|
INTRODUCTION GENERALE
Depuis l'avènement relativement récent du
règne informatique, les systèmes matériels et logiciels
ont gagné régulièrement en complexité et en
puissance. Ils ont envahi toute notre vie quotidienne et sont désormais
incontournables dans la majorité des secteurs clefs de l'industrie. Peu
de domaines ont échappé à cette révolution au point
que la cohésion de nos sociétés fortement
industrialisées reposent sur la disponibilité des systèmes
complexes qui rythment notre activité de tous les jours : les
transactions bancaires, les télécommunications, l'audiovisuel,
internet, le transport de personne ou de bien (avion train ou voiture), les
systèmes d'informations des entreprises et les services fournis par ces
dernières, etc.
Produire les systèmes stables demande de passer
beaucoup de temps en études et en analyses. Heureusement, il existe des
techniques simples permettant de pallier à la fiabilité des
systèmes complexes, qu'ils soient matériels ou logiciels.
Plutôt que de chercher à rendre ces systèmes stables, on
peut inverser la démarche et intégrer à la source la
notion de panne dans l'étude de ces systèmes : si l'on peut
prévoir la panne d'un composant matériel ou logiciel, on peut
alors l'anticiper et mettre en oeuvre une solution de substitution. On parle
alors de disponibilité du service, voire de Haute Disponibilité
selon la nature de l'architecture mise en place
Aujourd'hui, la trop grande importance que
révèlent les services qu'on offre impose un certain niveau de
sécurité, les solutions de RAID et autres viennent se greffer
à des nouvelles solutions pour assurer une haute disponibilité
des services vitaux, car en effet très souvent d'énormes revenus
sont liés à la disponibilité plus ou moins parfaite de
certains services et ce, en fonction des domaines d'activités.
Voilà pourquoi dans ce présent travail nous
allons longuement parlé de la technologie de haute disponibilité
qui est le cluster d'équilibrage de charge réseau
I. PROBLEMATIQUE
La problématique est l'ensemble des questions
posées dans un domaine de la science, en vue d'une recherche des
solutions à un problème1(*)
La productivité au sein d'une structure
d'entreprise ou autres structures commerciales constituent une mesure de
l'utilisation efficace des facteurs de production, c'est-à-dire de
l'ensemble des moyens techniques, financiers et humains dont dispose cette
entité.
Cette productivité doit être optimale et
surtout ininterrompue ;
En effet, l'arrêt même momentané d'un
module du système d'informations peut paralyser le bon fonctionnement de
l'entreprise pendant la période de remise en production du maillon
manquant.
Par exemple, si le serveur de messagerie ne fonctionne
plus durant une demi-journée suite à un disque dur
défectueux, le temps de remplacer celui-ci et de faire la restauration ;
le service commercial ainsi que la direction sont dans l'incapacité de
répondre aux appels d'offres, le service clients ne peut plus faire le
suivi des réclamations, le service technique ne peut plus passer de
commandes aux distributeurs de matériels. La structure est
paralysée pour tous les échanges de courrier électronique,
qui représente un pourcentage conséquent de la gestion des
activités au sein d'une structure commerciale.
Comme conséquence, des contrats sont perdus, des
bénéfices sont en moins, des heures de travail sont perdues, des
sanctions pour l'équipe de commerciaux et pour le service informatique
peuvent aussi avoir lieu.
Conformément à tous ces problèmes,
nous nous sommes posé des questions qui suivent :
v Quelle technologie peut être mise en place pour
éviter ces genres de scénario catastrophe ?
v Comment faire pour s'assurer que cette technologie
réponde toujours aux critères de la haute disponibilité
des services ?
II. HYPOTHESES
Une hypothèse est, selon le dictionnaire Robert
Méthodique, une proposition relative à l'expression des
phénomènes naturels et qui doit être vérifié
par les faits2(*)
A ces préoccupations exprimées sous forme
des questions au niveau de la problématique, nous avons proposé
les réponses provisoires ci-dessous :
v La mise en place de la technologie du clustering
Network Load Balancing serait une solution pour assurer une haute
disponibilité sans interruption des services
v Pour s'assurer que cette technologie réponde
toujours aux critères de la haute disponibilité, il devrait
être administré et dépanner grâce à certains
utilitaires intégrés au système d'exploitation.
III. DELIMITATION DU SUJET
Toute observation scientifique exige de focaliser son
attention sur un objet en vue d'en tirer les bonnes impressions. Il serait donc
nécessaire que lorsque le sujet est défini, de limiter le cadre
de sa recherche.
Ainsi, pour éviter tout débordement, nous
avons délimité notre sujet dans le temps et dans
l'espace.
Du point de vue temporel, ce travail a été
effectué durant la période allant de Novembre 2015 et Juin
2016.
Du point de vue spatial, dans ce travail nous nous sommes
limités à parler uniquement sur la fonctionnalité de haute
disponibilité qui est le Cluster d'équilibrage de charge
réseau, NLB en sigle ; et cela à déployer à la
direction générale de l'Office Congolais
contrôle/Kinshasa.
IV. METHODES ET
TECHNIQUES
Pour arriver à la finalité de ce travail,
nous avons fait recours à certaines méthodes et techniques pour
la collecte et l'analyse de toutes nos données. Il s'agit ici
de :
v Technique d'observation :
qui nous a permit de constater de manière directe les faits ayant trait
à notre étude.
v L'interview : nous a
permit d'entrer en interaction verbale avec les personnes qui nous ont
accueillies sur notre site de recherche pour la collecte des
informations.
v Technique documentaire :
nous a permit de nous familiariser avec les différents manuels pour
trouver les données pouvant contribuer à l'enrichissement de ce
sujet.
v Méthode
structuro-fonctionnelle : nous a permit de rechercher
les impératifs fonctionnels et structurels pour maintenir
l'équilibre du système.
V. CHOIX ET INTERET DU SUJET
V.1 CHOIX
La chose qui nous a
poussé au choix de ce travail est la curiosité de savoir comment
pouvons-nous assurer dans une entreprise les services sans interruption afin de
gagner en temps et en revenu.
V.2 INTERET
Ce travail présente un intérêt non
négligeable du point de vue personnel et un autre, du point de vue
scientifique.
v Sur le plan personnel :
grâce à ce travail nous avons eu à développer plus
les connaissances en nous lançant dans la recherche des solutions de
haute disponibilité pouvant permettre à toute entreprise de
répondre favorablement aux attentes de ses clients.
v Sur le plan
Scientifique : ce travail va servir d'une base des
données aux futurs chercheurs à la compréhension de
fonctionnement des technologies pouvant assurer une haute disponibilité
en entreprise jusqu'à 99,99%
VI. DIFFICULTES
RENCONTREES
En effectuant nos recherches pour l'élaboration de
notre travail de fin de cycle, nous nous sommes heurtés à
certaines difficultés :
v La recherche documentaire a été
compliquée car nous n'avons pas pu avoir des documents suffisant pour
l'enrichissement de ce sujet. Cela se justifie par le manque des moyens
suffisants pour l'accession à des bibliothèques dans des
conditions normales.
v Les informations nous ont été
données après avoir souffert par des rendez-vous qui ne se
terminaient pas.
v L'indisponibilité des personnes qui devraient
toujours nous faire les informations dont nous avions besoin pour faire ce
travail.
VII. SUBDIVISION DU TRAVAIL
Hormis l'introduction générale et la
conclusion générale, ce travail est subdivisé en quatre
chapitres :
Le premier qui a été consacré
à des notions des généralités sur les
réseaux informatiques.
Le deuxième chapitre a présenté les
notions sur la fonctionnalité du clustering Equilibrage de charge
réseau.
Le troisième chapitre parle du site auquel nous
avons effectué nos recherches qui est l'office congolais de
contrôle.
Le dernier a montré les démarches pour
mettre en place la fonctionnalité du cluster NLB et comment
l'administrer et la dépanner en cas de nécessité.
CHAPITREN I : GENERALITES SUR
LES RESEAUX INFORMATIQUES
I.1 Introduction
Un système entant que dispositif ou une mise en
commun d'un certain nombre d'éléments ayant une fonction bien
déterminée a besoin d'un fonctionnement général de
tout ce qui le constitue pour arriver à sa finalité.
Et pourtant le réseau informatique entant que
système est constitué des plusieurs éléments tant
physiques que logiques qui sont obligés de collaborer afin de permettre
une communication.
Il est aussi un vaste domaine dont la compréhension
doit partir d'un certain nombre des concepts de base.
I.2 Définition des concepts
de base
I.2.1 Le réseau
C'est un ensemble d'objets interconnectés les uns
avec les autres et permet de faire circuler les éléments entre
chacun de ces objets selon les règles bien définies3(*).
I.2.2 Le réseau
informatique
C'est un ensemble des ordinateurs ou autres
équipements interconnectés entre eux afin d'échanger les
informations.
I.2.3 La communication
C'est le processus de transmission d'informations. Elle
est l'action de communiquer, de transmettre les informations ou des
connaissances à quelqu'un ou, s'il y a échange, de le mettre en
commun.
I.2.4
Télécommunication
Ce mot vient de la préfixe grecque
télé, signifiant loin, et du latin communicare, signifiant
partagé.
C'est une science qui s'intéresse à la
transmission des signaux à distance au moyen des supports de
transmission4(*).
I.2.5 La
télémaintenance
Elle consiste à prendre le contrôle d'un
ordinateur distant, généralement celui d'un utilisateur en
difficulté via le réseau local ou l'internet, afin d'effectuer
à distance certaines opérations sur cet ordinateur.
I.3 Les différents types
des réseaux informatiques
On peut regrouper les types des réseaux
informatiques selon plusieurs paramètres ou découpages parmi
lesquels le découpage géographique, fonctionnement,...
I.3.1 Découpage
Géographique
Nous allons ici présenter différents types
des réseaux informatiques selon ce découpage dont la subdivision
a été rendue possible suivant leurs tailles, débit ou aire
géographique.
Il en existe plusieurs qui se résument en trois
grandes catégories
Le réseau LAN (Local Area Network)
Ce type de réseau est encore appelé le
réseau local d'entreprise (RLE) ; C'est un ensemble d'ordinateur et
équipements reliés les uns aux autres dans un même
bâtiment ou des bâtiments différents mais ayant une aire
géographiquement proche (généralement pas plus de 10Km).
Ce genre de réseau est local
Le réseau MAN (Metropolitan Area Network)
Celui-ci fait allusion à l'interconnexion des
réseaux locaux se trouvant dans une ville ou dans une même
région. On fera ici usage des lignes du réseau public ou
privé pour permettre la liaison entre les sites. Les utilisateurs se
trouvant à des endroits géographiques différents pourront
partager les ressources comme s'ils étaient dans un LAN
Le réseau WAN (Wide Area Network)
Il s'agit ici d'un ensemble des réseaux locaux
interconnectés les uns aux autres sur un étendu national ou
international. Comme le MAN, il utilise aussi les lignes du réseau
public ou privé pour établir l'interconnexion entre les
différents LAN. Il est aussi appelé réseau étendu.
Au delà de ces trois grands types de réseau
selon le découpage géographique on peut encore trouver d'autres
types.
Le réseau PAN (Personnal Area Network)
C'est un réseau personnel qui peut s'étendre
sur un rayon de quelques 1O mètres. Ici nous trouvons les technologies
comme le Bluetooth pour faire l'échange des fichiers textes,
vidéo et audio,... entre deux ordinateurs, deux téléphones
mobiles ou un téléphone et un ordinateur.
I.3.2 Découpage
fonctionnement
Le réseau Intranet
C'est un réseau informatique utilisant les services
du protocole TCP/IP pour assurer la communication. C'est-à-dire un
réseau dont la configuration se fait sur base du protocole TCP/IP.
Le réseau Extranet
Celui-ci est un réseau Intranet auquel on ajoute
une connexion externe comme l'Internet.
L'Internet
C'est le réseau public mondial utilisant le
protocole de communication IP rendant les services comme le courrier
électronique, l'échange des fichiers, la discussion à
distance accessible au public
I.4 Les topologies
réseaux
Il existe des différentes sortes des topologies
réseaux mais qui sont groupés selon deux grands
types ;
1.4.1 La topologie physique
Celle-ci indique la façon dont les
différents équipements sont reliés dans un
réseau.
Cette topologie est subdivisée en plusieurs autres
dont les trois premières et les plus connues sont : la topologie en
bus, en étoile et en anneau
La topologie en Bus
Cette topologie se repose généralement sur
un câble coaxial sur lequel viennent se connecter des noeuds grâce
à des prises qu'on appelle T-connecteur, les BNC puis les terminaux
ayant tous 50 ohms de résistance sur les deux extrémités
du câble appelé terminator. Ici les ordinateurs sont liés
à une même et seule ligne de transmission.

Fig. I.1. Topologie en bus
La topologie en étoile

Dans un réseau en étoile, les ordinateurs
sont reliés sur un point central qui peut être un concentrateur
(hub) ou un commutateur (Switch) possédant des ports RJ45 capables de
recevoir un câble à double paire torsadée pouvant assurer
la liaison entre un noeud et un point central et puis entre le point central et
les noeuds.
Fig. I.2. Topologie en
étoile
La topologie en anneau
Dans la topologie en anneau, les ordinateurs sont
reliés à un répartiteur appelé MAU qui va
gérer la communication entre les PC qui lui sont reliés en
impartissant à chacun d'eux un temps de parole. C'est-à-dire que
les ordinateurs communiquent chacun à son tour

Fig. I.3. Topologie en anneau
I.4.2 La topologie logique
Cette topologie nous indique la façon dont
les informations circulent ou sont transmises dans un réseau. Bref,
définit comment se passe la communication dans la topologie
physique5(*)
Le réseau Ethernet
Cette famille de réseau repose sur la
méthode d'accès multiple et écoute de la porteuse par
détection de collision appelé CSMA/CD6(*).
Cette architecture a plusieurs
caractéristiques parmi lesquelles nous pouvons citer : le
débit de 10 Mbits à 1 Gbits/s, la transmission en bande basse,
topologie en bus ou en étoile, support de type de câble coaxial,
paire torsadée ou fibre optique.
Le réseau Token ring
Ce type de réseau intervient dans
l'interconnexion de deux réseaux en anneau à travers des ponts
qui permettent de relier les différents réseaux venant des
topologies différentes ou des routeurs différents. Ici chaque
ordinateur intervient grâce à son jeton qui lui est
attribué et selon le principe qu'aucun jeton ne doit circuler deux fois
de suite avec le même niveau de priorité7(*).
I.5 Les méthodes
d'accès
Il existe plusieurs méthodes
d'accès qui permettent de réglementer la circulation des
données dans un réseau et partager les informations entre
ordinateurs du réseau
I.5.1 Méthode TDMA (Time
Division Multiplexing Access)
C'est une méthode selon laquelle le temps
est divisé en tranche attribué à chacun des noeuds
c'est-à-dire qu'une station peut émettre des messages pendant le
temps qui lui est attribué. Ici il n'existe pas des collisions.
I.5.2 CSMA/CD (Carrier Sense
Multiple Access with Collision Detect)
Elle est encore appelée la méthode
d'écoute de la porteuse. C'est la méthode la plus simple par sa
façon de fonctionner. Ici plusieurs stations peuvent tenter
simultanément d'accéder au port, si le réseau est
occupé la station va différer le message et dans le cas
contraire, il passe directement.
I.5.3 La méthode de
jeton
Cette méthode est souvent utilisée
dans la topologie en anneau et en bus. Le jeton a deux états
différents qui sont l'état libre et l'état
occupé
Elle consiste donc à ce que le jeton passe
devant une station et doit être mis en route munie d'une adresse et d'un
message qui doit parcourir toutes les stations qui jouent le rôle des
répétiteurs car ils génèrent le signal
capté.
I.6 Architectures
réseau
Une architecture d'un réseau est la
représentation structurelle et fonctionnelle d'un réseau
informatique. Il en existe deux types entre autre l'architecture poste à
poste et celle client-serveur
I.6.1 L'architecture poste
à poste
C'est un réseau qui ne nécessite pas
la présence d'un serveur dédié. Elle est constituée
de deux ou plusieurs ordinateurs interconnectés où chaque machine
est maître de ses ressources et peut être lui-même
considéré comme un serveur (non dédié)
Son avantage est qu'il a un coup réduit, une
simplicité et une rapidité d'installation
Il présente des failles comme la
sécurité très faible, la maintenance du réseau
difficile, manque de fiabilité,...
I.6.2 L'architecture
client-serveur
C'est une architecture dans laquelle nous avons un
poste central qui est un serveur qui gère le réseau avec toutes
ses ressources. Avec cette architecture nous avons une meilleure
sécurité et un accroissement d'interchangeabilité, une
unicité d'information, une meilleure fiabilité du
réseau.
Son seul inconvénient est qu'il est d'un
coup élevé côté bande passante,
câbles,...
I.7 Les Equipements d'un
réseau informatique
I.7.1 Ordinateur
C'est une machine automatique de traitement de
l'information permettant de conserver, d'élaborer et de restituer des
données sans intervention humaine en effectuant sous le contrôle
de programmes enregistrés des opérations arithmétiques et
logiques8(*).

Fig. I.4. Ordinateur
1.7.2 Serveur
C'est un ordinateur puissant choisit pour coordonner,
contrôler et gérer les ressources d'un réseau. Il accomplit
une opération sur demande d'un client et lui transmet le
résultat. Il est la partie de l'application qui offre un service, il
reste à l'écoute des requêtes du client et répond au
service demandé par lui9(*)

Fig. I.5. Serveur
I.7.2.A Type des serveurs
On distingue des serveurs dédiés et des
serveurs non dédiés
Le serveur dédié c'est un ordinateur
spécialisé qui ne peut pas exécuter des applications comme
client mais qui est optimisé pour répondre à des
requêtes. Il est conçu pour fonctionner spécialement comme
serveur.
Le serveur non dédié c'est un ordinateur
dans son environnement poste-à-poste qui peut à la fois
être utilisé comme client ou comme serveur.
I.7.2.B Caractéristiques des serveurs
Le serveur peut présenter plusieurs
caractéristiques internes qu'externes. Nous pouvons citer :
v Technologie de disque dur
spécifique ;
v Sécurisation des données en cas de crash
disk avec disques configurés en RAID ;
v Sauvegarde quotidienne des données par bande ou
disque dur externe ;
v Périphériques internes remplaçable
à chaud ;
I.7.2.C Fonction ou rôles d'un serveur
v Serveur de fichier : permet de distribuer les
fichiers aux clients qui les demandent
v Serveur de base des données : c'est un
serveur capable de traiter les requêtes des plusieurs ordinateurs clients
simultanément et permet aux utilisateurs de gérer une grande
quantité d'informations.
v Serveur d'impression : il travaille en accord avec
le serveur des fichiers en stockant localement les travaux d'impression en
attente.
v Serveur de messagerie : il centralise la gestion
des messages électroniques dans un réseau.
v Contrôleur de domaine : il centralise la
gestion des comptes utilisateurs dans un réseau.
v Serveur DHCP : il gère les adresses IP d'un
réseau.
1.7.3 Le concentrateur (Hub)
C'est un matériel du réseau qui permet la
connexion des plusieurs noeuds sur un même point d'accès en se
partageant la bande passante totale. Il est un simple répéteur
des données ne permettant pas la protection des données et
dépourvue de la confidentialité.
Il est caractérisé par la bande passante, le
nombre des ports, le débit, la tension qu'il utilise,...

Fig. I.6. Concentrateur (Hub)
I.7.4 Le commutateur
Un Switch ou commutateur est un dispositif
électronique permettant de créer un réseau informatique
local de type Ethernet.
Ce dispositif est dit intelligent par opposition au hub
car, alors que ce dernier fait transiter les données par toutes les
machines, le Switch permet de diriger les données uniquement vers la
machine destinataire en mémorisant les adresses MAC de chaque
hôte. Cette adresse est l'identifiant d'une carte réseau et est
représentée sur six octets en hexadécimal

Fig. I.7. Commutateur
I.7.5 Le routeur
C'est un équipement du réseau qui permet
d'effectuer le routage des paquets. Lorsqu'il reçoit un paquet, il
consulte sa table de routage pour choisir à partir de l'adresse de
destination, vers quelle interface et donc vers quel réseau il va
diriger le paquet pour le rapprocher de sa destination. Grâce au routeur
il ya une optimisation des transmissions entre réseaux ou
sous-réseaux.
I.7.6 La carte réseau
La carte réseau est aussi appelée NIC en
anglais, pour Network Interface Card. C'est le composant le plus important,
elle est indispensable car c'est par elle que transitent toutes les
données à envoyer et à recevoir du réseau dans un
ordinateur. Elle a un identifiant unique que lui attribue son fabriquant qui
est un adresse MAC et c'est grâce à cette dernière qu'un
ordinateur communique en réseau10(*).
I.7.7 Le modem
Le modem signifiant modulateur-démodulateur est un
équipement réseau qui transforme les données
numériques émises sur le port en données analogiques qui
peuvent être envoyées sur une ligne11(*).
I.8 Les supports de
transmission
Un support de transmission est un canal physique qui,
grâce à lui on peut faire circuler les informations dans un
réseau. Il en existe deux types : les supports limités ou
câblés et les supports non limités ou sans fils.
I.8.1 Les supports
limités
Ce sont des supports palpables qu'on peut voir, qu'on peut
toucher et qui conduisent un signal électrique ou lumineux.
Le câble coaxial
C'est un câble qui intervient pour connecter un
réseau informatique de topologie physique en bus ou pour connecter une
antenne et un modem. Il est constitué d'une partie centrale qui est un
fil de cuivre appelé âme enveloppé dans un isolant puis
d'un blindage métallique tressé et enfin d'une gaine qui permet
de protéger le câble de l'environnement extérieur.
Le câble à paire torsadée
Il est encore appelé câble à double
paire torsadée. Il décrit un modèle un modèle du
câblage où une ligne de transmission qui est constitué de
deux brins de cuivre entrelacés en torsade est recouverte d'isolants.
La configuration présente sert à maintenir
précisément la distance entre les fils qui permet à son
tour de définir une impédance caractéristique de la paire
afin de supprimer les réflexions des signaux aux raccords et en bout de
ligne.
Il existe deux types des câbles à paire
torsadée parmi lesquels nous avons les UTP qui sont dépourvue
d'un blindage protecteur et sont utilisés à l'intérieur du
bâtiment. Nous avons aussi les STP qui sont pourvu d'un e couche
conductrice de blindage pour permettre une meilleure protection contre les
interférences.
La fibre optique
C'est un support de transmission qui véhicule une
information en forme lumineuse. Il nécessite un émetteur et un
récepteur optique.
Ce support a plusieurs avantages parmi lesquels la vitesse
est élevée, bonne qualité de la transmission avec l'ordre
de 1Ghz pour 1km, très souple.
Son seul et unique inconvénient réside au
niveau de son déploiement. Il y a beaucoup de difficultés de
raccordement12(*).
Les faisceaux Hertziens
Ces genres de supports sont utilisés pour des
communications interurbaine et cela pour une portée de 50 à 100
Km.
Les faisceaux hertziens utilisent les antennes
d'émissions et de réception qui doivent être en
visibilité directe.
Pour une bonne connexion il faut placer une antenne
après chaque 50 à 60 Km13(*).
I.9 Les protocoles de
communication14(*)
La transmission d'une information d'un émetteur
vers un récepteur nécessite un ensemble des
éléments tant physique que logique qui sont d'un rôle
important pour l'organisation et la sécurité de ces
données. Ces données pour être transférées
doivent circuler dans des supports de transmission par le moyen de certaines
procédures ou certains protocoles qui font partie des
éléments logiques.
Un protocole est un ensemble de règles qui
définissent comment se produit une communication dans un
réseau15(*)
I.9.1 Le protocole TCP/IP
C'est une suite protocolaire signifiant Transmission
Control Protocol/Internet Protocol qui provient de noms des deux protocoles
majeures TCP et IP. Il présente la façon dont les ordinateurs
communiquent sur internet en se basant sur l'adressage IP.
A ses origines, le protocole TCP/IP a été
crée pour un but militaire et sa connaissance est nécessaire pour
les personnes désirant administrer ou maintenir un réseau
fonctionnant dans un système de TCP/IP.
La suite protocolaire TCP/IP assure des rôles en
commun qui peuvent être résumés de la façon
ci-dessous :
v Le transfert des fichiers
v La connexion interactive à distance
v La messagerie électronique
v Le système de fichiers répartis
v L'impression à distance
v L'exécution à distance
v Les serveurs des noms
v Les serveurs des terminaux
v Le système de fenêtrage orienté
réseau
Au-delà de ces rôles qu'ils assurent en
commun, chacun d'eux a ses rôles spécifiques dont en voici pour
chacun
Le protocole TCP
La transmission Control Protocol est un protocole fiable
de transmission en mode connecté qui assure les rôles particuliers
ci-dessous :
v L'établissement d'une connexion
v Le transfert des données
v Les numéros de séquence et
d'acquittement
v La temporisation
v Le contrôle des flux
v Le contrôle de congestion
v La terminaison d'une connexion
Le protocole IP
Internet Protocol est un protocole réseau qui
définit le mode d'échange élémentaire entre les
ordinateurs participants au réseau en leur donnant une adresse unique
sur le réseau.
Ce protocole a connu une évolution en deux versions
différentes :
Le protocole IPV4
C'est un protocole qui traite de l'adressage, du routage
des paquets, de la fragmentation puis du réassemblage des
paquets.
L'IPV4 est la première version d'IP à avoir
été largement déployée et forme encore la base de
l'internet. Il utilise une adresse IP sur 32bits reparties en 4champs de
8bits.
Un adressage IP codé sur 4 octets se
décompose en un numéro de réseau et un numéro de
noeud au sein de ce réseau afin de s'adapter aux différents
besoins des utilisateurs.
Il a la forme X.X.X.X où chaque X représente
8bits en notation décimale pointée de 0 à 255.
Il utilise cinq classes différentes : A, B, C,
D et E. seules les trois premières sont utilisées en
production.
v Classe A : varie entre 1 et 126 et a un masque
255.0.0.0
v Classe B : varie entre 128 et 191 et a un masque
255.255.0.0
v Classe C : varie entre 192 et 223 et a un masque
255.255.255.0
v Classe D : varie entre 224 et 239
v Classe E : varie entre 240 et 255
Le protocole IPV6
C'est le successeur du protocole IPV4. Il permet
d'utiliser un peu plus de 4 milliards d'adresses différentes pour
connecter les ordinateurs et les autres appareils reliés au
réseau. Il utilise à son tour une adresse IP longue de 128bits
répartis en 16 Octets.
Il abandonne la notation décimale pointée
employée pour les adresses IPV4 au profit d'une écriture
hexadécimale où les 8 groupes de 16 Octets sont
séparés par un signe de deux points :
X:X:X:X:X:X:X:X où chaque X représente 16
bits.
I.10 Le modèle de
référence OSI16(*)
Le modèle OSI (Open Systems Interconnection
: « interconnexion de systèmes ouverts ») est une
façon standardisée de segmenter en plusieurs blocs le processus
de communication entre deux entités. Chaque bloc résultant de
cette segmentation est appelé couche. Une couche est un ensemble de
services accomplissant un but précis. La beauté de cette
segmentation, c'est que chaque couche du modèle OSI communique avec la
couche au-dessus et au-dessous d'elle (on parle également de couches
adjacentes). La couche au-dessous pourvoit des services que la couche en cours
utilise, et la couche en cours pourvoit des services dont la couche au-dessus
d'elle aura besoin pour assurer son rôle.
Ainsi le modèle OSI permet de comprendre de
façon détaillée comment se passe la communication entre un
ordinateur A et un ordinateur B.
En effet, il se passe beaucoup de choses dans les
coulisses entre l'instant t, où on, a envoyé une
information et l'instant t1, où le destinataire le
reçoit.
Voilà pourquoi le modèle OSI a
segmenté la communication en 7 couches différentes qui
sont :
v Application
v Présentation
v Session
v Transport
v Réseau
v Liaison des données
v Physique
Expliquons comment fonctionnent ces différentes
couches lorsqu'on veut par exemple envoyer un mail à son
ami :
g. Couche applicative
Vous avez besoin d'accéder aux services
réseaux. La couche applicative fait office d'interface pour vous donner
accès à ces services, qui vous permettent notamment de
transférer des fichiers, de rédiger un mail, d'établir une
session à distance, de
visualiser une page web... Plusieurs protocoles assurent
ces services, dont FTP (pour le transfert des fichiers), Telnet (pour
l'établissement des sessions à distance), SMTP (pour l'envoi d'un
mail), etc.
f. Couche présentation
Elle s'occupe de la sémantique, de la syntaxe, du
cryptage/décryptage, bref, de tout aspect « visuel » de
l'information. Un des services de cette couche, entre autres : la conversion
d'un fichier codé en EBCDIC vers un fichier codé en ASCII.
Certains protocoles, tels que le HTTP, rendent la distinction entre la couche
applicative et la couche de présentation.
e. Couche session
Une fois que vous êtes prêt(e) à
envoyer le mail, il faut établir une session entre les applications qui
doivent communiquer. La couche session du modèle OSI vous permet
principalement d'ouvrir une session, de la gérer et de la clore. La
demande d'ouverture d'une session peut échouer. Si la session est
terminée, la « reconnexion » s'effectuera dans cette
couche.
d. Couche transport
Une fois la session établie, le mail doit
être envoyé. La couche de transport se charge de
préparer le mail à l'envoi. Le nom de cette
couche peut prêter à confusion : elle n'est pas responsable du
transport des données proprement dit, mais elle y contribue.
En fait, ce sont les quatre dernières couches
(transport, réseau, liaison de données et physique) qui toutes
ensemble réalisent le transport des données. Cependant, chaque
couche se spécialise. La couche de transport divise les données
en plusieurs segments (ou séquences) et les réunit dans la couche
transport de l'hôte récepteur. Cette couche permet de choisir, en
fonction des contraintes de communication, la meilleure façon d'envoyer
une information.
La couche de transport modifie également
l'en-tête des données en y ajoutant plusieurs informations, parmi
lesquelles les numéros de ports de la source et de la destination. Le
protocole TCP (Transmission Control Protocol) est le plus
utilisé dans la couche de transport.
c. Couche réseau
Maintenant que nous savons quel numéro de port
utiliser, il faut aussi préciser l'adresse IP du récepteur. La
couche réseau se charge du routage des données du point A au
point B et de l'adressage. Ici aussi, l'en-tête subit une modification.
Il comprend désormais l'en-tête ajouté par la couche de
transport, l'adresse IP source et l'adresse IP du destinataire. Se fait
également dans cette couche le choix du mode de transport (mode
connecté ou non connecté). Le protocole le plus utilisé
à ce niveau est bien sûr le protocole IP.
b. La couche liaison
Ici on doit s'assurer si certaines opérations sont
déjà effectuées entre autre :
Présentation effectuée ? O.K.
Session établie ? O.K.
Transport en cours ? O.K.
Adresses IP précisées ? O.K.
Il reste maintenant à établir une liaison
« physique » entre les deux hôtes. Là où la
couche réseau effectue une liaison logique, la couche de liaison
effectue une liaison de données physique.
Elle fragmente les données en plusieurs trames, qui
sont envoyées une par une dans un réseau local
a. La couche physique
Notre mail est en cours de transport, mettons-le sur le
média. La couche physique reçoit les trames de la couche de
liaison des données et les « convertit » en une succession de
bits qui sont ensuite mis sur le média pour l'envoi. Cette couche se
charge donc de la transmission des signaux électriques ou optiques entre
les hôtes en communication.
CONCLUSION PARTIELLE
En guise de cette partielle conclusion, nous avons
présenté dans le présent chapitre quelques notions de base
sur les réseaux informatiques où nous avons parlé des
différents équipements qui doivent être utilisés
suivant certaines topologies et avons expliqué par un bref exemple
comment une information envoyée sur un réseau passe les
différentes couches du modèle OSI avant d'arriver à
destination.
CHAPITRE II : PRESENTATION DU
CLUSTER D'EQUILIBRAGE DE CHARGE RESEAU
II.1 Idée
générale sur le cluster
II.1.1 Définition
Un cluster est un ensemble des serveurs
indépendants qui fonctionnent ensemble pour augmenter la
disponibilité de services et d'applications sur un réseau
informatique17(*)
Les services notamment sur internet nécessitent une
montée équivalente au nombre grandissant d'utilisateurs leur
faisant appel. Pour assurer cette montée et garantir une
disponibilité de ces services, plusieurs méthodes étaient
envisageables entre autre la mise jour de l'architecture matérielle
afin d'augmenter la puissance de traitement de la machine, l'augmentation du
nombre d'ordinateurs exécutant le service en utilisant un processus
permettant l'équilibrage de la charge de travail. Aujourd'hui plusieurs
technologies sont venues pour faciliter cela, rendant ainsi ces services
disponibles parmi lesquelles nous pouvons citer la répartition de charge
réseau (Network Load Balancing), le basculement automatiques des
requêtes entre les noeuds d'une même grappe, qui sont des
éléments importants lors de la mise en place des services
amenés à croître.
La recherche dans ce domaine est trop poussée avec
un marché représentant le 3 ou 4% de la vente des serveurs ces
dernières années permettant ainsi de satisfaire les
énormes besoins de performances, d'évolutivité et de
disponibilité.
Dans cette partie nous allons présenter de
façon générale les notions sur la solution du clustering
Network Load Balancing.
II.1.2 Historique18(*)
Les clusters sont apparus au moment de l'explosion du prix
des supercalculateurs alors que les microprocesseurs devenaient de ^plus en
plus rapides et de moins en moins chers. A partir de la fin des années
80, les ingénieurs ont commencés à développer ce
qu'ils appelaient alors un « multi-ordinateur »
En 1987, l'université du Mississipi a
commencé à travailler sur les clusters basés sur le Sun
4/110.
C'est toute fois le projet Beowulf2 (l'utilisation d'un
système d'exploitation Linux sur des PC communs) qui a
véritablement lancé l'intérêt pour les clusters, ces
grappes d'ordinateurs qui fournissent en commun un travail de calcul en
parallèle sur un seul problème complexe. Le cout et la
modularité d'un cluster rendant les opérations de calcul moins
onéreuses qu'un superordinateur.
II.2 Le Cluster Network Load
Balancing
Un cluster network Load Balancing dit cluster
d'équilibrage de charge réseau est un ensemble des machines
physiques travaillant en collaboration ou, à minima, échangeant
des informations sur leurs propres fonctionnement19(*).
C'est donc un ensemble des noeuds (serveurs physiques)
participant dans le même cluster. L'ensemble de ces serveurs physiques
indépendants fonctionnant comme un seul système est ce qu'on
appelle une grappe des serveurs.
Le client communique avec cette grappe comme s'il
s'agissait d'une machine unique.
Dans sa forme la plus simple, un cluster est un ensemble
de deux ordinateurs ou plus, appelés noeuds ou
« node » en anglais, qui travaillent ensemble pour fournir
un service.
Et donc la disponibilité d'un serveur est sa
capacité à fournir un service en tout temps, sous toutes
conditions, de l'ordre de 99,99%.
Nous comprendrons aisément qu'il est impossible
d'obtenir une disponibilité de 100%, personne n'étant à
l'abri d'une machine incroyable. Or l'informatique occupant une place
très importante au sein d'une structure d'entreprise ou d'autre
entité organisationnelle, les ordinateurs sont des maillons importants,
voire obligatoire dans leur système de production mais aussi un maillon
très fragile car une panne matérielle, logicielle ou
réseau peut survenir à tout instant et souvent, de manière
invisible.
II.2.1 Avantages et
inconvénients
En gérant mieux la charge des requêtes
arrivant sur les ressources à disposition, il est possible d'augmenter
la satisfaction des clients du système. Le Load Balancing est donc un
moyen économique d'augmenter les performances d'un système
informatique. En conséquence, le Load Balancing augmente la satisfaction
des requêtes et la consommation des ressources informatiques (il n'est
plus nécessaire d'investir dans les ressources supplémentaires
qui ne seront utilisées que 10% de temps).
L'avantage du Load Balancing par rapport à une
augmentation pure et dure des ressources informatiques apparait donc
évident.
Ce pendant, le Load Balancing est assez récent et
se développe très vite. Pour un novice en informatique, il est
difficile d'y prendre part et de comprendre toutes les implications rapidement
car les moyens de Load Balancing restent particulièrement centrés
sur des grosses entreprises disposant des services informatiques pour
gérer leur propre réseau.
a. Avantages
Le cluster d'équilibrage de charge réseau a
comme avantage :
v Augmenter la disponibilité des ressources sur le
cluster
Celles-ci sont garanties disponibles à 99,9% du
temps. Dans le cas où l'un des noeuds du cluster ne pourrait plus
fournir des réponses aux requêtes des clients, alors les autres
noeuds du cluster prennent le relai. Ainsi, la communication avec les clients
et l'application hébergée ou autres ressources sur le cluster ne
subit pas d'interruption ou une très courte interruption.
v Faciliter l'évolutivité
Lorsque la charge totale excède les
capacités des systèmes du cluster, d'autres systèmes
peuvent lui être ajoutés. En architecture multiprocesseur, pour
étendre les capacités du système il faut dès le
départ opter pour des serveurs haut de gamme couteux autorisant l'ajout
d'autres processeurs, des lecteurs et la mémoire
supplémentaire.
v Faciliter l'adaptabilité
Il est possible d'ajouter un à plusieurs noeuds ou
d'ajouter des ressources physiques (disques, processeurs, mémoires
vives) à un noeud du cluster. En effet, il est possible que de part les
trop nombreuses requêtes sur les serveurs que celui-ci soit en saturation
au niveau de la charge processeur, mémoire ou autre, dans quel cas il
est nécessaire d'ajouter des éléments, voire un autre
noeud.
v Faciliter la gestion du processeur, mémoire vive,
disque dur, bande passante réseau.
b. Inconvénients
Le cluster NLB, entant que tout système nous
présente des inconvénients qui sont les suivants :
v Cout élevé ;
v Déploiement technique complexe ;
v Cout de maintenance élevé ;
v Ne prend pas en compte l'utilisation des ressources pour
effectuer l'équilibrage de charge ;
v Les serveurs peuvent posséder une charge
inégale ;
v En cas de panne d'un serveur lors du traitement d'une
requête, il n'y a pas de transfert des requêtes vers d'autres
serveurs.
II.2.2 Architecture
II.2.2.A Sans répartiteur
La méthode la plus simple d'opérer une
répartition de charge consiste à dédier des serveurs
à des groupes des clients prédéfinis. Si cette
méthode est simple à mettre en oeuvre pour un intranet, elle est
très complexe, voire impossible pour des serveurs internet.
Dans ce cas, un paramétrage spécifique du
DNS (Domain Name Server) au niveau réseau et/ou l'optimisation
applicative (Niveau 7) sont un premier pas vers une démarche de
répartition de charge sans répartiteur.
Dans la majorité des cas, la méthode du
DNS en rotation (round robin) est un bon début en
matière de répartition de charge. Pour un même nom de
serveur particulier, le serveur DNS dispose de plusieurs adresses IP de
serveurs, qu'il présente à tour de rôle aux clients, dans
un ordre cyclique.
Pour l'utilisateur, cette méthode est totalement
transparente car il ne verra que l'adresse du site. On utilise
généralement la répartition par DNS pour les moteurs de
recherche, des serveurs POP (messagerie) ou des sites proposant des contenus
statique.
Sans répartiteur, il est donc possible d'engager
une démarche de répartition de charge. Néanmoins, les
méthodes décrites ci-dessus ne fournissent aucun contrôle
de la disponibilité et exigent donc des moyens additionnels pour tester
en permanence l'Etat des serveurs et basculer le trafic d'un serveur
surchargé vers un autre, le cas échéant.
Ces méthodes ne constituent donc pas une solution
de répartition de charge principale mais conservent leur
intérêt et restent complémentaires à la mise en
place d'un répartiteur.
II.2.2.B Avec répartiteur de charge (Load
Balancing)
Le répartiteur de charge ou Load Balancer est la
couche supplémentaire qui permet d'optimiser et de réguler le
trafic, tout en soulageant les serveurs, en répartissant la charge selon
les algorithmes prédéfinis (niveau 3, 4 et 7) et/ou selon des
fonctions intelligentes capables de tenir compte du contenu de chaque
requête (Niveau 7)20(*).

Fig. II.1 Load Balancing
Le répartiteur peut être un routeur, un
Switch, un système d'exploitation ou un logiciel applicatif.
Il repartit les demandes en les distribuant
automatiquement aux serveurs disponibles. Le destinataire des demandes peut
également être imposé. Le répartiteur simule la
présence d'un serveur : les clients communiquent avec le
répartiteur comme s'il s'agissait d'un serveur21(*). Celui-ci repartit les
demandes provenant des clients, les transmets aux différents serveurs.
Lorsqu'un serveur répond à une demande, celle-ci est transmise au
répartiteur ; puis le répartiteur transmet la réponse
au client en modifiant l'adresse IP de l'expéditeur pour faire comme si
cette réponse provenait du serveur.
La répartition de charge de niveau 3 / 4
Celle-ci consiste à travailler sur les paquets
réseaux en agissant sur leur routage (TCP/IP). Le répartiteur de
niveau 3 / 4 intervient donc à l'ouverture de la connexion TCP puis
aiguille les paquets en fonction des algorithmes retenus, selon 3
méthodes :
v Le routage direct
Avec cette méthode, le répartiteur distribue
les cartes. Elles se chargent de repartir les requêtes sur une même
adresse entre les serveurs locaux. Les serveurs répondent ensuite
directement aux clients
On parle alors de DSR (Direct Server return) ; retour
direct du serveur en français.
Simple à mettre en oeuvre car ne nécessitant
aucune modification au niveau IP, cette méthode requiert des solides
compétences du modèle TCP/IP pour obtenir une configuration
correcte et optimale. Elle implique en outre la proximité des serveurs,
qui doivent se trouver sur le même segment réseau que le
répartiteur.
v Le tunneling
Le tunneling est une évolution du routage direct
qui permet de s'amender de la problématique de proximité des
serveurs grâce à la mise en place des tunnels entre des serveurs
distants et le répartiteur.
v La translation d'adresses IP
Dans ce cas, le répartiteur centralise tous les
flux : les requêtes (comme dans le cas du routage direct) sont
reparties entre les serveurs mais aussi les réponses. Il masque ainsi
l'ensemble de la ferme de serveurs, qui ne nécessitent aucun
paramétrage particulier.
En revanche, cette méthode implique une
configuration applicative très stricte afin notamment que les serveurs
évitent de retourner leurs adresses internes dans les
réponses.
En outre, cette méthode augmente
considérablement la charge du répartiteur qui doit convertir les
adresses dans les deux sens, maintenir lui-même une table des sessions et
supporter la charge du trafic retour22(*).
La répartition de charge de niveau 7
(Applicatif)
En s'attaquant à la couche applicative, le
répartiteur de charge ne se contente pas plus d'aiguiller aveuglement
les requêtes. Il analyse le contenu de chaque requête HTTP, RDP ou
autre pour décider du routage.
Le reverse proxy
Dans son rôle de transmission du trafic, le
répartiteur de niveau 7 agit comme un reverse proxy et prétend
être serveur. Il a alors pour rôle d'accepter les connexions
à destination du client et d'établir des connexions avec les
serveurs pour faire transiter les données (requêtes et
réponses).
Cette méthode implique que les serveurs ne
puissent pas être joints directement par les utilisateurs et
nécessite aucune configuration particulière côté
serveur.
Dans ce cas, le répartiteur de niveau 7
nécessite plus de puissance que les solutions matérielles
agissant au niveau du réseau.
Ils fournissent cependant un premier niveau de
sécurité en ne transmettant au serveur que ce qu'ils
comprennent.
v Le reverse proxy transparent
Parfois, la répartition de charge de niveau 7 peut
se heurter à des contraintes d'intégration des serveurs
(surveillance des logs ou pare-feu de niveau 3 / 4) ou de protocole
FTP.
Dans ce cas, le répartiteur peut simuler l'adresse
IP du client en source des connexions qu'il établit vers les serveurs.
On parle alors du reverse proxy transparent.
Nécessitant un mode coupure, le reverse proxy
transparent implique que les serveurs soient non seulement
configurés pour joindre les clients à travers le Load Balancer,
mais aussi se trouver sur un segment réseau différent des
clients.
II.3 Fonctionnement23(*)
II.3.1 Fonctionnalités de
la répartition de la charge réseau
La répartition de charge réseau fonctionne
en trois modes différents de répartition :
La répartition manuelle
Elle permet de répartir le poids pour chaque noeud
du cluster basé sur un poids de charge. Si trois serveurs sont
configurés avec le poids 50, 30 et 20 ; le premier va recevoir la
moitié des requêtes, le second 30% et le dernier 20%.
La répartition égale
Elle permet de répartir de façon
égale les requêtes sur l'ensemble des serveurs composant le
cluster. S'il y a trois serveurs dans la ferme du cluster, chacun recevra 33%
des requêtes.
La répartition prioritaire
Elle permet de mettre en place la notion de
tolérance de panne en spécifiant un serveur prioritaire.
L'ensemble du trafic est tout d'abord acheminé sur l'hôte ayant la
priorité 1. Si celui-ci tombe en panne, l'ensemble du trafic sera
envoyé au serveur de priorité 2 et ainsi de suite.

Fig. II.2 Répartition prioritaire de
charge
Lorsqu'un serveur membre de la ferme du cluster tombe en
panne, le cluster passe en mode de convergence pendant lequel une
élection est effectuée afin de repartir selon les règles
de la configuration de répartition de charge réseau. Pendant ce
temps les clients en communication avec le serveur en panne n'accèdent
pas aux services jusqu'au moment où la convergence est terminée.
Ce qui permet de repartir ces clients sur les autres serveurs.
Dans le cadre d'une répartition égale entre
trois serveurs, les requêtes sont reparties à 33% sur chacun des
serveurs. Si l'un des serveurs tombe en panne, la convergence démarre et
la répartition se fait à 50% sur les deux serveurs.

Fig. II.3 Convergence en cas de panne
serveur
Lors de la montée en charge d'un serveur pour un
service web, un service VPN ou autre... il est intéressant d'envisager
une solution adoptant la technologie de répartition de charge
réseau. Le mode NLB proposé par Microsoft permet
l'intégration de 32 noeuds au sein d'un même cluster, l'ensemble
de ces noeuds pourront répondre aux requêtes
simultanément.
Prenons un exemple simple et très
utilisé : vous avez un cluster NLB composé des plusieurs
noeuds, ces derniers sont des serveurs web (Windows server avec IIS) ayant pour
but de fournir une infrastructure web. Ils contiennent tous en local une copie
identique de préférence du site web que vous hébergez et
se connectent à un serveur de base des données externe au cluster
pour le stockage des données.
Les connexions clientes seront alors reparties entre les
différents serveurs web afin de répondre aux différents
pics de charge.
Cependant, cette mise en place peut s'avérer plus
complexe dans certains cas notamment avec l'utilisation des sessions ou encore
la gestion du panier sur le site e-commerce où ces informations
précieuses ne doivent pas être perdues en cas de panne du serveur
web qui traitait la demande. Il est judicieux de stocker ces informations
également en externe des serveurs web.
Par défaut, chaque noeud d'un cluster informe ses
partenaires de sa présence au travers d'un Heartbeat (battement du
coeur). Ce Heartbeat est envoyé sous forme de broadcast après
chaque 5 secondes.
Le cluster a une vision précise de quels noeuds
sont des membres valides à un instant t.
Lorsqu'une application devient indisponible, soit parce
que c'est elle-même qui a un problème, soit parce que c'est le
noeud qui l'héberge qui a un problème, l'application peut,
automatiquement être déplacée vers un noeud disponible. Il
est évidemment plus rapide de basculer une application de cette
façon que de restaurer un serveur depuis une ou plusieurs bandes de
sauvegarde.
Dans ce mode de fonctionnement, on passe sur
« actif/passif » et ou dans ce mode tous
les noeuds sont sollicités continuellement de façon
répartie. Attention, répartie ne veut pas dire équitable,
car cela dépend de la configuration que vous effectuez sur le
cluster.
Ce qui est sûr c'est que tous vos noeuds doivent
être opérationnels, car ils sont susceptibles d'être mis en
contribution à tout moment.
Le service d'équilibrage de charge réseau
(NLB) augmente la disponibilité et l'évolution des applications
serveurs Internet, telles que celles utilisées sur les serveurs web,
FTP, pare-feu, proxy, VPN et d'autres serveurs stratégiques.
Un ordinateur unique exécutant Windows offre une
fiabilité des serveurs et une évolutivité des performances
limitées
Toute fois, en associant les ressources d'au moins deux
ordinateurs exécutant l'un des produits de la famille Windows server
dans un seul cluster, l'équilibrage de la charge réseau est
à même de garantir la fiabilité et les performances dont
les serveurs web et autres serveurs stratégiques ont besoin.
Chaque hôte exécute des copies
séparées des applications serveurs souhaitées, telles que
des applications serveur web, FTP et Telnet. L'équilibrage de charge
réseau distribue les requêtes client entrantes sur les hôtes
dans le cluster.
Le poids de charge devant être traité par
chaque hôte peut être configuré le cas
échéant. Vous pouvez aussi ajouter des hôtes au cluster de
façon dynamique afin de gérer l'augmentation de la charge de
travail. En outre, l'équilibrage de la charge réseau peut
diriger tout le trafic vers un hôte unique désigné,
appelé l'hôte par défaut.
L'équilibrage de la charge réseau permet
à tous les ordinateurs du cluster d'être adressés via le
même ensemble d'adresses IP du cluster (mais il préserve
également leurs adresses IP dédiés uniques.
Pour les applications faisant objet de
l'équilibrage de charge lorsqu'un hôte présente une
défaillance ou est mis en mode hors connexion, la charge est
automatiquement redistribuée parmi les ordinateurs en état de
fonctionnement.
Les applications s'exécutant sur un seul serveur
voient leur trafic redirigé vers un hôte spécifique.
Lorsqu'un ordinateur est en défaillance ou est mis en mode hors
connexion, les connexions actives au serveur défaillant ou hors
connexions sont perdues.
Cependant, si vous mettez un hôte hors service
intentionnellement, vous pouvez utiliser la commande drainstop pour
gérer toutes les connexions avant de mettre l'ordinateur hors
connexion. Dans les deux cas, lorsque l'ordinateur hors connexion est
prêt, il peut en toute transparence rejoindre le cluster et gérer
à nouveau sa part de la charge de travail.
II.4 Les modes
d'opérations, de filtrage et d'affinité du cluster24(*)
II.4.1 Modes
d'opérations
Trois modes d'opération du cluster sont
disponibles : monodiffusion, multidiffusion et multidiffusion IGMP
Monodiffusion (Unicast)
Ce mode attribue une adresse MAC unique à
l'ensemble des noeuds du cluster. Ce pendant cela pose problème au
niveau de Switch puis que par définition un Switch attribue une adresse
MAC par port. Il ne peut pas enregistrer deux fois la même adresse
MAC.
Ce problème de diffusion obligera le Switch
à flooder l'ensemble des ports pour savoir réellement à
qui appartient cette adresse. Cela fonctionnera mais va générer
une quantité de trafic importante. Une solution annexe mais ne faisant
pas partie des bonnes pratiques, consiste à placer un hub entre le
Switch et les noeuds du cluster, comme ça l'adresse MAC sera
enregistrée uniquement sur un port du Switch et le trafic
redistribué à l'ensemble des noeuds grâce au hub.
Multidiffusion (Multicast)
Ce mode règle les problèmes liés
à l'unicité de l'adresse MAC lorsqu'un de type multidiffusion est
utilisé, tout en empêchant les équipements réseaux
de mémoriser l'adresse MAC du cluster.
Par contre, ce mode ne résout pas le
problème de flooding sur le port du Switch.
Certains commutateurs peuvent être configurés
partiellement en hub, ce qui permet d'indiquer à l'équipement de
transférer systématiquement les paquets pour l'adresse MAC du
cluster au port où sont connectés les noeuds.
Multidiffusion IGMP
Ce mode reprend le comportement du mode
précédent sauf que l'on ajoute l'utilisation de l'IGMP (Internet
Group Management Protocol) de ce fait, les noeuds du cluster s'enregistrent
avec une adresse IP de classe D. avec ce mode le problème de flooding
n'existe plus.
Pour rappel, la classe D contient les adresses IP de
224.0.0.0 à 239.0.0.0 et est réservée uniquement aux
communications multicast25(*).
II.4.2 Modes de filtrage
Le choix du mode de filtrage permet de définir le
mode de fonctionnement du cluster au niveau des flux réseaux.
Hôtes multiples
Ce mode est plus intéressant et permet une
véritable répartition de charge entre les noeuds du cluster. En
effet, il est de type actif/actif donc plusieurs noeuds travaillent
simultanément pour se répartir la charge.
Hôte Unique
Ce mode est de type actif/passif et va à l'encontre
de la répartition des charges. Le noeud avec le plus petit ID sera actif
et sera le seul à recevoir le flux réseau.
Aucun
Ce mode de filtrage permet de bloquer le trafic sur
certains ports définis. Intéressant pour protéger les
noeuds du cluster
II.5 Le modes
d'affinités
Lorsqu'on choisit le mode de filtrage `hôte
multiple' afin de faire de la véritable répartition de charge, on
aura le choix entre trois modes d'affinités : Aucun, Unique et
Réseau.
II.5.1 Aucune
Ce mode assure la meilleure répartition de charge
puisqu'à chaque connexion TCP d'un même client, cette
dernière sera redirigée vers le noeud ayant les moins des clients
à l'instant t.
Tout de même, si ce mécanisme
d'affinité est utilisé sur un site comprenant une gestion des
sessions voir même des paniers cela pourrait poser problèmes. Il
vaut mieux garder le client sur l'intégralité de sa
connexion.
II.5.2 Unique
Ce mode maintien le client sur un même noeud par
rapport à son adresse IP, tant que la topologie du cluster n'est pas
modifiée. C'est-à-dire tant qu'il y a pas d'ajout ou de
suppression de noeud.
Si les clients arrivent tous avec une adresse IP
derrière le NAT ou un proxy, la répartition ne sera pas
équitable. Il est important que chaque client arrive avec sa propre
adresse IP pour assurer une meilleure répartition.
II.5.3 Réseau
Plutôt que de répartir les clients par
rapport à leurs adresses IP, la répartition est effectuée
par rapport au réseau. Par exemple, tous les clients du réseau
192.168.1.0/24 iront sur un noeud et tous ceux du réseau 192.168.2.0/24
sur un autre noeud.
Cette méthode peut s'avérer utile et
pertinente lorsqu'il s'agit de l'utilisation des plusieurs sous-réseaux,
sinon un seul noeud recevra toute la charge. Ce qui n'est pas le but du
clustering.
II.6 Les caractéristiques
du Network Load Balancing26(*)
Le network Load Balancing doit répondre à
des certaines caractéristiques qui sont :
v Support de TCP/IP;
v Répartition de charge ;
v Haute disponibilité ;
v Mise à l'échelle ;
v Administration distante.
II.7 Les règles de ports
de l'équilibrage de la charge réseau
L'équilibrage de la charge réseau va
être défini grâce à la création de la
règle de port qui va permettre de spécifier les
propriétés de répartition selon les critères
suivants : numéro de port et protocoles (TCP et UDP)
concernés par la règle, le mode d'équilibrage de charge
(hôte multiple, hôte unique, désactiver les ports) et
l'ensemble des paramètres propre au mode
sélectionné27(*).
II.8 Autres logiciels de Load
Balancing
v Nginx :
réalise le Load Balancing en proxy inverse et s'est
démarqué par ses grandes performances (meilleures que celle
d'Apache) à partir de peu des ressources. Nginx est très flexible
puisqu'il prend en charge des nombreux protocoles comme HTTP, HTTPS, IMAP,
SMTP,... ce qui n'est pas le cas des toutes les solutions proposées.
Pour autant, Nginx n'est pas le plus facile des softwares de Load Balancing
à prendre en main. La difficulté de création des modules
sous Nginx Load Balancing a été des nombreuses fois
soulignée.
v HA Proxy :
C'est la solution d'équilibrage de charge la plus
discrète et la plus légère, ce logiciel convient bien pour
les petites applications qui utilisent de préférence l'algorithme
de répartition en fonction du nombre de connexion.
v Varnish :
est pratique et se distingue parce qu'il est formé
d'un plugin. Conçu spécifiquement pour fonctionner en tant que
proxy inverse (au contraire de Nginx), Varnish est particulièrement
adapté pour les sites à données massives où les
utilisateurs ont tendance à revenir. En effet, il évite que les
utilisateurs qui aient déjà visités la page n'aient
à la retélécharger et donc à utiliser les
ressources des serveurs du site. Néanmoins, Varnish ne gère que
le protocole http, ce qui peut fortement bloquer l'utilisation pour certaines
applications.
Microsoft a implémenté à part la
technologie du clustering à équilibrage de charge, deux autres
technologies de clustering.
v Le cluster Scientifique qui est la technologie qui
intervient au niveau du stockage des informations.
v Le cluster MSCS, dit failover cluster en anglais. Cette
technologie est en français, Cluster de basculement. Il résous le
plus grand problème qui s'observe au niveau du cluster
d'équilibrage de charge réseau. Là, lorsqu'il y a un
serveur qui tombe en panne pendant qu'il traitait des requêtes, ces
dernières se perdent toutes. Mais avec cette technologie du failover
clustering, lorsque ce serveur tombe en panne, toutes les requêtes qui
étaient en train d'être traitées seront automatiquement
basculées sur un autre serveur qui fonctionne et cela c'est grâce
à un disque dit de quorum qui est placé entre les serveurs de la
grappe et qui garde les informations à échanger entre les
serveurs.
Une autre architecture qui est le CLB, est souvent
couplée à l'architecture de cluster NLB, dans le cas de serveur
WEB basé sur le commerce e-électronique.
CONCLUSION PARTIELLE
Nous avons passé en revue dans ce chapitre les
notions générales sur le cluster d'équilibrage de charge
réseau qui permet d'assurer une haute disponibilité de
façon efficace avec une possibilité d'assurer en permanence une
bonne gestion et répartition de la charge réseau ainsi que la
haute disponibilité des applications.
CHAPITRE III.
PRESENTATION DE L'ENTREPRISE
III.0 Introduction
Tout travail de fin de cycle
parlant sur les réseaux informatiques comme celui-ci doit porter soit
sur une étude ou une mise en place. Ce dernier s'appliquant dans un
milieu professionnel donné, il nous sera alors question de
présenter ici l'institution au sein de laquelle nous avons
effectué nos recherches qui est l'office congolais de contrôle,
O.C.C en sigle.
III.1 Cadre juridique et nature de l'O.C.C
L'office congolais de contrôle est un organisme
public à caractère technique et scientifique depuis le
décret n° 09/42 du 03 décembre 2009 fixant les statuts d'un
établissement public à caractère scientifique et technique
dénommé Office Congolais de Contrôle
« O.C.C. » en sigle. Doté de la personnalité
juridique et placé sous la tutelle du Ministère du commerce, il a
été créé par l'ordonnance-loi n° 74/ 013/ du
13 janvier 1974.
Ainsi donc, les différents textes de base
régissant ses activités sont :
a) L'Ordonnance-Loi
n° 74/013 du 10 janvier 1974 portant création de
l'OZAC ;
b) La Loi n°73/009 du 05 janvier
1973 particulière sur le commerce telle que modifiée et
complétée par la Loi n°74/014 du 10 janvier
1974 ;
c) L'Ordonnance-Loi n°74/219 du 05
mai 1978 portant statut de l'O.C.C ;
d) Le décret- loi n°09/42 du
03 décembre 2009 fixant les statuts d'un établissement public
à caractère scientifique et technique O.C.C.
Entant qu'organisme tierce partie, impartial et dont la
structure, le personnel, la compétence et l'intégrité
permettent d'accomplir son rôle d'arbitre selon des critères
définis, l'Office Congolais de Contrôle est un organisme
d'évaluation de la conformité : il est membre correspondant de
l'Organisation Internationale de la Normalisation ``ISO''
membre du programme des pays affiliés à la Commission
Electrotechnique Internationale ``CEI'' et membre de
l'Organisation Régionale Africaine de la Normalisation
« ORAN » 28(*).
III.2 Brève historique
L'historique de l'OCC date de l'époque coloniale.
En effet, il existait une société à statut privé,
de droit suisse, dénommée `' Société
Générale de Surveillance'' SGS qui, créée en 1919
et dont les attributions étaient quasi-semblables à celles de
l'actuel OCC, avait son siège social à Genève.
C'est en 1949 que la SGS implante une filiale au Congo sous la dénomination de
Société Congolaise de Surveillance (SCS) dont les principales
activités furent:
v Assurer le contrôle de la qualité et de la
quantité des produits du sol ;
v Assurer le constat d'avaries ;
v Assurer la gestion des silos de Kinshasa ;
v Effectuer le contrôle des importations à
destination du Congo.
Cependant, quelques temps après
l'indépendance du pays, la décision du Bureau Politique du
Mouvement Populaire de la Révolution (M.P.R.) du 27 octobre 1971 portant
changement du nom du Congo à celui du Zaïre, la S.C.S. devint la
Société Zaïroise de Surveillance (S.Z.S.) et poursuivit
toujours ses activités en tant que filiale de la S.G.S. Mais qui sera
dissoute à la suite des mesures économiques du 30 novembre 1973
et qui donnera naissance à l'office Zaïrois de contrôle en
1974.
Néanmoins, avec la politique de la
Zaïrianisation, le président en exercice à l'époque,
le feu Maréchal Joseph MOBUTU Seseseko, promulgue l'Ordonnance-Loi
n°74/013 du 10 janvier 1974 portant création de l'Office
Zaïrois de Contrôle « OZAC » qui se veut
alors une entreprise de droit public à caractère technique et
commercial doté de la personnalité juridique et non plus cette
société privée d'avant 1974.
Avec le renversement du
régime de l'ex-Zaïre de MOBUTU par l'arrivée au pouvoir de
Laurent Désiré KABILA le 17 mai 1997 et le pays étant
devenu la République Démocratique du Congo (R.D.C.), l'Office
Zaïrois de Contrôle changea également d'appellation et devint
l'Office Congolais de
Contrôle, « O.C.C. ».
III.3 Localisation
Notons que, à Kinshasa, le siège social de
l'OCC (la Direction Centrale) est situé au n° 98 sur l'avenue du
Port, dans la commune de Gombe.
III.4
Missions et Objectifs
III.4.1 Missions
En sa qualité d'organisme public à
caractère technique et scientifique, l'O.C.C a pour missions
légales :
v Préserver les intérêts
économiques en assurant les contrôles de la qualité, de la
quantité et de la conformité de toutes les
marchandises ;
v Analyser tous les échantillons et produits pour
protéger les clients ;
v Garantir la sécurité des installations,
machines, appareilles, travaux et étalonnages ;
v Prévenir les sinistres et procéder au
constat des dommages ou des avaries ;
v Exercer toutes opérations quelconques se
rapportant directement à son activité légale, sauf les
opérations de l'achat en vue de la revente.
Partant de ces missions, l'O.C.C. a comme devise :
« la confiance n'exclut pas le contrôle, le
contrôle renforce la confiance ».
III.4.2 Objectifs de l'O.C.C.
Les principaux objectifs de l'OCC
peuvent se résumer en trois volets comme ci-après :
a) En faveur de
l'Etat :
v Aider l'Etat à juguler la fraude fiscale et
à maîtriser la balance de paiements extérieurs par le
contrôle des prix ;
v Aider l'Etat à disposer des statistiques fiables
dans le commerce extérieur et à maîtriser la valeur en
douane de la marchandise ;
v Soutenir l'Etat dans ses efforts de développement
intégral.
b) En faveur de
l'opérateur économique :
v Rassurer les importateurs, les exportateurs et les
assureurs ainsi que les fournisseurs de la qualité, de la
quantité, de la conformité et du prix réel des
marchandises et produits ;
v Aider les opérateurs économiques et
industriels à s'assurer du respect des normes.
c) En faveur du
consommateur et de l'usager
v Sécuriser et rassurer le consommateur et l'usager
de la qualité du produit identifié et retenu comme propre
à la consommation ou des ouvrages en chantier prêts à
être utilisés ;
v Sécuriser l'usager sur le lieu de
travail ;
v Prévenir les atteintes à l'environnement
humain.
III.5 Relation entre L'OCC et le
gouvernement et d'autres Institutions
Dans le cadre de son mandat légal, l'office
congolais de contrôle collabore avec des nombreux ministères et
d'autres institutions ou organismes auxquels il fournit des renseignements
utiles ou signale certaines constatations.
Parmi eux nous pouvons citer : le ministère de
l'économie nationale, ministère de commerce, ministère de
l'environnement, la banque centrale du Congo, et beaucoup d'autres.
III.6 Les activités
normatives
L'OCC s'est également vu confié par l'Etat
la mission d'assurer l'évaluation de la conformité de la
production locale aux normes, en vue de leur conférer une plus grande
compétitivité sur le marché interne et externe, et aussi
pour assurer une plus grande sécurisation du consommateur.
L'OCC a ainsi été amené à
s'investir dans le domaine de la normalisation et de ses activités
connexes pour préparer le pays à répondre aux défis
de la régionalisation et de la mondialisation.
Et conscient de la suppression progressive des
barrières tarifaires et de l'augmentation sans cesse croissante du flux
des marchandises et des services entre les différents pays du monde, il
a accordé à l'activité normative une importance
primordiale, et ce, dans la mesure où elle permet une bonne
intégration dans le système économique mondial et fait
profiter au pays de l'ouverture es marchés régionaux et
internationaux.
Ce faisant, il vise une recherche plus accrue de la
qualité grâce au respect des normes.
Il sied de signaler que l'OCC a été admis
comme membre correspondant d'organisation internationale de normalisation
« ISO » et siège depuis bientôt quatre ans au
conseil d'administration de l'organisation régionale africaine de
normalisation « ORAN »
III.7 Structure Organique Et
Fonctionnelle
Conseil d'Administration
III.7.1 Organigramme de l'Office
Congolais de Contrôle
Division médicale
Coordination du secrétariat de la
D.G
Collège des commissaires aux comptes
Direction générale
Cellule d'études près DG
Division Relation Publique
D.comm.
D.Norm
D.certific.pr.
D. labo
D.metro cont
D.con.avaries
D.con.export
D.con.import
D. Financière
Div stat.
D. informat.
D.plan&dev.
D. juridique
Corp d conseil
Corp d audit.
Div.Hardware
Div.software
Div.Man&qual
Div. Doc.
Div.Statistique
Div.Gest. patrim.
D. Audit
D. sce générale
D. Admin.
Div.Pha
Div.micr.
Div.Gest
Div.Coo
Div.gen
Div.Pha
Div.Ingénierie
Div. Comm.
Div.micr.
Div.gen
Div.Aéroalim.
Div.Gest
Div expertise
Div.Gest
Div.Aérochim.
Div. CEDIN
Div.dev. nor
Div. Cooper
Div. Market
Div.Aéroalim.
Div.Phar et cosm.
Div.tarif et prom
Div.Metrolog.
DivVer export
Div.Protdu trav.
Div suivi exp
Div.Industrie
Div cont
Div.gen
Div.Adm.&f.
Div. Du pers.
Div. Suivi exploit.
Div.compt.
Div. Etudes
Div. Suivi Adm. Fin.
Div.budg.
Div.Approvis
Div. sociale
Div.Rémuner.
Div. Hydrocarbures
Div.Tresor.
Div.Suivi arts.
Div.Analys
Fonction de coordination
D. Coord.
Fonction Technique
Div. Format.
Div.Coo
Fonction financière
Fonction de support
Div.recouvr.
DIREQ
DIRBAC
DIRKIN
DIRNOKI
DIREST
DIRPOR
DIRKOR
DIRCENTR
DIKAT
III.7.2 Fonctionnement de
l'Office Congolais de Contrôle
L'office congolais de contrôle est placé sous
la tutelle du ministère de l'économie nationale et du commerce,
petites et moyennes entreprises pour les matières à
caractère organisationnel et fonctionnel telles que :
v Organisation des services, le cadre organique, le statut
du personnel, le barème des rémunérations ;
v L'Etablissement des départements centraux,
directions provinciales, agences et postes à l'intérieur du
pays ;
v Les rapports annuels ;
v Les emprunts et les prêts ;
v Les prises et cessions des participations
financières, etc...
L'organisation et le fonctionnement des structures
organiques de l'OCC sont régis par les articles 7 à 26 de la loi
n°78 002 du 06 janvier 1978 portant dispositions
générales applicables aux entreprises publiques.
A. Conseil D'administration
Le conseil d'administration est l'organe de conception,
d'orientation, de contrôle et décision de l'office.
Il définit la politique générale, en
détermine le programme, arrête le budget et approuve les
états financiers de fin d'exercice.
A ces fins, le conseil d'administration
délibère sur toutes les matières relatives à
l'objet de l'office et dispose notamment des compétences
de :
v Arrêter le plan de développement, les
programmes généraux d'activité et d'investissements, les
budgets ainsi que les comptes de l'office ;
v Décider de la prise, de l'extension ou de la
cession de participations financières ;
v Fixer les orientations de la politique tarifaires de
l'office, les conditions générales de passation des contrats,
conventions et contrats et règles générales d'emploi de
disponibilités et des réserves ; décider des
acquisitions, aliénations, échanges et le soumettre pour
approbation à l'autorité de tutelle ;
v Fixer, proposition de la direction
générale, le cadre organique et le statut du personnel et le
soumettre pour approbation à l'autorité de tutelle ;
v Le conseil d'administration est composé de cinq
membres, en ce compris le directeur général ;
v Les membres du conseil d'administration sont
nommés, relevés de leurs fonctions et, les cas
échéants, révoqués par ordonnance du
président de la république, sur proposions du gouvernement
délibéré en conseil des ministres.
v Le mandat des membres du conseil d'administration est de
cinq ans renouvelable une fois.
v Le président de la république nomme, parmi
les membres du conseil d'administration, un président autre qu'un membre
de la direction générale ;
v Nul ne peut détenir plus d'un mandat
d'administrateur.
B. La Direction
Générale
v La direction générale est l'organe de
gestion de l'office ;
v La direction générale exécute les
décisions du conseil d'administration et assure la gestion courante de
l'office ;
v Elle exécute le budget, élabore les
états financiers de l'office et dirige l'ensemble de ses
services ;
v Elle représente l'office vis-à-vis des
tiers. A cet effet, elle a tous les pouvoirs nécessaires pour assurer la
bonne marche de l'office et pour agir en toute circonstance en son
nom ;
v L'office est géré par un directeur
général, assisté d'un directeur général
adjoint, tous nommés et relevés de leurs fonctions et, cas
échéant, révoqués par ordonnance du
président de république, sur proposition du gouvernement
délibérée en conseil des ministres.
C. Les Autres départements
C1. Les
départements Centraux d'exploitation
v Département Contrôle des
Importations (D.C.I.)
Le D.C.I. a pour mission d'organiser, de réaliser
des contrôles des importations conformément aux textes
légaux et réglementaires et d'optimiser les activités des
Contrôles des importations soit seul, soit en collaboration avec ses
mandataires étrangers dont BUVAC international.
Ce Département poursuit les objectifs majeurs
ci-dessous:
· Sauvegarder les intérêts des
opérateurs économiques grâce aux redressements qualitatif
et quantitatif des produits et marchandises importées,
· Sauvegarder la santé du Consommateur par la
surveillance de la qualité des produits alimentaires et
pharmaceutiques.
Il existe deux contrôles principaux sur toutes les
importations vers la République Démocratique du Congo :
Contrôle avant embarquement
Du lieu ou du pays d'origine, l'Office a donné
mandat à BUVAC international de contrôler la qualité, la
quantité et le prix avant embarquement du produit. Ainsi, le BUVAC joue
le rôle de mandataire. A l'issu des contrôles, le BUVAC émet
l'attestation de vérification « AV ».
A l'arrivée en République
démocratique du Congo, l'Office Congolais de Contrôle effectue une
deuxième vérification pour s'assurer que la marchandise est
toujours dans la même condition qu'à l'embarquement. Ce
contrôle est particulièrement important pour les produits
pharmaceutiques et les denrées périssables.
Contrôle à l'arrivée
Pour certains produits, notamment les produits
pétroliers et ceux en provenance des pays où le BUVAC n'a pas des
bureaux de collaboration comme en Chine. L'Office Congolais de Contrôle
effectue tous les contrôles requis, à l'issue desquels, il
émet une attestation de vérification.
Ces contrôles qui s'exercent à l'embarquement
au départ de l'étranger par les mandataires ou à
l'arrivée, aux différents postes frontaliers présentent un
intérêt majeur pour la protection du consommateur face à la
tendance criminelle de certains pays développés à vouloir
déverser verts le tiers monde les excédents des marchandises et
produits à la qualité douteuse ou avariée. Les mêmes
contrôles garantissent la conformité des prix.
v Département Contrôle des
Exportations (D.C.E.)
Les missions poursuivies par le D.C.E. sont entre autres :
Concevoir et optimiser les nouvelles techniques de contrôle des
exportations sur l'ensemble du territoire de la République
Démocratique du Congo de manière à les
généraliser. Ce contrôle s'exerce sur les produits miniers,
pétroliers, agricoles et des plantes médicinales et de plus en
plus sur les produits manufacturés ou fabriqués en R.D.C.
Il permet notamment :
· De sauvegarder l'image de marque du pays par
l'exportation des produits de qualité garantie et
compétitifs ;
· De favoriser le juste rapatriement des recettes en
certifiant les prix sur base des mercuriales aux prix fiables.
v Département Commissariat
d'Avaries (D.C.A.).
Le D.C.A. a la mission de constater les avaries, subies
par les marchandises sur le territoire national et d'établir les
Certificats d'Avaries devant permettre à l'assuré de se faire
indemniser par son assureur.
Autrement dit, le D.C.A. apporte aux assureurs les
éléments d'appréciation relatifs aux dommages frappant un
lot de marchandises réceptionnées par l'assuré.
v Département des Laboratoires
(D.L.)
Le Département des laboratoires a pour but de
déterminer par les analyses physico-chimiques et microbiologiques, la
qualité et la conformité des produits importés, des
productions locales destinées à la consommation intérieure
ou à l'exportation.
Ce Département exerce son activité à
partir des échantillons, l'analyse de ceux-ci, l'établissement et
la transmission aux importateurs, aux exportateurs et autres productions
locales des résultats d'analyse.
v Département Contrôle des
Produits Locaux (D.C.P.L.)
Les missions assignées au D.C.P.L sont celles
d'organiser, de réaliser et d'améliorer les techniques des
Contrôles de la production locale et de tous les produits circulant sur
le territoire National Conformément aux textes légaux et
réglementaires afin d'assurer la sécurité des
consommateurs et de crédibiliser les produits locaux.
Les contrôles des produits locaux s'effectuent aux
lieux de production, c'est-à-dire en cours de fabrication et/ou avant la
sortie des usines des marchandises et produits ou pour les produits issus des
transactions locales, aux points de remplir des charges (ports,
aéroports, gares, aérogares, ...).
v Département des Contrôles
techniques (D.C.T)
Ce Département a pour missions fondamentales
:
· d'assurer que les dispositions légales ou
réglementaires relatives à la sécurité et à
la salubrité sur les lieux de travail soient
observées ;
· de protéger les usagés contre
l'emploi incorrect et déloyal des instruments utilisé dans le
commerce ;
· d'attester que les conditions techniques de
conservation des denrées périssables dans les unités
frigorifiques soient remplies,
· d'assurer la surveillance de la flotte de transport
(aéronefs, unités fluviales et lacustres, véhicules
automobiles) ;
· d'assurer le contrôle de qualité des
produits et équipements produits localement ou
importé ;
· de garantir la bonne réalisation des
ouvrages et fournir les éléments d'appréciation des
sinistres au Commissariat d'Avarie et aux assureurs ;
· d'expertiser les installations et les appareils,
machines, ..., soit à la demande de tiers (clients), soit pour le compte
de l'Etat ;
Dans le domaine des contrôles techniques, l'Office
oeuvre en partenariat avec certains ministères notamment :
· le Ministère de Travail et Prévoyance
Sociale (Sécurité et Salubrité sur les lieux du
travail),
· le Ministère de l'Economie et Industrie
(métrologie légale-production industrielle locale),
· le Ministère des Transports et
Communications (les unités fluviales et lacustre, contrôles
automobiles).
. DEPARTEMENT
CENTRAUX D'APPOINT
Dans la réalisation de son objet social, l'Office
Congolais de Contrôle recourt généralement au soutien
logistique des départements suivants : Administration, Informatique,
Services Généraux, Etudes et Organisations, Audit et Inspection,
Secrétariat de la Délégation Générale et la
Finance.
v Département Administratif (D.A.)
La mission du D.A. est d'assurer la gestion du personnel
de l'Office en vue de garantir la paix sociale par une bonne application des
dispositions légales et conventionnelles en matière du travail et
par une politique saine (rationnelle) et objective en matière de la
gestion du personnel.
v Département Informatique
(D.I.).
Ce Département a la mission de concevoir,
planifier, contrôler, organiser et gérer l'ensemble des
activités informatique de l'Office.
A moyen terme, l'entreprise se propose de
généraliser son programme d'informatisation de manière
à intégrer tous les départements.
v Département Services
Généraux (D.S.G.)
La mission principale de ce Département est de
mettre à la disposition de l'Office :
· L'acquisition et la gestion des biens meubles et
immeubles,
· L'acquisition des fournitures de bureau et
imprimé de valeur,
· L'entretien et réparation des
machines.
v Département Etudes et
Organisations (D.E.O.)
Ce Département a pour mission de :
· mener des études et des actions permettant
d'acquérir et de développer les ressources humaines
compétentes à l'Office,
· mener des recherches en vue de mettre sur pied ou
d'améliorer l'organisation et les procédures de gestion et de
contrôle de l'Office,
· centraliser et optimiser l'exploitation des
données des statistiques de l'Office.
Ce Département met à la disposition de
toutes les activités un recueil des instructions actualisées et
adaptées à l'évolution des données du
terrain.
Avec ses données statistiques, le
Département Etudes et Organisation reste une véritable banque de
données au service de l `Office, du Gouvernement et des autres
institutions et organismes nationaux et internationaux.
v Département Audit et Inspection
(D.A.I.)
Il a pour mission de s'assurer du respect des instructions
en vigueur au sein de l'Office dans le domaine administratif et financier et
proposer des solutions en vue de remédier aux anomalies
constatées.
Il veille, en outre, à la régularité
de procéder au contrôle et à la conformité des
normes établies. En outre, ce Département se présente
comme le conseiller de l'Office dans la recherche d'une gestion saine,
rigoureuse et transparente.
v Département Secrétariat
de la Délégation Générale (D.S.D.G.)
Le D.S.D.G. apparaît comme un instrument de
coordination qui dessert toute l'entreprise et aide le Comité de Gestion
à jouer pleinement son rôle d'impulsion. C'est dans ce
département qui est rattaché le service de communication et
presse (dénommé compresse).
Sa mission s'articule autour des axes ci- après
:
· assurer le secrétariat du Comité de
Gestion et du Conseil d'Administration de la Délégation
Générale dans son ensemble,
· assurer la couverture juridique de tous les
dossiers et la gestion des différents contrats et convention conclu avec
les clients,
· suivre la législation intéressant
l'Office et la légalité des décisions et solutions
préconisées par le Comité de Gestion,
· veiller à la diffusion de l'information et
à sauvegarder l'image de marque de l'Office,
· assurer la promotion des activités de
l'Office par des stratégies de marketing,
· s'occuper des voyages et séjour des agents
et de marque de l'O.C.C.,
· réaliser toutes les taches techniques
relatives aux soins médicaux curatifs et préventifs aux agents et
aux membres de leur famille ainsi qu'aux abonnés,
· élaborer les synthèses des
différents rapports pour permettre au Comité de Gestion
d'orienter ses prises de décision de manière
conséquente.
v Département Financier
(D.F.)
Ce Département Financier a pour
mission :
· d'assurer régulièrement à
l'Office les fonds nécessaires à son équipement et
à son fonctionnement,
· d'apporter les états financiers et
comptables,
· de mettre à la disposition de la
Délégation Générale un tableau de bord pouvant lui
permettre de suivre le mouvement des comptes bancaires ainsi que la situation
journalière des caisses de l'entreprise,
· de veiller à la gestion comptable de biens
meubles et immeubles,
· de procéder au recouvrement des
créances de l'Office, de s'acquitter régulièrement des
obligations de l'entreprise vis-à-vis de l'Etat, des
Fournisseurs...
Dans chaque province de la République
Démocratique du Congo, il existe une Direction Provinciale
(DIPRO).
Les activités de la DIRKIN sont coordonnées
et supervisées par le Chef de Direction Provinciale (C.D.P.) qui est le
représentant légal de l'Administrateur
Délégué Général de l'O.C.C. (A.D.G.)
à Kinshasa. Il est secondé par un adjoint, le Chef de Direction
Provinciale Adjoint (C.D.P.A.) qui assume son intérim en cas de
nécessité.
III.8 Inventaire des
équipements Informatiques existants à L'OCC29(*)
|
EQUIPEMENTS
|
MARQUES
|
QUANTITE
|
|
Ordinateurs
|
HP, DELL, ACER, COMPAQ, HDD varie entre 80 à
500Go, RAM varie entre 512Mo à 4Go, CPU varient entre 1Ghz à
4Ghz, Lecteur CD-DVD,...
|
295
|
|
Imprimantes
|
HP Laser jet
|
118
|
|
Onduleurs
|
APC, 700VA
|
156
|
|
Scanners
|
Epson Expression Home XP 235
|
08
|
|
Photocopieuses
|
HP Laser Jet Pro CF 1025
|
13
|
|
Serveurs
|
HP Proliant DL 380P Gn8
|
4
|
|
Les Câbles
|
Paire torsadée UTP
|
-
|
|
Equipements logiciels
|
|
Système d'exploitation
|
· Windows xp, 7, 8 Pro 32 et 64
Bits ;
· Windows serveur 2003 ;
· LINUX/Redhat
|
-
|
|
Antivirus
|
Kaspersky
|
-
|
Tableau III.1 Inventaire des
équipements
III.9 Plan d'adressage
Existant
L'office congolais de
contrôle disposant d'une trois centaines des PC a une adresse
réseau 192.168.1.0 et d'un masque de sous réseau
équivalent à la /23 ou 255.255.254.0
Caractéristiques du
réseau
|
Type
|
LAN
|
|
Topologie Physique
|
En Etoile
|
|
Topologie Logique
|
Ethernet
|
|
Architecture
|
Client/serveur
|
Tableau III.3
Caractéristique du réseau existant
III.8 Présentation du
Schéma du réseau De L'office Congolais de Contrôle

L'office congolais de contrôle dispose d'un grand
parc informatique dont les équipements sont sophistiqués et de
grande performance. Ainsi, nous allons présenter ici le schéma du
système informatique qui y existe.
III.11 Critique de L'existant
Nous venons de présenter le système
informatique existant au sein de l'office congolais de contrôle où
nous avons vu que l'OCC étant une grande entreprise, a des
équipements informatiques parmi lesquels nous trouvons des serveurs avec
à l'intérieur plusieurs services.
Ces serveurs malheureusement connaissent souvent des
montées en charge causées par un grand nombre des requêtes
qu'envoient les utilisateurs ; chose qui provoque l'interruption de
travail au sein de l'entreprise, la lenteur pour avoir des réponses aux
requêtes envoyées par les utilisateurs ou même
l'indisponibilité de ces serveurs.
III.12 Proposition des
Solutions
En vue de palier à ce problème de
montée en charge, nous allons mettre en place un système qui nous
permettra, d'assurer la haute disponibilité,
l'évolutivité et l'adaptabilité des ressources des
serveurs, avec une possibilité de fournir les services jusqu'à
99,99% pour assurer la continuité de traitement des requêtes.
CONCLUSION PARTIELLE
Notre site qui était l'Office congolais de
contrôle vient d'être présenté dans toute son
intégralité avec ses failles que nous avons
démontrées et avons proposé des solutions en vertu de la
critique que nous avons formulée au regard de son système
informatique.
Le chapitre qui suivra concernera la mise en place de
notre système qui va fonctionner au sein de l'entreprise pour
résoudre les multiples problèmes que nous avons
énumérés lors de la critique de l'existant.
CHAPITRE IV. MISE EN PLACE DU
SYSTEME
IV.1 Introduction
Dans le chapitre précédent nous avions
présenté le site au sein de laquelle notre système sera
implanté et ce chapitre est consacré à la mise en place de
la fonctionnalité du cluster d'équilibrage de charge
réseau.
IV.2 Explication du travail
Ce travail est orienté vers la mise en place d'un
cluster d'équilibrage de la charge réseau.
Dans un cluster chaque hôte exécute une copie
distincte des applications de serveur souhaitées. Le
NLB distribue les connexions entrantes entres les hôtes
actif du cluster. Ce cluster a une adresse IP globale et conserve des adresses
IP fixes sur chacun des membres du cluster. Si par exemple le cluster a une
adresse IP de 192.168.0.3 et qu'on essayait de se connecter sur le serveur Web
à cette adresse, la connexion sera redirigée vers l'un des
membres du cluster.
En cas d'échec sur une application
équilibrée, ou de passage hors connexion (serveur
éteint pour maintenance ou panne technique), la charge est alors
automatiquement redistribuée entre les serveurs toujours en
fonctionnement mais toutes les connexions qui étaient en cour de
traitement sur ce serveur seront perdues. En revanche si la mise hors
connexion d'un serveur est nécessaire, il est alors possible de
conserver les connexions en cours. On utilisera la commande
drainstop.
En permanence, des heartbeats
(pulsations) sont envoyés entre les serveurs du cluster, si aucun
Heartbeat ne parvient pendant 5 secondes, le serveur en
question est considéré comme en
échec.
IV.3 Choix de la technologie
Il est sans doute connu qu'il existe plusieurs
applications qui peuvent assurer l'équilibrage de charge réseau
parmi lesquels nous avons énumérés certaines d'entre
elles. Mais quant à nous nous avons opté de choisir pour
l'application Network Load Balancing (NLB) car il présente plusieurs
avantages. C'est un produit Microsoft qui a été
intégré tout d'abord au système d'exploitation Windows
server d'où la facilité d'en avoir et la mise en place qui est
facile et adapté.
IV.4 Analyse des besoins
Etant donné que notre site dispose
déjà d'un grand réseau informatique avec des
matériels sophistiqués, nous allons juste présenter ici
les éléments importants ou manquants pour la mise en place de
notre système
|
Matériels
|
Description
|
Caractéristiques
|
Quantité
|
|
Serveurs
|
HP Proliant Micro Server Gn8
G161DT
|
2,3GHz, 16Go RAM, 2To HDD
|
3
|
|
Switch
|
TP-Link Jet stream T1600G-52TS
|
48 Ports 10/100/1000 Mbps
|
1
|
|
Système d'exploitation
|
Os Windows server 2008 R2
entreprise
|
-
|
3
|
|
Câbles
|
RJ45 Cat 5e/UTP
|
-
|
1 rouleau
|
Tableau IV.1 Analyse des besoins
IV.5 Nomenclature des noeuds
Pour permettre à l'administrateur du cluster de
bien gérer facilement cette fonctionnalité, il est
conseillé de nommer les équipements ou les noeuds pour qu'il se
retrouve lorsqu'il voudra par exemple effectuer une tâche de maintenance
ou toute autre action. Voilà pourquoi nous pensons à proposer
cette nomenclature des équipements dont nous aurons besoin.
|
Noeuds
|
Nomenclatures
|
|
HP Proliant Micro Server Gn8 (1)
G161DT
|
Cluster-web
|
|
HP Proliant Micro Server Gn8 (2)
G161DT
|
Cluster-data
|
|
HP Proliant Micro Server Gn8 (3) G161DT
|
Cluster-Toip
|
|
Switch TP-Link Jet stream
T1800G-52TS
|
Load_Balancer
|
Tableau IV.2 Description de la
nomenclature
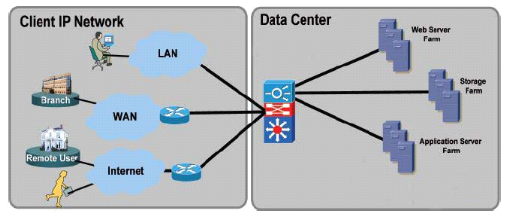
IV.6 Schéma du nouveau
système
IV.7 Interprétation du
schéma
Il s'agit ici de notre schéma du cluster
d'équilibrage de charge réseau que nous sommes en train
d'implanter. Les clients qui peuvent être soit sur le réseau
local, soit sur le WAN ou soit sur Internet, vont envoyés des
requêtes au serveur ; ces requêtes vont s'arrêter au
répartiteur de charge qui est dans ce cas le Switch. Le NLB qui est
logique sur ce Switch va faire la translation de l'adresse IP source en Adresse
IP virtuelle (Network Ardess Translation, NAT en sigle) et ce
répartiteur va alors voir quel serveur parmi tous de la grappe a moins
de charge et c'est là qu'il va envoyer cette requête. Lorsque le
serveur répond, il répond au voyant qui est notre
répartiteur, il va encore faire la translation de l'adresse IP de
destination en une adresse IP virtuelle et va répondre au client. Le
client ne se rendra pas compte de ce qui se passe entre l'envoie de la
requête et la réception de la réponse.
Les noeuds du cluster doivent s'écouter grâce
à un battement de coeur qu'on appelle Heart Beat. Son signal doit
arriver toutes les 5 secondes. Au cas contraire ce qu'il y a un problème
au niveau des noeuds.
IV.8 Plan d'adressage
|
Hôte
|
Adresse IP
|
Masque de sous réseau
|
Passerelle par défaut
|
|
Serveur I
|
192.168.1.2
|
255.255.224.0
|
192.168.1.1
|
|
Cluster-web
|
192.168.1.3
|
255.255.224.0
|
192.168.1.1
|
|
Serveur II
|
192.168.1.4
|
255.255.224.0
|
192.168.1.1
|
|
Cluster-data
|
192.168.1.5
|
255.255.224.0
|
192.168.1.1
|
|
Serveur III
|
192.168.1.6
|
255.255.224.0
|
192.168.1.1
|
|
Cluster-ToIP
|
192.168.1.7
|
255.255.224.0
|
192.168.1.1
|
Tableau IV.3 Plan d'adressage des
équipements
IV.9 Mise ne place et
configuration du système
Nous allons voir dans cette partie, comment installer et
configurer simplement un cluster d'équilibrage de charge réseau.
Comme beaucoup de fonctionnalité de Windows Server 2008
R2, NLB s'installe et se paramètre très
aisément.
Ce pendant, quelques pré-requis au niveau logiciel
doivent déjà être présents :
Réseaux : Les
configurations des contrôleurs réseaux doivent être
identiques, les adresses IP des serveurs doivent être fixes.
DNS : Les serveurs doivent
tous utiliser le DNS (la version dynamique est utilisable).
Active Directory : Les
serveurs doivent être dans le même Active Directory.
Contrôleurs de
domaine : Les serveurs doivent tous être des
serveurs membres.
Pour effectuer les procédures qui vont suivre, vous
devez être membre du groupe administrateur, ou être administrateur
de l'hôte que vous configurez.
Passons maintenant à l'installation de cette
fonctionnalité d'équilibrage de charge réseau
Dans un premier temps, ouvrer l'interface de gestion du
serveur. Sélectionnez dans l'arborescence à droite
Fonctionnalités puis à gauche Ajouter des
fonctionnalités.

Fig. IV.1 Ajout des
fonctionnalités.
Dans la liste des fonctionnalités disponibles avec
Windows Server 2008 R2, cochez Equilibrage de la charge
réseau, puis cliquez sur suivant.
Fig. IV.2 Liste des fonctionnalités de WS
2008 R2
La fenêtre suivant vous avertit de
l'éventualité d'un redémarrage système. Continuer
et cliquez sur Installer. L'installation est rapide et ne
nécessite que quelque seconde. NLB est maintenant
installé sur votre serveur. Il suffit de répéter cette
action sur tous les serveurs qui seront dans le cluster.
Nous allons maintenant créer et configurer notre
cluster. Ouvrez le menu Démarrer >
Outils d'administration > Gestionnaire de
l'équilibrage réseau.
Dans la fenêtre qui s'affiche, faite un clic droit
puis Nouveau cluster sur l'onglet Clusters
d'équilibrage de la charge réseau.
Fig. IV.3 Console de gestion de
l'équilibrage de la charge réseau
On va dans un premier temps choisir un hôte à
ajouter au cluster. Rentrer l'adresse IP ou le nom de la machine dans
Hôte, puis cliquez sur Connexion. Si l'hôte
en question est trouvé, toutes ses connexions réseaux sont
affichées en dessous. Choisissez l'interface réseau que vous
souhaitez utiliser. Dans notre exemple, ça sera l'adresse
192.168.0.1.
Fig. IV.4 Ajout du premier hôte dans le futur
cluster
Dans la fenêtre suivante, il va falloir
définir la priorité de l'hôte sur le cluster. Le
paramètre Priorité spécifie un
identificateur unique pour chaque hôte. L'hôte dont la
priorité numérique est la plus basse parmi les membres actuels du
cluster traite tout le trafic réseau du cluster. Nous laisserons 1 dans
notre cas ainsi que l'état
démarré par défaut.
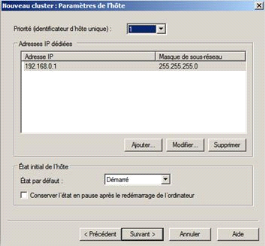
Fig. IV.5 Configuration de la priorité de
l'hôte
Après avoir cliquez sur Suivant, il
est maintenant temps de définir une IP au cluster. Cliquez sur
Ajouter... puis dans IPv4 rentrez l'IP et le masque. Ici l'IP
principal de notre cluster est 192.168.0.3 et un masque de 225.255.255.0, puis
passez à l'étape suivante.
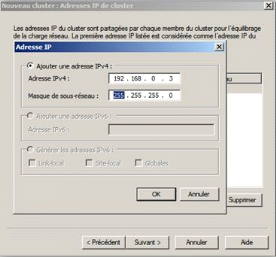
Fig. IV.6 Paramétrage de l'adresse IP du
cluster
Après avoir définit les paramètres
réseaux du cluster, nous allons lui donner un Nom Internet
Complet. Dans notre cas
« cluster-web » et un mode
d'opération.
Le paramètre Nom Internet complet indique
un nom global au cluster NLB. Ce nom est utilisé pour
accéder au cluster dans son ensemble. Dans notre cas nous avons
décidé de choisir le mode multidiffusion.
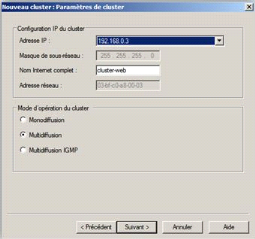
Fig. IV.7 Configuration du cluster
Dans la fenêtre suivante, vous avez la
possibilité de définir des règles de port. Par
défaut le cluster utilise les ports de 0 à 65635. Nous choisirons
la règle par défaut. Mais vous la modifié à votre
guise.
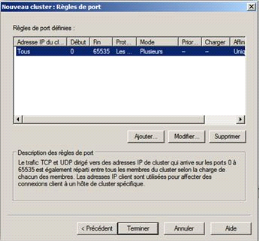
Fig. IV.8 Définition des règles de
ports
Cliquez sur Terminer.
Fig. IV.9 Cluster avec un
hôte
Notre premier noeud a été correctement
configuré. Nous allons maintenant ajouter notre 2ème noeud au
cluster-web pour valider la fonctionnalité NLB.
On ouvre le menu contextuel de notre
« Cluster-web » pour ajouter le
2ème hôte à notre cluster et on procède de la
même façon que pour notre premier noeud pour installer notre
second noeud.
Fig. IV.10 Ajout d'un nouvel hôte au
cluster
Il suffit dans un premier temps de rentrer son adresse IP
ou son nom de machine
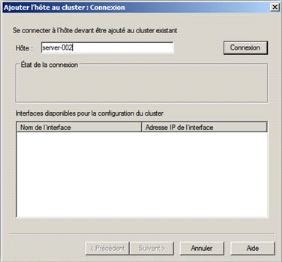
Fig. IV.11 Connexion à
l'hôte
Cliquez ensuite sur Suivant puis
terminer. Vous vous retrouvez sur l'interface de gestion de NLB. Vous pouvez
voir dans le fenêtre de droite que vous avez vos deux hôtes dans le
cluster. Le premier et dans l'état Convergé, il est donc
prêt et le deuxième est en attente. Il faut patientez une minute
pour que le deuxième hôte soit dans l'état
Convergé.

Fig. IV.12 Etat des hôtes dans le
cluster
En bas de la fenêtre du gestionnaire, vous avez un
historique de l'activité de votre cluster.
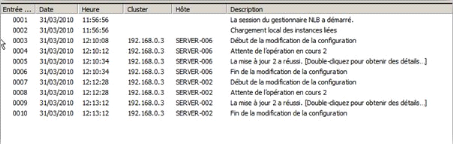
Fig. IV.13 Historique du cluster
Votre cluster est donc prêt, chacun des
hôtes est prêt. En cas d'échec d'un des hôtes une
petite croix rouge apparait à côté de l'hôte en
question. La configuration d'un cluster est donc très simple, nous
rappelons qu'il est possible de mettre 32 hôtes dans un même
cluster et qu'un hôte disposant de deux cartes réseaux peut
appartenir à deux clusters différents.
Après la configuration il sera utile de tester la
connectivité entre les différents noeuds du cluster. Pour ce
faire, plusieurs utilitaires intégrés au système
d'exploitation Windows permettent de le faire.
Parmi ces utilitaires nous pouvons
énumérés :
v PING
Utilitaire utilisé pour tester la
connectivité d'hôte à hôte, par l'envoi de paquet
ICMP dont la taille est de 32 bits et qui permet l'analyse de la connexion, la
durée de vie des paquets (TTL).
v PATHPING
Polymorphe entre PING et TRACERT, permet d'identifier la
route en indiquant les routeurs par lesquels les paquets transitent, et le
temps de réponse des paquets entre deux hôtes.
v NETDIAG
Permet de déterminer l'état de votre
réseau client, en effectuant une série de tests, il permet
notamment de vérifier les paramètres WINS et DNS.
v NSLOOKUP
Utilitaire permettant de vérifier la
résolution de nom DNS.
v NETSTAT
Utilitaire permettant d'observer les statistiques de la
connexion TCP/IP.
v TRACERT
Permet de tracer la route précise que prend un
paquet d'un point à un autre. Des paquets ICMP sont envoyés, les
différents paramètres des routeurs sont alors envoyés
à l'hôte avec l'IP du routeur et le temps TTL mis pour atteindre
celui-ci. Cet utilitaire est très utile dans le cas où l'on
souhaite déterminer le point de dysfonctionnement du chemin entre 2
hôtes.
v ARP
Utilitaire permettant de faire de la translation adresse
IP en adresse MAC.
On test alors l'accès web sur notre cluster-web via
l'adresse IP 192.168.0.3 et on voit que notre cluster
fonctionne donc bien car la page par défaut de IIS7 s'affiche. La
requête du client a été dirigée vers l'un des deux
serveurs core de test.
Fig. IV.2 Test de la connexion au
cluster-web
IV.10 L'administration Et
Dépannage Du Cluster NLB
L'administration d'un cluster nécessite une
administration sur chaque noeud. Il est donc important d'avoir une approche
d'une administration centralisée ou automatisée.
Afin de faciliter l'administration du cluster, des
utilitaires ont été conçues pour répondre à
ce besoin d'administration simple et efficace dans un environnement de
cluster.
IV.10.1 Administration du cluster
via le Shell
L'administration du cluster par ligne de commande
s'effectue avec la commande WLBS.EXE
Cet utilitaire permet de stopper ou de démarrer le
cluster, examiner le statut du cluster, contrôler le cluster,
désactiver ou activer des règles de ports et autres tâches
d'administration.
Pour ce servir de cet utilitaire, on doit ouvrir l'invite
de commande, tapez WLBS.EXE suivi de la commande adéquate.
Il y a des différentes syntaxes pour cet utilitaire
selon qu'on veut l'exécuter sur le noeud local, sur le cluster tout
entier ou sur un autre noeud spécifique.
Sur le noeud local on a la syntaxe : wlbs
command
Exemple : wlbs Stop
Sur le cluster tout entier on aura : wlbs
command nom_du_cluster
Exemple : wlbs Start
Cluster1
Sur un noeud spécifique du cluster :
wlbs command nom_du_cluster: nom_hôte
Exemple : wlbs Start Cluster1 :
Eliya
Il ya d'autres commandes dites des commandes de
contrôle du cluster qu'on peut utiliser pour voir les
propriétés des noeuds, accéder aux fichiers d'aides,
contrôler les statuts des adresses MAC ou des hôtes et des
données du cluster comme : Display, Help, IP2MAC, query,...
Il ya d'autres utilitaires d'administrations comme le
Windows Management Instrumentation, le SDK WMI, Windows Host script... que nous
n'allons pas aborder ici mais qui assurent aussi l'administration du
cluster.
Lorsqu'une erreur survient dans le cluster NLB, il est
parfois difficile de déterminer d'où vient la panne. Il existe
des utilitaires intégrés au système Windows qui
permettront de détecter la source des erreurs.
Voici les quelques erreurs que nous pouvons
énumérées et les solutions y
afférentes :
v Une boîte de dialogue affiche le message suivant :
« Le système a détecté une adresse IP en conflit
avec un autre système sur le réseau. »
Cause : il y a conflit
d'adresses. Deux adresses IP différentes de cluster ont
été configurées dans les propriétés
réseau des noeuds.
Solution : Utiliser une
unique adresse IP de cluster et configurer cette IP sur tous les noeuds du
cluster.
v Après le démarrage du cluster, celui
commence la convergence, mais celle-ci n'arrive jamais à la fin. La
convergence ne se fait pas dans la totalité.
Cause : Différents
numéros de ports ou certains ports incompatibles ont été
paramétrés sur les différents noeuds du
cluster.
Solution : Dans les
propriétés du Network Load Balancing, vérifiez que les
règles de ports sont identiques sur tous les noeuds.
v Après avoir démarré le cluster, et
une fois la convergence effectuée, le système indique plusieurs
noeuds par défaut.
Cause : Les noeuds du
cluster font partis de différents sous réseaux, ils ne sont donc
pas accessible par le même réseau.
Solution : Vérifier
que tous les noeuds peuvent communiquer entre eux.
v Le réseau n'apparaît pas sur un ou
plusieurs noeuds du cluster.
Cause : Le pilote NLB ne
s'est pas chargé correctement lors du démarrage du
système. Cela peut venir si c'est le NLB qui est dépendant ou si
c'est le pilote NLB lui-même qui est corrompu.
Solution : Exécuter
la commande wlbs query pour vérifier que le pilote
s'est bien chargé, dans le cas où celui-ci ne s'est pas
chargé, il faut consulter le journal des événements pour
voir pourquoi le pilote ne s'est pas chargé.
IV.11 Chronogramme
d'activités
|
N°
|
Activités
|
1èr jour
|
2ème jour
|
3ème jour
|
4ème jour
|
5ème jour
|
6ème jour
|
7ème jour
|
8ème jour
|
9ème jour
|
|
1
|
Récolte des données
|
|
|
|
|
|
|
|
|
|
|
2
|
Analyse des données
|
|
|
|
|
|
|
|
|
|
|
3
|
Préparation du bilan
|
|
|
|
|
|
|
|
|
|
|
4
|
Achat matériels
|
|
|
|
|
|
|
|
|
|
|
5
|
Configuration du système
|
|
|
|
|
|
|
|
|
|
|
6
|
Test du système
|
|
|
|
|
|
|
|
|
|
|
7
|
Formation
|
|
|
|
|
|
|
|
|
|
Tableau IV.3 Chronogramme
d'activité
IV.12 Coût du
système
|
N°
|
Libellés
|
Quantité
|
Prix unitaire
|
Prix Total
|
|
1
|
Serveurs HP Proliant Micro Server Gn8
G161DT
|
3
|
315.000Fc
|
945.000Fc
|
|
1
|
Os Windows server R2 entreprise
|
3
|
752.000Fc
|
2.256.000Fc
|
|
2
|
Switch TP-Link Jet stream T1800G-52TS
|
1
|
405.000Fc
|
405.000Fc
|
|
3
|
Rouleau de câble UTP
|
1
|
28.000Fc
|
28.000Fc
|
|
4
|
Transport DHL
|
25Kg
|
747.000Fc
|
747.000Fc
|
|
3
|
Total partiel
|
-
|
2.247.000Fc
|
4.381.000Fc
|
|
4
|
Imprévue
|
-
|
10%
|
438.100Fc
|
|
5
|
Main d'oeuvre
|
-
|
30%
|
1.314.300Fc
|
|
6
|
Total général
|
-
|
-
|
6.133.400Fc
|
Tableau IV.4 Coût du
système
IV.12 CONCLUSION PARTIELLE
Nous venons ici dans ce chapitre de présenter la
mise en place de notre système de haute disponibilité où
nous avons mis toutes les étapes de configuration ainsi que les
éléments dont nous aurons besoin pour cette fin et le coût
lié leurs installations.
CONCLUSION GENERALE
Nous voici au terme de ce travail de fin du premier cycle
universitaire, qui a parlé de la fonctionnalité du cluster
d'équilibrage de charge réseau
Le développement des idées sur ce dit sujet
n'a pas été pour nous un temps perdu mais nous a aidé
beaucoup plus car grâce à elle nous avons été en
mesure d'acquérir des connaissances sur les solutions de haute
disponibilité qui paraissent de très grande importance dans
toute entreprise qui doit croître car ces dernières assureront
une disponibilité des applications et des services jusqu'à 99,99%
et ainsi améliorer la productivité au sein de la firme où
elle pourra être implantée.
Étant donné les différents
résultats présentés dans ce travail départ son
installation, nous pouvons en conclure que notre équilibrage de charge
réseau fonctionne parfaitement puisqu'il permet aux clients
d'accéder au site plus rapidement en cas d'encombrement tout en
réduisant les ressources nécessaires sur les diverses machines du
cluster. De plus la solution de haute disponibilité nous assure une
sécurité supplémentaire en cas de défaillance au
niveau de l'équilibreur, d'un serveur ou de la base des
données.
Sachant que toute oeuvre humaine ne manque jamais
d'imperfections, nous laissons porte ouverte à toute personne qui voudra
bien apporter un plus sur ce travail qui n'a été qu'une partie.
NOTES BIBLIOGRAPHIQUES
OUVRAGES
v Claude Castelluccia, Introduction à la
téléinformatique, Ed. 7 écrits, Bruxelles, 2003,
Pg. 162
v Cyril DUFRENES, Les Clusters, Ed. Tintin
Ronald, Paris, 2004, Pg.69
v Jean-François D., Initiation théorique
à l'informatique, Ed. Les étoiles, Burkina-Faso, 1991,
Pg. 29
v Jean-Luc Archimbaud, Ethernet Norme
IEEE802.3, Ed. endymion , Paris, 1991, Pg.22
v Tarreau W. et Train W. , Le loadbalancing pour les
nuls, édition First, Paris, 2010, Pg.10
ARTICLES
v Antoine RICHET, In Fonctionnalités de la
répartition de charge réseau (NLB), laboratoire supinfo
des technologies Microsoft.
v Damien RIVET, In Règle des ports,
laboratoire supinfo des technologies Microsoft
v Florian BURNEL, In mise en place de cluster NLB avec
Windows Server 2012 R2, Le 20 novembre 2014
v Sammy POPOTE, in Concepts de la répartition
de charge réseau, laboratoire Supinfo des technologies
Microsoft
NOTES DES COURS
v Emmanuel MATONDO, Cours de réseau
informatique II, ISIPA, TM3/A, 2015-2016, Kinshasa, Pg. 16
v Henry KISOKI, Cours des
télécommunications, ISIPA, TM2/A, 2014-2015,
Kinshasa, Pg. 68.
v MIZONZA Dior, Cours de réseau informatique
I, ISIPA, TM2/A, 2014-2015, Kinshasa, Pg. 112.
v Professeur Eugène MBUYI M., Cours de
télématique, Université de Kinshasa,
G3 Informatique, 2013-2014
v René KALONDA M., Méthodes de
recherches scientifiques, ISIPA, TM2/A, Pg. 20
WEBOGRAPHIE
v
http://www.april.org, mercredi le 19 novembre 2015
16h30 `
v
http://www.cluster.top500.org , samedi 21 novembre 2015,
13h00'
v
www.commentçamarche.com
v
www.openclassroom.com
v www.TechNet.fr
AUTRES DOCUMENTS
v Département Administratif,
Présentation de l'office congolais de contrôle,
Kinshasa 2010
v Département Informatique, Synthèse
parc informatique OCC, site de Kinshasa, Division Hardware
2012.
v Le Dictionnaire Robert Méthodique
Table des matières
INTRODUCTION GENERALE
1
I. PROBLEMATIQUE
1
II. HYPOTHESES
2
III. DELIMITATION DU SUJET
3
IV. METHODES ET TECHNIQUES
3
V. CHOIX ET INTERET DU
SUJET
4
V.1 CHOIX
4
La chose qui nous a poussé au choix de
ce travail est la curiosité de savoir comment pouvons-nous assurer dans
une entreprise les services sans interruption afin de gagner en temps et en
revenu.
4
V.2 INTERET
4
VI. DIFFICULTES RENCONTREES
4
VII. SUBDIVISION DU TRAVAIL
4
CHAPITREN I : GENERALITES SUR LES RESEAUX
INFORMATIQUES
6
I.1 Introduction
6
I.2 Définition des concepts de
base
6
I.2.1 Le réseau
6
I.2.2 Le réseau
informatique
6
I.2.3 La communication
6
I.2.4
Télécommunication
6
I.2.5 La
télémaintenance
7
I.3 Les différents types des
réseaux informatiques
7
I.3.1 Découpage
Géographique
7
I.3.2 Découpage
fonctionnement
8
I.4 Les topologies réseaux
8
1.4.1 La topologie physique
8
I.4.2 La topologie logique
10
I.5 Les méthodes
d'accès
10
I.5.1 Méthode TDMA (Time Division
Multiplexing Access)
10
I.5.2 CSMA/CD (Carrier Sense Multiple Access
with Collision Detect)
11
I.5.3 La méthode de jeton
11
I.6 Architectures réseau
11
I.6.1 L'architecture poste à
poste
11
I.6.2 L'architecture
client-serveur
11
I.7 Les Equipements d'un réseau
informatique
12
I.7.1 Ordinateur
12
1.7.2 Serveur
12
1.7.3 Le concentrateur (Hub)
13
I.7.4 Le commutateur
14
I.7.5 Le routeur
14
I.7.6 La carte réseau
14
I.7.7 Le modem
14
I.8 Les supports de transmission
15
I.8.1 Les supports limités
15
I.9 Les protocoles de
communication
16
I.9.1 Le protocole TCP/IP
16
Le protocole TCP
17
Le protocole IP
17
I.10 Le modèle de
référence OSI
18
CHAPITRE II : PRESENTATION DU CLUSTER
D'EQUILIBRAGE DE CHARGE RESEAU
22
II.1 Idée générale sur le
cluster
22
II.1.1 Définition
22
II.1.2 Historique
22
II.2 Le Cluster Network Load
Balancing
23
II.2.1 Avantages et
inconvénients
24
II.2.2 Architecture
25
II.3 Fonctionnement
28
II.3.1 Fonctionnalités de la
répartition de la charge réseau
28
II.4 Les modes d'opérations, de filtrage
et d'affinité du cluster
32
II.4.1 Modes d'opérations
32
II.4.2 Modes de filtrage
33
II.5 Le modes d'affinités
34
II.5.1 Aucune
34
II.5.2 Unique
34
II.5.3 Réseau
35
II.6 Les caractéristiques du Network
Load Balancing
35
II.7 Les règles de ports de
l'équilibrage de la charge réseau
35
II.8 Autres logiciels de Load
Balancing
35
v Nginx
35
v HA Proxy
36
v Varnish
36
CHAPITRE III. PRESENTATION DE
L'ENTREPRISE
38
III.0 Introduction
38
Tout travail de fin de cycle parlant sur les
réseaux informatiques comme celui-ci doit porter soit sur une
étude ou une mise en place. Ce dernier s'appliquant dans un milieu
professionnel donné, il nous sera alors question de présenter ici
l'institution au sein de laquelle nous avons effectué nos recherches qui
est l'office congolais de contrôle, O.C.C en sigle.
38
III.1 Cadre juridique et nature de
l'O.C.C
38
III.2 Brève historique
39
III.3 Localisation
40
III.4 Missions et Objectifs
40
III.4.1 Missions
40
III.4.2 Objectifs de l'O.C.C.
40
III.5 Relation entre L'OCC et le gouvernement
et d'autres Institutions
41
III.6 Les activités
normatives
41
III.7 Structure Organique Et
Fonctionnelle
43
III.7.1 Organigramme de l'Office Congolais de
Contrôle
43
III.7.2 Fonctionnement de l'Office Congolais de
Contrôle
44
C1. Les départements Centraux
d'exploitation
45
Contrôle avant embarquement
46
Contrôle à
l'arrivée
46
. DEPARTEMENT CENTRAUX D'APPOINT
48
III.8 Inventaire des équipements
Informatiques existants à L'OCC
51
Tableau III.1 Inventaire des
équipements
51
III.9 Plan d'adressage Existant
51
L'office congolais de contrôle disposant
d'une trois centaines des PC a une adresse réseau 192.168.1.0 et d'un
masque de sous réseau équivalent à la /23 ou
255.255.255.254
51
Tableau III.3 Caractéristique du
réseau existant
52
III.8 Présentation du Schéma du
réseau De L'office Congolais de Contrôle
53
III.11 Critique de L'existant
54
III.12 Proposition des Solutions
54
CHAPITRE IV. MISE EN PLACE DU
SYSTEME
55
IV.1 Introduction
55
IV.2 Explication du travail
55
IV.3 Choix de la technologie
55
IV.4 Analyse des besoins
56
IV.5 Nomenclature des noeuds
56
IV.6 Schéma du nouveau
système
57
IV.7 Interprétation du
schéma
57
IV.8 Plan d'adressage
57
IV.9 Mise ne place et configuration du
système
58
IV.10 L'administration Et Dépannage Du
Cluster NLB
66
IV.10.1 Administration du cluster via le
Shell
66
IV.11 Chronogramme
d'activités
68
IV.12 Coût du système
69
NOTES BIBLIOGRAPHIQUES
71
OUVRAGES
71
ARTICLES
71
NOTES DES COURS
71
WEBOGRAPHIE
72
AUTRES DOCUMENTS
72
Table des
matières..........................................................................................................................................73
*
1René KALONDA M.,
Méthodes de recherches scientifiques, ISIPA, TM2/A, Pg.
20
* 2 Le Dictionnaire
Robert Méthodique
* 3
MIZONZA Dior, Cours de réseau informatique I, ISIPA,
TM2/A, 2014-2015, Kinshasa, Pg. 112.
* 4 Henry KISOKI,
Cours des télécommunications, ISIPA, TM2/A,
2014-2015, Kinshasa, Pg. 68.
* 5
www.openclassroom.com
* 6
Jean-Luc Archimbaud, Ethernet Norme IEEE802.3, Ed.
Endymion, Paris, 1991, Pg.22
* 7MIZONZA Dior,
Op-cit. Pg. 112.
* 8 Jean-François
D., Initiation théorique à l'informatique, Ed.
Les étoiles, Burkina-Faso, 1991, Pg. 29
*
9Eugène MBUYI M., Cours de
télématique, Université de Kinshasa,
G3 Informatique, 2013-2014
* 10
www.commentçamarche.com
* 11
Idem
* 12 Henry KISOKI,
Cours des télécommunications, ISIPA, TM2/A,
2014-2015, Kinshasa, Pg. 68.
* 13
Idem
* 14
Op.cit.
* 15
www.classroom.com
* 16 Op.cit.
* 17
www.TechNet.fr
* 18
http://www.april.org,
mercredi le 19 novembre 2015 16h30 `
* 19
Cyril DUFRENES, Les Clusters, Ed. Tintin Ronald, Paris, 2004,
Pg.69
* 20
Tarreau W. et Train W. , Le loadbalancing pour les nuls,
édition First, Paris, 2010, Pg.10
* 21
Op.cit ;
* 22
http://www.cluster.top500.org
, samedi 21 novembre 2015, 13h00'
* 23 Antoine
RICHET, In Fonctionnalités de la répartition de charge
réseau (NLB), laboratoire supinfo des technologies
Microsoft.
* 24 Florian BURNEL,
In mise en place de cluster NLB avec Windows Server 2012 R2, Le
20 novembre 2014
* 25 Emmanuel MATONDO,
Cours de réseau informatique II, ISIPA, TM3/A,
2015-2016, Kinshasa, Pg. 16
* 26 Sammy POPOTE,
in Concepts de la répartition de charge réseau,
laboratoire Supinfo des technologies Microsoft
* 27 Damien RIVET,
In Règle des ports, laboratoire supinfo des
technologies Microsoft
* 28 Département
Administratif, Présentation de l'office congolais de
contrôle, Kinshasa 2010
* 29 Département
Informatique, Synthèse parc informatique OCC, site de
Kinshasa, Division Hardware 2012.
| 

