|
Copyright (c) Cedric TEMPLE
Permission is granted to copy, distribute and/or modify this
document under the terms of the GNU Free Documentation License, Version 1.2 or
any later version published by the Free Software Foundation;
with no Invariant Sections, no Front-Cover Texts, and no
Back-Cover Texts. A copy of the license is included in the section entitled
"GNU
Free Documentation License".
Stage de Master 1 Informatique
TEMPLE Cédric.


Responsables : M. BLANC Michel (ERASME) et M DELOT
Thierry
(UVHC-ISTV)
Résumé
Ce rapport présente le travail effectué lors du
stage réalisé dans le cadre du Master Informatique
Première Année à l'Université de Valenciennes et du
Hainaut Cambrésis, Institut des Sciences et Techniques de
Valenciennes(Nord) sous la tutelle de Monsieur DELOT Thierry. Ce stage a
été fait à ERASME, le service des Technologies de
l'Information du Département du Rhône, sous la direction de
Monsieur BLANC Michel, Ingénieur Systèmes/Réseaux.
Il sera présenté dans ce document la mission
ERASME ainsi que les différents projets auquel elle participe. Puis la
problématique du sujet, suivi du développement. Enfin les
conclusions et les perspectives seront présentées.
Remerciements
Je tiens à remercier particulièrement Monsieur
BLANC Michel pour m'avoir fait confiance, m'avoir permis de travailler avec
autonomie, m'avoir proposé ce sujet, de m'avoir conseillé et
aidé lorsque des problèmes se posaient.
Je voudrais remercier aussi Monsieur LACROIX Daniel pour
d'avoir pris sur son temps pour développer une bonne partie du serveur,
d'être resté disponible lors de mes questions sur la base de
données et sur le langage PERL.
J'aimerais remercier aussi l'ensemble des personnes qui
travaillent à ERASME pour leur accueil et leur gentillesse.
Merci au personnel du Centre d'hébergement et au
Conseil Général du Rhône pour m'avoir hébergé
gratuitement au Centre d'hébergement et avoir toléré ma
présence, même le week-end et les jours fériés.
Table des matières
I Présentation d'ERASME 5
1 Infrastructure 7
1.1 Le Centre Serveur Départemental 7
1.2 Le Centre d'hébergement 8
1.3 Le Centre de Formation 8
2 Les projets d'ERASME 9
2.1
Laclasse.com: un portail
éducatif 9
2.2 ProjetHartur 9
2.3 Désenclavement avec le Wifi 10
2.4 Arbresdeconnaissances 10
2.5 Autresprojets 12
II Description de l'outil 13
3 Buts/Objectifs 14
3.1 Présentation 14
3.2 Problèmes 14
3.3 Buts à atteindre 16
4 Présentation de l'environnement 17
4.1 Base de données 17
4.2 Langage de développement 17
4.3 Système d'exploitation 17
4.4 Outils de développement 18
4.4.1 argoUML 18
4.4.2 Poséidon for UML 18
4.5 Navigateurs Web 19
4.6 Editeur de texte 19
III Architecture de l'outil 21
5 Côté serveur 23
5.1 Description de la partie serveur 23
5.2 Adaptation de la partie serveur 23
5.2.1 Le fichier de configuration 23
5.3 Intégration des requêtes Whois 26
5.3.1 Description de whois 26
5.3.2 Intégration de whois au serveur 29
6 Côté client 30
6.1 Description de l'interface 30
6.1.1 Visualisation des sous-réseaux 30
6.1.2 Affichage des informations d'une plage 32
6.1.3 Recherche de plages libres 32
6.1.4 Recherche de plages selon un filtre 33
6.1.5 Navigation dans la partie visualisation 33
6.1.6 Historique 33
6.2 Architecture du client 33
6.2.1 Outils pour l'interface 34
6.2.2 Interface Graphique 36
7 Perspectives 40
7.1 Implémentation d'un cache 40
7.2 Différentes visualisations 40
7.3 Ajout des plugins côté serveur 40
8 Conclusion 41
IV Annexes 42
Première partie
Présentation d'ERASME
ERASME est une mission du Conseil Général du
Département du Rhône pour le développement des Nouvelles
Technologies de l'Information. Créé en 1999, sur le canton de
communauté de communes de Saint Laurent de Chamousset, à Saint
Clément les Places, au coeur des Monts du Lyonnais, le Centre
Multimédia ERASME a pour mission le déploiement des nouvelles
technologies de l'information dans le département du Rhône. Mais
sa fonction ne s'arrête pas là et il sera présenté
les projets auxquels il participe.
Chapitre 1
Infrastructure
Les Autoroutes Rhodaniennes de l'Information sont
constituées d'un réseau hybride fibre/coaxial sur 289 communes du
département. Ne font pas partie du projet les communes
déjà dans le plan câble et desservies par d'autres
technologies à haut débit (Lyon, Villeurbanne, Bron, Saint
Priest, St Fons, Décines, Meyzieu) et des communes n'ayant pas
souhaité adhérer au projet (St Germain au mont d'or, Arnas,
Riverie, Jons). Le réseau opéré par UPC [UPC] apporte au
moins un point de livraison optique par commune et couvre au moins 70 % des
foyers en zone rurale. La téléphonie, la télévision
et l'Internet à haut débit sont les trois services fournis. Il
existe donc déjà une forte capillarité de déserte
à haut débit sur le Rhône. Les batiments publics
raccordés sont les services des communes et du département:
mairies, Maisons du Rhône (MDR : décentralisation des services
offerts par le département), les bibliothèques, les
collèges (97) et les écoles (700).
1.1 Le Centre Serveur Départemental
Aussi appelé Centre Multimédia, il fait office
de serveur de ressources brutes: images, sons, vidéos; de documents
multimédias pédagogiques (les enseignants ont leur propre page
personnelle où ils peuvent déposer leurs documents et supports de
cours qui seront consultables par les élèves, voir [lac]); d'un
moteur de recherche; d'un proxy Internet et d'un serveur de messagerie. Une
salle de formation et un amphithéâtre permettent d'accueillir des
personnes en formation. Une salle d'accès libre permet aux habitants des
communes alentour d'avoir un accès Internet.
ERASME est chargé du support technique aux
différents établissements mais aussi de la mise en place ou de
l'aide à la mise en place de différents services comme une radio
Intranet, un journal de classe, publications de connaissances; le routage
Internet est aussi assuré.
Une autre partie de la charge ERASME se trouve dans la veille
technologique et le test de nouvelles technologies. Un exemple de ceci est les
tests actuellement effectués sur le Wifi pour la mise en place de points
d'accès ainsi que leur sécu-
risation et leur suivi. Le but général de ERASME
est le développement rural des TIC dans tout le département du
Rhône.
1.2 Le Centre d'hébergement
Situé à proximité du Centre
Multimédia, le Centre d'hébergement permet d'accueillir des
personnes effectuant une formation au Centre de Formation ainsi que les
stagiaires. Composé de 60 chambres individuelles et d'un service de
restauration sur place, il augmente les possibilités de formation d'une
durée importante (plusieurs jours) et permet un bon accueil des
stagiaires.
1.3 Le Centre de Formation
Le Centre de Formation se situe juste à
côté du Centre d'hébergement. A l'intérieur, il y a
un amphithéâtre de 80 places avec double rétro-projecteur,
deux salles informatiques pour des travaux de groupes (quinze personnes) et
deux salles de travail libre.
Les formations sont ouvertes à tous, professeurs,
élus, personnels du Conseil Général ainsi qu'à
toute personne ou groupe de personnes le demandant. Les formations sont
diverses et vont des bases de l'informatique avec Internet, le courrier
électronique, Star Office jusqu'à la mise en place d'un site Web,
le traitement de l'image, PHP , la pratique de la réalisation
vidéo en studio, l'administration de Windows 2000.
Chapitre 2
Les projets d'ERASME
Laclasse.com ([lac]) est un portail
éducatif exploitant les ressources du haut débit pour fournir aux
enseignants et élèves une bibliothèque multimédia,
des outils de communication et de publication. Hébergé par le
Centre Multimédia, il permet la mutualisation des moyens et
l'accès à des contenus en ligne, facilitant l'autoformation des
élèves et des enseignants. Les personnes y ayant un accès
total sont les enseignants des collèges et écoles du
département du Rhône ainsi que les élèves de ces
établissements. Les contenus libres de droit sont consultables par tout
internaute en se loguant sous le nom «demo» et le mot de passe
«demo». Les établissement extérieurs au
département peuvent demander un compte à titre
expérimental.
Les contenus (cartes, textes, sons, ...) peuvent être
utilisés comme support de cours, comme rapports d'expériences
pédagogiques ou auto-formation des enseignants. Les enseignants peuvent
ainsi s'échanger des cours ou des plans de cours, les
élèves peuvent publier leurs recherches pour leur classe,
participer à des discussions avec des élèves d'autres
classes. Les parents d'élèves peuvent consulter l'agenda de la
classe et entrer en contact avec les enseignants.
2.2 Projet Hartur
Hartur signifie: «Hypermédia d'Archives
Régionnales d'Actualités Télévisées sur
l'Urbanisme dans le Rhône». C'est un projet mis en place par le
département du Rhône, l'Institut National de l'Audiovisuel (INA)
et le Centre Régional de Documentation Pédagogique (CRDP) de Lyon
à destination des 160 collèges du Département du
Rhône. Il permet la consultation en ligne d'une cinquantaine d'extraits
de films vidéo sur le thème de l'architecture et de l'urbanisme.
Ce service s'appuie sur une technologie innovante de navigation,
«Hypermédia», développée par l'INA, qui permet
d'indexer et de consulter de manière interactive et est
hébergé au Centre Multimédia. L'indexation est
organisée pour pouvoir accéder directement au passage pertinent
à l'intérieur d'un document vidéo et de pouvoir naviguer
dans cette
vidéo. L'utilisateur final peut réaliser une
production simple et la stocker ainsi que les commentaires sur les
résultats de sa recherche dans un espace qui lui est alloué. Le
contenu pédagogique a été réalisé sous la
responsabilité du CRDP de Lyon, en liaison étroite avec le Centre
Académique de Ressources pour l'Informatique Pédagogique qui
relève du Rectorat.
2.3 Désenclavement avec le Wifi
Du fait des limites d'extension physique du réseau
câblé, des lieux-dits et des foyers en zone rurale ne seront pas
desservis par le câble. ERASME étudie la possibilité de
connecter ses différents lieux en Wifi (voir la figure 2.3 page 11
tiré du document «présentation_projet_wifi.doc» sur le
site [era]). L'étude des sites à desservir a permis de
dégager des caractéristiques générales:
- l'existence d'un nombre important de zones à
étendre
- l'existence à l'intérieur de chaque zone d'un
nombre relativement faible de clients finaux
- la possibilité de liaison avec un point
câblé du réseau départemental situé dans la
quasi totalité des cas à moins de 3 kilomètres.
Comparée à d'autres technologies, le Wifi
répond le mieux aux besoins:
- coût de déploiement limité et
évolution aisée (multiplications des infrastructures)
- bande passante partagée suffisante pour un petit nombre
d'utilisateurs
- portée de liaison suffisante (un test sur deux
kilomètres a été effectué au Centre ERASME en mai
2002)
- le Département souhaite s'engager dans une voie
innovante sur le plan technique et collaboratif.
Des tests sont actuellement effectués pour
l'installation et la configuration des matériels, la mis en place d'une
politique de sécurité (définition d'une liste d'adresses
MAC autorisées à se connecter, cryptage des données via
une clé WEP 64 ou 128 bits, tunneling IP SEC, adjonction d'un serveur
d'authentification), ainsi que la meilleure localisation pour placer l'antenne,
les combinaisons
points d'accès/antennes les plus performantes.
Unejournée spéciale wifi était
organisée le samedi 14juin, intitulée «Wifi, c'est parti
!», où les maires de communes ainsi que le public pouvaient
s'informer sur le matériel, la mise en place et la
sécurité d'un réseau wifi. Une conférence sur les
généralités du wifi et une, un peu plus technique, sur la
sécurité, ont été présentées par des
membres de l'association «wireless Lyon» ([wir]) et l'on pouvait
participer à des ateliers comme la fabrication d'une antenne.
2.4 Arbres de connaissances
ACNE [acn] signifie «Arbres de Connaissances pour une
Nouvelle Ecole». Michel AUTHIER et Pierre LEVY, mathématiciens,
sociologues et chercheurs, ont
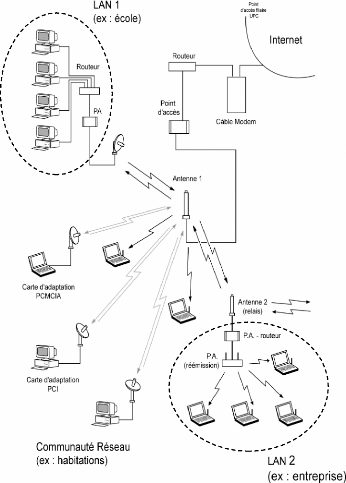
3
4 5
1
2
CHAPITRE 2. LES PROJETS D'ERASME 11
FIG. 2.1 - Exemple de
raccordements wifi
mis au point le principe appelé "arbre des
connaissances" et l'outil informatique permettant seul de réaliser la
gestion globale des connaissances, des compétences et de la formation
dans les organisations (communautés scolaires ou territoriales ou
sociales, entreprises ....). Un arbre de connaissances permet de faciliter
l'échange réciproque de savoir entre individus et de situer
l'ensemble des ses connaissances par rapport au groupe auquel il appartient. Le
but est de constituer progressivement les arbres des différentes
communautés concernées, à savoir:
- l'arbre de chaque classe,
- l'arbre de chaque école,
- l'arbre de chaque communauté éducative (parents,
enseignants, ...)
- l'arbre de chaque village, quartier, environnement, canton
...
- l'arbre collectif de plusieurs sites (classes uniques,
réseau, ...)
- l'arbre collectif de tous les sites.
2.5 Autres projets
Le projet Olivier est un projet qui associe le Conseil
Général, l'Institut National des Sciences Appliquées de
Lyon et Handicap International qui a pour but de favoriser la
coopération en ligne entre plusieurs établissements
d'enseignement spécialisé (pour des jeunes en difficulté
ou porteurs de handicap).
Le projet «Apprendre le Net à
l'hôpital», porté par Handicap International, vise à
apporter aux personnes hospitalisées pour une longue durée une
initiation à l'utilisation de l'Internet. Trois établissements
hospitaliers du Rhône sont associés à ce projet.
Deuxième partie
Description de l'outil
Chapitre 3
Buts/Objectifs
3.1 Présentation
Le Centre Multimédia a développé un
réseau auquel se connectent les écoles, mairies, collèges
et d'autres infrastructures du département du Rhône. Des sous
réseaux ont été constitués pour chaque
«catégorie» d'infrastructure. Chaque catégorie a
ensuite été subdivisée en un sous réseau pour une
entité, comme par exemple le collège d'une commune.
Toutes les données de ce réseau sont dans une
base MySQL. Le modèle entité/association de la partie de la base
de données utilisées se trouve à la page 15.
3.2 Problèmes
Toutes les données de ce réseau sont dans une
base MySQL. Cependant, toutes ces données sont «à plat»
et il devient très difficile d'avoir une vue globale facilement
compréhensible par un humain. L'appartenance d'un sous réseau
à un réseau est très difficile à déterminer
et il faut faire une recherche non pas sur l'adresse mais sur l'entité
qui l'intègre. Par exemple, lorsque l'on veut savoir à quel
réseau appartient le sous réseau Ecole de Saint Clément
les Places, il faut effectuer une recherche sur le nom du sous réseau
qui contient le terme «Ecole» et non sur l'adresse CIDR. Auparavant,
cette recherche était effectuée suivant une table de
correspondance, dans un manuel papier.
De même, la recherche d'une plage suivant un filtre
doit s'effectuer avec une requête SQL directement. Il est obligatoire de
se connecter à distance au serveur MySQL et de taper la requête.
Ce qui est assez désagréable et entraîne une perte de
temps, notamment lors d'une intervention sur un site. De plus, ne disposant pas
de toute la documentation à disponibilité immédiate comme
par exemple le diagramme Entité/Association de la base de
données,il faut se souvenir précisément de ce
diagramme.
Enfin, il est impossible de voir les plages libres (non
affectées) à l'intérieur
Canton
Id Lib
Type _etb
1..n
Id
lib
dsc
Id
Nom cp
tel
web mail
Commune
Id lib
1
1..n
Etablissement
1
1..n
1
FIG. 3.1 - Modèle entité/association de la partie
de la base de données utilisée
d'un sous réseau sans lister toutes les plages et
calculer «à la main». Il manque donc un outil de visualisation
représentant les sous réseaux, les plages libres d'une
manière aisée et facilement interprétable. Un module de
recherche des plages libres d'une taille donnée dans un sous
réseau particulier permettra de vérifier aisément les
«trous» dans un sous réseau. On pourra ensuite passer à
la visualisation de ce sous réseau pour faciliter, en plus,
l'interprétation.
3.3 Buts à atteindre
Le principal but à atteindre est la visualisation
immédiate et aisément interprétable de tout le
réseau et de ses sous réseaux. Le deuxième est la
navigation à l'intérieur de ce réseau : pouvoir changer de
plage, aller à la précédente et la suivante. Enfin des
modules de recherche amélioreront l'utilisabilité du logiciel.
L'ajout de fonctionnalités selon l'avancée du projet devra
être le plus aisé possible.
Chapitre 4
Présentation de l'environnement
4.1 Base de données
L'environnement de départ repose sur une base de
données existante. En effet, la base de données a
été développée avant même l'idée de
création de cet outil de visualisation. C'est d'ailleurs à la vue
de la difficulté de visualisation des données contenues dans la
base que l'idée de développer un outil de visualisation s'est
faite sentir. Ensuite, l'extension vers tout l'Internet est venue
naturellement. Ainsi, lors par exemple de vérification des fichiers
journaux de serveurs, si une alerte apparaît avec l'adresse IP d'une
machine ayant essayer de pénétrer de manière non
autorisée, on peut visualiser les informations renvoyées par une
requête whois . Le serveur est MySQL dans sa version 3.23.x.
4.2 Langage de développement
L'outil devant être le plus accessible, quel que soit
le Système d'Exploitation, le responsable de stage a demandé
à ce que l'outil soit une applet, donc une application écrite en
langage Java et pouvant être utilisée depuis un navigateur Web
compatible avec le langage Java. En effet, l'utilisateur final de l'outil sera
peut être amené à intervenir sur des sites distants et il
devra avoir accès à cette application, les applets sont donc
l'outil idéal pour ce genre d'utilisation.
4.3 Système d'exploitation
Le Système d'Exploitation de la station sur laquelle a
été écrite le logiciel est laissé libre au choix du
stagiaire. Il a été choisi une distribution Linux, environnement
utilisé le plus par le stagiaire lors de ses études. Tous les
outils sont laissés libres. Ce libre choix est un point très
positif, notamment cela permet de s'intégrer très rapidement car
l'on s'habitue beaucoup plus rapidement à son environnement de
travail.
4.4 Outils de développement
Différents outils de développement ont
été utilisés. Pour la modélisation en UML du
logiciel, deux outils ont participé, argoUML (voir [arg]) dans sa
version 0.12 et Poséidon for UML ([gen]) dans la version Community
Edition 1.6.1. Un éditeur de texte pour taper le code source :
emacs([ema]). Différents navigateurs Web pour les tests de l'applet :
Mozilla ([moz]), Netscape([net]) et Galeon([gal]). Ces navigateurs ont aussi
servi à consulter la documentation disponible sur Internet.
4.4.1 argoUML
argoUML est un outil de modélisation UML. C'est un
Logiciel Libre, sous licence BSD ([bsd]). Ce logiciel a été pour
la première fois utilisé pour les travaux pratiques dans le cadre
du cours de Génie Logiciel de M Kolski, travaux pratiques
encadrés par M Adam. Lors de ces premières utilisations en TP, de
nombreux problèmes sont apparus au niveau graphique comme par exemple
les onglets qui grandissaient lorsque l'on ajoutait des paramètres aux
fonctions ou qu'on modifiait leur type et un redémarrage de argoUML
était nécessaire. Ce problème était peut être
dû au langage Java lui même (voir paragraphe sur Poseidon for UML).
Cependant lors du stage, après avoir téléchargé sur
le site et installé la dernière version du logiciel, ses
problèmes ne se sont pas présentés.
Mais d'autres sont apparus. Un onglet permet de documenter
chaque méthode, chaque attribut et l'intégrer directement au code
source lors de la génération du code. Lors de la sauvegarde et de
la restauration du fichier cette documentation avait tendance à
disparaître, ce qui est gênant voir frustrant. Lors de la
génération de code, si le fichier était déjà
présent sur le disque, le logiciel tentait de «corriger» ce
fichier en y ajoutant ou supprimant ce qu'il fallait. Cependant, ce fichier
n'était alors pas syntaxiquement correct (la compilation ne
réussissait pas). Ce problème ne se posait pas lorsque le
répertoire de destination était vide. De même de temps
à autre, lors d'une tentative de chargement le fichier de sauvegarde se
retrouvait corrompu, il fallait alors importer depuis les sources. Ce
n'était pas un gros problème lorsque l'on pensait à
générer le code source dans un répertoire vide
après avoir sauvegardé. Ces problèmes devenant vite
difficiles à gérer lors du développement, il a
été décidé de se tourner vers un autre outil.
4.4.2 Poséidon for UML
Poséidon for UML est un outil de modélisation
UML comme argoUML. Poséidon est en fait basé sur la version 0.9.4
d'argoUML, mais il faut noter que les architectures diffèrent et les
modifications apportées sur argoUML ne sont pas directement
intégrables dans Poséidon. La version utilisée est la
version gratuite, la «Community Edition». Les différences avec
argoUML se situent au niveau de la stabilité principalement et des
fonctionnalités. Cependant, les fonctionnalités uti-
lisées lors du stage sont aussi disponibles sur argoUML.
La grande stabilité de Poséidon lui a donc permis d'être
utilisé plutôt que argoUML.
A noter que Poseidon réclame au minimum la version
1.4.1 du JDK, malgré cela, son utilisation avec la version 1.4.2 pose
quelques problèmes graphiques de dimensionnement, comme pour argoUML,
mais ici c'est directement dans la fenêtre principale, lors de la
sélection des classes, la taille du composant diminue et les noms des
méthodes ne sont plus lisibles (pour ne pas dire qu'elles deviennent
illisibles). Ce problème ne se pose pas avec le JDK 1.4.1.
Poséidon connaît quelques problèmes d'import (lecture de
code source) notamment sur les gros fichiers où, après avoir
modifier le code de plusieurs fichiers, un import a été
réalisé mais le logiciel a «perdu» des variables de
classes et le code de certaines méthodes (les constructeurs
d'objets).
4.5 Navigateurs Web
Différents navigateurs Web ont été
testés pour vérifier que l'applet donnait les mêmes
résultats. Les navigateurs de tests ont été Mozilla dans
sa version 1.3, Nets-cape dans sa version 7.0 et Galeon, installé de
base avec la Red Hat. L'applet s'est comportée de la même
manière avec les trois navigateurs, même dans un problème
rencontré. La description du problème est la suivante : au
chargement de l'applet, lorsque l'on souhaite entrer du texte dans l'une des
cases disponibles (un objet JTextfield), il est impossible de le faire
directement sans changer tout d'abord de fenêtre. En effet, les
navigateurs refusaient de mettre le focus dans la case correspondante, il
fallait alors changer de fenêtre (donner le focus à un terminal ou
un éditeur de texte par exemple) puis revenir dans le navigateur. Ce
problème est maintenant réglé de manière
complètement artificielle : l'applet étant signée car
demandant un certains nombres de privilèges (comme lancer plusieurs
threads ou se connecter à un serveur), juste avant la fin du chargement
une fenêtre s'ouvre demandant si l'utilisateur souhaite faire confiance
à l'applet. C'est l'ouverture de cette fenêtre qui règle le
problème précédent. Il semble cependant que le
problème ne soit qu'en partie réglé car lors du
rechargement de l'applet, la fenêtre ne s'ouvre plus car l'utilisateur a
déjà donné son accord pour le chargement de l'applet, ce
qui implique qu'il faut alors sortir de la fenêtre puis y revenir.
Un autre petit problème vient de l'affichage de
l'applet dans une fenêtre de taille maximale. En effet, à la
demande du responsable, un bouton permet de «sortir» l'applet du
navigateur et de la voir dans une autre fenêtre. Cependant, lorsque l'on
maximise la fenêtre, les proportions des différents composants
à l'intérieur de la fenêtre ne sont plus du tout
respectées et l'affichage devient très
désagréable.
4.6 Editeur de texte
Le code source peut être édité directement
dans Poséidon. Cependant, Poséidon consommant de nombreuses
ressources mémoire, l'ouverture d'un navigateur Web
pour consulter la documentation disponible sur le Web (l'API
du JDK [API] sur le site de Sun) et de l'applet les ressources de la machine
devenant vite très limitées. Un éditeur de code source se
révèle donc plus léger mais aussi beaucoup plus
fonctionnel, notamment pour l'indentation et la navigation entre
différents fichiers. Emacs a donc permis l'édition du code source
d'une manière bien plus aisée.
Troisième partie
Architecture de l'outil
L'outil est en fait séparé en plusieurs
parties. La partie interface graphique et la partie interaction avec la base de
données. Ces deux parties communiquent au travers le réseau de
façon client/serveur. Il sera présenté dans cette partie
l'architecture du serveur et l'architecture du client.
Chapitre 5
Côté serveur
5.1 Description de la partie serveur
Le serveur est écrit en langage PERL. Ce langage est
«imposé«, car une grosse partie a été
écrite par Daniel LACROIX, qui le maintiendra dans le futur et
continuera à le développer si le besoin s'en faisait sentir.
Daniel a commencé par écrire les fonctions de gestions des sous
réseaux comme par exemple récupérer le masque du sous
réseau, obtenir l'adresse de broadcast, tester si un sous réseau
appartient à un réseau... Ensuite il a écrit les fonctions
et procédures qui récupèrent les sous réseaux
correspondant à un filtre de recherche; les procédures de
communication et enfin le programme qui crée un nouveau processus
à chaque demande de connexion. Cette première écriture a
permis de développer rapidement l'interface graphique et d'avoir un
premier outil disponible. Cependant, les possibilités d'extension et de
configuration sont un peu limitées par rapport à ce que l'on
souhaitait obtenir mais cela a permis d'analyser son code source et, ne
connaissant pas Perl, d'obtenir un très bon point de départ pour
la suite.
5.2 Adaptation de la partie serveur
La première chose à effectuer était de
faire un fichier de configuration, facilement modifiable pour y incorporer un
système de «plugins» . Ensuite ajouter les
fonctionnalités qui n'étaient pas encore
développées. Ce fichier de configuration doit être le plus
facilement extensible et l'ajout éventuel de données ne doit pas
influer sur le code, autrement que par l'ajout des outils
nécessaires.
5.2.1 Le fichier de configuration
Perl se marie très bien avec XML (eXtensible Markup
Language), c'est pourquoi ce choix s'imposait. De plus, XML permet de valider
le fichier de configuration avec le mécanisme des Document Type
Definition (DTD). La facilité de récupération des
données est aussi entrée en compte et le choix d'un parser
(outil
du langage permettant de parcourir le fichier et d'obtenir le
contenu des balises tout en ayant la possibilité ou non de le valider)
est conséquent. Perl fournit en effet de nombreux parsers tels que:
- XML : :Parser: parser non validant. C'est sur ce parser que
sont basés la plupart des autres. Il est plutôt simple à
utiliser. En effet, il suffit d'écrire deux procédures pour
chaque balise : une procédure pour la balise ouvrante, cette
procédure portant le même nom que la balise et une
procédure pour la balise fermante portant le même nom que la
balise, suffixée par le caractère «souligné ("_" ou
"underscore"). Il est pas obligatoire de créer toutes les
procédures. Ensuite il suffit d'écrire une balise appelé
dans tous les cas non pris en compte. Cependant, il devient difficile à
utiliser lorsque l'on veut avoir un groupe de noeuds. Son point fort est sa
très grande rapidité.
- XML : :Simple : un parser développer essentiellement
pour les fichiers de configurations, dont le but est d'être très
simple d'utilisation. Cependant, il est encore en version bêta et non
disponible dans la version standard donc il n'a pas été
utilisé.
- XML: :SAX: l'implémentation de l'autre API standard
du W3C. Alors que DOM est tourné vers la représentation du
fichier XML sous forme d'arbre, SAX est tourné vers
l'événementiel, comme XML: :Parser, ce qu'il fait qu'il est
rapide par rapport à DOM tout en l'étant moins que XML:
:Parser.
- XML: :DOM: l'implémentation de l'API standard
définie par le W3C1.
Le fichier est représenté sous forme
arborescente. On parcourt le fichier en
sélectionnant les noeuds que l'on souhaite et on
travaille sur ces noeuds.
Le problème qui se pose avec cette représentation
est que chaque retour à la
ligne est interprété et lorsque l'on parcours la
liste des noeuds fils d'un noeud
particulier il faut vérifier le type du noeud pour
s'assurer que ce n'est pas du
texte (la valeur du noeud). Un facteur limitant est la lenteur
de ce parser,
mais pour le fichier de configuration, lu une seule fois lors
du démarrage du
serveur, ce n'est pas important. C'est donc ce parser qui a
été utilisé.
La première chose était de sortir les
données stockées «en dur» (c'est à dire sous la
forme d'une structure de données) dans le programme. Ces données
n'existent pas dans la base car elles n'ont aucun sens réel. En effet,
les réseaux ne sont pas rattachés à un
établissement, ce qui implique qu'il aurait fallu représenter
explicitement la notion de sous réseaux d'un réseau et donc cela
aurait engendré des modifications trop importantes de la base de
données. Ces données ont donc été stockées
dans un fichier XML externe au fichier de configuration et une balise dans le
fichier de configuration fait mention du fichier de données à
parser.
Ensuite il fallait prendre en compte le cas où l'on
pouvait avoir plusieurs bases de données complètement
différentes. En effet, il se peut que plus tard la base soit
«éclatée» sur plusieurs serveurs, il serait dommage de
devoir étudier de nouveau le logiciel pour ce cas. On stocke donc dans
le fichier le type du serveur (MySQL, Oracle, DB, ...), le nom ou adresse IP de
la machine sur laquelle est lancée le ser-
FIG. 5.1 - Modèle entité/association No 1
Etablissement
Numero Subnet Numero NumRue Adresse Ville
|
|
FIG. 5.2 - Modèle entité/association No2
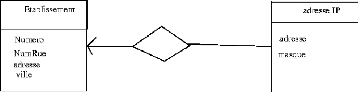
veur, son port de communication, l'identifiant et le mot de
passe pour la connexion au serveur, la plage la plus grande contenue dans la
base et les requêtes que l'on va effectuer. La plage la plus grande est
une plage de la forme 172.0.0.0/4, par exemple, qui contient toutes les autres
plages. Il se peut que certaines plages ne soient pas connues dans la base mais
ce n'est grave, on fera une recherche, au pire, non utile mais ce n'est pas ce
qui coûte le plus (ce sont les requêtes whois, voir plus loin). Les
requêtes sont des requêtes SQL, qui possèdent chacune un nom
pour une recherche donnée. Par exemple, une requête listant tous
les sous réseaux portera le nom de «liste_subnets». Si la
requête n'est pas définie, on n'effectue pas la recherche dans
cette base. Toutes les requêtes de même nom doivent avoir le
même format de «sortie», ce qui est très simple à
faire en SQL. Un exemple permettra d'éclaircir ce qui a
été dit précédemment. On cherche à obtenir
toutes les adresses IP de deux bases distinctes. Les modèles
entités/associations des deux bases sont donnés par les figures
5.2.1 et 5.2.1.
On écrit donc les deux requêtes pour chaque base;
la première (figure 5.2.1 page 25):
SELECT subnet AS subnet_Lan,
numero as numero
FROM Etablissement
et la deuxième (figure 5.2.1 page 25):
SELECT
CONCAT(adresseIP.adresse, »/»,masque) AS
subnet_Lan,
etablissement.numero AS numero
FROM etablissement, adresseIP
WHERE etablissement.numero = adresseIP.numero;
et on a ainsi en sortie deux résultats ayant les
mêmes noms de colonnes et le programme peut utiliser les requêtes
de la même manière. Le code Perl (mais se serait la même
chose pour Java ou tout autre langage) reste identique et se base sur les noms
de colonnes.
Actuellement il y a trois types de requêtes : une pour
obtenir toutes les plages et leurs informations, une pour faire une recherche
selon le nom du propriétaire et une pour faire une recherche sur le nom
de l'enregistrant. Cependant, si l'on veut ajouter d'autres requêtes, il
est inutile d'ajouter du code au parser. En effet, le parser et la structure du
fichier XML sont étudiés pour que la requête soit
directement stockée dans la structure de données et il suffit de
récupérer le code de la requête en l'appelant par son nom.
Pour ajouter une nouvelle requête, non encore étudiée, il
suffit d'aj outer une balise au fichier XML dans la balise «requete»,
mettre à jour la DTD (il suffit juste de signaler le nom de la
requête dans la liste des attributs de la requête) et prendre en
compte la modification dans le fichier principal du serveur (traitement des
communications et recherches). Il n'y a aucun besoin de modifier le parser, ce
cas de figure est pris en compte.
5.3 Intégration des requêtes Whois
5.3.1 Description de whois
whois est un utilitaire permettant de récupérer
les informations concernant une plage ou un nom de domaine. Cet utilitaire
interroge les serveurs whois et affiche le résultat à
l'écran. Les informations fournies sont: le nom du groupe qui a
enregistré la plage; le nom du groupe auquel est enregistré la
plage; la plage d'adresses; les différents contacts disponibles ;... Un
exemple de requête sur un nom de domaine: whois
erasme.org
Domain ID :D101339-LROR
Domain Name :ERASME.ORG
Created On :02-Jan-1 99705 :00 :00 UTC
Last Updated On :05-Jun-2003 16 :44 :26 UTC
Expiration Date :01-Jan-2005 05 :00 :00 UTC
Sponsoring Registrar :R54-LROR
Status :OK
Registrant ID :ER11162-NBAY
Registrant Name :MARTIN YVES-ARMEL
Registrant Organization :ERASME
Registrant Street1 :29-31, COURS DE LA LIBERTE
Registrant City :LYON CEDEX 03 Registrant State/Province :FR
Registrant Postal Code :69483 Registrant Country :FR
Registrant Phone :+ 33.4 74706840 Registrant Email :
YAMARTIN@ASI.FR Admin
ID :MA88224-NBAY
Admin Name : YVES-ARMEL MARTIN Admin Street1
:407ROUTEDEBAYERES Admin City :CHA TILL ON
Admin State/Province :FR
Admin Postal Code :69380
Admin Country :FR
Admin Phone :+ 33.4 74706840 Admin Email :YAMAR
TIN@ASI.FR Billing ID
:AI31456-NBAY
Billing Name :JACQUES MOLINES Billing Organization :AIC
NETWORK Billing Street1 :8, rue Colonnel Chambonnet
Billing City :BRON
Billing State/Province :FR
Billing Postal Code :69500
Billing Country :FR
Billing Phone :+33.4 723 72315 Billing Email :tech@
aic.fr
Tech ID :AI22257-NBAY
Tech Name :SAMIA CHIKER
Tech Organization :AIC NETWORK
Tech Street1 :8, rue Colonnel Chambonnet Tech City
:BRON
Tech State/Province :FR
Tech Postal Code :69500
Tech Country :FR
Tech Phone :+ 33.4 72372315 Tech Email :tech@
aic.fr
Name Server :NS0.ERASME. ORG Name Server
:NS1.ERASME.ORG
Un exemple de requête depuis une adresse:
whois 1 93.50.192.40
Donne le résultat:
inetnum: 193.50.192.0 - 193.50.197.255 netname :
FR-UVHC
descr: University of VALENCIENNES Campus
descr : Le Mont Houy BP 311, 59304 Valenciennes,
France
country : FR
admin-c : JA2966-RIPE tech-c : JP1641-RIPE tech-c :
FV982-RIPE
status : ASSIGNED PA mnt-by : RENATER-MNT
changed: RenSVP@Renater.Fr 19991230
source : RIPE
route: 193.50.192.0/24 descr : FR-UVHC
origin : A S2200
mnt-by : RENATER-MNT
changed:
RenSVP@Renater.fr
19991008
source : RIPE
person : Jean-Claude ANGUE address: Universite de
Valenciennes
address : Le Mont Houy - BP 311
address: 59313 VALENCIENNES CEDEX3
phone: +33327511234 fax-no: +33327511360
e-mail :
president@univ-valenciennes.fr
nic-hdl: JA2966-RIPE mnt-by : RENATER-MNT
changed:
rensvp@renater.fr
19991229
changed:
rensvp@renater.fr
20000211
source : RIPE
person : Francis VANHUYSSE address : Le Mont Houy address :
BP 311
address: 59304 VALENCIENNES CEDEX
phone:+33 327141128 fax-no:+33327 141183
e-mail:
vanhuysse@univ-valenciennes.fr
nic-hdl: FV982-RIPE mnt-by : RENATER-MNT
changed:
rensvp@renater.fr
19991230
source : RIPE
person : Jean-Luc PETIT address : Le Mont Houy address : BP
311
address: 59304 VALENCIENNES CEDEX
phone: +33327511128 fax-no: +33327511340
e-mail :
jlpetit@univ-valenciennes.fr
nic-hdl: JP1641-RIPE
mnt-by : RENATER-MNT
changed:
rensvp@renater.fr
19991221 changed:
rensvp@renater.fr
20000211 source : RIPE
5.3.2 Intégration de whois au
serveur
Pour intégrer les requêtes whois au serveur il
faut utiliser une bibliothèque annexe au langage que l'on trouve sur le
site officiel des bibliothèques deu langage Perl ([cpa]), il s'agit de
la bibliothèque Net: :XWhois. Il y avait aussi la bibliothèque
Net: :Whois mais elle est beaucoup moins évoluée, notamment elle
ne per-met pas d'obtenir directement une valeur d'un paramètre, il faut
pour cela parser le résultat obtenu. Par contre, la bibliothèque
Net: :XWhois est très simple à utiliser: il suffit de faire la
requête et de récupérer la valeur du champ souhaité
(par exemple desc). De plus, les requêtes whois étant assez
lentes, il fallait développer un système de cache pour
éviter de refaire des appels faits précédemment.
Cependant, ce développement n'a pas été nécessaire
car ce système est inclus directement dans la bibliothèque elle
même, ce qui facilite grandement les choses. Enfin, lorsque l'on effectue
une requête, il faut tenir compte que l'on obtient pas directement les
données souhaitées, il faut en fait faire une première
requête, vérifier si les données sont suffisantes sinon
refaire une deuxième requête qui permettra d'obtenir plus
d'informations et ainsi de suite.
Chapitre 6
Côté client
La partie cliente doit principalement s'attacher au
problème de représentation de la base, c'est le point le plus
important à considérer. Le responsable de stage a défini
ce qu'il désirait comme interface, ce qu'il désirait obtenir
comme visualisation la plus compréhensible possible et
interprétable.
6.1 Description de l'interface
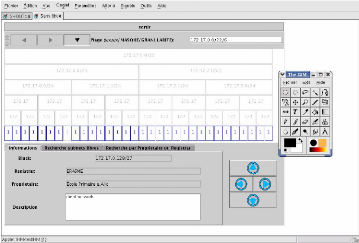
6.1.1 Visualisation des sous-réseaux
L'affichage principal est un tableau de sous-réseaux. Le
premier sous-réseau, par exemple 172.17.0.0/22, celui dont on cherche
à avoir un découpage est affiché sur la première
ligne. Puis, ce sous réseau est découpé en deux parties,
172.17.0.0/23 et 172.17.2.0/23 qui sont ajoutés sur la deuxième
ligne, on réitère en découpant les deux sous
réseaux en deux et on place les quatre sous réseaux ainsi obtenus
(172.17.0.0/24, 172.17.1.0/24, 172.17.2.0/24 et 172.17.3.0/24) sur la
troisième ligne. On peut choisir le nombre de lignes que l'on cherche
à obtenir, en entrant en fait la plage de départ et en ajoutant
un '/' et le nombre de lignes, ce qui donne dans notre exemple :
172.17.0.0/22/5. Cette manière d'entrer les informations a
été préférée, notamment par M Blanc,
utilisateur final de l'outil, car il est beaucoup plus rapide de taper une
seule fois de cette manière plutôt que de cliquer sur une case,
entrer la plage, cliquer sur une boite de sélection pour le masque,
cliquer sur une autre boite de sélection pour le nombre de niveaux et
enfin cliquer sur un bouton de validation. La figure 6.1.1 page 31
représente un schéma de ce qui est représenté
à l'écran.
De plus, lors de la requête, les cases sont de couleur
grisâtres (comme un bouton que l'on ne pourrait pas cliquer), ce qui
indique que pour le moment, il n'y a pas d'informations disponibles pour la
case considérée. Puis lorsque des informations parviennent, les
cases changent de couleur pour indiquer que, maintenant, des informations sont
disponibles (voir capture 6.1.1 page 31).
Si aucune plage n'est trouvée dans ce réseau, une
boite de dialogue s'ouvre
CHAPITRE 6. COTÉ CLIENT 31
FIG. 6.1 - Capture
d'écran de la représentation de sous réseaux
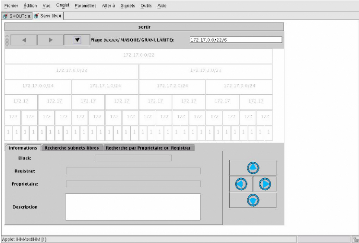
FIG. 6.2 - Arrivée des informations
pour demander à l'utilisateur s'il désire
remonter dans l'arborescence pour trouver la première plage parente.
Cette fonctionnalité est très utile, notamment lorsque l'on
cherche à qui appartient une plage ou de quelle catégorie
(«Mairies», «Écoles», «Collèges»)
elle fait partie.
Un clic droit sur une case donnée affichera un menu
permettant de zoomer sur la plage sélectionnée, d'afficher les
informations détaillées sur cette plage ou d'ouvrir une page Web
permettant d'accéder à des informations encore plus
détaillées sur cette plage. Cependant, il faut noter que cette
dernière possibilité n'est envisageable que pour les plages
contenues dans la base de données MySQL. En effet, cette page s'ouvre
vers un logiciel écrit précédemment, qui n'affiche les
informations disponibles que pour les sous réseaux contenus dans la base
de données.
6.1.2 Affichage des informations d'une
plage
La plage, son adresse au format CIDR, est affichée
directement dans la case prévue à cet effet. D'autres
informations sont importantes comme à qui appartient la plage
(«Mairie de Saint-Clément-les-Places» ou «École de
Sainte-Foyl'Argentière» ), le groupe qui l'a enregistrée
(ERASME) et une description. Cependant, la place manquait vite dans les cases
et il a fallu trouver autre chose. L'idée, très simple, est de
déporter l'affichage en bas de l'écran, dans un onglet, et
qu'à chaque fois que la souris passe sur une case les informations sont
affichées touj ours au même endroit. L'affichage est
déporté en bas, dans un onglet, et non sur la gauche ou la droite
car le problème de place se posait essentiellement à l'horizontal
et non à la vertical.
6.1.3 Recherche de plages libres
La recherche est dans un onglet, comme l'affichage des
informations. Cette table à onglets permet de gagner de la place et est
légitime car il ne sera pas nécessaire de vérifier les
informations sur une plage donnée en même temps que l'on recherche
une liste des plage libres.
La recherche s'effectue par l'entrée d'une valeur dans
une case de texte puis par pression de la touche <ENTRÉE> ou par
un clic sur le bouton prévu à cet effet. On peut choisir
d'afficher la liste des plages depuis le début ou depuis la fin. Le
paramètre devant avoir la forme suivante:
X.X.X.X/MASQUE/MASQUE_RECHERCHE. Les quatre X
séparés par un point identifie une adresse IP, MASQUE
complétant cette adresse pour obtenir une plage sous la forme d'une
notation CIDR dans laquelle rechercher les plages libres. Enfin
MASQUE_RECHERCHE spécifie la taille des plages recherchées. Par
exemple on veut trouver la liste des plages de taille /27 disponibles dans le
réseau
172.17.0.0/22, il suffit d'entrer : 172.17.0.0/22/27 et de
presser la touche <ENTRÉE>. Il est à noter que si une plage
libre est de taille /26, alors le serveur la découpe en deux plages de
tailles /27 consécutives. Toutes les plages obtenues s'affichent dans un
tableau et il suffit de cliquer sur une des plages pour que l'affichage
principal «zoome» sur cette plage.
Il faut noter que la recherche de plages libres n'a aucun
sens dans le cas de requêtes whois. Elle n'est utilisée que pour
rechercher des plages du réseau géré par ERASME pour
allouer des plages à de nouvelles écoles ou mairies.
6.1.4 Recherche de plages selon un filtre
Cette recherche est aussi située dans un onglet. Pour
effectuer la recherche, on entre de la même manière une plage au
format CIDR, on choisit la catégorie: soit le propriétaire, soit
le registrar (organisme ayant enregistré la plage). Ensuite on entre le
filtre de recherche et on appuie sur la touche <ENTRÉE> ou on
clique sur le bouton prévu à cet effet. Le filtre accepte les
«jokers» du langage SQL, c'est à dire des caractères
symbolisant n'importe quel caractère ou groupe de caractères. Par
exemple, le filtre «e%e» affichera toutes les plages
commençant par la lettre 'e' et se terminant par cette même
lettre. La recherche n'est pas sensible à la casse, ainsi
«ERASME», «ErAsMe», «erasme» donnera exactement
le même résultat.
De même, les plages s'ajoutent dans un tableau et la
sélection d'une de ses plages la fera s'afficher dans la partie
visualisation.
6.1.5 Navigation dans la partie
visualisation
Après avoir entré une plage et l'avoir
visualisée, on peut, grâce à un panneau de navigation,
remonter, aller à la plage suivante, aller à la plage
précédente, descendre. Lorsque l'on remonte, on va en fait
à la plage immédiatement supérieure de la plage actuelle.
Par exemple, après avoir entré : 172.17.6.0/23/6 et la pression
sur le bouton permettant le remonté sélectionnera la plage
172.17.4.0/22/6. Lorsque l'utilisateur cliquera ensuite sur le bouton
permettant d'aller à la plage précédente, la navigation le
dirigera vers la plage 172.17.0.0/22/6 alors que la navigation l'aurait
emmené vers la plage 172.17.10.0/22/6 s'il avait voulu obtenir la plage
suivante. Pour aller vers le bas, en fait augmenter le masque d'une
unité, le choix se pose. En effet, le découpage d'une plage /26
donne deux plages /27. Par défaut, l'utilisateur sera dirigé vers
la première plage à partir de la gauche.
6.1.6 Historique
Une autre fonctionnalité intéressante est
l'historique. Il y a trois boutons en haut à gauche permettant de
naviguer comme dans les butineurs Web : page précédente, page
suivante et aller directement à une page par sélection sur un
menu surgissant (popup menu).
6.2 Architecture du client
Le client est séparé en deux packages. Un package
est un regroupement logique de classes. Le premier package est un package
outil, il permet de manipuler des
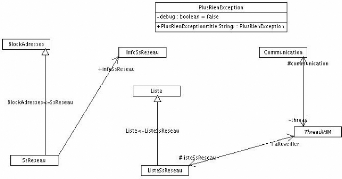
FIG. 6.3 - Schéma simplifié du diagramme des
classes des outils
plages, des listes de plages, de faire les communications
avec le réseau et possède un modèle d'interface graphique.
Le deuxième package est constitué des classes permettant de faire
l'applet: c'est le package ayant permis de faire l'interface graphique ou
interface homme/machine (IHM).
6.2.1 Outils pour l'interface
La première classe, BlockAdresses, permet de
gérer les plages sous formes CIDR ou non. Elle permet d'obtenir
l'adresse réseau d'un sous réseau, de récupérer le
masque, d'obtenir l'adresse de broadcast, d'obtenir les adresses suivantes,
précédentes, parentes... Cette classe était
nécessaire pour faciliter grandement le développement futur. Pour
le schéma simplifier du diagramme des classes, voir la figure 6.2.1 page
34.
La classe SsReseau hérite de cette classe et a une
association avec une autre classe: InfoSsReseau, qui stocke les informations
sur un sous réseau: le propriétaire, le registrar, la
description, l'identifiant. L'identifiant est une chaîne de
caractère inexploitable par le client. En effet, le client ne peut que
stocker cette valeur et la récupérer mais ne connaît pas la
manière de l'utiliser. Cet identifiant est utilisé par le serveur
qui fournit la bonne adresse (URL) pour ouvrir le document Web sur un
établissement particulier. Cette méthode a été
utilisée pour éviter de devoir changer le code du client (parser
l'identifiant notamment) si l'établissement a été
changé de base de données ou si le stockage est différent
(«éclatement» de la base de données sur plusieurs
serveurs). De plus, ce n'est pas à lui de savoir comment sont
gérés les sous réseaux, si ils proviennent bien d'une base
de données plutôt que de fichiers ou d'une requête whois.
Deux classes pour gérer les listes. Une classe Liste
qui définit les méthodes se positionnant au premier ou au dernier
élément, et des méthodes pour savoir si le suivant et le
précédent existent. Ensuite une autre classe ListeSsReseaux qui
per-
met d'ajouter un sous réseau et de
récupérer le suivant ou le précédent sous
réseau. Pourquoi avoir séparé en deux classes? Tout
simplement, la première permet de définir une classe
générique, ne connaissant pas ce qu'il y a l'intérieur de
la liste mais où toutes les méthodes sont mutuellement exclusives
l'une de l'autre (méthodes «synchronized» : on ne peut pas
appeler une deuxième méthode tant que la première
méthode appelée n'a pas libéré le verrou en se
terminant). Ensuite, une classe ListeSsReseaux spécialise cette classe
pour ajouter ou récupérer un et un seul type d'objet: chaque
classe sera alors spécifique à un objet, ce qui permet de ne pas
rencontrer de problème lors de la récupération des
informations. De même, chaque méthode sera de type
«synchronized». Ceci parce que les communications sont
gérées de telles manières que des données peuvent
arrivées alors que l'interface homme-machine récupère les
données précédentes en même temps et il peut y avoir
conflit. Mais ce sera expliqué plus en profondeur plus loin. Ces deux
classes peuvent générer une exception PlusRienException, lorsque
l'on essaye d'accéder au delà des bornes de la liste.
La classe Communication permet de gérer les
communications avec le serveur. Cette classe hérite de Thread. En effet,
étant donné que les requêtes whois peuvent prendre beaucoup
de temps, il se peut que cela bloque l'affichage pendant un long moment, sans
qu'il ne soit possible d'arrêter la requête. En procédant
comme cela, il est très simple de l'arrêter car on lance le
thread, on attend les résultats, lorsque les résultats arrivent
au fur et à mesure, un autre thread peut les afficher, puis si le temps
est trop important pour l'utilisateur, il peut faire une autre requête,
avec ou sans l'arrêt du thread courant. Ceci aurait été
beaucoup plus compliqué à mettre en oeuvre sans les threads, il
aurait fallu pour cela utiliser des méthodes de lecture non bloquantes
sur la socket et s'assurer à intervalle régulier de la
réception des informations. Cependant, ceci aurait du être fait du
côté de l'IHM, ce qui était inacceptable. Comme cela le
problème est simplifié et le codage de l'IHM n'a pas à se
soucier de ce cas de figure: les données lui arrivent automatiquement
par un processus décrit ci après.
Une classe permet de modéliser l'arrivée
d'informations de la part de la communication: la classe ThreadIHM. Cette
classe modélise en fait un «écouteur de communication».
En effet, lors de la création d'un objet de la classe Communication, il
faut lui passer comme argument un objet d'une classe héritant de
ThreadIHM pour que les méthodes de cet objet soient appelées par
l'objet de la classe Communication. Certaines méthodes abstraites de la
classe ThreadIHM doivent être écrites pour que la méthode
soit appelée. Ces méthodes sont:
- aAppeler: qui prend comme paramètre un sous
réseau. Cette méthode est appelée lorsqu'une nouvelle
donnée arrive depuis le réseau.
- erreur: qui prend comme paramètre un message
d'erreur. Cette méthode est appelée lorsqu'une erreur de
communication est arrivée.
- terminer: cette méthode est appelée
lorsque la communication est terminée et que toutes les données
sont parvenues.
D'autres méthodes ne sont pas modifiables, ne peuvent pas
être ré-écrites lors de l'héritage : ceci permet
l'intégrité et l'assurance que les messages d'erreur et les
données parviendront à l'objet correspondant. Il
s'agit de run et de arrete qui per-met d'arrêter la
communication des deux côtés (côté client et
côté serveur).
Cette méthode de communication et d'utilisation avec
l'interface graphique ou textuelle permet une mise en place aisée : il
suffit de créer une classe héritant de ThreadIHM et
implémentant les méthodes déclarées comme
abstraites; créer un objet de la classe Communication avec comme
paramètre un objet de la classe précédente et
appelée l'une des méthodes de Communication. Ce processus permet
de ne pas geler l'IHM, car d'autres choses (réaction lors d'un clique
sur un bouton, entré de nouveaux paramètres, ...) peuvent
être effectuées en même temps que l'interrogation du serveur
à lieu et l'on peut facilement arrêter la communication en cours.
Notamment, les interfaces graphiques se prêtent très bien à
ce type de méthodes.
6.2.2 Interface Graphique
L'interface graphique est composée de plusieurs parties
: la visualisation des sous réseaux, la partie recherche de plages
libres, la partie recherche selon un filtre et la partie navigation. Les
communications entre ces trois parties, par appel de méthodes,
s'effectuent selon le schéma 6.2.2 à la page 37.
Pour le schéma simplifié du diagramme des
classes, voir la figure 6.2.2 page 38.
Au début, la partie visualisation était
composée de boutons (JButton du package javax.swing). Cependant, de
nombreux problèmes de placement de ces boutons étaient
présents : malgré l'utilisation d'un outil de placement de
composants graphiques sous la forme d'un tableau ( GridBagLayout) avec hauteur
et largeur définie (grâce à GridBagConstraints), les
composants ne se plaçaient pas exactement comme il leur était
imposé. En fait, leur position x et y était correct, cependant,
leur taille, surtout la largeur, ne restait pas constante. Certains boutons se
superposaient et lors d'affichage de nombreux boutons, cela devenait
inutilisable. De plus, les performances d'affichage n'étaient pas
suffisantes. Sous les conseils du responsable, il a été choisi de
dessiner directement les cases et non d'ajouter des boutons. Cela s'est
avéré être un très bon choix, les performances ont
été bien meilleures et le placement correspondait exactement
à ce qui était demandé. De plus, la modification a
été très rapide à effectuer, il a suffit de ne pas
faire hériter notre bouton de JButton et de faire une méthode
dessine, les coordonnées, la taille (hauteur et largeur)
étant calculer précédemment.
Chaque partie de l'interface utilisant la classe Communication
est un thread, ce qui fait qu'il y a deux threads par partie négociant
avec le serveur, un pour un objet de la classe Communication, un pour le
composant effectuant l'affichage, soit au total et au maximum six threads
simultanés. Il est spécifié «au maximum» car il
se peut et ce sera la majorité du temps, qu'il n'y ait que deux threads
exécutés en même temps. Cependant, des tests ont
été effectués pour lancer les six threads en même
temps, les arrêter et les relancer de nombreuses fois sans que cela ne
pose le moindre problème. Il faut aussi noter que si la visualisation
est lancée et
FIG. 6.4 - Schéma de représentation des
communications dans l'interface graphique. La classe ThreadIHM a
été ajouté pour simplifier la compréhension
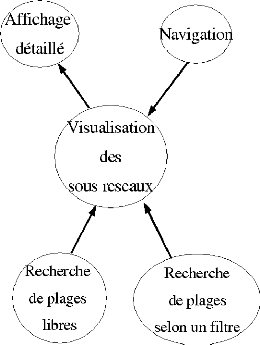
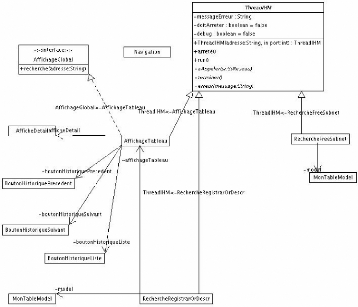
que l'utilisateur essaye de naviguer ou sélectionne une
plage trouvée lors d'une recherche alors que le thread de visualisation
n'est pas terminé (autrement dit: la communication entre la
visualisation et le serveur n'est pas finie), les threads sont automatiquement
arrêtés et la visualisation est relancée sur cette nouvelle
information. Ce qui fait que chaque thread est indépendant des autres
mais le thread visualisation peut être interrompu par l'utilisateur
lorsqu'il sélectionne une plage trouvée par une recherche ou
naviguer ou qu'il souhaite sélectionner une plage dans l'historique.
Chapitre 7
Perspectives
7.1 Implémentation d'un cache
Les requêtes prennent du temps et il seraient bien
d'éviter de surcharger le serveur. En effet, pour le moment, le client
effectue plusieurs fois la même requête si on le lui demande. Un
cache côté client serait utile pour éviter ce cas de
figure.
De plus, si des modifications de la base de données
sont effectuées, les répercussions ne seraient pas prises en
compte. Un bouton ou autre composant graphique devra permettre la remise
à zéro du cache.
7.2 Différentes visualisations
Une fonctionnalité qui pourrait permettre une meilleure
compréhension de la répartition des plages serait de pouvoir
choisir entre différentes vues, différentes
représentations de la base. Une vue possible serait par exemple un arbre
dépliant, dans le type des systèmes de fichiers: on rentre une
plage, l'outil affiche sous forme d'arbre toutes les plages libres du niveau le
plus haut et lorsque l'on sélectionne un sous niveau, il se
déplie (on effectue une recherche de sous niveaux dans cette plage).
Ainsi, par analogie au système de fichier, un répertoire serait
un sous niveau qui aurait d'autres sous niveaux et un fichier serait un sous
niveau sans sous niveau.
7.3 Ajout des plugins côté serveur
L'ajout de plugins côté serveur se fait assez
simplement. En effet, il faut ajouter quelques lignes dans le parser du fichier
XML pour prendre en compte le plugin (rappel: si ce n'est que l'ajout du code
d'une requête pour une base de données, cette partie est inutile).
Ensuite il faut modifier la partie communication avec le client si
nécessaire (pour l'ajout des requêtes whois, ce point n'a pas eu
lieu d'être, car ce n'est pas au client de savoir pour quelles plages on
interroge la base de données ou un serveur whois) et écrire le
code qui permet de faire les nouvelles recherches et renvoyer le
résultat.
Chapitre 8
Conclusion
Ce stage, le premier pour moi, m'a permis d'apprécier
le travail dans une «société» tournée vers
l'informatique. Le statut particulier de la mission ERASME n'a pas, je suppose,
une organisation si éloignée d'une PME notamment les contraintes
de budget et de temps ou l'obligation de résultats.
Le sujet m'a permis de toucher des domaines assez
variés comme les bases de données, UML, le modèle
client/serveur, la programmation multithreadée avec concurrence, XML et
les DTDs, deux langages de programmation (Java et Perl) et l'adressage sous
forme CIDR des réseaux.
La contrainte de temps a été bien
gérée, ce qui est un des points les plus intéressants et
les plus essentiels en gestion de projet. La distance du lieu de travail et de
mon domicile ne s'est pas fait réellement sentir, malgré ce que
je pensais au premier abord.
Bref, ce stage m'a permis de parfaire ma formation et a aussi
fait office de première expérience professionnelle dans le monde
de l'informatique. Cette première expérience c'est bien
passée, ce qui est positif pour l'avenir.
Quatrième partie
Annexes
Table des figures
2.1 Exemple de raccordements wifi 11
3.1 Résumé du modèle
entité/association de la base 15
5.1 Modèle entité/association No1 25
5.2 Modèle entité/association No2 25
6.1 représentation de sous réseaux 31
6.2 Arrivée des informations 31
6.3 diagramme des classes des outils 34
6.4 Communications dans l'IHM 37
6.5 Diagramme des classes de l'interface graphique 38
Bibliographie
[acn] Arbres de connaissance pour une nouvelle education.
www.erasme.org/acne/index.html.
[API] Api de j2se v1 .4.1. http ://
java.sun.com/j2se/1 .4.
1/docs/api/. [arg] site web de argouml. http ://
argouml.tigris.org.
[bsd] Licence bsd. http ://
opensource.org/licenses/bsd-license.php.
[cpa] Site des bibliothèques et outils pour le perl.
www.cpan.org. [ema] site web de emacs.
www.gnu.org/software/emacs/emacs.html.
[era] site web de erasme.
www.erasme.org.
[gal] navigaeur web galeon. http ://
galeon.sourceforge.net.
[gen] Site web de poseidon for uml.
www.gentleware.com. [lac] Projet
de cartable électronique.
www.laclasse.com. [moz] navigateur
web mozilla.
www.mozilla.org.
[net] navigateur web netscape.
www.netscape.fr.
[UPC] Site web de upc.
www.upcfrance.com.
[wir] Site de l'association wireless lyon.
www.wireless-lyon.org.
Index
ACNE, 10 argoUML, 18
Centre d'hébergement, 8 Centre de Formation, 8 Centre
Multimédia, 7 Centre Serveur, 7 CRDP, 9
DTD, 23 ERASME, 6
Hartur, 9 INA, 9
laclasse.com, 9
package, 33
parser XML, 23 plugins, 23
Poseidon, 18
réseau,sous-réseaux, 14 whois, 17
XML, 23
GNU Free Documentation License Version 1.2 November
2002
Copyright (C) 2000,2001,2002 Free Software Foundation, Inc.
59 Temple Place, Suite 330, Boston, MA 02111-1307 USA Everyone is
permitted to copy and distribute verbatim copies of this license document, but
changing it is not allowed.
0. PREAMBLE
The purpose of this License is to make a manual, textbook, or
other functional and useful document "free" in the sense of freedom: to assure
everyone the effective freedom to copy and redistribute it, with or without
modifying it, either commercially or noncommercially. Secondarily, this License
preserves for the author and publisher a way to get credit for their work,
while not being considered responsible for modifications made by others.
This License is a kind of "copyleft", which means that
derivative
works of the document must themselves be free in the same sense.
It complements the GNU General Public License, which is a copyleft license
designed for free software.
We have designed this License in order to use it for manuals for
free software, because free software needs free documentation: a free program
should come with manuals providing the same freedoms that the software does.
But this License is not limited to software manuals; it can be used for any
textual work, regardless of subject matter or whether it is published as a
printed book. We recommend this License principally for works whose purpose is
instruction or reference.
1. APPLICABILITY AND DEFINITIONS
This License applies to any manual or other work, in any medium,
that contains a notice placed by the copyright holder saying it can be
distributed under the terms of this License. Such a notice grants a world-wide,
royalty-free license, unlimited in duration, to use that work under the
conditions stated herein. The "Document", below, refers to any such manual or
work. Any member of the public is a licensee, and is addressed as "you". You
accept the license if you copy, modify or distribute the work in a way
requiring permission under copyright law.
A "Modified Version" of the Document means any work containing
the Document or a portion of it, either copied verbatim, or with
modifications and/or translated into another language.
A "Secondary Section" is a named appendix or a front-matter
section of the Document that deals exclusively with the relationship of the
publishers or authors of the Document to the Document's overall subject (or to
related matters) and contains nothing that could fall directly within that
overall subject. (Thus, if the Document is in part a textbook of mathematics, a
Secondary Section may not explain any mathematics.) The relationship could be a
matter of historical connection with the subject or with related matters, or of
legal, commercial, philosophical, ethical or political position regarding
them.
The "Invariant Sections" are certain Secondary Sections whose
titles are designated, as being those of Invariant Sections, in the notice that
says that the Document is released under this License. If a section does not
fit the above definition of Secondary then it is not allowed to be designated
as Invariant. The Document may contain zero Invariant Sections. If the Document
does not identify any Invariant Sections then there are none.
The "Cover Texts" are certain short passages of text that are
listed,
as Front-Cover Texts or Back-Cover Texts, in the notice that
says that the Document is released under this License. A Front-Cover Text may
be at most 5 words, and a Back-Cover Text may be at most 25 words.
A "Transparent" copy of the Document means a machine-readable
copy, represented in a format whose specification is available to the general
public, that is suitable for revising the document
straightforwardly with generic text editors or (for images
composed of pixels) generic paint programs or (for drawings) some widely
available drawing editor, and that is suitable for input to text formatters or
for automatic translation to a variety of formats suitable for input to text
formatters. A copy made in an otherwise Transparent file
format whose markup, or absence of markup, has been arranged to
thwart or discourage subsequent modification by readers is not Transparent. An
image format is not Transparent if used for any substantial amount of text. A
copy that is not "Transparent" is called "Opaque".
Examples of suitable formats for Transparent copies include plain
ASCII without markup, Texinfo input format, LaTeX input format, SGML or XML
using a publicly available DTD, and standard-conforming simple HTML, PostScript
or PDF designed for human modification. Examples of transparent image formats
include PNG, XCF and JPG. Opaque formats
include proprietary formats that can be read and edited only by
proprietary word processors, SGML or XML for which the DTD and/or processing
tools are not generally available, and the
machine-generated HTML, PostScript or PDF produced by some word
processors for output purposes only.
The "Title Page" means, for a printed book, the title page
itself,
plus such following pages as are needed to hold, legibly, the
material this License requires to appear in the title page. For works in
formats which do not have any title page as such, "Title Page"
means the text near the most prominent appearance of the work's title,
preceding the beginning of the body of the text.
A section "Entitled XYZ" means a named subunit of the Document
whose title either is precisely XYZ or contains XYZ in parentheses following
text that translates XYZ in another language. (Here XYZ stands for a specific
section name mentioned below, such as "Acknowledgements", "Dedications",
"Endorsements", or "History".) To "Preserve the Title"
of such a section when you modify the Document means that it
remains a section "Entitled XYZ" according to this definition.
The Document may include Warranty Disclaimers next to the notice
which states that this License applies to the Document. These Warranty
Disclaimers are considered to be included by reference in this License, but
only as regards disclaiming warranties: any other implication that these
Warranty Disclaimers may have is void and has no effect on the meaning of this
License.
2. VERBATIM COPYING
You may copy and distribute the Document in any medium, either
commercially or noncommercially, provided that this License, the copyright
notices, and the license notice saying this License applies
to the Document are reproduced in all copies, and that you add no
other conditions whatsoever to those of this License. You may not use technical
measures to obstruct or control the reading or further copying of the copies
you make or distribute. However, you may accept compensation in exchange for
copies. If you distribute a large enough number of copies you must also follow
the conditions in section 3.
You may also lend copies, under the same conditions stated above,
and you may publicly display copies.
If you publish printed copies (or copies in media that commonly
have printed covers) of the Document, numbering more than 100, and the
Document's license notice requires Cover Texts, you must enclose the copies in
covers that carry, clearly and legibly, all these Cover Texts: Front-Cover
Texts on the front cover, and Back-Cover Texts on the back cover. Both covers
must also clearly and legibly identify you as the publisher of these copies.
The front cover must present the full title with all words of the title equally
prominent and visible. You may add other material on the covers in addition.
Copying with changes limited to the covers, as long as they preserve the title
of the Document and satisfy these conditions, can be treated as verbatim
copying in other respects.
If the required texts for either cover are too voluminous to fit
legibly, you should put the first ones listed (as many as fit reasonably) on
the actual cover, and continue the rest onto adjacent pages.
If you publish or distribute Opaque copies of the Document
numbering more than 100, you must either include a machine-readable Transparent
copy along with each Opaque copy, or state in or with each Opaque copy a
computer-network location from which the general network-using public has
access to download using public-standard network protocols a complete
Transparent copy of the Document, free of added material. If you use the latter
option, you must take reasonably prudent steps, when you begin distribution of
Opaque copies in quantity, to ensure that this Transparent copy will remain
thus accessible at the stated location until at least one year after the last
time you distribute an Opaque copy (directly or through your agents or
retailers) of that edition to the public.
It is requested, but not required, that you contact the authors
of the Document well before redistributing any large number of copies, to give
them a chance to provide you with an updated version of the Document.
4. MODIFICATIONS
You may copy and distribute a Modified Version of the Document
under the conditions of sections 2 and 3 above, provided that you release the
Modified Version under precisely this License, with the Modified Version
filling the role of the Document, thus licensing distribution and modification
of the Modified Version to whoever possesses a copy of it. In addition, you
must do these things in the Modified Version:
A. Use in the Title Page (and on the covers, if any) a title
distinct from that of the Document, and from those of previous versions (which
should, if there were any, be listed in the History section of the Document).
You may use the same title as a previous version if the original publisher of
that version gives permission.
B. List on the Title Page, as authors, one or more persons or
entities responsible for authorship of the modifications in the Modified
Version, together with at least five of the principal authors of the Document
(all of its principal authors, if it has fewer than five), unless they release
you from this requirement.
C. State on the Title page the name of the publisher of the
Modified Version, as the publisher.
D. Preserve all the copyright notices of the Document.
E. Add an appropriate copyright notice for your modifications
adjacent to the other copyright notices.
F. Include, immediately after the copyright notices, a license
notice giving the public permission to use the Modified Version under the terms
of this License, in the form shown in the Addendum below.
G. Preserve in that license notice the full lists of Invariant
Sections and required Cover Texts given in the Document's license notice.
H. Include an unaltered copy of this License.
I. Preserve the section Entitled "History", Preserve its Title,
and add to it an item stating at least the title, year, new authors, and
publisher of the Modified Version as given on the Title Page. If there is no
section Entitled "History" in the Document, create one stating the title, year,
authors, and publisher of the Document as given on its Title Page, then add an
item describing the Modified Version as stated in the previous sentence.
J. Preserve the network location, if any, given in the Document
for public access to a Transparent copy of the Document, and likewise the
network locations given in the Document for previous versions it was based on.
These may be placed in the "History" section. You may omit a network location
for a work that was published at least four years before the Document itself,
or if the original publisher of the version it refers to gives permission.
K. For any section Entitled "Acknowledgements" or "Dedications",
Preserve the Title of the section, and preserve in the section all the
substance and tone of each of the contributor acknowledgements and/or
dedications given therein.
L. Preserve all the Invariant Sections of the Document,
unaltered in their text and in their titles. Section numbers or the equivalent
are not considered part of the section titles.
M. Delete any section Entitled "Endorsements". Such a section
may not be included in the Modified Version.
N. Do not retitle any existing section to be Entitled
"Endorsements" or to conflict in title with any Invariant Section.
O. Preserve any Warranty Disclaimers.
If the Modified Version includes new front-matter sections or
appendices that qualify as Secondary Sections and contain no
material copied from the Document, you may at your option designate some or all
of these sections as invariant. To do this, add their titles to the list of
Invariant Sections in the Modified Version's license notice. These titles must
be distinct from any other section titles.
You may add a section Entitled "Endorsements", provided it
contains nothing but endorsements of your Modified Version by various
parties--for example, statements of peer review or that the text has been
approved by an organization as the authoritative definition of a standard.
You may add a passage of up to five words as a Front-Cover Text,
and a passage of up to 25 words as a Back-Cover Text, to the end of the list of
Cover Texts in the Modified Version. Only one passage of Front-Cover Text and
one of Back-Cover Text may be added by (or through arrangements made by) any
one entity. If the Document already includes a cover text for the same cover,
previously added by you or by arrangement made by the same entity you are
acting on behalf of, you may not add another; but you may replace the old one,
on explicit permission from the previous publisher that added the old one.
The author(s) and publisher(s) of the Document do not by this
License give permission to use their names for publicity for or to assert or
imply endorsement of any Modified Version.
5. COMBINING DOCUMENTS
You may combine the Document with other documents released under
this License, under the terms defined in section 4 above for modified versions,
provided that you include in the combination all of the Invariant Sections of
all of the original documents, unmodified, and list them all as Invariant
Sections of your combined work in its license notice, and that you preserve all
their Warranty Disclaimers.
The combined work need only contain one copy of this License, and
multiple identical Invariant Sections may be replaced with a single copy. If
there are multiple Invariant Sections with the same name but different
contents, make the title of each such section unique by adding at the end of
it, in parentheses, the name of the original author or publisher of that
section if known, or else a unique number. Make the same adjustment to the
section titles in the list of
Invariant Sections in the license notice of the combined work.
In the combination, you must combine any sections Entitled
"History" in the various original documents, forming one section Entitled
"History"; likewise combine any sections Entitled "Acknowledgements", and any
sections Entitled "Dedications". You must delete all sections Entitled
"Endorsements".
6. COLLECTIONS OF DOCUMENTS
You may make a collection consisting of the Document and other
documents released under this License, and replace the individual copies of
this License in the various documents with a single copy that is included in
the collection, provided that you follow the rules of this License for verbatim
copying of each of the documents in all other respects.
You may extract a single document from such a collection, and
distribute it individually under this License, provided you insert a copy of
this License into the extracted document, and follow this License in all other
respects regarding verbatim copying of that document.
7. AGGREGATION WITH INDEPENDENT WORKS
A compilation of the Document or its derivatives with other
separate and independent documents or works, in or on a volume of a storage or
distribution medium, is called an "aggregate" if the copyright resulting from
the compilation is not used to limit the legal rights of the compilation's
users beyond what the individual works permit. When the Document is included in
an aggregate, this License does not apply to the other works in the aggregate
which are not themselves derivative works of the Document.
If the Cover Text requirement of section 3 is applicable to these
copies of the Document, then if the Document is less than one half of the
entire aggregate, the Document's Cover Texts may be placed on covers that
bracket the Document within the aggregate, or the electronic equivalent of
covers if the Document is in electronic form. Otherwise they must appear on
printed covers that bracket the whole aggregate.
8. TRANSLATION
Translation is considered a kind of modification, so you may
distribute translations of the Document under the terms of
section 4. Replacing Invariant Sections with translations requires special
permission from their copyright holders, but you may include translations of
some or all Invariant Sections in addition to the original versions of these
Invariant Sections. You may include a translation of this License, and all the
license notices in the
Document, and any Warranty Disclaimers, provided that you also
include the original English version of this License and the original versions
of those notices and disclaimers. In case of a disagreement between the
translation and the original version of this License or a notice or disclaimer,
the original version will prevail.
If a section in the Document is Entitled "Acknowledgements",
"Dedications", or "History", the requirement (section 4) to Preserve its Title
(section 1) will typically require changing the actual title.
9. TERMINATION
You may not copy, modify, sublicense, or distribute the Document
except as expressly provided for under this License. Any other attempt to copy,
modify, sublicense or distribute the Document is void, and will automatically
terminate your rights under this License. However, parties who have received
copies, or rights, from you under this License will not have their licenses
terminated so long as such parties remain in full compliance.
10. FUTURE REVISIONS OF THIS LICENSE
The Free Software Foundation may publish new, revised versions
of the GNU Free Documentation License from time to time. Such new
versions will be similar in spirit to the present version, but may differ in
detail to address new problems or concerns. See
http://www.gnu.org/copyleft/.
Each version of the License is given a distinguishing version
number. If the Document specifies that a particular numbered version of this
License "or any later version" applies to it, you have the option of following
the terms and conditions either of that specified version or of any later
version that has been published (not as a draft) by the Free Software
Foundation. If the Document does not specify a version number of this License,
you may choose any version ever published (not as a draft) by the Free Software
Foundation.
| 

