CHAPITRE VI : TRANSITION
Ce chapitre sera tourné sur le déploiement de
l'application, ses différentes interfaces.
La phase de transition permet de faire passer le
système informatique des mains des développeurs à celles
des utilisateurs finaux.
6.1. Diagramme de déploiement
En UML, un diagramme de déploiement
est une vue statique qui sert à représenter
l'utilisation de l'infrastructure physique par le système et la
manière dont les composants du système sont
répartis ainsi que leurs relations entre eux. Les éléments
utilisés par un diagramme de déploiement sont
principalement les noeuds, les composants,
les associations et les artefacts.
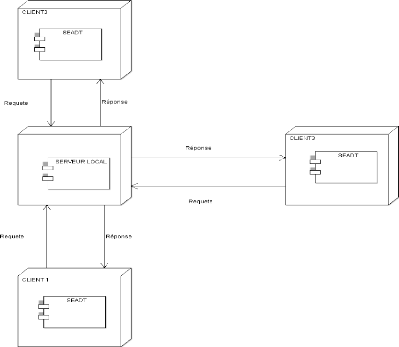
Figure n°19 : Diagramme de déploiement.
[81]
6.2. Présentation des quelques interfaces de
l'application
Nous présentons ici quelques interfaces de notre
application :
a. Interface d'authentification.
C'est une fenêtre qui permet aux utilisateurs de pouvoir
se connecter au système afin d'explorer toutes les options possibles de
l'application.
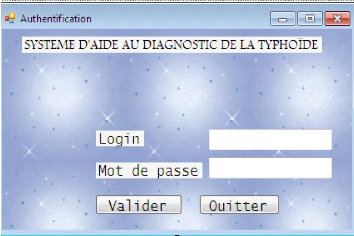
Figure n°20 : Fenêtre d'authentification.
b. Fenêtre d'enregistrement de
patients
Elle permettre au médecin d'enregistrer l'identité
du malade qui sera évidemment consulté.
[82]

Figure n°20 : Fenêtre d'enregistrement du patient.
c. Fenêtre de diagnostic
C'est cette fenêtre qui permet au médecin de
diagnostic les patients sur base de ses symptômes que ces derniers
répondront par vrai ou faux aux questions du médecin.
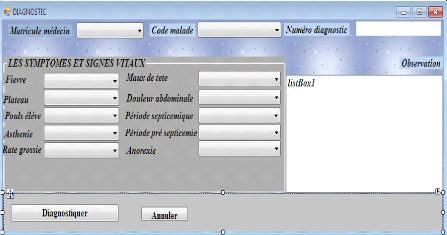
Figure n°22: Fenêtre du diagnostic.
[83]
CHAPITRE VII : CONCLUSION GENERALE
Nous voici arrivé au terme de ce travail qui a
porté sur la modélisation et l'implémentation d'un
système d'aide à la décision pour le diagnostic de la
fièvre typhoïde. A travers cette étude, notre souci majeur
était de chercher comment mettre au point un outil pouvant aider les
médecins à pouvoir décider à travers des
différents symptômes du diagnostic différentiel de la
fièvre typhoïde afin de prendre des mesures sévères
pour une bonne prise en charge de patients atteints par cette maladie.
Pour y parvenir, nous avons porté notre choix sur un
des modèles graphiques probabilistes notamment le réseau
bayésiens, ce qui nous a permis de pouvoir introduire les
différents symptômes de la maladie. Lesquels symptômes ont
été soumis à une certaine probabilité. Cette
méthode probabiliste nous a aidé à gérer
l'incertitude dans le diagnostic.
Dans le souci de mener à bien cette étude, nous
sommes allés d'une démarche très méthodique, en
commençant par une conception de notre application et cela avec le
recours de la méthode UP par une adaptation 2TUP ainsi que le langage
UML ce qui nous a permis d'avoir déjà une esquisse de
l'application qui a été mise au point.
Comme signalé plus haut, pour ce qui est du
modèle de notre base des connaissances, nous avons appliqué les
modèlesbayésiens dans sa méthode de construction
manuelle.Ce choix se justifie car comme d'aucuns pouvaient bien le constater
que dans un diagnostic, à partir des symptômes observés(les
signes cliniques), le médecin identifie les facteurs prédisposant
et sur la base desquels plusieurs hypothèses sont établies.
Le développement ou la mise en oeuvre de ce
système a fait recours à plusieurs outils ou technologies
notamment le langage de modélisation bayésien Netica qui nous a
aidé de construire la base de connaissance, le langage de programmation
C#, les documents XML pour présenter les différents noeuds que
propose le modèle sous formes d'arborescences, enfin en ce qui concerne
la partie opérationnelle de l'application nous avons utilisé le
SGBD Microsoft SQL Serveur 2008, un SGBD de type relationnel.
[84]
BIBLIOGRAPHIE
I. Ouvrages
1. BINDUNGWA, M., Comment élaborer un travail de fin
de cycle ? Contenu et étapes, éd. Médiaspaul,
Kinshasa 2008.
2. JACKSON, SATZINGER et BURD., Analyse et conception de
systèmes d'information, 2ème
éd. Goulet, Paris, 2003.
3. LERAY, P et GALLINARI, P., Architecture neuro
bayésien par le traitement spatioètemprel d'alarme, application
au diagnostic dans le réseau téléphonique, 1977.
4. MUKUNA, B., Essai méthodologique sur la
rédaction d'un travail scientifique, éd. CRIGED, Janvier
2006,
ISC/Kinshasa, p.28
5. PATRICK, N., PIERRE-HENRI, V., PHILIPP, L., ANNA, B.,
Réseaux bayésiens, Ed. Eyrolles, Paris, 2002.
6. R. LINDSAY, B. BUCHANAN, E.FEIGNBAUM., Application of
artificial intelligence toorganic chemistri : the dendra project, Mc
Graw-hill 1980.
7. RICH, E., Intelligence artificielle, Ed. Masson,
paris 1987.
8. ROQUES, P. et VALLEE, F., UML 2 en action de l'analyse
des besoins à la conception, Ed. EYROLLES, Paris, 2005,
9. ROQUES,P., VALLEE, F., UML 2 en action,
4ème Ed. Eyrolles, Paris 2007.
10. PASCAL, R., UML 2 par la pratique étude de cas
et exercices
corrigés, 5èmeEd. Eyrolles,
Paris, 2008.
[85]
II. Notes de cours
1. KUTANGILA, D., Intelligence artificielle et
systèmes experts approfondis, L1 Info, ISC-KIN, 2013-2014.
2. MVIBUDULU, J.A., Note de cours de théorie des graphes,
L2 Info, ISC, 2014-2015.
3. MVIBUDULU, J. A., Cours de conception des systèmes
d'information, L2 Info, ISC-KIN, 2014-2015.
III. Mémoires et Thèses
1. HEDIDAR , A., Conception et réalisation d'une
application mobile m-banking, mémoire, Université Virtuelle de
Tunis, 2011-2012.
2. DJEBBAR, A., « une modélisation de la base de
cas par un réseau bayésien ; application à l'aide du
diagnostic médical », Thèse de magister, Université
d'Annaba, 2006.
3. MUJINGA, S., Conception et réalisation d'un
système expert pour le diagnostic du cancer de la peau, Faculté
des sciences, Unikin, 2014.
[86]
Table des matières
IN MEMORIAM i
EPIGRAPHE ii
DEDICACE iii
REMERCIEMENTS iv
Liste de tableaux v
Liste de figures vi
Chapitre I : INTRODUCTION 1
1.1. Mise en contexte 8
1.2. Problématique 8
1.2.1. Objectif de la recherche Erreur ! Signet non
défini.
1.2.2. Questions de la recherche Erreur ! Signet non
défini.
1.3. Choix et intérêt du sujet Erreur !
Signet non défini.
1.4. Délimitation du travail 9
1.5. Méthode et techniques utilisées 10
a. Méthode 10
b. Techniques 10
1.6. Difficultés rencontrées 10
1.7. Canevas du travail 11
CHAPITRE II : APPROCHES THEORIQUES 12
2.1. Généralités sur l'intelligence
artificielle 12
2.1.1. Définition 12
2.1.2. Branches de l'intelligence artificielle 13
2.1.3. Avantages de l'IA 14
2.2. Le système expert 14
2.2.1. Introduction 14
2.2.2. Définition 14
2.2.3. Les acteurs 15
2.2.4. Architecture d'un système expert 15
2.2.5. Composants d'un système expert 16
[87]
2.2.6. Les apports des systèmes experts 18
2.2.7. Avantages des systèmes experts 19
2.2.8. Inconvénients du système expert 19
2.3. Le processus unifie (UP) 19
2.3.1. Les Principes d'UP 20
2.3.2. Les phases du processus unifie et les activités
21
2.3.3. Activités du processus 22
Expression des besoins 22
Analyse 23
Conception 23
Implémentation 23
Test 23
2.3.4. Adaptation du processus unifié 23
2.4. Généralités sur le langage UML 24
2.5. Le diagnostic de la fièvre typhoïde 26
2.5.1. Le diagnostic 26
2.5.2. La fièvre typhoïde 26
CHAPITRE III : SPECIFICATIONS DES BESOINS ET ETUDES DE
FAISABILITE
27
3.1. Narration 27
3.2. Etudes de faisabilité 27
3.2.1. Faisabilité fonctionnelle 27
3.2.2. Faisabilité opérationnelle 27
3.3. Choix de la méthode d'ordonnancement 28
3.3.1. Présentation de la méthode PERT 29
3.3.2. Identification et dénombrement des tâches
29
3.3.3. Planning d'exécution des taches et estimations
de durées. 30
3.3.4. Etablissement des liens d'antériorité
31
3.3.5. Détermination du niveau des graphes 31
3.3.6 Elaboration du graphe 32
3.3.7. Détermination des dates au plus tôt et au
plus tard 33
[88]
3.3.8. Détermination des marges 34
3.3.9 Détermination du chemin critique 35
3.4. Diagramme de GANNT 37
3.4.1. Faisabilité financière 37
3.4.2. Calendrier d'exécution du projet 38
3.5. Modélisation fonctionnelle 38
3.5.1. Capture de besoins fonctionnels 38
a. Identification des acteurs 39
b. Identification de cas d'utilisation 40
Les relations entre acteurs et cas d'utilisation 41
3.5.1.1. Diagramme de cas d'utilisation 42
a. Cas d'utilisation pour la consultation 42
b. Cas d'utilisation pour la gestion des utilisateurs 43
Diagramme de cas d'utilisation globale 43
3.5.1.1.1. Description de cas d'utilisation 44
a. Cas d'utilisation « S'authentifier » 45
b. Cas d'utilisation « consulter malade » 46
c. Cas d'utilisation « gérer utilisateurs »
47
3.5.1.2. Diagramme de séquence 47
a. Diagramme de séquence « s'authentifier »
48
b. Diagramme de séquence « consulter malade
» 49
c. Diagramme de séquence « gérer
utilisateurs » 50
3.5.2. Capture des besoins techniques 50
1. Architectures Client/serveur 51
2. Choix du langage de développement 53
2.1. Présentation de Visual C# 53
3. Choix du SGBD 54
CHAPITRE IV : ELABORATION DU SYSTEME 55
4.1. Développement du modèle statique 55
4.1.1. Diagramme de classe 56
a. Formalisme 56
[89]
b. Concepts 56
4.1.1.1. Règle de gestion 57
4.1.1.2. Identification de classes 57
4.1.1.3. Dictionnaire de données 57
4.1.1.4. Présentation des classes 59
4.1.1.5. Association et Multiplicité 60
a. Association 60
Diagramme de classe 61
4.1.2. Règle de passage d'un diagramme de classe vers
un modèle
relationnel. 62
4.2. Développement du modèle dynamique 62
4.2.1. Diagramme d'activités 63
4.2.1.1. Diagramme d'activité « s'authentifier
» 64
4.2.1.4. Diagramme d'activités « Consultation
» 65
CHAPITRE V : CONSTRUCTION DU NOUVEAU SYSTEME 66
5.1. Modélisation de la base de connaissances. 66
5.1.1. Les réseaux bayésiens 67
5.1.2. Construction et présentation du modèle
68
5.1.3. Inférence du modèle bayésien 70
Algorithme Pearl 70
5.2. Implémentation du modèle 71
5.2.1. Le langage XML 71
5.2.2. Présentation des arborescences des noeuds du
modèle 72
5.2.3. Quelques codes sources de l'application en C# 74
CHAPITRE VI : TRANSITION 80
6.1. Diagramme de déploiement 80
6.2. Présentation des quelques interfaces de
l'application 81
a. Interface d'authentification. 81
b. Fenêtre d'enregistrement de patients 81
c. Fenêtre de diagnostic 82
CHAPITRE VII : CONCLUSION GENERALE 83
[90]
BIBLIOGRAPHIE 84
I. Ouvrages 84
II. Notes de cours 85
III. Mémoires et Thèses 85
Table de matières 82
| 

