ÉÜÜÜÜÜ?ÈÚÜÔáÇ
ÉÜÜÜÜÜÜÜ?ØÇÑÜÜÜÜÜÞã?ÏÜÜÜáÇ
ÉÜÜÜÜÜÜÜ?ÑÜÜÜÆÇÒÜÜÜÌáÇ
ÉÜÜÜÜÜÜ?ÑæÜÜÜÜÜãÌáÇ
Ministère de l'enseignement supérieur
et de la Ministère de la poste et des technologies de
recherche scientifique l'information et de la
communication
|
INSTITUT NATIONAL DES
TELECOMMUNICATIONS ET
DES
TECHNOLOGIES DE L'INFORMATION ET
DE LA COMMUNICATION
|
|
Ê?ÇÕÊ?á
íÜÜÜäØæáÇ
ÏÜÜÜÜÚãáÇ
áÇÕÊ?Ç æ
ã?Ú?Ç
ÊÇÜÜ?ÌæáæÜÜÜÜäßÊæ
|
PROJET DE FIN D'ETUDES
Pour l'obtention du Diplôme d' Ingénieur
d'Etat en Télécommunications
Thème :
Mise en oeuvre d'un coeur de
réseau IP-MPLS
Présenté par : ISMAIL
Encadreur :
Jury :
Président : Examinateurs :
PROMOTION : IGE 30
ANNEE UNIVERSITAIRE :
2009/2010
Table des matières
INTRODUCTION GENERALE 1
Chapitre I INTRODUCTION AUX RESEAU NGN
I.1 Introduction 2
I.2 Définition du NGN . 2
I-3 Les exigences de tourner vers NGN 2
I.4 Caractéristiques du réseau NGN
3
I.4.1 Une nouvelle génération de
commutation 3
I.4.2 Une nouvelle génération de
réseaux optiques 3
I.4.3 Une nouvelle génération de type
d'accès 3
I.4.4 Une nouvelle génération de gestion ..
3
I.5 Architecture en couches.. 3
I.5.1 Couche transport 3
I.5.2 Couche contrôle 4
I.5.3 Couche service 4
I.6 Principaux équipements du réseau NGN
5
I.6.1 Softswitch 5
I.6.2 Media Gateway 5
I.7 Conclusion 5
Chapitre II LES COEURS DE RESEAUX
II-1 Introduction . 6
II-2 Frame Relay et X25 . 6
II-2.a le protocole X25 . 6
II-2.b le protocole Frame Relay . 6
II-3 Migration d'ATM et IP/ATM vers la MPLS ..
7
II-3-a ATM . 7
II-3-b IP/ATM 7
II-3-c Convergence vers MPLS 8
II-4 Développement de la MPLS ... 8
II-5 Conclusion . 10
Chapitre III IP/MPLS
III.1 Introduction . 11
III.2 PRINCIPES ET CONCEPTS DE MPLS 11
III.2.1 Architecture de MPLS 11
III.2.1.a LSR (Label Switch Router) .. 11
III.2.1.b LER (Label Edge Router) .. 11
III.2.2 Principe de fonctionnement de MPLS ...
12
III.2.3 Structure fonctionnelle MPLS . 13
III.2.3.a Le plan de contrôle 13
III.2.3.b Le plan de données .. 14
III.2.4 Structures De Données Des Labels
14
Mise en oeuvre d'un coeur de réseau
IP/MPLS
Table des matières
III.2.4.a LIB (Label Information Base) 14
III.2.4.b LFIB (Label Forwarding Information Base) .
14
III.2.4.c FIB (Forwarding Information Base) ...
14
III.2.5 Construction des structures de données
14
III.3 Paradigme De La Commutation Dans MP 15
III.4 Les labels . 16
III4.1 L'encapsulation Label MPLS dans différentes
technologies 16
III4.2 L'entete MPLS 16
III.4.3 Pile de labels (Label Stack) ... 17
18
18
19
III.5 Distribution des labels .
III.5.1 Le protocole LDP
Chapitre IV LES APPLICATIONS DE MPLS
IV.1 Introduction 20
IV.2 Ingénierie de trafic 20
IV.2.1 Ingénierie de trafic sans MPLS ..
20
IV.2.2 Ingénierie de trafic avec MPLS .
22
IV.2.2.a Mécanisme MPLS-T 22
IV.2.2.b Le concept de Traffic Engineering
Trunk(TE-Trunk) . 23
IV.2.2 .c Le protocole CR-LDP (Constraint-based Routing
over LDP 24 24
IV.2.2 .d Le protocole RSVP (ReSerVation Protocol)
24
IV.2.2.e Routage par contrainte MPLS-TE .. 25
IV.2.2 .f Fonctionnalités MPLS-TE 27
IV.2.2 .h Suppression d'un LSP .. 27
IV.2.2 .g Préemption MPLS-TE . 27
IV.2.2 .h Suppression d'un LSP .. 27
IV.3 MPLS-VPN 28
IV.3.1 Introduction . 28
IV.3.2 Routeurs P, PE et CE 28
IV.3.3 Routeurs virtuels (VRF) 28
IV.3.4 Multi-Protocol Border Gateway Protocol (MP-BG) .
30
IV.3.4.a Notion de RD (Route Distinguisher)
30
IV.3.4.b Notion de RT (Route Target) 31
IV.3.5 Impact des topologies complexes de VPN sur VRF ...
31
IV.3.6 Transmission des paquets IP . 32
IV.4 MPLS-QS . 33
IV.5 Extension MPLS . 35
IV.6 Conclusion .. 35
Chapitre V Application
V.1 Introduction 36
V.2 Mise en oeuvre de la topologie réseau (la
maquette du backbone) 36
Table des matières
V.2.1 Mise en place d'un laboratoire virtuel
36
V2.1.a Logiciel utilisé pour la réalisation
36
V.2.1.b Logiciel utilisé pour la supervision de la
maquette .. 36
V.2.2 Analyse des propriétés fonctionnelles
d'un routeur 37
V.2.3 Mise en pratique des concepts fondamentaux des
réseaux .. 37
V.2.3.a Plan d'adressage . 37
V.2.3.b) Configuration de la maquette 38
V.3 Implémentation d'une VPN . 38
V.3.1 Configuration de VPN 40
V.3.2 Vérification de la configuration ..
40
V.4 Implémentation se service VOIP .
40
V.4.1 Introduction 40
V.4.2 TRIXBOX . 40
V.4 .3 Configuration supplémentaire au VPN
42
V.4 .4 Vérification de la configuration ..
43
V.5 Implémentation de MPLS TE 43
V.5.a Configuration de MPLS TE .. 44
V.5.b Vérification de la configuration
45
V.6 Conclusion 48
CONCLUTION GENERALE 49
INTRODUCTION GENERALE
Au cours de ces dernières années, Internet a
évolué et a inspiré le développement de nouvelles
variétés d'applications. Ces applications ont des besoins
garantissant en termes de bande passante et de sécurité de
service. En plus des données traditionnelles, Internet doit maintenant
transporter voix et données multimédia. Les ressources
nécessaires pour ces nouveaux services, en termes de débit et de
bande passante, ont entraîné une transformation de
l'infrastructure d'Internet. Cette transformation du réseau, d'une
infrastructure par paquets à une infrastructure en cellules, a introduit
de l'incertitude dans un réseau jusque-là déterministe.
L'augmentation de la connectivité des réseaux et
l'intégration de plusieurs services dans un même système de
communication (intégration de voix et données,
téléphonie mobile, développements de la
téléphonie sur plates-formes IP, etc.) a engendré une
croissance significative de la complexité du métier de concepteur
d'architectures de réseaux.
D'une part, sur des aspects de dimensionnement matériel
puisque les structures de communication doivent fédérer un nombre
croissant de points de raccordement. D'autre part, la convergence des
médias où l'on cherche à faire passer sur un méme
support physique les données, la voix, la vidéo, entraîne
l'ajout de nouveaux équipements.
Avec l'évolution rapide des technologies de transports
à haut débit, il devient évident qu'ATM n'est plus une
solution d'avenir pour les coeurs de réseaux IP, d'une part parce qu'il
est difficile d'intégrer d'autres technologies dans une signalisation
ATM, et d'autre part parce que la taxe de cellule (cell tax) devient
prohibitive lorsque le débit augmente et qu'on ne sait plus construire
de cartes capables de segmenter et de réassembler des paquets en
cellules à la vitesse des liens. MPLS est donc une solution prometteuse
parce qu'elle permet d'intégrer très facilement de nouvelles
technologies dans un coeur de réseau existant.
La mise en oeuvre d'un coeur de réseau basé sur
une plateforme IP/MPLS est le projet de fin d'étude que nous avons
développé dans ce mémoire, qui est axé sur les cinq
chapitres suivants :
le premier chapitre est une introduction aux
réseaux de nouvelle génération (NGN) comme un bon exemple
de coeur de réseaux basés sur le MPLS.
Le chapitre suivant décrit les différents coeurs de
réseaux existants et les exigences pour évoluer vers une dorsale
IP/MPLS
le troisième chapitre est une
présentation des concepts de base de la technologie MPLS et leur
mécanisme de fonctionnement
Le quatrième chapitre décrit
les applications de MPLS celui ci sera divise en trois sections, la
première section explique les mécanismes de l'ingénierie
de trafic basé sur MPLS (MPLSTE) , la deuxième section
développe la technologie MPLS-VPN , la troisième section
décrit brièvement les paramètres et les modèles de
la qualité de service et l'implémentation MPLS-QS
Dans le cinquième chapitre nous
présentons une application pratique dans laquelle nous avons
émulé un coeur de réseau utilisant la technologie IP
MPLS
I.1 Introduction
Depuis de nombreuses années, l'industrie des
télécommunications cherche à orienter sa technologie de
manière à aider les opérateurs à demeurer
compétitifs dans un environnement caractérisé par la
concurrence et la déréglementation accrues.
Les réseaux de la prochaine génération
(NGN ou Next Generation Network en anglais), avec leur architecture
répartie, exploitent pleinement des technologies de pointe pour offrir
de nouveaux services sophistiqués et augmenter les recettes des
opérateurs tout en réduisant leurs dépenses
d'investissement et leurs coûts d'exploitation.
L'évolution d'un réseau existant vers cette
nouvelle structure nécessitera une stratégie de migration
progressive visant à réduire au minimum les dépenses
d'investissement pendant la phase de transition, tout en tirant parti
très tôt des avantages qu'elle présente. Toute
démarche entreprise lors de cette étape de transition devra
simplifier l'évolution du réseau vers l'architecture NGN à
commutation de paquets. Pendant plusieurs années encore, les
Services de commutation traditionnels vont devoir coexister avec
des éléments de réseau mettant en oeuvre de nouvelles
technologies.
I.2 Définition du NGN
"Next Generation Network" ou "NGN"
(littéralement "Réseau de Nouvelle
Génération") est une expression fréquemment
employée dans l'industrie des télécommunications,
notamment depuis le début des années 1990. Il n'existe pas de
définition unique. Le sens varie en fonction du contexte et du domaine
d'application. Toutefois, le terme désigne le plus souvent le
réseau d'une compagnie de télécommunications dont
l'architecture repose sur un plan de transfert en mode paquet, capable de se
substituer au réseau téléphonique commuté et aux
autres réseaux traditionnels. L'opérateur dispose d'un coeur de
réseau unique qui lui permet de fournir aux abonnés de multiples
services (voix, données, contenus audiovisuels...) sur
différentes technologies d'accès fixes et mobiles. Autrement,
"NGN" est également utilisé très souvent à des fins
marketings par les opérateurs et les fabricants pour rendre compte de la
nouveauté d'un réseau ou d'un équipement de
réseau.
I-3 Les exigences de tourner vers NGN
Depuis quelques années, les laboratoires des
constructeurs et les organismes de standardisation se penchent sur une nouvelle
architecture réseau les Next Generation Networks (NGN) pour
répondre aux exigences suivantes :
· Les réseaux de télécommunication
sont spécialisés et structurés avant tout pour la
téléphonie fixe ;
· Le développement de nouveaux services:
évolution des usages du réseau d'accès fixe et
l'arrivée du haut débit ;
· La migration des réseaux mobiles vers les
données.
· Difficulté à gérer des
technologies multiples (SONET, ATM, TDM, IF) Seul un vrai système
intégré peut maîtriser toutes ces technologies reposant sur
la voix ou le monde des données ;
· Prévision d'une progression lente du trafic
voix et au contraire une progression exponentielle du volume de données
=> baisse de la rentabilité des opérateurs si pas
d'évolution.
I.4 Caractéristiques du réseau NGN
I.4.1 Une nouvelle génération de
commutation

Figure I.1: Caractéristiques du réseau
NGN
Les solutions de commutation de nouvelle
génération fournissent une gamme complète de la
catégorie de commutation, voix over IF adaptée aux besoins des
abonnés complétées par des applications convergées
de voix/données pour établir un réseau de nouvelle
génération (une commutation par paquets).
I.4.2 Une nouvelle génération de
réseaux optiques
Les solutions de système optique de nouvelle
génération rassemblent les deux réseaux optiques existants
y compris celui du multiplexage DWDM et les réseaux optiques SDH. Avec
la nouvelle génération de systèmes optiques, des
réseaux IF optimisés peuvent être établis. Les
fonctions de données et Ethernet sont ajoutées aux dispositifs
classiques de transport.
I.4.3 Une nouvelle génération de type
d'acc~s
Les solutions d'accès de nouvelle
génération combinent des concepts prouvés de
l'accès des équipements existants ajouté à une
architecture modulaire commune avec différentes qualités:
voix-centralisée, donnée-centralisée et multiservice.
I.4.4 Une nouvelle génération de
gestion
Des solutions de gestion de réseau de nouvelle
génération sont optimisées pour la gestion des alarmes,
gestion de configuration et d'exécution et de sécurité des
modules du réseau NGN. Basé sur un concept modulaire de gestion
d'élément et de domaine de gestion et d'applications, le
réseau NGN supporte pleinement les opérations d'exploitation,
d'administration et de maintenance (OA&M), la configuration de
réseau et l'approvisionnement de service comprenant un
déploiement de masse. Ayant des interfaces ouvertes pour une
intégration facile.
I.5 ARCHITECTURE EN COUCHES
Les réseaux NGN reposent sur une architecture en
couches indépendantes (transport, contrôle, services) communiquant
via des interfaces ouvertes et normalisées. Les services doivent
être évolutifs et accessibles indépendamment du
réseau d'accès utiisé.
I.5.1 Couche transport :
Cette couche se divise en deux sous-couches
1' La couche accès regroupe les fonctions
et équipements permettant de gérer l'accès des
équipements utilisateurs au réseau, selon la technologie
d'accès ;
1' La couche transit est responsable de
l'acheminement du trafic voix ou données dans le coeur de réseau
IP, selon le protocole utiisé. L'équipement important à ce
niveau dans une architecture NGN est le « Media Gateway » (MGW)
responsable de l'adaptation des protocoles de transport aux différents
types de réseaux physiques disponibles (RTC, IP, ATM, ...).
I.5.2 Couche contrôle
Cette couche gère l'ensemble des fonctions de
contrôle des services en général, et de contrôle
d'appel en particulier pour le service voix. L'équipement important
à ce niveau dans une architecture NGN est le serveur d'appel, plus
communément appelé «softswitch », qui fournit, dans le
cas de services vocaux, l'équivalent de la fonction de commutation.
I.5.3 Couche service
L'ensemble des fonctions permettant la fourniture de services
dans un réseau NGN. En termes d'équipements, Cette couche
regroupe deux types d'équipement les serveurs d'application (ou
application servers) et les « enablers », qui sont des
fonctionnalités, comme la gestion de l'information de présence de
l'utilisateur, susceptibles d'être utilisées par plusieurs
applications. Cette couche inclut généralement des serveurs
d'application SIP (Session Initiation Protocol), car il est utilisé dans
une architecture NGN pour gérer des sessions multimédias en
général, et des services de voix sur IP en particulier.
Ces couches sont indépendantes et communiquent entre
elles via des interfaces ouvertes. Cette structure en couches est sensée
garantir une meilleure flexibilité et une implémentation de
nouveaux services plus efficace. La mise en place d'interfaces ouvertes
facilite l'intégration de nouveaux services développés sur
un réseau d'opérateur mais peut aussi s'avérer essentielle
pour assurer l'interconnexion d'un réseau NGN avec d'autres
réseaux qu'ils soient NGN ou traditionnels. L'impact majeur pour les
réseaux de téléphonie commutée traditionnels est
que le commutateur traditionnel est scindé en deux
éléments logiques distincts : le media Gateway pour assurer le
transport et le softswitch pour assurer le contrôle d'appel. Une fois les
communications téléphoniques « empaquetées »
grâce aux media Gateway, il n'y a plus de dépendance des services
vis-à-vis des caractéristiques physiques du réseau. Un
coeur de réseau paquet unique, partagé par plusieurs
réseaux d'accès constitue alors une perspective attrayante pour
des opérateurs. Bien souvent, le choix se porte sur un coeur de
réseau IP/MPLS commun au niveau de la couche de transport du NGN afin de
conférer au réseau IP les mécanismes de qualité de
service suffisants pour assurer une fourniture de services adéquate.
Cette architecture est illustrée par la figure ci-dessous
:

Figure I.2 Architecture NGN
I.6 Principaux équipements du réseau NGN
I.6.1 Softswitch
Dans une infrastructure NGN, un softswitch n'est autre qu'un
serveur informatique, doté d'un logiciel de traitement des appels
vocaux. Le trafic voix est en général paquetisé par le
media Gateway, et pris en charge par les routeurs de paquets du réseau
de l'opérateur. Un softswitch va identifier les paquets voix, analyser
leur contenu pour détecter le numéro vers lequel ils sont
destinés, confronter ces numéros avec une table de routage (qui
indique ce que le softswitch doit faire en fonction de chaque numéro),
puis exécuter une tâche (par exemple transmettre ou terminer).
I.6.2 Media Gateway
Les media Gateway constituent le deuxième
élément essentiel déployé dans un réseau
NGN. Un media Gateway peut par exemple se positionner entre le réseau de
commutation circuit et le réseau de commutation de paquets. Dans ce cas,
les media Gateway transforment le trafic circuit TDM en paquets, la plupart du
temps IF, pour que ce trafic puisse ensuite être géré par
le réseau NGN.
I.7 Conclusion
Dans ce chapitre nous avons introduit les NGN et
présenté l'intérêt de leur mise en ouvre,
caractéristiques et hiérarchie.
Dans le chapitre suivant on va décrire comment se fait
l'évolution d'un coeur de réseau
II-1 Introduction
Les techniques employees et utilisées dans les coeurs
de reseaux et les reseaux backbone ont subi une grande evolution jusqu'
à l'arrivée de la normalisation du protocole MPLS et leur
developpement. Dans ce chapitre nous allons decrire quelques technologies,
leurs limites et developpements, par la suite nous allons citer les etapes de
l'évolution de standards MPLS.
II-2 Frame Relay et X25 II-2.a le protocole
X25
A la fin des annees 1970 et au debut des annees 1990, la
technologie des reseaux etendus reliant deux sites utilisait generalement le
protocole X.25. Bien que considere actuellement comme un protocole d'ancienne
génération, le X.25 a été une technologie de
commutation de paquets très répandue car elle permettait
d'obtenir une connexion très fiable sur des infrastructures
câblees non fiables. Ce resultat etait obtenu grâce à des
contrôles de flux et d'erreur supplémentaires. Ces contrôles
alourdissaient cependant le protocole. Celui-ci trouvait son application
principale dans le traitement des autorisations de carte de credit et dans les
guichets automatiques. Dans cette partie de chapitre, nous ne citons le
protocole X.25 qu'à des fins historiques.
II-2.b le protocole Frame Relay
Lorsqu'on construit un réseau etendu, quel que soit le
mode de transport choisi, deux sites sont toujours relies par un minimum de
trois composants ou groupes de composants de base. Chaque site doit avoir son
propre equipement (ETTD) pour acceder au central telephonique local (DCE). Le
troisième composant se trouve entre les deux, reliant les deux points
d'accès. Dans la figure, il s'agit de la partie fournie par le
réseau fédérateur Frame Relay.

Figure II-1 réseau étendu frame
Relay
Le protocole Frame Relay demande moins de temps de traitement
que le X.25, du fait qu'il comporte moins de fonctionnalités. Par
exemple, il ne fournit pas de correction d'erreur, car les réseaux
étendus actuels permettent d'obtenir des connexions plus fiables que les
anciens. Lorsqu'il détecte des erreurs, le noeud Frame Relay abandonne
tout simplement les paquets sans notification. Toute correction d'erreur, telle
que la retransmission des données, est à la charge des composants
d'extrémité. La propagation des données d'une extremite
client à une autre est donc très rapide sur le reseau.
Frame Relay permet un traitement efficace en volume et en
vitesse, en reunissant les fonctions des couches liaison de donnees et reseau
en un seul protocole simple. En tant que protocole de liaison de
données, Frame Relay permet d'accéder à un réseau,
il délimite et fournit les trames dans l'ordre approprié et
détecte les erreurs de transmission par un contrôle de redondance
cyclique standard. En tant que protocole de reseau, il fournit plusieurs
liaisons logiques sur un même circuit physique et permet au reseau
d'acheminer les données sur ces liaisons jusqu'à leurs
destinations respectives.
Le protocole Frame Relay intervient entre un
périphérique d'utilisateur final, tel qu'un pont ou un routeur de
reseau local, et un reseau. Le reseau proprement dit peut utiliser n'importe
quelle méthode de transmission compatible avec la vitesse et
l'efficacité requises par les applications Frame Relay. Certains reseaux
fonctionnent avec le protocole Frame Relay lui-mrme, d'autres utilisent autres
technique qui peut être MPLS.
Le protocole Frame Relay demande moins de temps de traitement
que le X.25, du fait qu'il comporte moins de fonctionnalités. Par
exemple, il ne fournit pas de correction d'erreur, car les réseaux
étendus actuels permettent d'obtenir des connexions plus fiablesD que
les anciens. Lorsqu'il détecte des erreurs, le noeud Frame Relay
abandonne tout simplement les paquets sans notification. Toute correction
d'erreur, telle que la retransmission des données, est à la
charge des composants d'extrémité. La propagation des
données d'une extrémité client à une autre est donc
très rapide sur le réseau.
II-3 Migration d'ATM et IP/ATM vers la MPLS II-3-a
ATM
La technologie ATM a ete adoptee par l'Union Internationale
des Telecommunications (UIT) a la fin des annees 80 pour repondre a la demande
des operateurs de telecommunication d'un « Reseau Numerique à
Integration de Service Large Bande » unifiant dans un même protocole
leurs mecanismes de transport des donnees, d'images et surtout de la voix, et
garantissant la qualite de service. Les mecanismes propres aux donnees ont
ensuite ete affines par l'ATM Forum pour être utilisables dans les
reseaux locaux et les reseaux longue distance lorsque les debits excedent 34 ou
43 Mbit/s en inserant ATM entre IP et SDH.
II-3-b IP/ATM
IP sur ATM est l'approche privilegiee dans les reseaux IP
operationnels aux Etats-Unis entre 1994 et 1998 pour des debits de 155 puis 622
Mbit/s.
C'est sur des previsions qui, a l'epoque, voyaient dans
l'augmentation du trafic telephonique la source principale de croissance que se
sont bases les operateurs existants de telecommunication, aux Etats-Unis et
surtout en Europe, pour investir massivement dans ATM comme technologie de
leurs reseaux a 155 Mbit/s a partir de la première moitie des annees 90.
Malheureusement, si ATM est approprie lorsque le trafic est constitue
majoritairement de voix, il est inadapte lorsque le trafic est
majoritairement
constitue de données, ce qui est et sera de plus en plus
le cas avec l'explosion du trafic lie a l'Internet.
Une opportunité stratégique apparait, favorable
aux operateurs émergents qui s'appuient sur une unification autour de
IP, répute plus adaptes au transport de données. Les operateurs
historiques se trouvent pris en porte-à-faux par des investissements
élèves et des offres inadaptées.
Pour adjoindre - récemment - a IP les mécanismes
propres a garantir la qualité de service, les ingénieurs et les
chercheurs définissent a l'IETF des mécanismes internes au
réseau, tels que réservation de ressources ou contrôle
adaptatif dans le protocole TCP, dans les applications de diffusion et dans les
routeurs d'extrémité.
Dans le même temps, l'augmentation des
fonctionnalités de commutation réalisables directement de
manière optique conduira a terme IP a être le protocole unique,
soit directement sur fibre optique a 40 Gbit/s et au delà, soit sur de
multiples sous canaux (WDM) a des débits binaires moins
élèves (2,5 et 10 Gbit/s).
II-3-c Convergence vers MPLS
Avant l'apparition de la MPLS et des routeurs au débit
du support physique, la réponse au problème des performances de
routage des réseaux de routeurs consistait à superposer les
réseaux IP aux réseaux ATM, ce qui créait une topologie
virtuelle dans la couche ATM, dans laquelle tous les routeurs devenaient
adjacents, et réduisant ainsi au minimum le nombre de sauts IP entre les
routeurs.
Toutefois, cette superposition IP/ATM présentait un
inconvénient majeur : la nécessité de gérer
l'explosion du nombre de connexions de circuit virtuel ATM nécessaires
pour assurer un maillage complet des liaisons virtuelles entre les paires de
routeurs. En effet, le nombre de circuits virtuels ATM nécessaires
augmente comme le carré du nombre de routeurs connectés au nuage
ATM.
Le pire fut atteint lorsque les réseaux IP eurent
besoin d'augmenter leur bande passante ce que les réseaux ATM ne
pouvaient leur fournir ; il leur fallait des circuits à gigabits, alors
que les circuits ATM étaient limités à des débits
OC-12/STM-4 en raison des équipements.
Avec le remplacement progressif des réseaux IP par les
réseaux IP/MPLS, les
meilleures techniques des réseaux de routage et de
commutation se trouvent réunies. Les
réseaux IP/MPLS sont
capables de s'adapter aux besoins de forte croissance de l'internet,
et de prendre la place de l'ATM en faisant face aux très
grandes exigences du trafic professionnel.
De plus, les réseaux IP/MPLS sont prêts pour la
convergence des données, de la voix et de la vidéo sur IP. Il
n'est donc pas surprenant que l'IP/MPLS soit considéré par la
majorité des opérateurs de réseau comme le
réseau cible à long terme.
II-4 Développement de la MPLS
Le mécanisme de recherche dans la table de routage est
consommateur de temps CPU et avec la croissance de la taille des réseaux
ces dernières années, les tables de routage des routeurs ont
constamment augmenté. Il était donc nécessaire de trouver
une méthode plus efficace pour le routage des paquets, et nous avons vu,
précéde mment que le
|
Chapitre II
|
LES COEURS DE RESEAUX
|
|
|
débit d'information n'avait de cesse d'augmenter ces
dernières années. II a donc fallu mettre en place des protocoles
d'acheminement des données pouvant supporter d tels débits.
C'est pour cela que plusieurs techniques réseaux dont
le rôle principal sont de combiner les concepts de routage IP de niveau
trois, et les mécanismes de commutation de niveau deux ont
été normalises par I' IETF comme la MPLS.
L'Internet Engineering Task Force (IETF) a créé
le groupe de travail MPLS en mars 1997 pour définir une approche
normative de la commutation d'étiquettes. Dans l'attente de normes, les
mises en oeuvre de cette technologie, comme la commutation IP la commutation de
marqueurs de flux, la commutation IP avec agrégation de routes (ARIS) et
le routeur à commutation de cellules (CSR), cherchaient à
améliorer les performances de transfert des réseaux à
routeurs IP. C'était nécessaire car la détermination du
saut suivant sur la base de la recherche du plus long préfixe commun
dans une table de transfert toujours plus volumineuse ne pouvait suivre
l'augmentation des débits de support physique, tandis que la commutation
d'étiquettes pouvait se faire sans dégradation des
performances.
En regardant le graphique ci-dessous, des services tels que
l'ATM et relais de trame, qui pourrait être décrit comme les
protocoles existants, sont maintenant en déclin terminal. Toutefois, IP
sur MPLS et Ethernet. Le point à noter cependant, c'est que l'on
pourrait considérer que la croissance MPLS a mûri tout en Ethernet
est toujours en forte croissance.

Figure II-2 : croissance de trafic par
protocole
Comme un bon exemple de développement MPLS, la figure
suivante résume L'évolution de l'Internet :

Figure II-3 évolution des techniques
employés dans l'internet
Le développement de standard MPLS est passé par les
étapes suivantes :
ü 1ère etape Normalisation de la
MPLS (Multi Protocol Label Switching) Basé sur le trafic IP ;
ü 2ème étape Ajout du
service «Traffic Engineering» (MPLS-TE) ;
ü 3ème Etape :
Développement de MPëS (Multi Protocol Lambda
Switching) Basé sur les longueurs d'ondes et ajout d'un nouveau
protocole, LMP (Link Management Protocol) pour la gestion des liens et des
erreurs ;
ü 4ème etape: GMPLS (Generalized
MPLS)
Extension de MPLS-TE qui permet aux LSR de supporter Plusieurs
types de commutation, Paquets, TDM (SDH/SONET), Lambdas, Fibres ect...,
généralisation de la définition d'un label , ajout de la
signalisation via le protocole RSVP-TE ,et amélioration des protocoles
de routage pour décrire la topologie du réseau : OSPF et
IS-IS.
II-5 Conclusion
Le but de MPLS est de donner aux routeurs IP une plus grande
puissance de commutation, en basant la décision de routage sur une
information de label (ou tag) inséré entre le niveau 2 (Data-Link
Layer) et le niveau 3 (Network Layer).
La transmission des paquets était ainsi
réalisée en commutant les paquets en fonction du label, sans
avoir à consulter l'ent~te de niveau 3 et la table de routage. Alors,
MPLS combinait la souplesse du niveau 3 et la rapidité du niveau 2 .
Dans le chapitre suivant nous allons développer le
protocole MPLS, leur concept et mécanisme.
III.1 Introduction
A la fin de l'année 2001, MPLS (Multi Protocol Label
Switching) est le sujet d'un grand nombre d'articles et de conférences,
mais il est aussi l'objet d'un nombre croissant d'annonces de la part des
constructeurs de matériel réseau. À l'heure où les
premiers services commerciaux s'appuyant sur un coeur de réseau MPLS/IP
apparaissent, l'intérêt de la technologie semble
démontré par leur bon fonctionnement. Il reste nécessaire
de bien comprendre MPLS pour être capable de faire la part des choses.
C'est pourquoi, au-delà des effets de mode, les motivations ayant
présidé à la définition de MPLS et les réels
apports de MPLS et des technologies associées dans les coeurs de
réseaux modernes doivent être compris.
Le but de ce chapitre est de présenter les principaux
éléments de l'architecture Multi Protocol Label Switching, (MPLS)
et les mécanises de fonctionnent que l'on peut traduire par «
commutation d'étiquettes multiprotocolaire »
III.2 PRINCIPES ET CONCEPTS DE MPLS III.2.1 Architecture
de MPLS
L'architecture du réseau MPLS utilise des LSR (Label
Switch Router) et des LER (Label Edge Router):
III.2.1.a LSR (Label Switch Router)
Le LSR est un équipement de type routeur, ou commutateur
qui appartient au domaine MPLS dont Les fonctions sont :
· l'échange d'informations de routage ;
· l'échange des labels ;
· l'acheminement des paquets.
III.2.1.b LER (Label Edge Router)
LER est un LSR qui fait l'interface entre un domaine MPLS et
le monde extérieur. En général, une partie de ses
interfaces supportent le protocole MPLS et l'autre un protocole de type IP. Les
deux types de LER qui existent sont :
· Ingress LER est un routeur qui gère le trafic qui
entre dans un réseau MPLS ;
· Egress LER 'est un routeur qui gère le trafic qui
sort d'un réseau MPLS.
La figure ci-dessous représenté l'architecture du
réseau MPLS

Figure III.1 : Architecture MPLS
III.2.2 Principe
de fonctionnement de MPLS
La mise en oeuvre de MPLS repose sur la détermination
de caractéristiques communes à un ensemble de paquets et dont
dépendra l'acheminement de ces derniers. Cette notion de
caractéristiques communes est appelée Forwarding
Equivalence Class (FEC). Une FEC est la représentation
d'un ensemble de paquets qui sont transmis de la même manière ,
qui suivent le même chemin au sein du réseau et ayant la
même priorité.
MPLS constitue les FEC selon de nombreux critères :
adresse destination, adresse source, application, QoS, etc.
Quand un paquet IP arrive à un ingress
LER, il sera associé à une
FEC. Puis, exactement comme dans le cas d'un routage
IP classique, un protocole de routage sera mis en oeuvre pour découvrir
un chemin jusqu'à l'egress LER (Voir Figure
III.2 , les flèches rouges). Mais à la
différence d'un routage IP classique cette opération ne se
réalise qu'une seule fois. Ensuite, tous les paquets appartenant
à la même FEC seront acheminés
suivant ce chemin qu'on appellera Label Switched Path
(LSP). Un LSP est le chemin établi au travers d'un ou
plusieurs LSRs pour rejoindre plusieurs LERs au sein d'un réseau MPLS,
configuré uniquement via le mécanisme des labels, pour une FEC
particulière. Il peut être établi statiquement ou
dynamiquement.
Ainsi on a eu la séparation entre fonction de routage
et fonction de commutation : Le routage se fait uniquement à la
première étape. Ensuite tous les paquets appartenant à la
même FEC subiront une commutation simple à travers ce chemin
découvert.
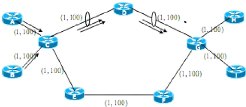
Pour que les LSR puissent commuter correctement les paquets,
le Ingress LER affecte une étiquette
appelée Label à ces paquets
(label imposition ou label
pushing). Ainsi, si on prend l'exemple de la figure III.2
, Le LSR1 saura en consultant sa table de commutation que tout paquet
entrant ayant le label L=18 appartient à la FEC tel et donc doit
être commuté sur une sortie tel en lui attribuant un nouveau label
L=21 (label swapping). Cette opération de
commutation sera exécuter par tous les LSR du LSP jusqu'à aboutir
à l'Egress LER qui supprimera le label (label
popping ou label disposition)
et routera le paquet de nouveau dans le monde IP de façon
traditionnelle, mais Comme les opérations de routage sont complexes et
coûteuses, il est recommandé d'effectuer l'opération de
dépilement sur le dernier LSR (Penultimate node)
du LSP (avant-dernier noeud du LSP avant le LER) pour
éviter de surcharger le LER inutilement.
Un Penultimate node est le routeur immédiat
précédent le routeur LER de sortie pour un LSP donné au
sein d'un réseau MPLS. C'est l'avant denier saut sur un LSP. Il joue un
rôle particulier pour l'optimisation.
L'acheminement des paquets dans le domaine MPLS ne se fait
donc pas à base d'adresse IP mais de label (commutation
de label).
Il est claire qu'après la découverte de chemin
(par le protocole de routage), il faut mettre en oeuvre un protocole qui permet
de distribuer les labels entre les LSR pour que ces derniers puissent
constituer leurs tables de commutation et ainsi exécuter la commutation
de label adéquate à chaque paquet entrant. Cette tâche est
effectuée par "un protocole de distribution de label
" tel que LDP (Label Distribution
Protocol) ou RSVP-TE (ReSerVation Protocol-Traffic
Engineering).
Les trois opérations fondamentales sur les labels
(Pushing, swapping et popping) sont tout ce qui est nécessaire pour
MPLS. Le Label pushing/popping peut être le résultat d'une
classification en FEC aussi complexe qu'on veut. Ainsi on aura placé
toute la complexité aux extrémités du réseau MPLS
alors que le coeur du réseau exécutera seulement la fonction
simple de label swapping en consultant la table de commutation.
La figure ci-dessous représenté la fonction du
réseau MPLS

Figure III.2 Commutation d'étiquettes dans
MPLS
III.2.3 Structure fonctionnelle MPLS
Le protocole MPLS est fondé sur les deux plans principaux
:
III.2.3.a Le plan de contrôle :
contrôle les informations de routages de niveau 3 grâce à
des protocoles tels que (OSPF, IS-IS ou BGP) et les labels grâce à
des protocoles comme (LDP : Label Distribution Protocol), BGP (utilisé
par MPLS VPN) ou RSVP (utilisé par MPLS TE)) échangés
entre les périphériques adjacents.
III.2.3.b Le plan de données : est
indépendant des algorithmes de routages et d'échanges de label
Utilisation d'une base appelée Label Forwarding Information Base (LFIB)
pour forwarder les paquets avec les bons labels, Cette base est remplie par les
protocoles d'échange de label.
Exemple
1' Réception du label 17 pour les paquets à
destination du 10.0.0.0/8
1' Génération d'un label 24 pour ces paquets et
expédition de l'information aux autres routeurs
1' Insertion de l'information dans la LFIB

Figure III.3 : structure fonctionnelle du routeur MPLS
III.2.4 STRUCTURES DE DONNEES DES LABELS
Le protocole MPLS utilise les trois structures de données
LIB, LFIB et FIB pour acheminer les paquets :
III.2.4.a LIB (Label Information Base)
C'est La première table construite par le routeur MPLS
est la table LIB. Elle contient pour chaque sous-réseau IP la liste des
labels affectés par les LSR voisins. Il est possible de connaître
les labels affectés à un sous-réseau par chaque LSR voisin
et donc elle contient tous les chemins possibles pour atteindre la destination
;
III.2.4.b LFIB (Label Forwarding Information Base)
A partir de la table LIB et de la table de routage IP, le
routeur construit une table LFIB qui contient que les labels du meilleur
prochain saut qui sera utilisée pour commuter les paquets
labelisé ;
III.2.4.c FIB (Forwarding Information Base)
Appartient au plan de donnée, c'est la base de
donnée utilisé pour acheminer les paquets non labelisé.
III.2.5 Construction des structures de
données
La construction des structures de données
effectuées par chaque routeur LSR doivent suivre les étapes
suivantes :
v' élaboration des tables de routages par les protocoles
de routage ;
'' allocation indépendamment d'un label à chaque
destination dans sa table de routage par le LSR ;
v' enregistrement dans la LIB des labels alloués ayant
une signification locale,
v' enregistrement dans la table « LFIB » avec l'action
à effectuer de ces labels et leur prochain saut sont ;
v' Envoi par le LSR les informations sur sa « LIB »
à ces voisins ;
v' enregistrement par chaque LSR des informations reçues
dans sa « LIB » ; v' Enregistrement des informations reçues
des prochains sauts dans la « FIB ».

Figure III.4Utilisation des structures de
données pour l'acheminement
III.3 Paradigme Be La Commutation Bans MPLS
Un LSR peut effectuer l'un des trois scénarios
d'acheminement d'un paquet :
· Le paquet arrivant à l'entrée du domaine
MPLS (I-LSR) ne contient que les adresses IP, l'acheminement est basé
sur la table FIB en ajoutant « Push »un Label. ;
· Le paquet arrivant a la sortie du domaine MPLS (E-LSR)
contient que des adresses IP, l'acheminement est basé sur la FIB sans
l'utilisation d'un label (routage IP) ;
· Le paquet arrivant contient un label, dans ce cas
l'acheminement sera basé sur la table LFIB et le label sera
échangé (Swapping).
La figure ci-dessous représenté le Paradigme de
commutation dans MPLS
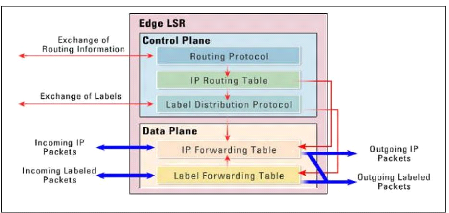
Figure III.5 Paradigme de commutation dans
MPLS
III.4 Les labels
III.4.1 L'encapsulation Label MPLS dans
différentes technologies
Le protocole MPLS, basé sur le paradigme de changement
de label, dérive directement de l'expérience acquise avec l'ATM
(étiquettes VPI/VCI). Ce mécanisme est aussi similaire à
celui de Frame Relay ou de liaisons PPP. L'idée de MPLS est de rajouter
un label de couche 2 aux paquets IP dans les routeurs frontières
d'entrée du réseau.

Figure III.6 L'encapsulation MPLS dans
différentes technologies
III.4.2 I 'I1têtI MPLS
L'entête MPLS se situe entre les entétes des
couches 2 et 3, où l'entête de la couche 2 est celle du protocole
de liaison et celle de la couche 3 est l'entête IP. L'entête est
composé de quatre champs:
v' Le champ Label (20 bits).
v' Le champ Exp ou CoS (3 bits) pour la classe de service
(Class of Service). 1' Un bit Stack pour supporter un label hiérarchique
(empilement de labels). v' Et un champ TTL (Time To Live) pour limiter la
durée de vie du paquet (8
bits). Ce champ TTL est le même que pour IP.

Figure III.7 : Figure Entête MPLS III.4.3 Pile de
labels (Label Stack)
Comme on l'a déjà évoqué, il est
commun d'avoir plus qu'un label attaché à un paquet. Ce concept
s'appelle empilement de label. L'empilement de label permet en particulier
d'associer plusieurs contrats de service à un flux au cours de sa
traversée du réseau MPLS.
Les LSR de frontière de réseau auront donc la
responsabilité de pousser ou tirer la pile de labels pour
désigner le niveau d'utilisation courant de label.
Les applications suivantes l'exigent :
v' MPLS VPN : MP-BGP (MultiProtocol Border Gateway Protocol) est
utilisé pour propagé un label secondaire en addition à
celui propagé par TDP ou LDP ;
" MPLS TE : MPLS TE utilise RSVP TE (Ressource Reservation
Protocol TE) pour établir un tunnel LSP (Label Switched Path). RSVP TE
propage aussi un label en addition de celui propagé par TDP ou LDP.
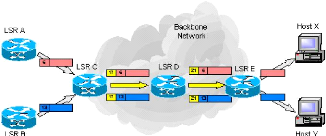
Figure III.8 : pile de labels
Le champ STACK permet d'identifier le classement du
label dans la pile, s'il est égal à 1 alors il s'agit du dernier
label avant l'entête IP.

Figure III.9 : Exemple d'utilisation du champ STACK III.5
Distribution des labels
Les LSR se basent sur l'information de label pour commuter les
paquets au travers du coeur de réseau MPLS. Chaque routeur, lorsqu'il
reçoit un paquet taggué, utilise le label pour déterminer
l'interface et le label de sortie. Il est donc nécessaire de propager
les informations sur ces labels à tous les LSR. Pour cela, suivant le
type d'architecture utilisée, différents protocoles sont
employés pour l'échange de labels entre LSR ; en voici quelques
exemples :
1' TDP/LDP (Tag/Label Distribution Protocol) : mapping des
adresses IP unicast ;
1' CR-LDP, RSVP-TE : utilisés en Traffic Engineering pour
établir des LSP en fonction de critères de ressources et
d'utilisation des liens ;
1' MP-BGP (MultiProtocol Border Gateway Protocol) pour
l'échange de routes VPN.
Chaque paquet MPLS est susceptible de transporter plusieurs
labels, formant ainsi une pile de labels, qui sont empilés et
dépilés par les LSR. Cela permet entre autre d'interconnecter
plusieurs réseaux, chacun possédant son propre mécanisme
de distribution des labels.
Lorsqu'un LSR commute un paquet, seul le premier label est
traité. Cette possibilité d'empiler des labels,
désignée sous le terme de Label Stacking, est aussi
utilisée par le Traffic Engineering et MPLS / VPN.
III.5.1 Le protocole LDP
Le protocole LDP est un protocole de signalisation (plus
précisément, de distribution des labels) héritier du
protocole propriétaire TDP (Tag Distribution Protocol). Pour en
décrire le fonctionnement, rappelons la notion de l'arbre de plus court
chemin : pour un préfixe d'adresse, le protocole de routage classique
définit implicitement un arbre de plus court chemin, arbre ayant pour
racine le LSR de sortie (celui qui a annoncé le préfixe) et pour
feuilles les différents routeurs d'entrée. Le routeur de sortie
va annoncer le préfixe à ses voisins, tout y en associant un
label. Les messages de signalisation vont «monter>> jusqu'aux
routeurs d'entrée, permettant a chaque LSR intermédiaire
d'associer un label au préfixe. Pourtant ce protocole (par ailleurs
raisonnablement simple) présente deux grandes limitations:
ü Lsp contraintes posées par le protocole de
routage
Les Lsp établis par le protocole LDPsont contraints par
le protocole de routage, car il est impossible de spécifier des routes
autres que celles définies par le protocole de routage.
ü Impossibilité de réaliser une
réservation de ressources
le protocole n'a aucun moyen de spécifier des
Paramètres pour l'agrégat de trafic a acheminer sur le LSP.

Figure III.10 ' MMIDANnEdVIIIDeMs EviaE ' 3
Dans le chapitre suivant nous allons étudier les deux
protocoles qui répondent aux limitations du protocole LDP : CR-LDP, et
le protocole RSVP-TE.
III .5 Conclusion
Dans ce chapitre, nous avons présenté le
mécanise de fonctionnent de l'architecture MPLS, ses
éléments les plus importants (LSR, LSP, FEC,..), leurs
déférents rôles, et les structure de fonctionnement de la
MPLS. Dans les chapitres suivants, nous allons voir les applications de la
MPLS
IV.1 INTRODUCTION
Les principaux atouts de la technologie MPLS concernent sa
capacité à intégrer des solutions de gestion de la
qualité de service et d'ingénierie de trafic sur un réseau
IP. En effet, les opérateurs ont besoin de contrôler leur
réseau plus finement que ce que leur permet le routage IP classique,
sans pour autant abandonner la souplesse qu'il apporte. Du fait qu'un chemin
virtuel est créé pour transporter les paquets IP, MPLS est un
candidat idéal pour supporter des fonctions évoluées
d'ingénierie de trafic et ajouter des fonctionnalités de gestion
de la qualité de service dans les coeurs de réseau. De plus, MPLS
permet de déployer des fonctions évoluées en reportant la
complexité de mise en oeuvre aux frontières du réseau et
en conservant de bonnes propriétés de résistance au
facteur d'échelle.
IV.2 Ingénierie de trafic
Les application de La convergence des réseaux
multiservices, qui transportent le trafic Internet, VoIP (Voice/Video over IP),
IP TV, vidéo à la demande et le trafic VPN, nécessite une
optimisation de l'utilisation des ressources pour limiter les coûts
d'investissement, une garantie stricte de la qualité de service (QoS) et
une disponibilité élevée. A tous ces besoins s'ajoute le
besoin de limiter les coûts d'exploitation. Par conséquent, des
mécanismes de trafic s'avèrent nécessaires pour
répondre à tous ces besoins. On appelle ingénierie de
trafic l'ensemble des fonctions permettant de contrôler l'acheminement du
trafic dans le réseau afin d'optimiser l'utilisation des ressources et
de réduire les risques de congestion tout en garantissant la QoS.
Dans cette section, nous introduisons l'ingénierie de
trafic dans les réseaux IP. Ensuite, nous détaillons
l'application de la technologie MPLS à l'ingénierie de trafic.
Ceci inclura la présentation du mécanisme MPLS-TE, du routage par
contrainte MPLS-TE et de quelques options qui se présentent lors de la
conception d'un réseau MPLS-TE.
IV.2.1 Ingénierie de trafic sans MPLS
Il existe plusieurs méthodes d'ingénierie de
trafic dans les réseaux IP. Une solution consiste à manipuler les
métriques des protocoles de routage IP. En effet, le routage IP repose
sur le plus court chemin vers une destination donnée. Tout le trafic
vers une même destination ou un même point de sortie du
réseau emprunte le même chemin. Il arrive que le chemin IP soit
congestionné alors que des chemins alternatifs sont sous-
utilisés. L'ingénierie de trafic avec IP (IP-TE)
représente une solution pour dépasser les limitations du routage
IP. Elle calcule un ensemble de chemins pour répondre aux demandes de la
matrice de trafic sans saturer les liens, et calcule des métriques pour
satisfaire ces chemins. Ensuite, un partage de charge offert par le protocole
de routage peut être utilisé pour permettre à un routeur de
partager équitablement la charge entre tous les chemins de coût
égal.
Un routage optimal (selon un critère d'optimisation
donné) nécessite la détermination des coûts sur
chaque lien qui répondent au critère d'optimisation. Un large
ensemble de solutions a été proposé pour l'IP-TE .Toutes
ces solutions consistent à optimiser les poids des liens utilisés
par la suite par le protocole de routage. Cette ingénierie de trafic
basée sur l'optimisation des métriques IP peut bien fonctionner
uniquement sur des petites topologies avec un faible nombre de routeurs
d'accès. Changer les coûts des liens sur tous les chemins pour une
grande topologie reste très difficile à mettre en oeuvre tenant
compte des risques d'instabilité, des problèmes de convergence
IGP et des problèmes liés aux boucles de routage. A fin de
gérer l'aspect dynamique du réseau, ont proposé des ont
considéré dans leur solution des cas de panne solutions qui
prennent en compte les scénarios de cas de panne dans le
réseau. Les qui peuvent se produire et également
le changement de la matrice de trafic. Cette solution simule des cas de
changement périodique du trafic qui se produisent pendant un jour. Pour
cela, elle se base sur quelques matrices représentatives de ces
changements journaliers pour couvrir toutes les matrices de trafic possibles.
Les auteurs ont montré que l'adaptation à ces changements ne
nécessite pas un grand nombre de coûts de liens à
changer.
Cette solution reste limitée car un changement brusque
de la matrice de trafic, dû par exemple à une catastrophe
naturelle (par exemple un séisme) ou à un événement
à l'échelle nationale (par exemple résultats du
baccalauréat ou fêtes de fin d'année), ainsi que les cas de
pannes multiples, restent difficiles à prédire.
Aussi les solutions d'IP-TE ne s'appliquent
généralement pas lorsque l'on a des chemins de capacités
différentes. En effet, les routeurs ne sont pas capables de faire un
partage de charge tenant compte de la capacité des liens.
La figure. IV.1 montre un exemple où les
routages IP, IP-TE et MPLS-TE sont appliqués. La figure
IV.1(a) représente un réseau comportant 9 noeuds
et 9 liens bidirectionnels.
Les liens sont caractérisés par leurs
métriques IP (égales à 1) et leurs capacités en
Mbit/s (égales à 100 Mbit/s). Toutes les métriques du
réseau sont égales à 1. Deux demandes de trafic arrivent
au réseau. Le premier est de 60 Mbit/s entre A et H et la
deuxième demande est de 50 Mbit/s entre B et I. Les trafics A-H et B-I
emprunteront le plus court chemin IP, c'est-àdire le chemin C-D-G avec
un coût de 2. Le tronçon C-D-G de capacité 100 Mbit/s est
donc soumis à une charge de 110 Mbit/s. Par conséquent, un cas de
congestion, entraînant une perte de paquets, s'est produit ; cela
engendre une dégradation de la qualité de service. Une solution
pour remédier à ce problème est d'utiliser le routage
IP-TE avec un partage de charge donné par le protocole de routage
IGP.
Lorsqu'il y a plusieurs plus courts chemins de même
coût pour aller à une destination donnée, un routeur peut
partager équitablement la charge sur ces chemins. Il envoie alors la
même quantité de trafic sur tous les chemins. Ce mécanisme
est appelé ECMP.
La figure IV.1(b) montre que si on applique
le routage IP-TE, en mettant les métriques à 2 sur les liens C-D,
D-G et C-E, on se retrouve alors avec deux chemins de coût égal
(coût de 4) entre C et G. Dans ce cas, le routeur G effectue un partage
de charge entre les deux chemins. Il envoie 50% du trafic sur le tronçon
du haut et 50% du trafic sur le tronçon du bas.
On a donc une charge de 55 Mbit/s sur les deux chemins. En
conséquence, la congestion est évitée. Dans cet exemple,
le routage IP-TE est efficace ; il a permis d'éviter la congestion et de
router tout le trafic arrivant. En revanche, il ne fonctionne pas lorsque l'on
a des chemins de capacités différentes. La figure
IV.1(c) montre que si le lien E-F est à 50 Mbit/s et
tous les autres liens restent à 100 Mbit/s, le partage de charge ECMP ne
permet pas d'éviter la congestion. Le chemin d'en bas est soumis
à une charge de 55 Mbit/s alors qu'il a une capacité de 50
Mbit/s.
(a) Cas de congestion avec le routage IP

(b) Routage IP-TE avec partage de charge (EGMP)

(c) Gas de congestion avec EGMP
Figure IV.1
Limitation du routage IP et IP-TE
L'application de MPLS à l'ingénierie de trafic,
appelée MPLS-Trafic Engineering (MPLSTE), représente une
alternative pour répondre aux limitations de l'IP-TE. Elle Offre
essentiellement un routage explicite entre deux points du réseau. Geci
consiste à Laisser une entité spécialisée
décider des chemins et procéder à leur
établissement dans le réseau. Le routage explicite assure une
bonne souplesse pour optimiser l'utilisation des ressources. En plus de cette
propriété fondamentale (le routage explicite), MPLS-TE offre
aussi la fonctionnalité de re-routage rapide (MPLS Fast Re-route). Gette
fonctionnalité, permet, en cas de panne dans le réseau, de
garantir un temps de réparation très court (moins de 100 ms).
IV.2.2 Ingénierie de trafic avec MPLS IV.2.2.a
Mécanisme MPLS-TE
L'ingénierie de trafic MPLS (MPLS-TE) représente
une solution pour pallier aux limitations du routage IP en terme
d'ingénierie de trafic. MPLS-TE permet d'établir des LSP pour
l'ingénierie de trafic, appelés TE-LSP. Les TE-LSP sont
routés de façon explicite en prenant compte des contraintes de
trafic (bande passante, etc.) et les ressources disponibles dans le
réseau. Ges TE-LSP peuvent être utilisés par la suite pour
transporter du trafic entre les routeurs d'accès du réseau.
MPLS-T'assure des fonctions d'ingénierie de trafic
telles que l'optimisation de l'utilisation des ressources, la garantie de la
qualité de service (QoS) et le re-routage rapide après une panne
de noeud ou de lien dans le réseau.
MPLS-TE permet de résoudre le problème de
partage de charge présenté dans l'exemple de la figure
IV.2. Gomme le montre la figure 1.5, deux tunnels MPLS-TE
peuvent être établis pour router les trafics A-H et B-I. Le tunnel
T1 de A à H, de bande passante 60 Mbit/s emprunte le tronçon du
haut et le tunnel T2 de B à I, de bande passante 50 Mbit/s emprunte le
tronçon du bas.
|
Chapitre IV
|
LES APPLICATIONS DE MPLS
|
|
|
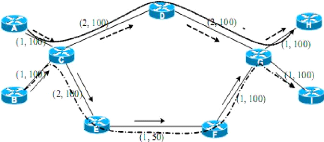
Figure IV.2 Routage MPLS-TE
MPLS-TE combine le routage explicite offert par MPLS et le
routage par contrainte
Ce routage par contrainte repose sur une fonction de
découverte dynamique de la bande passante réservable sur un lien,
une fonction de calcul de chemin explicite contraint, ainsi qu'une fonction
d'établissement de LSP explicites avec réservation de ressources
et distribution de label le long du chemin explicite. Avant de commencer
à détailler le Routage par contrainte MPLS-TE, il est
intéressant d'introduire le concept de "Trafic Engineering Trunk"
(TE-Trunk) utilisé dans MPLS-TE.
IV.2.2.b Le concept de Traffic Engineering
Trunk(TE-Trunk)
Un TE-Trunk a été défini comme
étant un ensemble d'un ou plusieurs TE-LSP utilisés pour router
du trafic agrégé entre deux points d'extrémité pour
une classe de service donnée. Un TE-Trunk est caractérisé
par sa bande passante réservée et un ensemble de
paramètres TE (par exemple la classe de service, le délai ,etc
.).
Le mécanisme de routage par contrainte MPLS-TE cherche
à router des TE-Trunks dans le réseau, c'est-à-dire des
agrégats de trafic entre deux routeurs. Ceci permet de découpler
la quantité des états nécessaires pour
l'établissement et le maintien des LSP, du volume du trafic
transporté (nombre de flux) .
Le concept de TE-Trunk permet également de mettre en
oeuvre le mécanisme de partage de charge. Un ensemble d'un ou plusieurs
LSP peut être utilisé pour acheminer une demande globale de trafic
entre deux points d'extrémité dans le réseau. Lorsqu'un
TE-Trunk inclut plus d'un LSP, le mécanisme de partage de charge est
sollicité pour Sélectionner le LSP qui sera employé pour
acheminer un flux donné.

Figure IV.3 Le Traffic- Engineering Trunk
(TE-Trunk)
Dans ce même but, MPLS introduit un concept de
hiérarchie au niveau des LSP et d'empilement des labels. Il est donc
possible de construire des LSP, encapsulés dans un autre LSP,
lui-même encapsulé dans un LSP, etc. Ce concept d'encapsulation
rappelle évidemment la possibilité en ATM de mettre des VC dans
des VP. Cependant, en MPLS, le nombre de niveaux d'encapsulation (ou de
hiérarchie) n'est pas limité à 2 .
IV.2.2 .c Le protocole CR-LDP (Constraint-based Routing
over LDP)
Le protocole CR-LDP est une version étendue de LDP,
où CR correspond à la notion de « routage basé sur
les contraintes des LSP ». Tout comme LDP, CR-LDP utilise des sessions TCP
entre les LSR, au cours desquelles il envoie les messages de distribution des
étiquettes. Ceci permet en particulier à CR-LDP d'assurer une
distribution fiable des messages de contrôle.
Les échanges d'informations nécessaires à
l'établissement des LSP utilisant CR-LDP sont décrits dans la
figure suivante :
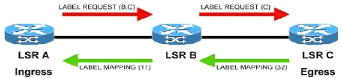
Figure IV.4 Etablissement d'un LSP par CR-LDP IV.2.2 Le
protocole RSVP (ReSerVation Protocol)
Le protocole RSVP utilisait initialement un échange de
messages pour réserver les ressources des flux IP à travers un
réseau. Une version étendue de ce protocole RSVP-TE , en
particulier pour permettre les tunnels de LSP, autorise actuellement RSVP
à être utilisé pour distribuer des étiquettes
MPLS.
RSVP est un protocole complètement séparé de
la couche IP, qui utilise des datagrammes IP ou UDP (User Datagram Protocol)
pour communiquer entre LSR.
RSVP ne requiert pas la maintenance nécessaire aux
connexions TCP, mais doit néanmoins être capable de faire face
à la perte de messages de contrôle.
Les échanges d'informations nécessaires à
l'établissement de LSP permettant les tunnels de LSP et utilisant RSVP
sont décrits dans la figure suivante :
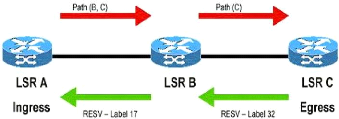
Figure IV.5 : Etablissement LSP par RSVP-TE
IV.2.2.e Routage par contrainte MPLS-TE
Le mécanisme de routage par contrainte MPLS-TE regroupe
un ensemble de fonctions permettant de router les TE-Trunks en fonction de
leurs contraintes TE et des ressources disponibles dans la topologie TE. Ce
mécanisme repose sur trois fonctions principales :
· La fonction de découverte de la
topologie
Cette fonction permet à tous les routeurs d'avoir une
vision actualisée de la topologie TE et en particulier de la bande
passante résiduelle réservable sur les liens. Cette fonction est
assurée par un protocole IGP-TE. Il s'agit d'un protocole IGP à
états de liens, étendu pour annoncer des informations TE et, en
particulier, la bande passante disponible sur les liens.
On distingue deux protocoles IGP-TE, avec des fonctions
similaires, ISIS-TE et OSPF-TE, extensions des IGP (Interior Gateway
Protocol-TE) à états de liens IS-IS et OSPF respectivement (nous
nous intéressons dans ce PFE seulement au protocole OSPF-TE). La
topologie TE est enregistrée par chaque routeur du réseau dans
une base de données TE appelée TED (pour TE Database), qui
enregistre pour chaque lien du réseau les paramètres TE
suivants:
1' bande passante maximale : il s'agit de la bande passante
maximale pouvant être utilisée sur un lien. Elle correspond
généralement à la bande passante physique du lien;
1' bande passante maximale réservable : il s'agit de
la quantité maximale de bande passante pouvant être
réservée par un ensemble de TE-LSP sur un lien. Cette bande
passante peut éventuellement être supérieure (overbooking)
ou inférieure (underbooking) à la bande passante maximale du lien
;
1' bande passante disponible : il s'agit de la bande passante
résiduelle réservable par des TE-LSP sur le lien. Elle est
modifiée dynamiquement lors de la création ou de la suppression
d'un TE-LSP. Ce paramètre TE comprend huit valeurs de bande passante.
Elles correspondent aux huit niveaux de priorité de préemption
des TE-LSP, Il s'agit de la bande passante réservable pour chaque niveau
de priorité de TE-LSP.
1' La métrique TE : cette métrique
complète la métrique IGP. Elle permet d'utiliser, pour le
placement des TE-LSP, une topologie avec des poids de liens différents
de la topologie IP. Il devient, par exemple, possible de calculer un plus court
chemin avec un délai contraint ; la métrique IGP
représentant le critère à optimiser et la métrique
TE le délai à borner.
· La fonction de calcul de chemin
Cette fonction permet de calculer les chemins pour les TE-LSP
en utilisant un algorithme de routage par contrainte (CSPF). Elle prend en
entrée les contraintes des TE-LSP (bande passante, groupes à
inclure/exclure, etc.) et la topologie TE (TED) alimentée par le
protocole IGP-TE.
· La fonction de signalisation des
TE-LSP
Une fois la route explicite pour un TE-LSP calculée,
la fonction de signalisation intervient pour établir le LSP. Get
établissement comprend le routage explicite du TE-LSP le long de la
route explicite, la réservation de ressource sur les liens
traversé ainsi que la distribution des labels sur le chemin. Gette
fonction est chargée également du maintien des LSP, de leur
Suppression et de la signalisation des erreurs. Elle est
réalisée par le protocole de signalisation RSVP-TE (ReSerVation
Protocol-TE) .Il s'agit du protocole RSVP conçu initialement pour la
réservation de ressources, étendu ici pour inclure des
procédures de routage explicite et de distribution de labels.
La figure en dessous représenté les fonctions du
routage par contrainte

Figure IV.6 Les fonctions du routage par
contrainte
· Établissement des LSP
L'établissement d'un LSP par RSVP-TE est
effectué en deux temps : un message Path contenant la route explicite et
l'ensemble des paramètres TE (identifiants LSP, source/destination,
bande passante, etc.) est tout d'abord envoyé de la source vers la
destination de proche en proche, le long de la route explicite. Il crée
un état RSVP correspondant au LSP sur tous les routeurs du chemin. En
réponse, le routeur de destination renvoie un message Resv de proche en
proche vers l'origine du LSP. Le message Resv réserve la bande passante
et distribue les labels (cf. figure 1.8 (a)). Il s'agit d'une distribution
sollicitée de labels (initiée par les routeurs en amont). Gela
entraîne une mise à jour des tables MPLS en transit et de la table
IP sur le routeur de tête du LSP. Lorsque le message Resv est
arrivé sur la tête et que la table de routage IP est mise à
jour, le tunnel peut être utilisé pour aiguiller du trafic le long
du LSP (cf. figure 1.8 (b)). Le mécanisme MPLS-TE dispose de plusieurs
fonctionnalités TE telles que la réoptimisation des LSP, la
restauration des LSP, la préemption et le crank-back. Ges
fonctionnalités permettant d'adapter les TE-LSP (route et taille) au
changement de la topologie (panne de noeud ou de lien dans le réseau,
modification de métrique, installation d'un nouveau lien) ou du trac
(augmentation ou diminution de la charge, congestion, etc.).
IV.2.2 .f Fonctionnalités MPLS-TE
Dans cette section, nous décrivons la
fonctionnalité TE (la préemption) qui sont supportées par
le mécanisme MPLS-TE .
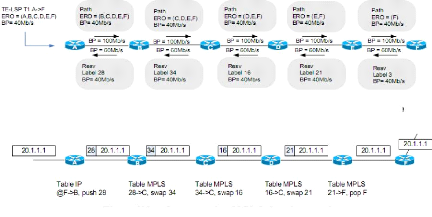
Figure IV.7 Propagation des messages Rath et Resv le
long de la route explicite
Figure IV.8 :Commutation MPLS dans le tunnel
ERO=Explicite Route Object BP= Bande passante
IV.2.2 .g Préemption MPLS-TE
Le mécanisme de préemption est inclus dans
l'architecture standard MPLS-TE et fait intervenir les protocoles RSVP-TE et
IGP-TE . Il permet de définir des niveaux de priorité pour les
TE-LSP. Un LSP prioritaire peut préempter un LSP moins prioritaire et
récupérer la bande passante allouée à ce dernier.
Le LSP moins prioritaire sera re-routé selon un ou plusieurs chemins
alternatifs. Les priorités de préemption sont codées sur 3
bits de 0 à 7, 0 étant la plus forte priorité.
IV.2.2 .h Suppression d'un LSP
La suppression explicite d'un LSP peut se faire par un
message PathTear envoyé de la source Vers la destination ou par un
message ResvTear de la destination vers la source. Le message PathTear
détruit les états RSB et PSB associés. En revanche, le
message ResvTear ne détruit que l'état RSB. Il doit être
suivi d'un message PathTear pour entraîner une destruction totale du LSP.
La suppression d'un LSP peut également être implicite, en cas
d'expiration des états RSVP.
IV.3 MPLS-VPN
IV.3.1 Introduction
MPLS VPN fournit une méthode de raccordement des sites
appartenant à un ou plusieurs VPN, avec possibilité de
recouvrement des plans d'adressage IP pour des VPN différents. En effet,
l'adressage IP privé est très employé aujourd'hui, et rien
ne s'oppose à ce que plusieurs entreprises utilisent les mêmes
plages d'adresses (par exemple 172.16.1.0/24). MPLS VPN permet d'isoler le
trafic entre sites n'appartenant pas au même VPN, et en étant
totalement transparent pour ces sites entre eux. Dans la visée MPLS VPN,
un VPN est un ensemble de sites placés sous la même
autorité administrative, ou groupés suivant un
intérêt particulier. Cette partie aborde les concepts de MPLS VPN,
en particulier avec les notions de routeurs virtuels (VRF) et le protocole
MP-BGP (Multi-Protocol Border Gateway Protocol), dédié à
l'échange des routes VPN.
IV.3.2 Routeurs P, PE et CE
Une terminologie particulière est employée pour
désigner les routeurs (en fonction de leur rôle) dans un
environnement MPLS VPN :
· Routeur P (Provider) ces routeurs,
composant le coeur du backbone MPLS, n'ont aucune connaissance de la notion de
VPN. Ils se contentent d'acheminer les données grâce à la
commutation de labels.
· Routeur PE (Provider Edge) ces routeurs
sont situés à la frontière du backbone MPLS et ont par
définition une ou plusieurs interfaces reliées à des
routeurs clients.
· Routeur CE (Customer Edge) ces
routeurs appartiennent au client et n'ont aucune connaissance des VPN ou
même de la notion de label. Tout routeur "traditionnel" peut être
un routeur CE, quelle que soit son type ou la version d'IOS utilisée.

Figure IV.9 emplacement des routeurs dans une
architecture MPLS
IV.3.3 Routeurs virtuels (VRF)
La notion de VPN implique aussi l'isolation du trafic entre
sites clients n'appartenant pas aux mêmes VPN. Pour réaliser cette
séparation, les routeurs PE ont la capacité de gérer
plusieurs tables de routage grâce à la notion de VRF (Virtual
Routing and Forwarding table). Une VRF est constituée d'une table de
routage, d'une FIB et d'une table CEF spécifiques, indépendantes
des autres VRF et de la table de routage globale. Chaque VRF est
désignée par un nom sur les routeurs PE. Les noms sont
affectés localement, et n'ont aucune signification vis-à-vis des
autres routeurs. Chaque interface de PE reliée à un site client
est rattachée à une VRF particulière. Lors de la
réception de paquets IP sur une interface client, le routeur PE
procède à un examen de la table de routage du routeur virtuel
à laquelle est rattachée l'interface, et donc ne consulte pas sa
table de routage globale. Cette possibilité d'utiliser plusieurs tables
de routage indépendantes permet de gérer un plan d'adressage par
sites, même en cas de recouvrement d'adresses entre VPN
différents.
Pour construire leurs tables VRF, les PE doivent
s'échanger les routes correspondant aux différents VPN. En effet,
pour router convenablement les paquets destinés à un PE
nommé PE-1, relié au site CE-1, le routeur PE-2 doit
connaître les routes VPN de PE-1. L'échange des routes VPN
s'effectue grâce au protocole MP-BGP, décrit dans le paragraphe
suivant. Les configurations des VRF ne comportant que des paramètres
relatifs à MP-BGP (notamment pour l'export et l'import des routes). Les
VRF disposant de tables de routage et de tables CEF spécifiques. La
table CEF permet de déterminer le Next-Hop, l'interface de sortie et les
labels utilisés pour atteindre un subnet particulier.

Figure IV.10 les routeurs virtuels IV.3.4 Multi-Protocol
Border Gateway Protocol (MP-BGP)
BGP (Border Gateway Protocol) est un EGP (Exterior Gateway
Protocol). Il est utilisé pour connecter des systèmes autonomes
différents grâce à ses fonctions et ses capacités
avantageuses qui permettent
1' L'change des routes (du trafic) entre organismes
indépendants : Opérateurs et gros sites mono ou multi
connectés ;
v' Une importante stabilité : supporte un large nombre
de routes ; 1' d'être indépendant des IGP utilisés en
interne à un organisme ; v' du supporter un passage à
l'échelle (de l'Internet) ;
v' du Minimiser le trafic induit sur les liens ;
1' du donner une bonne stabilité au routage.

Le protocole MP-BGP est une extension du protocole BGP 4, et
permettant d'échanger des routes Multicast et des routes VPNv4.
Le MP-BGP adopte une terminologie similaire à BGP
concernant la convergence:
· MP- BGP : convergence entre
routeurs d'un même AS (Autonome System).
· MP-eBGP : convergence entre
routeurs situés dans 2 AS différents.

Figure IV.11 les différentes composantes des VPN
MPLS IV.3.4.a) Notion de RD (Route Distinguisher) :
Le RD est employé pour transformer seulement des
adresses de 32 bits non-uniques de la version 4 d'IP de client (IPv4) en
adresses uniques de 96-bit VPNv4 (également appelées les adresses
de VPN IPv4). Les adresses VPNv4 sont échangées seulement entre
les routeurs PE, elles ne sont jamais employées entre les routeurs CE.
Le protocole BGP doit donc supporter l'échange des préfixes IPv4
traditionnels aussi bien que l'échange des préfixes VPNv4 entre
les routeurs PE. Une session de BGP entre les routeurs PE s'appelle par
conséquent une session Multi-Protocole BGP (MP-BGP).
Figure IV.12 adresse VPNv4
La propagation de la route du client à travers un
réseau MPLS VPN est faite en utilisant le processus suivant :
· Étape 1 : le routeur CE envoie
une mise à jour du cheminement IPv4 au routeur PE.
· Étape 2 : le routeur PE ajoute un
RD 64-bit à la mise à jour du routage IPv4, ayant pour
résultat un préfixe globalement unique de 96-bit VPNv4.
· Étape 3 : le préfixe VPNv4
est propagé par l'intermédiaire d'une session interne MPIBGP
(Multi-Protocol Internal Border Gateway Protocol) à d'autres routeurs
PE.
· Étape 4 : les routeurs de
réception PE dépouillent le RD du préfixe VPNv4, ayant
pour résultat un préfixe IPv4.
· Étape 5 : le préfixe
IPv4 est expédié à d'autres routeurs CE dans une mise
à jour du routage IPv4.
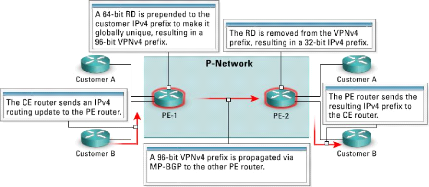
Figure IV.13 propagation de la route du custome IV.3.4.b
Notion de RT (Route Target)
Le RD permet de garantir l'unicité des routes VPNv4
échangées entre PE, mais ne définit pas la manière
dont les routes vont être insérées dans les VRF des
routeurs PE. L'import et l'export de routes sont gérés
grâce à une communauté étendue BGP (extended
community) appelée RT (Route Target). Les RTs ne sont rien de plus que
des sortes de filtres appliqués sur les routes VPNv4. Chaque VRF
définie sur un PE est configurée pour exporter ses routes suivant
un certain nombre de RT. Une route VPN exportée avec un RT donné
sera ajoutée dans les VRF des autres PE important ce RT.
IV.3.5 Impact des topologies complexes de VPN sur VRF
Une seule VRF peut être employée pour des sites
avec des conditions identiques de connectivité. Les topologies complexes
de VPN exigent, donc, plus d'une VRF par VPN. Puisque chaque VRF exige une RD
distinctive, le nombre de RDs dans un réseau de MPLS VPN augmente avec
l'introduction d'autres VPNs. d'aileurs, l'association simple entre le RD et
VPN qui était vrai pour VPNs simple est également disparu.
Exemple :

Figure IV.14 topologies complexes de VPN

Pour illustrer les conditions d'échange d'information
entre les tables de routage virtuelles multiples, on considère un
service de VoIP (Voice over IP) avec trois VPNs (client A, client B, et VoIP
VPN). Les besoins virtuels des tables de routage de ce service sont comme suit
:


Ainsi, dans cet exemple, plus de trois tables VRF
différentes sont nécessaires pour supporter trois VPNs. Il n'y a
aucun rapport linéaire entre le nombre des tables de routage virtuelles
(VRFs) et le nombre des VPNs.
IV.3.6 Transmission des paquets IP
La transmission des paquets IP provenant des routeurs CE sur le
backbone MPLS emploie la notion de label stacking. Pour atteindre un site
donné, le PE source encapsule deux labels : le premier sert à
atteindre le PE de destination, tandis que le second détermine
l'interface de sortie sur le PE, à laquelle est relié le CE. Le
second label est appris grâce aux mises à jour MP-BGP. Les tables
CEF des routeurs peuvent être consultées pour déterminer
les labels utilisées.

Figure IV.15 transmission des packets VPN a travers le
backbone MPLS VPN
IV.3.7 Propagation d'étiquette VPN
La deuxième étiquette est exigée pour
l'opération appropriée de MPLS VPN, Cette étiquette a
été assignée par le routeur PE de sortie. Cette
étiquette doit être propagée du routeur PE de sortie aux
routeurs PE d'entrée pour permettre la transmission de paquet
approprié.
MP-BGP a été choisi comme mécanisme de
propagation. Chaque mise à jour MP-BGP porte ainsi une étiquette
assignée par le routeur PE de sortie ainsi que le préfixe VPNv4
de 96-bit.
Le propagation d'étiquette VPN doit suivre les
étapes suivants
· Etape1 : le routeur PE de sortie assigne
une étiquette à chaque route VPN reçu des routeurs CE
attachés et à chaque route, il la récapitule à
l'intérieur du routeur PE. Cette étiquette est alors
employée comme la deuxième étiquette dans la pile
d'étiquette de MPLS par les routeurs PE d'entrée en marquant des
paquets VPN.
· Etape 2 : Les étiquettes de VPN
assignées par les routeurs PE de sortie sont
annoncées
à tous autres routeurs PE ainsi que le
préfixe VPNv4 dans les mises à jour MP-BGP.
· Etape 3 : le routeur PE d'entrée
a deux étiquettes liées à une route VPN distante, une
étiquette pour le prochain saut de BGP assigné par le prochain
saut du routeur P par l'intermédiaire de LDP aussi bien que
l'étiquette assignée par le routeur distant PE et propagée
par l'intermédiaire de la mise à jour MP-BGP. Les deux
étiquettes sont combinées dans une pile d'étiquette et
installées dans la table VRF.

Figure IV.16 propagation d'étiquette
VPN
IV.4 MPLS-QS
La qualité de service se décline principalement en
quatre paramètres : débit, délai, gigue
et perte.
· Le débit représente les ressources de
transmission occupées par un flot. Un flot est un ensemble de paquets
résultant d'une application utilisatrice.
· Le délai correspond au temps de transfert de bout
en bout d'un paquet.
· La gigue correspond aux variations de latence des
paquets. La gigue provient
essentiellement des variations de trafic sur les
liens de sorties des routeurs.
· Des pertes de paquets peuvent être dues à
des erreurs d'intégrité sur les données ou des rejets de
paquets en cas de congestion.
La qualité de service peut être fournie par deux
approches relativement différentes.

Le premier modèle, IntServ utilise la
réservation de ressources mise en place par RSVP. IntServ classifie les
données par flux. En effet, chaque flux va être placé dans
une file d'attente séparée. La granularité est forte, car
la classification se fait flux par flux selon le protocole de
réservation. En revanche, c'est un processus coûteux en ressources
machine, et qui supporte difficilement la montée en charge car les
routeurs de coeur doivent maintenir une liste des flux en cours afin de
rechercher à chaque fois la qualité de service à
appliquer. En effet, plus les flux seront nombreux, plus les traitements
à effectuer au niveau des routeurs seront importants notamment au niveau
de l'ordonnancement.
L'autre approche servant de support à la
qualité de service est DiffServ. Dans cette
configuration, les flux sont agrégés pour former des classes de
services. De cette manière les flux d'une même classe ont les
mêmes garanties de service. Par rapport à IntServ, la
granularité est donc beaucoup plus faible. Cependant, DiffServ repose
sur l'utilisation d'un système de marquage des paquets pour
définir le comportement à adopter par le noeuds recevant le
paquet. C'est ce que l'on nomme le Per-Hop Behavior. Le but
ici n'étant pas de détailler l'ensemble des mécanismes mis
en oeuvre dans DiffServ, nous allons donc voir l'utilisation de ces approches
dans MPLS.
DiffServ utilise les 8 bits de l'entête IP et les
divise comme présenté par le schéma cidessus. 6 bits sont
réservés pour les codes de différenciation de service
tandis que les deux derniers ne sont pour le moment pas utilisés.
Figure IV.17 Décomposition du DSCP
Comme vous avez sûrement pu le remarquer lorsque nous
avons abordé le format du label, le champ EXP réservé
à la qualité de service est sur 3 bits, alors que les DSCP sont
codés sur 6 bits. En dessous de 8 PHBs, cela ne pose pas de
problèmes car les 3 bits d'EXP suffisent à stocker les valeurs.
Cependant, pour un nombre de PHBs supérieur, le label est alors
utilisé en combinaison avec le champ EXP pour constituer les groupes de
PHBs.
Au niveau du choix d'une approche plus qu'une autre pour MPLS,
je dirais que les deux approches sont complémentaires. En effet, IntServ
réalise un contrôle de bout en bout des ressources
utilisées alors que DiffServ spécifie des comportements à
chaque saut. La signalisation de l'approche DiffServ est beaucoup moins
importante que IntServ, car elle ne nécessite pas de maintien de
l'état des flux par RSVP. On optera donc pour un contrôle
d'admission et un lissage du trafic en entrée du réseau
grâce à IntServ tandis que DiffServ lui sera
préféré en coeur de réseau pour limiter la
signalisation.
IV.5 Extension MPLS
Une première extension du MPLS est le Generalized
MPLS. Le concept de cette dernière technologie étend la
commutation aux réseaux optiques. Le label, en plus de pouvoir
être une valeur numérique peut alors être mappé par
une fibre, une longueur d'onde et bien d'autres paramètres. Le GMPLS met
en place une hiérarchie dans les différents supports de
réseaux optiques. GMPLS permet donc de transporter les données
sur un ensemble de réseaux hétérogènes en
encapsulant les paquets successivement à chaque entrée dans un
nouveau type de réseau. Ainsi, il est possible d'avoir plusieurs niveaux
d'encapsulations selon le nombre de réseaux traversés, le label
correspond à ce réseau étant conservé
jusqu'à la sortie du réseau. GMPLS reprend le plan de
contrôle de MPLS en l'étendant pour prendre en compte les
contraintes liées aux réseaux optiques. En effet, il va rajouter
une brique à l'architecture : Gestion des liens. Cette
brique comprend un ensemble de procédures utilisées pour
gérer les canaux et les erreurs rencontrées sur ceux-ci.

Figure IV.18Architecteur GMPLS
IV.6 Conclusion
Dans ce chapitre, nous avons présenté les
composantes relatives à l'ingénierie de trafic dans MPLS, et mise
en ouvre d'un VPN dans MPLS, ainsi nous présentons les différents
modèles utilisés pour la gestion de la QoS au niveau des
réseaux MPLS.
V.1 Introduction
Pour appliquer les concepts introduits
précédemment, nous avons choisi une topologie de réseau
qui permet la mise en oeuvre d'un coeur de réseau IP /MPLS d'un
fournisseur de service et simuler les différentes applications
appropriées à MPLS (MPLS-TE, MPLS-VPNs,.....), ainsi que
l'implémentation de la VOIP qui peut être offerte par les
fournisseurs de service .
Pour cela on a élaboré une maquette sur laquelle
on a appliqué les techniques décrites précédemment,
donc on a réalisé une émulation comprenant les
étapes suivantes :
· Réalisation de la maquette du backbone avec MPLS
VPN
· L'implémentation du service VoIP sur la
maquette
· L'implémentation de MPLS-TE
V.2 0 N IFn oeXVIH EI la topologie réseau (la
maquette du backbone)
V.2.1 Mise en SOFH d'XORWLDWIII IIIrtXEl
V2.1.a Logiciel utilisé pour la
réalisation
Pour réalisé cette maquette et simuler la mise en
oeuvre de topologie réseau complexe on a dû utiliser les logiciels
GNS3 et VMWar :
ü Le logiciel GNS3
Le GNS3 est un logiciel d'émulation de routeur Cisco
au mode graphique. Ce logiciel permet de simuler matériellement des
routeurs 7200, 3600 et 2600... en utilisant l'IOS de Cisco,il fonctionne avec
un outil de supervision des routeurs émulés : Dynagen. Ces outils
fonctionnent sous Linux et Windows et permettent de simuler des topologies
incluant tous les protocoles de l'IOS (RIP, EIGRP,
OSPF[ 1) et les interfaces associées au routeur (Frame
Relay, ATM,...), il est possible de s'en servir pour tester les
fonctionnalités des IOS Cisco ou de tester les configurations devant
être déployées dans le futur sur des routeurs
réels.
ü Le logiciel VMwareWorkstation
Est un logiciels de virtualisation qui permet d'avoir
plusieurs machines avec des systèmes d'exploitations différents
qui s'exécutent sur le mrme ordinateur, ceux-ci pouvant être
reliés au réseau local avec une adresse IP différente,
tout en étant sur la même machine physique . Il est possible de
faire fonctionner plusieurs machines virtuelles en même temps, la limite
correspondant aux performances de l'ordinateur hôte.
ü Installation du serveur FTP
FTP, ou File Transfert Protocol (protocole de transfert de
fichier) est, comme son nom L'indique, un protocole pour le transfert de
fichier. Il s'agit donc d'un langage utilisé par deux ordinateurs pour
s'échanger des fichiers. FTP propose une architecture client/serveur, le
serveur sert de dépôt central de fichiers et les clients y
récupèrent ou y déposent des fichiers
en utilisant le protocole.
V.2.1.b Logiciel utilisé pour la supervision de la
maquette
Les logiciels utilisés pour la supervision et la gestion
de la maquette sont : Solarwinds Orion, Net Flow et Wireshark :
1' Solarwinds Orion : est un logiciel qui
permet la visualisation en temps réel des statistiques et de
disponibilité du réseau, ainsi que la surveillance et l'analyse
détaillées des données des routeurs, commutateurs,
serveurs et tous les autres dispositifs SNMP fournit aux utilisateurs une vue
complète de la santé de leur réseau. Orion permet de
surveiller : Disponibilité, Utilisation de la mémoire et du CPU,
Latence du réseau, Utilisation de la bande passante, Statut des noeuds,
des interfaces, Taux d'erreur et de rejet des interfaces.
v' Wireshark : (anciennement Ethereal) est un
logiciel libre d'analyse de protocole, ou« packet sniffé »,
utilisé dans le dépannage et l'analyse de réseaux
informatiques, le développement de protocoles, l'éducation et la
rétro-ingénierie, mais aussi le piratage.
1' Net Flow : Orion Net Flow Traffic Analyzer
(NTA) vous permet de quantifier exactement la façon dont votre
réseau est utilisé, par qui et dans quel but. Et notre nouvelle
fonctionnalité avancée d'application de cartographie en
corrélation le trafic en provenance de ports désignés, IP
source, IP de destination, et même les protocoles, les noms de
l'application, vous pouvez facilement reconnaître. Orion NTA, il est
facile d'obtenir une vue d'ensemble de votre trafic réseau, trouver les
goulets d'étranglement, et arrêter les porcs de la bande
passante.
V.2.2 Analyse des propriétés fonctionnelles
d'un routeur
Nous avons utilisé pour la réalisation de la
maquette les routeurs de la gamme 7200 pour les raisons suivantes :
a) Le routeur Cisco 7200 est un routeur compact haute
performance, conçu pour un déploiement à la
périphérie du réseau et dans le centre de données,
où performances et services sont essentiels pour faire face aux besoins
des entreprises, des administrations et des fournisseurs de services.
b) Le routeur Cisco 7200 capable de gérer les
applications suivantes :
v' Accès haut débit à Internet pour
professionnel particuliers
v' Messagerie électronique v' Téléphonie
IP et FAX IP v' Vidéo MPEG
1' Services VPN (Virtual Private Networking)
v' E-business
V.2.3 Mise en pratique des concepts fondamentaux des
réseaux :
V.2.3.a Plan d'adressage
Le choix des adresses est arbitraire. Dans ce cadre nous avons
choisit des adresses de class C avec un masque /30 pour les connexions point
à point et /24 pour les connexions avec les hauts de l'Edge, et class B
pour l'adressage des interfaces loop back (interface de bouclage locale).
V.2.3.b) Configuration de la maquette
Pour la réalisation de la maquette on a utilisé
:
3 routeurs représentant le core MPLS (des routeurs P)
simulant les routeurs P1, P2, et P3 2 routeurs représentant l'Edge MPLS
(des routeurs PE) et simulant les routeurs PE1, PE2
2 routeurs désignant les deux sites d'un client VPN (des
routeurs CE), chaque routeur CE connecté a un PE (CEa, CEb).
Les routeurs PE, P et CE utilise la version IOS «c7200-
p-mz[1].124-10b.bin» supportant ainsi la technologie MPLS.
La figure suivante représente la topologie utilisée
dans la maquette

Figure V.1 la Maquette de simulation
Pour la configuration du backbone on est amené à
suivre les phases suivantes :
Phase 1 : activation du routage classique
L'activation du routage classique Au niveau du
backbone (PE-P et P-P), le protocole de routage utilisé est l'OSPF, le
choix de ce protocole est justifier par les raisons suivantes :
ü Protocole de routage a état de lien.
ü Supporte le trafic engineering.
ü Rapidité de convergence.
ü Il a une zone de type dorsale (backbone) .
La configuration d'OSPF est requis les étapes suivants
:
ü Activation de Processus OSPF
ü Déclaration des réseaux participent au
processus
ü Désignation de la zone administrative
ü Désignation de l'identificateur de routeur

Les étapes de configuration pour les routeurs de coeur P2,
P3 et les routeur l'Edge PE1, PE2 sont les même que pour le routeur P1
.
Nous avons utilisé le protocole de routage RIPv2 entre
les routeurs client et edge (CE-PE) a cause du MPLS- VPN qui offre la
possibilité d'utiliser n'import quel protocole de routage dans les sites
des clients ainsi l'échange des routes entre les routeurs PE est
assuré par le protocole MP-BG
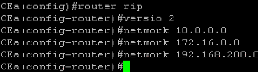
Phase 2 : activation du MPLS
Avant la configuration du MPLS dans les routeurs il est
indispensable d'activer le CEF (Cisco Expresse Forwarding). L'activation de
MPLS diffère suivant l'emplacement du routeur dans le backbone, dans les
3 routeurs P nous avons activé MPLS sur toutes les interfaces tandis que
dans les 2 routeurs PE, MPLS est activé seulement sur les interfaces
liant ces routeur aux routeurs P. Nous avons choisit le protocole LDP pour
distribuer les labels MPLS.
Configuration de routeur P1 :

V.3 IP ScéP I-nARRWIMI- 19 31
L'une des applications les plus importantes du protocole MPLS
est de pouvoir créer des réseaux privés virtuels VPN
(Virtual Private Network), pour cela on va implémenter dans notre
maquette un vpn mpls qui relie entre deux cites d'un client, cite A
(représenté par routeur CEa) et cite B (représenté
routeur CEb) .
Pour assurez l'isolation du trafic entre les différents
clients nous avons créé dans les routeurs Edge qui connectent les
réseaux des clients un VRF pour chaque client, pour
notre client de démonstration, nous avons défini un VRF avec les
paramètres suivants:
Route distinguisher 999:1
Route target import 64999:1
Route target export 64999:1
V.3.1 Configuration de VPN
La configuration du VPN est réalisée après
celle de L'IGP et l' activation de MPLS dans les routeurs du Backbone ,en
passant par les phases suivantes :
Phase 1 : création et configurations des
VRFs
· Création de VRF : pour crée des VRFs on va
configurer les deux Edges PE1 et PE2 par les command suivants :
PE1 (config) #ip vrf Client A
PE1 (config-vrf) #route-target both 64999:1 PE1 (config-vrf) #rd
999:1
· Assignement des VRF a des interfaces : PE1 (config-vrf)
#int s1/0
PE1 (config-if) #ip vrf forwarding Client A
PE1 (config-if) # ip address 10.0.0.2 255.255.255.252 PE1
(config-if)#no shut
Des configurations similaire doit etre fait dans le router PE2
le seul différance c'est l'adresse ip de l'interface qui égale a
10.0.0.5.
Phase 2 : configuration des protocoles de
routage :
· Maintenant nous configurons le protocole de routage
MP-BGP pour assurer communication entre les VRF des différents PE par
les commandes suivantes :
PE1 (config) #ROUTER BGP 1
PE1 (config-router) #NO BGP DEFAULT IPV4-UNICAST
PE1 (config-router) #NEIGHBOR 172.16.0.5 REMOTE-AS 64999
PE1(config-router)#NEIGHBOR 172.16.0.5 UPDATE-SOURCE LO0
PE1 (config-router) #ADDRESS-FAMILY VPNV4
PE1 (config-router-af) #NEIGHBOR 172.16.0.5 ACTIVATE
activation de RIP par VRF:
PE1 (config) #ROUTER RIP
PE1 (config-router) #VERSION 2
PE1 (config-router) #ADDRESS-FAMILY IPV4 VRF clientA PE1
(config-router-af) #NETWORK 10.0.0.0
PE1(config-router-af)#NO AUTO-SUMMARY
P
· hase 3 configuration du protocole
de routage RIP entre le CE et le PE et le MP-BGP entre les PEs et activation de
la distribution des routes entre les deux protocoles IGP et EGP.
|
Activation de la distribution des routes de RIP par BGP
|
|
P
· E1(config)#ROUTER BGP 1
PE1(config-router)#ADDRESS-FAMILY IPV4 VRF client A
PE1(config-router-af)#REDISTRIBUTE RIP METRIC 1
· Activation de la distribution des routes BGP de par RIP
P
· E1(config-router-af)#ROUTER RIP
PE1(config-router)#VERSION 2
PE1(config-router)#ADDRESS-FAMILY IPV4 VRF client A
PE1(config-router-af)#REDISTRIBUTE BGP 1 METRIC 1
Remarque : dans les routeurs clients CEa et
CEb aucune configuration spéciale n'est nécessaire car les
routeurs clients n ' ont pas de connaissance de VPN et réagissent comme
s'ils étaient directement reliés, de même pour les routeurs
P du coeur qui pour routage des paquets se basent seulement sur les labels.
V.3.2 Vérification de la configuration
Apres la configuration de notre VPN avec succès on a
capturée le trafic entre les routeurs P1et P2 par le logiciel wireshark
pour voir l'encapsulation des paquets,

Figure V-2 Paquet d'un VPN MPLS capturé entre
deux routeurs p
Interprétation des résultats
Les résultats donnés par le wireshark et
représentés par la figure précédente justifient que
MPLSVPN utilise deux labels (le LABEL STACK), le premier indique le
Egress-router (label 23) et le deuxième définit le VPN (label
27).
V.4 Implémentation du service VOIP
V.4.1 Introduction
La voix sur IP (Voice over IP) est une technologie de
communication vocale en pleine émergence. Elle fait partie d'un tournant
dans le monde de la communication. En effet, la convergence du triple play
(voix, données et vidéo) fait partie des enjeux principaux des
acteurs de la télécommunication aujourd'hui
Dans cette partie nous allons implémenter le service VOIP
dans notre maquette par l'ajout du serveur d'appel TRIXBOX.
V.4.2 TRIXBOX
Est une distribution Linux comprenant un ensemble
d'éléments permettant de créer facilement un IPBX.
L'élément principal est le logiciel Asterisk, entouré d'un
ensemble d'autres logiciels pour le gérer.
V.4 .3 Configuration d'un VPN complexe
Pour pouvoir offre des services tel que VOIP a notre clients on
va ajouter un nouveau site appelé voip_server qui a la
possibilité de communiquer avec tous autres sites clients,pour cela
il est indispensable de rendre notre VPN complexe :
Premièrement on ajoute un nouveau VRF au routeur sur
lequel on connecte notre serveur TRIXBOX en utilisant les paramètres
suivants :
Route distanguisher : 666:1 Route target export : 9999:2 Route
target import : 9999 :1
Dans notre exemple on va connecter le serveur TRIXBOX au routeur
auquel est relié le client A. Deuxièmement on ajoute pour chaque
VRF de site client une nouvelle route target afin de pouvoir communiquer avec
le serveur TRIXBOX :
Route target export : 9999 :1
Route target import : 9999 :2
Il faut remarquer que la deuxième valeur de route
target export ajoutée aux VRF clients est égale a la valeur de
route target import de la VRF voip_server et vise versa, pour permettre
l'échange des tables de routage entre les deux VPN.
V.4 .3.a Vérification de la configuration
Apres les configurations mentionnées au dessus nous avons
capturée le trafic entre les routeurs P1et P2 par le logiciel wireshark,
le résultat est illustré par la figure V.3

Figure V-3 protocole SIP capturé entre deux
routeurs p
V.4.3.b Interprétation des résultats
Les résultats donnés par le wireshark
représentés par la figure précédente illustrent
l'encapsulation d'un paquet de protocole de signalisation (SIP) qui est
utilisé pour L'ouverture des sessions permettant de réaliser les
communications VOIP entre deux clients.
Cette capture démontre bien que le trafic VOIP emprunte
le tunnel du VPN car les paquets sont encapsulés par deux labels (label
stack).
V.5 Implémentation de MPLS TE
Le protocole de routage utilisé dans notre maquette
est un IGP classique (OSPF), a cause de sa limitation en matière
d'ingénierie de trafic tous le trafic généré de
routeur CEa vers CEb suit le chemin le plus court (PE1 P1 P 2 PE2)
créant ainsi une congestion (dégradation de la Qos) tandis que
l'autre chemin (PE1 P1 P 3 P 2 PE2) reste sous utilisé, pour
remédier a cela on va appliquer l'ingénierie de trafic sur le
backbone.
V.5.a Configuration de MPLS TE
Cette section vous présente les étapes de la
configuration des routeurs Cisco en mettant en oeuvre MPLS TE. Il est alors
suivi par un paragraphe décrivant le processus de configuration
réelle sur une topologie composée de cinq routeurs dans lequel
plusieurs chemins d'accès peuvent être utilisés à
des fins de Traffic engineering
étape 1 : activation de MPLS TE dans
tous les routeurs PE et P, et dans toutes les interfaces qui vont participer a
la création des tunnels.

Etape 2 : configuration la bande passante
réservable dans l'interface MPLS TE par RSVP

Etape 3 : Configuration des Paramètres
de l'Interface Tunnel on PE1 » :
· création d'une interface tunnel
· spécification de l'adresse destination du
tunnel
· Le tunnel est défini un besoin de bande passante
de 100 Kb/s
Voici les command de configuration de tunnel 0 :

Des configurations similaires sont nécessaires pour le
tunnel 1.
· spécification de la méthode du choix du
chemin (lsp) qui va être emprunté par le tunnel, il peut
être configuré manuellement ou dynamiquement
> Configuration du chemin en mode dynamiquement :

> Configuration du chemin en mode explicite-chemin
(manuellement)

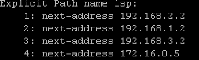
Définition explicite de LSP Path

Etape 4: Configuration IGP pour MPLS TE
Pour cette configuration on a crée deux tunnels «
tunnel0 et tunnel1 » allant de PE1vers PE2 passant par deux chemins
différents, le tunnel 0 emprunte le plus court chemin.
· pour résoudre le problème de congestion
on propose les deux solutions suivantes : Première
solution
On assigne les tunnels à une «Load Sharing» qui
permet le routage de n'import quelle trafic vers les deux tunnels en partage de
charge.
V.5.b Vérification de la configuration
Pour vérifier que notre configuration a été
correctement faite nous avons effectué les tests suivants: Premier
test
On a lancé un téléchargement ) 73
IdPnIs1-111-KIE1-lM au routeur PE1 vers un PC relié au routeur PE 2.
Puis on a surveillé le trafic qui passe par les interfaces de P1 avec
SOLARWINDS, après dix minutes On a activé dans les deux tunnels
MPLS la commande Load Sharing. Le résultat est
illustré par la Figure V-4

Figure V-4 MPLS-TE et partage de charge
(Première test )
Interprétation des résultats
Nous remarquons que pendant les 10 premières minutes tous
les trafic passe par l'interface S1/0 qui relie P1 a P2 (le graphe en bleu) car
MPLS TE n'a pas été activé,
A la dixième minute : activation de MPLS TE alors le
trafic FTP emprunte les deux tunnels (tunnel 0 et tunnel 1) pour la même
destination donc il y a eu partage de charge.
Deuxième test
on a surveillé le trafic qui passe par les interfaces de
P1(LSR1) avec NET FLOW, après dix minutes de l'activation de MPLS
TE(Load Sharing). Le résultat est illustré par la Figure V-5
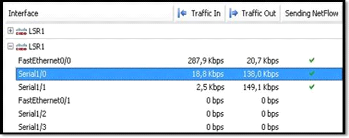
Figure V-5 MPLS-TE et partage de charge(Deuxième
test )
Interprétation des résultats
Nous remarquons que le trafic est partagé vers les deux
interfaces serial 1/0 et serial 1/1
Deuxième solution
On a assigné les tunnels à une « Static
Routes» qui permet l1-ITIutET1- I'ESSaFEtion FTP et VOIP vers les deux
tunnels mais avec un ordre de priorité, chaque service routé vers
un tunnel.
La service VOIP est plus sensible au QoS pour cela on le assigne
a tunnel 0 (le plus court chemin).
2 QE lEcFp un tplpFIEU1-m1-QN173 1d71 s1-1v1-XII1-li1- EX3( 1
1v1-1301 P& 1r1-lip[E343( L 1-t o na lancé un appel
téléphonique après sept minute.
ü Première test
on a surveillé le trafic qui passe par les interfaces de
P1 avec SOLARWINDS, le résultat est illustré par la Figure V.6

Figure V.6 $ SSMINQU IAKIIInieM EH MINE (Première
test )
Interprétation des résultats
Pendant les sept premiers minutes le trafic de FTP suit le
tunnel 1 (S1/1 via P3) a partir de la septième minute on a
réactivé MPLS-TE (active route statique) alors on remarque que le
trafic voix router vers le tunnel 0 (S 1/0)
ü Deuxième test
Le trafic du téléchargement et de la VOIP passant
par les interfaces de P1 surveillé par NET FLOW, est illustré par
les Figures V.7.a et V.7.b
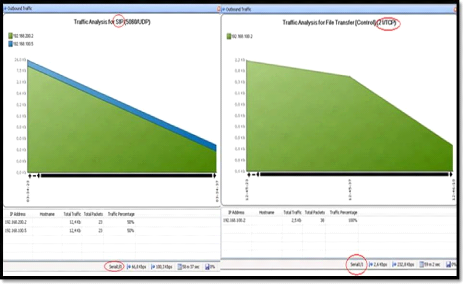
Figure V-7-a trafic VOIP Figure V-7-b trafic FTP
Figure V- E rl ssaaAiiosi mziPQIIMe IArUIP 7 ipq IqPI
IAMA ) Interprétation des résultats
Les résultats donnés par le NET FIOW et
représentés par la figure précédente
démontrent que l'activation de MPLS-TE permet la distribution du trafic
nous remarquons que :
le trafic FTP passe par l'interface S1/1 (tunnel 1) qui relie P1
a P2 a travers P3 (figure V-7-b) .
le trafic de la VoIP est passe par l'interface serial S1/0
(tunnel 0) qui relie P1 a P2 (figure V-7-a).
V.6 Conclusion
On a pu confirmer à travers cette simulation .certains
aspects théoriques déjà étudiés auparavant,
et cela en utilisant des logiciels de supervision. Ceci nous a permis de
visualiser l'encapsulation des paquets au coeur de réseau MPLS et au
tunnel VPN ainsi que le type de trafic empruntant le réseau en agissant
sur le MPLS-TE.
On a ainsi montré dans notre application que
l'implémentation de l'ingénierie de trafic dans un coeur de
réseau quelque soit sa dimension, est indispensable, car sa congestion
sera une certitude dans son futur proche avec la croissance des applications
multimédia.


