|

[1]
REPUBLIQUE DEMOCRATIQUE DU CONGO
MINISTERE DE L'ENSEIGNEMENT SUPERIEUR ET INSTITUT
SUPERIEUR DE COMMERCE DE UNIVERSITAIRE
KINSHASA
«I.S.C/KIN»
SECTION: SCIENCES COMMERCIALES, FINANCIERES
ET
INFORMATIQUE DE GESTION
DEPARTEMENT D'INFORMATIQUE
CYCLE DE
LICENCE
B.P.16596
KINSHASA-GOMBE
MODELISATION ET IMPLEMENTATION
D'UN
SYSTÈME D'AIDE A LA DECISION POUR LE
DIAGNOSTIC DE LA FIEVRE
TYPHOÏDE
MISSWAY KINDIA Josué
Travail de fin d'études présenté et
défendu en
vue de l'obtention de titre de licencié
en
informatique de gestion.
Option: Conception des Systèmes
d'Information
Directeur: Professeur MUSANGU LUKA Rapporteur: Assistant
KABAMBA MBIKAY
Année académique : 2014-2015
[2]
IN MEMORIAM
A mon père Anicet MISSWAY KINDIA pour son amour et
surtout son souci qu'il avait de me faire un vrai homme utile à la
société.
Ma reconnaissance à son égard se voudra grande et
profonde.
[3]
EPIGRAPHE
« La preuve de la valeur d'un système informatique
est son existence. »
Alan Jay Perlis
[4]
DEDICACE
A ma mère,
Et à mes frères et soeurs
MISSWAY KINDIA Josué
[5]
REMERCIEMENTS
Ce travail qui sanctionne la fin de notre cycle de licence est
le résultat abattu avec le concert de quiconque. C'est pourquoi la
reconnaissance nous oblige de pouvoir remercier sincèrement tous ceux ou
toutes celles qui ont apporté leur pierre à cet
édifice.
Aussi voudrons-nous avant toute chose, exprimer notre profonde
gratitude au Professeur MUSANGU LUKA, qui nonobstant ses multiples occupations
n'a pas hésité d'assurer la direction de ce travail. Ses riches
conseils, sa disponibilité, ses remarques et critiques constructifs nous
ont été d'une grande utilité. Qu'il veuille bien accepter
nos vifs et sincères remerciements.
Nous tenons ensuite à remercier de tout coeur notre
rapporteur, le doctorant Hervé KABAMBA MBIKAYI, pour les encouragements
e conseils pratiques.
Nos remerciements vont aussi droit à tous les membres
du corps académique.
Nous pensons également à notre oncle Alexis
TURI, notre beau-frère Guylain IKAVU ainsi que sa fille Guyslaine, la
famille TOKO, et à tous nos oncles, tantes, cousins, cousines,
grands-parents, neveux et nièces dont le soutien moral, matériel
et financier nous ont été inestimables. Qu'ils trouvent tous ici
l'expression sincère de notre gratitude.
Nous tenons aussi à exprimer notre reconnaissance aux
messieurs et demoiselles : Paul OLEKO, Délux LUKUSA, Hervé
MUYEMBE, Olivier NIAMADJOMI, Jethro FUABONGO, Grace NSELE, Jonathan MPOYI,
Meilleur NSANGANI, Steve NANGO, Placide GABIE, Grace MALULU, Glodi BIMA, Serge
MFUNYI, Hester WEDJOLO, Ruth NGEYITALA, Sharonne MBOMBO, Sarah FUTI, Parfait
LUBAMBA, Phillip KASUKUMA, Reagan MBUYA, Michel BINDA, Hardy MUPU, Fabrice
KAMULETE, Harvey FAYA, Eben MAMBUVE, Jabin MUZIR, Sylvain PITAMA, Paul NGANGU,
Merveille MUDE, Gustave MUTHI, Félicien TUTU, Reagan IKIE et Albert
BOMBO. Qu'ils trouvent dans ces lignes l'expression de notre grande et profonde
reconnaissance.
Enfin, que tous ceux ou toutes celles qui ont contribué
directement ou indirectement à notre devenir et dont les noms ne sont
pas expressément cités daignent croire ici en l'expression de
notre grande reconnaissance.
[6]
Liste de tableaux
Tableau 1 : Dénombrement des taches 30
Tableau 2 : Planning 30
Tableau 3 : Diagramme de Gantt 37
Tableau 4 : Estimation de durée et cout. 37
Tableau 5 : Calendrier d'exécution du projet 38
Tableau 6 : Acteurs et cas d'utilisation recensés.
41
Tableau 7 : Description du C.U « S'authentifier »
45
Tableau 8 : Description du C.U « consulter malade »
46
Tableau 9 : Description du C.U « gérer
utilisateurs » 47
Tableau 10 : Dictionnaire de données. 58
Tableau 11 : Liste des classes 59
Tableau 12 : Multiplicités 60
Tableau 13 : Représentation des associations simples
61
Tableau 14 : Diagramme de classe. 61
[7]
Liste de figures
Figure 1 : Structure d'un système expert
Figure 2 : Caractéristique de l'approche
itérative
Figure 3 : processus de développement 2TUP
Figure 4 : Branche gauche de Y
Figure 5 : Diagramme de C.U Consultation
Figure 6 : Diagramme de C.U gérer utilisateur
Figure 7 : DCU global
Figure 8 : Diagramme de séquence « s'authentifier
»
Figure 9 : Diagramme de séquence « consulter malade
»
Figure 10 : Diagramme de séquence « gérer
utilisateurs »
Figure 11: Situation de la capture des besoins techniques dans
2TUP
Figure 12: Architecture simple tiers
Figure 13: Architecture client-serveur
Figure 14:architecture 3 tiers
Figure 15:Branche gauche du cycle en Y
Figure 16 : Diagramme d'activités s'authentifier
Figure 17: Modèle bayésien
Figure 18:Diagramme de déploiement
Figure 19 : Fenêtre d'authentification
Figure 20 : Fenêtre d'enregistrement du patient
Figure 21: fenêtre du diagnostic
[8]
CHAPITRE I : INTRODUCTION 1.1. Mise en
contexte
Depuis plusieurs décennies et cela de par le monde, les
entreprises, les institutions aussi bien commerciales que sanitaires, bref les
hommes éprouvent les besoins du progrès social; pour y parvenir,
ils visent à minimiser les coûts et maximiser les revenus. Le
diagnostic rapide de maladies devient un aspect non négligeable à
la rentabilité et à l'émergence du secteur sanitaire et
surtout il est une étape très cruciale dans la thérapie de
maladies, de surcroît la réduction de la pauvreté.
La bonne prise de décision rapide et optimale
grâce à l'outil informatique avec la pluralité d'avantages
qu'il offre est un facteur de développement harmonieux dans l'atteinte
de tous les objectifs assignés par l'institution.
Compte tenu du fait que les NTIC ont une influence très
considérables sur la productivité et le profit, à l'issue
de cette étude, nous tacherons de modéliser et mettre en oeuvre
un système expert qui assistera le corps médical à
diagnostiquer rapidement la maladie du patient afin d'assurer la bonne prise en
charge de ce dernier.
1.2. Problématique
Aujourd'hui la fièvre typhoïde parait un
fléau qui touche beaucoup plus des pays sous-développés.
La République démocratique du Congo n'est pas en reste, en ce
sens que la majeure partie de la population n'a pas accès à l'eau
potable et aux soins de santé.
Face à cette situation précaire, il a
été constaté qu'à l'absence de médecins
considérés comme experts dans certaines formations
médicales, le diagnostic de cette maladie combien mortelle
dévient de plus en plus difficile.
Or, nous sommes sans ignorés que le diagnostic est l'un
des éléments non négligeables dans la décision
médicale car il est généralement le préalable d'une
meilleure prise en charge du patient. Les médecins qui en assurent font
parfois face à des multiples problèmes d'ordre familial,
personnel, que professionnel qui peuvent surement entraver leur prise de
décision ou d'influer négativement sur la décision prise.
Raison pour laquelle, la mise au point d'un système expert de diagnostic
de la fièvre typhoïde pourrait résoudre effectivement ce
problème.
Cette problématique se résume autour des
questions ci-après :
[9]
V' Quelle est la quintessence ou le bien fondé
du système expert de diagnostic de la fièvre typhoïde ?
V' Est-il vrai que cet outil pouvait être un
début de solution dans l'amélioration de la prise en charge de la
fièvre typhoïde ?
V' Quels sont les aspects techniques, économiques
et sociaux à donner au futur système ?
1.3. Hypothèse
De tout ce qui précède, à l'issue de
cette étude, nous pensons mettre à la disposition du
médecin un outil d'aide à la décision grâce à
un modèle probabiliste notamment le réseau bayésien
à partir d'un ordinateur pouvant aider le personnel médical dans
le diagnostic de la fièvre typhoïde en vue d'assurer au mieux la
prise en charge de patients.
1.4. Choix et intérêt du sujet
Le choix de notre sujet sur la modélisation et
l'implémentation d'un système d'aide à la décision
pour le diagnostic de la fièvre typhoïde s'avère très
judicieux d'autant plus que la situation sanitaire en ROC est très
précaire, nous avons voulu à travers ce sujet apporter notre
contribution dans la réduction de ce fléau en y apportant une
solution informatique.
Quant à son intérêt, il est triple :
V' Sur le plan économique, c'est outil
s'avère être un véritable moteur de développement
car il permettra au médecin dans un temps record de diagnostiquer plus
d'un patient ; d'où un gain en temps, or le temps est un grand facteur
d'émergence.
V' Sur le plan scientifique, il est un outil de
recherche pour toute personne intéressée au domaine de conception
des systèmes d'information et plus précisément
l'intelligence artificielle.
V' Enfin sur le plan personnel, c'est une
façon pour nous de pouvoir contribuer à la réduction de la
fièvre typhoïde qui touche beaucoup des congolais
1.5. Délimitation du travail
Ce travail visant contribuer à résoudre un
problème réellement constaté dans un contexte purement
congolais, puis qu'il est ici question du diagnostic de la fièvre
typhoïde il ne s'avère pas indispensable qu'il
[10]
soit délimité dans l'espace, ni dans le temps car
le diagnostic est effectif partout et il est un processus continu.
1.6. Méthode et techniques
utilisées
a. Méthode
La méthode se définit comme étant
l'ensemble de règles et de disciplines qui organisent le mouvement
d'ensemble de la connaissance, c'est-à-dire les relations entre l'objet
de la recherche et le chercheur, entre les informations concrètes
rassemblées à l'aide des techniques et le niveau de la
théorie et des concepts.1
Ainsi pour la conception de l'application qui sera
développée nous avons opté pour la méthode UP
construit sur UML ; un processus itératif et incrémental.
En ce qui concerne la méthode de conduite du projet
nous avons opté pour la méthode PERT.
b. Techniques
La technique est l'ensemble de procédés ou de
moyens pratiques pouvant aider à concrétiser les principes
fixés par la méthode2.Bref, elle permet la collecte
des informations.
Afin de recueillir toutes les informations utiles de notre
recherche nous avons recouru aux techniques ci-après :
y' Technique d'interview : elle nous a permis de
poser des questions aux personnes concernées de notre étude en
vue de récolter les données nécessaires pour celle-ci.
y' Technique d'observation : elle nous a aidé
de voir à l'oeil nu la façon dont se déroule le processus
de diagnostic des maladies.
y' Technique documentaire : elle nous a permis de
consulter tous les ouvrages nécessaires pour notre étude.
1.7. Difficultés rencontrées
A titre de rappel, ce travail aborde le diagnostic qui est
évidemment un domaine sanitaire, tout au long de sa recherche nous avons
heurtés plusieurs difficultés dans la récolte de
données auprès des
1MUKUNA, B., Essai méthodologique sur la
rédaction d'un travail scientifique, éd. CRIGED, Janvier
2006, ISC/Kinshasa, p.28
2BINDUNGWA, M., Comment élaborer
un travail de fin de cycle ? Contenu et étapes, ed.
Médiaspaul, Kinshasa 2008.
[11]
experts du domaine, la première difficulté est
liée à l'inadéquation due au jargon médical, la
seconde c'est dans la mise en application du réseau bayésien dans
ce diagnostic.
1.8. Canevas du travail
Le présent travail est divisé en sept chapitres
de valeurs non négligeables.
Au premier chapitre nous allons présenter
l'introduction générale de notre travail.
Au deuxième chapitre intitulé les approches
théoriques. Nous aborderons les généralités sur
l'intelligence artificielle, le système expert, le langage de
modélisation ainsi que les concepts liés au sujet.
Le chapitre troisième s'articulera sur la
spécification des besoins et études de faisabilité. Dans
cette partie, nous allons décrire les besoins fonctionnels et non
fonctionnels du système en plus l'étude de faisabilité de
notre projet.
Le quatrième chapitre qui constitue un de noeuds
essentiels de notre travail sera synonyme de l'élaboration de notre
système. Ici nous allons faire la modélisation statique et
dynamique du système.
Le chapitre cinquième développera la
construction de notre système. Il nous aidera à construire et
implémenter le modèle de la base de connaissances.
Le sixième chapitre et avant dernier chapitre gravitera
autour de la transition. Ici, il sera question de mettre l'outil à la
disposition des utilisateurs finaux.
Enfin, le septième chapitre marquera la conclusion de ce
travail.
[12]
CHAPITRE II : APPROCHES THEORIQUES
Dans ce chapitre, il est question d'aborder les
généralités sur l'intelligence artificielle, objet de la
première section, le système expert qui est une branche de
l'intelligence artificielle, objet de la deuxième section, le processus
unifié objet de la troisième section, le langage UML comme objet
de la quatrième section et enfin le diagnostic comme objet de la
cinquième section.
2.1. Généralités sur l'intelligence
artificielle 2.1.1. Définition
L'intelligence artificielle étant un concept a par
conséquent plusieurs définitions :
A en croire LAROUSSE, elle se définit comme
étant un ensemble de théories et de techniques mises en oeuvre
pour réaliser des machines dont le fonctionnement s'apparente à
celui d'un cerveau humain.
D'après BUCHANAN3, l'intelligence
artificielle est définie comme le domaine informatique qui effectue les
traitements symboliques et qui emploie des méthodes non
algorithmiques.
RICH pour sa part soutient que l'intelligence artificielle est
le domaine qui étudie comment faire exécuter par ordinateur des
tâches pour lesquelles l'homme est encore toujours
meilleur4.
Nous pouvons encore définir l'intelligence artificielle
selon quatre approches suivantes5 :
Systèmes qui pensent comme les humains
L'intelligence artificielle est l'automatisation des
activités que nous lions au processus de pensée comme la prise de
décision, la résolution des problèmes,
apprentissage,...(Bellman, 1978)
Systèmes qui pensent rationnellement
C'est l'étude des facultés mentales à
l'aide de l'usage des modèles computationnels. (Charniak et McDermott,
1985).
3 R. Lindsay, B. Buchanan, E.Feignbaum.,
Application of artificial intelligence to organic
chemistri : the dendra project, Mc Graw-hill 1980.
4RICH, E., Intelligence artificielle, Ed.
Masson, paris 1987.
5 KUTANGILA, D., Intelligence artificielle et
systèmes experts approfondis, L1 Info, ISC-KIN, 2013-2014.
[13]
Systèmes qui agissent comme les humains
Elle est l'art de développer des machines avec
capacités pour réaliser des fonctions qui, quand elles sont
réalisées par des personnes, exigent de l'intelligence.
(Kurzweil,1990).
Systèmes qui agissent rationnellement
Selon Nilson, l'intelligence artificielle est en rapport avec
la conduite intelligente des automates.
2.1.2. Branches de l'intelligence
artificielle
L'intelligence artificielle a plusieurs branches parmi
lesquelles :
Les systèmes experts : un système expert est un
système de traitement qui émule l'habilité de prendre de
décisions comme un spécialiste humain
La robotique : Larousse définit la robotique comme
étant une science et technique de conception et construction des robots.
Il est à signaler que présentement dans les usines il ya des
robots industriels qui ont fait leur apparition.
La parole : malgré l'évolution technologique,
l'humanité est encore loin de produire un logiciel capable de
reconnaitre les paroles d'un quelconque locuteur et cela essentiellement
d'autant plus que la compréhension d'un mot, d'une phrase requiert
beaucoup d'information extra-langagière.
Le langage naturel
Les systèmes artificiels neuronaux : durant les
années 80 surgissent un nouveau développement dans la
programmation des paradigmes les systèmes neuronaux
artificiels basé sur la manière dont le cerveau
traite
l'information. Ce paradigme est parfois appelé connexionisme,
d'autant plus qu'il modélise les solutions aux problèmes en
entrainant des neurones simulés, connectés à un
réseau de travail.
La compréhension
La vision artificielle
[14]
2.1.3. Avantages de l'IA
L'intelligence artificielle offre plusieurs avantages notamment
:
La limitation d'erreurs
L'homme est dispensé de certains travaux pénibles
La pérennité des connaissances
Les machines sont exemptes à la fatigue
2.2. Le système expert
2.2.1. Introduction
Le système expert est l'un des domaines de
l'intelligence artificielle relatif à la conception des systèmes
d'aide à la décision à base de connaissances.
Il est de surcroit un programme informatique intelligent,
capable d'agir comme expert dans un domaine. Aujourd'hui, de par le monde, les
industries utilisent beaucoup des systèmes experts pour assurer la
maintenance, la réparation des machines complexes.
2.2.2. Définition
Il y a plusieurs façons de définir le
système expert. Le professeur Edward Feigenbaum de l'Université
de Stamford, pionnier en technologie des systèmes experts, le
définit comme étant un programme de traitement intelligent qui
utilise des connaissances et les procédures d'inférence pour
résoudre des problèmes tellement difficiles qu'ils exigent une
expérience significative pour leur solution.
Un système expert est un système d'aide à
la décision basé sur un moteur d'inférence et une base de
connaissances. Il est la transcription logicielle de la réflexion d'un
expert dans un domaine donné. Néanmoins, il reste un outil d'aide
à la décision et loin de prétendre remplacer
l'intelligence humaine.
Il est aussi important de signaler que les termes
systèmes experts ou systèmes à base de connaissances ou
système expert basé sur la connaissance s'utilisent comme
synonymes.
[15]
2.2.3. Les acteurs
La mise en oeuvre d'un système expert est un processus
d'ingénierie de connaissances qui impliquent plusieurs personnes
notamment :
? Expert
Un expert ou un spécialiste est une personne qui a une
parfaite connaissance dans un domaine, due à une longue durée de
travail. Il est considéré comme le socle même du
développement d'un système expert. De ce fait, il doit être
disponible lors de la phase d'extraction de ses connaissances car c'est lui qui
a le monopole de savoir et de savoir-faire de son domaine d'expertise. C'est
l'expert qui fournit les connaissances nécessaires liées au
problème.
? Le cogniticien
Autrement appelé Ingénieur des connaissances,
c'est une personne ayant des bonnes bases en informatiques et
généralement ingénieur en intelligence artificielle. Il
est chargé d'extraire les connaissances auprès de l'expert. A ce
titre, il établit un dialogue avec l'expert pour obtenir ses
connaissances, il le codifie de façon explicite dans la base de
connaissances sous formes des règles.
? Les managers : sont des personnes pour qui on développe
le système.
2.2.4. Architecture d'un système
expert
La structure ou l'architecture d'un système expert se
présente dans la figure ci-dessous :
[16]
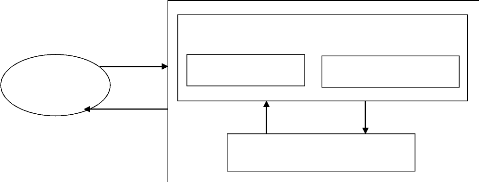
Utilisateur
Base de faits
Base de connaissances
Moteur d'inférence
Base de règles
Figure 1 : Structure d'un système expert 2.2.5.
Composants d'un système expert
Selon son architecture simple présentée
ci-dessus, nous distinguons trois composants de base d'un système expert
notamment :
? La base de connaissances ? La base de faits
? Le moteur d'inférence
2.2.5.1. La base de connaissances
Elle contient la connaissance qui permet au mécanisme
d'inférence de tirer de conclusions ; celles-ci sont de réponses
du système à la consultation spéciale de l'utilisateur.
2.2.5.2. La base de faits
Elle contient tout ce que le système expert sait sur le
cas étudié. La base de faits est ainsi variable au cours de
l'exécution et est vidée lorsque l'exécution se
termine.
Les faits sont des connaissances factuelles et les
règles constituent des connaissances opératoires.
[17]
2.2.5.3. Le moteur d'inférence
Autrement dit mécanisme d'inférence, il
contrôle l'exécution des règles. Il décide sur
quelles règles exécuter et quand. Il permet d'inférer des
connaissances nouvelles à partir de la base de connaissances du
système.
Il est le coeur du système, et qui contient un
algorithme de résolution dont la fonction consiste à effectuer
des déductions en partant des faits initiaux et en s'appuyant sur les
règles contenues dans la BR, dans le but final de produire
(c'est-à-dire de déduire) de nouveaux faits. Il peut fonctionner
en chaînage avant, chaînage arrière ou chaînage
mixte6.
? Chaînage avant : le principe
du chaînage avant est simple, il requiert l'accès aux
prémices afin de déclencher les règles d'inférences
adéquates définies par les mérules. L'application de
règles donne des résultats, ceux-ci sont évalués
afin de savoir si l'on accédé à une solution finale
potentielle. Si c'est le cas, on arrêté et cette solution est
proposée. Si c'est le cas, la solution est proposée à
l'utilisateur. S'il la valide, la solution est enregistrée dans la base
de faits comme solution, sinon comme simple résultat et on continue dans
le cas suivant.
? Chaînage arrière : le
principe du chaînage arrière est plus compliqué, il s'agit
dans ce cas de partir d'un effet ou d'une solution et de tenter de remonter la
chaîne afin de déterminer les causes d'un effet (fait). La
procédure est à partir d'un effet, de déterminer,
grâce aux métarules, les règles d'inférence qui
aurait pu être à l'origine de ce fait et de déterminer les
paramètres les plus probables. A partir de là, on analyse les
paramètres : Si le paramètre est un fait enregistré dans
la base de fait, c'est qu'il est le résultat d'une règle. La
procédure précédemment décrite est donc
relancée. Si le paramètre n'est pas un fait de la base de fait,
on en reste là.
? Chaînage mixte :il utilise
une combinaison de ces deux approches chaînage avant et chaînage
arrière.
6 MUJINGA, S., Conception et réalisation d'un
système expert de diagnostic du cancer de la peau, mémoire,
Unikin, 2013.
[18]
2.2.6. Les apports des systèmes
experts
Les motivations pour une entreprise de réaliser un
système expert sont regroupées en trois catégories :
? La gestion de l'expertise
? L'augmentation de la capacité de l'expert ? La diffusion
des connaissances
2. 2. 6.1. La gestion de l'expertise
Le rôle d'une entreprise est de prendre en charge
l'intelligence qu'elle utilise qui naturellement est distribuée, de la
formaliser et de la sauvegarder. En effet, les experts sont des hommes rares,
très chers et difficiles à remplacer.
D'où l'impérieuse nécessité pour
une entreprise de s'approprier de la technique des systèmes experts et
de conserver ainsi l'expertise sous une forme aussi claire et accessible
à tous. Le système expert dévient alors un moyen de
formation.
2.2.6. 2. L'augmentation de la capacité de l'expert
Un système peut donc assister un spécialiste du
fait que sa connaissance provient de plusieurs experts. D'autres parts,
l'expert étant un homme, il peut donc être sujet à la
fatigue, à l'oubli, etc. alors que le système expert est
insensible à de telles considérations. On peut ainsi au moyen
d'un système expert, trouver plus rapidement une solution à un
problème en donnant accès aux connaissances des autres experts du
domaine.
2.2.6.3. La diffusion de l'information
Les experts étant des hommes, il est souvent
nécessaires pour une entreprise que leur expertise soit diffusée
à des nombreux services afin de décentraliser les prises de
décisions et d'ainsi accroitre la rapidité et
l'homogénéité. Ainsi, la diffusion permet aux utilisateurs
de disposer à tout moment de l'expertise.
[19]
2.2.7. Avantages des systèmes experts
Les systèmes experts présentent plusieurs
avantages que nous
citons :
> Danger réduit : les systèmes
peuvent être utilisés dans des environnements qui pourraient
être dangereux pour un humain.
> Permanence : l'expérience est
permanente.
> Grande disponibilité :
l'expérience est disponible pour tout matériel de traitement
adéquat.
> Explication : le système expert peut
expliquer clairement et en détail le raisonnement qui conduit à
une conclusion, cela augmente la confiance que la décision prise
était correcte.
> Enseignement intelligent : un système
expert peut agir comme un enseignant intelligent en laissant que
l'étudiant exécute.
> Réponse rapide : u système expert
peut répondre plus rapidement qu'un spécialiste humain.
2.2.8. Inconvénients du système
expert
Le système expert présente deux
inconvénients majeurs :
> Le chômage du moment où il peut
à lui seul réaliser ce qui pourrait se faire un groupe de
personnes.
> Le système s'appuie à des
connaissances même si il ne plus utilisable.
2.3. Le processus unifie (UP)
Le processus unifié est un processus de
développement moderne, itératif, efficace sur des projets
informatiques de toutes tailles. Très complet, il couvre l'ensemble des
activités, depuis la conception du projet jusqu'à la livraison de
la solution.
Intégrant une organisation de projet type, une
méthodologie utilisant UML et un ensemble de bonnes pratiques
cohérentes entre elles, il permet de circonvenir aux problèmes
récurrents que rencontrent nombre de réalisations : dérive
des coûts et des délais, qualité insuffisante,
réponse incomplète aux attentes des utilisateurs.
[20]
Un point d'excellence de cette démarche est son
adaptabilité : UP peut se décliner en fonction de l'ampleur d'un
projet, de l'expérience de l'équipe qui l'assume, de la nature de
la solution à construire.
2.3.1. Les Principes d'UP
Le processus de développement UP, associé
à UML, met en oeuvre les principes suivants :
· processus guidé par les cas d'utilisation,
· processus itératif et incrémental,
· processus centré sur l'architecture,
· processus orienté par la réduction des
risques.
Ces principes sont à la base du processus unifié
décrit par les auteurs d'UML.
a) Processus guidé par les cas
d'utilisation
L'orientation forte donnée ici par UP est de montrer
que le système à construire se définit d'abord avec les
utilisateurs. Les cas d'utilisation permettent d'exprimer les
interactions du système avec les utilisateurs, donc de capturer les
besoins.
b) Processus itératif et
incrémental
Ce type de démarche étant relativement connu
dans l'approche objet, il paraît naturel qu'UP préconise
l'utilisation du principe de développement par itérations
successives. Concrètement, la réalisation de maquette et
prototype constitue la réponse pratique à ce principe. Le
développement progressif, par incrément, est
aussi recommandé en s'appuyant sur la décomposition du
système en cas d'utilisation.
Les avantages du développement itératif se
caractérisent comme
suit :
· Les risques sont évalués et
traités au fur et à mesure des itérations ;
· Les premières itérations permettent
d'avoir un feed-back des utilisateurs ;
· Les tests et l'intégration se font de
manière continue,
· Les avancées sont évaluées au fur
et à mesure de
l'implémentation.
[21]
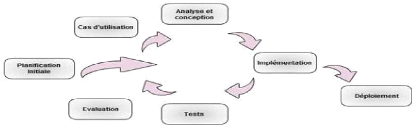
Figure 2 : Caractéristiques de l'approche
itérative
c) Processus centré sur
l'architecture
Les auteurs d'UP mettent en avant la préoccupation de
l'architecture du système dès le début
des travaux d'analyse et de conception. Il est important de définir le
plus tôt possible, même à grandes mailles, l'architecture
type qui sera retenue pour le développement, l'implémentation et
ensuite le déploiement du système. Le vecteur des cas
d'utilisation peut aussi être utilisé pour la description de
l'architecture.
d) Processus orienté par la réduction des
risques
L'analyse des risques doit être
présente à tous les stades de développement d'un
système. Il est important de bien évaluer les risques des
développements afin d'aider à la bonne prise de décision.
Du fait de l'application du processus itératif, UP contribue à la
diminution des risques au fur et à mesure du déroulement des
itérations successives.
2.3.2. Les phases du processus unifie et les
activités
Les phases d'un processus de développement sont des
états de celui-ci à un instant t. Le cycle de
développement du Processus Unifié organise les tâches et
les itérations en quatre phases7 :
? Inception ou (commencement) : Cette phase
correspond à l'initialisation du projet où l'on
mène une étude d'opportunité et de faisabilité du
système à construire. Une évaluation des risques est aussi
réalisée dès cette phase.
7ROQUES, P. et VALLEE, F., UML 2 en action de
l'analyse des besoins à la conception, Ed. EYROLLES, Paris,
2005,
[22]
En outre, une identification des principaux cas d'utilisation
accompagnée d'une description générale est
modélisée dans un diagramme de cas d'utilisation afin de
définir le périmètre du projet.
? Élaboration : Cette phase reprend les
résultats de la phase
d'inception et élargit l'appréciation de la
faisabilité sur la quasi-totalité des cas
d'utilisation. Ces cas d'utilisation se retrouvent dans le diagramme des cas
d'utilisation qui est ainsi complété.
Cette phase a aussi pour but d'analyser le domaine technique
du système à développer afin d'aboutir à une
architecture stable. Ainsi, toutes les exigences non recensées dans les
cas d'utilisation, comme par exemple les exigences de performances du
système, seront prises en compte dans la conception et
l'élaboration de l'architecture.
? Construction : Cette phase correspond
à la production d'une première version du
produit. Elle est donc fortement centrée sur les activités de
conception, d'implémentation et de test.
En effet, les composants et fonctionnalités non
implémentés dans la phase précédente le sont
ici.
? Transition :Après les
opérations de test menées dans la phase précédente,
il s'agit dans cette phase de livrer le produit pour une
exploitation réelle. C'est ainsi que toutes les actions liées au
déploiement sont traitées dans cette phase. De plus, des «
bêta tests » sont effectués pour valider le nouveau
système auprès des utilisateurs.
2.3.3. Activités du processus
Les activités représentent les actions à
effectuer au cours d'une phase : une phase passe par l'ensemble des
activités. Le temps passé par activité est fonction des
phases.
Nous nous limiterons donc à ne donner qu'une
brève explication de chaque activité.
Expression des besoins
UP propose d'appréhender l'expression des
besoins en se fondant sur une bonne compréhension du domaine
concerné pour le système à développer et une
modélisation des procédures du système existant.
Ainsi, UP distingue deux types de besoins :
? les besoins fonctionnels qui conduisent à
l'élaboration des cas
d'utilisation,
? les besoins non fonctionnels (techniques) qui aboutissent
à la
rédaction d'une matrice des exigences.
[23]
Analyse
L'analyse permet une formalisation du
système à développer en réponse à
l'expression des besoins formulée par les utilisateurs. L'analyse se
concrétise par l'élaboration de tous les diagrammes donnant une
représentation du système tant statique (diagramme de classe
principalement), que dynamique (diagramme des cas d'utilisation, de
séquence, d'activité, d'état-transition...).
Conception
La conception prend en compte les choix
d'architecture technique retenus pour le développement et l'exploitation
du système. La conception permet d'étendre la
représentation des diagrammes effectuée au niveau de l'analyse en
y intégrant les aspects techniques plus proches des
préoccupations physiques.
Implémentation
Cette phase correspond à la production du
logiciel sous forme de composants, de bibliothèques ou de
fichiers.
Test
Il permet de vérifier :
? La bonne implémentation de toutes les exigences
(fonctionnelles et techniques),
? Le fonctionnement correct des interactions entre les objets,
? La bonne intégration de tous les composants dans le
logiciel.
2.3.4. Adaptation du processus unifié
Il existe plusieurs processus de développement qui
implémente UP dont les plus connues sont :
? RUP : Rational Unified Process
? XP : eXtreme Programming
? 2TUP : Two Tracks Unified Process,
Dans le cadre de notre étude, nous allons utiliser le
2TUP, tout développement peut être décomposé et
traités en parallèle selon un axe fonctionnel et un axe
technique. Nous pouvons ainsi suivre les évolutions liées aux
changements des besoins fonctionnels et aux changements des besoins
techniques8.
8ROQUES, P et VALLEE F, op.cit
P14.
[24]
La schématisation du processus de développement
correspond alors à un Y. Les deux perspectives se rejoignant lors de la
phase de conception préliminaire.
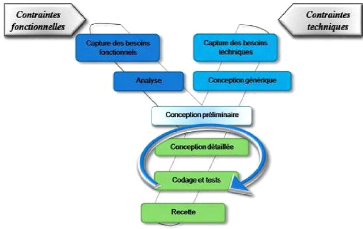
Figure 3 : Processus de développement
2TUP
La branche fonctionnelle contient :
la capture des besoins et de leurs analyses. Les résultats de l'analyse
sont indépendantes des technologies utilisés.
La branche technique contient : la
capture des besoins techniques et de la conception générique.
L'architecture technique construit le squelette du
système informatique indépendamment des besoins fonctionnels.
Les deux branches sont ensuite fusionnées en une seule
branche qui prend en charge la conception préliminaire (cartographie des
composants à développer), conception détaillée
(comment réaliser chaque composant), codage (production des composants),
tests et étapes de validation des fonctions
développées.
2.4. Généralités sur le langage
UML
UML (Unified Modeling Language) est un langage formel et
normalisé en termes de modélisation objet. Son
indépendance par rapport aux langages de programmation, aux domaines de
l'application et aux processus, son caractère polyvalent et sa souplesse
ont fait de lui un langage universel. En plus UML est essentiellement un
support de communication, qui facilite la représentation et la
compréhension de
[25]
solution objet. Sa notation graphique permet d'exprimer
visuellement une solution objet, ce qui facilite la comparaison et
l'évaluation des solutions. L'aspect de sa notation, limite
l'ambigüité et les incompréhensions.
UML fournit un moyen astucieux permettant de
représenter diverses projections d'une même représentation
grâce aux vues.
Une vue est constituée d'un ou plusieurs diagrammes. On
distingue deux types de vues:
La vue statique, permettant de
représenter le système physiquement :
Diagrammes de classes: représentent des collections
d'éléments de modélisation statiques (classes,
paquetages...), qui montrent la structure d'un modèle.
Diagrammes d'objets: ces diagrammes montrent des objets
(instances classes dans un état particulier) et des liens (relations
sémantiques) entre objets.
Diagrammes de composants: permettent de décrire
l'architecture physique statique d'une application en termes de modules :
fichiers sources, librairie exécutables, etc.
Diagrammes de déploiement: montrent la disposition
physique du matériel qui compose le système et la
répartition des composants sur ce matériel.
La vue dynamique, montrant le fonctionnement
du système :
Diagrammes de collaboration: montrent des interactions entre
objet (instances de classes et acteurs).
Diagrammes de cas d'utilisation: identifient les utilisateurs
du système (acteurs) et leurs interactions avec le système.
Diagrammes de séquence: permettent de
représenter des collaborations eu objets selon un point de vue temporel,
on y met l'accent sur la chronologie (envois de messages).
Diagrammes d'états-transitions: permettent de
décrire les changements d'états d'un objet ou d'un composant, en
réponse aux interactions avec d'autres objets/composants ou avec des
acteurs.
Diagrammes d'activités: (une variante des diagrammes
d'états-transitions) servent à représenter graphiquement
le comportement d'une méthode ou déroulement d'un cas
d'utilisation.
[26]
2.5. Le diagnostic de la fièvre typhoïde
2.5.1. Le diagnostic
Le diagnostic n'est rien d'autre que l'identification d'une
maladie par ses symptômes. Il permet de reconnaitre une maladie pour en
assurer la prise en charge appropriée. Le diagnostic est
l'élément essentiel de la décision médicale qui
relève de la compétence du médecin.
Ce concept remonte aux origines de la médecine. La
rationalité de la démarche diagnostique s'est enrichie au cours
des deux derniers siècles des apports de la science. Le schéma
selon lequel le diagnostic est issu du recueil et de la hiérarchisation
des symptômes et des signes cliniques, confirmé et
précisé par les examens complémentaire doit être
gardé en mémoire comme un principe fondamental.
L'élaboration du diagnostic bénéficie de
nombreuses innovations. Elles concernent les moyens techniques disponibles
(biologie, imagerie) et les nouvelles méthodes pour tirer parti des
données (statistiques, algorithme).
Le développement des moyens de diagnostic impose des
nouvelles responsabilités aux médecins : renouvellement des
connaissances, exigeant une formation continue et efficace, bon usage des
moyens disponibles imposant l'évaluation des pratiques professionnelles.
La mise en oeuvre du diagnostic doit tenir compte de l'évolution de la
société.
2.5.2. La fièvre typhoïde
La fièvre typhoïde (du grec tuphos, torpeur) ou
typhus abdominal est une maladie infectieuse décrite en 1818 par Pierre
Bretonneau, causée par une bactérie de la famille
Entérobactérie, du genre des salmonelles, et dont les
espèces responsables sont: Salmonella enterica - typhi ou paratyphi A,
B, C -. Salmonella enterica typhi est
encore appelée bacille d'Eberth. C'est une maladie
bactérienne
transmissible strictement humaine. Elle est
provoquée par des salmonelles que l'on trouve dans le lait, la
nourriture ou l'eau contaminé.
La faisabilité opérationnelle s'intéresse
plus aux besoins non fonctionnels car elle décrit toutes les contraintes
possibles notamment
[27]
CHAPITRE III : SPECIFICATIONS DES BESOINS ET ETUDES DE
FAISABILITE
Ce chapitre va s'atteler autour des besoins fonctionnels et
non fonctionnels du projet et enfin les faisabilités nécessaires
pour la matérialisation du projet. Il sied de signaler que c'est la
phase cruciale du développement 2TUP dans la mesure où elle
aidera à identifier les acteurs et exprimer les besoins sous formes de
cas d'utilisation.
3.1. Narration
Avec les enjeux de la mondialisation qu'assiste
l'humanité tout entière, les scientifiques mettent au point
plusieurs outils pour faciliter l'homme dans l'exercice de ses fonctions. Le
diagnostic de maladies n'est pas du reste, motif pour lequel nous pensons
mettre à la disposition du personnel soignant un système expert
pouvant l'assister dans le diagnostic de maladies notamment la fièvre
typhoïde.
En ce qui concerne le système qui sera
implémenté, à l'arrivée du patient, il est
directement reçu par un médecin pour consultation afin de lui
soumettre toutes ses plaintes et signes vitaux qu'il présente. Le
médecin pour sa part va interroger le système bien entendu dans
l'interface de diagnostic. Après quoi, il sera déclenché
un message pour signaler la présence de la fièvre typhoïde,
en cas d'éventualité, le patient sera soumis à un examen
clinique pour ainsi confirmer la présence ou non de la typhoïde.
3.2. Etudes de faisabilité
3.2.1. Faisabilité fonctionnelle
Cette partie très importante listera toutes les
fonctionnalités de notre application. Elle s'attardera sur les exigences
fonctionnelles de tous les différents acteurs dans le cas d'utilisations
que nous évoquerons plus tard.
3.2.2. Faisabilité
opérationnelle
[28]
ergonomiques, techniques et esthétiques auxquelles est
soumis le système pour sa réalisation et son bon
fonctionnement9.
Dans le cadre de notre système expert, nous avons pu
relever des besoins ci-après :
La fiabilité : les données de l'application doivent
être fiables ; Robustesse : l'application réagira mieux même
si l'on s'écarte aux conditions normales d'utilisation ;
Convivialité de l'interface graphique : l'interface
sera à même de mettre chaque utilisateur à l'aise par la
beauté de son interface graphique ;
La disponibilité : l'application s'utilisera par tout
utilisateur de la boite.
L'intégrité : l'application sera
sécurisé contre toute modification ;
L'intégrité : elle tiendra compte de
l'évolution.
3.3. Choix de la méthode
d'ordonnancement
Le modèle d'ordonnancement présente plusieurs
avantages :
La facilitation de l'établissement du planning
prévisionnel de réalisation du projet ;
La spécification de l'ordre d'exécution des
différentes tâches ;
La minimisation de la durée d'exécution des travaux
;
La facilitation de la construction du diagramme de GANNT pour
un bon suivi du projet.
Il existe par ailleurs plusieurs méthodes
d'ordonnancement pour élaborer le planning prévisionnel des
projets notamment la méthode PERT, de potentiel mettra (MPM). Mais dans
le cadre de ce projet, nous optons pour la méthode PERT.
9HEDIDAR , A., Conception et
réalisation d'une application mobile m-banking, mémoire,
Université Virtuelle de Tunis, 2011-2012.
[29]
3.3.1. Présentation de la méthode
PERT
Le bon ordonnancement des taches élémentaires
concourant à la réalisation d'un ensemble complexe a
été, de tout temps, un souci majeur pour les responsables
d'entreprise.
Un nouvel outil est intervenu à l'occasion de la
réalisation par les spécialistes en recherche
opérationnelle de la Marine US et le célèbre cabinet de
conseil BOOZALLEN&HAMILTON. Il s'agissait de mettre au point une
méthode de planification susceptible de s'assurer de l'achèvement
d'un modèle, nécessitant de très nombreux sous-traitants,
à une date précise10.
Le nom P.E.R.T (Program Evaluation Review Technic) a
été attribué à ce nouvel outil de travail. P.E.R.T
peut-être traduite par « méthode critique d'évaluation
et de contrôle de projet »11.
S'agissant du principe de cette méthode, les taches
sont représentées par les arcs. La valeur de chaque arc sera la
durée de la tâche.
3.3.2. Identification et dénombrement des
tâches
Le tableau suivant comprend toutes les tâches
identifiées pour la réalisation de ce projet ainsi que les
contraintes de réalisation de chaque tâche.
10MVIBUDULU, J.A., Note de cours de théorie
des graphes, L2 Info, ISC, 2014-2015. 11 Idem.
[30]
Tableau 1 : Dénombrement des taches
|
Tâches
|
LIBELLE
|
TACHES
ANTERIEURES
|
|
A
|
Expression de besoins
|
|
|
B
|
Analyse de besoins
|
A
|
|
C
|
Etude de faisabilité
|
B
|
|
D
|
Elaboration du système
|
C
|
|
E
|
Construction du système
|
D
|
|
F
|
Déploiement
|
E
|
|
G
|
Test de l'application et production du guide d'utilisation.
|
E, F
|
|
H
|
Formation du personnel
|
G
|
|
I
|
Livraison de l'application
|
H
|
3.3.3. Planning d'exécution des taches et
estimations de durées.
Tableau 2 : Planning
|
TACHES
|
Libelle
|
TACHES
ANTERIEURE
S
|
DUREE
/JOUR
S
|
NBRE COUT /$
PERS.
|
|
A
|
Expression de besoins
|
|
7
|
200
|
|
B
|
Analyse de besoins
|
A
|
19
|
320
|
|
C
|
Etude de faisabilité
|
B
|
23
|
350
|
|
D
|
Elaboration du systèmez
|
C
|
24
|
450
|
|
E
|
Construction du système
|
D
|
13
|
2550
|
|
F
|
Déploiement
|
E
|
7
|
1200
|
|
G
|
Test de l'application et
production du guide
d'utilisation.
|
e,f
|
16
|
2 50
|
|
H
|
Formation du personnel
|
G
|
31
|
1500
|
|
I
|
Livraison de l'application
|
H
|
13
|
2000
|
[31]
3.3.4. Etablissement des liens
d'antériorité
C'est ce qu'évoque le tableau précédent.
3.3.5. Détermination du niveau des graphes
Nx est le nombre d'étape maximal
Nx-1 = [10J = R9
Nx-2 = [9J = R8
Nx-3 = [8J = R7
Nx-4 = [7J = R6
Nx-5 = [6J = R5
Nx-6 = [5J = R4
Nx-7 = [4J = R3
Nx-8 = [3J = R2
Nx-9 = [2J = R1
Nx-10 = [1J = R0
N0 N1 N2 N3 N4 N5 N6 N7 N8 N9

93
93
G
109 109
F
7
16
8
7
0
1
0
A
7 19
2 3
7 7
B
26 26
C
23
49
4
49 D
24
73
5
73 E
13
86
6
86
0
31
H
140
140
0
9
13
7'
153 153
i
86 93
[32]
3.3.6 Elaboration du graphe
[33]
3.3.7. Détermination des dates au plus tôt
et au plus tard Date au plus tôt (Dto) :
La date au plus tôt (dto) est la date la plus
rapprochée à laquelle il est possible de réaliser une
étape. Elle se calcule par la formule suivante :
dto(x)=Max{dto(y)+d(i)}.
dto(x) est considéré comme 2e
étape, dto(y) est considéré comme
1èreétape et i comme une tâche.
Calcul
Dto(1) =0
Dto(2)= Dto(1) +d(a)=0+7=7 Dto(3)= Dto(2) +d(b)=7+19=26 Dto(4)=
Dto(3) +d(c)=26+23=49 Dto(5)= Dto(4) +d(d)=49+24=73 Dto(6)= Dto(5) +d(e)=
73+13=86
Dto(7)= MaxDto(5) +d(e)=Max 86 +7 = 93 (qui est la valeur
maximum) Dto(6) +d(f') 86+0
Dto(8)= Dto(7) +d(g)=93+16=109 Dto(9)= Dto(8) +d(h)=109+31=140
Dto(10)= Dto(9) +d(i)=140+13=153 Date au plus tard (Dta) :
C'est la date à laquelle il faut impérativement
démarrer la tâche x si on veut terminer absolument le projet dans
sa durée minimale.
Sa formule est : dta(y)=Min dta(x)-d(i).
Calcul:
Dta(10)=153
Dta(9) = Dta(10)-d(i)=153-13=140
[34]
Dta(8) = Dta(9)-d(h)=140-31=109
Dta(7) = Dta(8)-d(g)=109-16=93
Dta(6) = Dta(7)-d(f)=93-7=86
Dta(6) = Dta(7)-d(f')=93-0=93
Dta(5) = Max Dta(6)-d(f)=Max 86-13=73
Dta(4) = Dta(5)-d(d)=73-24=49
Dta(3) = Dta(4)-d(c)=49-23=26
Dta(2) = Dta(3)-d(b)=24-19=7
Dta(1) = Dta(2)-d(a)=7-7=0
3.3.8. Détermination des marges
Marge libre : elle est le délai de la
mise en route de la tâche (i) sans compromettre la dto de l'étape
(y). elle se calcule par la formule :
ML(i)= Dto(y)-d(i),
Sur base de cette formule que nous allons chercher les marges
libre de nos tâches.
Calcul :
ML(a)=dto(2)-dto(1)-d(a)=7-0-7=0 tâche critique
ML(b)=dto(3)-dto(2)-d(b)=26-7-19=0 tâche critique
ML(c)=dto(4)-dto(3)-d(c)=49-26-23=0 tâche critique
ML(d)=dto(5)-dto(4)-d(d)=73-49-24=0 tâche critique
ML(e)=dto(6)-dto(5)-d(e)=86-73-13=0 tâche critique
ML(f)=dto(7)-dto(6)-d(f)=93-86-7=0 tâche critique ML
(f')=dto(7)-dto(6)-d(f')=93-86-0=7 tâche non critique
ML(g)=dto(8)-dto(7)-d(g)= 109-93-16=0 tâche critique
ML(h)=dto(9)-dto(8)-d(h)=140-109-31=0 tâche critique
Le chemin critique est celui qui relie toute les tâches
dont la marge totale (mt) est nul c'est-à-dire a, b, c, d,e,f, g, h,
i.
[35]
ML(i)=dto(10)-dto(9)-d(i)=153-140-13=0 tâche critique
Pour que nous puisons déterminer les chemins critiques,
lesquelles sont les chemins que nous allons suivre, il nous faut utiliser cette
formule (dta-dto).
Marge Totale: on appelle marge totale,
notée MT(i) le délai disposé pour la mise en route de la
tâche (i) sans modifier la dta de l'étape (y) (x) étant le
sommet initial de la tâche (i) et y son sommet terminal.
Sa Formule est :
MT(i)= dta(y)-dto(x)-d(i).
dta(y) est le sommet terminal, dto(x) est le
sommet initial.
Calcul:
MT(a)=dta(2)-dto(1)-d(a)=7-0-7=0
MT(b)=dta(3)-dto(2)-d(b)=26-7-19=0 MT(c)=dta(4)-dto(2)-d(c)=49-26-23=0
MT(d)=dta(5)-dto(3)-d(d)=73-49-24=0 MT(e)=dta(7)-dto(4)-d(e)=86-73-13=0
MT(f)=dta(6)-dto(5)-d(f)=93-86-7=0 MT(f')=dta(7)-dto(6)-d(f')=93-93-0=0
MT(g)=dta(8)-dto(7)-d(g)=109-93-16=0 MT (h)=dta(9)-dto(8)-d(h)=140-109-31=0
MT(i)=dta(10)-dto(9)-d(i)=153-140-13=0 NB: - Sidto et dta
c'est à dire si dto=dta alors l'étape est critique
- Lorsque la ML(i) est égale MT(i) alors la tâche
est critique.
3.3.9 Détermination du chemin critique

93
93
G
109 109
F
7
16
8
7
0
0 A 7 7
B
26 26
C 49 49 D 73
73 E
86
86
31
H
1
7 19
2 3
23
4
24
5
13
6
140
140
9
13
153 153
i
[36]
[37]
3.4. Diagramme de GANTT
Ce diagramme nous permet de déterminer les
différentes taches à réaliser et leurs durées,
à définir les relations d'antériorité entre ces
taches, de les représenter par un trait parallèle en
pointillé à la tache planifiée par la progression
réelle du travail.
Tableau 3 : Diagramme de Gantt
|
JA NVIER
|
FEVRIER
|
MARS
|
AVRIL
|
MAI
|
JUIN
|
|
12 15 18
|
06
|
10
|
25
|
01
|
15
|
25
|
07
|
14
|
30
|
05
|
15
|
31
|
01
|
13
|
25
|
|
A
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
B
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
C
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
D
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
E
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
F
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
G
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
H
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
I
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.4.1. Faisabilité financière
Tableau 4 : Estimation de durée et
cout.
|
TACHES
|
Libelle
|
TACHES
ANTERI
EURES
|
DUREE
/JOUR
S
|
NBRE COUT /$PERS.
|
|
A
|
Expression des besoins
|
|
7
|
200
|
|
B
|
Analyse de besoins
|
A
|
19
|
320
|
|
C
|
Etude de faisabilité
|
B
|
23
|
350
|
|
D
|
Elaboration du système
|
C
|
24
|
450
|
|
E
|
Construction du système
|
D
|
13
|
2550
|
|
F
|
Déploiement
|
E
|
7
|
1200
|
|
G
|
Test de l'application
|
e,f
|
16
|
2 50
|
|
H
|
Formation du personnel
|
G
|
31
|
1500
|
|
I
|
Livraison de l'application
|
H
|
13
|
2000
|
a) La durée d'exécution du projet est de 153 jours
qui est dta(10) et dto(10) ;
b) Le coût total du projet : 8820$
[38]
3.4.2. Calendrier d'exécution du
projet
Comme en témoigne bien le tableau ci-dessous qui
présente le planning de réalisation de notre projet, la
durée de réalisation de notre projet est de 153 jours à
dater du 12 Janvier au 13 Juin 2015.
Tableau 5 : Calendrier d'exécution du
projet
|
Date début exécution
|
TACHES
|
Date fin d'exécution
|
|
Le 12 Janvier 2015
|
A
|
Le 18 Janvier 2015
|
|
Le 18 Janvier 2015
|
B
|
Le 06 Février 2015
|
|
Le 06 Février 2015
|
C
|
Le 01 Mars 2015
|
|
Le 01 Mars 2015
|
D
|
Le 25 Mars 2015
|
|
Le 25 Mars 2015
|
E
|
Le 07 Avril 2015
|
|
Le 07 Avril 2015
|
F
|
Le 14 Avril 2015
|
|
Le 14 Avril 2015
|
G
|
Le 30 Avril 2015
|
|
Le 30 Avril 2015
|
H
|
Le 31 Mai 2015
|
|
le 31 Mai 2015
|
I
|
Le 13 Juin 2015
|
3.5. Modélisation fonctionnelle
3.5.1. Capture de besoins fonctionnels
Comme le montre la figure ci-dessous, la capture des besoins
fonctionnels est la première étape de la branche gauche du cycle
en Y.
Elle formalise et détaille ce qui a été
ébauché au cours de l'étude préliminaire. Elle est
complétée au niveau de la branche droite du Y par la capture des
besoins techniques et prépare l'étape suivante de la branche
gauche : l'analyse.12
12PASCAL R., UML 2 modéliser une
application Web, 4ème Ed. Eyrolles, Paris 2006.
[39]

a. Identification des acteurs
Un acteur représente un rôle joué par une
entité externe (utilisateur humain, dispositif matériel ou autre
système) qui interagit directement avec le système
étudié.
Un acteur peut consulter et/ou modifier directement l'état
du système, en émettant et/ou en recevant des messages
susceptibles d'être porteurs de données13.
Selon le professeur MVIBUDULU, les acteurs sont des
classificateurs qui représentent des rôles au travers d'une
certaine utilisation (cas) et non pas des personnes physiques.14

Acteur
Il existe en UML deux types d'acteurs qui sont :
Acteur principal : celui pour qui le cas d'utilisation produit
la plus-value métier. En conséquence, l'acteur principal est la
plupart du temps (mais pas forcément, comme dans le cas
précité des traitements batch) le déclencheur du cas
d'utilisation.
13PASCAL, R., UML 2 par la pratique étude
de cas et exercices corrigés, 5ème Ed. Eyrolles, Paris,
2008.
14MVIBUDULU, J. A., Cours de conception des
systèmes d'information, L2 Info, ISC-KIN, 2014-2015.
[40]
Acteurs secondaires : Sont des autres participants du cas
d'utilisation. Les acteurs secondaires sont typiquement sollicités
à leur tour par le système pour obtenir des informations
complémentaires.
Les acteurs ci-dessous ont été identifiés
pour notre système :
Utilisateur il peut être médecin ou tout
personnel du corps soignant.
Cogniticien
Administrateur : c'est généralement un
informaticien. Il aura comme tache la gestion de tous les utilisateurs.
b. Identification de cas d'utilisation
Un cas d'utilisation en anglais « use case
»représente un ensemble de séquences d'interactions entre le
système et ses acteurs.
Il est tout de même, l'expression d'un service
réalisé de bout en bout, avec un déclenchement, un
déroulement et une fin, pour l'acteur qui l'initie. On peut donc le
considérer comme une abstraction de plusieurs chemins d'exécution
d'une utilisation du système.
Il sied de rappeler que le diagramme de cas d'utilisation est
représenté par une ellipse à l'intérieur duquel un
verbe à l'infinitif.

Cas d'utilisation
Nous présentons dans le tableau ci-dessous les
différents acteurs et les cas d'utilisation de notre système.
[41]
Tableau 6 : Acteurs et cas d'utilisation
recensés.
|
Acteurs
|
Cas d'utilisation
|
|
Médecin
|
Etre consulté
|
|
Ajouter patient
|
|
Supprimer
|
|
Identifier maladie
|
|
Modifier
|
|
Identifier
|
|
Administrateur
|
Gérer utilisateurs
|
|
Ajouter utilisateur
|
|
Supprimer utilisateur
|
Les relations entre acteurs et cas
d'utilisation
Il est parfois intéressant d'utiliser des liens entre
cas (sans passer par un acteur), UML en fournit de deux types : la relation
utilise (include) et la relation étend (ex-tend).
Inclusion de cas (include) : La relation
d'inclusion (include) est employée quand deux cas d'utilisation ont en
commun une même fonctionnalité et que l'on souhaite factoriser
celle-ci en créant un sous cas, ou cas intermédiaire, afin de
marquer les différences d'utilisation.
Extension de cas (extend) :
Schématiquement, nous dirons qu'il y a extension d'un cas d'utilisation
quand un cas est globalement similaire à un autre, tout en effectuant un
peu plus de travail (voire un travail plus spécifique). Cette notion
à utiliser avec discernement permet d'identifier des cas particuliers
(comme des procédures à suivre en cas d'incident) dès le
début ou lorsque l'attitude face à un utilisateur
spécifique du système doit être spécialisée
ou adaptée. Il s'agit grosso modo d'une variation du cas d'utilisation
normale.
Généralisation :
[42]
3.5.1.1. Diagramme de cas d'utilisation
Le diagramme de cas d'utilisation sert à identifier les
utilisations du nouveau système. Autrement dit, il spécifie la
façon dont le système sera utilisé15. Il est en
essence un résumé du tableau des événements.
Ainsi, pour la compréhension de notre système, nous
représentons les différents acteurs et cas d'utilisations dans
les diagrammes de cas d'utilisation ci-dessous :
a. Cas d'utilisation pour la consultation

Figure 4 : Diagramme de C.U consultation
15JACKSON, SATZINGER ET BURD., Analyse et
conception de systèmes d'information, 2ème éd.
Goulet, Paris, 2003.
[43]
b. Cas d'utilisation pour la gestion des
utilisateurs

Figure 5 : Diagramme de C.U gérer utilisateur
Diagramme de cas d'utilisation globale
Tout ceci peut être représenté dans le
diagramme global ci-dessous :
[44]

Figure 6 : DCU globale.
3.5.1.1.1. Description de cas d'utilisation
Il s'agit ici de faire la description textuelle de chaque cas
d'utilisation i.e. associer à chaque cas d'utilisation un nom, un
objectif, les acteurs qui y participent, les pré-conditions et des
scénarii.
[45]
a. Cas d'utilisation « S'authentifier ))
Tableau 7 : Description du C.U « S'authentifier
))
|
Sommaire d'identification
|
|
Titre : s'authentifier
But : permet à chaque acteur muni d'un compte valide de se
connecter au système.
Acteurs : Utilisateurs, administrateur, cogniticien.
|
|
Enchainement
|
|
Pré conditions :
|
Post-Condition
|
|
Introduire login et mot de passe
|
l'utilisateur est connecté au
système
|
|
Scénario nominal
|
|
Ja: L'acteur se connecte au système moyennant son login et
son mot de passe.
1b : l'utilisateur annule l'authentification.
2: L'acteur saisit le login et le mot de passe.
|
|
Scenario alternatif
|
|
1a : le système affiche l'interface de connexion.
1b : le système ferme l'authentification du
système.
2 : - si le compte et le mot de passe saisis sont valides,
l'acteur accède au système et l'interface principale s'affiche
- Dans le cas contraire, l'accès est refusé et le
message J s'affiche.
|
[46]
b. Cas d'utilisation « consulter malade »
Tableau 8 : Description du C.U « consulter
malade »
|
Sommaire d'identification
|
|
Titre : But : Acteur
|
consulter malade.
diagnostiquer la maladie du patient. Médecin
|
|
Enchainements
|
|
Pré conditions :
|
Post-Condition
|
|
l'acteur s'authentifie au système
|
consultation effectuée.
|
|
Scénario nominal
|
1: L'acteur se connecte au système moyennant son login et
son mot de passe.
Jb : l'utilisateur annule l'authentification.
2: L'acteur saisit le login et le mot de passe
3 : le système affiche l'interface
4 : l'acteur enregistre les informations en rapport avec le
malade
5 : le système affiche le formulaire de recensement des
plaintes
6 : l'utilisateur rempli le formulaire puis valide.
7 : le système renvoie le résultat du diagnostic
puis prescrit le
médicament.
|
|
Scenario alternatif
|
|
Ja : le système affiche l'interface de connexion.
Jb : le système ferme l'authentification du
système.
2 : - si le compte et le mot de passe saisis sont valides,
l'acteur accède au système et l'interface principale s'affiche
- Dans le cas contraire, l'accès est refusé et le
message 1 s'affiche.
|
[47]
c. Cas d'utilisation « gérer utilisateurs
»
Tableau 9 : Description du C.U « gérer utilisateurs
»
|
Sommaire d'identification
|
|
Titre But
Acteur.
|
gérer utilisateurs
il assure la gestion de tout utilisateur du système. A ce
titre, il l'ajoute, le modifie ou le supprime.
Administrateur
|
|
Pré conditions :
|
Post-Condition
|
|
Introduire login et mot de passe
|
l'utilisateur est ajouté, supprimé ou
modifié
|
|
Scénario nominal
|
|
1a: L'acteur se connecte au système moyennant son login et
son mot de passe.
1b : l'utilisateur annule l'authentification.
2: L'acteur saisit le login et le mot de passe.
3 : le système affiche le formulaire de gestion des
utilisateurs.
4 : l'administrateur fait l'opération correspondante puis
valide
5 : le système enregistre les opérations
effectuées.
|
|
Scenario alternatif
|
|
1a : le système affiche l'interface de connexion.
1b : le système ferme l'authentification du
système.
2 : - si le compte et le mot de passe saisis sont valides,
l'acteur accède au système et l'interface principale s'affiche
- Dans le cas contraire, l'accès est refusé et le
message 1 s'affiche.
|
3.5.1.2. Diagramme de séquence
Un diagramme de séquence illustre la série
d'interactions qui se déroulent entre les objets durant le flux des
événements pour un scénario ou un cas d'utilisation. Il
comprend quatre symboles de base :
1. Le symbole d'acteur représenté par un bonhomme
stylisé ;
2. Le symbole d'objet, qui correspond à un rectangle
avec un nom souligné ;
3. Le symbole de ligne, représenté par une
ligne pointillé ou un rectangle vertical étroit et
4. Le symbole de message, désigné par une
flèche directionnelle avec un descripteur de message.
[48]
Ainsi donc, dans les lignes qui suivent nous
représentons les différentes interactions de notre système
dans les diagrammes de séquence ci-dessous.
a. Diagramme de séquence « s'authentifier
»

Figure 7 : Diagramme de séquence « s'authentifier
»
[49]
b. Diagramme de séquence « consulter malade
»

Figure 8 : Diagramme de séquence « consulter malade
»
[50]
c. Diagramme de séquence « gérer
utilisateurs »

Figure 9 : Diagramme de séquence « gérer
utilisateurs »
[51]
3.5.2. Capture des besoins techniques
A ce stade, il sied de s'intéresser à la branche
droite du cycle en Y qui est « la capture des besoins techniques »en
couvrant avec celle des besoins fonctionnels les contraintes qui ne traitent
pas la description applicative.
Nous choisissons lors de cette phase l'environnement de
travail ainsi que l'architecture globale utilisée pour notre
système.

Figure 10 : Situation de la capture des besoins
techniques dans 2TUP
I. Architectures Client/serveur
L'expression des besoins techniques implique également
le choix d'architecture. Ce choix est crucial puisqu'il intervient dans
l'évolutivité du système, le temps de
développement, le coût et les performances.
1.1 Architecture simple tiers
La conception de l'application est élaborée de
manière à fonctionner sur un ordinateur unique. En fait, tous les
services fournis par l'application résident sur la même machine et
sont inclus dans l'application.
[52]
Toutes les fonctionnalités sont donc comprises dans une
seule couche logicielle.

Figure 11 : Architecture simple tiers. 1.2 . Architecture
client/serveur
C'est une architecture 2-tiers appelée aussi
architecture client lourd/serveur. Elle est assez simple dans sa mise en
oeuvre. Ce type d'architecture est constitué uniquement de deux parties
: le «client lourd» demandeur de service d'une part et le
«serveur de données» qui fournit le service d'autre part.
Nous aurons donc la base de données qui sera
délocalisée sur un serveur dédié appelé le
serveur de données qui fournira les données à
exploiter.

Figure 12 : client-serveur
1.3 . Architecture trois tiers
Cette architecture physique est assez semblable à
l'architecture client/serveur, mais en plus des « clients» et du
serveur de données évoquées plus haut, un serveur
d'application intervient comme un troisième tiers. En effet, les
machines clientes, également appelées «clients
légers» ne contiennent que l'interface de l'application de
manière qu'elles déchargées de tout traitement.
[53]
En effet, le traitement est ainsi assuré par le serveur
d'application, qui sert de liaison entre l'interface applicative et les
données localisées au niveau du serveur de données.

Figure 13 : Architecture 3 tiers.
Pour ce qui est de notre système, nous avons
opté pour l'architecture client-serveur un-tiers.
2. Choix du langage de développement
Pour le développement de notre système d'aide
à la décision, nous optons pour le langage de programmation
Visual C#.
2.1. Présentation de Visual C#
Le C# est un langage de programmation orienté objet
à typage fort, créé par la société
Microsoft, et notamment un de ses employés du nom d'Anders Hejlsberg, le
créateur du langage Delphi pour la société Borland.
Il a été créé afin que la
plate-forme
Microsoft.NET soit dotée d'un
langage lui permettant d'utiliser toutes ses capacités. Il est
très proche du Java dont il reprend la syntaxe générale
ainsi que les concepts (la syntaxe reste cependant relativement semblable
à celle de langages C et C++). Un ajout notable au C# est la
possibilité de surcharge des opérateurs inspirés du C++.
Néanmoins, l'implémentation de la redéfinition est plus
proche de celle du Pascal objet. Sa plate-forme d'exécution est
Microsoft.NET.
[54]
3. Choix du SGBD
Pour le développement opérationnel de notre
système nous portons notre choix sur le SGBD Microsoft SQL Serveur dans
sa version 2008. Ce choix se justifie sur le fait que Microsoft SQL serveur est
un SGBD de type relationnel
[55]
CHAPITRE IV : ELABORATION DU SYSTEME
Tout au long de ce chapitre, il sera question de pouvoir
entamer la conception du système en présentant d'abord la vue
statique à travers le diagramme de classe comme objet de la
première section, puis la vue dynamique au moyen du diagramme
d'activités comme objet de la seconde section.
4.1. Développement du modèle
statique
Le développement du modèle statique constitue la
deuxième activité de l'étape d'analyse. Comme le montre la
figure ci-dessous, elle se situe sur la branche gauche du cycle en
Y16. Il permet de décrire les entités
concernées par l'automatisation. Ce système comprend plusieurs
diagrammes; pour notre cas, nous allons nous attarder sur le diagramme de
classe.
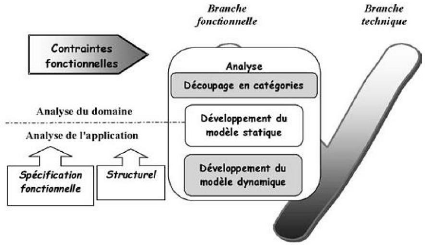
Figure 14 : Branche gauche du cycle en Y.
16ROQUES,P., VALLEE, F., UML 2 en action,
4ème Ed. Eyrolles, Paris 2007.
[56]
4.1.1. Diagramme de classe
Le diagramme de classes est le point central dans un
développement orienté objet. En analyse, il a pour objectif de
décrire la structure des entités manipulées par les
utilisateurs.
En conception, le diagramme de classes représente la
structure d'un code orienté objet ou, à un niveau de
détail plus important, les modules du langage de
développement.
Il exprime d'une manière générale la
structure statique du système en termes de classe et de relations entre
ces classes. Le diagramme de classes met en oeuvre des classes, contenant des
attributs et des opérations, et reliées par des associations ou
des généralisations.
a. Formalisme
Classe A
Attribut Attribut : Attribut
Méthodes
classe B
Attribut Attribut : Attribut
Méthodes

Association
b. Concepts
Etant le socle même d'UML, ci-dessous les différents
concepts liés à cette notion de classe :
? Classe : elle représente la description abstraite
d'un ensemble d'objets possédant les mêmes
caractéristiques. On peut parler également de type.
? Attributs : il s'agit de données, dont les valeurs
représentent l'état de l'objet.
? Méthode : ces sont des opérations applicables
aux objets.
? Association : une association représente une relation
sémantique durable entre deux classes.
[57]
4.1.1.1. Règle de gestion
Une règle de gestion décrit une condition
d'exécutions d'une action. Les règles de gestion ci-dessous ont
été recensées pour le développement de notre
système:
- Administrateur gère un ou plusieurs utilisateurs.
- Un utilisateur est géré par un et un seul
administrateur
- Le médecin assure un ou plusieurs diagnostics.
- Un diagnostic est assuré par un et un seul
médecin
- Diagnostic concerne un ou plusieurs patients.
- Un patient est concerné à un et un seul
diagnostic.
4.1.1.2. Identification de classes
Les classes ci-dessous ont été recensées
pour la présentation de notre diagramme de classe :
? Administrateur
? Médecin
? Utilisateur
? Diagnostic
? Patient
4.1.1.3. Dictionnaire de données
Nous présentons dans le tableau ci-dessous, les
différentes classes recensées sur base de la règle de
gestion ci-dessus, ses attributs et les structurer en taille et en type.
[58]
Tableau 10 : Dictionnaire de données.
|
N°
|
Attribut
|
Libellé
|
Type
|
Taille
|
|
1
|
id_util
|
Identifiant de
l'utilisateur
|
Chaine de caractère
|
8
|
|
Nom_utilis
|
Nom de l'utilisateur
|
Chaine de caractère
|
30
|
|
Pseudo_ut
|
Pseudo de l'utilisateur
|
Chaine de caractère
|
10
|
|
Mot_pass
|
Le mot de passe de l'utilisateur
|
Chaine de caractère
|
9
|
|
2
|
Matricule_med
|
Matricule du médecin
|
Chaine de caractère
|
5
|
|
Nom_med
|
Nom du médecin
|
Chaine de caractère
|
30
|
|
Spécialité_med
|
Spécialité du médecin
|
Chaine de caractère
|
25
|
|
Nationalite_me d
|
nationalité du médecin
|
Chaine de caractère
|
15
|
|
Téléphone_me d
|
Téléphone du médecin
|
Chaine de caractère
|
|
|
3
|
Id_admin
|
Identification de
l'administrateur
|
Chaine de caractère
|
5
|
|
Nom adm
|
Nom de l'administrateur
|
Chaine de caractère
|
30
|
|
Pseudo_Admin
|
Pseudo de
l'administrateur
|
Chaine de caractère
|
30
|
|
MotPasse_adm in
|
Mot de passe de
l'administrateur
|
Chaine de caractère
|
10
|
|
4
|
Numéro_diagn
|
Numéro du diagnostic
|
Chaine de caractère
|
10
|
|
Signes_vitaux
|
Signes vitaux
|
Chaine de caractère
|
300
|
|
Date_diagn
|
Date du diagnostic
|
Date
|
|
|
Observation
|
Observation
|
Chaine de caractère
|
40
|
|
5
|
CodeMal
|
Code malade
|
Chaine de caractère
|
8
|
|
NomMal
|
Nom du malade
|
Chaine de caractère
|
30
|
|
Sexe
|
Sexe du malade
|
Chaine de caractère
|
1
|
|
AgeMal
|
Age du malade
|
Chaine de caractère
|
10
|
|
Pouls
|
Pouls
|
Chaine de caractère
|
10
|
|
TensionArt
|
Tension artérielle
|
Chaine de caractère
|
10
|
|
Temperature
|
Température
|
Chaine de caractère
|
10
|
[59]
4.1.1.4. Présentation des classes
Nous présentons dans le tableau ci-dessus les
différentes classes identifiées ainsi que leurs attributs et
méthodes.
Tableau 11 : Liste des classes
|
N°
|
Nom de la classe
|
Attribut
|
Méthodes
|
|
1
|
Utilisateur
|
id_util
|
Avoir_accès Afficher() Supprimer ()
|
|
Nom_utilis
|
|
Pseudo_ut
|
|
Mot_pass
|
|
2
|
Médecin
|
Matricule_med
|
Consulter() Prescrire()
|
|
Nom_med
|
|
Spécialité_med
|
|
Nationalite_med
|
|
Téléphone_med
|
|
3
|
Administrateur
|
Id_admin
|
Avoir_accès() Modifier ()
|
|
Nom adm
|
|
Pseudo_Admin
|
|
MotPasse_admin
|
|
4
|
Diagnostic
|
Numéro_diagn
|
Afficher () Ajouter ()
Rechercher ()
|
|
Signes_vitaux
|
|
Date_diagn
|
|
Observation
|
|
5
|
Patient
|
CodeMal
|
Payer_consultation() Faire_examen
|
|
NomMal
|
|
Sexe
|
|
AgeMal
|
|
Pouls
|
|
TensionArt
|
|
Temperature
|
[60]
4.1.1.5. Association et Multiplicité
a. Association
Une association représente une relation
sémantique durable entre deux classes. Le modèle de
données d'UML comprend trois associations génériques
principales :
Généralisation, association, dépendance
à partir de ces trois associations de base, nous représentons
ainsi les différents types d'association qui décrivent les
dépendances entre les classe déjà citées.
Association simple : les associations simples
sont des liaisons logiques entre entités.
a. Les
cardinalités/Multiplicité
Le nombre d'association qui surviennent entre des
éléments spécifiques. Par exemple, un client peut passer
plusieurs commandes et un employé travaille dans un service.
Il sied toutefois de rappeler qu'à l'approche
orienté objet, on parle de multiplicité.
Le tableau ci-dessous illustre d'ailleurs les différentes
multiplicités : Tableau 12 : Multiplicités
|
Multiplicités
|
Désignation
|
|
1
|
Un et un seul
|
|
0...1
|
Zéro ou un
|
|
N
|
Entier naturel
|
|
m...n
|
De m à n (deux entiers naturels)
|
|
0...*
|
De 0 à plusieurs
|
|
1...*
|
De 1 à plusieurs
|
Tableau 14 : Diagramme de classe.
[61]
Nous représentons les différentes
multiplicités de notre système dans le tableau suivant :
Tableau 13 : Représentation des associations simples
|
N°
|
Désignation
|
Classes participantes
|
Cardinalités
|
|
1
|
Gérer
|
Administrateur-Utilisateurs
|
1..*-1
|
|
2
|
Ajouter
|
Administrateur-Médecin
|
1..* -1
|
|
3
|
Assurer
|
Diagnostic-Médecin
|
1..*-1
|
|
4
|
Créer
|
Administrateur-Médecin
|
1-1..*
|
|
5
|
Concerner
|
Diagnostic-Patient
|
1..*-1
|
Diagramme de classe
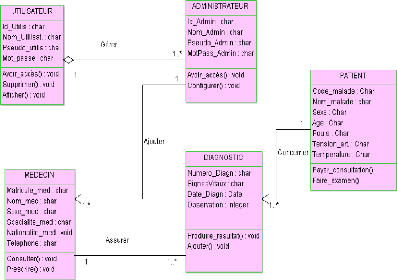
[62]
4.1.2. Règle de passage d'un diagramme de classe
vers un modèle relationnel.
Le passage d'un diagramme de classe vers un modèle
relationnel est rendu possible suivant un certain nombre des règles.
Parmi ces règles nous avons :
y' Toute classe du diagramme devient une table dans laquelle
les attributs deviennent les colonnes et choisir un attribut pour la
clé
y' Association 1.. : on ajoute un attribut de type clé
étrangère dans la relation fils de l'association. l'attribut
porte le nom de la clé primaire de la relation père de
l'association.
y' Association plusieurs vers plusieurs (*..*) : la classe
association devient une relation. La clé primaire de cette relation est
la concaténation des identifiants des classes connectées à
l'association.
y' Association 1..1 : il faut ajouter un attribut de type
clé étrangère dans la relation dérivée de la
classe ayant la multiplicité minimale égale à un.
L'attribut porte le nom de la clé primaire de la relation
dérivée de la classe connecté à l'association. Si
les deux multiplicités minimales sont à un, il est
préférable de fusionner les deux classes en une seules.
4.2. Développement du modèle
dynamique
Le développement du modèle dynamique constitue
la troisième activité de l'étape d'analyse. Elle se situe
sur la branche gauche du cycle en Y. Il s'agit d'une activité
itérative, fortement couplée avec l'activité de
modélisation statique, décrite au chapitre
précédent.
Le modèle dynamique montre les comportements du
système et l'évolution des objets dans le temps. Dans la
même perspective, son but c'est de trouver les relations temporelles et
évènementielles entre les objets.17
17MVIBUDULU, J.A Opcit P30.
[63]

4.2.1. Diagramme d'activités
Diagramme de flux de travaux qui décrit les
activités des utilisateurs et leur séquence de
déroulement.
Le diagramme d'activité permet de représenter le
déclenchement d'évènements en fonction des états du
système et de modéliser des comportements parallélisables.
Il donne une vision des activités propres à une opération
ou à un cas d'utilisation.
Il sied toutefois de rappeler qu'une activité est une
opération d'une certaine durée qui peut être
interrompue.
[64]
4.2.1.1. Diagramme d'activité «
s'authentifier »
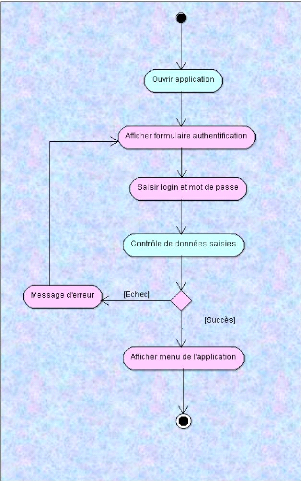
Figure n° 16 : Diagramme d'activité
s'authentifier
[65]
4.2.1.4. Diagramme d'activités « Consultation
»
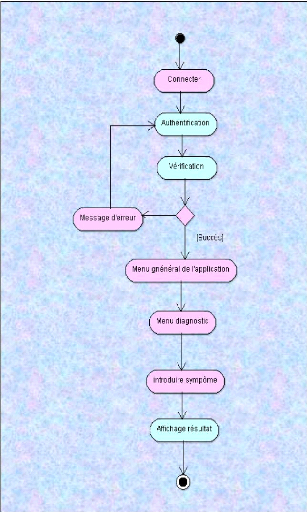
Figure n°17 : Diagramme d'activité « consulter
malade »
[66]
CHAPITRE V : CONSTRUCTION DU NOUVEAU SYSTEME
Le développement de ce chapitre sera centré sur
la modélisation de la base de connaissances qui fera l'objet de la
première section, implémentation de la base de connaissances
objet de la deuxième section et enfin la codification comme objet de la
troisième et dernière section.
5.1. Construction de la base de faits
Nous décrivons dans les lignes suivantes les
différents symptômes
(faits) :
F1 : Patient a une fièvre en plateau ;
F2 : patient a une asthénie physique ;
F3 : patient a un pouls élevé ;
F4 : patient a de l'anorexie ;
F5 : patient a une rate grossie inconstante ;
F6 : patient a de maux de tête intense ;
F7 : Patient a des douleurs abdominales ;
F8 : patient est dans la septicémie.
5.2. Construction de la base de
connaissances.
Il existe plusieurs modèles ou mécanismes de
représentation des connaissances d'un expert. Citons à titre
d'exemple, les règles de production, les objets, les réseaux
sémantiques, les graphes conceptuels, la logique avec le calcul de
prédicats, la logique floue, les réseaux bayésiens.
Dans le langage informatique, nous appellerons :
V' Clinique ou symptômes : Fait
V' Méthode de diagnostic : règle de production V'
Ensemble de méthodes ; base de règles
Pour ce qui nous concerne, puisqu'il s'agit d'une
décision médicale, nous utilisons dans le cadre de notre
diagnostic les modèles probabilistes notamment le réseau
bayésiens (RB) du fait que dans le
[67]
raisonnement de médecin plusieurs symptômes
identiques peuvent aboutir à des maladies différentes.
Le raisonnement médical part d'un examen clinique
cognitif qui est un ensemble de données interrogatoires. En effet,
à partir des symptômes observés(les signes cliniques), le
médecin identifie les facteurs prédisposant et sur la base
desquels plusieurs hypothèses sont établies.
5.2.1. Les réseaux bayésiens
Un réseau bayésien est en informatique et en
statistique un modèle graphique probabiliste qui aide à
gérer l'incertitude. Graphiquement, un réseau bayésiens
est une succession acyclique de noeuds, qui représentent des
états incertains de variables, reliées par des flèches qui
sont les relations de cause à effet entre les variables.
A chaque variable est associée une table contenant les
probabilités d'un nombre fini d'états mutuellement exclusifs. Si
un noeud ne possède pas de flèche entrante, alors la table
contiendra des probabilités non conditionnelles. Si par contre, il en
reçoit, il devient le noeud enfant d'un ou plusieurs parents, et la
table associée à ce noeud contiendra des probabilités
conditionnelles dépendantes des variables des noeuds parents.
Intuitivement, ils sont à la fois :
? des modèles de représentation des connaissances
;
? des « machines à calculer » les
probabilités conditionnelles ;
? une base pour des Système d'aide à la
décision.
En ce qui concerne notre diagnostic, il sera question de
décrire les relations causales entre variables d'intérêt
par un graphe. Dans ce graphe, les relations de cause à
effet entre les variables ne sont pas déterministes, mais
probabilistes. Ainsi, l'observation d'une cause ou de
plusieurs causes n'entraîne pas systématiquement l'effet ou les
effets qui en dépendent, mais modifie seulement la probabilité de
les observer.
L'intérêt particulier des réseaux
bayésiens est de tenir compte simultanément de connaissances a
priori d'experts (dans le graphe) et de l'expérience contenue dans les
données.
[68]
5.2.2. Construction et présentation du
modèle
Il existe trois méthodes de construction des
réseaux bayésiens18 que nous citons :
Automatique : elle est faite par application d'un algorithme
d`apprentissage à une base de données.
Manuel : à l'aide d'expert humain en l'occurrence les
médecins, les spécialistes en ingénierie de connaissances
interrogent les experts et ajoutent les noeuds, les liens, et les
probabilités conditionnelles au réseau sur la base de
connaissances recueillie.
Hybride : dans cette approche, la structure du réseau
est décrite avec l'aide des experts humains et les probabilités
sont obtenues à partir d'une base de données.
En ce qui nous concerne, puisqu'il s'agit d'un diagnostic
différentiel, le modèle a été construit suivant une
méthode manuelle, ce qui nous a permis d'entrer en contact avec les
experts du domaine notamment les médecins généralistes
dont : Dr Christian MPAMU et Jean-Jacques MUYEMBE Fils où nous
étions appelés à acquérir toutes les connaissances
en termes de symptômes et signes possibles de la maladie ainsi que ses
différentes probabilités.Nous même avons joué le
rôle d'ingénieur de connaissances, ce qui nous a d'abord
aidé à représenter ces différentes connaissances
par un graphe causal et pour cela nous avons fait appel au logiciel de
réseau bayésien Netica.
Nous présentons ci-dessous notre modèle
bayésien pour la
représentation de notre base de connaissances
18Patrick, N., Pierre-Henri, V., Philipp, L., Anna,
B., Réseaux bayésiens, Ed.
Eyrolles, Paris,2002.
[69]

Figure 18: Modèle bayésien construit sur Netica.
[70]
Le modèle ci-haut présenté nous aide
à représenter des connaissances qualitatives et quantitatives
exprimant l'incertitude pour le diagnostic de la fièvre typhoïde.
Chaque noeud du modèle est soumis à une certaine
probabilité dans la table, lesquelles probabilités nous ont
été donné par les experts du domaine que nous avons
cités plus haut. Ces différentes probabilités doivent
ainsi être évaluées.
5.1.3. Inférence du modèle
bayésien
L'inférence consiste à calculer la
probabilité d'un ou plusieurs noeuds du réseau bayésien
conditionnellement à un ensemble d'observation. Cette partie permet
d'évaluer, tirer ou contrôler les probabilités de la
distribution de probabilités postérieures. Elle sert à
fournir le résultat final du diagnostic par l'utilisation d'un
algorithme.
Il existe plusieurs algorithmes pour la mise en oeuvre du
réseau bayésien dans le cadre du diagnostic et plus
particulièrement le diagnostic médical, par exemple, la logique
floue, l'algorithme K2, IC, IC*, PC, MWST, pour ne citer que ceux-ci.
Pour ce qui nous concerne, nous appliquons l'algorithme
Pearl.
Algorithme Pearl
Il passe par deux étapes :
1. étapes de propagation : son principe est simple, il
fonctionne comme suit :
a. initialisation des probabilités des variables du
réseau.
b. Faire passer le message ð entre les variables du
réseau appelées autrement paramètres.
c. Chaque variable reçoit le message ð doit avoir
envoyé le message qui porte la probabilité du parent.
d. A la réception du message ð, les
récepteurs des messages des niveaux supérieurs mettent à
jour leurs probabilités puis ils recalculent le message ð pour
obtenir la probabilité actuelle par la formule suivante :
( ) ( ) ( )
e. le premier niveau calcule sa probabilité par la
formule :
( ) ( )
[71]
f. pour les valeurs du dernier niveau il n'y a pas de message
à envoyer, ils mettent à jour ses probabilités à la
lumière du message reçu.
2. Etape de recherche
Le point d'arrêt de l'étape de propagation
représente le point de départ pour l'étape de recherche
qui fournira le résultat final du diagnostic. Au dernier niveau on a le
résultat du diagnostic ayant la probabilité sachant les
observations.
( ( ))
Où M=maladie, e= évidence.
Dans notre cas, le réseau bayésien est sans
circuit, ce qui nous a permis d'utiliser l'algorithme d'inférence de
Pearl. Avec cet algorithme il est possible d'inférer la valeur n'importe
quelle variable du graphe. Ce qui donne des probabilités d'utilisation
plus adaptée.
5.2. Implémentation du modèle
Pour implémenter notre base de connaissance construit
au modèle bayésien, nous allons stockerles différents
noeuds sous forme d'arborescence, et cela avec le langage XML.
5.2.1. Le langage XML
L'Extensible Markup Language
(XML, (< langage à balise extensible
» en français) est un langage informatique de balisage
générique qui dérive du SGML. Cette syntaxe est dite (<
extensible » car elle permet de définir différents espaces
noms, c'est-à-dire des langages avec chacun leur vocabulaire et leur
grammaire, comme XHTML, XSLT, RSS, SVG... Elle est reconnaissable par son usage
des chevrons (< >) encadrant les balises.
L'objectif initial est de faciliter l'échange
automatisé de contenus
complexes (arbres, texte riche...) entre
systèmes
d'informationshétérogènes
(interopérabilité). Avec ses outils et langages associés,
une application XML respecte généralement certains principes :
? la structure d'un document XML est définie et validable
par un schéma;
[72]
? un document XML est entièrement transformable dans un
autre document XML.
5.2.2. Présentation des arborescences des noeuds
du modèle
<?xml version="1.0"encoding="iso-8859-1"?>
<thyphoide>
<fievre>
<plateau>
<probabilite>0.75</probabilite>
<etat1>oui</etat1> <etat2>non</etat2>
<pouls_eleve><probabilite>0.30</probabilite>
<etat1>oui</etat1>
<etat2>non</etat2>
</pouls_eleve>
<plus_15_jours>
<insomnie><probabilite> 0.25</probabilite>
<etat1>oui</etat1>
<etat2>non</etat2> </insomnie>
<maux_de_tete>
<probabilite>0.60 </probabilite>
<etat1>oui</etat1> <etat2>non</etat2>
</maux_de_tete>
<rate_grossie>
<probabilite>0.50</probabilite>
[73]
<etat1>oui</etat1> <etat2>non</etat2>
<inconstant><probabilite>0.40</probabilite>
<etat1>oui</etat1> <etat2>non</etat2>
</inconstant>
<constant><probabilite>0</probabilite>
<etat1>oui</etat1> <etat2>non</etat2>
</rate_grossie>
<asthenie><probabilite>0.50</probabilite>
<etat1>oui</etat1> <etat2>non</etat2>
</asthenie>
</plus_15_jours>
</plateau>
<sans_plateau>
<probabilite>0.10</probabilite>
<etat1>oui</etat1> <etat2>non</etat2>
<moins_15_jours><probabilite></probabilite>
<etat1>oui</etat1> <etat2>oui</etat2>
<anorexie>
<probabilite>0.05</probabilite>
<etat1>oui</etat1>
[74]
<etat2>non</etat2> </anorexie>
<asthenie>
<probabilite>0.75</probabilite>
<etat1>oui</etat1>
<etat2>non</etat2> </asthenie>
<maux_de_tete>
<probabilite>0.75</probabilite>
<etat1>oui</etat1> <etat2>non</etat2>
</maux_de_tete> </sans_plateau>
<douleur_abdominale>
<probabilite>0.75</probabilite>
<etat1>oui</etat1> <etat2>non</etat2>
</douleur_abdominale>
</fievre>
</thyphoide>
</?xml>
5.2.3. Quelques codes sources de l'application en
C#
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
[75]
using System.Data.SqlClient;
namespace FORM_MAJ_MALADE
{
public partial class Form5 : Form
{
private string INSERTSQL = "INSERT INTO [Patient] ([CodMal]
,[NomMal],[SexMal],[AgeMal],[Pouls],[TensArt],[Temperature])
"+
" VALUES
(@CodMal
,@NomMal,@SexMal,@AgeMal,@Pouls,@TensArt,@Temperature)";
private string UPDATESQL = "UPDATE [Patient]
SET
[NomMal]=@NomMal,[SexMal]=@SexMal,[AgeMal]=@AgeMal,[Pouls]=@P
ouls,[TensArt]=@TensArt,[Temperature]=@Temperature WHERE
[CodMal]=@CodMal ";
private string DELETESQL = "DELETE FROM [Patient] WHERE
[CodMal]=@CodMal";
private string SELECTSQL = "SELECT [CodMal]
,[NomMal],[SexMal],[AgeMal],[Pouls],[TensArt],[Temperature]FROM
[Patient]";
private string CONDITION = "WHERE CodMal=@CodMal";
private SqlConnection ConnexionBD= new SqlConnection("Data
Source=.;Initial Catalog=BDDSAD;Integrated Security=True");
public Form5()
{
InitializeComponent();
}
private void button1_Click(object sender, EventArgs e) {
if (txtCodeMalade.Text != "") {
using (SqlCommand cmd =new SqlCommand(INSERTSQL)){ cmd.Connection
= ConnexionBD;
cmd.Parameters.AddWithValue("@CodMal", txtCodeMalade.Text);
cmd.Parameters.AddWithValue("@NomMal", txtNomMalade.Text);
cmd.Parameters.AddWithValue("@SexMal", cboSexeMalade.Text);
cmd.Parameters.AddWithValue("@AgeMal", txtAgeMalade.Text);
cmd.Parameters.AddWithValue("@Pouls", txtPoulsMalade.Text);
cmd.Parameters.AddWithValue("@TensArt",
txtTempArtMalade.Text);
MessageBox.Show("Malade Modifie", "Information",
MessageBoxButtons.OK, MessageBoxIcon.Information);
[76]
cmd.Parameters.AddWithValue("@Temperature",
txtTemperatureMalade.Text);
if (cmd.ExecuteNonQuery() != 0) {
MessageBox.Show("Malade Enregistré",
"Information",
MessageBoxButtons.OK, MessageBoxIcon.Information);
clean();
}
}
}
else {
MessageBox.Show("Veuillez introduire le Code du Malade",
"Information", MessageBoxButtons.OK, MessageBoxIcon.Exclamation);
}
}
private void button2_Click(object sender, EventArgs e)
{
if (txtCodeMalade.Text != "")
{
using (SqlCommand cmd = new SqlCommand(UPDATESQL))
{
cmd.Connection = ConnexionBD;
cmd.Parameters.AddWithValue("@CodMal",
txtCodeMalade.Text);
cmd.Parameters.AddWithValue("@NomMal",
txtNomMalade.Text);
cmd.Parameters.AddWithValue("@SexMal",
cboSexeMalade.Text);
cmd.Parameters.AddWithValue("@AgeMal",
txtAgeMalade.Text);
cmd.Parameters.AddWithValue("@Pouls",
txtPoulsMalade.Text);
cmd.Parameters.AddWithValue("@TensArt",
txtTempArtMalade.Text);
cmd.Parameters.AddWithValue("@Temperature",
txtTemperatureMalade.Text);
if (cmd.ExecuteNonQuery() != 0)
{
I
[77]
clean();
I
I
I else
{
MessageBox.Show("Veuillez introduire le Code du Malade",
"Information", MessageBoxButtons.OK, MessageBoxIcon.Exclamation);
I
I
private void button3_Click(object sender, EventArgs e) {
if (txtCodeMalade.Text != "")
{
using (SqlCommand cmd = new SqlCommand(DELETESQL))
{
cmd.Connection = ConnexionBD;
cmd.Parameters.AddWithValue("@CodMal",txtCodeMalade.Text);
if (cmd.ExecuteNonQuery() != 0)
{
MessageBox.Show("Malade Supprimé", "Information",
MessageBoxButtons.OK, MessageBoxIcon.Information);
clean();
I
I
I
else
{
MessageBox.Show("Veuillez introduire le Code du Malade",
"Information", MessageBoxButtons.OK, MessageBoxIcon.Exclamation);
I
I
private void button4_Click(object sender, EventArgs e) {
this.Hide();
[78]
private void btnRechercher_Click(object sender, EventArgs e) {
if (txtCodeMalade.Text != "")
{
using (SqlCommand cmd =new SqlCommand(SELECTSQL +
CONDITION)){
cmd.Connection = ConnexionBD;
cmd.Parameters.AddWithValue("@CodMal", txtCodeMalade.Text);
SqlDataReader Rs = cmd.ExecuteReader(); if (Rs.Read()) {
txtNomMalade.Text = Rs.GetString(1); cboSexeMalade.Text =
Rs.GetString(2); txtAgeMalade.Text = Rs.GetString(3); txtPoulsMalade.Text =
Rs.GetString(4); txtTempArtMalade.Text = Rs.GetString(5);
txtTemperatureMalade.Text = Rs.GetString(6);
}else{
MessageBox.Show("Malade non Trouvé", "Information",
MessageBoxButtons.OK, MessageBoxIcon.Information);
}
}
}
else
{
MessageBox.Show("Veuillez introduire le Code du Malade",
"Information", MessageBoxButtons.OK, MessageBoxIcon.Exclamation); }
}
private void textBox1_TextChanged(object sender, EventArgs e)
{
}
private void label7_Click(object sender, EventArgs e) {
}
private void clean() {
txtCodeMalade.Text = "";
[79]
txtNomMalade.Text = "";
cboSexeMalade.Text = "";
txtAgeMalade.Text = "";
txtPoulsMalade.Text = "";
txtTempArtMalade.Text = "";
txtTemperatureMalade.Text = "";
I
private void Form5_Load(object sender, EventArgs e)
{
try {
ConnexionBD.Open();
I
catch (Exception ex) {
MessageBox.Show(ex.Message, "Error", MessageBoxButtons.OK,
MessageBoxIcon.Error);
I
I
I
I
[80]
CHAPITRE VI : TRANSITION
Ce chapitre sera tourné sur le déploiement de
l'application, ses différentes interfaces.
La phase de transition permet de faire passer le
système informatique des mains des développeurs à celles
des utilisateurs finaux.
6.1. Diagramme de déploiement
En UML, un diagramme de déploiement
est une vue statique qui sert à représenter
l'utilisation de l'infrastructure physique par le système et la
manière dont les composants du système sont
répartis ainsi que leurs relations entre eux. Les éléments
utilisés par un diagramme de déploiement sont
principalement les noeuds, les composants,
les associations et les artefacts.
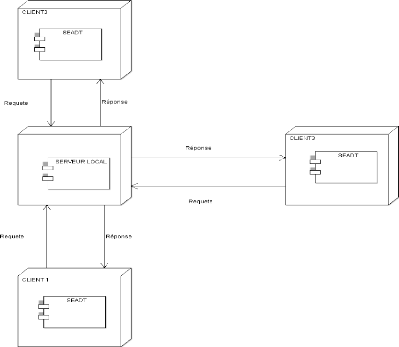
Figure n°19 : Diagramme de déploiement.
[81]
6.2. Présentation des quelques interfaces de
l'application
Nous présentons ici quelques interfaces de notre
application :
a. Interface d'authentification.
C'est une fenêtre qui permet aux utilisateurs de pouvoir
se connecter au système afin d'explorer toutes les options possibles de
l'application.
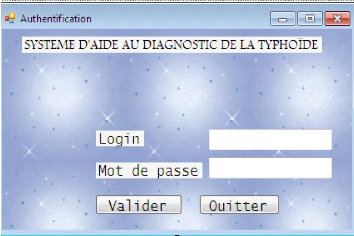
Figure n°20 : Fenêtre d'authentification.
b. Fenêtre d'enregistrement de
patients
Elle permettre au médecin d'enregistrer l'identité
du malade qui sera évidemment consulté.
[82]

Figure n°20 : Fenêtre d'enregistrement du patient.
c. Fenêtre de diagnostic
C'est cette fenêtre qui permet au médecin de
diagnostic les patients sur base de ses symptômes que ces derniers
répondront par vrai ou faux aux questions du médecin.
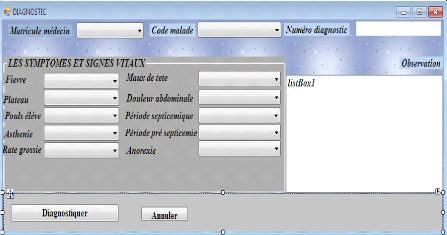
Figure n°22: Fenêtre du diagnostic.
[83]
CHAPITRE VII : CONCLUSION GENERALE
Nous voici arrivé au terme de ce travail qui a
porté sur la modélisation et l'implémentation d'un
système d'aide à la décision pour le diagnostic de la
fièvre typhoïde. A travers cette étude, notre souci majeur
était de chercher comment mettre au point un outil pouvant aider les
médecins à pouvoir décider à travers des
différents symptômes du diagnostic différentiel de la
fièvre typhoïde afin de prendre des mesures sévères
pour une bonne prise en charge de patients atteints par cette maladie.
Pour y parvenir, nous avons porté notre choix sur un
des modèles graphiques probabilistes notamment le réseau
bayésiens, ce qui nous a permis de pouvoir introduire les
différents symptômes de la maladie. Lesquels symptômes ont
été soumis à une certaine probabilité. Cette
méthode probabiliste nous a aidé à gérer
l'incertitude dans le diagnostic.
Dans le souci de mener à bien cette étude, nous
sommes allés d'une démarche très méthodique, en
commençant par une conception de notre application et cela avec le
recours de la méthode UP par une adaptation 2TUP ainsi que le langage
UML ce qui nous a permis d'avoir déjà une esquisse de
l'application qui a été mise au point.
Comme signalé plus haut, pour ce qui est du
modèle de notre base des connaissances, nous avons appliqué les
modèlesbayésiens dans sa méthode de construction
manuelle.Ce choix se justifie car comme d'aucuns pouvaient bien le constater
que dans un diagnostic, à partir des symptômes observés(les
signes cliniques), le médecin identifie les facteurs prédisposant
et sur la base desquels plusieurs hypothèses sont établies.
Le développement ou la mise en oeuvre de ce
système a fait recours à plusieurs outils ou technologies
notamment le langage de modélisation bayésien Netica qui nous a
aidé de construire la base de connaissance, le langage de programmation
C#, les documents XML pour présenter les différents noeuds que
propose le modèle sous formes d'arborescences, enfin en ce qui concerne
la partie opérationnelle de l'application nous avons utilisé le
SGBD Microsoft SQL Serveur 2008, un SGBD de type relationnel.
[84]
BIBLIOGRAPHIE
I. Ouvrages
1. BINDUNGWA, M., Comment élaborer un travail de fin
de cycle ? Contenu et étapes, éd. Médiaspaul,
Kinshasa 2008.
2. JACKSON, SATZINGER et BURD., Analyse et conception de
systèmes d'information, 2ème
éd. Goulet, Paris, 2003.
3. LERAY, P et GALLINARI, P., Architecture neuro
bayésien par le traitement spatioètemprel d'alarme, application
au diagnostic dans le réseau téléphonique, 1977.
4. MUKUNA, B., Essai méthodologique sur la
rédaction d'un travail scientifique, éd. CRIGED, Janvier
2006,
ISC/Kinshasa, p.28
5. PATRICK, N., PIERRE-HENRI, V., PHILIPP, L., ANNA, B.,
Réseaux bayésiens, Ed. Eyrolles, Paris, 2002.
6. R. LINDSAY, B. BUCHANAN, E.FEIGNBAUM., Application of
artificial intelligence toorganic chemistri : the dendra project, Mc
Graw-hill 1980.
7. RICH, E., Intelligence artificielle, Ed. Masson,
paris 1987.
8. ROQUES, P. et VALLEE, F., UML 2 en action de l'analyse
des besoins à la conception, Ed. EYROLLES, Paris, 2005,
9. ROQUES,P., VALLEE, F., UML 2 en action,
4ème Ed. Eyrolles, Paris 2007.
10. PASCAL, R., UML 2 par la pratique étude de cas
et exercices
corrigés, 5èmeEd. Eyrolles,
Paris, 2008.
[85]
II. Notes de cours
1. KUTANGILA, D., Intelligence artificielle et
systèmes experts approfondis, L1 Info, ISC-KIN, 2013-2014.
2. MVIBUDULU, J.A., Note de cours de théorie des graphes,
L2 Info, ISC, 2014-2015.
3. MVIBUDULU, J. A., Cours de conception des systèmes
d'information, L2 Info, ISC-KIN, 2014-2015.
III. Mémoires et Thèses
1. HEDIDAR , A., Conception et réalisation d'une
application mobile m-banking, mémoire, Université Virtuelle de
Tunis, 2011-2012.
2. DJEBBAR, A., « une modélisation de la base de
cas par un réseau bayésien ; application à l'aide du
diagnostic médical », Thèse de magister, Université
d'Annaba, 2006.
3. MUJINGA, S., Conception et réalisation d'un
système expert pour le diagnostic du cancer de la peau, Faculté
des sciences, Unikin, 2014.
[86]
Table des matières
IN MEMORIAM i
EPIGRAPHE ii
DEDICACE iii
REMERCIEMENTS iv
Liste de tableaux v
Liste de figures vi
Chapitre I : INTRODUCTION 1
1.1. Mise en contexte 8
1.2. Problématique 8
1.2.1. Objectif de la recherche Erreur ! Signet non
défini.
1.2.2. Questions de la recherche Erreur ! Signet non
défini.
1.3. Choix et intérêt du sujet Erreur !
Signet non défini.
1.4. Délimitation du travail 9
1.5. Méthode et techniques utilisées 10
a. Méthode 10
b. Techniques 10
1.6. Difficultés rencontrées 10
1.7. Canevas du travail 11
CHAPITRE II : APPROCHES THEORIQUES 12
2.1. Généralités sur l'intelligence
artificielle 12
2.1.1. Définition 12
2.1.2. Branches de l'intelligence artificielle 13
2.1.3. Avantages de l'IA 14
2.2. Le système expert 14
2.2.1. Introduction 14
2.2.2. Définition 14
2.2.3. Les acteurs 15
2.2.4. Architecture d'un système expert 15
2.2.5. Composants d'un système expert 16
[87]
2.2.6. Les apports des systèmes experts 18
2.2.7. Avantages des systèmes experts 19
2.2.8. Inconvénients du système expert 19
2.3. Le processus unifie (UP) 19
2.3.1. Les Principes d'UP 20
2.3.2. Les phases du processus unifie et les activités
21
2.3.3. Activités du processus 22
Expression des besoins 22
Analyse 23
Conception 23
Implémentation 23
Test 23
2.3.4. Adaptation du processus unifié 23
2.4. Généralités sur le langage UML 24
2.5. Le diagnostic de la fièvre typhoïde 26
2.5.1. Le diagnostic 26
2.5.2. La fièvre typhoïde 26
CHAPITRE III : SPECIFICATIONS DES BESOINS ET ETUDES DE
FAISABILITE
27
3.1. Narration 27
3.2. Etudes de faisabilité 27
3.2.1. Faisabilité fonctionnelle 27
3.2.2. Faisabilité opérationnelle 27
3.3. Choix de la méthode d'ordonnancement 28
3.3.1. Présentation de la méthode PERT 29
3.3.2. Identification et dénombrement des tâches
29
3.3.3. Planning d'exécution des taches et estimations
de durées. 30
3.3.4. Etablissement des liens d'antériorité
31
3.3.5. Détermination du niveau des graphes 31
3.3.6 Elaboration du graphe 32
3.3.7. Détermination des dates au plus tôt et au
plus tard 33
[88]
3.3.8. Détermination des marges 34
3.3.9 Détermination du chemin critique 35
3.4. Diagramme de GANNT 37
3.4.1. Faisabilité financière 37
3.4.2. Calendrier d'exécution du projet 38
3.5. Modélisation fonctionnelle 38
3.5.1. Capture de besoins fonctionnels 38
a. Identification des acteurs 39
b. Identification de cas d'utilisation 40
Les relations entre acteurs et cas d'utilisation 41
3.5.1.1. Diagramme de cas d'utilisation 42
a. Cas d'utilisation pour la consultation 42
b. Cas d'utilisation pour la gestion des utilisateurs 43
Diagramme de cas d'utilisation globale 43
3.5.1.1.1. Description de cas d'utilisation 44
a. Cas d'utilisation « S'authentifier » 45
b. Cas d'utilisation « consulter malade » 46
c. Cas d'utilisation « gérer utilisateurs »
47
3.5.1.2. Diagramme de séquence 47
a. Diagramme de séquence « s'authentifier »
48
b. Diagramme de séquence « consulter malade
» 49
c. Diagramme de séquence « gérer
utilisateurs » 50
3.5.2. Capture des besoins techniques 50
1. Architectures Client/serveur 51
2. Choix du langage de développement 53
2.1. Présentation de Visual C# 53
3. Choix du SGBD 54
CHAPITRE IV : ELABORATION DU SYSTEME 55
4.1. Développement du modèle statique 55
4.1.1. Diagramme de classe 56
a. Formalisme 56
[89]
b. Concepts 56
4.1.1.1. Règle de gestion 57
4.1.1.2. Identification de classes 57
4.1.1.3. Dictionnaire de données 57
4.1.1.4. Présentation des classes 59
4.1.1.5. Association et Multiplicité 60
a. Association 60
Diagramme de classe 61
4.1.2. Règle de passage d'un diagramme de classe vers
un modèle
relationnel. 62
4.2. Développement du modèle dynamique 62
4.2.1. Diagramme d'activités 63
4.2.1.1. Diagramme d'activité « s'authentifier
» 64
4.2.1.4. Diagramme d'activités « Consultation
» 65
CHAPITRE V : CONSTRUCTION DU NOUVEAU SYSTEME 66
5.1. Modélisation de la base de connaissances. 66
5.1.1. Les réseaux bayésiens 67
5.1.2. Construction et présentation du modèle
68
5.1.3. Inférence du modèle bayésien 70
Algorithme Pearl 70
5.2. Implémentation du modèle 71
5.2.1. Le langage XML 71
5.2.2. Présentation des arborescences des noeuds du
modèle 72
5.2.3. Quelques codes sources de l'application en C# 74
CHAPITRE VI : TRANSITION 80
6.1. Diagramme de déploiement 80
6.2. Présentation des quelques interfaces de
l'application 81
a. Interface d'authentification. 81
b. Fenêtre d'enregistrement de patients 81
c. Fenêtre de diagnostic 82
CHAPITRE VII : CONCLUSION GENERALE 83
[90]
BIBLIOGRAPHIE 84
I. Ouvrages 84
II. Notes de cours 85
III. Mémoires et Thèses 85
Table de matières 82
| 

