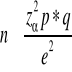Les effets du commerce informel sur la vie socio-économique des ménages. Cas des vendeuses du quartier Ndoshopar Rachel ASIFIWE YVETTE Institut Supérieur de Statistique et des Nouvelles Technologies (ISSNT/Goma) - Graduat en statistique 2016 |

CHAPITRE II. THEORIES SUR LES METHODES UTILISEESII.1. DÉFINITIONS DE BASE EN STATISTIQUEII.1 DEFINITIONS DE BASE EN STATISTIQUE Par définition, la statistique est l'ensemble des méthodes scientifiques à partir desquelles on recueille, organise, résume, présente et traite les données et qui permettent d'en tirer des conclusions judicieuses pour l'amélioration de la connaissance humaine et pour faire avancer la science11(*). La statistique est une science moderne et positive car elle met en lumière les faits les plus obscurs. · La statistique descriptive inscrit par ordre et décrit un ensemble des données numériques, tandis que l'inférence statistique généralise sur la population dans certaines conditions les conclusions obtenues. · La population statistique : c'est l'ensemble des éléments du même genre sur lesquels portent les observations. · Décision statistique : c'est une décision prise au sujet d'une population à partir de l'information que donne un échantillon. · L'échantillon : c'est une partie de la population sur la quelle portent les examens, il est dit représentatif si les conclusions tirées à partir de lui, représentent mieux celles de la population d'où il est prélevé avec la formule qui estime sa taille12(*).
n = taille de l'échantillon ; z = niveau de confiance à 95% ( Sa valeur type est 1,96) q=1-p : la proportion des personnes ne présentant pas l'évènement (50%); p= Proportion de la population concernée par l'événement (50%) ; e= Marge d'erreur (9%). L'application de la formule ci-dessous nous a permis de trouver un échantillon de Base de 118, 56 que nous avons arrondi à 120 Femmes exerçant le commerce informel. Dans le but de nous rassurer de la représentativité de notre échantillon, nous avons appliqué l'échantillonage en grappe en un degré. Pour ce faire, nous avons avons fait la selection aleatoire de 5 marchés informel du Quartier Ndosho en Raison du marché termunus (entrée ulpgl), Marché Cajed, marché Saint Michel, Marché Station Mode et le marché Antenne Kabasha. Pour ce qui concerne la collecte de données, nous avons procédé par une selection aléatoire de femmes en raison de 24 femmes commercantes par marché. · Une variable : est une propriété d'un objet ou évènement qui peut prendre différentes valeurs. Ici on distingue : · Les variables discrètes ou discontinues qui sont celles qui prennent des valeurs par bond sans qu'elles ne puissent prendre des valeurs intermédiaires. Par exemple nombre des vieillards. · Les variables continues qui peuvent théoriquement prendre toutes les valeurs dans un intervalle qualitatif. · Variables quantitatives, qui peuvent prendre toutes les valeurs dans un intervalle quantitatif. Par exemple revenu d'un commerçant, les points d'un élève...13(*) · Un paramètre : c'est une mesure qui se réfère à l'ensemble de la population. · Hypothèses statistiques : pour prendre une décision statistique, il convient de faire des hypothèses sur la population correspondante. a) Hypothèse nulle (Ho) :c'est une hypothèse statistique formulée dans le seul but de la rejeter ou de l'annuler. Au cas où cette hypothèse est acceptée, ça veut dire que la différence observée entre la réalité et les résultats de l'hypothèse ne peut être attribué qu'aux fluctuations dues à l'échantillonnage dans la population. b) Hypothèse alternative (H1) : c'est toute hypothèse qui diffère de l'hypothèse nulle donnée. La variation des résultats constatés ne peut pas être due à la seule loi du hasard, mais bien à une différence dans les populations étudiées. Ainsi, l'hypothèse de recherche correspond à l'hypothèse alternative. On peut conclure que l'hypothèse est vraie si les données de l'échantillon permettent de rejeter l'hypothèse nulle. Si on accepte ou si on rejeté, le jugement se trouve dans le tableau ci-dessous : Tableau n°4: Jugement des hypothèses statistique
Source : notes de cours de statistiques appliquée o L'erreur du type I ou du 1ere espèce consiste à rejeter Ho lorsqu'elle est vraie ; o L'erreur du type II ou de 2eme espèce consiste à accepter Ho alors qu'en réalité elle est fausse. * 11 Jonathan KABAKA, Coursde Statistique descriptive, inédit, G1 statistique, 2014-2015 * 12 Jonathan KABAKA, Coursde Théories et pratique de sondage, inédit, G2 statistique, 2015-2016 * 13HOWELL C.D: Méthodes statistiques en sciences humaines, éd. deboeck, liège, juillet 2014 |
|