides. Ce sont des
caractéristiques fortes de ce package.
2. Phase de prédiction
a) Premier cas
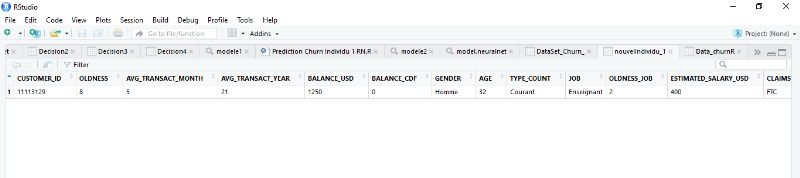
Figure 4.49: Nouvel individu
à prédire cas 1. [RStudio]
Ci-dessous le résultat de la prédiction, le
vecteur « predict » contient la sortie de la
fonction d'activation (Sigmoïde) du neurone de sortie. On
binarise le resultat avec un seuil à 0.5 :
Code illustratif :
> nouvelIndividu_ <- data.frame(CUSTOMER_ID=11113129,
OLDNESS=8, AVG_TRANSACT_MONTH=5, AVG_TRANSACT_YEAR=21, BALANCE_USD =1250,
BALANCE_CDF=0, GENDER="Homme", AGE=32, TYPE_COUNT="Courant",
JOB="Enseignant",OLDNESS_JOB=2, ESTIMATED_SALARY_USD=400, CLAIMS="FTC")
> Decision.neuralnet <- predict(model.neuralnet, newdata =
nouvelIndividu_1)
> print(Decision.neuralnet)
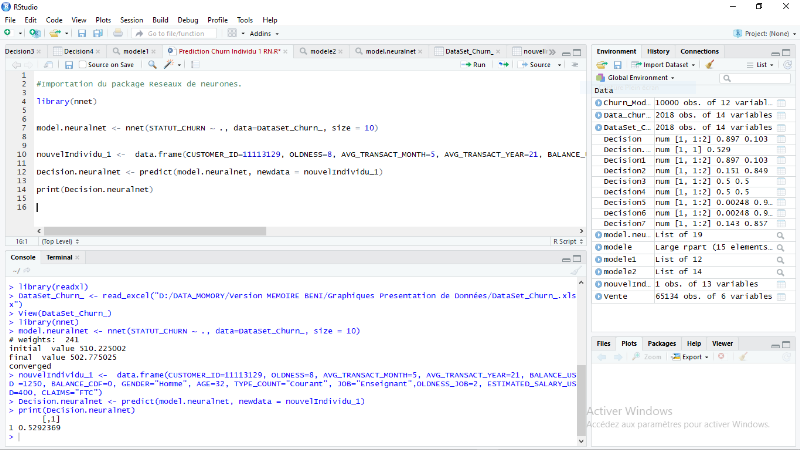
Figure 4.50: Classement du
nouvel individu premier cas (1).[RStudio]
Interprétation cas
1 :Après avoir exécuter les codes ci haut,
nous remarquons que le résultat dans la figure
4.49, montre que le classifieur prédit le nouvel individu
dans la classe 1 à un taux de 0.5292369. Donc cet
individu présente un statut de
« Churner ».
b) Deuxième cas

Figure 4.51: Nouvel individu
à prédire deuxième cas (2). [RStudio].
Comme dans le cas précédent, le vecteur
« predict » contient la sortie de la fonction
d'activation (Sigmoïde) du neurone de sortie. On binarise
toujours le resultat avec un seuil à 0.5 :
Code illustratif :
nouvelIndividu_4 <- data.frame(CUSTOMER_ID=10, OLDNESS=1,
AVG_TRANSACT_MONTH=0, AVG_TRANSACT_YEAR=200, BALANCE_USD =6000, BALANCE_CDF=0,
GENDER="Homme", AGE=70, TYPE_COUNT="Epargne", JOB="Professeur",OLDNESS_JOB=30,
ESTIMATED_SALARY_USD=3000, CLAIMS="Lenteur")
> Decision.neuralnet <- predict(model.neuralnet, newdata =
nouvelIndividu_4)
> print(Decision.neuralnet)
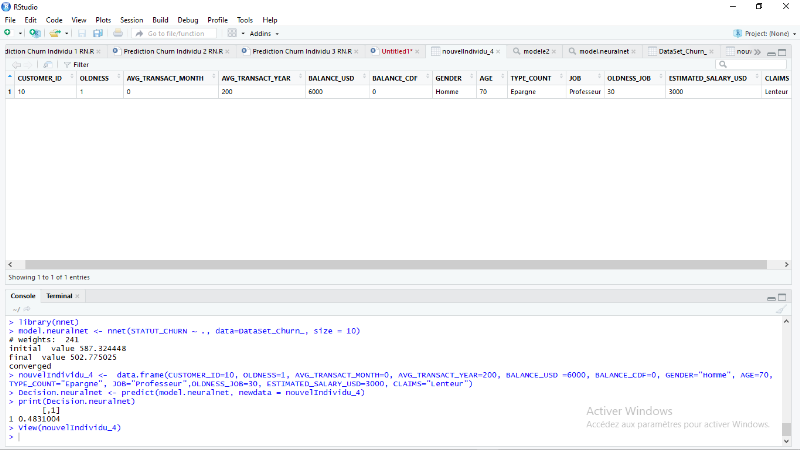
Figure 4.52: Classement du
deuxième nouvel individu deuxième cas 2. [RStudio]
Interprétation cas
2 :Dans le second cas remarquons que le résultat dans
la figure 4.51, le classifieur prédit le
nouvel individu dans la classe 1 à un taux de
0.4831004. Ceci prouve que l'individu ne peut pas appartenir
dans cette classe mais plutôt dans la classe 0
« NonChurner ».
CONCLUSION PARTIELLE
Au cours de ce dernier chapitre de notre travail
intitulé implémentation et interprétation des
résultats, nous avons eu à concevoir et à
implémenter notre modèle de prédiction tout en
commençant par une intégration de données qui
étaient des sources plus variées et non structurées dans
une base de données NoSQL orientées docuent (MongoDB) avec une
importation d'un Dataset. Après cette intégration, nous avons
également intégré d'autres outils Big Data tels que
Navicat-premium, Jupyter RStudio pour les analyses et intégration des
données. Ensuite, nous avons exporté notre Datasetvers excel pour
la présentation des différents graphiques expriment les
comportements des clients selon le cas des variables prédictives
définies dans notre travail, d'une part.
D'autre part, nous avons eu à appliquer, à
l'aide d'un Dataset, l'algorithme des réseaux de neurones pour pouvoir
prédire le nouveau comportement des nouveaux individus. Bref, nous avons
utilisé l'algorithme des réseaux de neurones de sorte que
celui-ci puisse classifier d'une manière automatique la classe à
laquelle appartiennent les nouveaux individus. Et enfin, nous avons
interpréter le résultat.
CONCLUSION GENERALE
Nous voici à la fin de notre travail qui a
consisté à la mise oeuvre d'un outil d'aide à la
décision à temps réel. Le présent travail repose
sur la construction d'un modèle prédictif à partir du Big
Data basé sur l'administration d'un Big Data sous MongoDB et extraction
de connaissance par réseau de neurones : application de l'analyse
de churn dans une institution bancairequi nous a permis de prédire les
risques de départ des clients.
Sur ce, pour atteindre nos fins, nous avons parlé des
Big Data au premier chapitre. Au chapitre second, nous avons traité sur
les SGBDs orientés document et MongoDB ; ici nous avons parlé des
différentes bases des données NoSQL qui existent actuellement,
MongoDB qui étaient d'ailleurs le noeud de notre question. Au chapitre
troisième, on a parlé de fouille de données et
réseau de neurones. En fin le quatrième et dernier chapitre,
consacré à l'implémentation et interprétation de
résultats. Dans ce dernier nous avons proposé les outils Big Data
pour différentes analyses et les langages de programmation python et R,
pour l'implémentation de notre système prédictif.
Sachant qu'il existe plusieurs technologies permettant de
résoudre les problématiques, les bases de données NoSQL
orientées-documents, nous nous sommes servi du système de gestion
des bases des données orientées-documents de la firme MongoDB
foundation, qu'on appelle MongoDB.
Comme tout oeuvre humaine, ce travail n'est pas scellé
par un seau d'achèvement, nous osons croire que les différentes
personnes qui auront l'opportunité de nous lire à travers
celui-ci, les feront avec bienveillance, dévouement et voudrons bien
apporter leurs suggestions et remarques en vue de permettre à la science
d'évoluer à travers d'autres esprits curieux car l'informatique
évolue du jour le jour dit-on.
BIBLIOGRAPHIE
I. OUVRAGES
1. BENSABAT Patrick, GAULTIER Didier, Livre blanc du Big
Data au Big Business, Ed. Eyrolles, Paris, 2017.
2. CORNUÉJOLS Antoine, Apprentissage artificiel :
Concepts et algorithmes, Ed. Eyrolles Deuxième tirage, Paris,
2003.
II. MEMOIRES
3. BALANGA Joe K., Apprentissage artificiel à
partir le Big Data basé sur les supports vector (SVM),
Mémoire de licence en Sciences, Département de
Mathématique et Informatique, Faculté des Sciences,
Université Pédagogique Nationale, 2016-2017.
4. KAMINGU Gradi L.,Base des
données orientées-graphe : Migration du Relationnel vers
le NoSQL, Mémoire de licence en Sciences Informatiques,
Département deMathématique et Informatique, Faculté des
Sciences, Université de Kinshasa, 2014-2015.
5. ILUNGA Hervé K., Extraction des connaissances
dans un Big Data à l'aide des outils B.I pour l'analyse des ventes,
Mémoire de licence en Sciences, Département de
Mathématique et Informatique, Faculté des Sciences,
Université Pédagogique Nationale, 2015-2016.
III. NOTES DE COURS, GUIDES ET SYLLABUS
6. BRUCHEZ Rudi, Les bases de données NoSQL et le
Big Data, Ed. Eyrolles 2è édition, Paris,
2016.
7. DIKOUE, Approche de migration d'une base de
données relationnelles vers une base, Guide du SGBDR et
NoSQL, France, 2014-2015.
8. DRISSI Noureddine, MongoDB Administration, Support
de formation MongoDB Administration, 2015.
9. FOUCRET A., NoSQL une nouvelle approche du stockage et
la manipulation des données. Guide administration du Big Data,
France, 2011.
10. KAMINGU Gradi L., Cours de Programmation en
Python, Académie des Sciences et de Technologie, Kinshasa,
2018-2019.
11. KAMINGU Gradi L., Cours de programmation en R pour
Économistes, Département d'Analyse des données et
Recherche Opérationnelle, Laboratoire d'Analyse-Recherche en
Économie Quantitative, 2015.
12. LAMBERGER Pirmin, BATTY Marc, Big Data et Machine
Learning : Manuel du data Scientist,Ed. DUNOD, 5è rue
Laromiguière, Paris,2015.
13. PREUX Philippe, Fouille de données, Notes de
cours destiné aux étudiants de master, Informatique,
Faculté des sciences,Université de Lille 3, 2009-2010.
14. TAFFAR Mokhtar,Initiation à
l'apprentissageautomatique, Support de Cours
destiné aux étudiants de Master en Intelligence Artificielle,
Informatique, Faculté des sciences Exactes,
Université de Jijel, Nantes, 2010.
IV. ARTICLES ET CONFERENCES
15. AL-AMRANI Yasine, « Algorithme de
K-moyennes », Café scientifique, vol.1, pp.5-7, 2014.
16. FROIDEFOND Éric A., « Le Big Data
dans l'assurance », travaux de l'Ecole Nationale d'Assurances,
Paris, Mai 2018.
17. NDEYE Niang, "Big Data Seminar", Clustering,
AIMS-Sénégal, vol.2, pp.7, Décembre 2016.
18. NDEYE Niang, "Big Data
Seminar»,Introduction-Big Data Analystics fundementals,
AIMS-Sénégal vol.1, pp.7-20, Décembre 2016.
19. TREGUIER V., « Très courte histoire
du Big Data », Congres d'économétrie vol.3, pp.45,
2013-2014
V. SITES WEB, BLOGS, FORUMS
1.
https://fr.m.wikipédia.org/wiki/Jupyter(11/09/2019)
2. https://www.mongodb.org(11/09/2019)
3.
https://blog.mongodb.org(12/09/2019)
4.
https://fr.m.wikipédia.org/wiki/Orange/Data-mining(02/08/2019)
5.
https://fr.m.wikipédia.org/wiki/Anaconda(05/08/2019)
6.
https://fr.m.wikipédia.org/wiki/Rstudio(18/07/2019)
7.
http://www.decideo.fr/bruley/(13/10/2019)
8.
http://www.wikipédia.com(16/06/2019)
9.
http://www.grappa.univ-lille3.fr(15/09/2019)
10.
http://www.asterdata.com/product/faq.php(22/08/2019)
11. http://www.axiodis.com(16/07/2019)
12. http://www.enass.fr(04/07/2019)
13.
www.reportingbusiness.fr(17/07/2019)
14.
www.ledicodumarketing.fr(10/10/2019)
15.
https://fr.m.wikipédia.org/wiki(11/10/2019)
16.
www.definitions-marketing.com(13/10/2019)
17. www.e-marketing.fr(10/10/2019)
18. www.inetrnaute.com(12/09/2019)
19. https://fr.mailjet.com(06/10/2019)
20.
www.marketing-etudiant.fr/memoires(15/05/2019
21.
www.custup.com/calcul-attrition-portefeuille-abonnes(26/09/2019)
22.
www.1min30.com/dictionnaire-du-web/churn-rate-taux-attrition(22/09/2019)
23.
www.memoireonline.com(22/09/2019)
24.
https://www.businessdecision-university.com/datas(18/07/2019)
25.
www.datacamp.com/community/(18/08/2019)
26.
http://en.wikipedia.org/wiki/Nosql(05/09/2019)
27.
http://en.wikipedia.org/wiki/Nosql-oriented-document(05/09/2019)
28.
http://en.wikipedia.org/wiki/Big Data/aspect (03/08/2019)
TABLE DES MATIERES
IN MEMORIAM
i
ÉPIGRAPHE
ii
DÉDICACE
iii
REMERCIEMENTS
iv
AVANT-PROPOS
vi
LISTE DES ABRÉVIATIONS
UTILISÉES
vii
LISTE DES FIGURES
viii
LISTE DES TABLEAUX
x
INTRODUCTION GENERALE
1
1. CONTEXTE
1
2. PROBLEMATIQUE
2
3. HYPOTHESE
3
4. CHOIX ET INTERET DU SUJET
3
4.1. Choix du sujet
3
4.2. Intérêt du
sujet
3
5. METHODES ET TECHNIQUES
UTILISEES
4
5.1. Méthodes
4
5.2. Techniques
4
6. SUBDIVISION DU TRAVAIL
4
CHAPITRE I: BIG DATA [1], [6], [12], [16],
[19]
5
I.1. INTRODUCTION
5
I.2. APERÇU HISTORIQUE
6
I.3. PRESENTATION DE L'ASPECTS BIG
DATA
7
I.4. OBJECTIFS
8
I.5. CARACTERISTIQUES
9
I.6. DEFINITION DU BIG DATA
10
I.6.1. Première définition de
Big Data
10
I.6.2. Deuxième définition de
Big Data
11
I.7. TYPES DES DONNEES DU BIG
DATA
11
I.7.1. Données
structurées
11
I.7.2. Données non
structurées
12
I.8. TECHNIQUES D'ANALYSE ET DE
VISUALISATION DU BIG DATA
12
I.8.1. Visualisation
13
I.9. DIFFERENCES AVEC L'INFORMATIQUE
TRADITIONNELLE OU DECISIONNELLE
13
I.10. BIG DATA ET SES
TECHNOLOGIES
14
I.10.1. Solutions de stockage
14
I.10.1.1. Bases des Données
NoSQL
15
1)
Théorème du CAP (d'Eric Brewer)
15
2) Principes ACID et
BASE
16
3) Critères
de Migration vers le principe CAP NoSQL
18
I.11. TYPES DE BASE DE DONNEES
NoSQL
19
I.11.1. Bases de données
orientées-document
19
I.11.2. Bases de données
orientées-colonne
20
I.11.3. Bases de données
orientées-graphe
20
I.11.4. Bases de données
orientées-clé-valeur
21
4) Outils MapReduce
et Hadoop
23
a) MapReduce
23
b) Hadoop
24
I.12. SOLUTIONS LOGICIELLES
24
I.12.1. Moteurs Sémantiques (Text
Mining)
24
I.12.2. Solutions
d'Analytiques
24
I.12.3. Solutions matérielles et/ou
architecturales
25
I.12.3.1. Cloud Computing
25
I.12.3.2. Super Calculateurs Hybrides (HPC :
High Performance Computing)
26
I.12.3.3. Stockage des Données en
Mémoire :
26
I.12.3.4. Serveurs des Traitements
Distribués :
26
I.13. CHOIX DU BIG DATA [1]
26
I.13.1. Big Data et recrutement
26
I.13.2. Métiers du Big
Data
27
CONCLUSION PARTIELLE
28
CHAPITRE II : SYSTÈME DE GESTION
DE BASE DE DONNEES ORIENTE DOCUMENT ET MONGODB [7],[9]
29
II.1. SGBD ORIENTE DOCUMENT
29
II.1.1. Introduction
29
II.1.2. Définition
29
II.1.3. Types de modèle de SGBD NoSQL
[7]
30
II.1.4. Comparaison des outils de gestion
des BD NoSQL
30
II. 2. MongoDB
31
II.2.1. Présentation
31
II.2.2. Schéma
32
II.2.2.1. Document
32
II.2.2.2. Collection
32
II.2.2.3. Documents
intégrés
33
II.2.3. Caractéristiques
33
II.2.4. Structure des
données
33
II.2.5. Stockage des objets
larges
34
II.2.6. Traitement des
données
35
II.2.7. Mise en oeuvre
35
II.2.7. Installation
35
II.2.7.2. Invite interactive
35
II.2.7.3. Programmation cliente
36
II.2.7.4. Administration
36
II.2.7.5.
Sécurité
37
II.2.7.6. Réplication
37
II.2.7.7. Répartition
(sharding)
37
CONCLUSION PARTIELLE
38
CHAPITRE III : FOUILLE DE DONNEES
ET RESEAUX DE NEURONES [13], [14], [18]
39
III. 1. FOUILLE DE DONNEES
39
III.1.1. Présentation
39
III.1.2. Objectifs de la Fouille de
données
39
III.1.3. Méthodes (Algorithmes) de
Fouille de données
40
III.1.4. Concepts de base de Fouille de
données
43
III.2. ALGORITHME DE   -MEANS [2], [15]
45 -MEANS [2], [15]
45
III.2.1. Introduction
45
III.2.2. Théorème de
Hyugens
46
III.2.3. Principe général des
méthodes des centres mobiles
46
III.2.4. Déroulement de
l'algorithme
47
III.3. RESEAUX DE NEURONES
48
III.3.1. Historique
48
III.3.2. Présentation des
réseaux de neurones
49
III.3.3. Neurone biologique
50
III.2.4. Structure du réseau de
neurones
51
III.3.5. Réseaux de neurones
artificiels (RNA)
52
III.3.5.1. Quelques définitions sur
le RNA
52
III.3.5.2. Comportement du neurone
artificiel
54
III.3.6. Neurone formel
55
III.3.7. Sortes de réseau de
neurones
56
III.3.8. Topologie d'un réseau de
neurones
56
III.4. APPRENTISSAGE DES RESEAUX DE
NEURONES
59
III.4.1. Algorithmes
d'apprentissage
61
III.4.1.1. Algorithme de HEBB
62
III.4.1.2. Algorithme d'apprentissage du
perceptron
62
III.4.1.3. Algorithme de propagation de
gradient pour un perceptron
63
CONCLUSION PARTIELLE
64
CHAPITRE IV : IMPLEMENTATION ET
INTERPRETATION DE RESULTATS [3], [4], [5], [6]
65
IV.1. INTRODUCTION
65
IV.2. ANALYSE PREALABLE : PRESENTATION
DE LA BANQUE COMMERCIALE DU CONGO
66
IV.2.1. Brève aperçue
historique de la BCDC
66
IV.2.2. Objectifs & Missions de la
BCDC
68
IV.2.3. Quelques directions de la
BCDC
68
IV.2.4. Siège
69
IV.2.5. Organigramme de la BCDC
69
IV.3. LE CHURN [3], [17]
70
IV.3.1. Notions
70
IV.3.2. Définitions
71
IV.4. Présentation des Outils
utilisés [10], [11]
71
IV.4.1. Langages de programmation :
Python et R [10]
71
IV.4.2. Environnement de
développement intégré (EDI)
75
IV.4.2.1. Jupyter [10]
76
IV.4.2.2. RStudio [11]
77
IV.4.3. Système de gestion de base de
données : MongoDB [8], [9]
78
IV. 4.3.1. Administration de Big Data sous
le SGBD MongoDB
78
IV.5. Présentation des
données
81
IV.5.1. Présentation des
données existantes d'analyse
81
IV.6. Implémentation et Analyse des
résultats
85
1. Phase
d'apprentissage
85
2. Phase de
prédiction
86
CONCLUSION PARTIELLE
85
CONCLUSION GENERALE
86
BIBLIOGRAPHIE
87
TABLE DES MATIERES
89

* 1Traduction
française : « La plupart des connaissances
dans le monde à venir vont être extraites par des machines et
résideront dans des machines ».
* 2
http://en.wikipedia.org/wiki/Big
Data/aspect
* 3Ceci d'autant plus que les
Big data impliquent de nouvelles formes de raisonnements, qui embrassent
notamment les formes de raisonnements inductifs. On peut sans grand risque
parler des Big data comme d'une nouvelle philosophie et une nouvelle
façon de penser le marketing.
* 4Pour la paternité
des 3V et les nombreux prétendants à leur invention, voir
l'article de Doug Laney : « Deja VVVu: Others Claiming Gartner's Construct
for Big Data » :
http://blogs.gartner.com/doug-laney/deja-vvvue-others-claiming-gartners-volume-velocity-variety-construct-for-big-data
* 5Il est à noter
cependant que des progrès notables restent à faire dans le
domaine de l'exploitation de ces données multimédia.
* 6Exemples de données
semi structurées : messages mail, log etc.) ; et non structurées
: photo, vidéo, son.
* 7IaaS : Infrastructure as a
Service, c'est-à-dire la capacité d'acheter de l'infrastructure
déportée et de la consommer à la demande, de la même
manière que ce que l'on fait pour les logiciels SaaS (Software as a
Service).
* 8BENSABAT Patrick, 2017 Op
cit.
* 9 KAMINGU Gradi L., 2014 Op
cit.
* 10Le
théorème d'une conjecture d'Eric Brewer, informaticien, de
l'Université de Californie à Berkeley lors du Symposium sur les
principes de l'informatique distribuée (Symposium on Principles of
Distributed Computing (PODC)). En 2002, Seth Gilbert et Nancy Lynch du MIT ont
publié une preuve formelle de la vérifiabilité de la
conjecture de Brewer et en ont fait un théorème établi.
* 11KAMINGU Gradi L.,
2014 Op cit.
* 12KAMINGU Gradi L.,
2014 Op cit.
* 13Framework
logiciel : est un ensemble méthodologique et d'outillage lié
à un langage de programmation. Cf.
http://fr.wikipedia.org/wiki/Framework
* 14Patrick Bensabat et
Didier Gaultier, Du Big Data au Business, phénomène de mode
facteur de performance.
* 15Éric Alain
FROIDEFOND, Le Big Data dans l'assurance, travaux de l'Ecole Nationale
d'Assurances.
* 16 KITONDUA L.N.N
Richard : Intelligence artificiel et systèmes d'aide, Note de cours L1
CSI/UPN, 2015-2016, inédit.
* 17 Antoine
Cornuéjols, Une Introduction à l'apprentissage artificiel, Tom
Mitchell, 2006.
* 18ILUNGA KAYEMBE
Hervé : Extraction des connaissances dans un Big Data à
l'aide des outils B.I pour l'analyse des vents. Cas de canal plus,
Mémoire de licence, UPN, Faculté des sciences, Département
Math-Info, septembre 2016.
* 19
www.bcdc.cd/ historique
* 20
www.bcdc.cd /mission
* 21
www.bcdc.cd/a propos
* 22
www.bcdc.cd/ localisation
* 23 Organigramme de la
Banque Commerciale Du Congo depuis 2014.
* 24
www.definitions-marketing.com/definition/churn/
*
25www.wikipédia.com
*
26www.definitions-marketing.com
*
27www.wikipédia.com
* 28
www.definitions-marketing.com/glossaire/fidelisation-crm-crc/
* 29
www.definitions-marketing.com/definition/attrition/
*
30www.custup.com/calcul-attrition-portefeuille-abonnes/
* 31 KAMINGU Gradi. L.,
Cours de Programmation en Python, Académie des Sciences et de
Technologie, 2018-2019.
* 32
https://fr.wikipedia.org/wiki/Python_(langage)/Caracteristiques
* 33 KAMINGU, G. L.,
Guide de Programmation R pour Économistes, Laboratoire
d'Analyse-Recherche en Économie Quantitative, 2017, inédit.
* 34Traduction
française de IDE :
Environnement
de Développement Intégré : Éditeur des
codes et scripts pour le langages de programmation.
* 35R est
un
langage de
programmation et un
logiciel libre
destiné aux
statistiques et
à la
science des
données soutenu par la R Foundation for Statistical Computing.
* 36Une
API
orientée
objet et développée en
C++, conjointement par
The Qt Company et
Qt
Project.
* 37Un
langage de
programmation
interprété,
multi-
paradigme
et
multiplateformes.
* 38 Noureddine DRISSI,
Guide MongoDB, Administration,2019, inédit.
| 

