CHAPITRE 3. CONSTRUCTION D'UN SYSTÈME
D'INTÉGRATION DE DONNÉES
doc.getDocumentElement().normalize();
doc.getDocumentElement().getNodeName();,
-- création une liste de Noeuds et se poser les tags
comme des attributs, création une liste de
éléments et se pose les valeurs de ces tags(Liste
de Noeuds) :
NodeList nList = doc.getElementsByTagName(Le nom de Noeud
principale);
Node nNode = nList.item(i ? 0· · · n
n c'est le nombre de noeuds);
Element eElement = (Element) (nNode);
String name= ( eElement).getElementsByTagName.
Implémentation de Xwrapper
Algorithm 1 Algorithme de Xwapper .
La source de XML fichier :Employee.xml
Array List<String> Valeurs;
String attributs;
HashMap <String, ArrayList<String> > hash_xml;
DOM libraries pour lecture et manipuler XML fichier :
-- lire XML fichier comme un document,
-- analyse le contenu de ce fichier(détecter les Tags, et
les information entre eux),
-- création une liste de Noeuds et en se pose les tags
comme des attributs, création une liste
de éléments et se pose les valeurs de ces
tags(Liste de Noeuds).
Node Noeuds;
N ? lenombredeNoeuds;
for i ? 0 N
do
Noeuds · i ?
chaquetagdeceXMLfichier; attributs ? Noeuds ·
nomi
for j ? 0 les nombres des atrributs
do valeurs ? Noeuds ·
valuedeelements;
end for
hash_xml · put < attributs,
valeurs>;
end for
32
Le résultat de cet algorithme pour réaliser
Xwrapper c'est dans la figure suivante :
33
CHAPITRE 3. CONSTRUCTION D'UN SYSTÈME
D'INTÉGRATION DE DONNÉES

FIGURE 3.2 - Implémentation de
Xwrapper
Le xwrapper permet d'extraire les données depuis le
source XML parmi DOM d'une manière arborisant celui qui fait le stockage
facile. Xwrapper base sur la structure Hash Map pour stocker
les données par les attributs avec ses valeurs, nous assurons dans ce
cas les informations sont récupérées avec un taux faible
de perte.
Wrapper de source HTML
Le wrapper de source HTML où Hwrapper permet d'extraire
les données de source HTML d'une façon spécielle de codage
d'information dans HTML, nous utilisons l'outil jsoup pour
analyser et obtient le contenu de source HTML.
Outil Jsoup
L'outil jsoup contient plusieurs fonctions pour traiter le
fichier HTML et spécialement d'extraire les informations, nous utilisons
dans ce Hwrapper les fonctions : Select, Parse, Node; qu'ils font la
lecture de source HTML et disposent les attributs comme des noeuds sur lesquels
nous prenons les valeurs avec ces attributs..
Implémentation de Hwrapper
nous implémentons le Hwrapper sous Java en utilisant le
package de jsoup et nous stockons les contenants de source HTML dans le
HashMap.
34
CHAPITRE 3. CONSTRUCTION D'UN SYSTÈME
D'INTÉGRATION DE DONNÉES
Algorithm 2 Algorithme de Hwapper .
La source de HTML fichier :Employee.htm
Array List<String> Valeurs;
String attributs;
HashMap <String, ArrayList<String> > hash_html;
Outil Jsoup pour traiter HTML fichier :
-- detecter tous les têtes de cette fichier qui s'appelle
body tel que le format
c'est :<body>....<\body>,
-- pour chaque tête en prennent les noms de Tags qui ayant
la forme :<nom de Tag> et
contennent dans la tête de HTML fichier,
-- la sélection de valeurs entourêes par les Tags et
qui s'appelle Child tel que :<nom de Tag>
Child <\nom de Tag>.
Têtes=t1, t2,....,
tn
N - lenombredeTags;
for i - 0 to le nombre de têtes do t
· i;
for j - 0 to N do
attributs - ti · nomdeTagj ;
valeurs - nomdeTagj · Childj
end for
hash_html · put < attributs, valeurs>;
end for
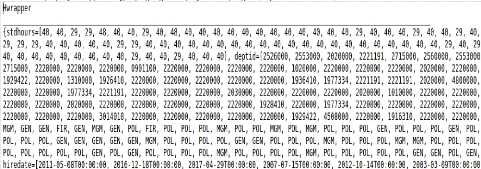
FIGURE 3.3 - Implémentation de
Hwrapper
Dans la Fig3.3 l'exécution de Hwrapper affiche une
partie des données de source HTML, tel que le HashMap affiché
enregistre les attributs avec ses valeurs d'une manière organisée
et correcte.
35
| 

