Chapitre2
Techniques de conception et de gestion des
bases de données réparties
2.1 Introduction
Avant de concevoir une base de données
répartie, il est nécessaire de bien comprendre les étapes
de conception, car différentes méthodes de conception existent et
chacune d'elles nous offre une approche très différente de
l'autre.
Dans le cas d'une base de données répartie, la
difficulté réside dans le choix des techniques de conception, un
mauvais choix pourrait conduire à la création d'un système
inefficace.
La conception d'une base de données répartie
peut être le résultat de deux approches totalement distinctes,
soit d'une part le regroupement d'une multitude de bases de données
déjà existantes oil d'autre part, que cette dernière soit
construite du zéro.
2.2 Conception d'une base de données répartie
La définition du schéma de répartition
est la partie la plus délicate de la phase de conception d'une BDR, car
il n'existe pas de méthode miracle pour trouver la solution optimale.
L'administrateur doit donc prendre des décisions dont l'objectif est de
minimiser le nombre de transferts entre sites, les temps de transfert, le
volume de données transférées, les temps moyens de
traitement des requêtes, et le nombre de copies de fragments, ... etc.
2.2.1 Méthodes de conception
Deux approches fondamentales sont à l'origine de la
conception des bases de données réparties : la conception
descendante 'Top down design' et la conception ascendante 'Bottom
up design'.
2.2.1.1 Conception ascendante
Cette approche se base sur le fait que la répartition
est déjà faite, mais il faut réussir à
intégrer les différentes BDs existantes en une seule BD globale.
En d'autre terme, les schémas conceptuels locaux
(LCS1) existent et il faut réussir à les
unifier dans un schéma conceptuel global (GCS2).
[Kar05]
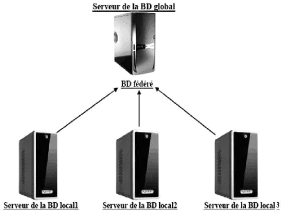
FIG. 2.1 - Architecture de la conception ascendante.
2.2.1.2 Conception descendante
On commence par définir un schéma conceptuel
global de la base de données répartie, puis on le distribue sur
les différents sites en des schémas conceptuels locaux. La
répartition se fait donc en deux étapes, en première
étape la fragmentation et en deuxième étape l'allocation
de ces fragments aux sites. [Des00]
L'approche top down est intéressante quand on part du
néant. Si les BDs existent déjà, la méthode bottom
up est utilisée.
1Local Conceptual Schema 2Global
Conceptual Schema
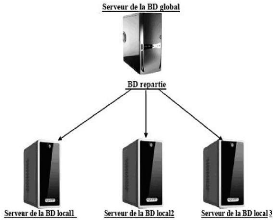
FIG. 2.2 - Architecture de la conception descendante.
2.2.2 La fragmentation
2.2.2.1 Définition
La fragmentation est le processus de décomposition
d'une base de données en un ensemble de sous bases de données.
Cette décomposition doit être sans perte d'information. La
fragmentation peut être coûteuse s'il existe des applications qui
possèdent des besoins opposés. [Gui04]
2.2.2.2 Objectif de la fragmentation
Les applications ne travaillent que sur des sous-ensembles
des relations. Une distribution complète des relations
générerait soit beaucoup de trafic, soit une réplication
des données avec tous les problèmes que cela occasionne :
problèmes de mises à jour, problèmes de stockage. Il est
donc préférable de mieux distribuer ces sous-ensembles.
L'utilisation de petits fragments permet de faire tourner plus
de processus simultanément, ce qui entraîne une meilleure
utilisation des capacités du réseau d'ordinateurs.
2.2.2.3 Les problèmes de la fragmentation
La fragmentation peut être coûteuse s'il existe
des applications qui possèdent des besoins opposés. On est en
quelque sorte dans le cas d'une exclusion mutuelle qui empêche une
fragmentation correcte.
Par ailleurs, la vérification des dépendances sur
différents sites peut être une opération très
longue.
2.2.2.4 Types de fragmentation
· La fragmentation horizontale :
C'est un découpage d'une table en sous tables par
utilisation de prédicats permettant de sélectionner les lignes
appartenant à chaque fragment. L'opération de fragmentation est
obtenue grâce à la sélection des tuples d'une table selon
un ou des critères bien précis et la reconstitution de la
relation initiale se fait grâce a l'union (U) des sous-relations.
[Mou05]
Exemple :
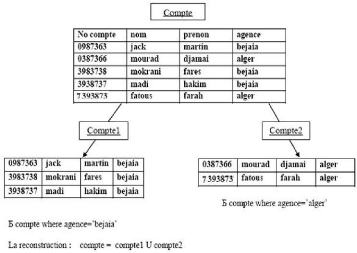
FIG. 2.3 Exemple de fragmentation horizontale.
· La fragmentation verticale :
Elle est le découpage d'une table en sous tables par
projection permettant de sélectionner les colonnes composant chaque
fragment. La relation initiale doit pouvoir être recomposée par la
jointure des fragments. [Gui04]
Exemple :
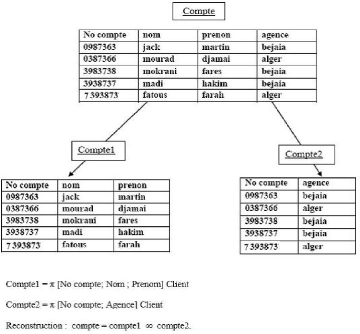
FIG. 2.4 - Exemple de fragmentation verticale.
· La fragmentation mixte :
Elle résulte de l'application successive
d'opérations de fragmentation horizontale et verticale sur une relation
globale.
2.2.2.5 Les règles de la fragmentation
Un problème qui se pose pour la fragmentation est comment
définir un bon degré de fragmentation. Il existe trois
règles pour la fragmentation :
1. Complétude : pour toute donnée d'une relation
globale R, il existe au moins un fragment Ri de la relation R qui
possède cette donnée.
2. Reconstruction : pour toute relation R
décomposée en un ensemble de fragments Ri, il existe une
opération de reconstruction à définir en fonction de la
fragmentation. Pour les fragmentations horizontales, l'opération de
reconstruction est une union. Pour les fragmentations verticales c'est la
jointure.
3. Disjonction : une donnée n'est présente que
dans un seul fragment, sauf dans le cas de la fragmentation verticale pour la
clé primaire qui doit être présente dans l'ensemble des
fragments issus d'une relation. [Des00]
2.2.2.6 L'allocation des fragments
Suite à la fragmentation des données, il est
nécessaire de les placer sur les différentes machines. Un
schéma doit être élaboré afin de déterminer
la localisation de chaque fragment et sa position dans le schéma global,
c'est ce qu'on appelle l'allocation. [Spa98]
2.2.2.7 Le schéma de répartition
Pour fragmenter les requêtes, il est nécessaire
de connaître les règles de localisation des données. Lors
de l'exécution d'une requête, le SGBDR doit décomposer la
requête globale en sous requêtes locales en utilisant le
schéma de répartition.
2.3 Techniques de répartition avancées
2.3.1 Allocation avec duplication
Cette technique consiste à dupliquer des parties de la
base c'est-à-dire les fragments sont dupliqués sur un seul site,
voir plusieurs sites selon les besoins. Cette approche est très
intéressante car elle améliore considérablement les
performances du système, étant donné que les fragments
sont dupliqués un peu partout et que les accès aux données
sont locaux, évitant ainsi la congestion du réseau et
améliorant les temps de réponse. Le principal inconvénient
de cette technique est la difficulté des mises à jour de tous les
fragments dupliqués. [Spa98]
2.3.2 Allocation dynamique
Avec cette technique, l'allocation d'un fragment peut changer
en cours d'utilisation de la BDR, c'est-à-dire qu'un fragment qui se
trouve sur un site A à un instant T, peut être retrouvé sur
un site B à un instant T+1. Cette technique est efficace mais exige le
maintien du schéma d'allocation et des schémas locaux. [Spa98]
2.3.3 Fragmentation dynamique
Cette technique consiste à profiter de l'allocation
dynamique des fragments, c'est-à-dire que dans certains cas, il est
possible que deux fragments complémentaires (verticalement ou
horizontalement) se trouvent sur le même site suite au mouvement
d'un fragment d'un site A vers un site B. Donc, il est alors intéressant
de les fusionner.
A l'inverse, si une partie d'un fragment est appelée
sur un autre site, il peut être intéressant de décomposer
ce fragment et de ne migrer que la partie concernée. Ces modifications
du schéma de fragmentation se répercutent sur le schéma
d'allocation et sur les schémas locaux. [Spa98]
2.4 La replication
La réplication consiste à copier les
informations d'une base de données sur une autre. Elle peut être
accompagnée d'une transformation des données sources, voir
souvent d'une agrégation. Dans tous les cas, il s'agit d'une redondance
d'information.
L'objectif principal de la réplication est de faciliter
l'accès aux données en augmentant la disponibilité. Soit
parce que les données sont copiées sur différents sites
permettant de répartir les requêtes, soit parce qu'un site peut
prendre la relève lorsque le serveur principal s'écroule. Une
autre application tout aussi importante est l'amélioration des
performances des requêtes sur les données locales, et ceci permet
d'éviter les transferts de données et d'accroître la
résistance aux pannes. [Mey05]
2.4.1 Principe
Le principe de la réplication, qui met en jeu au minimum
deux SGBDs, est assez simple et se déroule en trois étapes :
[SL06]
1. La base maître reçoit un ordre de mise à
jour (INSERT, UPDATE ou DELETE).
2. Les modifications faites sur les données sont
détectées et stockées dans un fichier ou une file
d'attente en vue de leur propagation.
3. Le processus de réplication prend en charge la
propagation des modifications à faire sur une seconde base dite esclave.
Il peut bien entendu y avoir plus d'une base esclave.
2.4.2 Type de réplication
2.4.2.1 Réplication asymétrique
La réplication asymétrique distingue un site
maître appelé site primaire, chargé de centraliser les
mises à jour. Il est le seul autorisé à mettre à
jour les données, et chargé de diffuser les mises à jour
aux copies dites secondaires. [Gui04]
Le plus gros problème de la gestion asymétrique
est la panne du site primaire. Dans ce cas, il faut choisir un
remplaçant si l'on veut continuer les mises à jour. On aboutit
alors à une technique asymétrique mobile dans laquelle le site
primaire change dynamiquement. On distingue l'asymétrie synchrone et
l'asymétrie asynchrone :
· Réplication asymétrique synchrone : elle
utilise un site primaire qui pousse les mises à jour en temps
réel vers un ou plusieurs sites secondaires. La table
répliquée est immédiatement mise à jour pour chaque
modification par utilisation de trigger sur la table maître. [Mey05]
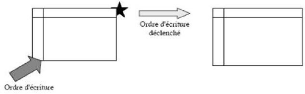
FIG. 2.5 - Réplication asymétrique synchrone.
· Réplication asymétrique asynchrone :
elle pousse les mises à jour en temps différé via une file
persistante. Les mises à jour seront exécutées
ultérieurement, à partir d'un déclencheur externe,
l'horloge par exemple. [Mey05]
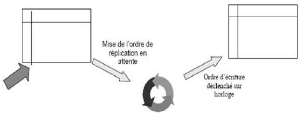
FIG. 2.6 Réplication asymétrique
asynchrone.
24
2.4.2.2 Réplication symétrique
A l'opposé de la réplication
précédente, la réplication symétrique ne
privilégie aucune copie c'est-à-dire chaque copie peut être
mise à jour à tout instant et assure la diffusion des mises
à jour aux autres copies. [Gui04]
Cette technique pose problème de la concurrence
d'accès risquant de faire diverger les copies. Une technique globale de
résolution de conflits doit être mise en oeuvre. On distingue la
symétrie synchrone et la symétrie asynchrone :
· Réplication symétrique synchrone : Lors
de la réplication symétrique synchrone, il n'y a pas de table
maître. L'utilisation de trigger sur chaque table doit
différencier une mise à jour client à répercuter
d'une mise à jour par réplication. Cette technique
nécessite l'utilisation de jeton. [Mey05]
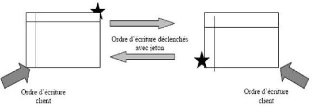
FIG. 2.7 - Réplication symétrique synchrone.
· Réplication symétrique asynchrone : Dans
ce cas, la mise à jour des tables répliquées est
différée. Cette technique risque de provoquer des
incohérences de données.
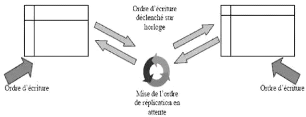
FIG. 2.8 Réplication symétrique asynchrone.
2.4.3 Vue matérialisée
Une vue matérialisée (VM3)
est un moyen simple de créer une vue physique d'une table. Elle
correspond à une photo instantanée des données au moment
de l'exécution de la requête. À la différence d'une
vue standard, le résultat de la requête est physiquement
stocké dans la base de données.
Les vues matérialisées peuvent porter sur des
tables, mais aussi des vues ou des vues matérialisées. [Del08]
Exemple :
CREATE MATERILIZED VIEW mz-relation REFRESH COMPLET
ON DEMAND
AS
SELECT col1, col2 ... FROM ma-table;
2.4.3.1 Objectifs
L'utilisation des vues matérialisées permet
l'amélioration des performances d'accès et la réduction du
trafic sur le réseau, elles sont mises à jour
périodiquement, ce qui les rendent très efficaces. [Del08]
2.4.3.2 Mise à jour des vues
matérialisées
Afin d'assurer une certaine cohérence des
données, il faut mettre à jour les vues
matérialisées et les tables périodiquement. Il existe
trois façons de mises à jour qui sont la
régénération complète, rapide et forcée :
· Rafraîchissement complet :
Il va ré-exécuter la requête basée
sur la table de base et remplace l'ensemble des données de la VM par les
données obtenues et ceci même si la table de base n'a pas
été modifiée, selon le volume de données qui
satisfait la requête, ce rafraîchissement peut être gourmant
en ressource. [Wos05]
· Rafraîchissement incrémental :
Son principe est de propager uniquement les données
modifiées depuis le dernier
rafraîchissement. Ce type de
rafraîchissement dit aussi rapide nécessite que la base
de
données stocke les modifications enregistrées sur les
données des tables de base,
3Vue Matérialisée/En Anglais :
Materialized View
on utilise pour cela un journal (fichier Log). Ces
données sont stockées jusqu'à ce que le
rafraîchissement ait été effectué. [Wos05]
Ce type de rafraîchissement est particulièrement
efficace si les tables de base sont relativement peu modifiées. On
considère que si plus de la moitié des lignes sont
modifiées un rafraîchissement complet sera plus efficace.
[Wos05]
· Rafraîchissement forcé :
Dans ce type de rafraîchissement, lorsqu'une
régénération rapide n'est pas possible, alors une
régénération complète est
exécutée.
2.4.4 Les avantages de la réplication
Les avantages de la réplication sont assez nombreux,
selon le type on trouve :
- Allégement du trafic réseau en
répartissant la charge sur divers sites. Par conséquent,
rapidité des accès aux données.
- Amélioration des performances des requêtes.
- Résistance aux pannes par l'augmentation de la
disponibilité des données.
2.5 Gestion des données réparties
2.5.1 Mise à jour des données distantes
2.5.1.1 Requêtes réparties en lecture
Lors de l'exécution d'une requête en lecture, la
base de données répartie va décomposer la requête
globale en sous requêtes locales à l'aide des méta
données de distribution.
2.5.1.2 Requêtes réparties en écriture
La mise à jour des données sur une base de
données réparties nécessite la validation préalable
de chaque site avant la demande du site coordinateur. Ce protocole se nomme
'Validation à deux phases' 2PC4 et garantit le tout
ou rien dans une base de données répartie. [Mey03]
La première phase réalise la préparation de
l'écriture des résultats des mises à jour dans la base de
données et la centralisation du contrôle.
4Two Phases Commit
Par contre la seconde phase 'phase de validation'
n'est réalisée qu'en cas de succès de la phase 1, elle
intègre les résultats des mises à jour dans la base de
données répartie. Le contrôle du système
réparti est centralisé sous la direction d'un site appelé
coordinateur. Les autres sites sont nommés des participants. [BM07]
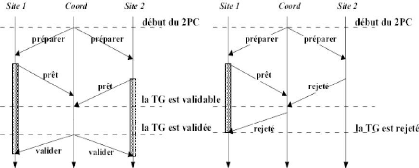
FIG. 2.9 - Protocole de validation à deux phases -
2PC.
2.5.2 Contraintes déclaratives
Il est impératif dans une base de données
répartie de placer des contraintes déclaratives sur les
données qui seront stockées dans le dictionnaire de
données.
Dans une base de données répartie, il est
nécessaire de dissocier deux types de contraintes :
2.5.2.1 Contraintes locales
Les contraintes locales sont des contraintes placées sur
un seul site (schéma local). Ces contraintes sont donc
stockées dans le dictionnaire de chaque site. [Mey03]
2.5.2.2 Contraintes globales
Les contraintes globales doivent être placées
sur la relation globale, il n'est pas possible de les matérialiser. Nous
pouvons dire qu'il est impossible de créer des contraintes sur des vues,
mais il est plus important de comprendre qu'une contrainte globale doit
être placée dans plusieurs dictionnaires. [Mey03]
Le schéma global n'étant pas physiquement
implémenté, il n'est pas possible de mettre en place ces
contraintes de manière déclarative.
2.6 Conclusion
Les bases de données réparties constituent un
domaine important pour la gestion des informations stockées sur
différents sites.
Dans ce chapitre, nous avons présenté les
principes de la répartition des données. Cette répartition
peut se faire selon différents scénarios choisis par le
concepteur, tout en prenant en compte les restrictions et les obligations de
conception.
Nous avons vu également, comment gérer une base de
données répartie avec les principes de réplication
symétrique et asymétrique.
| 

