Chapitre 04 :

Implémentation
Chapitre 4 : Implémentation 52
1. Introduction
Dans ce chapitre, nous discuterons les étapes suivies
pour implémenter notre approche basée sur d'algorithmes de
réseau de neurones convolutifs pour la prédiction des
défauts logiciels. Tout d'abord, nous discuterons l'environnement de
développement, langage utilisé pour implémenter notre
système, et les détails des bibliothèques utilisées
dans la programmation de notre système d'apprentissage profond pour la
prédiction de défauts logiciels SFP-NN. Ensuite, nous avons
présentés quelques captures d'écran montrant les
différentes étapes de notre approche, et nous poursuivons ce
chapitre par la présentation des différents résultats
expérimentaux obtenus
2. Implémentation du SFP-NN
proposé
2.1. Environnement de développement
Matériel Marque : HP.
Mémoire (RAM) : 8 Go.
Processeur : i5.
Système d'exploitation : Windows 10.
2.1.1. Langage de développement
Python
Python est un langage de programmation portable, dynamique,
extensible, gratuit, structuré et open source, c'est une syntaxe simple
et facile à comprendre, ce qui permet d'économiser du temps et
des ressources. Le langage Python, l'un des meilleurs langages pour commencer
dans le monde de la programmation, permet une approche modulaire et
orientée objet de la programmation et le plus utilisé dans le
domaine d'apprentissage automatique, du Big Data et de la Data Science. Il a
été initialement développé par Guido Van Rossum en
1993 et géré par une équipe de développeurs un peu
partout dans le monde. [57]
2.1.1.1. Caractéristiques du langage de
développement Python
La syntaxe de Python est très simple, ce qui donne des
programmes à la fois très compacts et très lisibles. Il
est orienté objet et peut gérer ses ressources (mémoire,
descripteurs de
Chapitre 4 : Implémentation 53
fichiers, etc.) sans intervention du programmeur. Les
bibliothèques et packages Python standards permettent d'accéder
à divers services : chaînes et expressions
régulières, services UNIX standards (fichiers, pipes, signaux,
sockets, threads, etc.), protocoles Internet (Web, news, FTP, CGI), HTML ... ),
persistance et base de données, interface graphique. En fait, Python est
un langage en évolution. [57]
2.1.1.2. Bibliothèques utilisées de
Python
En Python, une bibliothèque est un ensemble de modules
logiciels qui peuvent ajouter des fonctions étendues à Python.
Ils sont nombreux, et c'est l'une des grandes forces de python. Les
bibliothèques Python utilisées dans notre travail sont les
suivantes:
· Tensrflow: TensorFlow [58] est
une bibliothèque open source, permettant de développer et
d'exécuter des applications de d'apprentissage automatique et de Deep
Learning. TensorFlow est une boîte à outils permettant de
résoudre des problèmes mathématiques extrêmement
complexes. Elle permet aux chercheurs de développer des architectures
d'apprentissage expérimentales et de les transformer en logiciels.
Créé par l'équipe Google Brain en 2011.
· Keras: Keras [59] est une
bibliothèque open source qui a été initialement
écrite
par François Chollet en Python. Dans ce cadre, Keras
ne fonctionne pas comme un framework propre mais comme une interface de
programmation applicative (API) pour l'accès et la programmation de
différentes applications. Le but de cette bibliothèque est de
permettre la constitution rapide des réseaux neuronaux.
· NumPy : numpy [60] est une
bibliothèque numérique apportant le support efficace des larges
tableaux multidimensionnels, et des routines mathématiques de haut
niveau (fonctions spéciales, algèbre linéaire,
statistiques, etc.).
· Panda : Pandas [61]
est une bibliothèque écrite pour le langage de programmation
Python permettant la manipulation et l'analyse des données. Elle propose
en particulier des structures de données et des opérations de
manipulation de tableaux numériques et de séries temporelles.
Chapitre 4 : Implémentation 54
Son nom est dérivé du terme "données de
panel", un terme d'économétrie pour les jeux de données
qui comprennent des observations sur plusieurs périodes de temps pour
les mêmes individus.
· Matplotib : matplotlib est
une bibliothèque Python capable de produire des graphes de
qualité. Matplotlib essai de rendre les tâches «simples»
et de rendre possible les choses compliqués. Vous pouvez
générer des graphes, histogrammes, des spectres de puissance, des
graphiques à barres, des graphiques d'erreur, des nuages de dispersion,
etc... en quelques lignes de code. [62]
· Seaborn : Seaborn [63] est une
bibliothèque permettant de créer des graphiques statistiques en
Python. Elle est basée sur Matplotlib, et s'intègre avec les
structures Pandas. Cette bibliothèque est aussi performante que
Matplotlib, mais apporte une simplicité et des fonctionnalités
inédites. Elle permet d'explorer et de comprendre rapidement les
données.
2.1.2. Environement Google Colab
Colab est un produitproposée par Google Research.
C'est un environnement particulièrement adapté au machine
Learning, à l'analyse de données et à l'éducation.
En termes plus techniques, Colab est un service hébergé de
notebooks Jupyter qui ne nécessite aucune configuration et permet
d'accéder gratuitement à des ressources informatiques. [64]
Colaboratory, souvent raccourci en "Colab", permet
d'écrire et d'exécuter du code Python dans votre navigateur. Il
offre les avantages suivants : Aucune configuration requise , accès
gratuit aux GPU(Graphics Processing Unit) et Partage facile des
ressources.

Chapitre 4 : Implémentation 55

Figure 4.1. Google Collab
2.2. Présentation de déroulement de
l'application
2.2.1. Importation des bibliothèques
Cette étape constitue la phase initiale du
développement de notre approche. La figue 4.2 montre l'importation des
bibliothèques nécessaires.

Figure 4.2. Importation des bibliothèques
2.2.2. Description de la base de données
utilisée
Chapitre 4 : Implémentation 56
Plusieurs ensembles de données publics ou
privés sont disponible pour la prédiction des défauts
logiciels. Dans notre travail, nous avons opté pour les deux ensembles
NASA MDP et SOFTLAB. Les caractéristiques de ces deux ensembles ont
été définies dans les années 70 pour tenter de
caractériser objectivement les fonctionnalités de code
associées à la qualité logicielle. Dans la figure (4.3) et
(4.4), nous montrons les bases de données PC1 et AR1 qui appartiennent
à NASA MDP et SOFTLAB, respectivement.

Figure 4.3. Base de données PC1

Figure 4.4. Base de données AR1
- Importation de l'ensemble de
données
Cette phase désigne l'importation des données
nécessaires pour l'apprentissage et le test du modèle. Les
fichiers d'entrée des bases de données sont disponible dans un
répertoire sous forme .csv de cette façon : « ../Data/data
/mc1.csv »
Chapitre 4 : Implémentation 57

Figure 4.5. Lecture de l'ensemble de données
2.2.3. Prétraitement de
données
Chacun des ensembles de données avait initialement son
identifiant de module et son attribut de densité d'erreur
supprimés, car ils ne sont pas requis pour la classification. Une phase
de prétraitement alors, consiste à préparer les
données pour les étapes suivantes.
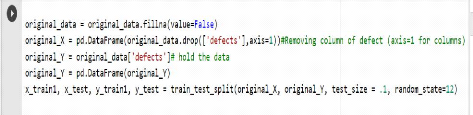
Figure 4.6. Préparation des données
- Partitionnement de la base de données utilisant
la technique SMOTE
Rééchantillonner l'ensemble de données
après l'avoir divisé en partitions de train et de test à
l'aide de la technique SMOTE, et à partir de là, nous prenons des
ensembles d'apprentissage et de validation. L'utilisation de SMOTE lors de la
division de chacun des ensembles de données en ensembles d'apprentissage
et de test est importante pour améliorer les résultats anormaux
possibles.
Cette fonction gère les problèmes de
classification déséquilibrée à l'aide de la
méthode SMOTE. A savoir, un nouvel ensemble de données "SMOTed"
peut être généré qui résout le
problème de déséquilibre de classe. Alternativement, il
peut également exécuter un algorithme de classification sur ce
nouvel ensemble de données et renvoyer le modèle
résultant. [65]
Chapitre 4 : Implémentation 58

Figure 4.7. Partitionnement d'ensemble de données
utilisant SMOTE
2.2.4. Apprentissage et création du modèle
CNN
Dans cette partie, nous allons nous focaliser sur un des
algorithmes les plus performants du Deep Learning, le réseau de neurones
convolutifs (CNN), ce sont des modèles de programmation puissants. Nous
avons mené plusieurs tests expérimentaux afin de choisir au mieux
différents paramètres pour s'adapter à la base
d'entrée du mélanome.
L'impact de nombre de filtres, la fonction d'activation et
nombre d'époques, font partie de l'ensemble de paramètres sur
lesquels nous avons effectué divers changements et expériences.
La figure 4.8 montre l'appel de la méthode CNN ainsi que les
paramètres choisis pour la réalisation de cette application.

Figure 4.8. Présentation des paramètres de
l'algorithme CNN.
Chapitre 4 : Implémentation 59
3. Résultats obtenus
Dans la présente étude, un système de
prédiction des défauts logiciels a été
proposé basé sur l'apprentissage profond. Cette technique qui a
prouvé son efficacité dans plusieurs domaines notamment dans le
domaine du génie logiciel. Un ensemble de (14) bases de données
des projets extraient de NASA MDP et SOFTLAB ont contribué à
l'évaluation de notre système. Ces bases de données ont
été partitionnées en un ensemble d'apprentissage et de
test utilisant la technique SMOTE.
3.1. La précision et la perte du SFP-NN
proposé
Résultats de la table ci-dessous décrit les
résultats de l'approche SFP-NN proposée en termes d'accuracy et
loss.
TABLE 4.1. PERFORMANCES DES PREDICTEURS UTILISANT CNN
SUR LES ENSEMBLES DE
DONNEES DE LA NASA MDP ET SOFTLAB
Base de Données
|
Accuracy
|
Loss
|
KC1
|
0.97
|
0.06
|
K
|
0.92
|
0.19
|
MC1
|
0.99
|
0.01
|
M
|
0.95
|
0.14
|
CM1
|
0.90
|
0.20
|
PC1
|
0.93
|
0.18
|
P
|
0.99
|
0.02
|
PC3
|
0.94
|
0.17
|
PC4
|
0.97
|
0.06
|
AR1
|
0.95
|
0.09
|
AR3
|
0.98
|
0.07
|
AR4
|
0.97
|
0.08
|
AR5
|
0.98
|
0.06
|
AR6
|
0.90
|
0.29
|
|
Les résultats tabulés révèlent
clairement l'amélioration de la précision de la prédiction
des défauts logiciels sur les ensembles de données du
système spatial.
Chapitre 4 : Implémentation 60
La précision et le taux de perte du modèle CNN
en fonction de nombre d'époques sur l'ensemble des 14 bases de
données sont illustrée par la figure 4.9.

Base de données KC1

Base de données K

Base de données MC1
Chapitre 4 : Implémentation 61

Base de données M


Base de données PC1
Base de données P
Base de données CM1
Chapitre 4 : Implémentation 62

Base de données de PC3


Base de données AR1
Base de données AR3
Base de données PC4
Chapitre 4 : Implémentation 63

Base de données AR4
Base de données AR5
Base de données AR6
Figure 4.9. La précision et le taux de perte de notre
modèle CNN
3.2. Matrice de confusion
Une matrice de confusion est une technique de mesure des
performances. C'est une sorte de tableau (voir chapitre 01) qui vous aide
à connaître les performances du modèle de
Chapitre 4 : Implémentation 64
classification sur un ensemble de données de test
[66]. La matrice de confusion insique le nombre les (FP, FN, TP et TN). Dans
notre travail, 14 matrices de confusion ont été calculé,
chaque matrice représente les résultats obtenus de chaque base de
données. La figure ci-dessous monte les matrices de confusions
obtenues

KC1 K MC1

M CM1 PC1
Chapitre 4 : Implémentation 65

P PC3 PC4

AR1 AR3 AR4

AR5 AR6
Figure 4.10. Matrices de confusions obtenues
Chapitre 4 : Implémentation 66
La table 4.2. Suivant présente les résultats de
performance du CNN en termes de la précision, Rappel,
F1-score, sensibilité et spécificité
TABLE 4.2 : LE RESEAU DE NEURONES CONVOLUTIFS RESULTATS
OBTENUS
Base de données
|
Précision
|
Rappel
|
F1-score
|
Spécificité
|
Sensibilité
|
KC1
|
0.92
|
0.98
|
0.96
|
0.95
|
0.92
|
K
|
0.87
|
0.90
|
0.94
|
0.92
|
1.00
|
MC1
|
0.92
|
0.97
|
0.98
|
0.95
|
0.89
|
M
|
0.98
|
1.00
|
0.97
|
1.00
|
0.94
|
CM1
|
0.93
|
0.97
|
0.92
|
0.90
|
0.89
|
PC1
|
1.00
|
0.91
|
0.90
|
0.98
|
0.90
|
P
|
0.95
|
1.00
|
0.97
|
0.95
|
0.92
|
PC3
|
0.90
|
0.99
|
0.91
|
0.88
|
0.87
|
PC4
|
0.94
|
0.99
|
0.87
|
0.95
|
0.99
|
AR1
|
0.92
|
1.00
|
0.94
|
0.96
|
0.97
|
AR3
|
0.90
|
1.00
|
0.80
|
1.00
|
0.91
|
AR4
|
0.96
|
1.00
|
0.9
|
0.84
|
0.98
|
AR5
|
0.97
|
1.00
|
0.88
|
0.99
|
0.89
|
AR6
|
0.79
|
0.98
|
0.92
|
0.86
|
0.88
|
|
Nous avons obtenu de bons résultats utilisant notre
classifieur CNN. Le F1-score est un bon indicateur de performance de tout
système. Un F1-score = 0.97 est obtenu avec la base de données P
et un f1-Score = 0.9 est obtenu avec la base de données AR4 de
l'ensemble SOFTLAB. Ce qui rend notre système performant dans la
prédiction de pannes logicielles.
Chapitre 4 : Implémentation 67
3.3. Calcul de l'AUC
L'aire sous la courbe (AUC) [67] de la fonction
d'efficacité du récepteur (ROC) est utilisée dans
l'évaluation des classificateurs. ROC est une fonction
paramétrée de la sensibilité et la
spécificité en fonction du seuil variant entre 0 et 1. La courbe
ROC est tracée donc au moyen de deux variables: une variable binaire et
une autre continue. Le modèle est évalué en
considérant toutes ses valeurs comme des seuils potentiels qui peuvent
être utilisés pour décider si une classe est
défectueuse ou non défectueuse. Hosmer et Lemeshow ont
proposé l'utilisation des règles suivantes pour évaluer la
performance des Classificateurs :
· AUC = 0.5 signifie mauvaise classification,
assimilée à une classification aléatoire.
· 0.5 < AUC < 0.6 signifie faible classification.
· 0.6 < AUC < 0.7 signifie classification
acceptable.
· 0.7 < AUC < 0.8 signifie bonne classification.
· 0.8 < AUC < 0.9 signifie très bonne
classification.
· 0.9 < AUC signifie excellente classification.
La figure 4.11 présente le résultat d'AUC de chaque
ensemble de données utilisé dans notre approche :

KC1 K

MC1 MC2
Chapitre 4 : Implémentation 68


AR3 AR4
P PC3
PC4 AR1
CM1 PC1
Chapitre 4 : Implémentation 69

AR5 AR6
Figure 4.11. Présentation des courbes ROC des
différentes bases de données
4. Comparaison de l'approche proposée
Dans cette section, et afin d'évaluer
l'efficacité de l'approche proposée, des expériences
similaires ont été réalisées à l'aide des
algorithmes telle que Machine a vecteur support [1],
Foret aléatoire [2], la régression
Logistique [3]. Les résultats moyens pour chaque ensemble de
données sont présentés dans la table 4 qui compare les
résultats de la précision de chaque classifieur.
4.1. Les paramètres
expérimentaux
Les données d'apprentissage du classifieur
Machine à vecteur support (SVM) (x_train)
et (y _train) feront l'entrée de
la fonction LinearSVC(). C'est l'implémentation de Machine à
vecteur de support avec une fonction noyau « linéaire
».
Le hyperparamètre utilisé dans le foret
aléatoire c'est n_estimators de valeur= 100
qui indique le nombre d'arbres construits par l'algorithme avant de prendre un
vote ou de faire une moyenne de prédictions.
La fonction LogisticRegression()
prédit la probabilité d'une variable aléatoire de
Bernoulli (c'est-à-dire de valeur 0,1) à partir d'un ensemble de
variables indépendantes continues.
4.2. Résultats obtenus
Les tables 4.3, 4.4 et 4.5 suivants présentent les
résultats de performance des classifieurs Machine à
vecteur support, Foret aléatoire et régression logistique,
respectivement. Ces résultats sont calculés en termes de
précision, Rappel, f1-score, accuracy.
Chapitre 4 : Implémentation 70
TABLE 4.3. RESULTATS OBTENUS DU CLASSIFIEUR SVM
|
Base de
données
|
Précision
|
Rappel
|
F1-Score
|
Accuracy
|
|
KC1
|
0.92
|
0.81
|
0.86
|
0.79
|
|
K
|
0.87
|
0.61
|
0.72
|
0.60
|
|
MC1
|
0.98
|
0.30
|
0.46
|
0.31
|
|
M
|
0.47
|
0.84
|
0.64
|
0.47
|
|
CM1
|
0.85
|
0.41
|
0.56
|
0.46
|
|
PC1
|
0.84
|
0.83
|
0.84
|
0.73
|
|
P
|
0.88
|
0.47
|
0.64
|
0.47
|
|
PC3
|
0.95
|
0.86
|
0.90
|
0.83
|
|
PC4
|
0.91
|
0.99
|
0.95
|
0.90
|
|
AR1
|
0.92
|
0.92
|
0.92
|
0.92
|
|
AR3
|
0.86
|
0.90
|
0.92
|
0.86
|
|
AR4
|
0.98
|
0.50
|
0.67
|
0.64
|
|
AR5
|
0.93
|
0.67
|
0.80
|
0.75
|
|
AR6
|
0.86
|
0.67
|
0.75
|
0.64
|
TABLE 4.4. RESULTATS OBTENUS DU CLASSIFIEUR FORET ALEATOIRE
|
Base de
données
|
Précision
|
Rappel
|
F1-
Score
|
Accuracy
|
|
KC1
|
0.90
|
0.80
|
0.89
|
0.73
|
|
K
|
0.80
|
0.90
|
0.91
|
0.82
|
|
MC1
|
0.90
|
0.91
|
0.87
|
0.85
|
|
M
|
0.56
|
0.62
|
0.70
|
0.59
|
|
CM1
|
0.84
|
0.90
|
0.87
|
0.78
|
|
PC1
|
0.80
|
0.93
|
0.57
|
0.71
|
|
P
|
0.85
|
0.89
|
0.89
|
0.84
|
|
PC3
|
0.76
|
0.88
|
0.53
|
0.65
|
|
PC4
|
0.80
|
0.78
|
0.92
|
0.80
|
|
AR1
|
0.75
|
0.95
|
0.96
|
0.77
|
|
AR3
|
0.67
|
0.80
|
0.80
|
0.79
|
|
AR4
|
0.77
|
0.67
|
0.80
|
0.82
|
Chapitre 4 : Implémentation 71
|
AR5
|
0.80
|
0.83
|
0.80
|
0.75
|
|
AR6
|
0.65
|
0.70
|
0.89
|
0.72
|
TABLE 4.5. RESULTATS OBTENUS DU CLASSIFIEUR REGRESSION
LOGISTIQUE
|
Base de
données
|
Précision
|
Rappel
|
F1-
Score
|
Accuracy
|
|
KC1
|
0.65
|
0.73
|
0.66
|
0.73
|
|
K
|
0.80
|
0.80
|
0.80
|
0.89
|
|
MC1
|
0.52
|
0.87
|
0.51
|
0.80
|
|
M
|
0.71
|
0.70
|
0.70
|
0.71
|
|
CM1
|
0.53
|
0.87
|
0.52
|
0.87
|
|
PC1
|
0.57
|
0.60
|
0.57
|
0.71
|
|
P
|
0.50
|
0.42
|
0.46
|
0.84
|
|
PC3
|
0.59
|
0.77
|
0.53
|
0.65
|
|
PC4
|
0.59
|
0.78
|
0.55
|
0.66
|
|
AR1
|
0.50
|
0.19
|
0.28
|
0.38
|
|
AR3
|
0.90
|
0.80
|
0.80
|
0.92
|
|
AR4
|
0.80
|
0.88
|
0.80
|
0.82
|
|
AR5
|
0.75
|
0.83
|
0.73
|
0.70
|
|
AR6
|
0.70
|
0.83
|
0.69
|
0.73
|
Les résultats obtenus des trois classifieurs sont
satisfaisant, cependant, notre approche a pu surpasser les trois techniques de
classifications traditionnelles. La Table 4.6 montre les résultats de la
comparaison.
Chapitre 4 : Implémentation 72
TABLE 4.6. COMPARAISON DE L'APPROCHE PROPOSEE AVEC LES TECHNIQUES
TRADITIONNELLES D'APPRENTISSAGE AUTOMATIQUE
|
Base de
données
|
|
SVM RF LR SFP-NN
|
|
|
|
KC1
|
0.79
|
0.73
|
0.73
|
0.97
|
|
K
|
0.60
|
0.82
|
0.89
|
0.92
|
|
MC1
|
0.31
|
0.85
|
0.80
|
0.99
|
|
M
|
0.47
|
0.59
|
0.71
|
0.95
|
|
CM1
|
0.46
|
0.78
|
0.87
|
0.90
|
|
PC1
|
0.73
|
0.71
|
0.71
|
0.93
|
|
P
|
0.47
|
0.84
|
0.84
|
0.99
|
|
PC3
|
0.83
|
0.65
|
0.65
|
0.94
|
|
PC4
|
0.90
|
0.80
|
0.66
|
0.97
|
|
AR1
|
0.92
|
0.77
|
0.38
|
0.95
|
|
AR3
|
0.86
|
0.79
|
0.92
|
0.98
|
|
AR4
|
0.64
|
0.82
|
0.82
|
0.97
|
|
AR5
|
0.75
|
0.75
|
0.70
|
0.98
|
|
AR6
|
0.64
|
0.72
|
0.73
|
0.90
|
4.3. Discussions
La prédiction précise des défauts
logiciels est très précieuse pour les ingénieurs, en
particulier ceux qui s'occupent des processus de développement de
logiciels. Ceci est important pour minimiser les coûts et
améliorer l'efficacité du processus de test logiciel. Les
résultats de la méthodologie proposée sur les 14 ensembles
de données ont encore montré les bénéfices
d'utilisation de l'apprentissage profond dans la tache de prédiction. On
a atteint une précision de 0.96 avec la base de données P aussi
un F1- score = 0.97 est obtenu avec la même base de données.
Nous avons aussi comparé notre approche avec des
approches traditionnelles d'apprentissage automatique. Nous avons
remarqué que notre SFP-NN a dépassé d'une manière
significative les résultats obtenus par ces algorithmes. Ce qui nous
permet de dire, que L'apprentissage profond et plus spécialement le
réseau de neurones convolutifs constitue une voie de recherche
très prometteuse dans le domaine du génie logiciel.
Chapitre 4 : Implémentation 73
5. Conclusion
Dans ce chapitre nous avons montré les
différents résultats de notre système proposé ainsi
le déroulement de notre application qui a pour but de résoudre ce
problème de prédiction des défauts logiciels, et nous
avons vu les outils nécessaires pour la réalisation de notre
application et cité l'environnement de développement. De plus,
nous avons détaillé l'architecture et les résultats
obtenus de notre étude. Nous avons clôturé notre chapitre
par une comparaison avec des techniques d'apprentissage automatique.
Conclusion Générale 75
| 

