DEDICACE
iii
A nos parents.
iv
REMERCIEMENTS
Au moment où nous terminons la rédaction de ce
mémoire, avant de laisser choir notre plume, nous voudrions nous
acquitter d'un devoir de probité intellectuelle, en remerciant ceux qui
par leur franche et précieuse contribution nous ont apporté du
soutien tout au long de ce travail.
Nos remerciements vont donc au Dr NNEME NNEME
Léandre, Chef de Département du Génie
Informatique de l'ENSET de Douala qui a toujours été disponible
pour la supervision de ce travail.
Nous remercions également M. MAMVOULA NGUIAMBA
Albert Franklin pour les sacrifices consentis pendant le suivi et la
mise en oeuvre de ce travail.
Nous tenons aussi à remercier M. ONDAPHE Arthur
pour le coup de pouce qu'il a eu à nous donner pour la
modélisation en UML.
Nous remercions M. Ndjehoya Jean Baptiste
pour l'aide qu'il nous a fourni pour la rédaction de
l'Abstract.
Merci aux membres du Jury qui ont
accepté de participer à ce Jury, nous en sommes très
honorés.
Merci à nos camarades de l'ENSET pour leur
présence dans les moments difficiles. Nous ne saurions oublier les
membres de nos familles pour leur soutien sans limite. A tous ceux qui, de
près ou de loin ont contribué à la réussite de ce
travail
v
AVANT PROPOS
L'Ecole Normale Supérieure d'Enseignement Technique
(ENSET) créée au Cameroun par arrêté
présidentiel N° 260 / CAB / PR du 10 aout 1979 est un
établissement d'enseignement supérieur situé à
Douala. Elle a pour missions :
· La formation des enseignants destinés aux
lycées d'enseignement technique du Cameroun ;
· Le recyclage et le perfectionnement du personnel
enseignant dans le cadre de la formation continue ;
· La recherche appliquée pédagogique.
Cependant, en tant qu'école technologique et au regard
de sa vocation régionale en matière des nouvelles technologies,
l'ENSET adopte le système LMD (Licence-Master-Doctorat) en 2007. Ce
système s'articule autour du savoir, du savoir-faire, du faire-savoir et
du savoir-être, ainsi à l'ENSET un accent particulier a
été mis une fois de plus sur la professionnalisation et la
qualité des enseignements afin de donner l'opportunité à
l'enseignant d'être non seulement un spécialiste de l'enseignement
mais aussi de répondre de manière efficace aux exigences des
nouvelles technologies dans le milieu industriel.
A l'issue de la formation, chaque élève
professeur doit présenter conformément a l'arrêté
ministériel N° 03 / BU / du 26 novembre 1985 :
· Un projet de mémoire pour la fin de ses
études du 1er cycle, étude sanctionné par
l'obtention du Diplôme de Professeur d'Enseignement Technique premier
grade (DIPET I) ;
· Un mémoire pour la fin de ses études du
2nd cycle sanctionnée par l'obtention du Diplôme de
Professeur d'Enseignement Technique deuxième grade (DIPET II).
C'est dans cette optique que nous nous sommes investis dans
la « Conception et la réalisation d'une application de gestion du
presse-papier de Windows 7 » et présentons ce document dont le
titre est ainsi énoncé, réalisé en vue de
l'obtention du DIPET II.
RESUME
L'informatique a connu un essor sans précédent
ces dernières décennies au point où il devient quasi
impossible à l'homme de se passer de l'utilisation de l'outil
informatique. Les logiciels d'application sont de plus en plus devenus
indispensables pour l'homme. La duplication des données ne s'est pas
mise à l'écart de ses besoins. Elle se fait d'une source vers une
cible à l'aide des opérations classiques de copie à savoir
le « copier-coller » ou le « couper-coller ». Mais il vient
que ces opérations peuvent dans certains cas être
confrontées à des insuffisances de certaines applications du
système d'exploitation Windows. En effet lorsqu'une copie est
effectuée, elle est stockée en mémoire grâce
à une application que Microsoft a intégré à partir
de sa version 3.1 de son système d'exploitation Windows à savoir
« Clipboard » plus connu sur le nom de « presse-papier
» en français. Le presse-papier de Windows ne peut
garder en mémoire qu'une seule copie. La copie multiple n'est pas
possible car la copie chargée en mémoire est
écrasée une fois qu'une nouvelle copie ait été
réalisée. L'incapacité d'effectuer des
copies multiples crée ainsi un problème de gestion de
temps. C'est dans l'optique de résoudre ce problème
qu'il nous vint à l'esprit de mettre sur pied une application «open
source» de gestion du presse-papier de Windows. La faible
documentation sur le concept « presse-papier » a orienté notre
étude vers des éléments qui lui sont intimement
liés à savoir le noyau de Windows qui est
responsable de toute application fonctionnant dans ce système
d'exploitation. Il a donc été question :
· D'étudier l'architecture du noyau de Windows
71. Ceci a fait l'objet de notre revue de littérature.
· De comprendre le fonctionnement du presse-papier natif
de Windows et d'étudier quelques applications de gestion du
presse-papier. Ce qui nous a permis d'élaborer un cahier de charges qui
fut un guide pour l'atteinte de nos objectifs.
· D'analyser (notation UML) et d'implémenter
(langage de programmation C#) l'application proprement dite grâce
à l'étude effectuée autour des logiciels de gestion du
presse-papier.
· De réaliser les tests sur l'application.
Ceux-ci ont confirmé l'atteinte à 95% du cahier
de charges.
Ce travail nous a permis de faire des perspectives pour la suite
des recherches autour du
presse-papier.
vi
1 Qui repose sur la version 6.2 de Windows NT
vii
ABSTRACT
Computer science has expanded these last decades in an
unprecedented way. As a result, it has become almost impossible for man to do
without the computer technology. Application software is increasingly
indispensable in everyday activities. Data duplication has also significantly
grown. In fact, data duplication is carried out from a source to a specific
target through copying operations, namely «copy-paste» or
«cut-paste» activities.
However, these operations might be limited by some Windows
applications because when a copy is made, it is saved in the memory thanks to
the «Clipboard» application incorporated by Windows from its 3.1
version on. The major difficulty is that Windows clipboard can save only one
copy at a time in its memory. Therefore multiple copying is not possible
because the copy saved in the memory is immediately replaced with the most
recent one. This gives rise to the double problem of time management and task
optimisation. In our quest for a solution, we have created the «Open
Source» Windows clipboard management application.
The limited documentation on the «clipboard»
concept has oriented our study towards an element which is closely linked to
the clipboard, namely the Windows core which manages all applications working
within the Windows system. So we had to:
· Study the framework of Windows 72 core which
is dealt with in our literature review
· Understand how Windows original clipboard works. This has
enabled us to draft a roadmap which guided our study throughout
· Analyse the application (with UML) and implement it (with
C#) thanks to the study of some clipboard software
· Test the application. These tests have enabled us to
conclude that the goals defined in our roadmap where met at 95%
This study has opened up new prospects for further research on
the clipboard.
2 Which is based on the 6.2 NT version Windows
viii
LISTE DES TABLEAUX
Tableau 2.1: Formats standard du presse-papier 18
Tableau 2.2 : formats de synthèse du presse-papier
[12] 22
Tableau 2.3 : Fonctions de la classe Clipboard. [14] 24
Tableau 2.4 : Liste de quelques applications de gestion du
presse-papier [15] 29
Tableau 2.5 : Tableau comparatif de quelques logiciels de
gestion du presse-papier 30
Tableau 3.1 : Relations entre les acteurs et leurs
rôles. 37
Tableau 3.1 : Les classes de l'architecture .NET 55
Tableau 4.1 : Détail des besoins pour la
réalisation du projet 63
Tableau 4.2 : Paramètres associés au type de
projet [23] 65
Tableau 4.3 : Coût du développement 66
ix
LISTE DES FIGURES
Figure 1.1 : Representation de l'architecture de windows nt
[3] 8
Figure 1.2 : Architecture des elements du nt executive [3]
10
Figure 2.1 : Transferer les donnees au fornat text dans le
presse-papier 23
Figure 2.2 : Recuperer les donnees au format text du
presse-papier 23
Figure 2.3 : Reconstitution de la structure du presse-papier
par reverse engineering [8] 24
Figure 3.1 : Historique de la constitution d'uml [16] 35
Figure 3.2 : Trois axes de modelisation uml [17] 36
Figure 3.3 : Diagramme de cas d'utilisation de la gestion
d'une collection 38
Figure 3.4 : Diagramme de cas d'utilisation de la gestion
d'un groupe 39
Figure 3.5 : Diagramme de cas d'utilisation de la gestion
d'une copie 39
Figure 3.6 : Diagramme de cas d'utilisation globale de
l'application 40
Figure 3.11 : Representation graphique d'une classe 45
Figure 3.12 : Diagramme de classe de l'application
pressepapier1.0 46
Figure 3.13 : Package de l'application pressepapier1.0 47
Figure 3.14 : Package des classes du systeme d'exploitation
48
Figure 3.14 : Diagramme de package du pressepapier1.0 49
Figure 3.15 : Schema fonctionnel de l'application 50
Figure 3.16 : Fenêtre principale 51
Figure 3.17 : Fenêtre de configuration 52
Figure 3.18 : Fenêtre d'ajout d'une nouvelle collection
52
Figure 3.19 : Fenêtre d'ajout d'un nouveau groupe (de
copies) 52
Figure 3.20 : Inscription d'une application comme visionneuse
du presse-papier 57
Figure 3.21 : Sauvegarde du contenu du presse-papier «
clipboard » 58
Figure 4.1 : Fenêtre principale 60
Figure 4.2 : Presentation du menu « fichier » 61
Figure 4.3 : Fenêtre de creation d'une nouvelle
collection 62
Figure 4.4 : Fenêtre de creation d'un nouveau groupe
62
x
LISTE DES SIGLES ET DES ABREVIATIONS
ACL: Access Control List
ANSI: American National Standard
Institute
API: Application Programming Interface
ASP: Active Server Page
CAO: Conception Assistée par
Ordinateur
CF: Clipboard Format
CLR: Common Language Run-time
COCOMO: Constructive Cost Model
COM: Component Object Model
CP/M: Control Program for Microcomputers
DIB: Device Independent Bitmap
DIF: Data Interchange Format
DLL: Dynamics Library Link
EMF: Enhanced Metafile Format
GDI: Graphical Device Interface
HAL: Hardware Abstraction Layer
HURD: Hurd of Interfaces Representing
Depth
I/O: Input/output
IDE: Integrated Development Environment
IHM: Interface Homme Machine
JIT: Just In Time
LPC: Local Procedure Call
NFS : Network File System
NGWS: Next Generation Web Services
NT: New Technology
NTFS: New Technology File System
OCL: Object Contraint Language
OEM: Original Equipment Manufacturer
OMG: Object Management Group
OMT: Object Medeling Technique
OOPSLA: Object Oriented Programming Systems,
Languages and Applications
OOSE: Object Oriented Software
Engineering
OS: Operating System
xi
PPP : Point to Point Protocol
RIFF: Resource Interchange File Format
RTF: Rich Text Format
RTOS: Real Time Operating System
SAT: Secure Access Tocken
SGR: Standard Group Report
SMP: Symmetric Multi-Processing
SRM: Security Ressource Manager
SUN: Standard University Network
TCP/IP: Transfer Control Protocol / Internet
Protocol
TIC: Technologie de l'Information et de la
Communication
TIFF: Tagged Image File Format
UML: Unified Modeling Language
WOW: Windows On Windows
XML: eXtensible Markup Language
XP: eXtreme Programming
xii
TABLE DES MATIERES
DEDICACE iii
REMERCIEMENTS iv
AVANT PROPOS v
RESUME vi
ABSTRACT vii
LISTE DES TABLEAUX viii
LISTE DES FIGURES ix
LISTE DES SIGLES ET DES ABREVIATIONS x
TABLE DES MATIERES xii
INTRODUCTION GENERALE 1
CHAPITRE 1 : REVUE DE LA LITTERATURE 3
1.1. Noyau d'un système d'exploitation
4
1.1.1. Généralités 4
1.1.2. Systèmes à noyaux restreints et Fonctions
généralement remplies par un noyau 6
1.1.2.1. Systèmes à noyaux restreints 6
1.1.2.2. Fonctions généralement remplies par un
noyau 6
1.2. Architecture du noyau de Windows 7. 7
1.2.1. Architecture générale de Windows NT 7
1.2.1.1. Le HAL (Hardware Abstraction Layer) 9
1.2.1.2. Le noyau 9
1.2.1.3. Les services du NT Executive 10
1.2.1.4. Les sous systèmes d'environnement 13
1.3. Les noyaux de Mac OS et de Linux 14
1.3.1. Le noyau de Mac OS 14
1.3.2. Le noyau de Linux 15
CHAPITRE 2 : LE PRESSE-PAPIER 17
2.1. Présentation du presse-papier 17
2.1.1. Les formats de données 18
2.1.1.1. Les formats de données standard 18
2.1.1.2. Formats inscrits du presse-papier 20
2.1.1.3. Formats privés du presse-papier 21
2.1.1.4. Formats multiples du presse-papier 21
2.1.1.5. Formats de synthèse du presse-papier 21
2.1.2. Fonctionnement du presse-papier 22
2.1.2.1. Description du processus d'extraction des
données 23
2.1.2.2. Les fonctions du presse-papier 24
2.2. Limites du presse-papier de Windows 27
2.2.1. Saisie d'un mémoire avec Latex 27
xiii
2.2.2. Manipulation des images 28
2.3. Développement logiciel autour du
presse-papier 28
2.4. Cahier des charges 31
2.4.1. Description de l'existant 31
2.4.2. Expression des besoins 31
2.4.2.1. Besoins fonctionnels 31
2.4.2.2. Besoins non fonctionnels 31
2.4.3. Solution adopté 32
2.4.3.1. Choix de la méthode d'analyse et de conception
32
2.4.3.2. Choix du langage de programmation 32
CHAPITRE 3 : DEVELOPPEMENT LOGICIEL 34
3.1. Analyse et conception 34
3.1.1. Présentation de UML 36
3.1.2. Les vues et diagrammes d'UML 36
3.1.2.1. La vue fonctionnelle 37
3.1.2.2. La vue dynamique 40
3.1.2.3. La vue structurelle ou statique 43
3.2. Schéma fonctionnel de l'application
50
3.3. Les interfaces du logiciel 51
3.4. Implémentation 53
3.4.1. Environnement de développement et langage de
programmation 53
3.4.1.1. Présentation de Visual Studio 2010 53
3.4.1.2. L'architecture .Net 53
3.4.1.3. Présentation du langage de programmation C#
56
3.4.2. Présentation des différents modules 56
3.4.2.1. La gestion de la copie 56
3.4.2.2. La gestion des collections et des groupes. 57
3.4.2.3. La sauvegarde et la restauration des données
59
CHAPITRE 4 : TESTS ET GUIDE D'UTILISATION 60
4.1. Présentation de l'application 60
4.1.1. Fenêtre principale 60
4.1.2. Fonctionnalités de l'application 61
4.2. Configuration minimale 62
4.3. Coût estimatif du projet 62
4.3.1. Estimation du coût des équipements 63
4.3.2. Estimation du coût de développement 63
4.3.2.1. Contexte de développement d'un logiciel 63
4.4.2.2. Estimation de la charge 63
CONCLUSION GENERALE 67
REFERENCES BIBLIOGRAPHIQUES 68
1
INTRODUCTION GENERALE
Les informations que manipulent les utilisateurs de l'outil
informatique sont généralement mutées d'une source vers
une autre. Parfois il arrive que certaines de ces informations soit totalement
déplacées3. De là, survient donc une
préoccupation majeure, celle de savoir ce qui se passe lorsqu'on
décide par exemple de couper un morceau de texte lors d'une saisie pour
la coller à la place d'une autre et par mégarde au moment du
collage de ce dernier au lieu de faire un Ctrl+V après sélection
de la portion à remplacer on en fait plutôt un Ctrl+C. Il vient
que le morceau de texte qui a été coupé a
été écrasé par celui copié par
mégarde. Il est donc important pour nous de se poser la question de
savoir : où se trouve ce texte et comment faire pour le
récupérer ? Lorsqu'on effectue une opération
de copie4, l'élément copié est chargé
dans une application de Windows appelée Clipboard soit «
presse-papier » en français. En effet le presse-papier gère
les fonctionnalités de « copier/coller » et «
couper/coller » des systèmes d'exploitation. Intégré
depuis le début des interfaces graphiques, il est devenu une seconde
nature pour les utilisateurs. En revanche, il n'a jamais vraiment
évolué depuis son introduction dans Windows.
Pourquoi est-il donc important de remplacer le presse-papier
de Windows ? Il ressort qu'au sein du système d'exploitation de
Microsoft, cette fonction est en effet limitée : vous pouvez effectuer
un « copier » ou un « couper » (ou encore une impression
d'écran) pour envoyer un élément (texte, image ou autre)
dans le presse-papier, mais Windows ne peut stocker en mémoire
qu'un élément à la fois. Très gênant
au vue de l'exemple présenté ci-dessus. Notons cependant qu'une
application comme Microsoft Office, depuis sa version XP, gère au
plus 24 éléments dans son presse-papier
amélioré.
De même, le presse-papier de Windows ne
différencie pas la nature des éléments qui lui sont
présentés : un texte a même valeur qu'une image par
exemple. Enfin, l'intégration du presse-papier dans Windows se limite au
simple « Copier », « Couper » et « Coller » du
menu contextuel. Aucune fonctionnalité particulière n'est
prévue. Par exemple, par défaut, il est impossible de copier d'un
clic le chemin de l'emplacement d'un programme dans le disque dur.
[1]
Ce sont toutes ces limites, et bien d'autres encore, qui ont
suscitées à la suite d'une étude préalable du
presse-papier le souci de mettre sur pied une application de gestion du
presse-
3 Dans le sens d'un « couper-coller »
4 «copier-coller» ou
«couper-coller»
2
papier de Windows. Le rapport qualité
prix de cette application est donc meilleur que d'autres applications
payantes.
A travers notre application, il sera donc possible à
tout utilisateur de visualiser et d'un seul clic récupérer une
copie perdue par le presse-papier de Windows, de stocker dans un groupe un
ensemble de copies constamment utilisé par exemple :
· Des structures et commandes utilisées lors de la
rédaction d'un mémoire ou d'une thèse de doctorat avec
l'éditeur Latex ;
· Des fragments de code utilisés dans le cadre d'un
développement logiciel ;
· des images utilisées dans le cadre des conceptions
graphiques.
Tous pouvant être facilement
récupérés en un seul clic.
Nous offrons donc ainsi à tout utilisateur de l'outil
informatique un presse-papier qui fonctionne même après un
redémarrage de Windows et dont le nombre de copie
maximale passe de 24 à un nombre théoriquement
infini.
Ce travail se divise en deux étapes : une
théorique et l'autre pratique. Dans l'étape théorique,
nous avons d'abord fais une étude sur le noyau des systèmes
d'exploitations en général et de celui de Windows en particulier.
Ensuite nous avons fait une étude du presse-papier de Windows. Enfin une
analyse des besoins nous a permis de rédiger le cahier de charges.
L'étape pratique a consisté à analyser et à
concevoir via UML (Unified Modeling Language) l'application de gestion du
presse-papier. A la suite de cette analyse, nous avons proposé une
implémentation en C# de l'application et réalisé des tests
sur celle-ci.
Ce mémoire est ordonné comme suit :
l'architecture du noyau de Windows NT 6.2 et sa relation avec le presse-papier
sont présentées dans le chapitre 1. Le chapitre 2 présente
le presse-papier dans sa globalité et son fonctionnement particulier au
sein du système d'exploitation Windows. Les différentes phases
d'analyse et de conception de l'application ainsi que son implémentation
sont présentés dans le chapitre 3. Le chapitre 4 détaille
les tests sur l'application, la configuration minimale d'utilisation et le
coût estimatif du projet.
3
REVUE DE LA LITTERATURE
|
|
CHAPITRE
1
|
|
|
|
En informatique, le
presse-papier5 est une fonctionnalité qui
permet de stocker des données que l'on souhaite dupliquer ou
déplacer. Il utilise une zone de la mémoire volatile de
l'ordinateur, pouvant contenir des informations de nature diverse (texte,
image, fichier, etc.). Ces informations sont stockées en zone
mémoire lorsqu'elles ont fait l'objet d'un appel à la fonction
copier ou couper du système d'exploitation ou d'un
logiciel. Elles sont réutilisables par la suite par l'appel de la
fonction « coller », qui replace l'objet. Ces
opérations sont possibles dans plusieurs systèmes d'exploitation
et sont utilisées chaque jour par des utilisateurs ; ceci demande une
grande manoeuvre à l'intérieur du système d'exploitation
qui doit être capable de stocker en mémoire les informations
à manipuler. Mais pouvons-nous parler de mémoire sans toutefois
parler de l'élément essentiel de tout système
d'exploitation qui de par ses fonctions assurent aussi celle de la gestion de
la mémoire ? Il s'agit ici du noyau du système d'exploitation
communément appelé Kernel en anglais.
On distingue plusieurs systèmes d'exploitation possédant un
presse-papier parmi lesquels WINDOWS 3.X, WINDOWS NT, WINDOWS 2000, WINDOWS ME,
WINDOWS XP, WINDOWS 7, WINDOWS 8, LINUX, UNIX, MAC OS, CHROME OS, ANDROID mais
un seul fera l'objet de notre étude à savoir Windows 7. Le
système d'exploitation stocke le contenu du presse-papier dans la
mémoire volatile de l'ordinateur. La gestion de cette mémoire est
une tâche réservée au noyau du système
d'exploitation; son étude est plus qu'indispensable pour la
compréhension de la relation qui existe entre le presse-papier et la
mémoire. L'objet de ce chapitre est de faire une étude globale de
l'architecture du noyau d'un système d'exploitation en
générale et en particulier de celui de Windows 7 dans un premier
temps et dans un second temps établir l'importance du choix de ce
dernier en le comparant aux noyaux de deux autres systèmes
d'exploitation à savoir Mac OS et Linux dans leurs versions
équivalentes à celle de Windows 7.
5 ou « presse-papiers »
selon l'ancienne orthographe
4
1.1. Noyau d'un système d'exploitation
1.1.1. Généralités
Le noyau d'un système d'exploitation est
lui-même un logiciel, mais ne peut cependant utiliser tous les
mécanismes d'abstraction qu'il fournit aux autres logiciels. Son
rôle central impose par ailleurs des performances élevées.
Cela fait du noyau la partie la plus critique d'un système
d'exploitation et rend sa conception et sa programmation
particulièrement délicates. Plusieurs techniques sont mises en
oeuvre pour simplifier la programmation des noyaux tout en garantissant de
bonnes performances.
En informatique, le noyau d'un système d'exploitation est
le logiciel qui assure :
· la communication entre les logiciels et le
matériel ;
· la gestion des divers logiciels
(tâches) d'une machine (lancement des programmes,
ordonnancement...) ;
· la gestion du matériel (mémoire,
processeur, périphérique, stockage...).
La majorité des systèmes d'exploitation est
construite autour du noyau. L'existence d'un noyau, c'est-à-dire d'un
programme unique responsable de la communication entre le matériel et le
logiciel, résulte de compromis complexes portant sur des questions de
performance, de sécurité et
d'architecture des processeurs.
L'existence d'un noyau présuppose selon Andrew
Tanenbaum6 une partition virtuelle de la
mémoire vive physique en deux régions
disjointes, l'une étant réservée au noyau (l'espace
noyau) et l'autre aux applications (l'espace utilisateur). Cette
division, fondamentale, de l'espace mémoire en un espace noyau et un
espace utilisateur contribue beaucoup à donner la forme et le contenu
des actuels systèmes généralistes (GNU/Linux,
Windows, Mac OS X, etc.), le noyau ayant de grands pouvoirs sur
l'utilisation des ressources matérielles, en particulier de la
mémoire. Elle structure également le travail des
développeurs : le développement de code dans l'espace noyau est
a priori plus délicat que dans l'espace utilisateur car la
mémoire n'y est pas protégée. Ceci implique que des
erreurs de programmation, altérant éventuellement les
instructions du noyau lui-même, sont potentiellement beaucoup plus
difficiles à détecter que dans l'espace utilisateur où de
telles altérations sont rendues impossibles par le mécanisme de
protection.
6 Andrew Tanenbaum, Operating Systems: Design and
Implementation, Prentice Hall, 3rd ed. (ISBN 0-13-142938-8), chapitre 1,3
- 1,4 - 4.
5
Le noyau offre ses fonctions (l'accès aux ressources
qu'il gère) au travers des appels système. Il transmet ou
interprète les informations du matériel via des interruptions.
C'est ce que l'on appelle les entrées et sorties.
Diverses abstractions de la notion d'application
sont fournies par le noyau aux développeurs. La plus courante est
celle de processus (ou tâche). Le noyau du système d'exploitation
n'est en lui-même pas une tâche, mais un ensemble de fonctions
pouvant être appelées par les différents processus pour
effectuer des opérations requérant un certain niveau de
privilèges. Le noyau prend alors en général le relais du
processus pour rendre le service demandé et lui rend le contrôle
lorsque les actions correspondantes ont été
réalisées.
Il peut arriver cependant que le processus puisse poursuivre
une partie de son exécution sans attendre que le service ait
été complètement réalisé. Des
mécanismes de synchronisation sont alors nécessaires entre le
noyau et le processus pour permettre à celui-ci, une fois qu'il est
arrivé au point où il a besoin que le service ait
été rendu, d'attendre que le noyau lui notifie l'exécution
effective du service en question.
Un processeur est capable d'exécuter un seul
processus, un multiprocesseur est capable de gérer autant de processus
qu'il a de processeurs. Pour pallier cet inconvénient majeur, les noyaux
multitâches permettent l'exécution de plusieurs processus sur un
processeur, en partageant le temps du processeur entre les processus.
Lorsque plusieurs tâches doivent être
exécutées de manière parallèle, un noyau
multitâche s'appuie sur les notions de :
· commutation de contexte :
(context switch en anglais) en informatique consiste à
sauvegarder l'état d'un processus pour restaurer à la place celui
d'un autre dans le cadre de l'ordonnancement d'un système d'exploitation
multitâche.
· ordonnancement : c'est le fait
d'ordonner des tâches à exécuter selon certaines
contraintes. Ces tâches peuvent être l'exécution
d'opération sur les entrées-sorties ou le traitement de
processus. Les contraintes peuvent être temporelles ou dimensionnelles.
;
· temps partagé.
Les entrées et les sorties font l'objet d'un
traitement spécifique par l'ordonnanceur. De l'anglais
scheduler, il désigne dans un système d'exploitation le
composant du noyau chargé de choisir l'ordre d'exécution des
processus d'un ordinateur. Il s'avère donc important de mettre un accent
sur les fonctions remplies par un noyau.
6
1.1.2. Systèmes à noyaux restreints et
Fonctions généralement remplies par un noyau
1.1.2.1. Systèmes à noyaux
restreints
Il existe de nombreux noyaux aux fonctionnalités
restreintes tels que les micro-noyaux, les systèmes sans noyau (MS-DOS,
CP/M) ou les exo-noyaux.
Ces systèmes sont généralement
adaptés à des applications très ciblées mais posent
des problèmes variés (de sécurité avec MS-DOS, de
performances avec HURD ou QNX). La plupart d'entre eux sont actuellement
inadaptés pour une utilisation généraliste, dans des
serveurs ou ordinateurs personnels.
1.1.2.2. Fonctions généralement remplies
par un noyau
Les noyaux ont comme fonctions de base d'assurer le
chargement et l'exécution des processus, de gérer les
entrées/sorties et de proposer une interface entre l'espace noyau et les
programmes de l'espace utilisateur.
À de rares exceptions, les noyaux ne sont pas
limités à leurs fonctionnalités de base. On trouve
généralement dans les noyaux les fonctions des micronoyaux : un
gestionnaire de mémoire et un ordonnanceur, ainsi que des fonctions de
communication interprocessus.
En dehors de fonctions précédemment
listées, de nombreux noyaux fournissent également des fonctions
moins fondamentales telles que :
· la gestion des systèmes de fichiers ;
· plusieurs ordonnanceurs spécialisés
(batch7, temps réel, entrées/sorties, etc.) ;
· des notions de processus étendues telles que les
processus légers ;
· des supports réseaux (TCP/IP, PPP, pare-feu, etc.)
;
· des services réseau (NFS, etc.).
Enfin, la plupart des noyaux fournissent également des
modèles de pilotes et des pilotes pour le matériel.
En dehors des fonctionnalités de base, l'ensemble des
fonctions des points suivants (y compris les pilotes matériels, les
fonctions réseaux et systèmes de fichiers ou les services) n'est
pas nécessairement fourni par un noyau de système d'exploitation.
Ces fonctions du système d'exploitation peuvent être
implantées tant dans l'espace utilisateur que dans le noyau
lui-même. Leur implantation dans le noyau est faite dans l'unique but
d'augmenter les
7 Traitement par lot.
7
performances. En effet, suivant la conception du noyau, la
même fonction appelée depuis l'espace utilisateur ou l'espace
noyau a un coût temporel notoirement différent. Si cet appel de
fonction est fréquent, il peut s'avérer utile d'intégrer
ces fonctions au noyau pour augmenter les performances.
Ces techniques sont utilisées pour pallier des
défauts des noyaux tels que les latences élevées. Autant
que possible, il est préférable d'écrire un logiciel hors
du noyau, dans l'espace utilisateur. En effet, l'écriture en espace
noyau suppose l'absence de mécanismes tels que la protection de la
mémoire. Il est donc plus complexe d'écrire un logiciel
fonctionnant dans l'espace noyau que dans l'espace utilisateur, les bugs et
failles de sécurité sont bien plus dangereux.
[2]
1.2. Architecture du noyau de Windows 7.
Windows 7 est un système d'exploitation
créé par Microsoft pour remédier les problèmes
rencontrés par les utilisateurs de Windows Vista. Construit sur une
version amélioré du noyau de Windows Vista (NT 6.0), le noyau de
Windows 7 (NT 6.1) à une architecture assez complexe qui malgré
tout permet une étroite collaboration entre les ressources
matérielles et logicielles dont a besoin un système
d'exploitation pour bien fonctionné. De la création du premier
système d'exploitation de Microsoft baptisé MS-DOS pour Microsoft
Disk Operating System (système d'exploitation du disque) jusqu'à
la version Windows 3.0 on ne parlait pas du presse-papier qui est un
élément très important qui fonctionne en étroite
collaboration avec le noyau de Windows à partir de la version Windows NT
3.1 jusqu'à la version du noyau de Windows NT 6.1 sous lequel fonctionne
Windows 7. Le but de cette partie est de présenter l'architecture du
noyau de Windows 7 en occurrence le NT 6.1 et de dégager le rapport qui
existe entre le presse-papier de Windows et son noyau (Kernel).
1.2.1. Architecture générale de Windows
NT
Pour mieux parler du noyau Windows NT 6.1 il est
nécessaire de faire une étude globale de l'architecture
générale de Windows NT. Ceci dans le but de mieux nous
éclairer sur la base de l'administration des noyaux des systèmes
d'exploitation de Windows car tous ces derniers sont conçu autour d'un
noyau de base dont les versions diffère selon les besoins du
système d'exploitation. Windows NT fonctionne dans deux modes
différents, le mode utilisateur et le mode
noyau: [3]
· Le mode utilisateur est le mode dans
lequel tournent les programmes qui sont soumis à la
sécurité du système d'exploitation, fournie justement par
les programmes qui
tournent en mode noyau. On y trouvera tous les programmes des
utilisateurs, mais aussi certains programmes du système d'exploitation
qui ont été placés ici pour ne pas trop charger de
programmes en mode noyau (peut-être aussi parce-que leurs programmes ne
sont pas stables et qu'il ne vaut mieux pas qu'ils puissent accéder
à toute la mémoire...).
· Le mode noyau est le mode dans lequel
tournent les fonctions vitales du système d'exploitation. C'est un mode
protégé où le code est très optimisé. Un
programme tournant dans ce mode n'est pas soumis aux divers contrôles de
sécurité, comme par exemple vérifier si la mémoire
à laquelle il accède lui est bien attribuée. Les
programmes ne doivent contenir aucune bogue car la sécurité est
réduite au minimum. Les programmes doivent à tout prix respecter
leur espace d'adressage. On retrouve dans ce mode tous les programmes
utilisés en permanence par le système d'exploitation. Il est
impossible de faire tourner ces propres programmes dans ce mode.
La stabilité de Windows NT est assurée
grâce à ces deux modes. Le mode noyau est le coeur du
système d'exploitation, la partie la plus petite possible, la plus
optimisée et sans aucune bogue. Tout ce qui tourne en mode utilisateur
est contrôlé par les programmes du mode noyau et ne peut donc pas
faire planter le système, en théorie bien sûr. La
Figure 1.1 montre la séparation entre les deux modes.
Cette séparation est matérialisée par une ligne
horizontale en pointillés :
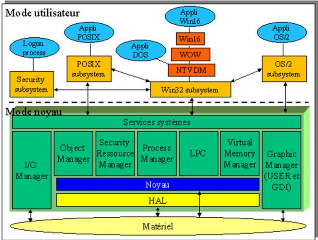
8
Figure 1.1 : Représentation de l'architecture de
Windows NT [3]
9
Tout ce qui est représenté en vert
c'est-à-dire tout ce qui est en mode noyau sauf le matériel,
s'appelle le NT Executive. Il regroupe le noyau, la HAL et les
services systèmes. Les services systèmes sont tous les modules
tournant en mode noyau, autour du noyau (ne pas confondre noyau et
mode noyau) : l'I/O8 Manager, l'Object Manager, le
Security Ressource Manager, le Process Manager, le LPC, le Virtual Memory
Manager et le Graphic Manager. Sur la Figure 1.1, les services
systèmes sont représentés comme une surcouche, c'est en
fait la vision que tout programme tournant en mode utilisateur a du
système d'exploitation. Les programmes vont faire appel aux services
système via des API9 appelées "Native API". Ils ne
vont pas s'adresser directement à tel ou à tel service. Le
rôle de chacune de ces boites noires est détaillé
ci-dessous :
1.2.1.1. Le HAL (Hardware Abstraction Layer)
HAL pour Hardware Abstraction Layer, ou en français,
Couche d'Abstraction Matérielle. C'est grâce à cette couche
que Windows NT est portable sur plusieurs types de machines. Son rôle est
de masquer complètement la partie matérielle au système
d'exploitation lui-même. Tout matériel va être
représenté virtuellement au système d'exploitation. Le
système d'exploitation va utiliser le matériel via une interface
unique, sans se soucier du matériel. C'est à la couche
d'abstraction matérielle de traduire les demandes au système
physique. A un type de machine correspond une couche HAL spécifique.
Grâce à cette couche, Windows NT peut tourner sur plusieurs types
de microprocesseurs : Intel, MIPS, PowerPC, Alpha. C'est encore la couche HAL
qui gère les systèmes multiprocesseurs, en intégrant
l'interface SMP (Symmetric Multi Processing). La couche HAL est
différente suivant le nombre de processeurs dans le système.
La couche HAL représente chaque processeur comme un
processeur virtuel au noyau. Le noyau, allouera ses tâches sur ces
différents processeurs. Que ce soient des processeurs Alpha, Intel ou
autre, le noyau voit toujours des processeurs virtuels. La couche HAL n'est
accessible que par le NT Executive. Pour accéder au matériel, les
programmes utilisateurs sont donc obligés de passer par les Native
APIs.
1.2.1.2. Le noyau
Le noyau, aussi appelé micro-noyau ou Kernel pour les
anglicistes. Son principal rôle est de planifier les threads sur les
différents processeurs virtuels, en fonction de leur priorité. Il
va préempter les processus qui n'auront pas rendu d'eux-mêmes la
main après le quantum de
8 Input/Output équivalent anglais de E/S pour
Entrées/Sorties en français.
9 Application Programming Interface ou interface de
programmation d'application en français.
10
temps (slice) attribué. Il traite toutes les
interruptions système. Il traite les exceptions processeurs (divisions
par zéro, ou toute opération que le processeur s'interdit
lui-même de faire). Le noyau est aussi un programme et ce noyau tourne
sur chaque processeur. Il ne peut être préempté et ne peut
donc pas non plus être swappé10. Les parties critiques
du noyau sont écrites en assembleur et par conséquent tout ce que
le noyau ne fait pas est fait par les services du NT Executive.
1.2.1.3. Les services du NT Executive
Les services du NT Executive tournent aussi en mode noyau. Ce
sont donc des parties importantes, indispensables au système
d'exploitation. Leur rôle est de fournir les services de base aux
sous-systèmes d'environnement. La Figure 1.2
présente les différents services du NT Executive.
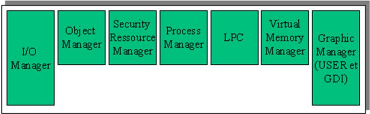
Figure 1.2 : Architecture des éléments
du NT Exécutive [3] Pour mieux comprendre cette figure,
énumérons un peu le rôle de chacun :
· l'Object Manager, ou Gestionnaire d'Objets
:
Sous Windows NT, tout est représenté sous forme
d'objet : un processus, un thread, un périphérique quelconque
sont des objets. Chaque objet contient une ACL : Access Control List, Liste de
Contrôle d'Accès, une liste définissant les droits que les
autres objets ont sur lui. Pour travailler avec un objet, on utilise un
handle11. Ce handle est une référence
représentant l'objet. Il contient notamment un pointeur sur l'objet
ainsi que les droits que l'on possède sur cet objet. C'est le
gestionnaire d'objets qui fournit tous les handle que les autres objets lui
demandent. Les objets sont créés, modifiés et
supprimés par le gestionnaire d'objets. Le gestionnaire d'objets
supprime les objets orphelins. Un objet ne doit exister que s'il est
utilisé. Le gestionnaire d'objet compte le nombre d'objets utilisant
chaque objet. Quand ce nombre
10 Swappé signifie que le
code d'exécution est transféré de la mémoire vive
vers le disque pour récupérer un peu de mémoire ; il sera
replacé en mémoire quand on en aura besoin.
11 Un handle est une valeur
numérique identifiant un objet informatique.
11
arrive à zéro, l'objet n'est plus
utilisé, donc supprimé. Le gestionnaire d'objet veille à
ce que chaque objet ne consomme pas trop de ressources.
s le Process Manager, ou Gestionnaire de
processus
Son rôle est de créer, modifier l'état et
supprimer les threads. Il renseigne sur l'état de chaque thread. Son
rôle n'est pas de cadencer les threads. Tout processus contient au moins
un thread initial, dans laquelle tourne effectivement le programme.
s Le Virtual Memory Manager, ou gestionnaire de
mémoire virtuelle
Son rôle est d'allouer 4 Go d'espace mémoire
à tous les processus en exécution, indépendamment de
l'espace mémoire effectivement disponible sur le système. Sur ces
4 Go, 2Go seront réservés au système, les deux restants
seront à la disposition du programmeur. Sur les systèmes
contenant suffisamment de mémoire, il sera possible d'allouer plus
d'espace pour la partie applicative (donc moins pour le système).
Il s'assure que chaque application reste dans son espace
d'adressage attribué. C'est le gestionnaire de mémoire virtuelle
qui gère le swap. Les programmes demandent des pages mémoire au
gestionnaire. Le gestionnaire leurs fournit, qu'elles soient en mémoire
vive ou swappées.
s Le LPC: Local Procedure Call, ou Appel de
Procédure Locale
Dans un système d'exploitation, tournent en permanence
un certain nombre de threads. Tous les services systèmes par exemple
sont des threads ; les sous-environnements aussi. Viennent ensuite les
applications utilisateur. Tous ces threads dialoguent en permanence entre
elles, les applications vers le sous-système d'environnement, le
sous-système d'environnement vers les services système, les
services système entre eux. Tous ces dialogues passent par le LPC qui
gère la communication entre threads. C'est un programme
spécifiquement développé pour optimiser les communications
locales entre processus.
s Le SRM : Security Ressource Manager, ou gestionnaire
de sécurité des ressources
Son rôle est de gérer la sécurité
en local sur la machine. Il sécurise l'accès à tout objet
du système. Quand un utilisateur veut utiliser un objet, il fait une
demande de handle auprès du gestionnaire d'objet. Le gestionnaire
d'objet demande au SRM quels droits l'utilisateur a effectivement sur l'objet
demandé. Le SRM compare le SAT (Secure Access Tocken, Jeton
d'accès sécurité) de l'utilisateur, contenant les droits
de l'utilisateur (appartenance aux groupes
12
donc héritage), à l'ACL de l'objet
demandé et en déduit le niveau d'accès de l'utilisateur
sur l'objet. Ce niveau d'accès sera stocké dans le handle.
· Le I/O Manager, ou Gestionnaire
d'Entrées-Sorties
C'est une grosse partie du système d'exploitation. Il
est divisé lui-même en plusieurs couches de manière
à être le plus modulaire possible. Il est constitué de
telle manière que lorsque l'on veut ajouter ou changer un driver
quelconque (disque dur, carte réseau) on ait le moins de code possible
à développer. Il faudra simplement ajouter la couche qui va bien
au bon endroit. Celle-ci s'appuiera sur ses couches supérieures et
inférieures, qui n'auront pas à être modifiées. Plus
les couches sont hautes, moins elles connaissent le système physique.
Le gestionnaire d'entrées-sorties coordonne et
gère les communications entre drivers. Ces communications se font avec
des messages spéciaux appelés I/O Request Packets. Le
gestionnaire d'entrées-sorties gère notamment les systèmes
de fichiers et les redirecteurs réseau (c'est grâce à lui
que peuvent cohabiter plusieurs systèmes de fichier, par redirection des
packets vers la bonne couche suivant leur type). Un redirecteur réseau
n'est en fait rien d'autre qu'un système de fichier spécial. Pour
une application, la méthode pour aller chercher une information sur le
serveur ou sur un map réseau est strictement identique. Le gestionnaire
d'entrées-sorties gérant les systèmes de fichier, il est
normal qu'il gère aussi le cache disque (c'est le cache qui optimise les
lectures sur le disque). Au lieu de diriger les requêtes disques
directement vers le disque, il regarde d'abord dans le cache. S'il ne trouve
pas le bloc demandé, il va alors transmettre la requête au disque.
La réponse repassera forcément par le cache, qui cette fois ci
stockera l'information. [3]
· Le Graphic Manager, ou gestionnaire
graphique
Il regroupe les deux sous-modules GDI et USER, correspondant
respectivement à l'interface graphique et au gestionnaire de
fenêtres. Ce module n'était pas présent dans le NT
Executive sur Windows NT3, ceci a été présent à
partir du Windows NT4 et présent aujourd'hui dans les autres Windows NT
jusqu'à la version 6.1 correspondant au noyau de Windows 7. Sous Windows
NT3, GDI et USER se trouvaient dans le sous-environnement Win32. Leur choix,
contesté par certains, a été justifié pour la
raison suivante : Sous Windows NT3, quand le sous-environnement Win32 plantait,
on ne pouvait absolument plus rien faire, le système était
bloqué. En le mettant dans le NT Executive, lorsque le
sous-environnement Win32 plante, le noyau est capable de repeindre votre
écran en bleu et vous afficher des informations susceptibles de vous
aider à résoudre, du moins comprendre, le problème. De
plus, par la commande CTRL-ALT-SUPPR, il décharge le système
d'exploitation. [3]
13
1.2.1.4. Les sous-systèmes d'environnement
Tous les sous-systèmes d'environnement tournent en
mode utilisateur. Ils sont au nombre de trois : Win32, POSIX et OS/2. Leur
rôle est d'offrir aux applications un environnement d'exécution.
Le sous-environnement natif de Windows NT est Win32. Les deux autres ont
étés rajoutés pour que Windows NT se dise compatible.
Windows NT sait dans quel sous-environnement faire tourner une application
grâce à l'entête du fichier. [3]
· Le sous-système d'environnement
Win32
Comme énoncé précédemment, il
s'agit du sous-système d'environnement natif à Windows NT. C'est
lui qui gère le clavier et la souris, les autres sous-systèmes
d'environnement passent donc obligatoirement par Win32 en traduisant leurs API
en API Win32. Win32 a donc une grande importance, s'il plante, on n'a plus
d'accès aux applications tournant sur les autres sous-systèmes.
Toutes les applications utilisent les API Win32 pour dialoguer avec le
système. Les applications Win32 disposent donc leur propre espace
d'adressage. [3]
· Le sous-système d'environnement
POSIX
POSIX signifie "Portable Operating System Interface" et comme
son nom l'indique, définit une interface commune à tout
système d'exploitation qui veut être à la norme POSIX. La
norme POSIX est définie sur 13 niveaux, de 0 à 12, 12
étant la norme la plus complète. Windows NT est conforme à
la norme POSIX.1, autant dire qu'il ne l'est pas. Enfin, cette norme
définit quelques critères sur le format des noms du
système de fichiers que NTFS (système de fichier sous le quel
fonctionne Windows 7) respecte. Les fonctions réseau et système
ne sont donc pas POSIX. Pour ceux qui tiennent à faire tourner une
application POSIX dans ce sous-système, les applications ont leur propre
espace d'adressage et tournent en mode multitâches
préemptif12.
· Le sous-système d'environnement
OS/2
OS/2 est l'interface de présentation qu'avait choisie
Microsoft au départ pour Windows NT, mais face au succès de
Windows 3.X (Win16), c'est Win32, une évolution de Win16, qui a
été finalement adopté. Windows NT respecte la norme OS/2
1.X, c'est à dire OS/2 mode caractère (OS/2 2.X étant le
mode graphique). On dispose cette fois ci de quelques supports
12 Se dit d'un système d'exploitation
multitâche lorsque celui-ci peut à tout moment arrêter une
application pour passer la main à la suivante.
14
réseaux. Comme pour le sous-environnement POSIX, les
applications disposent de leur propre espace d'adressage et tournent en mode
multitâches préemptif.
Comme nous l'avons présenté ci-dessus il en
ressort que le presse-papier étant une application (logiciel), sa
communication avec le matériel est assurée ici par le noyau du
système d'exploitation. Dans tout système d'exploitation, les
opérations de « copier-coller », « couper-coller »
sont assurées par une application virtuelle nommée Clipboard.
Cette application utilise la mémoire vive de l'ordinateur. Cette
mémoire vive représentée par deux régions
disjointes selon Andrew Tanebaum, l'une étant
réservée aux applications (espace utilisateur) et l'autre au
noyau (espace noyau) est l'élément sans lequel le presse-papier
ne peut exister. Il vient donc que le presse-papier fonctionne grâce
à la présence de la mémoire et que la gestion de cette
dernière est assurée par le noyau du système
d'exploitation. D'où le rapport existant entre le presse-papier et le
noyau de Windows. Ceci étant il est nécessaire de se poser la
question suivante : quand est-il du fonctionnement du noyau dans les
systèmes d'exploitation Mac OS et Linux ? La réponse à
cette interrogation nous amène à une brève étude
des noyaux de Mac OS et Linux sous les versions équivalentes à
celle de Windows 7.
1.3. Les noyaux de Mac OS et de Linux
L'étude que nous venons de mener sur l'architecture du
noyau de Windows nous amène à jeter un coup d'oeil au sein des
noyaux des autres systèmes d'exploitation assez utilisé au
même titre que celui de Windows à savoir Mac OS et Linux. Pour
cela nous allons faire une brève étude des noyaux de ces deux
systèmes.
1.3.1. Le noyau de Mac OS
Mac OS est un système d'exploitation de la
société Apple doté de plusieurs versions parmi laquelle
celle sortie en 2009 (Mac OS 10.6 Snow Leopard) année
proche de la sortie de Windows 7 tourne sur un noyau 32 bits pouvant
gérer des applications 64 bits. Actuellement Mac OS X est le seul
système d'exploitation qui permet d'avoir un noyau 32 bits et des
applications 64 bits. Windows 64 bits a été excessivement
difficile à se déployer, car le noyau étant 64 bit, il a
fallu que tous les pilotes le soient pour que l'adoption soit massive : elle ne
l'est pas encore. La technologie pour faire tourner des applications 32 bits
dans Windows 64 bits est WOW (Windows On Windows) : une surcouche d'abstraction
difficile à mettre en oeuvre et à maintenir.
[4]
Cependant, Mac OS 10.6 Snow Leopard est
livré avec deux noyaux. Le premier est un noyau en mode architecture 32
bits le second en 64 bits. Sur la majorité des Macs, le noyau
15
utilisé par défaut est le noyau 32 bits. Ceci
étant les applications fonctionnant sur cette version de Mac contiennent
du code prévu pour être lancé sur les deux architectures
à la fois et qui pénalisent donc le poids du fichier (qui
contient en pratique deux fois plus de code) et sa vitesse d'exécution
car il est très difficile d'optimiser un programme lorsque le code doit
pouvoir s'exécuter sur plusieurs architectures, complètement
différentes de surcroît. [5]
Il en ressort de cette brève étude qu'il est
difficile de programmer des applications fonctionnant sur Mac OS 10.6
Snow Leopard car fonctionnant avec deux noyaux : un noyau 32 bits et
un autre 64 bits dont le démarrage des applications se fait avec le 32
bits par défaut. Faire une application fonctionnant à sur deux
noyaux n'étant pas aisé surtout que le noyau de Mac OS 10.6 Snow
Leopard n'est pas totalement ouvert aux développeurs. C'est la raison
pour laquelle nous avons choisi de travailler sur Windows 7 car il est ouvert
aux développeurs et une grande communauté s'offre le luxe de
concevoir des applications tournant en mode noyau ; ceci pouvant nous servir de
modèle et de guide dans la réalisation de notre application.
1.3.2. Le noyau de Linux
Linux est de natif un noyau qui a été
créé en 1991 par Linus Torvald. [6] Il s'agit
d'un noyau POSIX, respectant les normes POSIX13 1003.1 et 1003.2.
C'est le noyau (version 2.6) du système d'exploitation Linux version LTS
8.04 qui retiendra notre attention car son année de sortir est proche de
celle de Windows 7.
En fait le noyau Linux est la base de tout système
Linux. C'est la partie qui réalise toute l'abstraction du
matériel, assure la gestion des droits, gère les processus, etc.
Le noyau Linux constitue de ce fait la partie d'un système Linux qui
répond strictement à la définition de système
d'exploitation. [7]
Comme tout noyau, Linux 2.6 fournit en son coeur les quatre
services de base que sont : le support du processeur, le gestionnaire
mémoire, le gestionnaire d'interruption et l'ordonnanceur.
Le noyau linux 2.6 est un noyau
monolithique14/hybride qui offre une grande ouverture de
programmation et d'intégration aux développeurs mais ce qui a
poussé notre choix vers le système d'exploitation Windows 7 et
non pas sur Linux relève du fait que le noyau Windows NT.6.1 reste
stable jusqu'à la mise en place d'un autre système d'exploitation
contrairement à
13 POSIX: Portable Operating
System for Computer Environment. C'est une norme Unix de L'IEEE qui
spécifie le noyau du système.
14 Noyau en un seul fichier executable.
16
celui de Linux 2.6 qui est passé en 2009 à sa
version 2.6.21 et dont le fonctionnement des applications écrites sur la
base du fonctionnement du 2.6 nécessiteraient parfois des mises à
jour.
Tout au long de notre étude, il a été
question pour nous de présenter dans un premier temps l'architecture
d'un noyau d'un système d'exploitation et s'attarder sur l'étude
de celui de Windows NT 6.1. Dans un second temps il a été
question pour nous de présenter le noyau de Mac OS version 10.6
surnommé Snow Leopard et celui de Linux
à sa version 2.6 ce qui nous permis de dégager
les raisons pour lesquelles nous avons choisies de travailler sur le noyau
Windows NT 6.1 dont repose le système d'exploitation Windows 7 et qui
d'après notre étude reste le plus stable à la
programmation.
17
LE PRESSE-PAPIER
Le presse-papier a été intégré
dans la famille des systèmes d'exploitation Windows à partir de
Windows 3.1. Windows utilise le presse-papier pour transférer les
données entre les applications. Il établit ainsi un lien entre
les fonctions de l'utilisateur (manipulées par user32.dll) et celles du
noyau (manipulé par win32k.sys). Cette dichotomie différencie le
presse-papier du processus, de la configuration et de l'activité du
réseau qui sont des fonctions du noyau du Système
d'Exploitation.[8] Certaines versions de Windows telles que Windows 98 et
Windows NT intègre des programmes de visionneuse de presse-papier qui
montrent le contenu courant du presse-papier.[9] Ce chapitre présente le
fonctionnement du presse-papier de Windows, ses limites ainsi que les
développements logiciels autour du presse-papier. Nous finirons en
présentant le cahier des charges d'une l'application de gestion du
presse-papier que nous allons développer afin de pallier aux limites du
presse papier natif de Windows.
2.1. Présentation du presse-papier
Le presse-papier est le mécanisme que le
système d'exploitation Microsoft Windows utilise pour permettre à
des données d'être partagées entre les applications. [9] Le
presse-papier est axé sur l'utilisateur c'est-à-dire qu'aucune
application ne doit faire appel à ce dernier à l'insu de
l'utilisateur.
Le presse-papier est sollicité chaque fois qu'une des
opérations « couper », « copier », « coller
» est effectuée. Avant que les données ne soient
copiées dans le presse-papier, l'utilisateur doit sélectionner
l'information spécifique à copier. Cette information doit
appartenir à l'un des formats de données pris en charges par le
presse-papier. Dans le cas contraire, il sera automatiquement converti en un
format de données proche de celui-ci.
18
2.1.1. Les formats de données
Microsoft Windows met à la disposition de l'utilisateur
trois (03) types de formats de données pour stocker les informations
dans le presse-papier. Ceux-ci sont sollicités lors d'une
opération devant impliquer le presse-papier.
2.1.1.1. Les formats de données standard
Les formats de presse-papier définis par le
système sont appelés format standard du
presse-papier. Ces formats prédéfinis sont
préfixés par CF (Clipboard Format) et définis dans
WINUSER.H. Le tableau suivant décrit ces différents formats.
Tableau 2.1: Formats standard du presse-papier
[10]
Constante
|
Valeur
|
Description
|
CF_TEXT
|
0x0001
|
Format texte. Chaque ligne se termine par une combinaison
retour chariot / saut de ligne (CR-LF). Un caractère zéro signale
la fin des données. Utilisez ce format pour les textes ANSI.
|
CF_BITMAP
|
0x0002
|
Spécifie un format de données de bitmap
Microsoft Windows. (HBITMAP).
|
CF_METAFILEPICT
|
0x0003
|
Spécifie le format de données de l'image du
métafichier Windows.
|
CF_SYLK
|
0x0004
|
Spécifie le format de données de lien
symbolique Windows.
|
CF_DIF
|
0x0005
|
Spécifie le format d'échange de données
Windows. (DIF, Data Interchange Format)
|
CF_TIFF
|
0x0006
|
Spécifie le format de données TIFF (Tagged
Image File Format)
|
CF_OEMTEXT
|
0x0007
|
Spécifie le format de données de texte
Windows OEM standard. Chaque ligne se termine par une
combinaison retour chariot / saut de ligne (CR-LF). Un caractère
zéro signale la fin des données.
|
|
19
CF_DIB
|
0x0008
|
Spécifie le format de données bitmap
indépendant
du périphérique (DIB, Device
Independent
Bitmap).
|
CF_PALETTE
|
0x0009
|
Spécifie le format de palette Windows. Chaque fois
qu'une application met des données dans le
presse-papier qui dépend d'une palette de
couleurs
ou l'assume, elle doit mettre aussi mettre la palette dans le presse-papier.
|
CF_PENDATA
|
0x000A
|
Spécifie le format de données de stylet
Windows, constitué de traits de stylet dans le cas de
logiciels prenant en charge l'écriture manuscrite.
|
CF_RIFF
|
0x000B
|
Spécifie le format de données audio RIFF
(Resource Interchange File Format). Les
données
audio ici sont plus complexes que celles du format wave standard CF_WAVE.
|
CF_WAVE
|
0x000C
|
Représente les données audio dans l'un des formats
standards wave.
|
CF_UNICODETEXT
|
0x000D
|
Spécifie le format de texte Unicode. Chaque ligne se
termine par une combinaison retour chariot / saut de ligne (CR-LF). Un
caractère zéro signale la fin des données.
|
CF_ENHMETAFILE
|
0x000E
|
Spécifie le format de métafichier
amélioré
(EMF, Enhanced Metafile Format) Windows.
|
CF_HDROP
|
0x000F
|
Un identifiant du type HDROP qui identifie
une liste de fichiers. Une application peut retrouver
les informations concernant les fichiers en
passant l'identifiant à la
fonction
DragQueryFile.
|
CF_LOCALE
|
0X0010
|
Spécifie le format de données de
paramètres
régionaux (culture) Windows.
|
|
CF_DIBV5
0x0017
Spécifie un objet contenant une structure
BITMAPV5HEADER suivie d'information sur l'espace de couleur
bitmap et de chiffres binaires bitmap.
20
Les formats de données les plus courants sont [11] :
· Texte (texte brut) : texte sans mise
en forme de police, couleur, images. Lorsqu'il est collé dans un
logiciel de traitement de texte, il s'affiche juste comme si vous aviez
tapé sur le clavier.
· RichText Format (Texte
formaté) : il contient les informations de mise en forme telle que la
police, la taille, la couleur...
· HTML (texte et les images
copiées à partir de navigateurs) : il contient aussi la mise en
forme et les tableaux.
· Bitmap : toutes les données
d'image sur le presse-papier utilise ce format, même si on copie une
image de type JPEG, GIF ou PNG à partir d'un navigateur web.
· Image : "autre" format d'image,
utilisé pour les dessins vectoriels faits avec un logiciel de CAO
(Conception Assistée par Ordinateur), ou l'outil de dessin dans
Microsoft Word.
· Pointeurs de fichiers : ceux-ci sont
présents sur le presse-papier lorsque vous "copiez" des fichiers ou des
dossiers dans l'Explorateur Windows. Notez que les fichiers eux-mêmes ne
sont pas vraiment sur le presse-papier ; c'est juste un «pointeur»
qui indique où se trouvent les fichiers et les dossiers à
copier.
2.1.1.2. Formats inscrits du presse-papier
De nombreuses applications fonctionnent avec des
données qui ne peuvent pas être traduites en un format standard de
presse-papier sans perte d'information. Ces applications peuvent créer
leurs propres formats de presse-papier. Par exemple, si à partir d'une
application de traitement de texte, on copie du texte formaté dans le
presse-papier en utilisant un format de texte standard, les informations de
formatage seront perdues. La solution sera d'enregistrer un nouveau format de
presse-papier tel que Rich Text Format (RTF) qui contiendrait en plus des
données, les différentes informations concernant le formatage
du
texte. La fonction
RegisterClipboardFormat15 permet d'enregistrer un
nouveau format de presse-papier.
2.1.1.3. Formats privés du presse-papier
Une application peut déclarer un format presse-papier
privé en définissant un identifiant dans la plage allant de
CF_PRIVATEFIRST à CF_PRIVATELAST.
[10]On utilise un format privé lorsque les données qu'on manipule
n'ont pas besoin d'être enregistrées dans le système. Les
ressources sollicitées lorsque le programme utilise un format
privé de presse-papier ne sont pas libérées
automatiquement après usage. On peut utiliser un message
WM_DESTROYCLIPBOARD pour libérer toutes les ressources
associées lorsque l'opération est terminée.
2.1.1.4. Formats multiples du presse-papier
Lorsqu'une application place une donnée dans le
presse-papier, elle devrait fournir des données dans autant de format
que possible. Ceci permet que la donnée stockée dans le
presse-papier puisse être utilisée par le plus d'application
possible.
Prenons par exemple un tableur (MS
Excel). On ne peut y copier que des tableaux. Ces données (tableaux)
sont probablement stockés dans le presse-papier dans un format de texte
basique, séparé par des virgules afin qu'un autre tableur ou une
application de gestion des bases de données puissent les utiliser.
Imaginons maintenant que l'on veuille exploiter les données dans une
application de traitement de texte. Il serait souhaitable de définir un
autre format de données plus adapté à cette circonstance
d'où la nécessité d'utiliser des formats de données
multiples dans le presse-papier.
Le format de presse-papier qui contient le plus d'information
doit être placé en premier sur le presse-papier, suivi des formats
moins descriptifs. Lorsqu'on souhaite coller une information à partir
d'une application, celle-ci récupère généralement
dans le presse-papier le premier objet dans le format qu'il reconnait. Les
formats du presse-papier sont classés du plus descriptif au moins
descriptif, le premier format reconnu est aussi le plus descriptif.
2.1.1.5. Formats de synthèse du
presse-papier
Le système convertit implicitement des données
vers certains formats de presse-papier. Par exemple si une application
sollicite une donnée dans un format qui n'est pas dans le
21
15 Fonction de la statique Clipboard du Framework
.NET
22
presse-papier, le système convertit un des formats
disponibles en format demandé. Les données sont converties comme
indiqué dans le tableau suivant :
Tableau 2.2 : formats de synthèse du
presse-papier [12]
Format de presse-papier
|
Format de conversion
équivalent
|
CF_BITMAP
|
CF_DIB
|
CF_BITMAP
|
CF_DIBV5
|
CF_DIB
|
CF_BITMAP
|
CF_DIB
|
CF_PALETTE
|
CF_DIB
|
CF_DIBV5
|
CF_DIBV5
|
CF_BITMAP
|
CF_DIBV5
|
CF_DIB
|
CF_DIBV5
|
CF_PALETTE
|
CF_ENHMETAFILE
|
CF_METAFILEPICT
|
CF_METAFILEPICT
|
CF_ENHMETAFILE
|
CF_OEMTEXT
|
CF_TEXT
|
CF_OEMTEXT
|
CF_UNICODETEXT
|
CF_TEXT
|
CF_OEMTEXT
|
CF_TEXT
|
CF_UNICODETEXT
|
CF_UNICODETEXT
|
CF_OEMTEXT
|
CF_UNICODETEXT
|
CF_TEXT
|
|
2.1.2. Fonctionnement du presse-papier
Pour qu'une application puisse envoyer des données
dans le presse-papier, il faut d'abord qu'elle réserve un espace
mémoire en utilisant les méthodes GlobalAlloc(), GlobalLock()
et GlobalUnlock(). Ensuite elle ouvre le presse-papier via la
méthode OpenClipboard() , le vide via la méthode
EmptyClipboard(), y place les données via la méthode
SetClipboard() et enfin ferme le presse-papier via la méthode
CloseClipboard().[13]

Figure 2.1 : Transferer les données au fornat
Text dans le presse-papier
Obtenir des données du presse-papier est encore plus
facile et implique d'ouvrir le presse-papier, déterminer lequel des
formats disponible dans le presse-papier est compatible à l'application
(cette opération est spécifique à l'application),
récupérer la donnée puis fermer le presse-papier.

Figure 2.2 : Récupérer les
données au format Text du presse-papier 2.1.2.1. Description du
processus d'extraction des données
L'extraction des données du presse-papier contenues
dans l'espace alloué par le système se déroule en quatre
(04) étapes (Figure 2.3). On identifie d'abord les
fonctions de user32.dll ou win32k.sys
permettant l'accès aux données du presse-papier. Les
fonctions décrites dans ces deux fichiers [14] fournissent un bon point
de départ pour choisir les fonctions les plus appropriées. Puis
on applique le Reverse Engineering16 sur ces fonctions pour
reconstituer la structure du presse-papier. Pendant l'étape suivante, on
ajoute la capacité de rechercher des structures (données dans un
format bien précis) au programme d'analyse de mémoire. Enfin,
23
16 Reverse Engineering : technique de
décompilation d'un programme informatique.
24
on recherche dans l'espace mémoire réservé
au presse-papier des données compatible à l'application et on
effectue la copie du presse-papier.
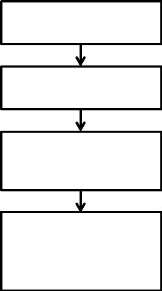
Reconstituer la structure du presse-papier
Coder les structures dans le
programme d'analyse
de
mémoire
Exécuter l'analyse de la
mémoire sur
l'espace
mémoire réservé au presse-
papier
Identifier les fonctions appropriées
Figure 2.3 : Reconstitution de la structure du
presse-papier par Reverse Engineering [8]
2.1.2.2. Les fonctions du presse-papier
Le presse-papier via la classe Clipboard expose 24
méthodes (Tableau 2.3). Ces méthodes permettent
d'obtenir des informations sur l'état du presse-papier, de le vider, d'y
envoyer des données, d'extraire son contenu etc. Chacune de ces
méthodes est sollicitées à un moment ou à un autre
du fonctionnement du presse-papier en fonction de l'opération encours.
La classe Clipboard est statique, on n'a donc pas besoin de l'instancier pour
pouvoir l'utiliser.
Tableau 2.3 : Fonctions de la classe Clipboard.
[14]
Nom
|
Description
|
Clear
|
Supprime toutes les données du Presse-papier.
|
ContainsAudio
|
Indique si le Presse-papier contient des données au
format WaveAudio.
|
|
25
ContainsData
|
Indique si le Presse-papier contient des données au
format spécifié ou qui peuvent être converties dans ce
format.
|
ContainsFileDropList
|
Indique si le Presse-papier contient des données au
format FileDrop ou qui peuvent être converties dans ce format.
|
ContainsImage
|
Indique si le Presse-papier contient des données au
format Bitmap ou qui peuvent être converties dans ce format.
|
ContainsText
|
Indique si le Presse-papier contient des données au
format Text ou UnicodeText, selon le système d'exploitation.
|
ContainsText(TextDataFormat)
|
Indique si le Presse-papier contient des données
textuelles au format indiqué par la valeur TextDataFormat
spécifiée.
|
Equals(Object)
|
Détermine si le Object spécifié est
égal au Object actif. (Hérité de Object.)
|
Finalize
|
Autorise Object à tenter de libérer des ressources
et d'exécuter d'autres opérations de nettoyage avant que Object
soit récupéré par l'opération garbage collection.
(Hérité de Object.)
|
GetAudioStream
|
Récupère un flux audio dans le Presse-papier.
|
GetData
|
Récupère des données du Presse-papier dans
le format spécifié.
|
GetDataObject
|
Récupère les données figurant dans le
Presse-papier système.
|
GetFileDropList
|
Récupère une collection de noms de fichiers du
Presse-papier.
|
|
26
GetHashCode
|
Sert de fonction de hachage pour un type particulier.
(Hérité de Object.)
|
GetImage
|
Récupère une image du Presse-papier.
|
GetText
|
Récupère des données textuelles du
Presse-papier dans le format Text ou UnicodeText, selon le système
d'exploitation.
|
GetText(TextDataFormat)
|
Récupère des données textuelles du
Presse-papier dans le format indiqué par la
valeur TextDataFormat spécifiée.
|
GetType
|
Obtient le Type de l'instance actuelle. (Hérité de
Object.)
|
MemberwiseClone
|
Crée une copie superficielle de
l'objet Object actif. (Hérité de Object.)
|
SetAudio( Byte ())
|
Ajoute un tableau Byte au Presse-papier dans le format WaveAudio
après l'avoir converti en Stream.
|
SetAudio(Stream)
|
Ajoute Stream au Presse-Papier dans le format WaveAudio.
|
SetData
|
Ajoute des données au Presse-papier dans le format
spécifié.
|
SetDataObject(Object)
|
Place les données non persistantes dans le Presse-papier
système.
|
SetDataObject(Object, Boolean)
|
Place les données dans le Presse-papier système et
spécifie si les données doivent rester dans le Presse-papier
lorsque l'utilisateur quitte l'application.
|
SetDataObject(Object, Boolean, Int32, Int32)
|
Tente de placer les données dans le Presse-papier
système le nombre spécifié de fois et dans le délai
spécifié entre les tentatives, en laissant éventuellement
les données dans le Presse-papier lorsque l'utilisateur quitte
l'application.
|
|
27
SetFileDropList
Ajoute une collection de noms de fichiers au Presse-papier dans
le format FileDrop.
|
SetImage
|
Ajoute Image au Presse-Papier dans le format Bitmap.
|
SetText(String)
|
Ajoute des données textuelles au Presse-papier dans le
format Text ou UnicodeText, selon le système d'exploitation.
|
SetText(String, TextDataFormat)
|
Ajoute des données textuelles au Presse-papier dans le
format indiqué par la valeur TextDataFormat spécifiée.
|
ToString
|
Retourne un String qui représente le Object actif.
(Hérité de Object.)
|
|
2.2. Limites du presse-papier de Windows
Bien qu'étant la plaque tournante de l'échange
des données entre les applications, le presse-papier de Windows est
quelque peu limité. En effet le presse-papier ne permet de sauvegarder
qu'une seule donnée à la fois. Par exemple, si nous copions de
suite deux textes différents dans le presse-papier, seul le dernier
texte à avoir été copié sera conservé. Il en
est de même pour les données de nature différente. Le
presse-papier est tout simplement un bloc de mémoire partagée, et
s'il peut contenir le même bloc de données
représenté dans une variété de formats (formats
multiple de presse-papier), il n'en demeure pas moins qu'il ne peut contenir
qu'un seul élément à la fois. Ceci pose un
réel problème dans la réalisation efficace de certaines
tâches.
2.2.1. Saisie d'un mémoire avec Latex
Lors de la saisie d'un mémoire avec Latex, certaines
structures sont régulièrement utilisées. Certaines phrases
font régulièrement leur apparition. Alors supposons par exemple
qu'une phrase ou une structure utilisée constamment soit
conservée dans le presse-papier de Windows après une
opération de copie pour une utilisation future ; et que pendant la
saisie une autre phrase ou structure devra être également
utilisé plusieurs fois. La première phrase ou structure qui
était sauvegardée dans le presse-papier sera
écrasée par la nouvelle. Il sera donc très avantageux de
pouvoir sauvegarder autant de phrases et structures dans le presse-papier en
vue d'un gain de temps de travail qui nous évitera à chaque fois
d'aller à une tierce page pour faire du « copier-coller ».
D'où la mise sur pied d'une application capable de
28
conserver plusieurs copies (c'est-à-dire conserver
autant de phrases et de structures que l'on souhaite dans le presse-papier)
à la fois.
2.2.2. Manipulation des images
Imaginons un infographe qui désire réaliser un
spot publicitaire constitué d'un ensemble d'images devant être
traité séparément avant d'être assemblées.
Supposons qu'au moment d'assembler ces dernières une opération de
coupage soit faite sur une des images traitées et qu'au moment de la
« coller » au lieu de faire un Ctrl+V on fait plutôt par
mégarde un Ctrl+C. Le presse-papier de Windows écrasera la
première image qui a été coupée et la remplacera
par la nouvelle copie faite par mégarde. Il est donc question pour cet
infographe de prendre un temps supplémentaire pour refaire nouvellement
les mêmes traitements sur cette image à cause d'une insuffisance
du presse-papier de Windows. D'où la nécessité d'une
application permettant de sauvegarder plus d'une image dans le presse-papier et
de pouvoir l'utiliser lorsque le besoin se fait ressentir.
Au regard de ces limites du presse-papier, il parait
nécessaire d'apporter une solution pour palier à cette
insuffisance. C'est en ce sens que de nombreuses applications de gestion du
presse-papier ont été développées.
2.3. Développement logiciel autour du
presse-papier
Certaines applications récentes fournissent
directement un gestionnaire de presse-papier qui supporte des transactions
multiples de « copier-coller ». Dans ces applications, le
presse-papier se comporte comme une pile. L'opération « copier
» ou « couper » place la donnée copiée ou
coupée au-dessus de la pile. L'opération « coller »
pointe vers la copie la plus récente. Cependant, certaines de ces
applications offrent la possibilité via une interface de consulter
l'historique des transactions, de choisir une copie plutôt qu'une autre,
d'éditer une copie, de changer de format et même d'effectuer une
recherche. La plupart de ces applications ne sauvegarde pas le contenu de leur
presse-papier. Le contenu de ce dernier est remis à zéro
lorsqu'on ferme l'application. Le tableau suivant présente une liste
non-exhaustive de quelques applications de gestion du presse-papier.
29
Tableau 2.4 : Liste de quelques applications de gestion
du presse-papier [15]
Une étude de quelques logiciels de gestion du
presse-papier de Windows nous a permis de réaliser une comparaison sur
la base des critères suivant : gestion des sessions/groupes, gestion des
sauvegardes, nombre maximum de copie sauvegardé, prise en charge de
l'édition du contenu, les fichiers, des dossiers, prise en main,
ergonomie, type de licence.
Ce qui a conduit au tableau comparatif ci-après :
30
Tableau 2.5 : Tableau comparatif de quelques logiciels
de gestion du presse-papier
Critères de
comparaison
|
3D Clipboard
|
ArsClip
|
CLIPTRAY 1.61
|
ClipMate
|
Gestion des Sessions/Groupes
|
Non
|
Mauvaise
|
Non
|
Excellente
|
Gestion des Sauvegardes
|
Oui
|
Oui
|
Oui
|
Oui
|
Nombre maximum de copie sauvegardé
|
99
|
999
|
500
|
Configurable
|
Prise en charge de l'édition du contenu
|
Oui
|
Oui
|
Non
|
Oui
|
Prise en charge des fichiers audio
|
Non
|
Oui
|
Oui
|
Oui
|
Prise en charge des fichiers vidéo
|
Non
|
Oui
|
Oui
|
Oui
|
Prise en charge des images
|
Oui
|
Oui
|
Oui
|
Oui
|
Taille maximum des images prise en charges
|
32767K
|
configurable
|
Non définie
|
Non définie
|
Prise en charge des fichiers
|
Non
|
oui
|
Oui
|
Oui
|
Prise en charge des dossiers
|
Non
|
oui
|
Oui
|
Oui
|
Prise en main
|
Facile
|
difficile
|
Très facile
|
Facile
|
Ergonomie
|
Moyenne
|
Pas bonne
|
Bonne
|
Bonne
|
Type de licence
|
Gratuit
|
Gratuit
|
Gratuit
|
Commerciale
|
Site web
|
3dclipboard.com
|
joejoesoft.com
|
cliptray.f2o.org
|
thornsoft.com
|
|
Pendant notre étude, nous avons constaté qu'il
y avait sur le marché des logiciels libres et payants pour la gestion du
presse-papier. Ces deux types de logiciels offrent des possibilités plus
ou moins semblable. Il nous a été donnée de constater par
contre que les logiciels payants offraient des possibilités beaucoup
plus évoluées pour ce qui est de l'édition de contenu, de
la gestion des sauvegardes, de la gestion des sessions/groupes. Une grande
partie de ces logiciels prennent également en charge plusieurs formats
de données, se rapprochant ainsi du presse-papier natif de Windows en
plus évolué.
L'idée nous est donc venue de concevoir et
d'implémenter un logiciel de gestion du presse-papier qui serait
à la fois libre et performant. Son cahier de charges sera
détaillé dans la section suivante.
2.4. Cahier des charges
L'objet de ce cahier des charges est d'une part de
définir la liste des fonctionnalités à développer
afin de disposer d'un logiciel permettant de gérer efficacement les
opérations du presse-papier.
Ce cahier de charges spécifie aussi la méthode
selon laquelle le logiciel devra être développé. Outils
logiciels, environnement de développement, documentation ...
2.4.1. Description de l'existant
Quelques travaux dans le sens de l'optimisation du
presse-papier en général et de celui de Windows en particulier
ont déjà été réalisé. Ceux-ci sont
brièvement décrits dans la section 2.3 de ce chapitre.
2.4.2. Expression des besoins
Cette section décrit les besoins (fonctionnels et non
fonctionnels) auxquels doit répondre l'application à
développer.
2.4.2.1. Besoins fonctionnels
Ils sont directement liés aux tâches que le
logiciel devrait pouvoir exécuter. Notre future application doit pouvoir
:
· Prendre en charge toutes les opérations impliquant
le presse-papier de Windows ;
· Gérer (créer, ouvrir, sauvegarder) les
collections et les groupes ;
· Conserver un certain nombre de copie dans chacune des
sessions.
2.4.2.2. Besoins non fonctionnels
Cette application doit être compatible avec plusieurs
plate-forme Windows (XP, Vista, Seven...) Elle doit aussi satisfaire aux
besoins suivant :
· Etre ergonomique17 ;
· Prendre en charge plusieurs formats de données
;
· Etre invisible : son fonctionnement ne doit pas
interférer avec celui des autres applications. Il doit être aussi
transparent que le presse-papier natif de Windows.
31
17 Facilité et souplesse pour l'utilisation.
32
2.4.3. Solution adopté
Le logiciel devant faire preuve de transparence et de
performance, le choix de la méthode d'analyse et du langage de
programmation ne doit pas être fait au hasard.
2.4.3.1. Choix de la méthode d'analyse et de
conception
Une méthode d'analyse et de conception a pour objectif
de formaliser les étapes préliminaires du développement
d'un système afin de rendre son développement plus fidèle
aux besoins du client. Il existe plusieurs méthodes d'analyse et de
conception à savoir : RACINES, MERISE,
NIAM, OMT (Object Modeling Technique),
Booch, UML etc. Chacune de ces
méthodes a été mise sur pied pour résoudre un
problème persistant (robustesse, maintenance, sécurité...)
dans l'industrie du développement logiciel. Le choix d'une
méthode d'analyse dépend essentiellement de la composition de
l'équipe. Il n'est pas conseillé de choisir une méthode
qui implique une formation préalable de la majorité des membres
du groupe. Afin de réduire le temps d'apprentissage d'une nouvelle
méthode, nous avons opté pour la méthode d'analyse UML.
2.4.3.2. Choix du langage de programmation
Il existe de nombreux langages de programmation qui
permettent d'écrire le code dans un langage devant être
compilé afin d'être compréhensible par l'ordinateur. Le
choix de ce langage est primordial, car de lui va dépendre le temps de
développement et la performance de l'application. Plusieurs langages
s'offrent à nous à savoir Java, C++, C, C#, PHP etc.
Notre choix porte sur le langage C# ceci pour les raisons
ci-après :
· C'est un langage développer par Microsoft et donc
parfaitement compatible.
· C'est un langage facile à prendre en main.
· Son IDE (Visual Studio), est suffisamment riche et
propose assez d'outils permettant de faciliter le développement
(coloration syntaxique, complétion automatique, compilateur
intégré, aide locale et en ligne, debugger très
performant).
· Il utilise le Framework.NET18 de
Microsoft.
· C'est un langage qui nous est familier.
18
Framework.NET:
composant logiciel pouvant être ajouté au système
d'exploitation Microsoft Windows afin de faciliter le développement des
applications
33
Une application de gestion du presse-papier doit primer par sa
performance, sa transparence et son ergonomie. De nombreux logiciels de gestion
du presse-papier ont été développés pour optimiser
le presse-papier de Windows. Malgré cela, ceux-ci (les versions libres)
restent peu performantes et pas ergonomique, d'où la
nécessité d'implémenter une solution libre, ergonomique,
transparente et performante. Le chapitre suivant détaille
l'implémentation des modules principaux de notre application.
34
DEVELOPPEMENT LOGICIEL
Analyser et implémenter une solution informatique a
toujours été une tâche rigoureuse. Elle requiert ainsi des
connaissances particulières sur des méthodes d'analyse, les
langages de modélisation et de programmation. Il sera d'abord question
pour nous dans ce chapitre de présenter très brièvement
l'outil d'analyse que nous avons utilisé pour implémenter les
modules principaux de l'application. Ensuite produire un organigramme de
fonctionnement de l'application et présenter les interfaces de
l'application. Enfin nous ferons l'implémentation proprement dite de ces
modules.
3.1. Analyse et conception
L'analyse et la conception d'une application font appel aux
méthodes et langages de modélisation orientée objet.
À chacune des différentes phases de la conception d'un logiciel
correspondent des problèmes ou des contraintes différentes.
Naturellement, ces niveaux ont fait l'objet de recherches
méthodologiques considérables depuis les années 80. Il en
résulte que de nombreuses méthodes de développement ou
d'analyse de logiciel ont vu le jour, chacune plus ou moins
spécialisée ou adaptée à une démarche
particulière, voire à un secteur industriel particulier (bases de
données, matériel embarqué, etc.). Celles-ci ayant
été développées indépendamment les unes des
autres, elles sont souvent partiellement redondantes ou incompatibles entre
elles lorsqu'elles font appel à des notations ou des terminologies
différentes.
De plus, à chaque méthode correspond un ou
plusieurs moyens (plus ou moins formel) de représentation des
résultats. Celui-ci peut être graphique (diagramme synoptique,
plan physique d'un réseau, organigramme) ou textuel (expression d'un
besoin en langage naturel, jusqu'au listing du code source). Dans les
années 90, un certain nombre de méthodes orientées objets
ont émergé, en particulier les méthodes :
· OMT (Object Modeling Technique) de James
RUMBAUGH
· BOOCH de Grady BOOCH
·
35
OOSE (Object Oriented Software Engineering) de Ivar
JACOBSON à qui l'on doit les Use Cases.
En 1994, on recensait plus de 50 méthodologies
orientées objets. C'est dans le but de remédier à cette
dispersion que les « poids-lourds » de la méthodologie
orientée objets ont entrepris de se regrouper autour d'un standard.
En octobre 1994, Grady Booch et James Rumbaugh se sont
réunis au sein de la société RATIONAL19 dans le
but de travailler à l'élaboration d'une méthode commune
qui intègre les avantages de l'ensemble des méthodes reconnues,
en corrigeant les défauts et en comblant les déficits. Lors de
OOPSLA'95 (Object Oriented Programming Systems, Languages and
Applications, la grande conférence de la programmation
orientée objets), ils présentent UNIFIED METHOD V0.8. En 1996,
Ivar Jacobson les rejoint. Leurs travaux ne visent plus à constituer une
méthodologie, mais un langage. Leur
initiative a été soutenue par de nombreuses
sociétés, que ce soit des sociétés de
développement (dont Microsoft, Oracle, Hewlett-Packard, IBM - qui a
apporté son langage de contraintes OCL -, ...) ou des
sociétés de conception d'ateliers logiciels. Un projet a
été déposé en janvier 1997 à l'OMG
(Object Management Group, qui s'est rendu célèbre pour
la norme CORBA20) en vue de la normalisation d'un langage de
modélisation. Après amendement, celui-ci a été
accepté en novembre 97 par l'OMG sous la référence
UML-1.1. La version UML-2.0 est la plus rependue et la plus utilisée
à nos jours. [16] C'est cette dernière que nous utiliserons pour
la modélisation de notre application. Nous pouvons résumer
l'historique de la constitution d'UML par la figure ci-dessous.
Figure 3.1 : historique de la constitution d'UML
[16]
19
http://www.rational.com/UML/resources.html:
site de RATIONAL (principal acteur de UML) 20
http://www.omg.org: Object
Management Group
36
3.1.1. Présentation de UML
UML est un langage graphique de modélisation. UML est
issue de la fusion en 1997 de trois langages de modélisation (les plus
utilisés à l'époque) à savoir : OMT (Object
Modeling Technique) de James RUMBAUGH, BOOCH de Grady BOOCH et OOSE (Object
Oriented Software Engineering) de Ivar JACOBSON comme nous l'avons
précisé plus haut. UML est aujourd'hui le standard de
modélisation orienté objet le plus utilisé en génie
logiciel, il est géré par l'OMG (Object Management Group) qui
fait évoluer le standard. Cette partie sera essentiellement basée
sur la présentation des vues et diagrammes principaux associés
à chaque vue.
3.1.2. Les vues et diagrammes d'UML
UML est un langage graphique, il est donc basé sur
l'utilisation des diagrammes (13 au total). Ces diagrammes sont
organisés en vues. Une vue étant un moyen de décrire un
système suivant un angle donnée. A chaque vue correspond des
diagrammes UML. UML modélise un système selon trois axes ou vues
à savoir : la Vue fonctionnelle, la vue
dynamique et la vue statique. On peut
observer ci-dessous à la figure 3.2 le schéma
modélisant ces trois axes (les diagrammes mis entre
parenthèses sont ceux qui retiendront notre attention dans chaque
vue).
FONCTION
(Diagramme des cas d'utilisation)
Diagramme des séquences

STATIQUE (Diagramme de classe) (Diagramme de
packages) Diagramme d'objets Diagramme de structure
|
DYNAMIQUE (Diagramme de séquence)
Diagramme d'Etats Diagramme d'Activité Diagramme de communication
|
|
Figure 3.2 : Trois Axes de modélisation UML
[17]
37
3.1.2.1. La vue fonctionnelle
Aussi appelé vue interactive (ou des interactions) ;
elle illustre les interactions entre les différents acteurs/utilisateurs
et le système, sous forme d'objectif à atteindre d'un
côté et sous forme chronologique de scénarios
d'interactions typiques de l'autre. Elle se compose de trois diagrammes :
le diagramme des cas d'utilisation, le diagramme des
séquences, diagrammes de communication.
Diagramme des cas d'utilisation :
Les diagrammes des cas d'utilisation permettent de
représenter les exigences du point de vue purement fonctionnel du
système à réaliser. Un cas d'utilisation fait
référence à un usage particulier du système
utilisé à une fin précise. A chaque cas d'utilisation doit
être associé un acteur (utilisateur humain, dispositif
matériel ou autre système) du système qui peut le
réaliser. Un cas d'utilisation peut être inclus dans un autre ou
étendre un autre. Les relations d'inclusion sont utilisées pour
indiquer que la réalisation d'un cas d'utilisation passe par la
réalisation préalable d'une autre tandis que la relation
d'extension quant à elle est utilisée pour indiquer qu'un cas
d'utilisation ajoute un comportement à un autre.
Présentation des cas d'utilisation de
l'application :
Pour mieux comprendre les cas d'utilisation que nous allons
présenter ci-dessous il est intéressant d'identifier chaque
acteur avec ses différents rôles pour enfin ressortir facilement
ces cas d'utilisation. Pour cela nous avons le tableau ci-dessous :
Tableau 3.1 : Relations entre les acteurs et leurs
rôles.
ACTEURS
|
ROLES
|
CAS D'UTILISATION
|
Utilisateur
|
Créer une collection
|
Gérer une
|
|
|
|
|
|
Créer un groupe
|
Gérer un
|
|
|
|
|
|
|
Utilisateur
|
Faire une copie
|
|
|
|
|
Renvoie le contenu du presse-papier à l'application
|
|
|
|
|
Supprime une collection
|
|
|
|
|
De ce qui précède il vient que nous avons trois
cas d'utilisation dont nous illustrerons les diagrammes dans la suite.
Cas d'utilisation 1 : Gérer Une
Collection.
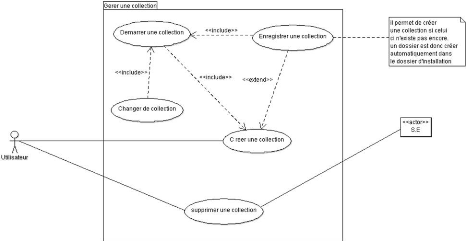
38
Figure 3.3 : diagramme de cas d'utilisation de la
Gestion d'une collection
39
Cas d'utilisation 2 : Gérer un groupe.
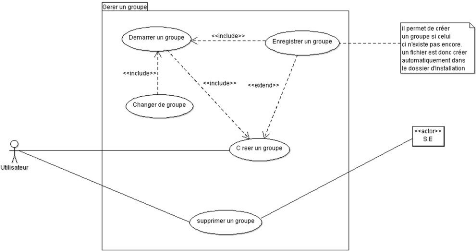
Figure 3.4 : Diagramme de cas d'utilisation de la
Gestion d'un groupe
Cas d'utilisation 3 : Gérer une
copie.
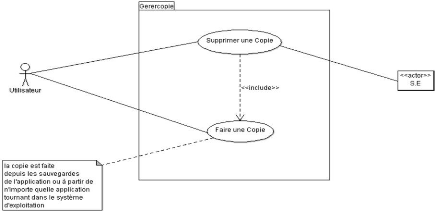
Figure 3.5 : Diagramme de cas d'utilisation de la
Gestion d'une copie
De ces trois cas d'utilisation on peut donc déduire le
diagramme de cas d'utilisation complet de l'application.
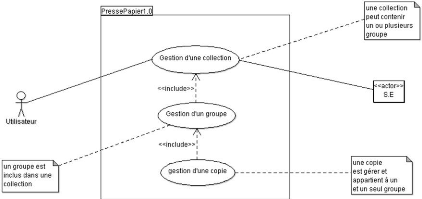
40
Figure 3.6 : Diagramme de cas d'utilisation globale de
l'application
Tous les cas d'utilisation étant recenser et
modéliser il est important de décrire l'aspect comportementale de
ces cas d'utilisation d'où la nécessité de la vue
dynamique.
3.1.2.2. La vue dynamique
La vue dynamique est orientée algorithme et
traitement, elle vise à décrire l'évolution (la dynamique)
des objets complexes du programme tout au long de leur cycle de vie. De leur
naissance à leur mort, les objets voient leurs états
changés et ce à cause de leur interaction avec d'autres objets du
programme. La vue dynamique est constituée des diagrammes
d'états, des diagrammes d'activité,
des diagrammes de séquence et des diagrammes de
communication.
Diagramme de séquence :
Un diagramme de séquence sert à la description
d'un scénario possible dans la description d'un cas d'utilisation d'une
fonction. Les diagrammes de séquences mettent en valeur les
échanges de messages (déclenchant des événements)
entre acteurs et objets (ou entre objets et objets) de manière
chronologique (l'évolution du temps se lisant de haut en bas). Chaque
colonne correspond à un objet (décrit dans le diagramme des
classes), ou à un acteur (introduit dans le diagramme des cas). La ligne
de vie de l'objet représente la durée de son interaction avec les
autres objets du diagramme. Notons que le même besoin dans un logiciel
peut être réalisé à travers plusieurs
scénarios, dans ce cas on aura donc plusieurs diagramme de
séquence pour ce même besoin.
41
Diagramme de séquence associé à
chaque cas d'utilisation :
Gérer une collection : une collection
est gérée par un utilisateur, le logiciel lui-même et le
système d'exploitation dans le quel tourne l'application.
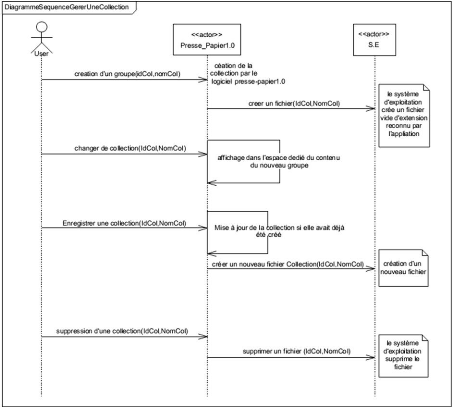
Figure 3.7 : Diagramme de séquence de la
gestion d'une collection.
42
Gérer un groupe : un groupe est
contenu dans une collection. Pour cela on suppose qu'une collection a
été démarrée. Le diagramme de séquence
ci-dessous est celui d'un groupe qui sera créé et contenu dans
une collection.
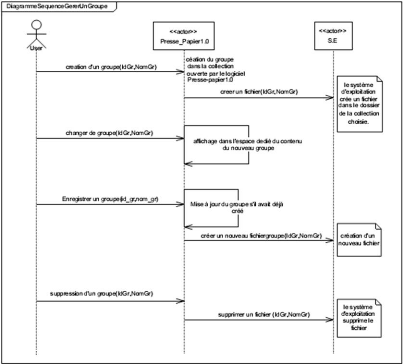
Figure 3.8 : Diagramme de séquence de la
gestion d'un groupe.
Gérer une copie : une copie est
contenue dans un et un seul groupe. Pour cela on suppose que le comportement de
la copie dont le diagramme de séquence est donné ci-dessous est
dans un groupe qui lui-même est dans une collection ; bien
évidemment le groupe et la collection étant ouverts.
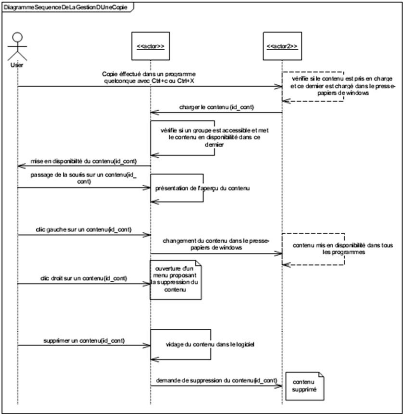
43
Figure 3.9 : Diagramme de séquence de la gestion
d'une copie.
Ces diagrammes de séquences nous ont permis d'avoir un
comportement détaillé de chaque objet de notre application et de
ressortir les différentes méthodes associées à
chacun d'eux. Tout ceci étant fait on peut donc présenter la vue
statique de notre application.
3.1.2.3. La vue structurelle ou statique
La vue structurelle présente la structuration des
données et identifie les objets/composants constituant le programme,
leurs attributs, opérations et méthodes, ainsi que les liens ou
associations qui les unissent. Elle regroupe également les classes
fortement liées entre elles en des composants les plus autonomes
possibles. Cette vue a pour objectif principal de modéliser la structure
des différentes classes d'une application orientée objet ainsi
que leurs relations [18]. La vue statique est
constituée des diagrammes de classes, des
diagrammes de
44
packages, des diagrammes
d'objets, des diagrammes de structure composite, des
diagrammes de déploiement.
· Le diagramme de classe :
Le diagramme de classe est le diagramme le plus
important dans la modélisation UML (il est le diagramme
prioritaire pour les outils de génération automatique de code).
Ces diagrammes sont représentés avec plus ou moins
d'exhaustivité selon que l'on est en phase d'analyse, de conception ou
d'implémentation. Avant de dessiner un diagramme de classe il est donc
important de tenir compte de la phase dans laquelle on se trouve ; ainsi donc
:
En phase d'implémentation on cherche à
décrire chaque classe, ses attributs et ses méthodes en pensant
déjà au code qui les implémentera tout en prenant en
compte les contraintes matérielles de temps d'exécution,
d'architecture, etc.
Présentation des concepts utilisés dans le
diagramme de classe
Les concepts élémentaires que nous
présentons dans cette section sont les plus employés pour la
réalisation de la vue structurelle d'un modèle UML et ceux que
nous avons utilisé pour la réalisation de notre diagramme de
classe.
Une classe :
De façon sémantique : En UML,
une classe définit la structure commune d'un ensemble d'objets et permet
la Construction d'objets instances de cette classe. Une classe est
identifiée par son nom. [18]
De façon graphique : Une classe se
représente à l'aide d'un rectangle sous forme de tableau à
une colonne et trois lignes ; qui contient le nom de la classe (première
ligne et éventuellement le nom du package auquel elle appartient)
viennent ensuite les propriétés (deuxième ligne) de la
classe puis ses opérations (troisième ligne). La Figure
3.11 illustre la classe nommée User.
Les propriétés ou attributs
Pour une classe, une propriété peut être
vue comme une forme simple d'association entre les objets (instances) de la
classe et un objet de classe standard. Il s'agit d'une variable qui est en
général propre à l'objet ou qui est peut être commun
à tous les objets de la classe (on parle alors de
propriété de classe). Dans un diagramme de classe les
propriétés de la classe sont notées de la façon
suivante :
<NomAttribut> : <Type> = [<valeur par
défaut>]. (Voir deuxième ligne Figure
3.11)
Les opérations
Une opération peut être vue comme une
tâche que doit effectuer l'objet lorsqu'on lui fait appel. En
programmation elle représente une méthode de la classe. Dans un
diagramme de classe la notation des opérations se fait de la
façon suivante :
<NomOpération> (ListeParamètres) :
<TypeRetour>(Voir troisème ligne Figure
3.11) On distingue deux catégories
d'opérations :
· celles qui modifient l'état de l'objet (ses
attributs) : ces opérations sont appelées modifiants ou
mutateurs.
· A l'opposé des opérations d'accès ou
accesseurs qui ne se contentent que de retourner la valeur d'une
propriété.
De ce qui précède on a donc la Figure 3.11
suivante :
User
IdUser : integer Nom : string
Creer( ) Demarrer( ) Changer ( )
|
|
Figure 3.11 : Représentation graphique d'une
classe
Les associations
Les associations représentent des relations entre
objets, c'est-à-dire entre des instances de classes. Aux
extrémités d'une association figure la multiplicité
(cardinalité) qui est une énumération sous forme
d'intervalle d'entiers positifs ou nuls indiquant le nombre d'objets qui
peuvent participer à une relation avec l'objet de l'autre classe dans le
cadre d'une association. Les multiplicités sont notées de la
manière suivante
1 : Obligatoire (un et un seul)
0..1 : Optionnel (0 ou 1)
0..* ou * : Quelconque
n..* : Au moins n
n..m : Entre n et m (n et m en entier)
I,n,m : I, n, ou m
45
Les multiplicités les plus utilisées sont : 1,*,
1..* et 0..1.
46
Ayant présenté de façon très
brève les concepts du diagramme de classe, et les informations acquises
lors de la réalisation des diagrammes de cas d'utilisation et de
séquence ; ces informations nous ont permis d'avoir le diagramme de
classe suivant :
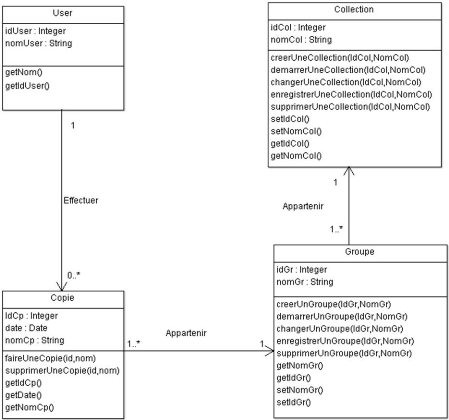
Figure 3.12 : Diagramme de classe de l'application
PressePapier1.0
· Le diagramme de package
Un package est un regroupement de classes présentant
des liens sémantiques entre elles. Le regroupement de classes en package
est une activité délicate mais d'une importance capitale dans les
logiciels de grande taille. Le regroupement de classes en packages les plus
indépendants possibles améliore la modularité du logiciel
et son développement par des équipes séparées (en
évitant les interactions) ou encore en utilisant les classes statiques
déjà développées et pouvant se mettre en relation
avec les classes de l'application qu'on veut
47
implémenter. La structuration d'un modèle en
package doit respecter deux principes fondamentaux à savoir : la
cohérence et l'indépendance.
La cohérence consiste à regrouper
les classes qui sont proches d'un point de vue sémantique.
Le principe de l'indépendance vise
à concentrer les efforts pour minimiser les relations entre les packages
(autrement dit les relations entre classes de packages différents).
Les classes de la Figure 3.12 étant en
relation avec les classes statiques du système d'exploitation dont un
héritage n'est possible il est vient donc qu'il soit possible de les
mettre en relation grâce aux packages. D'où les packages suivant
:
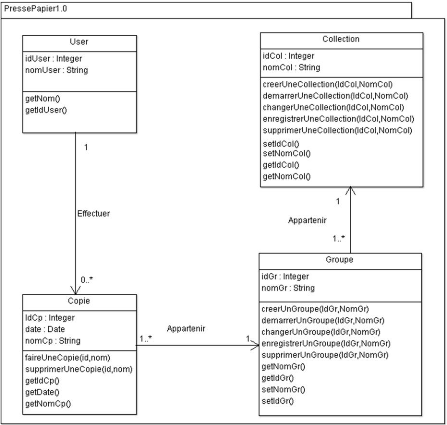
Figure 3.13 : Package de l'application
PressePapier1.0

Figure 3.14 : Package des classes du système
d'exploitation
48
Des Figure 3.13 et Figure 3.14
on obtient le diagramme de package suivant :
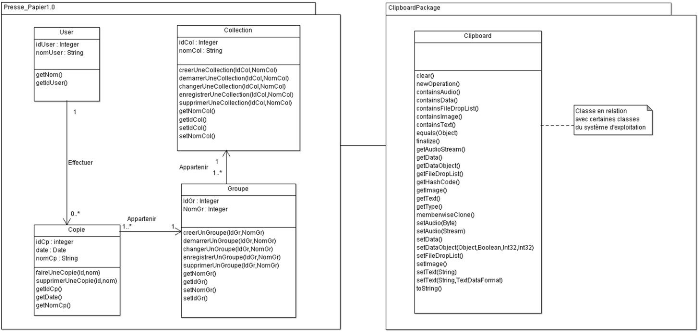
49
Figure 3.14 : Diagramme de package du
PressePapier1.0.
3.2. Schéma fonctionnel de l'application
La figure ci-dessous représente le schéma
fonctionnel de l'application. Son observation permet de comprendre les
différents processus mis en oeuvre pendant le fonctionnement de
l'application, de la détection d'un événement sur le
presse-papier (Clipboard) jusqu'à la sauvegarde de la copie.
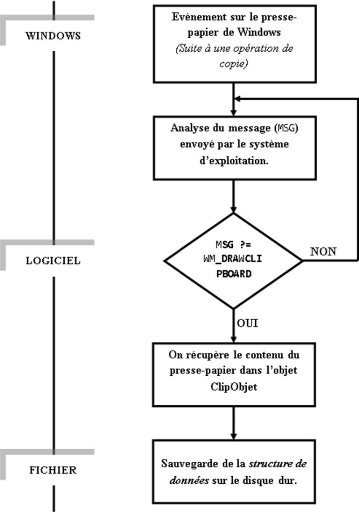
50
Figure 3.15 : Schéma fonctionnel de
l'application
51
Cette figure illustre le fonctionnement (en
arrière-plan) global de l'application. Celui-ci est masqué
à l'utilisateur par le biais des interfaces graphiques qui permettent
d'assurer l'ergonomie et la convivialité de l'application.
3.3. Les interfaces du logiciel
L'interface utilisateur (encore
appelé Interface Homme Machine - IHM) représente le moyen
d'interaction disponible sur un système informatique. Les IHM modernes
facilitent la communication entre l'application et l'utilisateur en offrant
toute une gamme de moyens d'action et de visualisation comme des menus
déroulants ou contextuels, des palettes d'outils, des boîtes de
dialogues, des fenêtres de visualisation, etc. Cette combinaison possible
d'options d'affichage, d'interaction et de navigation aboutie aujourd'hui
à des interfaces de plus en plus riches et puissantes. [19]
Les figures suivantes représentent les
différentes interfaces21 de notre application. Elles sont
susceptibles de changer pendant la phase d'implémentation.
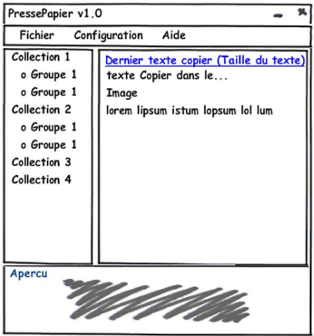
Figure 3.16 : fenêtre principale
21 Interfaces réalisé avec le logiciel
« Balsamiq Mockups ».
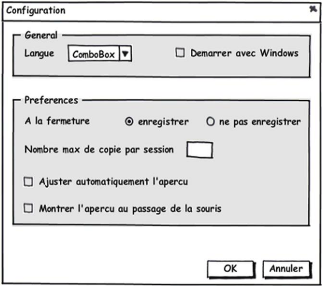
52
Figure 3.17 : fenêtre de
configuration
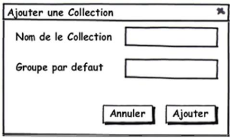
Figure 3.18 : fenêtre d'ajout d'une nouvelle
Collection
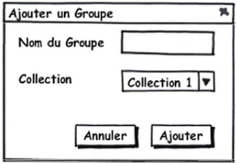
Figure 3.19 : fenêtre d'ajout d'un nouveau groupe
(de Copies)
53
Ces différentes interfaces représentent le point
de départ de l'implémentation de l'application en C# avec l'IDE
Visual Studio 2010.
3.4. Implémentation
L'implémentation (codage ou programmation) est «
la traduction dans un langage de programmation des fonctionnalités
définies lors de la phase de conception ». [19] Le codage de
l'application s'est fait suivant les principes des méthodes
agiles22 (XP dans notre cas). Dans cette section, nous
présentons d'abord l'environnement de développement Visual Studio
2010. Ensuite nous présenterons le langage de programmation
utilisé et les différents modules développés
enfin.
3.4.1. Environnement de développement et langage de
programmation
3.4.1.1. Présentation de Visual Studio 2010
Visual Studio est un ensemble complet d'outils de
développement permettant de générer des applications Web
ASP.NET, des Services Web XML, des
applications bureautiques et des applications mobiles. Visual Basic, Visual C#
et Visual C++ utilisent tous le même environnement de
développement intégré (IDE), qui permet le partage
d'outils et facilite la création de solutions à plusieurs
langages. Par ailleurs, ces langages utilisent les fonctionnalités du
.NET Framework, qui fournit un accès à des technologies
clés simplifiant le développement d'applications Web ASP et de
Services Web XML. [20]
3.4.1.2. L'architecture .Net
L'architecture .NET (nom choisi pour montrer l'importance
accordée au réseau, amené à participer de plus en
plus au fonctionnement des applications grâce aux services Web),
technologie appelée à ses balbutiements NGWS (Next Generation Web
Services), consiste en une couche Windows, ou plutôt une collection de
DLL librement distribuable et maintenant directement incorporée dans le
noyau des nouvelles versions de Windows.
Cette couche contient un nombre impressionnant (plusieurs
milliers) de classes (tous les langages de .NET doivent être
orientés objet), ainsi que tout un environnement d'exécution (un
run-time, ou couche logicielle si vous préférez) pour les
programmes s'exécutant sous contrôle de l'environnement .NET. On
appelle cela le mode géré ou managé (managed code). La
notion de run-time n'a rien de nouveau : les programmeurs en Visual Basic la
connaissent depuis longtemps. Les programmeurs Java connaissent aussi la notion
de machine virtuelle.
22 Comme précisé dans le cahier de
charge.
54
Néanmoins, même si le run-time .NET est, dans les
faits, une machine virtuelle, Microsoft a toujours soigneusement
évité d'employer ce terme, sans doute trop lié à
Java et à Sun (Standard University Network)... Un run-time fournit des
services aux programmes qui s'exécutent sous son contrôle. Dans le
cas de l'architecture .NET, ces services font partie de ce que l'on appelle le
CLR (Common Language Run-time) et assurent :
· le chargement (load) et l'exécution
contrôlée des programmes ;
· l'isolation des programmes les uns par rapport aux autres
;
· les vérifications de type lors des appels de
fonctions (avec refus de transtypages hasardeux) ;
· la conversion de code intermédiaire en code
natif lors de l'exécution des programmes, opération
appelée JIT (Just In Time Compiler) ;
· l'accès aux métadonnées
(informations sur le code qui font partie du code même) ;
· les vérifications lors des accès
à la mémoire (pas d'accès possible en dehors de la zone
allouée au programme) ainsi qu'aux tableaux (pas d'accès en
dehors de ses bornes) ;
· la gestion de la mémoire, avec ramasse-miettes
automatique ;
· la gestion des exceptions ;
· la sécurité ;
· l'adaptation automatique des programmes aux
caractéristiques nationales (langue, représentation des nombres
et des symboles, etc.) ;
· la compatibilité avec les DLL et les modules
COM actuels qui s'exécutent en code natif non contrôlé par
.NET.
Les classes .NET peuvent être utilisées par tous
les langages prenant en charge l'architecture .NET. Ces classes sont
regroupées dans des espaces de noms (namespaces) qui se
présentent en quelque sorte comme des répertoires de classes.
Quelques espaces de noms et quelques classes (quelques-uns seulement, parmi des
milliers) :
55
Tableau 3.1 : Les classes de l'architecture
.NET
Espace de noms
|
Description
|
Exemples de classes
|
System
|
Accès aux types de base Accès à la
console.
|
Int32, Int64, Int16 Byte, Char String Float, Double, Decimal
Console Type
|
System.Collections
|
Collections d'objets.
|
ArrayList, Hashtable, Queue, Stack,
SortedList
|
System.IO
|
Accès aux fichiers.
|
File, Directory,
Stream, FileStream,
BinaryReader, BinaryWriter TextReader, TextWriter
|
System.Data.Common
|
Accès
ADO.NET aux bases de données.
|
DbConnection, DbCommand, DataSet
|
System.Net
|
Accès au réseau.
|
Sockets
TcpClient, TcpListener UdpClient
|
System.Reflection
|
Accès aux métadonnées.
|
FieldInfo, MemberInfo, ParameterInfo
|
System.Security
|
Contrôle de la sécurité.
|
Permissions, Policy Cryptography
|
System.WinForms
|
Composants orientés Windows.
|
Form, Button, ListBox
MainMenu, StatusBar, DataGrid
|
System.Web.UI.WebControls
|
Composants orientés Windows.
|
Button, ListBox, HyperLink DataGrid
|
|
56
3.4.1.3. Présentation du langage de
programmation C#
Sous la demande de Microsoft, Anders Hejlsberg23 a
mis au point un système pour rendre le développement
d'application Windows et Web beaucoup plus aisé. [21] Une nouvelle
architecture est née suivit d'un langage qui devient aussi tôt la
référence et le principal langage pour Microsoft : c'est le
« C Sharp » ou encore C#.
C'est le langage star de la nouvelle version de Visual Studio
et de l'architecture .NET. Il est dérivé du C++. Il reprend
certaines caractéristiques des langages apparus ces dernières
années et en particulier de Java (qui reprenait déjà
à son compte des concepts introduits par Smalltalk24 quinze
ans plus tôt) mais très rapidement, C# a innové et les
concepts ainsi introduits sont aujourd'hui communément repris dans les
autres langages.
C# peut être utilisé pour créer, avec une
facilité incomparable, des applications Windows et Web. C# devient le
langage de prédilection d'
ASP.NET qui permet de créer des
pages Web dynamiques avec programmation côté serveur.
C# s'inscrit parfaitement dans la lignée C ?
C++ ? C# : [22]
· le langage C++ a ajouté les techniques de
programmation orientée objet au langage C (mais la
réutilisabilité promise par C++ ne l'a jamais été
qu'au niveau source) ;
· le langage C# ajoute au C++ les techniques de
construction de programmes sur base de composants prêts à l'emploi
avec propriétés et événements, rendant ainsi le
développement de programmes nettement plus aisé. La notion de
briques logicielles aisément réutilisables devient
réalité.
3.4.2. Présentation des différents
modules
L'application est constituée de modules qui assurent
chacun la réalisation d'une de ses fonctions. Ces modules assurent la
gestion des copies, des groupes, des collections, de la sauvegarde et de la
restauration des données.
3.4.2.1. La gestion de la copie
La gestion les copies représente la fonction principale
de l'application. Pouvoir récupérer le contenu du presse-papier
chaque fois qu'il est modifié est le défi qu'il a fallu relever
à ce niveau. Ce module est le plus important de l'application.
23 Né au Danemark en 1961, il est le concepteur
du C# et principal architecte chez Microsoft.
24 Langage de programmation
L'élément clé de ce module est la classe
ClipObjet. Cette classe expose des méthodes permettant de sauvegarder
les données contenues dans le presse-papier. L'application étant
inscrite comme visionneuse du presse-papier (voir figure
3.20), chaque fois que l'utilisateur effectue une
copie, Windows lui envoie un message qui est traité dans sa WndProc. Si
le message envoyé est WM_DRAWCLIPBOARD25, le contenu du
presse-papier est stocké dans une liste chainée de ClipObjet,
LinkedList<ClipObjet> (Voir figure 3.21).
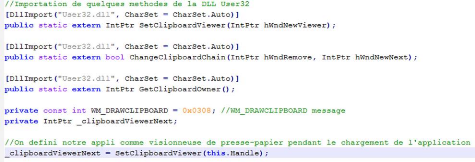
Figure 3.20 : inscription d'une application comme
visionneuse du presse-papier 3.4.2.2. La gestion des collections et des
groupes.
a. Gestion des Groupes
Un groupe est considéré dans l'application comme
étant un ensemble de copies réalisées par l'utilisateur.
Chacune des copies réalisées est stockée dans la
même structure à savoir une liste chainée dans laquelle
chaque nouvelle copie vient se positionner au-dessus de la pile.
L'implémentation de ce comportement est illustrée à la
Figure 3.21.
57
25 Message envoyé quand le contenu du
presse-papier change.
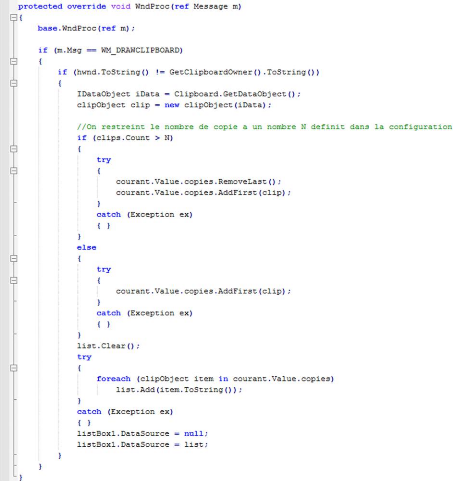
58
Figure 3.21 : sauvegarde du contenu du presse-papier
« Clipboard »
Ceci rend la structure d'un groupe assez intéressante.
En plus de contenir des propriétés permettant de l'identifier
dans la chaine de données de l'application, elle contient
également une liste chainée de copie. L'objet groupe est
représenté par la classe GroupeClass. Cette
classe expose les méthodes Del, DelCopie, AddCopie qui
permettent respectivement de supprimer le groupe, de supprimer une copie dans
un groupe et d'ajouter une copie dans un groupe.
59
b. Gestion des Collections
Une collection est considérée comme étant
un conteneur de groupe. Elle peut contenir un ou plusieurs groupes.
La structure d'une collection est assez simple. Elle est
représentée par la classe CollectionClass qui
contient des propriétés permettant de l'identifier. Cette classe
expose les méthodes Add et Delete qui permettent respectivement
d'ajouter et de supprimer une collection dans la chaine de données de
l'application. Il est important de noter que la suppression d'une collection
entraine la suppression de tous les groupes qu'elle contient.
3.4.2.3. La sauvegarde et la restauration des
données
Le module de gestion de la sauvegarde et de la restauration
des données est celui qui permet de conserver toutes les données
manipulées par l'application. Il permet aussi pendant le lancement de
l'application de restaurer les données présentes à la
fermeture. Sa mise en oeuvre a été facilitée par la
sérialisation et la désérialisation.
La sérialisation consiste à rendre un objet
susceptible d'être enregistré sur un disque ou d'être
transmis à une autre machine via une ligne de communication. La
désérialisation consiste à créer et initialiser un
objet à partir des informations provenant d'un fichier. [22]
Lorsqu'on ferme une application,
l'évènement Closing est déclenché
juste avant que l'application ne se ferme. On capture cet
évènement qu'on traite. Le traitement de cet
évènement consiste à sérialiser la chaine de
données manipulées par l'application.
Les données sauvegardées sont restaurées
pendant le chargement de l'application. Ceci est géré dans
l'évènement Load qui est déclenché
pendant le lancement de l'application. La mise en oeuvre de la
désérialisation permet de réaliser cette restauration.
Le travail ci-dessus a été réalisé
en trois grandes étapes. La première a consisté à
modéliser à travers les différents diagrammes d'UML les
cas d'utilisations, le comportement et obtenir ainsi la vue statique de
l'application. La deuxième étape a été
consacrée à la réalisation des interfaces de
l'application. La troisième a consisté à
l'implémentation des modules principaux de l'application. Ces trois
étapes nous ont permis d'avoir un prototype fonctionnel de notre
application dont les tests et le coût estimatif feront l'objet du
chapitre suivant.
60
TESTS ET GUIDE D'UTILISATION
Ce chapitre marquera la fin de notre travail. Nous y
présenterons d'abord les cas d'utilisation du logiciel et ses
différentes fonctionnalités à travers des interfaces.
Ensuite il sera question pour nous de donner les configurations minimales
requises pour l'utilisation du logiciel et enfin nous allons donner un
coût estimatif de la réalisation de cette application.
4.1. Présentation de l'application
4.1.1. Fenêtre principale
Dès le lancement de l'application, la fenêtre
suivante s'affiche.
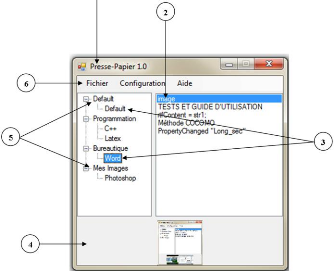
Figure 4.1 : fenêtre principale
1-
61
Barre de titre : elle contient le nom
d'application (PressePapier1.0)
2- Espace de visualisation des copies : elle
contient les différentes copies appartenant à un groupe. (Dans
notre cas, ces copies appartiennent au groupe Word.)
3- Groupes : contiennent un ensemble de
copies.
4- Espace d'aperçu d'une image : il
présente l'aperçu d'une image lorsque l'on clique sur une copie
correspondant à une image.
5- Collections : elles contiennent un ou
plusieurs groupes
6- Barre de menu : elle contient les
différents menus qui donnent accès à toutes les
fonctionnalités de l'application
4.1.2. Fonctionnalités de l'application
L'application permet de :
· Créer une nouvelle collection
· Créer un nouveau groupe
· Enregistrer les structures de données de
l'application
La création d'une collection, d'un groupe et
l'enregistrement de la structure de donnée de l'application se font
à partir du menu Fichier de l'application. La
Figure 4.2 présente le menu
Fichier.
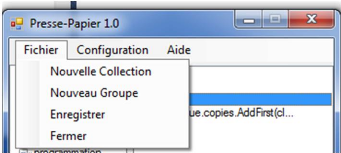
Figure 4.2 : présentation du menu «
fichier »
En cas de clique sur « nouvelle collection » ou
« nouveau groupe », les fenêtres présentées
respectivement à la Figure 4.3 et la Figure 4.4
s'affichent.
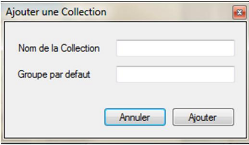
62
Figure 4.3 : Fenêtre de création d'une
nouvelle Collection
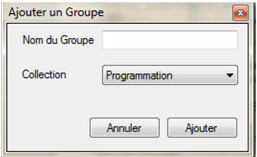
Figure 4.4 : Fenêtre de création d'un
nouveau Groupe
4.2. Configuration minimale
L'application nécessite pour fonctionner, les
caractéristiques minimales suivantes :
· 933 Mhz de processeur
· Une RAM de 256 Mo
· Une carte graphique de 32 Mo
· Un système d'exploitation Windows XP
· Un écran 10»
· La Framework .NET 2.0 ou plus.
4.3. Coût estimatif du projet
Cette section donne une estimation du coût total du projet
c'est-à-dire les coûts développement de l'application et
des équipements nécessaires pour sa réalisation.
63
4.3.1. Estimation du coût des équipements
Pour la réalisation de ce projet, nous avons eu
besoins des outils détaillés dans le tableau ci-dessous :
Tableau 4.1 : Détail des besoins pour la
réalisation du projet
Désignation
|
Prix Unitaire
|
Quantité
|
Prix Total
|
Hardware
|
Ordinateur Portable
|
450 000
|
2
|
900 000
|
Disque Dur externe
|
50 000
|
1
|
50 000
|
Clé internet
|
35 000
|
2
|
70 000
|
Software
|
Windows 7 Pro
|
150 594,9826
|
2
|
301 189,96
|
Visual Studio 2010
|
1 088 838
|
1
|
1 088 838
|
PowerAMC
|
84 838
|
1
|
84 838
|
Balsamiq Mockups
|
20 000,7
|
1
|
20 000,7
|
Autres
|
Connexion internet
|
60 000 (x2)
|
5 (mois)
|
600 000
|
|
Total
|
3 114 066,66
|
|
4.3.2. Estimation du coût de développement
4.3.2.1. Contexte de développement d'un
logiciel
Le développement d'un logiciel se fait
généralement dans un contexte où on a un client
(entreprise, particulier) qui demande à des ingénieurs en
informatique de lui développer un logiciel. La précision de ce
contexte est importante pour la compréhension des notions telles que le
coût de développement ou le contrat des besoins du client (la
typologie des logiciels).
4.3.2.2. Estimation de la charge
a. Définition des concepts clés pour la
compréhension de l'estimation de la charge
La charge est la quantité de travail
qu'une personne peut réaliser en jour/homme (J/h), en
mois/homme27 (M/h) ou en année/homme
(A/h). [23]
26 Les prix des software ont été
converti du dollar au F CFA en prenant 1$ = 502 F CFA.
27 C'est la charge sur un moi : en
général 20 jours.
64
La taille du projet se mesure à sa
charge. L'ordre de grandeur est donné selon les normes
ISO [23]:
|
|
Charge < 6 M/h
|
|
6 M/h <charge <12
M/h
|
|
12 M/h <charge <30
M/h
|
|
30 M/h <charge <100
M/h
|
|
100 M/h <charge
|
|
|
très petit projet
petit projet
projet moyen
grand projet
très grand projet
La durée du projet dépend de la
charge et du nombre de personnes infectées. Par exemple
60 M/h peuvent être fait [23] :
· par 1 personne pendant 5
ans
· Par 10 personnes pendant 6
mois
· Par 60 personnes pendant 1
mois.
b. Estimation de la charge
Barry W. Boehm propose en 1981 une méthode
(COCOMO : Constructive Cost Model) basée sur la
corrélation entre la taille d'un projet et sa charge en fonction des
hypothèses suivantes :
· Il est facile à un informaticien d'estimer le
nombre de lignes source.
· La complexité d'écriture d'un programme est
la même quel que soit le langage de programmation.
Les formules suivantes permettent d'estimer la charge et le
délai d'un projet :
Charge = a. (K isl)b Délai = c.
(Charge)d
Avec: K isl égale au nombre de milliers
de lignes sources.
Et les paramètres a, b, c et d
qui dépendent de la catégorie du projet.
Classification : [23]
Projet simple: < 50 000 lignes
Projet moyen: 50 000 < lignes <
300 000 Projet complexe: > 300 000 lignes
65
Tableau 4.2 : Paramètres associés au type
de projet [23]
Type de projet
|
Charge en M/h
|
Délai en M
|
|
a = 3.2
|
c = 2.5
|
Simple
|
|
|
|
b = 1.05
|
d = 0.38
|
|
a = 3
|
c = 2.5
|
Moyen
|
|
|
|
b = 1.12
|
d = 0.35
|
complexe
|
a = 2.8
|
c = 2.5
|
|
b = 1.2
|
d = 0.32
|
|
Selon la classification de la méthode
COCOMO il vient que notre projet corresponde à un projet simple au vue
de ses 1556 lignes de codes. Ainsi pour le calcul de la charge et du
délai nous avons les paramètres a = 3.2, b = 1.05, c =
2.5, d = 0.38 qui conduisent aux calculs suivants :
Charge = 3, 2 x 1, 5561,05 5M/h
Délai = 2, 5 x 50,38 5Mois
c. Cout du logiciel
L'unité de coût des logiciels s'exprime
traditionnellement en Mois/homme (M/h) ou en Année/homme (A/h) qu'il ne
faut pas confondre avec la durée du développement. Par exemple
l'emploi de trois ingénieurs sur une durée de
18 mois correspond à un coût de 54 M/h
ou 4,5 A/h. Le « volume » ou la «
taille » d'un logiciel est généralement exprimé en
nombre de lignes de code source ou d'instructions (en abrégé ls
ou kls pour millier de lignes source) que comporte le logiciel livré et
prêt à l'emploi. C'est ce paramètre, qui correspond
à la partie exécutable sur machine, qui a été
retenu comme indicateur principal de la quantité d'information contenue
dans le logiciel. La productivité d'un développement s'exprimera
en ls/h. Cet indicateur dénote la difficulté de fabrication du
logiciel. Ces unités peuvent avoir, selon la SGR
(Standish Group Report) un ordre de grandeur. On a :
· 1 H/An = 1350h,
· 1h ~ 50€,
· Productivité 2 à 5
lignes/h.
66
Ainsi notre logiciel correspond à une charge de
5M/h O, 4A/h ce qui nous donne une durée de
540 heures avec une productivité de 2 à 3 lignes de code par
heure. On a donc le tableau suivant :
Tableau 4.3 : Coût du
développement
|
Nombre de lignes
|
A/h
|
Heures
|
Coût
|
|
1 556
|
0,4
|
540
|
17 550 000 FCFA
|
Du coût estimatif de la recherche et celui du logiciel
on obtient un coût total estimatif de 20 664 066,66
FCFA.
Tout au long de ce chapitre nous avons d'abord
présenté les fonctionnalités du logiciel à travers
des interfaces, ensuite nous avons donné les configurations minimales
d'utilisation et enfin nous avons pu estimer le coût du projet.
67
CONCLUSION GENERALE
Ce mémoire rédigé dans le cadre des
travaux de fin d'étude du second cycle à l'ENSET de Douala en vue
de l'obtention du DIPET 2, nous a conviés à l'étude d'un
concept (presse-papier) régulièrement utilisé par la
population du village planétaire des TIC (Technologie de l'information
et de la communication) ; mais peu connu de ce grand public. D'où la
nécessité d'une application de gestion du presse-papier.
La mise sur pied d'une telle application permettra à
tout utilisateur de pouvoir faire des copies multiples et les utiliser lorsque
le besoin se fera ressentir, d'automatiser des tâches
régulièrement exécutées en vue d'une optimisation
du temps de travail.
Pour atteindre nos objectifs nous avons dû
procéder de manière méthodique. Ainsi une étude
préalable du noyau du système d'exploitation
Windows nous a permis de comprendre le fonctionnement du presse-papier au sein
d'un système d'exploitation en général et en particulier
au sein de Windows. Les connaissances acquises en matière d'outils
d'analyse tel qu'UML et de programmation orienté objet au cours de notre
formation à l'ENSET de Douala nous ont permis d'une part de
rédiger un cahier de charges et d'autre part d'implémenter notre
application.
Une fois la phase de développement achevée et en
dépit de tous les problèmes rencontrés, la
réalisation des essais a permis de confirmer à 95%
les attentes du cahier de charges.
Il sera intéressant dans le cadre des recherches
futures d'approfondir l'étude sur l'architecture du noyau de Windows et
du fonctionnement de ce dernier, d'étendre cette application sous
d'autres plates-formes et même de permettre une intégration dans
certaines applications régulièrement utilisées dans le
cadre de la duplication des données.
68
REFERENCES BIBLIOGRAPHIQUES
[1]
http://www.clubic.com/article-309932-1-remplacer-presse-papiers-windows.html
(Visité le 19-03-2013)
[2]
http://fr.wikipedia.org/wiki/Noyau_de_système_d'exploitation
(Visité le 24-11-2012)
[3] Jason Garms & AL-S & SM, Ressources
d'Expert
[4]
http://maclocal.free.fr/files/snow_leopard_noyau_64bit.html
(Visité le 10-12-2012)
[5]
http://www.t411.me/torrents/mac-osx-snow-leopard-v10-6-7
(Visité le 10-12-2012)
[6] Philipe Thierry, Présentation du
noyau de linux, projets pluridisciplinaire en équipe, 16 Novembre
2010
[7]
http://www.linuxcertif.com/doc/Compiler_le_Noyau_Linux/
(Visité le 10-12-2012)
[8] James Okolica, Gilbert L. Peterson,
Extracting the windows clipboard from physical memory, Digital Investigation 8
(2011)
[9] Charles Petzold, Programming Windows: The
definitive guide to the Win32 API, Fifth Edition, Microsoft Press, Dec 2001,
1290Pages
[10]
http://msdn.microsoft.com/en-us/library/windows/desktop/ms649013,
(visité le 30/01/2013)
[11]
http://www.clipboardextender.com/end-user-articles/using-the-clipboard,
(visité le 10/04/2013)
[12]
http://msdn.microsoft.com/en-us/library/windows/desktop/ms649013(v=vs.85).aspx#_
win32_Synthesize _Clipboard_Formats, (visité le 10/04/2013)
[13]
Microsoft.com How to add data to the
clipboard,
http://www.microsoft.com/windowsxp/
using/setup/tips/clip-book.mspx, (visité le 8/02/11).
[14] Charles Petzold, Programming Windows:
Fifth Edition. Microsoft Press 1999.
[15]
http://en.wikipedia.org/w/index.php?title=Clipboard_(computing)&oldid=531773363,
[visité le 30/01/2013]
[16] Olivier Sigaud : Introduction à la
modélisation orientée objets avec UML, support de cours «
Génie Logiciel et Programmation Orientée Objet » de l'ENSTA,
2004
69
[17] Pascal Roques : UML par la pratique,
5e Edition, EYROLLES ISBN 2-212-12014-1
[18] Xavier Blanc, Isabelle Mounier
avec la contribution de Cédric Besse : UML2
pour les développeurs, EYROLLES ISBN 2-212-12029-X
[19] Laurent AUDIBERT, UML 2, Édition
2007-2008
http://www-lipn.univ-paris13.fr/audibert/pages/enseignement/cours.htm
(Visité le 24/04/2009)
[20]
msdn.microsoft.com/fr-fr/library/vstudio/fx6bk1f4(v=vs.100).aspx
(Visité le 31/05/2013)
[21]
http://www.laboratoire-microsoft.org/articles/dev/csharp/
(Visité le 31/05/2013)
[22] Gérard Leblanc, C# et .Net Versions
1 à 4, Eyrolles 2009, ISBN : 978-2-212-12604-4
[23] DI GALLO Frédéric, Cours de
Génie Logiciel ; CNAM BORDEAUX 1999-2000
| 

