3.5.7 Leviers d'ajustement
Rappelons que l'objectif du modèle est la bonne
généralisation de la règle induite par l'apprentissage. On
entend par « bonne » généralisation un niveau
d'apprentissage qui ne soit ni insuffisant ni trop élevé
(Al-Behadili, et al., 2018). Pour obtenir le meilleur taux de réussite
possible en production, il faut éviter le
sous-apprentissage et le sur-
apprentissage, comme on peut le
voir sur la figure 15 :
35
Figure 14 - Exemple de matrice de confusion
accompagnée de la F-mesure (F1) (AWS, s.d.)
· Le sous-apprentissage arrive
lorsque le
modèle n'a presque rien appris à partir des données
d'apprentissage.
· Le sur-apprentissage arrive quand le modèle de
classification prédit exactement le label des données
d'apprentissage, alors qu'il est incapable de prédire correctement le
label de nouvelles données.
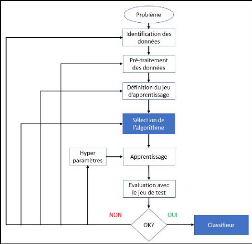
Figure 16 - Processus de modélisation d'un classifieur
(Osisanwo, 2017)
36
Plusieurs méthodes permettent de réduire ces
risques. La régularisation est la technique la plus utilisée,
mais on peut jouer sur les données en elles-mêmes en
répartissant les données d'apprentissage et de validation, en
réduisant la dimensionnalité (le nombre de variables), en
supprimant les données aberrantes (le bruit) ou même, en optant
pour un algorithme plus puissant. Cette façon itérative de
rechercher la meilleure optimisation d'un classifieur est inhérente
à la démarche du ML comme on peut le voir sur la figure 16.
3.5.7.1 La Régularisation
La régularisation est l'action qui permet d'ajuster au
mieux les paramètres de l'algorithme, celle-ci est effectuée via
les hyperparamètres qui sont propres à chaque famille
d'algorithmes. L'objectif est de trouver la valeur du paramètre qui
équilibre le mieux le sous-apprentissage et le sur-apprentissage pour
offrir la meilleure précision possible sur le jeu de test (Russell &
Norvig, 2010). Cet ajustement est manuel, mais il est possible d'utiliser la
méthode Grid Search qui est un programme qui va tester automatiquement
tous les paramètres possibles d'un algorithme, comme vu
précédemment.
3.5.7.2 Les données
Si les variables sélectionnées ne sont pas
représentatives du corpus de données, il sera nécessaire
de revoir le pré-traitement des données, par exemple en changeant
de méthode de représentation des données, ou en utilisant
une autre méthode de sélection de variables (Géron,
2017).
3.5.7.3 La validation croisée
L'approche traditionnelle de découpage du jeu
d'entrainement en deux sous-ensembles peut amener le modèle à
sur-apprendre, c-à-d que le résultat en production sera
très différent de celui attendu. C'est ce qui arrive lorsque la
distribution de variables est déséquilibrée dans le jeu de
données. Pour diminuer ce risque, il est possible de découper en
petit sous-ensembles les jeux de données d'apprentissage et de
validation. Cette technique augmente l'intégrité des
résultats du modèle. (Aphinyanaphongs, et al., 2014)
| 

