|

L'intelligence artificielle : outil de la
gestion
des connaissances

Thèse professionnelle
Comment automatiser la classification d'une
base
documentaire grâce au Machine Learning ?
|
Jamal EL MAHDALI
MASTERE SPECIALISÉ
MANAGEMENT DES SYSTEMES D'INFORMATION
DÉCEMBRE 2018
|
|
1
Remerciements
La réalisation de ce mémoire a été
possible grâce au concours de plusieurs personnes à qui je
voudrais témoigner toute ma reconnaissance.
Je remercie bien sûr mon tuteur école, Alain RIVET,
pour ses conseils dans l'approche de cette étude.
Le sujet de l'étude a été proposé par
TCS et je tiens à remercier Hervé LEBEL, Manager, et Charles
SIMILIA, Directeur de projets pour leur participation.
Mes remerciements vont aussi à tous les professionnels qui
ont accepté de partager leur expérience.
Enfin, je suis reconnaissant envers ma famille et mes proches qui
m'ont encouragé et soutenu dans cette entreprise. Et je tiens à
remercier particulièrement mon épouse pour son soutien et sa
patience sans lesquels ce travail n'aurait pu aboutir.
2
Résumé
Cette étude a pour objectif de proposer une
série de recommandations dans le cadre d'un projet pilote, pour
automatiser la classification d'une masse importante de documents textuels. Les
méthodes utilisées dans ce mémoire sont classiques,
à savoir une revue de littérature complétée par une
série d'entretiens avec des professionnels.
A l'époque de l'économie de la connaissance,
l'enjeu de la gestion des connaissances et en particulier de la gestion
d'information est crucial pour les entreprises. L'accès aux documents,
support de la connaissance explicite, est de plus en plus difficile pour les
utilisateurs, eu égard à l'infobésité galopante et
à la structure hiérarchique des bases documentaires
étouffées par les strates accumulées au fil des
années.
Certaines entreprises profitent des opportunités
offertes par la transformation digitale pour basculer leurs bases
documentaires, importante partie de leur patrimoine informationnel, vers des
solutions cloud de type ECM afin de mieux les gérer. Ces nouveaux outils
issus du web 2.0 apportent une multitude de fonctionnalités qui
permettent d'accroître la productivité des utilisateurs, en
facilitant le transfert des connaissances. L'accès aux informations sur
ces outils est facilité par une organisation de la connaissance
basée sur l'étiquetage des documents, via la méthode des
métadonnées. Ces nouveautés apportent leur lot de
changements d'usage qu'il faut gérer avec une stratégie de
conduite du changement.
Une autre problématique, plus technique, empêche
la faisabilité du projet. D'une part, l'étiquetage de documents
est difficilement automatisable, car la complexité de la tâche
requiert un système de règles dont le coût ne serait pas
justifié. D'autre part, la quantité astronomique de documents
à étiqueter n'est pas réalisable manuellement, ce qui
mène le projet à une impasse.
Une discipline, très médiatisée ces
derniers temps, propose des solutions à ce type de problème,
c'est le Machine Learning. Ce domaine a connu des progrès spectaculaires
ces vingt dernières années, grâce aux progrès des
capacités de calcul et à l'explosion des données
disponibles. Ces méthodes sont totalement différentes des
solutions classiques, car elles se basent sur une démarche empirique qui
consiste à construire une solution qui imite le processus cognitif
humain simplement à partir d'exemples.
La littérature est relativement fournie à ce
sujet, surtout sur les aspects techniques. Nous avons pu y relever un certain
nombre de spécificités propres au traitement de données
textuelles, ainsi que d'autres comme l'implication des métiers au point
de le faire participer aux tâches de construction de la solution.
Le retour d'expérience des professionnels valide en
grande partie les informations issues de la littérature, et
complète celle-ci par certaines informations concernant les aspects
organisationnels à appliquer dans le cadre de cette démarche.
Nous n'avons pas relevé de contradictions dans cette
étude entre la littérature et le monde professionnel, ce qui a
facilité la rédaction des recommandations. Ces dernières
font un focus sur les méthodes et techniques à privilégier
dans le cadre de la modélisation d'une solution de classification
automatique de documents.
3
Table des matières
Remerciements 1
Résumé 2
Table des matières 3
Table des figures 5
Liste des tableaux 5
1 INTRODUCTION GENERALE 6
1.1 Contexte de l'étude 7
1.1.1 Etat des lieux 7
1.1.2 Les bases documentaires IT 7
1.2 Problématique 8
1.2.1 Questions de recherche 8
1.3 Méthodologique 9
1.3.1 Revues de littératures 9
1.3.2 Entretiens 9
2 GESTION DES CONNAISSANCES ET CLASSIFICATION 11
2.1 La gestion des connaissances 11
2.1.1 Définition du KM 11
2.1.2 La connaissance 12
2.1.3 Création et transfert de la connaissance 13
2.2 Gestion documentaire 14
2.2.1 Outils et méthodes 14
2.2.2 Classification de documents 16
2.2.3 Accès à l'information 16
2.2.4 Métadonnée 17
2.3 Etiquetage manuel 17
2.4 Conclusion 18
3 L'INTELLIGENCE ARTIFICIELLE ET LA CLASSIFICATION DE DOCUMENTS
19
3.1 L'intelligence artificielle 19
3.1.1 Différentes définitions 19
3.1.2 Historique de l'intelligence artificielle 19
3.1.3 L'intelligence artificielle est déjà
là ! 20
3.1.4 Enjeux pour les entreprises 21
3.2 Les domaines de l'intelligence artificielle 22
3.2.1 Les approches 23
4
3.2.2 Les sous-domaines de l'intelligence artificielle 23
3.3 La classification de document 25
3.4 Le traitement automatique du langage naturel 25
3.5 Le Machine Learning 26
3.5.1 Les modes d'apprentissage et les types de problèmes
à résoudre 27
3.5.2 Les étapes du Machine Learning supervisé
27
3.5.3 Les données 29
3.5.4 Les algorithmes utilisés en Machine Learning 30
3.5.5 Algorithmes adaptés à la classification de
document textuel 32
3.5.6 La mesure des performances du modèle 33
3.5.7 Leviers d'ajustement 35
3.6 Spécificités de la classification de texte
37
3.6.1 Etapes du pré-traitement des données
textuelles 37
3.7 Outils 40
3.8 Conclusion 41
4 ENTRETIENS 42
4.1 Aspect projet 42
4.1.1 Quelle méthode de projet choisir ? 42
4.1.2 Phase de cadrage 42
4.1.3 Quels sont les rôles et compétences
nécessaires ? 43
4.1.4 Comment définir la qualité du livrable ?
43
4.1.5 Comment estimer l'opportunité ? 43
4.1.6 Quels sont les principaux risques ? 44
4.1.7 Faut-il prévoir une MCO particulière ? 44
4.2 Aspect technique 45
4.2.1 Comment préparer les données ? 45
4.2.2 Choix de l'algorithme 45
4.2.3 Validation et régularisation du classifieur 46
4.2.4 Outillage 46
4.3 Conclusion 47
5 RECOMMANDATIONS SYNTHÉTISÉES 48
6 CONCLUSION 50
BIBLIOGRAPHIE 52
ANNEXE 58
5
Table des figures
FIGURE 1- INTERDISCIPLINARITE DE LA GESTION DES CONNAISSANCES
(DALKIR, 2013) 12
FIGURE 2 - PYRAMIDE DIKW (ERMINE, ET AL., 2012) 12
FIGURE 3 - MODELE SECI (NONAKA, ET AL., 2000) 13
FIGURE 4 - CYCLE CONNAISSANCE-INFORMATION (BLUMENTRITT &
JOHNSTON, 1999) 14
FIGURE 5 - INTEGRATION DE LA GESTION DOCUMENTAIRE DANS L'ECM
(KATUU, 2012) 15
FIGURE 6 - CYCLE DE VIE DU DOCUMENT (CABANAC & AL, 2006)
16
FIGURE 7 - ADOPTION DE L'IA PAR LES ENTREPRISES (MIT, 2017) 21
FIGURE 8 - CHAMPS DE L'IA (VILLANUEVA & SALENGA, 2018) 23
FIGURE 9 - L'IA : UNE INTERCONNEXION D'APPLICATIONS, DE DOMAINES
ET DE METHODES (SEE, 2016) 24
FIGURE 10 - LA CLASSIFICATION, A LA CROISEE DES CHEMINS DE L'IA
25
FIGURE 11 - LES DEUX PHASES DE L'APPRENTISSAGE AUTOMATIQUE
(CHAOUCHE, 2018) 26
FIGURE 12 - ETAPES DE MODELISATION D'UN CLASSIFIEUR 28
FIGURE 13 - IMPORTANCE DES DONNEES PAR RAPPORT AUX ALGORITHMES
(BANKO ET BRILL - 2001) 29
FIGURE 14 - EXEMPLE DE MATRICE DE CONFUSION ACCOMPAGNEE DE LA
F-MESURE (F1) (AWS, S.D.) 35
FIGURE 15 - CONSEQUENCES DU SOUS-APPRENTISSAGE ET DU
SUR-APPRENTISSAGE SUR LE TAUX D'ERREUR (AL-BEHADILI, ET AL.,
2018) 35
FIGURE 16 - PROCESSUS DE MODELISATION D'UN CLASSIFIEUR (OSISANWO,
2017) 36
FIGURE 17 - PRE-TRAITEMENT DES DONNEES TEXTUELLES 37
FIGURE 18 - ETAPES DU PRE-TRAITEMENT DES DONNEES TEXTUELLES
(OSISANWO, 2017) 38
FIGURE 19 - COMPARAISON DES MLAAS DE AWS, MS, GOOGLE ET IBM
(ALTEXSOFT, 2018) 40
FIGURE 20 - AZURE ML TEXT CLASSIFICATION WORKFLOW (ABDEL-HADY,
2015) 40
Liste des tableaux
TABLEAU 1 - REPRESENTATION DES DONNEES SOUS FORME D'UNE MATRICE
(BIERNAT & LUTZ, 2015) 30
TABLEAU 2 - EXEMPLES D'ALGORITHMES (BIERNAT & LUTZ, 2015)
31
TABLEAU 3 - MATRICE DE CONFUSION 34
TABLEAU 4 - MATRICE DOCUMENT-TERMES 39
6
1 INTRODUCTION GENERALE
La maxime "Scientia potentia est"1 est plus
pertinente que jamais dans le monde d'aujourd'hui. Ce qu'une entreprise sait
est souvent plus important que ce qu'elle produit. La bonne gestion des
connaissances au sein des organisations est une question stratégique,
plus encore pour le domaine de l'informatique, car marqué par une
rotation des employés et des technologies. Dans ce secteur, le
patrimoine informationnel doit être maintenu pour garantir sa
qualité et en faciliter sa circulation. Malheureusement encore trop
d'entreprises stockent leurs documents sur des serveurs bureautique, se coupant
ainsi de l'apport des technologies du web 2.0, connues pour faciliter
l'échange informationnel et la collaboration.
Une grande entreprise consciente de l'enjeux a
décidé d'actionner ce levier. La DSI2 de cette
organisation a pris la décision de basculer ses bases documentaires vers
la solution cloud SharePoint Online. Pour bénéficier des
fonctionnalités de recherche de SharePoint, les documents doivent tous
être taggués (étiquetés) avec leur(s)
catégorie(s) en utilisant les métadonnées. Pour valider la
faisabilité de ce projet, une opération pilote sur les bases
documentaires du département EUS3 de la DSI doit être
effectuée. Cette opération ne peut pas être
effectuée manuellement, car le corpus compte plusieurs dizaines de
milliers de documents, il faut donc automatiser cette tâche.
Avec l'arrivée de l'intelligence artificielle,
l'automatisation n'est plus confinée aux seules tâches courantes,
les progrès rapides dans ce domaine annoncent le remplacement d'un plus
grand nombre d'activités par des machines. Ainsi elle ouvre
d'innombrables perspectives aux entreprises en termes de productivité.
Des spécialistes de renom proposent d'explorer ces opportunités
pour améliorer la performance de la gestion des connaissances. Parmi ces
solutions, le Machine Learning est la discipline qui se distingue le plus. Elle
s'est considérablement développée au cours des quinze
dernières années en raison de la croissance de la puissance de
calcul disponible ainsi que des progrès réalisés dans la
conception d'algorithmes.
Il nous parait nécessaire d'explorer cette
méthode pour savoir si elle peut solutionner notre problème, et
si oui, comment ?
Nous commencerons par une revue de littérature qui va
porter dans un premier temps, sur l'enjeu pour les entreprises de gérer
efficacement leur capital informationnel, ensuite nous étudierons le
rôle que joue la classification dans la gestion d'information. Dans un
deuxième temps, nous essayerons de comprendre ce qu'est l'intelligence
artificielle avant de passer au coeur de la partie théorique,
c-à-d rechercher les méthodes du Machine Learning applicables au
domaine de la gestion documentaire, et plus particulièrement à la
classification de documents.
Nous compléterons la revue de littérature par
une série d'entretiens auprès de professionnels du secteur pour
collecter des retours d'expériences, qui ne sont pas légion dans
ce domaine.
Enfin, l'analyse des résultats de cette recherche
permettra de proposer des recommandations.
1 Le savoir est pouvoir
2 Direction des systèmes d'information
3 End User Services : support aux utilisateurs
7
1.1 Contexte de l'étude
Dans le cadre d'un projet de transformation digitale,
l'entreprise TCS4 recherche une solution pour préparer la
migration des bases documentaires d'une grande entreprise française vers
le cloud. Le premier objectif est l'identification et la classification des
bases de connaissances, le deuxième est l'implémentation d'un
outil pour aider l'utilisateur à mieux classer les nouveaux documents.
Afin d'atteindre cet objectif, TCS souhaite intégrer une solution de
classification automatique basée sur l'intelligence artificielle. Cette
étude a pour objectif d'éclairer le sujet à travers une
série de recommandations.
1.1.1 Etat des lieux
La DSI du groupe a décidé de transférer
une partie de son patrimoine informationnel, composé de nombreuses bases
documentaires actuellement stockées sur ses serveurs, vers le cloud,
plus précisément vers la solution ECM5 de Microsoft :
SharePoint Online. Le but est de promouvoir un usage des informations contenues
dans les documents qui soit plus intuitif et collaboratif. La
problématique principale consiste à préparer cette
migration, en effet, les bases documentaires ne sont pas
systématiquement structurées de façon hiérarchique,
c-à-d que les documents sont éparpillés sur
différents dossiers partagés. Il faut trouver une solution pour
classifier ces documents avant de les transférer sur le cloud. Une autre
problématique concerne l'implémentation d'une solution
d'assistance « en ligne » complétement automatisée, qui
aidera les utilisateurs à mieux classer leurs nouveaux documents sur le
cloud, ce deuxième point ne sera pas abordé dans cette
étude.
La contrainte principale est le temps nécessaire pour
classer manuellement les éléments de ces bases documentaires, car
d'une part, le nombre de fichiers à classer est important et d'autre
part, la tâche de classification manuelle prend du temps eu égard
au processus cognitif nécessaire pour classer un document dans la bonne
catégorie. Or, l'entreprise n'a ni le temps ni le budget suffisant pour
préparer les bases documentaires manuellement.
1.1.2 Les bases documentaires IT
La gestion des connaissances dans le domaine de l'informatique
est importante, les bases documentaires le sont aussi parce qu'elles sont le
support principal du transfert de l'information et donc des connaissances. Une
bonne gestion des connaissances répond aux contraintes inhérentes
de la vie d'un service informatique, notamment :
4 TATA Consultancy Services
5 Entreprise Content Management
·
8
L'obsolescence technologique : Le domaine informatique est
très dépendant de la technologie. Contrairement à d'autres
métiers, il faut régulièrement mettre à jour les
outils, mais aussi les compétences des collaborateurs. En effet,
l'obsolescence des compétences est un phénomène qui
survient régulièrement à la suite d'une évolution
technologique (Geyer, 2017).
· Le turn-over : Le taux de turn-over dans le secteur
informatique est le plus élevé du marché, avec près
de 20% (Lo, 2014) , il n'est pas nouveau et est propre au secteur, les
entreprises doivent éviter de perdre une partie de leurs connaissances
avec le départ de collaborateurs (Chafiqi & El Moustafid, 2006).
· L'externalisation : 90% des entreprises en France ont
eu recours à l'externalisation de leur informatique, ce type
d'activité est marqué par un niveau d'externalisation
élevé (ABSYS, 2016), il faut gérer au mieux la transition
entre les fournisseurs, notamment le transfert des connaissances (Grim-Yefsah,
et al., 2010).
De façon générale, les acteurs du domaine
de l'informatique sont soucieux du niveau de qualité de leur base de
connaissances (Jäntti & Cater-Steel, 2017).
1.2 Problématique
Quelles sont les bonnes pratiques qui permettent de
réussir l'implémentation d'une solution basée sur
l'intelligence artificielle pour automatiser la classification d'une base
documentaire ?
1.2.1 Questions de recherche
Dans un premier temps, nous essayerons de comprendre
l'importance de la classification des données dans le cadre de la
gestion des connaissances et plus particulièrement de la gestion
documentaire, ainsi que du rôle des métadonnées.
Question de recherche 1 : Quelle est
l'importance de la classification et du rôle des
métadonnées dans le domaine de la gestion des connaissances et en
particulier pour la gestion documentaire ?
Une seconde question permettra de comprendre ce qu'est
l'intelligence artificielle et les sous-domaines la composant afin de cibler
les méthodes applicables à notre étude.
Question de recherche 2 : Quelles
méthodes basées sur l'intelligence artificielle permettent
d'automatiser la tâche de classification manuelle des documents textuels
d'une base documentaire ?
Enfin, la dernière question devra mettre en exergue
les bonnes pratiques pour réussir l'implémentation d'une solution
basée sur l'intelligence artificielle, notamment dans le contexte de
notre étude, en utilisant les retours d'expériences d'experts
dans le domaine.
Question de recherche 3 : Quelles sont les
bonnes pratiques à appliquer pour réussir l'automatisation de la
classification de documents ?
9
1.3 Méthodologie
Une série de recommandations sera formulée dans le
chapitre 5 à partir de l'analyse de la revue de littérature et
des entretiens.
1.3.1.1 Revue de littérature
Nous abordons notre étude par une revue de
littérature qui va porter sur les grands thèmes de cette
problématique. Dans le chapitre 2, nous verrons l'importance que
requière la gestion des connaissances pour les entreprises, ensuite nous
ferons un focus sur le rôle de la gestion documentaire, puis nous
finirons sur les méthodes de structuration de bases documentaires et
leur importance. Dans le chapitre 3, nous verrons les enjeux de l'intelligence
artificielle pour les organisations, puis nous rechercherons les
méthodes du Machine Learning qui conviennent le mieux à notre
problématique.
1.3.2 Entretiens
Pour compléter la revue de littérature, des
données ont été collectées auprès
d'entreprises qui utilisent ou délivrent des services dans le domaine du
Machine Learning, à travers cinq entretiens semi-directifs.
L'entretien est une technique d'investigation qui nous permet
de recueillir des informations auprès de professionnels. Il existe trois
types d'entretiens, directif, non-directif et semi-directif, c'est ce dernier
qui a été choisi. La réalisation de l'entretien
semi-directif implique la prise en compte d'un certain nombre
d'éléments parmi lesquels figurent les buts de l'étude, le
cadre conceptuel, les questions de recherche (Imbert, 2010).
La méthode de l'entretien semi-directif a
été retenue car d'une part le sujet est assez cadré, et
d'autre part cela donne une plus grande liberté à
l'interrogé de développer sur des sujets non relevés dans
la revue de littérature.
Un guide d'entretien a été rédigé
grâce à la revue de littérature, il comporte vingt-quatre
questions et est divisé en deux parties, la première est
centrée sur les sujets d'ordre organisationnel tel que la gestion de
projet, la deuxième porte sur les aspects techniques de l'étude.
Les questions sont disponibles en annexe. Chaque entretien a duré
environ une heure.
Les entretiens ont été retranscrits,
analysés, codés et synthétisés. La synthèse
est présentée dans le chapitre 4 à travers dix sujets
répartis dans deux thèmes ; les questions relevant de la gestion
de projet, et celles consacrées aux méthodes techniques.
Présentation des fonctions des experts interrogés
ainsi que leur entreprise :
10
1.3.2.1 MS Azure CS
Consultant expert en data science, il travaille pour
l'éditeur Microsoft sur l'offre de service Microsoft Azure cognitive
services, qui est une plate-forme cloud du géant américain
dédiée à l'intégration et au développement
de solutions basées sur l'intelligence artificielle. (Microsoft,
2018)
1.3.2.2 Upfluence
Docteur en Machine Learning, il travaille pour une start-up
nommée Upfluence dont le coeur de métier est le marketing
d'influence sur Internet, cette entreprise utilise beaucoup les technologies de
l'intelligence artificielle, elle compte parmi ses clients de grandes
entreprises françaises. (Upfluence, 2018)
1.3.2.3 Antidot
Responsable R&D de l'entreprise Antidot, qui est un
éditeur spécialiste dans les solutions de recherche
d'accès à l'information, cette entreprise développe
notamment des solutions basées sur le Machine Learning. (Antidot,
2018)
1.3.2.4 Bull-Atos
Directeur innovation de l'agence Bull Atos de Grenoble, cette
entreprise est un géant des prestations de services numériques,
elle intervient dans le domaine du Machine Learning en déléguant
des spécialistes techniques auprès de clients grands comptes.
(Bull-Atos, 2018)
1.3.2.5 Sinequa
Consultants Machine Learning chez Sinequa, qui est un
éditeur de solutions basées sur les technologies de
l'intelligence artificielle, cette entreprise est spécialisée
dans l'intégration de moteurs de recherches d'entreprises et
développe des solutions basées sur le Machine Learning. (Sinequa,
2018)
Ces cinq entreprises ont en commun le fait de
développer des solutions basées sur le Machine Learning pour de
grandes organisations, ce qui correspond à notre contexte.
11
2 GESTION DES CONNAISSANCES ET CLASSIFICATION
A notre époque, les entreprises sont
confrontées à un environnement en perpétuelle
évolution, la capacité d'adaptation est devenue essentielle,
parmi les leviers de performance organisationnelle, la gestion des
connaissances joue un rôle important. La gestion documentaire est un
vecteur de transferts des connaissances. Elle connait une mutation au travers
des outils de dernière génération qui offrent des
fonctionnalités permettant d'améliorer la circulation des
connaissances, notamment en simplifiant l'accès aux documents.
2.1 La gestion des connaissances
D'après Jean-Louis Ermine, nous sommes entrés
depuis 20 ans dans l'économie de la connaissance, la prise en compte de
cette réalité pour les organisations n'est plus un choix mais une
nécessité (Ermine, 2018). Depuis la version 2015 de la norme ISO
9001, un chapitre concernant la connaissance a fait son apparition. Afin
d'être en règle, les organismes certifiés sont tenus de
mettre en place une gestion de la connaissance qu'ils considèrent comme
nécessaire à la mise en oeuvre de leurs processus. Le savoir et
la connaissance deviennent des ressources importantes pour l'organisation
(AFNOR, 2015).
Les entreprises sont donc confrontées à la
recherche de démarches spécifiques de gestion des connaissances,
que l'on désigne le plus souvent sous le nom de KM ou « knowledge
management » (Dudezert, 2013). Parmi les facteurs qui poussent les
organisations à adopter une démarche KM on retrouve (Dalkir,
2013) :
· La globalisation de l'économie qui exacerbe la
nécessité de trouver de nouveau levier pour se distinguer de la
concurrence
· L'impact des progrès technologiques de
l'informatique qui ont complexifié l'environnement de travail
· La mobilité des employés qui appauvrit
le capital connaissance
2.1.1 Définition du KM
Il n'y a pas de définition généralement
acceptée de la gestion des connaissances, mais la plupart des praticiens
et des professionnels s'accordent à dire que la gestion des
connaissances est le processus de création, de partage, d'utilisation
des connaissances et des informations d'une organisation (Girard & Girard,
2015). Le KM n'est pas une nouvelle démarche managériale, elle
est pratiquée dans une grande diversité de contextes sous
différentes appellations. Son champ d'application est large et
interconnecté avec de nombreuses disciplines comme le montre la figure 1
(Dalkir, 2013) :

12
Figure 1- interdisciplinarité de la gestion des
connaissances (Dalkir, 2013)
L'objectif principal de la gestion des connaissances est de
faciliter la circulation des informations entre l'organisation et les individus
en améliorant le travail de chacun et la connaissance métier.
Ceci dans le but de renforcer ou sauvegarder les compétences de
l'organisation. L'une des caractéristiques les plus importantes du KM
réside dans le fait qu'elle traite à la fois de la connaissance
et de l'information.
2.1.2 La connaissance
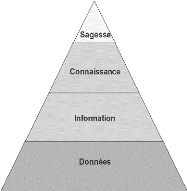
Figure 2 - Pyramide DIKW (Ermine, et al., 2012)
La description des constituants de la connaissance est un bon
moyen de définir la connaissance, la pyramide DIKW6 est la
façon la plus connue d'illustrer ses constituants. Cette
représentation suggère que les éléments
supérieurs dépendent de leur base, ainsi la connaissance est
construite à partir de l'information et celle-ci à partir de
données. (Ermine, et al., 2012)
Les données sont des faits bruts qui ont
été accumulés par des personnes ou des machines, elles
sont donc une collection de « faits » et de nombres bruts. Robert
Reix explique le lien entre les données et l'information : « passer
du monde des symboles à celui du sens, des significations, donc des
données à l'information, n'est pas automatique, mais se
réalise par l'intermédiaire de processus spécifiques
d'interprétation, de cognition » (Reix, 2016), l'information est
donc produite lorsque les données sont assez structurées et
organisées pour produire du sens. Enfin, la connaissance se construit
à partir de l'information. Pour un individu, le processus de
création de connaissances consiste à analyser, comprendre et
assimiler l'information pour en produire
6 Data, Information, knowledge and wisdom
13
une représentation personnelle. Du point de vue de
l'organisation, la connaissance est la faculté à donner aux
informations reliées un sens en son sein. Autrement dit, les
connaissances organisationnelles sont « un ensemble de connaissances
individuelles, spécifiques ou partagées » (Bouhedi,
2017).
2.1.3 Création et transfert de la connaissance
|
Selon la théorie de la création de la
connaissance dans les organisations (Nonaka et al., 1995), les connaissances
surgissent d'une interaction entre deux types de connaissances : les
connaissances explicites et les connaissances tacites.
La connaissance explicite fait référence au
« savoir » verbalisable, transmissible oralement ou par
l'écriture. La connaissance tacite se réfère plutôt
au « savoir-faire », c'est une connaissance pratique qui
résulte de l'expérience et se traduit par le geste.
|
|
|
Figure 3 - Modèle SECI (Nonaka, et al., 2000)
|
Ces connaissances circulent dans l'organisation selon un
processus de transfert. Le modèle SECI7
représenté ci-dessus est sans doute l'un des plus populaires. Il
décrit le processus de création et de transfert des connaissances
en quatre étapes :
1. La socialisation : processus de transfert du savoir tacite
entre individu
2. L'externalisation : formalisation sous forme de concept de
connaissances explicites
3. La combinaison : reformulation d'une donnée
explicite
4. L'internalisation : transfert des connaissances explicites
vers des connaissances tacites, ce processus correspond à
l'apprentissage et à la transformation du savoir vers le savoir-faire,
où les connaissances explicites transmises sont assimilées par
les individus qui acquièrent de nouvelles connaissances (Bouhedi,
2017).
7 SECI : Socialisation, Externalisation, Combination,
Internalisation
Cette dernière étape s'appuie sur les
connaissances explicites qui sont formalisées, codifiées,
transformées et partagées sous forme de documents ou de base de
données (Wallez, 2010). Autrement dit, la connaissance redevient de
l'information, ce qui permettra la sauvegarde et le transfert de celle-ci
à travers le cycle connaissance-information (fig. 4).
L'interaction entre le transfert de connaissances et le
stockage de connaissances est donc cruciale pour le KM (Jasimuddin, 2005). Pour
assurer cette mission, les organisations doivent disposer d'un
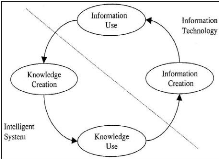
Figure 4 - Cycle connaissance-Information (Blumentritt &
Johnston, 1999)
14
mécanisme de partage des connaissances qui s'appuie sur
des documents électroniques sous forme de bases de connaissances
(Janicot & Mignon, 2008). Cette méthode de gestion est
communément appelée gestion documentaire ou GED qui est une
branche de la gestion des connaissances (Dalkir, 2013).
2.2 Gestion documentaire
Une organisation se doit de conserver certains contenus,
indispensables au maintien des activités de l'organisation, le chapitre
7.1.6 de la norme ISO 9001 (2015) en fait référence.
Le document est certainement le support de la connaissance le
plus connu. Selon la définition de l'ISO, un document est un ensemble
constitué d'un support d'informations et des données
enregistrées sur celui-ci sous une forme généralement
permanente et lisible par l'homme ou par une machine. Le document est donc la
conséquence de l'interaction d'une information, d'une connaissance et
d'un support. Ce support est souvent un document électronique sous forme
de fichier bureautique.
Ces documents peuvent former des bases de connaissances
(Janicot & Mignon, 2008), cependant, il est important de préciser
que parmi les documents, certains servent directement ou indirectement de
support de capitalisation de connaissances, mais d'autres ne le sont pas
(MAHÉ, et al., 2012).
La gestion de ces documents, est un enjeu de plus en plus
important pour les entreprises (Dupoirier, 2009), ainsi les systèmes de
gestion documentaire peuvent améliorer significativement la gouvernance
de l'information (Hubain, 2016) et par conséquent la performance du
KM.
2.2.1 Outils et méthodes
La gestion documentaire ou GED est le contrôle
automatisé des documents électroniques tout au long de leur cycle
de vie au sein d'une organisation, de la création à l'archivage
final (Nastase & al., 2009).

Figure 5 - Intégration de la gestion documentaire
dans l'ECM (Katuu, 2012)
Elle est à la fois une méthode et un outil qui
permet de gérer une base documentaire composée principalement de
fichiers bureautiques (Crozat, 2016). Sa fonction première est le
stockage des documents électroniques pour en assurer la qualité,
c-à-d la disponibilité, l'intégrité et la
confidentialité, conformément aux critères de
sécurité du système d'information DICP8 (Faris,
2013).
Depuis l'arrivée dans les organisations des outils du
web 2.0, on voit l'intégration de la gestion documentaire dans une
solution plus large qui englobe tous type de support d'information, on peut en
voir une représentation sur la figure 5. Cette méthode,
appelée ECM9, a pour but de centraliser l'information pour
faciliter la circulation des connaissances en favorisant le partage des
connaissances et la collaboration (Alalwan & Heinz, 2012).
Parmi les usages nouveaux, on peut citer la coédition,
la gestion du « versionning » et l'utilisation des
métadonnées pour classer les documents.
Mais ce genre d'applications n'est à la portée
que de grandes organisations. Microsoft a ainsi réalisé des
partenariats pour intégrer sa solution ECM SharePoint au sein des
grandes organisations. Cependant, la valeur ajoutée de ces solutions
n'est pas assez exploitée (Alalwan & Heinz, 2012), il est
nécessaire de revoir l'usage de ces applications, notamment la
façon d'organiser et d'exploiter ce type d'informations.
15
8 DICP : Disponibilité,
Intégrité, Confidentialité, Preuve
9 Enterprise Content Management
16
2.2.2 Classification de documents
Pour rappel, l'un des objectifs de la gestion des
connaissances est de faciliter la circulation des connaissances, à
travers notamment l'information contenue dans les bases documentaires.
|
La diffusion et l'exploitation sont au coeur du cycle de vie
du document comme le montre la figure 6 (Cabanac & al, 2006),
l'accessibilité des documents est une question importante, c'est
pourquoi la structure de la base documentaire doit être pensée de
façon à faciliter l'accès aux informations
recherchées, notamment en structurant la base documentaire de sorte que
le stockage et la recherche de documents soit le plus intuitif possible pour
les utilisateurs. L'organisation des documents a un impact important sur la
circulation des informations, alors, quelle structure choisir ?
|
|
|
Figure 6 - Cycle de vie du document (Cabanac & al,
2006)
|
D'après Michèle Hudon, il ne peut exister de
structure idéale et absolue pour organiser les connaissances, cependant
le processus d'organisation suppose presque toujours une opération de
classification.
La classification est la méthode classique de
structuration, elle est définie comme l'opération qui organise
des entités en classes, de sorte que les entités semblables ou
parentes soient regroupées et séparées des entités
non semblables ou étrangères. Par analogie, la classification
documentaire est donc l'opération qui consiste à regrouper en
classes les documents semblables ou liés, en les séparant des
documents avec lesquels ils n'entretiennent aucun lien ou n'ont aucune
caractéristique commune. Le plus souvent, la classification est
fondée sur la thématique du contenu du document (Hudon & El
Hadi, 2010).
La représentation des documents est propre à
chaque organisation, et dépend principalement du domaine métier
et de l'organisation interne.
2.2.3 Accès à l'information
Il existe, dans les organisations, deux types d'accès
à l'information : la navigation à travers une structure
hiérarchique et la recherche de documents (Voit, et al., 2011) :
· La navigation est la méthode classique. Elle
consiste à franchir une hiérarchie de dossiers
(représentants des catégories ou des classes) en naviguant
jusqu'au document contenant l'information. Comme toute structure
hiérarchique, elle est rigide, il n'est, par exemple, pas évident
de déplacer une sous-catégorie d'une catégorie à
une autre. De plus, un document ne correspond pas obligatoirement à une
seule catégorie (Francis & Quesnel, 2007).
· La recherche permet de retrouver et d'accéder
directement au document recherché. Les outils habituellement
utilisés s'appuient sur le mécanisme d'indexation. Le
système indexe en amont les informations contenues dans les documents,
l'utilisateur doit alors renseigner des éléments
caractérisant le document pour le retrouver, ce qui n'est pas
évident dans le cas d'indexation plein texte tel que proposé par
les systèmes d'exploitation.
L'augmentation de la quantité de documents rend la
classification d'une base documentaire plus complexe, il est alors
nécessaire de trouver une solution pour accéder plus facilement
à l'information. Les outils modernes comme l'ECM10 propose
une indexation intelligente des informations, ils tirent parti des
métadonnées pour améliorer la pertinence des recherches de
document.
2.2.4 Métadonnée
Les métadonnées, littéralement «
les données des données », sont les propriétés
d'un document, décrit sous trois aspects : technique, administratif et
descriptif. Les métadonnées permettent d'identifier chaque
document et de le relier à l'ensemble de la base (Westeel, 2010).
L'approche fondée sur les métadonnées
pour structurer une base documentaire n'utilise pas de dossiers pour organiser
le contenu. Les documents sont étiquetés avec
des valeurs descriptives telles que « classe de document », «
date de création », « utilisateur », « client
», « projet », « fournisseur », «
mots-clés », « description ». La structure des
métadonnées est entièrement personnalisable (
GED.fr, s.d.). Enfin, cette méthode
permet d'associer un document à plusieurs catégories.
La recherche basée sur l'indexation des
métadonnées facilite l'accès et l'échange
d'informations (Morel-Pair, 2005), et par conséquent améliore le
transfert de connaissances.
2.3 Etiquetage manuel
Nous venons de voir l'avantage d'utiliser la classification
par l'étiquetage des éléments composant une base
documentaire pour en faciliter l'exploitation, voyons maintenant comment
s'effectue une tâche d'étiquetage.
L'opération consiste à analyser le contenu pour
trouver des éléments distinctifs qui serviront à prendre
la décision de classer le document dans telle ou telle catégorie.
Ce processus, lorsqu'il est effectué par un humain peut être long
et donc couteux, surtout si la quantité de documents est importante. La
solution est alors de chercher à automatiser la tâche.
L'automatisation de ce genre de tâches est
réalisée habituellement en développant un logiciel. Cette
tâche de classification nécessite un certain niveau d'analyse qui
ne peut être traité par un programme informatique classique. En
effet, la complexité cognitive du traitement de l'information par
l'être humain n'est reproductible que par l'approche symbolique des
systèmes de règles aussi appelés
17
10 Entreprise Content Management
18
systèmes experts. Cependant, le temps et le coût
élevé de modélisation d'un tel système sont
inadaptés à notre situation.
Une autre approche dite numérique propose d'imiter ce
type de tâche, elle se base sur la notion d'apprentissage. K.C. Laudon
propose, pour améliorer la performance de la gestion des connaissances,
d'explorer les opportunités offertes par l'intelligence artificielle. Le
domaine du Machine Learning permet d'imiter l'intelligence humaine (Laudon,
2013).
2.4 Conclusion
Nous avons exploré le domaine de la gestion
documentaire qui est un enjeu important pour les organisations, en ce sens
qu'elle améliore la circulation de l'information métier. D'autre
part, les outils de gestion ECM propose une meilleure organisation de
l'information basée sur les métadonnées. Cette
méthode de recherche d'informations accélère grandement
l'accès aux informations contenues dans les bases documentaires.
Nous avons ainsi répondu à la première
question de recherches, dont l'objectif était de comprendre le sens du
projet de migration ainsi que la nécessité d'automatiser la
classification des documents à migrer. Nous allons maintenant nous
plonger dans le domaine de l'intelligence artificielle et notamment le Machine
Learning.
19
3 L'INTELLIGENCE ARTIFICIELLE ET LA CLASSIFICATION DE
DOCUMENTS
3.1 L'intelligence artificielle
L'intelligence artificielle est une technologie qui arrive
aujourd'hui à maturité (Panetta, 2018). Elle trouve des
débouchés croissants dans les entreprises qui la
considèrent comme un levier de compétitivité. Mais elle ne
touche pas que le monde des entreprises, elle est déjà
présente dans nos vies de tous les jours.
Alors, qu'est-ce que l'intelligence artificielle ?
3.1.1 Différentes définitions
Il est difficile de donner une définition unique de
l'intelligence artificielle car elle peut être abordée de
différentes manières, elle touche ainsi différentes
disciplines, tels que la philosophie, les mathématiques,
l'économie, les neurosciences, la psychologie ainsi que l'informatique
qui nous intéressera tout particulièrement dans cette
étude.
Il y a donc plusieurs définitions de l'intelligence
artificielle, mais en voici deux qui caractérisent bien les deux champs
couverts par l'intelligence artificielle dans notre sujet, la première
est issue du Mercator : « Discipline qui travaille sur les méthodes
et les programmes informatiques permettant de résoudre des tâches
complexes que les êtres humains accomplissent aujourd'hui en utilisant
des processus mentaux de haut niveau (comme l'apprentissage et le
raisonnement)» (Lendrevie & Lévy, 2014). La seconde est celle
de Cédric Vilani, député et célèbre
mathématicien qui a été chargé par le gouvernement
d'une mission sur l'intelligence artificielle : « L'intelligence
artificielle, c'est l'art de la programmation qui permet à un
algorithme, un ordinateur de réaliser des tâches subtiles en
tenant compte de nombreux paramètres » (Ceaux, 2018).
Pour résumer, l'intelligence artificielle est la mise
en oeuvre de solutions techniques pour automatiser des tâches complexes
nécessitant jusqu'alors l'intervention de l'homme.
Beaucoup pourraient croire que l'intelligence artificielle
est une innovation récente tellement le sujet est rabâché
à longueur d'articles depuis quelques années, elle n'est pourtant
pas un concept nouveau. La notion a été introduite il y a environ
70 ans.
3.1.2 Historique de l'intelligence artificielle
L'histoire de l'intelligence artificielle est parsemée
de succès, de déceptions et de prédictions non
réalisées. Dès 1950, Alan Turing tente d'établir un
critère permettant de juger de l'intelligence d'une
20
machine à travers le test dit « de Turing »,
il prédisait qu'en l'an 2000 personne ne pourrait distinguer les
réponses données par un homme ou un ordinateur (De Ganay &
Dominique, 2017). La naissance à proprement dit de l'intelligence
artificielle date de l'été 1956 sur le campus de Dartmouth
College aux USA durant lequel une dizaine de chercheurs définissent ce
nouveau domaine de recherche, et parmi eux John Mc Carthy et Marvin Lee Minsky
qui co-fondent en 1959 le groupe d'intelligence artificielle du MIT (MIT AI
Lab) grand artisan du développement de cette discipline (Russell &
Norvig, 2010).
Jusqu'au milieu des années 70, c'est l'euphorie, la
recherche n'a pas de mal à trouver du financement et les espoirs sont
grandissants. Certains experts prédisent même que « des
machines seront capables, d'ici 20 ans, de faire le travail que toute personne
peut faire ». Malheureusement les résultats ne seront pas au
rendez-vous, principalement à cause d'un manque de maturité des
algorithmes et aux faibles capacités du « hardware » de
l'époque. Les principaux financeurs se désengagent des
différents projets et la discipline connaitra un hiver qui durera
jusqu'aux années 90.
En parallèle, un nouveau type de solution apparait,
c'est le « système expert » qui est basé sur un
ensemble de règles configurées par des experts humains. Il
connaitra un succès certain avec par exemple, dans le domaine
médical MYCIN qui contenait 450 règles, ce système
réussissait à diagnostiquer à un niveau proche des experts
humains. Ces systèmes seront progressivement adoptés par
l'industrie dans les années 80 (Russell & Norvig, 2010).
A partir de 1987, l'intelligence artificielle adopte les
méthodes scientifiques, ce qui va accélérer les
progrès en la matière. La victoire du superordinateur d'IBM
« Deep Blue » sur le champion des échecs Garry Kasparov en
1997 marque un premier tournant en matière de progrès de
l'intelligence artificielle (Russell & Norvig, 2010). Les années
suivantes seront marquées par l'explosion de données disponibles,
qui, conjuguées aux progrès énormes en matière de
puissance de calcul vont booster cette discipline tout au long des
années 2000. La démonstration de la solution actuelle d'IBM
« Watson » qui gagne aux jeux de Jeopardy en 2011, et l'an dernier
celle de Google « AlphaGO Zero » au jeu de go en sont de belles
illustrations.
3.1.3 L'intelligence artificielle est déjà
là !
L'intelligence artificielle est longtemps restée
cloitrée dans un rôle d'expert, en effet les systèmes
experts ne se sont pas popularisés à cause du coût
prohibitif et du champ d'application limité à un certain niveau
de complexité. Depuis une quinzaine d'années, les progrès
du Machine Learning, la puissance de calcul et les données de plus en
plus disponibles ont permis de « démocratiser » l'usage de
l'intelligence artificielle. Aujourd'hui, ces solutions sont déjà
à l'oeuvre dans de nombreux domaines, en voici quelques exemples :
· Le géant Google a utilisé sa solution
phare « DeepMind » pour améliorer l'efficience
énergétique de ses datacenters. L'algorithme a été
entrainé avec plusieurs années de données de consommations
électriques et de données météorologiques. La
consommation électrique a diminué de 40% (MANAGERIS, 2018).
· Airbus a décidé d'implémenter de
l'intelligence artificielle dans la gestion des interruptions de productions de
son nouvel appareil l'A350. La solution a été
implémentée en intégrant toutes les données
historiques. Lorsqu'un problème survient, le système analyse les
données
21
contextuelles et donne à l'équipe une
recommandation. Cela a permis de réduire d'un tiers le temps
nécessaire à la gestion des interruptions de production (MIT,
2017).
· La société JobiJoba a
développé un outil basé sur l'intelligence artificielle
appelé "CV Catcher", celui-ci a déjà été
implémenté sur les sites de recrutement de 40 grandes entreprises
comme SFR, la SNCF et EDF. L'algorithme permet au candidat de connaitre,
immédiatement après avoir uploadé son CV, les postes
à pourvoir qui correspondent à son profil.
· Tout un chacun profite déjà de
l'implémentation de solution d'intelligence artificielle comme, le
filtre anti-spam de nos boites email, la traduction automatique en ligne, et
plus récemment avec l'apparition d'assistants virtuels sur nos
smartphones comme Siri, Google Assistant ou Cortana qui simplifie au quotidien
nos usages personnels.
Bien entendu, ces quelques exemples sont loin d'être
exhaustifs, notons néanmoins que le champ d'application des solutions
d'intelligence artificielle est vaste, car elles visent à
améliorer d'une manière générale la
productivité. C'est pourquoi de plus en plus d'entreprises
s'intéressent de près à ces solutions (MIT, 2017).
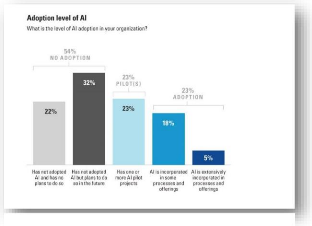
Figure 7 - Adoption de l'IA par les entreprises (MIT,
2017)
3.1.4 Enjeux pour les entreprises
Cette technologie n'en est qu'à ses débuts et
nous sommes encore loin de la phase d'intégration à grande
échelle dans les entreprises.
Une étude menée l'an dernier par le MIT
auprès de 3000 entreprises montre qu'il y a un grand écart entre
les ambitions et la mise en pratique en matière de
stratégie d'intelligence
artificielle (MIT, 2017)
ainsi 85% des dirigeants interrogés estiment que l'intelligence
artificielle leur permettra d'obtenir ou de conserver un avantage
concurrentiel, alors que 40% ont mis en place une stratégie
d'intelligence artificielle et seule une entreprise sur vingt a
intégré l'intelligence artificielle dans ses offres ou ses
processus (figure 7).
Avant de mettre en oeuvre une gouvernance de l'intelligence
artificielle, les entreprises attendent de tirer les leçons des
premières expériences (CIGREF, 2017). Et celles-ci montrent qu'il
y a des conditions à respecter pour réussir l'intégration
de solution d'intelligence artificielle, en voici quelques exemples :
·
22
Définir le besoin : La solution
à implémenter doit répondre à un besoin clairement
identifié, il convient de bien comprendre la problématique
business et de s'assurer que l'intelligence artificielle est capable de la
résoudre (Caseau, 2018).
· Disposer de données :
S'assurer de disposer de données en quantité et en
qualité. Il a été prouvé que la performance de ces
solutions est proportionnelle à la quantité de données
à disposition (Banko & Brill, 2001).
· Adopter une démarche empirique :
Les solutions « clés en main » n'existe pas en IA,
chaque solution doit s'imprégner du contexte métier du
problème à résoudre. Car aucun modèle et algorithme
ne fonctionne bien pour tous les problèmes, on parle du
théorème « No free lunch » (Wolpert & Macready,
1997).
· Acquérir les compétences
: L'implémentation d'une solution d'intelligence artificielle
demande l'intervention de profils spécifiques tel que les data
scientistes, qui doivent bien entendu être accompagnés par le
business afin de cadrer le besoin (MANAGERIS, 2018).
· Prévoir une MCO : Il est
nécessaire dès le début du projet de prévoir la MCO
(maintenance en condition opérationnelle) en effet, les mutations que
peuvent subir les données dans le temps entraineront à coût
sûre une dégradation du niveau de qualité de la machine,
sans compter les mises à jour nécessaires (MANAGERIS, 2018).
Les enjeux de l'intelligence artificielle notamment
opérationnels sont considérables, mais avant d'entamer la phase
de « transition intelligente » les entreprises doivent apprivoiser
cette révolution technologique (CIGREF, 2017).
3.2 Les domaines de l'intelligence artificielle
Il faut distinguer 2 formes d'intelligence artificielle,
« l'intelligence artificielle forte » (Artificial General
Intelligence) et « l'intelligence artificielle faible » (en anglais
Artificial Narrow Intelligence) (Gonenc, et al., 2016) :
· L'intelligence artificielle « forte » se
rapproche du raisonnement humain. Ce type d'intelligence artificielle est
capable d'appliquer l'intelligence à tout problème contrairement
à l'intelligence artificielle faible. A ce jour il n'existe aucune AGI
opérationnelle, ce domaine se cantonne (pour l'instant) à la
recherche. Le grand public a tendance à penser que c'est ce type
d'intelligence artificielle qui est appliqué alors qu'il relève
de la science-fiction tout comme une troisième forme nommée ASI
(Artificial Super Intelligence) et qui prévoit le sur-classement de
l'homme par la machine dans 30 ans.
· L'intelligence artificielle « faible »
beaucoup plus « terre à terre » vise à imiter
l'intelligence pour répondre à un problème
spécifique, la machine ne fait que donner une impression d'intelligence.
Toutes les applications actuelles sont basées sur des solutions
d'intelligence artificielle faible !
23
3.2.1 Les approches
Depuis les débuts de l'intelligence artificielle dans
les années 1950, deux approches ont été employées
:
Dans la première approche dite symbolique, on
programme des règles et résout un problème à
travers une série d'étapes (les pionniers de l'intelligence
artificielle, pour la plupart logiciens, appréciaient beaucoup cette
méthode). Elle a culminé dans les années 1980 avec le
développement des systèmes experts, programmes dont le but
était d'intégrer une base de connaissances et un moteur de
décision venant de spécialistes de domaines pointus. Cette
approche souffre d'un manque de souplesse, par exemple il faut repartir de
zéro lorsque l'on développe un nouveau modèle.
Dans la deuxième approche dite numérique, on se
concentre sur les données. Les solutions vont rechercher des
corrélations au sein d'ensemble de données de différentes
formes. Cette approche connait depuis une vingtaine d'années une
évolution croissante grâce à l'augmentation de la puissance
de calcul avec notamment l'utilisation des GPU et l'explosion de la
quantité de données disponibles. La plupart des systèmes
actuels utilise le Machine Learning 11, une méthode
fondée sur une représentation mathématique, stochastique
et informatique.
3.2.2 Les sous-domaines de l'intelligence artificielle
Dans certains articles on peut trouver une
représentation classique de l'intelligence artificielle (figure 8) mais
il est difficile de parler d'un domaine avec ses sous branches, l'intelligence
artificielle est plus un concept qui rassemble d'elle-même une multitude
de disciplines scientifiques, d'applications et de méthodes. Toutes plus
ou moins interconnectées. Il est donc difficile de présenter une
liste exhaustive des domaines, cependant voici une présentation des
principaux « sous-domaines » (INRIA, 2016) (Russell & Norvig,
2010) :

Figure 8 - Champs de l'IA (Villanueva & Salenga,
2018)
11 Apprentissage automatique
· Représentation des connaissances :
Cette branche traite de la formalisation des connaissances, le but est
d'implémenter dans les systèmes les représentations
symboliques du savoir humain. C'est là un des secteurs les plus
importants de la recherche en intelligence artificielle.
· Traitement du langage naturel : Cette
discipline vise à étudier la compréhension et
l'utilisation du langage naturel des humains par les machines, on parle de
langage naturel par opposition au langage codé de l'informatique.
· Vision artificielle : Le but de cette
discipline est de permettre aux ordinateurs de comprendre les images et la
vidéo.
· Robotique : Ce sous-domaine vise
à fabriquer des machines physiques, ce qu'on appelle habituellement un
robot. Les robots industriels sont utilisés depuis longtemps, mais ici
on vise à créer des robots avec une certaine autonomie et
capables de percevoir et d'interagir avec leur environnement.
· Machine Learning : Le Machine
Learning vise à automatiser l'analyse de grands ensembles de
données en utilisant des méthodes stochastiques,
mathématiques et d'optimisation. Le but est de trouver des
corrélations dans les données de façon autonome ou non.
Les applications sont diverses.
· Moteurs de règle et système
experts : un système expert est un programme configuré
par un spécialiste qui effectue des tâches précises afin de
simuler le comportement humain.
Ces sous-domaines ne fonctionnent pas en silos, il y a des
interactions fortes entre eux (Russell & Norvig, 2010) (Cambrai, 2017). Par
exemple on peut en NLP utiliser le Machine Learning (Machine

Figure 9 - L'IA : une interconnexion d'applications, de
domaines et de méthodes (See, 2016)
24
25
Learning), les langages développés dans la
représentation des connaissances peuvent servir de base à des
systèmes experts. La figure 9 illustre bien les liens complexes qu'il y
a entre les applications (à gauche), les sous-domaines et les
méthodes d'intelligence artificielle.
Notre étude porte sur la recherche d'une solution qui
permet de classer des données au format texte, c'est
précisément le but d'une tâche qui est au croisement de
deux sous-domaines du TALN12 (en anglais NLP13) et du
Machine Learning : La classification de documents (document classification en
anglais).
3.3 La classification de documents
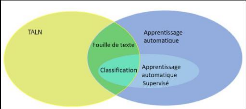
Figure 10 - La classification, à la croisée
des chemins de l'IA
Parmi la multitude d'applications de l'intelligence
artificielle, la classification de documents consiste à regrouper les
documents en catégories en fonction de leur contenu. La classification
des documents joue un rôle essentiel dans diverses
applications d'intelligence artificielle
traitant de
l'organisation, de la classification et de la recherche de quantités
importantes de données textuelles. La classification de documents est
une discipline étudiée de longue date dans les disciplines de la
recherche d'information (Power, et al., 2010) (Patra & Singh, 2013). C'est
aussi une des tâches de la fouille de texte qui utilise les techniques et
méthodes du TALN et le Machine Learning (figure 10).
3.4 Le traitement automatique du langage naturel
Le TALN (NLP en anglais) ou TAL est le domaine de
l'intelligence artificielle qui s'intéresse à l'analyse et
à la compréhension des langues naturelles. Bien que cette
discipline ait plus de soixante ans, ce n'est qu'à partir des
années 90 qu'elle se développe, grâce aux progrès de
l'informatique qui a permis le traitement du texte au format numérique.
Les techniques utilisées aujourd'hui sont issues de l'informatique, de
la linguistique et du Machine Learning (Tellier, 2010).
Il existe deux approches distinctes, l'approche linguistique
et l'approche syntaxique (aussi appelée stochastique), cette
dernière s'appuie sur les méthodes numériques,
principalement statistiques et probabilistes, elle ne cherche pas à
comprendre le texte mais à étudier les corrélations
présentes dans celui-ci. Depuis que les chercheurs se sont
tournés vers ces nouvelles méthodes de l'intelligence
12 Traitement automatique de la langue naturelle
13 Natural language Processing
26
artificielle, le TALN a connu une avancée remarquable,
parmi les applications que le grand public utilise, il y a la correction
orthographique des logiciels de traitement de textes, la reconnaissance de
caractère, et plus récemment la traduction automatique et la
reconnaissance vocale.
Nous ferons un focus sur ces méthodes
appliquées à la classification textuelle qui sont principalement
issues du Machine Learning.
3.5 Le Machine Learning
Comme toutes les branches de l'intelligence artificielle, les
domaines du Machine Learning et du TALN partagent l'objectif de douer les
machines de certaines capacités humaines (Tellier, 2010), comme nous
l'avons vu plus haut le TALN utilise les méthodes du Machine Learning en
particulier dans les tâches de fouille de textes et de recherche
d'informations. Le Machine Learning est un domaine vaste et complexe, nous nous
limiterons aux aspects qui s'appliquent à notre sujet.
Le Machine Learning est la voie qui donne aujourd'hui les
meilleurs résultats dans les applications d'intelligence artificielle.
Cette discipline étudie, développe des techniques et
méthodes qui permettent à un algorithme d'apprendre à
partir d'exemples. C'est une démarche empirique qui tient plus de
l'observation que de la logique mathématique.
Parmi les nombreuses définitions du Machine Learning
celle-ci résume assez bien le but du Machine Learning : « une
machine14 est censée apprendre, si à partir d'une
expérience E en respectant les classes de la tâche T et en
mesurant la performance P sa performance à exécuter la
tâche T mesuré par P s'améliore avec l'expérience E
» (Mitchell & al., 1997), en d'autres termes il s'agit
d'améliorer la performance d'un algorithme à réaliser la
tâche en utilisant un ensemble d'exercices d'apprentissage.
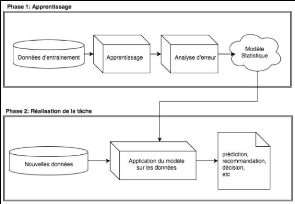
Figure 11 - Les deux phases de l'apprentissage automatique
(Chaouche, 2018)
Rappelons que la plupart des applications de Machine Learning
ont pour objectif d'automatiser, tout ou partie, des tâches complexes
accessibles seulement à l'être humain. Le ML15
répond ainsi aux problématiques non résolues par les
systèmes basés sur l'approche symbolique traditionnelle de
l'intelligence artificielle. Ceux-ci ne peuvent être
modélisés et configurés que par des spécialistes,
cette approche devient problématique lorsque la complexité
augmente et limite le
champ d'application de
l'intelligence artificielle. Au
contraire, le ML qui se
base principalement sur une approche
analogiste va limiter
14 « Machine » est pris au sens informatique,
autrement dit c'est un programme
15 Machine Learning
l'intervention d'experts, ce système utilise des
exemples déjà vus pour prendre des décisions. Dans une
première phase, il va rechercher des corrélations à partir
d'un jeu de données en entrée pour créer une règle,
puis le but est de généraliser cette règle apprise
à de nouvelles données dans une deuxième phase (figure
11).
3.5.1 Les modes d'apprentissage et les types de
problèmes à résoudre
Il existe plusieurs techniques de Machine Learning (Russell
& Norvig, 2010) :
· L'apprentissage supervisé : Un
expert labelise une partie des données qui va servir à
l'apprentissage. L'algorithme va alors apprendre la tâche de
classification en se basant sur les données labelisées.
· L'apprentissage non supervisé
: L'algorithme doit découvrir de lui-même les
ressemblances et différences dans les données fournies pour
apprendre la tâche.
· L'apprentissage semi-supervisé :
Les algorithmes fonctionnent comme pour l'apprentissage
supervisé mais acceptent en plus des données non
labelisées pendant la phase d'apprentissage.
· L'apprentissage par renforcement :
L'algorithme doit apprendre les actions à partir d'expériences,
de façon à gagner une récompense et à éviter
un gage.
Il existe deux types de problèmes bien distincts pour
lesquels le ML propose une solution, la classification et la
régression.
· Classification : Un problème
d'apprentissage supervisé où la réponse à apprendre
est celle d'un nombre infini de valeurs possibles. C'est un type de tâche
qui va chercher à catégoriser des éléments à
partir d'autres. Quand il n'y a que deux valeurs possibles, on dit que c'est un
problème de classification binaire, s'il y en a plus on parle de
classification multi-classes.
· Régression : Un
problème d'apprentissage supervisé où la réponse
à apprendre est une valeur continue. L'algorithme va chercher à
prédire un chiffre.
La tâche à traiter dans notre contexte
relève de la classification supervisée, nous ne nous
intéresserons pas aux autres cas dans la suite de ce chapitre. Le
modèle de classification supervisée à construire est
communément appelé « classifieur » (Boucheron, et al.,
2005).
27
3.5.2 Les étapes du Machine Learning
supervisé
28
La résolution d'un problème par l'apprentissage
machine peut se résumer en trois étapes, voir quatre si on estime
que la compréhension de la problématique posée entre dans
le processus d'apprentissage (Chaouche, 2018) :
· La tâche spécifique :
comprendre le problème à résoudre
· Les données : préparer les
données
· L'algorithme d'apprentissage : choisir
et paramétrer un algorithme
· La mesure des performances du modèle :
évaluer le modèle pour ajuster au mieux ses paramètres.
Avant de démarrer un projet de Machine Learning il est
nécessaire de comprendre la problématique afin de
sélectionner les bonnes données, le bon algorithme et les bons
paramétrages.

Figure 12 - Etapes de modélisation d'un
classifieur
Comme toute démarche empirique, le processus
d'apprentissage est itératif, il est peu probable d'arriver au meilleur
résultat possible du premier coup. Il sera donc nécessaire de
revenir sur certaines étapes pour améliorer le résultat.
L'évaluation permet de cibler les paramètres à optimiser
tant au niveau de l'algorithme que du pré-traitement des données
(figure 12).
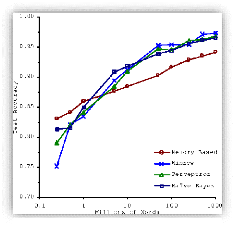
Figure 13 - Importance des données par rapport aux
algorithmes (Banko et Brill - 2001)
3.5.3 Les données
Le traitement des données est une étape
cruciale dans le processus de construction du modèle.
3.5.3.1 Quantité suffisante
Sans les données, il ne peut y avoir d'apprentissage,
c'est donc la première étape dans ce genre de projet :
vérifier que l'on dispose d'assez de données pour que le projet
soit viable.
29
D'ailleurs, il est prouvé que la performance de
l'apprentissage machine s'améliore avec la quantité de
données en entrée. Comme on peut le constater dans la figure
13,
l'augmentation des performances résultant de
l'utilisation de plus de données dépasse toute différence
de choix d'algorithmes. Un algorithme médiocre avec cent millions de
mots d'apprentissage dépasse le meilleur algorithme connu avec un
million de mots indépendamment de la technique choisie (Banko &
Brill, 2001).
Peter Norvig avance même que les données sont
plus importantes que les algorithmes notamment dans le cas de résolution
de problèmes complexes (Halevy, et al., 2009).
3.5.3.2 Donnée représentative
Les résultats seront bons si, et seulement si, les
données sont représentatives du corpus à traiter en
production. La sélection des données pour l'entrainement aura
donc un impact important sur la performance du modèle construit
(Géron, 2017).
3.5.3.3 Structure exploitable
Toutes sortes de données peuvent être
exploitées, bases de données, images, documents textuels,
à condition de les préparer, car les algorithmes ne traitent les
données que sous forme matricielle. En effet, elles sont rarement
stockées dans un fichier csv prêt à l'emploi, on parle
alors de nettoyage et de pré-traitement des données.
Ce traitement ne sera pas le même en fonction de la
structuration des données :
· Données structurées : ce sont des
données qui peuvent être organisées sous forme de tableaux.
Ces données peuvent être affichées par un tableur et
contiennent des lignes et des colonnes de variables, variables dont l'ensemble
des valeurs possibles peuvent être déterminées. C'est le
cas d'une base de données ou d'un fichier csv.
· Données non structurées : ce sont
principalement des documents textuels, audios ou graphiques.
30
Seules les données structurées peuvent
être directement représentées dans un tableau. Quant aux
données non-structurées, elles doivent subir un
pré-traitement pour les convertir en chiffres. Nous verrons que les
données textuelles doivent subir un traitement spécifique pour
être exploitées par les algorithmes de Machine Learning.
3.5.3.4 Représentation des données
Tout objet est décrit par un ensemble de variables.
L'objectif du Machine Learning est de rechercher des régularités
dans ces données grâce à l'observation d'un grand nombre
d'objets. On représente ces objets caractérisés par leur
variable de façon matricielle, chaque ligne est un objet (un document
dans notre contexte) et chaque colonne, une variable (attribut, ou feature en
anglais), qui peut être représenté comme ceci :
|
Variables
|
|
|
|
|
v 1
|
|
|
|
|
|
|
|
|
v n
|
|
|
...
|
|
|
Objets
|
o 1
|
o
|
o
|
x1,1
|
|
|
x1,n
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
...
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
xm,1
|
|
|
|
|
o m
|
|
|
xm,n
|
|
|
|
|
|
|
Tableau 1 - Représentation des données sous
forme d'une matrice (Biernat & Lutz, 2015)
Ce n'est en fait qu'un tableau composé de n variable(s)
et m objet(s) ! On obtient donc un ensemble de données de M vecteurs
à N dimensions. Dans le cas de la classification supervisée,
chaque vecteur sera labelisé, c'est-à-dire qu'on associera
à chaque vecteur, du jeu de données d'entrainement, une
catégorie.
3.5.3.5 Répartition des données
Le jeu de données doit être découpé
en deux parties, la première servira à l'entrainement et la
seconde est réservée aux tests pour la mise en production
(Géron, 2017). Le jeu d'entrainement est lui-même scindé en
deux, un pour l'entrainement et l'autre pour l'évaluation du
modèle (Ibekwe-Sanjuan, 2007). Pour résumer, les données
qui permettent de construire et valider un modèle de classification sont
réparties de la manière suivante :
· Le jeu d'entrainement : 80%
o Dont 80% pour le jeu d'apprentissage
o Dont 20% pour le jeu de validation (20%)
· Le jeu de test : 20%
Ce découpage n'est nécessaire que lorsque le
problème est complexe, en effet, dans les cas les plus simples, on
pourra n'utiliser que le jeu d'entrainement, c'est-à-dire 80% pour
l'apprentissage et 20% pour la validation.
3.5.4 Les algorithmes utilisés en Machine
Learning
Les algorithmes sont les outils essentiels du Machine
Learning, ils sont basés sur des règles statistiques et
probabilistes. Un algorithme va analyser des données et extraire des
régularités qui les
31
caractérisent. C'est ce qui permettra l'apprentissage.
Dans le cas de la classification, le but est de séparer, identifier ou
discriminer des données par rapport à d'autres.
3.5.4.1 Spécialisation des algorithmes
Les algorithmes sont souvent dédiés à un
type d'apprentissage, en voici quelques exemples :
Algorithme
|
Mode d'apprentissage
|
Type de problème à traiter
|
Régression linéaire
|
Supervisé
|
Régression
|
Régression polynomiale
|
Supervisé
|
Régression
|
Naive Bayes
|
Supervisé
|
Classification
|
Régression logistique
|
Supervisé
|
Classification
|
Arbres de décision
|
Supervisé
|
Régression ou classification
|
Random forest
|
Supervisé
|
Régression ou classification
|
Gradient boosting
|
Supervisé
|
Régression ou classification
|
Support Vector Machine
|
Supervisé
|
Régression ou classification
|
Clustering
|
Non supervisé
|
-
|
|
Tableau 2 - Exemples d'algorithmes (Biernat & Lutz,
2015)
3.5.4.2 Que fait l'algorithme dans le cas de la
classification supervisée ?
Le programme recherche une fonction qui prendra, en
entrée, un vecteur (ligne du tableau) et fournira, en sortie, le nom
d'une classe (catégorie). Ce cheminement n'est pas automatique, il
nécessite un ajustement. Le but étant de sélectionner une
fonction qui décrit au mieux les données du jeu d'apprentissage,
on parle alors de minimisation du risque empirique. Les valeurs de la fonction
seront interprétées de façon différente selon la
famille de l'algorithme, il en est de même pour le seuil qui fixe
l'appartenance à telle ou telle classe (Ibekwe-Sanjuan, 2007).
3.5.4.3 Comment choisir l'algorithme ?
Un théorème mathématique prouve qu'il
n'existe pas de meilleure méthode que toutes les autres sur tous les
problèmes de Machine Learning possibles, c'est le « NO FREE LUNCH
» (Wolpert & Macready, 1997). En d'autres termes, si un algorithme de
Machine Learning fonctionne bien sur un type de tâche
particulière, il sera moins performant en moyenne sur d'autres types de
tâches. Il faut donc rechercher et tester l'algorithme qui sera le plus
adapté pour la tâche à accomplir.
Voici trois critères de choix qui permettent de faire une
première sélection :
· Type de tâche
Le tableau 2 nous montre que les algorithmes sont
spécialisés, seuls certains pourront répondre à
notre contexte.
· Type de données
Certains algorithmes seront plus performants que d'autres en
fonction des données, par exemple les documents textuels contiennent
beaucoup de dimensions, par conséquent il faut un algorithme assez
puissant pour traiter ce type de données.
· 32
Adaptabilité
Cette notion d'adaptabilité concerne le fait de
pouvoir mettre à jour le modèle construit, en effet certains
algorithmes peuvent être facilement mis à jour alors que d'autres
pas du tout. Ce critère est fonction de l'utilisation, par exemple un
modèle de classification de données en masse aura moins besoin
d'être mis à jour qu'un modèle de traitement de
données en continu.
Le choix de l'algorithme sera donc fait en fonction du
problème à résoudre.
3.5.5 Algorithmes adaptés à la
classification de documents textuels
Certains programmes sont plus performants que d'autres, parmi
ceux qu'on retrouve dans la littérature, le SVM et le Bayésien
Naïf sont souvent en tête pour les tâches de classification de
document textuel (Osisanwo, 2017) (Kotsiantis, et al., 2007) (Mertsalov,
2009).
3.5.5.1 Les SVM
Le SVM16 est un classifieur linéaire,
c-à-d que les données doivent être linéairement
séparables. Les données sont représentées dans un
espace vectoriel. La fonction va rechercher le meilleur séparateur pour
partager les données en deux classes via une ligne, ou un hyperplan, qui
sera placée de façon à maximiser les marges la
séparant des points, représentant les variables, les plus
proches. Si les données ne sont pas linéairement
séparables, on utilise alors la technique du « noyau » qui
consiste à considérer le problème dans un espace de
dimension supérieure, ainsi on augmente grandement les chances de
trouver une séparation.
C'est algorithme de classification binaire, mais il existe
des méthodes pour l'adapter à la classification multi-classes,
notamment la technique « one-vs-all ».
Le SVM est largement accepté dans l'industrie ainsi
que dans le monde académique. Par exemple, Health Discovery Corporation
utilise le SVM dans un outil d'analyse d'images médicales actuellement
sous licence de Pfizer. Dow Chemical utilise le SVM dans ses recherches pour la
détection des valeurs aberrantes et Reuters l'utilise pour la
classification de textes (Mertsalov, 2009).
Ils sont particulièrement bien adaptés aux
problèmes de classification binaire dans des espaces vectoriels de
grande dimension. Les documents textuels étant par définition
composé d'un grand nombre de dimensions, le SVM est donc
particulièrement performant sur ce type de données (Amancio,
2014). Le SVM surclasse les autres algorithmes sur les aspects de
surdimensionnement, de redondance des fonctionnalités, de robustesse et
donc de précision de la classification (Luo & Li, 2014). De plus, il
performe bien avec peu d'exemples.
Malheureusement, il n'est pas incrémental (Tellier,
2010), il ne peut s'adapter au changement de nature inhérents aux
document textuels. Mais d'autres le sont, notamment le Bayésien
naïf.
3.5.5.2 Le Bayésien naïf
C'est un classifieur17 probabiliste, basé
sur le théorème de Bayes. Ces programmes sont simples, rapides et
relativement efficaces pour les données textuelles. Un de leur principal
intérêt est leur
16 Support Vector Machine
17 Modèle de classification
33
caractère quasi-incrémental. Comme le
»modèle» sur lequel il repose n'est fait que de comptes de
nombres d'occurrences, il est très facile à mettre à jour
si de nouveaux exemples sont disponibles. C'est probablement pour cela qu'ils
sont utilisés pour ranger en »spam» ou »non spam»
des emails qui arrivent en flux continus dans les gestionnaires de courriers
électroniques (Tellier, 2010).
Malgré le fait que l'algorithme suppose une
indépendance entre les caractéristiques d'un exemple
d'entraînement, son efficacité rivalise tout de même avec
des algorithmes plus puissants. Il peut être considéré
comme un très bon classifieur (Ting, 2011).
3.5.5.3 Le paramétrage des algorithmes
Pour améliorer la performance du modèle il est
généralement utile de régler les paramètres de
l'algorithme, on les nomme hyperparamètres.
Il est possible de le faire manuellement mais des outils
permettent de rechercher automatiquement les paramètres optimaux, le
plus connu est le Grid Search. Cette méthode consiste à balayer
tous les paramètres possibles dans un espace déterminé
(Bergstra, 2012). C'est un programme qui automatise l'étape de choix et
de paramétrage de l'algorithme.
3.5.6 La mesure des performances du modèle
La troisième étape de l'apprentissage consiste
à évaluer la performance du modèle construit en
prédiction. Un bon classifieur est un classifieur qui
généralise bien, c-à-d qu'il aura appris suffisamment de
situations pour prédire correctement. C'est ce critère de
performance qu'il faut mesurer. Les métriques les plus utilisées
sont le taux de succès, la précision, le rappel et la F-mesure
(ou f1-score), (Tellier, 2010). Ces mesures serviront à vérifier
la capacité d'un classifieur à bien généraliser.
3.5.6.1 La matrice de confusion
La matrice de confusion indique le niveau de performance du
classifieur, les résultats serviront de base aux calculs des
différents types de métriques.
Dans le cas d'un problème à deux classes
(catégories), considérons les classes A et B d'un jeu de
données composé de documents. Après la phase
d'apprentissage, la phase de test consiste à soumettre au classifieur le
jeu de données de test durant lequel il classera les documents soit en
catégorie A soit en catégorie B. Il en résultera 4 cas
:
· Nombre de documents A classé A : Vrai positif
noté VP
· Nombre de documents A classé B : Faux
négatif noté FN
· Nombre de documents B classé A : Faux positif
noté FP
· Nombre de documents B classé B : Vrai
négatif noté VN
La matrice est complétée avec ces 4
résultats :
34
Classes Prédites
|
|
Classe B
|
Classes Réelles
|
Classe A
|
VP
|
FN
|
|
FP
|
VN
|
|
Tableau 3 - Matrice de confusion
Même si cette matrice fournit beaucoup d'informations,
elle n'est pas utilisable en production, on utilisera pour cela les
métriques suivantes.
3.5.6.2 Le taux de succès
Le taux de succès ou exactitude s'obtient avec le calcul
suivant :
Cette métrique désigne simplement la proportion
de classes qui ont été bien classées. En
général, on l'utilise pour avoir une première vue de
l'apprentissage. Si la répartition des classes est
déséquilibrée, cette métrique ne sera pas
pertinente. Pour valider le classifieur on utilisera plutôt les
métriques précision/rappel et F-mesure.
3.5.6.3 La précision
La précision s'obtient avec le calcul suivant :
Cette métrique permet de connaitre les
prédictions de type vrai (positive, c-à-d la classe A), mais elle
n'est pas complète car avec cette seule valeur, nous ne pouvons pas
connaitre le nombre de documents de classe A mal classés, c'est pourquoi
il faut l'associer au rappel.
3.5.6.4 Le rappel
Le rappel s'obtient avec le calcul suivant :
VP
Rappel =
VP + FN
Le rappel nous permet donc d'avoir la proportion de bonne
prédiction de la classe A sur le nombre total. L'utilisation de la
courbe précision/rappel permet d'avoir une visualisation graphique qui
peut faciliter l'interprétation.
3.5.6.5 La F-Mesure
La F-Mesure est la moyenne harmonique du rappel et de la
précision qui s'obtient avec le calcul
2 x (Précision x Rappel)
F-Mesure =
suivant : Précision x Rappel
Figure 15 - Conséquences du sous-apprentissage et
du sur-apprentissage sur le taux d'erreur (Al-Behadili, et al., 2018)
Cette métrique résume assez bien
l'évaluation, cependant il faut quand même vérifier la
précision et le rappel afin de mieux cerner le comportement du
classifieur. La F-mesure est également appelée F1, car les
valeurs de rappel et de précision ont la même pondération
(Aphinyanaphongs, et al., 2014). Accompagner cette métrique de la
matrice de confusion permet de mieux visualiser la situation (figure 14).
3.5.7 Leviers d'ajustement
Rappelons que l'objectif du modèle est la bonne
généralisation de la règle induite par l'apprentissage. On
entend par « bonne » généralisation un niveau
d'apprentissage qui ne soit ni insuffisant ni trop élevé
(Al-Behadili, et al., 2018). Pour obtenir le meilleur taux de réussite
possible en production, il faut éviter le
sous-apprentissage et le sur-
apprentissage, comme on peut le
voir sur la figure 15 :
35
Figure 14 - Exemple de matrice de confusion
accompagnée de la F-mesure (F1) (AWS, s.d.)
· Le sous-apprentissage arrive
lorsque le
modèle n'a presque rien appris à partir des données
d'apprentissage.
· Le sur-apprentissage arrive quand le modèle de
classification prédit exactement le label des données
d'apprentissage, alors qu'il est incapable de prédire correctement le
label de nouvelles données.
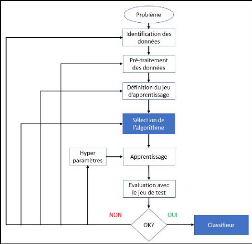
Figure 16 - Processus de modélisation d'un classifieur
(Osisanwo, 2017)
36
Plusieurs méthodes permettent de réduire ces
risques. La régularisation est la technique la plus utilisée,
mais on peut jouer sur les données en elles-mêmes en
répartissant les données d'apprentissage et de validation, en
réduisant la dimensionnalité (le nombre de variables), en
supprimant les données aberrantes (le bruit) ou même, en optant
pour un algorithme plus puissant. Cette façon itérative de
rechercher la meilleure optimisation d'un classifieur est inhérente
à la démarche du ML comme on peut le voir sur la figure 16.
3.5.7.1 La Régularisation
La régularisation est l'action qui permet d'ajuster au
mieux les paramètres de l'algorithme, celle-ci est effectuée via
les hyperparamètres qui sont propres à chaque famille
d'algorithmes. L'objectif est de trouver la valeur du paramètre qui
équilibre le mieux le sous-apprentissage et le sur-apprentissage pour
offrir la meilleure précision possible sur le jeu de test (Russell &
Norvig, 2010). Cet ajustement est manuel, mais il est possible d'utiliser la
méthode Grid Search qui est un programme qui va tester automatiquement
tous les paramètres possibles d'un algorithme, comme vu
précédemment.
3.5.7.2 Les données
Si les variables sélectionnées ne sont pas
représentatives du corpus de données, il sera nécessaire
de revoir le pré-traitement des données, par exemple en changeant
de méthode de représentation des données, ou en utilisant
une autre méthode de sélection de variables (Géron,
2017).
3.5.7.3 La validation croisée
L'approche traditionnelle de découpage du jeu
d'entrainement en deux sous-ensembles peut amener le modèle à
sur-apprendre, c-à-d que le résultat en production sera
très différent de celui attendu. C'est ce qui arrive lorsque la
distribution de variables est déséquilibrée dans le jeu de
données. Pour diminuer ce risque, il est possible de découper en
petit sous-ensembles les jeux de données d'apprentissage et de
validation. Cette technique augmente l'intégrité des
résultats du modèle. (Aphinyanaphongs, et al., 2014)
3.5.7.4 L'algorithme
Il y a des algorithmes qui sont sensibles au sur-apprentissage et
inversement il y en a qui sont sujets au sous-apprentissage car trop simples.
C'est pourquoi, lorsque les leviers précédents n'ont pas
été suffisants, le changement d'algorithme devient
nécessaire (Kotsiantis, et al., 2007).
3.5.7.5 La réduction de dimension
La matrice dans laquelle est représenté le jeu
de donnée peut être de très grande dimension, ce qui risque
de consommer énormément de temps et de ressources pour traiter
les données, on nomme ce risque « la malédiction de la
dimension » (Biernat & Lutz, 2015). Il faut réduire la
37
dimension. L'idée principale est de sélectionner
un sous-ensemble de termes caractéristiques du document, et ce, en
gardant les mots dotés des scores ou poids les plus
élevés, en appliquant des mesures confirmant l'importance des
termes sélectionnés. De nombreuses mesures d'évaluation
des termes sont utilisées dans la littérature, en voici quelques
un : le seuillage de fréquence, le Gain d'information, la mesure de x2
et Odds Ratio (Bazzi, 2016).
3.6 Spécificités de la classification de
textes
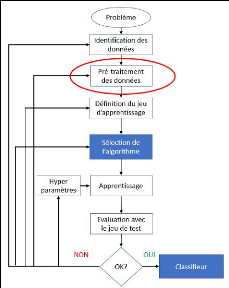
Figure 17 - Pré-traitement des données
textuelles
Contrairement aux données structurées, les
données textuelles doivent subir une modification car elles ne sont pas
exploitables par les algorithmes telles quelles, il faut les rendre
mathématiquement intelligibles en les transformant en chiffres (Leopold
& Kindermann, 2002).
La représentation des documents textuels au format
numérique n'est pas simple. Une des particularités du
problème de classification de textes est le nombre de variables, qui
peut facilement atteindre les dizaines de milliers, car dans l'absolu, une
variable peut représenter un mot ou une chaine de caractères.
Cela peut poser de nombreux problèmes aux algorithmes qui auront du mal
à traiter un espace d'une telle dimension. Le pré-traitement des
données répond à cette problématique en
réduisant le nombre de variables grâce à différentes
techniques (Ikonomakis, et al., 2005). Il a été
démontré que la phase de pré-traitement (figure 17)
était très importante pour augmenter la qualité d'un
classifieur (Ting, 2011).
L'objectif de ce processus sera de déterminer les
variables les plus pertinentes pour la classification. En effet, certaines
variables sont beaucoup plus susceptibles d'être corrélées
à la distribution de classes que d'autres. Une grande
variété de méthodes est proposée dans la
littérature afin de déterminer les caractéristiques les
plus importantes pour la classification (Aggarwal & Zhai, 2012). Le choix
de combinaisons appropriées de méthodes de pré-traitement
peut apporter une amélioration significative de la précision de
la classification (Gunal, 2014). Dans la suite de ce chapitre, nous choisirons
les techniques classiques à mettre en oeuvre.
3.6.1 Etapes du pré-traitement des données
textuelles
Le processus de pré-traitement est composé
habituellement de cinq étapes (figure 18), on commence d'abord à
segmenter le texte en token, c'est-à-dire en termes
(généralement en mots), ensuite un filtrage est effectué
pour ne prendre en compte que les mots qui ont du sens. Puis, une autre
technique
38
permet de réduire le nombre variable en ramenant les
mots à leur forme d'origine ou canonique. Chaque texte peut
désormais être représenté par un vecteur de nombres
qui correspond au nombre d'occurrences de chaque variable (mot). Enfin, la
phase la plus importante, celle qui aura le plus d'impact sur la qualité
du corpus, est la sélection des variables. On utilisera une technique de
pondération non-supervisée (Tellier, 2010).
3.6.1.1 Tokenisation
La tokenisation consiste à découper un texte en
mots (mots / phrases) appelés token. Il est ensuite possible de traiter
chacun de ces mots pour réduire la taille de chaque texte (Webster &
Kit, 1992).

Figure 18 - Etapes du pré-traitement des
données textuelles
(Osisanwo, 2017)
3.6.1.2 Lemmatisation
Il existe deux façons de fusionner des mots proches
pour diminuer la dimension : la racinisation et la lemmatisation. La
racinisation est plus adaptée à l'anglais alors que la
lemmatisation le sera pour le français.
La racinisation consiste à ramener un mot à sa
racine en se basant sur des règles et un lexique. La lemmatisation
consiste à remplacer un mot par sa forme canonique à partir de
son analyse morphosyntaxique. En d'autres termes, on tente de mettre les verbes
à l'infinitif et les noms au masculin singulier.
L'inconvénient de ces deux méthodes est la perte
de sens.
3.6.1.3 Filtrage
Le filtrage est généralement effectué
afin de supprimer certains mots. Un filtrage courant est la suppression des
mots vides, les stopwords. Ce sont les mots qui apparaissent très
fréquemment dans le texte, ou inversement les mots rarement
présents et qui n'ont que peu de pertinence, tous peuvent être
supprimés. Les seuils sont à déterminer en fonction du
contexte. Les ponctuations et les chiffres sont aussi filtrés, enfin, il
est aussi conseillé de normaliser la case.
3.6.1.4 Vectorisation des textes
La représentation de documents la plus utilisée
est appelée modèle vectoriel. Le principe est d'affecter une
dimension de l'espace à chaque variable présente dans les
documents du jeu de données. Les documents sont
représentés par des vecteurs de mots de grande dimension et
creux, en effet, un nombre important de cellules sera vide eu égard
à l'improbabilité d'avoir les mêmes mots dans tous les
documents.
Chaque document est donc un vecteur dont les
coordonnées sont la suite des nombres présents sur toute la
ligne. L'algorithme va considérer les nombres contenus dans chaque
colonne comme un point de coordonnées dans un espace vectoriel.
Mais cette représentation a des limites, la haute
dimensionnalité, la perte de corrélation avec les mots adjacents
et la perte de relation sémantique existants entre les termes d'un
document. Pour résoudre
|
Terme 1
|
Terme 2
|
...
|
...
|
Terme ri
|
39
ces problèmes, les méthodes de
pondération de termes sont utilisées pour attribuer une
pondération appropriée (Korde & Mahender, 2012).
3.6.1.5 Sélection des variables
Les variables sont définies, il n'y a plus qu'à
les compter. Le but est de rechercher des variables discriminantes, pour cela
il faut évaluer l'importance des variables dans un texte par rapport
à l'ensemble des documents. La méthode la plus simple est
basée sur la fréquence des variables le TF-IDF (Term
Frequency-Inverse Document Frequency). C'est une méthode de
pondération non-supervisée (Patra & Singh, 2013), le poids de
chaque variable augmente proportionnellement au nombre d'occurrences du mot
dans le document.
D'une part, il va augmenter, pour chaque document,
l'importance des mots présents plusieurs fois dans ce document, et
d'autre part, il va augmenter globalement l'impact des mots présents
dans peu de documents.
Les inconvénients sont le risque d'augmenter le bruit
et de biaiser l'algorithme, ils sont dus à la porosité de la
matrice. Les variables ne sont pas présentes dans tous les documents, on
aura beaucoup de cases à 0. Un autre inconvénient est la non
prise en compte des relations potentiellement précieuses de la
polysémie et de la synonymie (Luo & Li, 2014).
Une alternative basée sur la prédiction se nomme
le Word Embedding, par exemple les méthodes PCA, LSA ou LDA
basées sur la fréquence, ou des méthodes plus
récentes Word2vec ou Fastext. A la différence de TF.IDF, ces
méthodes prennent en compte le contexte de la variable, c-à-d les
variables qui l'entourent. Des variables souvent associées auront un
sens particulier, les vecteurs de comparaison seront plus précis.
Document 1
Document 2
...
...
...
Document m
Tableau 4 - Matrice Document-Termes
40
3.7 Outils
Figure 19 - Comparaison des MLaaS de AWS, MS, Google et IBM
(AltexSoft, 2018)
Pour développer une solution basée sur le
Machine Learning, il faut disposer d'un toolkit. Il en existe en open-source
à installer sur son ordinateur comme Knime ou Weka (Tellier, 2010). Mais
la tendance est l'utilisation de toolkit disponible sur le cloud, cette
solution permet de disposer immédiatement d'outils avec des ressources
de calculs et de mémoires bien supérieurs au poste de travail
traditionnel. Ce sont principalement les géants de l'internet
(GAFAMI18) qui
fournissent ces solutions
d'Machine Learning,
nommées MLaaS19 (Yao, 2017). Ils ont mis à disposition
l'ensemble des « briques de base » en open source (Caseau, 2018), et
permettent l'interopérabilité avec les outils de certaines
plateformes comme on peut le voir sur la figure 19 (AltexSoft, 2018).
Un autre avantage de ces plateformes propose des outils
entièrement automatisés qui optimisent les classifieurs en
utilisant des tests internes (Yao, 2017) comme nous l'avons vu
précédemment pour la technique du Grid Search.
Enfin, il y a deux façons de créer un
pipeline20 sur ces plateformes, soit en scriptant avec un langage
comme python soit en utilisant une interface graphique (figure 20) qui ne
nécessite aucune expertise technique.

Figure 20 - Azure ML text classification workflow
(Abdel-Hady, 2015)
18 Google, Amazon, Facebook, Apple, Microsoft, IBM
19 Machine Learning as a Service
20 Suite de brique séquentielle qui compose le
modèle
41
3.8 Conclusion
Parmi les branches de l'intelligence le domaine du Machine
Learning est le plus d'avancées. Cette méthode est celle qui est
la plus adaptée à l'automatisation de la classification de
documents, à travers la modélisation d'un classifieur
supervisé. C'est une démarche empirique qui se résume
à une succession de choix et d'expérimentations pour arriver
à construire le modèle qui répondra correctement aux
besoins du problème posé. Ceci répond donc à la
deuxième question de recherche.
Ces deux derniers chapitres nous ont permis de comprendre le
point de vue théorique du sujet, voyons maintenant quelles sont les
meilleures pratiques utilisées par les professionnels du secteur.
42
4 ENTRETIENS
La revue de littérature est complétée par
une série d'entretiens qui a permis de relever quelques précieux
retours d'expérience. En effet, d'après plusieurs professionnels
du secteur, le domaine du Machine Learning en entreprise est récent et
les retours d'expérience sont rares (DOCUMATION, 2018).
La synthèse de ces retours d'expérience est
présentée dans deux chapitres : le premier, relatif aux questions
organisationnelles et le second, aux questions techniques.
4.1 Aspect projet
4.1.1 Quelle méthode de projet choisir ?
Les méthodes de gestion de projet classiques peuvent
s'appliquer à ce type de solution (Microsoft, 2018). Cependant,
d'après tous les experts, les méthodes agiles sont mieux
adaptées au développement de solutions basées sur le
Machine Learning. Le mode de travail itératif, qui est une des
particularités des méthodes agiles, convient parfaitement
à la modélisation d'un classificateur qui est rarement construit
d'un seul tenant.
La première itération sert
généralement à définir le MVP21 qui est
l'objectif minimum à atteindre en termes de qualité (Microsoft,
2018). Le nombre d'itérations dépend du contexte (Sinequa, 2018),
plus il est complexe et plus il y en aura.
L'agilité permet d'impliquer le métier tout au
long du projet, ce qui est important car son rôle est primordial dans la
construction d'un modèle.
Enfin, il est important de noter que dans ce domaine, nous
sommes toujours en phase exploratoire. Les entreprises expérimentent
souvent cette technologie à travers des projets pilotes (Antidot, 2018)
(Microsoft, 2018), là encore l'agilité est bien
adaptée.
4.1.2 Phase de cadrage
Il ne faut jamais se lancer dans un tel projet sans partir
d'un besoin ou d'un cas d'usage (Microsoft, 2018) (Sinequa, 2018). Il faut par
exemple se poser la question suivante : « est-ce qu'un être humain
pourrait s'en sortir avec les informations mises à disposition ? »,
si la réponse est négative, il faut oublier le ML (Microsoft,
2018).
Ensuite, il faut s'assurer d'avoir le prérequis
essentiel : les données ! S'il n'y a pas de données on ne peut
pas lancer de projet, elles doivent être en quantité suffisante
(Antidot, 2018) (Sinequa, 2018).
21 Minimum Viable Product
43
4.1.3 Quels sont les rôles et compétences
nécessaires ?
La taille de l'équipe projet sera bien sûr
fonction du problème à résoudre, mais elle ne doit pas
dépasser quatre à cinq membres, et chacun d'eux doit comprendre
au minimum ce qu'est la démarche du Machine Learning (Antidot, 2018)
(Bull-Atos, 2018),.
Concernant les compétences, l'équipe doit
être composée d'au moins un spécialiste Machine Learning et
d'un expert métier (Antidot, 2018). Tous les experts sont unanimes pour
dire que le représentant métier joue un rôle important, en
ce sens qu'il participe véritablement à la construction du
modèle, tout en orientant l'utilité de la solution. En
conséquence, le spécialiste technique devra être capable de
comprendre les enjeux métiers, pour accompagner le métier dans
son rôle (Microsoft, 2018).
Le profil technique type est celui du data scientistes
(Antidot, 2018), cependant il est aujourd'hui de plus en plus facile de monter
en compétence un profil développeur (Microsoft, 2018) (Bull-Atos,
2018), car deux compétences techniques sont relativement
nécessaires en fonction des outils et du problème à
résoudre. La première est la compréhension des
mécanismes statistiques propres à la distribution des variables
dans un jeu de données. La deuxième est la capacité
à programmer les paramètres via les langages de script de type
python ou R, voir des langages classiques pour les solutions
d'éditeur.
Il est important de noter que les derniers progrès sur
les plateformes cloud de Machine Learning permettent de construire un
modèle sans être spécialiste en développement
(Upfluence, 2018) (Sinequa, 2018). En revanche, il faut être capable de
comprendre le fonctionnement d'un modèle du point de vue des
données (Sinequa, 2018).
4.1.4 Comment définir la qualité du livrable
?
Il est difficile de répondre à cette question
car cela dépend beaucoup du contexte, c'est-à-dire de la
problématique à résoudre et des données à
disposition.
D'abord, il est important de comprendre que la mesure de
performance en ML est particulière, par exemple un score de
prédiction de 100% est paradoxalement un mauvais score, car cela
signifie que le classifieur généralise mal (Antidot, 2018)
(Bull-Atos, 2018).
Le score de performance habituel d'un bon classifieur se situe
entre 80 et 90 %. Au-dessus, le score serait exceptionnel et en dessous, cela
dépendrait de la problématique à résoudre. Dans
certains cas un score de 50% reste acceptable car la moitié du travail
aura été fait, mais dans d'autres plus sensibles comme la
santé, le résultat serait inexploitable (Bull-Atos, 2018)
(Sinequa, 2018). Si le modèle de classification est exploité avec
un flux de données en continu, le score doit rester au-dessus de 90%
(Sinequa, 2018), ce type d'exploitation s'obtient avec des modèles
matures.
4.1.5 Comment estimer l'opportunité ?
Pour rappel, l'intégration de solutions du Machine
Learning dans les organisations est toujours en phase exploratoire, les projets
sont souvent des POC22 (projets pilotes) qui servent à
évaluer
22 Proof of concept
44
l'opportunité et la faisabilité de ce genre de
projet, notamment en termes de coût et de délai (Microsoft, 2018)
(Antidot, 2018) (Bull-Atos, 2018). Il est par conséquent difficile de
parler de ROI23. Concernant les projets appliqués à la
gestion documentaire, les retours d'expérience sont rares (DOCUMATION,
2018).
Les arguments justifiant ce type de projet pour les
entreprises sont de deux sortes (Microsoft, 2018) (Antidot, 2018) (Bull-Atos,
2018):
- Optimiser un processus métier
- Conquérir de nouveaux marchés, développer
de nouveaux usages
4.1.6 Quels sont les principaux risques ?
Un besoin mal défini représente un risque
important. Certaines entreprises pensent à tort que le Machine Learning
peut résoudre des problèmes non résolus avec les
méthodes classiques (Microsoft, 2018) (Sinequa, 2018). La méthode
du ML a besoin de données suffisamment pertinentes et en
quantité. Lancer un projet sans prendre en compte cette condition est
sans aucun doute une prise de risque.
Un facteur de risque important se situe pendant la phase de
construction du jeu de données d'entrainement. Pour construire un
classifieur, les données d'entrainement doivent être
étiquetées à la main. Cette tâche est
rébarbative car le nombre de documents à classer manuellement
peut être élevé. L'algorithme se basera sur ces
données pour construire le modèle, donc, si l'étiquetage
est mauvais, le classifieur le sera aussi (Sinequa, 2018) (GROUIN & FOREST,
2012). Par conséquent, le facteur humain doit être pris en
compte.
Un autre facteur de risque provient des métiers qui
peuvent accueillir ce genre de projets avec méfiance (Microsoft,
2018).
4.1.7 Faut-il prévoir une MCO24 particulière
?
Il convient de prévoir la gestion du cycle de vie de la
solution dès lors que la décision est prise de la mettre en
production, le processus doit comprendre trois actions (Microsoft, 2018)
(Antidot, 2018) (Sinequa, 2018):
- Une supervision pour vérifier la performance du
classifieur dans le temps est primordiale car
ce type de solution est sensible à l'évolution des
données en entrée qui sont inhérentes à tout type
de métier.
- La détection de baisse de performance doit
déclencher une phase de réapprentissage pour mettre à jour
le classifieur, cette action peut être prise en charge par le
métier.
- Si le réapprentissage ne suffit pas, il sera
nécessaire de faire appel à un spécialiste
technique
pour remonter les performances du classifieur.
23 Retour sur investissement
24 Maintien en condition opérationnelle
45
4.2 Aspect technique
4.2.1 Comment préparer les données ?
4.2.1.1 Vérifier les données à
disposition
La première phase consiste à vérifier que
les données à disposition sont exploitables. Il n'existe pas
d'outils pour évaluer la faisabilité du projet en fonction des
données disponibles (Microsoft, 2018). Cependant, on peut estimer qu'un
corpus d'environ 100 000 mots est suffisant pour construire un classifieur
correct, et même moins si le champ lexical est restreint (Antidot, 2018).
En effet, lorsque les variables discriminantes sont clairement identifiables,
le besoin en exemple lors de l'apprentissage est moindre (Sinequa, 2018).
4.2.1.2 Effectuer le prétraitement
Les données textuelles ne sont pas exploitables, il
faut les transformer numériquement. Cette opération
nécessite de réduire le nombre de variables, le plus souvent des
mots, en filtrant ceux qui ne portent pas de sens, et en les rapportant
à leur racine (Microsoft, 2018) (Upfluence, 2018) (Sinequa, 2018). La
première technique est le stopword et la deuxième, «
racinisation ».
La sélection de variables est l'opération la
plus importante du pré-traitement (Microsoft, 2018). Elle consiste
à sélectionner les éléments les plus pertinents qui
caractérisent chaque document (Upfluence, 2018) (Antidot, 2018).
L'implication du métier dans cette phase est primordiale (Sinequa,
2018).
Les techniques de sélection de variables sont
nombreuses. La plus classique se base sur la fréquence des mots,
nommée « tf.idf ». Les méthodes les plus
récentes sont basées sur la prédiction, elles semblent
être plus efficaces (Sinequa, 2018), car elles prennent en compte
l'aspect sémantique du texte en se basant sur une énorme base de
données. Cependant, elles ne sont pas efficaces sur les textes longs
(Upfluence, 2018), par exemple « word2vec » ou « fastext
».
4.2.1.3 Définir le jeu d'entrainement
Il faut définir une stratégie de
répartition de l'échantillon de données qui servira
à la construction du modèle. Il est conseillé de garder
une petite partie, en général 20 %, pour le test final avant mise
en production. Puis de scinder en deux le reste, la plus grande partie servira
à l'apprentissage et doit être étiqueter à la main
avec les métiers, attention c'est une phase sensible (Antidot, 2018)
(Sinequa, 2018).
La technique de « validation croisée »
augmente les chances de construire un bon classifieur (Microsoft, 2018)
(Sinequa, 2018), cette technique permet de diminuer le risque de
surapprentissage.
4.2.2 Choix de l'algorithme
En référence au théorème « No
Free launch », il n'y a pas de meilleur algorithme qui s'appliquerait sur
tous les problèmes, il faut donc faire un choix (Upfluence, 2018). Les
algorithmes « state of the art » sont connus et reconnus pour leur
performance, notamment pour la classification textuelle (Sinequa, 2018). C'est
le cas par exemple pour la famille d'algorithme SVM et les réseaux
bayésiens (Upfluence, 2018). Le SVM est robuste mais ne peut pas se
mettre à jour, le Bayésien Naïf performe bien avec peu de
données et se met à jour facilement.
46
Il existe aujourd'hui des techniques qui permettent de
sélectionner automatiquement le meilleur algorithme ainsi que les
paramètres optimisés en fonction des données en
entrée (Microsoft, 2018) (Upfluence, 2018) (Sinequa, 2018). Par exemple
la technique de « Grid Search » associée à la «
validation croisée » permet de tester dans un intervalle
prédéfini, à la main, tous les algorithmes et leurs
paramètres.
4.2.3 Validation et régularisation du
classifieur
4.2.3.1 La validation
Il y a différentes techniques de validation du
classifieur, la validation permet de construire le modèle en charge en
cherchant pourquoi il réagit de telle ou telle façon. C'est ce
qui guidera vers les paramètres à modifier (Sinequa, 2018).
La technique de validation classique consiste à
utiliser plusieurs mesures, il est conseillé de les utiliser dans
l'ordre suivant (Microsoft, 2018) (Upfluence, 2018) :
- Le taux de réussite pour s'assurer que le classifieur
fonctionne bien.
- La matrice de confusion pour analyser le fonctionnement du
classifieur pour voir en détail les
erreurs et leur origine.
- La F-Mesure (F1-score) permet d'avoir une métrique de
performance comme mesure de performance pour la supervision.
Le taux de réussite ne donne pas d'informations sur la
distribution des classes. Lors de la construction du modèle, il faudra
impérativement analyser la matrice de confusion pour déterminer
les leviers à utiliser pour régulariser le modèle. C'est
encore plus important si le classifieur est multi-classes (Microsoft, 2018)
(Upfluence, 2018).
4.2.3.2 La régularisation
Cette phase consiste à revenir sur certains
paramètres. Si l'algorithme a été
sélectionné avec une méthode automatique, la
régularisation consistera surtout à améliorer la
qualité du jeu d'entrainement, par exemple, en améliorant
l'apprentissage, en ajoutant de nouveaux exemples (Antidot, 2018), ou en
changeant la technique de sélection de variable comme le « word2vec
» (Upfluence, 2018).
4.2.4 Outillage
La quantité et la qualité de l'outillage
à disposition est un des facteurs qui facilite la modélisation
d'un classifieur (Sinequa, 2018).
Les plateforme cloud qu'on nomme MLaaS25 propose un
catalogue d'outillages et permet même l'interopérabilité
d'autres bibliothèques open source. C'est le cas de TensorFlow de google
(Upfluence, 2018), Microsoft offre aussi une plate-forme de Machine Learning
« MS azure ML studio » (Microsoft, 2018).
25 Machine Learning as a Service
47
Mais la solution peut aussi être construite par un
éditeur spécialisé, pour une prise en charge clés
en main du projet. C'est le cas des sociétés Sinequa et Antidot
qui développent et implémentent ce genre de solutions.
4.3 Conclusion
Ces entretiens ont confirmé en grande partie ce qui a
été relevé dans la littérature en termes de
solutions techniques, mais ils apportent aussi des éclairages sur les
pratiques à adopter en matière de management de projet.
Les difficultés rencontrées lors de projet
d'intégration de solution ML dans les entreprises s'expliquent par le
manque de compréhension de ce qu'est le ML par les métiers. Les
entreprises ont été habituées à exploiter des
solutions logiciel sur étagère, c'est pourquoi, beaucoup de
projets sont des pilotes. Les derniers progrès d'algorithmes
réutilisables sont trop récents pour imaginer des solutions
pseudo-génériques sur étagère.
En attendant l'arrivée de solutions
pseudo-génériques, l'approche actuelle consiste à
construire un modèle de prédiction via une démarche
empirique, qui est une succession de choix et d'expérimentations,
grâce à des outils toujours plus performants. Une fois construit
et mis en production, il faudra mettre à jour
régulièrement le modèle comme toute application.
Il est intéressant de noter que les outils actuels,
notamment disponibles sur le cloud, permettent d'automatiser en partie le
processus de création du modèle. Ce qui facilitera à
l'avenir la modélisation. En attendant, les bonnes pratiques qui
répondent à la troisième et dernière question de
recherche sont présentées dans le chapitre suivant.
48
5 RECOMMANDATIONS SYNTHÉTISÉES
Rappel de la problématique :
Quelles sont les bonnes pratiques qui permettent de
réussir l'implémentation d'une solution basée sur
l'intelligence artificielle pour automatiser la classification d'une base
documentaire ?
Réponses à la problématique :
Vérifier la quantité de données
disponibles
- La quantité minimum d'exemples nécessaires est
d'au moins 100 documents pour un corpus spécialisé.
Choisir une méthode de projet agile
- Cette méthode permet de planifier des
itérations calquées sur la démarche empirique du Machine
Learning.
Choisir un profil technique qui a les capacités
d'interpréter les résultats d'un cycle
d'apprentissage
- Un profil développeur ne suffit pas, il faut avoir
des bases solides en Machine Learning,
notamment être capable de
comprendre le comportement du modèle pour ajuster les paramètres
d'optimisation, notamment la sélection de variables qui nécessite
de comprendre le fonctionnement des méthodes.
Intégrer un spécialiste métier dans
l'équipe dès le début du projet et le faire monter en
compétence - Le métier doit comprendre le fonctionnement
des méthodes de Machine Learning, notamment les
spécificités de la classification supervisée de
données textuelles. Cela lui permettra de comprendre ce qu'on attend de
lui.
Démarrer la première itération avec
des méthodes classiques
- Cela permettra de définir une référence et
un objectif à atteindre pour les itérations suivantes.
Utiliser de préférence l'outillage
disponible sur les plateformes MLaaS
- Les outils présents sur ces framework permettent de
construire un modèle plus facilement, grâce à une interface
graphique et à des outils d'assistance au paramétrage.
Choisir un algorithme « state of the art »
connu pour performer sur la tâche de classification de textes
- Si l'outillage ne permet pas de choisir automatiquement un
algorithme et ses paramètres, alors il faut choisir l'algorithme SVM qui
est connu pour être le meilleur dans ce type de tâche. Essayer
d'abord la version linéaire, puis la version kernel.
Choisir aléatoirement l'échantillon de
données et utiliser une méthode de « validation
croisée »
- Cela diminuera le risque de distribution
déséquilibrée dans l'échantillon d'apprentissage,
et
donc de sur-apprentissage.
L'étiquetage des exemples doit être fait par
un spécialiste métier
49
- La phase la plus critique est l'étiquetage manuel des
documents qui serviront d'exemples pour
la phase d'apprentissage, il faut donc la traiter avec la plus
grande minutie.
Commencer par utiliser la méthode TF.IDF pour
sélectionner les variables
- C'est une méthode classique qui donne de bons
résultats. La phase de sélection de variables est importante, il
ne faut pas hésiter à utiliser d'autres méthodes plus
évoluées pour améliorer le modèle comme les
méthodes SVD ou LDA.
Mesurer la performance du modèle avec la matrice
de confusion
- La matrice de confusion permet de mieux comprendre le
comportement du modèle. Pour une métrique en production, choisir
la mesure F-mesure.
50
6 CONCLUSION
La question du transfert des connaissances est essentielle
pour les organisations. Une entreprise souhaite migrer ses bases documentaires
vers un outil récent pour profiter des fonctionnalités qui
facilitent le partage des connaissances. Cependant, ces documents doivent
être étiquetés avant la migration, au prix d'un travail
conséquent de classification manuelle. Les récents progrès
de l'intelligence artificielle permettent d'automatiser certaines tâches
lourdes et rébarbatives. La problématique de cette étude
était de rechercher les facteurs clés de réussite d'un
projet de Machine Learning pour automatiser la classification de documents.
Les outils récents, comme SharePoint, proposent de
structurer les bases documentaires à travers une classification
basée sur les métadonnées des documents, cette technique
facilite la circulation des informations. Pour cela chaque document doit
être étiqueté. Cependant, les bases documentaires
contiennent des centaines de milliers d'éléments, ce qui rend
impossible l'étiquetage manuel.
L'automatisation de la tâche de classification est
à la portée des solutions proposées par l'intelligence
artificielle, notamment le Machine Learning. Cette méthode est
déjà utilisée par certaines grandes entreprises pour
classer des documents. Elles se basent sur une démarche empirique qui
tranche avec les méthodes classiques de développement, le Machine
Learning explore les données pour construire un modèle de
classification automatique uniquement à partir d'exemples et sans
code.
Nous avons exploré différentes techniques sans
les mettre en pratique, cependant la littérature et les retours
d'expérience de professionnels confirment les capacités attendues
des méthodes du Machine Learning, à condition de respecter
certains principes et bonnes pratiques.
Ces principes sont assez simples et peuvent se résumer
en deux points. D'abord, posséder suffisamment d'exemples, cette
condition est un prérequis. Ensuite, impliquer le métier, la
classification en Machine Learning s'appuie sur des caractéristiques
clairement identifiées qui sont propres à chaque
métier.
Ces conditions doivent être accompagnées de
bonnes pratiques : Adopter une méthode de projet Agile, qui convient
parfaitement à une démarche empirique. Inclure le métier
dès le début du projet pour qu'il se sente concerné, et le
faire monter en compétence sur le ML pour qu'il comprenne ce qu'on
attend de lui. Choisir un expert technique surtout sur la base de ses
compétences en analyse de données, car un profil
développeur ne suffit pas, il faut comprendre ce qui se cache dans la
boite noire. Débuter le processus de modélisation en utilisant
des méthodes simples pour établir une référence.
Concentrer les efforts d'optimisation sur la phase de sélection des
variables. Enfin, la dernière condition concerne l'outillage qui doit
être adapté à la tâche de classification de
données textuelles, et qui sont notamment disponibles sur les
plateformes MLaaS dont l'utilisation est très intuitive, grâce
à des interfaces graphique qui vulgarisent la construction de
modèles.
Les progrès en matière de performance des
programmes utilisés sur ces plateformes cloud permettent d'automatiser
certaines tâches qui sont habituellement réalisées par les
data scientistes. Cela augure un virage dans l'adoption des solutions ML. En
effet, la première conséquence de ces progrès
technologiques est la vulgarisation progressive de la modélisation, les
profils aptes à intégrer ces solutions seront
mécaniquement plus nombreux. Ce phénomène
accélèrera probablement l'adoption de ces technologies par les
entreprises, car en parallèle, les données de ces
dernières sont en train de migrer massivement vers le cloud.
51
Enfin, la problématique de résistance au
changement induit par la classification basée sur les
métadonnées, qui est un problème adjacent mais
néanmoins corrélé au sujet initial, peut également
être solutionnée avec le Machine Learning. Ce changement d'usage
peut inclure un agent intelligent qui jouera le rôle d'assistant pour
aider les utilisateurs lors de la création d'un nouveau document,
l'agent pourra proposer, en analysant le contenu du document, une ou plusieurs
catégories que l'utilisateur devra valider ou modifier.
52
BIBLIOGRAPHIE
Abdel-Hady, M., 2015. Azure ML Text Classification Template.
[En ligne]
Available at:
https://blogs.technet.microsoft.com/machinelearning/2015/05/06/azure-ml-text-classification-template/
[Accès le 24 11 2018].
ABSYS, 2016. L'externalisation des services : des
études qui encouragent. [En ligne]
Available at:
https://www.absys.fr/lexternalisation-des-services-des-etudes-qui-encouragent/
[Accès le 12 10 2018].
AFNOR, 2015. ISO 9001:2015 : Qu'apporte le nouvel article sur
la gestion des connaissances à la gestion des compétences ?.
[En ligne]
Available at:
https://bivi.afnor.org/notice-details/iso-90012015-quapporte-le-nouvel-article-sur-la-gestion-des-connaissances-a-la-gestion-des-competences-/1296333
[Accès le 10 10 2018].
Aggarwal, C. C. & Zhai, C., 2012. A survey of text
classification algorithms. s.l.:Springer.
Alalwan, J. A. & Heinz, R. W., 2012. Enterprise content
management research: a comprehensive review. Journal of Enterprise
Information Management , 25(5), pp. 441-461.
Al-Behadili, H. N. K., Ku-Mahamud, K. R. & Sagban, R., 2018.
Rule pruning techniques in the ant-miner classification algorithm and its
variants: A review. IEEE Symposium on Computer Applications &
Industrial Electronics (ISCAIE), pp. 78-84.
AltexSoft, 2018. Comparing Machine Learning as a Service:
Amazon, Microsoft Azure, Google Cloud AI, IBM Watson. [En ligne]
Available at:
https://www.altexsoft.com/blog/datascience/comparing-machine-learning-as-a-service-amazon-microsoft-azure-google-cloud-ai-ibm-watson/
[Accès le 15 11 2018].
Amancio, D. R. e. a., 2014. A systematic comparison of supervised
classifiers. PloS one, 9(4). Antidot, 2018. Responsable R&D
[Interview] (8 11 2018).
Aphinyanaphongs, Y., Fu, L. D. & Li, Z. e. a., 2014. A
comprehensive empirical comparison of modern supervised classification and
feature selection methods for text categorization. Journal of the
Association for Information Science and Technology, 65(10), pp.
1964-1987.
AWS, s.d. Classification multiclasse. [En ligne]
Available at:
https://docs.aws.amazon.com/frfr/machine-learning/latest/dg/multiclass-classification.html
[Accès le 25 10 2018].
Banko, M. & Brill, E., 2001. Scaling to very very large
corpora for natural language disambiguation. Association for Computational
Linguistics, pp. 26-33.
Bazzi, E. e. a., 2016. Indexation automatique des textes arabes:
état de l'art. Electronic Journal of Information Technology,
Issue 9.
Bergstra, J. a. Y. B., 2012. Random search for hyper-parameter
optimization. Journal of Machine Learning Research, Volume 13, pp.
281-305.
53
Biernat, E. & Lutz, M., 2015. Data science : fondamentaux
et études de cas. s.l.:Eyrolles.
Boucheron, S., Bousquet, O. & Lugosi, G., 2005. Theory of
classification : a survey of some recent advances. ESAIM. Probability and
Statistics, Volume 9, p. 323-375.
Bouhedi, M.-C., 2017. Les pratiques de partage des connaissances
d'une unité de recherche pluridisciplinaire en interne et externe.
Communication & management, 14(1), pp. 71-88.
Bull-Atos, 2018. Directeur innovation [Interview] (20 11
2018).
Cabanac, G. & al, &., 2006. L'architecture CoMED pour la
gestion collective de documents électroniques dans l'organisation.
CIDE, Volume 9, pp. 237-252.
Cambrai, T., 2017. L'intelligence artificielle
expliquée. s.l.:Independently published.
Caseau, Y., 2018. Accompagner la dissémination de
l'intelligence artificielle pour en tirer parti. Enjeux numériques -
N°1 - Annales des Mines, Mars.
Ceaux, P., 2018. Cédric Villani : "L'intelligence
artificielle va bouleverser notre quotidien avec discrétion". [En
ligne] Available at:
https://www.lejdd.fr/societe/cedric-villani-lintelligence-artificielle-va-bouleverser-notre-quotidien-3589541
[Accès le 18 09 2018].
Chafiqi, A. & El Moustafid, S., 2006. Les SSII marocaines
face au turn-over des compétences: l'apport de la Gestion des
Connaissances. s.l.:L'Harmattan.
Chaouche, Y., 2018. Qu'est-ce que le machine learning ?.
[En ligne]
Available at:
https://openclassrooms.com/fr/courses/4011851-initiez-vous-au-machine-learning/4011858-quest-ce-que-le-machine-learning
[Accès le 10 09 2018].
CIGREF, 2017. Enjeux de la mise en oeuvre opérationnel
de l'intelligence artificielle dans les grandes entreprises. [En ligne]
Available at:
https://www.cigref.fr/wp/wp-content/uploads/2017/10/CIGREF-Cercle-IA-2017-Mise-en-oeuvre-operationnelle-IA-en-Entreprises.pdf
[Accès le 20 09 2018].
Crozat, S., 2016. Gestion de contenu : GED, ECM et au
delà.... [En ligne] Available at:
https://stph.scenari-community.org/doc/ecm.pdf
[Accès le 10 10 2018].
Dalkir, K., 2013. Knowledge management in theory and
practice. s.l.:Routledge.
De Ganay, C. & Dominique, G., 2017. L'OFFICE
PARLEMENTAIRE D'ÉVALUATION DES CHOIX SCIENTIFIQUES ET TECHNOLOGIQUES
POUR UNE INTELLIGENCE ARTIFICIELLE MAÎTRISÉE, UTILE ET
DÉMYSTIFIÉE. [En ligne]
Available at:
http://www.assemblee-nationale.fr/14/rap-off/i4594-tI.asp#P46273411
[Accès le 20 09 2018].
DOCUMATION, 2018. Ged, gestion de contenu et intelligence
artificielle (IA) : quelle valeur ajoutée pour quels usages. [En
ligne]
Available at:
https://www.youtube.com/watch?v=YN1PBr3U2qQ&vl=fr
[Accès le 10 09 2018].
54
Dudezert, A., 2013. La connaissance dans les entreprises.
Paris: La Découverte.
Dupoirier, G., 2009. Valorisation de l'information
non-structurée. s.l.:Techniques Ingénieur. Ermine, J.-L.,
2018. Knowledge Management - La boucle créative. s.l.:ISTE
éditions.
Ermine, J.-L., Moradi, M. & Brunel, S., 2012. Une
chaîne de valeur de la connaissance. Management international,
Volume 16, pp. 29-40.
Faris, S. e. a., 2013. Conception d'une Plateforme de gestion
des risques basée sur les systèmes multi-agents et ISO 27005
(JDTIC'13). Kénitra , s.n.
Francis, É. & Quesnel, O., 2007. Indexation
collaborative et folksonomies. Documentaliste-Sciences de l'information,
44(1), pp. 58-63.
GED.fr, s.d. INDEXATION DE DOCUMENTS,
CLASSIFICATION, RECHERCHE ET ORGANISATION DU CONTENU. [En ligne]
Available at:
https://www.ged.fr/indexation/
[Accès le 28 10 2018].
Géron, A., 2017. Machine learning avec Scikit-learn.
s.l.:DUNOD.
Geyer, C. P. D., 2017. L'obsolescence des compétences
: attention informaticiens pour votre carrière. [En ligne]
Available at:
https://www.journaldunet.com/solutions/expert/66445/l-obsolescence-des-competences---attention-informaticiens-pour-votre-carriere.shtml
[Accès le 12 10 2018].
Girard, J. & Girard, J., 2015. Defining knowledge management:
Toward an applied compendium. Online Journal of Applied Knowledge
Management, 3(1), pp. 1-20.
Gonenc, G., Ilay, Y. & Gunes, H., 2016. Stifling artificial
intelligence: Human perils. computer law & security review, Volume
32, p. 749-758.
Grim-Yefsah, M., Rosenthal-Sabroux, C. &
Thion-Goasdoué, V., 2010. Évaluation de la qualité d'un
processus métier à l'aide d'informations issues de réseaux
informels. Ingénierie des Systèmes d'Information, 15(6),
pp. 63-83.
GROUIN, C. & FOREST, D., 2012. Expérimentations et
évaluations en fouille de textes: Un panorama des campagnes DEFT..
s.l.:Lavoisier.
Gunal, A. K. U. a. S., 2014. The impact of preprocessing on text
classification. Information Processing & Management, 50(1), p.
104-112.
Halevy, A., Norvig, P. & Pereira, F., 2009. The unreasonable
effectiveness of data. IEEE Intelligent Systems, 24(2), pp. 8-12.
Help-Line, 2016. Le SERVICE DESK et son INFOGERANCE :
idées reçues et points de vigilance. [En ligne] Available
at:
http://www.itiforums.com/fichiers/2016
02 09 14 37 27 LivreBlancServiceDeskHelpLine.pdf [Accès le 30 10
2018].
Hubain, R. S. v. H. a. R. V., 2016. Classification
automatisée: rêve ou réalité? Analyse critique de
l'usage du text mining pour la conception de vocabulaires
contrôlés. I2D-Information, données & documents,
53(2), pp. 70-79.
55
Hudon, M. & El Hadi, W. M., 2010. ORGANISATION DES
CONNAISSANCES ET DES RESSOURCES DOCUMENTAIRES : De l'organisation
hiérarchique centralisée à l'organisation sociale
distribuée. Les Cahiers du numérique - Lavoisier, Volume
6, pp. 9-38.
Ibekwe-Sanjuan, F., 2007. Fouille de texte.
s.l.:Hermès-Lavoisier.
Ikonomakis, M., Kotsiantis, S. & Tampakas, V., 2005. Text
classification using machine learning techniques. WSEAS transactions on
computers, 4(8), pp. 966-974.
Imbert, G., 2010. L'entretien semi-directif: à la
frontière de la santé publique et de l'anthropologie.
Recherche en soins infirmiers, pp. 23-34.
INRIA, 2016. Intelligence Artificielle : Les défis
actuels et l'action d'Inria. [En ligne]
Available at:
https://www.inria.fr/actualite/actualites-inria/intelligence-artificielle-les-defis-actuels-et-l-action-d-inria
[Accès le 20 09 2018].
Janicot, C. & Mignon, S., 2008. Vers un modèle de
codification des connaissances: nature et perspectives. Systèmes
d'information & management, 13(4), pp. 95-125.
Jäntti, M. & Cater-Steel, A., 2017. Proactive management
of IT operations to improve IT services. Journal of Information Systems and
Technology Management, 14(2), pp. 191-218.
Jasimuddin, S. M., 2005. An integration of knowledge transfer and
knowledge storage: an holistic approach. Comput Sci Eng, 18(1), pp.
37-49.
Katuu, S., 2012. Enterprise content management (ECM)
implementation in South Africa. Records Management Journal , 22(1),
pp. 37-56.
KHICHANE, M., 2018. Data Science avec Microsoft Azure.
s.l.:ENI.
Korde, V. & Mahender, C. N., 2012. Text classification and
classifiers: A survey. International Journal of Artificial Intelligence
& Applications, 3(2), p. 85.
Kotsiantis, S. B., Zaharakis, I. & Pintelas, P., 2007.
Supervised machine learning: A review of classification techniques.
Emerging artificial intelligence applications in computer engineering,
Volume 160, pp. 3-24.
Laudon, K., 2013. In Management Information Systems: Managing
the Digital Firm. 11 éd. s.l.:GLOBAL EDITION.
Lendrevie, J. & Lévy, J., 2014. MERCATOR. 11e
éd. s.l.:DUNOD.
Leopold, E. & Kindermann, J., 2002. Text Categorization with
Support Vector Machines. How to Represent Texts in Input Space?. Machine
learning, 46(1-3), pp. 423-444.
Lo, J., 2014. Nouvelles perspectives pour réduire
l'impact du turnover dans l'informatique. [En ligne] Available at:
http://www.hec.fr/Knowledge/Strategie-et-Management/Management-des-Ressources-Humaines/Nouvelles-perspectives-pour-reduire-l-impact-du-turnover-dans-l-informatique
[Accès le 02 10 2018].
Luo, L. & Li, L., 2014. Defining and evaluating
classification algorithm for high-dimensional data based on latent topics.
PloS one, 9(1).
56
MAHÉ, S., RICARD, B., HAIK, P. & al., e., 2012.
GESTION DES CONNAISSANCES ET SYSTÈMES D'ORGANISATION DE CONNAISSANCES.
Lavoisier, « Document numérique », 13(2), pp.
57-73.
MANAGERIS, 2018. Intelligence artificielle : au-delà
du buzz, un défi d'envergure. [En ligne] Available at:
https://www.manageris.com/fr-synthese-intelligence-artificielle-au-dela-du-buzz-un-defi-d-envergure-20643.html
[Accès le 18 09 2018].
Mertsalov, K. a. M. M., 2009. Document classification with
support vector machines. Microsoft, A. C. S., 2018. Expert en data science
[Interview] (25 10 2018).
MIT, 2017. Reshaping Business with Artificial Intelligence.
[En ligne]
Available at:
https://sloanreview.mit.edu/projects/reshaping-business-with-artificial-intelligence
[Accès le 17 09 2018].
Mitchell, T. & al., 1997. Machine learning. Burr Ridge,
IL: McGraw Hill, 45(37), pp. 870-877.
Morel-Pair, C., 2005. Panorama : des
métadonnées pour les ressources, s.l.: Service Edition
Electronique - INIST-CNRS .
Nastase, P. & al., 2009. "From document management to
knowledge management. Annales Universitatis Apulensis: Series Oeconomica,
11(1), p. 325.
Nonaka, I., Ryoko, T. & Noboru, K., 2000. SECI, Ba and
leadership: a unified model of dynamic knowledge creation. Long range
planning, 33(1), pp. 5-34.
Osisanwo, F. Y. e. a., 2017. Supervised Machine Learning
Algorithms: Classification and Comparison. International Journal of
Computer Trends and Technology (IJCTT), 48(3), pp. 128-138.
Panetta, K., 2018. 5 Trends Emerge in the Gartner Hype Cycle
for Emerging Technologies, 2018. [En ligne]
Available at:
https://www.gartner.com/smarterwithgartner/5-trends-emerge-in-gartner-hype-cycle-for-emerging-technologies-2018/
[Accès le 17 09 2018].
Patra, A. & Singh, D., 2013. A survey report on text
classification with different term weighing methods and comparison between
classification algorithms. International Journal of Computer Applications,
75(7).
Power, R., Chen, J., Kuppusamy, T. K. & al., 2010. Document
Classification for Focused Topics. AAAI Spring Symposium: Artificial
Intelligence for Development.
Reix, R. e. a., 2016. Systèmes d'information et
management. s.l.:Vuibert.
Russell, S. & Norvig, P., 2010. Artificial Intelligence :
A modern Approach. 3e éd. s.l.:PEARSON EDUCATION.
Samain, O., 2018. Pour recruter, des entreprises misent
sur l'analyse automatique des CV. [En ligne] Available at:
http://www.europe1.fr/economie/pour-recruter-des-entreprises-misent-sur-lanalyse-automatique-des-cv-3696929
[Accès le 20 09 2018].
See, K., 2016. Navigating the Digital Transformation.
[En ligne] Available at:
57
http://web.luxresearchinc.com/hubfs/Lux
Executive Summit/Asia/2016/Presentations/LES Asia Se e1016.pdf
[Accès le 06 10 2018].
Sinequa, 2018. Consultant Machine Learning [Interview]
(22 11 2018).
Squicciarini, M., 2016. Routine jobs, employment and
technological innovation in global value chains. [En ligne]
Available at:
https://www.oecd.org/sti/ind/GVC-Jobs-Routine-Content-Occupations.pdf
[Accès le 18 09 2018].
Surkar, M. Y. R. a. S. W. M., 2014. A Review on Feature Selection
and Document Classification using Support Vector Machine. International
Journal of Engineering, 3(2).
Tellier, I., 2010. Apprentissage automatique pour le TAL.
ATALA, 3(50), pp. 7-21.
Tellier, I., 2010. Introduction au TALN et à
l'ingénierie linguistique. [En ligne] Available at:
http://www.lattice.cnrs.fr/sites/itellier/polyinfoling/info-ling.pdf
[Accès le 10 10 2018].
Tellier, I. & Dupont, Y., 2013. Symbolic and statistical
learning for chunking: comparison and combinations. Proceedings of TALN
2013, Volume 1, pp. 19-32.
Ting, S. L. W. H. I. a. A. H. T., 2011. Is Naive Bayes a good
classifier for document classification?. International Journal of Software
Engineering and Its Applications, 5(3), pp. 37-46.
Upfluence, 2018. Senior Machine Learning Researcher
[Interview] (31 10 2018).
Villanueva, M. & Salenga, L., 2018. Bitter Melon Crop Yield
Prediction using Machine Learning. International Journal of Advanced
Computer Science and Applications, 3(9).
Voit, K., Andrews, K. & Slany, W., 2011. TagTree: Storing
and re-finding files using tags. Berlin, s.n.
Wallez, N., 2010. Le Knowledge Management : Un partage de
connaissances... et d'expérience. Cahiers de la documentation-Bladen
voor documentatie, p. 1.
Webster, J. & Kit, C., 1992. Tokenization as the initial
phase in NLP. In Proceedings of the 14th conference on Computational
linguistics, Volume 4, p. 1106-1110.
Westeel, I., 2010. Indexer, structurer, échanger :
métadonnées et interopérabilité. s.l.:Presses
de l'ENSSIB.
Wolpert, D. & Macready, W., 1997. No free lunch theorems for
optimization. IEEE transactions on evolutionary computation, 1(1), pp.
67-82.
Yao, Y. e. a., 2017. Complexity vs. performance: empirical
analysis of machine learning as a service. Proceedings of the 2017 Internet
Measurement Conference. ACM.
58
ANNEXE
Questionnaire utilisé lors des entretiens
Aspects organisationnels
n Démarche projet
- Est-ce que l'aspect itératif de la méthode
ML26 supervisée est inhérent à tous les
problèmes ?
- Quelle méthode projet conseillez-vous ? L'approche
agile vous parait-elle adaptée ?
- Peut-on utiliser les retours d'expériences
passés (REX27), si oui quelles en sont les limites ?
n Contraintes projet
- Budget/ROI : Quels arguments pourraient valider le
business case d'un tel projet ?
- Délai : Quelle est la durée moyenne d'un
POC28 (en jours) hors phase de cadrage ?
- Qualité : quel score maximal (performance) peut-on
espérer avec cette méthode (%) ?
- Quels sont les risques habituellement rencontrés
?
n Rôles et compétences
- Quelle sont les parties-prenantes et quel est leur
rôle dans le projet ?
- Quelle sont les compétences nécessaires
minimales pour mener à bien un tel projet ? - Est-ce qu'un
profil avec peu d'expériences pourrait prendre en charge cette mission
?
n Maintenance de la solution
- Y a-t-il une MCO29 à prévoir
après la mise en production ?
- Est-ce qu'une ressource non spécialiste pourrait
prendre en charge la MCO ? Aspects techniques
- Quelle est la quantité minimale de données
nécessaires pour qu'un projet de ce type soit viable ?
- Est-ce qu'un corpus très limité est un point
bloquant ?
- Existe-il une méthode performante pour traiter un
jeu de données très limité ?
- Quelle méthode conseillez-vous pour réduire
la dimension d'un document textuel ?
26 Machine Learning
27 Retours d'expérience
28 Proof of concept : Projet pilote
29 Maintien en condition opérationnelle
59
- Quelles méthodes de pondération
conseillez-vous ?
- Quelle(s) famille(s) d'algorithme(s) sont les plus
adaptée(s) à la classification de données textuelles
multi-classes ?
- Quel est la meilleure métrique pour mesurer la
performance d'un « classifieur » ?
- Existe-il des algorithmes d'optimisation simples et faciles
à implémenter, par exemple avec peu de paramètres
?
- Le réglage des hyperparamètres est-il
obligatoire ou existe-il des algorithmes qui « s'auto-corrigent »
?
- Quelles techniques de validation conseillez-vous ?
- Quelle solution logicielle connaissez-vous et utilisez-vous
?
| 

