Chapitre 0. INTRODUCTION
GENERALE
Introduction
La biométrie est un ensemble des technologies
(appelée les technologies biométriques) qui exploitent des
caractéristiques humaines physiques ou comportementales telles que
l'empreinte digitale, la signature, l'iris, la voix, le visage, la
démarche, et un geste de main pour différencier des personnes.
Ces caractéristiques sont traitées par certain ordre des
processus automatisés à l'aide des dispositifs comme des modules
de balayage ou des appareils - photos. A la différence des mots de passe
ou des PINs (numéros d'identification personnelle) qui sont facilement
oubliés ou exposés à l'utilisation frauduleuse, ou des
clefs ou des cartes magnétiques qui doivent être portées
par l'individu et sont faciles à être volées,
copiées ou perdues, ces caractéristiques biométriques sont
uniques à l'individu et il y a peu de possibilité que d'autres
individus peuvent remplacer ces caractéristiques, donc les technologies
biométriques sont considérées les plus puissantes en
termes de sécurité.
En plus les mesures biométriques sont confortables
parce qu'elles n'ont pas besoin d'être portées
séparément. De telles caractéristiques peuvent être
bien employées pour obtenir l'identification/authentification pour
accéder à des systèmes tels ATMs (guichet automatique). La
biométrie se prouve également comme outil puissant
d'identification/vérification aux scènes de crime dans le secteur
juridique.
Un système biométrique est essentielle un
système de reconnaissance de formes qui fonctionne en acquérant
des données biométriques à partir d'un individuel,
extrayant un ensemble de caractéristiques à partir des
données acquises, et comparant ces caractéristiques contre la
signature dans la base de données. Selon le contexte d'application, un
système biométrique peut fonctionner en mode de
vérification ou mode d'identification :
· Vérification : le
système valide l'identité d'une personne en comparant les
données biométriques capturées à sa propre base de
données. Dans un tel système, un individu qui désire
être identifié réclame une identité, habituellement
par l'intermédiaire d'un PIN (numéro d'identification
personnelle), d'un nom d'utilisateur, ..., et le système conduit une
comparaison d'un - à - un pour déterminer si la
réclamation est vraie ou faux (est - ce que ces données
biométriques appartiennent à tel ?)
· Identification : le
système identifie un individu en recherchant les signatures (Template)
de tous les utilisateurs dans la base de données. Par conséquent,
le système conduit plusieurs des comparaisons pour établir
l'identité d'un individu (ou échoue si le sujet n'est pas inscrit
dans la base de données de système) sans devoir soumis
réclamer une identité.
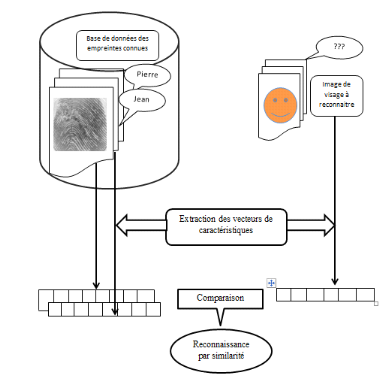
En général, tous les systèmes
biométriques partagent le même schéma de fonctionnement.
Ils se composent tous de deux processus suivant :
Template
Nom (PIN)

Vérification de qualité
Extraction des traits
BD
Interface d'utilisateur
Enrôlement
Identité réclamée
Nom (PIN)

Egaler
(1match)
Extraction des traits
BD
One
Template
Vraie /Faux
Interface d'utilisateur
Vérification
Identité réclamée
Nom (PIN)
Vraie /Faux
Interface d'utilisateur
Vérification
BD
Extraction des traits
Egaler
(N match)

N
Templates
Figure 0.1. Schéma de
fonctionnement d'un système biométrique
0.1.
Problématique
L'ingénieur étant une personne capable
d'apporter toujours des solutions aux problèmes de sa nation, nous nous
sommes proposés de concevoir et de mettre en place un système de
reconnaissance biométrique des empreintes digitales qui va rendre
l'authenticité des documents de trafic tels le passeport ou autres
documents aux citoyens détenteurs.
Comme il y a tant des fraudes des documents de trafic, la
reconnaissance biométrique des empreintes digitales est idéale
pour résoudre le problème de la sécurité lorsqu'on
effectue des trafics via différentes frontières. Nous allons donc
concevoir et mettre en place un système de reconnaissance
biométrique qui va minimiser les fraudes.
Nous nous permettons ici d'évoquer les besoins aux
quels notre système de reconnaissance d'empreinte doit
répondre :
§ Doit donner des résultats corrects de la
reconnaissance d'une manière claire et nette ;
§ Doit gérer si le document de trafic est actif ou
non - actif ;
§ Doit générer les rapports de trafic
pendant une période.
0.2. Hypothèse de la recherche
Selon Pinto - R1(*), « l'hypothèse est une proposition
des réponses aux questions que l'on se pose à propos de
l'objectif de recherche formulé tels que l'observation des faits et
l'analyse des données puisse fournir une réponse
précise »
Dans le cadre de travail et eu égard à la
problématique évoquée ci - dessus, nous émettons
les hypothèses suivantes, à priori, qui apparaissent dans les
lignes suivantes :
Ø Quelle est l'importance de la biométrie des
empreintes digitales ?
Ø Quelle est la technologie de la reconnaissance
biométrique la plus efficace ?
Ø Quels sont les problèmes rencontrés lors
de la reconnaissance biométrique des empreintes digitales ?
Tout au long de notre travail, nous continuerons à
développer ces différentes réponses.
0.3. Méthodologie de la recherche
Comme tout travail intellectuel, nous avons utilisé
une méthode d'analyse scientifique et descriptive ainsi qu'une technique
documentaire qui est d'une importance capitale car elle nous a permis de
récolter différentes données dans les revues, articles,
ouvrages, mémoires et autres sources qui peuvent nous fournir des
informations nécessaires à la réalisation de ce
travail.
0.4. Choix et intérêt du sujet
Notre travail s'inscrit dans le cadre d'une conception et
mise en place d'une plateforme de sécurisation par synthèse et
reconnaissance biométrique des documents de trafic. Partant de
certitude, nous disons que ce sujet revêtant d'une importance capitale a
attiré notre attention car, il nous permet de connaitre et de
comprendre explicitement le fonctionnement d'un système de
reconnaissance biométrique en général et celui de
reconnaissance des empreintes digitales en particuliers proposant la
sécurité des certains documents de trafic pour minimiser la
fraude.
Chapitre I. GENERALITE SUR
LA BIOMETRIE
I.1. Préambule
Les systèmes biométriques sont de plus en plus
utilisés depuis quelques années. L'apparition de l'ordinateur et
sa capacité à traiter et à stocker des données ont
permis la création des systèmes biométriques
informatisés. Il existe plusieurs caractéristiques physiques
uniques pour un individu, ce qui explique la diversité des
systèmes appliquant la biométrie, selon ce que l'on prend en
compte :
Ø L'empreinte digitale
Ø La géométrie de la main
Ø L'iris
Ø La rétine
Ø La voix ... etc.
Nous allons voir dans ce chapitre, les principales
technologies biométriques, puis nous allons nous focaliser sur les
systèmes de reconnaissance des empreintes digitales, leurs avantages et
les problèmes liés à leurs applications.
I.2. La biométrie
I.2.1. Définition
La biométrie peut être définie comme
étant « la reconnaissance automatique d'une personne en
utilisant des traits distinctifs ». Une autre définition de la
biométrie est « toutes caractéristiques physiques ou
traits personnels automatiquement mesurables, robustes et distinctives qui
peuvent être utilisées pour identifier ou pour vérifier
l'identité prétendue d'un individu » [1].
La biométrie consiste en l'analyse mathématique
des caractéristiques biologiques d'une personne et a pour objectif de
déterminer son identité de manière incontestable.
Contrairement à ce que l'on sait ou ce que l'on possède, la
biométrie est basée sur ce que l'on est et permet ainsi
d'éviter la duplication, le vol, l'oubli ou la perte.
Un système biométrique peut avoir deux modes
opératoires [4] :
· L'identification, elle permet d'établir
l'identité d'une personne à partir d'une base de données,
le système biométrique pose et essaye de répondre à
la question, « qui est la personne X ? », il s'agit
d'une comparaison du type un contre plusieurs (1 : N).
· La vérification ou l'authentification, le
système biométrique demande à l'utilisateur son
identité et essaye de répondre à la question,
« est - ce la personne X ? ». Dans une application de
vérification, l'utilisateur annonce son identité par
l'intermédiaire d'un mot de passe, d'un numéro d'identification,
d'un nom d'utilisateur, ou toute combinaison des trois. Le système
sollicite également une information biométrique provenant de
l'utilisateur, et compare la donnée caractéristique obtenue
à partir de l'information entrée, avec la donnée
enregistrée correspondante à l'identité prétendue,
c'est une comparaison un à un (1 :1). Le système trouvera ou
ne trouvera pas d'appariement entre les deux. La vérification est
communément employée dans des applications de contrôle
d'accès et de paiement par authentification [2].
La biométrie offre beaucoup plus d'avantages que les
méthodes existantes d'authentification (ID), les mots de passe et les
cartes magnétiques. En effet, elle fournit encore plus de
sûreté et de convenance ce qui engendre d'énormes avantages
économiques et elle comble les grandes failles de sécurité
des mots de passe.
I.3. Le marché mondial
de la biométrie
Régulièrement, un rapport sur le marché
de la biométrie est édité par IBG (International Biometric
Group). Cette étude est une analyse complète des chiffres
d'affaires, des tendances de croissance, et des développements
industriels pour le marché de la biométrie actuel et futur.
La lecture de ce rapport est essentielle pour des
établissements déployant la technologie biométrique, les
investissements dans les entreprises biométriques, ou les
développeurs de solutions biométriques. Le chiffre d'affaires de
l'industrie biométrique incluant les applications judiciaires et celles
du secteur public, se développe rapidement. Une grande partie de la
croissance sera attribuable au contrôle d'accès aux
systèmes d'information (ordinateur/réseau) et au commerce
électronique, bien que les applications du secteur public continuent
à être une partie essentielle de l'industrie.
On prévoit que le chiffre d'affaires des
marchés émergents (accès aux systèmes
d'information, commerce électronique et téléphonie,
accès physiques et surveillance) dépasse le chiffre d'affaires
des secteurs plus matures (identification criminelle et identification des
citoyens).

Figure I.1 : Evolution du
marché international de la biométrie [3].
I.4. Les parts de marché
par technologies
Les empreintes digitales continuent à être la
principale technologie biométrique en termes de part de marché,
près de 50% du chiffre d'affaires total (hors applications judiciaires),
dépasse la reconnaissance de la main, qui avait avant la deuxième
place en termes de sources de revenus après les empreintes digitales.
Biometric Revenues by Technology, 2009
Copyright(c)2008 international Biometric Group

Figure I.2 : Parts de
marché des différentes méthodes biométriques
[3].
I.5. Les techniques
biométriques
Il existe plusieurs techniques biométriques
utilisées dans plusieurs applications et secteurs, on peut en distinguer
deux catégories :
I.5.1. L'analyse morphologique
(physiologique)
Elle est basée sur l'identification de traits
physiques particuliers qui, pour toute personne, sont uniques et permanents.
Cette catégorie regroupe l'iris de l'oeil, le réseau veineux de
la rétine, la forme de la main, les empreintes digitales, les traits du
visage, les veines de la main, etc.
I.5.2. L'analyse
comportementale
Elle se base sur l'analyse de certains comportements d'une
personne. Cette catégorie regroupe la reconnaissance vocale, la
dynamique de frappe au clavier, la dynamique de la signature, l'analyse de la
démarche, etc. Il existe, par ailleurs,
une autre catégorie qui est l'étude des traces
biologiques telles que : l'ADN, le sang, la salive, l'urine, l'odeur, etc.
I.6. Architecture d'un
système biométrique
Il existe toujours au moins deux modules dans un
système biométrique : le module d'apprentissage et celui de
reconnaissance [4] [5]. Le troisième module est le module d'adaptation.
Pendant l'apprentissage, le système ca acquérir une ou plusieurs
mesures biométriques qui serviront à construire un modèle
de l'individu. Ce modèle de référence servira de point de
comparaison lors de la reconnaissance. Le modèle pourra être
réévalué après chaque utilisation grâce au
module d'adaptation.
I.6.1. Module
d'apprentissage
Au cours de l'apprentissage, la caractéristique
biométrique est tout d'abord mesurée grâce à un
capteur ; on parle d'acquisition ou de capture. En général,
cette capture n'est pas directement stockée et des transformations lui
sont appliquées. En effet, le signal contient de l'information inutile
à la reconnaissance et seuls les paramètres pertinents sont
extraits. Le modèle est une représentation compacte du signal qui
permet de faciliter la phase de reconnaissance, mais aussi de diminuer la
quantité de données à stocker.
Il est à noter que la qualité du capteur peut
grandement influencer les performances du système. Meilleure est la
qualité du système d'acquisition, moins il y aura de
prétraitements à effectuer pour extraire les paramètres du
signal. Cependant, les capteurs de qualité sont en général
coûteux et leur utilisation est donc limitée à des
applications de haute sécurité pour un public limité. Le
modèle peut être stocké dans une base de données.
I.6.2. Module de
reconnaissance
Au cours de la reconnaissance, la caractéristique
biométrique est mesurée et un ensemble de paramètres est
extrait comme lors de l'apprentissage (figure 3). Le capteur utilisé
doit avoir des propriétés aussi proches que possibles du capteur
utilisé durant la phase d'apprentissage. Si les deux capteurs ont des
propriétés trop différentes, il faudra en
général appliquer une série de prétraitements
supplémentaires pour limiter la dégradation des performances. La
suite de la reconnaissance sera différente suivant le mode
opératoire du système : identification ou
vérification.
En mode identification, le système doit deviner
l'identité de la personne. Il répond donc à la question de
type : « Qui suis - je ? ». Dans ce mode, le
système compare le signal mesuré avec les différents
modèles contenus dans la base de données (problème de type
1 : N). En général, lorsque l'on parle d'identification, on
suppose que le problème est fermé, c'est - à - dire que
toute personne qui utilise le système possède un modèle
dans la base de données.
En mode vérification, le système doit
répondre à une question de type : « Suis - je bien
la personne que je prétends être ? ».
L'utilisateur propose une identité au système et
le système doit vérifier que l'identité de l'individu est
bien celle proposée. Il suffit donc de comparé le signal avec un
seul des modèles présents dans la base de données
(problème de type 1 : 1). En mode vérification, on parle de
problème ouvert puisque l'on suppose qu'un individu qui n'a pas de
modèle dans la base de données (imposteur) peut chercher à
être reconnu.
Identification et vérification sont donc deux
problèmes différents. L'identification peut - être une
tâche redoutable lorsque la base de données contient des milliers,
voire des millions d'identités, tout particulièrement lorsqu'il
existe des contraintes de type « temps réel » sur le
système. Ces difficultés sont analogues à celles que
connaissent par exemple les systèmes d'indexation de documents
multimédia.
Hbhhhhhhhhj
Figure I.3 : Phase de
reconnaissance d'un système des empreintes digitales.
I.6.3. Module d'adaptation
Pendant la phase d'apprentissage, le système
biométrique ne capture souvent que quelques instances d'un même
attribut afin de limiter la gêne pour l'utilisateur. Il est donc
difficile de construire un modèle assez général capable de
décrire toutes les variations de cet attribut. De plus, les
caractéristiques de cette biométrie ainsi que ses conditions
d'acquisition peuvent varier. L'adaptation est donc nécessaire pour
maintenir voire améliore la performance d'un système utilisation
après utilisation. L'adaptation peut se faire en mode supervisé
ou non - supervisée mais le second mode est de loin le plus utile en
pratique.
Si un utilisateur est identifié par le module de
reconnaissance, les paramètres extraits du signal serviront alors
à ré - estimer son modèle. En général, le
taux d'adaptation dépend du degré de confiance du module de
reconnaissance dans l'identité de l'utilisateur. Bien entendu,
l'adaptation non - supervisée peut poser problème en cas
d'erreurs du module de reconnaissance. L'adaptation est quasi indispensable
pour le les caractéristiques non permanentes comme la voix [6].
I.7. Présentation de
quelques technologies biométriques
Aucune biométrie unique ne pouvait
répondre efficacement aux besoins de toutes les applications
d'identification. Un certain nombre de techniques biométriques ont
été proposées, analysées et évaluées.
Chaque biométrie à ses forces et ses limites, et en
conséquence, chaque biométrie est utilisée dans une
application particulière. Pour les caractéristiques physiques,
nous décrirons la reconnaissance de visage, les empreintes digitales, la
géométrie de la main et l'iris. Pour les caractéristiques
comportementales, nous décrirons les biométries basées sur
la voix et la signature.
Il existe d'autres systèmes biométriques
basés sur les veines de la main, l'A.D.N, l'odeur corporelle, la forme
de l'oreille, la forme des lèvres, le rythme de frappe sur un clavier,
la démarche, qui ne seront pas développées dans ce
chapitre.
I.7.1. Les empreintes
digitales
A l'heure actuelle, la reconnaissance des empreintes
digitales est la méthode biométrique la plus utilisée. Les
empreintes digitales sont composées de ligne localement
parallèles présentant des points singuliers (minuties) et
constituent un motif unique, universel et permanent. Pour obtenir une image de
l'empreinte d'un doigt, les avancées technologiques ont permis
d'automatiser la tâche au moyen de capteurs intégrés,
remplaçant ainsi l'utilisation classique de l'encre et du papier. Ces
capteurs fonctionnant selon différents mécanismes de mesure
(pression, champ électrique, température) permettent de mesurer
l'empreinte d'un doigt fixe positionné sur ce dernier (capteur
matriciel) ou en mouvement (capteurs à balayage).
L'image d'empreinte d'un individu est capturée
à l'aide d'un lecteur d'empreinte digitale puis les
caractéristiques sont extraites de l'image puis un modèle est
créé. Si des précautions appropriées sont suivies,
le résultat est un moyen très précis
d'authentification.
Les techniques d'appariement des empreintes digitales peuvent
être classées en deux catégories : les techniques
basées sur la détection locale des minuties et les techniques
basées sur la corrélation. L'approche basée sur les
minuties consiste à trouver d'abord les points de minuties puis trace
leurs emplacements sur l'image du doigt (figure I.4).

Figure I.4. Le processus de
reconnaissance par empreinte digitale.
Cependant, il y a quelques difficultés avec cette
approche lorsque l'image d'empreinte digitale est d'une qualité
médiocre, car l'extraction précise des points de minutie est
difficile. Cette méthode ne tient pas en compte la structure globale de
crêtes et de sillons. Les méthodes basées sur la
corrélation sont capables de surmonter les problèmes de
l'approche fondée sur les minuties. Ces méthodes utilisent la
structure globale de l'empreinte, mais les résultats sont moins
précis qu'avec les minuties. De plus, les techniques de
corrélations sont affectées par la translation et rotation de
l'image de l'empreinte. C'est pour cela que les deux approches sont en
général combinées pour augmenter les performances du
système.
I.7.2. La voix
De tous les traits humains utilisés dans la
biométrie, la voix est celle que les humains apprennent à
reconnaitre dès le plus jeune âge. Les systèmes de
reconnaissance de locuteur peuvent être divisés en deux
catégories : les systèmes dépendant du texte
prononcé et les systèmes indépendants du texte. Dans le
premier cas, l'utilisateur est tenu d'utiliser un texte (un mot ou une
phrase)fixe prédéterminé au cours des séances
d'apprentissage et de reconnaissance. Alors que, pour un système
indépendant du texte le locuteur parle librement sans texte
prédéfini.
Cette dernière catégorie est plus
difficile, mais elle est utile dans le cas où l'on a besoin de
reconnaitre un locuteur sans sa coopération. La recherche sur la
reconnaissance de locuteur est en pleine croissance, car elle ne
nécessite pas de matériel cher, puisque la plupart des
ordinateurs personnels de nos jours sont équipés d'un microphone.
Toutefois, la mauvaise qualité et le bruit ambiant peuvent influencer la
vérification et par suite réduire son utilisation dans les
systèmes biométriques.
Dans un système de reconnaissance vocal, le signal est
premièrement mesuré puis décomposé en plusieurs
canaux de fréquences passe - bande. Ensuite, les caractéristiques
importantes du signal vocal sont extraites de chaque bande. Parmi les
caractéristiques les plus communément utilisées sont les
coefficients Cepstraux. Ils sont obtenus par le logarithme de la
transformée de Fourier du signal vocal dans chaque bande. Finalement, la
mise en correspondance des coefficients Cepstraux permet de reconnaitre la
voix. Dans cette étape, généralement on fait appel
à des approches fondées sur les modèles de Markov
cachés, la quantification vectorielle, ou la déformation temps
dynamique.
Figure I.5. Spectre d'un signal
vocal.
I.7.3. L'iris
L'utilisation de l'iris comme caractéristique
biométrique unique de l'homme a donné lieu à une
technologie d'identification fiable et extrêmement précise. L'iris
est la région, sous forme d'anneau, située entre la pupille et le
blanc de l'oeil, il est unique. L'iris a une structure extraordinaire et offre
de nombreuses caractéristiques de texture qui sont uniques pour chaque
individu. Les algorithmes utilisés dans la reconnaissance de l'iris sont
si précis que la planète toute entière pourrait être
inscrite dans une base de données de l'iris avec peu d'erreurs
d'identification.
L'image de l'iris est généralement
capturée à l'aide d'une caméra standard. Cependant, cette
étape de capture implique une coopération de l'individu. De plus,
il existe plusieurs contraintes liées à l'utilisation de cette
technologie. Par exemple, il faut s'assurer que l'iris de l'individu est
à une distance fixe et proche du dispositif de capture, ce qui limite
l'utilisation de cette technologie.

Figure I.6. Photos d'iris
I.7.4. La signature
La vérification de la signature analyse la
façon dont un utilisateur signe son nom. Les caractéristiques
dynamiques de la signature comme la vitesse et la pression, sont aussi
importantes que la forme géométrique de la signature. Dans la
vérification de signature statique, seules les formes
géométriques de la signature sont utilisées pour
authentifier une personne. Dans cette approche, en règle
générale, la signature est normalisée à une taille
connue ensuite décomposée en éléments simples.
La forme et les relations de ses éléments sont
utilisées comme caractéristiques d'identification. Quant à
la deuxième approche de la vérification de signature elle
utilise, en plus de la forme géométrique, les
caractéristiques dynamiques telles que l'accélération, la
vitesse et les profils de trajectoire de la signature. Il est à noter
que la signature est une biométrie comportementale, elle évolue
dans le temps et est influencée par les conditions physiques et
émotionnelles de la personne.

Figure I.7. Signature
I.7.5. La
géométrie de la main
La géométrie de la main est une technologie
biométrique récente. Comme son nom l'indique, elle consiste
à analyser et à mesurer la forme de la main, c'est - à -
dire mesurer la longueur, la largeur et la hauteur de la main d'un utilisateur
et de créer une image 3-D. Des LEDs infrarouges et un appareil - photo
numérique sont utilisés pour acquérir les données
de la main.
Cette technologie offre un niveau raisonnable de
précision et est relativement facile à utiliser. Cependant, elle
peut être facilement trompée par des jumeaux ou par des personnes
ayant des formes de la main proches. Les utilisations les plus populaires de la
géométrie de la main comprennent l'enregistrement de
présence et le contrôle d'accès. Par contre, les
systèmes de capture de la main sont relativement grands et lourds, ce
qui limite leur utilisation dans d'autres applications comme l'authentification
dans les systèmes embarqués : téléphones
portables, voitures, ordinateurs portables, etc.

Figure I.8. Dispositif de
reconnaissance par géométrie de la main
I.7.6. Le visage
Nos visages sont des objets complexes avec des traits qui
peuvent varier dans le temps. Cependant, les humains ont une capacité
naturelle à reconnaitre les visages et d'identifier les personnes dans
un coup d'oeil. Bien sûr, notre capacité de reconnaissance
naturelle s'étend au - delà de la reconnaissance du visage,
où nous sommes également en mesure de repérer rapidement
des objets, des sons ou des odeurs. Malheureusement, cette aptitude naturelle
n'existe pas dans les ordinateurs. C'est ainsi qu'est né le besoin de
simuler artificiellement la reconnaissance afin de créer des
systèmes intelligents autonomes. Simuler notre capacité
naturelle de la reconnaissance faciale dans les machines est une tâche
difficile mais pas impossible. Tout au long de notre vie, de nombreux visages
sont vus et conservés naturellement dans nos mémoires formant une
sorte de base de données.
La reconnaissance faciale par ordinateur nécessite
également une base de données qui est habituellement construire
en utilisant des images du visage ou parfois des images différentes
d'une même personne pour tenir compte des variations dans les traits du
visage. Les systèmes actuels de reconnaissance faciale sont
composés d'un module d'acquisition d'images avec une caméra. Il
procède d'abord à une détection du visage dans l'image
acquise. Ensuite, l'image du visage détectée est
normalisée pour être transmise au module de reconnaissance qui va
la traiter en utilisant des algorithmes afin d'extraire une signature
faciale.
Finalement, cette signature est comparée, à
l'aide d'un classificateur, avec les signatures déjà existantes
dans une base de données locale, afin d'identifier l'individu en
question. Les différentes étapes de la reconnaissance faciale
sont illustrées dans la figure I.9.Durant la
dernière décennie de recherche, la performance des
systèmes de reconnaissance faciale s'est grandement
améliorée, mais les résultats sont encore loin
d'être parfaits. Ces systèmes sont très sensibles aux
variations d'illumination et de pose.

Figure I.9. Schéma
synoptique d'un système de reconnaissance faciale
I.8. Reconnaissance des
empreintes digitales.
La reconnaissance des empreintes digitales est tâche
que les humains effectuent naturellement sans effort dans leurs vies
quotidiennes. La grande disponibilité d'ordinateur puissants et peu
onéreux ainsi que des systèmes informatiques embarqués ont
suscité un énorme intérêt dans le traitement
automatique des empreintes digitales au sein de nombreuses applications,
incluant l'identification biométrique, l'interaction homme - machine, la
gestion de données multimédia.
La reconnaissance des
empreintes digitales, en tant qu'une des technologies de base, a pris une part
de plus en plus importante dans le domaine de la recherche, ceci étant
dû aux avances rapides dans des technologies telles les dispositifs
mobiles, les ordinateurs portables, des scanner d'identification des empreintes
digitales, des guichets automatiques pour certificat administratif à
authentification, ... le tout associé à des besoins en
sécurité sans cesse en augmentation.
La reconnaissance des empreintes digitales possède
plusieurs avantages sur les autres technologies biométriques :
petite taille facilitant son intégration dans la majorité des
applications (téléphones portables, ordinateurs portables),
faible coûts des grâce aux nouveaux capteurs, facile à
utiliser, ...
Idéalement, un système de reconnaissance des
empreintes digitales doit pouvoir identifier des empreintes dans une base de
données de manière automatique. Le système peut
opérer dans les deux modes suivants : authentification ou
identification.
I.8.1. Approches globales
La particularité des algorithmes basés sur
l'apparence, c'est l'utilisation directe des valeurs d'intensité des
pixels de l'image entière de l'empreinte digitale comme
caractéristique sur lesquelles la décision de reconnaissance sera
fondée. L'inconvénient de cette méthode c'est la taille
importante des données à traiter. Par ailleurs, les
méthodes globales peuvent être à leur tour
classifiées en deux grandes catégories à savoir les
méthodes linéaires et les méthodes non linéaires.
Ces méthodes appelées aussi méthodes de projections sont
baseées sur sur la décomposition de l'empreinte digitale sur un
sous espace réduit et sur la recherche d'un vecteur de
caractéristiques optimal décrivant l'empreinte digitale à
connaitre.
I.8.2. Méthodes locales
Les méthodes locales, basées sur des
modèles, utilisent des connaissances a priori que l'on possède
sur la morphologie de l'empreinte digitale et s'appuient en sur des points
caractéristiques de celui - ci. Kanade présenta
un des premiers algorithmes de ce type [7]en détectant certains points
ou caractéristiques d'une empreinte digitale puis en les comparants avec
des paramètres extraits d'autres empreintes digitales.
I.8.3. Méthodes
hybrides
Les méthodes hybrides permettent d'associer les
avantages des méthodes globales et locales en combinant la
détection de caractéristiques géométriques (ou
structurales) avec l'extraction de caractéristique d'apparence locales.
L'analyse de caractéristiques locales (LFA) [8] et les
caractéristiques extraites par ondelettes de Gabor (comme l'ElasticBunch
Graph Matching, EBGM), sont des algorithmes hybrides typiques.
Plus récemment, l'algorithme Log Gabor PCA (LG - PCA)
[9] effectue une convolution avec des ondelettes de Gabor orientées
autour de certains points caractéristiques de l'empreinte digitale afin
de créer des vecteurs contenant la localisation et la valeur
d'amplitudes énergétiques locales ; vecteurs sont ensuite
envoyés dans un algorithmes PCA afin de réduire la dimensions des
données.
I.9. Principales
difficultés de la reconnaissance des empreintes digitales
Pour le cerveau humain, les processus de la reconnaissance
des empreintes digitales est une tâche visuelle de haut niveau. Bien que
les êtres humains puissent détecter et identifier des empreintes
digitales dans une scène sans beaucoup de peine, construire un
système automatique qui accomplit de telles tâches
représente un sérieux défi. Ce défi est d'autant
plus grand lorsque les conditions d'acquisition des empreintes sont très
variables. Il existe deux types de variations associées aux images des
empreintes digitales : inter et intra sujet. La variation inter - sujet
est limitée à cause de la ressemblance physique entre les
individus. Par contre, la variation intra - sujet est plus vaste. Elle peut
être attribuée à plusieurs facteurs que nous analysons ci -
dessous.
I.9.1. Présence ou
absence des composants structurels
La présence des composants structurels telle que la
blessure ou bien d'autres substances peut modifier énormément les
caractéristiques d'empreinte digitale telle que la forme ou la taille de
l'empreinte digitale. De plus, ces composants peuvent cacher les
caractéristiques d'empreintes digitales de base causant ainsi une
défaillance du système de reconnaissance.
Chapitre II. TECHNIQUE DE
DETECTION ET VERIFICATION PAR RECONNAISSANCE DES EMPREINTES DIGITALEES.
II.1. Préambule.
Dans ce chapitre, nous présenterons un état de
l'art sur les techniques de détection des empreintes digitales et les
différentes méthodes les plus connues de reconnaissance des
empreintes digitales. Enfin, nous terminerons le chapitre par la
présentation de l'image d'empreinte digitale et prise de
décision.
II.2. Définition de
problème de vérification.
Ici, nous allons considérer le problème de
vérification biométrique de manière plus formelle. Dans un
problème de vérification, le signal biométrique qui
parvient de l'utilisateur est comparé avec un seul gabarit
enregistré. Ce gabarit est choisi en fonction de l'identité de
l'utilisateur. Chaque utilisateur i est représenté par
sa biométrie Bi. L'extraction des
caractéristiques va résulter en une représentation machine
Tide la biométrie capturée. Durant la
vérification, l'utilisateur énonce son identité j
et fournit un signal biométrique Tj. La
reconnaissance se fait en calculant le score de similarité S
(Ti ,Tj). L'identité
annoncée est supposée être réelle si S
(Ti, Tj) >th avec th
un seuil (threshold) de comparaison choisi ; son choix
détermine un compromis entre la convenance de l'utilisateur et la
sécurité du système comme il sera vu dans le paragraphe
suivant.
II.2.1. Evaluation de
performance.
La performance d'un système biométrique peut se
mesurer principalement à l'aide de trois critères : sa
précision, son efficacité (temps exécution) et le
volume de données qui doit être stocké pour chaque
locuteur. Nous nous concentrons sur le premier aspect.
II.2.2. Evaluation de la
vérification
Lorsqu'un système fonctionne en mode
vérification, celui - ci peut faire deux types d'erreurs. Il peut
rejeter un utilisateur légitime et dans ce premier cas, on parle de faux
rejet (false rejection). Il peut aussi accepter un imposteur et on parle dans
ce cas de fausse acceptation (false acceptance). La performance d'un
système se mesure donc à son taux de faux rejets (False Rajection
Rate ou FRR) et à son taux de fausse acceptation (False Acceptance Rate
ou FAR).
Idéalement, un système devrait avoir des FARs
et des FRRs égaux à zéro [10]. Le problème de
vérification peut être formulé de la manière
suivante :
Soient H0 l'hypothèse :
« la capture C provient d'un
imposteur » et H1 l'hypothèse :
« la capture C provient de l'utilisateur
légitime ». Il faut donc choisir l'hypothèse la
plus probable.
On considère que la capture Cprovient
d'un utilisateur légitime si P(H1/C)>P(H0/C).
En appliquant la loi de Bayes, on obtient :
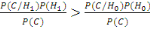 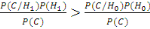 et donc et donc  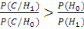
Le taux de vraisemblance (likelihood ratio) 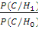 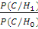 est comparé à un seuil èappeléseuil de
décision. est comparé à un seuil èappeléseuil de
décision.
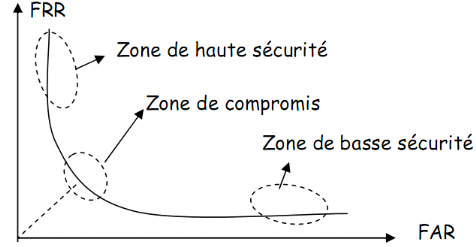
La courbe dite réceptrice des
caractéristiques de fonctionnement (ROC : Receiver
Operating Characteristic), représentée à la figure II.1,
permet de représenter graphiquement la performance d'un système
de vérification pour les différentes valeurs de è. Le taux
d'erreur d'égal (EqualErrot Rate ou EER) correspond au point FAR -
FRR, c'est - à - dire graphiquement à l'intersection de la
courbe ROC avec la première bissectrice. Ce taux est fréquemment
utilisé pour donner un aperçu de la performance d'un
système biométrique. Le seuil è doit donc être
ajusté en fonction de l'application ciblée : haute
sécurité, basse sécurité ou compromis entre les
deux.
Figure II. 1. La courbe
ROC
II.3. Les empreintes digitales
comme modalité biométrique
La reconnaissance d'empreinte digitale est la technique
biométrique la plus ancienne et c'est l'une des plus matures.
L'empreinte digitale se présente comme une alternance de crêtes et
de vallées. Leurs formations dépendent des conditions initiales
du mésoderme embryonnaire à partir duquel elles se
développent. Elles ne sont pas totalement déterminées par
la génétique puisque même des jumeaux monozygotes ont des
empreintes différentes [11]. Les empreintes ont formellement
été acceptées comme identificateur de personnes valide
dès le début du 20ème siècle. Elles ont
d'abord étaient utilisées dans les milieux juridiques, avant de
devenir une technique d'authentification effective. L'histoire des empreintes
est longue, elle s'amoncelle depuis l'ère égyptienne. Nous
donnons ici un bref aperçu[12]:
§ Les empreintes n'ont pas été
décrites sur les manuscrits jusqu'au 17ème
siècle. En 1686, Marcello Malpighi un professeur d'anatomie à
l'université de Bologne (Italie) décrit les crêtes
papillaires dans son traité.
§ En 1888, le Britannique F. Galton, un anthropologue
anglais et cousin de Charles Darwin démontre la permanence du dessin
papillaire de la naissance à la mort ainsi que son
inaltérabilité. Cet arrangement particulier des lignes
papillaires forme des points caractéristiques nommés
minuties ou points de Galton qui sont à l'origine de
l'individualité des dessins d'empreintes. En se basant
sur ses calculs, la probabilité pour que les empreintes de deux
individus différents se correspondent est de 10-24.
§ En 1901, les empreintes furent introduites pour
l'identification de criminels en Grande Bretagne. Les observations de Galton et
leur révision par Edward Henry ont été utilisées.
Cela marque le fondement du système de classification de Henry [13].
Depuis lors, en admettant son unicité, l'empreinte
digitale a été reçue comme une méthode
légale d'identification de personnes par la plupart des pays du monde.
L'utilisation des empreintes digitales s'est d'abord manifestée de
façon manuelle par des experts entraînés. L'exactitude de
leurs résultats est indiscutable, seul inconvénient majeur le
temps requis pour examiner des fichiers volumineux. L'avènement de
l'ordinateur et les progrès récents réalisés dans
le domaine de la reconnaissance des formes ont aidé à
développer un système d'identification automatique : Les
AFIS (AutomaticFingerprint Identification System) dont le plus connu est sans
doute le logiciel NIST utilisé en grande partie par le FBI [14]. Ces
systèmes ont considérablement amélioré la
productivité opérationnelle des agences de loi et ont
réduit le coût d'employer et de former les experts d'empreintes
digitales. Aujourd'hui des nouvelles technologies pour la surveillance
apparaissent plébiscitées par un besoin accru de contrôle
et de surveillance, et une avancée dans le domaine des capteurs
embarqués. Les empreintes digitales sont utilisées à
50%.
II.4. Définition d'une
empreinte digitale
L'empreinte digitale, Figure II.2, est constituée de
crêtes qui définissent des lignes. Ces lignes définissent
elles - mêmes des formes générales qui constituent trois
classes principales, figure II.3 :
· Les arcs : les lignes vont d'un bord à
l'autre du doigt
· Les boucles : les lignes ont un trajet
récurent et reviennent aux bords s dont elles sont parties.
· Les verticilles : les lignes présentent un
trajet plus au moins spiralé et limité vers les bords du doigt

Figure II.2. Exemple d'une
empreinte digitale

Figure II.3. Les
différents type d'empreintes : (a) image de type arc, (b) image de
type boucle et (c) image de type spiral.
Les empreintes digitales sont entièrement
formées à environ sept mois du développement du foetus et
les configurations des crêtes du doigt ne changent pas à moins
d'accidents telles que des contusions et des coupes sur les bouts du doigt.
Cette propriété fait des empreintes digitales une marque
biométrique très attrayante. En pratique, on
préférera extraire les caractéristiques principales
suivantes [15]:
Ø Coupure (fin d'arête)

Les minuties : Les empreintes digitales présentent
plusieurs types de points dont la détermination repose sur des
règles précises et complexes. Les bifurcations et les fins de
crêtes permettent la reconstitution de toutes les minuties, toute autre
minutie peut se composer de combinaison de bifurcations et de fins de
crêtes. Par exemple, les anneaux peuvent être visualisés en
tant que deux bifurcations qui se superposent en un ilot peut être
représenté par deux fins de crêtes à courte
distance, figure II.4.
Anneaux (médian ou clôture)
Division (Bifurcation)
Ilots (simple)
Figure II.4. Exemple de 4
familles de crêtes
Comme l'illustre la figure II.4, on distingue quatre familles
de crêtes : les coupures, les divisions, les anneaux et les ilots
qui se subdivisent selon leur forme telles que représentées ci -
dessous :
- Les coupures :
Dérivation
Arrêt
Interruption

- Les divisions :
Crochet
Embranchement
Double Bifurcation
Bifurcation
Trifurcation

- Les anneaux :
Latéraux
Médian


- Les ilots :
Dérivation
Arrêt
Interruption
Ø Les points singuliers :
- Le centre : le centre est de lieu de courbure maximale
des lignes d'empreinte les plus internes. Il est aussi appelé le
point core.
- Les deltas : un delta est proche du lieu où se
séparent deux lignes d'empreintes vérifiant les
propriétés suivantes : ces lignes se séparent suivant
deux directions orthogonales et sont les lignes les plus internes
vérifiant la propriété précédente.

Figure II.5. Les points
singuliers
II.4.1. Extraction des
caractéristiques
La représentation des attributs de l'empreinte
constitue la phase la plus cruciale lors de la conception d'un système
de vérification. La représentation détermine nettement la
précision du système. Les systèmes existants se basent sur
les détails des minuties, les descripteurs de texture ou sur la
représentation de l'image entière [16]. Il reste néanmoins
que les minuties sont de loin les attributs les plus largement utilisés.
Les minuties marquent des points de discontinuités locales (figure
II.6). Dans ce travail, c'est le modèle d'identification qui sera
utilisé, il repose sur deux types minuties : les terminaisons qui
marquent les fins de crêtes et les bifurcations qui correspondent aux
points où la crête se diverge.

Figure II.6. Quelques minuties
sur une image d'empreinte digitale
Les avantages d'une représentation par minuties peuvent
être énumérés par les points suivants :
· Les experts légistes utilisent aussi les
détails de minuties pour comparer deux empreintes.
· La représentation en minuties est couverte par
différents standards comme le ANSI - NIST et le CBEFF2(*) ce qui assure
l'interopérabilité des différents algorithmes de
reconnaissance.
· L'appariement basé sur les minuties
possède des performances comparables à celles des algorithmes de
corrélation sophistiqués. Cependant, alors que les algorithmes
basés sur la corrélation nécessitent des gabarits de
grande taille, les minuties requièrent une représentation
très compacte qui dépasse rarement 1KO.
· Les minuties ont été historiquement
prouvées comme étant distinctives entre deux individus et
différents modèles théoriques existent fournissant des
approximations raisonnables de cette individualité [17]. De tels
modèles n'ont jamais été décrits pour des
descripteurs basés sur la texture ou sur l'image tout entière.
· Les minuties sont des informations locales qui ne
dépendent pas de détails globaux comme le point core. En effet,
ces singularités particulières sont difficiles à estimer
surtout pour des images de faible qualité.
· Les points minuties sont invariants par rapport aux
déplacements et aux rotations contrairement aux attributs de texture.
II.4.2. Les approches
d'extraction à partir de l'image en niveau de gris.
Peu d'approches d'extraction de minuties ne suivent pas le
schéma conforme de binarisation - squelettisation ont été
proposées :
M.T. Leung et al introduisent dans [18] un réseau de
neurones pour la détection des minuties. Une autre approche plus directe
a été proposée par Maio et Maltoni dans [19]. Cette
approche traque les crêtes en localisant les maxima locaux par un suivi
de lignes le long du flot directionnel des crêtes. Seulement, avec cette
approche les maxima locaux peuvent ne pas être bien définis dans
le cas d'une image de mauvaise qualité. Néanmoins, les approches
de niveau de gris possèdent de nombreux avantages :
· Le schéma de binarisation implique quelques
formes de seuillage. Un simple seuillage n'est pas adéquat lorsque
l'image n'a pas une illumination uniforme, ce qui est commun pour les capteurs
optiques. Un seuillage n'est pas très fiable dans une image de faible
qualité.
· L'étape de squelettisation est gourmande en
temps machine dans le sens où elle est impartialement récursive.
Le suivi de ligne est beaucoup plus rapide.
· Le suivi de crêtes est intrinsèquement
immunisé contre les coupures de crêtes souvent présentes
dans l'empreinte contrairement aux autres procédés de
binarisation qui restent très sensibles à ce genre de bruit et
nécessitent systématiquement un post traitement.
II.4.3. Les approches de
binarisation
Dans cette approche, l'image en niveau de
gris est convertie en une image binaire. Malgré le fait que les
algorithmes existants différent dans les divers aspects
d'implémentation, ils suivent tous les étapes communes suivantes
(figure II.7)
1. Segmentation /binarisation
Dans cette étape, l'image est convertie en une image
binaire à travers un processus de seuillage ou une méthode de
binarisation adaptative. Le but est le repérage des crêtes. Cette
étape est aussi dans la littérature
segmentation. Toutefois, cela ne doit pas se confondre avec la
segmentation de l'image entre région d'intérêt de fond lors
de la génération du masquage des régions.
2. Amincissement
L'image binaire est ensuite amincie à travers un
schéma itératif morphologique résultant en une carte de
crêtes d'une largeur d'un pixel.
3. Détection de minuties
Dans le cas où l'amincissement serait utilisé,
cette étape devient triviale. Elle se base sur une scrutation de
voisinage. Les fins de crêtes ont un seul voisin et les bifurcations
possèdent plus de deux voisins. Dans les algorithmes qui n'utilisent pas
d'amincissement, la détection de minuties est faite par un appariement
de gabarit.
4. Post traitement

L'extraction de minuties peut produire deux sortes
d'erreurs : les fausses détections c'est - à - dire des
minuties qui n'existent pas sur l'image originale et les minuties
oubliées qui sont de vraies minuties qui n'apparaissent pas sur le
gabarit résultat. Alors que rien ne peut être fait pour
éviter les oublis de vraies minuties, les fausses minuties peuvent
être éliminées en considérant leurs relations
spatiales. Différentes heuristiques peuvent être appliquées
pour filtrer les fausses positives.
Figure II.7. Extraction des
minuties par binarisation.
II.4.4. Les problèmes
rencontrés lors de l'extraction des minuties.
Un fiable algorithme d'extraction de caractéristiques
est une étape critique pour la performance d'un système
automatique d'authentification d'identité en utilisant l'empreinte
digitale. La performance d'un algorithme d'extraction et de mise en
correspondance des images d'empreintes digitales dépend fortement de la
qualité de l'image en entrée. Les algorithmes
présentés ultérieurement opèrent bien à
condition que l'image en entrée soit de bonne qualité (quand la
qualité de l'empreinte ne peut pas être mesurée de
façon objective, elle peut être grossièrement
déduite de la clarté de la structure des crêtes : Une
image de bonne qualité possède un fort contraste et un ensemble
de crêtes et des vallées bien définies). Cependant, dans la
pratique un pourcentage signifiant d'images est en mauvaise qualité.
Cela est dû :
o Aux conditions d'acquisition.
o A l'état de l'épiderme.
o Au dispositif de prise de vue.
o A une mauvaise coopération du sujet.
La qualité de l'empreinte rencontrée durant la
vérification est très incertaine, elle varie sur une grande
portée. La plus grande partie est endommagée par l'état de
l'épiderme (figure II.8) :
o Les crêtes se cassent par la présence de
blessures, de coupures.
o Des empreintes très sèches donnent des
crêtes fragmentées.
o Les empreintes qui transpirent font une sorte de pontage
entre les lignes de crêtes (raccordement).

Figure II.8. Des images
d'empreintes de différentes qualités. La qualité
décroît de gauche vers la droite. (a) image de bonne
qualité avec un bon contraste, (b) distinction insuffisante sur le
centre de l'image et (c) une empreinte sèche.
Cela peut engendrer les problèmes suivants :
o Création de fausses minuties.
o Ignorance de vraies minuties.
o Introduction d'erreurs de localisation (position et
direction).
Par la suite, une carte de fausses minuties va engendrer
l'échec de l'algorithme d'appariement. Une étape de pré -
traitement pour améliorer la clarté s'avère donc
nécessaire. Ce qui explique le fait que la plupart des recherches soient
principalement vouées à l'amélioration de l'image en
entrée.
II.4.5. Amélioration de
l'image d'empreintes digitales.
La robustesse d'un système de reconnaissance peut
nettement accroître en ajustant un processus d'amélioration avant
d'extraire les caractéristiques. A cause de la non -
stationnarité de l'image d'empreinte, les algorithmes classiques connus
dans le traitement d'image ne sont pas très adéquats à cet
égard, bien qu'ils puissent être utilisés comme une
étape de pré - traitement dans le schéma global
d'amélioration orientées pixel comme légalisation
d'histogramme, la normalisation de la moyenne et de la variance, le filtrage de
Winner améliorent la lisibilité de l'empreinte sans
altérer la structure globale des crêtes.
De plus, les définitions du bruit d'une image
générique et d'une image d'empreinte semblent être
largement différentes. Le bruit dans une empreinte s'exprime en termes
de cassures dans le flux directionnel des crêtes. Cette remarque sur le
bruit n'est pas anodine. Elle est même capitale lorsqu'on est
amené à travailler sur les images d'empreintes. En effet, les
méthodes classiques connues en traitement d'image ont tendance à
augmenter le contraste ou à réduire le bruit. Ces méthodes
ne sont pas à exclure mais elles doivent s'agencer à un processus
d'amélioration plus adapté aux images d'empreintes. On a bien
compris, la définition du bruit lorsqu'il s'agit de traiter des images
d'empreintes devient plus spécifique !
Généralement, une image d'empreintes digitales
contient les trois catégories de régions suivantes (figure
II.9) :
· Région bien définie : les
crêtes et les vallées sont visibles pour une extraction
possible.
· Région irrécupérable : les
régions sont très touchées par le bruit.
Récupération impossible. Si la portion de cette région est
importante, le système va refuser cette image.
Un algorithme d'amélioration a comme but de
récupérer la région d'intérêt et de
l'améliorer et de masquer la région
irrécupérable.

Figure II.9. Les régions
dans une empreinte. (a) région bien définie, (b) région
récupérable, (c) région
irrécupérable.
II.5. Propriétés
des images d'empreintes digitales.
Les travaux qui ont été faits dans le domaine
de l'analyse d'empreintes s'appuient sur les propriétés
intrinsèques qui caractérisent ce type d'image :
· L'empreinte est par essence une image de lignes.
· Une empreinte est une alternance de crêtes et de
vallées qui évoluent dans une direction précise. Un bloc
de l'image bien défini possède une direction locale constante.
· Sur un bloc, les niveaux de gris des crêtes et
des vallées constituent une forme sinusoïdale le long de la
direction normale à l'orientation locale des crêtes (figure
II.10). L'amplitude, la fréquence de cette forme sont des indicateurs
sur le type de la région constituant le bloc considéré.
Seuls les points singuliers constituent une discontinuité de cette forme
présumée.
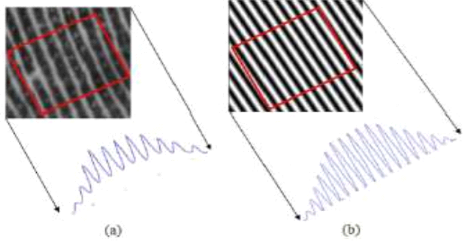
Figure II.10. Projection des
crêtes sur une image orientée. (a) un échantillon
d'empreinte, (b) une empreinte synthétique.
· L'empreinte est une image texturée.
· Les valeurs des niveaux de gris atteignent leur maximum
local le long de la direction normale aux crêtes.
· Lors de la saisie d'une empreinte digitale, il arrive
assez souvent que certaines parties de l'empreinte soient sous ou sur
encrées, ce qui être gênant pour les traitements
ultérieurs. La définition précédente nous indique
que cette image est non stationnaire. En effet ; la
moyenne de niveaux de gris dans une fenêtre de la partie
sous-encrée est différente de la moyenne dans une fenêtre
d'une partie «normale » de l'empreinte. Pour
remédier à cette contrainte, beaucoup d'algorithmes utilisent une
étape de normalisation.
Ces propriétés peuvent être
matérialisées par des représentations spécifiques
sous forme d'image appelée images intrinsèques. Cela
inclut :
· L'image d'orientation : l'image d'orientation O
représente l'orientation locale des crêtes sur chaque point
d'image [20].
· L'image de fréquence : la fréquence
locale des crêtes indique la distance moyenne entre les crêtes sur
un bloc [21].
· Le masque des régions : le masque indique
l'ensemble des régions ou apparaissent des crêtes. Il est aussi
appelé masque région fond. D'autres masques [22] sont capables de
distinguer les régions exploitables parmi celles qui sont
irrécupérables.
Le calcul de ces images intrinsèques forme une
étape critique dans un processus d'extraction de
caractéristiques. Une erreur survenue lors de leur calcul va se propager
le long de tout le procédé. L'image d'orientation est
utilisée pour l'amélioration de l'image, la détection des
points singuliers, la segmentation et la satisfaction des images. Le masque est
utilisé pour éliminer les fausses minutes.
II.6. Les problèmes de
la reconnaissance automatique des empreintes digitales.
Les problèmes de la reconnaissance des empreintes
digitales est un problème de reconnaissance de caractéristiques
(pattern recognition). Un tel système est un système automatique
de prise de décision qui requiert : (i) des données en
entrée (ii) une représentation interne de ces données en
utilisant des procédures d'extraction de caractéristiques (iii)
et enfin une décision est prise en se basant sur l'information extraite
appelée modèle ou gabarit
(template).
Le composant de prise de décision se manifeste
communément sous deux formes distinctes :
appariement et classification (matching and
classification). Un appariement rejette/accepte l'hypothèse que deux
gabarits soient les mêmes. Une classification détermine la classe
d'appartenance parmi un nombre de classes prédéterminées.
Ces deux opérations ne s'excluent pas, elles peuvent Co - exister sur le
même système. Prenant l'exemple d'un fichier de criminels qui
répertorie l'identité des personnes avec leurs empreintes. En
mode identification, le problème est de chercher une personne sur tout
le fichier aussi volumineux soit - il à partir de son unique empreinte.
Le temps de recherche devient alors prohibitif ! Pour faciliter la
recherche l'opération de comparaison peut être
précédée par une opération de classification afin
de procéder à une navigation intelligente sur la base de
données.
II.6.1. Capture de l'empreinte
digitale.
La capture de l'image d'une empreinte digitale consiste
à trouver les lignes tracées par les crêtes (en contact
avec le capteur) et les vallées (creux). L'image d'une empreinte est
acquise par des procédés directs (online) ou indirects (offline).
Celle acquise par des procédés indirects, l'est par le biais d'un
objet intermédiaire. Il existe deux méthodes pour avoir une
impression d'empreinte indirecte :
i) L'empreinte acquise par encre
(inkedfingerprint) : après l'avoir enduit
d'encre, le doigt est imprimé sur un bout de papier. Ce papier passe
ensuite au scanner standard pour être numérisé. Cette
ancienne technique a perduré pendant environ un siècle et a
été couramment utilisée dans les phases
d'enrôlement. L'image ainsi prise présente de larges crêtes
mais souffre d'une grande déformation due à la nature du
processus d'acquisition. Il est clair que cette méthode n'est pas
adaptée aux procédés automatiques temps réel.
ii) Les empreintes latentes : elles sont
formées suite à une légère trace laissée sur
un objet due à la sécrétion constante de la sueur. Les
services de sécurité décèlent ce genre de
détails sur les lieux de crime à l'aide d'une poudre
spéciale. Le terme procédé directe (live - scan) est un
terme collectif englobant les images d'empreintes directement obtenues sur
l'étape intermédiaire de l'impression sur du papier. En
l'occurrence un dispositif spécial est utilisé, les capteurs dont
voici une énumération des différents types :
§ Le capteur optique : la
technologie la plus répondue dans les systèmes d'acquisition par
capteur est celle qui utilise le principe de la réflexion de la
lumière. Un prix acceptable constitue l'avantage principal des
systèmes optiques ; leur inconvénient est qu'ils sont
faciles à détourner. L'autre problème est celui des
empreintes latentes : l'empreinte digitale du doigt
précédent, qui a été placée sur le capteur,
peut rester. Les scanners optiques sont facilement intégrables dans
diverses applications telles que les ordinateurs portables, les cellulaires et
les mémentos électroniques.
§ Le capteur thermique : la
méthode thermique est moins habituelle. Actuellement, le seul capteur
thermique est le FingerChip fabriqué par
Atmel3(*).
Cette méthode donne une image d'excellence qualité même sur
des empreintes de qualité médiocre ; permettant ainsi au
FingerChip d'être l'une des capteurs le plus résistant par rapport
aux autres technologies.
iii) Le capteur à ultrasons : la
lecture par ultrasons d'empreinte n'est pas courante. C'est une sorte
d'échographie du doigt. La lecture par ultrasons requiert un assez gros
dispositif et est assez chère. Ce n'est pas une technique commode pour
de la production de volume à faible coût. Son principal
intérêt réside dans la lecture du derme, sous la surface,
plutôt que la surface elle - même.
iv) Le capteur intégré au
silicium : les puces siliciums (électronique) peuvent
être vues comme une variante des caméras CMOS : au lieu
d'utiliser les photons, un autre effet physique est utilisé. La quasi -
totalité des capteurs d'empreinte digitale intégrés
commercialisés à l'heure actuelle sont de type capacitif :
§ Capteur capacitif : la sonde de
silicium et le doigt agissent comme les parois d'un condensateur. Un
défaut rédhibitoire connu pour ce genre de capteurs est leur
sensibilité aux forts champs électriques, comme ceux
provoqués par les décharges électrostatiques.
§ Capteur de pression : c'est l'une
des plus anciennes idées, car lorsque vous posez votre doigt, vous
appliquez une pression qui change suivant qu'on serait sur une crête ou
un creux. Elle procure des images binaires.
§ Capteur tactile : les dispositifs
micro usinés permettent la réalisation de très petits
interrupteurs. Lorsqu'une crête touche un interrupteur, elle le ferme. Il
n'existe pas encore de développement ayant dépassé le
stade du laboratoire.
Aujourd'hui, le silicium émerge dans le marché
des empreintes digitales (figure II.11). Ces puces peuvent être
fabriquées à moindre coût et en grande quantité
[23].
Secugen
www.secugen.com
BFM
www.bfm.com
www.secugen.com
FingerSec
www.fingersec.com
www.secugen.com
Atmel
www.atmel.com
www.secugen.com
Veridicom
www.veridicom.com
www.secugen.com

Digital Personna
www.digitalpersonna.com
www.secugen.com

Figure II.11. Quelques capteurs
d'empreintes commercialisés.
II.6.2. Représentation
de l'image d'empreinte et prise de décision.
Une empreinte apparaît comme une
surface alternée de crêtes et de vallées parallèles
sur la plupart des régions. Différentes caractéristiques
permanentes ou semi - permanentes tels que les blessures, les coupures et les
bleus sont aussi présentes sur l'empreinte. Qu'il s'agisse d'un
problème de vérification ou de classification, il est
nécessaire de définir sur l'empreinte une représentation
invariante : des caractéristiques qui ne s'altèrent pas avec
le temps. Cette représentation peut être globale prenant en compte
toute l'image ou, locale c'est - à - dire constituée d'un
ensemble de composantes dérivée chacune d'une région
restreinte sur l'empreinte.
Lorsqu'il est question d'un problème d'appariement
(vérification de la similarité entre deux empreintes), les
algorithmes d'appariement peuvent être classifiés en fonction de
la représentation de l'empreinte ; qui elle peut appartenir
à l'une des catégories suivantes :
II.6.2.1. Image

Dans cette représentation, c'est toute l'image qui est
considérée comme une représentation possible.
L'appariement est réalisé par corrélation. La
corrélation entre deux images I1(x, y),
I2(x, y), est donnée dans le domaine spatial
par :
Le corrélateur établit la correspondance par la
recherche de la magnitude du pic dans l'image de corrélation
Ic. La position du pic indique la translation entre les
images et la valeur du pic informe sur le degré de similarité.
L'exactitude de cette corrélation se dégrade avec les
transformations de l'image comme les phénomènes de translation et
de rotation. Le problème de distorsion peut être surmonté
par les méthodes de corrélation locales proposées dans
[24] et dans [25]. Un autre inconvénient est en relation avec la taille
conséquente de l'image à sauvegarder durant l'inscription.
II.6.2.2. Représentation en minuties
Le but d'un algorithme d'appariement est de comparer deux
images ou deux gabarits et de retourner le score de similarité qui
correspond à la probabilité que deux empreintes se correspondent.
A l'exception des algorithmes basés sur la corrélation, la
plupart des algorithmes extraient des caractéristiques dans le but de
faire l'appariement. Les détails de minuties constituent la
représentation la plus populaire de toutes les représentations
existantes, elles répondent efficacement au problème de taille
posé précédemment.
Les minuties représentent des discontinuités
locales et marquent les positions où la crête se termine ou
bifurque. Cela constitue les types de minutie les plus fréquentes, bien
qu'un total de 18 types de minuties ait été identifié.
Chaque minutie peut être décrite par un nombre d'attributs tels
que la position (x, y), l'orientation è et d'autres informations
susceptibles d'aider à l'appariement.
Cependant, la plupart des algorithmes considèrent
seulement sa position et orientation.

Figure II.12. Les
caractéristiques principales des minuties.
Les minuties peuvent être appariées en
considérant le problème comme un problème d'appariement de
primitives point (point pattern matching). La figure suivante est une
représentation en minuties d'une empreinte digitale :

Figure II.13. Exemple d'une
représentation d'une empreinte digitale par sa carte de minuties. La
carte de minutie assure l'unicité de l'empreinte.
II.6.2.3. Les descripteurs de texture
Les algorithmes d'appariement basés sur les minuties
ne s'exécutent pas bien quand la surface de l'empreinte est petite
étant donné que le nombre de minuties n'est pas suffisant pour
l'appariement. De plus, le processus d'extraction des minuties est plus enclin
à l'erreur dans ce genre de cas. Prabhakar et al [26] proposent une
méthode basée sur un banc de filtres pour effectuer
l'appariement de cette sorte d'images. Ils décrivent un nouveau
descripteur de texture appelé « code d'empreinte ».
Les informations de texture (moyennes et variances) sont extraites en
effectuant une sectorisation [27] de l'image autour d'un point de
référence (le point core) ; et l'appariement est basé
sur le calcul de la distance euclidienne entre deux codes.
L'inconvénient de cette approche est que le point core doit être
localisé de façon exacte. Cela n'est pas possible pour des images
de mauvaise qualité. De plus, la performance est inférieure
comparée aux appariements basés sur les minuties. Cependant, une
décision qui combine les paramètres de texture et les minuties
aurait un meilleur rendement.
Chapitre III. CONCEPTS SUR
LES RESEAUX INFORMATIQUES
III.1. Introduction aux
réseaux informatiques
I.1. Définition
Un réseau informatique est un ensemble
d'équipements reliés entre eux pour échanger des
informations.
Un réseau en général est le
résultat de la connexion de plusieurs machines entre elles, afin que les
utilisateurs et les applications qui fonctionnent sur ces dernières
puissent échanger des informations. Le terme réseau en fonction
de son contexte peut désigner plusieurs choses. Il peut désigner
l'ensemble des machines, ou l'infrastructure informatique d'une organisation
avec les protocoles qui sont utilisés, ce qui est le
cas lorsque l'on parle de l'internet.
Le terme réseau peut également être
utilisé pour décrire la façon dont les machines d'un site
sont interconnectées. C'est le cas lorsque l'on dit que les machines
d'un site (sur un réseau local) sont sur un réseau
Ethernet, Token Ring, réseau en étoile, réseau en
bus, ...
Le terme réseau peut également être
utilisé pour spécifier le protocole sui est utilisé pour
que les machines communiquent. On peut parler de réseau TCP/IP,
DECNet (Protocol DEC), ...
I.2. Pourquoi les
réseaux informatiques
Les réseaux sont nés d'un besoin
d'échanger des informations de manière simple et rapide entre des
machines. Lorsque l'on travaillait sur une même machine, toutes les
informations nécessaires au travail étaient centralisées
sur la même machine. Presque tous les utilisateurs et les programmes
avaient accès à ces informations. Pour des raisons de coûts
ou de performances, on est venu à multiplier le nombre de machines. Les
informations devaient alors être dupliquées sur les
différentes machines du même site. Cette duplication était
plus ou moins facile et ne permettait pas toujours d'avoir des informations
cohérentes sur les machines. On est donc arrivé à relier
d'abord ces machines entre elles ; ce fût l'apparition des
réseaux locaux. Ces réseaux étaient souvent des
réseaux « maisons » ou propriétaires. Plus
tard on a éprouvé le besoin d'échanger des informations
entre des sites distants. Les réseaux moyenne et longue distance
commencèrent à voir le jour. Ces réseaux étaient
souvent propriétaires. Aujourd'hui, les réseaux se retrouvent
à l'échelle planétaire. Le besoin d'échange de
l'information est en pleine évolution. Pour se rendre compte de ce
problème, il suffit de regarder comment fonctionnent des grandes
sociétés.
III.2. Topologie des
réseaux informatiques
Une topologie de réseau est en informatique une
définition de l'architecture (physique ou logique) d'un réseau,
définissant les connexions entre ces postes et une hiérarchie
éventuelle entre eux ; elle peut définir la façon
dont les équipements sont interconnectés ou la
représentation, spatial du réseau (topologie physique) ou la
façon dont les données transitent dans les lignes de
communication (topologie logique).
III.2.1. Topologie en bus
Cette topologie est représentée par un
câblage unique des unités réseaux. Il a également un
faible coût de déploiement et la défaillance d'un noeud
(ordinateur) ne scinde pas le réseau en deux sous - réseaux. Ces
unités sont reliées de façon passive par dérivation
électrique ou optique. Les caractéristiques de cette topologie
sont les suivantes:
· Lorsqu'une station est défectueuse et ne
transmet plus sur le réseau, elle ne perturbe pas les réseaux
· Lorsque le support est en panne, c'est l'ensemble du
réseau qui ne fonctionne plus
· Le signal émis par une station se propage dans
un seul sens ou dans les deux sens
· Si la transmission est bidirectionnelle : toutes
les stations connectées reçoivent les signaux émis sur le
bus en même temps
· Le bus est terminé à ses
extrémités par des bouchons pour éliminer les
réflexions possibles du signal

Figure III.1. Topologie en
bus
III.2.2. Topologie en
étoile
C'est la topologie la plus courante actuellement.
Omniprésente, elle est très souple en matière de gestion
et dépannage de réseau ; la panne d'un noeud ne perturbe pas
le fonctionnement global du réseau. En revanche, l'équipent
central (un concentrateur ou HUB) et plus souvent sur les réseaux
modernes, un commutateur (switch) qui relie tous les noeuds constitue un point
unique de défaillance : une panne à ce niveau rend le
réseau totalement inutilisable. Le réseau Ethernet est un exemple
de topologie en étoile. L'inconvénient principal de cette
topologie réside dans la longueur des câbles utilisés.

Figure III.2. Topologie en
étoile
III.2.3. Topologie en
anneau
Un réseau a une topologie en anneau quand toutes ses
stations sont connectées en chaine les unes aux autres par une liaison
bipoint de la dernière à la première. Chaque station joue
le rôle de station intermédiaire. Chaque station qui reçoit
une trame, l'interprète et la ré - émet à la
station suivante de la boucle si c'est nécessaire. La défaillance
d'un hôte rompt la structure d'un réseau en anneau si la
communication est unidirectionnelle ; en pratique un réseau en
anneau est souvent composé de deux anneaux contra - rotatifs.
NB. Les ordinateurs d'un réseau en anneau ne sont pas
systématiquement reliés en boucle, mais peuvent être
connectés à un répartiteur appelé
« MAU », (Multistation Access Unit) qui va
gérer la communication entre les ordinateurs reliés en allouant
à chacun d'eux un « temps de parole ».
En cas de collision de deux messages, les deux seraient
perdus, mais les règles d'accès à l'anneau (par exemple,
la détection d'un jeton) sont censées éviter ce cas de
figure.

Figure III.3. Topologie en anneau
III.2.4. Topologie
maillée
Une topologie maillée correspond à plusieurs
liaisons point à point. Le réseau maillé es un
réseau dans lequel deux stations de travail peuvent être mises en
relation par différents chemins. La connexion est effectuée
à l'aide de commutateurs, par exemple les autocommutateurs PABX.
Justification de la commutation.
Si on veut mettre deux stations en relation, on peut utiliser
deux solutions. La première est de créer une connexion permanente
entre toutes les stations du réseau.

Ainsi, le nombre de connexion nécessaire pour
connecter les stations dépend de l'équation suivante :
Nbl 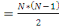 avec Nbl, le nombre de connexions et N, le nombre de stations. Donc si
un réseau comprend 15 stations il faudrait 105 connexions. Ce qui
impossible à câbler d'où l'intérêt des
commutateurs. Donc, on utilisera la deuxième solution que sont les
commutateurs. avec Nbl, le nombre de connexions et N, le nombre de stations. Donc si
un réseau comprend 15 stations il faudrait 105 connexions. Ce qui
impossible à câbler d'où l'intérêt des
commutateurs. Donc, on utilisera la deuxième solution que sont les
commutateurs.

Figure III.4. Topologie
maillée
III.3. Catégories de
réseaux informatiques
Selon le périmètre géographique qui
offre une connectivité (appelé zone de couverture), nous
distinguons généralement plusieurs catégories de
réseaux à savoir :
III.3.1. Le réseau local
personnal (PAN)
Un réseau personnel (ou Personal Area Network, PAN)
désigne un type de réseau informatique restreint en terme
d'équipements, généralement mis en oeuvre dans un espace
d'une dizaine de mètres. D'autres appellations pour ce type de
réseau sont : réseau domestique ou réseau individuel.
Les bus utilisés les plus courants pour la mise en
oeuvre d'un réseau individuel sont l'USB, les technologies sans fin
telles que Bluetooth, l'infrarouge (IR). Ce type de réseau sert
généralement à relier des périphériques
(imprimante, téléphone portable, appareils domestiques,...) ou
un assistant personnel (PDA) à un ordinateur sans liaison filaire ou
bien à permettre la liaison sans fil entre deux machines très
distantes.
III.3.2. Le réseau local
(LAN)
LAN signifie Local Area Network (en
français Réseau local). Il s'agit d'un ensemble d'ordinateurs
appartenant à une même organisation et reliés entre eux
dans une petite aire géographique par un réseau, souvent à
l'aide d'une même technologie (la plus répandue étant
Ethernet). Un réseau local est donc un réseau sous forme la plus
simple. La vitesse de transfert de données d'un réseau local peut
s'échelonner entre 10 Mbps (pour un réseau Ethernet par exemple)
et 1 Gbps (en FDDI ou Gigabit Ethernet par exemple). La taille d'un
réseau local peut atteindre jusqu'à 100 voire 1 000
utilisateurs.
En élargissant le contexte de la définition aux
services qu'apporte le réseau local, il est possible de distinguer deux
modes de fonctionnement :
- Dans un environnement « d'égal à
égal » (en anglais peer to peer), dans lequel il n'y a pas
d'ordinateur central et chaque ordinateur a un rôle similaire.
- Dans un environnement
« client/serveur », dans lequel un ordinateur central
fournit des services réseau aux utilisateurs.
III.3.3. Le réseau
métropolitain (MAN)
Les MAN (Metropolitain Area Network) interconnectent
plusieurs LAN géographiques proches (au maximum quelques dizaines de km)
à débits importants. Ainsi un MAN permet à deux noeuds
distants de communiquer comme s'ils faisaient partie d'un même
réseau local. Un MAN est formé de commutateurs ou de routeurs
interconnectés par des liens hauts débits (en
général en fibre optique).
III.3.4. Le réseau
étendu (WAN)
Un WAN (Wide Area Network ou réseau étendu)
interconnecte plusieurs LANs à travers de grandes distances
géographiques.
Les débits disponibles sur un WAN résultent d'un
arbitrage avec le coût des liaisons (qui augmente avec la distance) et
peuvent être faibles. Les WAN fonctionnent grâce à des
routeurs qui permettent de « choisir » le trajet le plus
approprié pour atteindre un noeud du réseau. Le plus connu des
WAN est Internet.
Internet est la suite du réseau militaire
américain ARPANET. Le but était de concevoir un réseau
résistant aux attaques : les communications ne passent plus selon
un mode linéaire, mais peuvent à chaque endroit emprunter
plusieurs routes.
Internet a donc été conçu dès
l'origine comme une toile d'araignée, d'où son nom anglais web
(qui veut dire tissage et toile d'araignée).
Fonctionnement

Cas normal, tout fonctionne correctement, les informations
empruntent le « chemin le plus direct ».
En cas de disfonctionnement : un relais ne fonctionne
plus, il existe alors au moins une autre possibilité pour acheminer les
informations.
L'interconnexion progressive de tous les ordinateurs de la
planète fonctionne donc comme un gigantesque réseau. Le mot
anglais pour réseau est « network ».
Or dans la
pratique, ces ordinateurs ne sont pas directement interconnectés entre
eux. Les ordinateurs sont d'abord interconnectés au sein d'un institut
ou d'un bâtiment formant ainsi une multitude de petits sous -
réseaux. Puis par sous réseau une machine est chargée de
s'interconnecter avec d'autres machines.
Enfin, progressivement la planète entière est
interconnectée avec à chaque étape du maillage une machine
désignée pour se connecter au niveau supérieur. On a ainsi
une interconnexion de toutes les machines par interconnexion de réseaux
successifs. D'où le terme Internet pour « INTER -
NETworks ».
III.3.4.1. Gestion des connexions
Chaque ordinateur connecté directement sur internet
possède un numéro d'identification unique (appelée adresse
IP) et peut envoyer et recevoir des informations avec n'importe quel autre
ordinateur ou machine possédant une adresse IP (voire même une
imprimante).
Par ailleurs, le temps d'acheminement ne dépend pas de
la distance mais plutôt de la qualité des lignes qui
séparent deux machines. Notons que vous pouvez être reliés
à Internet sans disposer de votre propre adresse IP. Il faut faire appel
à un serveur (FAI « Fournisseur d'Accès à
Internet ») qui vous en prête une le temps de votre connexion.
Ce réseau mondial utilise les mêmes protocoles
de communications (exemple TCP/IP) et fonctionne comme un réseau virtuel
unique et coopératif. Tous les ordinateurs et logiciels supportant les
mêmes protocoles pourront communiquer ensemble. Internet utilise un
système international d'adresses qui permet d'envoyer un message ou un
fichier sans ambiguïté à un correspondant connecté.
Chaque ordinateur a une adresse unique.
III.4. Architecture d'un
réseau informatique
III.4.1. Architecture client -
serveur
III.4.1.1. Présentation de l'architecture d'un
système client - serveur
De nombreuses applications fonctionnent
selon un environnement client - serveur, cela signifie que des machines
clientes (des machines faisant partie du réseau) contactent un serveur,
une machine généralement très puissante en termes de
capacités d'entrée - sortie, qui leur fournit des services. Ces
services sont des programmes fournissant des données telles que l'heure,
des fichiers, une connexion, etc.
Les services sont exploités par des programmes,
appelés programmes clients, s'exécutant sur les machines
clientes. On parle ainsi de client (client FTP, client de messagerie, etc.)
lorsque l'on désigne un programme tournant sur une machine cliente,
capable de traiter des informations qu'il récupère auprès
d'un serveur (dans le cas du client FTP il s'agit de fichiers, tandis que pour
le client de messagerie il s'agit de courrier électronique).
L'environnement client - serveur désigne un mode de
communication à travers un réseau entre plusieurs programmes ou
logiciels : l'un, qualifié de client, envoie des
requêtes ; l'autre ou les autres, qualifiés de serveurs,
attendent les requêtes des clients et y répondent. Par extension,
le client désigne l'ordinateur sur lequel est exécuté le
logiciel client, et le serveur, l'ordinateur sur lequel est
exécuté le logiciel serveur.
Il existe une grande variété de logiciels
serveurs et de logiciels clients en fonction des besoins à servir :
un serveur web publie des pages web demandées par des navigateurs
web ; un serveur de messagerie électronique envoie des mails
à des clients de messagerie : un serveur de fichiers permet de
stocker et consulter des fichiers sur le réseau, un serveur de
données à communiquer des données stockées dans une
base de données, etc.
III.4.1.2. Avantages de l'architecture client - serveur
Le modèle client - serveur est
particulièrement recommandé pour des réseaux
nécessitant de fiabilité, ses principaux atouts sont :
· Des ressources centralisées : étant
donné que le serveur est au centre du réseau, il peut
gérer des ressources communes à tous les utilisateurs, comme par
exemple une base de données centralisée, afin d'éviter les
problèmes de redondance et de contradiction.
· Une meilleure sécurité : car le
nombre de points d'entrée permettant l'accès aux données
est moins important
· Une administration au niveau serveur : les clients
ayant peu d'importance dans ce modèle, ils ont moins besoin d'être
administrés
· Un réseau évolutif : grâce
à cette architecture, il est possible de supprimer ou rajouter des
clients sans perturber le fonctionnement du réseau et sans modification
majeure.
III.4.1.3. Inconvénients de l'architecture client -
serveur
L'architecture client - serveur a tout de même quelques
lacunes parmi lesquelles :
· Un coût élevé
dû à la technicité du serveur
· Un maillon faible : le serveur
est le seul maillon faible du réseau client - serveur, étant
donné que tout le réseau est architecturé autour de
lui ! heureusement, le serveur a une grande tolérance aux pannes
(notamment grâce au système RAID).
III.4.1.4. Fonctionnement d'un système client -
serveur
Un système client - serveur fonctionne selon le
schéma suivant :
Requêtes
Réponses

Figure III.5. Fonctionnement d'un
système client - serveur
· Le client émet une requête vers le serveur
grâce à son adresse IP et le port, qui désigne un service
particulier du serveur
· Le serveur reçoit la demande et répond
à l'aide de l'adresse de la machine cliente et son port.
III.4.1.5. Fonctionnement de l'application en
réseaux.
Figure III.6. Fonctionnement de
l'application en réseaux
L'application fonctionnera dans l'architecture client -
serveur, c'est - à - dire que le client émet des requêtes
sur le serveur de données grâce à son adresse IP et le port
qui désigne un service particulier du serveur. Le serveur reçoit
la demande et répond à l'aide de l'adresse IP de la machine
cliente et son port.
Au centre, nous avons l'office qui
délivre les documents de trafics (passeports, cpgl, ...). Le client
vient pour l'achat du passeport, il sera premièrement
enrôlé, toutes ces informations seront directement stockées
dans la base de données. Une fois il sera en possession du passeport, il
peut vouloir sortir du pays (burundi) en passant par différentes
frontières burundaises. Il rencontrera certains officiers sur des postes
frontières qui vont passer à la vérification du passeport
pour voir si ce dernier a été délivré dans la voie
légale ou illégale moyennant l'empreinte digitale du
détenteur de passeport.
III.4.2. Architecture Peer to Peer (égal à
égal)
III.4.2.1. Présentation de l'architecture
égal à égal (Peer to Peer)
Dans une architecture d'égal à égal (en
anglais peer to peer), contrairement à une architecture de réseau
de type client - serveur, il n'y a pas de serveur dédié. Ainsi,
chaque ordinateur dans un tel réseau est un peu serveur et un peu
client. Cela signifie que chacun des ordinateurs du réseau est libre de
partager ses ressources. Un ordinateur relie à une imprimante pourra
donc éventuellement la partager afin que tous les autres ordinateurs
puissent y accéder via le réseau.
III.4.2.2. Avantages de architecture Peer to Peer
L'architecture d'égal à égal a tout de
même quelques avantages parmi lesquels :
· Un coût réduit (les coûts
engendrés par un tel réseau sont le matériel, les
câbles et la maintenance)
· Une simplicité à toute
épreuve !
III.4.2.3. Inconvénients de l'architecture Peer
to Peer
Les réseaux d'égal à égal ont
énormément d'inconvénients :
· Ce système n'est pas du tout centralisé,
ce qui rend très difficile à administrer
· La sécurité est très peu
présente
· Aucun maillon du système n'est fiable.
III.4.2.4. Mise en oeuvre d'un réseau Peer to
Peer
Les réseaux égal à égal ne
nécessitent pas les mêmes niveaux de performance et de
sécurité que les logiciels réseaux pour serveurs
dédiés. On peut donc utiliser Windows NT Workstation, Windows
pour Workgroups car tous ces systèmes d'exploitation intègrent
toutes les fonctionnalités du réseau égal à
égal.
La mise en oeuvre d'une telle architecture réseau repose
sur des solutions standards :
· Placer les ordinateurs sur le bureau des utilisateurs
· Chaque utilisateur est son propre administrateur et
planifie lui - même sa sécurité
· Pour les connexions, on utilise un système de
câblage simple et apparent
Il s'agit généralement d'une solution
satisfaisante pour des environnements ayant les caractéristiques
suivantes :
· Tous les utilisateurs sont situés dans une
même zone géographique
· La sécurité n'est pas un problème
crucial
III.4.3. Architecture Trois -
tiers
III.4.3.1. Présentation de l'architecture Trois -
tiers
Dans l'architecture à 3 niveaux
(appelée architecture 3 - tiers), il existe un niveau
intermédiaire, c'est - à - dire que l'on a
généralement une architecture partagée entre :
· Un client, c'est - à - dire l'ordinateur
demandeur de ressources, équipée d'une interface utilisateur
(généralement un navigateur web) chargée de la
présentation ;
· Le serveur d'application (appelé
également middleware), chargé de fournir la ressource mais
faisant appel à un autre serveur
· Le serveur de données, fournissant au serveur
d'application les données dont il a besoin.
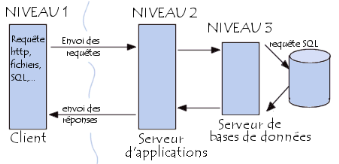
Figure III.6. Architecture Trois
- tiers
Chapitre IV. CONCEPTION ET
MODELISATION DE L'APPLICATION
IV.1. Préambule
Ce chapitre représente la conception
et la modélisation de l'application sur la conception et la mise en
place d'une plate-forme de la sécurisation par synthèse et
reconnaissance biométrique de documents de trafic. En effet, plusieurs
étapes sont nécessaires, l'étape d'extraction des
caractéristiques est la plus importante car la performance du
système en dépendent.
IV.2. Fonctionnement du système
Notre système permet d'illustrer le processus
d'identification des personnes par la reconnaissance biométrique
à partir de leurs empreintes digitales. Nous allons décrire dans
ce qui suit les différents événements qui s'y passent lors
de ce processus.L'application comporte trois phases : la première
phase qui est l'enrôlement, la deuxième phase qui est la
vérification enfin la troisième phase qui est la gestion de
trafic.
IV.2.1. l'enrôlement
Le client vient pour l'achat du passeport ; il sera
enregistré dans la base de données de l'office qui livre le
passeport (enrôlement) numéro passeport, nom, prénom, date
de naissance, photo, adresse, empreinte biométrique, etc. A l'instant
même, on lui livre un reçu d'achat qui lui permettra de
récupérer son passeport plus tard. Lorsqu'il reçoit son
passeport, il peut effectuer des trafics passant par différentes
frontières burundaises.
IV.2.2. La
vérification
Une fois il arrive sur l'une de frontières
burundaises, il passe par une vérification de son document (passeport)
via son empreinte biométrique pour vérifier si son passeport a
été livré dans une voie légale et sure.
Vérifier si le passeport du détenteur est actif ou non - actif.
IV.2.3. La gestion des
trafics
Cette application permettra la gestion de trafics des
détenteurs de passeports burundais entre autre :
- La gestion des entrées et sorties du trafic
- Générer les rapports de trafics pendant une
période donnée
IV.3. Langage de
modélisation avec UML et conception Base de données pour
l'application
IV.3.1. Etude comparative
entre UML et MERISE
MERISE (Méthode d'Etude et de
Réalisation Informatique pour les Systèmes d'Entreprise) est
une méthode d'analyse et de réalisation des systèmes
d'information qui est élaborée en plusieurs étapes :
schéma directeur, étude préalable, étude
détaillée et la réalisation.
Alors qu'UML (UnifiedModeling
Langage), est un langage de modélisation des systèmes
standard, qui utilise des diagrammes pour représenter chaque aspect d'un
système c'est - à - dire : statique, dynamique, ... en
s'appuyant sur la notion d'orienté objet qui est un véritable
atout pour ce langage.
Merise ou UML ?
Les « méthodologues » disent
qu'une méthode, pour être opérationnelle, doit avoir 3
composantes :
ü Une démarche (les étapes, phases et
tâches de mise en oeuvre) ;
ü Des formalismes (les modélisations et les
techniques de transformations) ;
ü Une organisation et des moyens de mise en oeuvre.
Merise s'est attachée, en son temps, à proposer
un ensemble « cohérent » sur ces trois composantes.
Certaines ont vieilli et ont dû être réactualisées
(la démarche), d'autre « tienne encore le chemin »
(la modélisation).
UML se positionne exclusivement comme un ensemble de
formalismes. Il faut y associer une démarche et une organisation pour
constituer une méthode.
Merise se positionne comme une
méthode de conception de système d'information organisationnel,
plus tournée vers la compréhension et la formalisation des
besoins du métier que vers la réalisation de logiciel. En sens,
Merise se réclame plus de l'ingénierie du système
d'information que du génie logiciel. Jamais Merise ne s'est voulu une
méthode de développement de logiciel ni de programmation.
UML, de par son origine (la programmation
objet) s'affirme comme un ensemble de formalismes pour la conception de
logiciel à base de langage objet.
Merise est encore tout à fait valable
pour :
ü La modélisation des données en vue de la
construction d'une base de données relationnelles, la
modélisation des processus métiers d'un système
d'information automatisé en partie par du logiciel,
ü La formalisation des besoins utilisateur dans la cadre
de cahier des charges utilisateur, en vue de la conception d'un logiciel
adapté.
UML estidéal pour:
ü Concevoir et déployer une architecture logiciel
développée dans un langage orienté objet (Java, C++,
VB.Net,...).
ü Pour modéliser les données (le
modèle de classe réduit sans méthodes et
stéréotypé en entités), mais avec des lacunes que
ne présentait pas l'entité relation de Merise.
ü Pour modéliser le fonctionnement métier
(le diagramme d'activité et de cas d'utilisation) qui sont des
formalismes très anciens qu'avait, en son temps, amélioré
Merise...
Après cette étude comparative, il est certes
que nous allons adopter UML comme langage de modélisation puisque nous
allons utiliser le concept de l'orienté objet ainsi en VB.Net comme
langage, pour développer l'application de synthèse et de
reconnaissance biométrique de documents de trafic.
IV.3.1.1. Diagramme de cas d'utilisation

Figure IV.1. Diagramme de cas
d'utilisation
IV.3.1.2. Diagramme de classe
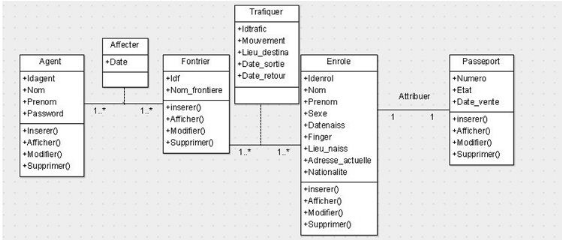
Figure IV.2. Diagramme de
classe
IV.3.1.3. Diagramme de séquence
Système d'application biométrique des
empreintes digitales
Agent office
Administrateur
S'authentifier au système
S'authentifier au système
Créer les comptes
d'utilisateurs
Vérifier les documents de trafic
Enrôler les citoyens
Modifier
les enregistrements
sur le compte agent office
Modifier les enregistrements
Enrôler les citoyens sur le compte
compte agent office
Vérifier les documents de
trafic
Générer les rapports de trafic
Figure IV.3. Diagramme de
séquence
IV.4. Conception Base de
données pour l'application
IV.4.1. Modèle conceptuel de données
(MCD)
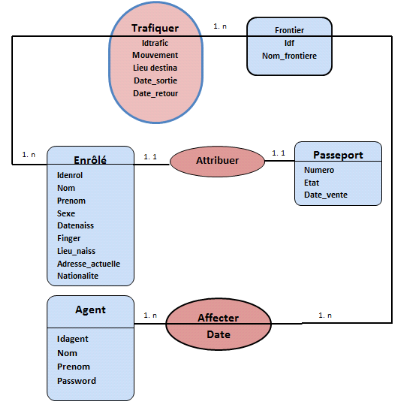
Figure IV.4. Modèle
conceptuel de données (MCD)
IV.4.2. Modèle logique de données (MLD)
Enrôlé (Idenrol, Nom,
Prenom, Sexe, Datenaiss, Finger, Lieu_naiss, Adresse_actuelle, Nationalite,
#Numero)
Passport (Numero, Etat, Date_vente)
Agent (Idagent, Nom, Prenom,
Password)
Fontiere(Idf, Nom_fontiere)
Trafiquer (Idtrafic, Mouvement,
Lieu_destina, Date_sortie, Date_retour, #Idf, #Idenrol)
Affecter (#Idagent, #Idf, Date)
IV.4.3. Dictionnaire de données
|
Champs
|
Libellé
|
Types de données
|
Contrainte d'intégrité
|
|
idenrol
nom
prenom
sexe
datenaiss
finger
lieu_naiss
adresse_actuelle
nationalite
numero
etat
date_vente
idagent
nom
prenom
password
idf
nom_frontiere
idtrafic
mouvement
|
identifiant d'un enrôlé
nom de l'enrôlé
prénom de l'enrôlé
sexe de l'enrôlé
date de naissance
fingerprint de l'enrôlé
lieu de naissance
adresse actuelle
nationalité de l'enrôlé
numéro passeport
etat du passeport
date de la vente du passeport
identifiant agent
nom de l'agent
prénom de l'agent
mot de passe de l'agent
identifiant frontière
nom de la frontière
identifiant du trafic
mouvement du trafic
|
Tinyint
Varchar(30)
Varchar(30)
Varchar(1)
Date
Varbinary (max)
Varchar(30)
Varchar(30)
Varchar(30)
Varchar(10)
Varchar(10)
Date
Tinyint
Varchar(30)
Varchar(30)
Varchar(20)
Tinyint
Varchar(30)
Tinyint
varchar(10)
|
-
-
-
-
= à 1900
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
|
|
Lieu_destina
Date_sortie
Date_retour
|
Lieu de destination
Date de sortie
Date de retour
|
Varchar(30)
Datetime
Datetime
|
-
Egale aujourd'hui
Egale aujourd'hui
|
Chapitre V. REALISATIONSET TESTS DE L'APPLICATION
V.1. Environnement du travail
Dans cette section, nous présenterons les
environnements matériel et logiciel de notre travail pour la
réalisation de cette application.
V.1.2. Environnement
matériel
Afin de mener à bien concevoir ce projet de
mémoire, il a été mis à notre disposition un
ensemble de matériels dont les caractéristiques sont les
suivantes :
Ø Un ordinateur TOSHIBA avec les
caractéristiques suivantes :
· Processeur : Intel®Celeron® CPU B800
1.50GHz
· RAM : 2.00 Go
· Disque Dur : 500 Go
· OS : Microsoft Windows Seven
Ø Un scanner biométrique des empreintes
digitales du type U.are.U 4000B dont les
caractéristiques sont les suivantes :
· Résolution de Pixel : dpi 512(x moyen, y au
- dessus de la zone de balayage)
· Données de balayage : gamme de gris de 8
bits (256 niveaux de gris)
· Zone de saisie de balayage : 14.6
millimètres (nom. Largeur au centre) 18.1 millimètres (nom.
Longueur)
· Taille de lecteur (approximative) : 70
millimètres X 36 millimètres
· Compatibilité : Microsoft Windows Seven,
Linux
· SDK : PersonalDigital
· Langages de programmation : VB.Net, Java, PHP, C#,
C++

Figure V.1. Scanner
biométrique d'empreinte digitale modèle U.are.U 4000b
V.1.3. Outils de
développement de l'application
Nous avons eu recours lors de l'élaboration de ce
projet de mémoire un langage de programmation orientée objet
appelée VB.Net avec sa plate-forme Microsoft Visual
Studio 2008 et une base de données qui tourne sous Microsoft SQL Server
que nous présenterons ci - dessous.
V.1.3.1. Microsoft Visual Studio 2008
Microsoft Visual Studio est une suite de
logiciels de développement pour Windows conçue par Microsoft. La
dernière version s'appelle Visual Studio 2010.
Visual Studio est un
ensemble complet d'outils de développement permettant de
générer des applications Web ASP.NET, des Services Web XML, des
applications bureautiques et des applications mobile. Visual Basic, Visual C#
et Visual J# utilisent tous le même environnement de développement
intégré (IDE, IntregratedDevelopmentEnvironment), qui leur permet
de partager des outils et facilite la création de solutions faisant
appel à plusieurs langages.
Par ailleurs, ces langages permettent de mieux tirer parti
des fonctionnalités du Framework.NET, qui fournit un accès
à des technologies clés simplifiant le développement
d'applications Web ASP et de Services Web XML grâce à Visual Web
Developer.
V.1.3.2. Microsoft SQL Server 2008
Microsoft SQL Server est un système
de gestion de base de données (abrégé en SGBD ou SGBDR
pour « Système de gestion de base données
relationnelles ») développé et commercialisé par
la société Microsoft.
V.2. Présentation de
l'application
On présente dans cette section les différents
aspects du système de reconnaissance biométrique des empreintes
et la suite de l'application.
V.2.1. Interface et
Présentation
L'application comporte 3 acteurs principaux à
savoir :
Ø L'administrateur
Ø Agent office
Ø Agent frontière
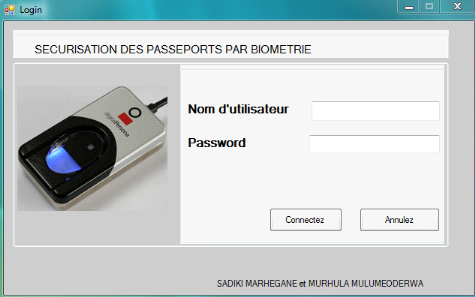
Au démarrage de l'application, apparait un formulaire
d'authentification. C'est ainsi que chaque acteur doit s'authentifier avant de
s'introduire dans le système.
Figure IV.6. Formulaire d'authentification
Figure V.2. Formulaire
d'authentification
Sur la fenêtre d'opération
L'administrateur du système aura la
possibilité :
· D'ajouter les nouveaux utilisateurs comme agent de
l'office et agent de la frontière, et chaque agent aura ses droits.
· De faire les nouveaux enrôlements des citoyens
qui veulent avoir le passeport.
· De vérifier si le passeport a été
livré dans la voie légale ou illégale moyennant
l'empreinte digitale du détenteur.
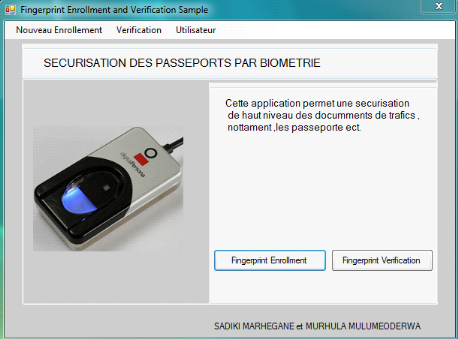
Figure V.3. Fenêtre
d'opération
Sur le formulaire de la gestion des
utilisateurs
L'administrateur, comme il a tout droit, il aura la
possibilité :
· Créer un nouveau utilisateur (agent office ou
agent frontière) en fonction du lieu de travail
· De supprimer un utilisateur (agents)
· De modifier un utilisateur (agents), soit son mot de
passe soit son lieu de travail.
Figure V.4. Formulaire de la
gestion des utilisateurs
Formulaire d'enrôlement
L'administrateur ou agent de l'office a la
possibilité :
· D'enrôler les citoyens qui veulent être en
possession du passeport moyennant la capture de son image, son identité
et son empreinte digitale.
· Après enrôlement, on donne au citoyen un
reçu impliquant qu'il reviendra récupérer son passeport
plus tard.

Figure V.5. Formulaire
d'enrôlement
Formulaire de la vérification du
document
Tous les agents auront la possibilité de
vérifier si le passeport a été livré dans une voie
légale ou illégale moyennant soit par le numéro du
passeport ou soit par biométrie d'empreinte digitale du
détenteur. Enfin, les agents regarderont l'état du passeport s'il
est actif ou non - actif, illustré dans la figure ci - dessous.

Figure V.6. Formulaire de
vérification biométrique par empreinte digitale
Une fois le détenteur pose son empreinte digitale sur
le capteur biométrique, la fenêtre suivante apparait dans la
figure illustrée dans l'exemple ci - dessous.

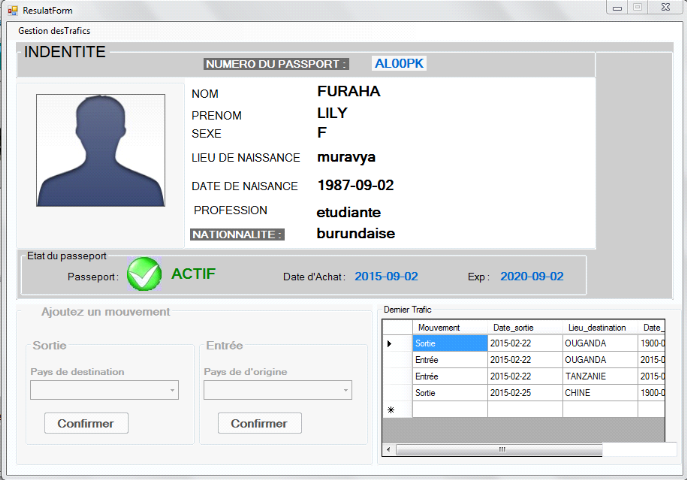
Figure V.7. Formulaire de
vérification
V.3. Démarche à
suivre pour la reconnaissance des empreintes digitales
La personne pose son doigt sur le capteur
d'empreintes digitales ; celui - ci capture l'image de l'empreinte de la
personne, le module de traitement récupère l'image et la traite
(renforcement de niveaux de gris, binarisation et recherche de minuties). Puis,
une fois le traitement terminé, les résultats sont envoyés
au module correspondant à l'identification qui permet de comparer les
données de l'individu avec celles présentes dans la base de
données d'empreinte des individus autorisés.
Conclusion
générale
La biométrie est un domaine à la fois
passionnant et complexe. Elle tente, par des outils mathématiques
souvent très évolués, de faire la distinction entre des
individus, nous obligeant à travailler dans un contexte de très
grande diversité. Cette diversité se retrouve également
dans le nombre considérable d'algorithmes qui ont été
proposés en reconnaissance des empreintes digitales.
Dans ce mémoire, nous nous sommes
intéressés au problème de la reconnaissance
biométrique des empreintes digitales. Nous avons souligné durant
l'influence néfaste des principales difficultés lors de la
reconnaissance biométrique des empreintes digitales et pour cela, nous
avons proposé quelques solutions qui ont été
évaluées durant la phase de test. Ces solutions ont donné
d'assez bon résultats.
Nous estimons avoir réalisé un système
répondant à l'objectif que nous nous sommes fixés au
départ, à savoir la mise en oeuvre d'un système permettant
la synthèse et la reconnaissance biométrique des empreintes
digitales d'individus et contrôle d'accès.
En guise de perspectives, une extension de ce travail peut
être réalisée en intégrant un système
d'acquisition des images dans les opérations d'enrôlement et de
vérification.
REFERENCES ET
BIBLIOGRAPHIES
[1]. John D. Woodward, Jr ; Christopher Horn, Julius
Gatune and Aryn Thomas, «Biometrics A look at Facial Recognition»,
documented briefing by RAND Public Safety and Justice for the Virginia State
Crime Commission, 2003.
[2]. Florent Perronnin, Jean - Luc Dugelay, «Introduction
à la biométrie : Authentification des individus par
traitement Audio - vidéo», Institut Eurocom, Multimedia
Communications Department, Revue Traitement du signal, vol.19, N°4,
2002.
[3].
http://www.biometricgroup.com
[4]. S.Liu, M. Silveman, «A pratical guide to biometric
security technology», IEEE Computer society, IT Pro - security, January -
February, 2001.
[5].A.K. Jain, L. Hong, S, Pankanti, «Biometrics:
Promising Frontiers for emerging identification market», Communications of
the ACM, pp. 91 - 98, February 2000.
[6]. C. Fredoville, J. Marie thoz, C. Jaboulet, J. Hennebert,
J. -F. Bonastre, C. Mokbel, F. Bimbot, «Behavior of a Bayesian adaptation
method for incremental enrollment in speaker verification», International
conference on acoustics speech, and signal processing, pp. 1197 - 1200,
Istanbul, Turquie, 5 - 9 Juin 2000.
[7]. T. Kanade «Computer Recognition of human
faces», Interdisciplinary systems research, vol. 47, 1977.
[8].P. Penev and J. Atick «Local features analysis: A
general statistical theory for object representation», Neural Systems,
vol. 7, N°3, pp. 477 - 500, 1996.
[9]. V. Perlibakas «Face recognition using principal
component analysis and log - Gabor Filters», March 2005.
[10]. P.J. Philips, A. Martin and M. Przybochi «An
introduction to evaluating Biometric systems», IEEE computer, vol. 33,
N°2, pp. 56 - 63, February 2002.
[11]. K. Beghad Bey «Techniques de classification
d'empreintes digitales», Mémoire de magister, Ecole Militaire
Polytechnique, Alger, décembre 2003.
[12].
http://onin.com/fphistory.html«the
history of fingerprint»
[13]. S. Prabhakar «Fingerprint classification and
Matching using filterbank», these de Doctorat en Informatique,
Université de Michigan, 2001.
[14]. M.D. Garris, C.I. Watson, R.M.McCabe, C.L.Wilson
«Users guide to nist fingerprint image software (nfis)», Technical
report NISTIR 6813, National Institute of Standards and Technology, 2002.
[15]. H. Tonati, N. Adlène «Identification des
empreintes digitales», Mémoire de fin d'études, Ecole
Militaire Polytechnique, Alger, 2004.
[16]. B.C. Seow, S.K.Yeoh, S.L.Lai, N.A.Abu «Image based
fingerprint verification», student conference on research and development
processing, Malaysia, 2002.
[17].S. Prabhakar, A. Jain, J. Wang, S. Pankanti, B. Bolle,
«Minutiae verification and classification for fingerprint matching»,
in international conference on pattern recognition, vol.1, pp. 25 - 29,
2000.
[18]. M.T. Leung, «Fingerprint image processing using
neural network», IEEE Proc on computer and communications system, 1990.
[19]. D. Maio, D. Maltoni, «Neural based minutiae
filtering in fingerprint images», in 14thinternational
conference on pattern recognition, pp. 1654 - 1658, 1998.
[20].Viscayaet Gerhardt, «A no linear orientation model
for global description of fingerprints», Pattern recognition, vol. 22,
N°7, pp. 1221 - 1231, 1996.
[21]. L. Hong, Y. Wan, A. Jain, «Fingerprint image
enhancement: Algorithm and performance evaluation», Pattern recognition
and image processing laboratory, Michigan State University, 1998.
[22]. D. Maio, D. Maltoni, «Direct Grey - scale minutiae
detection in fingerprint», IEEE Trans. Pattern Anal. Machin Intell, vol.
19, N°1, pp. 27 - 40, 1997.
[23]. G. Greavenitz, «Exposé sur la technologie
d'empreinte digitale», Berg dataBiometrics, Germany, 2003.
[24]. K. Nandakumar, A.K. Jain, «Local correlation -
based fingerprint matching», Indian conference on computer vision,
Graphics and image processing, pp. 503 - 508, 2004.
[25]. G.T.B. Verwaaijen, A.M. Baze, S.H. Garez, L.P.J.
Veelunturf, et B.J. Vander Zwaag, «A correlation - based fingerprint
verification system», IEEE Pro RISC 2000 workshop on circuits, systems and
signal processing , November 2000.
[26]. S. Prabhakar, A. Jain, L. Hongand S.
Pankanti«Finger code: A filter bank for fingerprint representation and
matching», 1999.
[27]. A.K. Jain, A. Ross, «Fingerprint mosaicking»,
IEEE international conference on ICASSP, vol.4, May, 2002.
* 1 PINTO et GRAWITZ,
« méthode de recherche en sciences sociales »
Dalloz, Paris, 1971
* 2http://www.nist.gov
* 3 http://www.atmel.com
| 

