Troisième partie
Architecture de l'outil
L'outil est en fait séparé en plusieurs
parties. La partie interface graphique et la partie interaction avec la base de
données. Ces deux parties communiquent au travers le réseau de
façon client/serveur. Il sera présenté dans cette partie
l'architecture du serveur et l'architecture du client.
Chapitre 5
Côté serveur
5.1 Description de la partie serveur
Le serveur est écrit en langage PERL. Ce langage est
«imposé«, car une grosse partie a été
écrite par Daniel LACROIX, qui le maintiendra dans le futur et
continuera à le développer si le besoin s'en faisait sentir.
Daniel a commencé par écrire les fonctions de gestions des sous
réseaux comme par exemple récupérer le masque du sous
réseau, obtenir l'adresse de broadcast, tester si un sous réseau
appartient à un réseau... Ensuite il a écrit les fonctions
et procédures qui récupèrent les sous réseaux
correspondant à un filtre de recherche; les procédures de
communication et enfin le programme qui crée un nouveau processus
à chaque demande de connexion. Cette première écriture a
permis de développer rapidement l'interface graphique et d'avoir un
premier outil disponible. Cependant, les possibilités d'extension et de
configuration sont un peu limitées par rapport à ce que l'on
souhaitait obtenir mais cela a permis d'analyser son code source et, ne
connaissant pas Perl, d'obtenir un très bon point de départ pour
la suite.
5.2 Adaptation de la partie serveur
La première chose à effectuer était de
faire un fichier de configuration, facilement modifiable pour y incorporer un
système de «plugins» . Ensuite ajouter les
fonctionnalités qui n'étaient pas encore
développées. Ce fichier de configuration doit être le plus
facilement extensible et l'ajout éventuel de données ne doit pas
influer sur le code, autrement que par l'ajout des outils
nécessaires.
5.2.1 Le fichier de configuration
Perl se marie très bien avec XML (eXtensible Markup
Language), c'est pourquoi ce choix s'imposait. De plus, XML permet de valider
le fichier de configuration avec le mécanisme des Document Type
Definition (DTD). La facilité de récupération des
données est aussi entrée en compte et le choix d'un parser
(outil
du langage permettant de parcourir le fichier et d'obtenir le
contenu des balises tout en ayant la possibilité ou non de le valider)
est conséquent. Perl fournit en effet de nombreux parsers tels que:
- XML : :Parser: parser non validant. C'est sur ce parser que
sont basés la plupart des autres. Il est plutôt simple à
utiliser. En effet, il suffit d'écrire deux procédures pour
chaque balise : une procédure pour la balise ouvrante, cette
procédure portant le même nom que la balise et une
procédure pour la balise fermante portant le même nom que la
balise, suffixée par le caractère «souligné ("_" ou
"underscore"). Il est pas obligatoire de créer toutes les
procédures. Ensuite il suffit d'écrire une balise appelé
dans tous les cas non pris en compte. Cependant, il devient difficile à
utiliser lorsque l'on veut avoir un groupe de noeuds. Son point fort est sa
très grande rapidité.
- XML : :Simple : un parser développer essentiellement
pour les fichiers de configurations, dont le but est d'être très
simple d'utilisation. Cependant, il est encore en version bêta et non
disponible dans la version standard donc il n'a pas été
utilisé.
- XML: :SAX: l'implémentation de l'autre API standard
du W3C. Alors que DOM est tourné vers la représentation du
fichier XML sous forme d'arbre, SAX est tourné vers
l'événementiel, comme XML: :Parser, ce qu'il fait qu'il est
rapide par rapport à DOM tout en l'étant moins que XML:
:Parser.
- XML: :DOM: l'implémentation de l'API standard
définie par le W3C1.
Le fichier est représenté sous forme
arborescente. On parcourt le fichier en
sélectionnant les noeuds que l'on souhaite et on
travaille sur ces noeuds.
Le problème qui se pose avec cette représentation
est que chaque retour à la
ligne est interprété et lorsque l'on parcours la
liste des noeuds fils d'un noeud
particulier il faut vérifier le type du noeud pour
s'assurer que ce n'est pas du
texte (la valeur du noeud). Un facteur limitant est la lenteur
de ce parser,
mais pour le fichier de configuration, lu une seule fois lors
du démarrage du
serveur, ce n'est pas important. C'est donc ce parser qui a
été utilisé.
La première chose était de sortir les
données stockées «en dur» (c'est à dire sous la
forme d'une structure de données) dans le programme. Ces données
n'existent pas dans la base car elles n'ont aucun sens réel. En effet,
les réseaux ne sont pas rattachés à un
établissement, ce qui implique qu'il aurait fallu représenter
explicitement la notion de sous réseaux d'un réseau et donc cela
aurait engendré des modifications trop importantes de la base de
données. Ces données ont donc été stockées
dans un fichier XML externe au fichier de configuration et une balise dans le
fichier de configuration fait mention du fichier de données à
parser.
Ensuite il fallait prendre en compte le cas où l'on
pouvait avoir plusieurs bases de données complètement
différentes. En effet, il se peut que plus tard la base soit
«éclatée» sur plusieurs serveurs, il serait dommage de
devoir étudier de nouveau le logiciel pour ce cas. On stocke donc dans
le fichier le type du serveur (MySQL, Oracle, DB, ...), le nom ou adresse IP de
la machine sur laquelle est lancée le ser-
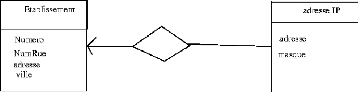
FIG. 5.1 - Modèle entité/association No 1
Etablissement
Numero Subnet Numero NumRue Adresse Ville
|
|
FIG. 5.2 - Modèle entité/association No2
veur, son port de communication, l'identifiant et le mot de
passe pour la connexion au serveur, la plage la plus grande contenue dans la
base et les requêtes que l'on va effectuer. La plage la plus grande est
une plage de la forme 172.0.0.0/4, par exemple, qui contient toutes les autres
plages. Il se peut que certaines plages ne soient pas connues dans la base mais
ce n'est grave, on fera une recherche, au pire, non utile mais ce n'est pas ce
qui coûte le plus (ce sont les requêtes whois, voir plus loin). Les
requêtes sont des requêtes SQL, qui possèdent chacune un nom
pour une recherche donnée. Par exemple, une requête listant tous
les sous réseaux portera le nom de «liste_subnets». Si la
requête n'est pas définie, on n'effectue pas la recherche dans
cette base. Toutes les requêtes de même nom doivent avoir le
même format de «sortie», ce qui est très simple à
faire en SQL. Un exemple permettra d'éclaircir ce qui a
été dit précédemment. On cherche à obtenir
toutes les adresses IP de deux bases distinctes. Les modèles
entités/associations des deux bases sont donnés par les figures
5.2.1 et 5.2.1.
On écrit donc les deux requêtes pour chaque base;
la première (figure 5.2.1 page 25):
SELECT subnet AS subnet_Lan,
numero as numero
FROM Etablissement
et la deuxième (figure 5.2.1 page 25):
SELECT
CONCAT(adresseIP.adresse, »/»,masque) AS
subnet_Lan,
etablissement.numero AS numero
FROM etablissement, adresseIP
WHERE etablissement.numero = adresseIP.numero;
et on a ainsi en sortie deux résultats ayant les
mêmes noms de colonnes et le programme peut utiliser les requêtes
de la même manière. Le code Perl (mais se serait la même
chose pour Java ou tout autre langage) reste identique et se base sur les noms
de colonnes.
Actuellement il y a trois types de requêtes : une pour
obtenir toutes les plages et leurs informations, une pour faire une recherche
selon le nom du propriétaire et une pour faire une recherche sur le nom
de l'enregistrant. Cependant, si l'on veut ajouter d'autres requêtes, il
est inutile d'ajouter du code au parser. En effet, le parser et la structure du
fichier XML sont étudiés pour que la requête soit
directement stockée dans la structure de données et il suffit de
récupérer le code de la requête en l'appelant par son nom.
Pour ajouter une nouvelle requête, non encore étudiée, il
suffit d'aj outer une balise au fichier XML dans la balise «requete»,
mettre à jour la DTD (il suffit juste de signaler le nom de la
requête dans la liste des attributs de la requête) et prendre en
compte la modification dans le fichier principal du serveur (traitement des
communications et recherches). Il n'y a aucun besoin de modifier le parser, ce
cas de figure est pris en compte.
| 

