|
N°2021/2020
íãáÚáÇ
ËÍÈáÇæ
íáÇÚáÇ
ãíáÚÊáÇ
ÉÑÇÒæ
|
Université Mohamed Chérif Messaadia - Souk
Ahras
Mohamed Chérif Messaadia University - Souk
Ahras
|
|
ÉíÏÚÇÓã
íÑÔáÇ ÏãÍã
ÉÜÚãÇÌ
ÓÇÑå
ÞæÓ
|
Faculté des Sciences et de la
Technologie
Année : 2021
Département de Mathématiques et
Informatique
MEMOIRE
Présenté en vue de l'obtention du
Diplôme de Master
PREDICTION DE DEFAUTS LOGICIELS UTILISANT DES TECHNIQUES
D'APPRENTISSAGE AUTOMATIQUE
Filière
Informatique
Spécialité
Génie Logiciel
par
Oulaceb Amina
DIRECTEUR DE MEMOIRE : Dr. Nawel ZEMMAL MCB U.
SOUK-AHRAS
Devant le jury
PRESIDENT : Mr. Mokdad AROUS MCB U.
SOUK-AHRAS
EXAMINATEUR : Mr. Ahcen MENASRIA MAA U.
SOUK-AHRAS
II
Remercîment
Je remercier tout d'abord Alah
A ma maitrise du mémoire Mademoisele Zemmal
Nawel j'ai eu le privilège d'être parmi vos
étudiants et d'apprécier vos qualités et
vos
valeurs. Votre sérieux, votre compétence et votre sens du devoir.
Veuilez trouver ici l'expression de ma respectueuse
considération et
ma profonde admiration pour toutes vos qualités. Ce travail
est pour moi l'occasion de vous témoigner ma
profonde
gratitude.
A mes maitres et juges du mémoire. Vous
m'avez fait l'honneur d'accepter avec une très grande
amabilité de siéger parmi mon jury de mémoire.
Veuilez accepter ce travail maitre, en gage de mon
grand respect et ma profonde reconnaissance. Veuilez trouver ici
l'expression de mon grand respect et mon vif remerciement. J'ai
adresse ma sincères remerciements à tous les professeurs,
intervenants et toutes les personnes qui par leurs paroles, leurs
écrits, leurs conseils et leurs critiques ont
guidé nos réflexions et ont accepté à ma
rencontrer et répondre à mes questions durant nos
recherches.
III
Dédicace
Je dédie ce modeste travail : A mon cher
père : Nourredine. Qui j'aime plus que tous au monde et
à lui je dois toute
ma vie et toutes mes réussites. Qui sans
lui je ne serais pas arrivé jusqu'ici. J'espéré
toujours rester fidèle aux valeurs
morales que tu m'as
apprises.
A ma chère mère : Malika. Aucune
dédicace ne saurait exprimer mon immense amour, mon estime, ma
profonde
affection et ma reconnaissance pour tous les sacrifices consentis
pour mon bonheur et ma réussite. Merci.
Je voudrais remercier ma soeur bien aimée Mariem
pour ses mots d'encouragement qu'ele m'a accordée.
Je vous
souhaite la plus belle vie. A mes chers frères : Lazhar,
Mustapha, Abdenour Tous mes voeux de bonheur, de santé et
de
réussit inchallah. A toute ma famille A ma chère amie Sara
qui avec ele j'ai partage les moments difficiles de
ce
travail et qui est la puissance morale pendant la
réalisation de mon projet. A tous mes ami(e)s et mes
collègues
Résumé IV
Résumé
Les systèmes logiciels sont devenus plus grands et plus
complexes que jamais. De telles caractéristiques rendent très
difficile la prévention des défauts logiciels. La
découverte des défauts logiciels à un stade précoce
joue un rôle important dans l'amélioration de la qualité du
logiciel ; réduit le temps et les efforts qui devraient être
consacrés au développement de logiciels. Diverses approches ont
été proposées pour identifier et corriger de tels
défauts à un coût minimal. Cependant, les performances de
ces approches nécessitent une amélioration significative. Par
conséquent, dans ce travail, nous proposons une nouvelle approche SFP-NN
qui tire parti des techniques d'apprentissage en profondeur pour prédire
les défauts dans les systèmes logiciels. Tout d'abord, nous
commençons par une phase de prétraitement de l'ensemble de
données accessible au public. Deuxièmement, nous effectuons une
modélisation des données pour préparer les données
d'entrée pour le modèle d'apprentissage en profondeur.
Troisièmement, nous transmettons les données
modélisées à un modèle basé sur un
réseau de neurones convolutifs pour prédire la probabilité
des défauts. Pour valider notre approche, les expériences sont
menées sur quatorze (14) ensembles de données de la NASA et
SOFTLAB. Les résultats expérimentaux ont montré que, dans
la majorité des bases de données, SFP-NN était le plus
performant par rapport aux autres techniques d'apprentissage automatique.
Mots-clés : Prédiction
des Défauts Logiciels, Apprentissage Automatique, Apprentissage Profond,
Réseau de Neurones Convolutifs, Classification.
ÕÎáã V
ÕÎáã
|
ÈæíÚ
|
Ë æ
|
ÏÍ Úäã
ÉíÇÛáá
ÈÚÕáÇ äã
ÕÆÇÕÎáÇ
åÐå
|
áÚÌÊ
|
Ë íÍ
|
ìÖã ÊÞæ í
äã ÇðÏíÞÚÊ
ÑËßæ ÑÈß
悒틄釂
ÉãÙä ÊÍÈÕ
|
ÏåÌáÇæ
ÊÞæáÇ äã
ááÞí °
ÌãÇäÑÈáÇ
ÉÏæÌ äíÓÍÊ í
Çðãåã ÇðÑæÏ
ÉÑßÈã
ÉáÍÑã í
ÌãÇÑÈáÇ
ÈæíÚ ÇÔÊßÇ
ÈÚáí
.ÌãÇÑÈáÇ í
ßáÐ Úãæ
.ÉáßÊ áÞÈ
ÈæíÚáÇ åÐå
áËã ÍíÍÕÊæ
ÏíÏÍÊá
ÉáÊÎã ÞÑØ
ÍÇÑÊÞÇ ãÊ
.悒틄釂
ÑíæØÊ ìáÚ
ÇãåÞÇäÅ
íÛÈäí
äíÐááÇ
ÞíãÚáÇ
ãáÚÊáÇ
ÊÇíäÞÊ
äã
ÏíÊÓíÜá
ÇðÏíÏÌ ÇðÌåä
ÍÑÊÞä áãÚáÇ
ÇÐå í ßáÐá
.ÉÑíÈß
ÊÇäíÓÍÊ
ÈáØÊí
ÈíáÇÓáÇ åÐå
ÁÇÏ äÅ

áãÚÈ
ãæÞä ÇðíäÇË
.ÑæåãÌáá
ÉÍÇÊãáÇ
ÊÇäÇíÈáÇ
ÉÚæãÌãá
ÉÌáÇÚãáÇ
áÈÞ Çã
ÉáÍÑãÈ ÏÈä
ðáÇæ
.ÌãÇÑÈáÇ
ÉãÙä í
ÁÇØÎáÇÈ
ÄÈäÊáá
ÉßÈÔáÇ ìáÚ
ãÆÇÞ ÌÐæãä
ìáÅ
ÉÌÐãäãáÇ
ÊÇäÇíÈáÇ
ÉíÐÛÊÈ ãæÞä
ÇðËáÇË
.ÞíãÚáÇ
ãáÚÊáÇ
ÌÐæãäá
áÇÎÏáÅÇ
ÊÇäÇíÈ
ÏÇÏÚáÅ
ÊÇäÇíÈáÇ
ÉÌÐãä
ÉÚæãÌã ) 14( ÑÔÚ
ÉÚÈÑ ìáÚ
ÈÑÇÌÊáÇ
ÁÇÑÌÇ ãÊí ,
ÇäÌåä ÉÍÕ äã
ÞÞÍÊáá .ÈæíÚ
ËæÏÍ
ÉíáÇãÊÍÇÈ
ÄÈäÊáá
ÉííáÇÊáÇ
ÉíÈÕÚáÇ
ÉäÑÇÞã áÖÇSFP-NN
ÁÇÏ äÇß
ÊÇäÇíÈáÇ
ÏÚÇæÞ
ÉíÈáÇÛ í åä
ÉíÈíÑÌÊáÇ
ÌÆÇÊäáÇ
ÊÑåÙ ËíÍ SOFTLAB æ
NASA
.ìÑÎáÇ
íááÂÇ
ãáÚÊáÇ
ÊÇíäÞÊÈ
íäÕÊáÇ
ÉííáÇÊáÇ
ÉíÈÕÚáÇ
ÉßÈÔáÇ
ÞíãÚáÇ
ãáÚÊáÇ
íááÂÇ
ãáÚÊáÇ
悒틄釂
áÇØÚÈ
ÄÈäÊáÇ :
ÉíÍÇÊãáÇ
ÊÇãáßáÇ
Abstract VI
Abstract
Software systems have become bigger and more complex than
ever. Such characteristics make it very difficult to prevent software defects.
The discovery of software defects at an early stage plays an important role in
improving the quality of the software; reduces the time and effort that should
be spent on software development. Various approaches have been proposed to
identify and correct such defects at minimal cost. However, the performance of
these approaches requires significant improvement. Therefore, in this work, we
propose a novel SFP-NN approach that takes advantage of deep learning
techniques to predict faults in software systems. First, we start with a
preprocessing phase of the publicly available dataset. Second, we perform data
modeling to prepare the input data for the deep learning model. Third, we feed
the modeled data to a convolutional neural network-based model to predict the
probability of defects. To validate our approach, the experiments are carried
out on fourteen (14) data sets from NASA and SOFTLAB. Experimental results
showed that, in the majority of databases, SFP-NN performed better compared to
other machine learning techniques.
Keywords: Software Fault Prediction,
Machine Learning, Deep Learning, Convolutional Neural Network,
Classification.
VII
Table de matières
Table des matières
Remerciment II
Dédicace III
Résumé IV
ÕÎáã V
ABSTRACT VI
Table de matières VII
Liste des figures X
Liste des tables XI
Liste des abréviations XII
Introduction générale 1
Chapitre 1 :Prédiction des défauts
logiciels 5
1. Introduction 6
2. Étude sur la prédiction des défauts
logiciels 6
2.1. Définition 6
2.2. Processus de prédiction des défauts logicie
7
2.2.1. Base de données des défauts logiciels 8
2.2.2. Phase de prétraitement 8
2.2.3. Phase d'apprentissage des données 8
2.2.4. Phase de prédiction des défauts 9
3. État de l'art 9
3.1. Questions de recherche 9
4. Conclusion 19
Chapitre 2 : Apprentissage automatique 20
1. Introduction 21
2. Apprentissage supervisé 21
2.1. Définition 21
2.2. Les techniques d'apprentissage supervisé 22
2.2.1. Machine à vecteur support 22
2.2.2. Réseau de neurone artificiels 24
2.2.3. Les forêts d'arbre décisionnels 24
3. Apprentissage non supervisé 25
3.1.Définition 25
3.2. Les techniques d'apprentissage non supervisé 26
VIII
Table de matières
3.2.1. L'algorithme k-moyennes 26
3.2.2. Classification hiérarchique 27
3.2.3. Algorithme d'espérance maximisation 27
4. Apprentissage profond 28
4.1. Définition 28
4.2. Les réseaux de neurones convolutifs 28
4.2.1. Présentation 29
4.2.2. Blocs de construction 30
4.2.2.1. Couche de convolution 30
4.2.2.2. Couche de pooling 32
4.2.2.3. Couche de correction 33
4.2.2.4. Le flattening 34
4.2.2.5. Couche entièrement connecté 35
4.2.2.6. Couche de perte 35
4.2.3. Choix des hyperparamètres 36
4.2.3.1.Nombre de filtres 36
4.2.3.2. Forme de filtres 36
4.2.3.3. Forme du maxpooling 36
5. Conclusion 37
Chapitre 3 : SFP-NN Apprentissage profond pour la
prédiction des défauts logiciels 38
1. Introduction 39
2. Approche proposée 39
2.1. La base de données NASA et SOFTLAB 40
2.1.1. Présentation des bases de données 43
2.1.2. Les métriques de la NASA MDP et SOFTLAB 42
2.2. Normalisation 46
2.3. Prédiction utilisant CNN 47
2.4. Choix des hyperparamètres 48
3. Conclusion 50
chapitre 4 : Implémentation 51
1. Introduction 52
2. Implémentation du SF-NN proposé 52
2.1. Environnement de développement 52
2.1.1. Langage de développement python 52
2.1.1.1.Caractéristiques du langage de
développement python 52
2.1.1.2.Bibliothèques utilisées de python 53
2.1.2. Environnement google colab 54
2.2. Présentation de déroulement de l'application
55
2.2.1. Importation des bibliothèques 55
2.2.2. Description de la base de données utilisée
56
2.2.3. Prétraitement des données 57
2.2.4. Apprentissage et création du modèle CNN
58
3. Résultats obtenus 59
IX
Table de matières
3.1.La précision et la perte du SFP-NN proposé
59
3.2. Matrice de confusion 64
3.3. Calcul de l'AUC 67
4. Comparaison de l'approche proposée 70
4.1. Les paramètres expérimentaux 70
4.2. Résultats obtenus 70
4.3. Discussions 73
5. Conclusion 74
Conclusion générale 75
Bibliographie 77
X
Liste des Figures
Liste des Figures
Figure 1.1 : Processus de prédiction de défauts
logiciel. 7
Figure 1.2 : Métriques OO utiles pour la
prédiction des défauts logiciels. 12
Figure 1.3 : Ensembles de données pour la
prédiction des défauts logiciels. 13
Figure 2.1 : Processus d'apprentissage supervisé 22
Figure 2.2 : Séparateur à vaste marge. 23
Figure 2.3 : Réseaux de neurones artificiels. 24
Figure 2.4 : Les Forêts d'Arbres Décisionnels.
25
Figure 2.5 : Apprentissage non supervisé. 26
Figure 2.6 : Architecture de réseau de neurones
convolutifs. 30
Figure 2.7 : Couche de convolution. 31
Figure 2.8 : L'opération de convolution. 31
Figure 2.9 : Type de pooling. 33
Figure 2.10 : La fonction d'activation ReLU 34
Figure 2.11 : Mise à plat des images finales. 35
Figure 3.1 : Schéma du SFP-NN proposé. 40
Figure 3.2 : La carte thermique de quelques bases de
données de la NASA. 46
Figure 3.3 : Architecture de réseau CNN. 47
Figure 4.1 : Google Collab. 55
Figure 4.2 : Importation des bibliothèques. 56
Figure 4.3 : Base de données PC1. 56
Figure 4.4 : Base de données AR1. 56
Figure 4.5 : Lecture de l'ensemble de données. 57
Figure 4.6 : Préparation des données . 57
Figure 4.7 : Partitionnement d'ensemble de données.
58
Figure 4.8 : Le code du CNN. 59
Figure 4.9 : La précision et le taux de perte de notre
modèle CNN. 64
Figure 4.10 : Matrices de confusions obtenues. 66
Figure 4.11 : Présentation des courbes ROC des
différentes bases de données. 70
XI
Liste des Tables
Liste des Tables
Table 1.1 : Question de recherches 10
Table 1.2 :Matrice de confusion 14
Table 1.3 :Prédiction des défauts logiciels :
état de l'art 17
Table 3.1 : Présentation de l'ensemble de
données utilises 42
Table 3.2 : Description de l'ensemble de données
utilises 42
Table 3.3 : Les paramétres du classifieur CNN
utilisé 50
Table 4.1 : Performance des prédicteurs utilisant CNN
sur les données de la NASA et SOFTLAB
59
Table 4.2 : Le réseau de neurones convolutifs
résultats obtenus 67
Table 4.3 :Résultats obtenus du classifieur svm 71
Table 4.4 : Résultats obtenus du classifieur Foret
aléatoire 71
Table 4.5 : ésultats obtenus du classifieur
Régression logistique 72
Table 4.6 : Comparaison de l'approche proposé avec les
techniques traditionelles d'apprentissage
automatique 73
XII
Liste des abréviations
La liste des abréviations
IA Intelligence Artificial
ML Machine Learning
SFP Software fault prediction
SFP-NN Software fault prediction-neural
network
CNN Les réseaux de neurones
convolutif.
DL Deep Learning
MDP Metrics data program
ANN Artificiel neural network
SVM Support Vector Machines.
RF Random Forest
LR Logestique regression
NB Naïve bayes
EM Des algorithmes de maximisation de
l'espérance.
RNN Le reseau neuronal récurrent.
TN True Négative
FP False Positive
TVP Taux de vrais positifs
DNN Deep neural network
ReLu Unité Linéaire
Rectifiée
AUC Area Under curv
LOC Ligne of code
MLP Multi Layers Perceptron
NN Neural network
OO Orienté objet
Introduction Générale 1
Introduction générale
Contexte Général
Au cours des deux dernières décennies, la
demande de logiciels pour diverses applications a augmenté rapidement.
Pour répondre à la demande des clients, une énorme
quantité d'applications logicielles sont développées
à des fins d'entreprise ou d'utilisation quotidienne. En raison de la
production de masse d'applications logicielles, la qualité des logiciels
reste un problème non résolu qui donne des performances
insatisfaisantes pour les applications industrielles et individuelles. Par
conséquent, pour résoudre ce problème, des tests logiciels
sont introduits, ce qui aide à trouver les défauts ou les bogues
dans l'application logicielle et tente de les résoudre.
La complexité croissante des logiciels modernes a accru
l'importance de la fiabilité des logiciels. La création des
logiciels hautement fiables nécessite une quantité
considérable des tests et de débogage. Cependant, en raison du
budget et du temps limités, ces efforts doivent être
priorisés pour améliorer l'efficacité. En effet, la
présence de fautes dans un système logiciel dégrade non
seulement sa qualité, mais augmente également le coût de
son développement et de sa maintenance. Par conséquent, un
processus automatisé de test logiciel est requis, ce qui peut
entraîner une amélioration des performances et une minimisation
des coûts de mise en oeuvre. Pour cela les techniques de
prédiction des défauts logiciels qui prédit
l'apparition
Introduction Générale 2
d'erreurs ont été largement utilisées
pour aider les développeurs à déterminer la
priorité des tests et du débogage.
La prédiction des défauts logiciels est le
processus de création des classifieurs pour prédire si des
défauts existent dans une zone spécifique du code source. Du
point de vue de la granularité de la prédiction, la
prédiction des défauts logiciels peut inclure la
prédiction des défauts au niveau de la méthode, de la
classe, du fichier, du package et du changement. Pour la recherche actuelle,
nous nous sommes concentrés sur la prédiction des défauts
au niveau du fichier, car il existe une grande quantité de
données étiquetées. La prédiction typique des
défauts logiciels se compose de deux phases : l'extraction des
caractéristiques à partir d'artefacts logiciels tels que le code
source et la création des modèles de classification à
l'aide de divers algorithmes d'apprentissage automatique pour la formation et
la validation. La prédiction des défauts logiciels basée
sur les techniques d'apprentissage automatique a gagné un grand
intérêt et des résultats prometteurs ont été
obtenus. Cependant, ces méthodes traditionnelles d'apprentissage
souffrent de quelques lacunes. Récemment, dans le domaine de la
prédiction des défauts logiciels et dans le but de palier aux
problèmes des techniques traditionnelles d'apprentissage automatique,
les schémas basés sur l'apprentissage profond ont fourni des
performances significatives.
Depuis l'avènement d'AlexNet [14]en
2012, l'apprentissage en profondeur a été largement
utilisé dans des domaines tels que la reconnaissance d'images, la
reconnaissance vocale et le traitement du langage naturel, en effet,
L'apprentissage en profondeur surmonte la communauté de l'IA en
apportant des améliorations pour résoudre des problèmes
auxquels on résiste depuis de nombreuses années. Il introduit
plus de succès à l'avenir car il nécessite très peu
d'ingénierie à la main. L'apprentissage profond est
dérivé de l'apprentissage automatique où la machine est
capable d'apprendre par elle-même, qui est basé sur l'idée
des réseaux de neurones profonds. Il est devenu une technique puissante
pour la génération automatisée de caractéristiques,
car l'architecture d'apprentissage en profondeur peut capturer efficacement des
caractéristiques non linéaires très complexes. Un an plus
tard, la méthode de pointe exploitant le réseau de neurones
convolutifs (CNN) a été proposé pour apprendre la
sémantique du code source via des programmes AST [15],
qui se sont avérés surpasser les approches
traditionnelles basées sur les caractéristiques dans la
prédiction des défauts logiciels.
Introduction Générale 3
Le problème de prédiction des défauts
logiciels est devenu un sujet de recherche remarquable, attirant
l'intérêt des chercheurs. Un modèle de prédiction de
défaut logiciel peut être utilisé pour classer les modules
logiciels en défectueux ou non.
Motivation
La prédiction des défauts logiciels vise
à identifier les modules logiciels sujets aux pannes en utilisant
certaines propriétés sous-adjacentes du projet logiciel avant le
début du processus de test proprement dit. Que ce soit dans le domaine
du génie logiciel ou de la recherche, la maîtrise des
défauts est un aspect important.
Un grand nombre de recherches ont discuté les avantages
de l'utilisation de techniques d'apprentissage automatique pour la
prédiction des défauts logiciels telles que la machine à
vecteurs de support, le réseau de neurones artificiels, l'arbre de
décision, etc. Cependant, ces algorithmes présentent des limites
en raison de : (i) des connaissances d'experts sont nécessaires pour
traiter les données, (ii) Un niveau, comparativement
élevé, d'interaction humaine avec des experts est requis et (iii)
une quantité massive de données d'apprentissage est
nécessaire pour le bon fonctionnement du système, ce qui peut
devenir difficile dans un environnement dynamique. Pour répondre aux
restrictions ci-dessus, un sous-ensemble plus prometteur de l'apprentissage
automatique, l'apprentissage en profondeur, a été adopté
pour améliorer la prédiction et a permet d'obtenir des
performances remarquables.
Notre motivation dans cette recherche consiste à
introduire un nouveau modèle de prédiction des défauts
logiciels basé sur une technique avancée de l'apprentissage
automatique qui est l'apprentissage profond. Ce dernier offre des informations
précieuses sur prédiction des défauts logiciels et
l'ambiguïté afin d'obtenir la qualité, la
maintenabilité et la réutilisabilité des logiciels. Notre
intention est de pallier aux inconvénients des modèles de
classification classiques et des modèles basés sur le niveau de
sévérité et à orienter les tests plus
efficacement.
Contribution
Afin de répondre aux problèmes cités
ci-dessus et en vue de réaliser un système de prédiction
de défauts logiciels qui permet de classer aisément les anomalies
présentent dans les logiciels. Un système de prédiction de
défauts logiciels est proposé pour prédire les pannes
logicielles utilisant la technique de réseau de neurones convolutifs.
Nous visons par cette
Introduction Générale 4
proposition de mesurer l'efficacité des algorithmes
d'apprentissage en profondeur pour la prédiction de défauts
logiciels et déterminer la meilleure qualité d'algorithme. La
technique sera utile aux développeurs et aux testeurs pour se concentrer
sur le code, ce qui finira par réduire les coûts de test et de
maintenance tout en contribuant à l'amélioration du logiciel et
à la fiabilité de l'ensemble du produit.
Organisation du mémoire
Notre mémoire se subdivise en quatre chapitres auxquels
s'ajoutent une conclusion et quelques perspectives pour de futures extensions
:
Le première chapitre « Prédiction
des défauts logiciel », est consacré à la
présentation de la prédiction de défauts logiciel (sa
définition, ses composants, avantages ...), en dressant les états
de l'art des travaux proposés.
Dans Le deuxième chapitre « Apprentissage
automatique », nous présentons quelques définitions
formelles et essentielles pour comprendre l'apprentissage automatique en
passant par les différents types des techniques supervisés et non
supervisés. Nous introduisons aussi l'apprentissage en profondeur et
nous discutant en détail la description des réseaux de neurones
convolutifs comme étant un outil de classification puissant.
Dans Le troisième chapitre « SFP-NN :
Apprentissage profond pour la prédiction des défauts logiciels
» nous présentons les détails de notre approche
proposée ainsi que les ensembles de données qui ont
contribués à l'évaluation et la validation de l'approche.
En décrivons l'approche proposée par notre travail.
Le quatrième chapitre et le dernier chapitre
« Implémentation », présentera une
implémentation de système de prédiction de défauts
logiciel en utilisant le CNN comme méthode de classification.
Commençant par la description et la présentation de
l'environnement de développement, le langage de programmation et les
bibliothèques utilisées. Les résultats obtenus par notre
système seront présentés dans ce chapitre ainsi que les
comparaisons réalisées avec d'autres techniques traditionnelles
de l'apprentissage automatique.
Nous clôturons par une conclusion qui souligne
l'avantage de l'approche proposée tout en discutant les résultats
obtenus et sans oublier les perspectives à donner à ce
travail.

Chapitre 01 : Prédiction des
défauts logiciels
Chapitre 01 : Prédiction des défauts logiciels 5
Chapitre 01 : Prédiction des défauts logiciels
6
1. Introduction
Le développement des logiciels de haute qualité
est l'un des défis les plus importants pour les ingénieurs en
logiciel. Pour cela, le développement de logiciels doit passer par une
séquence d'activités sous certaines contraintes pour proposer des
logiciels fiables et de haute qualité. Pendant les phases de conception
ou de développement, certains défauts peuvent être
passés au niveau suivant sans les détecter et les corriger. Par
conséquent, la qualité du logiciel va être affectée
ce qui va générer par la suite un produit final peu fiable qui
n'acquière pas non plus la satisfaction du client. Il est donc important
et bénéfique de ne pas simplement détecter l'occurrence du
défaut mais aussi de les prédire afin d'empêcher le
défaut avant qu'il ne devient réel.
La prédiction des défauts logiciels est un
domaine économiquement important en génie logiciel depuis plus de
20 ans. Un module défectueux dans un logiciel entraîne des
coûts de réparation et de développement
élevés et réduit la qualité du logiciel. La
prédiction des défauts logiciels est l'une des modèles de
qualité qui aident à conduire sainement le cycle de vie du
développement logiciel, en effet, trouver et corriger des erreurs peut
coûter beaucoup d'argent. Par conséquent, il est très
pratique de vérifier les défauts du logiciel.
Dans ce chapitre nous allons discuter la prédiction
des défauts logiciels ainsi que les principaux composants des
systèmes de prédiction. Par la suite, nous allons
présenter et discuter les travaux d'état de l'art
proposés.
2. Étude sur la prédiction des
défauts Logiciels 2.1. Définition
La prédiction des défauts logiciel est une
activité très importante et essentielle afin d'améliorer
la qualité du logiciel et réduire l'effort de maintenance avant
le déploiement du système. La prédiction des
défauts logiciels vise à prédire les modules logiciels
sujets aux pannes en utilisant certaines propriétés sous-jacentes
du projet logiciel [1]. Il est généralement effectué en
entrainant un modèle de prédiction à l'aide des
caractéristiques de projet inconnu, puis en utilisant le modèle
de prédiction pour prédire les défauts de projets
inconnus. Donc la prédiction des défauts logiciels est
basée sur la compréhension que si un projet
développé dans un environnement conduit à des
défauts, alors tout module développé dans
l'environnement
Chapitre 01 : Prédiction des défauts logiciels
7
similaire avec des caractéristiques de projet
similaires finira par être défectueux. La détection
précoce des modules défectueux est très utile pour
rationaliser les efforts à appliquer dans les phases ultérieures
du développement logiciel en concentrant mieux les efforts d'assurance
qualité sur ces modules[1]. La figure 1.1 donne un aperçu du
processus de prédiction des défauts logiciels.

Figure 1.1. Processus de prédiction de défauts
logiciel [1]. 2.2. Processus de prédiction des défauts
logiciels
La figure 1 donne un aperçu du processus de
prédiction des défauts logiciels avec les composants importants
du processus. Dans une première étape, les données de
défaillance logicielles sont collectées à partir des
référentiels de projets logiciels contenant des données
liées au cycle de développement du projet logiciel telles que :
le code source, les journaux de modification et les informations de
défaillance sont collectées à partir des
référentiels de défauts correspondants. Ensuite, les
valeurs de diverses mesures logicielles (par exemple, LOC, complexité
cyclomatique, etc.) sont extraites, qui fonctionnent comme des variables
indépendantes et les informations de défaut requises par rapport
à la prédiction de défaut (par exemple, le nombre de
défauts, défectueux et non défectueux) fonctionnent comme
la variable dépendante.
En règle générale, des techniques
statistiques et des techniques d'apprentissage automatique sont
utilisées pour créer des modèles de prédiction des
pannes. Enfin, les performances du modèle de prédiction construit
sont évaluées à l'aide de différentes mesures
d'évaluation des performances telles que l'exactitude, la
précision, le rappel et l'AUC (Area Under the Curve). En plus de la
brève discussion sur ces composants susmentionnés de la
Chapitre 01 : Prédiction des défauts logiciels
8
prédiction des défauts logiciels, les sections
à venir présentent des revues détaillées sur les
composants de ce processus. [1]
2.2.1. Base de données des défauts
logiciels
L'ensemble de données de défaut logiciel, qui
sert de base de données d'apprentissage et de base de données de
test dans le processus de prédiction de défaut logiciel, se
compose principalement de trois parties: Un ensemble de mesures logicielles,
des informations sur les défauts, telles que les défauts de
chaque module et des méta-informations sur le projet.
L'ensemble de données des défauts logiciels agit
comme un ensemble de données d'apprentissage et un ensemble de
données de test pendant le processus de prédiction des
défauts logiciels. [2]
2.2.2. Phase de prétraitement
Le prétraitement des données de surveillance de
l'état est une étape très importante et fondamentale lors
du développement du systèmes de modèles de données.
La phase de prétraitement des données comprend la
préparation et la transformation des données pour un traitement
simple et efficace sur des outils logiciels pour la prédiction [3]
Les attributs de chaque jeu de données ont
été chargés sur des feuilles de calcul Excel et
enregistrés sous forme de fichiers .CSV pour être
exécutés par la suite dans des environnements tels que : WEKA [4]
...etc.). Les valeurs manquantes vont être éliminées du
traitement ultérieur. Cette phase aboutie à des données
d'apprentissage propres pour un traitement ultérieur à l'aide
d'algorithmes de sélection et de classification des
caractéristiques.[3]
2.2.3. Phase d'apprentissage des
données
L'idée de lancer une étape de
prétraitement est pour préparer les données pour la phase
d'apprentissage. Les données sont divisées en deux parties : une
partie d'apprentissage et une partie de test. L'étape d'apprentissage
utilise des techniques d'apprentissage
Chapitre 01 : Prédiction des défauts logiciels
9
automatique pour entrainer le modèle sur les
données entrées au système. Contrairement, l'étape
de test est utilisée pour évaluer les performances des
modèles entraînés. [5]
Après avoir partitionné les données
d'apprentissage en un ensemble d'apprentissage et de test, un modèle de
prédiction des défauts logiciels est construit en utilisant les
ensembles de données de la même ou de différentes versions
du projet logiciel ou des projets logiciels différents
(prédiction des défauts entre projets). Un modèle de
prédiction des défauts logiciels est utilisé pour classer
les modules logiciels en catégories défaillantes ou non
(classification binaire), pour prédire le nombre de défauts dans
un module logiciel ou pour prédire la gravité des défauts.
Diverses techniques d'apprentissage automatique et statistiques peuvent
être utilisées pour créer des modèles de
prédiction de défauts logiciels. [5]
2.2.4. Phase de prédiction des
défauts
Dans ce type de schéma de prédiction des
défauts, les modules logiciels sont classés en classes
défaillantes ou non défaillantes. Généralement, les
modules ayant un ou plusieurs défauts marqués comme
défectueux et les modules ayant zéro défaut marqués
comme non défectueux. Il s'agit du type de schéma de
prédiction le plus fréquemment utilisé. [1]
3. Etat de l'art
Dans cette section nous allons présenter quelques
travaux de prédictions des défauts logiciels utilisant des
techniques d'apprentissage automatique. Mais avant cela, nous allons
répondre sur quelques questions principales de recherches qui sont
fréquemment posées lors de développement d'un
système de prédiction.
3.1. Questions de recherche
La table 1.1 présente six questions de recherches
abordées lors de la réalisation de notre système. Nous
avons identifié les techniques d'apprentissage automatique
utilisées pour prédire les défauts logiciels (RQ1),
analysé ces études en utilisant les techniques d'apprentissage
automatique pour la prédiction des défauts logiciels afin
répondre à RQ2, RQ3, RQ4, RQ5 et RQ6. Cette section
détermine les métriques les plus utilisées, les
métriques utiles, les mesures de performance utilisées, et enfin,
nous avons mentionné les forces et les faiblesses des techniques
d'apprentissage automatique. [6]
Chapitre 01 : Prédiction des défauts logiciels
10
TABLE 1.1. QUESTIONS DE RECHERCHES
|
RQ #
|
Questions de recherche
|
Motivation
|
|
RQ1
|
Quelles techniques d'apprentissage Automatique ont
été utilisées pour la prédiction des défauts
logiciels ?
|
Identifier les techniques d'apprentissage
qui sont utilisés dans la prédiction des
défauts logiciels.
|
|
RQ2
|
Quelles métriques sont couramment utilisées
dans la prédiction des défauts logiciels ?
|
Identifier les métriques couramment utilisées pour
la prédiction des défauts logiciels.
|
|
RQ3
|
Quelles métriques sont utiles pour la prédiction
des défauts logiciels ?
|
Identifier les métriques
Signalées comme approprié pour la prédiction
des défauts logiciels.
|
|
RQ4
|
Quelles bases de données sont utilisés pour la
prédiction des défauts logiciels?
|
Identifier les ensembles de données Déclarés
approprié pour la prédiction des défauts logiciels .
|
|
RQ5
|
Quelles mesures de performance sont utilisées pour la
prédiction des défauts logiciels ?
|
Évaluer la performance d'apprentissage automatique
techniques pour
|
|
RQ6
|
Quelles sont les forces et les faiblesses des
techniques
d'apprentissage automatique ?
|
Déterminez les informations sur techniques d'apprentissage
automatique.
|
RQ1 : Quelles sont les techniques
d'apprentissage automatique qui ont été utilisées pour la
prédiction des défauts logiciels ?
Chapitre 01 : Prédiction des défauts logiciels
11
Les techniques d'apprentissage automatique utilisées
pour la prédiction des défauts définie comme suit :
· Arber de décision (DT)
· Apprenants Bayésiens (BL)
· Apprenants ensemble (EL)
· les réseaux de neurones (NN)
· Machine à vecteur de support (SVM)
· Apprentissage basé sur des règles (RBL)
· Algorithmes évolutionnaires (EA)
· Divers (Miscellaneous)
RQ2 : Quelles métriques sont couramment
utilisées dans la prédiction des défauts logiciels ?
Afin de prédire la propension aux pannes [6], les
études primaires utilisent des mesures logicielles comme variables
indépendantes. Il existe un certain nombre de mesures utilisées
dans le domaine du génie logiciel pour quantifier les
caractéristiques d'un logiciel. Nous définissons la
catégorisation des études primaires sélectionnées
en fonction du type de métrique utilisé par ces études
pour prédire la sensibilité aux pannes comme suit :
· Études utilisant des métriques
procédurales : Ces études utilisent des métriques
qui incluent les métriques de code statique traditionnelles qui sont
définies par Halstead et McCabe ainsi que les métriques de taille
telles que la métrique LOC (Lines of Code). [6]
· Études utilisant des métriques
orientées objet : Ces études utilisent des
métriques qui mesurent divers attributs d'un logiciel orienté
objet (OO) comme la cohésion, le couplage et l'héritage pour une
classe orienté objet. Bien que LOC soit une métrique
traditionnelle, de nombreuses études incluent également LOC ou
SLOC (Source Lines of Code) tout en utilisant des métriques
orienté objet [6]
· Études utilisant des métriques
hybrides : Certaines études utilisent à la fois des
métriques orienté objet et des métriques
procédurales pour la prédiction de défauts.
· Mesures diverses (Miscellaneous): ces
études incluent des mesures telles que les mesures d'exigence, les
mesures de changement, les mesures de réseau extraites du graphique de
dépendance, les mesures de désabonnement, le glissement des
erreurs par les mesures, les mesures de processus, l'âge du fichier, la
taille, les changements et les erreurs des mesures des versions
précédentes, les métriques élémentaires
d'évolution de la conception et autres
RQ4 : Quels Base de données sont
utilisés pour la prédiction des défauts logiciels ?
Chapitre 01 : Prédiction des défauts logiciels
12
métriques diverses qui ne peuvent pas être
regroupées en tant que métriques procédurales ou
orienté objet. [6]
Les métriques procédurales sont les
métriques les plus couramment utilisées (51%) dans les
études primaires sélectionnées [6]. Un certain nombre de
métriques orienté objet ont également été
utilisées pour la prédiction des défauts logiciels et la
collection de métriques la plus couramment utilisée a
été définie par Chidamber et Kemerer qui a
été utilisée dans les 28% des études qui utilisent
des métriques orienté objet.
RQ3 : Quelles sont les métriques utiles
pour la prédiction des défauts logiciels ?
Certaines études rapportent des métriques
orienté objet qui sont fortement corrélées à la
prédisposition aux défauts. Les métriques orienté
objet jugées utiles pour la prédiction des défauts
logiciels. CBO (Coupling Between Objects), RFC (Response for a Class) et LOC
sont des métriques très utiles pour la prédiction des
défauts logiciels utilisant des méthodes de sélection de
caractéristiques. Cependant, les études utilisant des techniques
d'extraction de caractéristiques n'ont pas clairement
spécifié des métriques utiles pour la prédiction
des défauts logiciels.
En ce qui concerne l'utilité des métriques
procédurales, les études ne donnent pas de résultat
concluant car les études primaires ne comparent pas l'utilité de
métriques procédurales spécifiques. [6]

Figure 1.2. Métriques Orienté objet utiles pour
la prédiction des défauts logiciels [6]
Chapitre 01 : Prédiction des défauts logiciels
13
Divers ensembles de données ont été
utilisés dans les études de prédiction de défauts
logiciels. Les ensembles de données utilisés peuvent être
accessibles au public ou de nature privée. Les ensembles de
données publics sont disponibles gratuitement tandis que les ensembles
de données privés ne sont pas partagés par les chercheurs
et les résultats sur ces ensembles de données ne peuvent donc pas
être vérifiés et ces études ne sont pas
reproductibles [6]. Les principaux ensembles de données utilisés
et leur catégorisation sont les suivants :
- Ensembles de données de la NASA :
Ces ensembles de données sont accessibles au public dans le
référentiel de la NASA par le programme de données de
métriques de la NASA et sont les ensembles de données les plus
couramment utilisés pour SFP. Ils sont utilisés dans 60% des
études primaires sélectionnées.
- Ensembles de données du
référentiel PROMISE : Ces données sont librement
accessibles au public dans le référentiel PROMISE [51] et
comprennent des ensembles de données SOFTLAB, des ensembles de
données du logiciel Jedit ainis que d'autres ensembles de
données. Ils sont utilisés dans 15% des études primaires
sélectionnées.
- Ensemble de données Eclipse :
environ 12% des études ont utilisé l'ensemble de
données Eclipse, qui est un projet open source dont l'ensemble de
données sur les défauts est accessible au public. Ce projet est
un environnement de développement intégré
développé en langage Java.
- Ensembles de données de projet Open Source :
cette catégorisation implique des études qui utilisent
d'autres projets open source tels que Lucene, Xylan, Ant, Apache, POI, etc.,
Ils sont utilisés par environ 12% des études.
- Ensemble de données étudiantes :
il s'agit d'un logiciel académique développé par
les étudiants.
- Autres : Cette catégorie comprend
certains ensembles de données industriels et privés comme celui
d'une banque commerciale, une application commerciale Java, un ensemble de
données d'entreprise de télécommunications, etc. Ils sont
utilisés par environ 9% des études.
Chapitre 01 : Prédiction des défauts logiciels
14

Figure 1.3. Ensembles de données utilisés pour la
prédiction des défauts logiciels [6]
RQ5 : Quelles mesures de performance sont
utilisées pour la prédiction des défauts logiciels ?
Un certain nombre de mesures sont utilisées pour
évaluer les performances de différents modèles de
prédiction de défauts logiciels [6]. Ces mesures de performance
sont utilisées pour comparer et évaluer les modèles
développés à l'aide de diverses techniques d'apprentissage
automatique et statistiques. La détection d'anomalies est
évaluée en analysant les anomalies qui ont été
incorrectement ou correctement détectées comme un comportement
anormal ou normal. Les méthodes qui nous intéressent pour la
détection des anomalies sont la classification et le clustering.
Les résultats attendus et les résultats obtenus
par la prédiction (apprentissage supervisé ou non
supervisé) sont alors organisés dans une matrice de confusion
composées des métriques principales suivantes :
- Vrai négatif ou True Negative (TN) : est le nombre de
non-défectueux cas classés non-défectueux.
- Vrai positif ou True Positive (TP) : est le nombre de cas
défectueux classés comme défectueux.
- Faux positif ou False Positive (FP) : est le nombre de cas
non-défectueux classés comme défectueux.
- Faux négatif ou False Négative (FN) : est le
nombre de cas défectueux classé non-défectueux. TABLE 1.2.
MATRICE DE CONFUSION [7]
Chapitre 01 : Prédiction des défauts logiciels
15
|
Positifs
Réels
|
Négatifs
Réels
|
|
Positifs Prédits
|
TP
|
FP
|
|
Négatifs Prédits
|
FN
|
TN
|
Plusieurs indicateurs peuvent être dérivés
de ces principaux indicateurs. Parmi Celles utilisées dans notre
domaine, on retrouve l'exactitude (accuracy), la précision, Le rappel
est également appelé taux de vrais positifs (TVP).
- L'exactitude (Accuracy) :
C'est le rapport entre les sujets correctement
étiquetés et l'ensemble des sujets. L'accuracy est la plus
intuitive. Il s'agit de l'indicateur le plus naturel et le plus évident
permettant d'évaluer les performances d'un système de
classification. Cette valeur simple à calculer, correspond au
pourcentage d'éléments correctement identifiés par le
système. [8]
|
Accuracy =
|
TP + TN
|
(1)
|
|
TP+TN+FP+FN
|
|
- Mesure (F1-score) : La F-mesure correspond
à une moyenne harmonique de la précision et du rappel.
- La Précision :
C'est le nombre de vrais positifs divisé par le nombre de
vrais positifs et faux positifs.
- Le Rappel (TVP): Le rappel est le nombre de
vrais positifs divisé par le nombre de vrais positifs et le nombre de
faux négatifs.
Chapitre 01 : Prédiction des défauts logiciels
16
(2 * Rappel * Précision)
(4)
F1 - score =
(Rappel + Précision)
Le paramètre â permet de pondérer la
précision ou le rappel et vaut généralement 1.
L'avantage de ce choix est que lorsque la précision est
égale au rappel, on obtient : Précision = Rappel = F1-mesure.
Ceci facilite la lecture et on recherche à maximiser la F1-mesure en
maximisant simultanément la précision et le rappel [8].
- Sensibilité et spécificité
:
La sensibilité d'un test mesure sa capacité
à donner un résultat positif lorsqu'une hypothèse est
vérifiée. Elle s'oppose à la spécificité,
qui mesure la capacité d'un test à donner un résultat
négatif lorsque l'hypothèse n'est pas vérifiée [8].
Elle est donnée par :
|
Sensibilité =
|
TP
|
(5)
|
|
TP + FN
|
|
Une mesure de la sensibilité s'accompagne toujours d'une
mesure de spécificité qui est donnée par :
|
Spécificité =
|
TN
|
(6)
|
|
TN+FP
|
|
RQ6 : Quelles sont les forces et les faiblesses
des techniques d'apprentissage automatique ?
Dans cette section, nous décrivons les forces et les
faiblesses présentées par les techniques d'apprentissage
automatique.
Il a été rapporté que la technique NB
(naïve bayes) présente de bonnes performances dans les
problèmes de prédiction de défauts et est également
efficace pour gérer plusieurs ensembles de données avec des
propriétés variables. Dans le même temps, cette technique
ne tient pas compte de la corrélation entre les caractéristiques
de l'entrée et les performances de la technique
Chapitre 01 : Prédiction des défauts logiciels
17
naïve bayes varient fortement en fonction de la technique
de sélection d'attribut utilisée. La machine a vecteur de support
SVM a été applaudi pour son excellente capacité à
gérer les caractéristiques redondantes. L'algorithme de forets
aléatoires est simple dans sa mise en oeuvre et fournit de bons
résultats, c'est donc un bon moyen d'inclure la puissance de
l'apprentissage automatique dans ses recherches sans trop de frais
généraux. [6]
Généralement, différentes techniques ont
des avantages différents et il n'y a pas de solution universelle au
problème de la prédiction des défauts logiciels. Tout
dépend du domaine d'application, dans une situation où les faux
positifs sont fatals, favoriserait certaines techniques par rapport à
une situation où le coût est un facteur.
Récemment, des techniques d'apprentissage profond ont
été développées et qui ont prouvées leurs
efficacités dans de nombreux domaines. Ces techniques ont plusieurs
avantages (Données non structurées, système
d'apprentissage autonome, algorithme basé sur le réseau neuronal
d'algorithmes, identifie automatique des caractéristiques
discriminantes...etc.) mais malheureusement jusqu'à présent
seulement peut de travaux ont été publiés. [6]
Dans le tableau 1.2 nous allons résumer quelques
travaux et l'état de l'art. Nous présentons dans ce tableau, les
bases de données utilisées, les techniques d'apprentissage
automatique utilisées ainsi que les résultats obtenus par ces
travaux.
TABLE 1.3. PREDICTION DES DEFAUTS LOGICIELS : ETAT DE L'ART
|
Reference
|
Dataset
|
ML
|
Accuracy
|
[9]
|
PROMISE
|
Random Forest
|
PC3=0.96
|
|
dataset
|
|
MW1= 0.95
|
|
|
|
KC1= 0.92
|
|
|
|
PC4= 0.89
|
|
|
|
CM1= 0.93
|
[10]
|
C/C++ programs within
|
LSTM
|
0.92
|
|
Code4Bench.
|
RF
|
0.85
|
[11]
|
real test-and-
|
ANN
|
DS1= 0.938
|
|
debug data
|
|
DS2=0.954
|
|
|
|
DS3= 0.963
|
|
|
RF
|
DS1= 0.951
|
|
|
|
DS2=0.972
|
|
|
|
DS3=0.990
|
|
|
DT
|
DS1= 0.989
|
|
|
|
DS2=0.950
|
|
|
|
DS3=0.954
|
[12]
|
|
NASA Dataset
|
DBN
|
JW1= 0.785
|
|
|
|
|
MC1=0.977
|
|
|
|
M= 0.648
|
Chapitre 01 : Prédiction des défauts
logiciels 18
|
|
|
PC1= 0.913
|
|
LR
|
JW1=0.788 MC1=0.973 M=0.664 PC1=0.894
|
|
RF
|
JW1=0.778 MC1=0.977 M=0.688 PC1=0.909
|
|
SVM
|
JW1= 0.790 MC1= 0.977 M= 0.680 PC1= 0.913
|
|
PROMISE Dataset
|
DBN
|
XALAN V2.6= 0.536 ANT V 1.7= 0.77 JEDIT V4.0= 0.755 LOG4J V1.0=
0.748
|
|
LR
|
XALAN V2.6= 0.733 ANT V 1.7= 0.820 JEDIT V4.0= 0.755 LOG4J V1.0=
0.733
|
|
RF
|
XALAN V2.6= 0.743 ANT V 1.7= 0.815 JEDIT V4.0= 0.780 LOG4J V1.0=
0.759
|
|
SVM
|
XALAN V2.6= 0.731 ANT V 1.7= 0.813 JEDIT V4.0= 0.768 LOG4J V1.0=
0.756
|
|
AEEEM Dataset
|
DBN
|
LC=0.907 JDT= 0.793 PDE=0.86 ML= 0.868
|
|
LR
|
LC= 0.841 JDT= 0.856 PDE= 0.856 ML= 0.861
|
|
RF
|
LC= 0.917 JDT= 0.840 PDE= 0.864 ML= 0.865
|
|
SVM
|
LC= 0.907 JDT= 0.849 PDE= 0.861 ML= 0.869
|
|
RELINK Dataset
|
DBN
|
Apache= 0.448 Safe= 0.607 Zxing= 0.704
|
|
LR
|
Apache= 0.624 Safe= 0.732 Zxing= 0.679
|
|
RF
|
Apache= 0.691 Safe= 0.705 Zxing= 0.679
|
|
SVM
|
Apache= 0.660 Safe= 0.571 Zxing= 0.692
|
|
[13]
|
|
SVM
|
AR1= 0.81 AR3= 0.625
|
Chapitre 01 : Prédiction des défauts logiciels
19
|
SOFTLAB dataset
|
|
AR5= 0.833
|
|
DT
|
AR1= 0.901
|
|
|
|
AR3= 0.906
|
|
|
|
AR5= 0.778
|
|
|
BPNN
|
AR1= 0.918
|
|
|
|
AR3= 0.906
|
|
|
|
AR5= 0.702
|
|
|
RF
|
AR1= 0.946
|
|
|
|
AR3= 0.947
|
|
|
|
AR5= 0.818
|
4. Conclusion
Les techniques d'apprentissage automatique se sont
avérés être des techniques de pointe pour des
problèmes de prédiction des défauts logiciels. Cela permet
au gestionnaire de logiciel d'allouer efficacement les ressources du projet
vers les modules qui nécessitent plus d'efforts. Cela permettra
éventuellement aux développeurs de corriger les bogues avant de
livrer le produit logiciel aux utilisateurs finaux.
Dans ce chapitre d'état de l'art on essayer d'exposer
les processus de prédiction des défauts logiciels. Nous avons
aussi présenté la question de recherches qui ont posé lors
de la réalisation de notre approche et nous avons clôturé
le chapitre par des travaux proposés dans la littérature
utilisant des différentes techniques d'apprentissage automatique dans la
tâche de prédiction.

Chapitre 02 : Apprentissage

Automatique
Chapitre 2 : Apprentissage automatique 20
1. Chapitre 2 : Apprentissage automatique 21
Introduction
Depuis 1956, l'intelligence artificielle (IA) en tant que
domaine scientifique a représenté un ensemble de théories
et de technologies. Des programmes informatiques complexes ont
été développés capables de simuler certaines
caractéristiques de l'intelligence humaine (inférence,
apprentissage, etc.). I'IA couvre toutes les disciplines, où se
côtoient philosophes, psychologues, informaticiens et autres qui
s'intéressent aux divers problématiques de l'intelligence.
L'apprentissage automatique constitue un domaine de recherche
très important en intelligence artificielle, qui permet aux ordinateurs
d'apprendre sans programmation explicite. Cependant, pour apprendre et se
développer, les ordinateurs ont toutefois besoin de données
à analyser et sur lesquelles s'entraîner. L'apprentissage
automatique peut être défini comme l'étude des algorithmes
qui apprennent à partir d'un ensemble d'échantillons
observés pour prédire les valeurs d'échantillons
invisibles. Ces algorithmes ont récemment gagné un grand
intérêt et sont davantage appliqués dans les produits et
services en raison de l'augmentation de la puissance de calcul, de la
disponibilité de techniques d'apprentissage automatique open source et
de vastes quantités de données
Parmi les techniques d'apprentissage automatique les plus
importantes, l'apprentissage en profondeur qui permet de modéliser les
méthodes d'apprentissage automatique de manière très
abstraite, et les données sont acquises via des architectures
articulées de différentes transformations non
linéaires.
Dans le cadre de ce chapitre, nous allons détailler
les concepts de base de l'apprentissage automatique ainsi que ses
différentes techniques et les algorithmes utilisés dans chaque
type. Ensuite, nous allons présenter l'apprentissage en profondeur tout
en mettant l'accent sur le fonctionnement des Réseaux de Neurones
à Convolution qui sont utilisés dans notre travail.
2. Apprentissage supervisé 2.1.
Définition
L'apprentissage supervisé est une classe technique
d'apprentissage automatique (le plus fréquemment utilisé)
où l'on cherche à produire automatiquement des règles
à partir d'une base de données d'apprentissage contenant des
échantillons déjà étiquetés
[16].
Chapitre 2 : Apprentissage automatique 22
En d'autres termes, l'apprentissage supervisé vise
à estimer une fonction f: x - y telle que la sortie d'un objet de test
xi (qui n'a pas été traité pendant la phase
d'apprentissage) peut être prédit avec une grande
précision. L'apprentissage supervisé peut être
formulé de la manière suivante :
Une instance xi signifie un objet spécifique, elle est
typiquement représentée par un vecteur de caractéristique
de dimension D, X = {xi}i=1
?? avec D E RD et les Yi =
{y?? i }??=1
?? représentent les étiquettes de classe de
l'iémeobjet. K est le nombre de variables
de sortie que peut avoir un objet d'entrée (Si
Y est une valeur discrète, on parle de
classification, et Si Y est une valeur continue, on
parle de régression) [10].
Dans l'apprentissage supervisé, un ensemble d'exemples,
« l'ensemble d'apprentissage », est soumis à l'entrée
du système pendant la phase d'apprentissage. Par la suite, chaque
entrée est étiquetée avec une valeur de sortie
désirée [17]. La figure 2.1 illustre le
processus d'apprentissage supervisé.

Figure 2.1. Processus d'apprentissage supervisé
[17].
2.2. Les Techniques D'apprentissage supervisé
2.2.1. Machine à Vecteur de Support
Machine à Vecteur de Support (en anglais : Support
Vector Machine (SVM)) est un algorithme d'apprentissage supervisé, le
principe derrière cet algorithme est d'utiliser une ligne pour
séparer les données en plusieurs catégories, de sorte que
la distance entre les différents types de données et la
frontière qui les sépare soit maximale [18]. Cette distance est
également appelée «marge» définie comme la
distance entre le point le plus proche et l'hyperplan de séparation.
Pour un hyperplan H on a :
Chapitre 2 : Apprentissage automatique 23
Marge(H) = min d (x??, H) (1)
????
Les SVM linéaires cherchent le séparateur
(l'hyperplan de séparation) qui maximise la marge et on appelle cela
« séparateur à vaste marge » [18].
L'hyperplan de marge maximale est obtenu en utilisant
l'équation (2) :
|
??
??(x) = ?w??x??+ b=
|
???,??? + b
|
(2)
|
??=1
Le vecteur de support est la donnée la plus proche de
la limite. Si ???? est un vecteur de support et H = { w . x + b =
0}, alors la marge est donnée par l'équation (3) :
|
Marge = 2
|
| w .x?? + b| (3)
||w||
|

Figure 2.2. Séparateur à vaste marge [19].
Pour que le classifieur SVM puisse trouver cette
frontière, il est nécessaire de lui donner des données
d'apprentissage. En l'occurrence, on donne au classifieur SVM un ensemble de
points. A partir de ces données, le classifieur SVM estimera la position
la plus raisonnable de la frontière [18].
Une fois la phase d'apprentissage est terminée, le
classifieur SVM a ainsi trouvé, à partir de données
d'apprentissage, l'emplacement supposé de la frontière. En
quelque sorte, il a « appris» l'emplacement de la frontière
grâce aux données d'apprentissage et il est maintenant capable de
prédire à quelle catégorie appartient une entrée
qu'il n'avait jamais vue avant, et sans intervention humaine [18][19].
Chapitre 2 : Apprentissage automatique 24
2.2.2. Réseaux de neurones artificiels
(ANN)
Un réseau de neurones artificiels (en anglais :
Artificial Neural Network (ANN)) est un modèle de calcul pour effectuer
des tâches telles que la prédiction, la classification, la prise
de décision, etc [20]. Comme l'indique la partie «neurale» de
son nom, c'est un système inspiré du cerveau conçus pour
imiter la façon dont nous, les humains, apprenons.
Les réseaux de neurones artificiels ont une fonction
d'auto-apprentissage, et lorsque plus de données sont obtenues, ils
peuvent produire de meilleurs résultats. Un réseau de neurones
artificiels est un ensemble de plusieurs perceptrons / neurones sur chaque
couche. Le classifieur ANN est également appelé réseau de
neurones à action directe, car l'entrée n'est traitée que
dans un sens direct [20].
Un réseau neuronal se compose de trois couches. La
première couche est la couche d'entrée. Elle contient des
neurones d'entrée qui envoient des informations à la couche
cachée. Cette dernière effectue les calculs sur les
données d'entrée et transfère la sortie vers la couche de
sortie. Elle comprend le poids, la fonction d'activation et la fonction de
coût [21]. L'architecture des réseaux de neurones artificiels est
présentée dans la Figure ci-dessous :

Figure 2.3. Réseaux de neurones artificiels.[21]
2.2.3. Les forêts d'arbres décisionnels
Les forêts d'arbres décisionnels (en anglais :
Random forest (RF)) est un algorithme d'ensemble ayant un ensemble
différent d'hyperparamètres et entraînés sur
différents
Chapitre 2 : Apprentissage automatique 25
sous-ensembles de données, largement utilisé
dans la régression, la classification et d'autres tâches.
L'algorithme crée un certain nombre d'arbres de décision et les
combine en un seul modèle. Pour les problèmes de classification,
la prédiction finale faite par l'algorithme est basée sur un vote
majoritaire de tous les arbres où chaque arbre fait une
prédiction de classe [23].
Une sélection aléatoire de
caractéristiques est utilisée lors de la croissance des arbres et
de la division de chaque noeud. Dans l'algorithme standard, l'ensemble de
caractéristiques est vérifié à chaque noeud pour
trouver la caractéristique la plus importante à diviser. En
revanche, pour diviser chaque noeud dans la forêt, un sous-ensemble
aléatoire de m <M caractéristiques est
considéré, où M est le nombre total
d'entités [22]. La meilleure façon de
déterminer combien d'arbres sont nécessaires est de comparer les
prédictions faites par une forêt aux prédictions faites par
un sous-ensemble d'une forêt. Lorsque les sous-ensembles fonctionnent
ainsi que la forêt complète, cela indique qu'il y a suffisamment
d'arbres [23].
La figure 2.4 montre comment un exemple est classé en
utilisant n arbres où la prédiction finale est faite en
prenant un vote de tous les n arbres.

Figure 2.4. Les Forêts d'Arbres Décisionnels
[23]
3. Apprentissage non supervisé
3.1. Définition
L'apprentissage non supervisé est une classe technique
d'apprentissage automatique où les exemples d'apprentissage fournis par
le système ne sont pas étiquetés avec la classe
Chapitre 2 : Apprentissage automatique 26
d'appartenance. Il s'agit d'extraire des classes ou groupes
d'individus présentant des caractéristiques communes.
L'apprentissage non supervisé est un problème plus difficile que
l'apprentissage supervisé en raison de l'absence d'un objectif bien
défini indépendant de l'utilisateur. [17]
Étant donné un vecteur de caractéristique
?? = {????}?? =??=1
?? , et une mesure de similarité entre des
paires de vecteur k : ?? × ?? ? R. Le but de
l'apprentissage non supervisé est de partitionner l'ensemble de telle
sorte que les objets au sein de chaque groupe soient plus semblables les uns
aux autres que les objets entre les groupes [17]. La figure
2.5 représente le déroulement du processus d'apprentissage non
supervisé.

Figure 2.5. Apprentissage non supervisé
[17].
3.2. Les techniques d'apprentissage non supervisé
3.2.1. L'algorithme K-moyennes
L'algorithme K-moyennes (en anglais : K-means) est un
algorithme de clustering qui tente de regrouper les observations en
différents clusters. Plus précisément, le but de cet
algorithme est de minimiser les différences au sein des clusters et de
maximiser les différences entre les clusters [24].
L'entrée de cet algorithme est composée du
nombre de clusters et l'ensemble de données non étiqueté.
C'est un outil de partitionnement des données non-hiérarchique
qui permet de répartir les données en clusters
homogènes [24]. Pour cela, il cherche à minimiser la
variance interclasse :
Chapitre 2 : Apprentissage automatique 27
1 ??
? ???? -????????
??=
?
???? ??=1 ???????
2 (4)
Pour effectuer un regroupement, la première
étape consiste à spécifier le nombre de clusters (K).
Ensuite, l'algorithme K-moyennes attribuera chaque observation à
exactement l'un des K-clusters. C'est un problème mathématique
assez simple et intuitif
[25].
3.2.2. Classification hiérarchique
C'est une méthode de classification itérative
automatique utilisée en analyse des données. L'objectif est de
créer une décomposition ou un regroupement hiérarchique
des objets ou des clusters les plus proches en fonction de certaines
conditions. Cette méthode est basée sur le calcul de la distance
et est organisée sous la forme d'une structure arborescente[26]. Il
existe deux niveaux de méthodes :
- Le clustering hiérarchique ascendant
(agglomératif) : est une méthode de classification
automatique utilisée pour analyser les données d'un groupe de
n individus, afin d'assigner ces individus à un certain nombre
de catégories, nous pouvons utiliser la distance pour mesurer la
différence. [26]
- Le clustering hiérarchique descendant (divisif)
: Les méthodes de cette catégorie commencent avec un seul
cluster qui contient toutes les données, puis les divisent selon des
critères à chaque étape jusqu'à ce qu'un ensemble
de clusters différents soit obtenu
[26].
3.2.3. Algorithme
d'espérance-maximisation
L'algorithme d'espérance-maximisation (en anglais :
Expectation Maximization (EM)) est une classe d'algorithmes qui permettent
principalement de trouver le maximum de vraisemblance des paramètres de
modèles probabilistes lorsque le modèle dépend de
variables latentes non observables dans le cadre des problèmes
liés aux données incomplètes (consiste à associer
à un problème aux données incomplètes) [28].
L'algorithme EM se déroule en deux étapes :
- Étape d'Expectation : Dans cette phase
l'algorithme peut estimer des données inconnues en considérant et
en comprenant les données observées et les valeurs des
paramètres déterminées lors de l'itération
précédente [27].
Chapitre 2 : Apprentissage automatique 28
Étape de Maximisation : Dans cette phase
l'algorithme maximise la vraisemblance en utilisant l'estimation des
données inconnues de l'étape précédente et met
à jour les valeurs des paramètres pour l'itération
suivante [27].
4. Apprentissage profond
4.1. Définition
L'apprentissage profond est une branche récente de
l'apprentissage automatique, dans laquelle les machines peuvent apprendre par
elles-mêmes. L'apprentissage profond utilise l'apprentissage
supervisé une technique qui consiste à fournir à un
programme des milliers de données étiquetées, qu'il devra
apprendre à reconnaître (voir section 2.2). L'apprentissage en
profondeur est basé sur des déclarations similaires qui imitent
les méthodes d'apprentissage que les humains utilisent pour
acquérir certains types de connaissances, tandis que les modèles
d'apprentissage en profondeur sont basés sur des réseaux de
neurones artificiels (voir section 2.2).[29]
L'apprentissage profond a été appliqué
dans plusieurs domaines et a prouvé son efficacité notamment dans
: domaine médical où certains programmes qui utilisent
l'apprentissage profond sont parfois plus fiable que l'analyse humaine [31],
domaine scientifique [32], domaine de l'automobile [33], de l'industrie [34],
le domaine militaire (45) ...etc. [30]
La différence entre les techniques traditionnelles de
l'apprentissage automatique et l'apprentissage profond est que dans les
techniques traditionnelles l'extraction des caractéristiques pertinentes
se fait manuellement (en utilisant des techniques d'extraction des
caractéristiques), contrairement à l'apprentissage profond, les
données brutes font l'entrée du réseau et l'extraction des
caractéristiques se fait d'une manière automatique à
l'intérieur du réseau.
4.2. Les réseaux de neurones
convolutifs
L'idée de base des réseaux de neurones
convolutifs appelé aussi ConvNets (en anglais : Convolutional Neural
Network (CNN)) s'inspire d'un concept de biologie appelé champ
réceptif. Les champs réceptifs sont une caractéristique du
cortex visuel animal. Ils agissent en tant que détecteurs sensibles
à certains types de stimulus, par exemple, les bords. Les neurones de
cette zone du cerveau sont arrangés de manière à ce
qu'ils
Chapitre 2 : Apprentissage automatique 29
correspondent à des zones qui se chevauchent lors du
pavage du champ. Cette fonction biologique peut être approchée par
ordinateur en utilisant l'opération convolutif [35].
4.2.1. Présentation
Un réseau de neurone convolutif est une forme
spéciale de réseaux de neurones convolutif conçue pour
traiter des données avec plusieurs tableaux et topologies en forme de
grille. Ce classifieur Convolutif a connu un énorme succès et il
a de large applications pratiques, y compris la reconnaissance vocale [37], la
classification d'images [38] le traitement du langage naturel [39] et autres
domaines. Désignés par l'acronyme CNN, il comporte deux parties
bien distinctes : (i) une partie convolutive du modèle, (ii) une partie
classification du modèle qui correspond à un modèle MLP
(Multi Layers Perceptron). Récemment, il a été
découvert que le classifieur CNN possède également
d'excellentes capacités d'analyse de séquences de données
[36]. En général, CNN se compose de couches
convolutives et de regroupements (sous-échantillonnage) et suivies d'une
ou plusieurs couches entièrement connectées, ces couches
empilées les unes sur les autres pour former un modèle profond.
Les couches convolutives apprennent les représentations des
entités de leur entrée et les neurones sont organisés en
une carte de caractéristiques (feature map) [40].
CNN a montré le potentiel pour résoudre les
problèmes dans plusieurs domaines notamment dans le domaine du
génie logiciel [41]. Un réseau CNN
présente deux caractéristiques clés qui sont une
connectivité clairsemée et des poids partagés et ses
paramètres sont appris à l'aide de la rétro-propagation.
Le réseau se distingue de l'architecture traditionnelle avec deux
aspects : la connectivité locale et le partage des paramètres.
Les cellules de la couche cachée du CNN ne sont connectées
qu'à un petit nombre de cellules, correspondant à la zone locale
de l'espace. Ce processus réduit le nombre de paramètres dans le
réseau, la charge mémoire et le risque de sur-apprentissage. De
plus, CNN réduit également le nombre de paramètres
d'apprentissage en partageant la même fonction de base
(c'est-à-dire le filtre de convolution) à différentes
positions de l'image [36].
Un réseau CNN typique a une couche d'entrée et
une couche de sortie, ainsi que plusieurs couches cachées. Les couches
cachées d'un CNN se composent généralement d'une
série de couches convolutives. ReLU est une fonction d'activation
typique, qui est
Chapitre 2 : Apprentissage automatique 30
normalement suivie par des opérations
supplémentaires telles que la mise en commun des couches, des couches
entièrement connectées et des couches de normalisation. La
rétro-propagation est utilisée pour la distribution des erreurs
et l'ajustement du poids. La figure 2.6 illustre la structure de CNN. [42]

Figure 2.6. Architecture de réseau de neurones convolutifs
[43]
4.2.2. Blocs de construction
L'architecture du CNN se compose d'un ensemble de couches de
traitement indépendantes, Chaque couche reçoit des données
d'entrées et produit des nouvelles données en sortie. Ici, nous
discuterons en détail le fonctionnement des différentes couches
du CNN.
4.2.2.1. Couche de convolution
La couche de convolution est le bloc de construction de base
d'un CNN. Son but est de repérer la présence d'un ensemble de
caractéristiques (éléments ou patterns) dans les
images reçues en entrée. La convolution est une opération
mathématique pour fusionner deux ensembles d'informations,
appliquée sur les données d'entrée à l'aide d'un
filtre de convolution pour produire une carte de caractéristiques. Le
principe est de faire "glisser" une fenêtre représentant
les caractéristiques sur l'image, et de calculer le produit de
convolution entre la caractéristique et chaque portion de
l'image balayée. Une caractéristique est alors vue comme
un filtre : les deux termes sont équivalents dans ce
contexte[44][45].
On distingue trois hyper-paramètres utilisés
pour déterminer le volume de la couche de convolution :
Chapitre 2 : Apprentissage automatique 31
- la profondeur de la couche c'est le nombre des noyaux
de convolution (ou
nombre de neurones associés à un même champ
récepteur)[5]
- le pas qui contrôle le chevauchement des
champs récepteurs. Plus le pas est petit,
plus les champs
récepteurs se chevauchent et plus le volume de sortie sera grand[5] .
- la marge, parfois, il est commode de mettre des
zéros à la frontière du volume
d'entrée. La
taille de ce zero-padding est le troisième hyper-paramètre. Cette
marge permet de contrôler la dimension spatiale du volume de sortie. En
particulier, il est parfois souhaitable de conserver la même surface que
celle du volume d'entrée [5].

Figure 2.7. Couche de convolution [35].
Dans une couche de convolution un produit de convolution est
appliqué qui consiste à multiplier chaque pixel du filtre par la
valeur du pixel correspondant dans l'image. Ensuite, les résultats sont
additionnés et divisés par le nombre total des pixels du filtre.
Ce produit de convolution sert à extraire des caractères
spécifiques dans l'image traitée [35].
L'opération de convolution est illustrée dans la figure
ci-dessous :

Figure 2.8. L'opération de convolution
[35]
Chapitre 2 : Apprentissage automatique 32
Contrairement aux méthodes traditionnelles, les
caractéristiques ne sont pas prédéfinies selon
une forme spécifique, mais sont apprises par le réseau lors de la
phase d'apprentissage. Le noyau du filtre fait référence au poids
de la couche convolutive. Ils sont initialisés puis mis à jour
par rétropropagation du gradient. C'est là que
réside l'avantage des réseaux de neurones convolutifs : ils
peuvent déterminer les éléments discriminants de
l'entrée en s'adaptant à la question posée. Par exemple,
si le problème est de faire la distinction entre les chats et les
chiens, des caractéristiques définies automatiquement peuvent
décrire la forme des oreilles ou des pattes [45].
4.2.2.2. Couche de pooling
Après l'opération de convolution, un
regroupement est effectué généralement pour réduire
la dimensionnalité (pooling). Cette couche située entre deux
couches convolutives, elle reçoit en entrée plusieurs feature
maps, et applique une opération de maximum locale (Max Pooling)
à chacune d'entre elles l'opération de pooling. Pour
cela, elle divise une carte de caractéristiques en petites
fenêtres de même taille qui peuvent se recouvrir. En fait, seule la
valeur maximale est conservée dans chaque fenêtre. Par
conséquent, la couche de pooling produit donc en sortie une carte de
caractéristiques plus petite, ce qui permet de réduire le nombre
des paramètres et de calculs dans le réseau et de contrôler
également le sur-apprentissage (overfitting) [45]. On distingue
principalement trois types de pooling :
- Le max pooling : C'est le type le plus
utilisé car il est rapide à calculer et permet
de simplifier efficacement l'image, qui revient à
prendre la valeur maximale de la sélection. [46].
- Le mean pooling (ou average pooling), Soit la
moyenne des pixels sélectionnés
: on calcule la somme de
toutes les valeurs puis on divise par le nombre de valeurs. Nous avons donc
obtenu une valeur intermédiaire pour représenter ce lot de
pixels. La mise en commun moyenne utilise uniquement la réduction de
dimensionnalité comme mécanisme de suppression du bruit [46].
- Le sum pooling est la moyenne sans avoir
divisé par le nombre de valeurs (on ne
calcule que leur somme)
[46].
Chapitre 2 : Apprentissage automatique 33

Figure 2.9. Type de pooling [46].
D'un autre côté, la différence entre le
pooling max et le pooling moyen est plus évidente (et importante) : en
termes de nature, le pooling max aura tendance à retenir les
caractéristiques les plus importantes et les plus simples dans la
sélection des pixels. Au contraire, le pool moyen est une valeur
moyenne, et seules les caractéristiques moins significatives
apparaîtront [45].
4.2.2.3. Couche de correction (ReLU)
ReLU (abréviation de Unité Linéaire
Rectifiée) désigne la fonction réelle non-linéaire.
ReLU remplace toutes les valeurs négatives sur la carte des
caractéristiques par des zéros comme le montre la figure (2.10)
ci-dessous. Donc l'objectif de ReLU est d'introduire la
non-linéarité dans notre ConvNet, la plupart des données
du monde réel apprises par ConvNet sont non linéaires (la
convolution est une opération linéaire), la matrice est
multipliée et ajoutée élément par
élément, et les fonctions non linéaires (telles que ReLU)
sont introduites pour résoudre des problèmes non
linéaires[47][49].
La fonction d'activation ReLU est une fonction dite «
rectifier » très utilisée en Deep Learning [46].
Définie par??(??) = max (0, ??). Dans les réseaux de neurones
convolutifs, il est souvent appliqué à la sortie d'une couche de
convolution pour les raisons suivantes :
· Comme mentionné ci-dessus, une convolution va
réaliser des opérations d'additions/multiplications, les valeurs
en sorties sont donc linéaires par rapport à celles en
entrées.
· ReLU, selon sa définition, est une fonction qui
vient briser (une partie de) la linéarité en supprimant une
partie des valeurs (toutes celles négatives) [46].
Chapitre 2 : Apprentissage automatique 34
· ReLU permet également d'accélérer
les calculs, en supprimant une partie des données.
· On ne modifie pas les données positives, ReLU
n'affectera pas les caractéristiques mises en évidence par la
convolution, au contraire : il les mettra davantage en évidence en
élargissant l'écart "entre" (valeur négative) entre les
deux caractéristiques[46].

Figure 2.10. La fonction d'activation ReLU [48]
La correction Relu [5] est préférable, mais il
existe d'autres fonctions sont également utilisées pour augmenter
la non-linéarité comme :
· La correction par tangente hyperbolique :
· La correction par la fonction sigmoïde :
??(??) = (1 +
??-??)-1 (6)
4.2.2.4. Le flattening
Dernière étape de la partie «extraction des
informations», flatening consiste à convertir les données en
un tableau à une dimension pour les saisir dans la couche suivante. Nous
aplatissons la sortie des couches convolutives pour créer un seul
vecteur de caractéristiques long [49].
Chapitre 2 : Apprentissage automatique 35

Figure 2.11. Mise à plat des images finales [46]
4.2.2.5. Couche entièrement
connectée
La couche entièrement connectée (en anglais :
Fully connected (FC)) reçoit donc un vecteur de nombres en entrée
et modifie ces valeurs pour produire un nouveau vecteur et renvoie des
probabilités pour chaque classe de prédiction. Les couches FC
sont typiquement présentes à la fin des architectures des CNN et
chaque noeud de la couche est connecté avec tous les neurones de la
couche précédente [45].
- Comment connait-on la valeur de ces poids ?
Le réseau de neurones convolutif apprend les valeurs
des poids de la même manière qu'il apprend les filtres de la
couche de convolution : lors de phase d'apprentissage, par
rétro-propagation du gradient.
La couche FC détermine la relation entre la position de
l'entité dans l'image et la classe. En fait, la table d'entrée
est le résultat de la couche précédente, qui correspond
à la carte d'activation d'une caractéristique donnée : des
valeurs élevées indiquent l'emplacement de la
caractéristique dans l'image (plus ou moins selon le regroupement).
[45]
4.2.2.6. Couche de perte
La couche de perte (LOSS) est la dernière couche dans
le réseau. Elle spécifie comment l'apprentissage du réseau
pénalise l'écart entre le signal prévu et le signal
réel. La sortie du neurone de la couche entièrement
connectée est convertie en probabilité par la fonction
d'activation "softmax". La perte softmax permettra de
générer un score de probabilité normalisé, la somme
des probabilités sera égale à 100%, soit 1. [50]
Chapitre 2 : Apprentissage automatique 36
4.2.3. Choix des hyperparamètres
Les réseaux de neurones convolutifs utilisent plus
d'hyperparamètres.
Essentiellement, tout paramètre que vous pouvez
initialiser (avant d'entraîner le modèle de réseau
neuronal) peut être considéré comme un
hyperparamètre
Au cours de chaque cas de test, différents
hyperparamètres seront modifiés pour vérifier leur effet
sur la précision et l'ajustement des hyperparamètres
dépend généralement de l'expérience que des
connaissances théoriques. Il n'y a pas de règles stables pour
choisir les bons paramètres, et le choix dépend de la taille de
l'ensemble de données d'entraînement et du type. Donc, Le
réglage des hyperparamètres est important pour choisir les
paramètres corrects afin d'obtenir les résultats
souhaités. Le choix des paramètres corrects est essentiel, mais
considéré comme une partie complexe de la formation en
réseau. [35]
4.2.3.1. Nombre de Filtres
Dans les réseaux de neurones, il existe des couches
pour effectuer des calculs. Chaque couche est constituée d'un nombre
spécifique de neurones. Ainsi, le nombre de filtres dans CNN est le
nombre de neurones présents dans un réseau neuronal. Chaque
neurone effectue une convolution différente Le nombre de filtres est le
nombre de neurones. Afin de rendre les calculs de chaque couche égaux,
le produit de la quantité de caractéristiques et du nombre de
pixels traités est généralement sélectionné
pour être approximativement constant entre les couches. [35]
4.2.3.2. Forme du filtre
La forme du filtre est très variable dans la
littérature. Ils sont généralement
sélectionnés en fonction de l'ensemble de données. Les
meilleurs résultats pour les images (28x28) se situent
généralement à moins de 5x5 du première couche,
tandis que les ensembles de données d'images naturelles
(généralement des centaines de pixels dans chaque dimension)
peuvent utiliser un filtre de première couche plus grand de 12 x 12 ou
même 15 x 15. Par conséquent, le défi est de trouver le bon
niveau de granularité pour créer des abstractions à la
bonne échelle et s'adapter à chaque situation. [35]
4.2.3.3. Forme du Max Pooling
La valeur typique est 2 × 2. Un volume d'entrée
très important peut justifier l'utilisation d'un pooling 4×4 dans
la première couche. Cependant, le choix d'une forme plus grande
Chapitre 2 : Apprentissage automatique 37
réduira considérablement la taille du signal et
peut entraîner la perte d'une trop grande quantité d'informations.
[35]
5. Conclusion
L'apprentissage automatique est devenu l'outil de choix pour de
nombreuses applications, regroupe les techniques permettant à une
machine d'adapter et d'améliorer ses performances par
l'expérience. Ces dernières années, le domaine
d'intelligence artificiel a connu un grand renouveau avec les techniques de
l'apprentissage profond, inspirées des réseaux de neurones du
cerveau qui a particulièrement fait parler de lui.
L'apprentissage profond et plus précisément les
réseaux de neurones convolutifs ont obtenus des performances
remarquables dans divers domaines. C'est pour ce succès que nous avons
choisis cet algorithme afin de l'appliqué dans la prédiction des
défauts logiciels.

Chapitre 03 : SFP-NN :
Apprentissage profond pour
la détection des défauts
logiciels
Chapitre 03 : SFP-NN : Apprentissage profond pour la
prédiction des défauts logiciels | 38
Chapitre 03 : SFP-NN : Apprentissage profond pour la
prédiction des défauts logiciels | 39
1. Introduction
La prédiction des défauts logiciels donnera
à l'équipe de développement plus de possibilités
d'exécuter des tests plus d'une fois sur des modules ou les fichiers les
plus susceptibles d'échouer. Cela conduira à une plus grande
attention aux modules défectueux. En conséquence, la correction
des défauts permet de fournir aux utilisateurs finaux des logiciels plus
qualifiés. Cette approche réduit également les travaux de
maintenance et de support du projet. Bien évidemment, une mauvaise
qualité logicielle peut être causée par des défauts
logiciels, ces défauts nécessitent beaucoup d'efforts pour les
corriger et réduire leur impact. La prédiction des défauts
logiciels réduit également les coûts, le temps et les
efforts à consacrer aux produits logiciels.
L'apprentissage automatique est largement utilisé dans
ce domaine. L'utilisation des algorithmes d'apprentissage automatique a permis
d'améliorer la précision des prédictions. Cependant, ces
algorithmes présentent des limites en raison de : (i) des connaissances
d'experts sont nécessaires pour traiter les données, (ii) Un
niveau, comparativement élevé, d'interaction humaine avec des
experts est requis et (iii) une quantité massive de données
d'apprentissage est nécessaire pour le bon fonctionnement du
système, ce qui peut devenir difficile dans un environnement dynamique.
Pour répondre aux restrictions ci-dessus, un sous-ensemble plus
prometteur de l'apprentissage automatique, l'apprentissage en profondeur, a
été adopté pour améliorer la prédiction et a
permet d'obtenir des performances remarquables.
Pour explorer la puissance de l'apprentissage profond pour la
prédiction des défauts et améliorer encore la
précision de la prédiction, dans ce travail, nous proposons une
nouvelle approche de prédiction des défauts, la prédiction
des défauts basée sur le réseau de neurones (SFP-NN).
Dans ce chapitre nous allons décrire notre approche
proposée. Par la suite, nous allons détailler chaque étape
du processus de prédiction ainsi que les bases données que nous
avons utilisés pendant notre étude expérimentale.
2. Approche proposée
Les trois éléments importants du processus de
prédiction des défauts logiciels sont : jeu de données sur
les défauts logiciels, techniques de prédiction des
défauts logiciels et mesures d'évaluation des performances.
Chapitre 03 : SFP-NN : Apprentissage profond pour la
prédiction des défauts logiciels | 40
Dans notre étude, nous proposons une approche
basée sur une technique avancée de l'apprentissage automatique
qui est le deep learning. Nous avons opté pour l'algorithme
d'apprentissage profond qui est le réseau de neurones convolutifs (CNN)
qui a prouvé son efficacité dans plusieurs domaines. La figure
3.1 ci-dessous montre le déroulement du SFP-NN proposé, nous
avons commencé avec une collection de bases de données
sélectionnés avec divers pourcentages de pannes. Une étape
de prétraitement est achevée afin de normaliser les
données ainsi que les préparer pour l'étape suivante. Par
la suite, la collection des bases de données est partitionnée en
un ensemble d'apprentissage et un ensemble de test. Le classifieur CNN commence
la phase d'apprentissage en initialisant les paramètres (couches,
fonctions d'activation...etc.) afin de créer un bon modèle de
classification. Enfin, une phase de test est appliquée afin de mesurer
les performances du modèle créé

Figure 3.1. Schéma du SFP-NN proposé
2.1. Présentation des bases de données NASA
et SOFTLAB
Dans cette étude, nous utilisons plusieurs ensembles de
données de défauts logiciels de différentes entreprises
comme données sources. Les ensembles de données SOFTLAB et
Chapitre 03 : SFP-NN : Apprentissage profond pour la
prédiction des défauts logiciels | 41
NASA ont été collectés respectivement
auprès d'une société de logiciels turque et de nombreux
sous-traitants du référentiel MDP (en anglais : Metrics Data
Program) de la NASA [60], c'est une base de données qui stocke
les données relatives aux problèmes, aux produits et aux mesures.
Pour l'ensemble de données SOFTLAB, nous utilisons cinq projets AR1,
AR3, AR4 , AR5 et AR6 qui sont des logiciels de contrôleur
intégrés dans le référentiel PROMISE. Nous
utilisons sept projets de la NASA : KC1, K, MC1, M, CM1, PC1, P, PC3 et PC4,
qui ont les mêmes métriques dans le référentiel
PROMISE [51]. Les auteurs dans ont constaté que l'ensemble de
données de la NASA sont incohérents et contient des cas de
conflit. Par conséquent, nous utilisons une phase de
prétraitement des ensembles de données de la NASA pour la
préparer aux étapes suivantes. [52]
Il existe 28 métriques communes entre la NASA et
SOFTLAB. Ces métriques sont les métriques cyclomatiques de
Halstead et McCabe, mais la NASA a des métriques de complexité
supplémentaires telles que le nombre de paramètres et le
pourcentage de commentaires.
Les mesures de complexité et de taille comprennent des
mesures bien connues, telles que Halstead, McCabe, le nombre de lignes, le
nombre d'opérateurs / opérandes et les mesures de nombre de
succursales. Les métriques Halstead sont sensibles à la taille du
programme et aident à calculer l'effort de programmation en mois. Les
métriques McCabe mesure la complexité du code (flux de
contrôle) et aident à identifier le code vulnérable. Les
différentes métriques de McCabe comprennent la complexité
cyclométrique, la complexité essentielle, la complexité de
la conception et les lignes de code [2]
Les métriques cibles (variables dépendantes)
sont le «nombre d'erreurs» et les «défauts».
«Nombre d'erreurs» fait référence au nombre d'erreurs
de module associées à l'ensemble correspondant de
métriques du logiciel prédicteur, tandis que la métrique
«Défaut» indique si le module est sujet aux pannes ou sans
défauts. [2]
Chapitre 03 : SFP-NN : Apprentissage profond pour la
prédiction des défauts logiciels | 42
TABLE 3.1. PRESENTATION DE L'ENSEMBLE DE DONNEES UTILISES
|
Base de données
|
Attributs
|
Instances
|
Langage
|
Défectueux%
|
|
KC1
|
21
|
2107
|
C++
|
15.45%
|
|
K
|
40
|
458
|
C++
|
20.50%
|
|
MC1
|
39
|
9466
|
C &C++
|
0.7%
|
|
M
|
39
|
161
|
C++
|
32%
|
|
CM1
|
40
|
505
|
C
|
9.83%
|
|
PC1
|
40
|
1107
|
C
|
6.94%
|
|
P
|
40
|
5589
|
C
|
0.4%
|
|
PC3
|
40
|
1563
|
C
|
10%
|
|
PC4
|
40
|
1458
|
C
|
12%
|
|
AR1
|
31
|
121
|
C
|
7.44%
|
|
AR3
|
31
|
63
|
C
|
12.7%
|
|
AR4
|
31
|
107
|
C
|
18.69%
|
|
AR5
|
31
|
36
|
C
|
22.22%
|
|
AR6
|
31
|
101
|
C
|
14.85%
|
TABLE 3.2. DESCRIPTION DES METRIQUES UTILISEES
Base de Langage Description
données
|
Kc1
|
C++
|
Gestion du stockage pour la réception et le traitement des
données au sol
|
|
Kc2
|
C++
|
Traitement des données scientifiques
|
|
mc1
|
C++
|
__
|
|
mc2
|
C++
|
Système de guidage vidéo
|
|
cm1
|
C
|
Un instrument de vaisseau spatial de la
NASA
|
|
pc1
|
C
|
Un système de satellites en orbite terrestre.
|
|
pc2
|
C
|
Simulateur dynamique pour systèmes de contrôle
d'altitude
|
|
pc3
|
C
|
Logiciel de vol pour satellite en orbite terrestre
|
|
pc4
|
C
|
Logiciel de vol pour satellite en orbite terrestre
|
|
Ar1
|
C
|
Contrôleur embarqué
|
|
Ar3
|
C
|
Contrôleur embarqué
|
Chapitre 03 : SFP-NN : Apprentissage profond pour la
prédiction des défauts logiciels | 43
|
Ar4
|
C
|
Contrôleur embarqué
|
|
Ar5
|
C
|
Contrôleur embarqué
|
|
Ar6
|
C
|
Contrôleur embarqué
|
2.1.1. Les métriques de la NASA MDP
Les métriques logicielles fournissent des informations
pour la prédiction des défauts. À l'heure actuelle, il
existe de nombreuses mesures pour évaluer risques logiciels. Et parmi
elles, trois catégories contiennent les métriques les plus
utilisées. Ils sont McCabe, Métriques Halstead et lignes de code
(LOC) métriques.
Chaque numéro de ligne du fichier CSV représente
chacun de ces attributs, Y indique qu'il a détecté des pannes
sujettes à des lignes de code, le tableau suivant montre les
différents types de métriques et ces rôles :
|
Les Métriques de McCabe
|
CYCLOMATIC_COMPLEXITY - nombre cyclomatique
(quantité de logique de décision) (V(g)).
DESIGN_COMPLEXITY - quantité de logique
impliquée dans les appels de sous-programmes (IV(G)).
ESSENTIAL_COMPLEXITY - mesurer la
quantité de logique mal structurée (ev(G)).
|
|
LOC_BLANK - Compte de McCabe des lignes vides
dans le module.
|
|
LOC_CODE_AND_COMMENT - nombre de lignes
contenant à la
|
|
LOC
|
fois du code et des commentaires dans le module.
|
|
Métriques
|
LOC_COMMENTS - nombre de lignes de code de
commentaires dans le module.
|
|
LOC_EXECUTABLE - le nombre de lignes de code
exécutable pour un module (pas de blanc ni de commentaire).
|
|
LOC_TOTAL - Le nombre total de lignes pour un
module donné.
|
|
NUM_OPERANDS - nombre total
d'opérandes.
|
|
NUM_OPERATORS - nombre total
d'opérateurs.
|
|
NUM_UNIQUE_OPERANDS - le nombre
d'opérandes distincts.
|
|
Métriques des
|
NUM_UNIQUE_OPERATORS - le nombre
d'opérations distinctes.
|
|
opérateurs
|
- Operators : traditionnel (+, ++,>), mots-clés
(return, if, continue)
|
|
- Operands: identifiants, constants
|
Chapitre 03 : SFP-NN : Apprentissage profond pour la
prédiction des défauts logiciels | 44
|
HALSTEAD_CONTENT - Le contenu en
demi-longueur d'un module u = u1 + u2
|
|
Les métriques
|
HALSTEAD_DIFFICULTY : (taux d'erreur)
proportionnel au nombre
|
|
de Halsted
|
d'opérateurs uniques.
|
|
HALSTEAD_EFFORT (E) - La métrique
d'effort à mi-course d'un module E = V L
|
|
HALSTEAD_ERROR_EST- La métrique
d'estimation d'erreur de
|
|
Halstead d'un module B = E2 / 3 1000
|
|
HALSTEAD_LENGTH (N) - le total de toute la
longueur dans les méthodes de (opérande / opérateurs).
|
|
HALSTEAD_LEVEL (L) - l'inverse de la tendance
à l'erreur du programme.
|
|
HALSTEAD_PROG_TIME (T)- La métrique de
temps de programmation à mi-course d'un module T = E 18.
|
|
HALSTEAD_VOLUME (V) - est le contenu
informationnel du programme (bit) il décrit la taille
d'implémentation d'un algorithme.
|
|
label {Y,N} - module a / n'a pas un ou plusieurs
défauts signalés (oui ou
|
|
Autres
|
non).
|
|
BRANCH_COUNT - du graphique de flux.
|
Les variables d'un ensemble de données peuvent
être liées pour de nombreuses raisons. Il peut être utile
dans l'analyse des données et la modélisation pour mieux
comprendre les relations entre les variables. La relation statistique entre
deux variables est appelée leur corrélation.
Une corrélation peut être positive, ce qui
signifie que les deux variables évoluent dans la même direction,
ou négative, ce qui signifie que lorsque la valeur d'une variable
augmente, les valeurs des autres variables diminuent. La corrélation
peut également être neuronale ou nulle, ce qui signifie que les
variables ne sont pas liées. Nous avons utilisé la carte
thermique (en anglais : Correlation Heat Map) [53] pour présenter la
corrélation entre les attributs de quelque ensemble de
données.
Chapitre 03 : SFP-NN : Apprentissage profond pour la
prédiction des défauts logiciels | 45

KC1 K
CM1 PC1
AR1 AR3


Chapitre 03 : SFP-NN : Apprentissage profond pour la
prédiction des défauts logiciels | 46
AR4 AR6
Figure 3.2. La carte de corrélation de quelques bases de
données de la NASA
2.2. Normalisation
La normalisation des données est une technique
couramment utilisée qui transforme de grandes plages de valeurs de
données en petites valeurs de plage (ou valeurs binaires). Notamment,
nous effectuons une normalisation min-max car il s'agit d'une approche de
normalisation couramment utilisée en raison de sa grande
précision et de sa vitesse d'apprentissage élevée. De
plus, la normalisation min-max ne modifie pas la distribution de l'ensemble de
données [54].
Nous effectuons la normalisation des données pour les
raisons suivantes. Premièrement, la gamme de mesures logicielles
extraites varie considérablement. Deuxièmement, il est
obligatoire lors de l'utilisation d'algorithmes d'apprentissage en profondeur.
Enfin, cela peut réduire les erreurs d'estimation et le temps de calcul
(requis dans le processus d'apprentissage). La normalisation min-max peut
être définie dans la formule (1) comme suit:
smL' - min (sm') (1)
Normalisation = (smL') =
max(sm') - min (sm')
où min (sm') et max
(sm') représentent les valeurs minimales et
maximales d'une métrique logicielle sm',
respectivement, sm' représente une valeur de
transformation logarithmique de
Figure 3.3. Architecture de réseau CNN
Chapitre 03 : SFP-NN : Apprentissage profond pour la
prédiction des défauts logiciels | 47
la métrique, et la normalisation (?????? ')
représente la valeur normalisée de ?????? '. Après la
normalisation des données, le module m peut être
défini comme suit:
?? = < ????1 '' , ????2 '' , ... , ??????'' > (2)
Où ?? est un ensemble de métriques logicielles
transformées en log et normalisées. [54] 2.3.
Prédictions utilisant le CNN
Les avantages de l'utilisation de la capacité du CNN
pour les taches de classification sont formés pendant le processus de
rétro-propagation et l'introduction de couches de max pooling, cela
s'est avéré utile dans beaucoup d'applications.
Les réseaux convolutifs se sont avérés
efficaces pour diverses tâches telles que la classification des
numéros d'écriture manuscrite, la classification des images
médicales et la détection des visages. La performance promise
nous incite à l'utiliser dans la prédiction de défauts
logiciels.[55]
Dans le processus d'apprentissage du CNN, j'ai
été guidé en obtenant la plus grande précision et
en déterminant l'effet de la modification de l'architecture du
modèle. Lorsqu'un paramètre (tel que le numéro
d'époque) était modifié, il y avait une
amélioration de la précision. Le paramètre a
été modifié régulièrement et les meilleurs
résultats obtenus ont été utilisés lors de
ré-expérimentations afin d'obtenir le résultat
satisfaisant.

Chapitre 03 : SFP-NN : Apprentissage profond pour la
prédiction des défauts logiciels | 48
Les paramètres qui doivent être définis
pour le réseau incluent les paramètres de la fonction
d'activation, le nombre de couches cachées et d'autres
hyperparamètres. Dans cette section nous allons présenter les
paramètres de notre classifieur CNN.
2.4. Choix des hyperparamètres
Différents hyperparamètres ont été
modifiés au cours de chaque cas de test, pour examiner l'impact de
celui-ci sur la précision. Le réglage de l'hyperparamètre
est important pour choisir les bons paramètres afin d'obtenir les
résultats souhaités. Il n'y a pas de règles
précises pour choisir exactement les bons paramètres, en
général, le choix dépend du type et de la taille de
l'ensemble de données d'apprentissage. Le choix des paramètres
corrects est essentiel mais considéré comme une partie complexe
de la formation du CNN. Cependant, le réglage de l'hyperparamètre
dépend souvent de l'expérience plutôt que des connaissances
théoriques. Les compromis sont intrinsèques à la
sélection des paramètres en raison de restrictions telles que la
limitation de la mémoire [56]
Pendant la phase expérimentale, et lorsque nous
atteignons le meilleur nombre pour l'un de ces hyperparamètres, on
commence alors à manipuler d'autres hyperparamètres pour obtenir
le meilleur résultat. Après cela, nous comparons les valeurs qui
améliorent les performances du CNN. Les valeurs qui n'ont pas eu d'effet
positif sur les résultats de l'algorithme sont supprimés.
- Nombre d'époques : Une
époque est le nombre de passages dans l'ensemble de données [56]
Dans notre expérience, nous avons testé plusieurs nombre
d'époques (jusqu'à 70 époques), pour déterminer le
meilleur nombre d'époques pour que le réseau converge
correctement.
- Taille du lot (Batchsize) : est le
nombre d'échantillons d'apprentissage. Batchsize est utilisé pour
contrôler de nombreuses prédictions qui doivent être faites
à la fois et s'adapter au modèle. En général, la
plus grande taille de lot nécessitait plus d'espace mémoire [56].
D'autre part, les tailles de petits lots sont préférables car
elles tendent à produire une convergence dans un petit nombre
d'époques.
- Nombre de couches cachées :
De nombreux facteurs peuvent influencer grandement les performances des
réseaux, tels qu'un certain nombre de couches cachées, des
neurones dans la couche cachée. Le nombre de couches devient le
critère le plus important dans l'architecture des réseaux [56].
Dans notre travail, et après plusieurs tests
Chapitre 03 : SFP-NN : Apprentissage profond pour la
prédiction des défauts logiciels | 49
empiriques, nous avons opté pour quatre (04) couches de
convolution, une couche Flatten et une couche FC pour générer le
résultat de prédiction.
- Fonctions d'activation : La
fonction d'activation d'un neurone artificiel définit la sortie de ce
neurone en fonction de l'entrée ou de l'ensemble d'entrées.
Chaque fonction d'activation prend une entrée x et
exécute un calcul mathématique spécifique dessus. Les
fonctions d'activation courantes utilisées dans le réseau de
neurones profonds sont la fonction Sigmoid, Unité Linéaire
Rectifiée (ReLU) et tangente hyperbolique.
La fonction Sigmoïde :
fréquemment utilisé en rétro-propagation du
gradient. C'est une extension appropriée de la
non-linéarité qui limite les utilisations
précédentes dans les réseaux de neurones. Elle
présente également un degré de lissage adéquat [56]
.
Unités linéaires rectifiées
(ReLU): utilisé comme fonction d'activation pour les
couches cachées dans notre réseau de neurones profonds. Elle est
largement utilisée pour former un réseau beaucoup plus profond
que les fonctions d'activation Sigmoïde ou Tanh. ReLU fournit un
apprentissage plus rapide et plus efficace pour le réseau de neurones
profonds sur des données complexes et de grande dimension. L'avantage le
plus important de ReLU est qu'il ne nécessite pas de calcul
coûteux, juste une comparaison et une multiplication. ReLU a une
rétro propagation efficace sans problème d'explosion/ disparition
du gradient, ce qui en fait un choix particulièrement approprié
pour le réseau de neurones profond. [56]
Les fonctions ReLU et Sigmoïde ont été
utilisé comme des fonctions d'activation dans notre réseau de
neurones convolutifs. Afin de résumer les paramètres de notre
réseau de neurones convolutifs, ces paramètres nous a permis
d'obtenir des résultats prometteurs, la table 3.3 présente chaque
hyperparamètre avec les valeurs appropriées
Chapitre 03 : SFP-NN : Apprentissage profond pour la
prédiction des défauts logiciels | 50
TABLE 3.3. LES PARAMETRES DU CLASSIFIEUR CNN UTILISE
|
Les couches de
convolutions
|
Parameters
|
|
Conv1
|
Conv2D(128, kernel_size=1, activation='relu')
|
|
Conv2
|
Conv2D(64, kernel_size=1, activation='relu')
|
|
Conv3
|
Conv2D(32, kernel_size=1, activation='relu')
|
|
Conv4
|
Conv2D(16, kernel_size=1, activation='relu')
|
|
Flattening
|
Flatten()
|
|
Fully Connected
|
Sigmoïde
|
3. Conclusion
Les objectifs de cette thèse sont d'étudier les
capacités et le potentiel des algorithmes d'apprentissage profond,
d'améliorer les performances de SFP et de déterminer les
meilleurs algorithmes qui pourraient être utilisés à cette
fin.
Nous avons mené des expériences suivies
d'analyses et de comparaisons pour vérifier l'efficacité des
algorithmes d'apprentissage profond (CNN). Les expériences ont
été appliquées sur 14 ensembles de données. Les
résultats des expériences ont été
évalués en utilisant l'exactitude, la perte. Enfin, l'analyse et
les comparaisons ont été effectuées pour démontrer
les objectifs de notre étude.
Chapitre 4 : Implémentation 51

Chapitre 04 :

Implémentation
Chapitre 4 : Implémentation 52
1. Introduction
Dans ce chapitre, nous discuterons les étapes suivies
pour implémenter notre approche basée sur d'algorithmes de
réseau de neurones convolutifs pour la prédiction des
défauts logiciels. Tout d'abord, nous discuterons l'environnement de
développement, langage utilisé pour implémenter notre
système, et les détails des bibliothèques utilisées
dans la programmation de notre système d'apprentissage profond pour la
prédiction de défauts logiciels SFP-NN. Ensuite, nous avons
présentés quelques captures d'écran montrant les
différentes étapes de notre approche, et nous poursuivons ce
chapitre par la présentation des différents résultats
expérimentaux obtenus
2. Implémentation du SFP-NN
proposé
2.1. Environnement de développement
Matériel Marque : HP.
Mémoire (RAM) : 8 Go.
Processeur : i5.
Système d'exploitation : Windows 10.
2.1.1. Langage de développement
Python
Python est un langage de programmation portable, dynamique,
extensible, gratuit, structuré et open source, c'est une syntaxe simple
et facile à comprendre, ce qui permet d'économiser du temps et
des ressources. Le langage Python, l'un des meilleurs langages pour commencer
dans le monde de la programmation, permet une approche modulaire et
orientée objet de la programmation et le plus utilisé dans le
domaine d'apprentissage automatique, du Big Data et de la Data Science. Il a
été initialement développé par Guido Van Rossum en
1993 et géré par une équipe de développeurs un peu
partout dans le monde. [57]
2.1.1.1. Caractéristiques du langage de
développement Python
La syntaxe de Python est très simple, ce qui donne des
programmes à la fois très compacts et très lisibles. Il
est orienté objet et peut gérer ses ressources (mémoire,
descripteurs de
Chapitre 4 : Implémentation 53
fichiers, etc.) sans intervention du programmeur. Les
bibliothèques et packages Python standards permettent d'accéder
à divers services : chaînes et expressions
régulières, services UNIX standards (fichiers, pipes, signaux,
sockets, threads, etc.), protocoles Internet (Web, news, FTP, CGI), HTML ... ),
persistance et base de données, interface graphique. En fait, Python est
un langage en évolution. [57]
2.1.1.2. Bibliothèques utilisées de
Python
En Python, une bibliothèque est un ensemble de modules
logiciels qui peuvent ajouter des fonctions étendues à Python.
Ils sont nombreux, et c'est l'une des grandes forces de python. Les
bibliothèques Python utilisées dans notre travail sont les
suivantes:
· Tensrflow: TensorFlow [58] est
une bibliothèque open source, permettant de développer et
d'exécuter des applications de d'apprentissage automatique et de Deep
Learning. TensorFlow est une boîte à outils permettant de
résoudre des problèmes mathématiques extrêmement
complexes. Elle permet aux chercheurs de développer des architectures
d'apprentissage expérimentales et de les transformer en logiciels.
Créé par l'équipe Google Brain en 2011.
· Keras: Keras [59] est une
bibliothèque open source qui a été initialement
écrite
par François Chollet en Python. Dans ce cadre, Keras
ne fonctionne pas comme un framework propre mais comme une interface de
programmation applicative (API) pour l'accès et la programmation de
différentes applications. Le but de cette bibliothèque est de
permettre la constitution rapide des réseaux neuronaux.
· NumPy : numpy [60] est une
bibliothèque numérique apportant le support efficace des larges
tableaux multidimensionnels, et des routines mathématiques de haut
niveau (fonctions spéciales, algèbre linéaire,
statistiques, etc.).
· Panda : Pandas [61]
est une bibliothèque écrite pour le langage de programmation
Python permettant la manipulation et l'analyse des données. Elle propose
en particulier des structures de données et des opérations de
manipulation de tableaux numériques et de séries temporelles.
Chapitre 4 : Implémentation 54
Son nom est dérivé du terme "données de
panel", un terme d'économétrie pour les jeux de données
qui comprennent des observations sur plusieurs périodes de temps pour
les mêmes individus.
· Matplotib : matplotlib est
une bibliothèque Python capable de produire des graphes de
qualité. Matplotlib essai de rendre les tâches «simples»
et de rendre possible les choses compliqués. Vous pouvez
générer des graphes, histogrammes, des spectres de puissance, des
graphiques à barres, des graphiques d'erreur, des nuages de dispersion,
etc... en quelques lignes de code. [62]
· Seaborn : Seaborn [63] est une
bibliothèque permettant de créer des graphiques statistiques en
Python. Elle est basée sur Matplotlib, et s'intègre avec les
structures Pandas. Cette bibliothèque est aussi performante que
Matplotlib, mais apporte une simplicité et des fonctionnalités
inédites. Elle permet d'explorer et de comprendre rapidement les
données.
2.1.2. Environement Google Colab
Colab est un produitproposée par Google Research.
C'est un environnement particulièrement adapté au machine
Learning, à l'analyse de données et à l'éducation.
En termes plus techniques, Colab est un service hébergé de
notebooks Jupyter qui ne nécessite aucune configuration et permet
d'accéder gratuitement à des ressources informatiques. [64]
Colaboratory, souvent raccourci en "Colab", permet
d'écrire et d'exécuter du code Python dans votre navigateur. Il
offre les avantages suivants : Aucune configuration requise , accès
gratuit aux GPU(Graphics Processing Unit) et Partage facile des
ressources.

Chapitre 4 : Implémentation 55

Figure 4.1. Google Collab
2.2. Présentation de déroulement de
l'application
2.2.1. Importation des bibliothèques
Cette étape constitue la phase initiale du
développement de notre approche. La figue 4.2 montre l'importation des
bibliothèques nécessaires.

Figure 4.2. Importation des bibliothèques
2.2.2. Description de la base de données
utilisée
Chapitre 4 : Implémentation 56
Plusieurs ensembles de données publics ou
privés sont disponible pour la prédiction des défauts
logiciels. Dans notre travail, nous avons opté pour les deux ensembles
NASA MDP et SOFTLAB. Les caractéristiques de ces deux ensembles ont
été définies dans les années 70 pour tenter de
caractériser objectivement les fonctionnalités de code
associées à la qualité logicielle. Dans la figure (4.3) et
(4.4), nous montrons les bases de données PC1 et AR1 qui appartiennent
à NASA MDP et SOFTLAB, respectivement.

Figure 4.3. Base de données PC1

Figure 4.4. Base de données AR1
- Importation de l'ensemble de
données
Cette phase désigne l'importation des données
nécessaires pour l'apprentissage et le test du modèle. Les
fichiers d'entrée des bases de données sont disponible dans un
répertoire sous forme .csv de cette façon : « ../Data/data
/mc1.csv »
Chapitre 4 : Implémentation 57

Figure 4.5. Lecture de l'ensemble de données
2.2.3. Prétraitement de
données
Chacun des ensembles de données avait initialement son
identifiant de module et son attribut de densité d'erreur
supprimés, car ils ne sont pas requis pour la classification. Une phase
de prétraitement alors, consiste à préparer les
données pour les étapes suivantes.
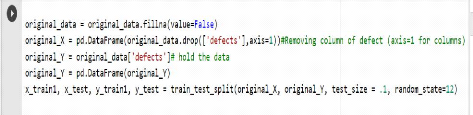
Figure 4.6. Préparation des données
- Partitionnement de la base de données utilisant
la technique SMOTE
Rééchantillonner l'ensemble de données
après l'avoir divisé en partitions de train et de test à
l'aide de la technique SMOTE, et à partir de là, nous prenons des
ensembles d'apprentissage et de validation. L'utilisation de SMOTE lors de la
division de chacun des ensembles de données en ensembles d'apprentissage
et de test est importante pour améliorer les résultats anormaux
possibles.
Cette fonction gère les problèmes de
classification déséquilibrée à l'aide de la
méthode SMOTE. A savoir, un nouvel ensemble de données "SMOTed"
peut être généré qui résout le
problème de déséquilibre de classe. Alternativement, il
peut également exécuter un algorithme de classification sur ce
nouvel ensemble de données et renvoyer le modèle
résultant. [65]
Chapitre 4 : Implémentation 58

Figure 4.7. Partitionnement d'ensemble de données
utilisant SMOTE
2.2.4. Apprentissage et création du modèle
CNN
Dans cette partie, nous allons nous focaliser sur un des
algorithmes les plus performants du Deep Learning, le réseau de neurones
convolutifs (CNN), ce sont des modèles de programmation puissants. Nous
avons mené plusieurs tests expérimentaux afin de choisir au mieux
différents paramètres pour s'adapter à la base
d'entrée du mélanome.
L'impact de nombre de filtres, la fonction d'activation et
nombre d'époques, font partie de l'ensemble de paramètres sur
lesquels nous avons effectué divers changements et expériences.
La figure 4.8 montre l'appel de la méthode CNN ainsi que les
paramètres choisis pour la réalisation de cette application.

Figure 4.8. Présentation des paramètres de
l'algorithme CNN.
Chapitre 4 : Implémentation 59
3. Résultats obtenus
Dans la présente étude, un système de
prédiction des défauts logiciels a été
proposé basé sur l'apprentissage profond. Cette technique qui a
prouvé son efficacité dans plusieurs domaines notamment dans le
domaine du génie logiciel. Un ensemble de (14) bases de données
des projets extraient de NASA MDP et SOFTLAB ont contribué à
l'évaluation de notre système. Ces bases de données ont
été partitionnées en un ensemble d'apprentissage et de
test utilisant la technique SMOTE.
3.1. La précision et la perte du SFP-NN
proposé
Résultats de la table ci-dessous décrit les
résultats de l'approche SFP-NN proposée en termes d'accuracy et
loss.
TABLE 4.1. PERFORMANCES DES PREDICTEURS UTILISANT CNN
SUR LES ENSEMBLES DE
DONNEES DE LA NASA MDP ET SOFTLAB
Base de Données
|
Accuracy
|
Loss
|
KC1
|
0.97
|
0.06
|
K
|
0.92
|
0.19
|
MC1
|
0.99
|
0.01
|
M
|
0.95
|
0.14
|
CM1
|
0.90
|
0.20
|
PC1
|
0.93
|
0.18
|
P
|
0.99
|
0.02
|
PC3
|
0.94
|
0.17
|
PC4
|
0.97
|
0.06
|
AR1
|
0.95
|
0.09
|
AR3
|
0.98
|
0.07
|
AR4
|
0.97
|
0.08
|
AR5
|
0.98
|
0.06
|
AR6
|
0.90
|
0.29
|
|
Les résultats tabulés révèlent
clairement l'amélioration de la précision de la prédiction
des défauts logiciels sur les ensembles de données du
système spatial.
Chapitre 4 : Implémentation 60
La précision et le taux de perte du modèle CNN
en fonction de nombre d'époques sur l'ensemble des 14 bases de
données sont illustrée par la figure 4.9.

Base de données KC1

Base de données K

Base de données MC1
Chapitre 4 : Implémentation 61

Base de données M


Base de données PC1
Base de données P
Base de données CM1
Chapitre 4 : Implémentation 62

Base de données de PC3


Base de données AR1
Base de données AR3
Base de données PC4
Chapitre 4 : Implémentation 63

Base de données AR4
Base de données AR5
Base de données AR6
Figure 4.9. La précision et le taux de perte de notre
modèle CNN
3.2. Matrice de confusion
Une matrice de confusion est une technique de mesure des
performances. C'est une sorte de tableau (voir chapitre 01) qui vous aide
à connaître les performances du modèle de
Chapitre 4 : Implémentation 64
classification sur un ensemble de données de test
[66]. La matrice de confusion insique le nombre les (FP, FN, TP et TN). Dans
notre travail, 14 matrices de confusion ont été calculé,
chaque matrice représente les résultats obtenus de chaque base de
données. La figure ci-dessous monte les matrices de confusions
obtenues

KC1 K MC1

M CM1 PC1
Chapitre 4 : Implémentation 65

P PC3 PC4

AR1 AR3 AR4

AR5 AR6
Figure 4.10. Matrices de confusions obtenues
Chapitre 4 : Implémentation 66
La table 4.2. Suivant présente les résultats de
performance du CNN en termes de la précision, Rappel,
F1-score, sensibilité et spécificité
TABLE 4.2 : LE RESEAU DE NEURONES CONVOLUTIFS RESULTATS
OBTENUS
Base de données
|
Précision
|
Rappel
|
F1-score
|
Spécificité
|
Sensibilité
|
KC1
|
0.92
|
0.98
|
0.96
|
0.95
|
0.92
|
K
|
0.87
|
0.90
|
0.94
|
0.92
|
1.00
|
MC1
|
0.92
|
0.97
|
0.98
|
0.95
|
0.89
|
M
|
0.98
|
1.00
|
0.97
|
1.00
|
0.94
|
CM1
|
0.93
|
0.97
|
0.92
|
0.90
|
0.89
|
PC1
|
1.00
|
0.91
|
0.90
|
0.98
|
0.90
|
P
|
0.95
|
1.00
|
0.97
|
0.95
|
0.92
|
PC3
|
0.90
|
0.99
|
0.91
|
0.88
|
0.87
|
PC4
|
0.94
|
0.99
|
0.87
|
0.95
|
0.99
|
AR1
|
0.92
|
1.00
|
0.94
|
0.96
|
0.97
|
AR3
|
0.90
|
1.00
|
0.80
|
1.00
|
0.91
|
AR4
|
0.96
|
1.00
|
0.9
|
0.84
|
0.98
|
AR5
|
0.97
|
1.00
|
0.88
|
0.99
|
0.89
|
AR6
|
0.79
|
0.98
|
0.92
|
0.86
|
0.88
|
|
Nous avons obtenu de bons résultats utilisant notre
classifieur CNN. Le F1-score est un bon indicateur de performance de tout
système. Un F1-score = 0.97 est obtenu avec la base de données P
et un f1-Score = 0.9 est obtenu avec la base de données AR4 de
l'ensemble SOFTLAB. Ce qui rend notre système performant dans la
prédiction de pannes logicielles.
Chapitre 4 : Implémentation 67
3.3. Calcul de l'AUC
L'aire sous la courbe (AUC) [67] de la fonction
d'efficacité du récepteur (ROC) est utilisée dans
l'évaluation des classificateurs. ROC est une fonction
paramétrée de la sensibilité et la
spécificité en fonction du seuil variant entre 0 et 1. La courbe
ROC est tracée donc au moyen de deux variables: une variable binaire et
une autre continue. Le modèle est évalué en
considérant toutes ses valeurs comme des seuils potentiels qui peuvent
être utilisés pour décider si une classe est
défectueuse ou non défectueuse. Hosmer et Lemeshow ont
proposé l'utilisation des règles suivantes pour évaluer la
performance des Classificateurs :
· AUC = 0.5 signifie mauvaise classification,
assimilée à une classification aléatoire.
· 0.5 < AUC < 0.6 signifie faible classification.
· 0.6 < AUC < 0.7 signifie classification
acceptable.
· 0.7 < AUC < 0.8 signifie bonne classification.
· 0.8 < AUC < 0.9 signifie très bonne
classification.
· 0.9 < AUC signifie excellente classification.
La figure 4.11 présente le résultat d'AUC de chaque
ensemble de données utilisé dans notre approche :

KC1 K

MC1 MC2
Chapitre 4 : Implémentation 68


AR3 AR4
P PC3
PC4 AR1
CM1 PC1
Chapitre 4 : Implémentation 69

AR5 AR6
Figure 4.11. Présentation des courbes ROC des
différentes bases de données
4. Comparaison de l'approche proposée
Dans cette section, et afin d'évaluer
l'efficacité de l'approche proposée, des expériences
similaires ont été réalisées à l'aide des
algorithmes telle que Machine a vecteur support [1],
Foret aléatoire [2], la régression
Logistique [3]. Les résultats moyens pour chaque ensemble de
données sont présentés dans la table 4 qui compare les
résultats de la précision de chaque classifieur.
4.1. Les paramètres
expérimentaux
Les données d'apprentissage du classifieur
Machine à vecteur support (SVM) (x_train)
et (y _train) feront l'entrée de
la fonction LinearSVC(). C'est l'implémentation de Machine à
vecteur de support avec une fonction noyau « linéaire
».
Le hyperparamètre utilisé dans le foret
aléatoire c'est n_estimators de valeur= 100
qui indique le nombre d'arbres construits par l'algorithme avant de prendre un
vote ou de faire une moyenne de prédictions.
La fonction LogisticRegression()
prédit la probabilité d'une variable aléatoire de
Bernoulli (c'est-à-dire de valeur 0,1) à partir d'un ensemble de
variables indépendantes continues.
4.2. Résultats obtenus
Les tables 4.3, 4.4 et 4.5 suivants présentent les
résultats de performance des classifieurs Machine à
vecteur support, Foret aléatoire et régression logistique,
respectivement. Ces résultats sont calculés en termes de
précision, Rappel, f1-score, accuracy.
Chapitre 4 : Implémentation 70
TABLE 4.3. RESULTATS OBTENUS DU CLASSIFIEUR SVM
|
Base de
données
|
Précision
|
Rappel
|
F1-Score
|
Accuracy
|
|
KC1
|
0.92
|
0.81
|
0.86
|
0.79
|
|
K
|
0.87
|
0.61
|
0.72
|
0.60
|
|
MC1
|
0.98
|
0.30
|
0.46
|
0.31
|
|
M
|
0.47
|
0.84
|
0.64
|
0.47
|
|
CM1
|
0.85
|
0.41
|
0.56
|
0.46
|
|
PC1
|
0.84
|
0.83
|
0.84
|
0.73
|
|
P
|
0.88
|
0.47
|
0.64
|
0.47
|
|
PC3
|
0.95
|
0.86
|
0.90
|
0.83
|
|
PC4
|
0.91
|
0.99
|
0.95
|
0.90
|
|
AR1
|
0.92
|
0.92
|
0.92
|
0.92
|
|
AR3
|
0.86
|
0.90
|
0.92
|
0.86
|
|
AR4
|
0.98
|
0.50
|
0.67
|
0.64
|
|
AR5
|
0.93
|
0.67
|
0.80
|
0.75
|
|
AR6
|
0.86
|
0.67
|
0.75
|
0.64
|
TABLE 4.4. RESULTATS OBTENUS DU CLASSIFIEUR FORET ALEATOIRE
|
Base de
données
|
Précision
|
Rappel
|
F1-
Score
|
Accuracy
|
|
KC1
|
0.90
|
0.80
|
0.89
|
0.73
|
|
K
|
0.80
|
0.90
|
0.91
|
0.82
|
|
MC1
|
0.90
|
0.91
|
0.87
|
0.85
|
|
M
|
0.56
|
0.62
|
0.70
|
0.59
|
|
CM1
|
0.84
|
0.90
|
0.87
|
0.78
|
|
PC1
|
0.80
|
0.93
|
0.57
|
0.71
|
|
P
|
0.85
|
0.89
|
0.89
|
0.84
|
|
PC3
|
0.76
|
0.88
|
0.53
|
0.65
|
|
PC4
|
0.80
|
0.78
|
0.92
|
0.80
|
|
AR1
|
0.75
|
0.95
|
0.96
|
0.77
|
|
AR3
|
0.67
|
0.80
|
0.80
|
0.79
|
|
AR4
|
0.77
|
0.67
|
0.80
|
0.82
|
Chapitre 4 : Implémentation 71
|
AR5
|
0.80
|
0.83
|
0.80
|
0.75
|
|
AR6
|
0.65
|
0.70
|
0.89
|
0.72
|
TABLE 4.5. RESULTATS OBTENUS DU CLASSIFIEUR REGRESSION
LOGISTIQUE
|
Base de
données
|
Précision
|
Rappel
|
F1-
Score
|
Accuracy
|
|
KC1
|
0.65
|
0.73
|
0.66
|
0.73
|
|
K
|
0.80
|
0.80
|
0.80
|
0.89
|
|
MC1
|
0.52
|
0.87
|
0.51
|
0.80
|
|
M
|
0.71
|
0.70
|
0.70
|
0.71
|
|
CM1
|
0.53
|
0.87
|
0.52
|
0.87
|
|
PC1
|
0.57
|
0.60
|
0.57
|
0.71
|
|
P
|
0.50
|
0.42
|
0.46
|
0.84
|
|
PC3
|
0.59
|
0.77
|
0.53
|
0.65
|
|
PC4
|
0.59
|
0.78
|
0.55
|
0.66
|
|
AR1
|
0.50
|
0.19
|
0.28
|
0.38
|
|
AR3
|
0.90
|
0.80
|
0.80
|
0.92
|
|
AR4
|
0.80
|
0.88
|
0.80
|
0.82
|
|
AR5
|
0.75
|
0.83
|
0.73
|
0.70
|
|
AR6
|
0.70
|
0.83
|
0.69
|
0.73
|
Les résultats obtenus des trois classifieurs sont
satisfaisant, cependant, notre approche a pu surpasser les trois techniques de
classifications traditionnelles. La Table 4.6 montre les résultats de la
comparaison.
Chapitre 4 : Implémentation 72
TABLE 4.6. COMPARAISON DE L'APPROCHE PROPOSEE AVEC LES TECHNIQUES
TRADITIONNELLES D'APPRENTISSAGE AUTOMATIQUE
|
Base de
données
|
|
SVM RF LR SFP-NN
|
|
|
|
KC1
|
0.79
|
0.73
|
0.73
|
0.97
|
|
K
|
0.60
|
0.82
|
0.89
|
0.92
|
|
MC1
|
0.31
|
0.85
|
0.80
|
0.99
|
|
M
|
0.47
|
0.59
|
0.71
|
0.95
|
|
CM1
|
0.46
|
0.78
|
0.87
|
0.90
|
|
PC1
|
0.73
|
0.71
|
0.71
|
0.93
|
|
P
|
0.47
|
0.84
|
0.84
|
0.99
|
|
PC3
|
0.83
|
0.65
|
0.65
|
0.94
|
|
PC4
|
0.90
|
0.80
|
0.66
|
0.97
|
|
AR1
|
0.92
|
0.77
|
0.38
|
0.95
|
|
AR3
|
0.86
|
0.79
|
0.92
|
0.98
|
|
AR4
|
0.64
|
0.82
|
0.82
|
0.97
|
|
AR5
|
0.75
|
0.75
|
0.70
|
0.98
|
|
AR6
|
0.64
|
0.72
|
0.73
|
0.90
|
4.3. Discussions
La prédiction précise des défauts
logiciels est très précieuse pour les ingénieurs, en
particulier ceux qui s'occupent des processus de développement de
logiciels. Ceci est important pour minimiser les coûts et
améliorer l'efficacité du processus de test logiciel. Les
résultats de la méthodologie proposée sur les 14 ensembles
de données ont encore montré les bénéfices
d'utilisation de l'apprentissage profond dans la tache de prédiction. On
a atteint une précision de 0.96 avec la base de données P aussi
un F1- score = 0.97 est obtenu avec la même base de données.
Nous avons aussi comparé notre approche avec des
approches traditionnelles d'apprentissage automatique. Nous avons
remarqué que notre SFP-NN a dépassé d'une manière
significative les résultats obtenus par ces algorithmes. Ce qui nous
permet de dire, que L'apprentissage profond et plus spécialement le
réseau de neurones convolutifs constitue une voie de recherche
très prometteuse dans le domaine du génie logiciel.
Chapitre 4 : Implémentation 73
5. Conclusion
Dans ce chapitre nous avons montré les
différents résultats de notre système proposé ainsi
le déroulement de notre application qui a pour but de résoudre ce
problème de prédiction des défauts logiciels, et nous
avons vu les outils nécessaires pour la réalisation de notre
application et cité l'environnement de développement. De plus,
nous avons détaillé l'architecture et les résultats
obtenus de notre étude. Nous avons clôturé notre chapitre
par une comparaison avec des techniques d'apprentissage automatique.
Conclusion Générale 75
Conclusion générale
La prédiction des défauts logiciels (SFP) est
l'une des modèles de qualité qui aident à conduire
sainement le cycle de vie du développement logiciel. Il est donc
important et bénéfique de ne pas simplement détecter
l'occurrence du défaut en tant que pré-activité mais aussi
de les prédire afin d'empêcher le défaut avant qu'il ne
devienne réel.
Dans ce cadre que s'inscrit notre travail, nous avons
utilisé une technique d'apprentissage automatique dont le but est de
prédire les défauts logiciels lors de la phase initiale. Pour
réaliser notre travail on a utilisé une technique avancée
d'apprentissage automatique qui est l'apprentissage profond. Récemment,
cette technique a été adopté pour améliorer des
tâches de recherche en génie logiciel. L'approche proposée
dans ce mémoire, utilise l'algorithme de réseau de neurones
convolutifs (CNN) afin de prédire les défauts logiciels et ce
dans le but de conduire le cycle de vie du développement logiciel
sainement. Ce choix est justifié par la simplicité et
l'efficacité de la méthode.
Nous avons proposé un modèle CNN
amélioré pour la prédiction des défauts logiciels
afin de valider l'hypothèse selon laquelle les modèles CNN peut
surpasser les modèles d'apprentissage automatique traditionnels. Nous
avons choisi deux ensembles de données : 09 projets ont
été choisis de la base de données NASA MDP et 05 projets
de SOFTLAB. Plusieurs métriques ont été extraient de ces
bases données afin de construire les données d'apprentissage/test
du CNN. Après une phase de prétraitement des données, une
phase d'apprentissage est lancée pour créer le modèle CNN
approprié. Plusieurs mesures de
Conclusion Générale 76
performances telles que : précision, F1-score, recall
ont contribué à l'évaluation expérimentale de notre
SFP-NN. Notre approche a obtenu des résultats satisfaisants, comparables
ou meilleurs que les modèles de pointe existants. Nous avons obtenus un
accuracy égal à 0.99 pour MC1, 0.98 pour AR5, et 0.99 pour P et
le reste d'ensembles de données utilisé dans notre approche ont
également obtenu de bons résultats comme PC1= 0.93, KC1 = 0.97,
AR4= 0.97 etc... .
Afin de valider notre SFP-NN, nous l'avons comparé avec
d'autres techniques d'apprentissage traditionnelles : Foret aléatoire,
machine à vecteur de support et la régression logistique qui sont
évalués à l'aide de précision, de la recall, du F1-
score, du rappel et de l'exactitude. Nous avons obtenu avec SVM sur
PC1 un accuracy de 0.73, F1- score = 0.84, recall= 0.83 et précision =
0.84. Avec foret aléatoire sur PC1 un accuracy de 0.71, F1-
score = 0.57, recall = 0.93 et une précision de 0.80. Avec la
régression logistique sur PC1 nous avons obtenus un accuracy de 0.71,
F1- score était 0.57, recall était 0.60 et précision
était 0.57.
Le résultat obtenu lors de la phase de test confirme
l`efficacité de notre approche. Notre travail n`est que dans sa version
initiale, on peut dire que ce travail reste ouvert pour d'autres extensions.
Comme extension du travail proposé :
- Nous pouvons bénéficier des avantages des
autres techniques de deep learning et les comparer avec notre SFP-NN
- Appliquer des techniques de sélection d'attributs
afin de garder seulement les attributs les plus pertinents et pour avoir un jeu
de données équilibré et normalisé,
- D'autres techniques de prétraitement peuvent
être envisageable afin de rendre l'ensemble de données
d'apprentissage le plus optimal que possible,
77
Bibliographies 77
Bibliographies
[1]: Rathore. S, Kumar. S. (2019). A study on software fault
prediction techniques. Artif Intell Rev 51, pp 255-327.
[2]: Challagulla. V. U. B, Bastani. F. B, I-Ling. Y, Paul. R. A.
(2005). Empirical assessment of machine learning based software defect
prediction techniques. IEEE International Workshop on Object-Oriented
Real-Time Dependable Systems, pp. 263-270.
[3]: Shomona. R, Geetha. R. (2017). The International Arab
Journal of Information Technology.(Université Anna ).Vol. 14, No.
2.pp.1-7.
[4] :
https://fr.wikipedia.org/wiki/Weka
(informatique) [Accès le 10 /06/2021]
[5]:
https://datasciencetoday.net/index.php/en-us/deep-learning/173-les-reseaux-de-neurones-convolutifs
[Accès le 30/05/2021]
[6]: Ruchika. M. (2015). A systematic review of machine learning
techniques for software fault prediction. Applied Soft Computing. Vol 27. pp.
504-518.
[7] :
|
Carla. S. (2016). Monitoring et détection d'anomalie
par apprentissage dans les
|
|
|
infrastructures virtualisées. pp.1-175.
[8] : Chaib. R. (2019). Classification multimodale de la
maladie de mélanome utilisant les classifieurs CNNs et la
représentation de texture LBP. (mémoire Master).
Université BADJI MOKHTAR .Annaba.
[9]: Prabha. C. L, Shivakumar. N. (2020). "Software Defect
Prediction Using Machine Learning Techniques. 4th International Conference on
Trends in Electronics and Informatics (48184), pp. 728-733,
[10]: Amirabbas. M, Mojtaba. V. A, Alireza. K, Pooria. P-T,
Hassan. H. (2020). SLDeep: Statement-level software defect prediction using
deep-learning model on static code features. Expert Systems with Applications.
Vol. 147
[11]: Hammouri. A, Hammad. M, Alnabhan. A, Alsarayrah. F.
(2018). Software Bug Prediction using Machine Learning Approach. (IJACSA)
International Journal of Advanced Computer Science and Applications, Vol. 9,
No. 2.
78
Bibliographies 78
[12]: Tianchi. Z, Xiaobing. S, Xin. X, Bin. L, Xiang. C. (2019).
Improving defect prediction with deep forest. Information and Software
Technology. Vol 114. Pages 204-216.
[13] : Kulamala. K. V, Kumari. P. A, Chatterjee. D. P. (2021).
Software Fault Prediction Using Random Forests. Mohapatra National Institute of
Technology, India.
[14] :
https://en.wikipedia.org/wiki/AlexNet
[Accès le 24/06/2021]
[15] :
https://deepsource.io/glossary/ast/
[Accès le 24/06/2021]
[16] : Qiong. L, Ying. W. (2012). Supervised Learning.
Encyclopedia of the Sciences of Learning. Springer. PP. 3243-3245. Boston.
[17] : Zemmal. N. (2017/2018). Techniques d'apprentissage pour
la sélection d'attributs : Application à la reconnaissance des
formes. (Thèse doctorat). Université Badji Mokhtar, Annaba.
[18]: Awad. M, Khanna. R. (2015) Support Vector Machines for
Classification. In: Efficient Learning Machines. Apress, Berkeley
[19]:
http://cedric.cnam.fr/vertigo/Cours/ml2/coursSVMLineaires.html[Accès
le 20/05/2021]
[20]: Crescenzio. G. (2015). Artificial Neural Networks:
tutorial. Book. Vol 10.
[21] :
https://techvidvan.com/tutorials/artificial-neural-network/[
Accès le 21/05/2021]
[22]: AYHAM. A, MARWA. S. K. (2020). Evaluation of Adaptive
random forest algorithm for classification of evolving data stream.
(Mémoire Licence). School of Electrical Engineering and Computer
Science. Stockholm , suede. [23]:
https://www.analyticsvidhya.com/blog/2020/12/lets-open-the-black-box-of-random-forests/
[Accès le 20/05/2021]
[24] : Morissette, Laurence, Chartier, Sylvain. (2013). The
k-means clustering technique: General considerations and implementation in
Mathematica. Journal, Tutorials in Quantitative Methods for Psychology. vol 9,
pp. 15-24.
[25]: Christian. B. (2013). Lecture Notes on k-Means Clustering
(I). Technical Report. pp. 1-6
[26] :
https://fr.wikipedia.org/wiki/Regroupement_hi%C3%A9rarchique
[Accès le 20/05/2021]
[27] : Jean-louis. F. (2002). Algorithme EM : théorie et
application au modèle mixte. Journal de la société
française de statistique, tome 143, no 3-4 (2002), p. 57-109.
[28] : Algorithme espérance-maximisation --
Wikipédia (
wikipedia.org) [Accès
le 02/06/2021]
[29] :Marc-Adélard. T. (1968). Initiation à la
recherche dans les sciences humaines. Professeur d'anthropologie,
Université Laval, Québec.
[30] : LeCun. Y, Bengio. Y, Hinton. G. (2015). Deep learning.
pp. 436-444
[31] : Paillé. P, Mucchielli. A. L'analyse qualitative
en sciences humaines et sociales.
[32] :
https://www.monde-diplomatique.fr/1958/11/A/58714
[Accès le 14/06/2021]
[33] :Benkhelifa. A. (2018). Les systèmes
embarqués dans l'automobile. (Travail de Bachelor réalisé
en vue de l'obtention du Bachelor HES). Haute École de Gestion de
Genève.
[34] :
https://www.hydrauliquesimple.com/quelle-est-la-definition-du-secteur-industriel/
[Accès le 15/06/2021]
79
Bibliographies 79
[35] : Chaib. R. (2019). Classification multimodale de la
maladie de mélanome utilisant les classifieurs CNNs et la
représentation de texture LBP.(mémoire Master).Université
Badji mokhtar .Annaba
[36] : Osama. A. Q, Mohammed .A, Mamdouh. A. (2020). The
Influence of Deep Learning Algorithms Factors in Software Fault Prediction.
IEEE, pp 1-16.
[37]: Boukada. Y, Bemmoussat. M. H . (2018). Mise au point
d'une application de reconnaissance vocale. (Mémoire Master).
Université abou beker bekaid. Tlemcen.
[38] : Asma. O. (2012). Segmentation et classification dans
les images de documents numérisés. Autre [cs.OH]. INSA de Lyon.
Français.
[39] : Tannier. X. (2006). Traitement automatique du langage
naturel pour l'extraction et la recherche d'informations. Ecole Nationale
Supérieure des Mines de Saint-Etienne. France .
[40] : Keunyoung. P, Doo-Hyun. K. (2018). Accelerating Image
Classification using Feature Map Similarity in Convolutional Neural Networks.
Applied Sciences. Konkuk University. Seoul. Korea.
[41] : Pan, Cong, Lu, Minyan. X, Biao. Gao, Houleng. (2019).
"An Improved CNN Model for Within-Project Software Defect Prediction"
Appl. Sci. 9, no. 10: 2138.
[42]: Wenbo .Z, Yan .M, Yizhong .Z, Michal. B, Jose. R.
(2018). Deep Learning Based Soft Sensor and Its Application on a Pyrolysis
Reactor for Compositions Predictions of Gas Phase Components. ScienceDirect.
Vol 44. Pages 2245-2250.
[43] :
https://www.researchgate.net/figure/Architecture-classique-dun-reseau-de-neurones-convolutif-Une-image-est-fournie-en_fig5_330995099
[Accès le 30/05/2021]
[44] : Jianxin. W, Lamda. G. (2017). Introduction to
Convolutional Neural Networks. Nanjing University, China.
[45] : Découvrez les différentes couches
d'un CNN - Classez et segmentez des données visuelles -
OpenClassrooms [Accès le 18/06/2021]
[46] : Focus : Le Réseau de Neurones Convolutifs -
Pensée Artificielle (
penseeartificielle.fr)
[Accès le 18/05/2021]
[47] : Hidenori. I, Takio. K. (2017]. Improvement of learning
for CNN with ReLU activation by sparse regularization. Conférence Paper.
Pp 1-9.
[48] :
https://www.kaggle.com/kanncaa1/convolutional-neural-network-cnn-tutorial?select=train.csv
[Accès le 03/06/2021]
[49] :
https://towardsdatascience.com/the-most-intuitive-and-easiest-guide-for-convolutional-neural-network-3607be47480
[Accès le 04/06/2021]
[50] :
https://fr.wikipedia.org/wiki/R%C3%A9seau
neuronal convolutif [Accès le
13/06/2021]
[51]:
http://promise.site.uottawa.ca/SERepository/datasets-page.html
[Accès le 14/06/2021]
[52] : Ozturk. M, Zengin. A. (2016). New findings on the use
of static code attributes for defect prediction.
[53]:
https://fr.wikipedia.org/wiki/Heat
map [Accès le 14/06/2021]
80
Bibliographies 80
[54] : Lei. Q, Xuesong. L, Qasim. U, Ping. G. (2020). Deep
learning based software defect prediction. Neurocomputing. Vol 385, pp
100-110.
[55]: Al Qasem. O, Akour. M. (2019). Software Fault Prediction
Using Deep Learning Algorithms. International Journal of Open Source
Software and Processes (IJOSSP), Vol 10(4), pp. 1-19
[56]: Osama. A. Q, Mohammed .A, Mamdouh. A. (2020). The
Influence of Deep Learning Algorithms Factors in Software Fault Prediction.
IEEE, PP 1-16.
[57] :
https://fr.bitdegree.org/tutos/bibliotheque-python/#heading-13
[Accès le 18/06/2021]
[58] :
https://www.infoworld.com/article/3278008/what-is-tensorflow-the-machine-learning-library-explained.html
[Accès le 18/06/2021]
[59] :
https://www.ionos.fr/digitalguide/web-marketing/search-engine-marketing/quest-ce-que-keras/
[Accès le 18/06/2021]
[60] :
https://informatique-python.readthedocs.io/fr/latest/Cours/science.html
[Accès le
18/06/2021]
[61] :
https://fr.wikipedia.org/wiki/Pandas
[Accès le 18/06/2021]
[62] :
https://he-arc.github.io/livre-python/matplotlib/index.html
[Accès le 18/06/2021]
[63] :
https://datascientest.com/seaborn
[Accès le 18/06/2021]
[64]:
https://research.google.com/colaboratory/faq.html#:~:text=Colaboratory%2C%20or%20
%E2%80%9CColab%E2%80%9D%20for,learning%2C%20data%20analysis%20and%20edu
cation. [Accès le 18/06/2021]
[65]:
https://www.rdocumentation.org/packages/DMwR/versions/0.4.1/topics/SMOTE
[Accès le 18/06/2021]
[66]:
https://www.guru99.com/confusion-matrix-machine-learning-example.html
[Accès le 18/06/2021]
[67]: Moudache. S. (2018). Prédiction du risque logiciel,
une approche basée sur la probabilité et l'impact des fautes :
évaluation. (Mémoire). Université du Québec.
Québec
| 

