III.3. L'étape logique
L'étape logique va réellement
s'intéresser à l'utilisation de la base de données sans se
soucier malheureusement du langage de programmation à utiliser. Nous
parlerons de deux points : le MLD et Le MLT.
III.3.1. Le modèle logique de données
Le modèle logique de données établit la
structure de données utilisées. Au niveau de ce modèle,
parlerons de trois choses : le besoins des utilisateurs, le choix du
système de gestion de base de données et de la
présentation proprement dite du MLD.
Besoins des utilisateurs
Pendant nos recherches au sein du service de
l'état-civil de différentes communes visitées, nous avons
pu remarquer que les états tels que l'acte de naissance, le tableau
statistique des naissances étaient des besoins prioritaires. Il faut
signaler que la liste n'est pas exhaustive.
Choix du système de gestion de base de
données
Le système de gestion de bases de données
rappelons-le, est un logiciel qui sert à gérer les bases de
données. Dans le cadre de notre travail, nous avons opté pour le
prestigieux Microsoft SQL serveur version 2000.
Règles de passage du MOD au MLD
|
Tout objet conceptuel devient une table logique,
Tout identifiant devient une clé primaire ;
--tout CIF disparaît et le père cède sa
clé à son fils ;
Toute relation n à n entraîne la création
d'une table. Et la table ainsi crée va hériter les clés
des objets réunis en dehors de ses propres propriétés.
|
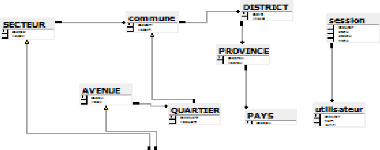
Le modèle logique de données
brut
PAYS (codpay,liPay)
VILLE (codVil, libVil,
#codPay)
DISTRICT (codDist, libDist,
#codVil)
COMMUNE/TERRITOIRE (codCom, libCom,
#codDist)
SECTEUR (codSec, libSec, codCom
QUARTIER (codQuart, libQuart,
#codCom)
AVENUE (codAven, libAven,
#codquart)
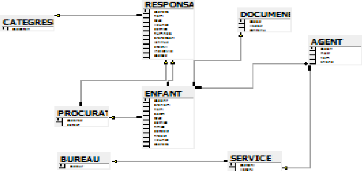
QUALITRESP (codcateg, libcateg)
RESPONSABLES (codresp, nom, lieuNce, datNce,
profession, numhabit, langue, sexe,
etatciv, indicevie, #codAven, #codSec,
#codcateg)
PROCURATION (codproc, datecrit,
#codresp)
AGENT (matr, nomAgent, grade, numPhone,
#codServ)
BUREAU (codBur, libBur,
#codAven)
SERVICE (codServ, libSer,
#codbur)
Document (codoc, libdoc, contenu)
ENFANT (numActNce, nomEnf, sexe, datnce,, hrNce, datDeclar,
heurDeclar, lieuNce,
#codresp, #codDoc, #codproc, #matr)
Utilisateur (coduser, nom, login pword)
Session (#coduse, dtcnx, dtdcnx,,
hrcnx, hrdcnx)
Normalisation et vérification du modèle
logique de données
Il me semble que programmer une application avec ce
modèle, entraînerait certaines redondances, synonymies et
polysémies. D'où, nous allons maintenant normaliser et formaliser
notre modèle logique de données considéré comme
brut.

La normalisation consiste:
A vérifier pour chaque objet si il a un identifiant et si
ses propriétés sont atomiques (1ere FN) ;
A vérifier si toutes les propriétés de
chaque objet dépendent directement de leur identifiant et si ce dernier
est atomique (2ème FN).
A vérifier si toutes les propriétés de
chaque objet dépende pleinement de leur identifiant (3ème FN).
Quant à la vérification, il s'agira de voir si
la base des données n'entraîne pas des synonymies (plusieurs
objets ayant le même sens), ou de polysémies (un même objet
ayant plusieurs sens).
Présentation du modèle logique de
données valide
| 

