3.6 Spécificités de la classification de
textes
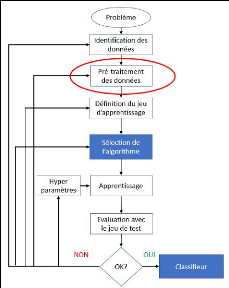
Figure 17 - Pré-traitement des données
textuelles
Contrairement aux données structurées, les
données textuelles doivent subir une modification car elles ne sont pas
exploitables par les algorithmes telles quelles, il faut les rendre
mathématiquement intelligibles en les transformant en chiffres (Leopold
& Kindermann, 2002).
La représentation des documents textuels au format
numérique n'est pas simple. Une des particularités du
problème de classification de textes est le nombre de variables, qui
peut facilement atteindre les dizaines de milliers, car dans l'absolu, une
variable peut représenter un mot ou une chaine de caractères.
Cela peut poser de nombreux problèmes aux algorithmes qui auront du mal
à traiter un espace d'une telle dimension. Le pré-traitement des
données répond à cette problématique en
réduisant le nombre de variables grâce à différentes
techniques (Ikonomakis, et al., 2005). Il a été
démontré que la phase de pré-traitement (figure 17)
était très importante pour augmenter la qualité d'un
classifieur (Ting, 2011).
L'objectif de ce processus sera de déterminer les
variables les plus pertinentes pour la classification. En effet, certaines
variables sont beaucoup plus susceptibles d'être corrélées
à la distribution de classes que d'autres. Une grande
variété de méthodes est proposée dans la
littérature afin de déterminer les caractéristiques les
plus importantes pour la classification (Aggarwal & Zhai, 2012). Le choix
de combinaisons appropriées de méthodes de pré-traitement
peut apporter une amélioration significative de la précision de
la classification (Gunal, 2014). Dans la suite de ce chapitre, nous choisirons
les techniques classiques à mettre en oeuvre.
3.6.1 Etapes du pré-traitement des données
textuelles
Le processus de pré-traitement est composé
habituellement de cinq étapes (figure 18), on commence d'abord à
segmenter le texte en token, c'est-à-dire en termes
(généralement en mots), ensuite un filtrage est effectué
pour ne prendre en compte que les mots qui ont du sens. Puis, une autre
technique
38
permet de réduire le nombre variable en ramenant les
mots à leur forme d'origine ou canonique. Chaque texte peut
désormais être représenté par un vecteur de nombres
qui correspond au nombre d'occurrences de chaque variable (mot). Enfin, la
phase la plus importante, celle qui aura le plus d'impact sur la qualité
du corpus, est la sélection des variables. On utilisera une technique de
pondération non-supervisée (Tellier, 2010).
3.6.1.1 Tokenisation
La tokenisation consiste à découper un texte en
mots (mots / phrases) appelés token. Il est ensuite possible de traiter
chacun de ces mots pour réduire la taille de chaque texte (Webster &
Kit, 1992).

Figure 18 - Etapes du pré-traitement des
données textuelles
(Osisanwo, 2017)
| 

