I.6.2.2. Architecture pair-à-pair (peer-to-peer ou
P2P)
Le pair-à-pair est un modèle de réseau
informatique proche du modèle client-serveur mais où chaque
ordinateur connecté au réseau est susceptible de jouer tour
à tour le rôle de client et celui de serveur.
P2P est une architecture pouvant être centralisée
(les connexions passant par un serveur central intermédiaire) ou
décentralisée (les connexions se faisant directement). Le
pair-à-pair peut servir au partage de fichiers en pair à pair, au
calcul distribué ou à la communication entre noeuds ayant la
même responsabilité dans le système.
La particularité des architectures pair-à-pair
réside dans le fait que les données peuvent être
transférées directement entre deux postes connectés au
réseau, sans transiter par un serveur central. Cela permet ainsi
à chaque ordinateur d'être à la fois serveur de
données et client des autres. On appelle souvent noeud les
postes connectés par un protocole réseau pair-à-pair.
Outre, les systèmes de partage de fichiers
pair-à-pair permettent de rendre les ressources d'autant disponibles
qu'elles sont populaires, et donc répliquées sur un grand nombre
de noeuds. Cela permet alors de diminuer la charge (en nombre de
requêtes) imposée aux noeuds partageant les fichiers dans le
réseau. C'est ce qu'on appelle le passage à
l'échelle. Cette architecture permet donc de faciliter le partage
des ressources. Elle rend aussi la censure ou les attaques légales ou
pirates plus difficiles.
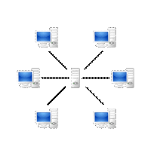
Figure 4: Architecture pair-à-pair
Ces atouts font des systèmes pair-à-pair des
outils de choix pour décentraliser des services qui doivent assurer une
haute disponibilité tout en permettant de faibles coûts
d'entretien. Toutefois, ces systèmes sont plus complexes à
concevoir que les systèmes client-serveur.
Dans ce chapitre, nous nous sommes focalisé
sur les conceptsde base des systèmes distribués. Nous avons
donné en détail les caractéristiques des systèmes
distribués, leurs architectures ainsi que les domaines concrets de leur
application. Dans le prochain chapitre, nous abordons le concept Base de
données répartie.
| 

