|
|
|
Université de Maroua The University of Maroua
**** ****
Institut Supérieur du Sahel The Higher Institute of the
Sahel
**** ****
Département d'Informatique et des Department of
Computer Science and
Télécommunications
Telecommunications
**** ****
|
|
CONCEPTION ET IMPLEMENTATION D'UNE
|
|
APPLICATION DE GESTION DES DOSSIERS DE
|
|
DEMANDE D'EQUIVALENCE DES DIPLOMES
|
|
Mémoire présenté et soutenu en vue de
l'obtention du Diplôme d'INGENIEUR DE
|
|
CONCEPTION EN INFORMATIQUE OPTION RESEAU
|
|
Par
|
|
GBITHICKI NDANGA BRICE ARSENE
|
|
Matricule : 11V126S
|
|
Ingénieur des Travaux en Informatique
|
|
Sous la Direction de
|
|
Dr EMVUDU WONO YVES
|
|
Devant le jury composé de :
|
|
Président : Pr LOURA BENOIT
|
|
Rapporteur : Dr EMVUDU WONO YVES
|
|
Examinateur : Dr VIDEME BOSSOU OLIVIER
|
|
Année Académique 2012 / 2013
|
|
DEDICACE

A mon enseignant d'informatique Dr Ndi Nyoungui André de
regretté mémoire.
REMERCIEMENTS
Que les personnes suivantes trouvent ici l'expression de tous mes
remerciements : Je remercier :
- Le Président du Jury Pr LOURA Benoît pour avoir
présider ce jury;
- L'examinateur Dr VIDEME BOSSOU Olivier pour avoir examiner ce
travail ; - Le rapporteur Dr EMVUDU WONO Yves pour avoir rapporter ce
travail.
Je tiens à remercier le corps enseignant de l'ISS de
Maroua pour les enseignements dispensés, en particulier notre chef de
département Dr VIDEME BOSSOU Olivier;
Merci à ma grande famille NDANGA pour leur soutient tout
au de ses moment difficiles ;
Un merci aux camarades de promotion pour la sympathie qui nous a
animées durant cette formation de deux ans. Merci particulier à
notre délégué pour sa volonté dans ses missions
;
II
Enfin merci à mes amis et tous ceux qui ont
contribué à la réalisation de ce travail.
III
Table des matières
DEDICACE I
REMERCIEMENTS II
Table des matières III
Liste des abréviations VI
RESUME VII
Liste des illustrations IX
Liste des tableaux XIII
INTRODUCTION 1
Chapitre I : CONTEXTE ET PROBLEMATIQUE
2
I.1. Contexte et problématique 2
I.2. Méthodologie de résolution du problème
3
I.3. Objectifs visés 4
Chapitre II : GENERALITES DE LA PLATE FORME J2EE
5
II.1. Présentation de J2EE 5
II.1.1. Concept de la plate forme J2EE 5
II.1.2. Le paradigme MVC (Modèle-Vue-Contrôleur)
6
II.2. Apache Maven 2 : Outil de build 7
II.2.1. Principe de fonctionnement 8
II.2.2. La structure de répertoires 9
II.3. Le serveur SVN 10
II.4. Spring : Faciliter le développement et les tests
10
II .5. Apache Wicket : Mettre en place le MVC 11
II.6. Hibernate et DAO : le mapping objet/relationnel 11
II.6.1. Data Access Object (DAO) 12
II.6.2. Hibernate 13
II.6.3. JPA Java Persistance API 13
Chapitre III : SPECIFICATION DES BESOINS 15
III.1. Initialisation du projet 15
III.1.2. Livrables attendus 15
III.1.3 Composition de l'équipe 15
III.1.4. contraintes techniques 16
III.1.5. Identification de la méthode utilisée
16
III.1.6. Outils logiciels 17
III.1.7. Identification des risques 18
III.1.8. Planning prévisionnel 19
III.2. Expression des besoins 20
III.2.1. Etude de l'existant 20
III.2.2. Règles de gestion 22
III.2.3. Besoins fonctionnels 23
III.2.4. Besoins non fonctionnels 24
III.2.5. Architecture 24
III.2.5.1. Architecture Physique 24
III.2.5.1. Architecture en couche 25
IV
III.2.6. Gestion des besoins 26
Chapitre IV : ANALYSE ET CONCEPTION DU
SYSTEME 28
VI.1. ANALYSE 28
IV.1.1. Modèles de cas d'utilisation 28
IV.1.1.1. Démarche des modèles de cas d'utilisation
28
IV.1.1.2. Identification des acteurs 30
IV.1.1.3. Identification des cas d'utilisation métier
30
IV.1.1.4. Structuration en packages 30
IV.1.1.5. Relations entre les cas d'utilisation métier
31
IV.1.1.6. Classement des cas d'utilisation métier 32
IV.1.1.7. Planification du projet en itérations 33
IV.1.1.8. Traçabilité des cas d'utilisation avec
les besoins textuelles 34
IV.1.1.9. Maquette du système 35
IV.1.2. Modèles d'analyse 35
IV.1.2.1. Démarche des modèles d'analyse 35
IV.1.2.2. Analyse des cas d'utilisations 36
IV.1.2.3. Réalisation des cas d'utilisation 54
IV.1.3. Modèles navigationel 64
IV.1.3.1. Démarche des modèles navigationnel 64
IV.1.3.2. Conventions spécifiques 65
IV.1.3.3. Structuration de la navigation 66
IV.1.3.4. Diagramme de navigation des cas d'utilisation 67
IV.2. CONCEPTION 68
IV.2.1. Démarche de conception objet 68
IV.2.2. Digramme d'interaction 69
IV.2.2.1. Règles de conception des diagrammes de
séquence objet 70
IV.4.2.2. Notation détaillée des diagrammes de
séquence 70
IV.2.3. Classes de conception 74
IV.2.3.1. Méthode des liens durable ou temporaires 75
IV.2.3.2. Structuration en packages de classes 77
IV.2.3.3. Diagrammes de classes des packages de la couche
métier 80
Chapitre V : IMPLEMENTATION DU SYSTEME
83
V.1. Environnement de développement 83
V.1.1. Installation de Maven 2 83
V.1.2. Mise en place du projet dans Maven2 84
V.1.3. Installation du serveur Jetty 84
V.2. Composants logiciels utilisés 84
V.2.1. Couche présentation 85
V.2.1.1. Le client léger 85
V.2.1.2. Le client lourd 85
V.2.3. Couche service 85
V.2.3.1. La génération de document 85
V.2.3.2. L'envoi de mail 86
V.2.3.3. Gestion des traces applicatives 86
V.3. Paquetage du système 86
V
V.3.1. Paquetage « service » 87
V.3.2. Paquetage « entities » 87
V.3.3. Paquetage « web » 87
V.3.4. Paquetage « dao » 87
V.4. Mise en oeuvre de l'architecture en couche du
système 87
V.4.1. Description de la couche présentation 88
V.4.2. Description de la couche métier 90
V.4.3. Description de la couche service 90
V.4.4. Description de la couche DAO 91
V.5. Sécurité 93
V.5.1. Accès à l'application 93
V.5.2. Chiffrage du mot de passe 93
V.5.3. La session 94
VI.5. Déploiement du système 94
VI.5.1. Génération du fichier war 94
VI.5.2. Déploiement sur le serveur web 95
Chapitre VI : RESULTATS ET TESTS
96
VI.1. Les formulaires 96
VI.1.1. Authentification système 96
VI.1.2. Accueil 97
VI.1.3. Evaluation d'un dossier 98
VI.2. Les états 98
VI.2.1. Lettre 98
VI.2.2. Faux diplôme 100
CONCLUSION ET PERSPECTIVE 101
BIBLIOGRAPHIE 102
GLOSSAIRE 103
VI
Liste des abréviations
API: Application Programming Interface
D-AC : Dossier d'Analyse et Conception
DAO: Data Access Object
DCP : Diagramme de Classe Participante
D-I : Dossier d'Implémentation
D-CC: Dossier de Cahier des charges
DSS: Diagramme de Séquence Système
EA: Enterprise Architect
EJB: Entreprise Java Bean
FF: FireFox
HTML: Hypertext Transfer Markup Language
IE: Internet Explorer
IHM : Interface Homme Machine
IMAP : Internet Mail Access Protocol
ISS: Institut Supérieur du Sahel
J2EE : Java Entreprise Edition
JDBC: Java DataBase Connector
JPA : Java Persistance API
JSP: Java Server Page
LOSEQUIV : Logiciel du Suivi et Traitement des Dossiers
d'Equivalence
MINESUP : Ministère de l'Enseignement
Supérieur
MS: Microsoft
MVC : Model View Controller
ORM: Objet Relationnel Mapping
POJO : Plain Old/Ordinary Java Object
POM : Project Object Model
POP3 : Post Office Protocol
RUP: Rational Unified Processs
SDE : Sous-direction des équivalences
SGBD: Système de Gestion de Base de Données
SI: Système d'Information
SMS: Short Message System
SQL: Structure Query Language
UC : Use Case
UML: Unified Modeling Language
UP : Unified Process
XML: Extensible Markup Language
VII
RESUME
Dans le cadre de notre formation de fin d'étude, nous
avons effectué un stage allant de la période du 20 Mars au 30
juin 2013 au Ministère de l'Enseignement Supérieur du Cameroun,
sanctionné à la fin par la rédaction de ce mémoire
de fin d'étude. Durant cette période, nous avons
développé une application de suivi des dossiers
d'équivalence des diplômes. Cette application comporte cinq
modules : le module de gestion des dossiers qui permet de créer,
modifier, supprimer les dossiers des candidats ; Le module d'évaluation
qui permet d'évaluer les dossiers des candidats sollicitant une demande
d'équivalence ; Le module de transmission pour l'envoi des dossiers dans
les différents services ; Le module position qui permet de donner la
position d'un dossier dans un service ; et enfin le module imprime pour
l'impression des différents documents (lettre de demande
d'équivalence, liste des faux diplômes).
Mots clés : Equivalence, dossier, suivi,
traitement, diplôme.
VIII
Asbtract
As part of our training at the end of study, we completed an
internship from the period 20 March to 30 June 2013 the Ministry of Higher
Education of Cameroon, sanctioned by the end of writing this dissertation
study. During this period, we have developed a monitoring application records
equivalency diplomas allowed to solve problems (poor organization, delays in
processing losses) that met the executives of this sub-direction. The system we
have developed has been deployed in the local network of the Ministry on the
Tomcat application and database on the MySQL server.
Key words : Equivalence, folder, monitoring, treatment,
diploma.
IX
Liste des illustrations
Figure 1-1 : découpage 3
Figure 2-1 : Outils J2EE 5
Figure 2-2 : Architecture d'une application J2EE 7
Figure 2-3 : Maven. 8
Figure 2-2 : Structure du répertoire maven2 9
Figure 2-5 : fonctionnement du serveur svn 10
Figure 2-6 : Mapping objet/relationnel 12
Figure 3-1 : Cycle de vie du processus unifié 17
Figure 3-2 : Planning prévisionnel 19
Figure 3-3 : Architecture physique 25
Figure 3-4 : Architecture logicielle 25
Figure 3-5 : Gestion des besoins. 27
Figure 4-1 : Démarche des besoins qui conduisent à
des cas d'utilisation et à une
maquette. 29
Figure 4-2 : Synoptique de la démarche. 29
Figure 4-3 : Organisation des cas d'utilisation et des acteurs en
packagent. 31
Figure 4-4 : Diagramme des relations entre les cas d'utilisation
métier. 31
Figure 4-5 : Suite du diagramme des cas d'utilisation 32
Figure 4-6 : Matrice de relations entre cas d'utilisation et
besoins sous EA. 34
Figure 4-7 : Maquette système. 35
Figure 4-8 : Démarche des cas d'utilisation qui conduisent
au diagramme de séquence
et de classes participantes. 36
Figure 4-9 : Diagramme des cas
d'utilisation d'analyse du chef de la sous direction. 37
Figure 4-10 : Diagramme des cas d'utilisation des cadres. 37
Figure 4-11 : Suite du diagramme des cas d'utilisation des
cadres. 38
Figure 4-12 : Use case 1- créer dossier. 39
Figure 4-13 : Diagramme de séquence créer dossier.
41
Figure 4-10 : IHM créer dossier 42
Figure 4-14 : Use case 2 envoyer dossier. 42
X
Figure 4-15: Diagramme de séquence envoyer dossier. 44
Figure 4-16 : IHM envoyer dossier. 44
Figure 4-17 : Use case 3 créer comptes. 45
Figure 4-18 : Diagramme de séquence créer comptes.
47
Figure 4-19 : IHM créer comptes 47
Figure 4-20 : Use case 4 créer établissement.
48
Figure 4-21 : Diagramme de séquence créer
établissement. 50
Figure 4-22 : IHM créer établissement. 50
Figure 4-23 : Élaboration de la matrice de validation.
51
Figure 4-24 : Opérations système. 52
Figure 4-25 : Opérations système structurés
en interfaces. 52
Figure 4-27 : Concepts liés à la gestion des
dossiers. 56
Figure 4-28 : Concepts liés à l'initiation de la
lettre 56
Figure 4-29 : Concepts liés à l'évaluation
des dossiers. 57
Figure 4-30 : Concepts liés à l'envoie des
dossiers. 57
Figure 4-31 : Exemple d'entité, de contrôle et
dialogue 60
Figure 4-32 : Exemple de diagramme de classe participante. 60
Figure 4-33 :DCP gérer dossiers. 61
Figure 4-34 : DCP Initier lettre. 62
Figure 4-35 : DCP évaluer dossier. 63
Figure 4-36 : DCP envoyer dossier. 63
Figure 4-37 : Démarche de la maquette et DCP qui
conduisent à un diagramme de
navigation. 64
Figure 4-38 : Conventions graphiques spécifiques. 65
Figure 4-39 : Début des diagrammes de navigation. 66
Figure 4-40 : Diagramme global simplifié de la navigation.
67
Figure 4-41 : Démarche de réalisation de diagrammes
d'interaction et de classes de
conception 68
Figure 4-42 : Suite démarche de
réalisation de diagrammes d'interaction et de classes
de conception. 69
Figure 4-43 : Passage de l'analyse à la conception
préliminaire 70
XI
Figure 4-40 : Notation détaillée des diagrammes
de séquence 70
Figure 4-44 : Notation détaillé de diagramme de
séquence 71
Figure 4-45 : Diagramme de séquence
détaillée créer dossier. 71
Figure 4-46 : Diagramme de séquence
détaillée créer dossier avec erreur. 72
Figure 4-47 : Diagramme de séquence
détaillée suppression dossier. 72
Figure 4-48 : Diagramme de séquence
détaillée évaluer dossier. 73
Figure 4-49 : Diagramme de séquence
détaillée valider statut dossier. 73
Figure 4-50 : Diagramme de séquence
détaillée envoyer dossier. 74
Figure 4-51 : Exemple liens temporaires et dépendances
75
Figure 4-53 : DCP détaillé évaluer
dossier 75
Figure 4-52 : DCP détaillé gérer dossier.
76
Figure 4-48 : DCP détaillé gérer dossier
76
Figure 4-54 : DCP détaillé envoyer dossier.
76
Figure 4-55 : Diagramme de packages de l'architecture logique.
77
Figure 4-57 : Détail de l'architecture logique 78
Figure 4-58 : Découpage en packages montrant leur
indépendance. 79
Figure 4-59 : Suite découpage en packages montrant leur
indépendance. 80
Figure 4-60: Diagramme de classe du package dossier. 80
Figure 4-61 : Diagramme de classe du package traitement. 81
Figure 4-62 : Diagramme de classe du package suivi. 81
Figure 4-63 : Diagramme synthétique. 82
Figure 5-1 : Swing. 85
Figure 5-2 : Paquetage système. 86
Figure 5-3 : Architecture en couche du système 87
Figure 5-4 : Suite architecture en couche du système.
88
Figure 5-5 : Architecture couche présentation. 89
Figure 5-6 : Architecture couche métier 90
Figure 5-7 : Architecture couche service 91
Figure 5-8 : Architecture couche DAO. 92
Figure 5-9 : Accès application. 93
Figure 5-10 : Chiffrage du mot de passe. 93
XII
Figure 5-11 : Création session. 94
Figure 6-1 : Authentification système. 96
Figure 6-2 : Accueil. 97
Figure 6-3 : Formulaire d'évaluation. 98
Figure 6-4 : Etat lettre. 99
Figure 6-5 : Etat faux diplôme 100
XIII
Liste des tableaux
Tableau 3-1 : Livrables attendus 15
Tableau 3-2 : Outils logiciels 18
Tableau 3-3 : Identification des risques 18
Tableau 4-1 : Classement des cas d'utilisation 32
Tableau 4-2 : Planifications des itérations obtenu
grâce aux cas d'utilisation. 34
Tableau 4-3 : Description des cas d'utilisation d'analyse.
38
Tableau 4-4: Scenario nominal use case 1. 40
Tableau 4-5: Fonction qualité mesure use case 1. 41
Tableau 4-4: Scenario nominal use case 2. 43
Tableau 4-5: Fonction qualité mesure use case 2. 43
Tableau 4-6: Scenario nominal use case 3. 45
Tableau 4-7: Fonction qualité mesure use case 3. 46
Tableau 4-8: Scenario nominal use case 4. 48
Tableau 4-9: Fonction qualité mesure use case 4. 49
Tableau 5-1 : configuration maven2 83
Tableau 5-2 : Mise en place losequiv 84
Tableau 5-3 : Configuration jetty 84
Tableau 5-4 : génération du fichier war 95
1
INTRODUCTION
L'émergence du Cameroun passera non seulement par
l'agriculture mais aussi par la maitrise et l'application des nouvelles
technologies en insistant sur la pluridisciplinarité des formations.
Ainsi dans le but principal d'enrichir le pays de nouvelles disciplines, la
jeunesse Camerounaise sollicite de plus en plus des formations
étrangères. Ceci étant, de retour au pays, les
diplômes étrangers pour leur mise en application doivent suivre
une procédure de validation. Cette validation passe par l'obtention d'un
document officiel nommé équivalence qui permettra au
récipiendaire de postuler à un emploi ou à un concours. Au
Cameroun, l'équivalence d'un diplôme est délivrée
par le ministère de l'enseignement supérieur notamment par sa
sous-direction des équivalences qui se charge de l'étude des
dossiers de demande d'équivalence. L'équivalent d'un
diplôme étranger confère à ce dernier le même
droit que celui délivré par le Cameroun.
Face donc à la demande d'équivalence de plus en
plus grandissante, les cadres de la sous-direction d'équivalence
rencontrent d'énormes difficultés dans l'étude des
dossiers de demande d'équivalence. Il était donc question de
trouver une solution à ces difficultés. Solution que nous avons
adoptée avec la conception et implémentation d'une application de
suivi et traitement des dossiers des demandes d'équivalence des
diplômes.
Ce mémoire comporte six chapitres. Le premier chapitre
décrit le contexte de l'étude et pose la problématique. Le
chapitre deux présente l'ensemble des technologies java web
nécessaire à la conception et à l'implémentation du
système. Le chapitre trois définit les besoins du système
et des utilisateurs. Le chapitre quatre décrit le comportement et la
conception des différents composants du système. Le chapitre cinq
présente les différents paquetages. Et enfin le chapitre six
présente les résultats et tests.
2
Chapitre I : CONTEXTE ET PROBLEMATIQUE
Il sera question dans ce chapitre non seulement de décrire
le contexte de l'étude et de poser la problématique mais
également de décrire la méthodologie utilisée et
enfin définir les objectifs à atteindre.
I.1. Contexte et problématique
Le MINESUP, structure en charge de l'enseignement
supérieur au Cameroun, dispose d'une direction de coordination des
activités académiques dans laquelle on retrouve la Sous-direction
des Equivalences, qui est chargé de l'étude des dossiers de
demande d'équivalence. Cette SDE reçoit
régulièrement les dossiers des candidats sollicitant une demande
d'équivalence d'un diplôme obtenu dans un pays étranger.
L'équivalence étant l'assimilation des diplômes
délivrés par un système éducatif d'un pays
étranger aux diplômes délivrés par le système
éducatif Camerounais, sur la base d'un ensemble de conditions telles que
celles relatives à l'inscription, au nombre d'années
d'études, au contenu des programmes et aux procédures
d'évaluation des connaissances (cf.1). Grâce à
l'équivalence, un diplôme étranger acquiert la même
valeur que ceux délivrés au Cameroun et son titulaire disposera,
sauf exceptions, des mêmes droits que le possesseur d'un diplôme
Camerounais et pourra par exemple avec cette équivalence postuler
à un concours dans les secteurs publics et privés, à une
offre d'emploi ou de formation.
Face à la demande de plus en plus grandissante des
candidats sollicitant une équivalence de diplôme, les cadres de la
SDE rencontrent d'énormes difficultés à savoir :
- Une mauvaise organisation des dossiers qui entraine des
recherches longues et fastidieuses, parfois la perte de ceux-ci ;
- Des lenteurs de traitements des dossiers par certains
services retardent le
processus de demande d'équivalence ;
1 Inspiré du document : Guide pratique pour les
équivalences de diplôme,
http://www.cire.be/component/docman/doc_download/207-guide-pratique-pour-les-equivalences-de-diplome
- Difficulté à traiter les lettres de demande
d'équivalence des candidats ;
- L'impossibilité d'informer le candidat de venir
compléter les pièces manquantes ou de la délivrance ou le
refus de son équivalence;
Comment permettre aux cadres de cette sous-direction d'avoir
une meilleure organisation des dossiers ? D'éviter les lenteurs de
traitement des dossiers par certains services ? De traiter facilement les
lettres de demande ? D'informer les candidats ?
Dans le cadre de notre formation de fin d'étude, il nous a
été demandé de trouver une solution aux problèmes
d'études des dossiers d'équivalences que rencontrent les cadres
de la Sous-direction des équivalences du MINESUP.
I.2. Méthodologie de résolution du
problème
La méthodologie de cette solution commencera la
rédaction du dossier d'initiation et d'expression des besoins qui
définiront le cahier des charges du système; Ensuite un dossier
d'analyse et conception sera défini, avec pour but ici d'apporter une
solution informatique par les modèles de cas d'utilisation, d'analyse,
de navigation et de conception. Enfin le dossier d'implémentation nous
conduira au codage et déploiement définitif du système. La
figure suivante illustre cette méthodologie.
Définition du cahier des charges
Analyse et conception du système
Implémentation et test du
système
3
Figure 1-1 : découpage
4
I.3. Objectifs visés
L'objectif est de concevoir et implémenter une application
de gestion des dossiers des demandes d'équivalence des diplômes
qui permettra de résoudre les difficultés que les cadres
rencontrent. Cette application devra ainsi permettre :
- Une meilleure organisation des dossiers de demande
d'équivalence ;
- Un accès facile et une recherche rapide des dossiers
;
- La sauvegarde et archivages automatique des dossiers ;
- Informer les candidats de la délivrance ou le refus
d'une équivalence par Email;
- Informer les cadres en cas de lenteurs de traitement des
dossiers par certains
services;
- Permettre le traitement automatisé des lettres de
demande d'équivalence des
candidats ;
- Permettre un suivi complet des dossiers d'un service à
un autre.
Chapitre II : GENERALITES DE LA PLATE FORME J2EE
Dans ce chapitre nous allons décrire les principales
généralités de la plate forme J2EE nécessaires
à la mise en place du système. Nous commencerons par une
présentation de J2EE, ensuite le constructeur de projet maven. Nous
continuerons par la description du gestionnaire de version svn, ensuite du
conteneur léger Spring, le Framework composant Wicket et enfin le
mapping objet/relationnel de hibernate/ JPA.
II.1. Présentation de J2EE
Le terme « Java EE » signifie Java Enterprise
Edition, et était anciennement raccourci en « J2EE ». Il fait
quant à lui référence à une extension de la
plate-forme standard. Autrement dit, la plate-forme Java EE est construite sur
le langage Java et la plate-forme Java SE (Java Standard Edition), et elle y
ajoute un grand nombre de bibliothèques remplissant tout un tas de
fonctionnalités que la plate-forme standard ne remplit pas d'origine.
L'objectif majeur de Java EE est de faciliter le développement
d'applications web robustes et distribuées, déployées et
exécutées sur un serveur d'applications (MOLIERE, 2005).
II.1.1. Concept de la plate forme J2EE
La figure suivante présente les différentes
technologies utilisées par la plate forme J2EE.
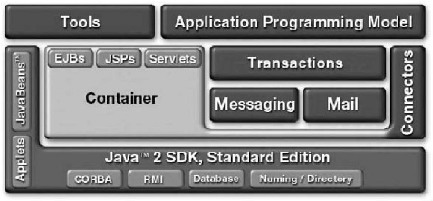
Source : (ROQUES, 2002). Figure 2-1 : Outils J2EE
5
6
Avec le langage Java est apparue une nouvelle technologie :
les servlets. Ces petits «serveurs» ou «services» sont
écrits en langage Java et utilisent une API spécifique. Les
performances sont améliorées par les fonctionnalités
multithreads des serveurs J2EE, évitant la création de processus
externes (MOLIERE, 2005).
Cependant, le développeur doit toujours mixer le code
Java et HTML. De plus, la moindre modification oblige à recompiler la
servlet et à la recharger. Les JSP, ou Java Server Pages, viennent
résoudre ces problèmes de recompilation. Ici, c'est le code Java
que l'on incorpore dans la page HTML avec des techniques de scripting. Le
serveur compile automatiquement la page en une servlet et l'exécute
ensuite. Les approches à base de scripting nécessitent
l'incorporation importante de code applicatif dans le HTML. Ces techniques
limitent aussi la réutilisation de code (MOLIERE, 2005).
Pour ce qui est du monde Java, il a donc été
proposé de faire collaborer les servlets et les JSP dans les
applications. Les servlets sont utilisées par les développeurs
pour gérer les aspects programmation d'une application web et les JSP
sont utilisées par les infographistes pour effectuer l'affichage. On
retrouve ainsi une servlet et une JSP par requête possible sur le site
web. La servlet ne contient plus de HTML, et la JSP contient juste le code
nécessaire à l'affichage. Ce style de programmation respecte le
paradigme MVC.
II.1.2. Le paradigme MVC
(Modèle-Vue-Contrôleur)
Le paradigme MVC est un schéma de programmation qui
propose de séparer une application en trois parties :
· le modèle, qui contient la logique et
l'état de l'application ;
· la vue, qui représente l'interface utilisateur
;
· le contrôleur, qui gère la synchronisation
entre la vue et le modèle.
Le point essentiel consiste à séparer les
objets graphiques des objets métier, afin de pouvoir les faire
évoluer indépendamment et les réutiliser.
7
On peut également gérer facilement plusieurs vues
du même modèle.
Au final, une telle séparation favorise le
développement et la maintenance des applications :
· Le modèle étant séparé des
autres composants, il est développé indépendamment. Le
développeur du modèle se concentre sur le fonctionnel et le
transactionnel de son application.
· Le modèle n'est pas lié à une
interface, il peut donc être réutilisé (passage d'une
application avec interface en Java à une application avec interface
web). Dans les applications J2EE, le modèle est assuré par des
EJB et/ou des JavaBeans, le contrôleur est assuré par des servlets
et la vue par des JSP (voir la figure 2-2 suivante).
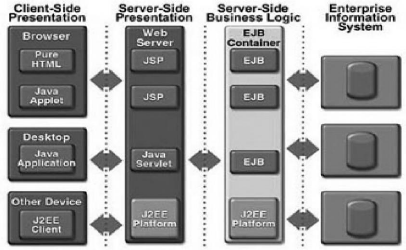
Figure 2-2 : Architecture d'une application J2EE
Source : (ROQUES, 2002)

II.2. Apache Maven 2 : Outil de build Apache
Maven 2 est un outil « open source » de Apache Jakarta. Il permet de
faciliter et d'automatiser la gestion et la construction d'un projet java
(VONGVILAY Michel, 2004). Le premier but de Maven est de permettre aux
développeurs de connaitre rapidement l'état
global du développement du projet. C'est dans ce but que Maven :
· Facilite le processus de construction
· Fournit un système de construction uniforme
· Fournit des informations utiles sur le projet
· Fournit clairement les grandes lignes directrices de
développement
· Fournit les éléments nécessaires
pour faire des tests complets
· Fournit une vision cohérente et globale du
projet
· Permet d'ajouter de nouvelles fonctionnalités de
façon transparente
Maven est basé sur le concept de « Project Object
Model » (POM). Le développement et la gestion du projet sont
contrôlés depuis le POM.
II.2.1. Principe de fonctionnement
La figure 2-3 suivante illustre le principe de fonctionnement du
constructeur de projet maven.
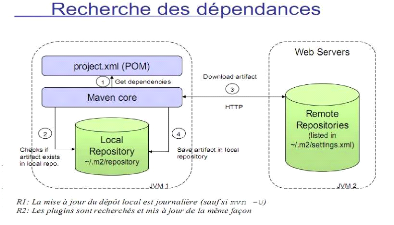
Figure 2-3 : Maven.
8
Source :
linsolas.developpez.com/articles/java/builds
1. Maven commence par définir la liste des
dépendances nécessaires au projet, via la lecture du fichier
pom.xml du projet ;
2. Maven interroge alors le repository local afin de trouver
les dépendances utilisés ;
3. Si la dépendance n'est pas trouvée, alors
maven va interroger les repositories distants ;
4. les dépendances absences du repository local sont
alors téléchargées depuis les repositories distants, de
telles façon a ce qu'elles disponibles lors des prochains builds ;
5. Maven peut alors utiliser la dépendance pour la
construction du projet.
L'intérêt de ce mécanisme, en plus de sa
simplicité, est que nous ne définissons plus que les
dépendances directes de notre projet. Les dépendances de nos
dépendances, autrement appelées dépendances transitives
sont directement gérées par Maven2, et ne préoccupent plus
l'esprit du développeur (VONGVILAY Michel, 2004).
II.2.2. La structure de répertoires
Une partie de la puissance de Maven vient des pratiques
standardisées qu'il encourage. Un développeur qui a
déjà travaillé sur un projet Maven se sentira tout de
suite familier avec la structure et l'organisation d'un autre projet Maven. Il
n'y a pas besoin de gaspiller du temps à réinventer des
structures de répertoires, des conventions, et à adapter des
scripts de build Ant pour chaque projet (SMART, 2005). Même s'il est
possible de redéfinir l'emplacement de chacun des répertoires
vers une localisation spécifique, il est réellement
intéressant de respecter la structure de répertoire standard
de Maven 2 autant que possible, et ce pour plusieurs raisons
:
· Cela rend le fichier POM plus court et
plus simple ;
· Cela rend le projet plus simple à comprendre et
rend la vie plus simple au pauvre développeur qui devra maintenir le
projet quand vous partirez ;
·
9
Cela rend l'intégration de plug-ins plus simple.
II.3. 10
Le serveur SVN
SVN signifie Subversion est un système de gestion de
version, conçu pour remplacer CVS. Concrètement, ce
système permet aux membres d'une équipe de développeur de
modifier le code du projet quasiment en même temps. Le projet est en
effet enregistré sur un serveur SVN et à tout moment, le
développeur peut mettre à jour une classe avant de faire des
modifications pour bénéficier de la dernière version et a
la possibilité de comparer deux versions d'un même fichier.
Le principe de fonctionnement est le suivant :
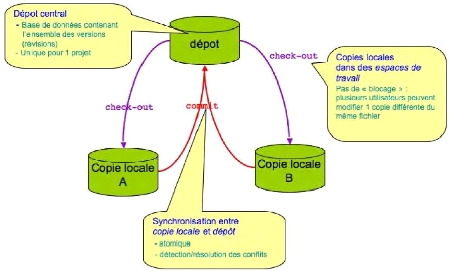
Figure 2-5 : fonctionnement du serveur svn
II.4.

Spring : Faciliter le développement et les
tests
Le Framework Spring est un conteneur dit « léger
», c'est-à-dire une infrastructure similaire à un serveur
d'application J2EE (FERRAN, 2008). Il prend donc en charge la création
d'objets et la mise en relation d'objets par l'intermédiaire d'un
fichier de configuration qui décrit les objets à fabriquer et les
relations de
11
dépendances entre ces objets (IoC - Inversion of
Control). Le gros avantage par rapport aux serveurs d'application est qu'avec
SPRING, les classes n'ont pas besoin d'implémenter une quelconque
interface pour être prises en charge par le Framework. C'est en ce sens
que SPRING est qualifié de conteneur « léger ».
L'idée du pattern IoC est très simple, elle consiste, lorsqu'un
objet A à besoin d'un objet B, à déléguer à
un objet C la mise en relation de A avec B (FERRAN, 2008).

II .5. Apache Wicket : Mettre en place le
MVC
Apache Wicket est un Framework pour la création
d'applications web qui repose presque entièrement sur Java et HTML comme
moyens pour bâtir ses interfaces. Wicket est YAJF (Yet Another JavaEE
Framework), mais orienté composants. Il se distingue par certaines
grandes particularités :
· Pas de JSP !
· Aucun tag de logique (boucle, condition)
mélangé au HTML
· Les composants web sont créés dans des
classes Java "à la Swing" avant d'être simplement placés
aux endroits souhaités dans le fichier HTML ;
· Une gestion particulièrement simple de
tâches récurrentes dans le développement de sites web comme
la validation de formulaires, le passage de paramètres entre les pages
et la navigation ;
· Un Framework créé dans l'idée de
vouloir faciliter le développement de composants
réutilisables.
II.6. Hibernate et DAO : le mapping
objet/relationnel
Les difficultés de cohabitation entre les mondes
objets et relationnels sont résolues grâce au concept de Mapping
objet-relationnel (O/R Mapping), qui est le nom donné aux techniques de
transformation des modèles objets en modèles relationnels (ROS,
2003).
Les choix architecturaux d'une application sont
décisifs dès lors qu'ils interviennent sur les performances,
l'évolutivité, les temps de développement, et bien
sûr les coûts.
Les sages d'aujourd'hui prônent une séparation
en différentes couches des applications, et parlent alors d'applications
multi niveaux (n-tier applications) voir figure 2-6.
|
Figure 2-6 : Mapping objet/relationnel
|
|
12
L'ORM est nécessaire parce la représentation
sous forme Relationnelle n'entre pas en correspondance avec la
représentation Objet.
· Objet : notions d'héritage et de polymorphisme
;
· Objet : pas d'identifiant (pointeur) ;
· Objet : les relations n:m sont modélisées
par des containers.
II.6.1. Data Access Object (DAO)
Quel que soit le système sur lequel vous
développez, vous pourrez toujours accéder à vos
données relationnelles. Vous utiliserez alors des API telles que JDBC,
ADO,
ADO.Net, et pourrez alors exécuter
des requêtes SQL, ou obtenir des objets représentant des tables et
leurs champs.
Ces outils sont suffisants mais ne permettrons jamais
à eux seuls une vraie abstraction de la base de données
sous-jacente. Par exemple vous ne pourrez pas obtenir toutes les commandes d'un
client donné avec une seule ligne de code. De plus, chaque fois que vous
voudrez supprimer un client, vous devrez supprimer manuellement son adresse,
alors que cela pourrait être fait automatiquement (ROS, 2003).
Tous ces problèmes doivent être
gérés par une couche d'accès aux données
chargée de communiquer avec le serveur de bases de données, et de
renvoyer des objets
13
métiers au programmeur ; Ce denier n'aurait alors plus
besoin de taper des requêtes SQL, comprendre les relations entre les
tables, ou connaître tous les paramètres des procédures
stockées, ou encore d'autres éléments. Lorsqu'on parle de
séparation des couches par responsabilité, il y a va
également de la séparation des compétences de chaque
développeurs.
II.6.2. Hibernate
Outil de mapping objet/relationnel pour le monde Java. Le
terme mapping objet/relationnel (ORM) décrit la technique consistant
à faire le lien entre la représentation objet des données
et sa représentation relationnelle basée sur un schéma
SQL.
Non seulement, Hibernate s'occupe du transfert des objets
Java dans les tables de la base de données (et des types de
données Java dans les types de données SQL), mais il permet de
requêter les données et propose des moyens de les
récupérer. Il peut donc réduire de manière
significative le temps de développement qui aurait été
autrement perdu dans une manipulation manuelle des données via SQL et
JDBC.
Le but d'Hibernate est de libérer le
développeur de 95 pourcent des tâches de programmation
liées à la persistance des données communes. Hibernate
n'est probablement pas la meilleure solution pour les applications
centrées sur les données qui n'utilisent que les
procédures stockées pour implémenter la logique
métier dans la base de données, il est le plus utile dans les
modèles métier orientés objets dont la logique
métier est implémentée dans la couche Java dite
intermédiaire (ROS, 2003). Cependant, Hibernate vous aidera à
supprimer ou à encapsuler le code SQL spécifique à votre
base de données et vous aidera sur la tâche commune qu'est la
transformation des données d'une représentation tabulaire
à une représentation sous forme de graphe d'objets.
II.6.3. JPA Java Persistance API
JPA permet de manipuler des données en base de
données relationnelle directement à partir d'objets Java sans
écrire du code SQL. Comme pour JDBC,
14
l'utilisation de JPA nécessite un fournisseur de
persistance qui implémente les les classes et méthodes de l'API
lasses et méthodes de l'API.
Les classes dont les instances peuvent être
persistantes sont appelées des entités dans la
spécification de JPA Le développeur indique qu'une classe est une
entité en lui associant l'annotation @Entity. Ne pas oublier d'importer
javax.Persistence.Entity dans les classes entités (idem pour toutes les
annotations).
~ Configuration de la connexion
Il est nécessaire d'indiquer au fournisseur de
persistance comment il peut se connecter à la base de données.
Les informations doivent être données dans un fichier
persistence.xml situé dans un répertoire META-INF dans le
classpath. Ce fichier peut aussi comporter d'autres informations.
~ Gestionnaire d'entités
Classe javax.persistence.EntityManager, le gestionnaire
d'entités (GE) est l'interlocuteur principal pour le développeur.
Il fournit les méthodes pour gérer les entités : les
rendre persistantes, les supprimer de la base de données, retrouver
leurs valeurs dans la base, etc.
~ Contexte de persistance
La méthode persist(objet) de la classe EntityManager
rend persistant un objet. L'objet est ajouté à un contexte de
persistance qui est géré par le GE (gestionnaire
d'entités). Toute modification apportée à un objet du
contexte de persistance sera enregistrée dans la base de données.
L'ensemble des entités gérées par un GE s'appelle un
contexte de persistance.
Dans le cadre d'une application autonome, la relation est
simple : un GE possède un
contexte de persistance, qui n'appartient
qu'à lui et il le garde pendant toute son
existence. Lorsque le GE
est géré par un serveur d'applications, la relation est
plus
complexe ; un contexte de persistance peut se propager d'un GE à
un autre et il peut
être fermé automatiquement à la fin
de la transaction en cours.
15
Chapitre III : SPECIFICATION DES BESOINS
Ce chapitre va nous permettre de décrire le
référentiel qui nous guidera durant la conception et
implémentation du système. Nous commencerons dans la partie
initialisation par définir le cadre de déroulement de ce projet
de conception, ensuite dans la partie expression des besoins par définir
les besoins du système.
III.1. Initialisation du projet
La conception et implémentation du système
à commencer par l'initialisation du projet qui à définir
les livrables attendus, la composition de l'équipe projet, les
contraintes techniques, la méthodologie technique utilisée, les
outils logiciels, les risques identifiés et le planning
prévisionnel.
III.1.2. Livrables attendus
Tableau 3-1 : Livrables attendus
N°
|
Type
|
Code
|
Nom du livrable
|
Date de livraison
|
2
|
Document
|
D-CC
|
Dossier de Cahier des Charges
|
10 /04/2013
|
3
|
Document
|
D-AC
|
Dossier d'Analyse et
Conception
|
01/05/ 2013
|
4
|
Document
|
D-I
|
Dossier d'Implémentation
|
28/05/2013
|
5
|
Logiciel
|
losequiv
|
Logiciel du Suivi et Traitement
des dossiers d'Equivalence
de
diplôme
|
03/06/2013
|
|
III.1.3 Composition de l'équipe
L'équipe intervenante dans la mise du système est
répartir comme suit :
· Chef Projet
Dr EMVUDU Yves : Directeur des Systèmes d'Information
(SI) du ministère de l'enseignement supérieur
· Réalisateur du projet :
GBITHICKI NDANGA Brice Arsène : Etudiant Master
Informatique ISS Maroua
16
III.1.4. contraintes techniques
La conception et implémentation du système de
suivi et traitement des dossiers d'équivalence des diplômes devra
être un système multiutilisateur pour permettre à chaque
cadre de la sous-direction d'effectuer ses tâches. Aussi ce
système devra être accessible à travers un navigateur et
indépendamment de tout système d'exploitation utilisé.
Pour ce faire, nous avons opté d'utiliser une solution web à
plusieurs couches basée sur la plate forme J2EE car cette
dernière facilite le développement des applications web en
structurant l'architecture en plusieurs couches et fournissant les composants
déjà implémentés de chaque couche à travers
un serveur d'application. Cette plate forme propose une architecture MVC qui
apporte de réels avantages telle que :
· Une conception claire et
efficace grâce à la séparation des
données de la vue et du contrôleur ;
· Un gain de temps de maintenance et
d'évolution du système ;
· Une plus grande souplesse pour
organiser le développement du logiciel entre les différents
développeurs (indépendance des données, de l'affichage et
des actions).
III.1.5. Identification de la méthode
utilisée
Nous avons choisi d'utiliser la méthode UP
(Unified Process) qui est un processus de développement
logiciel « itératif et incrémental, centré sur
l'architecture, conduit par les cas d'utilisation et piloté par les
risques » (ROQUES, 2002). La gestion d'un tel processus est
organisée suivant les quatre phases suivantes : initialisation,
élaboration, construction et transition.
Les activités de développement sont
définies par cinq disciplines fondamentales qui décrivent la
capture des besoins, l'analyse et la conception, l'implémentation, le
test et le déploiement.
Le cycle de vie du projet décrit l'ensemble des
activités de développement que préconise la méthode
UP. Ces activités sont décrites de façon
indépendantes et
peuvent jouer un rôle plus ou moins important dans une
phase, parfois ne jouer aucun rôle.
La figure 3-1 ci-dessous illustre ce cycle de vie.
Phases
Activités
Initialisation
Elaboration
Construction
Transition
Besoins
Analyse et Conception
Implémentation
Tests
Déploiement
|
|
|
17
Figure 3-1 : Cycle de vie du processus
unifié
III.1.6. Outils logiciels
Nous prévoyons de travailler simultanément sur
deux systèmes d'exploitation (Windows Seven et Ubuntu 12.10). Une de nos
premières tâches sera de nous constituer une « boite à
outils » constituée d'outils à la fois portables mais
surtout compatibles les uns avec les autres (voir tableau 3-2):
18
Tableau 3-2 : Outils logiciels
Logo
|
Description
|
Rôle
|
|
Bureautique :
.docx (Microsoft Word) ou .odt (Open
Office)
|
Utilisés pour la rédaction des documents
|
|
|
Gestion de projet : MS Project
|
Nécessaire à l'élaboration du planning
prévisionnel
|
|
DropBox
|
stocker en ligne les
différents documents et les rendre accessibles depuis
n'importe quel ordinateur
|
|
Modélisation : Enterprise Achitect
|
Dessiner les différents model d'UML2
|
|
Editeur de code source : Notepad ++
|
|
|
Environnement de développement Intégré:
Eclipse for J2EE
|
|
|
Navigateurs: IE8 (Trident), FF17.0 (Gecko), Chrome (Webkit)
|
|
|
III.1.7. Identification des risques
Ce tableau 3-3 présente les différents risques
identifiés et pourront constitués un frein à la mise en
place de l'application.
Tableau 3-3 : Identification des risques
RISQUES
|
GRAVITE
|
PLAN D'ACTION
|
Accumulation du retard
|
Très importante
|
Remise en question du planning (réévaluation
éventuelle des charges)
|
|
|
Faire régulièrement le point sur
|
|
Mauvaise compréhension des
|
Très importante
|
l'avancement du projet et
|
besoins
|
|
organiser des réunions avec les cadres de la sous
direction des équivalences afin de mieux comprendre leurs exigences
|
|
|
sauvegarde régulière des
|
Perte de documents
|
importante
|
documents lors de leur rédaction; en plus, il faut
|
|
|
«commiter» un document sur le répositoire
DROPBOX après chaque modification importante
|
|
III.1.8. Planning prévisionnel
Le planning ci-dessous a été réalisé
à l'aide de l'outil MS Project. Il contient l'ensemble des tâches
à réaliser afin de mener à bout le projet,
regroupées en phases et sous-phases (voir figure 3-2).
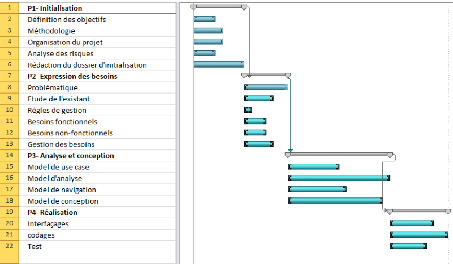
Figure 3-2 : Planning prévisionnel
19
20
III.2. Expression des besoins
L'expression des besoins nous à permit de faire une
étude de l'existant. De cette étude de l'existant ont
découlés les règles de gestion à mettre en place
ainsi que les besoins fonctionnels et non fonctionnels du système.
III.2.1. Etude de l'existant
Les candidats sollicitant une demande d'équivalence
vont déposer un dossier comprenant un ensemble de pièces au
courrier central du MINESUP. Ces pièces sont les suivantes :
- une demande timbrée adressée au MINESUP avec
précision de l'adresse personnelle, numéro de
téléphone et numéro d'étudiant à
l'étranger ;
- Une copie certifiée conforme de l'acte de naissance
;
- Photocopie certifié conforme des diplômes
à évaluer ;
- Programme des cours qui ont précédé
l'obtention des diplômes ; - Photocopies certifiés conformes de
tous les diplômes antérieurs ; - Trois photocopies de chacun des
diplômes ;
- Adresse complète et exacte des établissements
de formation ayant délivré les diplômes à
évaluer ;
- Préciser le centre d'écrit pour les examens
étrangers présentés au Cameroun ;
- Autorisation de l'étudiant pour solliciter les
renseignements le concernant auprès de son établissement ;
- Copie de la thèse pour les détenteurs du Master.
Ces dossiers vont suivre les étapes suivantes :
Etape 1 : La Sous-direction des Equivalences
va étudier le dossier des candidats en vérifiant les informations
sur le diplôme présenté.
21
Etape 2 : Ensuite collecte d'information
nécessaire à l'évaluation du diplôme
présenté, du système d'enseignement, des
conditions de formation, d'admission, et du statut de
l'établissement dans le pays de délivrance.
Etape 3 : Les cadres de la SDE montent les
dossiers d'équivalence (initié une lettre qui sera joint avec
certaines pièces) et les envois au chef de la sous-direction pour
signature.
Etape 4 : Lorsque le dossier d'un candidat
n'est pas complet le cadre appelle le candidat et lui informe de venir
compléter les pièces manquantes.
Etape 5 : Après signature des
dossiers par le chef de la Sous-direction, les cadres les envois dans les
ambassades respectifs pour vérification du dossier (authenticité
du diplôme, statut de l'école, système d'enseignement) par
l'intermédiaire du service courrier.
Etape 6 : Après la réponse de
l'ambassade, si l'établissement n'est pas reconnu dans le pays où
le diplôme a été délivré, une
délivrance ne peut être accordée.
Etape 7 : Une fois que les informations
nécessaires sont disponibles pour qu'elle se prononce sur
l'équivalence à accorder. Les sous commissions techniques
siègent à l'avance et émettent des avis
préparatoires et préalables aux délibérations de la
commission Nationale qui se tient deux semaines après.
Etape 8 : Les résultats des
délibérations sont ensuite acheminés aux cadres de la SDE
pour l'élaboration d'un projet d'équivalence des
diplômes (établissement des attestations de diplôme, niveau
et arrêtés) à soumettre à la signature du
MINESUP.
Etape 9 : Après signature du MINESUP
les dossiers sont renvoyés à la SDE. Affichage des
résultats au MINESUP et diffusion des résultats sur le site du
MINESUP.
Etape 10 : La SDE établie des
extraits d'équivalence (Document) et les envois au chef
de la Sous-direction pour signature.
22
Etape 11 : Les Candidats se présentent
à la SDE pour retrait des extraits d'équivalence et des
photocopies certifiées conformes des extraits de
l'arrêté d'équivalence sous présentation de
leur carte nationale d'identité.
III.2.2. Règles de gestion
R1 : Le candidat dépose un dossier de demande
d'équivalence d'un diplôme obtenu dans un pays l'étranger
;
R3 : Les cadres de la Sous-direction des équivalences
collecte des informations nécessaires à l'évaluation du
diplôme ;
R3 : Les cadres initiés une lettre qui sera joint avec
les certaines pièces ;
R4 : Ils envois les dossiers au chef de la Sous-direction pour
signature ;
R5: Les dossiers sont ensuite envoyés dans les
ambassades respectifs pour authentification des différentes
pièces ;
R6 : L'établissement qui délivre le
diplôme doit être reconnu dans ce pays sinon la demande
d'équivalence sera pas accordée ;
R7 : Délibération des dossiers
d'équivalence devant la commission nationale d'équivalence ;
R8 : Les résultats des délibérations
sont ensuite acheminés aux cadres de la Sous-direction pour
l'élaboration d'un projet d'équivalence des
diplômes à soumettre à la signature du MINESUP
;
R9 : Après signature du MINESUP les dossiers sont
renvoyés aux cadres de la Sous-direction pour l'établissement des
extraits d'équivalence, puis envoyés pour
signature au chef de la Sous-direction;
R10 : Retrait des extraits d'équivalence et des
photocopies certifiées conformes des extraits de
l'arrêté d'équivalence sous présentation de
leur carte nationale d'identité du candidat.
23
III.2.3. Besoins fonctionnels
Les fonctionnalités du système à mettre
en place sont les suivantes.
· Gérer les dossiers de demande
d'équivalence des candidats :
La gestion des dossiers va consister en : L'enregistrement,
la modification, la recherche et la suppression.
· traiter les lettres de demande des candidats
:
Permettra de créer une lettre qui sera joint avec les
pièces du candidat
· Evaluer les dossiers de demande
d'équivalence des candidats :
Qui consistera à vérifier l'originalité
du diplôme présenté, le niveau d'étude, le
système d'enseignement, les conditions de formation, d'admission, et du
statut de l'établissement.
· Envoyer les dossiers dans un service
:
Les dossiers devront être acheminés d'un service
à un autre tout en conservant la traçabilité de ceux-ci.
Les cadres seront informés de la durée des dossiers dans chaque
service.
· Etablir un projet d'équivalence
:
Après que la commission nationale à
siéger, établir un projet d'équivalence des candidats dont
les dossiers ont été approuvés. Il s'agit des
attestations de diplôme, de niveau, des arrêtés et
des extraits d'équivalence ;
· Consultation les dossiers :
Voir la liste des dossiers, Informer les candidats de la
position de leurs dossiers, Imprimer les extraits et arrêtés
d'équivalence ;
24
III.2.4. Besoins non fonctionnels
Il est nécessaire de confronter le futur
système à un certain nombre de besoins non fonctionnels afin
qu'il puisse répondre avec satisfaction à son utilisation.
· Disponibilité
Vu la forte demande d'équivalence des diplômes,
le système devra être capable de répondre à une
exigence de disponibilité extrêmement importantes. Il sera
nécessaire de veiller à concevoir une architecture suffisamment
importante et éventuellement des moyens de secours permettant de palier
à un incident.
· Sécurité
Pour poursuivre dans cette idée de
disponibilité du système, il faudra bien évidemment
répondre à un besoin de sécurité extrêmement
important. Il sera en effet vital d'assurer authentification de chaque
utilisateur, ceci permettra d'avoir une structure sécurisée
d'accès à l'application et de pouvoir suivre toutes les
opérations jugées critiques.
· Ergonomie
Enfin, le système devra répondre à
l'exigence globale d'ergonomie par une navigation simple de l'application, Une
mise en page de l'application qui facilitera au maximum la démarche
à l'aide d'une présentation claire et intuitive.
III.2.5. Architecture
Nous distinguons deux types d'architecture, une basée
sur une architecture physique et une autre sur architecture logicielle.
III.2.5.1. Architecture Physique
Le système est une application Web, les utilisateurs
peuvent se connecter à l'application par Internet ou intranet. Voila, la
figure 3-3 suivante donne une vue de l'architecture physique du
système.
Serveur d'application
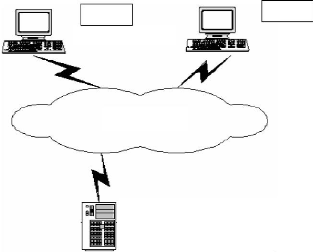
Client 2
INTRANET
Client 1
COUCHE PRESENTATION
COUCHE SERVICE
COUCHE DAO
Figure 3-3 : Architecture physique
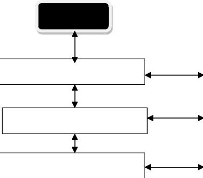
III.2.5.1. Architecture en couche
L'application est destinée à être
déployée dans un environnement J2EE (Java 2 Enterprise Edition)
définissant une norme proposée par la société Sun.
L'architecture que nous proposons repose sur les principes d'une architecture
4-tiers. Elle permet de diviser notre système en plusieurs couches (voir
figure 3-4) :
Utilisateur
25
Figure 3-4 : Architecture logicielle
|
SGBD
|
|
26
La couche présentation correspond à la partie de
l'application visible et avec laquelle les utilisateurs vont interagir ;
La couche service fournit un ensemble de méthodes pour
le traitement des données qui seront présenter à la couche
présentation ;
La couche d'accès aux données (DAO) regroupe un
ensemble d'objets permettant d'accéder à une base de
données. ;
La couche métier est responsable de la manipulation
des entités de l'application. Elle fournit ces entités aux
couches présentation, service et dao.
L'application pourra être exécutée sur
les plates formes Windows et Linux. Nous privilégierons le
développement sur un poste de travail Linux, le déploiement sur
un serveur Linux pour sa facilité, sa souplesse et sa robustesse. Nous
prendrons un soin de nous fier au standard Web pour avoir une même
représentation des données indépendantes du navigateur.
III.2.6. Gestion des besoins
« La gestion des Besoins est l'ensemble des
activités permettant de définir et de suivre les besoins d'un
système au cours d'un projet. Elle va nous permettre de s'assurer de la
cohérence entre ce que fait réellement le projet et ce qu'il doit
faire, de faciliter l'analyse d'impact en cas de changement » (ROQUES,
2002).
Grace l'outil EA (Entreprise Architect), nous avons
décrit les Besoins comme des éléments de
modélisation à part entière. Les Besoins ont au moins un
type, un identifiant et un texte descriptif, comme indiqué sur la figure
3-5 suivante.
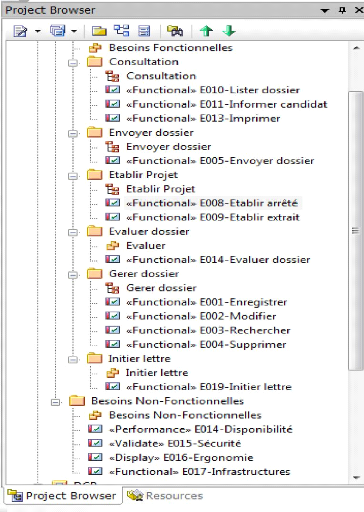
27
Figure 3-5 : Gestion des besoins.
« Ces Besoins sont classés suivant plusieurs
critères tels que la priorité fonctionnelle, la difficulté
technique. Cette gestion de Besoins nous permettra par la suite de conserver la
traçabilité entre les Besoins textuelles et les cas d'utilisation
du projet » ;
28
Chapitre IV : ANALYSE ET CONCEPTION DU SYSTEME
Nous rappelons que nous utilisons la méthode
UP qui est un processus itératif et incrémental,
guidé par des cas d'utilisation centré sur l'architecture
(ROQUES, 2002). Cette méthode utilise le langage UML 2
pour la modélisation des données. Nous
préciserons ici que l'ensemble des diagrammes et figures qui seront
présentés dans ce chapitre ont été
développé grâce l'outil de modélisation de projet
Entreprise Achitect.
Une fois que les besoins des utilisateurs ont
été identifiés au chapitre trois, il est question de
migrer ses besoins vers une solution informatique par le concept des
modèles de UML2. Nous débuterons dans la partie analyse par une
description détaillée du comportement du système ensuite
dans la partie conception par une spécification de la façon dont
chacun des composants du système seront réalisés et
comment ils interagiront.
VI.1. ANALYSE
Nous présenterons dans cette section les
modèles de cas d'utilisation, ensuite les modèles d'analyse et
enfin les modèles navigationnel.
IV.1.1. Modèles de cas d'utilisation
La réalisation des modèles de cas d'utilisation
débutera par la présentation d'une démarche,
l'identification des acteurs et cas d'utilisation à partir des besoins
fonctionnels décrits précédemment. Ensuite nous
structurons, relirons et classerons ces cas d'utilisation ainsi que les
représentations graphiques UML associées. Encore nous
planifierons et sortirons la traçabilité entre les besoins
textuels et les cas d'utilisation et enfin nous déduirons la maquette de
notre système.
IV.1.1.1. Démarche des modèles de cas
d'utilisation
L'expression préliminaire des besoins des utilisateurs
donne lieu à une modélisation par les cas d'utilisations et
à une maquette d'interface homme-machine (IHM) (ROQUES, 2002). La figure
4-1 ci-dessous nous décrit cette démarche :
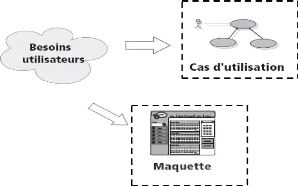
Figure 4-1 : Démarche des besoins qui
conduisent à des cas d'utilisation et à une
maquette.
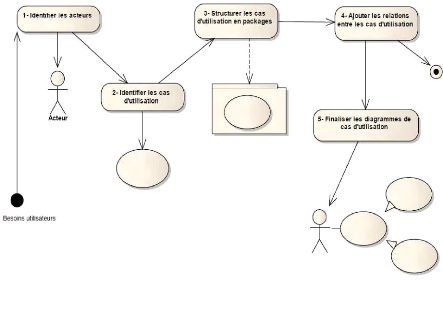
Figure 4-2 : Synoptique de la
démarche.
29
A partir des besoins nous allons identifier les acteurs,
identifier les cas d'utilisation, structurer les cas d'utilisation en packages,
ajouter les relations entre les cas d'utilisation et enfin finaliser les
diagrammes de cas d'utilisation (voir synoptique de la figure 4-2
ci-dessous).
30
IV.1.1.2. Identification des acteurs Les acteurs
de notre système sont :
· Cadres ;
· Chef de la Sous-direction.
IV.1.1.3. Identification des cas d'utilisation
métier
· Gérer dossier
· Gérer lettre
· Evaluer dossier
· Envoyer dossier
· Gérer établissement
· Imprimer
· Paramétrages
· S'authentifier
Le cas d'utilisation S'authentifier est
utilisé afin de permettre aux cadres d'exécuter ses propres cas
d'utilisation majeurs. Nous qualifierons donc ce petit cas d'utilisation de
« fragment » : il ne représente pas un
objectif à part entière des cadres, mais plutôt un objectif
de niveau intermédiaire (ROQUES, 2002).
IV.1.1.4. Structuration en packages
Nous allons organiser les cas d'utilisation et les regrouper
en ensembles fonctionnels cohérents. Pour ce faire, nous utilisons le
concept général d'UML, le package. Les acteurs
ont également été regroupés dans un package. Le cas
d'utilisation s'authentifier sera structuré dans un package à
part intitulé use case de second rang.
Le sigle UC pour use case sera
utilisé pour raccourcir les noms de packages.
La figure 4-3 suivante montre l'organisation des cas
d'utilisation et des acteurs en packagent.
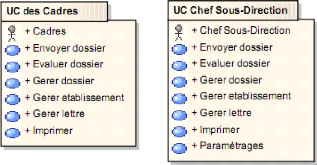
Figure 4-3 : Organisation des cas
d'utilisation et des acteurs en packagent.
IV.1.1.5. Relations entre les cas d'utilisation
métier
Nous allons dans la figure 4-4 suivante montrer les relations
entre les cas d'utilisation et les acteurs.
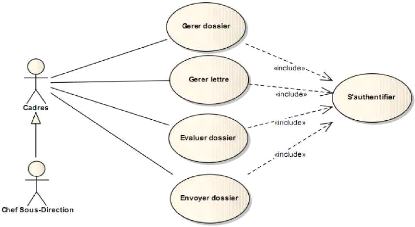
Figure 4-4 : Diagramme des relations entre
les cas d'utilisation métier.
31
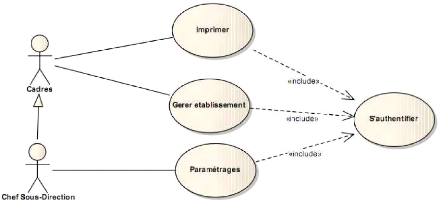
32
Figure 4-5 : Suite du diagramme des cas
d'utilisation.
IV.1.1.6. Classement des cas d'utilisation
métier
Après tout ce travail d'identification des cas
d'utilisation, nous pouvons maintenant les classifier en tenant compte des deux
facteurs suivants (ROQUES, 2002) :
· la priorité fonctionnelle,
déterminée par la Sous-direction des équivalences ;
· le risque technique, estimé par le chef de projet.
Le tableau suivant illustre cette démarche sur notre étude de
cas.
Tableau 4-1 : Classement des cas
d'utilisation
Cas d'utilisation
|
Priorités
|
Risques
|
Gérer dossier
|
Haute
|
Haut
|
Gérer lettre
|
Haute
|
Haut
|
Evaluer dossier
|
Haute
|
Haut
|
Envoyer dossier
|
Haute
|
bas
|
Gérer établissement
|
Moyenne
|
bas
|
|
33
Imprimer
Moyenne
|
bas
|
Paramétrages
|
Basse
|
bas
|
|
Dans ce classement des cas d'utilisation nous avons
distingués trois niveaux d'importance (Haute, Moyenne,
Basse). Les quatre priorités hautes des cas d'utilisation
Gérer dossier, Gérer lettre, Evaluer dossier, Envoyer dossier
sont celles sur lesquelles un accent sera mis tout au long du projet. Au
niveau technique les cas d'utilisation Gérer dossier, Gérer
lettre et évaluer dossier ont été classer avec le
risque le plus haut à cause de leurs complexités de mise en
oeuvre.
IV.1.1.7. Planification du projet en
itérations
À partir du classement précédent, nous
avons effectué le découpage en itérations suivant : Un des
bons principes du Processus Unifié consiste à identifier et lever
les risques majeurs au plus tôt. Nous devons donc prendre en compte de
façon combinée la priorité fonctionnelle et
l'estimation du risque (ROQUES, 2002):
· Si la priorité est haute et le risque
également, il faut planifier le cas d'utilisation dans une des toutes
premières itérations ;
· Si la priorité est basse et le risque
également, on peut reporter le cas d'utilisation à une des toutes
dernières itérations ;
· Lorsque les deux critères sont antagonistes, soit
on essaye de décider en pesant le pour et le contre, soit on
négocier avec les cadres de la SDE pour les convaincre qu'il vaut mieux
pour le projet traiter en premier un cas d'utilisation risqué mais peu
prioritaire, au lieu d'un cas d'utilisation plus prioritaire mais ne comportant
pas de risque (ROQUES, 2002).
Tableau 4-2 : Planifications des
itérations obtenu grâce aux cas d'utilisation.
Cas d'utilisation
|
Priorités
|
Risques
|
Itération#
|
Gérer dossier
|
Haute
|
Haut
|
1
|
Gérer lettre
|
Haute
|
haut
|
2
|
Evaluer dossier
|
Haute
|
Haut
|
4
|
Envoyer dossier
|
Haute
|
bas
|
3
|
Gérer établissement
|
Moyenne
|
bas
|
5
|
Consultation
|
Moyenne
|
bas
|
6
|
Paramétrages
|
Basse
|
bas
|
7
|
|
IV.1.1.8. Traçabilité des cas
d'utilisation avec les besoins textuelles
Nous avons établir dans cette figure des liens de
traçabilité entre besoins textuelles et les cas d'utilisations du
système (voir figure 4-6).
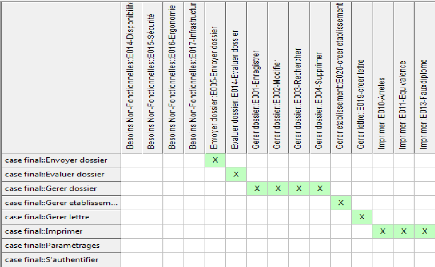
Figure 4-6 : Matrice de relations entre cas
d'utilisation et besoins sous EA.
34
35
Nous déduisons de cette matrice que toutes les besoins
textuelles ont bien été tracés par rapport à au
moins un cas d'utilisation. Par contre, les cas d'utilisation
paramétrages, s'authentifier doivent induire des
nouveaux besoins, puisqu'ils n'ont pas été reliés du tout.
Il est tout à fait courant que l'identification des cas d'utilisation
amène ainsi à une révision des besoins textuels.
IV.1.1.9. Maquette du système
De ces cas d'utilisation nous pouvons déjà
déduire nous marquette du logiciel du suivi des dossiers
d'équivalence suivante (voir figure 4-7).
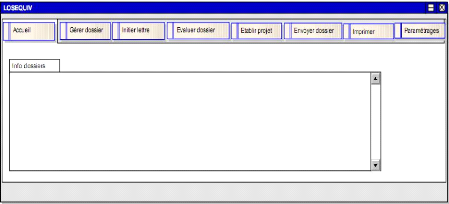
Figure 4-7 : Maquette système.
IV.1.2. Modèles d'analyse
Les modèles d'analyse vont nous permettre de faire une
description détaillée du système. Nous débuterons
cette description par une présentation de la démarche, ensuite
l'analyse des cas d'utilisations et enfin la réalisation des cas
d'utilisation d'analyse.
IV.1.2.1. Démarche des modèles
d'analyse
Nous rappelons que l'expression préliminaire des
besoins nous a donné lieu à une modélisation par les cas
d'utilisation métier et à une maquette d'interface homme-machine.
Nous allons maintenant apprendre à les décrire de façon
détaillée afin
36
d'obtenir une expression précise des besoins (ROQUES,
2002). La figure 4-8 ci-dessous illustre cette démarche :
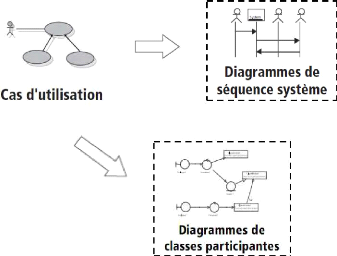
Figure 4-8 : Démarche des cas
d'utilisation qui conduisent au diagramme de séquence
et de classes
participantes.
IV.1.2.2. Analyse des cas d'utilisations
L'analyse des cas d'utilisation consiste à
élaborer des diagrammes de cas d'utilisation et faire une description de
ces cas d'utilisation. Ensuite élaborer la matrice de validation,
décrire les opérations système, structurer ces
opérations systèmes en interface et enfin les reliées au
cas d'utilisation.
a) Élaboration du diagramme des cas d'utilisation
d'analyse
Ce diagramme de cas d'utilisation d'analyse est plus
détaillé que celui présenté au paragraphe
précédent. En effet, nous sommes passés dans une phase
d'analyse qui correspond à une vue informatique du système.
~ Diagramme des cas d'utilisation d'analyse du chef de
la Sous-direction
Le diagramme de la figure 4-9 présente les cas
d'utilisation du chef de la sous-direction.
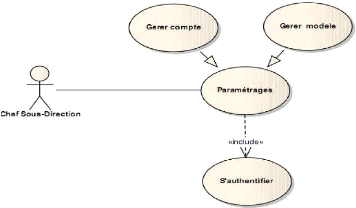
Figure 4-9 : Diagramme des cas d'utilisation
d'analyse du chef de la sous direction.
~ Diagramme des cas d'utilisation d'analyse des cadres
de la Sous-direction Le diagramme de la figure 4-10 présente
les cas d'utilisation des cadres
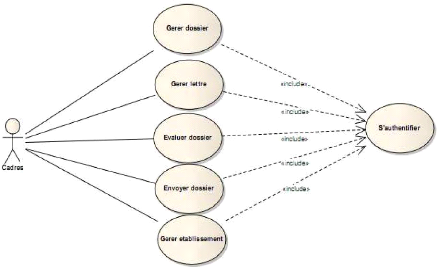
Figure 4-10 : Diagramme des cas d'utilisation
des cadres.
37
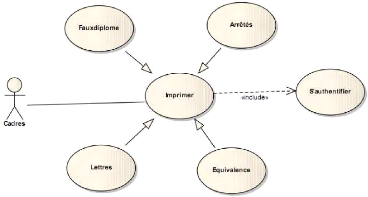
38
Figure 4-11 : Suite du diagramme des cas
d'utilisation des cadres. b) Description des cas d'utilisation
d'analyse
Nous allons décrire chaque cas d'utilisation d'analyse
dans l'ordre des itérations du tableau des planifications. Le tableau
suivant résume l'ordre d'analyse des cas d'utilisation
présenté dans la partie du modèle des cas d'utilisation
précédente.
Tableau 4-3 : Description des cas d'utilisation
d'analyse.
Itération
|
Cas d'utilisation métier
|
Cas d'utilisation d'analyse
|
1
|
Gérer dossier
|
Créer dossier Modifier dossier Supprimer dossier
Rechercher dossier
|
2
|
Gérer lettre
|
créer lettre
|
3
|
Evaluer dossier
|
Evaluer dossier
|
5
|
Envoyer dossier
|
Envoyer dossier
|
6
|
Gérer établissement
|
Créer établissement
|
7
|
Imprimer
|
Lettres
Faux-diplômes Arrêtés
|
|
|
|
Equivalences
|
8
|
Paramétrages
|
Gérer comptes Gérer modèle
|
|
Pour chaque cas d'utilisation, les sous-activités
suivantes de l'activité « Analyse des cas d'utilisation » sont
réalisées :
- Description textuelle du cas d'utilisation ; -
Elaboration du diagramme de séquence ; - Elaboration de l'interface
utilisateur.
Nous allons décrire les sous-activités des cas
d'utilisation suivant : créer dossier, envoyer dossier, créer
établissement, créer compte.
> Use case 1 : Créer
dossier
|
|
|
Figure 4-12 : Use case 1- créer
dossier.
|
|
|
|
|
|
39
1' Acteur principal : Cadres
1' Priorité : 1
1' Objectifs : sauvegarder les informations sur
le dossier des candidats
1' Pré-conditions :
· L'application est lancée,
· Le cadre s'authentifier,
· Le cadre se situé dans la page Gérer
dossier.
40
1' Post-conditions :
· Le dossier a été créé
· La page Gérer dossier est affichée 1'
Scénario nominal :
Tableau 4-4: Scenario nominal use case 1.
|
Action menée par le cadre
|
Action réalisée par le
système
|
|
1- Demande de création du dossier
|
|
|
2- Affiche le formulaire de saisi
|
3- Saisi les données relatives aux dossiers
|
|
4- Valide la saisie
|
|
|
5- Accède à la base de données et y ajoute
les données relatives au dossier
|
|
6- Informe le cadre que le dossier a été
créé
7- Affiche la page Gérer dossier
|
|
1' Alternatives :
· Le système signale le dysfonctionnement au
cadre
· Le système détecte des erreurs ou des
incohérences parmi les nouvelles informations
· Le cadre modifié toutes les informations
erronées et valide de nouveaux 1' Besoin IHM
· Un élément pour demander la création
d'un dossier,
· Un formulaire composé de composants de saisie
(champs de texte, listes de choix, etc.) pour saisir les informations
liées au dossier,
· Une zone de confirmation contenant un
élément de validation et un élément
d'annulation,
· Une barre des tâches pour informer de la
création du dossier ;
41
V' Fonction Qualité Mesure :
Tableau 4-5: Fonction qualité mesure use
case 1.
Fonction
|
Fréquence
|
Qualité
|
Mesure
|
Créer dossier
|
Régulière
|
Rapidité
|
Instantanée
|
|
Gère les accès concurrents aux
données de la base
|
|
V' Diagramme de séquence créer
dossier
Ce diagramme (voir figure 4-13) montre les interactions entre
les cadres et le système.
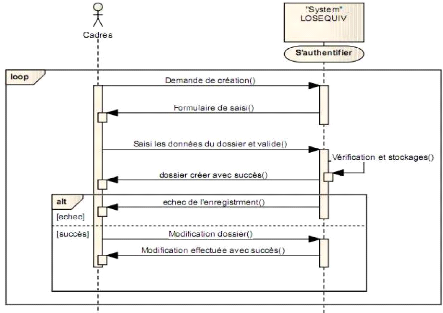
Figure 4-13 : Diagramme de séquence
créer dossier.
L'interface Homme Machine de la création des dossiers
pourra ressembler au dessin suivant (voir figure 4-10), réalisé
avec l'outil EA, permettant ainsi de relier les dessins de la maquette aux cas
d'utilisation.
|
Figure 4-10 : IHM créer dossier.
|
|
> Use case 2 : Envoyer dossier
|
|
|
Figure 4-14 : Use case 2 envoyer dossier.
|
|
|
42
" Acteur principal : Cadres
" Priorité : 2
" Objectifs : envoyer les dossiers dans un
service
" Pré-conditions :
· L'application est lancée,
· Le cadre s'authentifier,
· Le cadre se situé dans la page Envoyer dossier.
" Post-conditions :
· Le dossier a été envoyé
· La page Envoyer dossier est affichée
43
V' Scénario nominal :
Tableau 4-4: Scenario nominal use case 2.
|
Action menée par le cadre
|
Action réalisée par le
système
|
|
1- Demande d'envoi du dossier
|
|
|
2- Affiche le formulaire d'envoi
|
3- sélectionne le(s) dossier(s) de(s) candidat(s) et le
service
|
|
4- Valide l'envoi
|
|
|
5- Accède à la base de données et y ajoute
les données relatives a l'envoi
|
|
6- Informe le cadre que l'envoi s'est effectué
7- Affiche la page Envoyer dossier
|
|
V' Alternatives :
· Le système signale le dysfonctionnement au
cadre
· Le cadre modifié toutes les informations
erronées et valide de nouveaux V' Besoin IHM
· Un élément pour demander l'envoi des
dossiers,
· Un formulaire composé de composants de
sélection (listes de choix, checkbox, etc.) pour sélectionner les
informations liées a l'envoi du
dossier,
· Une zone de confirmation contenant un
élément de validation et un élément
d'annulation,
· Une barre des tâches pour informer de l'envoi du
dossier. V' Fonction Qualité Mesure :
Tableau 4-5: Fonction qualité mesure use
case 2.
Fonction
|
Fréquence
|
Qualité
|
Mesure
|
Créer dossier
|
Régulière
|
Rapidité
|
Instantanée
|
|
Gère les accès concurrents aux
données de la base
|
|
|
Figure 4-16 : IHM envoyer dossier.
|
|
44
i' Diagramme de séquence envoyer
dossier
Le diagramme de la figure 4-15 suivante montre l'interaction
de l'envoie d'un dossier entre le cadre et le système.
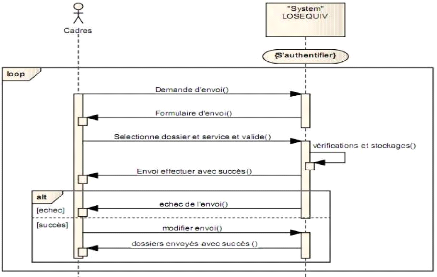
Figure 4-15: Diagramme de séquence
envoyer dossier.
L'interface Homme Machine (IHM) de l'envoi des dossiers pourra
ressembler au dessin suivant (voir figure 4-16).
> Use case 3 : Créer
comptes
|
Figure 4-17 : Use case 3
créer
comptes.
|
|
45
1' Acteur principal : Cadres
1' Priorité : 7
1' Objectifs : Enregistrer les comptes des
cadres
1' Pré-conditions :
· L'application est lancée,
· Le cadre s'authentifier,
· Le cadre se situé dans la page
Paramétrages. 1' Post-conditions :
· les comptes ont été crées
· La page Paramétrage est affichée 1'
Scénario nominal :
Tableau 4-6: Scenario nominal use case
3.
|
Action menée par le cadre
|
Action réalisée par le
système
|
|
1- Demande de création du compte
|
|
|
2- Affiche le formulaire de saisi
|
3- Saisi les données relatives aux compte
|
|
4- Valide la saisie
|
|
|
5- Accède à la base de données et y ajoute
les données relatives au compte
|
|
6- Informe le chef de la sous direction que le compte a
été créé
7- Affiche la page de Paramétrage
|
|
46
i' Alternatives :
· Le système signale le dysfonctionnement au
cadre
· Le système détecte des erreurs ou des
incohérences parmi les nouvelles
informations
· Le chef de la sous direction modifié toutes les
informations erronées et valide
de nouveaux i' Besoin IHM
· Un élément pour demander la création
d'un dossier,
· Un formulaire composé de composants de saisie
(champs de texte, listes de choix, etc.) pour saisir les informations
liées au dossier,
· Une zone de confirmation contenant un
élément de validation et un élément
d'annulation,
· Une barre des tâches pour informer de la
création du compte i' Fonction Qualité Mesure
:
Tableau 4-7: Fonction qualité mesure use
case 3.
Fonction
|
Fréquence
|
Qualité
|
Mesure
|
Créer compte
|
Occasionnelle
|
Rapidité
|
Instantanée
|
|
Gère les accès concurrents aux
données de la base
|
|
i' Diagramme de séquence créer
comptes
Le chef de la sous-direction devra définir au
préalable définir les comptes de tous les cadres qui devront
interagir avec le système. Pour création de chaque compte, il
clique sur le menu administration et choisi le menu nouveau utilisateur. La
figure suivante illustre la suite des opérations.
|
Figure 4-19 : IHM créer comptes.
|
|
47
i' Diagramme de séquence créer
comptes
Ce diagramme montre l'interaction entre le chef et le
système dans la création d'un comptes.
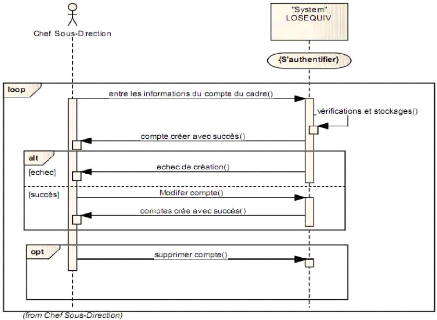
Figure 4-18 : Diagramme de séquence
créer comptes.
L'interface Homme Machine (IHM) de la création de compte
pourra ressembler au dessin suivant.
> Use case 4 : Créer
établissement
|
Figure 4-20 : Use case 4 créer
établissement.
|
|
48
" Acteur principal : cadres
" Priorité : 5
" Objectifs : Créer les
établissements
" Pré-conditions :
· L'application est lancée,
· Le cadre s'est authentifié. "
Post-conditions :
· les établissements ont été
crées " Scénario nominal :
Tableau 4-8: Scenario nominal use case
4.
|
Action menée par le cadre
|
Action réalisée par le
système
|
|
1- Demande de création de l'établissement
|
|
|
2- Affiche le formulaire de saisi
|
3- Saisi les données relatives à
l'établissement
|
|
4- Valide la saisie
|
|
|
5- Accède à la base de données et y ajoute
les données relatives a l'établissement
|
|
6- Informe le chef de la sous direction que
l'établissement a été créé
7- Affiche la page de Pa métrage
|
|
49
V' Alternatives :
· Le système signale le dysfonctionnement au
cadre
· Le système détecte des erreurs ou des
incohérences parmi les nouvelles
informations
· Le chef de la sous direction modifié toutes les
informations erronées et valide
de nouveaux V' Besoin IHM
· Un élément pour demander la création
d'un dossier,
· Un formulaire composé de composants de saisie
(champs de texte, listes de choix, etc.) pour saisir les informations
liées au dossier,
· Une zone de confirmation contenant un
élément de validation et un élément
d'annulation,
· Une barre des tâches pour informer de la
création de l'établissement V' Fonction Qualité
Mesure :
Tableau 4-9: Fonction qualité mesure use
case 4.
|
Fonction
|
Fréquence
|
Qualité
|
Mesure
|
|
Créer compte
|
Occasionnelle
|
Rapidité
|
Instantanée
|
|
Sécurité
|
Gère les accès concurrents aux
données de la base
|
V' Diagramme de séquence créer
établissement
Seul le chef de la sous-direction peut créer un
établissement, car nous avons spécifiés dans les besoins
que le chef approuve les établissements dont le statut est
authentifié au pas (voir figure 4-21).
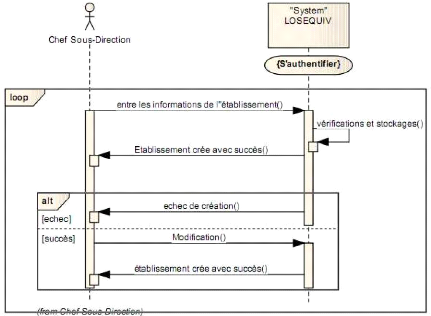
Figure 4-21 : Diagramme de séquence
créer établissement.
|
Figure 4-22 : IHM créer
établissement.
|
50
L'interface homme machine de création des
établissements pourra ressembler à ceci (voir figure 4-22).
c) 51
Élaboration de la matrice de
validation
La matrice de validation permet de vérifier que l'analyse
du cas est complète, c'est-à-dire que tous les cas d'utilisation
métier ont été intégrés. Elle permet aussi
d'établir une correspondance entre les cas d'utilisation métier
et les cas d'utilisation d'analyse (voir figure 4-23).
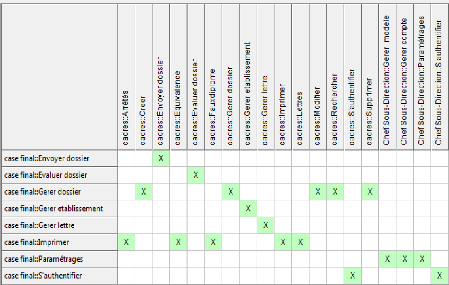
Figure 4-23 : Élaboration de la matrice
de validation.
d) Opérations système
Les événements système envoyés par
les acteurs au système LOSEQUIV déclenchent des traitements
internes que nous appellerons opérations système.
L'ensemble des opérations système de tous les
cas d'utilisation définit l'interface publique du système, qui
visualise le système comme une entité unique, boîte noire
offrant des services. En UML, le système pris dans son ensemble peut
être représenté par une classe, avec le mot-clé
«system», comme nous l'avons déjà fait dans les
diagrammes de séquence précédents (ROQUES, 2002). À
la suite de la création des différents DSS et en enrichissant
cette description préliminaire avec les
extensions des cas d'utilisation, nous obtenons la liste
d'opérations système suivante (voir figure 4-24).
|
Figure 4-24 : Opérations
système.
|
Cette liste n'est bien sûr pas exhaustive, car nous n'avons
pas encore décrit dans les détails tous les cas d'utilisation.
Elle sera donc progressivement complétée au fur et à
mesure des itérations successives. On commence cependant à voir
apparaître les fonctionnalités majeures du système,
à un niveau de détail proche de ce qui sera disponible dans
l'IHM.
e) Structuration des opérations systèmes en
interface
Il serait également possible de commencer à
définir des interfaces, pour découper l'ensemble des
opérations en groupes cohérents (voir figure 4-25).
Figure 4-25 : Opérations système
structurés en interfaces.
52
f) Opérations système structurés en
interfaces et reliées aux cas d'utilisation
Nous avons reliées chaque opération
système aux cas d'utilisation dans la figure 4-26 suivante.
53
Figure 4-26 : Opérations système
structurés en interfaces et reliées aux cas d'utilisation.
54
IV.1.2.3. Réalisation des cas
d'utilisation
Après avoir effectué l'analyse des cas
d'utilisation à la section précédente, nous allons donc
passer à la réalisation de ces derniers. Le procédé
de cette réalisation débutera par une identification des concepts
du domaine qui permettra de faire ressortir des entités et attributs.
Par la suite, ces entités et attributs seront mis en associations entre
eux. Enfin une description d'une typologie des classes d'analyse permettra la
réalisation des diagrammes de classes d'analyse participantes du
système. a) Identification des concepts du domaine
L'étape typiquement orientée objet de l'analyse
est la décomposition d'un domaine d'intérêt en classes
conceptuelles représentant les entités significatives de ce
domaine. Il s'agit simplement de créer une représentation
visuelle des objets du monde réel dans un domaine donné (ROQUES,
2002).
Comment identifier les concepts du domaine ? Plutôt que
de partir à l'aveugle et nous heurter à la taille du
problème à résoudre, nous allons prendre les cas
d'utilisation un par un et nous poser pour chacun la question suivante : quels
sont les concepts métier qui participent à ce cas d'utilisation
?
> Pour le cas d'utilisation Gérer dossiers,
nous identifions les concepts
fondamentaux suivants :
· Candidat ;
· Pièces ;
· Dossiers ;
· Etablissement ;
· Session ;
· Diplômes.
> Pour le cas d'utilisation Evaluer dossier, nous
identifions :
· Dossiers ;
· Types ;
· Statut.
55
> Pour le cas d'utilisation Envoyer dossiers, nous
identifions :
· Services ;
· Envoyer ;
· Alertes ;
· Dossiers.
> Pour le cas d'utilisation initier lettre, nous
identifions :
· Lettre ;
· Modèle ;
· Dossier.
> Enfin, pour le cas d'utilisation
Paramétrages, nous identifions :
· Comptes ;
· Modèle.
c) Ajout des associations et des attributs
Une fois que l'on a identifié les concepts fondamentaux,
il est utile d'ajouter :
· les associations nécessaires pour prendre en
compte les relations qu'il est fondamental de mémoriser ;
· les attributs nécessaires pour répondre aux
besoins d'information. Reprenons donc les cas d'utilisation majeurs un par
un.
" Gérer dossiers
Un candidat dépose un dossier pour une session qui est
composé de plusieurs pièces, ce candidat possède un
diplôme qui est obtenu dans un établissement (voir figure 427).
Figure 4-27 : Concepts liés à la
gestion des dossiers.
" Traiter lettre
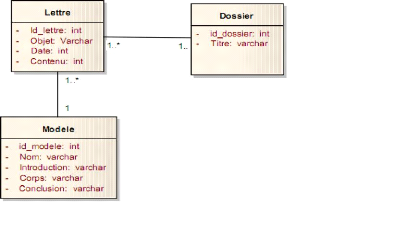
56
Figure 4-28 : Concepts liés à
l'initiation de la lettre.
Le traitement d'une lettre concerne un dossier appartement
à un modele (voir figure 4-28)
57
1' Evaluer dossiers
Les dossiers font l'objet d'une évaluation (voir figure
4-29).
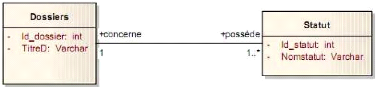
Figure 4-29 : Concepts liés à
l'évaluation des dossiers.
1' Envoyer dossiers
Les dossiers sont envoyés dans les services et un envoie
possède plusieurs alertes (voir figure 4-30)
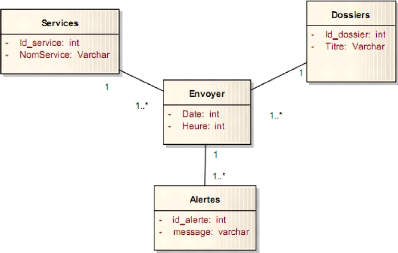
Figure 4-30 : Concepts liés à
l'envoie des dossiers.
58
d) Typologie des classes d'analyse
Pour élargir cette première identification des
concepts du domaine, nous allons utiliser une catégorisation des classes
d'analyse qui a été proposée par I. Jacobson et
popularisée ensuite par le RUP. Les classes d'analyse qu'ils
préconisent se répartissent en trois catégories (ROQUES,
2002):
· Celles qui permettent les interactions entre le
système et ses utilisateurs sont qualifiées de
dialogues. Il s'agit typiquement des écrans
proposés à l'utilisateur : les formulaires de saisie, les
résultats de recherche, etc. Ces classes proviennent directement de
l'analyse de la maquette. Il y a au moins un dialogue pour chaque paire
acteur-cas d'utilisation. Ce dialogue peut avoir des objets subalternes
auxquels il délègue une partie de ses responsabilités. En
général, les dialogues vivent seulement le temps durant lequel le
cas d'utilisation est concerné.
· Les classes qui contiennent la cinématique de
l'application sont appelées contrôles. Elles font
la transition entre les dialogues et les concepts du domaine, en permettant aux
écrans de manipuler des informations détenues par des objets
métier. Elles contiennent les règles applicatives et les isolent
à la fois des objets d'interface et des données persistantes. Les
contrôles ne donnent pas forcément lieu à de vrais objets
de conception, mais assurent que nous n'oublions pas de fonctionnalités
ou de comportements requis par les cas d'utilisation.
· Celles qui représentent les concepts métier
sont qualifiées d'entités. C'est elles que nous
avons appris à identifier au début de ce chapitre, cas
d'utilisation par cas d'utilisation. Elles sont très souvent
persistantes, c'est-à-dire qu'elles vont survivre à
l'exécution d'un cas d'utilisation particulier et qu'elles permettront
à des données et des relations d'être stockées dans
des fichiers ou des bases de données.
59
e) Classes d'analyse participantes des cas d'utilisation
du système
Il s'agit de diagrammes de classes participantes (DCP) UML qui
décrivent, cas d'utilisation par cas d'utilisation, les trois
principales classes d'analyse et leurs relations.
Règles
Pour compléter ce travail d'identification, nous allons
ajouter des attributs et des opérations dans les classes d'analyse,
ainsi que des associations entre elles (ROQUES, 2002).
· Les entités vont seulement
posséder des attributs. Ces attributs représentent en
général des informations persistantes de l'application.
· Les contrôles vont seulement
posséder des opérations. Ces opérations montrent
la logique de l'application, les règles transverses
à plusieurs entités, bref les comportements du système
informatique.
· Les dialogues vont posséder des
attributs et des opérations. Les attributs représenteront des
champs de saisie ou des résultats. Les résultats seront
distingués en utilisant la notation de l'attribut dérivé.
Les opérations représenteront des actions de l'utilisateur sur
l'IHM.
Nous allons également ajouter des associations entre les
classes d'analyse, mais en respectant des règles assez strictes :
· Les dialogues ne peuvent être reliés qu'aux
contrôles ou à d'autres dialogues, mais pas directement aux
entités.
· Les entités ne peuvent être reliées
qu'aux contrôles ou à d'autres entités.
· Les contrôles ont accès à tous les
types de classes, y compris d'autres contrôles.
Enfin, nous ajouterons les acteurs sur les diagrammes en
respectant la règle suivante : un acteur ne peut être lié
qu'à un dialogue (voir figure 4-31).
« Entité »
E
« Contrôle »
C
Opération1 () Opération2 () ...
« Dialogue»
D
|
Champ1 Champ2
|
|
Action IHM1 () Action IHM2 () ...
Figure 4-31 : Exemple d'entité, de
contrôle et dialogue.
60
« Contrôle»
Figure 4-32 : Exemple de diagramme de classe
participante.
" Gérer dossier
Le cadre à besoin de créer le dossier du
candidat qui a déposé la demande d'équivalence. Lorsque le
dossier du candidat a été créé, il doit être
en mesure de le modifier lorsque le candidat lui communique d'autres
informations supplémentaires ou de supprimer complètement le
dossier de l'application.
Nous supposerons que nous avons un seul écran, avec un
seul contrôle et un dialogue (voir figure 4-33).
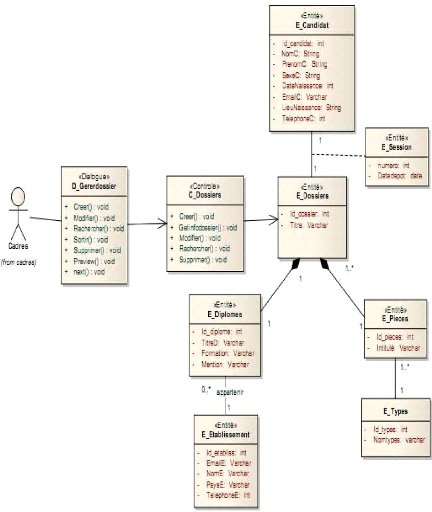
61
Figure 4-33 :DCP gérer dossiers.
62
1' Initier dossier
Une fois que le dossier à été créer,
le candidat initier la lettre du candidat.
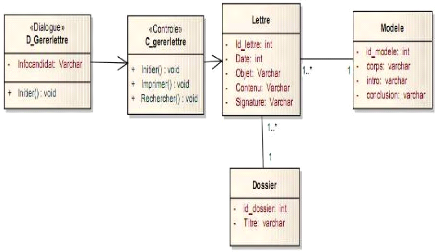
Figure 4-34 : DCP Initier lettre.
1' Evaluer dossier
Le cadre veut connaitre le statut du dossier du candidat. Il
s'agit notamment de vérifier si l'établissement qui a
délivré le diplôme a été reconnu, si le
diplôme a été également reconnu par cet
établissement. Il entre les informations du candidat et l'application
lui donne le statut du dossier.
Nous supposerons que la marquette va nous montrer deux
écrans :
· Un écran ou il entre les informations du candidat
;
· Un deuxième qui nous donne les résultats de
l'évaluation. La figure 4-36 suivante illustre ces l'évaluation
des dossiers.
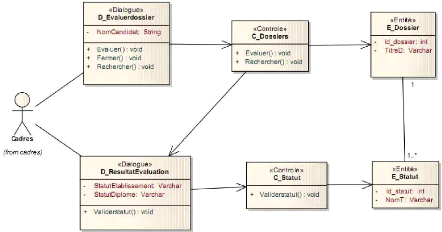
Figure 4-35 : DCP évaluer dossier.
1' Envoyer dossier
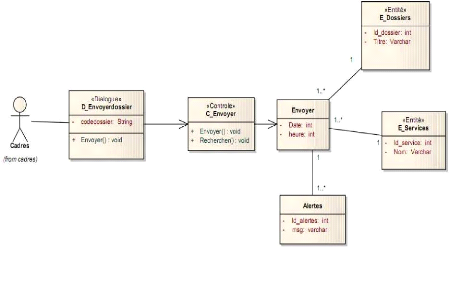
63
Figure 4-36 : DCP envoyer dossier.
Le cadre veut envoyer les dossiers des candidats à un
service. Sélectionne les dossiers des candidats et le service, puis
envoi. Nous supposerons que nous avons un seul écran, avec un seul
contrôle et un dialogue (voir figure 4-36).
IV.1.3. Modèles navigationel
Nous allons commencer par présenter la
démarche, ensuite définir quelques conventions
spécifiques, procéder à une structuration de la navigation
et terminer par une représentation des diagrammes de navigation.
IV.1.3.1. Démarche des modèles
navigationnel
Nous avons identifié à la section
précédente les principales classes d'IHM (dialogues) ainsi que
celles qui décrivent la cinématique de l'application
(contrôles). Pour que le tableau soit complet, il nous reste à
détailler une exploitation supplémentaire de la maquette ou une
extension éventuelle de celle-ci. Il s'agit de réaliser des
diagrammes dynamiques représentant de manière formelle l'ensemble
des chemins possibles entre les principaux écrans proposés
à l'utilisateur (ROQUES, 2002). Ces diagrammes s'appellent des
diagrammes de navigation (voir figure 4-37).

64
Figure 4-37 : Démarche de la maquette
et DCP qui conduisent à un diagramme
de navigation.
IV.1.3.2. Conventions spécifiques
Nous allons pousser un peu plus loin et nous servir du concept
d'état pour modéliser plusieurs concepts différents,
grâce aux conventions graphiques suivantes (ROQUES, 2002):
· une page complète de l'application
(«page»),
· un frame particulier à l'intérieur d'une
page («frame»),
· une erreur ou un comportement inattendu du système
(«exception »,
· une liaison vers un autre diagramme d'activité,
pour des raisons de structuration et de lisibilité
(«connector»).
Les concepts de page et de frame sont directement en rapport
avec les classes dialogues du chapitre précédent (voir figure
4-38).

65
Figure 4-38 : Conventions graphiques
spécifiques.
66
IV.1.3.3. Structuration de la navigation
Pour commencer le travail de modélisation, nous devons
d'abord le séparer en ensembles maîtrisables et les plus
indépendants possibles.
Début du diagramme de navigation des acteurs
(voir figure 4-39)
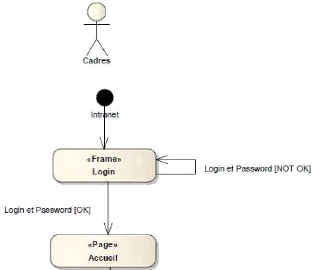
Figure 4-39 : Début des diagrammes de
navigation.

Le cadre se connecte au système à partir de
l'intranet. Il doit saisir son identifiant et son mot de passe dans un frame
particulier. Suivant le résultat du contrôle effectué par
le système, il se retrouve soit sur la page d'accueil propre à
son profil, soit de nouveau sur le frame d'identification avec un message
d'erreur. Nous n'avons pas modélisé la limite de trois erreurs
consécutives pour ne pas compliquer le diagramme, mais il faudrait bien
sûr le faire dans la réalité.
IV.1.3.4. Diagramme de navigation des cas
d'utilisation
Nous pouvons maintenant réaliser un diagramme global de
navigation du système. Il va comprendre l'ensemble des pages, frames et
actions principales des cas d'utilisation. Pour simplifier, nous n'avons pas
repris les exceptions.
Le schéma ainsi obtenu (figure 4-40) est très
intéressant, car il fournit sur une seule page les règles
fondamentales de déplacement dans l'application.
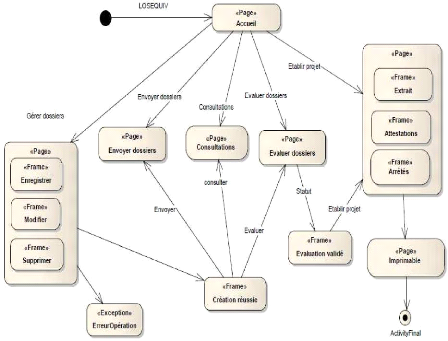
67
Figure 4-40 : Diagramme global simplifié
de la navigation.
IV.2. CONCEPTION
« L'attribution des bonnes responsabilités aux
bonnes classes est l'un des problèmes les plus délicats de la
conception orientée objet. Pour chaque service ou fonction, il faut
décider quelle est la classe qui va la contenir. Les diagrammes
d'interactions (séquence ou communication) sont particulièrement
utiles au concepteur pour représenter graphiquement ses décisions
d'allocation de responsabilités. Chaque diagramme va ainsi
représenter un ensemble d'objets de classes différentes
collaborant dans le cadre d'un scénario d'exécution du
système. Dans ce genre de diagramme, les objets communiquent en
s'envoyant des messages qui invoquent des opérations (ou
méthodes) sur les objets récepteurs. Il est ainsi possible de
suivre visuellement les interactions dynamiques entre objets, et les
traitements réalisés par chacun » (ROQUES, 2002).
Nous débuterons cette conception objet par une
description de la démarche de mise en place, ensuite la
réalisation d'un digramme d'interaction et enfin un diagramme de classes
de conception.
IV.2.1. Démarche de conception objet
Par rapport aux diagrammes de séquence système
du chapitre 4, nous allons remplacer le système vu comme une boîte
noire par un ensemble d'objets en interaction. Pour cela, nous utiliserons
encore dans ce chapitre les trois types de classes d'analyse, à savoir
les dialogues, les contrôles et les entités.
La figure 4-41 ci-dessous illustre la démarche
adoptée :
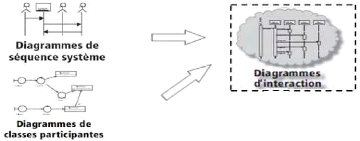
68
Figure 4-41 : Démarche de
réalisation de diagrammes d'interaction et de classes de
conception
69
Suite de la démarche de réalisation des digrammes
d'interaction et de classes (voir figure 4-42)
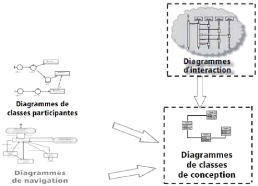
Figure 4-42 : Suite démarche de
réalisation de diagrammes d'interaction et de
classes de
conception.
IV.2.2. Digramme d'interaction
L'expression diagramme d'interactions englobe principalement
deux types de diagrammes UML spécialisés, qui peuvent servir tous
les deux à exprimer des interactions de messages similaires :
les diagrammes de communication et les diagrammes de
séquence. Les diagrammes de communication ne feront pas
l'objet de cette étude. Les diagrammes d'interactions font participer
des objets et non pas des classes. Il ne s'agit d'ailleurs pas forcément
d'occurrences spécifiques, mais plus généralement de
rôles possédant un type. Du coup, UML n'utilise pas directement la
notation des instances dans les diagrammes d'objets (nomObjet:NomClasse), mais
une notation légèrement différente, sans soulignement
(nomRÙle:NomType) (ROQUES, 2002).
Pour la représentation des diagrammes d'interaction
nous commencerons par définir quelques règles, ensuite nous
donnerons une notation détaillée. Nous avons choisit de
représenter les diagrammes de séquence qui avaient la
priorité fonctionnelle haute : créer et supprimer dossier,
évaluer et envoyer.
70
IV.2.2.1. Règles de conception des diagrammes de
séquence objet
Nous respecterons également les règles que nous
avions fixées sur les relations entre classes d'analyse, mais en nous
intéressant cette fois-ci aux interactions dynamiques entre objets
(ROQUES, 2002):
· Les acteurs ne peuvent interagir (envoyer des messages)
qu'avec les dialogues.
· Les dialogues peuvent interagir avec les
contrôles.
· Les contrôles peuvent interagir avec les dialogues,
les entités, ou d'autres contrôles.
· Les entités ne peuvent interagir qu'entre
elles.
Le changement de niveau d'abstraction par rapport au diagramme
de séquence système peut ainsi se représenter comme sur la
figure 4-43 ci-dessous.
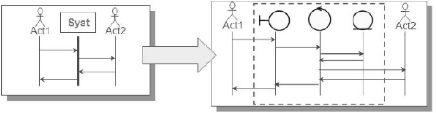
Figure 4-43 : Passage de l'analyse à la
conception préliminaire Source : (ROQUES, 2002)
IV.4.2.2. Notation détaillée des
diagrammes de séquence
Les diagrammes de séquence représentent les
interactions dans un format où chaque nouvel objet est ajouté en
haut à droite. On représente la ligne de vie de chaque objet par
un trait pointillé vertical. Cette ligne de vie sert de point de
départ ou d'arrivée à des messages
représentés eux-mêmes par des flèches horizontales
(voir figure 4-44). Par convention, le temps coule de haut en bas. Il indique
ainsi visuellement la séquence relative des envois et réceptions
de messages, d'où la dénomination : diagramme de
séquence.
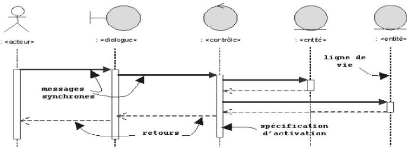
71
Figure 4-44 : Notation détaillé de
diagramme de séquence Source : (ROQUES, 2002)
Tout message est bon pour créer une instance, mais la
convention UML que nous appliquerons ici veut que l'on utilise à cet
effet un message standardisé appelé create. Le message create
peut comprendre des paramètres d'initialisation. Il peut s'agir, par
exemple, d'un appel de constructeur avec paramètres en Java ou en C#
(ROQUES, 2002).
De même, lorsque nous souhaiterons montrer explicitement
la destruction des objets, nous utiliserons le message standardisé
destroy.
> Diagramme de séquence créer dossier
(voir figure 4-45)
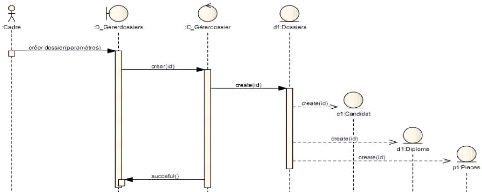
Figure 4-45 : Diagramme de séquence
détaillée créer dossier.
Le cadre entre les paramètres de création du
dossier, le dialogue passe la main à un contrôleur qui va
créer l'objet. Il peut aussitôt optionnellement évaluer le
dossier créé.
Nous n'avons représenté que le scénario
nominal sur ce diagramme ci-dessus, Cela signifie que tout « se passe bien
», le cadre abouti à la création du dossier.
Les cas d'erreur sont abordés avec le diagramme suivant
(voir figure 4-46).
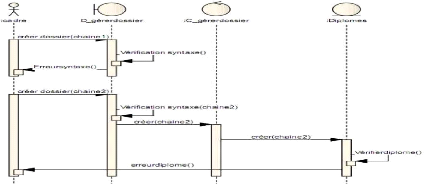
Figure 4-46 : Diagramme de séquence
détaillée créer dossier avec erreur. >
Diagramme de séquence suppression d'un dossier
La suppression ne peut être possible que si on a
supprimé au préalable le candidat, diplôme et pièces
correspondant au dossier (voir figure 4-47).
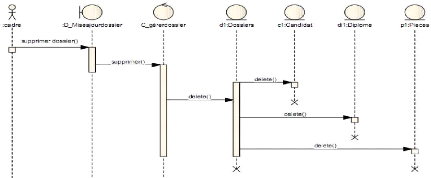
72
Figure 4-47 : Diagramme de séquence
détaillée suppression dossier.
73
> Diagramme de séquence d'évaluation
d'un dossier (voir figure 4-48)
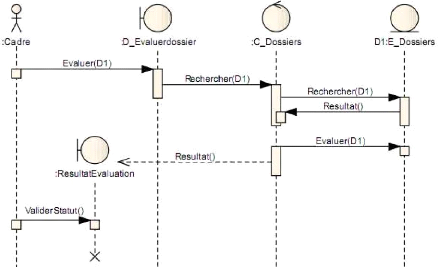
Figure 4-48 : Diagramme de séquence
détaillée évaluer dossier.
Le cadre entre le nom du dossier avant évaluation, si
ce dossier existe, il sera évalué. La fin de l'évaluation
nous indique si le dossier doit être approuvé ou rejeté. Le
diagramme suivant permet aux cadres de valider le statut du dossier (voir
figure 4-49).
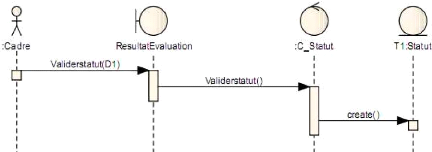
Figure 4-49 : Diagramme de séquence
détaillée valider statut dossier.
74
> Diagramme de séquence envoyer dossier (voir
figure 4-50)
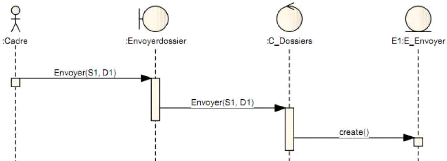
Figure 4-50 : Diagramme de séquence
détaillée envoyer dossier.
IV.2.3. Classes de conception
En partant du modèle d'analyse (voir section IV.2),
nous allons affiner et compléter les diagrammes de classes participantes
obtenus précédemment. Nous allons utiliser les diagrammes de
séquence que nous venons de réaliser pour (ROQUES, 2002):
· Ajouter ou préciser les opérations dans
les classes (un message ne peut être reçu par un objet que si sa
classe a déclaré l'opération publique correspondante).
· Ajouter des types aux attributs et aux
paramètres et retours des opérations.
· Affiner les relations entre classes : associations
(avec indication de navigabilité), généralisations ou
dépendances.
Nous utiliserons également le travail
réalisé à la section (IV.3) sur la navigation pour ajouter
les éventuels dialogues qui manquaient.
Nous débuterons cette conception par la
présentation de la méthode des liens durable ou temporaires qui
donnera lieu à une association navigable entre les classes
correspondantes ou une relation de dépendance. Ensuite une structuration
en package de classes en trois couches : couche présentation, couche
logique Applicative et la couche logique métier.
IV.2.3.1. Méthode des liens durable ou
temporaires
Un lien durable entre éléments va donner lieu
à une association navigable entre les classes correspondantes ; un lien
temporaire va donner lieu à une relation de dépendance.
« Sur l'exemple du schéma ci-dessous, le lien
entre les éléments: A et :B devient une association navigable
entre les classes correspondantes. Le fait que l'élément :A
reçoive en paramètre un message d'une référence sur
un objet de la classe C induit une dépendance entre les classes
concernées » (ROQUES, 2002).
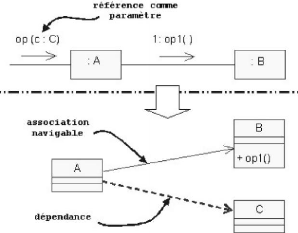
Figure 4-51 : Exemple liens temporaires et
dépendances.
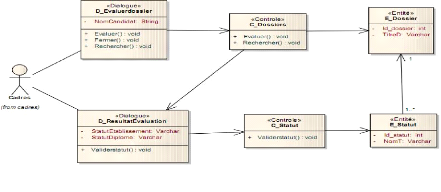
Figure 4-53 : DCP détaillé
évaluer dossier
75
> Diagramme de classe participante évaluer
dossier (voir figure 4-53)
> Diagramme de classe participante gérer
dossier (voir figure 4-52)
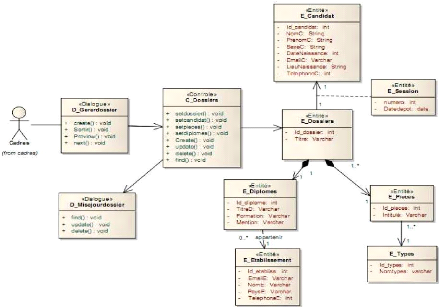
Figure 4-52 : DCP détaillé
gérer dossier.
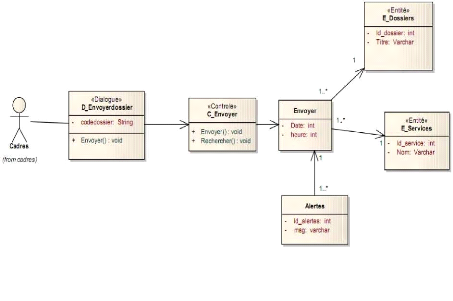
76
Figure 4-54 : DCP détaillé
envoyer dossier.
> Diagramme de classe participante envoyer dossier
(voir figure 4-54)
77
IV.2.3.2. Structuration en packages de
classes
« Pour structurer notre modèle, nous allons
organiser les classes et les regrouper en ensembles cohérents. Pour ce
faire, nous utilisons une fois de plus le concept général d'UML,
le package » (ROQUES, 2002).
Les systèmes informatiques modernes sont organisés
en couches horizontales, elles-mêmes découpées en
partitions verticales. Cette découpe est d'abord logique, puis
éventuellement physique en termes de machines.
Nous allons donc structurer les classes identifiées
jusqu'à présent en trois couches principales :
· une couche Présentation, rassemblant toutes les
classes dialogues ;
· une couche Logique Applicative, rassemblant toutes les
classes contrôles ;
· une couche Logique Métier, rassemblant toutes les
classes entités ;
L'architecture logique de notre étude de cas est ainsi
représentée par un premier diagramme de packages, comme
illustré par la figure 4-55 ci-dessous.


|
Figure 4-55 : Diagramme de packages
de
l'architecture logique.
|
|
V' Architecture en couches
« Le principal objectif de la séparation en
couches est d'isoler la logique métier des classes de
présentation (IHM), ainsi que d'interdire un accès direct aux
données stockées par ces classes de présentation. Le souci
premier est de répondre au critère d'évolutivité :
pouvoir modifier l'interface de l'application sans devoir modifier les
règles métier, et pouvoir changer de mécanisme de stockage
sans avoir à retoucher l'interface, ni les règles métier
»2.
Si nous répartissons maintenant les classes
identifiées précédemment, nous obtenons une structuration
comme celle illustrée sur la copie d'écran 4-52, issue de l'outil
Enterprise Architect.
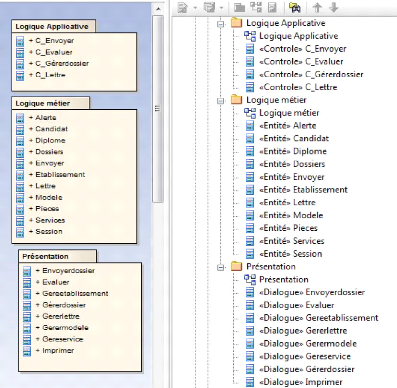
Figure 4-57 : Détail de l'architecture
logique
2 ROQUES Pascal (2002), p.140
78
« La structuration des couches Présentation et
Logique Applicative peut s'effectuer en tenant compte des cas d'utilisation. La
structuration de la couche Logique Métier est à la fois plus
délicate et plus intéressante, car elle fait appel à deux
principes fondamentaux : cohérence et indépendance »
(ROQUES, 2002).
V' Le premier principe consiste
à regrouper les classes qui sont proches d'un point de vue
sémantique. Un critère intéressant consiste à
évaluer les durées de vie des instances et à rechercher
l'homogénéité. Par exemple, les entités
Modèles, Services et Etablissement ont une durée de vie de
plusieurs mois, voire de plusieurs années. En contrepartie, les concepts
de Envoyer et Evaluer sont beaucoup plus volatiles. Il est donc naturel de les
séparer dans des packages différents.
V' Le deuxième principe
s'efforce de minimiser les relations entre packages, c'est à-dire plus
concrètement les relations entre classes de packages différents.
Les considérations précédentes amènent à une
solution naturelle consistant à découper le modèle en
trois packages comme indiqué sur la figure 4-58. Les packages ainsi
constitués vérifient bien les principes de forte cohérence
interne et de faible couplage externe.
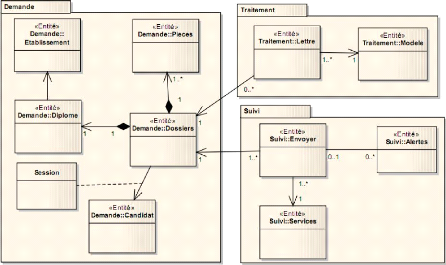
79
Figure 4-58 : Découpage en packages
montrant leur indépendance.
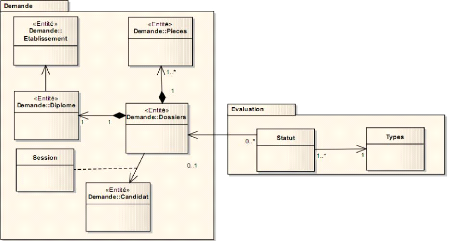
Figure 4-59 : Suite découpage en packages
montrant leur indépendance.
IV.2.3.3. Diagrammes de classes des packages de la couche
métier Terminons ce chapitre en peaufinant les diagrammes de
classes de chacun des packages.
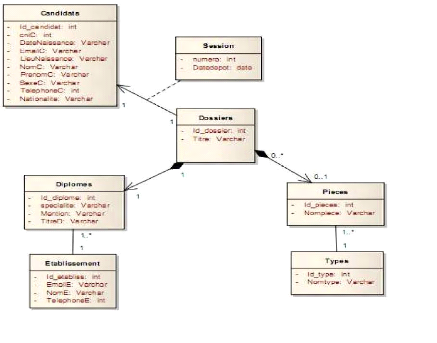
Figure 4-60: Diagramme de classe du package
dossier.
80
i' Diagramme de classe du package dossier (voir 4-60)
i' Diagramme de classe du package traitement
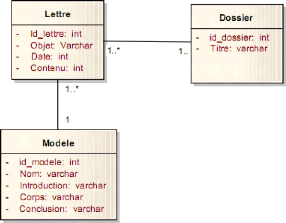
Figure 4-61 : Diagramme de classe du package
traitement. i' Diagramme de classe du package suivi (voir figure 4-62)
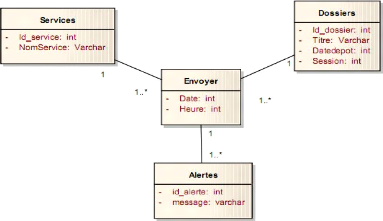
81
Figure 4-62 : Diagramme de classe du package
suivi.
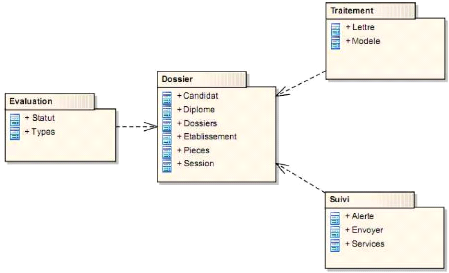
Figure 4-63 : Diagramme synthétique.
82
Les dépendances entre packages de la couche
métier sont représentées sur le diagramme
synthétique de la figure 4-63.
83
Chapitre V : IMPLEMENTATION DU SYSTEME
Le chapitre précédent sur l'analyse et
conception nous a permit de faire une migration des besoins vers une solution
informatique par le concept des modèles décrit par UML2, cela
nous à permit d'avoir une représentation du futur système
à mettre en place. Alors nous allons dans ce chapitre
débuté le codage effectif du système, nous commencerons
par une présentation de l'environnement de travail, ensuite une
description des composants logiciels utilisées. Nous continuerons avec
une description des paquetages du système, de la mise en oeuvre de
l'architecture en couche et enfin le déploiement de l'application.
V.1. Environnement de développement
Le respect de chartes de développement, les outils de
gestion de projet sont autant de points constituant un environnement de
développement. La méthodologie utilisée, elle aussi,
influe sur la façon de travailler et donc sur les structures et
procédures à mettre en place (MOLIERE, 2005). Nous allons de ce
point montré l'installation de l'outil de gestion maven et la mise en
place du système et du serveur d'application à partir de cet
outil de gestion.
V.1.1. Installation de Maven 2
Sous Linux, nous avons téléchargé et
décompresser le paquet maven2, ensuite écrire à partir
d'une console : # gedit .profile sous gnome, ou # kate .profile
sous KDE, puis ajouter les lignes suivantes :
Tableau 5-1 : configuration maven2
Dans la console Linux
|
export M2_HOME=/home/user/apache-maven-2.0.9 export
M2=$M2_HOME/bin
export JAVA_HOME=/usr/lib/java/jdk1.6.0_01/ PATH="$M2:$PATH"
|
84
V.1.2. Mise en place du projet dans Maven2
Après l'installation et la configuration de l'outil de
build maven, nous avons crée un nouveau projet du système
à partir de maven2 comme décrit ci-dessous.
Tableau 5-2 : Mise en place losequiv
Dans la console Linux
mvn archetype:create -DarchetypeGroupId=cm.minesup.equiv
alence-DarchetypeArtifactId=losequiv -DarchetypeVersion=1.4-SNAPSHOT
-DartifactId=project
V.1.3. Installation du serveur Jetty
A la suite de la mise en place du projet, nous avons
installé le serveur d'application à partir de maven2 comme
suit.
Tableau 5-3 : Configuration jetty
|
Ouvrir le fichier pom et ajouter
|
|
<plugin>
<groupId>org.mortbay.jetty</groupId>
<artifactId>jetty-maven-plugin</artifactId>
<version>8.1.5.v20120716</version> </plugin>
|
|
Puis exécuter la commande ci-dessous a partir du
terminal:
|
|
mvn jetty:run
|
V.2. Composants logiciels utilisés
Nous allons présenter ses composants logiciels selon
leurs interactions sur les couches présentation, service et DAO.
V.2.1. Couche présentation
« L'interface graphique d'une application est la partie
« visible » pour un utilisateur. La négliger annule tout le
travail fait en amont. L'ergonomie de notre application va donc conditionner
son utilisation. Réactivité, présentation,
sobriété, sont autant de facteurs à prendre en compte pour
ne pas passer à côté de nos objectifs » (MOLIERE,
2005). Nous distinguons deux clients au niveau de cette couche.
V.2.1.1. Le client léger
Le client léger s'appuiera sur la technologie du
Framework Wicket qui repose presque entièrement sur
Java et HTML comme moyens pour bâtir ses interfaces.
V.2.1.2. Le client lourd
Le client lourd possède une interface graphique propre.
Nous avons choisi d'utiliser la technologie Swing
associée à SwingX. Swing
est une bibliothèque graphique pour Java et offre la
possibilité de créer des interfaces graphiques identiques quelque
soit le système d'exploitation sous-jacent. De plus, elle dispose de
plusieurs choix d'apparence pour chacun des composants standards. Pour finir,
Swing peut être enrichie avec des APIs telles que SwingX ou JGoodies afin
de fournir des composants plus complexes ou de simplifier la validation de
données dans des champs de saisie (voir figure 5-1), par exemple
(MOLIERE, 2005).
85
V.2.3. Couche service
Cette couche fournit l'ensemble des méthodes
nécessaire au traitement des données du système, nous
décrivons ci-dessous les principaux composants utilisés.
V.2.3.1. La génération de
document
Lorsque l'extrait, l'arrêtés ont
été établis, ils peuvent être
générées. Ces documents doivent pouvoir être
exportées au format PDF afin de les archiver. Pour cela, nous utilisons
Jasperreport qui est un outil puissant pour la
génération d'état.
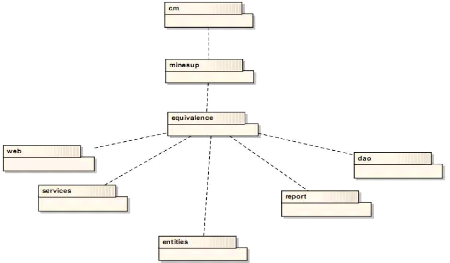
Figure 5-2 : Paquetage système.
86
V.2.3.2. L'envoi de mail
Pour avertir les candidats de la disponibilité de leurs
équivalences, notre application doit gérer l'envoi de mails.
L'envoi sera réalisé à l'aide de Java Mail API.
Java Mail est une API directement intégrée
à la spécification J2EE. De plus, elle est capable de
gérer l'envoi de mails pour différents protocoles (IMAP et
POP3).
V.2.3.3. Gestion des traces applicatives
Log4J permet de gérer traces applicatives lors des
tests unitaires. Le but de Log4J est d'accélérer les
procédures de correction d'erreurs en enlevant la place au doute. En
effet, une trace bien faite doit permettre de suivre étape par
étape le chemin de l'utilisateur jusqu'à l'erreur qu'il
signale.
V.3. Paquetage du système
La figure ci-dessous illustre les principaux paquets mis en place
dans le système. Ci-dessous, nous faisons une brève description
de chaque paquet.
V.3.1. Paquetage « service »
Le paquetage « service » contient les
méthodes d'accès aux traitements métiers permettant ainsi
de cacher l'implémentation de ceux-ci.
V.3.2. Paquetage « entities »
Le paquetage « entities » représente les
objets métiers dans un mécanisme de stockage persistant. Les
entités sont des POJOs ordinaires qui possèdent un certain nombre
d'annotations permettant de définir une représentation objet de
la base de données. Les principales méthodes sont les getters et
setters qui permettent d'accéder aux champs.
V.3.3. Paquetage « web »
Le paquetage « web » correspond à
l'implémentation du client léger grâce au Framework Wicket
qui permet de générer dynamiquement les pages Web.
V.3.4. Paquetage « dao »
Le paquetage « dao » représente la couche
d'accès aux données persistantes via l'intermédiaire
d'Entity Bean. Il joue le rôle de « Proxy » entre la couche
service et la base de données persistante (ou plus
précisément avec JPA).
V.4. Mise en oeuvre de l'architecture en couche du
système
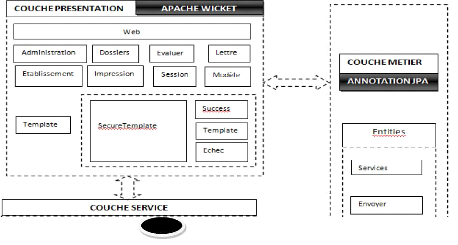
1
Figure 5-3 : Architecture en couche du
système
87
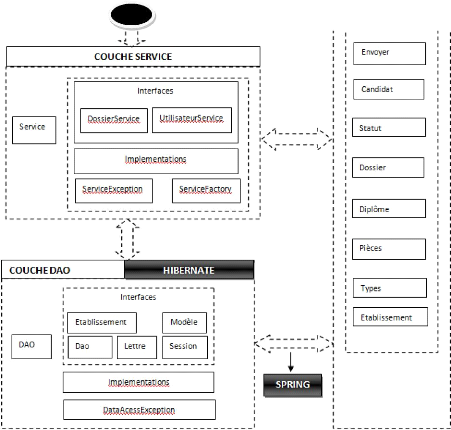
1
88
Figure 5-4 : Suite architecture en couche du
système.
V.4.1. Description de la couche présentation
Permet à l'utilisateur de piloter l'application et d'en
recevoir des informations (voir figure 5-5).
PACKAGE WEB
COUCHE PRESENTATION
Administration
Utilisateur Profil
Nouveau Lister
Edit
Template
Envoyer
Session
Nouveau
Liste
Nouveau
Liste
LOGIN
Nouveau
Rechercher
Lister
SetReponsePage
Success
Echec
Evaluer
Modèle
Nouveau
Modifier
Nouveau
Liste
Template
SecureTemplate
HOME
Dossier
Dossier
Etablissement
Candidat
« Extend »
Service
Template.properties
Wizardstep
Nouveau
Liste
Position
Nouveau
Liste
Diplome
Pieces
Lettre
Impression
Fauxdiplome Lettre
Arrêtés
Lettre
Nouveau Rechercher
Lister
Etablissement
Nouveau
Liste
Figure 5-5 : Architecture couche
présentation.
89
90
V.4.2. Description de la couche métier
La couche métier est la couche qui
applique les règles dites métier, c.à.d. la logique
spécifique de l'application, sans se préoccuper de savoir
d'où viennent les données qu'on lui donne, ni où vont les
résultats qu'elle produit (voir figure 56).
PACKAGE METIER
RESOURCES
persistance
META-INF
|
ENTITIES
|
|
|
DOSSIER
|
SERVICE
|
CANDIDAT
|
PIECES
|
|
|
ETABLISSEMENT
|
ENVOYER
|
DIPLOME
|
LETTRE
|
|
|
MODELE
|
STATUT
|
UTILISATEUR
|
TYPES
|
|
Figure 5-6 : Architecture couche
métier
V.4.3. Description de la couche service
Elle implémente les algorithmes " métier " de
l'application. Elle est indépendante de toute forme d'interface avec
l'utilisateur, utilisable aussi bien avec une interface console, web, client
riche (voir figure 5-7).
91
PACKAGE SERVICE
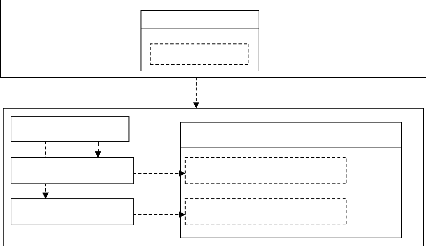
ServiceFactory
IUtilisateurService
IDossierService
CONFIG
Spring-bean
IMPLEMENTATION
UtilisateurServiceImpl
DossierServiceImpl
RESOURCES
Figure 5-7 : Architecture couche service
V.4.4. Description de la couche DAO
La couche DAO est la couche qui fournit
à la couche métier des données
préenregistrées (fichiers, bases de données, ...) et qui
enregistre certains des résultats fournis par la couche
métier.
La spécification JPA (Java Persistence
API) est utilisée pour standardiser la couche ORM. Hibernate est un
outil qui fait le pont entre le monde relationnel des bases de données
et celui des objets manipulés par Java.
Nous utiliserons le Framework Spring pour
lier la couche DAO et JPA/Hibernate. Le grand intérêt de Spring
est qu'il permet de lier les couches par configuration et non dans le code.
Avec Spring, les couches seront implémentées avec des
POJOs permettant la réutilisation de ceux-ci dans un
autre contexte. Ceux-ci auront accès aux services de Spring (pool de
connexions, gestionnaire de transaction) par injection de dépendances
dans ces POJOs : lors de la construction de ceux-ci, Spring leur injecte des
références sur les services dont ils vont avoir besoin.
PACKAGE DAO
COUCHE DAO
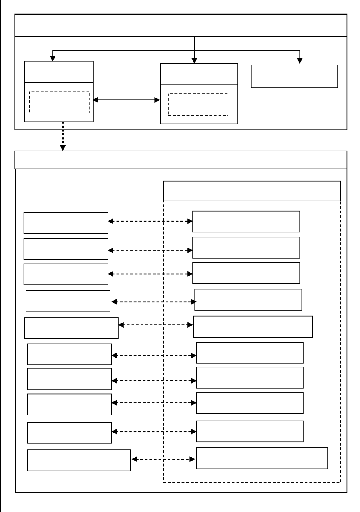
IUtilisateurDao
IServiceDao
ILettreDao
CONFIG
IEtablissementDao
ISessionDao
IEnvoyerDao
IDossierDao
ICandidatDao
IDao
DataAccessException
Spring-bean
RESOURCES
META-INF
IMPL
DAO
Persistence
IUtilisateurDaoImpl
IServiceDaoImpl
ILettreDaoImpl
IEtablissementDaoImpl
ISessionDaoImpl
IEnvoyerDaoImpl
IDossierDaoImpl
ICandidatDaoImpl
IDaoImpl
DataAccessExceptionImpl
LOG4J.Properties
Figure 5-8 : Architecture couche DAO.
92
V.5. Sécurité
Le système est application web qui devra fonctionner
dans un réseau informatique (Internet ou Intranet), dés lors
celui pourra être susceptible à une attaque provenant soit d'un
pirate informatique ou d'autres utilisateurs connectés sur le
réseau. Il est donc nécessaire de programmer une politique de
sécurité afin de prévenir tout risque qui pourra nuire au
bon fonctionnement de l'application.
V.5.1. Accès à l'application
La sécurité au niveau de l'accès de
l'application consiste à mettre en place une structure
sécurisée d'accès et de suivi de toutes les
opérations jugées critiques. Il nous parait anormal de mettre en
place une application multiutilisateur fonctionnant en mode client-serveur sans
pouvoir contrôler l'accès de chaque utilisateur. Une politique
d'identification par login et mot de passe ont été définie
pour chaque compte utilisateur.

Login et password
IDENTIFICATION
HOME
Figure 5-9 : Accès application.
93
V.5.2. Chiffrage du mot de passe
En plus du fait d'avoir definir une politique d'accès
à l'application sécurisé par login et mot de passe, il est
important de définir une politique de chiffrement du mot de passe. Ainsi
si un pirate snife l'echange entre le client et le serveur il ne pourra avoir
accès seulement au mot de passe codé. Le codage du mot de passe
s'est éffectué avec l'algorithme du SHA 256 (Secure Hash
Algorithm). Lorsque l'utilisateur saisit son mot de passe, il est codé
et la vérification s'effectué avec les deux versions
codées : celle de la base de données et celle saisie (voir figure
5-10).

Password chiffré
Serveur
Client
Figure 5-10 : Chiffrage du mot de passe.
V.5.3. La session
Notre application web est basée sur le protocole HTTP,
qui est un protocole dit "sans état" : cela signifie que le serveur, une
fois qu'il a envoyé une réponse à la requête d'un
client, ne conserve pas les données le concernant. C'est pour pallier
cette lacune que le concept de session a été créé :
il permet au serveur de mémoriser des informations relatives au client,
d'une requête à l'autre. La session représente un espace
mémoire alloué pour chaque utilisateur, permettant de sauvegarder
des informations tout le long de leur visite ;
le contenu d'une session est conservé jusqu'à ce
que l'utilisateur ferme son navigateur, reste inactif trop longtemps, ou encore
lorsqu'il se déconnecte du site ; La figure 5-11 ci-dessous illustre la
création d'une session.
IDENTIFICATION
getSession ()
Création d'un objet HttpSession, avec identifiant
unique
94
HOME
|
Figure 5-11 : Création session.
|
VI.5. Déploiement du système
Une fois l'application cliente prête, il faut la
diffuser aux utilisateurs. Dans notre cas, la diffusion se limite aux cadres de
la SDE via le réseau interne du ministère. Nous verrons comment
utiliser Maven2 pour déployer notre application sur le réseau
intranet. Alors nous verrons comment générer le fichier war et le
déployer sur un serveur web.
VI.5.1. Génération du fichier
war
La commande install, compile, test et mets en paquet vos
classes dans un fichier jar puis le deploy dans votre entrepôt
Maven2 local, d'où il peut être utilisé par d'autres
projets. Saisir la commande suivante à partir d'un terminal.
95
Tableau 5-4 : génération du
fichier war
Dans la console Linux
mvn package
VI.5.2. Déploiement sur le serveur web
Une fois que le système a été
réalisé, il ne reste plus qu'à le placer dans le
répertoire convenable sur la machine faisant office de serveur web. Pour
cela, il s'agira de faire une simple copie de fichiers. Nous allons donc faire
une copie du fichier généré dans répertoire du
serveur d'application.
96
Chapitre VI : RESULTATS ET TESTS
Nous avons commencé la conception et
implémentation de ce système par la définition des besoins
et de l'architecture au chapitre III, ensuite la modélisation de ces
besoins c'est opérer au chapitre IV et le codage du système au
chapitre V. Nous sommes arrivés au terme cette conception et
implémentation de l'application de suivi et traitement des dossiers
d'équivalence que nous avons nommé « losequiv
». Il est donc nécessaire de
présenter quelques résultats ainsi obtenu dans le chapitre qui
suit. Nous présenterons ces résultats avec quelques captures des
formulaires et états faites du système.
VI.1. Les formulaires
Les formulaires sont des pages sur lesquels on peut effectuer
un ensemble d'opération. Nous présenterons les formulaires
d'authentification, d'accueil et d'évaluation d'un dossier.
VI.1.1. Authentification système
Losequiv est application web, alors accessible à
travers un navigateur. Lorsque le cadre accède au système une
page d'authentification lui est présentée, il se doit de
renseigner son nom d'utilisateur et son mot de passe. Cette authentification
limite l'acces à toute personne malveillante et nous permet de connaitre
l'identité de toutes personnes sur le système (voir figure
6-1).

Figure 6-1 : Authentification système.
97
En cas de succès d'authentification, une page d'accueil
est affichée dans le cas contraire la même page d'authentification
reste présente. Bien attendu seul le chef de la sous-direction à
la responsabilité de crée les différents comptes des
cadres.
VI.1.2. Accueil
La page d'accueil contient les informations relatives au menu, au
profil des utilisateurs et alertes des dossiers (voir figure 6-2).

3
2
1
1
2
3
Figure 6-2 : Accueil.
Contient les informations relatives l'utilisateur
connecté.
Présente les différents menus du système
losequiv. Chaque menu peut dérouler
un sous-menu lorsqu'on clique dessus.
Présente les alertes des dossiers. Ces alertes sont de
deux types et sont notifier
automatiquement par le système ; Une alerte relative au
retard de traitement est notifier après un délai d'une semaine
pour les services interne et deux semaines pour les services externe. Et une
alerte relative au non évaluation d'un dossier est notifiée
après deux mois.
98
VI.1.3. Evaluation d'un dossier
Pour évaluer un dossier il faut entrer le code du
dossier, code générer automatiquement à la création
de celui. Ce code est unique à chaque dossier (voir figure 6-3).
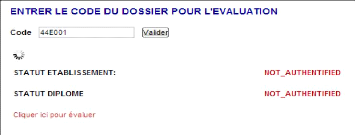
Figure 6-3 : Formulaire
d'évaluation.
Une fois le code renseigner, le cadre clique valider, ensuite on
obtient le statut de l'établissement et du diplôme qui peut avoir
comme valeur authentifier ou non authentifier. Par la suite on peut aller
modifier ses valeurs.
VI.2. Les états
Les états sont une représentation des informations
récupérées depuis une base de données et
affichés au format PDF. Nous allons présenter les états
sur les faux diplômes et la lettre.
VI.2.1. Lettre
L'état suivant est généré en PDF
grâce l'API jasper à partir des enregistrements issus de la base
de données sur le dossier du candidat Caco Paul sollicitant une demande
d'équivalence du diplôme de master en math. Cette lettre est
expédié par le ministère de l'enseignement
supérieur du Cameroun au Directeur de l'ENSAI de
N'Gaoundéré pour confirmer la délivrance et
l'authenticité du diplôme du candidat Caco.
|
REPURLIQLE DU CAMEROUN
MINLSTERE DE [.'ENSEIGNEMENTSUPERIEUR
DIRECTION DU DEy[LOPPEMENT DE L'ENSEIGNEMENT
Phone: 22132293 Etrait: minesup(ayahoe.fr
Site:
www.minesup.cm
|
août 20, 2013
|
A
Directeur ENSAI Nganundére
Objet: Demande d'authentification de
diplopie
Nous avons la bienveillance de venir xrupres de
vous solliciter l'authentification du diplomc de l'étudiant ci-dessous
obtenus dans votre. établissement
|
Nom: coco peul
Date de naissance : OS-janvier-MO
|
Liuu : dnuala
|
L)ipldmc ohrenu dans vûtrc
établissement : master en math Ann d'obrcnrïon :
2013
En effet, l'étudiant ci-dessus à dcposer
auprès de notre ministre une. demande d'équivalence du diplome
obtenus dans votre établissement_ Nous vous envoyons cette lettre pour
aunce[Ailler l'obtention de ce diplome dans votre établissement
Nous vous adressons nos salutations.
Yaoundi le 2010812013
Signature
99
Figure 6-4 : Etat lettre.
VI.2.2. Faux diplôme
Cet état représente la liste des faux
diplômes déclarés à l'issu de la 66eme session. Nous
avons le diplôme de BAC D du candidat Amana Klaise qui a
été déclaré faux (voir figure 6-5).

100
Figure 6-5 : Etat faux diplôme
101
CONCLUSION ET PERSPECTIVE
Le problème qui nous à été
confié au début de ce stage était de trouver une solution
aux difficultés que les cadres de la sous-direction d'équivalence
rencontraient dans l'étude des dossiers de demande d'équivalence
des diplômes. Solution adopté avec la conception et
implémentation d'une application de suivi et traitement des dossiers
d'équivalence.
En effet, la conception de ce système à
débuter avec la rédaction du cahier des charges qui à
permit d'identifier les besoins et faire ressortir l'architecture
générale. Ensuite nous avons migré ces besoins vers une
solution informatique par des modèles dans la partie analyse et
conception. A partir des modèles et de l'architecture
réalisée, nous avons effectué le codage et les tests qui
nous ont conduits au système final nommé losequiv (Logiciel du
Suivi et Traitement des dossiers d'équivalence).
Nous avons rencontré d'énormes
difficultés dans la réalisation de ce système. Dans un
premier temps le recueil des informations n'a pas été chose
aisé car le personnel de la sous-direction d'équivalence
était tous accablé par le travail et dont ne disposait pas assez
de temps pour répondre à nos interrogations. Aussi, sur le plan
technique, la faible maitrise au début de ce stage du
développement web avec la technologie J2EE était un frein au
déroulement de ce travail. Néanmoins, la
spécificité de J2EE à fait que nous avons dû
apprendre toutes les bases de cette nouvelle technologie, ce qui nous a pris
plus de temps que nous ne l'escomptions.
Les objectifs fixés au début de ce travail ont
été presque tous atteint. Le système est en mesure
d'informer les cadres de la position des dossiers dans un service,
d'évaluer ces dossiers, traiter les lettres, pour ne cité que ces
fonctionnalités. Faute de ressource matériel, nous n'avons pas pu
implémenter la notification par email et SMS du candidat de la
délivrance de son équivalence.
Ce système à été
développé afin de venir faciliter le travail des cadres dans la
gestion des dossiers d'équivalence. Il serait judicieux de permettre
d'effectuer une demande d'équivalence en ligne aux candidats. Ceci
contribuera à une meilleure informatisation du système
losequiv.
102
BIBLIOGRAPHIE
Ouvrage :
[1] DASHORST Martijn, HILLENIUS Eelcon, Wicket in
action, MANNING, USA, 2009.
[2] HEFFELFNGER David, JasperReports for Java
Developers, PACKT, Birmingham, UKRAINE, 2006.
[3] KENT KA Iok Tong, Enjoying Web development with
Wicket, First Edition, TipTec Development, 2007.
[4] MOLIERE Jérôme, Les cahier du
programmeur J2EE, 2eme Edition, EYROLLES, Paris, FRANCE, 2005.
[5] ROQUES Pascal, Les cahiers du programmeur UML2,
4eme Edition, EYROLLES, Paris, FRANCE, 2002.
[6] SEDDIGHI Ahmad Reza, Spring Persistence with
Hibernate, First Edition, PACKT, Birmingham, UKRAINE, 2009.
[7] SONATYPE, Maven guide, 1er Edition, Sonatype, Palo
Alto, 2009.
[8] VAYNBERG Igor, Apache Wicket Cookbook, PACKT,
Birmingham,
UKRAINE, 2011.
Article :
[9] ANDRIET Louis, DASTUGUE Julien, LAROCHE Sébastien,
MADEGARD Michaël, MYLLE Cédric, Cahier des charges
technique, p.19, 2007.
[10] DI GALLO Frédéric, Méthodologie
des systèmes d'information - UML, Octobre 2001, 59p.
[11] DEMICHIEL Linda, Java Persistence Criteria API,
20-62, Juin 2010.
[12] FERRAN Olivier, PAPON Guillaume, Rapport de Projet J2EE
Site de E-Commerce, p.5, 2008.
[13] MOUSSA Jawher, Exploration des modèles de
Wicket, p.12, 2008.
[14] ROS Sébastien, Livre blanc sur le Mapping
objet-relationnel, la couche d'accès aux données et les Framework
de persistance, p.3, 2003.
[15] SMART John Ferguson, CABASSON Denis, Introduction
à Maven 2, p.19 2005.
103
GLOSSAIRE
API : Interface de programmation (Application
Programming Interface ou API) définit la manière dont un
composant informatique peut communiquer avec un autre.
Apache Wicket : Framework pour la
création d'applications web qui repose presque entièrement sur
Java et HTML comme moyens pour bâtir ses interfaces.
Client léger : Dans le cadre d'une
application "web", on parlera de client léger en parlant du navigateur
internet.
Client lourd : Un client lourd est un
logiciel qui propose des fonctionnalités complexes avec un traitement
autonome. Contrairement au client léger, le client lourd ne
dépend du serveur que pour l'échange des données dont il
prend généralement en charge l'intégralité du
traitement.
Framework: En informatique, un Framework est
un espace de travail modulaire. C'est un ensemble de bibliothèques,
d'outils et de conventions permettant le développement rapide
d'applications. Il fournit suffisamment de briques logicielles et impose
suffisamment de rigueur pour pouvoir produire une application aboutie et facile
à maintenir.
IHM : Interface Homme Machine, ce qui est
visible par l'utilisateur. C'est une façon de concevoir des
systèmes informatiques qui soient ergonomiques, c'est-à-dire
efficaces, faciles à utiliser ou plus généralement
adaptés à leur contexte d'utilisation.
Java : Java est une technologie
développée par Sun Microsystems : (la technologie JavaTM). Elle
correspond à plusieurs produits et spécifications de logiciels
qui, ensemble, constituent un système pour développer et
déployer des applications.
Jasper Reports : Librairie Java open source
dédiée à l'ajout de capacités de reporting aux
applications Java, Web ou stand alone. Elle permet la représentation
104
de données sous forme textuelle, mais aussi la
génération de graphiques divers (sous forme de barre, courbe,
nuage de point).
JDBC : Java Database Connectivity: une
interface standardisée permettant à une application cliente sous
Java d'accéder à une base de données.
J2EE : Java 2 (Platform, Enterprise Edition)
est une spécification pour le langage de programmation Java de Sun plus
particulièrement destinée aux applications d'entreprise. Dans ce
but, toute implémentation de cette spécification contient un
ensemble d'extension au cadre d'applications Java standard (J2SE, Java 2
standard édition) afin de faciliter la création d'applications
réparties.
Java Persistence API : L'API de persistance
des données JPA fait parti de la spécification EJB3.
Spécification EJB3 qui fait elle-même parti de la plate-forme J2EE
5.0. La persistance des données en EJB3 est possible à
l'intérieur d'un conteneur EJB3 aussi bien que dans une application
autonome J2SE en dehors d'un conteneur particulier. Cette API réalise la
fusion des travaux sur Hibernate avec la continuité des
spécifications EJB précédentes 2.0 et 2.1.
POJO : Est un acronyme qui signifie Plain Old
Java Object. Il fait référence à un objet qui dispose d'un
constructeur sans paramètre ainsi qu'un couple d'accesseurs (get/set)
pour chacun de ses champs.
SGBDR: La gestion et l'accès à
une base de données sont assurés par un ensemble de programmes
qui constituent le Système de gestion de base de données.
Note : on peut parfois parler de SGBDO. `O' de objet signifie
que la base de donnée stocke l'information dans des objets, très
souvent une fiche individuelle, une machine, une ressource... à laquelle
on associe des valeurs, ses attributs.
Serveur d'applications : Un serveur
d'applications est un serveur sur lequel sont installées des
applications accessibles par le réseau à des utilisateurs.
| 

