|
~ i ~
Epigraphe
« En effet, Dieu ne nous a pas appelés à
l'impureté, mais à la consécration »
1 Thessaloniciens 4 : 7
~ ii ~
DEDICACE
A toute ma Famille ;
A tous ceux qui m'ont soutenu dans mes études ; A tous
ceux qui m'aiment ; Je dédie ce Mémoire. AKANGBA LOGO THIERRY
~ iii ~
REMERCIEMENTS
Sans la main extérieure, nous ne serions jamais
arrivés au chapeau de notre cycle de licence et de surcroit au bout de
ce mémoire. Pour ce faire, nous sommes appelés, après
notre cycle de licence, de présenter nos remerciements à tous
ceux qui ont contribué d'une manière ou d'une autre à la
réussite de ce mémoire.
Nous témoignons, en premier lieu, notre gratitude
à l'endroit de la bienveillance nous accordée par l'Eternel notre
Dieu qui n'a cessé de nous garantir protection et bonne santé du
début à la fin de notre cycle, que son nom soit grandement
loué.
Nos remerciements s'adressent à toute la
communauté académique de l'Université Adventiste de
Lukanga pour l'encadrement scientifique et spirituel à notre
égard.
Nous tenons à remercier le docteur Osée MASIVI,
Directeur de ce travail, pour l'intérêt qu'il a manifesté
tout au long de ce projet. Nous lui témoignons nos sentiments de
gratitude pour l'oeuvre accomplie malgré ses multiples occupations.
Nous remercions, d'une manière particulière, la
famille LOGO (JIBA) pour son sacrifice, amour et soutien de nos études
depuis notre bas âge jusque maintenant ; qu'ils trouvent ici le fruit de
leur dévouement inestimable. Sans oublier les frères, soeurs,
oncles, tantes, grand-mères, fils, filles, etc.
Aux camarades étudiants, compagnons de lutte, nous
disons également merci pour les moments de joie et de
compréhension mutuelle dont nous avons été
bénéficiaires ;
Des nombreuses références ont été
faites à la littérature existante, il convient de rendre hommage
à leurs auteurs pour nous avoir inspiré en la matière.
Enfin que toute personne ayant marquée de son empreinte ce travail,
trouve ici l'expression de notre profonde gratitude.
AKANGBA LOGO THIERRY
~ iv ~
SIGLES ET ABREVIATIONS
NTIC : Nouvelles Technologies de l'Information et de la
Communication
UML : Unified Modeling Language (Langage de
Modélisation Unifié)
SGBD : Système de Gestion de Base de données
SGBDR : Système de Gestion de Base de données
Relationnelles
BD : Base de données
BDR : Base de Données Réparties
ASP : Application Service Provider
P2P : Peer To Peer (Pair à Pair)
SGIF : Système de Gestion d'une Institution
Financière
SQL : Structured Query Language
LAN : Local Area Network
WAN : World Area Network
SRBDR : Système de Réplication de Base de
données Réparties
GUI : Graphical User Interface
IHM : Interface Homme Machine
Master : Serveur de Publication ou Serveur Maitre
Target : Serveur de Souscription ou Esclave
VB : Visual Basic
IP : Internet Protocol
~ V ~
TABLE DES MATIERES
Epigraphe i
DEDICACE ii
REMERCIEMENTS iii
SIGLES ET ABREVIATIONS iv
TABLES DES MATIERES v
TABLES DES FIGURES viii
RESUME x
ABSTRACT xi
INTRODUCTION 1
0. Problématique 1
1. Objectifs de l'étude 3
2. Choix et Intérêt du Sujet 3
3. Méthodes et Techniques de Travail 3
4. Délimitation du Sujet 4
5. Subdivision du Travail 4
PREMIER CHAPITRE 5
REVUE DE LITTERATURE 5
I.1. Base de Données Reparties ou Distribuées
5
I.2. Réplication de Base de Données 7
I.2.1. Réplication des Données 7
I.2.2. Algorithmes de Réplication 9
I.2.3. Durabilité dans les Systèmes
Répartis 9
I.4. Architecture Client - Serveur ou Centralisée 9
I.5. Disponibilité des Données dans les
Institutions Financières Congolaises 11
I.6. Discussion 12
~ vi ~
DEUXIEME CHAPITRE 13
METHODES ET TECHNIQUES DE RECHERCHE 13
II.1. MODELISATION 13
II.2. DEFINITION DES ALGORITHMES 15
II.3. PROTOTYPAGE 16
II.4. EXPERIMENTATION 16
II.5. SIMULATION 17
TROISIEME CHAPITRE 18
CONCEPTION DE LA SOLUTION 18
III.1. MODELISATION INFORMATIQUE D'UNE INSTITUTION FINANCIERE
18
III.1.1. FONCTIONNEMENT D'UNE INSTITUTION FINANCIERE 18
III.1.2. REGLES DE GESTION 19
III.1.3. MODELISATION FONCTIONELLE 20
III.1.4. MODELISATION STATIQUE : Diagramme des Classes 26
III.1.5. MODELISATION DYNAMIQUE 27
III.2. MODELISATION D'UN SYSTEME DE REPLICATION 29
III.2.1. PRÉSENTATION DE LA RÉPLICATION DE BASE
DE DONNÉES 29
III.2.1. MODELISATION FONCTIONNELLE 29
III.2.1. PRINCIPES DE LA RÉPLICATION 31
· Les Acteurs Principaux 32
· Les Acteurs Secondaires 33
III.2.3. MODELISATION STATIQUE 35
III.2.4. MODELISATION DYNAMIQUE 36
III.3. EXECUTION DE L'ALGORITHME DE REPLICATION SUR LA
MACHINE DE TURING 38
Figure 18 : Exécution des Algorithmes de
réplication sur la machine de Turing 38
Commentaires : 38
QUATRIEME CHAPITRE 39
~ vii ~
PRESENTATION DES RESULTATS 39
IV.1. PROTOTYPAGE 39
IV.1.1. PROTOTYPE D'UN DIAGRAMME DES RELATIONS POUR UNE BANQUE
COMMERCIALE 40
IV.1.2. PROTOTYPE D'UN DIAGRAMME DES RELATIONS D'UN SYSTEME DE
REPLICATION 41
IV.1.3. ENVIRONNEMENT DE TRAVAIL 42
IV.1.4. LES COMPOSANTS UTILISÉS DANS LA RÉPLICATION
43
IV.2. EXPERIMENTATION ET SIMULATION 44
IV.2.1. PROTOCOLE D'EXPÉRIMENTATION 44
4.2.2. RESULTATS DES TESTS 44
IV.2.3. PROCEDURES DE MISE EN PLACE DE LA REPLICATION 45
IV.2.4 INTERFACE HOMME - MACHINE 50
IV.3. SIMULATION 51
IV.3.1. ENONCE 51
IV.4. PRESENTATION ET DISCUSSION DES RESULTATS 53
IV.4.1. Résultats Obtenus 53
IV.4.2. Commentaires et Difficultés Rencontrées
55
BIBLIOGRAPHIE 58
ANNEXES 60
ANNEXE 1 : TRADUCTION DES ALGORITHMES DE REPLICATION SOUS
VB.NET 2008 60
ANNEXE 2 : SCRIPT DE REPLICATION GENERE APRES CREATION DE LA BASE
MAITRE
(PUBLICATION : REP_MY_BANK_SERVER) 63
~ viii ~
TABLE DES FIGURES
Figure 1 : Conception BD Répartie par
Décomposition et par Intégration (Mathieu EXBRAYAT,
2007) Page 6
Figure 2: Architecture Client - Serveur ... Page 11
Figure 3: Trois axes de modélisation UML (Pascal
Roques, 2006) .. ..Page 15
Figure 4 : De la Réflexion à la Programmation
Page 16
Figure 5 : Fonctions d'une Institution Financière
(Michel Lasserre, 2008) Page 19
Figure 6 : Diagramme des Cas d'Utilisation d'une institution
financière .. Page 22
Figure 7 : Diagramme d'Activités : Dépôt
et Retrait ..Page 25
Figure 8 : Diagramme d'Activités : Transfert et
Virement Page 26
Figure 9 : Diagramme des Classes : SGIF Page 27
Figure 10 : Diagramme de Séquence Système : SGIF
Page 28
Figure 11 : Diagramme d'états : SGIF Page 29
Figure 12 : Représentation du Système
Réparti considéré dans la Règle de Thomas (Pascal
MOLLI et
All, 2005) Page 31
Figure 13 : Diagramme des Cas d'utilisation de la
Réplication . .. Page 33
Figure 14 : Diagramme d'Activités de la
Réplication .. Page 35
Figure 15 : Diagramme des Classes de la Réplication .
... Page 36
Figure 16 : Diagramme de Séquence Système de la
Réplication Page 37
Figure 17 : Diagramme d'états du Système de
Réplication d'une Base de données Page 38
Figure 18 : Exécution des Algorithmes de
réplication sur la machine de Turing .Page 39
Figure 19 : Prototype d'un Diagramme des Relations d'une
institution Financière .Page 41
Figure 20 : Prototype d'un Diagramme des Relations d'un
Système de réplication Page 42
~ ix ~
Figure 21 : Environnement favorable pour la réplication
de bases de données Réparties ...Page 43
Figure 22 : Composants principaux dans la réplication
sous SQL Serveur ..Page 44
Figure 23 : Algorithme de sélection du Noeud
réplication pour commencer les configurations de mise
en place Page 46
Figure 24 : Vérification du Statut de l'Agent de
Publication ..Page 48
Figure 25 : Fonctionnement de l'Agent de Publication . Page
49
Figure 26: Etapes de Configuration du Serveur Maitre et du
Serveur Esclave Page 50
Figure 27: Filtrage de connexions des utilisateurs selon leur
groupe de travail ...Page 51
Figure 28: Interface de saisie des données de Test ..
Page 53
Figure 29: Interface de Réplication des Données
à propager . Page 53
Figure 30: Résultats obtenus après
Réplication des Données Page 54
~ X ~
RESUME
De nos jours, les bases de données réparties et
la réplication des données sont reconnues comme étant des
moyens efficaces pour augmenter la disponibilité et la fiabilité
des bases de données, nous nous sommes fixé l'objectif de
répondre à la question de savoir quel modèle informatique
permettrait de s'assurer de la disponibilité des informations
découlant des opérations en cours entre les sites distants afin
de répondre, en temps réel, aux différentes requêtes
que les utilisateurs peuvent exécuter à partir de n'importe
quelle base.
L'application du Langage de Modélisation Unifiée
(UML), des techniques algorithmiques, du prototypage, de
l'expérimentation et de la simulation nous a permis d'atteindre
l'objectif que nous nous étions fixé. Comme résultats,
nous avons conçu un modèle informatique de la réplication
des données sous forme de diagrammes UML. Nous avons également
testé ces algorithmes avec SQL Serveur et
VB.Net qui nous ont permis de faire le
monitoring des modifications qui se font au niveau de chaque site.
~ xi ~
ABSTRACT
Nowadays, distributed databases and data replication are
recognized as being efficient solutions to increase the availability and the
reliability of databases, we set the objective to answer the question to know
what data processing model would permit to ascertain the availability
information ensuing in progress of operations between distant sites in order to
answer, in real time, to the different requests that the users can execute from
any basis.
The application of the Unified Modeling Language (UML), of the
algorithmic techniques, the prototyping, the experimentation and the simulation
permitted us to reach the objective that we had set. As results, we conceived a
computer model of data replication under shape of UML diagrams. We also tested
these algorithms with SQL Server and
VB.Net that permitted us to make the
monitoring of the modifications that gets used in every site.
~ 1 ~
INTRODUCTION
0. Problématique
L'arrivée des Nouvelles Technologies de l'Information
et de la Communication (NTIC en Sigle) au sein des entreprises a
révolutionné les manières de travailler, que ce soit par
l'arrivée du fax, des ordinateurs, et depuis peu d'Internet. Il a
été constaté que les NTIC permettent aux entreprises de
répondre plus efficacement aux réalités du marché,
notamment grâce à l'utilisation d'Intranet qui permet aux
entreprises à succursales multiples à faire circuler les
informations inter-agences afin de favoriser l'interactivité, ce qui
permet ainsi une meilleure coordination automatisée des
opérations de l'Entreprise. L'Intranet permet donc une transformation
majeure des flux d'informations au sein de l'entreprise.
Les institutions financières ne sont pas en marge des
Nouvelles Technologies de l'Information et de la Communication. En effet, le
phénomène de globalisation financière initié depuis
le début des années 80 s'est accompagné d'un accroissement
notable des risques bancaires. Les marchés et les activités
bancaires sont devenus de moins en moins cloisonnés et les mouvements
internationaux de capitaux se sont intensifiés. Il en a
résulté une concurrence accrue et donc une réduction des
marges bancaires (réduction des bénéfices bancaires) qui
conduit les établissements bancaires à diversifier leurs
activités traditionnelles, qui ont contribué à une
certaine fragilité financière : les faillites bancaires se sont
multipliées. Paradoxalement, dans l'état actuel des choses, la
lutte contre les faillites bancaires passe notamment par l'utilisation des
moyens modernes de gestion d'informations inter-agences.
Pour des régions du monde où l'accès
à l'Internet demeure un problème, il est difficile de tirer
profit des avantages qu'apporte la technologie. Quelques Pays de l'Afrique en
font partie, notamment la République Démocratique du Congo. Ce
problème s'avère encore très grave pour des régions
du pays non électrifiés jusqu'à aujourd'hui. La ville de
Butembo fait donc face, non seulement au problème que pose le manque du
courant, mais aussi à la difficulté à laquelle se heurtent
les entreprises à succursales multiples, à l'instar des
Institutions Financières, qui, à tout moment, nécessitent
des données qui proviennent de différentes Agences.
~ 2 ~
Cet état de choses pose problème en termes de la
gestion de la file d'attente et handicape un certain nombre de transactions
faute de connexion au réseau ; un triste événement qui
survient au quotidien.
Hormis ce problème qui se pose dans la gestion des
Institutions Financières des pays du Tiers Monde, il y a aussi des
difficultés liées à la bancarisation qui n'est pas facile
à atteindre sans en payer le prix comme, par exemple, celui de rassurer
la population à faire confiance au système. Limiter les
problèmes ci-haut est un moyen sûr de gagner la confiance des
clients, car si on parvient à garantir la disponibilité des
données et des fonds, on peut y parvenir.
Toutes les institutions financières à
capacité financière élevée (les banques) et
même celles à faible capacité financière (les
microfinances) qui évoluent dans les régions du globe où
l'électrification et la communication via Internet ou Intranet demeurent
un défi, ont du mal à assurer la haute disponibilité des
informations de leurs clients ainsi que de leurs opérations, parce que
ces difficultés font que le partage des données entre sites ne se
fasse pas en temps réel. Cet état de chose pose également
problème en termes de la satisfaction des clients qui ne sont pas servis
au moment opportun faute de connexion au serveur des données.
Certaines institutions Financières multi sites luttent
tant bien que mal pour résoudre ce problème de
disponibilité des données, en imprimant par exemple, à
chaque début de la journée, les soldes des Clients afin d'avoir
en permanence les informations les concernant dans le but d'être capable
de les servir en temps réel. Cette façon de faire ne constitue
aucunement une solution adéquate, faute de temps que prennent ces
vérifications et même la difficulté de gérer les
opérations inter Agences en cours.
Les Institutions Financières sont, par
conséquent, obligées de trouver une solution à ces
différents dégâts qu'occasionnent les problèmes
précités de peur d'accuser une certaine fragilité dans
leurs Finances. C'est pour toutes les raisons précitées qu'il
convient de s'interroger sur le modèle informatique qui permettrait de
s'assurer de la disponibilité des informations découlant des
opérations en cours avec les autres bases afin de satisfaire en temps
réel les demandes des clients .
~ 3 ~
1. Objectifs de l'étude
Ce travail de recherche aura pour objectif de concevoir (et
tester) un Algorithme de Réplication des données d'une
Institution Financière afin de permettre cette dernière à
avoir en permanence les données des opérations avec les autres
agences dans l'objectif de répondre efficacement aux besoins de la
clientèle même lorsqu'il y a problème de connexion au
réseau ou coupure du courant dans l'une des agences.
2. Choix et Intérêt du Sujet
Tous les jours les Entreprises à succursales multiples,
par exemple les Institutions Financières, se partagent des informations
très utiles sans lesquelles aucune évolution ne serait possible.
Mais il arrive de temps à autre que ce partage devient difficile suite
aux problèmes que nous pouvons citer :
- Il arrive des fois que la connexion au serveur, pour l'une
des agences, soit impossible
- Il est des cas où il y a coupure au niveau du serveur
central ou au niveau de l'Agence d'où on attend des informations
- Etc.
Ce faisant, les gestionnaires de ces institutions se
retrouvent face à cette situation presque tous les jours et ne savent
pas comment la résoudre. Nous avons pensé qu'orienter nos
recherches dans ce sens serait non seulement utile pour ces gestionnaires,
aussi constituera-t-il une documentation pour ceux qui voudront mener des
travaux dans ce domaine. En outre, il sera aussi d'une grande importance dans
la mesure où, il aidera l'Institution non seulement à centraliser
ses opérations, mais aussi à satisfaire sa clientèle au
moment voulu.
3. Méthodes et Techniques de Travail
Pour bien mener nos recherches, nous userons de quelques
méthodes et techniques des recherches suivantes :
- le Langage de Modélisation Unifié (UML) pour
faire l'analyse et la conception de la solution à l'aide des algorithmes
que nous présenterons sous forme des diagrammes ;
~ 4 ~
- la définition des algorithmes que nous
représenterons sous forme de diagrammes d'activité, de
séquence système et d'états, mais aussi dans la Machine de
Turing;
- le prototypage, l'expérimentation et la
simulation.
4. Délimitation du Sujet
Vu l'objectif de notre recherche, ci-haut souligné,
nous nous limiterons dans la conception de l'algorithme de réplication
et les tests dans un système de gestion de base de données
d'architecture Distribuée et Client - Serveur, mais aussi dans un
langage de programmation et sur un ordinateur virtuel.
5. Subdivision du Travail
Hormis l'introduction et la conclusion, ce travail comporte
quatre chapitres dont :
1) la Revue de la Littérature;
2) les Méthodes et Techniques de Recherche;
3) La Conception de la Solution et
4) la Présentation des Résultats;
~ 5 ~
PREMIER CHAPITRE
REVUE DE LITTERATURE
Les bases de données réparties et la
réplication des données sont reconnues aujourd'hui comme
étant des moyens efficaces pour augmenter la disponibilité et la
fiabilité des bases de données. La réplication offre aux
utilisateurs de meilleures performances et une plus grande disponibilité
des données. (Lambert SONNA MOMO, 2001). De nombreuses recherches ont
mené à cette conclusion étant donné que la question
de la haute disponibilité des données ne date pas d'aujourd'hui,
et beaucoup d'auteurs se sont exprimés à propos.
Dans cette partie de notre recherche, nous souhaitons passer
en revue les théories, les méthodes et les résultats
obtenus par d'autres Auteurs au cours de leurs investigations. Cette revue
cherche donc à trouver une solution à la question de savoir quel
modèle informatique permettrait de s'assurer de la disponibilité
des informations découlant des opérations en cours entre les
bases de données afin de répondre, en temps réel, aux
différentes requêtes que les utilisateurs peuvent
exécuter.
I.1. Base de Données Reparties ou
Distribuées
En décembre 2007, Mathieu EXBRAYAT a
désigné par base de donnée répartie (ou
distribuée), une base de données logique dont les données
sont distribuées sur plusieurs SGBD et visibles comme un tout. Quoi
qu'Il s'est limité à expliquer les concepts liés à
la notion des bases de données reparties et leurs techniques de mise en
place. Ses recherches sont d'une importance capitale dans la mesure où
elles aident à bien comprendre différents concepts
utilisés dans la mise en place des bases de données
distribuées quand bien même qu'il n'offre aucun algorithme de
réplication des données capable de répondre à notre
question de recherche.
Pour J. Akoka et I. Wattiau (2011), une base de données
distribuée permet la création, l'accès et la manipulation
des données inter reliées sur différents sites d'un
réseau informatique. Ils ont listé quelques
éléments à retrouver dans une architecture
distribuée :
· Chaque site a une capacité de traitement local
autonome
· L'accessibilité, le partage, la performance et la
disponibilité sont améliorés
· l'optimisation globale des traitements, dans le but de
préserver les avantages de la base de données
centralisée.
~ 6 ~
Ils ajoutent quelques facteurs dont dépend la base de
données centralisée:
- Du coût de communication
- Du coût des traitements locaux
- De la stratégie d'allocation des données et
- De la stratégie d'exécution de traitements
MATHIEU EXBRAYAT présente deux approches de la
Conception répartie ; il s'agit de la Conception ascendante
c'est à dire qui intègre les bases locales dans un
schéma global (Décomposition) et la
conception descendante qui part du schéma global et le
scinde en schémas locaux (Intégration).
Graphiquement, sa conception produit la figure suivante :
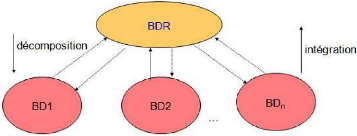
Figure 1 : Conception BD Répartie par
Décomposition et par Intégration (Mathieu
EXBRAYAT, 2007)
Ces notions sont d'une importance capitale dans la mesure
où elles facilitent la compréhension des concepts de bases de
données réparties étant des structures favorisant la
réplication préventive des données, c'est-à-dire
qui prévoit la tolérance aux pannes.
~ 7 ~
I.2. Réplication de Base de Données
La synchronisation des données a toujours
été un problème dans l'histoire de l'informatique en
général, et des SGBDR en particulier. La normalisation des
modèles a apporté une solution en l'évitant au maximum,
l'information ne devant se trouver qu'à un seul endroit. Pour s'assurer
de la disponibilité permanente des données, souvent, il est
nécessaire de répliquer de l'information. Les bonnes raisons pour
le faire sont nombreuses :
· Dénormalisation pour des questions de
performances
· Distributions géographiques,
décentralisation
· Récupération de données d'autres
environnements, centralisation
· Sécurisation, sites de secours distants
Comme l'affirme LAMBERT SONNA MONO (2001), les bases de
données réparties et la réplication des données
sont reconnues aujourd'hui comme moyens efficaces pour augmenter la
disponibilité et la fiabilité des bases de données. De
plus la réplication peut contribuer favorablement à
l'amélioration des performances en utilisant les copies locales voire
les copies plus proches.
En 2011, AKOKA et Wattiau définissent la
réplication selon son mode de mise à jour. Pour eux, une
réplication synchrone (réplication
transactionnelle, de capture instantanée) est celle qui permet une mise
à jour immédiate et qui utilise un protocole de validation
à deux phases, et une réplication asynchrone,
celle qui permet une mise à jour différée
(Réplication par fusion).
I.2.1. Réplication des Données
Pour MOLLI et Gérald (2005), répliquer revient
à dupliquer des données critiques pour la tolérance aux
pannes, pour la disponibilité et pour la performance. Pour eux, il
existe une différence entre répliquer et copier dans ce sens que
répliquer occasionne la cohérence des données et des
répliques. De ce fait la réplication est plus vaste qu'une simple
copie. D'où les concepts suivants sont nécessaires pour notre
sujet :
· Les Pannes :
Un système est en panne s`il ne sert pas les
données attendues en un temps attendu. Dans un système
distribué, on peut rencontrer de problèmes tels que :
- Un site peut s'arrêter pour une raison logicielle ou
matérielle ;
~ 8 ~
- Un site peut renvoyer des informations illisibles ou
incompréhensibles : pannes
byzantines ;
- Un lien peut être coupé ou marcher que dans un
sens ;
- Un message peut être perdu ou arrivé hors
délais ;
- Un message peut être altéré pendant le
transport (Byzantine Communication
Failure) ;
- Les erreurs de communication peuvent provoquer des partitions
réseaux ;
· La Réplication et le Système
Distribué
La réplication implique plusieurs sites
interconnectés, donc un ensemble des sites et des liens de
communication. Un site désigne, dans ce cas, un processus et un stockage
des données au niveau d'un serveur local et Un lien de communication
comme étant un canal de communication bidirectionnel entre deux sites.
Ces derniers communiquent en utilisant des messages et un protocole de
communication. La délivrance des messages n'est pas garantie dans un
temps maximum.
Pour Cédric COULON (2006), la haute performance et la
haute disponibilité des bases de données ont été
traditionnellement gérées grâce aux systèmes de
bases de données parallèles, implémentés sur des
multiprocesseurs fortement couplés. Le traitement parallèle des
données est alors obtenu en partitionnant et en répliquant les
données à travers les noeuds du multiprocesseur afin de diviser
les temps de traitement. Cette solution requiert un Système de Gestion
de Base de Données (SGBD) ayant un contrôle total sur les
données. Bien qu'efficace, cette solution s'avère très
coûteuse en termes de logiciels et de matériels.
Les grappes sont composées d'un ensemble de serveurs
(PC) interconnectés entre eux par un réseau. Ils permettent de
répondre aux problématiques de haute performance et de haute
disponibilité. Elles ont été utilisées avec
succès pour, par exemple, les moteurs de recherches Internet utilisant
des fermes de serveurs à grands volumes (e.g. Google). Les grappes
peuvent également être utilisées dans un nouveau
modèle économique, les Fournisseurs de Services d'Applications
(ASP - Application Service Providers). Dans un contexte ASP, les
applications et les bases de données des clients sont stockées
chez le fournisseur et sont disponibles, typiquement depuis Internet, aussi
efficacement que si elles étaient locales pour les clients.
Pour améliorer les performances, les applications et
les données peuvent être répliquées sur plusieurs
noeuds. Ainsi, les clients peuvent être servis par n'importe quel
noeud
~ 9 ~
en fonction de la charge. Cet arrangement fournit
également une haute disponibilité: dans le cas de la panne d'un
noeud, d'autres noeuds peuvent effectuer le même travail. Pour lui, Un
autre avantage du modèle ASP concerne le déploiement. La mise
à jour d'une application ou d'un SGBD ne demande pas le
déplacement d'un technicien chez tous les clients. La mise à jour
des noeuds chez le fournisseur est suffisante.
I.2.2. Algorithmes de Réplication
IMINE (2006), a conçu un éditeur collaboratif
fondé sur l'approche des transformées opérationnelles qui
peut être facilement déployé sur un réseau
Pair-à-pair (P2P). Il a aussi proposé un modèle formel
pour l'approche des transformées opérationnelles qui lui
permettrait de concevoir des algorithmes corrects. Son modèle permet de
spécifier et vérifier des objets synchronisés par une
transformation opérationnelle et a conçu un outil qui permet de
définir les opérations et l'algorithme de transformation pour un
objet donné (comme l'objet texte par exemple).
I.3. Durabilité dans les Systèmes
Répartis
Un système réparti est un système
informatique dont les composants logiciels s'exécutent sur des
ordinateurs(ou noeuds) interconnectés par un réseau. La notion de
durabilité est capitale dans les bases de données. Elle assure
que lorsqu'une base de données tombe en panne, les transactions qui ont
réussi leur commit sont effectivement préservées sur la
mémoire stable de la base de données. La durabilité est
donc une technique de tolérance aux pannes. (Lambert SONNA MOMO,
2001)
Il ajoute : « Une autre technique de tolérance
aux pannes est celle de la réplication, des copies multiples assurent
que, si une copie tombe en panne, les autres copies continuent de maintenir le
service. Naturellement, ces deux techniques de tolérance aux pannes ont
leur prix, que ce soit en termes de complicité ou de performance.
»
I.4. Architecture Client - Serveur ou
Centralisée
L'environnement client-serveur
désigne un mode de communication à travers un
réseau entre plusieurs programmes ou logiciels : l'un, qualifié
de client, envoie des requêtes ; l'autre ou les autres, qualifiés
de serveurs, attendent les requêtes des clients et y répondent.
Par
~ 10 ~
extension, le client désigne également
l'ordinateur sur lequel est exécuté le logiciel client, et le
serveur, l'ordinateur sur lequel est exécuté le logiciel serveur.
(Wikimedia Foundation, 2013). La comparaison des architectures
distribuées et client-serveur nous amènent à relever les
avantages et Inconvénients suivants :
a. Client-serveur
· Avantages
- Toutes les données sont centralisées sur un
seul serveur, ce qui simplifie les contrôles de sécurité,
l'administration, la mise à jour des données et des logiciels.
- Les technologies supportant l'architecture client-serveur
sont plus matures que les autres.
- La complexité du traitement et la puissance de
calculs sont à la charge du ou des serveurs, les utilisateurs utilisant
simplement un client léger sur un ordinateur terminal qui peut
être simplifié au maximum.
- Recherche d'information: les serveurs
étant centralisés, cette architecture est particulièrement
adaptée et véloce pour retrouver et comparer de vaste
quantité d'informations (moteur de recherche sur le Web), ce qui
semble être rédhibitoire pour le P2P beaucoup plus lent, à
l'image de Freenet.
· Inconvénients
- Si trop de clients veulent communiquer avec le serveur au
même moment, ce dernier risque de ne pas supporter la charge (alors que
les réseaux pair-à-pair fonctionnent mieux en ajoutant de
nouveaux participants).
- Si le serveur n'est plus disponible, plus aucun des clients
ne fonctionne (le réseau pair-à-pair continue à
fonctionner, même si plusieurs participants quittent le
réseau).
- Les coûts de mise en place et de maintenance peuvent
être élevés.
- En aucun cas les clients ne peuvent communiquer entre eux,
entrainant une asymétrie de l'information au profit des serveurs.
Une représentation graphique de l'Architecture Client -
Serveur se présente comme suit :
~ 11 ~
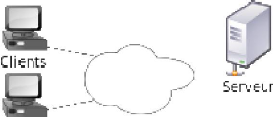
INTRANET
Figure 2: Architecture Client - Serveur b. Architecture
Distribuée
· Avantages
- Extensibilité
- partage des données hétérogènes et
réparties
- performances avec le parallélisme -
disponibilité avec la réplication
· Inconvénients
- administration complexe - distribution du contrôle -
difficulté de migration
I.5. Disponibilité des Données dans les
Institutions Financières
Congolaises
Les institutions Financières, autrement
appelées « Banques » constituent l'une de branches
économiques les plus méconnues tant par les utilisateurs (le
public), que par la plupart de ses employés (personnel). Selon l'usage
que l'on en fait, elles apparaissent soit comme des gardiennes de
dépôts de leurs clients, soit comme des distributrices de
crédit à partir des ressources collectées ou
créées, soit encore comme de conseillères
privilégiées. (Norbert VAGHENI, 2013). Ce faisant, elles
requièrent une grande attention de la part de toutes les parties
prenantes.
Dans sa politique de maximisation de la rentabilité et
de gestion des risques, le banquier se retrouve face à une multitude des
situations à gérer, entre autres : la gestion de la Relation
Client, la disponibilité des fonds mais aussi celle des données
de sorte que
~ 12 ~
l'information soit facilement accessible afin de
répondre aux demandes d'information par les clients, en temps
réel.
En RDC, les établissements de crédit ne font
pas face qu'aux situations ci-haut mentionnées, mais ils se confrontent
aussi à des problèmes liés au développement de la
région dans son ensemble : le problème de connexion au
réseau, le manque d'électricité, mais encore la
solvabilité des clients, sans oublier le faible taux de bancarisation
qui sévit dans les pays subsahariens. Les institutions
financières à capacité financière
élevée (les banques) ont profité de la solution
apportée par la banque centrale du Congo, qui leur a proposé un
logiciel de gestion bancaire unique.
Vu les coûts que cette solution exige, les institutions
financières de petite taille (les Microfinances) se retrouvent
incapables de l'envisager. Pour les relever, la solution la moins
coûteuse serait de mettre en place une architecture distribuée qui
puisse les permettre de répliquer les données provenant de
différentes bases de données reparties, tout en minimisant les
coûts.
I.6. Discussion
Les résultats fouillés des recherches ci-dessus
n'ont pas surement couvert le sujet en entier étant donné que
:
- Les algorithmes proposés ne tiennent pas compte de
la fréquence de lancement des requêtes des utilisateurs, mais non
plus de la consommation de la bande passante ;
- Les modèles proposés ne prévoient pas
de situation de manque d'électricité et de connexion permanente
au réseau privé (intranet) qui sont des facteurs clés dans
la recherche de la cohérence entre les données
répliquées.
De ce fait, cette affirmation hypothétique demeure :
« Si on parvient à Instaurer un système de
Réplication dans le but d'avoir en permanence les informations des
autres bases, alors la Conception d'un Algorithme de Réplication des
données selon la fréquence de lancement des requêtes des
utilisateurs serait une solution optimale pour minimiser les coûts
d'achat de la bande passante. »
Cette étude trouve son bien fondé, dans le fait
que cet angle de recherche n'a pas été sérieusement
exploité jusqu'ici.
~ 13 ~
DEUXIEME CHAPITRE
METHODES ET TECHNIQUES DE RECHERCHE
Pour répondre aux questions de notre recherche, nous
devrons avoir une marche à suivre, autrement dit un ensemble
d'étapes, une méthode. Mais pour un système aussi
complexe, une seule méthode ne sera pas suffisant, puisqu'il s'agit non
seulement d'instaurer un système de réplication de bases de
données permettant d'avoir en permanence, dans une base quelconque, les
informations enregistrées sur d'autres bases, mais aussi de concevoir et
tester les algorithmes en tenant compte de la fréquence de demandes des
utilisateurs pour minimiser le coût de la bande passante ; raison pour
laquelle nous avons combiné différentes méthodes et
techniques suivantes :
II.1. MODELISATION
De manière abstraite, la réplication des bases
de données, sera représentée, dans ce travail, avec le
langage de modélisation UML (Unified Modeling Langage) étant un
langage de modélisation orienté-objet utilisé dans la
conception des logiciels informatiques employant des concepts tels que : objet,
messages, classe, héritage, polymorphisme. Elle implémente, pour
ce faire, les formalismes tels que le modèle de classe, le modèle
d'objets, le modèle des états, le modèle des cas
d'utilisation, le modèle d'interaction, le modèle de
réalisation (Muyisa FRED, 2011). Aussi, avons-nous
représenté la réplication des données selon les
trois points de vue classiques de modélisation : fonctionnel, statique
et dynamique, en insistant sur les diagrammes prépondérants.
Graphiquement, la modélisation à faire se
résume dans la figure suivante :
~ 14 ~
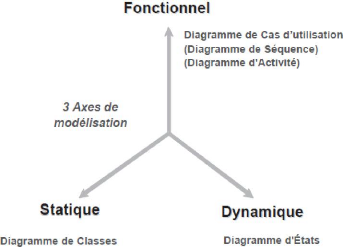
Figure 3: Trois axes de modélisation UML (Pascal
Roques, 2006)
· Du point de vue Fonctionnel, nous
avons tracé un Diagramme de cas d'Utilisation pour définir les
acteurs qui interagissent avec le système de réplication, mais
aussi un Diagramme d'Activité pour décrire le scénario
nominal des cas d'utilisation (des actions émis par les acteurs sur le
système et vis versa). Ces deux diagrammes renseignent sur le
fonctionnement des acteurs et du système de réplication
lui-même.
· Du point de vue Statique, nous avons
représenté le diagramme de Classes étant le point central
dans un développement orienté objet qui nous a permis de
décrire la structure des entités-objets manipulés par les
utilisateurs.
· Du point de vue Dynamique, nous avons
réalisé un diagramme de communication particulier (diagramme de
contexte dynamique) sous forme de diagramme de séquence système
afin de répertorier tous les messages que les acteurs peuvent envoyer au
système de réplication et recevoir de lui ; et un diagramme
d'états pour décrire avec précision les comportements
complexes. Dans le même contexte, nous avons créé une
machine de Turing (appelée machine à
états finis en UML) qui consiste à
s'intéresser au cycle de vie d'une instance générique
d'une classe particulière au fil de ses interactions avec le reste du
monde, dans tous les cas possibles. Cette vue locale d'un objet (un
enregistrement dans notre cas), qui décrit comment il réagit
à des
Nous avons fait recours aux techniques algorithmiques qui
nous permettront d'analyser le problème en quatre phases : la
Spécification ou cadrage, la Description du
~ 15 ~
événements en fonction de son état
courant et comment il passe dans un nouvel état (durant la
réplication), sera représentée, dans ce travail comme dans
beaucoup d'autres, graphiquement sous la forme d'un diagramme
d'états.
II.2. DEFINITION DES ALGORITHMES
Il ne s'agit pas ici de programmer avec un langage ou un
autre, mais bien de raisonner sur le problème afin de concevoir une
solution abstraite. Ce travail de réflexion et de conception
prépare le stade ultime de l'implémentation et du cycle
de vie du programme concret. Un algorithme, dans sa définition simple,
est une suite d'instructions qui, quand elles sont exécutées
correctement aboutissent au résultat attendu.
C'est un énoncé dans un langage clair, bien
défini et ordonné qui permet de résoudre un
problème, le plus souvent par calcul. Cette définition est
à rapprocher du fonctionnement de la machine de Turing qui avant
l'apparition de l'ordinateur utilisait cette démarche pour
résoudre de nombreux problèmes. L'algorithme est donc une recette
pour qu'un ordinateur puisse donner un résultat donné.
Il décrit formellement ce que doit faire l'ordinateur
pour arriver à un but bien précis. Ce sont les instructions qu'on
doit lui donner. Ces instructions sont souvent décrites dans un langage
clair et compréhensible par l'être humain : faire ceci, faire cela
si le résultat a telle valeur, et ainsi de suite.
Figure 4 : De la Réflexion à la Programmation
~ 16 ~
traitement ou des opérations en utilisant le Langage
de Description Formelle des Algorithmes (LDFA), la traduction des algorithmes
dans un langage de programmation et enfin la programmation et le jeu de test
des algorithmes que nous avons exécuté dans une Machine de
Turing.
II.3. PROTOTYPAGE
Une fois la modélisation et la définition des
algorithmes finies, nous avons retracé une maquette du nouveau
système : un prototype, dans le but de projeter ce à quoi va
correspondre le système à la fin de notre recherche. C'est
à niveau que nous essayerons de résoudre les problèmes que
les utilisateurs du système auront ciblé.
Ce processus pourra nous aider à véhiculer
l'expérimentation, et sa construction fournira un nouvel aperçu
sur le modèle prototypé. Voilà pourquoi il nous faudra
avoir un style qui traitera de la manière dont les solutions aux
problèmes ou les algorithmes seront formulées. Cette phase est
beaucoup plus utile étant donné que c'est la partie qui
intéresse les bénéficiaires finaux du système
à mettre en place.
II.4. EXPERIMENTATION
Bernard MORAND a écrit : « Un bon logiciel n'est
ni celui dont on peut exhiber la preuve, ni celui qui fait ce qui est
demandé, mais celui dont les utilisateurs se servent encore trois ans
après sa création ».
L'expérimentation nous a permis de tester notre
modèle et d'observer les effets afin de soumettre le système
réalisé à un ensemble d'expériences et
d'opérations destinées à l'étude et au test qui,
dans ce travail de recherche, seront conduits dans un laboratoire informatique.
Il est à signaler que l'expérimentation s'est fait selon la
complexité des algorithmes écrits pour dégager les
résultats attendus sous la contrainte du temps d'exécution et de
ressources mémoires exigées (espace).
Hormis le test de la complexité algorithmique, il
faudra expérimenter la nouvelle application dans un environnement
réseau, ce qui revient à dire qu'il faudra tester la
réplication entre base des données installées sur deux ou
trois sites distants afin d'être sûr que les questions de la
recherche avaient été partiellement ou totalement satisfaites.
~ 17 ~
II.5. SIMULATION
A défaut d'un environnement pour
l'expérimentation, nous avons créé nous-mêmes des
environnements des tests afin de dégager plus rapidement les
résultats attendus du système. Il s'agira d'un environnement
imaginaire favorable pour réplication des données entre les bases
de données installées sur différents serveurs. La
simulation sera faite de sorte que les serveurs s'échangent
continuellement les rôles comme dans un réseau pair à pair.
Un site sera donc à la fois maitre et esclave.
- La collecte des dépôts : les agents
économiques apportent leur trésorerie aux banques sous forme de
dépôts à vue, à terme ou d'épargne.
~ 18 ~
TROISIEME CHAPITRE
CONCEPTION DE LA SOLUTION
Dans ce chapitre, nous nous emploierons dans un premier temps
à concevoir un système d'information simple d'une institution
financière, qui est, comme signalé dans l'introduction de ce
travail, le champ de notre travail de recherche.
Dans un second temps, nous représenterons un
système de réplication de base de données avec UML, que
nous appliquerons sur la base de données de l'institution
financière précédemment modélisée.
III.1. MODELISATION INFORMATIQUE D'UNE
INSTITUTION
FINANCIERE
III.1.1. FONCTIONNEMENT D'UNE INSTITUTION FINANCIERE
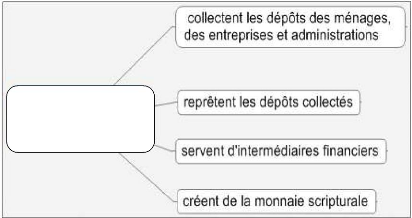
INSTITUTIONS FINANCIERES
Figure 5 : Fonctions d'une Institution Financière
(Michel Lasserre, 2008)
Les fonctions principales d'une institution financière
sont :
~ 19 ~
- La distribution du crédit : les banques apportent aux
agents économiques les crédits nécessaires à leurs
activités de consommation ou de production.
- L'intermédiation bancaire et Financière : une
partie de l'activité des banques est de servir d'intermédiaire
financier. Quand une entreprise ou l'Etat veut se refinancer, il émet
des titres qu'il vend par l'intermédiaire des banques commerciales. Ces
banques proposent ainsi à leur clientèle, divers produits
financiers (actions de société, obligations d'entreprises, bons
du Trésor, ...), ainsi que des services de gestion de ces produits.
- La Création de la monnaie scripturale en
émettant des effets de commerce (le Chèque par exemple)
III.1.2. REGLES DE GESTION
- Au sein d'une institution financière, les
opérations doivent appartenir à un exercice, celui-ci est
identifié par un code qui doit être unique, une description qui
informe sur la durée de l'exercice, une date de début, une date
de fin, un taux de change, un taux d'intérêt ;
- Pour les institutions financières, les principales
activités sont le dépôt et le retrait, le transfert entre
agences, le virement entre comptes internes et les emprunts. Ces
activités sont enregistrées comme des opérations : chaque
opération doit contenir deux ou plusieurs transactions, et doit avoir un
numéro, une date, un type, un libellé, une pièce
justificative ;
- Ces activités concernent les clients. Un client est
identifié par un numéro d'ordre, un nom, un post nom, un
prénom, un numéro de téléphone, une adresse et deux
mandataires au plus ;
- Un mandataire est identifié par un numéro
d'ordre, il a un nom, un prénom, un numéro de
téléphone et une adresse.
- Une transaction du guichet est contenue dans une
opération : c'est un billetage qui est identifié par un
numéro, le nombre des billets, la valeur de ces billets et une
observation.
~ 20 ~
- Une transaction de comptabilité est contenue dans une
opération. Elle est identifiée par un numéro, et elle
dépend d'au moins un compte à débiter ou à
créditer par un montant.
- Un compte a un numéro, un intitulé, une nature,
une classe et appartient à une masse ou un pallier.
- Une masse (pour les comptes du bilan) ou un palier (pour les
comptes de gestion) est identifié par un numéro et un
intitulé.
III.1.3. MODELISATION FONCTIONELLE
Diagramme des Cas d'Utilisation
~ 21 ~
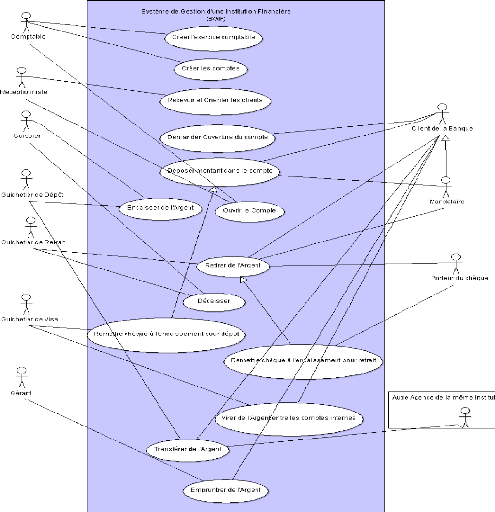
Figure 6 : Diagramme des Cas d'Utilisation d'une institution
financière
~ 22 ~
Identification des Acteurs
· Les Acteurs Principaux
Ce sont ceux qui interagissent directement avec le
système de gestion de l'Institution Financière :
- Le Comptable : il crée l'exercice
comptable conformément au principe comptable exigeant la
définition du début de l'exercice et de la fin de l'exercice, au
cours duquel toutes les opérations seront enregistrées. Il
crée les comptes, et les ouvre sur demande des clients.
- Le Réceptionniste : il
reçoit et oriente les clients vers divers d'autres acteurs (guichetier
de dépôt, guichetier de retrait, le guichetier de Visa) et
même chez le gérant en cas de sollicitation d'un prêt par
exemple.
- Le Caissier : il enregistre les
entrées et les sorties des fonds de la caisse et les gère. Il
reçoit toutes les sommes venant des transferts, et de versement, et de
transfert de banque en caisse
- Le Guichetier de Dépôt :
enregistre diverses entrées de fonds des clients et les apporte à
la caisse. Il assure également le transfert des fonds inter agences.
- Le Guichetier de Retrait : enregistre les
mouvements de sortie de fonds des clients.
- Le Guichetier de Visa : il vérifie
l'authenticité des documents émis par les clients pour les
opérations de retrait ou de transfert. Parmi ces documents, on peut
mentionner : le chèque et l'ordre de virement.
- Le Gérant : c'est le directeur des
services ; il coordonne les services, il analyse les demandes de prêt et
centralise les rapports émis par les services qu'il gère.
~ 23 ~
· Les Acteurs Secondaires
Ils n'interagissent pas directement avec le système,
mais ils déclenchent la plupart d'opérations.
- Le Client de la Banque : il a un compte
dans la banque qu'il modifie tous les jours par ses versements, ses retraits,
ses virements, ...
- Le Porteur d'un Chèque : il n'est
pas reconnu comme client de la banque, mais il se présente à la
banque sur ordre du propriétaire du compte dont les informations se
retrouvent sur son chèque.
- Le Mandataire : il est reconnu par la
banque comme suppléant au propriétaire du compte. Il n'a pas
besoin d'un chèque pour retirer de l'argent.
- Une autre Agence de l'Institution Financière
: elle intervient en cas de transfert des fonds d'un client de
l'agence A vers le client vers l'agence B de la même Institution
Financière.
~ 24 ~
Diagrammes d'Activités : Dépôt et
Retrait des Fonds
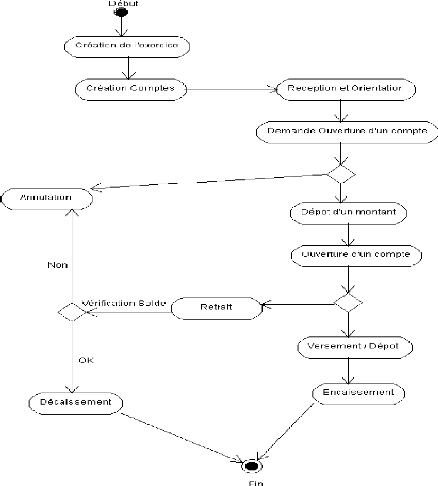
Refusée
Acceptée
Retrait
Dépôt
Figure 7 : Diagramme d'Activités : Dépôt et
Retrait
~ 25 ~
Diagramme d'Activités : Transfert et
Virement
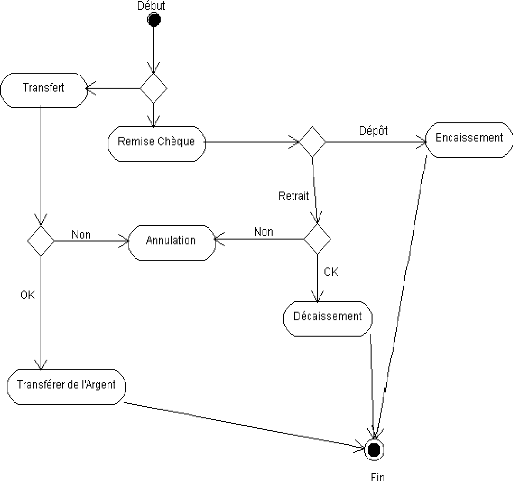
Figure 8 : Diagramme d'Activités : Transfert et
Virement
~ 26 ~
Figure 9 : Diagramme des Classes : SGIF
III.1.4. MODELISATION STATIQUE : Diagramme des Classes
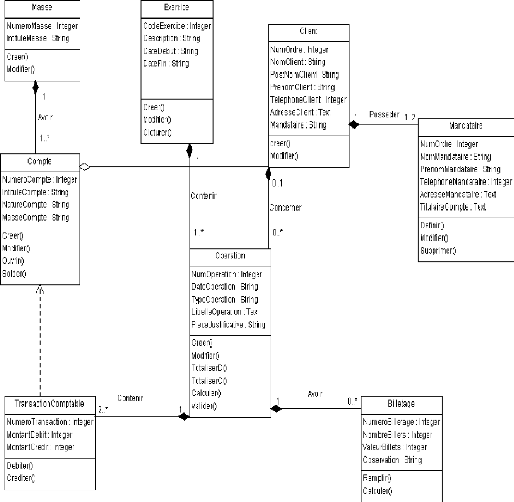
~ 27 ~
III.1.5. MODELISATION DYNAMIQUE
Diagramme de Séquence Système des
Scénarios Nominaux: Déposer et
Retirer
SGIF
|
Caissier Guichetier de
Retrait
|
Guichetier de
Dépôt
|
Déposer un Client
Comptable Montant
|
|
Ouverture Compte Client
|
|
|
Enregistrement Entrée des Fonds
Encaissement
Demande de Retrait
Interrogation sur le Solde
Vérification du Solde
Autorisation de Retrait
Décaissement
Clôture de la Journée

Figure 10 : Diagramme de Séquence Système : SGIF
Réponse
Retirer de l'Argent
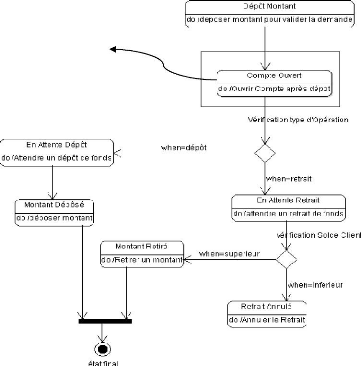
Figure 11 : Diagramme d'états : SGIF
~ 28 ~
III.2. Diagramme d'état
Sous - état
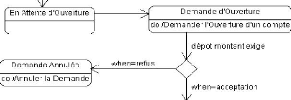
~ 29 ~
III.2. MODELISATION D'UN SYSTEME DE REPLICATION
III.2.1. PRÉSENTATION DE LA RÉPLICATION DE
BASE DE DONNÉES
La réplication est une puissante fonctionnalité
des SGBD (SQL Serveur, Oracle, MySQL, Access, ..) qui permet de distribuer les
données et d'exécuter les procédures stockées sur
plusieurs serveurs de l'entreprise. La technologie de réplication a
considérablement évolué et permet maintenant de copier,
déplacer les données à différents endroits et de
synchroniser automatiquement les données. La réplication peut
être mise en oeuvre entre des bases de données résidant sur
le même serveur ou sur des serveurs différents. Les serveurs
peuvent être sur un réseau local (LAN), réseau global (WAN)
ou sur Internet.
On distingue deux catégories de réplication :
- La réplication de serveur à serveur
- La réplication de serveur à clients
Dans le cas de la réplication de serveur à
serveur, la réplication permet une meilleure intégration ou
rapprochement des données entre plusieurs serveurs de base de
données. L'objectif de ce type de réplication est d'effectuer un
échange d'informations entre des serveurs de base de données. Les
utilisateurs qui travaillent sur les bases qui participent à la
réplication peuvent ainsi consulter des données de meilleure
qualité.
La réplication de serveur à clients concerne
principalement les utilisateurs déconnectés du réseau de
l'entreprise et qui souhaitent travailler avec tout ou partie des
données de l'entreprise.
III.2.2. MODELISATION FONCTIONNELLE
1. Un système de réplication optimiste est
constitué d'un ensemble de sites interconnectés par un
réseau.
2. Chaque site possède une copie des objets
partagés par exemple des documents textuels ou des images.
3. Sur un site, une réplique peut être
modifiée au moyen d'opérations.
4. Quand une réplique est modifiée sur un site,
l'opération correspondante est immédiatement
exécutée sur ce site, puis propagée aux autres sites pour
y être ré-exécutée.
5. Lorsque deux répliques de deux sites
différents sont modifiées en parallèle, les
répliques divergent.
~ 30 ~
6. Il est donc possible d'observer au même moment une
valeur sur un site et une autre valeur sur un autre site. Les algorithmes de
réplication doivent assurer la convergence des répliques.
7. Le système doit être convergeant quand le
système est au repos, c'est-`a-dire quand toutes les opérations
ont été propagées à tous les sites.
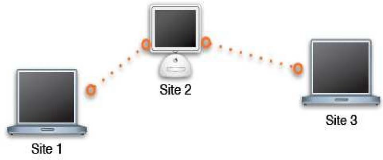
Figure 12 : Représentation du Système
Réparti considéré dans la Règle de Thomas (Pascal
MOLLI et All, 2005)
~ 31 ~
III.2.3. PRINCIPES DE LA RÉPLICATION
Le principe de la réplication, qui met en jeu au minimum
deux Bases de données installées sur des sites distants, est
assez simple et se déroule en trois temps :
1. La base maître reçoit un ordre de mise à
jour (INSERT, UPDATE ou DELETE).
2. Les modifications faites sur les données sont
détectées et stockées (dans une table, un fichier, une
queue) en vue de leur propagation.
3. Un processus de réplication prend en charge la
propagation des modifications à faire sur une seconde base dite esclave.
Il peut bien entendu y avoir plus d'une base esclave.
Toutefois, il est possible de faire de la réplication dans
les deux sens (de l'esclave vers le maître et inversement). On parlera
dans ce cas-là de réplication bidirectionnelle ou
symétrique. C'est le type de réplication que nous comptons
représenter dans cette partie.
~ 32 ~
Réalisation du diagramme des cas
d'utilisation
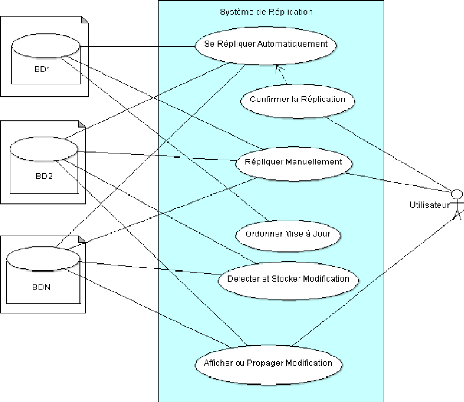
Figure 13 : Diagramme des Cas d'utilisation de la
Réplication
Identification des acteurs
· Les Acteurs Principaux
- Base de Données 1 : la base de
données sur laquelle s'effectuent les modifications. On l'appelle
autrement, Base Maitre. Elle est installée sur un serveur.
- Base de Données 2 : la base de
données qui attend les modifications apportées sur la
base de données installée sur l'autre site
grâce à la réplication. C'est la Base Esclave.
~ 33 ~
- Base de Données N : représente
le reste des bases de données réparties sur lesquelles la
réplication sera exécutée.
· Les Acteurs Secondaires
- Utilisateur : c'est l'utilisateur de la base
de données. Il déclenche le processus de la réplication
manuelle. Cette dernière prend effet lorsque le processus de la
réplication automatique n'a pas abouti ou quand l'heure prévue
pour la réplication n'a pas encore sonné.
~ 34 ~
Figure 14 : Diagramme d'Activités de la
Réplication
Diagramme d'Activités de
Réplication
~ 35 ~
III.2.4. MODELISATION STATIQUE Diagramme des
Classes
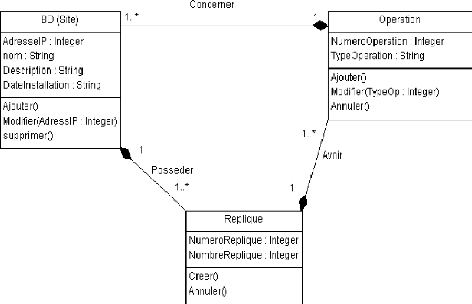
Figure 15 : Diagramme des Classes de la Réplication
~ 36 ~
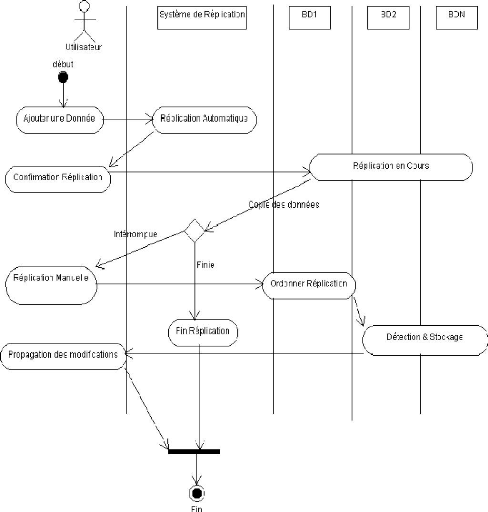
III.2.5. MODELISATION DYNAMIQUE Diagramme de
Séquence Système
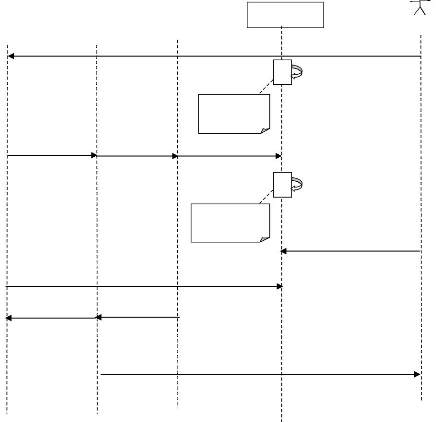
Utilisateur
SRBDR
BD2 BDN
BD1
Ajouter Donnée
Réplication Automatique
REPLICATION EN COURS
Opération de Copie
Réplication Manuelle
Ordonner Mise à Jour
DETECTION & STOCKAGE
Affichage des Modifications
Figure 16 : Diagramme de Séquence Système de la
Réplication
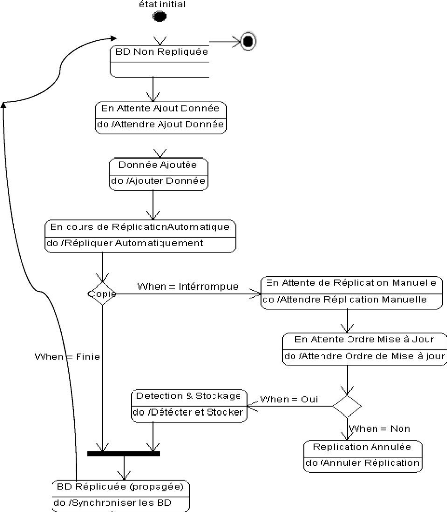
état final
Figure 17 : Diagramme d'états du Système de
Réplication d'une Base de données
~ 37 ~
III.1.3.2. Diagramme d'états : BD Non
Répliquée et BD Répliquée
~ 38 ~
III.3. EXECUTION DE L'ALGORITHME DE REPLICATION SUR
LA
MACHINE DE TURING
Dans les diagrammes d'activité, de séquence
système et d'états du système de réplication, nous
avons décrit les algorithmes de réplication. Ces algorithmes
offrent la possibilité de répliquer manuellement les informations
en cas d'interruption lors de la propagation des données. La figure
suivante décrit l'exécution de ces algorithmes sur la Machine de
Turing:
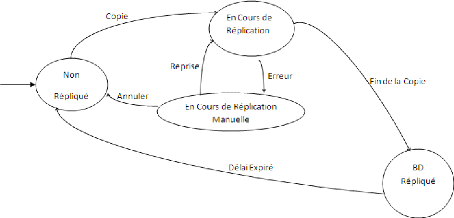
Figure 18 : Exécution des Algorithmes de
réplication sur la machine de Turing
Commentaires :
Cette figure représente la Machine de Turing qui est un
ordinateur virtuel décrivant le flux de traitement des informations en
précisant les différents états aux quels passent ces
états lors de l'exécution des algorithmes dans le système.
Les résultats des tests de nos algorithmes ont produit des automates
Déterministes et Non Déterministes à la fois. Pour
certains états, par exemple l'état Non Répliqué et
BD répliquée, on sait déjà le prochain état
par lequel on va passer, c'est le cas d'un automate déterministe. Mais
pour les autres états, comme En cours de Réplication, on ne sait
pas encore si on passera à l'état BD répliquée ou
En cours de Réplication Manuelle, tant qu'on n'a pas quitté
l'état actuel : c'est la situation d'un automate Non
Déterministe.
~ 39 ~
QUATRIEME CHAPITRE
PRESENTATION DES RESULTATS
Partant de notre affirmation hypothétique
formulée comme suit : « Si on parvient à Instaurer un
système de Réplication dans le but d'avoir en permanence les
informations des autres bases, alors la Conception d'un Algorithme de
Réplication des données selon la fréquence de lancement
des requêtes des utilisateurs serait une solution optimale pour minimiser
les coûts d'achat de la bande passante. », nous avons abouti
à des résultats que nous comptons vous présenter dans
cette dernière partie de notre travail de recherche.
Pour exécuter les algorithmes que nous vous avons
présentés dans le chapitre précédent sous forme de
diagrammes d'activité, de séquence système et
d'états, nous avons fait recours à trois méthodes : le
Prototypage, la Simulation et l'Expérimentation.
IV.1. PROTOTYPAGE
Le prototypage nous a été d'une grande
importance puisqu'il nous a permis de connaitre d'avance à quoi
ressemblerait le système à concevoir.
Le diagramme des classes modélisé à
partir de règles de gestion et de traitement établis au
début du chapitre précédent a dégagé le
diagramme des relations suivantes :
~ 40 ~
IV.1.1. PROTOTYPE D'UN DIAGRAMME DES RELATIONS POUR UNE
INSTITUTION FINANCIERE
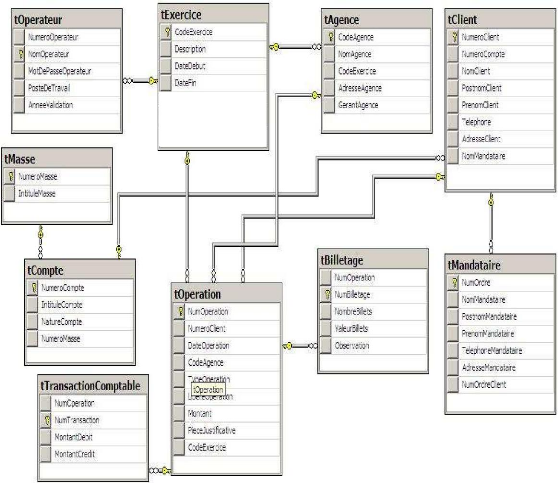
Figure 19 : Prototype d'un Diagramme des Relations d'une
institution Financière
~ 41 ~
Le diagramme de classes du système de
réplication a généré le diagramme des relations
suivant :
IV.1.2. PROTOTYPE D'UN DIAGRAMME DES RELATIONS D'UN
SYSTEME DE REPLICATION
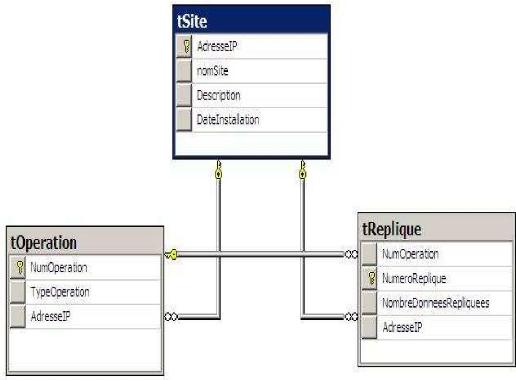
Figure 20 : Prototype d'un Diagramme des Relations d'un
Système de réplication
Figure 21 : Environnement idéal pour la réplication
de bases de données Réparties
~ 42 ~
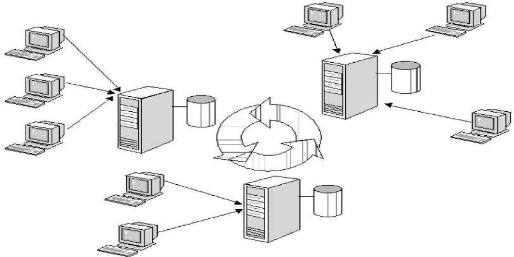
IV.1.3. ENVIRONNEMENT DE TRAVAIL
Pour mettre en place le système de réplication
de la base de données d'une institution financière, nous sommes
passés par les étapes suivantes :
- Sur deux ordinateurs de 2GB de RAM et de 2
GHz de processeur, nous avons installé Windows Serveur 2008
édition Entreprise, qui est l'environnement exigé par les
éditions Entreprise de SQL Serveur ;
- Pour mettre en réseau les
ordinateurs, nous avons utilisé un Switch D-Link 5-Port 10/ 100
Desktop.
- Nous y avons installé SQL Serveur
Management Studio Entreprise 2005 pour nous permettre la réplication de
base de données ;
- Nous y avons installé Microsoft
Visual Studios 2008, pour créer des interfaces pouvant faciliter la
saisie des informations de tests pour la réplication des données,
que nous avons connecté avec SQL Serveur ;
SITE 1
Réplication des données
SITE N
SITE 2
- pour toutes les configurations,
l'environnement idéal pour la mise en place de la réplication de
bases de données distribuées est décrit sur la figure
suivante :
~ 43 ~
SQL Serveur fournit trois types de réplication des
données, la méthode : par capture instantanée,
transactionnelle et par fusion. Chacun des types de réplication
répond à un besoin bien précis.
IV.1.4. LES COMPOSANTS UTILISÉS DANS LA
RÉPLICATION
Dans un premier temps, nous avons eu besoin d'un
serveur éditeur pour mettre à la disposition des
autres serveurs des données pour mettre en oeuvre la réplication.
L'éditeur conserve toutes les données publiées (celles qui
participent à la réplication) et tient à jour les
modifications intervenues sur ces données. Pour les données
publiées, l'éditeur est toujours unique.
Deuxièmement, il était question de mettre en
place un distributeur qui est un serveur SQL qui contient la
base de distribution, c'est-à-dire celle qui contient toutes les
informations utilisées par les abonnés pour tenir à jour
les données qu'ils contiennent.
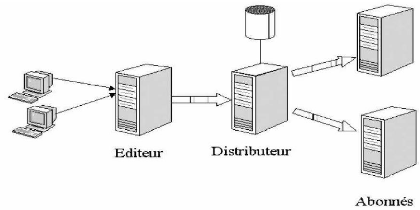
Enfin les abonnés, qui
désignent les serveurs SQL qui stockent une copie des informations
publiées puis reçoivent les mises à jour de ces
données. Dans les versions 6.x de SQL Server, il n'était pas
possible de modifier les données sur les abonnés. Il est
maintenant possible de modifier les données publiées sur
l'abonné. Un abonné peut devenir éditeur pour d'autres
abonnés.
Figure 22 : Composants principaux dans la réplication
sous SQL Serveur
~ 44 ~
IV.2. EXPERIMENTATION ET SIMULATION
L'objectif principal étant la conception d'un
algorithme de réplication adapté à la
réalité vécue dans les pays du sud, plus exactement en
RDC, nous ne nous sommes pas limiter à présenter ces algorithmes
sans pour autant présenter également les résultats obtenus
après nos tests d'expérimentation.
IV.2.1. PROTOCOLE D'EXPÉRIMENTATION
Après la configuration de l'environnement de travail
tel qu'expliqué au début de ce chapitre, nous sommes
passés à la configuration des ordinateurs à utiliser pour
les tests. Les données des tests ont été
exécutées sur deux ordinateurs de propriétés
suivantes :
- Modèle : Inspiron 3521 ;
- BIOS : InsydeH20 Version 03.72.24A05 ;
- Processeur : Intel(R) Celeron(R) CPU 1007U @1.50GHZ (2 CPUS),
~1.5GHZ ;
- Memory : 2048 MB RAM,
- Operating System : Windows Server Enterprise 2008
- Configurations de Réseau : - Ordinateur I : IP :
192.168.100.2/255.255.255.0
- Ordinateur II : IP : 192.168.100.3/ 255.255.255.0
4.2.2. RESULTATS DES TESTS
Pour tester nos algorithmes, nous sommes partis des
critères principaux de sélection d'une technologie de
réplication :
> la cohérence des données
répliquées ;
> l'autonomie des sites ;
> le partitionnement des données pour éviter les
conflits.
Il ne nous a pas été possible d'optimiser les trois
critères simultanément. Ainsi une
solution qui favoriserait la cohérence des
données devrait laisser une faible autonomie aux sites afin de
connaître à chaque instant l'ensemble des modifications qui ont
lieu sur les données. Ainsi, nous avons testé nos algorithmes
sous deux dimensions : la méthode transactionnelle et la méthode
par fusion.
~ 45 ~
IV.2.3. PROCEDURES DE MISE EN PLACE DE LA
REPLICATION
- Réplication de Fusion
Il s'agissait, dans cette méthode, de surveiller les
modifications de la base de données source et de synchroniser les
valeurs entre l'éditeur et les abonnés, es derniers pouvant tous
effectuer des opérations de mise à jour sur les données
distribuées. Si l'éditeur conserve la maîtrise de la
publication, ce n'est pas toujours les opérations effectuées sur
l'éditeur qui prennent le pas sur celles effectuées sur
l'abonné. Toutes les modifications apportées à la base
cible étaient reportées dans la base source.
Nous n'avons pas eu beaucoup du mal à configurer la
synchronisation des données à partir de SQL Server Management
Studio car il propose différents assistants graphiques pour mettre en
place, surveiller et paramétrer l'environnement de réplication.
Tous les éléments de configurations sont accessibles depuis le
noeud Réplication de l'explorateur d'objets.
Les algorithmes suivants décrivent les procédures
de la mise en place de la réplication entre les serveurs de base de
données :
~ 46 ~
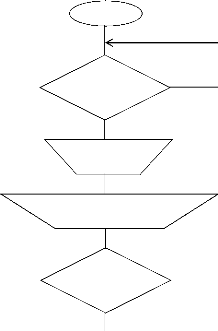
Début
Choix BD Cible
Choix type de publication
Choix
Réplication
Choix
Réplication
Fin
Sélection des Tables
Création
Création de la Publication
Echec de Création
Annulation
Création réussie
Continuer
Figure 23 : Algorithme de sélection du Noeud
réplication pour commencer les configurations de mise en place
~ 47 ~
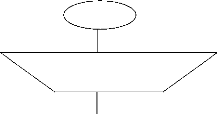
Début
Choix de la Publicité
Affichage des éléments du Menu
Contextuel
Liste
Affichage Statut de l'Agent de
Publication
Navigation
(Start, Stop, Monitor)

Fin
Figure 24 : Vérification du Statut de l'Agent de
Publication
~ 48 ~

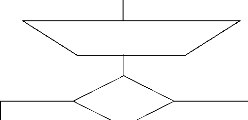
Début
Affichage état de l'Agent de
publication
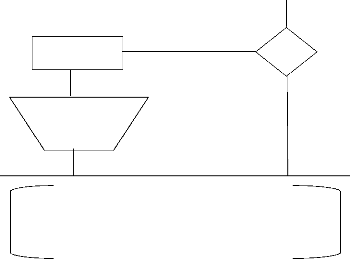
Démarrer
Arrêté
État
Démarré
Démarrage en Cours
Affichage à l'écran de l'état de l'Agent de
la BD Source + le nombre des Données Répliquées
Moniteur de Réplication

Fin
Figure 25 : Fonctionnement de l'Agent de Publication
~ 49 ~

Fin
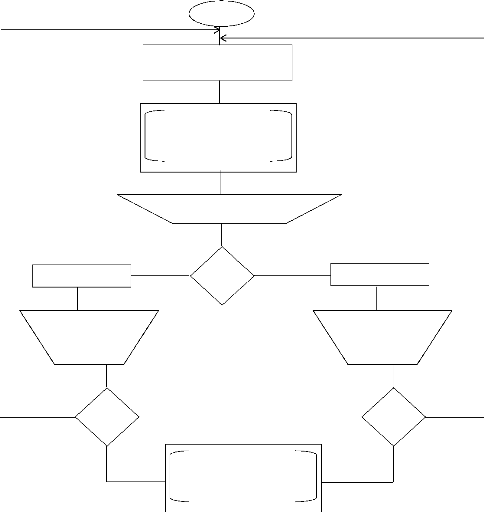
Echec
Configurer Esclave
Choisir Serveurs Cibles
Altern ative
Liste d'éléments Menu Contextuel
Multi Server Administration
SQL Agent
Début
Altern ative
Succès
Configurer Esclave
Choisir Serveur Cible
Altern ative
Echec
Figure 26: Etapes de Configuration du Serveur Maitre et du
Serveur Esclave
Figure 27: Filtrage de connexions des utilisateurs selon leur
poste de travail
~ 50 ~
- Réplication Transactionnelle
Après nos tests par la méthode transactionnelle,
nous avons constaté que cette méthode est facile à mettre
en place parce qu'elle ne nécessite pas de passer à des
configurations au niveau de l'agent de publication et de l'agent de
souscription ; c'est-à-dire que une fois qu'une opération est
effectuée sur la base maitre, les changements s'appliquent en temps
réel sur les bases esclaves.
IV.2.4 INTERFACE HOMME - MACHINE
L'application servira de monitoring de la réplication.
Nous avons souhaité mettre en place le prototype de ce qui serait une
vraie application intégrant des fonctionnalités avancées
des bases de données comme la Réplication des données, le
Back Up et le Compactage. Pour nos tests, nous n'avons travaillé qu'avec
quelques tables de la base de données que nous avons nommé My
Bank System.
- Pour des raisons de confidentialité, nous avons
pensé que mettre en place un système d'authentification par poste
de travail serait une solution optimale. L'interface suivant est donc utile
pour filtrer la connexion des utilisateurs au serveur étant donné
que la base de données est distribuée, car sinon tous les
utilisateurs auront accès à tout.
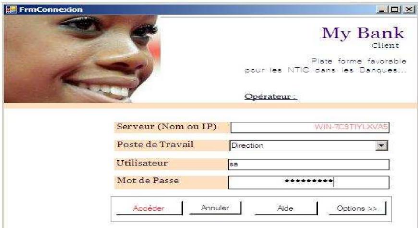
~ 51 ~
IV.3. SIMULATION
Nous avons fait recours à cette méthode parce
que nous avons effectué tous les tests dans un laboratoire informatique.
Dans notre laboratoire, nous sommes partis d'un énoncé pour
parvenir à simuler un environnement favorable à notre
étude:
IV.3.1. ENONCE
« Soit une Institution Financière
à caractère national qui cherche comment satisfaire, en temps
réel, les requêtes des clients pour les fidéliser. Elle ne
souhaite également pas engager beaucoup de ressources financières
pour y arriver. Quelle solution serait envisageable dans ce cas ?
»
- Données de Simulation
Soient A, B, N ; les Agences d'une institution
financière à dimension nationale. Dans l'Agence A, on enregistre
Dix opérations des clients qu'on souhaite partager en permanence avec
tous les autres sites dans le territoire national dans un environnement
instable quant à la connexion réseau et aux perturbations du
courant. Considérant les normes de confidentialité, Comment
procéder pour que l'Agence B et les Agences N puissent avoir ces
informations en permanence sur leurs sites ?
- Solution
Pour répondre à cette question, nous avons fait
recours à notre affirmation hypothétique selon laquelle si on
parvenait à Instaurer un système de Réplication dans le
but d'avoir en permanence les informations des autres bases, alors la
Conception d'un Algorithme de Réplication des données selon la
fréquence de lancement des requêtes des utilisateurs serait une
solution optimale pour minimiser les coûts d'achat de la bande
passante.
Pour des raisons de sécurité, nous avons
conçu une interface d'authentification (Figure 27) pour que les
informations confidentielles des autres bases ne soient accessibles que par les
ayant droits. A partir des algorithmes que nous avons proposés, nous
avons conçu une interface qui permet de saisir les informations dans la
base de données et de les répliquer avec les autres sites :
~ 52 ~
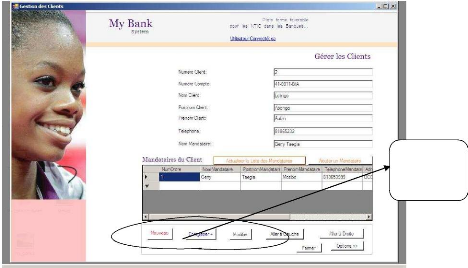
Saisie et
Validation
des Données
Figure 28: Interface de saisie des données de Test
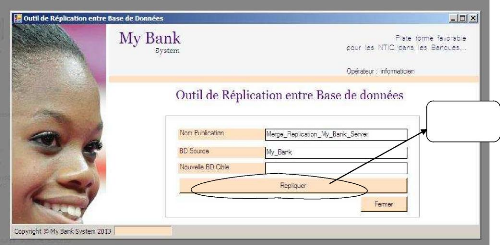
Propager les Données
Figure 29: Interface de Réplication des Données
à propager
~ 53 ~
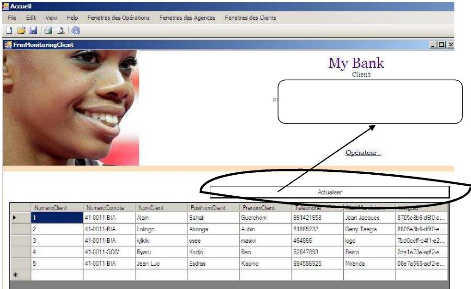
Actualiser le Site Esclave pour avoir les données en
permanence
Figure 30: Résultats obtenus après
Réplication des Données
- Conclusion
La politique de haute disponibilité des données
passant par la réplication des données dans une architecture
distribuée semble être une solution moins coûteuse, mais
efficace. Si cette institution financière souhaite pallier à ce
problème de disponibilité d'informations, elle peut recourir
à la mise en place d'un système de réplication qui prend
en compte les difficultés liées à l'environnement dans
lequel elle évolue, par exemple ce problème majeure de manque
d'énergie électrique et des perturbations réseaux.
IV.4. PRESENTATION ET DISCUSSION DES RESULTATS
IV.4.1. Résultats Obtenus
Tout au début de ce travail de recherche, nous nous
sommes fixés l'objectif de concevoir et tester les algorithmes de
réplication des données selon la fréquence de demandes des
clients d'une institution financière. Voici les résultats que
nous avons obtenus :
- Nous avons proposé un algorithme de
réplication de données, que nous avons présenté
sous forme de diagramme d'état dans le troisième chapitre, qui
offre la possibilité de
~ 54 ~
répliquer manuellement les données lorsqu'il y a
coupure du courant ou problème de connexion entre les bases de
données qui se partagent les informations ;
- Nous avons conçu avec UML des modèles de
traitement des données par le Système de Réplication de
bases de données, que nous avons décrit sous forme de diagramme
d'activité et de séquence système à partir des
quels nous avons-nous dégagé les états par lesquels
transite la base de données pendant la réplication ;
- Après exécution de ces instructions sur la
Machine de Turing, nous avons constaté que ces premières ont
produit des Automates Déterministes et des automates non
déterministes ;
- Le fait qu'il y a eu des automates non déterministes,
nous pouvons prouver les cas possibles d'interruption de la communication entre
les sites distants étant donné qu'on ne sait pas avec exactitude
si la réplication prendra fin sans qu'il y ait des perturbations.
- Sur un ordinateur physique, après la mise en place de
notre environnement de travail, nous testé la réplication entre
plusieurs bases de données de taille différente :
- pour les bases de données avec plus de Cinq tables,
la réplication se fait rapidement, et il n'y a pas de casse,
c'est-à-dire toutes les données sont répliquées
sans problème, mais pour des bases de données de plus de cinq
tables la réplication dure un moment, mais elle finit par prendre fin
;
- Sous Visual Basic, nous avons essayé
d'exécuter un script de réplication qui se déroule bien
avec les petites bases de données, c'est-à-dire avec tout au plus
cinq tables. mais sous SQL serveur quel que soit le nombre de tables, la
réplication se passe correctement malgré le temps que ça
dure ;
- Quant aux méthodes de réplication auxquelles
nous avons recourues pour les tests, nous avons constaté que la
méthode transactionnelle est la meilleure parce qu'elle ne demande pas
de faire une mise à jour sur la base cible pour que les modifications
soient propagées, mais lorsqu'il s'agit de la méthode par fusion
et de capture instantanée, on est obligé de redémarrer
l'agent de publication. Mais le désavantage de la méthode
transactionnelle, c'est qu'elle n'est pas programmable à partir de
VB.Net raison pour laquelle nous avons
programmé la méthode par Fusion (Merge Replication).
- Cette difficulté ne se fait sentir que par rapport au
nombre des tables, mais par rapport au nombre d'enregistrements dans les
tables, le problème ne se pose pas.
~ 55 ~
- Après l'implémentation de deux applications VB
: l'une Serveur (My Bank Server) et l'autre client (My Bank Client), nous
sommes parvenus à simuler l'environnement souhaité, celui d'une
architecture repartie ou distribuée.
- Sur la partie client, nous avons mis en place un
système de monitoring qui nous a permis de surveiller toutes les
modifications qui sont faites sur les différents sites distants.
- Le système mis en place sera donc capable
d'exécuter les tâches suivantes : la saisie des informations dans
la base des données (Figure 28), la mise à jour des
données après ajout de nouvelles informations (Figure 30), la
réplication de la base de données existante avec une nouvelle
base de données et afficher les modifications en temps réel des
différentes entités (Figure 29), mais aussi le back up des
données.
IV.4.2. Commentaires et Difficultés
Rencontrées
Au cours de nos investigations, nous nous sommes heurtés
à des difficultés que voici :
- Lorsque nous avons programmé la réplication
par la méthode de Fusion sous Visual Basic, nous ne sommes pas parvenu
à vérifier l'état de l'agent de réplication,
c'est-à-dire vérifier si l'agent de publication est
démarré (running) ou s'il ne l'est pas (not running). Mais nous y
sommes parvenus à partir de SQL Serveur ;
- Nous n'avons pas testé nos algorithmes sur internet
faute d'un environnement de travail nous permettant de le faire, mais nous
avons simulé un environnement intranet qui nous a permis de les
tester.
- Les scripts de réplication utilisés à
partir de
VB.net, ne permettent pas de
répliquer plusieurs tables à la fois, mais avec cinq tables en
moyenne, nous y sommes parvenus. C'est-à-dire pour les bases de
données ayant plus de cinq tables, la réplication ne se fait pas
correctement mais dans le cas d'une base de données ayant tout au plus
cinq tables, la réplication se passe avec succès,
c'est-à-dire toutes les tables sont répliquées avec les
données.
~ 56 ~
CONCLUSION GENERALE
Pour des régions du monde où l'accès
à l'Internet et l'électrification demeurent encore des grands
défis, il est difficile de tirer profit des avantages qu'apportent les
NTIC. Pourtant les entreprises en ont surement besoin pour bien
prospérer dans le nouveau climat des affaires que nous respirons de nos
jours.
Le principal enjeu de cette recherche, formulée
`Réplication de bases de données d'une Institution
Financière', était de trouver solution à la question de
savoir quel modèle informatique permettrait de s'assurer de la
disponibilité des informations découlant des opérations en
cours avec les autres bases afin de répondre, en temps réel, aux
demandes clients.
La solution que nous avons envisagée pour cette
question, est la mise en place d'une architecture distribuée favorisant
la propagation, en temps réel, des informations sur les
opérations enregistrées au niveau de chaque agence. C'est ainsi
que nous nous sommes fixé l'objectif de concevoir (et tester) un
Algorithme de Réplication des données d'une Institution
Financière afin de permettre cette dernière à avoir en
permanence les données des opérations avec les autres bases dans
l'objectif de répondre efficacement aux besoins de la clientèle
même lorsqu'il y a problème de connexion au réseau ou
coupure du courant dans l'une des agences.
La modélisation avec UML, la définition des
algorithmes, l'expérimentation et la simulation nous ont conduits aux
résultats suivants :
- Nous avons proposé un algorithme de
réplication de données, que nous avons présenté
sous forme de diagramme d'état dans le troisième chapitre, qui
offre la possibilité de répliquer manuellement les données
lorsqu'il y a coupure du courant ou problème de connexion entre les
bases de données qui se partagent les informations ;
- Nous avons conçu avec UML des modèles de
traitement des données par le Système de Réplication de
bases de données, que nous avons décrit sous forme de diagramme
d'activité et de séquence système à partir des
quels nous avons dégagé les états par lesquels transite la
base de données pendant la réplication ;
- Un prototype d'une application de gestion des institutions
financières pour surveiller (Monitoring) les modifications des autres
bases a été mis en place.
~ 57 ~
La solution proposée permet aux utilisateurs de
recourir à la réplication manuelle lorsque l'initialisation de la
réplication ne s'est pas parfaite avec succès ; dans le souci de
permettre aux entreprises qui connaissent au quotidien des coupures
intempestives entre les serveurs dues soit au problème de connexion ou
de manque d'électricité.
Si le modèle proposé venait à être
concrétisé dans les institutions financières, nous osons
croire qu'elles réussiront à pallier au problème de haute
disponibilité des données. Ainsi, elles seront capables de
satisfaire, en moindre coût, les requêtes de leurs clients.
Enfin, signalons que nous ne prétendons en aucun cas
avoir parfait le modèle informatique de la réplication des
données, quand bien même c'était notre idéal. Ainsi
donc, tout en endossant la responsabilité de tout genre de faille que
peut renfermer ce dernier, nous encourageons toutes les autres tentatives de
résolution des problèmes de haute disponibilité des
données dans les entreprises à succursales multiples. Cela
étant, nous restons ouvert à toutes les remarques et suggestions
tant à son fond qu'à sa forme.
~ 58 ~
BIBLIOGRAPHIE
Sébastien ROHAUT (2011), Algorithmique et techniques
fondamentales de programmation, éditions ENI.
Christophe HARO (2012), Algorithmique : raisonner pour concevoir,
éditions ENI, JONIFAR LINA.
Lambert SONNA MOMO (2001), Réplication et
Durabilité dans les systèmes répartis. Mathieu EXBRAYAT
(2007), Bases de Données Réparties Concepts et Techniques, ULP
Strasbourg.
J. AKOKA et I. WATTIAU (2011), Base de données
réparties, le Cnam édition.
Pascal MOLLI et Al (2005), Réplication des données,
édition INRIA Lorraine.
Pascal ROQUES (2006), UML 2 par la pratique: étude des cas
et exercices, 5ième édition EYROLLES, Paris.
Jérôme GABILAUD (2010), Administration de bases de
données avec SQL Server Management Studio 2008, Editions ENI, Pari.
Osée MUHINDO MASIVI (2012), Cours de Théorie des
Automates et Calculabilité, cours inédit.
Osée MUHINDO MASIVI (2012), Cours de Laboratoire
Informatique II, cours inédit.
Norbert VAGHENI (2012), Cours de Gestion des Institutions
Financières Congolaises, cours inédit.
Kasereka Mbahweka (2012), Séminaire de gestion des Micro
finances, inédit.
MUMBERE MUYISA (2012), Cours d'Administration des réseaux
informatiques, cours inédit.
Dominique LIEFFRING (2007), Cours de SQL SERVEUR 2005
Théorie, Institut d'Enseignement de Promotion Sociale de la
Communauté Française Arlon, Réf. : D-F04-09.
Cédric COULON (2006), Réplication Préventive
dans une grappe de bases de données, thèse Université de
Nantes.
ABDESSAMAD IMINE (2006), Conception Formelle d'Algorithmes de
Réplication Optimiste Vers l'Edition Collaborative dans les
Réseaux Pair-à-Pair, thèse, université Henri
Poincaré, Nancy 1.
Muyisa FRED (2011), modélisation informatique de la
gestion d'une bibliothèque universitaire, cas de l`UNILUK.
~ 59 ~
Mumbere MUYISA (2009), Mise en ligne d'une base de
données pour une institution universitaire, cas de l'UNILUK.
Jean-Eric PELET & Stéphane MENET (MSTC 2) (2003),
L'INTRANET dans une entreprise Pourquoi et comment, article.
PIERRE SUTRA MARC SHAPIRO (2007), Comparaison d'Algorithmes
Optimistes pour la Réplication de Bases de Données, INRIA /
LIP6.
Wikimedia Foundation (2013), Architectures Client Serveur.
Disponible sur
http://www.fr.wikipedia.org/client-serveur/
Microsoft Corporation (2003), how to Program the SQL Merge
Control by Using Visual Basic _NET-3.mht. Disponible sur
http://www.Support.microsoft.com/
~ 60 ~
ANNEXES
ANNEXE 1 : TRADUCTION DES ALGORITHMES DE REPLICATION
SOUS
VB.NET
2008
' Projet de Mémoire Akangba Logo Thierry
' Université Adventiste de Lukanga
' Sujet: Algorithme de Réplication de base de
données d'une institution financière ' copyright Thierry Logo
Akangba
'
My Bank Systems 2013
Imports SQLMERGXLib
'This class demonstrates using the SQL Server Merge Agent
replication control. Module MergeApp
Sub Merge_Replication()
Prior to running this code, replication needs to be setup as
follows:
Create a merge publication called "SampleMergePublication" and
configure it to allow pull subscriptions.
' This code will first generate the snapshot. Then the
subscription database
' and pull subscription will be created through code. Then the
snapshot will be applied at the subscriber
using
' the SQLMergeClass object.
'
' You will also need to set a reference to the following COM
dll:
' -Microsoft SQL Merge Control 8.0
'
Dim strPublisher As String Dim strDistributor As String Dim
strSubscriber As String Dim strPublisherDatabase As String
Dim strSubscriberDatabase As String
Dim strPublication As String
~ 61 ~
Dim oMerge As SQLMergeClass
strPublisher = "WIN-7C9TIYLXVA5" 'change to the name of your
publisher strDistributor = "WIN-7C9TIYLXVA5" 'change to the name of your
distributor strSubscriber = "WIN-7C9TIYLXVA5" 'change to the name of your
subscriber strPublication = "Ma Replication de Fusion"
strPublisherDatabase = "BDEssai"
strSubscriberDatabase = "Ngabo_DB"
oMerge = New SQLMergeClass()
'Set up the Publisher.
oMerge.Publisher = strPublisher
oMerge.PublisherSecurityMode =
SQLMERGXLib.SECURITY_TYPE.NT_AUTHENTICATION
oMerge.PublisherDatabase = strPublisherDatabase
oMerge.Publication = strPublication
'Set up the Distributor.
oMerge.Distributor = strDistributor
oMerge.DistributorSecurityMode =
SQLMERGXLib.SECURITY_TYPE.NT_AUTHENTICATION
'Set up the Subscriber.
oMerge.Subscriber = strSubscriber
oMerge.SubscriberDatabase = strSubscriberDatabase
oMerge.SubscriberSecurityMode =
SQLMERGXLib.SECURITY_TYPE.NT_AUTHENTICATION
'Set up the subscription.
oMerge.SubscriptionType = SQLMERGXLib.SUBSCRIPTION_TYPE.PULL
oMerge.SynchronizationType = SQLMERGXLib.SYNCHRONIZATION_TYPE.AUTOMATIC
oMerge.SubscriptionName = "PullMergeSubscription"
'Create the database and subscription.
oMerge.AddSubscription(SQLMERGXLib.DBADDOPTION.CREATE_DATABASE,
SQLMERGXLib.SUBSCRIPTION_HOST.NONE)
'Synchronize the subscription.
MsgBox("Starting synchronization...") oMerge.Initialize()
oMerge.Run()
~ 62 ~
oMerge.Terminate()
MsgBox("Synchronization completed.")
End Sub
End Module
` le Bouton BtnRepliquer fait appel à la fonction
Merge_Replication
Private Sub BtnRepliqer_Click(ByVal sender As System.Object,
ByVal e As System.EventArgs) Handles CmdRepliquer.Click
Merge_Replication()
End Sub
~ 63 ~
ANNEXE 2 : SCRIPT DE REPLICATION GENERE APRES
CREATION
DE LA BASE MAITRE (PUBLICATION : REP MY BANK SERVER)
-- Enabling the replication database
use master
exec sp_replicationdboption @dbname = N'My_Bank_Server', @optname
= N'publish', @value = N'true' GO
exec [My_Bank_Server].sys.sp_addlogreader_agent @job_login =
null, @job_password = null,
@publisher_security_mode = 0, @publisher_login = N'sa',
@publisher_password = N"
GO
exec [My_Bank_Server].sys.sp_addqreader_agent @job_login = null,
@job_password = null, @frompublisher =
1
GO
-- Enabling the replication database
use master
exec sp_replicationdboption @dbname = N'My_Bank_Server', @optname
= N'merge publish', @value = N'true'
GO
-- Adding the merge publication
use [My_Bank_Server]
exec sp_addmergepublication @publication = N'Rep_My_Bank_Server',
@description = N'Merge publication of database "My_Bank_Server" from Publisher
"WIN-7C9TIYLXVA5".', @sync_mode = N'native', @retention = 14, @allow_push =
N'true', @allow_pull = N'true', @allow_anonymous = N'true',
@enabled_for_internet = N'false', @snapshot_in_defaultfolder = N'true',
@compress_snapshot = N'false', @ftp_port = 21, @ftp_login = N'anonymous',
@allow_subscription_copy = N'false', @add_to_active_directory = N'false',
@dynamic_filters = N'false', @conflict_retention = 14, @keep_partition_changes
= N'false', @allow_synctoalternate = N'false', @max_concurrent_merge = 0,
@max_concurrent_dynamic_snapshots = 0, @use_partition_groups = N'false',
@publication_compatibility_level = N'90RTM', @replicate_ddl = 1,
@allow_subscriber_initiated_snapshot = N'false', @allow_web_synchronization =
N'false', @allow_partition_realignment = N'true', @retention_period_unit =
N'days', @conflict_logging = N'both', @automatic_reinitialization_policy = 0
GO
exec sp_addpublication_snapshot @publication =
N'Rep_My_Bank_Server', @frequency_type = 1, @frequency_interval = 0,
@frequency_relative_interval = 0, @frequency_recurrence_factor = 0,
@frequency_subday = 0, @frequency_subday_interval = 0,
@active_start_time_of_day = 500, @active_end_time_of_day = 235959,
@active_start_date = 0, @active_end_date = 0, @job_login = null, @job_password
= null, @publisher_security_mode = 1
~ 64 ~
exec sp_grant_publication_access @publication =
N'Rep_My_Bank_Server', @login = N'sa'
GO
exec sp_grant_publication_access @publication =
N'Rep_My_Bank_Server', @login = N'AUTORITE
NT\SYSTEM'
GO
exec sp_grant_publication_access @publication =
N'Rep_My_Bank_Server', @login =
N'BUILTIN\Administrateurs'
GO
exec sp_grant_publication_access @publication =
N'Rep_My_Bank_Server', @login = N'WIN-
7C9TIYLXVA5\SQLServer2005SQLAgentUser$WIN-7C9TIYLXVA5$MSSQLSERVER'
GO
exec sp_grant_publication_access @publication =
N'Rep_My_Bank_Server', @login = N'WIN-
7C9TIYLXVA5\SQLServer2005MSSQLUser$WIN-7C9TIYLXVA5$MSSQLSERVER'
GO
exec sp_grant_publication_access @publication =
N'Rep_My_Bank_Server', @login = N'WIN-
7C9TIYLXVA5\Administrateur'
GO
exec sp_grant_publication_access @publication =
N'Rep_My_Bank_Server', @login = N'distributor_admin'
GO
exec sp_grant_publication_access @publication =
N'Rep_My_Bank_Server', @login = N'informaticien'
GO
-- Ajout d'Articles de Fusion appelés Merge Articles
use [My_Bank_Server]
exec sp_addmergearticle @publication = N'Rep_My_Bank_Server',
@article = N'sysdiagrams', @source_owner = N'dbo', @source_object =
N'sysdiagrams', @type = N'table', @description = N", @creation_script = N",
@pre_creation_cmd = N'drop', @schema_option = 0x000000000C034FD1,
@identityrangemanagementoption = N'auto', @pub_identity_range = 10000,
@identity_range = 1000, @threshold = 80, @destination_owner = N'dbo',
@force_reinit_subscription = 1, @column_tracking = N'false',
@subset_filterclause = N", @vertical_partition = N'false',
@verify_resolver_signature = 1, @allow_interactive_resolver = N'false',
@fast_multicol_updateproc = N'true', @check_permissions = 0,
@subscriber_upload_options = 0, @delete_tracking = N'true',
@compensate_for_errors = N'false', @stream_blob_columns = N'false',
@partition_options = 0
GO
use [My_Bank_Server]
exec sp_addmergearticle @publication = N'Rep_My_Bank_Server',
@article = N'tExercice', @source_owner = N'dbo', @source_object = N'tExercice',
@type = N'table', @description = N", @creation_script = N",
~ 65 ~
@pre_creation_cmd = N'drop', @schema_option = 0x000000000C034FD1,
@identityrangemanagementoption = N'none', @destination_owner = N'dbo',
@force_reinit_subscription = 1, @column_tracking = N'false',
@subset_filterclause = N", @vertical_partition = N'false',
@verify_resolver_signature = 1, @allow_interactive_resolver = N'false',
@fast_multicol_updateproc = N'true', @check_permissions = 0,
@subscriber_upload_options = 0, @delete_tracking = N'true',
@compensate_for_errors = N'false', @stream_blob_columns = N'false',
@partition_options = 0
GO
use [My_Bank_Server]
exec sp_addmergearticle @publication = N'Rep_My_Bank_Server',
@article = N'tMasse', @source_owner = N'dbo', @source_object = N'tMasse', @type
= N'table', @description = N", @creation_script = N", @pre_creation_cmd =
N'drop', @schema_option = 0x000000000C034FD1, @identityrangemanagementoption =
N'none', @destination_owner = N'dbo', @force_reinit_subscription = 1,
@column_tracking = N'false', @subset_filterclause = N", @vertical_partition =
N'false', @verify_resolver_signature = 1, @allow_interactive_resolver =
N'false', @fast_multicol_updateproc = N'true', @check_permissions = 0,
@subscriber_upload_options = 0, @delete_tracking = N'true',
@compensate_for_errors = N'false', @stream_blob_columns = N'false',
@partition_options = 0
GO
use [My_Bank_Server]
exec sp_addmergearticle @publication = N'Rep_My_Bank_Server',
@article = N'tAgence', @source_owner = N'dbo', @source_object = N'tAgence',
@type = N'table', @description = N", @creation_script = N", @pre_creation_cmd =
N'drop', @schema_option = 0x000000000C034FD1, @identityrangemanagementoption =
N'none', @destination_owner = N'dbo', @force_reinit_subscription = 1,
@column_tracking = N'false', @subset_filterclause = N", @vertical_partition =
N'false', @verify_resolver_signature = 1, @allow_interactive_resolver =
N'false', @fast_multicol_updateproc = N'true', @check_permissions = 0,
@subscriber_upload_options = 0, @delete_tracking = N'true',
@compensate_for_errors = N'false', @stream_blob_columns = N'false',
@partition_options = 0
GO
use [My_Bank_Server]
exec sp_addmergearticle @publication = N'Rep_My_Bank_Server',
@article = N'tCompte', @source_owner = N'dbo', @source_object = N'tCompte',
@type = N'table', @description = N", @creation_script = N", @pre_creation_cmd =
N'drop', @schema_option = 0x000000000C034FD1, @identityrangemanagementoption =
N'none', @destination_owner = N'dbo', @force_reinit_subscription = 1,
@column_tracking = N'false', @subset_filterclause = N", @vertical_partition =
N'false', @verify_resolver_signature = 1, @allow_interactive_resolver =
N'false', @fast_multicol_updateproc = N'true', @check_permissions = 0,
@subscriber_upload_options = 0, @delete_tracking = N'true',
@compensate_for_errors = N'false', @stream_blob_columns = N'false',
@partition_options = 0
GO
use [My_Bank_Server]
~ 66 ~
exec sp_addmergearticle @publication = N'Rep_My_Bank_Server',
@article = N'tOperateur', @source_owner = N'dbo', @source_object =
N'tOperateur', @type = N'table', @description = N", @creation_script = N",
@pre_creation_cmd = N'drop', @schema_option = 0x000000000C034FD1,
@identityrangemanagementoption = N'none', @destination_owner = N'dbo',
@force_reinit_subscription = 1, @column_tracking = N'false',
@subset_filterclause = N", @vertical_partition = N'false',
@verify_resolver_signature = 1, @allow_interactive_resolver = N'false',
@fast_multicol_updateproc = N'true', @check_permissions = 0,
@subscriber_upload_options = 0, @delete_tracking = N'true',
@compensate_for_errors = N'false', @stream_blob_columns = N'false',
@partition_options = 0
GO
use [My_Bank_Server]
exec sp_addmergearticle @publication = N'Rep_My_Bank_Server',
@article = N'tClient', @source_owner = N'dbo', @source_object = N'tClient',
@type = N'table', @description = N", @creation_script = N", @pre_creation_cmd =
N'drop', @schema_option = 0x000000000C034FD1, @identityrangemanagementoption =
N'none', @destination_owner = N'dbo', @force_reinit_subscription = 1,
@column_tracking = N'false', @subset_filterclause = N", @vertical_partition =
N'false', @verify_resolver_signature = 1, @allow_interactive_resolver =
N'false', @fast_multicol_updateproc = N'true', @check_permissions = 0,
@subscriber_upload_options = 0, @delete_tracking = N'true',
@compensate_for_errors = N'false', @stream_blob_columns = N'false',
@partition_options = 0
GO
use [My_Bank_Server]
exec sp_addmergearticle @publication = N'Rep_My_Bank_Server',
@article = N'tMandataire', @source_owner = N'dbo', @source_object =
N'tMandataire', @type = N'table', @description = N", @creation_script = N",
@pre_creation_cmd = N'drop', @schema_option = 0x000000000C034FD1,
@identityrangemanagementoption = N'none', @destination_owner = N'dbo',
@force_reinit_subscription = 1, @column_tracking = N'false',
@subset_filterclause = N", @vertical_partition = N'false',
@verify_resolver_signature = 1, @allow_interactive_resolver = N'false',
@fast_multicol_updateproc = N'true', @check_permissions = 0,
@subscriber_upload_options = 0, @delete_tracking = N'true',
@compensate_for_errors = N'false', @stream_blob_columns = N'false',
@partition_options = 0
GO
use [My_Bank_Server]
exec sp_addmergearticle @publication = N'Rep_My_Bank_Server',
@article = N'tOperation', @source_owner = N'dbo', @source_object =
N'tOperation', @type = N'table', @description = N", @creation_script = N",
@pre_creation_cmd = N'drop', @schema_option = 0x000000000C034FD1,
@identityrangemanagementoption = N'auto', @pub_identity_range = 1000,
@identity_range = 100, @threshold = 80, @destination_owner = N'dbo',
@force_reinit_subscription = 1, @column_tracking = N'false',
@subset_filterclause = N", @vertical_partition = N'false',
@verify_resolver_signature = 1, @allow_interactive_resolver = N'false',
@fast_multicol_updateproc = N'true', @check_permissions = 0,
@subscriber_upload_options = 0, @delete_tracking = N'true',
@compensate_for_errors = N'false', @stream_blob_columns = N'false',
@partition_options = 0
GO
~ 67 ~
use [My_Bank_Server]
exec sp_addmergearticle @publication = N'Rep_My_Bank_Server',
@article = N'tBilletage', @source_owner = N'dbo', @source_object =
N'tBilletage', @type = N'table', @description = N", @creation_script = N",
@pre_creation_cmd = N'drop', @schema_option = 0x000000000C034FD1,
@identityrangemanagementoption = N'none', @destination_owner = N'dbo',
@force_reinit_subscription = 1, @column_tracking = N'false',
@subset_filterclause = N", @vertical_partition = N'false',
@verify_resolver_signature = 1, @allow_interactive_resolver = N'false',
@fast_multicol_updateproc = N'true', @check_permissions = 0,
@subscriber_upload_options = 0, @delete_tracking = N'true',
@compensate_for_errors = N'false', @stream_blob_columns = N'false',
@partition_options = 0
GO
use [My_Bank_Server]
exec sp_addmergearticle @publication = N'Rep_My_Bank_Server',
@article = N'tTransactionComptable', @source_owner = N'dbo', @source_object =
N'tTransactionComptable', @type = N'table', @description = N", @creation_script
= N", @pre_creation_cmd = N'drop', @schema_option = 0x000000000C034FD1,
@identityrangemanagementoption = N'none', @destination_owner = N'dbo',
@force_reinit_subscription = 1, @column_tracking = N'false',
@subset_filterclause = N", @vertical_partition = N'false',
@verify_resolver_signature = 1, @allow_interactive_resolver = N'false',
@fast_multicol_updateproc = N'true', @check_permissions = 0,
@subscriber_upload_options = 0, @delete_tracking = N'true',
@compensate_for_errors = N'false', @stream_blob_columns = N'false',
@partition_options = 0
GO
use [My_Bank_Server]
exec sp_addmergearticle @publication = N'Rep_My_Bank_Server',
@article = N'fn_diagramobjects',
@source_owner = N'dbo', @source_object = N'fn_diagramobjects',
@type = N'func schema only', @description = N", @creation_script = N",
@pre_creation_cmd = N'drop', @schema_option = 0x0000000008000001,
@destination_owner = N'dbo', @destination_object = N'fn_diagramobjects',
@force_reinit_subscription = 1 GO
use [My_Bank_Server]
exec sp_addmergearticle @publication = N'Rep_My_Bank_Server',
@article = N'sp_alterdiagram',
@source_owner = N'dbo', @source_object = N'sp_alterdiagram',
@type = N'proc schema only', @description = N", @creation_script = N",
@pre_creation_cmd = N'drop', @schema_option = 0x0000000008000001,
@destination_owner = N'dbo', @destination_object = N'sp_alterdiagram',
@force_reinit_subscription = 1 GO
use [My_Bank_Server]
exec sp_addmergearticle @publication = N'Rep_My_Bank_Server',
@article = N'sp_creatediagram',
@source_owner = N'dbo', @source_object = N'sp_creatediagram',
@type = N'proc schema only', @description = N", @creation_script = N",
@pre_creation_cmd = N'drop', @schema_option = 0x0000000008000001,
@destination_owner = N'dbo', @destination_object = N'sp_creatediagram',
@force_reinit_subscription = 1 GO
use [My_Bank_Server]
~ 68 ~
exec sp_addmergearticle @publication = N'Rep_My_Bank_Server',
@article = N'sp_dropdiagram',
@source_owner = N'dbo', @source_object = N'sp_dropdiagram', @type
= N'proc schema only', @description = N", @creation_script = N",
@pre_creation_cmd = N'drop', @schema_option = 0x0000000008000001,
@destination_owner = N'dbo', @destination_object = N'sp_dropdiagram',
@force_reinit_subscription = 1 GO
use [My_Bank_Server]
exec sp_addmergearticle @publication = N'Rep_My_Bank_Server',
@article = N'sp_helpdiagramdefinition', @source_owner = N'dbo', @source_object
= N'sp_helpdiagramdefinition', @type = N'proc schema only', @description = N",
@creation_script = N", @pre_creation_cmd = N'drop', @schema_option =
0x0000000008000001, @destination_owner = N'dbo', @destination_object =
N'sp_helpdiagramdefinition', @force_reinit_subscription = 1
GO
use [My_Bank_Server]
exec sp_addmergearticle @publication = N'Rep_My_Bank_Server',
@article = N'sp_helpdiagrams',
@source_owner = N'dbo', @source_object = N'sp_helpdiagrams',
@type = N'proc schema only', @description = N", @creation_script = N",
@pre_creation_cmd = N'drop', @schema_option = 0x0000000008000001,
@destination_owner = N'dbo', @destination_object = N'sp_helpdiagrams',
@force_reinit_subscription = 1 GO
use [My_Bank_Server]
exec sp_addmergearticle @publication = N'Rep_My_Bank_Server',
@article = N'sp_renamediagram',
@source_owner = N'dbo', @source_object = N'sp_renamediagram',
@type = N'proc schema only', @description = N", @creation_script = N",
@pre_creation_cmd = N'drop', @schema_option = 0x0000000008000001,
@destination_owner = N'dbo', @destination_object = N'sp_renamediagram',
@force_reinit_subscription = 1 GO
use [My_Bank_Server]
exec sp_addmergearticle @publication = N'Rep_My_Bank_Server',
@article = N'sp_upgraddiagrams',
@source_owner = N'dbo', @source_object = N'sp_upgraddiagrams',
@type = N'proc schema only', @description = N", @creation_script = N",
@pre_creation_cmd = N'drop', @schema_option = 0x0000000008000001,
@destination_owner = N'dbo', @destination_object = N'sp_upgraddiagrams',
@force_reinit_subscription = 1 GO
use [My_Bank_Server]
exec sp_changemergepublication N'Rep_My_Bank_Server', N'status',
N'active'
GO
-- Adding the merge subscriptions
use [My_Bank_Server]
exec sp_addmergesubscription @publication =
N'Rep_My_Bank_Server', @subscriber = N'WIN-7C9TIYLXVA5', @subscriber_db =
N'Ma_Bank_Client', @subscription_type = N'Push', @sync_type = N'Automatic',
@subscriber_type = N'Global', @subscription_priority = 75, @description = N",
@use_interactive_resolver = N'False'
~ 69 ~
exec sp_addmergepushsubscription_agent @publication =
N'Rep_My_Bank_Server', @subscriber = N'WIN-7C9TIYLXVA5', @subscriber_db =
N'Ma_Bank_Client', @job_login = null, @job_password = null,
@subscriber_security_mode = 1, @publisher_security_mode = 1, @frequency_type =
1, @frequency_interval = 0, @frequency_relative_interval = 0,
@frequency_recurrence_factor = 0, @frequency_subday = 0,
@frequency_subday_interval = 0, @active_start_time_of_day = 0,
@active_end_time_of_day = 235959, @active_start_date = 0, @active_end_date =
0
GO
| 

