|

REPUBLIQUE DU SENEGAL
UNIVERSITE CHEIKH ANTA DIOP de DAKAR
FACULTE DES SCIENCES ET TECHNIQUES
Département de Mathématiques et
Informatique
Mémoire de DEA d'Informatique
Option : Réseaux
~~cAsv7sMcE ~~~~~ ~~~~~~~ ~~ 1YECOQTAE~~E ~~
SE~YIC'ES DJ4WS £ES Ç~~LLES 1YE CJ4LC'VL
Présenté et soutenu par
Marie
Hélène Wassa Mballo
Samedi 25 juillet 2009
Sous la direction de :
Ibrahima NIANG Maître Assistant UCAD
Yahya SLIMANI Professeur Tunisie
Devant le jury composé de : Président
:
Chérif BADJI Professeur UCAD
Membres
:
Mamadou SANGHARE Professeur UCAD
Ibrahima NIANG Maître Assistant UCAD
Mbaye SENE Maître Assistant UCAD
Samba NDIAYE Maître Assistant UCAD
Abdourahmane RAIMY Maître Assistant UCAD
Karim KONATE Maître Assistant UCAD
REPUBLIQUE DU SENEGAL
FACULTE DES SCIENCES ET TECHNIQUES
Département de Mathématiques et
Informatique
Mémoire de DEA d'Informatique
Option : Réseaux

~~C~~~SME qyE cJYECO~4EqFE CD'E S SE~~IOFCD$jVS
£~~
ç~~~c's qy~ t)L gLc
Présenté et soutenu par
Marie Hélène Wassa
Mballo
Samedi 25 juillet 2009
Sous la direction de :
Ibrahima NIANG Maître Assistant UCAD
Yahya SLIMANI Professeur Tunisie
Devant le jury composé de : Président
:
Chérif BADJI Professeur UCAD
Membres
:
Mamadou SANGHARE Professeur UCAD
Mbaye SENE Maître Assistant UCAD
Samba NDIAYE Maître Assistant UCAD
Abdourahmane RAIMY Maître Assistant UCAD
Karim KONATE Maître Assistant UCAD
Résumé
Les grilles de calcul sont des systèmes
distribués à large échelle dont l'objectif est
l'agrégation et le partage de ressources
hétérogènes géographiquement réparties pour
répondre aux besoins des applications de haute performance. La
découverte de services constitue un des problèmes majeur pour ces
grilles. En effet, Plusieurs approches comme l'utilisation des services web ou
les ontologies sont proposées. Cependant, ces mécanismes de
découverte offerts présentent des insuffisances vu que les
critères de recherche de service obtenus sont limités et souvent
non pertinents pour un utilisateur. Dans cet, article nous proposons un
mécanisme de découverte de services flexible et optimisé
basé sur des critères multiples et fournissant des
résultats plus exhaustifs aux utilisateurs.
Mots clés : grilles de calcul, découverte de
services, service web, arbre, recherche multicritère
[Marie Hélène Wassa Mballo] Page 1
DEDICACES
? Je dédie ce travail :
? à mes très chers parents Michel Bocar
Mballo et Bernadette Thiaw ; des êtres exceptionnels qui m'ont permis
d'arriver à ce stade de ma vie
? à mes frères Ernest, Françis et
Alexandre.
? à tous mes professeurs de l'école primaire
à l'université.
? à mes amis de toujours, ceux-là avec qui
je partage mes inquiétudes et mes peines, mes joies et mes
espérances.
[Marie Hélène Wassa Mballo] Page
2
[Marie Hélène Wassa Mballo] Page 3
Remerciements
Je commencerais par remercier Dieu le tout puissant qui m'a
permis de réaliser ce
travail.
Mes remerciements vont aussi à l'endroit de mes
professeurs et encadreurs : Mr Ibrahima NIANG professeur au département
de mathématique-informatique et directeur du centre de calcul et Mr
Yahya SLIMANI professeur à l'université de Tunis, pour leur
confiance, leur aide, leur soutien sans faille, leur modestie, leur
disponibilité, et qui m'ont mis dans de bonnes condition de travail, les
membres du jury : Mr Chérif BADJI, Mr Mamadou SANGHARE, Mr Mbaye
Sène, Mr Samba NDIAYE, Mr Abdourahmane RAIMY, Mr Karim KONATE.
Ma reconnaissance va aussi à l'endroit de ceux qui
m'ont soutenu et qui m'ont aidé tout au long de ma scolarité. Je
pense à mes chers parents : mon père Michel Bocar Mballo qui nous
pousse tout le temps à étudier ma mère Bernadette Thiaw la
meilleur des mamans, je n'ai pas les mots pour la décrire tellement elle
est unique, à mes frères Ernest, Françis, Alexandre
(Boudio) que je taquine tout le temps, à Tonton Charles un ami de la
famille qui est toujours à nos cotés pour nous soutenir mes
oncles, tantes, cousins et cousines.
Merci à tous les camarades de la promotion
spécialement à Pascal Mbissane FAYE(mon cousin) qui a
été vraiment disponible durant mon travail sur le mémoire
avec ses conseils qui m'ont aidé réellement , Ndeye Arame DIAGO
une amie très fidèle , Ibrahima DiANE mon très cher
délégué avec qui j'ai partagé une même salle
durant tout le mémoire, Adama Ndiaye Mme MBOW qui est actuellement en
France qui m'a convaincu à faire la licence informatique et je ne le
regrette pas, Adèle Siga FAYE, Fatoumata BALDE Mme KASSE, Aissatou
GASSAMA, Baba Oumou Ly, Bassirou DIENE, Ousmane DIALLO, Massamba GAYE, Bassirou
NGOM, Ibrahima GUEYE, Fodé CAMARA, Ismaela THIOBANE, Macoumba GUEYE,
Lenad Ahmed, pour toutes ces années d'apprentissage, avec lesquels j'ai
partagé de grands moments.
Merci également à Déthié SARR et
Malick NDOYE qui sont mes aînés, pour leur conseil et leur aide au
début de mon mémoire.
[Marie Hélène Wassa Mballo] Page 4
Merci au personnel du centre de calcul spécialement au
directeur Mr NIANG que je cite encore, à Babacar NGOM, à Bassirou
KASSE, à Assane SECK, à Alboury FALL, à Mandikou BA pour
tout leur aide.
Merci à mes amies Jeannette DIANDY, Rose Michèle
D'ERNEVILLE (Ma star de tous les jours) à mes amis Antoine MANE, Lamine
SARR et particulièrement à Stéphane BASSENE.
Merci aux professeurs du département d'informatique
notamment Mr Joseph NDONG, Mr Idrissa SARR, Mr Mouhamed OULD DEYE, Mr Djamal
SECK, Mr Youssou KASSE, Mr Modou GUEYE, Mr THIOGANE.
Merci aux responsables des salles de cours Mr Cheikh KHOULE,
Mr. Mamadou NDIAYE, Mr Mamadou DJIGO.
Et enfin un grand merci pour toutes les personnes qui me sont
chères et qui m'aiment.
[Marie Hélène Wassa Mballo] Page
5
Titre : 2MDS-Mécanisme multicritère de
découverte de services dans les grilles
Résumé
Les grilles de calcul sont des systèmes
distribués à large échelle dont l'objectif est
l'agrégation et le partage de ressources
hétérogènes géographiquement réparties pour
répondre aux besoins des applications de haute performance. La
découverte de services constitue un des problèmes majeur pour ces
grilles. En effet, Plusieurs approches comme l'utilisation des services web ou
les ontologies sont proposées. Cependant, ces mécanismes de
découverte offerts présentent des insuffisances vu que les
critères de recherche de service obtenus sont limités et souvent
non pertinents pour un utilisateur. Dans ce mémoire nous proposons un
mécanisme de découverte de services flexible et optimisé
basé, sur des critères multiples et fournissant des
résultats de recherche plus exhaustifs pour les utilisateurs.
Mots clés : grilles de calcul, découverte de
services, service web, arbre, recherche multicritère
Title:2MSD- A new Multi-criteria Mechanism for Service
Discovery in grid computing
Abstract
Grid computing are systems distributed on a wide scale whose
objective is the aggregation and the sharing of heterogeneous resources
geographically distributed to come up the high performance applications needs.
The services discovery is one of the major problems for these grids. Indeed,
approaches such as the use of web services and ontologies are proposed.
However, these discovery mechanisms present deficiencies seeing that the obtain
results are limited and often irrelevant. In this paper we propose a mechanism
for services discovery flexible and optimized, based on multiple criteria for
research and providing more comprehensive results for users.
Keywords: grid computing, service discovery, web services, trees,
multicriterion search
[Marie Hélène Wassa Mballo] Page 6
Sommaire
INTRODUCTION GENERALE 11
CHAPITRE 1: LES GRILLES 14
1.1 LES SYSTEMES DISTRIBUES 15
1.1.1 LA NOTION DE TRANSPARENCE DANS LES SYSTEMES DISTRIBUES
16
1.1.2 AVANTAGES DES SYSTEMES DISTRIBUES 18
1.1.3 INCONVENIENTS DES SYSTEMES DISTRIBUES 19
1.1.4 LIMITES DES SYSTEMES DISTRIBUES 20
1.2 LES GRILLES 21
1.2.1 LES TYPES DE GRILLES 22
1.2.1.1 les grappes 22
1.2.1.2 Les grilles de calcul 23
1.2.1.3 Les grilles de données 24
1.2.2 ARCHITECTURE D'UNE GRILLE 25
1.2.4 LES CARACTERISTIQUES D'UNE GRILLE 27
1.3 PROBLEMATIQUES POSEES PAR LES GRILLES 28
CHAPITRE 2:LES SERVICES WEB 30
2.1 LA PROGRAMMATION ORIENTEE OBJET 31
2.2 LA PROGRAMMATION ORIENTEE COMPOSANT
32
2.3 LA PROGRAMMATION ORIENTEE SERVICE
35
2.4 LA GESTION DES SERVICES WEB 37
2.4.1 IMPLANTATION D'UN SERVICE WEB 38
2.4.2 RECHERCHE D'UN SERVICE WEB 39
CHAPITRE 3 : LA REHERCHE DE SERVICE DANS LES GRILLES
41
3.1 LES METHODES ET TECHNIQUES DE DECOUVERTE
42
3.1.1 RECHERCHE DE SERVICE BASEE SUR LA DESCRIPTION ONTOLOGIQUE
43
3.1.2 RECHERCHE BASEE SUR LE WEB SERVICE 45
3.1.2.1 L'utilisation de l'annuaire UDDI 45
[Marie Hélène Wassa Mballo] Page 7
3.1.2.2 Approche basée sur le web service modeling
ontology(WSMO) 46
3.1.3 ETUDE COMPARATIVE DES DIFFERENTES APPROCHES 48
3.2 APPLICATION DES RECHERCHES DE SERVICE DANS LES
INTERGICIELS 49
3.2.1 LA GESTION DES RESSOURCES DANS GLOBUS 49
3.2.1.1 Globus Toolkit 2 50
3.2.1.2 Globus Toolkit3 56
3.2.1.3 Globus toolkit4 60
3.2.2 LA GESTION DES RESSOURCES DANS GLITES 62
3.2.3 COMPARAISON DES DIFFERENTS INTERGICIELS 64
CHAPITRE 4 :MECANISME MULTICRITERE DE DECOUVERTE DE
SERVICE DANS LES
GRILLES (2MDS) 66
4.1 CONSTRUCTION ET FONCTIONNEMENT DE L'ARBRE
67
4.1.1 CHOIX DE NOTRE ARCHITECTURE 67
4.1.2 DESCRIPTION GENERALE 67
4.1.3 LES ALGORITHMES DE GESTION DE SERVICES 69
4.1.3.1 Insertion d'un service 69
4.1.3.2 La recherche au sein de l'arbre 72
4.1.3.3 La suppression d'un service 77
4.2 PLACEMENT DE L'ARBRE DANS LE RESEAU PHYSIQUE
80
4.2.1 APPROCHE CENTRALISEE 80
4.2.1.1 Principes et fonctionnement 80
4.2.1.2 Gestion des services 81
4.2.1.3 Tolérance aux pannes 82
4.2.1.4 Avantages et inconvénients 83
4.2.2 APPROCHE DISTRIBUEE 83
4.2.2.1 Principes et fonctionnement 83
4.2.2.2 Gestion des services 85
4.2.2.3 Tolérance aux pannes 86
4.2.2.4 Avantages et inconvénients 86
4.3 VALIDATION THEORIQUE 87
4.3.1 APPROCHE CENTRALISEE VS APPROCHE DISTRIBUEE 87
4.3.2 2MDS VS ANNUAIRE UDDI 90
4.4 EXEMPLE D'APPLICATIONS 93
4.4.1 INSERTION D'UN SERVICE 93
4.4.2 RECHERCHE D'UN SERVICE 94
4.4.3 Suppression d'un service 95
[Marie Hélène Wassa Mballo] Page
8
CONCLUSION GENERALE 96
REFERENCE ..103
TABLE DES FIGURES
FIGURE1.1 :EVOLUTION DE L'INFORMATIQUE 21
FIGURE1.2 : ARCHITECTURE D'UNE GRILLE
26
FIGURE 2.1 : LES TROIS ACTEURS DE LA SOP
35
FIGURE 2.2 :ILLUSTRATION DU ROLE DE PASSERELLE
JOUE PAR UNE
SERVLET..................................................................................................................................................39
Figure 2.3: découverte de service web à
partir de l'annuaire UDDI 40
FIGURE 3.1 PROCESSUS DU MATCHMAKING
44
FIGURE 3.2 FORMAT D'UN DOCUMENT WSMO
47
FIGURE 3.3 : MODULES DE GLOBUS 50
FIGURE 3.4: VUE D'ENSEMBLE DE GRAM
52
FIGURE 3.5 : DEFINITION DE DEUX CLASSES D'OBJET DE MDS
GLOBUSHOST ET
GLOBUSRESOURCE 54
FIGURE 3.6: REPRESENTATION D'UNE MACHINE A PARTIR
DU MDS 54
FIGURE 3.7: SOUS ENSEMBLE DU DIT DEFINI PAR MDS
55
FIGURE 3.8 MODELE CONCEPTUEL DE MDS
56
FIGURE 3.9 : UTILISATION DES WEB SERVICES DANS LA
GRILLE 58
FIGURE 3.10 VUE D'ENSEMBLE DE GLOBUS TOOLKIT 4
62
FIGURE 3.11 INTRODUCTION DU SERVEUR BDII
63
FIGURE 3.12: LES TROIS NIVEAUX DE BDII
63
FIGURE 3.13: BASE DE DONNEES VIRTUELLE DE R-GMA
64
FIGURE 4.1: STRUCTURE DE L'ARBRE DE SERVICE
68
FIGURE 4.2 ARCHITECTURE D'UNE APPROCHE CENTRALISEE
DE RECHERCHE DE
SERVICES 81
FIGURE 4.3 STRUCTURE DE L'APPROCHE DISTRIBUEE POUR
LA RECHERCHE DE SERVICES
84
[Marie Hélène Wassa Mballo] Page
9
FIGURE 4.4 : EXEMPLE DE METADONNEES U: UNIX, L:
LIBRE, J: JAVA, P: PROPRIETAIRE 85
FIGURE 4.5 : COUT DE MISE A JOUR DANS LES DEUX
APPROCHES 88
FIGURE 4.6 : REPRESENTATION DE L'INFORMATION AVEC
LE 2MDS 92
FIGURE 4.7 : REPRESENTATION DE L'INFORMATIONS AVEC
L'ANNUAIRE UDDI 92
FIGURE 4.8 : PROCESSUS D'INSERTION D'UN SERVICE
93
[Marie Hélène Wassa Mballo] Page
10
TABLE DES TABLEAUX
TABLEAU 3.1 TABLEAU COMPARATIF DES PRINCIPALES
TECHNIQUES DE DECOUVERTE DE
SERVICE 48
TABLEAU 3.2 :TABLEAU DES INTERFACES DEFINIS PAR
OGSA 57
TABLEAU 3.3 : TABLEAU COMPARATIF DES
INTERGICIELS 65
TABLEAU 4.1 VARIATION DU TEMPS DE TRAITEMENT
SUIVANT L'AUGMENTATION DU
NOMBRE DE MACHINES 89
TABLEAU 4.2 COMPARAISON APPROCHE CENTRALISEE VS.
APPROCHE DISTRIBUEE 90
TABLEAU 4.3 COMPARAISON ENTRE L'APPROCHE PROPOSEE
ET LES APPROCHES
BASEES SUR L'ANNUAIRE UDDI 93
[Marie Hélène Wassa Mballo] Page
11
INTRODUCTION
GENERALE
[Marie Hélène Wassa Mballo] Page 12
L'ordinateur occupe, de plus en plus, une place importante
dans nos vies quotidiennes, Les applications informatiques actuelles et futures
utilisent de très larges ensembles de données qui
nécessitent des puissances de calcul et des capacités de stockage
de plus en plus importantes. Il s'est avéré nécessaire de
mettre en place des infrastructures qui peuvent supporter ces charges de calcul
et de stockage [1,2]. Or, un calculateur unique, une grappe
d'ordinateurs ou même un supercalculateur spécialisé, ne
suffisent pas pour mettre à la disposition des utilisateurs les
capacités informatiques dont ils ont besoin pour exécuter leurs
applications
Pour répondre à ces besoins, les grilles de
calcul et de données ont été définies
[3]. L'objectif visé de ces grilles est de mettre
à la disposition des utilisateurs un très grand nombre
d'ordinateurs, (des stations de travail, des supercalculateurs, mais aussi des
bases de données sécurisées et des instruments tels que
des capteurs météorologiques et des dispositifs de visualisation
[4]). Les composants d'une grille sont bien évidemment
distribués car reliés entre eux à travers le réseau
Internet, avec comme objectif de les faire fonctionner comme un ordinateur
unique et très puissant [5].
Du point de vue des utilisateurs, les grilles peuvent
être perçues comme des fournisseurs de services. D'ou un des
problèmes essentiels relatif à l'exploitation d'une grille est
celui de la découverte de services [6]. En effet les
services peuvent être définis comme un ensemble d'applicatifs que
des serveurs mettent à disposition des utilisateurs. Partant du fait que
ces clients ne connaissent pas a priori les ressources disponibles sur la
grille, ils souhaiteraient découvrir les services afin d'exécuter
leurs applications à distance sur les serveurs [5].
Il est important de noter que les mécanismes actuels de
découverte de services manquent de fonctionnalités efficaces et
flexibles. et ils deviennent
inefficaces dans des environnements dynamiques à large échelle
comme dans les systèmes pair à pair.
Dans le cadre de notre travail, nous abordons cette
problématique de découverte de services, en proposant des
méthodes de découverte flexibles basé sur une recherche
multicritère. Notre solution est
[Marie Hélène Wassa Mballo] Page 13
utilisable dans un environnement dynamique à large
échelle (systèmes pairs à pairs) et tient compte de la
topologie du réseau physique sous-jacent.
Dans ce mémoire, Nous commençons d'abord
commencer par un état de l'art sur les grilles. Nous abordons ensuite
les paradigmes de programmation qui vont aboutir à la notion de service
web.
Dans la troisième partie, nous présentons les
méthodes de découverte de service qui ont été
proposées. Dans cette section, les techniques de découverte des
intergiciels globus et glite seront mis en exergue. Et une étude
comparative des solutions étudiées sera proposée Dans la
quatrième partie de notre travail, nous proposons un mécanisme de
découverte de services au sein des grilles. Cette solution sera
validée théoriquement avec des exemples d'application. Enfin nous
terminons par la conclusion et perspectives.
[Marie Hélène Wassa Mballo] Page
14
CHAPITRE 1:
LES GRILLES
[Marie Hélène Wassa Mballo] Page 15
Actuellement dans notre monde, les recherches et les
évolutions autour des techniques de réseaux, des microprocesseurs
et des supports de stockage de données ont fortement contribué
à l'émergence de l'informatique distribuée. Les
applications informatiques modernes (calcul scientifique, datamining,
simulation, météorologie, bioinformatique, traitement du
génome, etc.) sont de plus en plus courantes et nécessitent des
capacités de calcul et de stockage que ne peuvent pas offrir les
ordinateurs classiques. Pour cela la communauté informatique s'est
intéressé aux architectures distribuées à large
échelle, afin d'offrir des solutions pour le stockage de données
et le calcul réparti à un plus grand nombre d'applications et
d'utilisateurs. Parmi ces architectures, nous pouvons mentionner les grilles de
calcul et les grilles de données
1.1 Les systèmes distribués
Un système distribué 171 est un
ensemble de machines indépendantes agissant du point de vue de ces
utilisateurs comme un seul et unique système cohérent. Ces
machines sont connectées à l'aide d'un réseau de
communication 181.
Chaque machine exécute des composantes, par exemple des
séquences de calculs, issues du découpage d'un calcul global, et
utilise un intergiciel (middleware) qui a pour rôle d'activer les
composantes et de coordonner leurs activités.
Le concept de système distribué s'oppose au
concept de système centralisé tel qu'il existait dans les
années 60 191. Un système informatique d'une
entreprise était composé d'une seule et unique machine totalement
monolithique. Cette machine était partagée par tous les
utilisateurs, tous les processus tournaient sur le même processeur.
Si cette machine tombait en panne, c'est tout le
système informatique qui était indisponible. La plupart du temps
le système informatique se trouvait dans une seule salle, avec un seul
poste de contrôle. L'augmentation des besoins de l'entreprise impliquait
l'achat d'une nouvelle machine.
Un système distribué est aussi un système
qui s'adapte facilement à la charge. Le fait d'avoir plusieurs
composants permet facilement d'en ajouter de nouveaux ou alors remplacer un des
composants sans avoir à reconfigurer tout le système.
[Marie Hélène Wassa Mballo] Page 16
Une des propriétés fondamentales d'un
système distribué est sa robustesse . Si un des composants tombe
en panne, ce n'est pas tout le système informatique qui est
indisponible. Il est possible que certains services soit indisponibles
temporairement, mais dans un un système distribué robuste, des
mécanismes ont été mis en place pour que les services
restent disponibles même si une machine tombe en panne. Au pire les
performances du service pourraient baisser. Dans un système
distribué, toutes les procédures pour tolérer la panne de
machines et/ou de services, réparer, remplacer les
éléments défaillants, ajouter de nouveaux
éléments pour s'adapter à l'évolution de besoins
doivent se faire de manière transparente, de telle sorte que
l'utilisateur ne puisse pas se rendre compte de ces pannes
[8].
1.1.1 La notion de transparence dans les systèmes
distribués
Une propriété importante des systèmes
distribués est que la distribution doit être cachée aux
utilisateurs et aux développeurs d'applications. Le système est
vu comme un seul et unique élément .La transparence [8]
est un concept très important dans les systèmes
distribués. En effet, lorsqu'un service est délivré par un
système distribué, la localisation et la complexité de son
fonctionnement doivent être complètement cachées aux
utilisateurs. Nous distinguons plusieurs types de transparence :
· Accès
Un système distribué doit cacher aux
utilisateurs la façon dont les donnés sont obtenues et
manipulées. Par exemple, une application sous Windows ne doit pas avoir
à se préoccuper du fait que les données auxquelles elle
accède se trouvent sur un serveur sous UNIX, que l'accès se fait
de manière séquentielle, indexée ou directe. Cet aspect de
la transparence permet de concevoir des applications distribuées
totalement hétérogènes et indépendantes des
supports physiques.
· Localisation
La localisation physique des donnés dans le
système doit être cachée aux utilisateurs. Pour cela, il
faut attribuer des noms uniques (qui n'ont aucun lien avec leur location
physique) aux ressources du système. Grâce à cette
abstraction, la location d'une ressource n'a pas à être connue de
l'utilisateur. Un exemple de ce type de transparence, est l'utilisation des
URL's. Lorsque qu'un utilisateur tape l'adresse d'un site web, il ne sait pas
où le serveur, qui héberge le site, se trouve
·
[Marie Hélène Wassa Mballo] Page 17
Migration
Un système distribué doit permettre la
migration des applications et des donnés sans que l'utilisateur s'en
aperçoive. Cette migration est utilisée pour répondre
à divers objectifs : régulation de charge, amélioration
des performances, etc.
· Relocation
Il s'agit d'un type de transparence encore plus fort,
puisqu'il s'agit de pouvoir changer la location d'une ressource alors qu'elle
est en cours d'utilisation.
· Réplication
Dans ce type de réplication, c'est la présence
de plusieurs copies d'une donnée qui est cachée à
l'utilisateur. Pour cela, la transparence de location est nécessaire.
L'utilisateur utilise toujours la même adresse, mais c'est le
système qui décide de la copie qui sera utilisée.
· Concurrence
Un système distribué doit cacher le fait que
plusieurs utilisateurs accèdent à une même ressource de
manière concurrente. Cela implique l'utilisation de mécanismes et
techniques pour garder la ressource dans un état cohérent
· Défaillance
Un système distribué doit cacher à
l'utilisateur une défaillance d'un de ses composants, de telle sorte que
l'utilisateur ne doit pas se rendre compte de cette défaillance. Il ne
doit pas également se rendre compte que le système est en train
d'exécuter une procédure de tolérance de panne.
· Persistance
Ce type de transparence existe aussi sur les systèmes
centralisés. Il s'agit de cacher à l'utilisateur que les
données qu'il manipule sont dans la mémoire volatile (RAM) ou sur
le disque dur.
1.1.2 avantages des systèmes distribués
[Marie Hélène Wassa Mballo] Page 18
Les systèmes distribués contrairement aux
systèmes centralisés présentent un certain nombre
d'avantages tels que [10] :
Utilisation et partage des ressources
distantes
Les matériels, logiciels et données peuvent
être accédé à partir de n'importe quelle machine.
· La robustesse
Dans un système distribué, plusieurs machines
travaillent ensemble pour fournir un service ce qui confère au service
une meilleure robustesse comparé à un système
centralisé.
· Scalabilité (extensibilité) :
La Scalabilité d'un système est une
propriété qui lui permet de s'adapter facilement à une
augmentation de sa charge. Typiquement, un système scalable reste
performant lorsque que le nombre de ses utilisateurs augmente. Dans un
système distribué, cela est possible simplement en ajoutant une
nouvelle machine dans le système. De plus cela peut s'avérer une
solution beaucoup plus économique que dans le cas d'un système
centralisé.
· Disponibilité :
La disponibilité est la probabilité qu'un
service soit disponible à un moment donné. Dans le cas d'un
système centralisé, si le serveur est indisponible, le service
l'est aussi. Dans le cas d'un système distribué, la
présence de plusieurs machines permet une conception conférant au
service la possibilité de rester disponible, même si l'un des
serveurs est indisponible.
La puissance
La possibilité de combiner la puissance de plusieurs
machines est très avantageuse, en effet, non seulement les plus
puissants ordinateurs actuels sont extrêmement chers, mais en plus, ils
n'ont pas la puissance nécessaire pour exécuter les calculs en
des temps raisonnables. Combiner la puissance de plusieurs machines de
puissance moyenne revient bien moins cher et l'ajout de nouvelles machines
augmente la puissance globale du système.
[Marie Hélène Wassa Mballo] Page 19
Souplesse
Les systèmes distribués offrent une certaine
souplesse, dans la mesure où ils peuvent faire face aux problèmes
de montée en charge. Plusieurs mécanismes et outils sont
utilisés pour s'adapter à la charge, tels que la
réplication et la migration de tâches et/ou de données.
Tolérance aux pannes
Les systèmes distribués permettent d'être
plus tolérants aux pannes que les systèmes centralisés, en
utilisant la technique de réplication des composants physiques et
logiques qui les composent.
Hétérogénéité
Les composants physiques et logiques d'un système
distribués sont généralement
hétérogènes sur plusieurs niveaux : architectural (niveau
physique), systèmes d'exploitation, langages de programmation,
environnements de développement, environnement d'exécution,
protocoles de réseaux, etc.
1.1.3 Inconvénients des systèmes
distribués
Malgré leurs multiples avantages, les systèmes
distribués ont néanmoins un certain nombre d'inconvénients
que nous allons lister dans ce qui suit :
Certains systèmes distribués utilisent la
notion de serveur central pour répondre à des besoins
spécifiques. Dans ce cas, la panne de ce serveur peut avoir des
conséquences sur le fonctionnement global du système, sauf si des
techniques de tolérance aux pannes ont été mises en
place.
La communication représente l'un des problèmes
fondamentaux des systèmes distribués, et il est d'ailleurs
considéré comme étant la principale faille de ces
systèmes. Deux éléments peuvent avoir une
[Marie Hélène Wassa Mballo] Page 20
conséquence sur les performances d'un système
distribué : (i) une panne partielle ou totale du réseau ; (ii) la
surcharge du réseau.
La sécurité, qui est un problème
transversal aux systèmes distribués, devient plus importante dans
ce type de systèmes qui sont sujets à beaucoup d'attaques, issues
de sources différentes.
Un dernier inconvénient des systèmes
distribués est celui lié à leur gestion et à leur
administration. Etant donné qu'un système distribué
regroupe différentes machines, celles-ci utilisent
généralement des politiques de gestion et d'administration qui
sont hétérogènes et parfois incompatibles. Il faut donc
coordonner l'ensemble de ces politiques pour tirer profit des
potentialités des systèmes distribués.
1.1.4 limites des systèmes distribués
L'augmentation sans cesse croissante de la quantité de
données à traiter, dûe à l'utilisation des
technologies modernes de l'information, tend à rendre l'utilisation d'un
ordinateur classique totalement obsolète. D'une part, les ordinateurs
actuels n'arrivent plus à répondre aux besoins des applications
modernes, et les utilisateurs ont den nouvelles exigences, d'autre part.
Ceux-ci souhaiteraient pouvoir accéder à de l'information
à tout moment de n'importe où, et à partir de n'importe
quel dispositif physique (ordinateur, PDA, téléphone portable,
etc.
Or les systèmes distribués actuels sont
incapables de répondre, de manière satisfaisante et à
moindre coût, à ces exigences.
Une des solutions consisterait à agréger les
capacités de plusieurs ordinateurs pour satisfaire les besoins,
même les plus exigeants, des utilisateurs. Les infrastructures de type
grille permettent de réaliser ce type d'intégration. Cela rend
les possibilités d'évolution quasiment infinies mais pose tout de
même un certain nombre de problèmes dont il faudra
nécessairement prendre en compte. Ces problèmes sont de trois
types : (i) comment mettre en place des infrastructures de type grille
(problème de déploiement) ; (ii) comment profiter, au niveau des
applications, des potentialités de ces infrastructures ; et, enfin,
(iii) comment gérer ces infrastructures.
Pour terminer cette présentation, la figure 1.1 suivante
résume l'évolution de l'informatique depuis les années 60
jusqu'à l'apparition des grilles [11]

Figure 1.1: Evolution de
l'informatique
1.2 Les grilles
Une grille [12] informatique est une
infrastructure virtuelle constituée d'un ensemble de ressources
informatiques potentiellement partagées, distribuées,
hétérogènes, délocalisées et autonomes. Ces
systèmes de grille peuvent répondre à divers besoins des
utilisateurs.
Les grilles vont apporter des solutions par rapport à
certains problèmes [13,14] rencontrés par les
scientifiques dans le domaine de leur calcul tels que : permettre une
adaptabilité, une extensibilité et une évolutivité,
permettre aux différents systèmes administratifs
d'interopérer, permettre une qualité de service ...
La grille est qualifiée de virtuelle car les relations
entre les entités qui la composent n'existent pas sur le plan
matériel mais d'un point de vue logique.
[Marie Hélène Wassa Mballo] Page 21
[Marie Hélène Wassa Mballo] Page 22
Une grille se distingue des autres infrastructures dans son
aptitude à répondre adéquatement à des exigences
(accessibilité, disponibilité, fiabilité, ...) compte tenu
de la puissance de calcul ou de stockage qu'elle peut fournir .
Une grille se compose de ressources informatiques
[14] : tout élément qui permet
l'exécution d'une tâche ou le stockage d'une donnée
numérique. Cette définition inclut bien sûr les ordinateurs
personnels, mais également les téléphones mobiles, les
calculatrices et tout objet qui comprend un composant informatique .
1.2.1 Les types de grilles
Le terme « grille de calcul », a été
introduit pour la première fois en 1990 aux Etats-Unis par I. Foster
[12], elle a été définie pour
décrire une infrastructure de calcul répartie utilisée
dans des projets de recherche scientifique et industrielle
[15].
La notion de grille de calcul s'inspire de la grille
d'électricité (power grid) [12]. Vers le
début des années 1990, la génération
d'électricité était déjà technologiquement
possible et de nouveaux équipements utilisant la puissance
électrique avaient fait leur apparition. Cependant le fait que chaque
utilisateur opère son propre générateur
d'électricité était un obstacle majeur à l'adoption
de cette technologie. Ainsi la vraie révolution était la
construction de grille électrique et les réseaux de transmission
et de distribution associés. L'électricité est ainsi
devenue universellement disponible. C'est cette disponibilité
universelle et économiquement viable (bon marché) qui a permis
aux industries d'adopter cette technologie et d'évoluer et de se
développer par son biais.
Le concept de grille est né en fait d'une constatation
très simple [11]: les nombreux cycles de processeurs
inutilisés des ordinateurs peuvent être cédés,
échangés ou prêtés en vue de les
récupérer lors d'un besoin intensif de ressources de calcul.
Très vite, l'idée s'est étendue pour toutes les autres
ressources informatiques, aussi bien matérielles que logicielles.
Plusieurs types de grilles sont notés, notamment les
grilles de calcul, de données, d'information... même les grappes
peuvent être considérés comme des grilles. Dans la suite
nous verrons quelques types de grille [4].
[Marie Hélène Wassa Mballo] Page
23
1.2.1.1 les grappes
Une grappe (cluster en anglais) est un ensemble d'ordinateurs
reliés en réseau et considérés comme une ressource
unifiée de calcul [16].
Les grappes de calcul haut performance sont des solutions
puissantes, évolutives et rentables pour les environnements de calcul
intensif. La particularité des grappes est que les machines sont
situées dans un même endroit. D'autre part, son administration est
relativement simple car c'est une seule entité qui gère
l'ensemble des composants de la grappe [16].
Les grappes de calcul présentent plusieurs avantages tels
que :
· L'augmentation de la disponibilité
· La facilité de gestion de la montée en
charge
· La répartition de la charge
· La facilité de la gestion des ressources (CPU,
mémoire, disque, bande passante réseau)
Il faut noter que les grappes de calcul représentent
une infrastructure peu coûteuse, car elle consiste à
interconnecter plusieurs ordinateurs, généralement
homogènes, en réseau qui vont apparaître comme un seul
ordinateur ayant plus de capacités. Ce type de grappes est
essentiellement utilisé dans le cadre du calcul parallèle. Ainsi,
il n'est pas nécessaire d'acquérir une machine multiprocesseur
qui couterait beaucoup plus cher que le déploiement d'une grappe
à partir d'ordinateurs séparés et qui offrirait la
même puissance de calcul.
En effet, le coût d'une grappe de calculateurs
évolue linéairement par rapport au nombre de processeurs, ce qui
n'est pas le cas des architectures multiprocesseurs.
1.2.1.2 Les grilles de calcul
La grille de calcul a été mise en place pour
résoudre le problème de manque de puissance de calcul afin de
permettre à des applications complexes de s'exécuter dans des
délais raisonnables [17]. Il serait
[Marie Hélène Wassa Mballo] Page 24
bien évidemment possible d'exécuter ces
applications sur une seule et même machine mais les temps de traitement
seraient rédhibitoires (de l'ordre de plusieurs années pour la
décomposition du génome humain par exemple). Pour cela, il est
donc nécessaire et indispensable d'utiliser des infrastructures plus
performantes.
Dans la panoplie des grilles de calcul nous distinguons
principalement deux types de grilles: les grilles à base de stations de
travail où le service voulu est déployé à la
demande et non préinstallé et les grilles de serveurs qui
requièrent une plus grande puissance de calcul car elles sont
dédiées à des applications de calcul haute performance.
Les avantages des grilles de calcul peuvent se résumer
comme suit :
· Exploiter les ressources sous utilisés
: des études ont montré que les ordinateurs personnels
et les stations de travail sont inactifs la plupart du temps. Le taux
d'utilisation varie entre 5% et 30% . Les grilles de calcul permettront ainsi
d'utiliser les cycles processeurs durant lesquels les machines sont inactives
afin de les mettre à la disposition d'une application nécessitant
une puissance de calcul importante et que les machines qui lui sont
dédiées n'arrivent pas à assurer. Le même
raisonnement peut s'appliquer aux capacités de stockage.
· Fournir une importante capacité de
calcul parallèle : le fait de pouvoir fournir une importante
capacité de calcul parallèle constitue une caractéristique
importante des grilles de calcul. En plus du domaine académique, le
milieu industriel bénéficiera énormément d'une
telle capacité : bioinformatique, exploration pétrolière
etc.
· Meilleure utilisation de certaines ressources
: en partageant les ressources, une grille pourra fournir
l'accès à des ressources spéciales comme des
équipements spécifiques (microscope électronique, bras
robotique ...) ou des logiciels dont le prix de la licence est
élevé. De ce fait ces ressources exposées à tous
les utilisateurs seront mieux utilisées et partagées et ainsi
nous éviterons d'avoir recours à installer du nouveau
matériel ou acheter de nouvelles licences.
·
[Marie Hélène Wassa Mballo] Page 25
Fiabilité et disponibilité des services
: du fait que les ressources fédérées par une
grille de calcul soient géographiquement dispersées et
disponibles en importantes quantités permet d'assurer la
continuité du service si certaines ressources deviennent inaccessibles.
Les logiciels de contrôle et de gestion de la grille seront en mesure de
soumettre la demande de calcul à d'autres ressources.
1.2.1.3 Les grilles de données
Dans les grilles de données les ressources de stockage
et les échanges de données sont essentielles pour
l'efficacité de l'exécution des applications
[4].
Certaines applications, comme la physique des particules,
peuvent générer de larges ensembles de données pouvant
atteindre plusieurs téraoctets voir des pétaoctets. Ainsi il est
impossible de les stocker sur une seule et même machine, d'où la
nécessité de créer des espaces de stockage très
larges en mettant en commun les espaces de stockage de différentes
machines.
Une grille de données ne permet pas seulement de
fragmenter des fichiers et de les stocker dans plusieurs machines. Elle doit
également offrir des mécanismes de recherche, d'indexation,
d'intégrité et de sécurité pour assurer un
accès fiable et permanent aux données. Il faut aussi que la
répartition des données soit transparente pour l'utilisateur
final. En effet, il est impossible de savoir avec exactitude l'endroit
où chaque donnée est stockée. Par exemple un fichier peut
être découpé en plusieurs morceaux et réparti sur
plusieurs machines.
Pour une garantir meilleure disponibilité des
fichiers, il est possible de les répliquer sur plusieurs entités
du réseau. Il faudra alors avoir un mécanisme qui puisse à
la fois répartir la charge sur chaque serveur et garantir la
cohérence des différentes répliques d'un même
fichier.
Pour répondre à ces différentes
problématiques, un certain nombre de projets ont été
lancés à travers le monde. A titre d'exemple, nous pouvons citer
le projet DataGrid [18] qui est utilisé par le CERN,
l'agence spatiale européenne et le CNRS.
1.2.2 Architecture d'une grille
[Marie Hélène Wassa Mballo] Page 26
Une grille se définit une architecture en couches, dont
chacune assure une fonction spécifique [16]. D'une
façon générale, les couches hautes sont axées sur
l'utilisateur, tandis que les couches basses sont plus centrées sur le
matériel (voir figure 1.3).

Figure1.2 : architecture
d'une grille
Dans ce qui suit, nous allons présenter les
différentes couches d'une grille [4] :
Couche réseau : elle assure la connexion
des entre les différentes ressources qui composent une grille.
Couche ressource : cette couche est
constituée des ressources physiques faisant partie de la grille, telles
que les ordinateurs, les systèmes de mémoire, les catalogues de
données électroniques ou d'autres instruments
(électroniques) qui peuvent être connectés directement au
réseau
[Marie Hélène Wassa Mballo] Page 27
Couche intergicielle : les principaux
problèmes rencontrés par les concepteurs de grilles sont souvent
liés à la couche logicielle. En effet, il faut arriver à
rendre invisible l'accès aux couches inférieures (réseaux,
mémoires,...) pour permettre aux développeurs des couches hautes
de faire abstraction de tous les aspects liés aux ressources physiques,
aux systèmes d'exploitation, aux environnements de développement
et aux réseaux de communication. Cette abstraction est supportée
par une couche fondamentale dans les grilles (comme dans les systèmes
distribués), qui est appelée intergiciel ou middleware.
Cette couche va permettre une interaction entre les
utilisateurs, les applications et les ressources de la grille.
Un exemple très connu de middleware pour les grilles
est l'environnement Globus, qui est devenu un standard dans le
domaine des solutions pour le calcul distribué et la
fédération des ressources à une très grande
échelle.
Couche application : dans cette couche, nous
trouvons les applications des utilisateurs.
1.2.4 Les caractéristiques d'une grille
Différents éléments peuvent
caractériser une grille. Parmi les caractéristiques fondamentales
d'une grille, nous pouvons mentionner [6] :
> Existence de plusieurs domaines administratifs
: les ressources sont géographiquement distribuées et
appartiennent à différentes organisations dont chacune dispose de
sa propre politique de gestion et de sécurité. Il s'avère
important de respecter les politiques de chacune de ces organisations.
> Hétérogénéité
des ressources : dans une grille les ressources sont de nature
hétérogène. Cette
hétérogénéité s'applique aux
matériels, aux réseaux et aux logiciels.
> Passage à l'échelle
(scalabilité) : une grille peut être composée de
quelques dizaines de ressources mais également de millions voire des
dizaines de millions de ressources. Cela pose
de nouvelles contraintes sur les applications et les algorithmes
de gestion de ressources.
[Marie Hélène Wassa Mballo] Page 28
> Nature dynamique des ressources : dans
les grilles, le caractère dynamique des ressources est la règle
et non une exception comme dans le cas des systèmes distribués
qui sont plus ou moins stables. Cela pose des contraintes sur les applications
telles que l'adaptation au changement dynamique du nombre de ressources, la
tolérance aux pannes et aux délais...
1.3 Problématiques posées par les
grilles
Les principales difficultés rencontrées avec les
grilles informatiques sont [6] :
· la communication et la coopération des
matériels distants et hétérogènes (par leur mode de
fonctionnement comme par leur performance)
· le développement de systèmes permettant
de gérer et de distribuer efficacement les ressources disponibles dans
une grille
· la conception d'outils de programmation adaptés
au caractère distribué et parallèle de
l'exécution.
· les besoins en terme de réseaux, et qui sont
très importants, engendrent toute une série de contraintes, comme
par exemple le partage de la bande passante entre les différents
composants d'une grille.
· Equilibrage de charge :
l'homogénéité et la stabilité des ressources font
défaut dans les grilles de calcul. Par exemple le passage à
l'échelle peut être à la fois important et brusque. D'autre
part, les réseaux d'interconnexion au niveau des grilles
présentent des performances très diversifiées en ce qui
concerne les largeurs des bandes passantes. Enfin, les tâches soumises au
système peuvent être de nature très
irrégulière. Ces différentes caractéristiques
montrent qu'il est difficile, voire impossible de définir un
système d'équilibrage qui puisse intégrer tous ces
facteurs.
· [Marie Hélène Wassa Mballo] Page 29
La gestion de la sécurité et de l'identification
pose également des problématiques nouvelles dans le cas
grilles
> La notion de service dans les
grilles
Du point de vue utilisateur, une grille peut être
considérée comme un ensemble de services mis à la
disposition des utilisateurs [19]. De ce point de vue, une des
problématiques essentielles, pour l'utilisation d'une grille, concerne
la recherche de service. En effet, un utilisateur, pour utiliser un service,
devra d'abord le localiser. Pour cela, il faut qu'il dispose d'outils qui
l'assistent dans cette recherche de service. La mise en oeuvre de ces outils
nécessite de définir la notion de service de grille. Nous pouvons
définir un tel service, comme un service web particulier qui fournit,
à travers le réseau Internet, des interfaces bien définies
et qui suit des conventions spécifiques [20]. Un
service web peut être localisé grâce à un annuaire
(UDDI).
Nous venons de voir dans ce chapitre l'historique de la
grille, c'est à dire ce qui a motivé son apparition. Nous avons
parlé des différents types de grille, des caractéristiques
d'une grille. Nous avons également noté les inconvénients
de la grille dont le principal est la découverte de services.
Ces services sont définis comme des applications
mises à la disposition des clients, de ce fait au chapitre nous allons
quels outils utilisés pour développer ces services.
[Marie Hélène Wassa Mballo] Page
30
CHAPITRE 2:
LES SERVICES WEB
[Marie Hélène Wassa Mballo] Page 31
Les services étant définis comme des
applications, il est important de savoir comment les développer. De ce
fait nous allons parler des paradigmes de programmation, comme
définition nous pouvons dire que le paradigme est un style fondamental
de programmation informatique qui traite de la manière dont les
solutions aux problèmes doivent être formulées dans un
langage de programmer.
Actuellement avec les besoins des scientifiques
augmentant de jour en jour, les paradigmes de programmation ont connu de
grandes améliorations.
2.1 La programmation orientée objet
Un objet [21] est une structure de
données valuées et qui répond à un ensemble de
messages. Cette structure de données définit son
état tandis que l'ensemble des messages qu'il comprend
décrit son comportement
La programmation orientée objet consiste à
modéliser informatiquement un ensemble d'éléments d'une
partie du monde réel (que l'on appelle domaine) en un ensemble
d'entités informatiques. Ces entités informatiques sont
appelées objets. Il s'agit de données informatiques regroupant
les principales caractéristiques des éléments du monde
réel (taille, couleur, ...). La modélisation objet consiste
à définir, à qualifier dans un premier temps les
éléments sous forme de types, donc indépendamment de la
mise en oeuvre cette phase est appelée l'analyse orientée
objet ou OOA (Object Oriented Analysis).
Après cette phase une solution a été
proposée pour représenter les éléments
définis dans le système informatique, c'est ce qu'on appelle la
conception orientée objet ou OOD
(Object Oriented Design). A la fin de cette phase le modèle de
conception est établi, maintenant il est possible au développeur
de donner corps, au modèle, dans un langage de programmation, c'est qui
est appelée la programmation orientée objet
ou OOP (Object Oriented Programming).
> Avantages de la POO
Un problème se posait avant l'apparition de la POO, en
effet victimes de leur succès, les programmes informatiques doivent
répondre à l'accroissement continu du niveau de complexité
des applications à développer : ils deviennent de plus en plus
complexes et volumineux, donc ces programmes deviennent difficiles à
maintenir.
[Marie Hélène Wassa Mballo] Page 32
Un certain nombre de questions se posent : comment
réutiliser les programmes déjà développés
plutôt que de les réécrire, ce qui signifie comment
gérer la complexité ? Avec l'évolution de l'outil
informatique notamment la montée en puissance des processeurs, la
programmation objet a permis de répondre à ces questions
Dans la programmation orientée objet il faut s'assurer
à identifier les objets pertinents et à faire en sorte qu'ils
collaborent, et ces objets peuvent être réutilisés dans
d'autres contextes applicatifs et c'est ce qui fait tout l'art de l'analyse et
de la conception objet.
> Inconvénients de la POO [22]
Bien que la programmation orientée objet ait vraiment
servie dans la mise en place des logiciels des limites ont été
signalées par rapport à ses offres, en effet avec la crise du
logiciel leur taille et leur complexité croissent plus vite que les
ressources que nous sommes capable de consacrer à leur
développement.
Dans le paradigme orienté objet toutes les
préoccupations ne peuvent pas être encapsulé dans des
modules dominants, ce qui aura pour résultat d'avoir du code
dispersé à travers les modules avec des appels croisés
d'un module à l'autre
De ce fait des soucis de performance et d'efficacité
ont poussé à développer de nouveaux paradigmes
[23], dont le but premier est de programmer plus vite, et plus
simplement pour répondre aux attentes du marché informatique
2.2 La programmation orientée composant
La programmation par composants est un nouveau paradigme de
programmation post-objets qui répond à certaines faiblesses de la
programmation orienté objet. Donc la programmation orientée
composant est juste une évolution de la programmation orientée
objet.
La POC [24,25] n'est pas sans similitudes
avec la POO, puisqu'elle revient à utiliser une approche objet, non pas
au sein du code, mais au niveau de l'architecture générale du
logiciel.
[Marie Hélène Wassa Mballo] Page 33
La POC est particulièrement pratique pour le travail en
équipe et permet d'industrialiser la création de logiciels.
La programmation par composant est donc basée sur le
fait d'intégrer, d'emboîter des composants entre eux pour former
notre programme.
> Le composant
Le composant est une unité indépendante de
production et de déploiement qui est combinée à d'autres
composants pour former une application. L'objet reste au centre du composant
mais l'objectif diffère.
Le code d'un composant peut en effet être
séparé en deux parties. Tout d'abord, les méthodes et
données internes. Un composant peut implémenter des fonctions
qu'il utilise "pour son compte personnel", et qui ne sont pas accessibles de
l'extérieur. On parle de méthodes "privées". Ensuite, le
composant, pour pouvoir être utilisé, doit fournir un moyen de
communication avec les programmes clients. Certaines fonctions sont donc
accessibles de l'extérieur, et dévolues à être
appelées par ces programmes. On parle de méthodes publiques, ou
d'interface.
> Les avantages offerts par la programmation
orientée composant sont les suivants :
· spécialisation:
L'équipe de développement peut-être divisée
en sous-groupes, chacun se spécialisant dans le développement
d'un composant.
· sous traitance: Le
développement d'un composant peut-être externalisé,
à condition d'en avoir bien réalisé les
spécifications au préalable.
· facilité de mise à jour:
La modification d'un composant ne nécessite pas la
recompilation du projet complet.
· facilité de
livraison/déploiement: Dans le cas d'une mise à jour,
d'un correctif de sécurité, ... alors que le logiciel à
déjà été livré au client, la livraison en
est facilitée, puisqu'il n'y a pas besoin de re-livrer
l'intégralité du projet, mais seulement le composant
modifié.
· choix des langages de développement:
Il est possible, dans la plupart des cas, de développer les
différents composants du logiciel dans des langages de programmation
différents. Ainsi, un composant nécessitant une
fonctionnalité particulière pourra profiter de la puissance
d'un
[Marie Hélène Wassa Mballo] Page 34
langage dans un domaine particulier, sans que cela n'influe le
développement de l'ensemble du projet.
· productivité: La
réutilisabilité d'un composant permet un gain de
productivité non négligeable car elle diminue le temps de
développement, d'autant que le composant est réutilisé
souvent.
Bien que la programmation orientée composant soit une
évolution de la POO elle commençait à faire à
certaines limites face aux applications qui demandaient de plus en plus de
ressource
> inconvénients de la programmation
orientée composant [26]
La POC est réellement appréciable dans la
conduite d'un projet de développement, cependant elle pose quelques
désagréments.
Tout d'abord, la POC est une méthode dont le
bénéfice se voit surtout sur le long terme. En
effet, lorsque l'on parle de réutilisation, de facilité de
déploiement, c'est que le développement est sinon achevé,
du moins bien entamer. Mais factoriser un logiciel en composants
nécessite un important travail d'analyse. La
rédaction des signatures des méthodes devra être
particulièrement soignée, car modifier une signature
nécessitera de retravailler toutes les portions de codes du projet qui
font appel au composant, et l'on perdrait alors les bénéfices de
l'indépendance des briques logicielles.
En un mot, si la POC industrialise le développement,
la phase de conception du logiciel prendra un rôle encore plus
important.
Le fait de ne pas connaître l'implémentation
d'un composant (à moins d'avoir accès à la source), peut
également gêner certains chefs de projets qui veulent garder un
contrôle total sur leur logiciel.
Un autre problème qui se pose également c'est
avec les systèmes distribuées à large échelle il
faudra mettre en place des mécanismes qui permettront aux applications
de s'adapter à ces environnements.
Dans la prochaine section nous allons voir un autre type de
paradigme qui est beaucoup utilisé de actuellement
[Marie Hélène Wassa Mballo] Page
35
2.3 La programmation orientée service
Le terme de la programmation orientée service
(SOP) [27] désigne le fait de se concentrer sur «
que fait un bout de code ». Tout comme la POC, la SOP se base sur la
POO.
Dans la SOP les composants coopèrent via des
comportements. Un comportement, ou service, ou interface, permet de
séparer ce qui doit être réalisé (le contrat) de la
manière de le réaliser (implantation)
La SOP fait intervenir fait intervenir 3 acteurs [28]
dans la mise en place d'une application :
· Le client : correspond à
l'application cliente il peut correspondre également à un autre
service
· Le service : le client fait appel au
service pour une tâche précise
· Le registre : appelé
répertoire de service, le client y trouvera les informations à
propos du client. Ce répertoire peut être privé
c'est-à-dire interne à l'entreprise ou public

Figure 2.1 : les trois
acteurs de la SOP
Le service répond à trois fonctionnalités
caractéristiques :
· Il est indépendant
·
[Marie Hélène Wassa Mballo] Page 36
Il peut être découvert et appelé de
manière dynamique
· Il fonctionne seul
Le répertoire de service a un rôle primordial
dans la POS. C'est lui qui reçoit la requête du consommateur, lui
qui découvrira le service approprié, et lui agira en tant que
intermédiaire entre le consommateur et le service. En s'assurant que les
fournisseurs de services informent régulièrement les
répertoires de leurs nouveautés, le consommateur peut constamment
profiter de celles-ci sans pour autant devoir mettre à jour ses
méthodes.
> Apport de la programmation orientée
service
La programmation orientée service répond
à un besoin d'abstraction qui lui-même découle de la
complexité grandissante des projets informatiques, mieux
développer, et surtout mieux maintenir les fonctionnalités
conçues.
Ce paradigme va aider à gérer
l'hétérogénéité des milieux applicatifs, son
objectif est d'autoriser les applications ou service à communiquer et de
travailler ensemble quelque soit leur plate forme respective, donc la POS va
permettre l'accès et la manipulation des données partout.
La POS facilite non seulement les échanges entre les
applications de l'entreprise mais surtout permet une ouverture vers les autres
entreprises
L'architecture suit le modèle de programmation donc
nous aurons une architecture orientée service. Cette architecture repose
fondamentalement sur les services web, en effet elle utilise tous les standards
dédiés aux services web (XML, http, WSDL...) pour s'assurer de
l'interopérabilité de son fonctionnement
Il faudra faire la différence entre une architecture
orientée service (SOA) et les web services, en effet une SOA n'est pas
une technologie mais un principe de conception, tandis que les services web en
sont une implémentation technologique.
[Marie Hélène Wassa Mballo] Page
37
2.4 La gestion des services web
La création de services Web se justifie par
l'architecture orientée service, c'est-à-dire la volonté
de rendre accessible un service qui implémente un logique métier
cachée à des utilisateurs.
Un service web est un service offert par l'intermédiaire
du web. Autrement dit, le web est le média de communication
utilisé, et tous les services accessibles via ce média peuvent
être qualifiés de services web.
L'architecture des services web est constituée d'un
triplet qui assure toutes les caractéristiques requises:
UDDI (Universal Description Discovery and Integration)
[29]
Le référentiel UDDI permet d'exporter des
services Web pour ensuite les offrir à des applications clientes qui
viendront les trouver en effectuant des recherches à partir de plusieurs
critères. IL est essentiellement composé de quatre
éléments:
· businessEntity : contient les
informations sur chaque unité organisationnelle qui publie des
services.
· businessService : décrit
chaque service qu'un businessEntity offre, cette information est purement
descriptive et ne comporte d'instructions pour accéder ou utiliser un
service
· bindingTemplate: regroupe plusieurs
informations techniques destinées à décrire les points
d`accès aux services. Il représente le lien entre les
descriptions abstraites du businessService et des paramètres dont ces
services sont accédés.
· tModel: est le standard qui peut
décrire des détails spécifiques sur un businessService ou
un bindingTemplate. Pour la description il utilise une liste de paire
clé-valeur qui peut être associé à plusieurs objets
de la base de données UDDI.
WSDL (Web Service Description Language)
Permet de définir précisément quels sont
les services disponibles ainsi que la façon dont nous devons interagir
avec ceux-ci. Le WSDL est également fondé sur le formalisme
XML.
· Définition d'importation : le
document WSDL peut importer un autre document XML
· Définition des messages : un
message correspond aux données qui seront véhiculées entre
les participants, c'est-à-dire les applications clientes et les services
web
·
[Marie Hélène Wassa Mballo] Page 38
Définition des opérations : cette
définition est effectuée par l'intermédiaire de la section
portType qui est une énumération de descriptions
d'opérations.
· Définition des liaisons :
l'objectif de cette section est de préciser comment les
opérations vont être traitées par un protocole de
communication. Le protocole de communication utilisée ici est le
protocole SOAP
· Définition des services : cette
section définit le service en question, c'est-à-dire la liste de
ses points d'accès.
SOAP (Simple Object Access Protocol)
Un protocole de communication qui utilise le formalisme XML
pour, à la fois, définir les messages envoyés entre les
applications et représenter les données échangées ;
ce protocole appelé SOAP (Simple Object Access Protocol),
spécifié au sein du W3C. Ce protocole offre un mécanisme
de communication aussi bien pour l'intranet que pour l'Internet. Ce qui
signifie plus précisément, qu'une application envoie un message
SOAP vers une application, que celle-ci traite la demande effectuée par
ce message et renvoie un message de réponse à l'application
appelante.
2.4.1 Implantation d'un service web
La technologie des services web est une évolution des
environnements répartis, en effet beaucoup de fournisseurs
d'environnements répartis présentent aujourd'hui ces
environnements comme des plates formes d'implantation des services web.
En effet un service web n'est qu'une vue d'un service offert
sur le web ou du moins accessible via l'Internet, le comportement du service
offert doit être implanter ; cela implique l'utilisation de technologies
traditionnelles comme l'accès à des bases de données,
l'exécution des procédures de calculs, ..., toute la panoplie des
actions offertes par les plates formes du type environnement réparti.
C'est pour cela les plates formes réparties
traditionnelles telles que CORBA (Common Object Request Broker Architecture),
DCOM (Distributed Component Object Model), J2EE intègrent
progressivement le support des services web.
[Marie Hélène Wassa Mballo] Page 39
La mise en oeuvre d'un service web consiste à
développer une application qui répond à des messages SOAP.
Dans le cas d'une mise en oeuvre du type SOAP/http, la mise en oeuvre d'une
application serveur consiste à développer une servlet qui va
jouer le rôle de passerelle.
Actuellement plusieurs technologies tentent à
intégrer les services web. Nous avons l'environnement J2EE (Java 2
enterprise Edition) défini par Sun pour offrir un environnement de
développement d'applications serveurs écrites en java.
Tomcat qui est un outil de référence en terme de
conteneur de servlets et de JSP (Java Server Page), développé par
la fondation Apache (ASF, apache Software Foundation) sera combiné
à J2EE.
L'intérêt grandissant de tomcat s'explique du fait
que Sun et Apache ont annoncé que ce dernier deviendrait
l'implémentation officielle des spécifications des servlets et
des JSP.
Servlet jouant le rôle de paserelle

SOAP
Appel java vers le code
Implantation du service web
Figure2.2 : Illustration du rôle de passerelle
joué par une servlet
2.4.2 Recherche d'un service web [29]
Le référentiel UDDI permet d'exporter des
services Web pour ensuite les offrir à des applications clientes qui
viendront les trouver en effectuant des recherches à partir de plusieurs
critères.
Nous allons détailler les étapes pour la recherche
de service
1.
[Marie Hélène Wassa Mballo] Page 40
Tout d'abord le service doit s'inscrire auprès d'un
référentiel UDDI en indiquant plusieurs de ses
caractéristiques, y compris sa description WSDL
2. L'application cliente va consulter un
référentiel UDDI afin de sélectionner le service web qu'il
souhaite utiliser
3. Une fois le service sélectionné, sa
description WSDL peut être consultée pour savoir comment interagir
avec celui-ci. Cette description permet de savoir quel message SOAP est
à envoyer et quel message SOAP sera reçu en retour du traitement
souhaité.
4. Il faut à présent contacter le service web
et donc établir la communication avec ce dernier.
5. Le message reçu du coté service Web implique
un traitement. Le service web pouvant être un frontal d'un environnement
réparti, le traitement en cours peut nécessiter à son tour
diverses interactions au sein même du système d'information
impliqué dans le traitement.
6. Si aucune erreur ne se produit, une réponse est
émise à l'application cliente.

Figure 2.3: découverte de service web
à partir de l'annuaire UDDI
Dans ce chapitre nous venons de voir la programmation
objet qui a joué un rôle très important dans le
développement des logiciels, ce paradigme a connu des
améliorations avec les limites qui ont été notées,
de ce fait son évolution a aboutit à la notion de programmation
orienté composant et la programmation orienté service qui va
donner les services web.
Dans le chapitre suivant nous verrons la découverte
de service au sein des grilles, les mécanismes mis en place pour
localiser les services désirés.
[Marie Hélène Wassa Mballo] Page
41
CHAPITRE 3 :
LA REHERCHE DE
SERVICE DANS LES
GRILLES
[Marie Hélène Wassa Mballo] Page 42
Une des problématiques essentielles pour les
grilles est la découverte de service, en effet un service doit d'abord
être localisé avant son utilisation Dans cette partie nous allons
mettre l'accent sur notre problématique d'étude qui est la
découverte de service dans les grilles. La couche intergicielle permet
de découvrir les services dont nous avons besoin en effet il ya
répertoire qui permet d'accéder à des informations de la
grille.
Le gestionnaire de resources [30,31]
est l'élément central de la grille. La gestion des
ressources comprend la découverte de ressource, la surveillance des
ressources, l'inventaire des ressources, la prSovision des ressources,
l'isolation des pannes, un niveau de service de gestion des
activités.
3.1 Les méthodes et techniques de
découverte
Le gestionnaire de ressources est l'élément
central de la grille. La gestion des ressources comprend la découverte
de ressource, la surveillance des ressources, l'inventaire des ressources, la
provision des ressources, l'isolation des pannes, un niveau de service de
gestion des activités. Dans notre mémoire nous allons
plutôt nous intéresser à la découverte de
ressources. Des mécanismes de découverte de service ont
été proposés et dans cette partie nous allons en voir un
certain nombre. Nous étudions les différentes approches en nous
basant sur les critères ci dessous
Langage
Le langage va permettre de formuler une requête ainsi la
description d'un service est crucial pour le processus de découverte. Il
est important d'évaluer l'expression du langage et comment formuler des
requêtes facilement.
Scalabilité
La scalabilité montre comment le système
réagit par rapport aux changements des utilisateurs, des ressources...
il est important d'analyser comment le système réagit face
à une augmentation ou un retrait de ressources. Un autre aspect qui doit
être considéré est comment la scalabilité des sous
systèmes ou des systèmes connexes, affectent la
scalabilité du système général
[Marie Hélène Wassa Mballo] Page 43
Algorithme
Dans un processus de découverte un algorithme est
utilisé pour exécuter ce processus, l'étude de performance
de l'algorithme rend compte de la fiabilité de l'approche
utilisée.
Complexité
L'algorithme utilisé doit pouvoir permettre d'avoir des
résultats dans un temps raisonnable. Un algorithme peut demander
beaucoup de ressources (mémoire, temps, espace disque...) pour parvenir
à un résultat, tandis qu'autre mieux conçu le ferait de
manière plus efficace
brokering
Le brokering consiste à utiliser un agent [32] pour la
découverte de service. L'utilisation d'agents dans le processus de
découverte offre plusieurs avantages car les agents ont un comportement
autonome et sont très intelligents.
3.1.1 Recherche de service basée sur la description
ontologique
Actuellement nous parlons beaucoup de description ontologique
et il est important de connaître sa définition, donc l'ontologie
est un ensemble structuré de termes et concepts représentant le
sens d'un champ d'informations. L'ontologie constitue en soi un modèle
de données représentatif d'un ensemble de concepts dans un
domaine, ainsi que les relations entre ces concepts.
L'ontologie se réfère à la description
d'un service, la description ontologique améliore
l'interopérabilité entre les organisations virtuelles. Dans [33]
IL nous propose un framework de découverte de service avec un
mécanisme de matchmaking de service basé sur la
connaissance ontologique.
Un langage de description est utilisé pour ce type de
description et le premier langage à être utilisé est le RDF
(Resource description Framework Schema) [33,34] qui est un langage de
représentation d'information sur des ressources dans le World Wide Web.
La description des données se fait sous format xml. Pour identifier les
ressources RDF utilise les identifiants web appelés URI et les
données seront représentées sous forme de graphe.
[Marie Hélène Wassa Mballo] Page 44
La description ontologique se base sur l'utilisation d'un
agent qui sera chargé de la description du service en tant que tel et en
donnant tous les détails nécessaires. Dans cette approche la
découverte de service s'effectue en utilisant le processus de
matchmaking, dans ce Framework trois composants sont nécessaires, il
s'agit:
Du fournisseur de service: envoie ses services
au matchmaker
Du matchmaker: joue le rôle
d'intermédiaire entre le fournisseur de service et le demandeur. Ce
dernier est chargé de stocker l'information par rapport aux services
fournis par les fournisseurs.
Du demandeur: permet à l'application
cliente d'utiliser le service voulu. Il consulte le matchmaker pour savoir quel
fournisseur peut lui répondre par rapport à ses besoins.
Le processus de découverte dans le processus de
matchmaking est le suivant:
1) Le fournisseur de service enregistre la description du
service dans un répertoire d'une base de données
2) Le client qui a besoin d'un service envoie la
requête au matchmaker
3) Le matchmaker retourne les résultats au service
demandeur
4) Le service demandeur décide ensuite à quelle
ressource sera utilisé pour satisfaire les besoins de l'utilisateur

Figure 3.1 processus du matchmaking Les
étapes pour le processus de matchmaking :
2. Publication
3. Demande de service
4. Nom de service
5. Demande
6. Réponse
[Marie Hélène Wassa Mballo] Page 45
Cette approche ontologique se base sur un mécanisme de
matchmaking, un matchmaking qui est tout simplement un processus de
découverte d'un fournisseur approprié pour un demandeur en
utilisant un agent médian. L'agent sera chargé de prendre la
requête et de parcourir les noeuds pour faire une correspondance avec les
critères de recherche
> Limitation de l'approche ontologique
Cette approche présente une limite liée à
la gestion centralisée qui s'appuie sur un agent qui est chargé
de parcourir les pairs de la grille, dans le but de savoir si le service est
disponible, et les ressources qui interviennent dans l'exécution du
service
3.1.2 Recherche basée sur le Web service
3.1.2.1 L'utilisation de l'annuaire UDDI
Dans le chapitre 2 nous avons vu comment nous effectuons la
recherche d'un service web à partir de l'annuaire UDDI. Il est possible
d'effectuer la recherche dans le référentiel UDDI sous plusieurs
critères telles que par catégorie, par
service, par fournisseur de service ou en
utilisant le tmodel. Le référentiel donne
l'information nécessaire au client pour accéder au service web
choisi.
> Limitations des services web
· Les web services ne traitent que la syntaxe et pas la
sémantique. L'utilisation de XML permet de structurer et
spécifier les étapes dans la construction d'un document. Ils ne
permettent pas de spécifier le sens à donner au document.
· Les services web ne sont qu'un mécanisme de
transfert de données/ d'informations d'un système à
l'autre. Les services web n'apportent, en aucun cas, plus de valeurs à
l'information déjà possédée. Ils permettent juste
une meilleure diffusion auprès des clients et des fournisseurs.
· Il serait intéressant pour l'utilisateur qu'il
ait des résultats assez pertinents pour la recherche c'est-à-dire
qu'il obtienne des informations sur la fonctionnalité du service. un
autre problème qui se pose également est la recherche par
catégorie, en effet un service peut appartenir à
[Marie Hélène Wassa Mballo] Page 46
plusieurs catégories la question qui se pose c'est ou
classer ce service, et aussi en lançant une recherche nous pouvons avoir
un ensemble de résultats assez vaste.
3.1.2.2 Approche basée sur le web service
modeling ontology(WSMO)
Cette approche est un modèle hybride combinant service
web et la description ontologique. Cette méthode répond en partie
aux limitations des services web.
Nous avons vu que l'information transmise par les services de
grille n'était pas très détaillée et il serait
préférable de faire une description sémantique et c'est ce
qui sera fait avec le web servie modeling ontology
Le Web Service Modeling Ontologie (WSMO) utilise l'ontologie
[35] pour la description de divers les aspects liés au
service web sémantique [36] qui est une infrastructure
permettant l'utilisation de connaissances formalisées en plus du contenu
informel actuel du web. Le WSMO se base sur le Web Service Modeling Framework
(WSMF).
Le WSMO est considéré comme un
méta-modèle pour relater les aspects des services web
sémantiques. La spécification Meta Object Facility (MOF), qui est
un standard de l'OMG (Object Management Group) s'intéressant à la
représentation des métamodèles et leur manipulation, est
utilisée pour spécifier ce modèle, de ce fait nous aurons
une architecture à quatre couches:
· La couche information: comprenant les
données à décrire. Dans cette couche se trouve les
ressources décrites par les ontologies et échangées
à travers les services web.
· La couche modèle comprenant
les métadonnées qui décrivent les données de la
couche information. Dans cette couche nous avons les quatre notions du WSMF qui
sont les ontologies, les services web, les objectifs et les
médiateurs.
· La couche méta-modèle
comprenant les descriptions qui définissent la structure et la
sémantique des métadonnées. Correspondant au WSMO en tant
que tel.
· La couche
méta-méta-modèle comprenant la description de la
structure et la sémantique de la méta-métadonnée.
Le langage de description utilisée dans le WSMO correspond à
cette couche.
[Marie Hélène Wassa Mballo] Page 47
Le WSMF [37] est composé de quatre
principaux éléments pour la description des Web Services
sémantiques:
· Les ontologies qui fournissent de la
terminologie utilisée par d'autres éléments
· Les objectifs qui définissent les
problèmes qui devraient être résolus par des services
Web
· La description des services Web, qui
définissent les divers aspects d'un service Web
· Les médiateurs qui permettent de
passer outre les problèmes d'interprétation.
Un Langage est nécessaire pour représenter
l'information, de ce fait dans cette approche le langage utilisé est le
WSML [38] qui est un langage pour modéliser
les services web, les ontologies. IL se base sur des formalismes logiques, des
descriptions logiques. Pour accroître l'interopérabilité du
WSML les syntaxes se basent sur le XML et le RDF.
IL permet d'importer et d'utiliser les schémas RDF de
la description ontologique. Le WSML présente plusieurs variantes telles
que le WSML-Core qui est le langage le moins puissant de la famille des WSML
avec deux extensions qui sont le WSML-DL et le WSML-Flight, après nous
avons le WSML-Rule qui est une extension du WSML-Flight et enfin nous
retrouvons le WSML-Full qui est un regroupement du WSML-DL et le WSML-Rule,
dons dans la description l'une de ses variantes est utilisée pour
représentée l'information.
Le format d'un document WSMO est le suivant :

Figure 3.2 format d'un document WSMO
> Limitations de l'approche WSMO
Cette méthode répond en partie aux limitations
des services web. Cependant, le problème qui se pose est le
résultat donné aux utilisateurs lors d'une recherche. En effet,
de même que les services web, les critères de recherche dans
l'approche ontologique sont limités et ne prennent pas en compte
l'ensemble des besoins d'information que l'utilisateur devrait avoir pour une
utilisation efficiente des services.
3.1.3 Etude comparative des différentes
approches
Pour mieux comprendre l'étude des approches vues
précédemment nous allons utiliser un tableau comparatif avec
l'ensemble des critères vus précédemment
|
langage
|
scalabilité/
décentralisation
|
algorithme de recherche
|
complexité de recherche
|
Brokering
|
ontologie
|
RDF
|
Limitée avec un agent/ centralisé
|
matchmaking
|
O( n)
|
Les deux
|
Service web
|
xml
|
décentralisé
|
parcours
|
O(n)
|
requête
|
WSMO
|
WSML
|
décentralisé
|
matchmaking
|
O(n)
|
Les deux
|
|
Tableau 3.1 Tableau comparatif des principales
techniques de découverte de service
Langage
Ces trois approches utilisent le langage XML comme langage de
requête qui est actuellement très utilisé du fait de sa
puissance car permettant d'effectuer des recherches très facilement.
Scalabilité et la
décentralisation
Pour ces approches présentées, les services web
sont décentralisées car l'annuaire sera répliqué
sur plusieurs noeuds, la Scalabilité va dépendre de la plate
forme utilisé pour implémenter ces noeuds.
[Marie Hélène Wassa Mballo] Page 48
Complexité de l'algorithme
[Marie Hélène Wassa Mballo] Page 49
Ces trois approches présentent toutes une
complexité de recherche dans une machines, en O(n).
Brokering
L'approche ontologique et le WSMO utilisent un agent pour la
découverte de service cela veut dire qu'un agent logiciel est
chargé d'effectuer la recherche lancée par un utilisateur, tandis
que dans les services web la découverte se fait via des requêtes.
Les deux premières techniques sont meilleures que l'utilisation des
services web.
> Inconvénients des approches
Nous avons constaté des limitations pour ces
approches. Concernant l'approche ontologique le problème qui se pose
c'est qu'il soit centralisé, en effet l'agent parcours l'ensemble des
noeuds physique de la grille pour trouver des descriptions correspondant
à la requête posée par l'utilisateur.
La recherche avec les services web s'effectue grâce
à l'annuaire et les critères de recherche sont le nom du service,
la catégorie ou le fournisseur, cette méthode de recherche est
plutôt efficace pour rechercher des services traitant de commerce
c'est-à-dire le prix, faire des commandes en effet les informations
données par l'annuaire pour un service sont limitées car
l'utilisateur ne peut pas avoir accès à la description.
De ce fait un nouveau concept va être introduire, le
WSMO permettant d'avoir accès à la description du service.
Mais nous constatons toujours une limitation des
résultats fournis, car si nous voulons effectuer des recherches de
service dans les grilles de calcul il serait intéressant pour le client
d'avoir des informations plus détaillées sur le service. Ce qui
signifie donc proposer de nouveaux critères de recherche qui renseignent
sur la fonction des services proposés aux utilisateurs. Pour
résumer nous pouvons dire que ces approches présentent une
limitation sur la pertinence des résultats fournis lors d'une recherche,
car les critères de recherche sont limités.
[Marie Hélène Wassa Mballo] Page 50
Dans la section suivante nous donnons des applications de
recherche de services dans des intergiciels existants.
3.2 Application des recherches de service dans les
intergiciels
3.2.1 La gestion des ressources dans globus [39]
L'intergiciel assure la gestion de la grille, nous pouvons
même dire c'est le coeur de la grille. Actuellement chaque système
de grille possède un répertoire central dans lequel les services
sont classés manuellement dans diverses catégories, et ce
répertoire se trouve dans l'intergiciel, nous allons travailler avec
l'intergiciel globus et voir quel répertoire va permettre d'effectuer la
recherche de services. Dans globus plusieurs versions ont été
proposées, chaque version montre des nouveaux mécanismes de
recherche évoluant au cours du temps.

[Marie Hélène Wassa Mballo] Page 51
Figure 3.3 : modules de globus
Cette figure montre une vue d'ensemble de globus notamment la
version 4 que nous allons voir après. En regardant bien nous voyons que
globus est constitué de plusieurs modules et nous dans notre
étude ce qui nous intéresse c'est le module traitant de
l'information sur les services c'est-à-dire les ressources.
3.2.1.1 Globus Toolkit 2
Gestion des ressources
Les principaux composants de la gestion des ressources sont
le GRAM (Grid Resource Allocation Manager) et le GASS (Global Access to
Secondary storage)
GRAM (GLOBUS RESOURCE ALLOCATION MANAGER)
[39]
GRAM (« Globus Resource Allocation Manager ») est
le nom du composant de Globus permettant la gestion et la supervision des
ressources.
Chaque GRAM est responsable d'un ensemble de ressources
opérant selon une même politique d'allocation spécifique au
site dans lequel elles se trouvent, cette politique est souvent
implémentée par un système de gestion de ressources
locales tel que Condor ou LSF (Load Sharing Facility). Globus contient
plusieurs GRAMs, et chacun est responsable d'un ensemble de ressources
locales.
GRAM fournit une interface standard pour les systèmes
de gestion de ressources locales, de ce fait les outils et les applications des
grilles de calcul peuvent exprimer l'allocation de ressources et le processus
de gestion de requêtes en termes d'API (Application Programming
Interface) et les différents sites peuvent choisir les outils de gestion
de ressources qui leur conviennent. Avec cette API les requêtes sont
exprimées en langage RSL (Resource Specification Language).
RSL est utilisé pour représenter les besoins en
ressources d'une application qui va être exécutée. Une
variété d'agents courtiers implémente un domaine
spécifique de découverte de ressources et une politique de
sélection. Les agents coutiers transforment la requête
progressivement en expressions RSL selon les exigences jusqu'à ce que
l'ensemble des ressources soit identifié.
L'étape finale dans ce processus d'allocation de
ressources, est de décomposer le RSL en un ensemble de RSL et chaque RSL
est alloué au GRAM approprié. Pour une haute performance des
calculs il est
[Marie Hélène Wassa Mballo] Page 52
important de co-allouer les ressources ce qui permet d'avoir
un ensemble de ressources disponibles pour une utilisation simultanée.
Donc dans globus le co-allocateur ressource est chargé de fournir ce
service : décomposition du RSL, distribution de ces RSL sur les
GRAMs.

Figure 3.4: vue d'ensemble de GRAM
Quand un client (« GRAM client ») soumet une
tâche au serveur (« GRAM Server »), la requête est
envoyée au garde barrière (« gatekeeper ») de la
ressource. Ce dernier crée un gestionnaire de tâche (« Job
Manager ») qui lance et supervise le processus et renvoie au client des
informations sur l'état et les résultats de
l'exécution.
La commande globusrun soumet et gère les
jobs éloignés et est utilisé par les outils du client
GRAM.
GASS (Global Access to Secondary Storage)
GRAM utilise GASS pour fournir le mécanisme de
transfert des fichiers de sortie des serveurs aux clients.
Nous venons de voir comment estimer les besoins en ressource
d'une application, mais en parlant d'application c'est un service
installé au niveau de la grille et qu'un utilisateur veut
exécuter il serait judicieux de savoir donc si ce service est disponible
ou pas et ou le localiser pour cela nous allons consulter le service
information
[Marie Hélène Wassa Mballo] Page 53
Le service d'information
Les grilles de calcul dépendent de la
disponibilité de l'information sur l'infrastructure sous jacente. Cette
information comprend:
· Configuration des ressources :
quantité de mémoire, fréquence du processeur, nombre de
processeurs, nombre et type des interfaces réseaux
· Etat instantané d'une ressource :
charge du processeur, mémoire disponible, bande passante du
réseau
· Information sur les applications :
besoins en mémoire, processeur et stockage
Le MDS (Monitoring and Discovering Service)
[40] est conçu pour permettre l'accès à
de telles informations qui permet la découverte et la surveillance des
différents services et ressources de la grille. Ce module utilise les
web services pour publier ces informations.
Ce répertoire va permettre aux utilisateurs et aux
autres applications de découvrir les données concernant les
services et de les superviser.
En effet MDS utilise le standard LDAP (Lightweight
Directory Access Protocol) comme base pour la représentation et
l'accès aux données. Sur chaque machine de la grille, un annuaire
local est renseigné par des programmes appelés
fournisseurs d'information. Ces annuaires sont alors
centralisés sur une des machines de la grille.
Représentation de l'information dans le
MDS
Chaque entrée MDS est identifiée par un nom
unique appelé nom distingué. Pour simplifier le
processus de localisation d'une entrée MDS, les entrées sont
organisées sous une forme hiérarchique, un espace de nom d'arbre
structuré appelé DIT (Directory information tree).
Un nom distingué pour une entrée est construit
en spécifiant les entrées sur le chemin du DIT en partant de la
racine. Le nom distingué se compose de plusieurs attributs dont voici un
exemple :
< hn =
dark.mcs.anl.gov,
ou = MCS,
o = Argonne National Laboratory,
o = Globus,
c = US >
hn= host name, ou= organisation unit, o= organization,
c=country
Chaque entrée comprend 0 ou plusieurs attributs, et
chaque entrée a un type défini appelé sa classe d'objet.
La classe d'objet permet de définir quels attributs seront
associés à chaque entrée et les types de valeurs de ces
attributs. Ses classes d'objets seront d'abord définies pour cela nous
allons montrer la définition de classes d'objet. La classe d'objet est
composée de trois parties:
SUBCLASS: permet d'effectuer une extension de cette classe
à une classe déjà existante MUST CONTAIN: les attributs
qui doivent apparaître obligatoirement
MAY CONTAIN: les attributs optionnels
Un certain nombre d'attributs sont déjà
définis tels que cis (case-insentive strings) correspondant aux chaines
de caractères et le dn (distinguished names) pour le nom
distingué

[Marie Hélène Wassa Mballo] Page 54
Figure 3.5 :
définition de deux classes d'objet de MDS GlobusHost et
GlobusResource

[Marie Hélène Wassa Mballo] Page 55
Figure 3.6: représentation d'une machine
à partir du MDS
Les informations concernant cette entrée ci-dessus sont
représentées comme suit

Figure 3.7: sous ensemble du DIT défini par
MDS
Grid Resource Information Service (GRIS) [41]
: GRIS est le répertoire des informations des ressources
locales provenant des fournisseurs d'information. GRIS enregistre ses
informations à partir du serveur GIIS car il ne reçoit pas des
requêtes d'enregistrement. L'information au niveau du GRIS est mise
à jour quand elle est demandée et mise en cache pour un certain
temps qui est le TTL ; si aucune requête n'est reçue durant le TTL
l'information sera détruite.les serveurs GRIS peuvent
se trouver dans plusieurs endroits dans une grille et contiennent toute
information concernant les machines qui y sont enregistrées. Un serveur
GRIS ne contient jamais les informations concernant toutes les machines d'une
grille pour ne pas charger le serveur
[Marie Hélène Wassa Mballo] Page 56
Grid Index Information Service (GIIS) : GIIS
est le répertoire contenant les index des informations sur les
ressources enregistrées par les GRIS et d'autres GIIS. Il est
considéré comme un serveur grille d'un large volume de
données. Ce dernier contient des informations concernant la localisation
des serveurs GRIS et les noms des machines enregistrées. Ainsi un
utilisateur peut avoir des informations sur une machine particulière en
contactant le serveur GIIS qui a un nom unique. Le GIIS va jouer donc en
quelque sorte le rôle de cache pour les serveurs GRIS.
Fournisseur d'information: ce composant
assure la traduction des informations concernant les ressources selon le
schéma MDS. En ajoutant de nouvelles ressources des fournisseurs
d'information doivent être créés en même temps qui
seront responsables de la traduction de ces informations.
Client MDS: ce composant est basé sur
la commande client de LDAP, ldapsearch. Permet d'interroger le
MDS pour obtenir des informations sur une ressource.

[Marie Hélène Wassa Mballo] Page 57
Figure 3.8 modèle conceptuel de
MDS
3.2.1.2 Globus Toolkit3 [42]
Dans cette version de globus nous voyons l'apparition des
services de grille qui sont tout simplement une combinaison
des services web et les technologies de grille. De ce fait nous allons voir
apparaître de nouvelles notions l'OGSA et l'OGSI
L' OGSA (Open Grid storage
Architecture)
OGSA [43] est née sur la base d'un
changement de paradigme dans le monde du génie logiciel,
c'est-à-dire d'un passage d'une vision orientée système
vers une vision orientée service. Elle permet de marier les services web
et les technologies de grid, son objectif est d'exposer chaque ressource et
chaque noeud de la grille sous la forme d'un service web, en fait il permet de
spécifier les bases des grilles de calcul. OGSA définit la notion
de Service de Grille comme étant un Service Web enrichi par des
fonctionnalités de grille, fournissant un ensemble d'interfaces bien
définies. Ces interfaces adressent des requêtes de
découverte, de création et de gestion d'un service.
[Marie Hélène Wassa Mballo] Page 58
PortType(WSDL)
|
Opération
|
Description
|
|
GridService
|
FindServiceDate
|
Trouver les informations concernant l'instance du service
|
|
SetTreminationTime
|
Indiquer le temps de terminaison d'une instance d'un service
|
|
Destroy
|
Terminer une instance d'un service
|
|
NotificationSource
|
SuscribeToNotificationTopic
|
S'inscrire pour recevoir des notifications lorsque certain
évènement se produisent au niveau d'un service
|
|
NotificationSink
|
DelivrerNotification
|
Notifier la survenue d'un évènement
|
|
Registry
|
DelivrerService
|
Enregistrer un service auprès de l'annuaire
|
|
UnregistrerService
|
Enlever un service auprès de l'annuaire
|
|
Factory
|
CreateService
|
Créer une nouvelle instance d'un service
|
Tableau 3.1 :tableau des interfaces définis
par OGSA
L' OGSI
En se basant à la fois sur les technologies de grille
et les Services Web, l'OGSI définie les mécanismes de
création, de gestion et d'échange d'informations entre les
services de grille. Cet échange comprend la découverte des
services déjà créés et leur utilisation qui permet
une gestion des services sur le long terme tout en étant
sécurisé et résistant aux pannes. OGSI spécifie les
services à implémenter pour enrichir OGSA, ces services sont les
suivants :
· Prot Type extension
· Factory : permet de créer de
nouvelles instances d'un service de grille. Il retourne le Grid Service Handle
(GSH) comme décrit ci dessous, et maintient un ensemble
d'éléments qui peuvent être demandés.
·
[Marie Hélène Wassa Mballo] Page 59
Grid Service Handle (GSH) c'est un URL
utilisé comme nom global pour une instance de service pour toute sa
durée.
· Notification: permet aux clients
d'être informés de certains évènements survenant au
niveau de la grille
· Grid Service Reference (GSR) : permet
de spécifier une instance et une version bien précise d'un
service. Un GSR a une durée de vie limitée et pourra varier
durant le cycle de vie du service.
· Query permet de donner le langage de
requête utilisé pour trouver des informations par rapport à
un service, donc le langage utilisé dans ce cas est le XPath ou le
XQuery
· Registry permet d'enregistrer
périodiquement les services de grille
· Data Elements : permet d'associer
à chaque instance des opérations pour contrôler et modifier
la valeur des données disponibles
· Lifecycle Management : permet de
gérer la durée de vie des instances de service
Ces services sont fournis par un service nommé
Service Index qui est un service d'information utilisant un
Framework extensible pour la gestion des données statiques et
dynamiques
Au niveau des services des web il y a l'intervention des
trois acteurs, de même dans le cas des services web avec des
fonctionnalités de grille nous avons également l'intervention de
ces trois acteurs et à la place de service nous retrouvons les
applications et données qui se trouvent au niveau des ressources
physiques. Le schéma ci-dessous montre l'utilisation des services web
avec des fonctionnalités de grille:

Figure 3.9 : utilisation
des web services dans la grille
Les trois caractéristiques des services web avec des
fonctionnalités de grille sont les suivantes:
[Marie Hélène Wassa Mballo] Page 60
UDDI
Est utilisé pour trouver et utiliser les services de
grille
· BusinessEntity : dans la grille ce
composant peut être utilisé pour séparer
hiérarchiquement et former des relations entre les différents
groupes organisationnels au sein d'une grille ou de plusieurs grilles
· BusinessService
· bindingTemplate
· tModel
Cependant, UDDI conçu comme un système
d'annuaire d'entreprise a certaines limitations qui compliquent donc la
découverte de ressources dans la grille, comme exemple de
difficulté que rencontrent l'UDDI est la nature dynamique de
l'information (charge CPU...), qui requiert de fréquentes mises à
jour.
Pour remédier à ces limitations la
découverte se fera par une approche d'agent ou de
requête.
GWSDL (Grid Web Service Description
Language)
Il a une structure très similaire au WSDL. Comme vu
précédemment OGSI a la possibilité d'ajouter de nouvelles
interfaces ou les redéfinir. Le portType de WSDL sera redéfinit
en y ajoutant de nouveaux attributs en fonction des besoins, ceci permettra
à l'utilisateur de connaître l'identifiant et les interfaces du
service et il pourra également connaître son état
SOAP (Simple Object Access Protocol)
Permet la transmission et la réception de messages
pour l'accès aux ressources distribuées. L'utilisation de SOAP
sur HTTP est très idéale pour les services de grille
> Service Web et Service de
grille
Un Service Web a certaines limitations, il est sans
état (stateless) de façon qu'il ne puisse pas sauvegarder le
résultat d'une invocation à une autre.
[Marie Hélène Wassa Mballo] Page 61
Une autre limitation est la non persistance,
c'est-à-dire si deux clients invoquent le même Service Web et que
le premier client décide d'arrêter ce service (arrêter le
container du services), le deuxième client sera pénalisé
et ne pourra pas profiter de ce Service Web. Le container d'un Service Web ne
peut pas faire la différence entre deux invocations différentes
du même service.
Cependant, les services de grille ont résolu ces
problèmes grâce au "service Factory" qui permet d'instancier le
service de grille et de retourner le GSR et GSH, donc chaque service de grille
aura un nom unique utilisé pour l'identification. De plus les services
de grille supportent la notion d'"Elément de Données de Service
(Service Data Element)" qui permet d'associer à chaque instance des
opérations pour contrôler et modifier la valeur des données
disponibles, et grâce à la gestion du cycle de vie (Lifecycle
management), on peut faire la gestion des durées de vie des instances
des services de grille. Le service "Notification" permet aussi de
bénéficier des interfaces pour enregistrer les inscriptions des
instances et délivrer des notification si certains
événements surviennent (exemple de modification des
données).
Avec ces informations précédentes nous pouvons
tout simplement dire que les services de grille sont des services web
enrichis
Cette version 3 de globus a été une grande
évolution de globus en introduisant les services web qui prennent
actuellement une grande place dans les applications scientifiques, mais cette
notion de
service web sera toujours introduite en y apportant des
modifications, de ce fait nous allons voir
la version 4 de globus qui migre
carrément vers les services web
3.2.1.3 Globus toolkit4
Cette version 4 de globus migre entièrement vers les
services web Le globus toolkit 4 [44] utilise un autre langage
beaucoup plus puissant qui est le langage xpath, les données seront
représentées en utilisant un document xml . Le WSRF (Web Service
Resource Framework) défini un Framework pour modéliser et
accéder aux ressources en utilisant que les services web.
[Marie Hélène Wassa Mballo] Page 62
De ce fait dans le MDS4 des services nommés
aggregator seront chargés de collecter l'état actuel
d'une information provenant des sources d'information. Ces services aggregator
sont construits sur le Framework aggregator qui est un
framework logiciel. Nous distinguons trois services aggregator:
· Service index: il joue à la
fois le rôle de répertoire et de
cache. il met en cache les
dernières valeurs de toutes les données, ce qui veut dire que les
données ont une durée de vie bien déterminée. Ce
service d'index a un rôle similaire à l'annuaire UDDI.
· Service trigger: exécute les
actions spécifiées par les utilisateurs (tel que l'envoie d'email
ou générer l'entrée d'un fichier log) chaque fois que
l'information receuillie correspond aux critères définis par
l'utilisateur.
· Service archiver : stocke
l'information source dans une base de données efficaces, cet service est
en cours de construction
L'aggregator Framework obtient l'information via un composant
l'aggregator sources qui est une classe java une interface
collectant l'information sous format xml. Nous distinguons trois types
d'aggregator source
· Query Aggregator Source : collecte
l'information sur une ressource enregistrée au niveau de la grille.
· Subscription Aggregator Source
collecte les propriétés d'une ressource en utilisant le
WS-Notification subscription. Les données sont délivrées
quand les propriétés de la ressource sont changées
plutôt que de le faire périodiquement.
· Execution Aggregator Source qui
exécute un administrateur de programme fourni pour recueillir des
informations.
Information Provider
Ce composant est chargé de collecter l'information et
de la traduire selon le schéma défini pour le langage
utilisé dans la description des requêtes.
WebMDS
[Marie Hélène Wassa Mballo] Page 63
Permet aux utilisateurs d'accéder aux informations du
MDS via un simple navigateur web. Ceci permet de s'affranchir de l'installation
d'un logiciel supplémentaire.
Ce module est réalisé grâce à un
servlet qui permet de récupérer un document XML et de le
convertir grâce à une transformation XSLT.

Figure 3.10 vue d'ensemble de globus toolkit
4
3.2.2 la gestion des ressources dans glites
Glite [45] est considéré comme
une évolution de globus, donc glite va apporter des solutions par
rapport à certaines limitations rencontrées au niveau de globus.
Glite suit une architecture entièrement décentralisée, ce
qui signifie qu'il sera facile de relier le logiciel à d'autres services
de grille.
Le service d'information
Dans ce service nous avons deux modules: le MDS
utilisé pour la découverte de ressources ainsi que la publication
de leur état et le R-GMA (Relational Grid Monitoring Architecture)
utilisé pour la facturation, le suivi, et la publication des
informations sur les utilisateurs.
Pour résoudre les problèmes de montées
en charge au niveau du MDS de globus il ya l'introduction du serveur BDII
(Berkeley Database Information Index). Le BDII a la même
fonctionnalité que le GIIS, avec une implémentation
différente en effet elle permet une meilleure gestion de cache, il est
composé de trois niveaux :
·
[Marie Hélène Wassa Mballo] Page 64
resource-level BDII l'information fournit par le
fournisseur d'information est publié via ce serveurs
· Site-level BDII : permet de stocker et
de publier les données provenant de tous les resource-level BDII
· Top-level BDII: se situe au sommet de la
hiérarchie. A ce niveau BDII donne une vue d'ensemble de l'ensemble des
ressources de la grille. Ces BDII agissent comme des caches en stockant
l'information sur l'état des grilles dans leur base de données
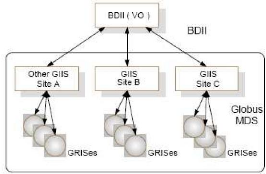
Figure 3.11 introduction du serveur
BDII

[Marie Hélène Wassa Mballo] Page 65
Figure 3.12: les trois niveaux de
BDII
R-GMA (Relational Grid Monitoring
architecture)
R-GMA est une implémentation relationnelle à base
de service web du GMA (Grid Monitoring architecture) [46]
standardisé par le GGF (Global Grid Forum). De ce fait
nous rencontrons une architecture à trois composants:
· Producteur: fournit l'information,
enregistre dans son répertoire et décrit le type et la structure
de l'information fournit.
· Consommateur: effectue une
requête, consulte le répertoire pour voir quel type d'information
est disponible et contacte le producteur pour obtenir l'information.
· Répertoire: établit la
communication entre les producteurs et les consommateurs
R-GMA utilise un sous ensemble de SQL comme requête de
langage. L'utilisateur publie ses tuples au producteur en envoyant une
requête SQL.
R-GMA présente ses informations dans une base de
données virtuelles contenant un ensemble de tables. Le schéma
contient le nom et la structure de chaque table virtuelle dans le
système.

[Marie Hélène Wassa Mballo] Page 66
Figure 3.13: base de données virtuelle de
R-GMA
3.2.3 Comparaison des différents intergiciels
Pour comparer les intergiciels présentés
ci-dessus nous avons choisi un certain nombre de critères telles que
:
· Collecteur d'information qui sera
chargé de collecter l'information et de le traduire selon le
schéma défini
· Serveur d'information consulté
par le composant client pour trouver l'information
· Serveur d'information agrégée
les serveurs d'informations le consulte pour trouver les
données dont ils doivent traiter
· Serveur répertoire sert de
répertoire pour l'ensemble des serveurs
· Langage de requête le langage
utilisé pour exprimer les requêtes
· Décentralisation un
système décentralisé est plus performant un système
centralisé
|
GLOBUS
|
Glite
|
propriétés
|
MDS2
|
MDS3
|
MDS4
|
MDS-glite
|
R-GMA
|
Collecteur d'information
|
Fournisseur d'information
|
Fournisseur d'information
|
Fournisseur d'information
|
Fournisseur d'information
|
producteur
|
Serveur
d'information
|
GRIS
|
Service index
|
Serveur index
|
GIIS
|
Servlet producteur
|
|
[Marie Hélène Wassa Mballo] Page 67
Serveur
d'information agrégée
|
GIIS
|
Service index
|
Serveur index
|
BDII
|
producteur
|
Serveur répertoire
|
GIIS
|
Service index
|
Serveur index
|
BDII
|
répertoire
|
Langage de
requête
|
Ldap
|
XPath
|
XPath
|
Ldap
|
SQL
|
décentralisé
|
Oui:
hiérarchique avec Ldap
|
Oui: utilisation
des services
web
|
Oui: Utilisation
des services
web
|
Oui: BDII avec 3 niveaux
|
Oui: Base de données virtuelles unique
|
|
Tableau 3.3 : tableau comparatif des
intergiciels
A la lecture du tableau 3.3, nous constatons que la
dernière version de Globus est très puissante avec le langage de
requête Xpath et l'utilisation des services web. Concernant gLite deux
modules permettent de découvrir les services. Il s'agit de MDS-gLite qui
améliore le MDS2 de Globus, et de R-GMA qui, a une architecture
similaire à celle des services web.
Dans ce chapitre nous avons étudié des
approches de découverte de services au sein des grilles. Dans cette
étude nous avons montré les avantages et les inconvénients
de chacune de ces approches.
Avec ces limitations notées au sein de ces
approches, nous allons proposer dans le chapitre suivant un nouveau
mécanisme de découverte de services.
[Marie Hélène Wassa Mballo] Page
68
CHAPITRE 4 :
MECANISME
MULTICRITERE DE
DECOUVERTE DE
SERVICES DANS LES
GRILLES (2MDS)
[Marie Hélène Wassa Mballo] Page 69
Dans ce chapitre, nous présentons notre solution de
découverte de services dans les grilles. Notre approche consiste
à améliorer la recherche au niveau de l'annuaire UDDI, en
permettant un accès plus rapide à l'information, avec la
combinaison de plusieurs critères de recherche lors d'une requête
envoyée par un utilisateur.
Pour rendre la recherche plus flexible et efficace,
l'information est représentée sous la forme d'un arbre qui permet
de limiter la masse d'informations à traiter.
4.1 Construction et fonctionnement de l'arbre
4.1.1 Choix de notre architecture
Notre architecture se base principalement sur le
modèle de service web qui est la plus adéquate par rapport
à nos besoins. Notre objectif est de mettre en place une solution de
gestion et de découverte de service permettant un accès rapide
à l'information avec des critères de recherche qui offrent aux
utilisateurs la possibilité de mieux percevoir la fonctionnalité
d'un service donné. Une première démarche serait
d'utiliser La solution WSMO qui apporte une amélioration par rapport au
traitement sémantique de l'information dans les services web. Mais comme
dans le cas de l'approche service web, les critères de recherche
proposés dans WSMO sont aussi limités.
L'approche de recherche de service dans les grilles que nous
proposons se base donc sur la technique des services web avec des
fonctionnalités telles que: la représentation et la gestion des
services. Notre proposition est ainsi motivée par deux
éléments : (i) les limitations des méthodes de recherche
basée sur l'annuaire UDDI ; (ii) les limitations de la solution hybride
basée sur les services web et les ontologies (WSMO).
4.1.2 Description générale
Il est important de noter que les approches de
découverte de service actuelles sont très limitées dans la
description des critères de recherche. La plupart d'entre elles
n'offrent qu'un nombre restreint de critères qui sont la
catégorie, le nom du fournisseur et le nom du service. Ce qui pose un
vrai problème pour l'identification optimale des services offerts. Dans
notre mécanisme, nous proposons d'intégrer cinq (5) autres
critères qui nous semblent importants pour un utilisateur, à
savoir le système d'exploitation, la licence, le langage de
développement, les fonctionnalités du service et son emplacement
dans la grille.
[Marie Hélène Wassa Mballo] Page 70
En plus, notre proposition utilise une structure d'arbre pour
représenter les services disponibles dans une grille. Dans ce cas chaque
critère représente un noeud logique et constitue un niveau de
l'arbre ainsi nous modélisons un noeud physique par un ensemble de
noeuds logiques formant l'arbre de services. Il est important de noter que
l'arbre peut grandir en largeur du fait que d'autres services soient
insérés. Nous notons également que les valeurs des noeuds
logiques suivant un niveau, sont classées par ordre lexicographique.
Donc, nous avons un arbre de services qui a une profondeur de
cinq (5), y compris la racine. Les quatre (04) niveaux les plus bas sont
définis comme suit (voir figure 4.1):
· Le niveau 1 permet de définir le type de
système d'exploitation dans lequel fonctionne un
service.
· Le niveau 2 est relatif au type de licence
(libre ou propriétaire) associé au service.
· Le niveau 3 définit le langage
dans lequel a été développé le service.
· Le niveau 4, feuille dans laquelle nous trouvons les
informations relatives à un service : le nom, site
d'implantation, description des fonctionnalités du service.
Notre mécanisme de gestion et découverte de
services s'appuie sur trois algorithmes (insertion, recherche et suppression)
avec des complexités optimisées que nous présentons dans
la suite du document.

Figure 4.1: structure de l'arbre de
service
[Marie Hélène Wassa Mballo] Page 71
4.1.3 Les algorithmes de gestion de services
Concernant la gestion des services, nous définissons
trois algorithmes qui sont : l'insertion, la recherche et la suppression.
Ensuite nous étudions la complexité des différents
algorithmes en considérant les paramètres suivants :
A : correspond au nombre de noeuds logiques du
niveau 1 qui peut varier de 1 à nsyst
B : correspond au nombre de fils maximum que
peut avoir un noeud du niveau 1, et ce paramètre varie de 1 à
nlic . Comme nous l'avons écrit dans la
partie 4.1.2, la licence ne peut être que deux types soit libre ou
propriétaire, donc nlic=2.
C : représente le nombre de fils
maximum que peut avoir un noeud du niveau 2. Ce nombre varie de 1 à
nlang.
D : représente le nombre de fils que
peut avoir un noeud du niveau 3. Cette variable est comprise entre 1 et
nserv.
Dans notre mémoire nous allons calculer la
complexité dans le pire des cas, c'est-à-dire nous allons
considérer que les valeurs maximales des paramètres cités
ci-dessus. Nous déterminons la complexité temporelle dans ce
mémoire, puisque ce qui est le plus important dans un algorithme c'est
d'exécuter des calculs dans des délais raisonnables.
4.1.3.1 Insertion d'un service
Un service hébergé par un serveur doit se
trouver dans l'arbre de services, dont l'évolution dépend des
arrivées et des départs des services.
Un noeud pair, voulant hébergeant un service, lance
une requête xml d'insertion au niveau de son arbre. Cette requête
prend comme paramètre le système d'exploitation,
la licence, le langage, le nom du
service, l'emplacement physique et la
description.
Lors de ce processus d'insertion, une recherche est
effectuée d'abord pour savoir si le noeud logique à
insérer ne se trouve pas déjà dans l'arbre.
Dans notre algorithme, l'opération de création
de noeuds est faite lorsque le noeud logique ne se trouve pas dans l'arbre.
Cette opération utilise deux fonctions : CreerNoeud(v),
ou v représente la valeur à insérer dans le
noeud logique et CreerNoeudfils(v) qui permet la
création des fils du nouveau noeud logique.
METHODE inserer
ENTREE A :arbre, syst :chaine,
lic :chaine ,lang :chaine, nomserv :chaine, @IP :nombre, description
:chaine
nfilsg :Noeud //noeud fils gauche du noeud courant
nfrdt :Noeud //noeud frère droit du noeud courant
nc :Noeud //nc est le noeud courant
nc(-A.racine
nc(-nfilsg
[Marie Hélène Wassa Mballo] Page
72
Tant que nc?null et nc.valeur?syst
et nc.valeur<syst //parcours du niveau 1
nc(-nfrdrt //nc.valeur=valeur contenue dans le noeud
courant
Fin tant que
Si nc=null ou
nc.valeur>syst
CreerNoeud(syst) //création d'un noeud
contenant la valeur du système
CreerNoeudfils(lic)//création du noeud fils
contenant la licence
CreerNoeudfils(lang)//création du noeuf fils
contenant le langage
CreerNoeudfils(nomserv,@IP,description)
Fin si
Si nc.valeur=syst
nc(-nfilsg
Tant que nc?null et nc.valeur?lic
et nc.valeur<lic /parcours du niveau 2
nc(-nfrdrt
Fin tant que
Si nc=null ou
nc.valeur>lic
CreerNoeud(lic)
CreerNoeudfils(lang)
CreerNoeudfils(nomserv,@IP,description)
Fin si
Si nc.valeur=lic
nc(-nfilsg
Tant que nc?null et nc.valeur?lang
et nc.valeur<lang /parcours du niveau 3
nc(-nfrdrt
Fin tant que
Si nc=null ou
nc.valeur>lang
CreerNoeud(lang)
CreerNoeudfils(nomserv,@IP,description)
Fin si
Si nc.valeur=lang
CreerNoeudfils(nomserv,@IP,description)
Fin si
Fin si
Fin si
Fin inserer
Etude de la complexité de l'algorithme
d'insertion
[Marie Hélène Wassa Mballo] Page
73
[Marie Hélène Wassa Mballo] Page 74
Nous rappelons que les opérations de création de
noeud dans l'arbre ont une complexité égale à 1. Pour
déterminer la complexité, nous avons les éléments
suivants :
· L'instruction 1 de l'algorithme d'insertion s'effectue
en O(nsyst), puisque nous cherchons l'existence du système
d'exploitation dans l'arbre avant de créer un nouveau noeud logique.
· L'instruction du bloc 4-9 de cet algorithme est une
constante qui s'effectue en O(5), puisque nous faisons un test sur la valeur du
noeud courant et ensuite un appel de quatre fois à l'opération de
création d'un noeud logique. La complexité de ce bloc est
inférieure à celle du bloc 10-34, donc nous ne comptabiliserons
que cette dernière.
· L'instruction du bloc 10-34 regroupe plusieurs
instructions, nous allons voir la complexité de chacune d'elles
o L'instruction 12 s'effectue en O(2) puisque une comparaison
est faite entre les noeuds logiques du niveau 2 et la licence passée en
paramètre
o L'instruction du bloc 15-19 se fait en O(4) puisque nous
faisons appel trois fois à l'opération de création de
noeuds. Cette instruction est inférieure au bloc d'instruction 20-32
donc nous considérons cette dernière.
o Le bloc 20-32 est composé de plusieurs
instructions
· L'instruction 22 s'effectue en O(nlang)
puisque nous parcourons les noeuds du niveau 3 pour voir si le type de langage
à insérer n'existe pas déjà dans l'arbre de
services.
· L'instruction du bloc 25-28 se fait en O(3) car nous
ajoutons deux noeuds logiques et avant cet ajout un test Si
est effectué.
· L'instruction du bloc 29-31 se fait en O(2) car un test
Si est effectué suivi de la création d'un noeud logique.
o La complexité totale du bloc 20-32 est égale
à la somme des complexités des différentes instructions
qui la composent, ce qui donne donc : O(nlang)+O(3)+O(2)=
O(nlang)
· La complexité du bloc 10-34 est égale
à O(2)+O(nlang)= O(nlang)
· En résumé, en parcourant toutes les
étapes de l'algorithme d'insertion nous voyons qu'il a une
complexité dans l'ordre de :
O(nlang)+ O(nsyst)
En effet cette complexité dépend du
nombre de noeuds logiques du niveau 3 et du niveau 1.
4.1.3.2 La recherche au sein de l'arbre
La recherche de services dans notre arbre se fait de
façon dichotomique de la gauche vers la droite puisque les noeuds de
chaque niveau sont classés suivant un ordre lexicographique. Cette
recherche se fait en largeur puis en profondeur pour descendre jusqu'aux
feuilles afin de trouver le ou les services.
Nous proposons deux algorithmes de recherche : le premier
prend en entrée le système d'exploitation, la
licence, le langage et dans le second
algorithme un nouveau paramètre est ajouté (nom
du service). Ce dernier permet d'avoir des
résultats concis. Dans cette approche suivant les paramètres
donnés en entrée les algorithmes retournent le contenu des
feuilles de l'arbre.
METHODE rechercher
//première solution
ENTREE A:arbre, syst : chaine, lic
: chaine,lang :chaine //syst=système d'exploitation,
lic=licence, lang=langage SORTIE nomserv, @IP, description
nfilsg :Noeud //noeud fils gauche nfrdrt
:Noeud //noeud frère droit nc :Noeud //nc noeud
courant nc(-A.racine
nc(-nfilsg
[Marie Hélène Wassa Mballo] Page
75
1 Tant que nc?null et
nc.valeur?syst et nc.valeur<syst /parcours du niveau
1
2 nc(-nfrdrt
[Marie Hélène Wassa Mballo] Page
76
3 fin tant que
4 si nc=null ou
nc.valeur>syst
5 exit
6 fin si
7 si nc.valeur=syst
8 nc(-nfilsg
9 tant que nc?null et
nc.valeur?lic et nc.valeur<lic /parcours du niveau
2
10 nc(-nfrdrt
11 Fin tant que
12 Si nc=null ou
nc.valeur>lic
13 Exit
14 Fin si
15 Si nc.valeur=lic
16 nc(-nfilsg
17 Tant que nc?null et nc?lang
et nc.valeur<lang //parcours du niveau 3
18 nc(-nfrdrt
19 Fin tant que
20 Si nc=null ou
nc.valeur>lang
21 Exit
22 Fin si
23 Si nc.valeur=lang
24 nc(-nfilsg
25 Tant que nc?null
26 nc(-nfrdrt
27 Retourner nc.valeur
28 Fin tant que
29 Fin si
30 Fin si
31 Fin si
32 Fin rechercher
Le deuxième algorithme proposé est le suivant.
Comme nous l'avons dit précédemment cet algorithme ajoute un
nouveau paramètre qui est le nom du service
ALGORITHME DE RECHERCHE
METHODE rechercher //
deuxième solution
ENTREE A :arbre, syst :chaine,lic
:chaine,lang :chaine, nomservice : chaine SORTIE
nomserv,description,@IP
nfilsg : Noeud //noeud fils gauche nfrdrt : Noeud //noeud
frère droit nc : Noeud //noeud courant
nc(-A.racine
nc(-nfilsg
[Marie Hélène Wassa Mballo] Page
77
1 Tant que nc?null et
nc.valeur?syst et nc.valeur<syst //parcours du niveau
1
2 nc(-nfrdrt
3 fin tant que
4 si nc=null ou
nc.valeur>syst
5 exit
6 fin si
7 si nc.valeur=syst
8 nc(-nfilsg
9 tant que nc?null et
nc.valeur?lic et nc.valeur<lic //parcours du niveau
2
10 nc(-nfrdrt
11 Fin tant que
12 Si nc=null ou
nc.valeur>lic
13 Exit
14 Fin si
15 Si nc.valeur=lic
16 nc(-nfilsg
17 Tant que nc?null et nc?lang
et nc.valeur<lang //parcours du niveau 3
18 nc(-nfrdrt
19 Fin tant que
20 Si nc=null ou
nc.valeur>lang
21 Exit
22 Fin si
23 Si nc.valeur=lang
24 nc(-nfilsg
25 Tant que nc?null et
nc.valeur.nomsev?nomservice
26 nc(-nfrdrt
27 Fin tant que
[Marie Hélène Wassa Mballo] Page
78
[Marie Hélène Wassa Mballo] Page 79
28 Retourner nc.valeur
29 Fin si
30 Fin si
31 Fin si
32 Fin rechercher
Etude de la complexité de l'algorithme de
recherche
L'étude de la complexité ne concerne que le
deuxième algorithme de recherche de services ceci est dicté par
le fait que dans cet algorithme le nom du service est spécifié.
Ce qui signifie qu'une fois au niveau des feuilles une comparaison est
effectuée pour retrouver le service correspondant au nom du service
passé en paramètre.
L'étude de l'algorithme pour trouver la complexité
donne les éléments suivants
· L'instruction 1 s'effectue en O(nsyst),
puisque nous cherchons l'existence du système d'exploitation dans
l'arbre, donc dans le pire des cas l'ensemble des noeuds du niveau 1 peuvent
être parcourus.
· L'instruction du bloc 4-6 est une constante qui
s'effectue en O(1), un test Si est effectué. La complexité de ce
bloc est inférieure à celle du bloc 7-32, nous ne
comptabiliserons que cette dernière
· L'instruction du bloc 7-32 regroupe plusieurs
instructions donc nous allons voir la complexité de chacune d'elles
o L'instruction 9 s'effectue en O(2) puisque le nombre
d'itération dépend du nombre maximal de noeuds au niveau 2 de
l'arbre de services, c'est une constante donc elle n'est pas
comptabilisée.
o L'instruction 12 se fait en O(1). Cette complexité
est négligée car elle intervient dans le cas où le
résultat de la recherche n'est pas trouvé.
o L'instruction du bloc 15-30 est composée de
plusieurs instructions dont nous allons étudier la complexité.
Marie Hélène Wassa Mballo Page 80
[Tapez le titre du document]
· L'instruction 17 s'effectue en O(nlang),
car le nombre d'itérations se fait nlang fois.
· L'instruction du bloc 20 se fait en O(1) un test Si
est effectué pour voir si le programme s'arrête à ce stade
ou si l'exécution continue.
· L'instruction du bloc 23-29 se fait en
O(nserv) elle ne dépend donc que de l'instruction 25 dont le
nombre d'itérations est de nserv fois.
o La complexité totale du bloc 15-30 est égale
à la somme des complexités de ces différentes instructions
O(nlang)+O(1)+O(nserv)= O(nlang)+ O(nserv)
· Ainsi notre algorithme de recherche a une
complexité qui est égale à la somme des complexités
des différentes instructions vues précédemment et nous
obtenons
O(nsyst) +O(nlang) +
O(nserv)
Cette complexité dépend du nombre de noeuds
pour le système d'exploitation, le langage et du nombre de feuilles.
4.1.3.3 La suppression d'un service
Un pair hébergeant un service a la possibilité
de le supprimer, pour cela une requête xml de suppression doit être
envoyée à l'arbre local du pair concerné. Ensuite la
requête est routée sur d'autres machines si le service y est
répliqué. Une recherche de ce service doit être
effectuée au préalable afin de le localiser. La suppression d'un
service fils unique entraine la suppression de son service pair.
Notre algorithme de suppression est le suivant il prend en
paramètre, le système d'exploitation, la licence, le langage, le
nom du service, l'adresse IP. Une fois le service trouvé, la fonction
detruire(nc) est appelée où nc est le noeud
courant.
Marie Hélène Wassa Mballo Page
81
[Tapez le titre du document]
ALGORITHME DE SUPPRESSION
METHODE supprimer
ENTREE syst :chaine, lic
:chaine, lang :chaine, A :arbre, nomser :chaine, @IP :nombre
nfilsg : Noeud //noeud fils
gauche
nfrdrt : Noeud //noeud frère
droit
nc(-A.racine //nc noeud courant
nc(-nfilsg
Tant que nc?null et nc.valeur?syst
et nc.valeur<syst nc(-nfrdrt
fin tant que
si nc=null ou
nc.valeur>syst
exit
fin si
si nc.valeur=syst
nc(-nfilsg
tant que nc?null et nc.valeur?lic
et nc.valeur<lic
nc(-nfrdrt
Fin tant que
Si nc=null ou
nc.valeur>lic
Exit
Fin si
Si nc.valeur=lic
Marie Hélène Wassa Mballo Page
82
[Tapez le titre du document]
nc(-nfilsg
Tant que nc?null et nc?lang et
nc.valeur<lang nc(-nfrdrt
Fin tant que
Marie Hélène Wassa Mballo Page
83
Si nc=null ou
nc.valeur>lang
Exit
Fin si
Si nc.valeur=lang
nc(-nfilsg
Tant que nc?null et
nc.valeur.nomserv?nomserv et
nc.valeur.adIP ?nc.valeur.adIP et
nc.valeur.nomserv<nomserv
nc(-nfrdrt
fin tant que
si nc.valeur.nomserv=nomserv et
nc.valeur.adIP =nc.valeur.adIP
detruire(nc)
fin si
Fin si
Fin si
Fin si
Fin supprimer
Etude de la complexité de l'algorithme de
suppression
Nous rappelons que la complexité de l'opération
detruire(n) a une complexité de 1
Le calcul de la complexité à partir de
l'algorithme de suppression donne les éléments suivants :
· L'instruction 1 s'effectue en O(nsyst),
puisque nous cherchons l'existence du système d'exploitation dans
l'arbre, ce qui signifie que les noeuds du niveau 1 sont parcourus nsyst fois
dans le pire des cas.
·
Marie Hélène Wassa Mballo Page 84
L'instruction du bloc 4-6 est une constante qui s'effectue en
O(1) puisque un test Si est effectué. La complexité de ce bloc
est inférieure à celle du bloc 7-35 donc nous ne comptabiliserons
que cette dernière
· L'instruction du bloc 7-35 regroupe plusieurs
instructions. Ainsi nous allons voir la complexité de chacune d'elles
o L'instruction 9 s'effectue en O(2), le nombre
d'itérations est de nlic.
o L'instruction 12 se fait en O(1), car un test Si est
effectué pour voir si le programme s'arrête à ce niveau ou
bien s'il continue.
o L'instruction du bloc 15-34 est composée de
plusieurs instructions dont nous allons étudier la complexité
· L'instruction 17 s'effectue en O(nlang), car
cette complexité dépend du nombre de noeuds du niveau 3.
· L'instruction du bloc 20 se fait en O(1), un test Si
est effectué. La complexité de cette instruction est
inférieure au bloc 23-33, donc la complexité du bloc 20 n'est pas
comptabilisée.
· L'instruction 25 se fait en O(nserv), le
nombre d'itérations dans le pire des cas est de nserv
fois.
· L'instruction 30 se fait en O(2), car un test Si est
d'abord effectué pour ensuite faire un appel de la fonction
detruire(nc)
· La complexité totale du bloc 23-33 est
égale à la somme des complexités de ses différentes
instructions O(2)+O(nserv)= O(nserv)
o La complexité du bloc 15-34 est égale à
la somme des différentes instructions qui la composent : O(nlang)+
O(nserv)
· Le bloc 7-35 a pour compléxité donc :
O(2)+O(1)+O(nlang)+ O(nserv)= O(nlang)+ O(nserv)
· Ainsi notre algorithme de suppression a une
complexité qui est égale à la somme des complexités
des différentes instructions, soient :
O(nsyst) +O(nlang) + O(nserv)
Marie Hélène Wassa Mballo Page 85
Les trois algorithmes présentent une complexité
linéaire, car cette dernière croit en fonction des modifications
de services dans l'arbre, cette modification est liée à l'ajout
et la suppression de services. L'arbre de services comme dit dans la
partie 4.1.2, a une hauteur fixe, donc elle ne grandit qu'en
largeur. Cette croissance en largeur se fait surtout sentir au niveau des
feuilles, car pour les systèmes d'exploitation, les plus utilisés
sont Unix, Windows xp ce qui entraine donc que le nombre
noeuds que nous pouvons avoir au niveau 1 est très réduit.
4.2 Placement de l'arbre dans le réseau
physique
Dans cette section nous allons voir comment l'arbre de
services est réparti à travers le réseau physique. Sur
chaque machine du site se trouve un arbre en local qui héberge les
services. Les arbres au niveau des machines n'ont pas la même taille, vu
que cette dernière dépend du nombre de services
insérés. Deux approches de placement des arbres sont
proposées, c'est-à-dire une approche distribuée et une
approche centralisée.
4.2.1 Approche centralisée
4.2.1.1 Principes et fonctionnement
Dans cette approche (voir figure 4.2), chaque machine d'un
site d'une grille stocke les services qu'il fournit dans un arbre. Parmi
l'ensemble des machines d'un site, nous choisissons un qui joue le rôle
de super noeud. Ce dernier a une vue globale sur l'ensemble des services du
site. Dans notre proposition, une grille est composée de plusieurs sites
ayant les caractéristiques que nous venons de décrire. Ainsi, la
gestion et la découverte des services peuvent se faire en local ou
globalement sur la grille.
L'organisation locale correspond à un site particulier
composé de machines. En effet, à son initialisation, une machine
du site est choisie comme super noeud selon sa puissance de stockage et de
traitement. Chaque machine peut contacter le super noeud en lui envoyant un
message réseau lorsqu'une modification de l'arbre de services a
été effectuée en local. En plus, une machine peut faire
appel au super noeud, lorsqu'il n'a pas réussi à trouver
localement un service.
La grille des services offerts est obtenue par
l'interconnexion de plusieurs sites à travers leur super noeud. Dans ce
cas, chaque super noeud dispose de l'ensemble des adresses IP des autres super
noeuds.
Marie Hélène Wassa Mballo Page 86
L'intérêt de cette organisation globale est que
si une recherche au niveau d'un super noeud n'aboutit pas, la requête est
diffusée aux autres supers noeuds. Cette architecture est définie
dans la figure 4.2.

Figu
re 4.2 architecture d'une approche centralisée
de recherche de services
4.2.1.2 Gestion des services
La gestion des services dans le cas d'une approche
centralisée nécessite la mise en oeuvre des algorithmes suivants
:
a) Recherche d'un service
Partant de ce schéma centralisé, le principe de
recherche de services peut être illustré par les trois cas de
figures suivants :
· Recherche locale : dans un premier
cas, la recherche d'un service se fait localement par rapport au site où
une requête utilisateur a été initialisée. Ainsi,
seul l'arbre local sera parcouru.
· Recherche dans le site: dans le cas
où la recherche locale d'un service échoue, la requête
utilisateur est alors transmise au super noeud. Etant donné que le super
noeud centralise toutes les informations relatives aux services d'une grille,
il peut déterminer la machine sur laquelle se trouve le service
recherché.
· Recherche globale dans la grille : Si
le service n'existe pas au niveau du super noeud la requête est transmise
par diffusion à l'ensemble des super noeuds se trouvant dans le
Marie Hélène Wassa Mballo Page 87
réseau formé par l'ensemble des sites. Donc le
nombre de messages envoyés à travers
le réseau va dépendre du nombre de sites
existants. Nous avons dans ce cas une communication inter-site.
b) Insertion et suppression d'un service
Dans le cas d'une insertion d'un nouveau service, les
opérations suivantes sont réalisées :
· Insérer le service au niveau local dans une
machine (mise à jour de l'arbre local de services).
· Envoyer un message d'information au super noeud qui va
les stocker comme nouveau service. Dans le champ données du datagramme
nous retrouvons la requête
d'insertion.
· L'algorithme de suppression fonctionne selon les
mêmes principes que celui de l'insertion (mise à jour local et au
niveau du super noeud).
4.2.1.3 Tolérance aux pannes
Cette première approche étant
centralisée, il est nécessaire de mettre en place des
mécanismes de tolérance aux fautes par rapport au super noeud.
Pour cela, nous préposons de répliquer le super noeud (ou super
noeud primaire) pour avoir une machine de secours. Pour que ces deux supers
machines puissent assurer convenablement leurs fonctionnalités, il est
nécessaire d'assurer leur cohérence afin qu'ils puissent
être interchangés de manière transparente par rapport
à l'utilisateur.
Le super noeud de secours est utilisé dans le cas ou
le super noeud courant ne répond pas ou est surchargé. Le nombre
de processus en traitement simultané ne doit pas dépasser un
pourcentage qui peut être fixé par l'administrateur. La
réplication des données dans le super noeud de secours se fait
dès qu'une mise à jour intervient dans l'arbre des services du
super noeud.
4.2.1.4 Avantages et inconvénients
Les avantages de l'approche centralisée peuvent se
résumer comme suit :
· Solution P2P: chaque machine du site peut jouer un
double rôle : offrir et demander des services.
·
Marie Hélène Wassa Mballo Page 88
En termes de nombre de messages, cette approche
nécessite deux messages lors d'une opération de recherche, de
suppression ou d'insertion de service : un message d'une machine vers le super
noeud, dans le cas où une recherche locale a échoué ; un
message du super noeud vers la machine où la recherche locale a
échoué, pour l'informer de l'emplacement physique du service
qu'il recherche.
· La réplication ne concerne que le super
noeud.
En ce qui concerne les inconvénients de l'approche
centralisée, nous notons que :
· Le principal inconvénient de cette approche est
dû à la centralisation. En effet, l'existence d'un super noeud
engendre un surcoût de communication, notamment pour les
opérations d'insertion, de suppression et de mise à jour des
services. Ce surcoût aura pour effet de surcharger le super noeud, avec
pour conséquence une augmentation des temps d'attente, voire
éventuellement une panne du super noeud.
· Modification des arbres : une modification
opérée en local doit également se répercuter au
niveau de l'arbre du super noeud avec une mise à jour du super noeud de
secours qui doit être effectuée. Ainsi, nous avons trois
opérations de mises à jour à effectuer à chaque
fois qu'un arbre est modifié. Si ces mises à jour sont
fréquentes, les performances des algorithmes de gestion des services
vont se dégrader.
4.2.2 Approche distribuée
4.2.2.1 Principes et fonctionnement
Dans cette approche il n'existe pas de super noeud
centraliseur (voir figure 4.3). Les machines sont
reliées directement entre eux et chaque machine dispose d'un arbre
local. Et la communication inter-sites se fait directement entre les
différents machines.
L'organisation locale de l'approche distribuée
concerne un site donné où chaque machine peut communiquer avec
n'importe quel autre machine du site. Cette communication est nécessaire
lorsqu'une recherche locale d'un service dans la machine échoue. Dans
cette approche, nous proposons des métadonnées (voir
figure 4.4) qui sont créées en faisant un regroupement
de services suivant le type de système d'exploitation, la licence et le
langage de développement des services, au niveau de chaque machine. Ces
métadonnées sont partagées entre les machines du site. Ce
qui permet
Marie Hélène Wassa Mballo Page 89
d'effectuer des envoies groupés (multicast) lorsque la
recherche en locale n'aboutit pas. Plutôt que d'aller chercher le service
sur toutes les autres machines, ce qui est pénalisant du point de vue
coût de communication et temps de localisation du service, une machine
fait appel uniquement aux machines qui, potentiellement, sont susceptibles de
contenir le service recherché. Ces machines sont alors choisies à
l'aide de ces métadonnées.
La recherche dans d'autres sites se fait lorsque celle
effectuée dans le site local n'a pas aboutit. La machine initie une
requête et contacte dans ce cas de façon aléatoire une
machine se trouvant dans un autre site pour y poursuivre la recherche. La
communication entre les sites se fait par des messages réseau car chaque
machine a dans sa table de routage l'adresse réseau des autres sites. La
machine qui est contactée de façon aléatoire continue le
même principe de recherche que dans l'organisation locale décrite
dans le paragraphe précédent.

Figure 4.3 structure de l'approche distribuée
pour la recherche de services

Figure 4.4 : Exemple de
métadonnées U: Unix, L: Libre, J: Java, P:
Propriétaire
De cet exemple, le premier groupe de
métadonnées concerne les pairs hébergeant des services
utilisant le système Unix, la licence libre
et le langage java. Pour le deuxième groupe,
il s'agit des pairs qui hébergent des services qui ont pour
système Unix, la licence propriétaire
et le langage java.
Marie Hélène Wassa Mballo Page
90
4.2.2.2 Gestion des services
a) Recherche d'un service
Les étapes de recherche de service dans le cas de
l'approche distribuée, sont définies comme suit :
· Recherche locale : la recherche de
service se fait dans la machine qui a initié une requête de
demande de service.
· Recherche dans le site : cette
étape est réalisée lorsque la recherche locale a
échouée (service non trouvé). Cette requête de
recherche est alors transmise à un sous-ensemble de machines qui est
défini grâce aux métadonnées.
· La recherche globale : est
initiée par la machine qui a lancé la requête, pour ce
faire une machine d'un autre site est choisi de façon aléatoire
pour que ce dernier puisse effectuer la recherche dans le site ou elle se
trouve.
b) Insertion et suppression d'un service
L'insertion d'un nouveau service nécessite la mise en
oeuvre des étapes suivantes :
· La machine, qui héberge un nouveau service,
lance une requête d'insertion pour rajouter ce service dans l'arbre. La
table des métadonnées est également mise à jour
selon la description du service.
· Une notification de mise à jour est
envoyée aux autres machines, pour qu'ils puissent mettre à jour
leurs métadonnées respectives.
· L'algorithme de suppression fonctionne selon les
mêmes principes que celui de l'insertion (mise à jour en local et
dans le site, mise à jour également des
métadonnées).
4.2.2.3 Tolérance aux pannes
Dans notre architecture, chaque machine dispose d'un arbre
local qui stocke des informations permettant d'accéder aux services. Il
est possible qu'une machine tombe en panne. Dans ce cas, nous
Marie Hélène Wassa Mballo Page 91
n'avons pas accès aux services de cette machine. Pour
tolérer ce type de défaillance, nous proposons de faire une
réplication de l'arbre de services en utilisant les
métadonnées. Pour savoir sur quelles machines sont
stockées les répliques. Il faut rappeler que la
réplication concerne les données se trouvant dans les feuilles de
l'arbre, à savoir le nom du service, son emplacement physique et sa
description. Un facteur de réplication k
permet de savoir le nombre de fois qu'un service est sera
répliqué sur k machines
différents. Ce facteur de réplication k
est choisi selon le nombre de machines appartenant au groupe de
métadonnées, et ce facteur ne dépasse pas la moitié
du nombre de machines dans un site, c'est-à-dire si le nombre de machine
dans un site est n, dans un groupe de
métadonnées nous pouvons avoir les n
machines alors la condition posée est que
k<=n.
4.2.2.4 Avantages et inconvénients
Les avantages de l'approche distribuée peuvent se
résumer comme suit :
· Elle permet d'éviter les problèmes de
l'approche centralisée et assure un certain équilibrage de charge
entre les différents machines qui composent l'architecture
distribuée.
· L'utilisation de métadonnées permet de
diminuer le nombre de messages à envoyer lorsqu'une recherche locale de
services échoue. Ces métadonnées permettent de faire une
recherche sélective qui évite ainsi d'effectuer une diffusion
pour la recherche d'un service. Les métadonnées sont construites
en faisant un regroupement des adresses IP des machines, selon le type de
système d'exploitation, le type de licence, et les langages de
développement des services. Le nom d'une métadonnée est
formé par la combinaison des initiales des noms du système
d'exploitation, de la licence et du langage de programmation du service
concerné.
Comme inconvénients de l'approche distribuée, nous
pouvons citer :
· La réplication : nous avons noté
précédemment que le facteur de réplication est choisi en
fonction du nombre de machine appartenant au groupe de
métadonnées du service qui doit être
répliqué. Dans le cas ou il y'a une seule machine dans le groupe
de métadonnées, c'est-à-dire
la machine hébergeant le service, donc nous n'auvons
pas la possibilité d'effectuer de répliques.
· Message réseau : le nombre de message
réseau envoyé peut devenir important dans un site si dans un
groupe de métadonnées nous retrouvons un nombre important de
machines.
4.3 Validation théorique
4.3.1 Approche centralisée vs. approche
distribuée
Dans l'étude comparative de l'approche
centralisée et de l'approche distribuée, nous nous limitons aux
critères suivants :
· Coût des mises à jour :
permet de définir le comportement des deux approches face aux mises
à jour. Dans le cas de l'approche centralisée, les mises à
jour s'effectuent entre le super noeud et les machines. Donc si le nombre de
services augmente de façon régulière alors les mises
à jour deviennent une véritable surcharge pour le super noeud.
Par contre, dans le cas de l'approche distribuée, les mises à
jour se font sur des machines choisies selon des métadonnées
définies. Ce qui permet de réduire la fréquence de mises
à jour.

Marie Hélène Wassa Mballo Page 92
Figure 4.5: Coût de mise à jour dans les
deux approches
Dans la figure 4.5 nous montrons les messages envoyés
lors d'une mise à jour, dans un site nous avons quatre machines. Avec
l'approche centralisée les quatre (4) machines peuvent envoyer
simultanément des messages de mise à jour au serveur, ce qui
entraine une saturation du serveur, car le nombre de
Marie Hélène Wassa Mballo Page 93
machines change de manière dynamique nous pouvons avoir
jusqu'à mille(1000) machines dans un site, il est vrai que nous avons
fixé un pourcentage de saturation, mais le problème de surcharge
demeure car le serveur peut être sollicité 24H sur 24. Il faut
également veiller à mettre en place un réseau à
moindre coût, or les serveurs sont très chers.
Dans le cas distribué une machine envoie des messages
de mise à jour en tenant compte des métadonnées et du
facteur de réplication (voir 4.2.2.3). Ce qui fait que
les machines sont moins sollicitées contrairement à l'approche
centralisée. Une condition posée est que le nombre de
messages qui peut être envoyé à une machine ne doit pas
dépasser la moitié des machines se trouvant dans le
site.
· Coût en réseau : lors
d'une modification d'un service dans le cas centralisé, la communication
se fait uniquement entre machine et super noeud. Ce qui permet de
réduire considérablement le nombre de messages. Alors que dans le
cas distribué, on utilise du multicast. Ce qui va augmenter le flux de
messages qui circulent dans le réseau.
En considérant la figure 4.5, le nombre de messages
réseau de mises à jour envoyé à travers un site par
une machine est de 1 dans le cas centralisé. Tandis que dans le cas
distribué le nombre de messages qui peut être envoyé au
maximum est égal au nombre de machines totales dans un site
divisé par 2.ce nombre de messages change suivant l'ajout ou le retrait
de machines.
Dans le cas d'un site avec 1000 machines, avec l'approche
centralisée une machine n'émet qu'un message de mise à
jour tandis dans le cas distribué une machine peut envoyer 500 messages.
Donc le nombre de messages envoyés dans le cas distribué est 500
fois plus grand que le cas centralisé.
· Temps de réponse pour la recherche
: si un service ne se trouve pas en local alors la requête est
routée dans le site. Le temps mis dans le cas centralisé est plus
important car la requête est routée au super noeud qui peut
être sollicité par plusieurs pairs.
Nous considérons toujours la figure 4.5, à
partir des complexités obtenues, nous pouvons déterminer le temps
qu'il faudra à telle ou telle machine pour mettre en oeuvre
l'algorithme.
Nous allons prendre un exemple avec un site de 1000 machines
; les machines ont un temps de traitement 1GHz ce qui signifie 106
opérations par seconde, nous disposons également d'un serveur de
3GHz utilisé dans l'approche centralisée. L'opération de
mise à jour est une insertion et nous avons
Marie Hélène Wassa Mballo Page 94
calculé dans 4.1.3 la complexité d'insertion qui
est de l'ordre de Cinsrt= O(nlang) + O(nsyst)=1000opérations
dans l'arbre de services du super noeud qui contient la totalité de
l'arbre du site, et 500 opérations pour un arbre de services d'une
machine simple.
|
|
centralisée
|
distribuée
|
|
Complexité d'insertion de l'arbre de services
|
1000
|
500
|
Nombre de
machines dans le site
|
1000
|
0,3s
|
0,25
|
|
0,6
|
0,5
|
|
SATURATION
|
0,75
|
|
Tableau 4.1 : variation du temps de traitement
suivant l'augmentation du nombre de machines
Le tableau 4.1 montre la variation du temps de recherche dans
le super noeud avec l'approche centralisée et une machine quelconque
avec l'approche distribuée. Comme nous l'avons dit
précédemment une machine de l'approche distribuée
reçoit au maximum n/2 messages si n=nombre de machines dans le site.
Nous constatons avec 3000 noeuds il ya une saturation avec l'approche
centralisée contrairement à l'approche distribuée.
L'arbre de services du super noeud est toujours plus grand
que l'arbre de services d'une machine locale, ce qui fait que le temps est
toujours plus grand dans l'approche centralisée.
En résumé, l'approche distribuée est
plus avantageuse, concernant la recherche de services, puisque l'arbre de
services est partagé entre les machines. L'inconvénient
noté pour cette approche est surtout lié au cout réseau,
mais l'utilisation des métadonnées réduit cette limitation
notée. Nous allons mettre dans le tableau ci-dessous la comparaison des
deux approches pour qu'elle soit plus explicite
|
Coût mise à jour
|
Coût en réseau
|
Temps de réponse pour la recherche
|
centralisé
|
Elevé : accès simultanée au serveur par
toutes les machines
|
Réduit: communication
pair-serveur
|
Élevé: surcharge du super noeud
|
|
Marie Hélène Wassa Mballo Page 95
distribué
|
Réduit: une machine est
|
Élevé: envoie multicast:
|
Réduit: arbre de services est
|
|
sollicitée par une mise à
|
plusieurs peuvent être
|
distribuée entre les machines
|
|
jour si elle appartient à
|
sollicitées
|
|
|
la métadonnée
|
|
|
|
Tableau 4.2 : comparaison approche centralisée
vs approche distribué
4.3.2 2MDS vs. annuaire UDDI
Nous proposons de faire l'étude comparative de
l'approche distribuée de notre proposition et l'annuaire UDDI
basé sur les services web, les paramètres suivants sont
considérés dans l'étude:
· La structure de représentation de
service : La structure de représentation de l'ensemble des
services est un élément important pour la recherche de service.
Selon la structure adoptée, la masse d'informations à
représenter peut être relativement importante et
l'opération de recherche peut être plus ou moins complexe. Dans
notre solution, nous utilisons la structure d'arbre pour représenter
l'information. Ce qui permet de réduire considérablement le temps
de traitement contrairement à l'annuaire UDDI qui a une structure
classique.
· La description du service : Dans le
cas des annuaires UDDI, l'utilisateur ne peut pas accéder à la
description des services tels que les fonctionnalités offertes par ce
dernier, les droits d'utilisation du service, etc. Notre approche propose cette
possibilité.
· Les critères de recherche :
dans les approches basées sur l'annuaire UDDI, les
critères de recherche sont principalement le nom du service
recherché, son fournisseur et la catégorie à laquelle
appartient le service. Dans notre approche, nous proposons d'autres
critères tels que le système d'exploitation sur lequel fonctionne
le service, le langage de développement et la licence d'utilisation ce
qui permet d'avoir une liste plus exhaustive de services pertinents.
·
Marie Hélène Wassa Mballo Page 96
La méthode de recherche de service :
Ce critère a pour objectif de déterminer la
méthode de recherche utilisée, pour évaluer le temps de
recherche d'un service.
Dans notre approche, puisque nous utilisons un arbre, le
parcours se fera de façon dichotomique de la gauche vers la droite car
les données sont stockées dans l'arbre par ordre lexicographique.
Ce qui permet de réduire de moitié le temps mis pour effectuer
une recherche, comparer à l'annuaire UDDI.
· La complexité de la recherche :
Pour les trois algorithmes que nous avons utilisés pour la
gestion des services, nous obtenons des complexités qui sont
définies dans le pire des cas (voir 4.1.3).
a) Complexité d'insertion Cette
complexité est de l'ordre de O(nsyst) +O(nlang)
Elle dépend des noeuds du niveau 1 et niveau 3 qui
correspond respectivement au type de système d'exploitation et au type
de langage. Car un noeud du niveau 1 a au maximum deux fils pour le niveau 2,
dont la complexité est négligée l'argumentation est
donnée au point 4.1.3.1.
b) Complexité de recherche
Cette complexité est de l'ordre de O(nsyst) +O(nlang)
+ O(nserv)
Dans cet algorithme, nous retrouvons la complexité de
l'algorithme d'insertion plus la complexité des noeuds du niveau 4 qui
correspond aux feuilles (se référer au point
4.1.3.2).
c) Complexité de suppression
Cette complexité est de l'ordre de O(nsyst) +O(nlang) +
O(nserv)
Elle a une complexité identique à celle liée
à la recherche (voir 4.1.3.3).
Dans notre mémoire, nous nous intéressons au
temps mis pour effectuer une recherche dans les grilles de calcul. C'est pour
cela nous limitons notre comparaison à l'algorithme de recherche. Sur le
tableau 4.1 nous voyons que L'annuaire UDDI présente une
complexité de l'ordre de O(n) alors notre solution a une
complexité de l'ordre de O(nsyst) +O(nlang) + O(nserv)
. Ainsi notre approche présente une complexité meilleure que
celle obtenue par l'annuaire UDDI car seule une partie des machines est
consultées lors d'une recherche. Ce qui n'est pas le
cas pour l'annuaire UDDI ou la totalité des machines participe à
la recherche.
Pour comprendre cette comparaison sur la complexité nous
allons donner un exemple

Marie Hélène Wassa Mballo Page 97
Figure 4.6: représentation de l'informations avec
Figure 4.7: représentation de l'informations avec
le 2MDS l'annuaire UDDI
Lors d'une requête XML de recherche en donnant comme
paramètre le nom du système d'exploitation : windows
98, la licence : libre, le langage :
java, et le nom du service : servastro.
Avec le 2MDS le nombre d'opération effectué est de
6 opérations en tenant de la complexité de recherche
défini au point 4.1.3.2 et de 20 opérations pour
l'annuaire UDDI car toute la base doit être parcouru, avant de connaitre
l'emplacement de la machine qui héberge le serveur.
|
Critères
approches
|
Structure de
représentation
|
Description de service
|
Critères de
recherche
|
Méthode de recherche
|
Complexité de la
recherche
|
|
UDDI
|
Classique
|
Non
|
Nom,
fournisseur, catégorie
|
Parcours
|
O(n)
|
|
Notre approche
|
Arbre
|
Oui
|
Nom, système
d'exploitation,
Licence,langage
|
Dicotomique
|
O(nsyst) +O(nlang) +
O(nserv)
|
Marie Hélène Wassa Mballo Page 98
Tableau 4.3 comparaison entre l'approche
proposée et les approches basées sur l'annuaire
UDDI
4.4 Exemple d'applications 4.4.1 Insertion d'un
service
La figure 4.8 montre le processus d'insertion dans un arbre de
services

Figure 4.8 : processus d'insertion d'un
service
Le service à insérer est
caractérisé par un système d'exploitation: unix
licence :propriétaire langage :java
nom :servchimie adresse : 192.168.10.4
description : fichier xml ces trois derniers
paramètres se trouvent dans les feuilles.
L'insertion de ce service se fait selon les étapes
définies ci-dessous :
Etape 1 : parcours du niveau 1 de l'arbre des
services
Le parcours du niveau 1 de l'arbre des services permet de
savoir si le système d'exploitation du service à insérer
existe ou non dans l'arbre. Dans le cas où il n'existe pas, il y aura la
création d'un nouveau noeud logique (système d'exploitation) et
de ses descendants pour ensuite insérer le nom du service, son
emplacement physique et sa description.
Marie Hélène Wassa Mballo Page 99
Etape 2 : parcours du niveau 2 de l'arbre des
services
Dans ce parcours, nous cherchons à savoir si la licence
existe ou pas. Comme dans le cas précédent, il y aura la
création d'un nouveau noeud logique si la licence recherchée
n'existe pas. Ensuite, un noeud fils sera créé pour
insérer le langage de développement du service.
Etape 3 : parcours du niveau 3 de l'arbre des
services
A ce niveau, nous recherchons le langage de développement
du service selon le même principe que les étapes 1 et 2.
Etape 4 : accès aux feuilles de l'arbre des
services
Dans cette 4ème et dernière
étape, les feuilles associées au nouveau service, qui vient
d'être inséré, sont créées.
4.4.2 Recherche d'un service
Pour rechercher un service, un utilisateur fournit les
paramètres suivants : le système d'exploitation, la licence
d'exploitation du service et son langage de développement. Pour
illustrer cette opération de recherche, supposons qu'un client lance une
requête de recherche avec comme paramètres : système
d'exploitation Unix, licence propriétaire
et langage java. La recherche du service
correspondant à ces paramètres se fait selon les étapes
suivantes :
Etape 1 : Recherche dans le niveau 1 de l'arbre de
services Si le système Unix ne s'y trouve pas,
alors le service recherché n'existe pas.
Etape 2 : Recherche dans le niveau 2 de l'arbre de
services
Le système Unix se trouve dans
l'arbre, la recherche continue pour voir s'il existe une licence de type
propriétaire associée à ce service. Si ce
type de licence n'existe pas, la recherche s'arrête et l'utilisateur est
avertit que le type de licence recherché n'existe pas actuellement.
Marie Hélène Wassa Mballo Page 100
Etape 3 : Recherche dans le niveau 3 de l'arbre de
services
A ce niveau, nous recherchons si le service trouvé est
développé dans le même langage que celui requis par
l'utilisateur. Deux cas sont possibles : le langage existe et donc la recherche
se fait avec succès. Dans le cas contraire, l'utilisateur est
informé que le langage recherché n'existe pas.
Etape 4 : Accès aux feuilles
Quand la recherche atteint cette étape, cela veut dire
que les critères de recherche définis par l'utilisateur ont
été tous validés. Dans ce cas, on affichera à
l'utilisateur l'ensemble des informations relatives au service
recherché. Rappelons que ces informations (notamment la description du
service) sont stockées dans les feuilles de l'arbre.
4.4.3 Suppression d'un service
La suppression d'un service suivra les mêmes
étapes que l'opération de recherche. Au fur et à mesure du
parcours de l'arbre de services, les informations relatives au service seront
supprimées, dans le cas où le service existe.
Dans ce chapitre nous avons présenté notre
apport dans la découverte de services au sein des grilles. En effet deux
approches ont été proposées : centralisé et
distribué. La dernière approche est la plus avantageuse du fait
qu'il yait pas d'élément centraliseur.
Nous avons également effectué une
comparaison de notre approche et l'annuaire UDDI, puisque notre apport se base
principalement sur ce dernier.
Cependant notre travail n'est pas encore terminé
puisque la validation expérimentale reste à faire.
Marie Hélène Wassa Mballo Page
101
CONCLUSION
GENERALE
Marie Hélène Wassa Mballo Page 102
Dans ce mémoire, nous nous sommes
intéressés à proposer des mécanismes de
découverte de services dans les grilles. Nos solutions permettent
d'effectuer des recherches multicritères et apportent une certaine
scalabilité. Ces nouvelles méthodes de recherche permettent de
diminuer les messages de communication avec une complexité moindre. Une
des caractéristiques principales de notre contribution est l'utilisation
d'arbre pour représenter les services, Ce qui permet d'optimiser
fondamentalement la recherche des services.
Ainsi, nous avons proposé deux architectures pour le
déploiement de nos solutions : une approche centralisée qui se
caractérise dans un site par l'utilisation d'un super noeud. Ce dernier
permet d'avoir une vue globale sur l'ensemble des arbres de services du site.
La communication inter site se fait par l'intermédiaire des super
noeuds. Nous avons constaté que les principaux inconvénients de
cette approche sont : la centralisation due à l'utilisation d'un super
noeud, la fréquence des mises à jour dégrade la
performance du système.
Pour apporter une réponse à ces manquements,
nous avons proposé une autre solution basée sur une architecture
totalement distribuée. Dans cette approche, la notion de super noeud
disparaît, et les machines sont reliées directement entre eux.
Chaque machine du site dispose de son arbre local. Une particularité de
cette approche est l'utilisation de métadonnées qui permettent
d'effectuer des envoies multicast. Une machine qui veut communiquer avec
d'autres machines consulte avant tout sa table de métadonnées
pour savoir quelle machine est susceptible de répondre à sa
requête.
Cependant, nous nous sommes limités à la
validation théorique de nos propositions. Une suite logique de ce
mémoire peut être résumé dans les points suivants :
(i) intégration de l'approche proposée dans un simulateur de
grilles; (ii) comparaison avec d'autres approches de découverte de
services afin de faire une validation expérimentale; (iii) étude
de la possibilité d'utiliser ces approches pour faire de la composition
de services puisque nous avons proposé des architectures de
découverte de service dans les grilles.
Marie Hélène Wassa Mballo Page 103
REFERENCE
[1] Quand l'union des PC fait la force, le
nouvel Hebdo (N60), 26/04/2002,
http://www.01net.com/article/182466.html?rub=3547
[2]Frédéric Bordage, Jérôme Saiz,
le grid computing, 2002,
http://www.01net.com/article/198199
a.html
[3] grille informatique,
http://fr.wikipedia.org/wiki/Grille_de_calcul,
2009
[4] Jérôme Deprez, Nicolas Deville, Grid
Computing, Master 2 SIR TER,
www.unige.ch/apropos/budget/rapport_gestion2005.pdf
,2006/2007
[5] Nicolas Jacq, Introduction aux grilles
informatiques, laboratoire de physique Corpusculaire, CNRS/IN2P3,
http://clrpcsv.in2p3.fr,2005
[6] Heithem ABBES, introduction aux grilles de
calcul, journées du Parallélisme 2005,
www2.lifl.fr/~boulet/HdR/hdr003.html,
www.Iri.fr/~cecile/PERSO/Stagelnserm.pdf ,2005
[7] Andres S. Tanenbaum, Maarten van Steen,
Distributed Systems prinviples and paradigms, Prentice Hall,
ISBN 0132392275, 2006
[8] Eric Cariou, Systèmes Distribués
Introduction, Université de Pau et des Pays de l'Adour
Département Informatique
Eric.Cariou@univ-pau.fr,
web.univ-pau.fr/~ecariou/cours/sd-l3/cours-intro.pdf
[9] Architecture Client/serveur Règle du
jeu, www710.univ-
lyon1.fr/~hbriceno/.../01_1_CS_intro_cir.pdf
[10]
http://fr.wikipedia.org/wiki/Calcul_distribué,
The International Conference on Dependable Systems and Networks ACM
Symposium on Principles of Distributed Computing
[11] Chetty, M. et R. Buyya, Weaving Computational
Grids: How Analogous Are they with Electrical Grids?, Computing in
Science & Engineering, July/August 2002
[12] Foster I, Kesselman C (eds.). The Grid:
Blueprint for a New Computing Infrastructure, Morgan Kaufmann: San
Fransisco, CA, 1999
[13] Buyya R, Giddy J, Abramson D. An evaluation of
economy-based resource trading and scheduling on computational power grids for
parameter sweep applications. Proceedings of the 2nd International
Workshop on Active Middleware Services (AMS '00), August 2000
[14] V. Bertis, Fundamentals of Grid
Computing, IBM Redpaper, October 2002
[15]
Marie Hélène Wassa Mballo Page 104
Dominique Lavanier, Hugues Leroy, Michel Hurfin, Rumen
Andonov, Laurent Mouchard, Frederic Guinand, le projet GénoGRID
: une grille expérimentale pour la génomique
[16] Peter Kacsuck, Springer-Verlag, Distributed and
Parallel Systems: Cluster and Grid Computing, ISBN 0387698574New York,
2007
[17] grilles de calcul : Etat de l'art juin
2003,
http://tonysoueid.multimania.com
[18] Erwin Laure, CERN,
http://indico.cern.ch/conferenceDisplay.py
?confId=a036278 ?, Europe/Zurich, 2004
[19] Dominique Boutigny, les grilles de calcul et de
données, réunion d'information sur la grille de calcul
et de données, EGEE-Observatoire de paris, 2008
[20] Pascal DUGENIE, Orientation et usage de
l'Architecture de services Grille OGSA, LIRMM CNRS &
Université de Montpellier II, 2005
[21] Isabelle Thieblemont, Programmation
orientée objet ,
Isabelle.Tieblemont@wanadoo.fr,
http://pagespersorange.fr/isabelle.thieblemont/poo/poointro.htm
[22] Antoine Marot ,l'animation d'algorithmes en
programmation orientée aspect, Université libre de
bruxelles faculté des Sciences département d'informatique
année académique 2005-2006
[23] Allouch Bachir & Trantoul Gilles, Les
nouvelles formes de programmation,
http://deptinfo.unice.fr/twiki/pub/Linfo/PlanningDesSoutenances2002/allouch-trantoul.pdf
juin 2003
[24] Grady BOOCH, James RUMBAUGH, Ivar JACOBSONT, the
Unified
Modeling Language - User Guide - 5ème
édition, édition ADDISON WESLEY ISBN : 0-
201-57168-4, octobre
1999
[25] Stéphane Frénot,
Compléments POO : Programmation orientée
composants, INSA Lyon, INRIA, 2002
[26] wikipédia,
http://www.techno-science.net/?onglet=glossaire&definition=5390,
2009
[27] Anand, S., S. Padmanabhuni, J. Ganesh,
Perspectives on service-oriented architecture, In ICWS, IEEE
Computer Society, 2005
[28] F. Baude, Introduction à l'archicture
Orientée Service, M2 MIAGE NTDP, 2008
[29] Jérôme Daniel, Services Web-
Concepts, techniques et outils, Viubert, Paris, 2003,
www.vuibert.fr
[30] Chaitanya Kandagatla, Survey and Taxonomy of Grid
Resource Management
Systems, University of Texas,Austin
http://www.cs.utexas.edu/users/browne/cs395f2003/projects/KandagatlaReport.pdf
[31]
Marie Hélène Wassa Mballo Page 105
Klaus Krauter, Rajkumar Buyya and Muthucumaru Maheswaran,
A taxonomy and survey of grid resource management systems for
distributed computing, Copyright 2001 John Wiley & Sons, Ltd. 17
September 2001
[32] Kyungkoo jun, Ldislau Boloni, Krzysztof Palacz, and Dan
C.Marinescu, Agent-Based Resource Discovery, computer Sceinces
Departement, Purdue University West Lafayette, In, 47907 email :
{junkk,boloni,palacz,dcm}@
cs.purdue.edu October 8,1999
[33] S. A. Ludwig, P. van Santen, A grid service
discovery matchmaker based on ontology description, Euroweb 2002- The
Web and the Grid: from e-science to e-business, 2002
[34] RDF/XML Syntax Specification (Revised),
http://www.w3.org/TR/2004/REC-rdf-syntax-grammar-20040210/
[35]Jos de Bruijn, Christophe Bussler, John Domingue, Dieter
Fensel, Martin Hepp, Michael Kifer, et al, D2v1.3. Web Service Modeling
Ontology (WSMO), WSMO Final Draft 2006,
http://www.wsmo.org/TR/d2/20061021/
[36] Philippe Laublet, Chantal Reynaud, Jean Charlet, Sur
quelques aspects du Web sémantique,
http://enssibal.enssib.fr/autres-sites/RTP/websemantique/articles/03-WebSemantique.pdf
[37] Christoph Bussler, Dieter Fensel, Alexander Maedche,
a conceptual architecture for semantic web enabled web
services, ACM SIGMOD, ISSN 0163-5808, 2002
[38] Nathalie Steinmetz, Ioan Toma, D16.1v1.0 WSML
Language Reference, WSML Final Draft 2008-08-08,
http://www.wsmo.org/TR/d16/d16.1/v1.0/
[39] I. Foster and C. Kesselman. The Globus Project:
A Status Report, In Proc. IPPS/SPDP'98 Heterogeneous Computing
Workshop 1998
[40] S. Fitzgerald, I. Foster, C. Kesselman, G. von
Laszewski, W. Smith, and S. Tuecke, A directory service for configuring
high-performance distributed computations, preprint, Mathematics and
Computer Science Division, Argonne National Laboratory, Argonne, Ill., 1997
[41] Luis Ferreira, Viktors Berstis, Jonathan Armstrong, Mike
Kendzierski, Andreas Neukoetter, MasanobuTakagi, et al, Introduction to
Grid Computing with Globus, septembre 2003
[42] WS Information Services: Key Concepts, the
globus toolkit,
http://www.globus.org/toolkit/docs/3.2/infosvcs/ws/key/usesbenefits.html
[43] Pascal DUGENIE, Orientation et usage de
l'Architecture de services Grille OGSA, LIRMM CNRS &
Université de Montpellier II, 2005
[44]
Marie Hélène Wassa Mballo Page 106
a globus Primer Or, Everything wanted to known about
Globus ,but were afraid to
Ask, Describing Globus Toolkit version 4
,
http://www.globus.org/toolkit/docs/4.0/key/GT4_Primer_0.6.pdf
[45] Stephen Burke, Simone Campana, Elisa Lanciotti, Patricia
M'endez Lorenzo, Vincenzo Miccio, Christopher Nater, et al, The
WORLDWIDE LHC COMPUTING GRID (worldwide LCG), Proceedings of the
Conference on Computational Physics 2006 - CCP 2006, Conference on
Computational Physics 2006, July 2007, Pages 219-223
[46] B. Tierney, R. Aydt, D. Gunter, W. Smith, M. Swany, ,
Taylor, R. Wolski, A Grid Monitoring Architecture
,16-January-2002,
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.18.3345,
| 

