Recherche bibliographique portant sur la " Contribution à la réalisation du problème d'emploi de temps par une approche évolutionnaire "( Télécharger le fichier original )par Mohamed Boukerroucha Université M'Hamed Bouguerra Boumerdes Algérie - Master 2 2013 |

On peut ainsi établir un ordre sur les fonctions les plus connues, afin de les utilisées dans q l'estimation de la complexité (trouver g) : log(n) « (n) « n « n.log(n) « 2h « eh « n! Un algorithme polynomial est un algorithme dont la complexité est è(g(n)) où g est une fonction polynomiale et n dénote la taille des entrées. On dit qu'un problème P1 se réduit à un problème P2, par la réduction polynomiale, s'il existe un algorithme polynomial A construisant, à partir d'une donnée D1 de P1, une donnée D2 de P2 telle que la réponse pourD1 soit oui si et seulement si la réponse pour D2 est oui. On dit aussi qu'un problème P1 se réduit à un problème P2 par la réduction de Turing s'il existe pour résoudre P1 un algorithme A1 utilisant comme sous-programme un algorithme A2 résolvant P2 , de telle sorte que la complexité de A1 est polynomiale, quand on remplace A2 par une constante qui l'évalue. En basant sur les notions citées précédemment, on peut facilement présenter les différentes classes de complexité : - La classe P (Polynomial time). Engendre les problèmes pour lesquels on peut construire une machine de Turing déterministe dont le temps d'exécution est de complexité polynomiale. Les algorithmes qui résoudre ce type de problèmes sont qualifiés par efficaces. - La classe NP (Non-deterministic Polynomial time). Engendre les problèmes pour lesquels on peut construire une machine de Turing non déterministe dont le temps d»exécution est de complexité polynomiale. - La classe NP-complets. Engendre un sous ensemble de la classe NP qui contient les problèmes les plus difficiles et qui possèdent la propriété que tout problème dans NP peut être réduit en ceux-ci en temps polynomial. - La classe NP-difficile. Engendre les problèmes qui n'appartient pas à la classe NP. Mais, ont la propriété que tout problème dans NP-complet peut être réduit en ceux-ci par la réduction de Turing. I.2 Types des problèmesUn problème combinatoire est un problème où il s'agit de trouver une combinaison adéquate parmi un ensemble très grand de combinaisons, où chacune peut être évaluée et présente une solution admissible. La réponse à la question : Est-ce-que une solution x est la meilleure solution dans un domaine de recherche? engendre un type de problèmes dite problèmes de décision où 4 CHAPITRE I. LE PROBLÈME D'EMPLOI DE TEMPSla résolution se limite à la réponse par « oui »» ou par « non ». Par contre, un Problème de recherche est un problème dont sa résolution ne s'arrête plus au point de savoir si le problème admet ou non une solution, mais, l'algorithme doit être capable de trouver la solution en question si elle existe. Par conséquent, tout problème de décision peut être étendu à un problème de recherche. Un problème d'optimisation combinatoire est obtenu à partir d'un problème de recherche en associant d'une manière injective à chaque solution une seule valeur. Ainsi, l'algorithme de résolution consiste à trouver parmi l'ensemble des solutions celle qui maximise ou minimise au mieux la valeur associée. Le premier type des problèmes d'optimisation combinatoire englobe les problèmes d'optimisation sans contraintes, dont la recherche de la solution optimale peut être s'effectuer en tout point de l'espace de recherche. Ceci est permet car il y absolument aucune contraintes à respecter. Par contre, si un problème n'a pas d'objectif à optimiser, mais seulement un ensemble de contraintes à respecter, il est qualifié comme problèmes de satisfaction de contraintes. Un problème d'optimisation mono-objectif est défini comme la recherche de l'opti-mum pour un seule objectif, si c'été pour deux, on dit que c'est un problème quadratique et si c'été plus, ce qui forme un vecteur de fonctions objectif, on dit que c'est un problème multi-objectif. L'union de ces derniers types de problèmes engendre un type plus général appelé problèmes d'optimisation combinatoire multi-objectif avec contraintes. Lors de l'étude des problèmes, on commence par les classer, si on parvient à montrer qu'un problème est polynomial, alors on peut trouver un algorithme exact et efficace pour le résoudre en temps polynomiale. Par contre, si on parvient à montrer qu'il est NP-complet ou NP-difficile, alors la recherche d'un algorithme exact ne sera pas de première priorité, il est approprié de se concentrer sur des méthodes heuristiques. Une méthode heuristique est souvent définie comme une procédure exploitant au mieux la structure du problème considéré, dans le but de trouver une solution de qualité raisonnable en un temps aussi faible que possible. I.3 Le problème d'emploi de temps (TTP)Parmi l'ensemble des problèmes de planification d'horaire, on repère celui de l'emploi du temps qui semble être au premier moment très difficile. La notion de difficulté prend son sens --exclusivement dans cette section-- dans la réalisation manuelle de ce dernier, car il demande la participation de plusieurs personnes aptes et capables de prendre des décisions cruciales, qui peuvent se durer plusieurs jours afin de mettre en oeuvre un emploi de temps acceptable. Or, la modification d'une donnée du problème initial peut changer complètement la solution trouvée, et par fois sa demande de recommencer à zéro le même travail. 5 CHAPITRE I. LE PROBLÈME D'EMPLOI DE TEMPSCette difficultés explique pourquoi aujourd'hui on est besoin d'un ordinateur pour automatiser ces tâches et pour générer des emplois du temps efficaces dans un temps acceptable en adoptant des outils basés sur des algorithmes d'optimisation robustes. La description générale de ce problème est la suivante : « le problème de l'emploi du temps consiste à définir un certain nombre d'affectations qui permettent d'assigner plusieurs ressources (humaines, matérielles) sur une période de temps, tout en respectant certaines contraintes qui peuvent différer d'un problème à un autre suivant la spécification et les caractéristiques attendues de l'emploi du temps en question ». Les contraintes sont souvent classées en deux catégories : la première regroupe les contraintes dures, dont l'emploi du temps qui ne les respecte pas sera inacceptable. La seconde catégorie regroupe des contraintes dites de préférence, dont la satisfaction décide ce que doit être le bon emploi du temps, mais dont le non respect n'empêchera pas de générer un emploi du temps plus au moins acceptable. I.4 Classification des problèmes d'emplois de tempsSelon son cycles du vie, un emploi de temps peut être quotidien, hebdomadaire, mensuel ou annuel et selon le domaine de l'application, on qualifie ce dernier par le nom de domaine, comme par exemple : l'emploi de temps éducatif, de sport, de transport ou de communication. Selon la littérature, l'emploi de temps éducatif est le problème le plus étudié, et il est classé en deux : l'emploi de temps des cours et l'emploi de temps des examens. Il y a, naturellement, des différences significatives entre les deux. Par exemple, un certain nombre d'examens peuvent être programmé dans une salle, ainsi, un examen peut être passé dans plusieurs salles. Cependant, un seul cours habituellement doit être programmé dans exactement une seule salle. I.5 Une instance de problème TTPOn va consacrer cette section pour décrire une instance de problème d'emploi de temps éducatif car il est le plus étudié. Mais ce dernier s'exprime en plusieurs formes dont chaque forme est spécifique à l'environnement ou à l'institution qui en a besoin. on va donc choisir notre université (UMBB) comme source d'inspiration. Pour notre université, les responsables pédagogiques ont besoin chaque année d'établir une nouvelle planification pour les différentes promotions en essayant au mieux de satisfaire le bien des enseignants et des étudiants, et de respecter les contraintes imposées par l'adminis-tration et celles qui sont liées aux ressources. Le département d'informatique, par exemple, propose différentes formations, dont leurs programmes pédagogiques sont connus à priori. Ce programme précise les modules à suivre, leurs volumes horaires et quelques informations pédagogiques (répartition en cours, travaux dirigés, travaux pratiques). Selon les besoins pédagogiques et les ressources disponible, chaque formation est structurée en promotions, en sections, et en groupes. Le nombre d'étudiants par groupe en travaux dirigés(TD) est limité pour assurer un meilleur suivi des étudiants. 6 CHAPITRE I. LE PROBLÈME D'EMPLOI DE TEMPSLes enseignants interviennent selon leur discipline et leur domaine de compétence. Administrativement, les enseignants doivent assurer un nombre minimal d'heures qui est défini dans leur statut. Lorsqu'un enseignant est chargé d'un enseignement donné, il est tenu d'en respecter le volume horaire prévu par le responsable pédagogique. En cas d'absence, l'enseignant doit prévoir des séances de rattrapage. Il doit donc connaître précisément la disponibilité des ressources de sa séance. Cette organisation garantit que touts les étudiants qui suivent une même formation auront eu le même volume horaire d'enseignement. En résumé, les données de cette instance de problème sont les suivants :
L'affectation des modules, des enseignants et des locaux à des périodes est soumise à des contraintes qui diffèrent selon leurs priorités (l'intérêt que recouvre la satisfaction d'une contrainte ou sa violation).Une contrainte ne revêt pas nécessairement un aspect absolu (soit elle est vérifiée ou violée) mais peut être formulée sous forme d'un objectif qui doit être approché autant que possible. Partant de ces aspects, on peut regrouper les différentes contraintes en deux : - Les contraintes dures. Doivent être obligatoirement satisfait dans toutes les situations car la violation de l'une de ces contraintes rend l'emploi du temps inefficace :
- Les contraintes de préférence. N'exigent pas la vérification stricte, mais de s'ap-procher au mieux de l'objectif voulu :
Ces contraintes ne forment pas une liste exhaustive, d'autres contraintes peuvent être ajoutées force à une obligation exigée par l'administration, donc elle s'inscrit dans les contraintes dures, ou à un désire souhaiter par un enseignant qui s'inscrit dans les contraintes de préférences. 7 CHAPITRE I. LE PROBLÈME D'EMPLOI DE TEMPS
La mise en oeuvre d'un emploi de temps pour une journée est facile, car le nombre des combinaisons possible est infime. Cependant, un emploi de temps mensuel ou annuel dont le nombre de combinaisons est très grand, ça sera beaucoup plus compliqué. Lorsque des solutions sont connues auparavant, une négociation permet de sélectionner la solution pertinente. En effet, chaque acteur négociant pourra donner son opinion, les points d'accord serons immédiatement accepter et les points litigieux serons discutés afin de trouver des solutions de compromis. La difficulté de négociation augmente avec l'augmentation de nombre d'ac-teurs et plus particulièrement avec l'augmentation de nombre des solutions (combinaisons) admissibles, ainsi l'aspect combinatoire prend son sens et rend plus difficile la négociation. I.7 ConclusionLe problème de l'emploi du temps est un problème classique de la recherche opérationnelle qui trouve son application dans plusieurs domaines. La plupart des chercheurs ont consacré leurs recherches sur l'emploi de temps éducatif (examen ou cours) [22, 11], et la version la plus simple est celle de « classe-professeur »présenté par Werra en1985 [6]. Cette version se concentre sur les contraintes agissant seulement sur les conflits produits par l'affectation des classes et des professeurs. Cependant, d'autres contraintes peuvent être ajoutées pour augmenter l'efficacité de l'emploi, mais ceci augmente considérablement la complexité du problème. Le problème d'emploi de temps est un problème d'optimisation combinatoire de nature multi- objectif et de la classe NP-complet [4]. Pour ces raisons, il est considérer comme un repère pour tester les différentes méta-heuristiques. Une méta-heuristique est l'outil critique en termes d'algorithme utilisée pour résoudre le problème d'emploi de temps. Ces méthodes sont généralement de type stochastique itératif, permettant d'une manière intelligente de s'échapper de l'optimum local et de s'approcher vers l'optimum global. Selon la littérature, plusieurs approches méta-heuristiques ont été adaptées au problème d'emploi du temps : S.Elmohamed, P.Coddington et G.Fox ont utilisé le recuit simulé [20], par contre, A.Schaerf a utilisé la méthode tabou [3], la même méthode mais avec deux versions (avec ou sans la recherche local) a été utilisée par A.Colorni, M.Dorigo et V.Maniezzo. Les mêmes auteurs ont utilisés aussi une version d'un algorithme génétique [2]. D.Abramson et j.Abela ont proposé un algorithme génétique parallèle [5]. M.Chiarandini, M.Birattari, K.Socha et O.Rossi-Doria ont utilisé une multiple hybridations entre plusieurs méta-heuristiques, essentiellement la méthode tabou et le recuit simulé, afin de trouver la bonne configuration qui permet de résoudre au mieux le problème en 2006 [18]. Enfin, un groupe surnommé ASAP travaille dans ce contexte, ces membres ont utilisé la majorité des méta-heuristiques et ils ont fourni des résultats expérimentaux consternant les configurations (paramètres) qui nous amènera à des bonnes solutions [10, 11]. 8 Chapitre IIMETHODES D'OPTIMISATIONAfin d'améliorer le comportement d'un algorithme de recherche lorsque ils parcoure un espaces de solutions assez grand, on fait appel à des heuristiques qui ont l'aptitude de guider le processus de recherche pendant son exploration de l'espace de recherche, et de sélectionner la solution qui semble être optimales. Selon Feignebaum et Feldman (1963) « Une heuristique est définie comme une règle d'estimation, une stratégie, une astuce, une simplification, ou tout autre sorte de système qui limite drastiquement la recherche des solutions dans l'espace des configurations possibles ». Selon Shaw et Simon (1957) « Un processus heuristique peut résoudre un problème donné, mais n'offre pas la garantie de le faire ». Dans la pratique, certaines heuristiques sont visées à résoudre des problèmes particuliers. En revanche, une méta-heuristique se place à un niveau plus général, et intervient dans toutes les situations où on ne connaît pas d'heuristique efficace, ou lorsqu'il estime qu'il ne dispose pas du temps nécessaire pour en déterminer une. Selon I.H.Osman et G.Laporte (En 1996) « Une méta-heuristique est un processus itératif qui subordonne et qui guide une heuristique, en combinant intelligemment plusieurs concepts pour explorer et exploiter tout l'espace de recherche. Des stratégies d'apprentissage sont utilisées pour structurer l'information afin de trouver efficacement des solutions optimales, ou presque optimales ». Selon le site « metaheuristics.org »(2006) « Une méta-heuristiques est un ensemble de concepts utilisés pour définir des méthodes heuristiques, pouvant être appliqués à une grande variété de problèmes. On peut voir la méta-heuristique comme une boîte à outils algorithmique, utilisable dans la résolution des problèmes d'optimisation, et ne nécessitant que peu de modification pour qu'elle puisse s'adapter à un problème particulier ». 9 CHAPITRE II. METHODES D'OPTIMISATIONII.1 Classification des méta-heuristiquesLes méta-heuristiques n'étant pas, a priori, spécifiques à la résolution d'un problème particulier, et leur classification reste assez arbitraire. selon le nombre de solution que retient l'algorithme a chaque cycle on peut distinguer : - Les approches en trajectoire. qui partent d'une solution initiale s0 et s'en éloignent progressivement, pour réaliser un parcours progressif dans l'espace des solutions. Dans cette catégorie, on trouve : la méthode de descente, le recuit simulé, la méthode Tabou. . . etc. - Les approches en population. qui travaillent sur un ensemble de solutions, que l'on fait évoluer graduellement. L'utilisation de plusieurs solutions simultanément permet naturellement d'améliorer l'exploration de l'espace des configurations. Dans cette seconde catégorie, on recense : les algorithmes génétiques, les algorithmes de colonies de fourmi, la méthode d'évolution différentielle, la méthode GRASP. . . etc. selon les domaines d'inspiration on distingue ainsi : - Les approches inspirées de la sélection naturelle. - Les approches inspirées de la physique. - Les approches inspirées des insectes sociaux. - Les approches inspirées de réseau de neurones. - Les approches inspirées de système immunitaire. - ...etc. On peut également raisonner par rapport à l'usage que font les méta-heuristiques de la fonction objectif. Certaines la laissent telle quelle est, tandis que d'autres la modifient en fonction des informations collectées au cours de l'exploration. L'idée étant toujours de s'échapper de l'optima local, pour avoir davantage de chance de trouver l'optimum global. La recherche locale guidée est un exemple de méta-heuristique qui modifie la fonction objectif. Enfin, il faut distinguer les méta-heuristiques qui ont la faculté de mémoriser des informations à mesure que leur recherche avance, de celles qui fonctionnent sans mémoire, en aveugle, et qui peuvent revenir sur des solutions qu'elles ont déjà examiné. Le meilleur représentant des méta-heuristiques avec mémoire est la recherche Tabou, dans les sans mémoire, on trouve le recuit simulé. II.2 Exposition de quelques méta-heuristiquesII.2.1 La méthode de descenteLa méthode de recherche locale la plus élémentaire est la méthode de descente (Basic Local Search). Elle consiste à démarrer d'une seule solution s et à choisir une solution s' dans un voisinage de s, tel que s' améliore la recherche. 10 CHAPITRE II. METHODES D'OPTIMISATIONAlgorithm: BASIC_LOCAL_SEARCH 1 : générer la solution initiale(s) 2 : repeat 3 : Choisir s' dans V (s) 4 : if f(s') < f(s) then 5 : s ? s' 6 : until (f(s') = f(s)) II.2.2 Le recuit simuléLe recuit simulé (Simulated Annealing) est une méthode très ancienne, et peut être la première à mettre en oeuvre une stratégie d'évitement des minima locaux (Kirkpatrick, Gelatt, Vecchi ,1983). Elle s'inspire d'une procédure utilisée depuis longtemps par les métallurgistes, qui, pour obtenir un alliage sans défaut, chauffent d'abord à blanc leur morceau de métal, avant de laisser l'alliage se refroidir très lentement. Pour simuler ce système physique, on part d'une seule configuration, et on fait subir au système artificiel une modification élémentaire. Si cette perturbation a pour effet de diminuer la fonction objectif, alors elle est acceptée. Sinon, elle est acceptée avec la probabilité exp(ÄE T ) (LE :la perturbation et T :la température). Algorithm: SIMULATED_ANNEALING 1 : générer une solution initiale(s) 2 : Poser T ? T - 0 3 : repeat : 4 : Choisir aléatoirements' dans V (s) 5 : Générer r dans [0, 1] 6 : if r < exp(f(s)-f(s') T then 7 : s ? s' 8 : Mettre à jour T 9 : until (critère d'arrêt) II.2.3 La méthode tabouLes principes de la méthode tabou (Tabou Search) ont été proposés par Fred Glover en 1986, et elle est devenue très classique en optimisation combinatoire. A l'inverse du recuit simulé, TS examine un échantillonnage de solutions voisines et retient la meilleure même si elle n'est pas meilleure que la solution globale. Le danger est de tourner en rond (cycle) autour d'une gamme de solutions. Pour éviter ceci, on mettre à jour une liste appelée Tabou qui mémorise les dernières solutions visitées et qui interdit tout déplacement vers une solution de cette liste. Mais, le statu tabou, peut crée un autre danger qui consiste à bloquer le processus de recherche en rendant tout les mouvements tabou. Cependant, le critère d'aspiration permet certainement de remédier de cet inconvénient en acceptant un mouvement même si il est Tabou. 11 CHAPITRE II. METHODES D'OPTIMISATIONAlgorithm : TABOU_SEARCH 1 : générer une solution initiale(s) 2 : poser T ? Ø et s* ? s 3 : repeat 4 : Choisir s'qui minimise f dans VT(s) 5 : if f(s') < f(s*) then 6 : s* ? s' 7 : s ? s' 8 : until (critère d'arrêt) II.2.4 Les algorithmes génétiquesLes algorithmes génétiques (Genetic Algorithms) sont des algorithmes évolutionnaires les plus connues et les plus utilisés, ils sont présentés par Holland en 1975 et Goldberg en 1989. La particularité de ces algorithmes est qu'ils font évoluer des populations d'individus codés généralement par des chaînes de bits en utilisant des opérateurs d'évolution génétique (la mutation et le croisement). Le principe est de partir d'une population de p individus, on sélectionne ceux qui sont capable à se reproduire. On croise ensuite ces derniers, de façon à obtenir une population d'enfants, dont on peut faire muter aléatoirement certains gènes. La performance des enfants est évaluée, grâce à la fonction fitness, et on sélectionne, dans la population totale résultante, les individus autorisés à survivre, de telle manière que l'on puisse repartir d'une nouvelle population de p individus. Algorithm : BASIC_GENETIC_ALGORITHM 1 : generer(P0) 2 : repeat 3 : selection pour la reproduction 4 : croisement 5 : mutation 6 : selection pour le remplacement 7 : until (critère d'arrêt) II.2.5 Les algorithmes de colonies de fourmisLes algorithmes des colonies de fourmis (Ants System) sont inspirés de la nature des insectes (les fourmis), ils ont été proposés par Doringo au début des années 90. Leur principe repose sur le comportement particulier des fourmis qui, font évoluer une population d'agents, selon un modèle stochastique : lorsqu'elles quittent leur fourmilière pour explorer leur environnement à la recherche de nourriture, finissent par élaborer des chemins qui s'avèrent fréquemment être les plus courts pour aller de la fourmilière à une source de nourriture intéressante. Chaque fourmi laisse en effet derrière elle une traînée de phéromone à l'attention de ses congénères. Les fourmis choisissant avec une plus grande probabilité les chemins contenant les plus fortes concentrations de phéromones. Le premier algorithme conçu selon ce modèle était destiné à résoudre le problème du voyageur de commerce. Le principe consiste à lancer des fourmis artificielles, et à les laisser élaborer CHAPITRE II. METHODES D'OPTIMISATIONpas à pas la solution, en allant d'une ville à l'autre. Afin de ne pas revenir sur ses pas, une fourmi tient à jour une liste, disant quelle est similaire à celle de la liste taboue, qui contient la liste des villes déjà visitées. Algorithm : ANT_SYSTEM 1 : A ?ensemble dek fourmis 2 : repeat 3 : for i = 1 to k do 4 : ConstruireTrajet(i) 5 : end for 6 : MettreàJourPheromones() 7 : until (critère d'arrêt) Dans la procédure ConstruireTrajet(i),chaque fourmi construit une route en choisissant les villes selon une règle de transition aléatoire très particulière : Si P ij(t) est la probabilité qu'à l'itération t la fourmi k choisisse d'aller de la ville i à la ville j alors :
12 ôij(t) : Le taux de phéromone sur la route ij à l'itération t. çij : L'inverse de la distance séparant les villes i et j. á : paramètre contrôlant l'inférence du taux de phéromone sur le trajet ij â : paramètre contrôlant l'inférence de la distance sur le trajet ij. En d'autres termes, plus il y a de phéromone sur le trajet reliant deux villes, plus la probabilité que la fourmi emprunte ce trajet est grande. Lorsque toutes les fourmis ont construit une solution, la procédure MettreaJourPhero-mones() modifie les taux de phéromone ô sur les routes en fonction des trajets effectivement empruntés par les fourmis, selon la formule : Äô ij(t) = Q Lk(t) si le trajet ij est dans la tournée de la fourmi k. Q : est une constante, etL (t) :est la longueur totale de la tournée de la fourmi k. Donc plus la route suivie par la fourmi a été courte, plus la qualité de phéromone laissée derrière elle est grande. Pour éviter que des chemins ne se forme trop vite, et ne convergent trop rapidement vers des optima locaux, on introduit le concept d'évaporation des pistes de phéromone, au travers du paramètrep(0 < p < 1) dans la formule complète de mise à jour suivante : ôij(t + 1) = (1 - p).ôij(t) + Äôij(t). ( Äôij(t) = >-I x=1 Äôx ij et k le nombre des fourmis). L'algorithme de colonies de fourmi présenté si dessus est un algorithme de base qui peut s'adapter à d'autres problèmes que le voyageur de commerce, en attribuant une signification plus générale aux facteurs ô et ç. 13 CHAPITRE II. METHODES D'OPTIMISATIONII.2.6 La méthode GRASPLa méthode GRASP (Greedy Randomized Adaptative Search Procedure) est une Méta- heuristique développée à la fin des années 90 par Feo et Resende. Elle est adaptée aux problèmes dont les solutions se construisent pas à pas. Son algorithme contient deux phases : une phase pour la construction et une phase pour l'amélioration des solutions. La phase d'amélioration sera souvent faite grâce à une autre méta-heuristique. L'algorithme maintient à jour une liste de fragments de solutions possibles (RCL, restricted candidate list). La liste RCL est mise à jour avec des éléments sélectionnés en fonction d'une heuristique spécifique, adaptée au problème considéré et le choix d'un élément dans la RCL pour construire la solution est aléatoire. Algorithm: GRASP 1 : s*+- Ø 2 : repeat 3 : s'+- ConstruireSolution(s) 4 : Améliorer(s') 5 : if f(s') < f(s*) then 6 : s* +- s' 7 : until (critère d'arrêt) Algorithm : CONSTRUIRE_SOLUTION 1 : s +- Ø 2 : while s n'est pas complète 3 : RCL +- GenererCandidat(s) 4 : x +- ChoisirAuHasard(RCL) 5 : s+-sU{x} 6 : end 6 : return s II.2.7 La méthode d'évolution différentielleL'évolution différentielle (Differential Evolution) appartient à la classe des algorithmes évolutionnaires, elle a été conçue, dés son origine Storn en 1995, pour des problèmes continus et elle utilise comme source de variations aléatoires une différence pondérée entre deux individus sélectionnés au hasard. Le principe de cette méthode, consiste à crée un nouveau individu, en additionnant la différence pondérée entre deux individus à un troisième. Considérant un problème à D dimensions avec une population de N individus évoluant à chaque génération t, selon trois opérateurs conçu comme suit : - Mutation : un individu mutant vi,t+1 est produit à partir d'un individu xi,t en relation avec trois autres individus suivant cette formule : vi,t+1 = xr1,t + F.(xr2,tcentsxr3,t). r1, r2, r3 :des indices différents choisis aléatoirement F E [0, 2]: un nombre réel appelé facteur d'amplification il faut noter que plus la différence (xr2,tcentsxr3,t) est faible, plus la perturbation est petite. CHAPITRE II. METHODES D'OPTIMISATION- Croisement : l'individu xi,t est mélangé avec le mutant, produisant ainsi le vecteur test ui,t+1 suivant cette formule : ui,t+1 = EDj=1 .uji,t. Où :
ui,t+1 = r(j) E [0, 1] : la jeme évaluation d'une distribution aléatoire uniforme CR :la constante de croisement. rn(i) E {1, 2, ... , D} : un indice aléatoire assurant que ui,t+1 obtient au moins un élément de vi,t+1. - Selection : un individu est sélectionné si l'individu test ui,t+1 permet une amélioration de la fonction objectif par rapport à xi,t. un individu sélectionné participe à la prochaine génération, dans le cas contraire, il est uniquement retenu pour servir de parent lors de la prochaine génération. Algorithm : DIFFERENTIAL_ EVOLUTION 1 :Generer (P0) selon une distribution uniforme 2 : for t = 0 to T do //T générations 3 : for i = 0 to N do // N individus 4 : choisirAléatoire (xr1,t, xr2,t, xr3,t) 5 : creeMutant(vi,t, xi,t,xr1,t, xr2,t, xr3,t) // mutation 6 : creeIndividuTest(ui,t, vi,t, xi,t) //croisement 7 : if f(ui,t) < f(xi,t) then 8 : xi,t+1 <-- ui,t // selection 9 : else xi,t+1 <-- xi,t 10 : end for 11 : end for II.2.8 DiscussionEn général, l'efficacité des méthodes de recherche locale simples est très peu satisfaisante. D'abord, par définition, la recherche s'arrête au premier minimum local rencontré, c'est là leur principal défaut. Le recuit simulé présente l'avantage d'offrir des solutions de bonne qualité, tout en restant simple à programmer et à paramétrer. Il offre autant de souplesse d'emploi que l'algorithme de recherche local classique. Aarts, Korst et Laarhoven (1997) ont démontré que, sous certaines conditions de décroissance de la température, l'algorithme du recuit simulé converge en probabilité vers un optimum global lorsque le nombre d'itérations tend vers l'infini. La méthode Tabou est une méthode de recherche locale, et la structure de son algorithme de base est assez proche de celle du recuit simulé, avec l'avantage, d'avoir un paramétrage Simplifié. En revanche, la méthode Tabou exige une gestion de la mémoire de plus en plus lourde à mesure que l'on voudra raffiner le procédé en mettant en place des stratégies de mémorisation complexe. Les algorithmes génétiques sont coûteux en temps de calcul, puisqu'ils manipulent plusieurs I vij,t+1 si (r(j) < CR ou j = rn(i)) xij,t si (r(j) > CR et j =6 rn(i)) 14 15 CHAPITRE II. METHODES D'OPTIMISATIONsolutions simultanément. C'est le calcul de la fonction de performance qui est le plus pénalisant, et on optimise généralement l'algorithme de façon à éviter d'évaluer trop souvent cette fonction. Le grand avantage des algorithmes génétiques est qu'ils parviennent à trouver de bonnes solutions sur des problèmes très complexes, où un grand nombre de paramètres entrent en jeu, et où l'on a besoin d'obtenir de bonnes solutions en quelques itérations. Les algorithmes de colonies de fourmis offrent beaucoup de souplesse, et il est possible de les adapter à tous les grands problèmes combinatoires classiques. En effet, ils ont été appliqués avec succès sur les problèmes d'affectation, de routage et de planification, et ils ont été la source d'inspiration de nouvelles méta-heuristiques. La méthode GRASP est relativement simple à programmer, et permet d'améliorer les résultats d'une simple recherche locale. Elle permet également de faire intervenir une heuristique spécialisée. Elle ne nécessite que peu de paramétrage : la taille de la liste, qui permet d'équi-librer la quantité d'adaptabilité (l'heuristique) et le facteur stochastique. Elle est en revanche moins performante que d'autres méta-heuristiques, du fait de son absence de mémoire : comme avec une recherche locale simple, rien ne garantit que l'algorithme ne fait pas des cycles et retomber sur les mêmes minima locaux. La méthode de l'évolution différentielle utilise les mêmes Opérateurs que les algorithmes génétiques. La différence principale en construisant de meilleures solutions est que les algorithmes génétiques se fondent sur le croisement tandis que le DE se fonde sur l'opération de mutation, cette opération principale est basée sur la différence des paires de solutions aléatoirement prélevées dans la population. II.3 Les algorithmes évolutionnairesLes algorithmes évolutionnaires sont des algorithmes d'optimisation stochastiques itératifs inspirés de la théorie darwinienne de l'évolution naturelle. Selon Darwin, les individus les plus compétant survivent à la sélection naturelle et se reproduisent d'une génération à une autre. Par analogie, l'évolution artificielle se traduit par un processus itératif de recherche de l'optimum dans un espace de recherche. II.3.1 Terminologie spécifique aux EAsUne solution possible à un problème est un point de l'espace de recherche, ce point est nommé individu, l'ensemble des individus constituent une population. La fonction objectif à optimiser est appelée fonction de performance (fitness en anglais), le calcul de cette fonction est appelé évaluation. Une Génération Correspond à une population en une seule itération. Le processus itératif de recherche des individus optimaux est appelé une évolution. Les Opérateurs de variation sont utilisés pour générer de nouveaux individus, il existe deux opérateurs: le croisement, qui consiste à échanger des composants entre deux individus et la mutation qui consiste à modifier un ou plusieurs composants d'un individu. Le choix des individus est appelé sélection, elle est basée généralement sur la valeur de fitness. La formation d'une nouvelle génération à partir des parents et des enfants consiste à les remplacer par ceux qui sont sélectionnés. 16 CHAPITRE II. METHODES D'OPTIMISATION
Figure II.1 - Principe de fonctionnement d'un AE selon Schoenauer 2003). II.3.2 Analyse de processus de recherche des AEsLa première étape est l'initialisation, elle est basée sur un tirage aléatoire dans le domaine de recherche pour choisir un nombre fini d'individus p qui forment la population initiale P0. Après l'évaluation de la population initiale, quelques individus sont choisis lors de l'étape de lasélection. L'application des opérateurs de variation permet de créer un nouvel ensemble d'individus, appelé population d'enfants. Dans l'étape de remplacement, les enfants sont évalués et intégrés avec leur parents afin de décider lesquels d'entre eux vont remplacer certains parents pour créer une nouvelle génération. Pour garantir l'efficacité d'un algorithme, il est important de trouver un facteur d'équilibre entre deux techniques : L'exploration et l'exploitation. L'exploitation (l'intensification) des meilleurs individus consiste à chercher dans leurs voisinages des individus qui sont encore performants. Cette technique peut orienter rapidement la recherche vers un optimum local. Pour s'échapper de ce dernier et orienter l'algorithme vers d'autres régions prometteuses (préserver la diversification génétique) on fait appel à l'exploration (diversification) (voir figure II.1) . II.3.3 Procédures de sélectionLors de la sélection, on choisit les meilleurs individus de manière déterministe ou aléatoire: - Sélection déterministe (élitiste).On sélectionne les meilleurs individus (au sens de leur fitness). Les individus les moins performants sont totalement éliminés de la population, et le meilleur individu sont toujours sélectionné on parle alors d'élitisme. - Le tirage à roulette.Une méthode stochastique, qui a été introduite par Holland et qui consiste à attribuer à chaque individu une probabilité d'être sélectionné proportionnellement à sa fitness. La boule est lancée dans la roulette (c'est une roulette artificielle) et l'individu représentant le secteur dans le quel la boule finit sa course sera choisi. - La sélection par tournoi.Une méthode stochastique, qui consiste à planifier des tournois entre deux ou plusieurs individus et le meilleur est sélectionné. La taille du 17 CHAPITRE II. METHODES D'OPTIMISATIONtournoi T est donnée par le nombre de solutions retenues lors de cette procédure. Une grande valeur de T augmente les chances de sélectionner les meilleurs individus, alors qu'une petite valeur de T donne aux individus moins performants une chance d'être sélectionnés. II.3.4 Les schémas d'évolutionLa sélection et le remplacement sont des opérations complémentaires qui constituent un moteur d'évolution. Selon la littérature, on distingue trois types : - Les algorithmes générationnels. A chaque génération, N parents sont sélectionnés par l'algorithme en utilisant une méthode de sélection stochastique pour donner naissance à exactement N enfants en appliquant les opérateurs de variations. Les enfants remplacent par la suite leurs parents lors de la procédure de remplacement déterministe. - Les algorithmes stationnaires (steady-state). Un seul enfant est généré à chaque génération en utilisant un ou deux parents sélectionnés généralement par tournoi. Après évaluation de l'enfant, ce dernier est intégré dans la population, afin de remplacer un parent en utilisant un tournoi inversé. - La stratégie d'évolution ((u(+ ; )ë)-ES).On distingue deux schémas et dans les deux cas, l'étape de sélection est un tirage uniforme (il n'y a pas de sélection au sens darwinien). À partir d'une population de taille u , ë enfants sont générés par application des opérateurs de variations. L'étape de remplacement est alors totalement déterministe. Dans le schéma (u; ë), les meilleurs u enfants deviennent les parents de la génération suivante, alors que dans le schéma(u + ë), les meilleurs des u + ë parents plus enfants sont les parents de la génération suivante. II.4 Notion préliminairesUn problème d'optimisation qui possède une seule fonction objective est un problème mono-objectif et celui qui possède plusieurs est un problème Multi-Objectif. Selon le problème à traiter, un ensemble de contraintes de type égalité ou inégalité doivent être respectées au cours d'optimisation. La forme générale des problèmes d'optimisation est donnée par le système suivant: ? ????? ????? min/max fm(x) (m=1,2,.. . ,M) sc
g (L) x = (x1, x2, ..., xn) : est un vecteur de n variables de décision. x (L) Les fonctions gj et hk sont les fonctions contraintes. Le vecteur fm(x) = (f1(x), f2(x), ..., fM(x))est le vecteur objectif. Chaque fonctions objectif est soit à maximiser ou à minimiser selon le problème à traiter. Une solution x qui ne satisfait pas la totalité des contraintes est une solution infaisable. L'ensemble des solutions faisables constitue la région faisable appelée S. 18 CHAPITRE II. METHODES D'OPTIMISATION
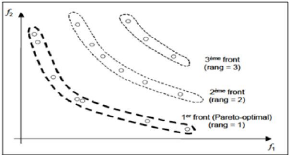
Figure II.2 - front de Parito . II.4.1 Le principe de dominanceCe principe est utilisé pour comparer deux solutions. On dit qu'une solution x domine une solution y si x est jugée la plus performante que y. Formellement, et pour un problème de minimisation, les deux conditions suivantes doivent être vérifiées : ( Vm E {1, 2, 3, ..., M} : fm(x) = fm(y) m E {1,2,3,...,M} : fm(x) < fm(y) Selon la littérature il y a quatre types de dominance: - Dominance stricte. Vm E {1, 2,3, ..., M} : fm(x) < fm(y) - Dominance faible. Vm E {1, 2,3, ..., M} : fm(x) = fm(y) - E-dominance EVm E {1, 2,3, ..., M} : E.fm(x) = fm(y) - E-dominance additive. EVm E {1, 2,3, ..., M} : fm(x) = E + fm(y) Les solutions qu'on ne peut pas les comparer deux à deux si on utilise le principe de dominance forment l'ensemble des solutions non dominées, appelé front de Pareto. (voir figure II.2) II.4.2 Les indicateurs de PerformancePlusieurs indicateurs de performance ont été proposés dans la littérature, leur but été d'étudier la qualité des algorithmes à proposer. Quelques indicateurs s'intéressent seulement à la diversité ou à la convergence au front de Pareto. - Indicateur d'Hyper-volume. Permet de mesurer le volume du parti faiblement dominée par un ensemble de point A. Pour calculer ce volume, il faut un point ou un ensemble de points de références R. Cet indicateur est noté I- H tel que : I- H(A) = I- H(R) - I- H(A). La qualité de l'algorithme augmente vers la diminution de la valeur de I- H. - Indicateur Epsilon.Il y a deux versions multiplicative et additive qui sont basées sur la notion de l'E-dominance. La forme binaire multiplicative de l'indicateur epsilon, notée I~(A, B) calcule la valeur minimum du facteur E par laquelle chaque point dans B peut être multiplié, pour que l'ensemble résultant de cette transformation soit faiblement dominé par A. 19 CHAPITRE II. METHODES D'OPTIMISATION
Figure II.3 - Rand de Parito . I(A, B) = inf(?R){Vz2 E B, z1 E A : z1 < z2} Où z représente un vecteur objectif et < la relation de l'epsilon-dominance multiplicative. De la même façon un indicateur un-aire d'un ensemble A, I(A) peut être défini comme suit : I(A) = I(A, R). Où R représente un ensemble de solutions de Référence. Par analogie, l'indicateur epsilon additif peut être obtenu en remplaçant la relation I par I+ . II.4.3 Procédures de comparaison et de classementPlusieurs procédures de comparaison et de classement des individus ont été proposées. Elles sont basées soit sur la dominance comme le rang de Pareto et le Strength, soit sur la densité ou sur les indicateurs de performance comme le critère d'encombrement, le critère du kime voisin et le critère de contribution à l'hyper-volume. - Rand de Pareto.Consiste à déterminer à chaque étape i les d'individus non dominés d'un ensemble A (sauf les individus qui ont déjà un rang) et de les attribuer le rang i qui doit être incrémenté à chaque étape. (voir figure II.3) - Le Strength.Chaque individu domine un nombre fini d'individu, ce nombre représente le Strength qui doit être attribué à celui-ci et qui est la base de classement. - Le critère d'encombrement. La distance de crowding d'une solution i se calcule en fonction du périmètre formé par les solutions du même front les plus proches de i sur chaque objectif. Le principe est de tri les solutions selon chaque objectif dans un ordre ascendant. Ensuite, pour chaque objectif, les individus possédant les valeurs limites (la plus petite et la plus grande valeur de fonction objective) se voient associés à une distance infinie. Pour les autres solutions intermédiaires, la distance de crowding égale à la différence normalisée des valeurs de fonctions objectives de deux solutions adjacentes. Ce calcul est réalisé pour chaque fonction objective. Le critère d'encombrement d'une solution est calculée en sommant les distances de crowding corresponds à chaque objectif. [15](voire figure II.4). 20 CHAPITRE II. METHODES D'OPTIMISATION
Figure II.4 - Crowding distance. - Le critère du kime voisin.Le critère de densité est défini comme étant l'inverse de la distance au kime point voisin. Plus précisément, pour chaque individu i, les distances le séparant de tous les autres individus j de la population sont calculés et ordonnés dans une liste. Le kime élément correspond à la distance recherchée dénotée ók i . La valeur de k est définie comme étant la racine carrée de la taille de l'ensemble des individus. - Le critère de contribution à l'hyper-volume.Le critère de contribution à l'hyper-volume repose sur l'utilisation de l'indicateur de l'hyper-volume. Ce critère mesure la qualité d'un point en calculant sa contribution à l'hyper-volume de l'ensemble de la population A. La mesure de la contribution d'un individu a à l'hyper-volume d'une population A est donnée par : ÄI- H(a, A) = I- H(A) - I- H(A \ a) Il est possible d'utiliser les indicateurs de performance cités précédemment comme mesure de comparaison entre individus. L'utilisation d'un indicateur évaluant la convergence et la diversité des individus en même temps (Indicateur de l'hyper-volume, indicateur epsilon) permet de considérer une mesure unique pour établir un ordre total dans l'ensemble des individus de la population. II.5 ETAT DE L'ART: (MOEAs)Nous présenterons dans cette section l'état de l'art des algorithmes évolutionnaire multi- objectif en se focalisant seulement sur les algorithmes de deuxième génération, qui utilisent des approches élitistes et manipulant une population secondaire externe. Les trois premiers algorithmes utilisent des schémas d'évolution stationnaire dont : l'algo-rithme SPEA2 proposé par Zitzler en 2001[8] représente une version corrigée de l'algorithme SPEA proposé auparavant par le même auteur. L'algorithme c-MOEA proposé par Deb en 2003[17] utilise le concept de l'c-dominance. L'algorithme IBEA proposer par le même auteur en 2004[9] a pour objectif d'apporter une solution au problème du « exploration / exploitation »auquel sont confrontés les MOEAs en proposant une généralisation du concept de dominance. Les trois derniers algorithmes sont des algorithmes génétiques dont l'algorithme NSGA-II proposé par Deb en 1995 [7] et ses étudiants [16] apparaît comme l'un des algorithmes de référence pour trouver l'ensemble optimal de Pareto avec une excellente variété de solu- 21 CHAPITRE II. METHODES D'OPTIMISATIONtions. Il est basé sur les trois caractéristiques suivantes : il utilise le principe de l'élitisme, il favorise les solutions non dominées, et il utilise une variété explicite des solutions, grâce au« distance crowding », l'algorithme micro-GA se rapporte à une petit-population génétique lors de l'initialisation. Selon Goldberg une population de 3
individus peut être convergée En 2001 Carlos Coello et Gregorio ont publié un article décrivant cet algorithme avec deux mémoires [1]. Contrairement aux algorithmes citer avant qui introduisent des compléments (opérateurs génétiques, mémoire externe...) pour rendre l'algorithme plus performant, d'autre algorithmes hybrides comme GA|PM par lequel en finira notre état de l'art , introduisent une recherche locale (Moscato, 1989; Moscato et Cotta, 2003), dont la forme la plus évoluée utilisant une mesure de distance afin d'apporter une certaine diversité dans les chromosomes avec la gestion de la population (Sorensen et Sevaux, 2003)[21]. II.5.1 SPEA-IISPEA-II (Strenght Pareto Evolutionary Algorithm) utilise une archive At de taille Narchive fixe qui est destinée à contenir un nombre limité de solutions non-dominées trouvées par l'algorithme au cours de l'optimisation. A chaque itération, les nouveaux individus non-dominés de la population Ptsont comparés aux membres de l'archive At en utilisant le critère de dominance. Si le nombre d'individus non-dominés n'est pas suffisant, l'archive est complétée par les meilleurs individus dominés. Le critère de classement est donnée par : F(i) = R(i) + D(i) R(i) est calculé comme suit : R(i) = X S(j) i?Pt?At,j<i . S(j) représente le Strength : S(j) =| {i : i E Pt U At et j < i} | Si R(i) = 0 alors l'individu i est non dominé, par contre si elle est élevée l'individu i est dominé par plusieurs individus. Ce critère a un inconvénient lorsque plusieurs individus ne dominent pas les uns les autres. Dans ce cas, le critère du kime voisin sera utilisé comme critère de diversité et la densité de chaque solution i est définie par : D(i) = 1 ók i +2 ók i : est la distance recherchée et k est définie comme étant la racine carrée de la taille de l'ensemble Pt U At i.e. k = vN + Narchive . 22 CHAPITRE II. METHODES D'OPTIMISATIONAlgorithm : SPEA-II 1 : t +- 0 , P0 +- random(), | P0 |+- N, A(t) +- 0, | A(t) |+- Narchive 2 : repeat 3 : At+1 +- Nno-dom (Pt U At) 4 : TriF(At) 5 : if | At+1 |> Narchive then 6 : At+1 +- At+1[0 : Narchive] 7 : else 8 : At+1 +- At+1 U TriF(Dom(Pt U At))[0 : Narchive-- | At+1 |] 9 : end if 10 : Pt+1 +- variation(Select(At+1)) 11 : t +- t + 1 13 : until (Critère d'arrêt) II.5.2 €-MOEAL'idée principale de l'c-MOEA (Epsilon Multi Objectif Evolutionary Algorithm) est de proposer une approche qui permet d'assurer la diversité des solutions obtenues avec un plus faible coût de calcul par rapport à NSGA-II et SPEA-II. c-MOEA considère deux populations qui évoluent en parallèle, une population principale de l'algorithme évolutionnaire P(t) et une population archive A(t) (t représente le compteur des générations). A chaque itération de l'algorithme, deux solutions sont choisies, la première p à partir de la population P(t) et la deuxième a à partir de l'archive A(t). Par la suite, À solutions sont crées en combinant les solutions p et a (ci, i = 1, 2, ..., À). Chacune des solutions crées est comparée avec les membres de l'archive A(t) et la population P(t) dans le but de tester leur possible inclusion. Pour s'intégrer à l'archive A(t), chaque solution ci est comparée avec chaque membre de l'archive au sens de l'c-dominance. Pour s'intégrer à la population P(t), chaque solution ci est comparée aux membres de la population principale au sens de la dominance. Si la solution ci domine une ou plusieurs solutions de la population, elle remplace une de ces solutions aléatoirement, si elle est dominée par au moins une solution de la population, elle sera rejetée et si les deux premiers test échouent, la solution ci remplace une solution choisie aléatoirement. Agorithm : c-MOEA 1 : t +- 0, P0 +-random(), | P0 |= N, A0 +- c-nondominés (P0) 2 : repeat 3 : {p1,p2} +- U(Pt) 4 : p +- select_dominance (p1,p2) ; a +- U(At) 5 : {ci, i = 1, 2, .. . , À} +- variation(p ,a) 6 : for i = 1 to À do 7 : Remplacement-archive (ci, At) 8 : Remplacement-archive (ci, Pt) 9 : end for 10 : t +- t + 1 11 : until (Critère d'arrêt). 23 CHAPITRE II. METHODES D'OPTIMISATIONAlgorithm : Remplacement-archive (ci, At) 1 : for i = 1 to À do 2 : if a EA(t): ci =~ a then 3 : At+1 ? (Qt U ci) \ {a E At : ci =~ e} 4 : else 5 : if a E A(t) : a =~ ci then 6 : ci est rejetée 7 : else 8 : remplacement-population(ci,At) 9 : end if 10 : end if 11 :end for Algorithm : Remplacement-population(ci,Pt) 1 : for i = 1 to À do 2 : if p E Pt : ci < p then 3 : Pt+1 ? (Pt U ci) \ {p} 4 : else 5 : if p E Pt : p < ci then 6 : ci est rejetée 7 : else 8 : Pt+1 ? (Pt U ci) \ {p ? UPt} 9 : end if 10 : end if 11 : end for II.5.3 IBEAL'idée principale de l'IBEA(Indicator Based Evolutionary Algorithm) est de formaliser les préférences entre individus en utilisant un indicateur de performance binaire de qualité I arbitrairement choisi. Donc l'algorithme n'aura pas besoin d'utiliser une technique de préservation de la diversité en tant que deuxième critère de comparaison. Cependant, la question qui se pose est de savoir comment I pourrait être intégré dans le calcul de la fitness dans un MOEA. Une possibilité serait d'attribuer à chaque individu une valeur de fitness F(x) correspondant à la mesure de la --perte en qualité-- si cet individu avait été retiré de la population. F0(x1) = X I({x2}, {x1}) x2?P\{x1}) Cette formule à été modifier pour augmenter l'influence des solutions non-dominées sur les solutions dominées : F0(x1) = X -eI({x2},{x1}) x2?P\{x1}) 24 CHAPITRE II. METHODES D'OPTIMISATIONOù k > 0 est un facteur d'échelle qui dépend de l'indicateur I utilisé et du problème à optimiser. Pour le choix de l'indicateur, les auteurs de l'algorithme comparent deux exemples : l'indi-cateur de l'hyper-volume et l'indicateur epsilon. Les résultats obtenus par les auteurs ont montré que les deux variantes permettent d'obtenir des meilleurs résultats que ceux obtenus avec NSGA-II et SPEA-II. Agorithm : IBEA 1 : t - 0 , P0-random(), P0 - N 2 : repeat 3 : Qt -variation (select (Pt)) 4 : Pt+1 - Qt U Pt 5 : TriF(Pt+1 ) 6 : while Pt+1 > N do 7 : Pt+1 - Pt+1 \ {x* - arg-maxF(x)} 8 : updateF (Pt+1) 9 : end whie 10 : t - t + 1 11 : until (Critère d'arrêt) II.5.4 NSGA-IIDans NSGA-II (Non-dominated Sorting Genetic Algorithm II), la population des enfants Qt est d'abord crée en utilisant la population des parents Pt. Les deux populations sont ensuite réunies pour former la population mixte Rt de taille 2N. En utilisant le critère du rang de Pareto, on doit trier Rt pour former les fronts successifs. Par la suite, la nouvelle population Pt+1 de taille N est crée en ajoutant au fur et à mesure les premiers fronts successifs et les autre sont éliminer ( Rt = 2N). Cependant, la dernier front ne peut être ajouté en totalité car sa taille sera peut être supérieure aux nombres de cases vides à remplir dans Pt+1. Dans ce cas, le critère de surpeuplement sera utilisé pour choisir parmi les solutions du dernier front. Algorthm : NSGA-II 1 : t - 0 , P0 - random(), P0 - N 2 : repeat 3 : Qt - variation(Select (Pt)) 4 : Rt - Pt U Qt 5 : F -tri-dominance(Rt) 6 : Pt+1 - 0, i - 0 7 : Whie Pt+1 +Fi < N do 8 : Pt+1 - Pt+1 U Fi ; i - i + 1 9 : end while 10 : Pt+1 - tri-surpeupement (Pt+1) 11 : Pt+1 - Pt+1[0 : N] 12 : t - t + 1 13 : until (Critère d'arrêt) 25 CHAPITRE II. METHODES D'OPTIMISATIONII.5.5 micro-GAL'algorithme micro-GA utilise deux mémoires : Une mémoire interne M, et une mémoire externe E. La population initiale est générer de façon aléatoire et met dans M. M et divisé en deux parties : remplaçable et non-remplaçable. La partie non-remplaçable de M ne changera jamais, elle sert pour fournir la diversité requise pour l'algorithme. Pendant un cycle, le micro- GA effectue les opérateurs génétiques conventionnels : sélection par tournoi, croisement de 2, mutation uniforme et en fin la sélection élitisme. Après chaque cycle et quand la convergence est réalisée, on choisi deux individus non dominés de Pi + 1 et on les compare au contenu de E. Si l'un ou l'autre reste comme non dominée alors ils sont jeté dans E en éliminant tous les individus dominés. Les deux individus sont aussi comparés avec les individus de la partie remplaçable de M. Si l'un ou l'autre domine un individu il le remplace. L'idée est que, avec le temps, la partie remplaçable de la mémoire de la population tendra à avoir des individus non dominés. Certains d'entre eux seront utilisés dans la population initiale du micro-GA pour recommencer à nouveaux le cycle évolutionnaire. Algorithm: Micro-GA
II.5.6 GA PMLe fonctionnement général du GA PM (Genetic Algorithm Population Managment )est basé sur un algorithme génétique. Cependant, l'amélioration des solutions est effectuée par une recherche locale. Le PM (Population Management) signifie qu'une nouvelle solution T ne peut intégrer la population courante que si sa distance à la population courante P est supérieur à un seuil donné: dp > S. Au départ, on génère une population initiale de petite taille et on choisit un paramètre fixant le niveau de dissemblance des solutions entre elles. Ensuite, on procède comme dans un algorithme génétique, on choisit deux individus que l'on croise pour obtenir deux enfants. Pour chacun on applique une recherche locale de façon à obtenir des optima locaux. S'ils ne répondent pas au critère de diversité, on applique un opérateur de mutation sur ces individus jusqu'à satisfaction de ce critère. Ensuite sous condition, on les insère dans la population a la place d'un autre individu. A chaque itération le paramètre gérant la diversité est mise à jour. 26 CHAPITRE II. METHODES D'OPTIMISATIONAlgorithm : GA|PM 1 : initialise P0 et placer le paramètre de diversité L 2 : repeat 3 : select : p1 and p2 from P 4 : crossover: c1,c2 +- p1 ® p2 5 : local search on c1 and c2 6 : for chaque enfant c do 7 : while dpT ~ L do mutate c 8 : if c satisfie des conditions d'addition then 9 : enlever la solution : P +- P \ b 10 : ajouter la solution : P +- P + c 11 : end if 12 : end for 13 : mise à jour du paramètre de diversité L 14 : until (critère d'arrêter) II.5.7 DiscussionAvec l'apparition des MOEAs au début des années 2000, plusieurs travaux dans la littérature se sont intéressés à la comparaison empirique des MOEAs sur des benchmarks de fonctions analytiques (Zitzler 2000 et Tan 2002). Cependant, ces comparaisons concernent seulement quelques algorithmes de l'état de l'art, et ne comparent pas tous les principaux algorithmes à la fois. Dans sa thèse [19] M.Yakoubi a présenté quelques règles de comparaison, puis il a effectué une comparaison entre les algorithmes de deuxième génération, et il a dit : « Le choix de la méthode d'optimisation doit se faire dans l'optique de réduire considérablement le coût global de l'optimisation. Cependant après comparaison des différents MOEAs de l'état de l'art, nous constatons qu'aucun de ces algorithmes ne permet de réaliser ce gain en termes de rapidité de convergence vers le front de Pareto ». II.6 CONCLUSIONLe passage à la deuxième génération des algorithmes évolutionnaires, où beaucoup de concepts sont ajoutés à la terminologie des algorithmes évolutionnaires classiques (front de Parito, mémoire externe...) permet de réduire considérablement la complexité de ces algorithmes, mais, ceci reste limité à des problèmes de quelques fonctions objectives faciles à calculer. Ceci revient généralement au problème de convergence vers le front de Parito. L'hybridation entre des méthodes de recherche locales ou de ceux qui fournissent une solution avec des déplacements dans l'espace comme la recherche tabou avec des algorithmes génétiques amènent des résultats très satisfaisantes, mais restent limité eux aussi devant quelques problèmes. Dans le chapitre qui suit (ChapitreIII), on va présenter une autre contribution pour améliorer le comportement des algorithmes évolutionnaires, cette façon a été suggérer par plusieurs chercheurs, parmi eux on trouve Lerman et Ngouenet dans leur article [14] et plus précisément dans la section 4 où ils ont dit « nous avons pris conscience de la nécessité impérieuse de paralléliser nos algorithmes ... ». 27 Chapitre IIIALGORITHMES EVOLUTIONNAIRESPARALLÈLESPour des problèmes réels, l'exécution d'un cycle de l'algorithme évolutionnaire sur un individu long ou une population large exige des ressources informatiques très élevées. Généralement, cette exigence due à la complexité de l'évaluation de fitness qui est considérer comme étant l'opération la plus coûteuse des EAs. En conséquence, plusieurs travaux ont été consacrés pour concevoir des Algorithmes efficaces, ceci revient à définir de nouveaux opérateurs, des algorithmes hybrides et des modèles parallèles. Dans ce domaine, il existe un grand nombre de contributions, ainsi beaucoup d'effort ont été consacrés à la conception, mais la conception n'est pas la seule question importante, au fait que, les EAs sont déjà préparés au parallélisme dû à la nature des opérations de variation. Cependant, ce qui est vraiment intéressant est l'utilisation des populations structurée, distribuer les individus dans des îles ou dans des grilles de diffusion. La nature intrinsèquement parallèle et distribuée des EAs n'a pas été échappée à l'attention des premiers chercheurs. Commençons par Hollande, qui a proposé une architecture pour effectuer des calcul parallèles, puis par les travaux de Bossert qui a utilisé la notion de concurrence multiples des sous-populations pour améliorer la diversité et causer un retard de stagnation de l`algorithme. Cependant, bien que les idées principales aient été comprises, la technologie parallèle et de l'informatique répartie était à une étape primitive dans cette époque (années 60). Il était, donc, difficile de créer des réalisations pratiques. Au début des années 80 les réalisations parallèles appropriées à apparaître. Grefenstette était le premier qui a examiner un certain nombre d'essais concernant aux réalisations parallèles du GAs en 1981. Grosso a essayé lui aussi de présenter le parallélisme par l'utilisation d'un modèle spatial de multi-population. Ceci a été suivi par des études plus systématiques par Cohoon, Tanese, Pettey, Leuze, Gorges-Schleuter, Mühlenbein, Manderick et Spiessens connues sous le nom de modèles en îles. Un autre modèle spatial a été popularisé par les premiers travaux des Gorges-Schleuter appeler un modèle de la diffusion cellulaire, il a été basé sur une population dans un'espace distribuée dans le quel les interactions génétiques peuvent seulement avoir lieu dans un petit voisinage de chaque individu. 28 CHAPITRE III. ALGORITHMES EVOLUTIONNAIRES PARALLÈLES
Figure III.1 - Architectures Parallèles. III.1 Les architectures parallèles selon FlynnLes ordinateurs parallèles sont des machines qui comportent une architecture parallèle, constituée de plusieurs processeurs identiques ou non (hétérogènes), qui coopèrent et concourent à la résolution d'un même problème informatique. La performance d'une architecture parallèle est reflétée par les performances de ses ressources et de l'intelligence de leur installation. Selon Les modèles standards de Flynn, une classification classique est basée sur la notion de flot de contrôles et de flot de données, ainsi distingue quatre types d'architecture(voire figure III.1) : - SISD. Une machine SISD est une machine séquentielle de Von Neuman, dont une seule instruction est exécutée sur une seule donnée à un instant donné. - SIMD. Une machine SIMD est une machine qui traite plusieurs données en même temps par une seule instruction, l'exécution parallèle de la même instruction se fait en même temps sur des processeurs différents (parallélisme de données synchrone), l'architecture SIMD est utilisé dans les gros ordinateurs vectoriels. - MISD. Une machine MISD peut exécuter plusieurs instructions en même temps sur la même donnée. - MIMD. Dans une machine MIMD, chaque processeur peut exécuter un programme différent sur des données différentes. Dans cette architecture, il existe plusieurs façons de couplages de mémoire, si la mémoire est partagée entre la totalité des processeurs qui possédant chacun sa propre horloge, ces derniers doivent lire et écrire des mots sur la même mémoire. En effet, La notion de cache ajoute une très grande difficulté à la gestion de la cohérence. Car à tout instant, les données doivent rester cohérentes pour toutes les caches. D'autre terme, il faut implémenter des mécanismes matériels ou logiciels permettant d'assurer une telle cohérence (les verrous, les sémaphores, les 29 CHAPITRE III. ALGORITHMES EVOLUTIONNAIRES PARALLÈLES
Figure III.2 - Architecture MIMD à mémoire partagée .
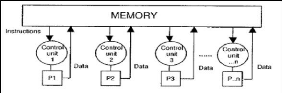
Figure III.3 - Architecture MIMD à mémoire non partagée. moniteurs.. . ).(voire figure III.2) Par contre, si la mémoire est distribuée à cause de l'éloignement physique des processeurs qui travaillent en mode asynchrone, ou une autre intention, la communication entre processus est réalisée par l'échange des messages. La synchronisation et l'échange de messages peut se faire par plusieurs façons, l'appel de procédures à distance (RPC) ou l'Envoi/ Réception des messages asynchrone (procédure handler) ou synchrone (rendezvous, barrière,horloge distribuée. . . ).(voire figure III.3) III.2 Etat de l'art : les modèles parallèles pour les EAsLes algorithmes évolutionnaires sont des algorithmes coûteux en temps calcul, notamment l'étape de l'évaluation de la performance qui prend en considération tout les individus de la population. Cette évaluation est constituée de calculs totalement indépendants, ce que met en évidence la nécessité de sa parallélisations. Cependant, la façon de lancer en parallèle les calculs de performance n'est pas la seule manière d'envisager la parallélisation des algorithmes évolutionnaires. Il existe d'autres façon de paralléliser ces algorithmes, partant de la simple parallélisation du calcul de performance jusqu'à la distribution complète de la population sur les divers processeurs disponibles. III.2.1 Parallélisation du calcul de performanceLa mise en oeuvre d'un algorithme évolutionnaire parallèle dépend généralement du problème à traiter et de l'algorithme parallèle choisi pour implémenter les fonctions objectives, si l'on dispose déjà d'un tel algorithme, on peut l'utiliser directement au sein d'un algorithme évolutionnaire standard. 30 CHAPITRE III. ALGORITHMES EVOLUTIONNAIRES PARALLÈLES
Figure III.4 - Distribution de calculs de performance. III.2.2 Distribution du calcul de performance- Distribution synchrone. Cette technique consiste à paralléliser l'étape d'évaluation. Une station maître gère tout l'algorithme (sélection, remplacement et opérateurs génétiques), sauf les calculs de performance qui doivent être envoyés à des stations esclaves. Dans ces conditions, si le temps de calcul de fitness varie d'un processeur à l'autre (hétérogénéité des processeurs), l'ensemble des processeurs doivent alors attendre le plus lent d'entre eux, et le gain apporté par ce modèle peut se dégrader. Pour donner une reboutasse à ce modèle, une solution peut être possible, si on pense à la gestion de la distribution des calculs et à l'aide d'une liste de calculs à effectuer, un processeur reçoit un nouveau calcul dés la fin du calcul précédent, ceci permet de limiter le phénomène d'attente sans complètement le supprimer, car si un processeur s'arrête, le maître se mettra en attente du résultat manquant. A noter que, dans ce modèle, l'algorithme parallèle se comporte comme un algorithme séquentiel. Cependant, pour des tailles de population ne dépassant pas quelques multiples du nombre de processeurs disponibles, le facteur d'accélération devient très proche du nombre de processeurs lorsque le ratio évaluation-évolution augmente. - Distribution asynchrone.Cette technique utilise un schéma d'évolution asynchrone, chaque processeur esclave effectue son calcul de performance, renvoie le résultat au maître et reçoit immédiatement un nouveau calcul, ainsi les étapes de « sélec-tion/remplacement »peuvent être effectuée individu par individu. Dans ces conditions, Le schéma stationnaire (steady-state) est la cible de ce modèle, chaque fois qu'un esclave renvoie la performance d'un enfant, le maître effectue l'étape de remplacement, de sélection et de l'application des opérateurs génétiques, et envoi le nouveau enfant à évaluer à l'esclave en question. L'inconvénient de ce modèle est que si le calcule de fitness d'un individu sur un processeur donné est plus long, il impliquera soit une population anachroniques ou l'élimination de cet individus avant d'avoir été sélectionné pour reproduction. 31 CHAPITRE III. ALGORITHMES EVOLUTIONNAIRES PARALLÈLES
Figure III.5 - Exemple de modèle en îlots. - Ni maitre ni dieu.Cette technique utilise généralement un serveur de fichiers pour centraliser la population qui doit être stockée dans un fichier. Dans ces conditions, Chaque processeur peut accéder au fichier et effectue l'ensemble des opérations (sélection, opérateurs, évaluation, remplacement) en lisant et écrivant dans ce dernier. L'inconvénient de ce modèle due au temps important nécessaire lors de l'ouvertures/fermeture et de l'lecture/ecriture sur le fichier, ainsi la contrainte d'écriture sur le fichier qui exige qu'un seul processus peut écrire en même temps. (voire figure III.5 ) III.2.3 Modèle en îlotsCe modèle consiste à diviser la population en sous-population, chaque sous-population évoluant sur sa propre processeur et envoie ses meilleurs individus soit vers des populations voisines soit dans un « pool »commun centralisé, cette dernière étape est connue sous le nom de migration. Le choix entre la migration vers le voisin ou vers le pool dépend fortement du coût des communications entre les processeurs. Chaque sous-population reçoit alors des individus soit envoyés par ses voisins soit pris de pool. Une des possibilités offerte par ce modèle est que chaque sous-population évolue en sa manière c.-à-d. en utilisant des paramètres différents, ainsi les paramètres peuvent être changés à chaque cycle de l'algorithme. Mais même lorsque les sous-populations utilisent exactement les mêmes paramètres, la dispersion topologique, fonction du mode de migration choisi, a pour effet de préserver la diversité génétique.(voire figure III.6) III.2.4 Population distribuéeCe modèle consiste à distribuer une population sur l'ensemble des processeurs. Les opérations de « sélection/remplacement fg et de croisement se font entre individus voisins au sens physique de la topologie du réseau de processeurs. Ce modèle génère lui aussi une nouvelle dynamique de l'algorithme, différente des précédentes, avec comme dans le modèle en îlots, l'apparition de niches écologiques distribuées par zones géographiques de processeurs, et permettant également la découverte d'optima multiples. Généralement, dans ce type de modèles, il existe un processeur superviseur (root), qui reçoit des informations de l'ensemble 32 CHAPITRE III. ALGORITHMES EVOLUTIONNAIRES PARALLÈLES
Figure III.6 - Population totalement distribuée. des processeurs dans le but de suivre précisément l'évolution et pour décider l'arrêt de l'al-gorithme.(voire figure III.7) III.2.5 DiscussionL'avantage d'un modèle distribué est qu'il est habituellement plus rapide qu'un algorithme panmictic, qui met seulement le calcule de fitness en parallèle. La raison de ceci est que le temps d'exécution et le nombre d'évaluations sont potentiellement réduits grâce à sa recherche séparée dans plusieurs régions. Les algorithmes distribués dEAs implémentant le modèle en îles et les algorithmes cellulaires cEAs implémentant le modèle de voisinages sont les algorithmes d'optimisation les plus populaires. Les cEAs peuvent être implémentés dans des ordinateurs MIMD avec mémoire distribuée, bien que leurs exécution normale est sur des ordinateur de types SIMD. Par contre, les algorithmes dEAs qui sont des modèles de multi-population (île) effectuant des échanges d'individus peuvent être implémentés dans des ordinateurs MIMD avec mémoire distribuée. III.3 Les outils de parallélismeNous présenterons dans cette section quelques outils de communication populaires utilisé pour implémenter les PEAs. Ces outils utilisent un modèle de communication appelé modèle de passage de messages, ce modèle nous permet d'utilisé plusieurs machines donc de profiter de plusieurs processeurs et des mémoires distribuées selon une architecture MIMD avec mémoire distribuée. Ceci revient au fait que c'est le seule matériel disposé dans les universités. Dans le modèle de passage de message, les processus dans le même ou différents processeurs communiquent uniquement en envoyant des messages entre eux. Les deux primitives de base sont send et receive. La forme la plus simple de ce modèle, est l`utilisation de multi-paire de processus émetteur/récepteur effectuant une copie de mémoire à mémoire, où chacun dispose de la primitive send /receive et un buffer local afin de contenir / recevoir les donnée. III.3.1 Les outils implémentant le modèle de passage de messages- les sockets. c'est une interface de programmation disponible sur toutes les plate-formes de programmation. A partir d'un ensemble de structure de données et de fonction 33 CHAPITRE III. ALGORITHMES EVOLUTIONNAIRES PARALLÈLESprimitive, un programmeur peut établir une connexion full duplex sur TCP ou UDP, et d'implémenter des programme parallèle synchrone ou asynchrone. - PVM. est un système logiciel qui soutient le paradigme de passage de messages et qui offre une suite de primitifs et d'interface pour la communication. L'avantage de ce dernier est la possibilité de construire un réseau hétérogène composé d'ordinateurs parallèles ou séquentiel, qui sont considérés comme des simple concurrents au calcule. - MPI. est une bibliothèque semblable à PVM mais plus complet, qui a était définie au milieu des années 90, et qui reflète tout les expériences concernant ce modèle. Le but était de développer une simple bibliothèque qui peut être mise en application sur des machines à multiprocesseurs. MPI a maintenant devenu un standard, et plusieurs réalisations existent, comme MPICH et LAM/MPI.2. - RMI. l'implémentation de RPC dans java est appelée Java-RMI. Celui-ci permet l'ap-pel des services à distance de façon transparente. III.3.2 DiscussionConcernant les outils, nous pensons que MPI est actuellement le meilleur choix pour mettre en application des algorithmes PEAs, ceci revient au fait que MPI supporte le langage c++ qui est un langage de programmation incontournable lorsque on parle de l'optimisation. MPI permet aussi de la gestion de groupe de processus communiquant dans un environnement unique, ainsi la possibilité de communication Peer to Peer, broadcasta et TokenRing qui sont sûrement utile dans notre contribution. III.4 ConclusionLe passage vers les algorithmes parallèles et vers des populations distribuées permet certainement de réduire le temps d'exécution. Ceci a été suggéré par plusieurs chercheurs, notamment par Enrique Alba et Marco Tomassini dans leur article [12]. On a commencé notre chapitre par la classification de Flynn, et il est claire que l'architec-ture MIMD est la seule architecture qui nous intéresse, ceci a été justifié par l'absence des supercalculateurs dans le monde universitaire. Puis on a traité les différents façons de lancer le calcule de performance d'un algorithme panmictic sur une machine parallèle, ainsi sur plusieurs machines concurrentes, échangeant des messages synchrones ou asynchrones selon différents modèles. A ce niveau le seul modèle qui nous intéresse est le modèle maitre esclave asynchrone, ceci revient au fait que la gestion de l'algorithme est contrôlé par un seul processus maitre, ce qui facilite la suivi de l'exécution de programme. Mais le coût d'échange de message est un coût supplémentaire à considérer comme inutile. Pour cela la technique de distribution de la population selon le modèle en îles permet de bien justifier cette échange comme technique de diversification. A la fin de ce chapitre en a constaté que l'implémentation normale de ce modèle est sur une architecture MIMD avec mémoire distribuée, et ceci n'a pas de contradiction avec notre compétences en terme de matérielle (plusieurs PCs) et de logicielle (MPI). 34 CONCLUSION GÉNÉRALE ETPERSPECTIVESL'objectif de cette recherche bibliographique est l'étude des approches de résolution des problèmes d'optimisation combinatoire et plus particulièrement le problème de l'emploi du temps, afin de proposer une approche qui peut contribuer à la résolution de ce problème. L'accent a particulièrement été mis sur l'utilisation de l'optimisation multi-objectif. Un choix justifié par la nature même du problème qui en réalité formuler sous forme d'un ensemble d'objectifs qui peuvent éventuellement être contradictoires. L'optimisation multi-objectif revêt deux aspects. Le premier concerne la manière dont l'uti-lisateur coopère avec l'algorithme de résolution. soit il choisira de formuler ces contraintes de préférences à priori et de lancé la recherche ou de lancé d'abord la recherche et de sélectionner les solutions qui répond aux mieux à ces besoins. Le deuxième aspect se rapporte à la signification donné à la notion d'optimalité. Selon cette distinction, les approches multi- objectifs peuvent être classées en trois catégories : les approches opérant par transformation du problème en un problème mono-objectif, les approches non Pareto et les approches Pareto. Parmi celles-ci, les approches Pareto semblent être les plus utilisées dans le domaine de l'optimisation. L'objectif de cette optimisation multi-objectif est de produire un ensemble de solutions efficaces, généralement Pareto optimales. Pour cette raison, les'algorithmes proposés stockent les meilleurs solutions trouvées durant la recherche. Dans les algorithmes de l'état de l'art comme NSGA-II ceci est réalisé en maintenant une population supplémentaire dite population Pareto ou archive. L'élitisme consiste à faire participer la population Pareto lors de la phase de sélection. Ce mécanisme sert généralement comme moyen d'intensification de la recherche. Un volume important de travail reste à faire. Premièrement, les MOEAs sont souvent critiqués pour leur lenteur, pour cela les mécanismes d'hybridation et de parallélisation sont à étudier. ils sont aussi connus pour leur sensibilité quant au choix de la population initiale. L'utilisation d'heuristiques pour la génération de cette population pour améliorer les performances de l'algorithme peuvent être étudiées afin d'assurer de bonnes solutions de départ. Deuxièmement, nous pouvons à la fin de choisir un algorithme et d'analyser ces performances et sa capacité d' adopté un modèle parallèle. En fin, l'implémentation de ce travail sur une structure logiciel et matériel permettant d'exposé les point essentiel de l'algorithme parallèle ou/et distribué et de tester sa robustesse par rapport à d'autres algorithmes. 35 Bibliographie
36 BIBLIOGRAPHIE[19] Yagoubi Mouadh. Optimisation évolutionnaire multi-objectif parallèle: application à la combustion diesel. 2012.
| 
Changeons ce systeme injuste, Soyez votre propre syndic 
"Je ne pense pas qu'un écrivain puisse avoir de profondes assises s'il n'a pas ressenti avec amertume les injustices de la société ou il vit" |