Chapitre II : GENERALITES DE LA PLATE FORME J2EE
Dans ce chapitre nous allons décrire les principales
généralités de la plate forme J2EE nécessaires
à la mise en place du système. Nous commencerons par une
présentation de J2EE, ensuite le constructeur de projet maven. Nous
continuerons par la description du gestionnaire de version svn, ensuite du
conteneur léger Spring, le Framework composant Wicket et enfin le
mapping objet/relationnel de hibernate/ JPA.
II.1. Présentation de J2EE
Le terme « Java EE » signifie Java Enterprise
Edition, et était anciennement raccourci en « J2EE ». Il fait
quant à lui référence à une extension de la
plate-forme standard. Autrement dit, la plate-forme Java EE est construite sur
le langage Java et la plate-forme Java SE (Java Standard Edition), et elle y
ajoute un grand nombre de bibliothèques remplissant tout un tas de
fonctionnalités que la plate-forme standard ne remplit pas d'origine.
L'objectif majeur de Java EE est de faciliter le développement
d'applications web robustes et distribuées, déployées et
exécutées sur un serveur d'applications (MOLIERE, 2005).
II.1.1. Concept de la plate forme J2EE
La figure suivante présente les différentes
technologies utilisées par la plate forme J2EE.
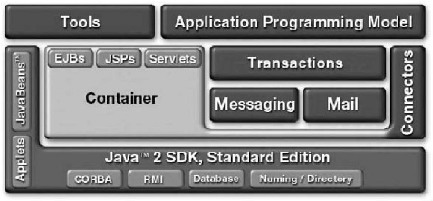
Source : (ROQUES, 2002). Figure 2-1 : Outils J2EE
5
6
Avec le langage Java est apparue une nouvelle technologie :
les servlets. Ces petits «serveurs» ou «services» sont
écrits en langage Java et utilisent une API spécifique. Les
performances sont améliorées par les fonctionnalités
multithreads des serveurs J2EE, évitant la création de processus
externes (MOLIERE, 2005).
Cependant, le développeur doit toujours mixer le code
Java et HTML. De plus, la moindre modification oblige à recompiler la
servlet et à la recharger. Les JSP, ou Java Server Pages, viennent
résoudre ces problèmes de recompilation. Ici, c'est le code Java
que l'on incorpore dans la page HTML avec des techniques de scripting. Le
serveur compile automatiquement la page en une servlet et l'exécute
ensuite. Les approches à base de scripting nécessitent
l'incorporation importante de code applicatif dans le HTML. Ces techniques
limitent aussi la réutilisation de code (MOLIERE, 2005).
Pour ce qui est du monde Java, il a donc été
proposé de faire collaborer les servlets et les JSP dans les
applications. Les servlets sont utilisées par les développeurs
pour gérer les aspects programmation d'une application web et les JSP
sont utilisées par les infographistes pour effectuer l'affichage. On
retrouve ainsi une servlet et une JSP par requête possible sur le site
web. La servlet ne contient plus de HTML, et la JSP contient juste le code
nécessaire à l'affichage. Ce style de programmation respecte le
paradigme MVC.
II.1.2. Le paradigme MVC
(Modèle-Vue-Contrôleur)
Le paradigme MVC est un schéma de programmation qui
propose de séparer une application en trois parties :
· le modèle, qui contient la logique et
l'état de l'application ;
· la vue, qui représente l'interface utilisateur
;
· le contrôleur, qui gère la synchronisation
entre la vue et le modèle.
Le point essentiel consiste à séparer les
objets graphiques des objets métier, afin de pouvoir les faire
évoluer indépendamment et les réutiliser.
7
On peut également gérer facilement plusieurs vues
du même modèle.
Au final, une telle séparation favorise le
développement et la maintenance des applications :
· Le modèle étant séparé des
autres composants, il est développé indépendamment. Le
développeur du modèle se concentre sur le fonctionnel et le
transactionnel de son application.
· Le modèle n'est pas lié à une
interface, il peut donc être réutilisé (passage d'une
application avec interface en Java à une application avec interface
web). Dans les applications J2EE, le modèle est assuré par des
EJB et/ou des JavaBeans, le contrôleur est assuré par des servlets
et la vue par des JSP (voir la figure 2-2 suivante).
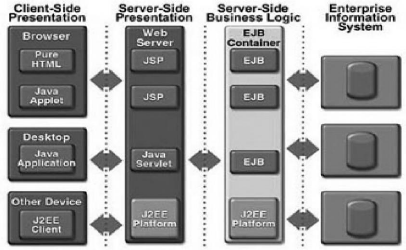
Figure 2-2 : Architecture d'une application J2EE
Source : (ROQUES, 2002)

II.2. Apache Maven 2 : Outil de build Apache
Maven 2 est un outil « open source » de Apache Jakarta. Il permet de
faciliter et d'automatiser la gestion et la construction d'un projet java
(VONGVILAY Michel, 2004). Le premier but de Maven est de permettre aux
développeurs de connaitre rapidement l'état
global du développement du projet. C'est dans ce but que Maven :
· Facilite le processus de construction
· Fournit un système de construction uniforme
· Fournit des informations utiles sur le projet
· Fournit clairement les grandes lignes directrices de
développement
· Fournit les éléments nécessaires
pour faire des tests complets
· Fournit une vision cohérente et globale du
projet
· Permet d'ajouter de nouvelles fonctionnalités de
façon transparente
Maven est basé sur le concept de « Project Object
Model » (POM). Le développement et la gestion du projet sont
contrôlés depuis le POM.
II.2.1. Principe de fonctionnement
La figure 2-3 suivante illustre le principe de fonctionnement du
constructeur de projet maven.
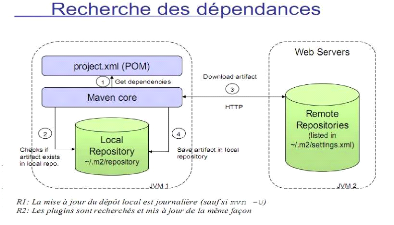
Figure 2-3 : Maven.
8
Source :
linsolas.developpez.com/articles/java/builds
1. Maven commence par définir la liste des
dépendances nécessaires au projet, via la lecture du fichier
pom.xml du projet ;
2. Maven interroge alors le repository local afin de trouver
les dépendances utilisés ;
3. Si la dépendance n'est pas trouvée, alors
maven va interroger les repositories distants ;
4. les dépendances absences du repository local sont
alors téléchargées depuis les repositories distants, de
telles façon a ce qu'elles disponibles lors des prochains builds ;
5. Maven peut alors utiliser la dépendance pour la
construction du projet.
L'intérêt de ce mécanisme, en plus de sa
simplicité, est que nous ne définissons plus que les
dépendances directes de notre projet. Les dépendances de nos
dépendances, autrement appelées dépendances transitives
sont directement gérées par Maven2, et ne préoccupent plus
l'esprit du développeur (VONGVILAY Michel, 2004).
II.2.2. La structure de répertoires
Une partie de la puissance de Maven vient des pratiques
standardisées qu'il encourage. Un développeur qui a
déjà travaillé sur un projet Maven se sentira tout de
suite familier avec la structure et l'organisation d'un autre projet Maven. Il
n'y a pas besoin de gaspiller du temps à réinventer des
structures de répertoires, des conventions, et à adapter des
scripts de build Ant pour chaque projet (SMART, 2005). Même s'il est
possible de redéfinir l'emplacement de chacun des répertoires
vers une localisation spécifique, il est réellement
intéressant de respecter la structure de répertoire standard
de Maven 2 autant que possible, et ce pour plusieurs raisons
:
· Cela rend le fichier POM plus court et
plus simple ;
· Cela rend le projet plus simple à comprendre et
rend la vie plus simple au pauvre développeur qui devra maintenir le
projet quand vous partirez ;
·
9
Cela rend l'intégration de plug-ins plus simple.
II.3. 10
Le serveur SVN
SVN signifie Subversion est un système de gestion de
version, conçu pour remplacer CVS. Concrètement, ce
système permet aux membres d'une équipe de développeur de
modifier le code du projet quasiment en même temps. Le projet est en
effet enregistré sur un serveur SVN et à tout moment, le
développeur peut mettre à jour une classe avant de faire des
modifications pour bénéficier de la dernière version et a
la possibilité de comparer deux versions d'un même fichier.
Le principe de fonctionnement est le suivant :
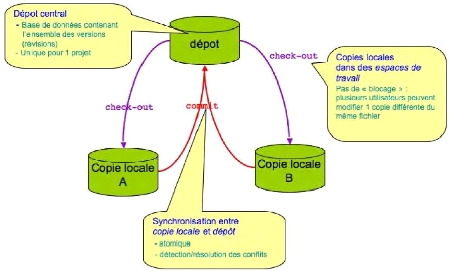
Figure 2-5 : fonctionnement du serveur svn
II.4.

Spring : Faciliter le développement et les
tests
Le Framework Spring est un conteneur dit « léger
», c'est-à-dire une infrastructure similaire à un serveur
d'application J2EE (FERRAN, 2008). Il prend donc en charge la création
d'objets et la mise en relation d'objets par l'intermédiaire d'un
fichier de configuration qui décrit les objets à fabriquer et les
relations de
11
dépendances entre ces objets (IoC - Inversion of
Control). Le gros avantage par rapport aux serveurs d'application est qu'avec
SPRING, les classes n'ont pas besoin d'implémenter une quelconque
interface pour être prises en charge par le Framework. C'est en ce sens
que SPRING est qualifié de conteneur « léger ».
L'idée du pattern IoC est très simple, elle consiste, lorsqu'un
objet A à besoin d'un objet B, à déléguer à
un objet C la mise en relation de A avec B (FERRAN, 2008).

II .5. Apache Wicket : Mettre en place le
MVC
Apache Wicket est un Framework pour la création
d'applications web qui repose presque entièrement sur Java et HTML comme
moyens pour bâtir ses interfaces. Wicket est YAJF (Yet Another JavaEE
Framework), mais orienté composants. Il se distingue par certaines
grandes particularités :
· Pas de JSP !
· Aucun tag de logique (boucle, condition)
mélangé au HTML
· Les composants web sont créés dans des
classes Java "à la Swing" avant d'être simplement placés
aux endroits souhaités dans le fichier HTML ;
· Une gestion particulièrement simple de
tâches récurrentes dans le développement de sites web comme
la validation de formulaires, le passage de paramètres entre les pages
et la navigation ;
· Un Framework créé dans l'idée de
vouloir faciliter le développement de composants
réutilisables.
II.6. Hibernate et DAO : le mapping
objet/relationnel
Les difficultés de cohabitation entre les mondes
objets et relationnels sont résolues grâce au concept de Mapping
objet-relationnel (O/R Mapping), qui est le nom donné aux techniques de
transformation des modèles objets en modèles relationnels (ROS,
2003).
Les choix architecturaux d'une application sont
décisifs dès lors qu'ils interviennent sur les performances,
l'évolutivité, les temps de développement, et bien
sûr les coûts.
Les sages d'aujourd'hui prônent une séparation
en différentes couches des applications, et parlent alors d'applications
multi niveaux (n-tier applications) voir figure 2-6.
|
Figure 2-6 : Mapping objet/relationnel
|
|
12
L'ORM est nécessaire parce la représentation
sous forme Relationnelle n'entre pas en correspondance avec la
représentation Objet.
· Objet : notions d'héritage et de polymorphisme
;
· Objet : pas d'identifiant (pointeur) ;
· Objet : les relations n:m sont modélisées
par des containers.
II.6.1. Data Access Object (DAO)
Quel que soit le système sur lequel vous
développez, vous pourrez toujours accéder à vos
données relationnelles. Vous utiliserez alors des API telles que JDBC,
ADO,
ADO.Net, et pourrez alors exécuter
des requêtes SQL, ou obtenir des objets représentant des tables et
leurs champs.
Ces outils sont suffisants mais ne permettrons jamais
à eux seuls une vraie abstraction de la base de données
sous-jacente. Par exemple vous ne pourrez pas obtenir toutes les commandes d'un
client donné avec une seule ligne de code. De plus, chaque fois que vous
voudrez supprimer un client, vous devrez supprimer manuellement son adresse,
alors que cela pourrait être fait automatiquement (ROS, 2003).
Tous ces problèmes doivent être
gérés par une couche d'accès aux données
chargée de communiquer avec le serveur de bases de données, et de
renvoyer des objets
13
métiers au programmeur ; Ce denier n'aurait alors plus
besoin de taper des requêtes SQL, comprendre les relations entre les
tables, ou connaître tous les paramètres des procédures
stockées, ou encore d'autres éléments. Lorsqu'on parle de
séparation des couches par responsabilité, il y a va
également de la séparation des compétences de chaque
développeurs.
II.6.2. Hibernate
Outil de mapping objet/relationnel pour le monde Java. Le
terme mapping objet/relationnel (ORM) décrit la technique consistant
à faire le lien entre la représentation objet des données
et sa représentation relationnelle basée sur un schéma
SQL.
Non seulement, Hibernate s'occupe du transfert des objets
Java dans les tables de la base de données (et des types de
données Java dans les types de données SQL), mais il permet de
requêter les données et propose des moyens de les
récupérer. Il peut donc réduire de manière
significative le temps de développement qui aurait été
autrement perdu dans une manipulation manuelle des données via SQL et
JDBC.
Le but d'Hibernate est de libérer le
développeur de 95 pourcent des tâches de programmation
liées à la persistance des données communes. Hibernate
n'est probablement pas la meilleure solution pour les applications
centrées sur les données qui n'utilisent que les
procédures stockées pour implémenter la logique
métier dans la base de données, il est le plus utile dans les
modèles métier orientés objets dont la logique
métier est implémentée dans la couche Java dite
intermédiaire (ROS, 2003). Cependant, Hibernate vous aidera à
supprimer ou à encapsuler le code SQL spécifique à votre
base de données et vous aidera sur la tâche commune qu'est la
transformation des données d'une représentation tabulaire
à une représentation sous forme de graphe d'objets.
II.6.3. JPA Java Persistance API
JPA permet de manipuler des données en base de
données relationnelle directement à partir d'objets Java sans
écrire du code SQL. Comme pour JDBC,
14
l'utilisation de JPA nécessite un fournisseur de
persistance qui implémente les les classes et méthodes de l'API
lasses et méthodes de l'API.
Les classes dont les instances peuvent être
persistantes sont appelées des entités dans la
spécification de JPA Le développeur indique qu'une classe est une
entité en lui associant l'annotation @Entity. Ne pas oublier d'importer
javax.Persistence.Entity dans les classes entités (idem pour toutes les
annotations).
~ Configuration de la connexion
Il est nécessaire d'indiquer au fournisseur de
persistance comment il peut se connecter à la base de données.
Les informations doivent être données dans un fichier
persistence.xml situé dans un répertoire META-INF dans le
classpath. Ce fichier peut aussi comporter d'autres informations.
~ Gestionnaire d'entités
Classe javax.persistence.EntityManager, le gestionnaire
d'entités (GE) est l'interlocuteur principal pour le développeur.
Il fournit les méthodes pour gérer les entités : les
rendre persistantes, les supprimer de la base de données, retrouver
leurs valeurs dans la base, etc.
~ Contexte de persistance
La méthode persist(objet) de la classe EntityManager
rend persistant un objet. L'objet est ajouté à un contexte de
persistance qui est géré par le GE (gestionnaire
d'entités). Toute modification apportée à un objet du
contexte de persistance sera enregistrée dans la base de données.
L'ensemble des entités gérées par un GE s'appelle un
contexte de persistance.
Dans le cadre d'une application autonome, la relation est
simple : un GE possède un
contexte de persistance, qui n'appartient
qu'à lui et il le garde pendant toute son
existence. Lorsque le GE
est géré par un serveur d'applications, la relation est
plus
complexe ; un contexte de persistance peut se propager d'un GE à
un autre et il peut
être fermé automatiquement à la fin
de la transaction en cours.
| 

