

MÉMOIRE
pour obtenir le grade de Master délivré par
Université Paris 8 Vincennes à Saint Denis
Mention Informatique
Parcours Big data et Fouille de
données
présenté et soutenu publiquement
par
Amassin NACERDDINE
le 12 septembre 2022
Prévison de date de passage des jalons avec les
méthodes de machine learning
Directeur de mémoire: Guille BERNARD
|
Maître d'apprentissage : Céline PREL
|
|
|
Alternance effectué à : Groupe Renault
1 Av.
du Golf,
78280 Guyancourt
COMUE Paris Lumières
Laboratoire d'Informatique Avancée de Saint
Denis
Laboratoire Paragraphe
|
M
A
S
T
E
R
|

Remerciements
Je tiens à apporter toute ma gratitude à mon
encadrant universitaire Monsieur Gilles BERNARD pour ses précieux
conseils son encadrement irréprochable ainsi que son écoute et sa
disponibilité.
Mes professeurs qui m'ont suivi durant tout mon parcours
académique Monsieur Sofian Aissani Monsieur Youcef TOUATI Monsieur
Jean-Jacques MARIAGE Madame Rakia JAZIRI.
Un grand merci à Madame Ana FERNANDEZ pour son
management et ses motivations. Madame Marie-Claire FEYEL pour ses avis toujours
très affûtés. Mais aussi Monsieur Abdel-Djalil OURABAH pour
son aide.
Enfin, merci aux membres de ma promo avec qui j'ai
passé des moments inoubliables, Ainsi que ma famille et mes amis qui
sont constamment restés à l'écoute Rayan Iness Maman et ma
mamie.

Sommaire
Remerciements 3
Introduction 7
I Problématique 9
I Le contexte de résolution du problème 13
II Le problème à résoudre 19
II État de l'art 35
III Techniques de traitement 39
IV Techniques d'évaluation 49
V Résultats obtenus 53
III Système réalisé 61
VI Méthodologie d'analyse et de conception 65
VII Outils utilisés 69
Conclusion 77
6 SOMMAIRE
Amassin NACERDDINE Université Paris 8 Vincennes
Table des figures 81
Liste des tableaux 83
Introduction
En cette ère moderne, on a de plus en plus besoin de
prédire ce qui va se passer dans un futur proche.
Dans le cadre de mon alternance que j'effectue au sein du
groupe Renault à la direction de la DEAGOM où nous sommes en
charge du suivi et du monitoring des projets véhicules nous devons
respecter un jalonnement bien spécifique pour les projets.
Néanmoins il s'avère que ces date
prévisionnelles qui sont saisies dans nos outils d'entreprise ne
s'avère pas toujours fiables et ne sont pas toujours
respectées.
Pour se faire j'ai réalisé deux outils dans le
cadre de ce travail qui permettent de faire,la prédiction de ces dates
en utilisant des méthodes de machine learning,et de la visualisation
pour faciliter la prise de décision.
En effet avoir une meilleure visibilité des dates
permet une meilleure planification ainsi qu'une meilleure répartition
des tâches des ressources, mais aussi directement impacter la
satisfaction client,car un client qui reçois sa voiture dans les temps
sera plus satisfait.
Par conséquent,des méthodes plus modernes et
plus performantes afin de déterminer toutes les caractéristiques
d'entrée des données que nous avons a notre disposition doivent
être proposées.
Cette étude se concentre sur une approche de Machine
Learning car elle a un potentiel élevé dans ce domaine,ces
méthodes de ML peuvent apprendre à partir de grands ensembles de
données.
Ce rapport est structuré comme suite :
· Chapitre 1 :Le contexte de résolution du
problème
· Chapitre 2 :Je présenterai la
problématique auquel nous faisons face en entreprise.
·
8 Introduction
Amassin NACERDDINE Université Paris 8
Vincennes
Chapitre 3 :Je dresserai un état de l'art de ce qui est
fait dans la littérature.
· Chapitre 4 :Je montrerai ensuite la méthode de
conception que nous adoptons.
· Chapitre 5 :Je vais lister les outils et technologies
utilisé durant le projet ainsi qu'un aperçu du résultat
final.
· Quant à la conclusion, elle dressera les
perspectives et la vue d'ensemble du projet.
9
partie I
Problématique

Table des matières
I Le contexte de résolution du problème
13
I.1 Introduction 14
I.2 Contexte 14
I.3 Contexte Logiciel 14
I.4 Jalonnement adopté 15
I.5 Semaines entre chaque jalon 16
I.6 Indicateurs 17
I.7 Conclusion 17
II Le problème à résoudre
19
II.1 Objectif 20
II.2 Règle 20
II.3 Données 21
II.4 Difficultés rencontrées 24
II.5 Décomposition du problème 24
II.6 Data pre-processing 24
II.7 Conclusion 33

Chapitre I
Le contexte de résolution du
problème
Sommaire
I.1 Introduction 14
I.2 Contexte 14
I.3 Contexte Logiciel 14
I.4 Jalonnement adopté 15
I.5 Semaines entre chaque jalon 16
I.6 Indicateurs 17
I.7 Conclusion 17
14 CHAPITRE I. CONTEXTE
Amassin NACERDDINE Université Paris 8 Vincennes
I.1 Introduction
Dans cette section je vais définir certaines notions
essentielles a la présentation de notre problème.
Le groupe Renault fait partie de l'alliance entre les trois
grands constructeurs automobiles Renault-Nissan-Mitsubishi. C'est le premier
constructeur mondial et compte plus de 100 000 collaborateurs à travers
37 pays dans le monde.
I.2 Contexte
Nous adoptons chez Renault une logique de
développement spécifique que nous appelons V3P (Value-up Product
Process Program).
Cette logique divise la phase de développement d'un
véhicule en plusieurs jalons (milestones).
Nous suivons le véhicule de la phase amont où
sont proposés le concept et le design du véhicule.
Viennent alors les deux phases de développement et
d'industrialisation qui sont au coeur de l'ingénierie ce sont les deux
phases qui nous intéressent le plus et pour lesquelles j'ai
consacré ce travail.
I.3 Contexte Logiciel
Ces dates sont introduites et modifiées au fur et
à mesure de l'avancement des projets dans notre outil d'entreprise GPS
(Global Planning System).
Les accès à cet outil ainsi qu'aux
données sont restreints de par la nature confidentielle de celles-ci.
I.4 Jalonnement adopté 15
I.4 Jalonnement adopté
Voici un schéma qui présente le jalonnement
adopté ainsi que les différents milestones.

PRéVISON DE DATE DE PASSAGE DES JALONS 2022
FIG. 1 : V3P4
Amassin NACERDDINE Université Paris 8 Vincennes
16 CHAPITRE I. CONTEXTE
I.5 Semaines entre chaque jalon
Les semaines des projets véhicules sont
divisées au préalable au lancement des projets, il
différent selon si on parle d'un véhicule utilitaire ou d'un
véhicule pour particuliers. Bien entendu plus de pièces à
développer, impliquent des validations plus longues.
On distingue également 5 typologies
différentes, en fonction de la complexité du projet.
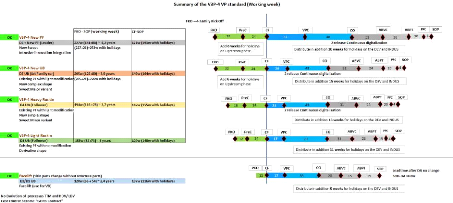
FIG. 2 : Semaines/jalon
I.6 Indicateurs 17
PRéVISON DE DATE DE PASSAGE DES JALONS 2022
I.6 Indicateurs
Nous suivons tout au long de cette logique de
développement des indicateurs qui sont parfois spécifiques
à chaque jalon.

FIG. 3 : Indicateurs
I.7 Conclusion
Les dates prévisionnelles de passage de ces jalons
sont planifiées et saisies dans nos outils d'entreprises. Toutefois ces
dates ne sont pas toujours respectées et dans la major partie des
projets décalées au fur et à mesure.

Chapitre II
Le problème à résoudre
Sommaire
|
|
|
II.1
|
Objectif
|
20
|
|
II.1.1
|
Métier
|
20
|
|
II.1.2
|
Technique
|
20
|
|
II.1.3
|
Stratégique
|
20
|
II.2
|
|
Règle
|
20
|
II.3
|
Données
|
21
|
|
II.3.1
|
Composition de données
|
21
|
|
II.3.2
|
Schéma de données
|
21
|
|
II.3.3
|
Nommage des projets
|
22
|
|
II.3.4
|
Zone architecture
|
23
|
II.4
|
Difficultés rencontrées
|
24
|
II.5
|
Décomposition du problème
|
24
|
II.6
|
Data pre-processing
|
24
|
|
II.6.1
|
Nettoyage des données
|
25
|
|
II.6.2
|
Chercher les valeurs aberrantes
|
25
|
|
II.6.3
|
Application des lois statistiques
|
26
|
|
II.6.4
|
Sélection des caractéristiques
intéressantes
|
30
|
|
II.6.5
|
Transformer les données
|
31
|
|
II.6.6
|
Augmentation de données
|
33
|
II.7
|
Conclusion
|
33
|
|
20 CHAPITRE II. LE PROBLÈME
Amassin NACERDDINE
Université Paris 8 Vincennes
II.1 Objectif
On distingue ici l'objectif métier, défini en
fonction du point de vue de l'utilisateur, l'objectif technique, défini
en fonction du point de vue du développeur informatique, et enfin un
objectif stratégique plus général à accomplir
durant ce travail.
II.1.1 Métier
D'un point de vue métier, on veut pouvoir donner une
meilleure estimation des dates de passage des jalons.
Les collaborateurs doivent être en mesure de visualiser
les dates des jalons et les décideurs doivent être alertés
et doivent être en mesure de prendre des décisions selon le
décalage plus ou moins important de ces dates.
II.1.2 Technique
Le problème d'un point de vue technique peut
être vu de deux façons différentes, à savoir un
problème de classification,ou un problème de
régression.
La classification et la régression sont des cas
d'apprentissage supervisé,où on entraîne des algorithmes
afin d'avoir une fonction de prédiction qui se rapproche le plus de la
réalité.
II.1.3 Stratégique
Ce projet est avant tout une preuve de concept (POC) afin de
montrer que les données peuvent être mieux exploitées et
afin d'adopter de nouvelles stratégies plus modernes au sein du
groupe.
Une fois ce types d'outils déployés ils
permettront aux décideurs d'adopter des choix selon les contraintes et
la complexité de la situation.
L'objectif final est bien entendu une meilleure satisfaction
clients,car un client auquel on promet une date de sortie fiable se tournera
rarement vers un constructeur concurrent.
II.2 Règle
Les indicateurs que nous suivons au sein de la DAGOM sont
parfois issue de différentes directions et ont des schémas de
données différents.
Les indicateurs auxquels je me suis particulièrement
intéressé sont les LUP (Liste unique de problème) et les
tickets Jira.
II.3 Données 21
PRévIsoN DE DATE DE PAssAGE DEs JALoNs 2022
En effet ces indicateurs recensent les problèmes qui
surviennent durant toute la phase de réalisation d'un
véhicule.
Il faut savoir que ces problèmes sont classés
selon leurs degrés de criticité qui va de K1 jusqu'à K4 (1
pour très critique).
Et si des tickets de criticité K1 (& ou) K2 sont
encore ouverts et pas encore traités le jalon ne passera pas et la date
de son passage systématiquement reportée et modifiée dans
nos outils d'entreprise.
Une fois que nous connaissons cette règle il est plus
simple d'appréhender le problème de base.
II.3 Données
II.3.1 Composition de données
Nous allons nous intéresser plus en détail sur la
composition et la structure de notre jeux de données.
Nous disposons en tout de 500 000 lignes soit 1/2 million de
tickets et LUP des projets entre 2018 et 2022.
En moyenne un projet peut avoir jusqu'à 4000 tickets
toute au long de son développement.
Les tickets sont saisies par les pilotes qui répertorient
les problèmes. La fréquence d'ouverture des tickets dépend
fortement de l'avancement du projet.
II.3.2 Schéma de données
Un ticket Jira ou une LUP c'est :
· Le projet véhicule qui est concerné par le
ticket : String
· la zone du véhicule qui est impactée
:String
· les dates de création et de fermeture (dans le cas
ou le problème est résolu) du ticket : Date
· La criticité du ticket qui représente le
degré d'importance du ticket (1..4) :Int
· Nom du pilote qui répertorie le problème
:String
· La direction en charge de régler le
problème : String
22 CHAPITRE II. LE PROBLÈME
· La description du problème : champs de type texte
en saisie libre pour le pilote afin de détailler au maximum le
problème : String

FIG. 4 : Schéma de données
II.3.3 Nommage des projets
Les règles de nommages sont définies chez Renault
de tel sorte qu'a partir de l'enco-dage d'un projet connaître le
modèle du véhicule la famille ainsi que le constructeur (Renault
Nissan Dacia ...).
Amassin NACERDDINE Université Paris 8 Vincennes
II.3 Données 23
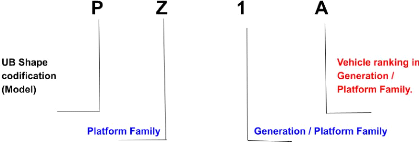
PRéVISON DE DATE DE PASSAGE DES JALONS 2022
FIG. 5 : Règles de nommage
II.3.4 Zone architecture
Les zones d'architecture d'un véhicule sont les
suivantes :
· FAV : Face avant du véhicule.
· FAR : Face arrière du
véhicule.
· LAT : Face latérale.
· SCA: Sous-caisse du véhicule.
· CMO : Compartiment moteur
· PDC : Poste de conduite
· INP : Intérieur et plancher
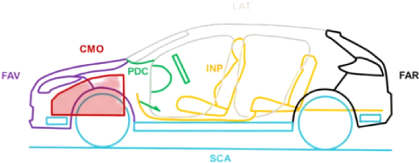
24 CHAPITRE II. LE PROBLÈME
Amassin NACERDDINE Université Paris 8 Vincennes
FIG. 6 : Zone Archi
II.4 Difficultés rencontrées
Les difficultés rencontrées sont : d'abord,les
difficultés liées à la réunion et la collecte des
données et l'intégration de celle-ci sur le cloud a partir de
l'outil d'en-treprise qui est Jira de façon automatique; ensuite, les
difficultés liées aux données (informations
erronées,inexactes,Données aberrantes,vides) ainsi qu'a la
transformation et l'anonymisation de certaines informations.
II.5 Décomposition du problème
Comme tout problème de machine learning celui-ci peut
être séparé en différent modules :
· Data pré-processing & intégration de
données.
· Application des modèles & optimisation
interprétation des résultats.
· et enfin post-processing &
présentation/visualisation
II.6 Data pre-processing
Cette étape consiste en l'extraction de
caractéristiques intéressantes des données et le nettoyage
de celle-ci.
II.6 Data pre-processing 25
PRévIsoN DE DATE DE PAssAGE DEs JALoNs 2022
En effet cette étape est importante dans
l'élaboration d'un projet de ML plus particulièrement pour
l'étape suivante qui consiste a appliquer les modèles,car le
modèle choisit est plus susceptible de retourner de meilleurs
résultat dans le cas ou les données sont bien
nettoyées.
II.6.1 Nettoyage des données
Cette étape consiste a éliminer toute les
informations que l'on ne souhaite pas conserver.
· informations erronées ,inexactes.
· informations vides ou non renseignés.
· informations redondantes
· informations sans intérêt pour l'analyse.
II.6.2 Chercher les valeurs aberrantes
L'un des moyens les plus efficace pour trouver les valeurs
aberrantes reste la visualisation.
En effet les valeurs qui sortent de l'ordinaire seront
facilement repérables.
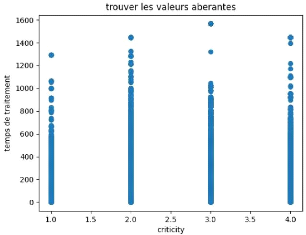
26 CHAPITRE II. LE PROBLÈME
Amassin NACERDDINE Université Paris 8 Vincennes
FIG. 7 : Visualisation des valeurs aberrantes
II.6.3 Application des lois statistiques
Voir si les données obéissent a une certaine loi
de probabilité
· loi de poisson
· loi exponentielle
· loi normale
· loi de Zipf
· Loi de Benford
On peut utiliser ces lois pour éliminer les valeurs
peut représentatives au vu de leur faible probabilité.(STEwART
, 2000)
II.6.3.1 Loi de Benford
: Une série de nombres réels en écriture
décimale suit la loi de Benford si la fréquence d'apparition du
premier chiffre significatif c vaut approximativement pour
II.6 Data pre-processing 27
tout c entre 1 et 9 où log désigne le logarithme
décimal(BENFORD , 1938) fc = log(c + 1) -
log(c) = log(1 + 1 c)
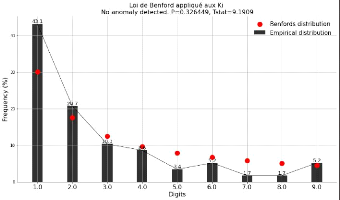
PRéVISON DE DATE DE PASSAGE DES JALONS 2022
FIG. 8 : Loi de Benford appliquée aux Ki
Amassin NACERDDINE Université Paris 8
Vincennes
28 CHAPITRE II. LE PROBLÈME
II.6.3.2 Loi de Zipf
: La loi de Zipf est une observation empirique concernant la
fréquence des mots dans un texte(PETRUSZEWYCZ , 1973)
La fréquence d'occurrence f(n) d'un mot est liée
à son rang n dans l'ordre des fréquences par une loi de la forme
où K est une constante :(MANDELBROT , 1957)
fc = Kn
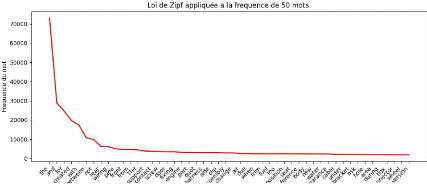
FIG. 9 : Loi zipf appliquée a la frequence des
mots
II.6 Data pre-processing 29
II.6.3.3 Loi normale
Une variable aléatoire continue X suit une
distribution normale si elle a la fonction de densité de
probabilité suivante (JEAN-JACQUES DROESBEKE , 2005)
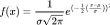
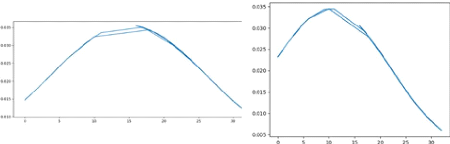
PRéVISON DE DATE DE PASSAGE DES JALONS 2022
FIG. 10 : Loi normale sur les K1/K2
30 CHAPITRE II. LE PROBLÈME
Amassin NACERDDINE Université Paris 8 Vincennes
II.6.4 Sélection des caractéristiques
intéressantes
Il existe des algorithmes d'apprentissage automatique tel que :
ACP,LDA... qui permettent de sélectionner les caractéristiques
les plus représentatives.
Mais aussi utiliser une matrice de corrélation et en
interpréter les résultats.(A.L. , 1901)
Ou encore demander l'avis des experts métier.
voici un aperçu de la matrice de corrélation
appliqué a nos features.(G.U , 1909)
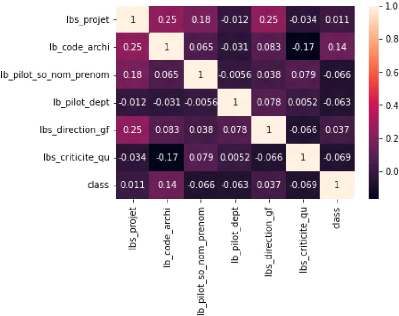
FIG. 11 : Corr matrix
II.6 Data pre-processing 31
PRéVISON DE DATE DE PASSAGE DES JALONS 2022
II.6.5 Transformer les données
La phase de préparation des données consiste
également a manipuler,modifier,voir encore créer de nouvelle
informations a partir d'information disponible.
-Dans mon cas un calcule sur le temps de traitement des tickets
fermés a dû être fait(différence entre deux
dates)Mais aussi dans certain cas et certain ticket le changement du fuseau
horaire.
-Une transformation sur le champ description a dû
être faite.
En effet ce champ représente du texte écrit en
différentes langues (Français,Anglais,Russe
,Allemand,Espagnol...) J'ai dû donc dans un premier temps traduire ce
texte en une langue commune (ici l'anglais).
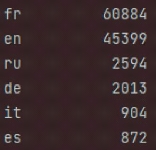
FIG. 12 : Langues dans le dataset
32 CHAPITRE II. LE PROBLÈME
Amassin NACERDDINE Université Paris 8
Vincennes
II.6.5.1 TF-IDF
Après cela une transformation de ce champs de
vecteur,pour ce faire j'ai appliqué la méthode de
pondération TF-IDF (M. J. McGILL , 1983) afin de
déterminer l'importance d'un mot ainsi que sa fréquence dans un
corpus.(JONES , 1972)
II.6.5.2 Word2Vec
Une fois notre vocabulaire déterminer nous pouvons
passer a l'étape de vectorisa-tion Word2Vec.(GOLDBERG et LEvy ,
2014)
FIG. 13 : Fréquence des mots
II.7 Conclusion 33
II.6.5.3 LabelEncoder
-L'encodage des caractéristiques catégorielles a
aussi été effectué sur certain champs(LabelEncoder).
FIG. 14 : LabelEncoder
II.6.5.4 Normalisation
-Une normalisation des données a dû être
effectué avant la passage a certain modèle.
II.6.6 Augmentation de données
On parle d'enrichissement de données lorsque on croise
les données existantes avec de nouvelle informations.
Dans notre cas on peut penser a ajouter plus de
caractéristiques liées au projet a savoir type de
moteur,Batterie,pays de fabrication...
Néanmoins et après réflexion ces
informations ne sont pas nécessaire a notre problématique de
base.
II.7 Conclusion
Cette étape représente une partie importante de
notre travail (60% du temps du projet) car elle inclus également une
bonne compréhension de l'aspect métier au préalable.
PRéVISON DE DATE DE PASSAGE DES JALONS 2022

35
partie II
État de l'art

Table des matières
III Techniques de traitement 39
III.1 Introduction 40
III.2 Machine Learning 40
III.3 Apprentissage supervisé 40
III.4 Régression ou classification 40
III.5 Algorithmes linéaires ou non linéaires
41
III.6 Modèles paramétriques ou non
paramétriques 41
III.7 Apprentissage hors ligne ou incremental 41
III.8 Modèles géométriques ou
probabilistes 42
III.9 Les principaux algorithmes 42
IV Techniques d'évaluation 49
IV.1 Performance d'un modèle et sur-apprentissage
50
IV.2 Évaluation de la classification 51
IV.3 Évaluation de la régression 52
V Résultats obtenus 53
V.1 Classification 54
V.2 Régression 58

Chapitre III
Techniques de traitement
Sommaire
III.1 Introduction 40
III.2 Machine Learning 40
III.3 Apprentissage supervisé 40
III.4 Régression ou classification
40
III.4.1 Problème de classification 40
III.4.2 Problème de régression 41
III.5 Algorithmes linéaires ou non linéaires
41
III.6 Modèles paramétriques ou non
paramétriques 41
III.7 Apprentissage hors ligne ou incremental
41
III.8 Modèles géométriques ou
probabilistes 42
III.9 Les principaux algorithmes 42
III.9.1 La régression linéaire 42
III.9.2 Les K plus proches voisins 43
III.9.3 Les arbres de décision 43
III.9.4 Les forêts aléatoire 44
III.9.5 Les machines à vecteurs de support 44
III.9.6 MLP 45
40 CHAPITRE III. TRAITEMENT
Amassin NACERDDINE Université Paris 8 Vincennes
III.1 Introduction
Dans cette section je vais présenter une étude
bibliographique sur les travaux connexes au notre ainsi que les modèles
de machine learning notamment les deux approches dont le problème peut
être traité.
III.2 Machine Learning
Le machine learning (ML) est un ensemble d'outils
statistiques et d'algorithmes informatiques qui permettent d'automatiser la
construction d'une fonction de prédiction f à partir d'un
ensemble d'observation que l'on appelle ensemble d'appren-tissage.
On peut donc considérer le ML comme étant une
discipline hybride entre plusieurs sciences et techniques qui sont l'analyse
statistique,l'intelligence artifi-cielle(IA) et l'IT.(LEMBERGER , 2022)
III.3 Apprentissage supervisé
L'apprentissage supervisé est la forme la plus courante
du ML.
Elle présuppose que l'on dispose pour un ensemble de
variables prédictives x1...xn les valeurs
de variables cibles y1...yn
Comme indiqué dans le chapitre précédant
nous disposons d'un jeux de données avec 500 000 tickets dont nous
connaissons le temps de traitement.
III.4 Régression ou classification III.4.1
Problème de classification
Nous pouvons voir le problème comme étant un
problème de classification,ou nous devons classer les tickets selon leur
temps de traitement.
Les variables cibles sont ici qualitatives.Elles
définissent une catégorie ou des classes. (Dans notre
cas la catégorie du ticket T.long,long,moyen,court).
III.5 Algorithmes linéaires ou non linéaires
41
III.4.2 Problème de régression
Le problème peut également être vu comme un
problème de régression.
Les variables cibles sont alors
quantitative.Ce sont des variables
numériques qui correspondent a des quantités.(Dans notre cas une
durée en jours)
III.5 Algorithmes linéaires ou non
linéaires
Un algorithme linéaire est par définition un
algorithme dont la fonction de prédiction f est une fonction de
combinaison linéaire des variables prédictives
a1x1 + ... + anxn (MITCHELL ,
2005). Considérée comme étant la technique la plus
célèbre de la recherche opérationnelle.(SAKAROvITCH ,
1984)
Quant aux algorithmes non linéaires ils visent a trouver
l'optimum d'une fonction non linéaire sur un sous ensemble convexe ou
non d'un espace de donnée.(OuRIEMCHI , 2005)
Les problèmes d'optimisation s'écrivent souvent
sous la forme suivante:
? ?
? Min f(x)
??
?????
sous contraintes
??h(x) = 0 ?
????? g(x) ? 0
|
f : Rn ? R h : Rn ? Rp g : Rn
? Rm x ? Rn
|
|
III.6 Modèles paramétriques ou non
paramétriques
On pale de modèles paramétriques lorsque la
fonction de prédiction f prend une forme particulière
comme exemple on peut voir la régression non linéaire ou on a une
relation de forme y = a1x1 + a x + ... + anxn n
+ c.(J , 2007)
Un tel modèle qui présuppose pour f
une forme particulière,avec un nombre de de paramètres
ajustables déjà spécifié est un
modèle paramétrique.(PFANzAGL , 1994)
Lorsque aucune forme particulière n'est
postulée pour la fonction de prédiction,on parle de
modèle non paramétrique.
III.7 Apprentissage hors ligne ou incremental
Dans le cas ou l'on connaît l'intégralité
des données d'apprentissage,on parle d'une méthode
d'apprentissage hors ligne ou
statique.(ref26)
Dans la situation ou il existe un flot continu d'informations
auxquels l'algorithme
PRévISON DE DATE DE PASSAGE DES JALONS 2022
42 CHAPITRE III. TRAITEMENT
Amassin NACERDDINE Université Paris 8 Vincennes
doit s'adapter et ajuster la fonction de prédiction
f au fur et à mesure que les données lui parviennent
sont dits online ou incrémentaux.
III.8 Modèles géométriques ou
probabilistes
On parle de modèles géométrique lorsque
il est question de distance ou de proximité entre les valeurs,à
titre d'exemple on peut citer l'algorithme KNN qui vas chercher lors de la
classification la classe la plus représentatif des K valeurs les plus
proches. On parle de modèles probabilistes lorsque les valeurs des
variables prédicatives et des variables cibles sont liées et
obéissent a une certaines loi de probabilité.
III.9 Les principaux algorithmes
Nous allons présenter dans cette section les
différents algorithmes utilisés
III.9.1 La régression linéaire
La régression linéaire est l'un des
modèles de ML supervisé et non paramétrique les plus
simple. il suppose que la fonction de
prédiction f qui lie les variables prédictives
a1x1 + ... + anxn a
la variable cible a la forme f(x) = a1x1 +
... + anxn + c. L'apprentissage du
modèle consiste a calculer les coefficients de tel sorte a minimiser les
erreurs de prédiction sur le jeux de données
d'apprentissage.(cette erreur est définie par la somme des carrés
des écarts entre les valeurs prédites et les valeurs
observées.)(T.HASTIE , 2009)
· Avantages : Peu être représenté
sous forme d'une expression mathématique,ce qui rend le modèle
simple a interpréter.
· Inconvénients :La relation que l'on
souhaite mettre en évidence doit être
linéaire. et le jeux de
données ne doit pas contenir de valeurs aberrantes.
III.9 Les principaux algorithmes 43
III.9.2 Les K plus proches voisins
L'algorithme des K plus proche voisins (KNN pour K Nearest
Neighbors) est un algorithme de classification supervisé et non
paramétrique.
On suppose qu'une observation est similaire a celle de ses
voisins,de par les distance qui les sépare.on cherche par ailleurs les K
points les plus proches de celui que l'on souhaite classer la classe ce la
variable cible est alors la majorité parmi les classes des k plus
proches.(S. MADEH PIRYONESI , 2009)
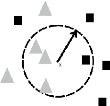
FIG. 15 : KNN
· Avantages : Simple à interpréter
· Inconvénients :Sensible au bruit
III.9.3 Les arbres de décision
Les arbres de décision sont des modèles de ML
supervisés et non paramétriques connu pour leurs
flexibilité.
Ils sont utilisables aussi bien pour la classification que
pour la régression.
L'idée consiste a classer (ou attribuer une valeur
dans le cas de la régression) à une observation a l'aide d'une
succession de questions,ou chaque question est représentée par un
noeud et chaque réponse correspond à une branche de l'arbre,la
classe (ou valeur)de la variable cible est alors déterminer par le noeud
terminal dans lequel parvient l'observation a l'issue des
questions.(B.JAKuBczYK , 2017) pour la phase d'apprentissage,elle consiste a
trouver les bonnes questions et de bien les ranger.
PRéVISON DE DATE DE PASSAGE DES JALONS 2022
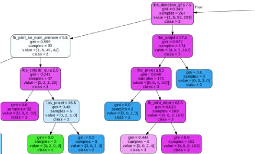
44 CHAPITRE III. TRAITEMENT
Amassin NACERDDINE Université Paris 8 Vincennes
FIG. 16 : Arbres de décision
· Avantages: Phase de préparation de données
simple
· Inconvénients : Risque de sur-apprentissage
dans le cas d'un mauvais élagage
III.9.4 Les forêts aléatoire
C'est un algorithme de classification et de régression
supervisé et non paramétrique.
Le but de l'algorithme des forêts aléatoires est
de tirer partie des avantages des arbres de décision tout en
éliminant leurs inconvénients a savoir la
vulnérabilité au sur-apprentissage.
· Avantages: En plus de regrouper tout les avantages des
arbres cité précédemment ces dernier ne souffrent pas du
problème du sur-apprentissage.
· Inconvénients: La complexité de
ce type d'algorithme rend leur implémentation délicate.
III.9.5 Les machines à vecteurs de support
Les SVM sont des algorithmes de classification binaire non
supervisé et non li-néaire(mais qui peuvent s'adapter au
multi-classe).Leurs principe est simple il consiste à construire une
séparation non linéaire entre les groupes d'observations,et
utiliser cette séparation comme repaire pour faire la
prédiction.
· Avantages : Traite des problèmes avec un grand
nombre de dimensions.
· Inconvénients: Le choix de la fonction
noyau k est délicate.
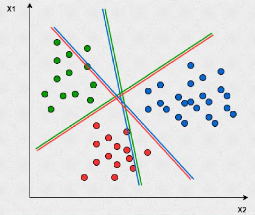
III.9 Les principaux algorithmes 45
PRéVISON DE DATE DE PASSAGE DES JALONS 2022
FIG. 17 : SVM
III.9.6 MLP
Cette architecture consiste à organiser les neurones
en couches successives avec des interconnexion avec les couches adjacentes.Ou
chaque neurone est porteur d'une valeur comprise en générale
entre 0 et 1 (d'où une normalisation
préalable).
Comme pour les autres algorithmes supervisés on
cherche a optimiser la transformation f afin que pour les observations
xn d'un ensemble d'entraînement les
prédictions f(x) soit aussi proche que possible des valeurs
yn observées. pour se faire on ajuste durant la
phase d'apprentissage des poids wn qui sont associé
a chaque lien du réseau.(ROSENBLATT , 1958)
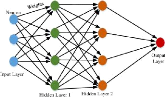
FIG. 18 : mlp
46 CHAPITRE III. TRAITEMENT
Amassin NACERDDINE Université Paris 8 Vincennes
Pour calculer la sortie du MLP en fonction des entrées
xn et des poids wn on procède
récursivement,couche par couche en combinant les deux opérations
d'addition et de multiplication passé a une fonction d'activation.
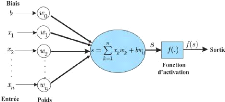
FIG. 19 : neurone-artificiel
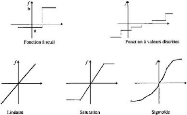
FIG. 20 : Fonctions d'activation les plus
utilisées
III.9 Les principaux algorithmes 47
PRévIsoN DE DATE DE PAssAGE DEs JALoNs 2022
III.9.6.1 rétropropagation
Pour expliquer le principe de rétropropagation on doit
comprendre le principe de l'erreur,la plus commune est l'erreur de la somme des
carrés des écarts.
E(w) = ?N n=1[f(xn; w) - Y n]2
Cette erreur E(w) s'exprime comme une somme de
contributions En(w) associé a chaque
observation(xn, yn).Ainsi pour trouver les
paramètres wn ou l'erreur E(w) atteint son
minimum,on calcule le gradient de ?En(w).
III.9.6.2 Initialisation judicieuse
Les expériences précédentes ont
montré qu'il est excrément utile d'initialiser judicieusement les
couches basses(la plus proche de l'entrée) pour améliorer les
performances d'un RN.
III.9.6.3 Utiliser le bon nombre de couches et de neurones
par couche
Les expériences précédentes en Deep
learning montrent qu'il est toujours intéressant d'avoir une couche
d'entrée qui a au moins la taille de vecteur d'entrer et les couches
suivantes qui représentent des puissances de deux.

Chapitre IV
Techniques d'évaluation
Sommaire
IV.1 Performance d'un modèle et sur-apprentissage
50
IV.2 Évaluation de la classification
51
IV.2.1 La matrice de confusion 51
IV.3 Évaluation de la régression
52
IV.3.1 RSS 52
IV.3.2 MSE 52
IV.3.3 RMSE 52
IV.3.4 RMSLE 52
Amassin NACERDDINE Université Paris 8 Vincennes
50 CHAPITRE IV. TRAITEMENT
IV.1 Performance d'un modèle et
sur-apprentissage
La performance d'un algorithmes de ML est bien entendu la
proportion de prédictions correctes(ou acceptable dans un certain sens)
faites sur le jeux de données utilisé pour
l'entraînement.
Néanmoins l'objectif du ML n'est pas de reproduire
avec une précision optimal les valeurs des variables cibles connues mais
bien de prédire les valeurs de celles qui n'ont pas encore
été observées et dont on ne connaît pas la
réponse.
En d'autres termes, il nous faut juger de la qualité
d'un algorithme de par sa capacité à généraliser
les associations apprises durant la phase d'entraînement à des
nouvelles observations.
IV.2 Évaluation de la classification 51
IV.2 Évaluation de la classification IV.2.1 La
matrice de confusion
la matrice de confusion est une matrice qui mesure la
qualité d'un système de classification. Chaque ligne correspond
à une classe réelle et chaque colonne correspond à la
classe estimée.
La cellule ligne L, colonne C contient le nombre
d'éléments de la classe réelle L qui ont été
estimés comme appartenant à la classe C DBD , 2022
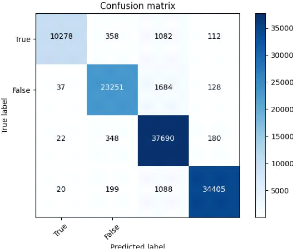
PRéVISON DE DATE DE PASSAGE DES JALONS 2022
FIG. 21 : Matrice de confusion
52 CHAPITRE IV. TRAITEMENT
Amassin NACERDDINE Université Paris 8 Vincennes
IV.3 Évaluation de la régression
Lorsque on parle d'évaluation de régression on
parle d'erreur, Celle-ci doit tendre vers 0.
IV.3.1 RSS
La somme des carrés des résidus, On calcule
pour chaque point xi du jeu de test la distance entre son
étiquette et la valeur prédite et en faire la somme.
RSS = ?n i=1(f(xi) -
yi)2
IV.3.2 MSE
Erreur quadratique moyenne, On garde les mêmes notion que
pour le RSS en
ajoutant la normalisation sur n nombre de points dans le jeu de
données.
?n
MSE = 1 i=1(f(xi) -
yi)2
n
IV.3.3 RMSE
Pour se ramener à l'unité de y , on peut prendre
la racine de la MSE. On obtient
v 1 ?n
ainsi la RMSE, ou Root Mean Squared Error. RMSE =
i=1(f(xi) - yi)2
n
IV.3.4 RMSLE
Le Root Mean Squared Log Errorr,pallie le problème des
étiquettes qui peuvent
prendre des valeurs qui s'étalent sur plusieurs ordres de
grandeur. v 1 ?n
RMSLE = i=1(log(f(xi) + 1) -
log(yi + 1))2
n
Chapitre V
Résultats obtenus
Sommaire
|
|
|
V.1
|
Classification
|
54
|
|
V.1.1
|
Sur l'ensemble du jeux de données
|
54
|
|
V.1.2
|
Sur un jeux de test aléatoire
|
57
|
|
V.1.3
|
Temps d'entraînement des algorithmes
|
57
|
V.2
|
Régression
|
58
|
|
V.2.1
|
Sur l'ensemble du jeux de données
|
58
|
|
V.2.2
|
Sur sur un jeux de test aléatoire
|
58
|
|
V.2.3
|
Temps d'entraînement des algorithmes
|
59
|
|
54 CHAPITRE V. TESTS
V.1 Classification
V.1.1 Sur l'ensemble du jeux de données
V.1.1.1 Random forest
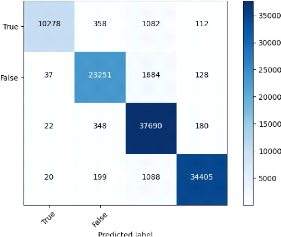
Amassin NACERDDINE Université Paris 8 Vincennes
FIG. 22 : Matrice de confusion RF
V.1 Classification 55
V.1.1.2 XGBOOST
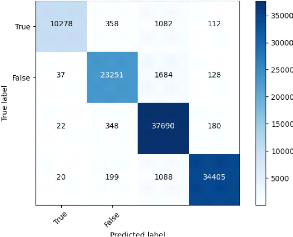
PRéVISON DE DATE DE PASSAGE DES JALONS 2022
FIG. 23 : Matrice de confusion XGBOOST
56 CHAPITRE V. TESTS
V.1.1.3 KNN
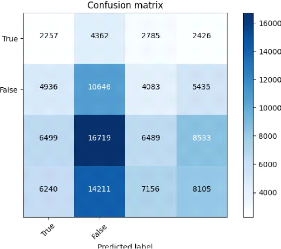
Amassin NACERDDINE Université Paris 8 Vincennes
FIG. 24 : Matrice de confusion KNN
V.1 Classification 57
PRévIsoN DE DATE DE PAssAGE DEs JALoNs 2022
V.1.2 Sur un jeux de test aléatoire
Algo Accuracy
Random Forest 84% XGBOOST 77%
MLP 75% KNN
73%
SVM 43%
V.1.3 Temps d'entraînement des algorithmes
Algo Temps d'entraînement
Random Forest 181 s
XGBOOST 656 s
MLP 365 s
KNN 14 s
SVM 2 h
58 CHAPITRE V. TESTS
Amassin NACERDDINE Université Paris 8 Vincennes
V.2 Régression
V.2.1 Sur l'ensemble du jeux de données
V.2.1.1 Random forest
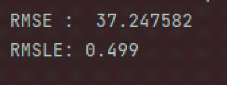
FIG. 25 : RMSE/RMSLE RF
V.2.1.2 KNN
V.2.1.3 RMSE & RMSLE
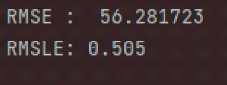
FIG. 26 : RMSE/RMSLE KNN
V.2.2 Sur sur un jeux de test aléatoire
|
Algo
|
RMSE
|
Régression Linéaire
|
0.095
|
Random Forest
|
59.63
|
KNN
|
76.2
|
XGBOOST
|
89.5
|
MLP
|
90.06
|
|
V.2 Régression 59
PRévIsoN DE DATE DE PAssAGE DEs JALoNs 2022
V.2.3 Temps d'entraînement des algorithmes
Algo Temps d'entraînement
Régression Linéaire 1.72 s
Random Forest 3597 s
KNN 14 s
XGBOOST 107 s
MLP 354 s

61
partie III
Système réalisé

Table des matières
VI Méthodologie d'analyse et de conception
65
VI.1 Introduction 66
VI.2 Méthode SCRUM 66
VI.3 Diviser pour régner 66
VII Outils utilisés 69
VII.1Introduction 69
VII.2 Logiciels et outils utilisé 70
VII.3 Aperçu de l'outil 75
Conclusion 77
Table des figures 81
Liste des tableaux 83

Chapitre VI
Méthodologie d'analyse et de
conception
Sommaire
VI.1 Introduction 66
VI.2 Méthode SCRUM 66
VI.3 Diviser pour régner 66
VI.3.1 Diviser l'équipe et attribution des rôles
66
VI.3.2 Diviser notre problème 66
VI.3.3 Diviser le temps 67
66 CHAPITRE VI. SYSTÈME
Amassin NACERDDINE Université Paris 8 Vincennes
VI.1 Introduction
Dans cette section je vais présenter la méthode
de conception adoptée pour la réalisation de ce projet. Il faut
savoir que chez Renault les méthodes qui sont adoptées sont les
méthodes agiles.
En effet elles sont favorisés par rapport au
méthodes plus classique car c'est relativement de gros projets et car
celle-ci permettent une meilleure adaptabilité, visibilité et
gestion des risques. On privilégie également les méthode
Agile pour nos projets car les besoins clients sont versatiles et
évolutifs.
VI.2 Méthode SCRUM
Pour la réalisation de notre projet nous avons
adopté la méthode agile SCRUM qui est parfaitement adapté
pour un développement rapide flexible et efficace de logiciels.ScHwABE ,
2016
Cette méthode tire son nom de la mêlée du
rugby,elle sous entend donc un grand travail d'équipe.GALiANA , 20
juillet 2017
L'approche SCRUM suit les principes de la méthodologie
Agile, c'est-à-dire l'im-plication et la participation active du client
tout au long du projet.APooRvA SRivAsTAvA , 6 May 2017
Ainsi notre équipe a du se réunit
quotidiennement lors d'une réunion de synchronisation, appelée
mêlée quotidienne, afin de suivre l'avancement du projet et la
répartition des taches quotidienne.BRENo Lisi RoMANo , 15 April
2015
VI.3 Diviser pour régner
VI.3.1 Diviser l'équipe et attribution des rôles
Les projets qui utilisent la méthode SCRUM se forment
autour d'une équipe auto-organisée et multifonctionnelle.MouLouzi
, 5 fev 2014 il n'y a pas de chef d'équipe qui décide des
rôles de chacun, ou de la manière dont un problème est
résolu, puisque ces problématiques sont traitées par
l'équipe dans son ensemble.ref7
VI.3.2 Diviser notre problème
Notre problème étant complexe il nous a donc
fallu le diviser en plusieurs sous problèmes qui étaient plus
faciles a appréhender.
VI.3 Diviser pour régner 67
VI.3.2.1 Les IHM
Les interfaces homme machine sont très importantes car
elles représentent le premier contact avec les utilisateurs on se doit
donc de les optimiser pour une meilleure ergonomie.
VI.3.2.2 Les données
Les données étant la partie la plus importante de
notre application nous ne devions en aucun cas négliger cette aspect
la.
Par ailleurs la méthode pour la sauvegarde de
données qui est adoptée chez Renault est le cloud qui
répond parfaitement au besoin des utilisateurs (les 3 v du big
data).GALIANA , 20 juillet 2017
VI.3.2.3 Les APIs et les Frameworks
Les APIs et les Frameworks étant nombreuses nous avions
l'obligation d'en apprendre le plus possible grâce a la documentation et
en maîtriser un maximum.Pour pouvoir passer au codage de
l'application.MouLouzI , 5 fev 2014
VI.3.3 Diviser le temps
La méthodologie SCRUM est basée sur le
découpage du projet en Sprint,qui peuvent durer entre quelques heures et
un mois.
VI.3.3.1 Sprint 1
Durant notre premier Sprint nous avons établie un
premier contacte avec le client afin de mieux comprendre ses besoins,nous nous
somme ensuit mis d'accord sur le fonctionnement du système et avons
émis les différents cas d'utilisations.
VI.3.3.2 Sprint 2
Durant notre second sprint nous avons
schématisé les interfaces de notre
applica-tions.et les avons
classé selon leur ordre de priorité.
VI.3.3.3 Sprint 3
Durant le 3ème Sprint nous avons validé les
technologies et plat formes a utiliser.Et avons synchronisé notre
travail dans un service web d'hébergement et de gestion
PRévIsoN DE DATE DE PAssAGE DEs JALoNs 2022
68 CHAPITRE VI. SYSTÈME
Amassin NACERDDINE Université Paris 8
Vincennes
de développement de logiciels.
VI.3.3.4 Sprint 4
Lors du 4eme sprint nous avons émis des propositions
aux clients et lui avons fournis un premier livrable afin qu'ils puissent
valider les technologies outils et interfaces.
Chapitre VII
Outils utilisés
Sommaire
VII.1 Introduction 69
VII.2 Logiciels et outils utilisé
70
VII.2.1 Python3 70
VII.2.2 Jira 71
VII.2.3 Pandas 71
VII.2.4 D3.js 71
VII.2.5 TensorFlow 72
VII.2.6 Scikit-Learn 72
VII.2.7 Keras 72
VII.2.8 Google Cloud Plate forme 73
VII.2.9 Flask 74
VII.2.10 HTML/CSS/JS 74
VII.2.11 Git & GitHub 74
VII.3 Aperçu de l'outil 75
VII.1 Introduction
Dans cette section je vais présenter les outils
utilisés pour la réalisation de application ainsi qu'un
aperçu du résultat de celle-ci.
J'ai choisi pour nom d'application Kairos.
Le kairos ( ) est un concept qui, adjoint à l'aiôn
et au chronos, permet, sinon
70 CHAPITRE VII. OUTIL
Amassin NACERDDINE Université Paris 8 Vincennes
de définir le temps, du moins de situer les
événements selon cette dimension. Faire le bon acte au bon moment
participe au Kaïros. Pour ce qui est de la pensée occidentale, le
concept de Kaïros apparaît chez les Grecs sous les traits d'un petit
dieu ailé de l'opportunité, qu'il faut attraper quand il passe
(saisir une opportuni-té).ELLENBERGER , 2020
VII.2 Logiciels et outils utilisé
VII.2.1 Python3
Le langage de programmation interprété,
multi-paradigme et multiplateformes python a était utilisé et
choisi pour ça productivité ainsi que pour ses outils de haut
niveau et une syntaxe simple à utiliser. En effet la récolte des
données a partir de Jira se fait en utilisant l'API python qui est
proposée par cette dernière.

FIG. 27 : Logo Python
VII.2 Logiciels et outils utilisé 71
PRéVISON DE DATE DE PASSAGE DES JALONS 2022
VII.2.2 Jira
Le système de suivi de bugs, de gestion des incidents
et de gestion de projets développé par Atlassiann est
utilisé au sein de notre entreprise afin de répertorier tout les
ticket d'incidents qui surviennent durant les projets véhicules.

FIG. 28 : Logo jira
VII.2.3 Pandas
La bibliothèque écrite pour le langage de
programmation Python permettant la manipulation et l'analyse des données
a été utilisée afin de pré traiter les
données avant leur intégration sur le cloud.

FIG. 29 : Logo Pandas
VII.2.4 D3.js
La bibliothèque graphique JavaScript qui permet
l'affichage de données numériques sous une forme graphique et
dynamique a été utilisé afin d'afficher les graphes de
façon intuitive et interactive.

FIG. 30 : Logo D3.js
72 CHAPITRE VII. OUTIL
Amassin NACERDDINE Université Paris 8 Vincennes
VII.2.5 TensorFlow
L'outil open source d'apprentissage automatique
développé par Google a été utilisé.

FIG. 31 : Logo TensorFlow
VII.2.6 Scikit-Learn
la bibliothèque libre Python destinée à
l'apprentissage automatique a également été
utilisé.

FIG. 32 : logo Scikit-Learn
VII.2.7 Keras
La bibliothèque Keras permet d'interagir avec les
algorithmes de réseaux de neurones profonds et d'apprentissage
automatique

FIG. 33 : logo keras
VII.2 Logiciels et outils utilisé 73
PRéVISON DE DATE DE PASSAGE DES JALONS 2022
VII.2.8 Google Cloud Plate forme
La plateforme de cloud computing qui est proposée par
Google est ce que nous utilisons au sein de notre entreprise.
En effet différentes briques qui sont proposées par
la plate forme on été utilisé lors de ce projet.
Entre autre la brique BigQuery qui permet l'analyse interactive
massive de grands ensembles de données et qui se relie facilement a
l'espace de stockage de Cloud storage.
Mais aussi des briques comme App Engine pour le
déploiement de notre outil et API translate pour la traduction de nos
tickets.
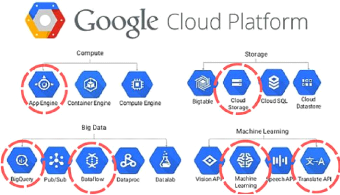
FIG. 34 : Briques GCP
74 CHAPITRE VII. OUTIL
VII.2.9 Flask
Le micro framework open-source de développement web en
Python a été utilisé pour sa simplicité et sa
légerté.

FIG. 35 : Flask
VII.2.10 HTML/CSS/JS
L'application que je propose est une application web de par
la facilité de déploiement de celle-ci ainsi que le grand nombre
de consultation/ jours,mois.

FIG. 36 : Logo HTML CSS JS
VII.2.11 Git & GitHub
Le service d'hébergement basé sur le Web GitHub
ainsi que le logiciel de gestion de versions Git on aussi étaient
très utiles pour le traitement des différentes versions de
l'application.

Amassin NACERDDINE Université Paris 8 Vincennes
FIG. 37 : Logo Git & GitHub
VII.3 Aperçu de l'outil 75
PRéVISON DE DATE DE PASSAGE DES JALONS 2022
VII.3 Aperçu de l'outil
Je propose dans un premier temps de choisir le projet
véhicule dont nous souhaitons visualiser les prédictions.
FIG. 38 : visualisation des projets
Ensuit un comparatif entre les dates qui sont sur l'outil
d'entreprise et les prédictions faites par l'outil Kairos.


FIG. 39 : Kairos vs GPS

Conclusion
Durant mon alternance au sein du groupe Renault j'ai pu
mettre en pratique mes connaissances théoriques dans des
problématiques d'entreprises réels en mettant en place un
système avec tout le cheminement de la donnée de la partie
récupé-ration/intégration de données jusqu'à
la partie pré-traitement/traitement et mise en place du système
et visualisation des résultats.
Certains aspects et certaines pratiques ont
particulièrement attiré mon attention dans le mode de l'industrie
automobile notamment.
· La difficulté pour avoir accès aux
données.
· Le passage d'anciennes pratiques à des
pratiques plus modernes prend plus ou moins longtemps à se mettre en
place.
· Difficulté pour déployer et valider un
outil.
· Difficulté de communication entre les
directions.
En effet savoir interpréter les besoins clients les
mettre en place et les adapter à des systèmes d'informations
modernes n'est pas une tache simple et nécessite une bonne
expérience et une forte connaissance de certains aspects
métier.
Au-delà de l'aspect humain où j'avais toute la
confiance et le respect de mes collègues; J'ai énormément
appris avec les équipes métiers et je sais à
présent que pour concevoir un véhicule il faut tout un
savoir-faire que des grands constructeurs comme Renault ont.
Mais j'ai également remarqué l'apport que
peuvent avoir les évolutions modernes que ça soit en informatique
en intelligence artificielle ou bien d'autres domaines à des
savoir-faire qui existent déjà.
j'ai eu le change d'avoir participé à une partie
de cette transition et cette révolution numérique. Cette
alternance chez Renault a été pour moi une expérience
très importante.

Bibliographie
[1] BOWLEY A.L. . « Elements of Statistics ». In
: Londres, King and Son 2-3 (1901).
[2] Shipra Saraswat APOORVA SRIVASTAVA Sukriti Bhardwaj. In :
SCRUM model for agile methodology (6 May 2017), p. 1.75.
[3] M.Szufel B.JAKUBCZYK . «A framework for sensitivity
analysis of decision trees. » In : Central European Journal of
Operations Research (2017).
[4] Frank BENFORD . « The law of anomalous numbers
». In : Proceedings of the American Philosophical Society
(1938).
[5] Alan Delgado da Silva BRENO LISI ROMANO . In :
Project Management Using the Scrum Agile Method : A Case Study within a
Small Enterprise (15 April 2015), p. 1.2.3.
[6] Ue DBD . « Confusion Matrix ». In : http
://www2.cs.uregina.ca/ dbd/cs831/notes/confusionmatri
(2022).
[7] H.F. ELLENBERGER . « Développement historique
de la notion de processus psychothérapique Psychotherapy and
Psychosomatics ». In : ISSN (2020).
[8] YULE G.U . « Les applications de la méthode
de corrélation aux statistiques sociales et économiques ».
In : compte rendu de la 12e session de Paris 2-3 (1909), p.
265-277.
[9] David GALIANA . In : Qu'est-ce que la
méthodologie Scrum ? (20 juillet 2017), p. 1.
[10] Yoav GOLDBERG et Omer LEVY . « word2vec Explained :
deriving Mikolov et al.'s negative-sampling word-embedding method ». In :
CoRR abs/1402.3722 (2014). URL :
http://arxiv.org/abs/1402.3722.
[11] Bickel Peter J . « Mathematical Statistics : Basic
and selected topics ». In : (2007).
[12] Michel Lejeune et Gilbert Saporta JEAN-JACQUES DROESBEKE
. « Modèles statistiques pour données qualitatives ».
In : (2005).
[13]
80 BIBLIOGRAPHIE
Amassin NACERDDINE Université Paris 8 Vincennes
Karen Spärck JONES . « A statistical interpretation
of term specificity and its application in retrieval ». In : Journal
of Documentation, vol. 28 28 (1972).
[14] Pirmin LEMBERGER . « BIG DATA ET MAACHINE LEARNING les
concepts et les outils de la data science ». In : DUNOD
(2022).
[15] Gerard Salton et M. J. MCGILL . « Introduction to
Modern Information Retrieval ». In : (1983).
[16] Benoît MANDELBROT . « Logique, langage et
théorie de l'information Étude de la loi d'Estoup et de Zipf :
fréquences des mots dans le discours ». In : Paris, Presses
universitaires de France (1957), p. 22-53.
[17] T. MITCHELL . « Generative and Discriminative
Classifiers : Naive Bayes and Logistic Regression ». In : (2005).
[18] Mohamed MOULOUZI . In : Scrum pour les nuls (5
fev 2014), p. 1.
[19] Mohammed OURIEMCHI . « Résolution de
problèmes non linéaires par les méthodes de points
intérieurs. Théorie et algorithmes.. Mathématiques ».
In : Université du Havre Français (2005).
[20] Micheline PETRUSZEWYCZ . « L'histoire de la loi
d'Estoup-Zipf ». In : documents » [archive du 5 juin 2011]
(1973), p. 41-56.
[21] Johann PFANZAGL . « Parametric Statistical Theory
». In : (1994).
[22] F. ROSENBLATT . « The perceptron : A probabilistic
model for information storage and organization in the brain. » In :
Psychological Review 65.6 (1958), p. 386-408. ISSN : 0033-295X. DOI :
10.1037/h0042519. URL :
http://dx.
doi.org/10.1037/h0042519.
[23] Tamer E. El-Diraby S. MADEH PIRYONESI . « Role of
Data Analytics in Infrastructure Asset Management : Overcoming Data Size and
Quality Problems. » In : Journal of Transportation Engineering
146 (2009).
[24] M. SAKAROVITCH . Optimisation combinatoire, graphes
et programmation linéaire. Paris : Hermann, 1984.
[25] Ken SCHWABE . In : SCRUM Development Process
(2016), p. 1..40.
[26] Ian STEWART . « 1 est plus probable que 9 ».
In : in Pour la science 2-3 (2000), p. 59-96.
[27] J.Friedman T.HASTIE R.Tibshirani. «The Elements of
Statistical Learning : Data Mining, Inference, and Prediction ». In :
(2009).
Table des figures
|
1
|
V3P4
|
15
|
|
2
|
Semaines/jalon
|
16
|
|
3
|
Indicateurs
|
17
|
|
4
|
Schéma de données
|
22
|
|
5
|
Règles de nommage
|
23
|
|
6
|
Zone Archi
|
24
|
|
7
|
Visualisation des valeurs aberrantes
|
26
|
|
8
|
Loi de Benford appliquée aux Ki
|
27
|
|
9
|
Loi zipf appliquée a la frequence des mots
|
28
|
|
10
|
Loi normale sur les K1/K2
|
29
|
|
11
|
Corr matrix
|
30
|
|
12
|
Langues dans le dataset
|
31
|
|
13
|
Fréquence des mots
|
32
|
|
14
|
LabelEncoder
|
33
|
|
15
|
KNN
|
43
|
|
16
|
Arbres de décision
|
44
|
|
17
|
SVM
|
45
|
|
18
|
mlp
|
45
|
|
19
|
neurone-artificiel
|
46
|
|
20
|
Fonctions d'activation les plus utilisées
|
46
|
|
21
|
Matrice de confusion
|
51
|
|
22
|
Matrice de confusion RF
|
54
|
|
23
|
Matrice de confusion XGBOOST
|
55
|
|
24
|
Matrice de confusion KNN
|
56
|
|
25
|
RMSE/RMSLE RF
|
58
|
|
26
|
RMSE/RMSLE KNN
|
58
|
|
27
|
Logo Python
|
70
|
|
28
|
Logo jira
|
71
|
|
29
|
Logo Pandas
|
71
|
|
30
|
Logo D3.js
|
71
|
|
31
|
Logo TensorFlow
|
72
|
|
82
|
TABLE DES FIGURES
|
|
32
|
logo Scikit-Learn
|
72
|
|
33
|
logo keras
|
72
|
|
34
|
Briques GCP
|
73
|
|
35
|
Flask
|
74
|
|
36
|
Logo HTML CSS JS
|
74
|
|
37
|
Logo Git & GitHub
|
74
|
|
38
|
visualisation des projets
|
75
|
|
39
|
Kairos vs GPS
|
75
|
|
Amassin NACERDDINE
|
Université Paris 8 Vincennes
|
Liste des tableaux

Table des matières
Remerciements 3
Introduction 7
I Problématique 9
I Le contexte de résolution du problème
13
I.1 Introduction 14
I.2 Contexte 14
I.3 Contexte Logiciel 14
I.4 Jalonnement adopté 15
I.5 Semaines entre chaque jalon 16
I.6 Indicateurs 17
I.7 Conclusion 17
II Le problème à résoudre
19
II.1 Objectif 20
II.1.1 Métier 20
II.1.2 Technique 20
II.1.3 Stratégique 20
II.2 Règle 20
II.3 Données 21
II.3.1 Composition de données 21
II.3.2 Schéma de données 21
II.3.3 Nommage des projets 22
II.3.4 Zone architecture 23
II.4 Difficultés rencontrées 24
II.5 Décomposition du problème 24
II.6 Data pre-processing 24
II.6.1 Nettoyage des données 25
86 TABLE DES MATIÈRES
Amassin NACERDDINE Université Paris 8 Vincennes
II.6.2 Chercher les valeurs aberrantes 25
II.6.3 Application des lois statistiques 26
II.6.4 Sélection des caractéristiques
intéressantes 30
II.6.5 Transformer les données 31
II.6.6 Augmentation de données 33
II.7 Conclusion 33
II État de l'art 35
III Techniques de traitement 39
III.1 Introduction 40
III.2 Machine Learning 40
III.3 Apprentissage supervisé 40
III.4 Régression ou classification 40
III.4.1 Problème de classification 40
III.4.2 Problème de régression 41
III.5 Algorithmes linéaires ou non linéaires
41
III.6 Modèles paramétriques ou non
paramétriques 41
III.7 Apprentissage hors ligne ou incremental 41
III.8 Modèles géométriques ou probabilistes
42
III.9 Les principaux algorithmes 42
III.9.1 La régression linéaire 42
III.9.2 Les K plus proches voisins 43
III.9.3 Les arbres de décision 43
III.9.4 Les forêts aléatoire 44
III.9.5 Les machines à vecteurs de support 44
III.9.6 MLP 45
IV Techniques d'évaluation 49
IV.1 Performance d'un modèle et sur-apprentissage 50
IV.2 Évaluation de la classification 51
IV.2.1 La matrice de confusion 51
IV.3 Évaluation de la régression 52
IV.3.1 RSS 52
IV.3.2 MSE 52
IV.3.3 RMSE 52
IV.3.4 RMSLE 52
V Résultats obtenus 53
V.1 Classification 54
TABLE DES MATIÈRES 87
PRévIsoN DE DATE DE PAssAGE DEs JALoNs 2022
V.1.1 Sur l'ensemble du jeux de données 54
V.1.2 Sur un jeux de test aléatoire 57
V.1.3 Temps d'entraînement des algorithmes 57
V.2 Régression 58
V.2.1 Sur l'ensemble du jeux de données 58
V.2.2 Sur sur un jeux de test aléatoire 58
V.2.3 Temps d'entraînement des algorithmes 59
III Système réalisé 61
VI Méthodologie d'analyse et de conception
65
VI.1 Introduction 66
VI.2 Méthode SCRUM 66
VI.3 Diviser pour régner 66
VI.3.1 Diviser l'équipe et attribution des rôles
66
VI.3.2 Diviser notre problème 66
VI.3.3 Diviser le temps 67
VII Outils utilisés 69
VII.1Introduction 69
VII.2 Logiciels et outils utilisé 70
VII.2.1 Python3 70
VII.2.2 Jira 71
VII.2.3 Pandas 71
VII.2.4 D3.js 71
VII.2.5 TensorFlow 72
VII.2.6 Scikit-Learn 72
VII.2.7 Keras 72
VII.2.8 Google Cloud Plate forme 73
VII.2.9 Flask 74
VII.2.10HTML/CSS/JS 74
VII.2.11Git & GitHub 74
VII.3 Aperçu de l'outil 75
Conclusion 77
Table des figures 81
Liste des tableaux 83
Amassin NACERDDINE Université Paris 8
Vincennes
88 TABLE DES MATIÈRES


