CHAPITRE 3. CONSTRUCTION D'UN SYSTÈME
D'INTÉGRATION DE DONNÉES
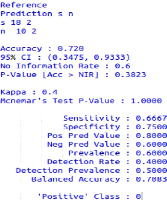
FIGURE 3.11 - Matrice de confusion 1 d'algorithme de
fusion(Logiciel R) Deusième cas
Nous posons dans ce cas que notre algorithme de fusion base
sur la comparaison avec la dic-tionnire de données pour obtennir la
distance de similarité, nous étudions la perfomance dans ce cas
par la matrice de confusion nous avons la résultat suivante
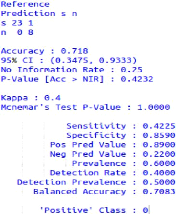
FIGURE 3.12 - Matrice de confusion 2 d'algorithme de
fusion(Logiciel R) Cas général
Dans ce contexte nous étudions la performance de notre
algorithme de fusion parmi la combinaison entre les deux cas
précédentes tels que nous utilisons la matrice de confusion
implémentée
52
CHAPITRE 3. CONSTRUCTION D'UN SYSTÈME
D'INTÉGRATION DE DONNÉES
en langage R pour obtenir la performance totale, on obtient les
résultats suivants :

FIGURE 3.13 - Matrice de confusion global
d'algorithme fusion
Résultats
Les expéréments de données parmi les
algorithmes réalisés donnent des études très
importantes telles que :
~ les techniques de rapprochement : algorithme de
Wrinkler-Jaro ayant la performance de 70% en prise en compte tous les types de
données, tel qu'il donne des meilleures valeurs pour les distances de
similarité;
~ la comparaison avec le dictionnaire de données donne la
maximale performance selon l'algorithme de Wrinkler-jaro tel qu'elle est 82.9%
et presque trouvé la plupart valeurs simulées; ~ la performance
globale de notre algorithme base sur ces deux cas d'étude
Par ailleurs nous étudions le temps d'exécution
de notre algorithme de fusion parmi l'effective de machine pour valider les
résultats. Nous observons le changement de temps dans certains nombres
de données, tel qu'en mesurant tanque l'algorithme de fusion arrive
l'exécution nous avons les valeurs suivantes.
53
CHAPITRE 3. CONSTRUCTION D'UN SYSTÈME
D'INTÉGRATION DE DONNÉES
|
Nombre de données
|
temps d'execution
|
|
l0
20 l00 200 400 l000 2000 4000 l0000 25000 35000
|
2.l 2.23 3.06 3.234 3.79 5.029 6.53 7.033 l2.25 l7.62 l7.83
|
TABLE 3.3 - Table de temps d'exécution selon le nombres
de données
Une présentation graphique est donnée dans la
Fig3.14
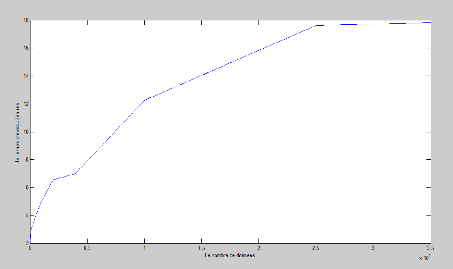
FIGURE 3.14 - Le temps d'exécution en ms depuis les
nombres de données
3.5 Conclusion
Dans ce chapitre nous introduisons la partie contribution avec
l'implémentation qui étudie les deux problématiques
générales dans l'intégration de données. nous
implémentons une médiation
54
| 

