sybase2postgresql
I.1 NOM
Convertisseur de base de donnee Sybase vers Postgresql
I.2 SYNOPSIS
Outils permettant de transformer (a partir de fichier scripts
SQL) une base Sybase vers une base PostgreSQL.
- Pour voir les options disponibles, tapper sybase2postgresql
-h
- La plupart des options permettent d'indiquer l'emplacement de
scripts SQL qui seront transformes pour etre utiisables par PostgreSQL.
- A partir du ficher SQL de creation des tables,
sybase2postregresql va produire les scripts de creation des tables, des
commandes pour bcp (recuperation des donnees), de mise a jour des sequences
(pour que l'incerementation automatique reprenne apres le dernier
enregistrement cree) qui devra etre execute apres l'insertion des donnees dans
la base
- Le programme peut tre appele en lignes de commandes
avec les options ou avec un fichier de configuration
- L'ensemble des operations peut etre automatise grace a
l'option -a
I.3 DESCRIPTION
Les Methodes "outils" configuration
Va lire le fichier de configuration passe en parametre et
initialise les variables en fonction de son contenu.
automatique
Automatise le fonctionnement du script: toutes les actions sont
effectuees automatiquement (a condition que tous les renseignements necessaires
soient fournis)
|
Documentation de sybase2postgresql
|
|
clear_line
Netoie une ligne passee en parametres en enlevant le retour
chariot, remplacant les lettres accentuees par des lettres "normales" et en
passant tout le texte en minuscules.
convert2cast
Transforme les fonction convert(type, variable) en fonction
CAST(variable AS type)
right2lpad
Transforme les fonction right('remplissage' + chaine, longueur)
en fonction lpad(chaine, longueur, 'remplissage')
Permet de palier au manque de booleen (renvoie 0) Permet de
palier au manque de booleen (renvoie 1)
decommente_fichier
Permet d'enlever les commentaires d'un fichier et de remettre les
fonctions (detectees par leurs parentheses) sur une seule ligne
Les Methodes "de transformation"
traite_table
Traite le fichier de script SQL de creation des tables.
traite_index
Traite le fichier de script SQL de creation des index.
traite_vue
Traite le fichier de script SQL de creation des vues
traite_procedure
Traite le fichier contenant les procedures afin de les rendre
utilisables par PostgreSQL.
traite_trigger
Traite le fichier contenant les procedures afin de les rendre
utilisables par PostgreSQL.
traite_donnee
Traite le fichier de donnees afin de modifier les rendre
assimilables par PostgreSQL lors du COPY
I.4 VOIR AUSSI
Documentation PostgreSQL, documentation BCP, ...
Problèmes spécifiques à chaque
type d'information à migrer
J.1 Les tables
J.1.1 Problèmes rencontrés
1. Certains types n'existent pas sous PostgreSQL (datetime,
image, tinyint, binary)
2. Dans certaines tables, le champ servant de clef est de type
"identity"
3. La casse des noms de tables n'est pas uniforme
(complètement en majuscules, complètement en minuscules ou une
partie en minuscules et une partie en majuscules)
4. Une table porte un nom avec un caractère
accentué (Paramètre)
5. Certaines colonnes ont des noms trop longs (>23
caractères) pour être correctement exportées par DbDk.
J.1.2 Solutions possibles
1. Pour les types inexistants, il y a deux
possibilités:
- Utiliser un autre type compatible (datetime transformé
en timestamp, image en bytea, tinyint en smallint et binary en bytea)
- Créer de nouveaux types de données (CREATE
TYPE)
2. Pour le champ identity, il est possible de le transformer
en séquence (CREATE SEQUENCE). Il faut noter que cette solution impose
la récupération des "bons" identifiants lors de l'import des
données et ensuite, de mettre à jour l'état de la
séquence grâce à la commande setval().
3. Pour la casse, PostgreSQL étant "casse sensitive"
alors que Sybase ne l'est pas, il est plus prudent et rationnel de transformer
tous les noms afin qu'ils soient tous en minuscules et que les appels se
fassent toujours de la même manière.
4. Les accents n'étant pas admis, il faut absolument
remplacer la lettre accentuée (è deviendra e)
5. Pour la longueur des colonnes, il faut soit utiliser un
autre outil pour l'export des schémas, soit utiliser une nouvelle
version de DbDk (les noms étant tronqués dans le fichier texte,
il n'est pas possible de gérer le problème à
posteriori).
|
Problèmes spécifiques a chaque type d'information
a migrer
|
|
J.2 Les index
J.2.1 Problèmes rencontrés
1. Certains index, sur des tables différentes, portent
des noms identiques.
2. Certains index sont de type CLUSTERED. Ceci signifie que
les enregistrements de la table sont classés physiquement en fonction du
champ sur lequel porte l'index.
J.2.2 Solutions possibles
1. La solution la plus simple et logique a mettre en place
est la modification de la politique de nommage pour ces index (le choix qui a
été fait est celui d'accoler le nom de la table et le nom de
l'index).
2. Ce type de contraintes n'existe pas réellement sous
PostgreSQL. Il est cependant possible d'utiliser la fonction CLUSTER qui
"range" a un instant donné la table selon le champ indiqué. Si on
percoit la nécessité de classer cette table
(démontrée par des tests de performance significatifs), il serait
possible de déclencher de manière régulière (par
exemple par l'utilisation de Cron) l'utiisation de la fonction CLUSTER. Le
choix d'utiliser ou non CLUSTER devra être fait en fonction des
performences et non de l'existence de CLUSTERED sous Sybase (leur
présence n'est pas/plus forcément judicieuse);
J.3 Les vues
J.3.1 Problèmes rencontrés
1. Les vues de la bases ne sont pas crées avec la
même syntaxe (=> difficile de faire une règle unique de
traitement):
- Utilisation de ", de ' ou rien pour les noms de colonne
- Utilisation ponctuelle de syntaxe du type "cci.." pour les
noms de table
2. Utiisation de caractères spéciaux (accents, ,
majuscules)
3. Les colonnes ne sont pas systématiquement
renommées
4. L'utiisation de " dans la clause WHERE n'est pas
interprétée par PostgreSQL comme un champ de texte.
5. Les jointures externes ne sont pas représentées
de la même facon sous Sybase et sous PostgeSQL.
6. Certaines fonction internes a Sybase (convert, isnull,
datepart, right, suser_id) n'existent pas sous PostgreSQL.
7. Certaines conversions de types existent sous Sybase mais pas
sous PostgreSQL (transformation de varchar en int et transformation de smallint
vers bit)
J.3.2 Solutions possibles
1. L'utiisation des ' ou " ainsi que l'utilisation du nom de
la base pour les tables (puisqu'on ne peut pas gérer de vue "interbase"
sous PostgreSQL) n'étant pas indispensable, ils peuvent être
supprimés.
16
17
18
19
20
21
22
23
24
25
26
27 28
Problèmes spécifiques à chaque type
d'information à migrer
2. Les caractères spéciaux doivent, comme pour les
tables, être remplacés par leur équivalent "simple".
3. il faut détecter le renomage (utilisation d'un
alias) grâce à la structure alias = nom_champ afin de le remplacer
par la structure nom_champ AS alias valide sous PostgreSQL.
Il faut cependant prendre garde au fonctions qui peuvent
être utilisées à la place du nom de champ et qui sont
parfois répartis sur plusieurs lignes (elles rendent la détection
de la fin de "nom_champ" plus difficile).
4. Remplacement des "par des'
5. Sous postgreSQL, la fonction de jointure ne s'utilise pas
totalement de la même façon que sous Sybase. Alors que sous Sybase
l'utiisation de "*=" ou de "=*" entre deux champs dans la clause "where" est
suffisante, sous PostgreSQL, il est nécessaire d'utiliser fonction
"left" ou "right outer join" entre les deux tables à joindre et de
préciser les champs dans une clause "on".
Certaines informations (comme la correspondance entre un champ
et la table à laquelle il appartient) n'étant pas disponibles
pour le programme Perl, il n'est pas possible d'automatiser cette
transformation: elle devra donc être réalisée
manuellement.
6. Il est souvent possible d'utiiser les fonctions
correspondantes sous PostgreSQL:
- "convert" est remplacé par "cast"
- "isnull" est remplacé par "coalesce"
- "datepart" est emplacé par "date_part"
- pour "right", il n'y a pas de fonction correspondante sous
PostgreSQL. Cependant, comme cette fonction est ici utilisée uniquement
pour compléter à gauche une chaine de caractère de '0'
pour qu'elle ait une taille fixe, il est possible de la remplacer la la
fonction lpad.
Les fonctions suser_id n'existent pas sous Sybase (et aucune
fonction correspondante n'existe). Il a donc faullu créer ces fonctions
de toute pièce grâce à pl/pgsql:
1
2
3
4
5
6
7
8
9
10
11
12
13
14 15
Source J.1 - Création des fonctions suser_id() et
suser_id(username)
CREATE OR REPLACE FUNCTION s user_id (text)
RETURNS integer
AS'
DECLARE
nom alias for $1;

uid integer;

BEGIN
SELECT INTO uid

usesysid

from pg_catalog .pg_shadow
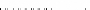
where usename=nom;
RETURN uid;

END;
' language 'plpgsql';
/*---------------------------------------*/
|
Problèmes spécifiques à chaque type
d'information à migrer
|
|
|
CREATE OR REPLACE FUNCTION s user_id () RETURNS
integer AS ' DECLARE
uid integer;
BEGIN
SELECT INTO uid
usesysid
from pg_catalog .pg_shadow
where usename=SESSION_USER;
RETURN uid;
END;
' language 'plpgsql';
|
|
7. En ce qui concerne la conversion de varchar en int, il est
possible de passer par un text (les conversions "varchar vers text" et "text
vers int" exitent toutes les deux. Il est alors possible, soit de modifier le
code source de la vue (mais cette solution n'est pas très "propre" car
elle nécessite une intervention manuelle), soit de créer un
nouveau type de conversion (CAST) dans PostgreSQL.
1
2
3
4
5
6
7
8
1
2
3
4
5
6
7
8
Source J.2 - Création d'une fonction de conversion de type
(varchar vers int)
CREATE OR REPLACE FUNCTION
varchar_to_int(character varying) RETURNS
int2 AS '
DECLARE
input alias for $1;
BEGIN
return (input:: text :: int2);
END;
' language 'plpgsql';
CREATE CAST (varchar AS int2)
WITH FUNCTION varchar_to_int (varchar);


Les smallint (aussi appelés int2) ne possédent
pas de conversion vers les bit alors que les autres types d'entiers
possèdent cette conversion. Tout comme pour la transformation à
partir du varchar, on peut donc créer une conversion passant par un type
intermédiaire (ici le int4).
Source J.3 - Création d'une fonction de conversion de type
(smallint vers bit)
CREATE OR REPLACE FUNCTION small in t _ to_bit
(in t 2) RETURNS bit AS '
DECLARE
input alias for $1;

BEGIN

return (input::int4 ::bit);
END;
' language 'plpgsql';
CREATE CAST (int2 AS bit) WITH
FUNCTION smallint_to_bit( int2);
|
Problèmes spécifiques à chaque type
d'information à migrer
|
|
J.4 Les données
J.4.1 Problèmes rencontrés
1. Le format d'export des dates par BCP n'est pas compatible avec
l'import dans PostgreSQL
J.4.2 Solutions possibles
1. Pour les dates, il n'y a pas moyen de modifier par une option
le format d'export de BCP.
Plusieurs solutions sont alors possibles:
- Utiliser une vue où la date serait convertie au bon
format et stockée au format texte (mais il faut alors également
utiliser une version récente de BCP qui supporte l'export de vues).
Cette solution est assez lourde et implique la création d'autant de vue
qu'il y a de tables contenant des dates avant de pouvoir effectuer la moindre
extraction (qui sera ralentie par la "surcouche" qu'amène la vue et les
fonctions utilisées).
- Utiliser un fichier format (formatfile) donné en
paramètre à BCP (option -f) et qui contient la description de
tous les champs de la table. Cette solution permet une modification "invisible"
pour l'export mais nécessite de créer les fichiers de format (et
également de décrire les colonnes qui ne sont pas de format date)
ce qui est fastidieux.
- Créer un script Perl qui modifiera les
données de type date (elles ont un "aspect" facilement repérable
dans un fichier (Mmm JJ AAAA HH :MM :SS :sss{ AM ou PM} ). Après
quelques tests, cette solution parait la plus facile à mettre en place
et à utiliser.
J.5 Les procédures et les triggers
Ces éléments n'ayant pas été
traités durant le stage (pas de migration effective), il n'est pas
possible de lister de manière exhaustive les problèmes
rencontrés et les solutions apportées.
Cependant, lors de la phase d'évaluation du temps
restant, il a fallu déterminer quels problèmes pourraient se
poser lors de la migration et l'impact qu'ils pourraient avoir sur la
difficulté de "traduction".
1. La déclaration des variables sous Sybase est
réalisées aussi bien avant que après le BEGIN alors que
sous PostgreSQL, elle doit être réalisée dans le
DECLARE.
2. La structure des procédure n'est pas toujours
clairement établie avec l'utilisation de DECLARE, BEGIN et END.
3. Dans les structures de boucles ou de choix, l'utilisation du
BEGIN et du END est courrante mais n'est pas
généralisée.
4. Sous Sybase, la fin d'une instruction n'est pas
forcément indiquée de manière réellement explicite
(par exemple avec un;) ce qui rend la détection plus complexe.
5.
|
Problèmes spécifiques a chaque type d'information
a migrer
|
|
|
|
La nature du résultat envoyé par une
procédure n'est pas explicite et peut poser des problèmes dans le
cas d'un résultats composé de plusieurs "colonnes" et plusieurs
"lignes" en comparaison d'une seule valeur.
6. Certaines fonctions internes a Sybase n'existent pas sous
PostgreSQL. Mais cet aspet peut être traité de la même facon
que lors qu traitement des vues.
7. L'utiisation de raiserror pour traiter les erreurs sous Sybase
ne peut pas être identique sous PostgreSQL.
| 

