|
Copyright (c) Virginie QUESNAY
Permission is granted to copy, distribute and/or modify this
document under the terms of the GNU Free Documentation License, Version 1.2 or
any later version published by the Free Software Foundation;
with no Invariant Sections, no Front-Cover Texts, and no
Back-Cover Texts. A copy of the license is included in the section entitled
"GNU
Free Documentation License".
|
VIRGINIE QUESNAY
Master OTSI
Année
03/04
|
|
C.C.I. DE LA
HAUTE-SAVOIE
5 rue du 27ème BCA - BP 2072
74011 Annecy
CEDEX
|
MEMOIRE PROFESSIONNEL
Étude d'une migration de Sybase vers PostgreSQL

Enseignant tuteur : Christian BRAESCH
Maître de stage : Christophe POLLIER INSTITUT UNIVERSITAIRE
PROFESSIONNALISE
DE GENIE DES SYSTEMES INDUSTRIELS
Genie des systèmes d'information
|
VIRGINIE QUESNAY
Master OTSI
Année
03/04
|
|
C.C.I. DE LA
HAUTE-SAVOIE
5 rue du 27ème BCA - BP 2072
74011 Annecy
CEDEX
|
MÉMOIRE PROFESSIONNEL
Étude d'une migration de Sybase vers PostgreSQL
|
VIRGINIE QUESNAY
Master OTSI
Année
03/04
|
|
C.C.I. DE LA
HAUTE-SAVOIE
5 rue du 27ème BCA - BP 2072
74011 Annecy
CEDEX
|
?
RÉSUMÉ:
Ce mémoire a été réalisé
lors de mon stage de fin d'études de Master a l'IUP-GSI d'Annecy le
Vieux. Celui-ci s'est déroulé au sein de la Chambre de Commerce
et d'Industrie de la Haute-Savoie du 8 mars au 25 juin 2004.
Le but de ce stage était d'étudier les
possibilités de migration d'une base de données de Sybase vers
PostgreSQL.
Ce mémoire est donc composé de trois parties:
- Le contexte du stage (l'existant);
- La problématique de migration de base de
données;
- L'illustration de cette problématique par le cas
concret qu'était mon étude.
MOTS-CLEFS:
PostgreSQL, Sybase, Perl, SQL, Migration, Traduction
Remerciements
Je tiens tout d'abord à remercier mon maître de
stage et chef de projet Mr Christophe POLLIER, pour m'avoir proposé un
sujet aussi interressant et formateur et de m'avoir guidée dans mon
travail tout en me laissant un maximum de libertés et d'initiatives.
Je tiens également à remercier tous les
collaborateurs de la CCI et tout particulièrement ceux du services TIC
dans lequel j'ai travailé : Grégory BENOIST, Vincent AUGIERMICOU,
Laurence BOQUET et Laurent POSSETY pour leur accueil sympathique et
chaleureux.
Enfin, je remercie Christian BRAESCH, mon tuteur de l'IUP GSI.
Table des matières
Remerciements i
Liste des illustrations v
Liste des tableaux vi
Liste des codes sources vii
Introduction 1
I L'existant 2
1 Presentation de la C.C.I 3
1.1 Son Histoire 3
1.2 Son implantation 3
1.3 Sa mission et ses objectifs 4
1.4 Son organisation 5
1.4.1 Les élus 5
1.4.2 Les collaborateurs 6
1.5 Le service TIC 6
1.5.1 Ses missions 6
1.5.2 Ses acteurs 6
2 Sujet et Objectifs 7
2.1 Presentation du contexte 7
2.1.1 Le Système d'Information de la CCI 7
2.1.2 Caracteristiques techniques du Système
d'Information 7
2.2 Presentation du projet 8
3 La problematique Système d'Information
9
II Étude de la problematique de migration de base
de données 11
4 Les approches possibles 12
4.1 L'approche "systematique" 12
4.2 L'approche "empirique" 13
4.3 Combinaison de l'approche "systematique" et de l'approche
"empirique" 15
5 Les outils et technologies applicables 16
5.1 Utiisation d'une interlangue 16
5.2 Traduction "manuelle" 18
5.3 Traduction automatique "monotraducteur" 18
5.4 Utiisation d'outils de "reverse-engenering" 19
6 Les méthodes de gestion de projet informatique
20
6.1 Méthode non formelle 20
6.2 XP : eXtreme Programing 20
6.3 RUP : Rational Unified Process 21
6.4 DSDN (RAD) 22
7 Combinaison des approches, des technologies et des
méthodes 23
8 Proposition d'une démarche et de "bonnes
pratiques" 25
8.1 Déterminer la nature du problème 25
8.2 Vérifier s'il existe des solutions 25
8.3 Effectuer la Migration 26
8.3.1 Si une solution existante a été
trouvée 26
8.3.2 Si aucune solution existante ne convient 26
III Application au contexte du stage 27
9 Les choix managériaux et technologiques
28
9.1 La gestion de projet 28
9.2 La démarche suivie 28
9.3 Les technologies utilisées 29
9.3.1 PostgreSQL 29
9.3.2 RedHat Database 30
9.3.3 Perl 30
10 Le travail réalisé 32
10.1 Évaluation de l'état de la base de
données existante 32
10.1.1 Découverte du fonctionnement et des
spécificités 32
10.1.2 Quelques chiffres 32
10.2 Étude des différentes techniques de migration
33
10.3 Écriture d'un traducteur en Perl 33
10.3.1 L'approche utiisée 33
10.3.2 Fonctionnement de l'application 34
10.4 Estimation du travail restant à effectuer 34
10.4.1 Méthode d'estimation 35
10.4.2 Réalisation des mesures 35
10.4.3 Résultats de l'estimation 36
11 Bilan du stage 38
11.1 Évaluation du travail réalisé 38
11.2 Problèmes rencontrés 38
11.2.1 Les problèmes techniques 38
11.2.2 Les problèmes liés à l'organisation
39
11.2.3 Les problèmes liés au manque de
connaissance 39
Conclusion 40
Annexes 41
A Les CCI en France 42
B La CCI de la Haute-Savoie 47
C Les Chiffres de la CCI de la Haute-Savoie
49
D Organigramme 51
E La licence BSD (Berkeley Software Distribution)
52
F Limitations de PostgreSQL 53
G Phases pour réaliser l'ensemble de la migration
54
H Options pour l'utilisation de sybase2postgresql
56
I Documentation de sybase2postgresql 58
J Problèmes spécifiques a chaque type
d'information a migrer 60
K Mesures pour les indicateurs de complexité des
procédures 66
L Installation de modules supplémentaires pour
Perl 69
M Enregistrement d'un fichier en UTF-8 sous Emacs
71
N Webographie 72
Bibliographie 74
Glossaire 76
Liste des illustrations
1.1 Nouveau bâtiment de la CCI dans le quartier Galbert
3
1.2 Implantations de la C.C.I. en Haute-Savoie 4
1.3 Organisation globale de la CCI 5
4.1 Utiisation d'une méthode systématique pour la
traduction de textes . . 12 4.2 Utiisation d'une méthode empirique pour
la traduction de textes . . . . 14
5.1 Méthode de traduction avec une interlangue 16
5.2 Méthode de traduction sans interlangue 17
5.3 Méthode de traduction automatique 18
7.1 Corrélation entre les approches, les technologies, les
méthodes et la
taille de l'équipe 23
7.2 Exemple de mauvaise
corrélation entre les approches, les technologies,
les méthodes et la taille de l'équipe 24
7.3
Exemple de bonne corrélation entre les approches, les technologies,
les
méthodes et la taile de l'équipe 24
A.1 Positionnement des CCI entre privé et public 43
A.2 Une organisation pyramidale mais non
hiérarchisée 45
C.1 Répartition des ressources de la CCI (13 328 M€)
49
C.2 Part de l'IATP dans le budget de la CCI 50
C.3 Répartition des ressortissants par secteur
d'activité en 2003 50
D.1 Organigramme simplifié de la CCI de la Haute-Savoie
51
K.1 Nombre de lignes par procédure 66
K.2 Nombre d'instructions SQL par procédure 67
K.3 Nombre de structures if ou while par procédure 67
K.4 Nombre de curseurs par procédure 68
K.5 Répartition des procédures par type 68
Liste des tableaux
10.1 Dénombrement du contenu des bases de données
32
10.2 Catégories de procédures 36
10.3 Estimation du temps de développement par
catégorie de procédures . 37
C.1 Répartition de la taxe professionelle
départementale 49
F.1 Limitations of PostgreSQL 53
Liste des codes sources
H.1 Options de sybase2postgresql affichées grâce
à l'option -h 56
H.2 Exemple de fichier de configuration de sybase2postgresql
57
J.1 Création des fonctions suser_id() et
suser_id(username) 62
J.2 Création d'une fonction de conversion de type (varchar
vers int) 63
J.3 Création d'une fonction de conversion de type
(smallint vers bit) 63
L.1 Fichier de configuration du module MCPAN 69
Introduction
Afin de valider l'année de master de la formation OTSI de
l'IUP GSI, chaque étudiant doit effectuer un stage de quatre mois en
entreprise.
Ce stage est une étape importante pour un
étudiant, non seulement du point de vue de la scolarité, mais
aussi d'un point de vue personnel. La vie en entreprise est en effet
nécessaire à la mise en pratique de l'enseignement reçu
à l'IUP.
Ce rapport présente l'ensemble des travaux que j'ai
effectués au cours de mon stage au siège de la CCI (Chambre de
Commerce et d'Industrie) de la Haute Savoie à Annecy.
Durant ces 16 semaines, l'activité du stagiaire doit se
partager entre une activité d'apprentissage "fondamental" (on pourrait
dire "théorique") et une activité d'apprentissage
"professionnel".
L'objectif de notre recherche est d'arriver à une
réflexion théorique sur la migration de bases de données
en se basant sur une expérience concrète qu'est la migration de
bases sous Sybase vers PostgreSQL.
Cette réflexion a pour but de faire ressortir les
approches et solutions possibles pour la résolution de cette
problématique.
Ce mémoire s'articulera donc autour de trois axes:
Tout d'abord, nous présenterons le cadre du stage, la CCI,
le sujet proposé et la problématique posée.
Ensuite, nous examinerons cette problématique et tenterons
de lui apporter des solutions.
Enfin, le reste du mémoire portera sur l'ensemble du
travail effectué : la méthodologie, les choix effectués,
les résultats obtenus, leur analyse et les perspectives
envisageables.
Ce rapport, produit avec LATEX2å, a
été compilé le 25 juin 2004.
Premiere partie
L'existant
Chapitre 1
Présentation de la C.C.I.
1.1 Son Histoire
C'est en 1899 (soit 39 ans après l'annexion de la
Savoie par la France) qu'un décret du Président Félix
Faure institue une Chambre de Commerce a Annecy. Elle rejoint ainsi la
vingtaine de Chambre de Commerces réparties sur l'ensemble du territoire
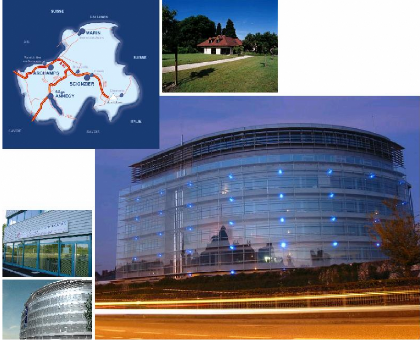
(voir Annexe A, page 42).
A l'origine, la Chambre naissante est hébergée
au rez-de-chaussée de la mairie d'Annecy puis dans l'ancien
évêché. En 1932, elle emménage dans des nouveaux
locaux qu'elle a fait construire rue du lac sur le terrain de l'ancienne
caserne du 50ème Régiment d'Infanterie. Depuis juillet 2003, la
Chambre de Commerce se trouve dans de nouveaux locaux (voir Annexe B, page 47),
construits eux aussi a l'emplacement d'une ancienne caserne (celle du
27ème BCA).

FIG. 1.1 - Nouveau bâtiment de la CCI dans le quartier
Galbert
1.2 Son implantation
Le département regroupe 4 poles économiques
distincts, dotés chacun d'une spécificité et d'une
problématique propre (Annecy, Genevois, Vallée de l'Arve et
Chablais). Dès 1992, la C.C.I. décide d'ouvrir des antennes
permanentes dans ces différent bas-sins d'emploi.
Aujourd'hui, la C.C.I. dispose d'un siège a Annecy et de
trois antennes permanentes a Archamps, Marin et Scionzier.
|
Présentation de la C.C.I.
|
|
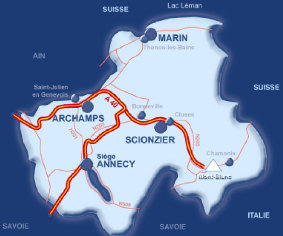
FIG. 1.2 - Implantations de la C.C.I. en Haute-Savoie
1.3 Sa mission et ses objectifs
La CCI de la Haute-Savoie a élaboré un projet
d'entreprise dont l'objectif est de détecter, répondre et
anticiper les besoins des 26 227 commerçants, industriels et
prestataires de services du département. Sa mission est d'optimiser les
performances des entreprises haut-savoyardes a travers une stratégie
fondée sur la dynamique commerciale des entreprises et des territoires.
Plusieurs actions phares concrétisent cet objectif :
- Faciliter la création et la reprise d'entreprises
- Pérenniser les jeunes entreprises
- Accompagner les chefs d'entreprises dans leur parcours
d'entrepreneur
- Préparer la transmission d'entreprises
- Dynamiser l'environnement local
- Gérer les infrastructures indispensables au
développement des entreprises (Aéroport d'Annecy Haute-Savoie,
Gares routières d'Annecy, Annemasse et Cluses, Centre Régional de
Douanes et de Transports d'Epagny)
Pour l'année 2004, la CCI a établi
différents objectifs qui lui permettront de poursuivre la mise en cuvre
de son Projet d'Entreprise:
- Offrir a ses clients (les entreprises) des prestations
déclinées dans un catalogue produits,
- Développer des projets avec ses partenaires1
par un renforcement de la démarche partenariale,
- Organiser des évènements destinés aux
entrepreneurs et aux entreprises.
1Collectivités territoriales et entreprises
participant a la création, la pérennisation, l'animation et la
transmission des entreprises.
Présentation de la C.C.I.
|
|
|
La création d'un catalogue produits a également
pour but de rendre la CCI beaucoup plus indépendante de l'Impôt
Additionnel à la Taxe Professionnelle (voir Annexe C, page 49) en
vendant de nouveaux types de prestations à ses clients.
1.4 Son organisation
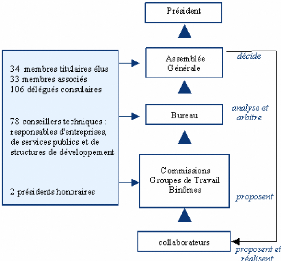
FIG. 1.3 - Organisation globale de la CCI
1.4.1 Les élus
Tous les 3 ans, les chefs d'entreprises de la Haute-Savoie
sont appelés à désigner, à l'occasion des
élections Consulaires leurs représentants à la CCI qui
sont répartis en différents collèges:
- 34 membres titulaires:
Ils forment l'Assemblée Générale qui est
l'instance souveraine. Les présidents, les membres du bureau et les
présidents de commissions, sont élus parmi eux et par eux. Ils
votent le budget annuel qui est ensuite soumis à l'approbation des
ministères de tutelle.
- 33 membres associés:
Au côté des 34 membres titulaires, ils sont
désignés après chaque élection et ils participent
aux Assemblées Générales avec une voix consultative.
- 106 délégués consulaires:
Ils sont élus et représentent la CCI dans les 33
cantons du département.
Présentation de la C.C.I.
|
|
|
1.4.2 Les collaborateurs
Les employés de la chambre de commerce sont
répartis en 13 services, plus l'accueil (voir Annexe D, page 51) et
répartis sur 6 "plateaux" (chaque plateau étant un étage
du bâtiment).
1.5 Le service TIC
1.5.1 Ses missions
Le service TIC a en charge les choix stratégiques
à court et moyen terme dans le domaine de l'informatique et des
nouvelles technologies de l'information et de la communication.
Les principaux axes d'intervention sont:
- La surveillance et l'intervention sur les équipements
informatiques (serveurs, postes clients, . . .).
- La mise en place et la maintenance du réseau
informatique.
- L'identification, l'évaluation et la quantification des
besoins exprimés par les services.
- La proposition de solutions adaptées (techniques,
logiciels, formations) en conservant au maximum une cohérence avec le
système d'information existant.
- La maintenance des applications propres à la CCI de la
Haute-Savoie.
- La veille technologique au sens large dans le secteur de
l'informatique et des TIC.
- Les formations spécifiques à la CCI.
1.5.2 Ses acteurs
- Christophe Pollier (Directeur)
- Grégory Benoist (Technicien administrateur
réseau)
- Vincent Augier-Micou (Développement et maintenance
SGBD)
- Laurence Boquet (Support utilisateur - Formation)
- Laurent Possety (Maintenance du parc informatique)
Chapitre 2
Sujet et Objectifs
2.1 Presentation du contexte
2.1.1 Le Système d'Information de la
CCI
La Chambre de Commerce et d'industrie de la Haute-Savoie s'est
dotée, au fur et à mesure de sa croissance de différents
outils informatiques.
Certains de ces outils sont des applications courantes et ont un
fonctionnement "imposé" (Xerox Docushare, Microsoft Exchange, . . .).
D'autres applications sont quant à elles
développées au sein de la CCI et continuent donc d'évoluer
parallèlement aux besoins.
L'application la plus importante est BEE (Base
Économique Événementielle), une application métier
développée sous 4D1 associée à une base
de données Sybase. C'est un outil de CRM qui constitue le coeur du
système d'information de la CCI puisque, comme son nom l'indique, son
but est de recenser tous les événements réalisés :
contact avec un ressortissant, courrier postal et électronique, contact
téléphonique ou email . . .
2.1.2 Caracteristiques techniques du Système
d'Information
Le serveur Sybase contient plusieurs bases de données
utilisées par les différentes applications de la CCI:
- base cci: Elle stocke les données concernant la CRM
(BEE), la taxe d'apprentissage, les formations et l'aéroport
(statistiques des vols).
- base consulaire : Elle stocke les fichiers "officiels" des
entreprises ainsi que les formalités d'export (ATA-VISA).
- base cfe : Elle stocke les données du centre de
formalités des entreprises. Elle n'est utilisée que pour
conserver l'historique car l'application traitant ce type de données est
maintenant nationale.
- base personnel: Elle stocke les données des Ressources
Humaines (principalement utilisée pour le trombinoscope et la gestion
des entretiens annuels).
Il y a actuellement 3 serveurs Sybase2 : 2 serveurs
en production (1 serveur principal
14D (4ème Dimension) est un atelier logiciel
de développement et de déploiement d'applications multipostes
crossplate-forme.
2Sybase version 11.0.2/P en production et version
11.0.3.3 en test
et 1 serveur avec une réplication3 quotidienne)
et 1 serveur en test.
2.2 Présentation du projet
Les applications métier de la CCI s'appuient, comme
nous l'avons précédemment indiqué (voir § 2.1.2, page
7), sur différentes bases de données fonctionnant sur un serveur
Sybase.
La version de Sybase utilisée étant
relativement ancienne, la CCI doit envisager une évolution importante,
que ce soit la migration vers une version plus récente de Sybase ou vers
un autre moteur de base de données.
Les collaborateurs de la CCI utiisent déjà avec
succès différents logiciels libres. Il a donc été
décidé d'évaluer l'opportunité d'effectuer cette
migration vers une base de données libre. Cependant, les applications
reposant sur cette base de données étant critiques pour le
fonctionnement de la CCI, une migration de cette ampleur ne peut se
décider à la légère.
Suite à ces différentes réflexions, il a
été décidé d'effectuer une étude
poussée afin de déterminer si cette migration était
possible.
Cette étude devait donc porter sur les points
suivants:
- Étude des différentes techniques de
migration;
- Choix de la méthodologie à employer;
- Migration des structures (tables, séquences, index,
vues);
- Migration des données;
- Migration des traitements (Triggers, Procédures);
- Mesure de l'efficacité du nouveau moteur de base de
données.
3Le serveur de réplication est un serveur
accessible depuis les applications cientes et dont le but est d'éviter
les surcharges du serveur principal (pour ne pas trop ralentir le serveur
principal avec de grosses requêtes ne nécessitant pas des
données ayant moins de 24 heures, celles-ci sont réalisées
sur le serveur de réplication).
Chapitre 3
La problematique Système
d'Information
Le problème de migration d'un SGBD a un autre,
lorsqu'on y regarde d'un peu plus près, est en fait, le passage d'un
langage a un autre. Or, lorsqu'on parle de traduction, on pense plus
généralement a la linguistique et a l'étude du langage
naturel.
Ce rapprochement, même s'il peut paraltre incongru a
première vue, est finalement assez logique car les langages dits
artificiels possèdent un grand nombre de caractéristiques
communes avec les langages naturels. Les travaux de Noam Chomsky [11] sur
l'approche de la linguistique générative ont fait ressortir des
similitudes entre les langages naturels et les langages informatiques. On peut
en effet y trouver des problématiques liées au lexique
(vocabulaire), a la syntaxe et a la sémantique.
Ce rapprochement est d'autant plus évident lorsqu'on
se base sur les travaux de recherche faits sur les compilateurs informatiques
[12] qui utiisent de facon importante les travaux effectués en
linguistique et sont des traducteurs (ils traduisent un langage écrit
par un humain vers un langage compréhensible par un ordinateur).
Bien évidemment, la complexité des
problèmes liés aux langages informatiques est moindre que celle
liée a l'étude des langages naturels car certains aspects de la
linguistique comme l'étude du langage parlé (phonétique,
phonologie) ne sont pas présents et que le lexique employé est
généralement moins conséquent.
Cependant, on peut tout de même retrouver, dans
l'étude des langages informatiques, certains des problèmes les
plus complexes de la linguistique et notamment les problèmes de
pragmatique (variation du sens en fonction du contexte), voire même se
trouver confronté a des situations oü le contexte n'est pas
exprimé explicitement (il dépend de l'état du
système ou d'autres données accédées directement en
interne par le SGBD par exemple).
De plus, l'écriture dans un langage informatique est
normalement plus rigoureuse, mais, tout comme les langages naturels, les
langages artificiels, assez simples lors de leur création, ont
évolué en gardant trace de leur histoire (on peut par exemple
utiiser plusieurs syntaxes ou un vocabulaire totalement différent pour
effectuer une même action).
Enfin, même si, comme nous l'avons dit, la
problématique de la traduction dans le cadre des langages artificiels
est beaucoup plus simple que pour les langages naturels, on peut rappeler que,
pour cette dernière, de nombreuses recherches sont encore en cours. La
traduction automatique est un problème qui a longtemps été
sous-estimé
La problématique Système d'Information
|
|
|
mais qui est en fait l'un des plus délicats à
effectuer pour un ordinateur. Aux phases lexicales et syntaxiques, à peu
près maîtrisées, s'ajoutent une analyse sémantique,
puis pragmatique, qui tentent de déterminer le sens particulier d'un
mot, dans le contexte oü il apparaît. Le contexte lui-même
pouvant s'étendre à l'ensemble du texte traduit.
Nous allons donc étudier les différentes
approches et méthodologies issues de la linguistique informatique pour
mener à bien un travail de traduction afin de déterminer quelles
solutions peuvent être envisagées lorsqu'on se trouve
confronté à un problème de migration de bases de
données.
Deuxième partie
Étude de la problématique de
migration de base de données
Chapitre 4
Les approches possibles
4.1 L'approche "systématique"
Comme la migration d'un gestionnaire de base de
données à un autre est assez semblable à la traduction
d'un langage (naturel ou artificiel) vers un autre, il est possible d'utiliser
une démarche proche de celles employées en ingénierie
linguistique.
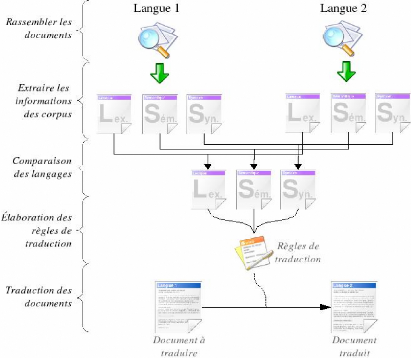
FIG. 4.1 - Utiisation d'une méthode systématique
pour la traduction de textes
Cette démarche passe tout d'abord par
l'élaboration d'un corpus [13]. Dans notre cas, le corpus
créé peut être composé des définitions du
langage utilisé par le SGBD, généralement fournies dans
les documentations techniques, et complétées par des exemples de
cas complexes.
Lorsque le corpus est assez complet, il est alors possible
d'en extraire le lexique, la syntaxe et la sémantique du langage.
Dans notre cas, nous cherchons à réaliser une
traduction d'un langage vers un autre, il faut donc effectuer ces
opérations pour les deux langages afin de pouvoir les comparer et
déterminer quels sont les éléments qui les
différencient et obtenir des règles de traduction.
Enfin, il est possible d'appliquer ces règles à
un document écrit dans un des langages pour obtenir sa traduction dans
l'autre.
Lorsqu'on applique une approche systématique au
traitement informatique d'une migration, on pourra assimiler cette
démarche à une approche descendante (également
appelée approche 'top-down').
Cette approche est à privilégier lorsqu'on se
trouve confronté à la traduction d'un grand nombre de documents
très hétérogènes ou à de nouveaux types de
documents. Cette approche est longue à mettre à place, non
seulement à cause de la nécessité de rassembler un corpus
de documents suffisamment vaste pour couvrir tous les aspects d'un langage,
mais aussi par la complexité d'extraction du lexique et de la grammaire
de ce corpus.
Cependant, dans les cas complexes, on préférera
ce type de cheminement car il per-met d'obtenir un traducteur
"générique", capable de faire face à un nouveau document
sans rencontrer de problèmes. Grâce à cela, il est
également possible d'obtenir assez facilement un traducteur pour un
langage "proche" (pour les langages informatiques comme pour les langages
naturels, il existe des "familles de langues"1 qui ont les
mêmes origines et donc un grand nombre de règles communes.
Suite à ces réflexions, on peut voir que
l'approche systématique est destinée à réaliser un
traducteur complet et flexible.
4.2 L'approche "empirique"
L'approche empirique, contrairement à l'approche
systématique, se base sur le document ou l'ensemble de documents qui
doivent être traduits et non sur un ensemble de documents de
référence.
Cette démarche passe tout d'abord par la traduction
"manuelle" de parties du document pour déterminer les règles de
traduction.
On traduit ainsi des parties dont le lexique, la
sémantique et la syntaxe sont différents jusqu'à obtenir
des règles permettant de traiter l'ensemble du document. Une fois ces
règles écrites, il est alors possible de les appliquer au
document afin d'en obtenir une traduction complète.
1Pour les langages naturels, on peut par exemple
citer le français, l'espagnol et l'italien qui sont des langues latines.
Pour l'informatique, on peut citer le C++ et la java qui ont des origines dans
le C ou Sybase et MS-SQL qui sont partis tous les deux d'une ancienne version
de Sybase
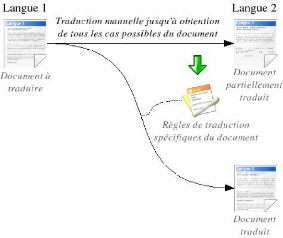
FIG. 4.2 - Utilisation d'une méthode empirique pour la
traduction de textes
Ici, cette approche peut être assimilée à
un approche montante (également appelée 'bottom-up') car on part
de "problèmes spécifiques" à un document jusqu'à
obtenir un traducteur par agrégation de ces problèmes.
Si on possède suffisamment de documents
différents et qu'ils couvrent tous les cas existants, on peut, par
empirisme, obtenir un traducteur aussi complet que celui qu'on obtiendrait par
une approche systématique mais cela nécessiterait une
quantité de travail bien supérieure.
De plus, la complexité non linéaire de cette
approche est un problème car chaque "cas particulier" résolu
risque de rentrer en conflit avec les cas résolus
précédemment ce qui implique que plus le nombre de règles
de traduction augmente, plus le nombre de contradictions possibles augmente.
En fait, cette approche n'est rapide à mettre en place
que si on a un nombre limité de "problèmes" de traduction et que
l'on veut obtenir un traducteur pour un faible nombre de documents (ou si ces
documents utilisent exactement les mêmes règles de traduction).
Cependant, cette démarche est limitée par le
fait que l'écriture des règles passe par une phase de traduction
manuelle. Si on doit traduire des documents très différents ou si
les schémas linguistiques ne se trouvent pas assez souvent
répétés, l'ensemble du travail de traduction sera
finalement réalisé manuellement. Par exemple, si on se trouve
dans le cas d'un document trop court, chaque élément traduit
manuellement créera une nouvelle règle mais celle-ci ne sera
utilisée que pour cet élément.
Comme les approches de type bottom-up ont une relation
très forte avec l'existant, elles sont beaucoup plus adaptées
dans le cas où on ne veut pas faire un outil généraliste
mais spécifique à une situation. L'approche empirique sera donc
réservée à la
résolution de problèmes ponctuels et à une
traduction unidirectionelle (car les problèmes liés à la
traduction ne sont pas forcément bijectifs).
4.3 Combinaison de l'approche "systématique" et de
l'approche "empirique"
Cette approche n'est généralement pas possible
à mettre en place car, si elle apporte une bien plus grande
fiabilité (il y a de grandes chances qu'aucun cas "spécifique" et
qu'aucune exception ne soit oubliés), apporte également une bien
plus grande complexité et un temps demise en oeuvre beaucoup plus grand
car il faut effectuer chacune des deux méthodes puis mettre en relation
les résultats obtenus pour obtenir un seul ensemble de règles de
traduction.
La combinaison de modules en vue d'obtenir une solution
cohérente est d'ailleurs, à elle seule, un sujet complexe
nécessitant des études poussées [14] car
l'efficacité de l'analyse lexicale dépend directement dont les
différentes parties de l'analyseur fonctionnent en corrélation et
non en opposition.
Chapitre 5
Les outils et technologies
applicables
Les deux approches décrites précédemment
(voir Chapitre 4, page 12) détaillent la démarche qui peut
être suivie afin d'obtenir un traducteur. Leur mise en oeuvre
nécessite des outils dont une partie va être
présentée ci-dessous.
5.1 Utilisation d'une interlangue
Les interlangues (ou langages pivots) sont fréquemment
utilisées dans le domaine de la traduction automatique. Une interlangue
est une langue artificielle qui sert d'intermédaire entre une langue
source et une langue cible.
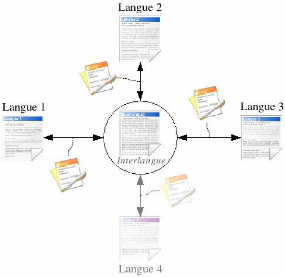
FIG. 5.1 - Méthode de traduction avec une
interlangue
Les outils et technologies applicables
|
|
|
Les interlangues sont généralement
utilisées lorsqu'on doit effectuer des traductions entre plusieurs
langages.
Un grand nombre de travaux de recherche en linguistique se
sont penchés sur les interlangues. On peut notamment parler du projet
Traduction de Langues Distribuée (en anglais : Distributed Language
Translation, en espéranto Distribuita Lingvo-Tradukado, en
abrégé DLT) qui était un projet de traduction de langues
de la Commission européenne1. Le projet avait pour but la
traduction automatique depuis et vers 12 langues européennes par le
biais d'une interlangue interne basée sur l'Espéranto, qu'on
nommait ILO (Internacia Lingvo = Langue Internationale).
En informatique, on utilise ce type d'outil dans la mise en
place d'EAI. Dans ce cas, l'EAI se sert d'une interlangue (par exemple le XML)
et se sert de traducteurs, appelés connecteurs, pour faire communiquer
des systèmes hétérogènes entre eux.
Les interlangues sont habituellement utiisées avec une
approche de type systématique car elles sont destinées à
obtenir des traducteurs généralistes et assez exhaustifs entre
plusieurs langages. Elles n'ont d'ailleurs d'intérêt que si on est
en présence de plus de trois langages.
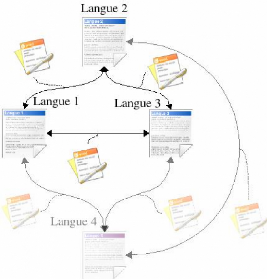
FIG. 5.2 - Méthode de traduction sans interlangue
1Dans la sphère de la traduction technique
(ex: entre le français et l'anglais, avec une traduction
intermédiaire en ILO -Internacia LingvO = Langue Internationale- et
retour) on atteignait 95% de précision sur les phrases traduites. Dans
la sphère de textes très généraux (ex:
comptes-rendus d'assemblées de l'UNESCO) la précision de la
traduction se situait entre 50 et 60 %.
Les outils et technologies applicables
|
|
|
En effet, lorsqu'on veut effectuer une traduction entre deux
langages, le passage par une interlangue nécessite plus de travail (deux
traducteurs au lieu d'un), mais, si on dépasse trois langages, on peut
voir que l'utilisation d'une interlangue (voir Figure 5.1, page 16) permet de
ne créer qu'un seul connecteur lors de l'ajout d'un quatrième
langage alors qu'il faut trois connecteurs lorsqu'on n'utilise pas
d'interlangue (voir Figure 5.2, page 17).
Cette solution, est donc très coûteuse pour un
petit nombre de langages alors qu'elle est beaucoup plus économique
lorsqu'on dépasse le seuil de trois langues.
C'est pourquoi, dans le cadre d'une migration entre
"seulement" deux systèmes, il est assez improbable que cette
méthode soit la plus intéressante à utiliser (à
moins de déjà disposer de traducteurs fiables vers une même
interlangue).
5.2 Traduction "manuelle"
La traduction manuelle, comme son nom l'indique, ne fait appel
à aucun mécanisme d'automatisation.
Dans ce cas, la traduction de tout le document est
effectuée par un traducteur humain. Bien que cela ne soit
généralement pas formalisé, les traducteurs utilisent
habituellement une approche de type empirique car, lorsqu'ils rencontrent un
problème et qu'ils le résolvent une première fois, ils
sauront comment le résoudre s'ils s'y trouvent confrontés une
seconde fois.
5.3 Traduction automatique "monotraducteur"
Aussi bien dans le cadre d'une approche systématique
que par l'application d'une approche empirique, on obtient un ensemble de
règles de traduction qui permettent ensuite d'effectuer automatiquement
la traduction de documents.
La traduction est réalisée par un logiciel
chargé d'appliquer les règles de traduction de façon
systématique.
Mais, avant d'utiiser un logiciel de traduction automatique, il
faut avoir préalablement définit ces règles et cela est
complexe et nécessite un fort investissement.

FIG. 5.3 - Méthode de traduction automatique
Les outils et technologies applicables
|
|
|
5.4 Utilisation d'outils de "reverse-engenering"
Généralement basés sur une approche
systématique, ce sont des outils dont le fonctionnement est proche de
celui de l'interlangue. Toutefois, le langage utiisé est sou-vent proche
de l'UML et ce sont des outils intégrés et fournis
"tels-quels".
Ces outils vendus ou mis à disposition par des
entreprises d'édition de logiciels, ce sont des solutions de type "clefs
en main". Cependant, comme l'import ou l'export depuis ou vers un SGBD se fait
par un traducteur spécifique, il faut que les connecteurs existent
(malheureusement si on utilise un ou des systèmes peu courants, il est
assez difficile de trouver un atelier de reverse-engenering proposant les
traducteurs nécessaires).
Chapitre 6
Les méthodes de gestion de projet
informatique
Comme tout autre projet informatique, et même
généralement comme tout projet, la migration de bases de
données doit être programmée, suivie, piotée et
analysée. Ces fonctions, remplies par le chef de projet, peuvent
s'appuyer sur différentes méthodologies couramment
employées.
La méthode employée ne doit pas être choisie
à la légère car la réussite ou non du projet en
dépendra fortement.
6.1 Méthode non formelle
Dans le cadre de projets avec peu de ressources (1 ou deux
personnes au maximum), l'affectation de temps à la gestion de projet
peut entraîner des surcoûts importants. Comme le nombre de
personnel est très faible, leur coordination et leur affectation ne pose
pas de problème et l'ordonnancement des tâches est très
simple (on ne peut faire qu'une seule chose à la fois).
De plus, des comptes-rendus réguliers au client lors
de réunions d'avancement et à la hiérarchie lors de
réunions de service ou de façon informelle, permettent de pioter
de façon assez fiable le projet et de réagir rapidement en cas de
dérive.
6.2 XP: eXtreme Programing
XP propose un ensemble de "Bests Practices" de
développement (travail en équipes, transfert de
compétences, . . .), c'est une méthode itérative, simple
à mettre en oeuvre destinée à des équipes de petite
taille composées de membres autonomes, c'est une méthode
très réactive mais qui demande une forte implication du
client.
- Gestion des livraisons : L'équipe fournit des
livraisons fréquentes au client. Le contenu de ces livraisons est
décidé par le client lui-même, à partir des
estimations fournies par les développeurs.
- Gestion des itérations : Les livraisons sont
réalisées en une suite d'itérations de 2 semaines environ,
au sein desquelles le projet est géré à un niveau de
détail plus fin.
Les méthodes de gestion de projet informatique
|
|
|
- Suivi du projet : L'avancement du projet est mesuré
de manière concrète par une batterie de tests de recette
automatiques. Le rythme de progression est réévalué
à chaque itération, et le plan de développement
lui-même est revu fréquemment pour tirer parti de
l'expérience acquise au cours du projet.
- Qualité du design et du code : Des pratiques
strictes permettent de garder une vitesse de développement
élevée tout au long du projet, tout en gardant une ouverture
maximale au changement. La conception reste toujours le plus simple possible,
le code est nettoyé en permanence et des tests unitaires de
non-régression sont écrits pour chaque classe.
- Travail en équipe : L'équipe travaille
réellement en équipe. Le code est partagé par tous, les
développeurs travaillent systématiquement en binômes, et
l'intégration est quasiment continue."
6.3 RUP: Rational Unified Process
RUP est à la fois une méthodologie et un outil
prêt à l'emploi (documents types partagés dans un
référentiel Web).
C'est est un processus de développement logiciel
itératif et incrémental, centré sur l'architecture,
conduit par les cas d'utiisation et pioté par les risques. Il est
destiné aux projets nécessitant un grand nombre de ressources
humaines. Il n'est d'ailleurs utilisable que si une personne est
affectée à temps complet (ou presque) à la gestion de
projet car il y a beaucoup d'étapes à suivre et de documents
à réaliser.
De plus, il faut commencer par adapter RUP à son
projet, ce qui le rend intéressant à utiliser uniquement dans le
cadre d'une équipe qui travaille toujours sur le même type de
projet et toujours avec RUP.
RUP présente un certain nombre de
caractéristiques, il est:
- Itératif et incrémental : le projet est
découpé en itérations de courte durée (environ 1
mois) qui permettent de mieux suivre l'avancement global. A la fin de chaque
itération, une partie exécutable du système final est
produite, de façon incrémentale.
- Directif: Spécifie le dialogue entre les
différents intervenants du projet (les livrables, les plannings, les
prototypes, ...) et propose des modèles de documents, et des canevas
pour des projets types.
- Centré sur l'architecture : tout système
complexe doit être décomposé en parties modulaires afin de
garantir une maintenance et une évolution faciitées. Cette
architecture (fonctionnelle, logique, matérielle, etc.) doit être
modélisée en UML et pas seulement documentée en texte.
- Pioté par les risques : les risques majeurs du
projet doivent être identifiés au plus tôt mais surtout
levés le plus rapidement possible. Les mesures à prendre dans ce
cadre déterminent l'ordre des itérations.
- Conduit par les cas d'utilisation : le projet est
mené en tenant compte des besoins et des exigences des utiisateurs. Les
cas d'utilisation du futur système sont identifiés,
décrits avec précision et priorisés.
Les méthodes de gestion de projet informatique
|
|
|
6.4 DSDN (RAD)
L'organisation d'un projet par une méthode de type RAD
s'appuie sur un principe fondamental : la séparation des rôles et
des responsabilités entre maîtrise d'ouvrage (MOA) et
maîtrise d'oeuvre (MOE).
La méthode RAD structure le cycle de vie du projet en 5
phases:
- L'initialisation définit l'organisation, le
périmètre et le plan de communication.
- Le Cadrage définit un espace d'objectifs, de solutions
et de moyens.
- Le Design modélise la solution et valide sa
cohérence systémique.
- La Construction réalise en prototypage actif
(validation permanente).
- La Finalisation est un contrôle final de qualité
en site piote.
La méthode DSDM propose une approche globale du
développement de logiciel dans un environnement de développement
rapide (RAD). DSDM fournit un canevas couvrant l'ensemble du cycle de
développement et un grand nombre de principes à suivre afin
d'assurer le succès du projet.
Chapitre 7
Combinaison des approches, des
technologies et des méthodes
Lors de la mise en place du projet, il est essentiel de
choisir les différents éléments (approche employée,
technologies utilisées, méthodologie suivie et taille de
l'équipe) de façon cohérente.
Combinaison des approches, des technologies et des
méthodes
|
|
|

FIG. 7.2 - Exemple de mauvaise corrélation entre les
approches, les technologies, les méthodes et la taille de
l'équipe
Par exemple, un projet suivant une approche
systématique, pour réaliser un outil basé sur une
interlangue, avec une gestion de projet non formelle et une grosse
équipe a de grande chance de foncer droit dans le mur.

FIG. 7.3 - Exemple de bonne corrélation entre les
approches, les technologies, les méthodes et la taille de
l'équipe
À l'opposé, un projet de traduction automatique
monotraducteur, employant une approche empirique, et gérant une
équipe projet grâce à une méthode non formelle
démontre une vision cohérente du projet. La cohérence de
cet ensemble de choix ne fera donc pas obstacle au bon déroulement du
projet.
Lors du lancement du projet, on veillera donc tout
particulièrement à ce que les différents
éléments (même si chacun pris séparément
semble être le meilleur choix) puissent être utilisés
ensembles.
Chapitre 8
Proposition d'une démarche et de
"bonnes pratiques"
Lors d'un projet de migration de base de données comme
dans tout autre projet informatique, il n'existe bien évidemment pas de
"solution miracle" pour réussir à coup sûr mais il est
possible de suivre une démarche et des bonnes pratiques (appelée
aussi best practices) qui permettront d'augmenter les chances de
réussite.
Cette démarche peut être découpée
en trois grandes étapes. Après chacune d'elle, il est
nécessaire de déterminer si le projet de migration est
réaliste et réalisable afin de ne pas effectuer d'investissements
inutiles.
8.1 Determiner la nature du problème
Dans un premier temps, l'étude doit porter sur la nature
du travail à effectuer:
- Quelles sont les informations qui doivent être
migrées (structure, données, traitements ou les trois)?
Une migration partielle est bien entendu plus simple à
réaliser.
- De quelles "familles" sont la base de données origine
et destination?
Si les bases de données sont de la même "famille"
(par exemple Sybase et MS-SQL ou deux versions d'une même base de
données), une migration nécessitera beaucoup moins de travail que
pour des bases de données d'origine totalement différente.
8.2 Verifier s'il existe des solutions
Après avoir déterminé de quel type
était le problème à traiter, la seconde étape
consiste à rechercher si des solutions existantes peuvent être
utilisées. Pour cela, il faut évidemment déterminer si les
technologies utilisées sont applicables mais aussi si leur coût
est acceptable.
Les outils de migration les plus courants sont basés sur
le principe de reverse-engenering. Ils sont peu nombreux et
particulièrement liés à une seule famille de base de
données (le nombre de connecteurs vers d'autres bases de données
est généralement limité).
On peut également trouver des solutions entièrement
externalisées : une société de
|
Proposition d'une démarche et de "bonnes pratiques"
|
|
services se charge d'effectuer toute la migration grâce
à des outils qu'elle développe elle-même.
8.3 Effectuer la Migration
8.3.1 Si une solution existante a été
trouvée
Si une solution existante est utiisable (l'outil a
été conçu pour les systèmes que l'on utilise) et
que son prix est acceptable, la solution doit être utiisée en
n'oubliant pas de continuer à pioter le projet de migration et à
éviter les dérives.
Une fois la migration réalisée, il ne reste
qu'à effectuer un ensemble de tests afin de vérifier que tout
s'est bien passé et affiner le paramètrage de la base de
données afin d'en améliorer les performances.
8.3.2 Si aucune solution existante ne
convient
Si aucune solution existante n'est adaptée à
notre problème et que l'on souhaite poursuivre le projet, il convient de
déterminer quelle approche et quelle solution doivent être
adoptées (en fonction de la nature de la migration et du type de
traducteur que l'on souhaite obtenir).
Troisième partie
Application au contexte du stage
Chapitre 9
Les choix managériaux et
technologiques
9.1 La gestion de projet
Ce stage était un projet informatique "comme un autre".
On peut donc supposer que l'utilisation d'une méthodologie de gestion de
projet informatique aurait été logique. Cependant, l'utilisation
d'une méthode "stricte" était en fait peu adaptée a ce cas
pour différents motifs:
- Le retour d'expérience sur ce genre de projet est
assez rare (aussi bien au niveau personnel que dans les documentations
disponibles), il n'y a donc pas d'indications sur le fonctionnement d'anciens
projets du même type.
- Dans le cadre de projets menés par une seule
personne (comme c'était le cas ici), la mise en place de
mécanismes complets de management de projet peut s'avérer
complexe et nécessiter plus de temps quelle n'en fait gagner.
Nous avons donc adopté une gestion de projet minimale,
essentiellement basée sur les comptes-rendus hebdomadaires lors des
réunions de service.
- Enfin, comme l'approche employée est de type
empirique, son évolution est par essence difcile a prévoir (car
on traite les problèmes au fur et a mesure de leur découverte).
Une prévision trop précise et un planning décidé
trop tot seraient remis en cause a chaque nouveau problème.
9.2 La démarche suivie
Ce projet a été découpé en quatres
grandes "étapes" qui seront développées dans les chapitres
suivants:
- Recherche et évaluation des solutions existantes (voir
Section 10.2, page 33);
- Choix d'une solution (voir Section 9.3, page 29);
- Mise en cuvre de la solution (voir Section 10.3, page 33);
- Evaluation du travail a venir (voir Section 10.4, page 34).
|
Les choix managériaux et technologiques
|
|
9.3 Les technologies utilisées
9.3.1 PostgreSQL
Présentation
PostgreSQL1 est un Système de Gestion de Base
de Données Relationnelle (SGBDR) open source2.
Il a été initialement développé
à l'Université de Berkeley sous le nom de Ingres (1977- 1985). Il
a été amélioré régulièrement au cours
de ses premières années par les sociétés Rational
Technologies et Ingres Corp.. Ces sociétés ont été
rachetées par la société nommée maintenant
Informix. Le projet a ensuite continué indépendamment à
Berkeley sous le nom de Postgres (1986-1994). Après l'apparition des
premières normes du langage SQL, le langage de requête de Postgres
a été remplacé par le langage SQL. En 1995, le projet a
ensuite été repris par des développeurs
indépendants de l'Université de Berkeley et renommé
Postgres95. Là, le projet s'est étoffé et
transformé à partir de 1997 en PostgreSQL lorsque l'ensemble des
fonctionnalités SQL a été intégré au
serveur.
Avantages
PostgreSQL est un logiciel libre, il possède donc tous les
avantages qui en découlent, entre autre:
- La gratuité;
- Le nombre de déploiements ilimité;
- La communauté de développement active et
réactive;
- Les possibiité d'extension à volonté
(le code source étant disponible gratuitement, il est possible de
modifier ou d'étendre les fonctionnalités de PostgreSQL de
façon autonome).
- . . .
PostgreSQL respecte la quasi totalité de la norme SQL
et propose la plupart des fonctionnalités présentes dans les
autres "grands" SGBD (gestion des transactions, procédures
stockées, gestion des droits d'accès aux données, . .
.).
Dans le monde du logiciel libre, (mis à part SAPDB qui
est actuellement en pleine mutation due à son rapprochement de MySQL)
PostgreSQL est certainement actuellement le seul SGBD permettant de
gérer des bases de données à gros volume et avec un grand
nombre de connexions notamment grâce à son haut degré de
scalabilité.
Les concurrents libres de PostgreSQL ne sont pas aussi
aboutis, tant pour la tenue en charge que pour le nombre de
fonctionnalités disponibles, c'est pourquoi le choix en terme de bases
de données assez limité.
Inconvénients
PosgreSQL n'est pas disponible nativement pour Windows, il
utilise une couche d'émulation (CygWin). Seules les prochaines versions
à partir de la numéro 8 (à venir) seront
développées pour Windows.
1Version utilisée : 7.3.4-RH
2Sous licence BSD (voir Annexe E, page 52)
Les choix managériaux et technologiques
|
|
|
PostgreSQL, s'il est connu pour sa robustesse, a
également la réputation d'être relativement lent
(même si chaque nouvelle version amène des progrès
notables). Cela est dû au grand nombre de mécanismes de
préservation et de protection des données qui sont activés
par défaut mais qui peuvent pour la plupart être
désactivés après une étude détaillée
des besoins.
9.3.2 RedHat Database Présentation
RedHat Database3 est une version de PostgreSQL
7.3.4. optimisée pour fonctionner avec un serveur Red Hat
Linux4 et qui bénéficie du back-portage des
améliorations apparues avec la version 7.4.
Avantages
Rhdb5 est librement téléchargeable sur
le serveur ftp de RedHat. Il est également possible d'acquérir un
contrat de service (3267€) chez RedHat contenant:
- Red Hat Database (intégré, testé et
optimisé Red Hat Linux)
- L'installeur Red Hat
- La documentation complète de RhDb et des outils
graphiques
- Le support par le web et téléphonique
- Une inscription mensuelle fournissant des mises à jour
régulières
La CCI possède actuellement un serveur sous RedHat et
un contrat de type "Red Hat Enterprise Linux ES". En cas de problèmes
non spécifiques à la base de données, il est donc possible
de profiter du contrat de support souscrit.
Inconvénients
Red Hat n'a pas une politique très claire en ce qui
concerne le support de ce produit. Certes, une équipe Red Hat travaille
en permanence sur ce projet et une offre de services est proposée mais
le site de vente de RedHat reste peu clair sur ses avantages : le contenu de
l'offre n'est pas très détaillé et la version actuellement
proposée est la 2.16 alors la version 3 existe depuis
plusieurs mois.
9.3.3 Perl Présentation
Crée en 1986 par Larry Wall, Perl (Practical
Extraction and Report Language) est un langage de programmation
interprété (avec une phase interne de pré-compilation). Sa
syntaxe dérive des scripts shell, et d'autres langages comme C, awk,
sed.
3Aussi appelé : PostgreSQL - Red Hat Edition
ou RhDb 4version 9 ou Fedora Core 1
5Version utilisée : 3.0 (sortie le 16 janvier
2004) 6optimisé Red Hat Linux 7.1 et PostgreSQL 7.1.2
Les choix managériaux et technologiques
|
|
|
Avantages
Pour tous ceux qui connaissent ces langages, notamment pour
ceux qui viennent du monde Unix, Perl est relativement facile à
apprendre.
Perl a été conçu selon un concept de
langage naturel : on écrit du Perl comme on pense. Cette
caractéristique de Perl se retrouve dans son slogan "there is more than
one way to do it".
La puissance de Perl pour la manipulation de chaînes de
caractères et de fichiers lui donne des atouts considérables pour
écrire des applications nécessitant des expressions
régulières, par exemple le traitement de texte avec la
création de pages à la volée. L'allocation de
mémoire est prise en charge par l'interpréteur, il n'y a donc pas
de gestion de mémoire, pas de limite de buffer.
Perl existe depuis plus de 15 ans, beaucoup de
bibliothèques et de modules d'extensions sont donc déjà
disponibles.
L'application première de Perl est l'administration
Unix (manipulation de textes, de fichiers et de processus), une personne ayant
ce type de compétences aura donc certainement des connaissances du
langage Perl et pourra ainsi reprendre, maintenir et modifier le code source si
cela est nécessaire.
Inconvénients
Perl possède certains inconvénients notamment
des soucis de sécurité intrinsèques à son statut de
langage interprété. Toutefois, il existe un mode "secure" qui
vérifie pour chaque variable si elle est sécurisée ou non.
Comme ce mode ralentit l'application, il est réservé au
débuggage.
Perl n'est pas efficace pour le calcul scientifique.
C'est un langage très permissif qui laisse les
programmeurs libres de coder selon leurs méthodes. Cependant, la
diversité des méthodes de codage qui est un gros avantage pour la
simplicité d'apprentissage du Perl est aussi un des principaux
inconvénients du langage : il est souvent difficile de reprendre le code
d'un autre développeur, surtout s'il n'est pas correctement
documenté.
Chapitre 10
Le travail réalisé
10.1 Evaluation de l'état de la base de
données existante
10.1.1 Découverte du fonctionnement et des
spécificités
Avant de pouvoir commencer tout autre travail, il faut commencer
par se familiariser avec l'environnement de travail. Ici, les principales
applications à connaître sont:
- BEE : l'application de CRM;
- Sybase et les outils qui permettent de s'y connecter (DbDK et
DBArtisan);
- Les bases de données présentes sur le serveur
Sybase.
10.1.2 Quelques chiffres
Pour réaliser la migration, il a tout d'abord fallu
étudier les bases un peu plus précisément afin de
déterminer dans quelles catégories les classer (base
principalement axée sur les données, sur les structures ou sur
les traitements) et quel type d'outil utiliser.
|
cci
|
cfe
|
consulaire
|
personnel
|
TOTAL
|
Groups
|
1
|
1
|
1
|
1
|
4
|
Indexes
|
528
|
354
|
232
|
23
|
1137
|
Segments
|
5
|
3
|
5
|
3
|
16
|
Tables
|
284
|
141
|
118
|
51
|
594
|
Triggers
|
280
|
0
|
0
|
0
|
280
|
User messages
|
19
|
0
|
19
|
49
|
87
|
Users
|
254
|
34
|
243
|
0
|
531
|
Views
|
130
|
58
|
83
|
1
|
272
|
Procedures
|
2431
|
1134
|
794
|
0
|
4359
|
Nb de lignes de code1
|
104296
|
34798
|
37396
|
0
|
176490
|
|
TAB. 10.1 - Dénombrement du contenu des bases de
données
De plus, il faut savoir que les plus grosses tables approchent
les 390 000 enregistrements et que le volume actuel des bases de données
est d'environ 18 Go.
Grâce à ces information, il est facile de
s'apercevoir que la base cci, en plus d'être la plus importante au niveau
utilisation est également celle contenant le plus
d'éléments à migrer.
1nombre de lignes de code de la totalité des
procédures (commentaires compris)
Durant le projet, c'est donc sur cette base que doit se focaliser
la majorité du travail.
10.2 Étude des différentes techniques de
migration
Toute étude doit commencer par l'inventaire des solutions
existantes de manière à ne pas se lancer dans un
développement coûteux si un produit répond
déjà à nos attentes.
La première piste explorée a été
celle du site internet de PostgreSQL qui répertorie une large gamme de
moyens pour migrer vers ce système.
On peut trouver dans cette catégorie nommée
"Converting from other Databases to PostgreSQL", des outils et des conseils
pour transformer des bases au format Dbase, FileMaker Pro, Interbase,
MS-Access, MySQL et Oracle.
En ce qui concerne Sybase, on peut utiiser les conseils
donnés pour MS-SQL mais ceux-ci sont très pauvres et ne donnent
que quelques idées pour réaliser une migration manuelle.
La seconde possibilité pour trouver des outils de
migration était de rechercher des outils ou des solutions "clefs en
main" pour la migration de Sybase vers PostgreSQL. Force est de constater que
même s'il existe des outils traitant chacune des bases de données,
il n'en existe pas qui posséde des connecteurs pour les deux
systèmes.
Aucune solution n'existant pour cette migration, la seule
méthode possible est de réaliser soi-même un outil qui
effectuera cette transformation.
10.3 Écriture d'un traducteur en Perl
10.3.1 L'approche utilisée
En vu de structurer la démarche du projet, la solution la
plus simple était de le découper en plusieurs phases.
Les choix
Nous avons tout d'abord du déterminer l'approche, la
technologie, la méthodologie et l'équipe employés.
Ces choix furent assez rapidement faits:
- Aucun salarié de la CCI n'étant disponible pour
ce projet, l'équipe ne pouvait être composée que d'une
seule personne.
- Après avoir effectué des recherches sur les
solutions existantes, il est apparu qu'aucun outil ne permettait de
réaliser une telle migration (voir § 10.2, page 33) et que
très peu d'information était disponible pour utiliser une
approche systématique. C'est donc l'utilisation d'une méthode
empirique qui s'est imposée.
- La technologie utilisée devait permettre de reproduire
cette migration même si quelques modifications apparaissaient dans le
base (ce qui exclut une traduction manuelle) mais devait être compatible
avec les choix déjà faits et le délai imparti. La
technique d'un traducteur automatique a donc été retenue.
-
Enfin, ayant très peu de ressources à
gérer et beaucoup d'autonomie quant au fonctionnement du traducteur, une
méthodologie de gestion de projet "lourde" n'aurait apporté aucun
bénéfice par rapport à l'utiisation d'une méthode
non formelle.
L'organisation
Le choix d'une approche de type empirique ne dispense pas de
structurer la démarche du projet. C'est pourquoi chaque type
d'élément de la base (tables, index, données,...) a
été traité indépendamment.
En outre, le fonctionnement même des bases de
données a imposé un certain ordre de traitement. Il faut
réaliser tout d'abord la transformation de la structure puis des
données et enfin des traitements.
Les iterations
Pour chacun des types d'élément, une approche
empirique peut se traduire par une suite d'itérations comprenant:
- La tentative d'utiliser le Script SQL "tel-quel";
- La recherche des problèmes empêchant le bon
fonctionnement;
- L'écriture en Perl d'un programme permettant de
régler le problème.
Une fois toutes les itérations effectuées pour
tous les types d'éléments, on dispose d'un programme Perl
permettant de résoudre tous les problèmes et d'effectuer la
migration.
10.3.2 Fonctionnement de l'application
L'un des ojectifs de ce projet était de
réaliser un outil de migration de la base de données qui soit
facilement réutilisable. Il fallait donc que son uilisation soit simple
et que son fonctionnement soit aisément compréhensible et
modifiable par une autre équipe.
Le traducteur appelé sybase2postrgesql propose donc
plusieurs modes de fonctionnement (voir Annexe J, page 60):
- Utilisation avec passage de paramètres en ligne de
commande ou par un fichier de configuration.
- Possibilité de traduire chaque fichier individuellement
ou d'automatiser l'ensemble du fonctionnement.
Par ailleurs, le programme a été documenté
(voir Annexe I, page 58) et le code commenté afin de rendre leur
réutilisation plus simple.
10.4 Estimation du travail restant a
effectuer
La migration qui semblait relativement simple à ses
débuts s'est révélée beaucoup plus complexe que
prévue et la charge de travail sous-estimée. En cours de projet,
les délais ont donc du être réévalués et il
s'est avéré que la migration des procédures ne pouvait
être réalisée dans le temps restant.
Suite à ce constat, nous avons déterminé
qu'il était préférable de réaliser un ensemble de
mesures afin d'estimer le temps nécessaire à l'achèvement
du projet.
10.4.1 Méthode d'estimation
Comme l'approche que nous avons employé est de type
empirique, il est difficile d'avoir, avant d'avoir effectuer le traducteur, des
indicateurs fiables concernant les points bloquants de la migration. Cependant,
certains problèmes sont proches de ceux rencontrés lors de la
migration de la structure de la base (et tout particulièrement des vues)
et d'autres peuvent être assez facilement repérés (nombre
de lignes de code, nombre de structures de boucles et de choix, . . .).
Ainsi, il n'est pas réellement possible de mesurer
précisément la complexité de la migration mais on peut en
faire une estimation.
Le travail à effectué ici s'apparente à
une mesure de complexité informatique [35] hormis que le but n'est pas
d'évaluer la performance d'un algorithme mais la difficulté
à le comprendre et le traduire et que les indicateurs disponibles sont
un peu plus "approximatifs".
Les outils de mesure de complexité sont assez rares et
ne permettent généralement de réaliser des tests que pour
des langages courants (C, java, .. .). Il était donc très
improbable de trouver un outil répondant à nos attentes
(fonctionnant pour du Transac SQL et réalisant des mesures permettant
d'évaluer la complexité de "compréhension").
Il a donc fallu mettre au point une méthode assez
proche d'une mesure de complexité. Cette dernière peut être
décomposée en trois grandes phases : la planification, la
réalisation et l'analyse. Et même si la méthode est
généralement présentée sous forme d'étapes,
en réalité, celles-ci ne sont pas forcément
effectuées séquentiellement et il y a habituellement plusieurs
itérations avant d'obtenir des résultats probants.
Nous allons donc suivre les points suivants:
1. Planification (déterminer quelles mesures vont
être réalisées):
- Sélectionner les variables qui vont être
observées.
- Indiquer la signification des plages de valeurs dans
lesquelles vont se trouver les variables.
- Spécifier le modèle qui va être
observé.
- Définir un ensemble de données
d'entraînement et de test pour évaluer le modèle.
2. Réalisation (effectuer les mesures):
- Tester le modèle sur les données de test et les
comparer aux résultats attendus.
- Obtenir les valeurs des différents indicateurs sur des
données réelles et complètes.
- Regrouper et présenter ces valeurs de manière
à ce qu'elles soient exploitables.
3. Analyse (traitement et interprétation des
résultats):
- Traitement des données afin de les rendre
compréhensibles.
- Recoupement des informations afin de faire ressortir les
éléments importants.
- Interprétation et analyse des résultats
obtenus.
10.4.2 Réalisation des mesures
Afin d'effectuer les mesures permettant d'évaluer le
travail restant, la première étape a été de
définir un ensemble d'indicateurs:
- nombre de lignes de codes par procédure
-
nombre d'instructions SQL par procédure
- nombre de conditions et de boucles par procédure
Il a ensuite fallu développer une application en Perl
pour effectuer les mesures qui correspondent à ces indicateurs.
En observant les résultats, il a été
possible d'ajouter quelques indicateurs pour affiner les mesures:
- nombre de curseurs par procédures
- nombre d'exécutions d'autres procédures par
procédure
De ces résultats, il a également été
possible de déterminer des catégories dans lesquelles se trouvent
les procédures.
Moins de 10 lignes
|
simple
|
Une seule instruction SQL, pas de curseur, pas de condition,
pas de boucle, pas d'instruction "exec"
OU que des instructions "exec" (et rien d'autre)
|
|
Un seul type d'instruction (par exemple que des updates), pas
de curseur, pas de condition, pas de boucle, pas d'instruction "exec"
|
|
Celles qui n'entrent pas dans les catégories
précédentes
|
Entre 10 et 40 lignes
|
Mêmes catégories que moins de 10 lignes
|
Entre 40 et 150 lignes
|
simples
|
Pas de condition, pas de boucle et pas de curseur
|
|
Celles qui n'entrent pas dans la catégorie
précédente
|
Plus de 150 lignes
|
Transformation manuelle (estimation du temps en fonction du
nombre de lignes : 150 lignes par jour/homme)
|
|
TAB. 10.2 - Catégories de procédures
Enfin, il a été possible de réaliser les
mesures définitives (voir Annexe K, page 66) qui seront exploitables
pour donner une évaluation du temps de travail nécessaire
à l'achèvement de la migration.
10.4.3 Résultats de l'estimation
Estimation grossière pour une traduction
manuelle
Afin d'évaluer la charge de travail que
représenterait la traduction manuelle des procédures, il convient
tout d'abord de mesurer le volume d'information à traiter. Nous avons
donc mesuré le nombre de lignes de code total que représentent
les procédures (environ 150 000 hors commentaires).
Une évaluation approximative permet d'atteindre un volume
de travail d'environ 1000 jours/homme (en comptant environ 150 lignes
écrites par jour/homme).
La conversion manuelle des procédures n'est donc que
difficilement envisageable. C'est pourquoi, il serait nécessaire de
disposer d'un outil permettant la migration automatique de la plus grande
partie des procédures.
Estimation affinée
À l'aide de l'ensemble des indicateurs, il est
possible de répartir les procédures en différents niveaux
de complexité et de calculer le nombre de jours de développement
nécessaires pour terminer l'application.
|
Nb. de procs.
|
% du
volume
|
Nombre de jours par niveau de complexité
|
Nb. total de jours
|
% du
temps total
|
|
Moyen
|
Complexe
|
|
1379
|
31,61
|
10
|
12
|
15
|
37
|
8,54
|
De 10 à 40 lignes
|
2103
|
48,2
|
12
|
15
|
20
|
47
|
10,85
|
De 40 à 150 lignes
|
709
|
16,25
|
15
|
|
25
|
40
|
9,23
|
Plus de 150 lignes
|
172
|
3,94
|
Nb. total de lignes : 46376
|
309,17
|
71,37
|
|
TAB. 10.3 - Estimation du temps de développement par
catégorie de procédures
On peut constater que, comme dans la plupart des projets, 80% du
volume des procédures peuvent être migrées pour 20% du
temps de travail.
Pour les procédures les plus difficiles à
migrer (celles qui prennent 80% du temps de développement), il faut
s'assurer de la pertinence et de l'utiité de chacune d'elle afin de ne
pas perdre de temps inutilement.
Chapitre 11
Bilan du stage
11.1 Evaluation du travail réalisé
L'objectif principal : évaluer si une migration de
Sybase vers PostgreSQL était possible, a été atteint.
En revanche, la réponse qui y a été
apportée n'est pas exactement celle à laquelle on pouvait
s'attendre : la migration paraissait simple mais elle s'est
avérée beaucoup plus complexe que prévue.
11.2 Problèmes rencontrés
L'ensemble du stage s'est bien déroulé. Mais,
comme dans tout projet, nous avons dû faire face à des
problèmes : ceux-ci ont été principalement de nature
technique, mais également organisationnels et au niveau des
connaissances acquises.
11.2.1 Les problèmes techniques
Les fonctions Sybase inexistantes sous
PostgreSQL
Comme toutes les bases de données, Sybase et
PostgreSQL possédent des fonctions internes conçues afin de
faciliter le travail des développeurs. Néanmoins, leur nom et
parfois même leur utilisation différe d'un sytème à
l'autre.
Lors de la migration des vues et des procédures, il
arrive que ce type de fonctions necessite une intervention pour
déterminer la solution à adopter.
Lorsque des fonctions de Sybase n'existent pas sous
PostgreSQL, la solution la plus simple serait de créer des fonctions en
pl/sql portant le même nom que la fonction Sybase et donnant le
même résultat.
Mais cela crée une surcouche et a un impact
néfaste sur les performances (une fonction externe utiisant une ou
plusieurs fonctions internes sera touj ours moins rapide qu'une seule fonction
interne).
Lors de l'écriture du programme de migration, nous
avons donc utilisé autant que possible, des fonctions internes de
PostgreSQL, même si cela nécessitait parfois de remanier les
scripts SQL.
Cependant, dans quelques rares cas, aucune fonction existante ne
pouvant être utiisée, il a fallu en créer des nouvelles
(par exemple voir Source J.1, page 62).
Les differences d'encodage
Le passage successif par différents systèmes met
en lumière les différences de normes d'encodage et d'affichage
(UTF8, ASCII, Latin1,...):
- passage de Sybase à un fichier texte en utilisant un
logiciel tiers (soit bcp soit DbDk) sous Windows,
- transformation par un script Perl sous Linux,
- intégration à PostgreSQL,
- affichage sous les outils RedHat (qui préfère
utiliser l'UTF8).
Ceci nécessite de modifier l'encodage par défaut
ou de forcer celui qui sert à l'affichage, voire même de modifier
l'encodage d'un fichier dans un éditeur de texte (voir Annexe M, page
71) sous peine d'obtenir des retours à la ligne fantaisistes et de
perdre tous les caractères accentués qui se trouvent dans les
documents.
Les problèmes de casse
Windows et Sybase ne gèrent pas les différences
de casse ("E" sera considéré de la même façon que
"e") tandis que Linux et PostgreSQL font cette différenciation. Pour
éviter des problèmes d'appel (par exemple lors de l'utiisation
d'une table ou d'une procédure) il faut uniformiser les noms.
L'ancienneté de la base de données
Sybase
La création de base de donnée sous Sybase a
commencé en 1994. De nombreuses personnes avec des connaissances et des
techniques de programmation différentes ont donc participé
à sa gestion et à l'écriture de nouvelles fonctions. De
plus, les technologies ont évolué : augmentation des
capacités du moteur debase de données, évolution de la
syntaxe utilisée pour la création de vues et des
procédures. Lors de l'écriture des scripts Perl, il a donc fallu
tenir compte des différents types d'écriture afin que toutes les
possibilités soient traitées.
11.2.2 Les problèmes lies a
l'organisation
Peu de problèmes se sont posés en ce qui
concerne l'organisation propre mais les objectifs proposés au
départ ont dû être modifiés. La plannification a
été constament réévaluée afin de tenir
compte des problèmes rencontrés et de l'approche empirique.
11.2.3 Les problèmes lies au manque de
connaissance
Le manque d'informations disponibles, s'est
révélé être un problème important:
très peu de documentation est disponible au sujet de Sybase (et la
plupart de sont prévues pour des versions plus récentes de
Sybase).
Les informations concernant les migrations de base de
données (et tout particulièrement les migrations à partir
de Sybase ou de MS-SQL) sont rares et peu complètes: les seules
indications fournies n'apportent quasiment aucune aide.
Conclusion
Les objectifs d'un stage professionnel sont multiples : le
stagiaire doit tirer une double expérience (immersion dans le monde du
travail et acquisition de nouvelles connaissances sur les activités en
entreprise) et pouvoir apporter à l'entreprise un bénéfice
aussi bien sous forme de nouvelles compétences liées à sa
formation qu'à sa personnalité.
Ce stage a été enrichissant, aussi bien au
niveau humain que professionel et sera un atout pour mon entrée dans la
vie active. Il m'a apporté de nouvelles connaissances tant
organisationnelles que techniques et m'a permis d'appronfondir les
compétences que j'ai acquises tout au long de ma scolarité.
Le projet a mis en évidence que la méthodologie
à mettre en oeuvre pour la migration de bases de données varie
beaucoup selon les systèmes en jeu. Elle varie également beaucoup
en fonction du "type" de migration désirée : migration "unitaire"
ou migration "reproductible".
Les possibiités d'une migration de Sybase vers
PostgreSQL était très mal connues et ce stage permet de se rendre
compte qu'elle n'est pas simple à pratiquer et permet de mieux les
connaître et les maitriser.
J'espère donc que l'ensemble formé par ce
rapport et le programme de migration sybase2postgresql pourra constituer une
première étape vers une migration définitive en direction
de Sybase.
Liste des annexes
A Les CCI en France 42
B La CCI de la Haute-Savoie 47
C Les Chiffres de la CCI de la Haute-Savoie
49
D Organigramme 51
E La licence BSD (Berkeley Software Distribution)
52
F Limitations de PostgreSQL 53
G Phases pour réaliser l'ensemble de la migration
54
H Options pour l'utilisation de sybase2postgresql
56
I Documentation de sybase2postgresql 58
J Problèmes spécifiques a chaque type
d'information a migrer 60
K Mesures pour les indicateurs de complexité des
procédures 66
L Installation de modules supplémentaires pour
Perl 69
M Enregistrement d'un fichier en UTF-8 sous Emacs
71
N Webographie 72
Annexe A
Les CCI en France
A.1 Historique
La première Chambre naît à Marseille en
1599. Le conseil de la vile décide de choisir, parmi ses membres, des
députés du commerce "chargés d'accroître la
prospérité de la ville". La raison d'être des Chambres de
Commerce est exprimée. Henri IV officialise l'institution et en profite
pour demander aux députés "des recommandations pour relever
l'économie du royaume". La fonction traditionnelle de consultation fait
sa première apparition.
Le nombre de Chambres de Commerce s'accroît. Louis XIV
crée un conseil du Commerce : le Roi veut recevoir des propositions pour
"augmenter le commerce en France et en dehors du royaume". La mission des
Chambres de Commerce est tracée.
La Révolution les supprime. Elles sont rétablies
sous le consulat par Bonaparte. Vingt deux nouvelles chambres sont
créées en France et dans l'Empire. Elles s'implantent partout
où l'économie locale a besoin de leur structure et de leurs
services. Elles vont se développer pendant tout le XIXè
siècle. Le réseau se met en place. En 1898, la loi vient
formaliser leur rôle et crée un statut original, celui
d'Etablissement Public représentant les intérêts
généraux du commerce et de l'industrie auprès des pouvoirs
publics. Le cadre juridique est fixé.
Durant le XXè siècle le visage contemporain des
Chambres de Commerce se dessine définitivement. On les appelle depuis
1960, Chambre de Commerce et d'Industrie (CCI); en 1964, le législateur
achève l'édifice en créant les Chambres Régionales
de Commerce et d'Industrie (CRCI), établissements publics, qui
fédèrent les CCI locales. Simultanément, la
création de l'Assemblée Permanente des Chambres de Commerce et
d'Industrie (APCCI) couronne le réseau en fournissant aux instances
nationales un interlocuteur privilégié. Depuis 1990, I'APCCI
s'est transformée en Assemblée des Chambres Françaises de
Commerce et d'Industrie (ACFCI).
A.2 Nature des CCI
Les Chambres de Commerce et d'Industrie sont à la fois des
organismes publics et professionnels puisque:
- elles sont régies par une loi et sous tutelle d'un
ministère représenté aux Assemblées
Générales par le Préfet du Département;
- elles sont composées et dirigées par des chefs
d'entreprise élus par leurs pairs, ressortissants de la CCI.
Il convient de ne pas les confondre avec les administrations
d'État (les CCI ne sont soumises à aucune autorité dans le
cadre de leur mission bien qu'ayant une tutelle mi-
nistérielle pour leur budget), ni avec les syndicats
professionnels et les associations de commerçants de statut
privé. Les CCI sont des organismes interprofessionnels dans la mesure
où elles regroupent systématiquement toutes les entreprises
inscrites au Registre du Commerce industriels, commerçants,
hôteliers, restaurateurs, transporteurs...



FIG. A.1 - Positionnement des CCI entre privé et
public
A.3 Les missions
Les missions des CCI s'organisent autour de 3 principaux
axes:
- Elles représentent toutes les entreprises
imatriculées au RCS (Registre du Commerce et de
Sociétés)
- elles veillent à la prise en compte de leurs
intérêts,
- elles facilitent les rapports avec les administrations,
- elles participent àla définition des politiques
de transport, d'équipement et d'aménagement.
- Elles accompagnent les entreprises dans leur phase de
développement en accompagnant, informant et conseillant les
créateurs et repreneurs d'entreprise;
- Elles conçoivent, réalisent et gérent des
équipements collectifs comme les aéroports, ports et gares
routières.
A.4 Les moyens
Tous les ans, l'Assemblée Générale de
chaque CCI vote son budget qui, pour un exercice, fixe le cadre d'action de la
Chambre en faveur de ses entreprises et de leur environnement. Approuvé
par les Ministères de l'Industrie et du Commerce, le budget fait l'objet
d'un contrôle à posteriori des Pouvoirs Publics qui s'assurent
ainsi de la régularité des opérations et de leur
conformité avec les décisions de l'Assemblée. Les Chambres
jouissent ainsi d'une large autonomie pour organiser leurs missions.
Ces missions peuvent être financées par:
- Des ressources propres : il s'agit des recettes provenant
des prestations qu'elles effectuent directement ou indirectement en faveur de
leurs ressortissants (droits de scolarité, de ports, d'aéroports,
frais d'études et de conseil...).
-
Des emprunts : les Chambres sont autorisées à
recourir à l'emprunt pour financer les équipements collectifs
d'intérêt général qu'elles gèrent.
- Des contributions publiques : dans le cadre d'actions de
partenariat avec les Pouvoirs Publics, les collectivités locales ou
régionales, les Chambres reçoivent des concours financiers pour
accompagner des initiatives spécifiques, réaliser des
études de projets ou encourager des actions pilotes. . .
- Des ressources fiscales : la loi a donné aux
Chambres le droit de voter l'impôt qui complète le financement de
leurs actions. Cet impôt collecté simultanément avec la
Taxe Professionnelle (ce qui lui a donné son nom d'Imposition
Additionnelle à la Taxe Professionnelle "IATP") n'assure que 27% de
leurs ressources et représente moins de 4% de la Taxe Professionnelle
elle-même.
L'I.A.T.P. est votée par les chefs d'entreprise qui
siègent à la CCI.
A.5 L'organisation
L'organisation des Chambres de Commerce et d'Industrie
découle de leurs principales missions:
- une mission d'animation et de développement de leurs
espaces économiques locaux, ce qui implique une structure très
décentralisée;
- une mission de représentation et de consultation
auprès des pouvoirs publics, ce qui nécessite d'être leur
interlocuteur à tous les niveaux (local, régional, national). Il
en résulte une structure à trois niveaux:
- 160 Chambres de Commerce et d'Industrie locales (les CCI).
Chacune est dotée d'un ensemble de services :
information, études et conseil, formation. Les CCI sont la maison des
entreprises. Elles s'appliquent à leur fournir les conditions optimales
de leur développement. C'est dans le cadre de cette mission du service
public qu'elles sont traditionnellement amenées à créer et
à exploiter des équipements collectifs d'intérêt
général.
- 20 Chambres Régionales de Commerce et d'Industrie (les
CRCI).
Elles représentent au niveau de la Région les
CCI de leur circonscription. Elles sont les interlocutrices et les partenaires
naturels des pouvoirs publics et des collectivités locales ainsi que de
tous les acteurs économiques qu'elles contribuent à
éclairer sur les choix des priorités et des investissements de
leur Région.
Elles sont aussi un lieu de concertation et de coordination des
Chambres locales avec lesquelles elles peuvent mener des actions communes
spécifiques.
- L' Assemblée des Chambres Françaises de Commerce
et d'Industrie (l'ACFCI). C'est l'établissement national
fédérateur et animateur des Chambres de Commerce et
d'Industrie.
national, européen
20 CRCCI
160 CCI
local
AFCCI
regional
FIG. A.2 - Une organisation pyramidale mais non
hiérarchisée
Cette activité est prolongée au niveau
international par 85 Chambres de Commerce et d'Industrie Françaises
à l'Étranger (CCIFE) dont la mission est de développer des
échanges France-Etranger.
A.6 les chiffres
Le réseau des CCI comporte 4500 membres titulaires
élus au suffrage universel des entreprises et 26 000 collaborateurs
répartis sur l'ensemble du territoire, reliés par Intranet. Le
budget global des CCI représente 3.4 milliards d'Euros, dont près
de 1 milliard provenant de l'IATP (soit 0,15% des prélèvements
obligatoires).
A.6.1 Les moyens humains
- 4 500 chefs d'entreprise élus (membres des CCI) et 26
000 salariés
- 1 800 000 entreprises bénéficiaires et
électrices.
A.6.2 Les moyens financiers
- Le budget global des Chambres représente 3,39 milliards
d'euros(dont 0,97 milliard d'euros d'IATP).
A.6.3 Creation d'entreprises
- 780 000 formalités liées à la
création, reprise ou transmission d'entreprise ont été
effectuées dans les centres de formalités d'entreprises (CFE) des
CCI;
- 150 000 porteurs de projets accueillis et
conseillés.
A.6.4 La formation (2ème acteur après
l'Education nationale)
- 540 établissements de formation
- 500 000 personnes formées chaque année
- 80 000 contrats d'apprentissage signés par an
A.6.5 La gestion des équipements
- 121 aéroports;
- 180 ports (commerce, pêche, plaisance, .. .), les
criées...
- 36 plates-formes multimodales
- 18 complexes routiers
- 28 entrepots ou parcs a vocation logistique
- 55 palais des congrès et parcs d'expositions
- 2 ponts (Normandie, Tancarville)
La CCI de la Haute-Savoie
B.1 Coordonnées
Chambre de Commerce et d'Industrie de Haute-Savoie 5 rue du
27ème BCA
BP 2072
74011 ANNECY Cedex
Tél. : 045033 72 00
Fax. :04 50 52 89 95
B.2 Heures d'ouverture CCI
Du lundi au jeudi de 8h00 a 12h00 et de 13h00 a 17h00 Le vendredi
de 8h00 a 12h00
B.2.1 C.F.E. (Centre de Formalités des
Entreprises)
Du lundi au jeudi de 9h00 a 12h00 et de 13h30 a 16h30
Le vendredi uniquement sur rendez-vous de 9h00 a 12h00
B.2.2 Espace Entreprises
Du lundi au jeudi de 8h30 a 12h00 et de 13h30 a 17h00 Le vendredi
de 8h30 a 12h00
B.3 Plan d'acces
|
CHAMBRE DE COMMERCE ET D'INDUSTRIE
DE LA HAUTE-SAVOIE
|
|
|
|
Accès en voiture
· Depuis l'autouroute / sortie Annecy-Nord :
prendre direction Annecy-centre / Avenue de Genève. Suivre
l'Avenue de Genève, puis tourner à gauche rue des Chasseurs,
tourner ensuite à gauche rue Joseph Dessaix et 2ème
à droite rue du 27ème BCA.
· Depuis l'autouroute / sortie Annecy-Sud :
prendre direction Annecy-le-Vieux / Thônes. Entrer dans Annecy,
continuer sur le boulevard de la Rocade. Après le 1er tunnel,
prendre la direction de la Roche sur Foron-Les Fins. Prendre à droite
Avenue de Genève. Sur l'Avenue de Genève, prendre à gauche
rue des Chasseurs, tourner ensuite à gauche rue Joseph Dessaix et
2ème à droite rue du 27ème BCA.
A41
SORTIE
ANNECY-NORD
A41
SORTIE
ANNECY-SUD
CCI
5, rue du 27ème BCA Annecy
GARE SNCF
Chambre de Commerce et d'Industrie de la
Haute-Savoie
5, rue du 27ème BCA - BP2072 - 74011
Annecy Cedex
Tél.: 04 50 33 72 00
www.haute-savoie.cci.fr
Les Chiffres de la CCI de la
Haute-Savoie
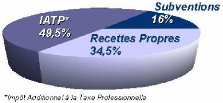
FIG. C.1 - Répartition des ressources de la CCI (13 328
M€)
|
COMMUNES
|
34,56%
|
|
DEPARTEMENT
|
25,39%
|
|
REGION
|
7,04%
|
|
INTERCOMMUNALITE
|
20,67%
|
|
CCI
|
1,87%
|
|
CHAMBRE DES METIERS
|
0,83%
|
|
FONDS PEREQUATION
|
2,20%
|
|
ETAT
|
7,44%
|
|
Montant global = 358,8 M€
|
TAB. C.1 - Répartition de la taxe professionelle
départementale
|
Les Chiffres de la CCI de la Haute-Savoie
|
|
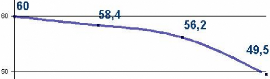

FIG. C.2 - Part de l'IATP dans le budget de la CCI
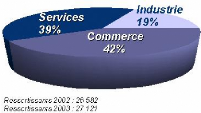
FIG. C.3 - Répartition des ressortissants par secteur
d'activité en 2003
Organigramme
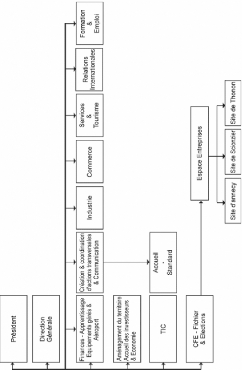
FIG. D.1 - Organigramme simplifié de la CCI de la
Haute-Savoie
La licence BSD (Berkeley Software
Distribution)
La licence BSD modifiée (flexible BSD licence) est une
licence de logiciel libre simple et permissive, sans gauche d'auteur,
compatible avec la GPL de GNU.
Elle ne met pas de conditions sur l'utilisation et la
rediffusion du logiciel qui peut ainsi être installé,
modifié et distribué par tout le monde gratuitement quelque soit
le but visé, qu'il soit privé, commercial ou
académique.
Dans sa version initiale (la license BSD originale), elle
incluait une clause obligeant les programmeurs qui l'utilisaient à
mentionner dans tous leurs documents publicitaires la citation suivante : "This
product includes software developed by the University of California, Berkeley
and its contributors" (Ce produit contient des logiciels
développés par l'Université de Californie, Berkeley et ses
collaborateurs).
Limitations de PostgreSQL
Les données fournies ci-dessous sont celles officiellement
annoncées sur le site de PostgreSQL1.
|
Maximum size for a database
|
unlimited (4 TB databases exist)
|
|
Maximum size for a table
|
16 TB on all operating systems
|
|
Maximum size for a row
|
1.6 TB
|
|
Maximum size for a field
|
1 GB
|
|
Maximum number of rows in a table
|
unlimited
|
|
Maximum number of columns in a table
|
250 - 1600 depending on column types
|
|
Maximum number of indexes on a table
|
unlimited
|
TAB. F.1 - Limitations of PostgreSQL
Of course, these are not actually unlimited, but limited to
available disk space and memory/swap space. Performance may suffer when these
values get unusually large.
The maximum table size of 16 TB does not require large file
support from the operating system. Large tables are stored as multiple 1 GB
files so file system size limits are not important.
The maximum table size and maximum number of columns can be
increased if the default block size is increased to 32k.
1Sources:
http://www.postgresql.org/users-lounge/limitations.html
Phases pour réaliser l'ensemble de
la migration
Afin de réaliser l'ensemble du processus de migration de
façon manuelle, il faut respecter une chronologie dans les actions
effectuées.
Lors de l'utilisation automatisée du processus, l'ensemble
des opérations sera également réalisé dans ce
même ordre par le programme Perl.
Traiter le fichier des tables
$sybase2postgresql -b ma_base -t mes _tables -S
mon_serveur -U utilisateur -P mot_de_passe
Traiter le fichier des index
$sybase2postgresql -b ma_base -i mes _index
Traiter le fichier des vues
$sybase2postgresql -b ma_base -v mes_vues
Traiter le fichier des triggers
$sybase2postgresql -b ma_base -g mes
_trigger
Traiter le fichier des procédures
$sybase2postgresql -b ma_base -f
mes_fonctions
Créer la base
$createdb -E LATIN1 ma_base
Créer le langage plpgsql
$createlang plpgsql ma_base
Appliquer les "patch" sur la base (création des fonctions
de Sybase n'existant pas sous PostgreSQL)
$psql -c '\i PATCH _pour _postgresSQL' ma_base
Créer les tables
$psql -c '\i postgres _mes _tables' ma_base
Créer les index
|
Phases pour réaliser l'ensemble de la migration
|
|
$psql -c '\i postgres _mes _index' ma_base
Créer les vues
$psql -c '\i postgres_mes_vue' ma_base
Exécuter le bcp des données
$bcp_mes_ tables
Traiter les fichiers des données (pour chacun des
fichiers listé dans bcp_out_mes_tables
$sybase2postgresql -b ma_base -g
mes_données
Intégrer les données
$psql -c 'COPY ma_table FROM "mon_fichier"
USING DELIMITER "|"'
Mettre à jour les séquences
$sybase2postgresql -b ma_base -g postgres _sequence
_mes _tables
Créer les triggers
$sybase2postgresql -b ma_base -t mes
_triggers
Créer les procédures
$sybase2postgresql -b ma_base -t
mes_fonctions
Options pour l'utilisation de
sybase2postgresql
Afin de permettre une utiisation souple du programme, il est
possible de le lancer avec différentes options.
Ces dernières peuvent être transmises soit
directement en ligne de commande, soit par l'instermédiaire d'un fichier
de configuration (lui même précisé en ligne de
commande).
Voici les options disponibles en ligne de commande:
Source H.1 - Options de sybase2postgresql affichées
grâce à l'option -h
1 Usage : sybase2postgresql [--h] [--a] [--b nom_base] [--t
fichier_table] [--i fichier_index] [--v fichier_vue] [--g fichier_trigger] [--d
fichier_donnees] [--f fichier_fonction]
[--S serveur_sybase] [--U utilisateur_sybase] [--P
mot_de_passe_sybase] [--c fichier_configuration]
2 --h affiche l 'aide
3 --a si les toutes les options necessaires sont definies
(ou
si le fichier de configuration contient les informations), tout le
traitement peut etre automatique (il n' est pas necessaire de donner de nom de
fichier pour les donnees car celui--ci est genere automatiquement)
4 --b nom de la base de donnees sur laquelle porte
la
transformation
5 --t fichier contenant la description des tables de la base
6 --i fichier contenant la description des index de la base
7 --v fichier contenant la description des vues de la base
8 --g fichier contenant la description des triggers de la base
9 --d fichier contenant les donnees d'une table
10 --f fichier contenant les fonctions (procedures) d'une base
11 --S nom (ou adresse) du serveur Sybase de la base origine
12 --U nom d' utilisateur pour la base Sybase
13 --P mot de passe pour la base Sybase
14 --c fichier de configuration contenant les options :
permet
de ne pas specifier chacune des options ci dessus
|
Options pour l'utilisation de sybase2postgresql
|
|
Dans le fichier de configuration, il est possible d'utilliser les
mêmes options qu'en ligne de commande mais sans les faire
précéder d'un tiret.
Chaque option doit se trouver sur une ligne distincte de la
forme:
option = valeur
L'option a n'a pas besoin de valeur car elle est de type
booléenne.
Il est possible d'insérer des commentaires en les faisant
précéder du signe # et les lignes vides seront
ignorées.
Pour les options précisant des noms de fichiers, il est
possible de préciser plusieurs fichiers pour une même options
(alors que ça n'est pas possible par un appel en ligne de commande) en
indiquant le nom de chaque fichier sur une ligne différente.
On aura donc un fichier de configuration du type:
1
2
3
4
5
6
7
8
9
10
11
12
Source H.2 - Exemple de fichier de configuration de
sybase2postgresql
# Fichier de configuration de La migration de La base
cci1
a
b = cci1
t = monrepertoire/mes_tables1 . sql t =
monrepertoire/mes_tables2. sql i = mes_indexs. sql
f = mes_fonctions . sql
# Serveur Sybase
S = monServeur U = utilisateur P = mot_de_passe
Documentation de
sybase2postgresql
I.1 NOM
Convertisseur de base de donnee Sybase vers Postgresql
I.2 SYNOPSIS
Outils permettant de transformer (a partir de fichier scripts
SQL) une base Sybase vers une base PostgreSQL.
- Pour voir les options disponibles, tapper sybase2postgresql
-h
- La plupart des options permettent d'indiquer l'emplacement de
scripts SQL qui seront transformes pour etre utiisables par PostgreSQL.
- A partir du ficher SQL de creation des tables,
sybase2postregresql va produire les scripts de creation des tables, des
commandes pour bcp (recuperation des donnees), de mise a jour des sequences
(pour que l'incerementation automatique reprenne apres le dernier
enregistrement cree) qui devra etre execute apres l'insertion des donnees dans
la base
- Le programme peut tre appele en lignes de commandes
avec les options ou avec un fichier de configuration
- L'ensemble des operations peut etre automatise grace a
l'option -a
I.3 DESCRIPTION
Les Methodes "outils" configuration
Va lire le fichier de configuration passe en parametre et
initialise les variables en fonction de son contenu.
automatique
Automatise le fonctionnement du script: toutes les actions sont
effectuees automatiquement (a condition que tous les renseignements necessaires
soient fournis)
|
Documentation de sybase2postgresql
|
|
clear_line
Netoie une ligne passee en parametres en enlevant le retour
chariot, remplacant les lettres accentuees par des lettres "normales" et en
passant tout le texte en minuscules.
convert2cast
Transforme les fonction convert(type, variable) en fonction
CAST(variable AS type)
right2lpad
Transforme les fonction right('remplissage' + chaine, longueur)
en fonction lpad(chaine, longueur, 'remplissage')
Permet de palier au manque de booleen (renvoie 0) Permet de
palier au manque de booleen (renvoie 1)
decommente_fichier
Permet d'enlever les commentaires d'un fichier et de remettre les
fonctions (detectees par leurs parentheses) sur une seule ligne
Les Methodes "de transformation"
traite_table
Traite le fichier de script SQL de creation des tables.
traite_index
Traite le fichier de script SQL de creation des index.
traite_vue
Traite le fichier de script SQL de creation des vues
traite_procedure
Traite le fichier contenant les procedures afin de les rendre
utilisables par PostgreSQL.
traite_trigger
Traite le fichier contenant les procedures afin de les rendre
utilisables par PostgreSQL.
traite_donnee
Traite le fichier de donnees afin de modifier les rendre
assimilables par PostgreSQL lors du COPY
I.4 VOIR AUSSI
Documentation PostgreSQL, documentation BCP, ...
Problèmes spécifiques à chaque
type d'information à migrer
J.1 Les tables
J.1.1 Problèmes rencontrés
1. Certains types n'existent pas sous PostgreSQL (datetime,
image, tinyint, binary)
2. Dans certaines tables, le champ servant de clef est de type
"identity"
3. La casse des noms de tables n'est pas uniforme
(complètement en majuscules, complètement en minuscules ou une
partie en minuscules et une partie en majuscules)
4. Une table porte un nom avec un caractère
accentué (Paramètre)
5. Certaines colonnes ont des noms trop longs (>23
caractères) pour être correctement exportées par DbDk.
J.1.2 Solutions possibles
1. Pour les types inexistants, il y a deux
possibilités:
- Utiliser un autre type compatible (datetime transformé
en timestamp, image en bytea, tinyint en smallint et binary en bytea)
- Créer de nouveaux types de données (CREATE
TYPE)
2. Pour le champ identity, il est possible de le transformer
en séquence (CREATE SEQUENCE). Il faut noter que cette solution impose
la récupération des "bons" identifiants lors de l'import des
données et ensuite, de mettre à jour l'état de la
séquence grâce à la commande setval().
3. Pour la casse, PostgreSQL étant "casse sensitive"
alors que Sybase ne l'est pas, il est plus prudent et rationnel de transformer
tous les noms afin qu'ils soient tous en minuscules et que les appels se
fassent toujours de la même manière.
4. Les accents n'étant pas admis, il faut absolument
remplacer la lettre accentuée (è deviendra e)
5. Pour la longueur des colonnes, il faut soit utiliser un
autre outil pour l'export des schémas, soit utiliser une nouvelle
version de DbDk (les noms étant tronqués dans le fichier texte,
il n'est pas possible de gérer le problème à
posteriori).
|
Problèmes spécifiques a chaque type d'information
a migrer
|
|
J.2 Les index
J.2.1 Problèmes rencontrés
1. Certains index, sur des tables différentes, portent
des noms identiques.
2. Certains index sont de type CLUSTERED. Ceci signifie que
les enregistrements de la table sont classés physiquement en fonction du
champ sur lequel porte l'index.
J.2.2 Solutions possibles
1. La solution la plus simple et logique a mettre en place
est la modification de la politique de nommage pour ces index (le choix qui a
été fait est celui d'accoler le nom de la table et le nom de
l'index).
2. Ce type de contraintes n'existe pas réellement sous
PostgreSQL. Il est cependant possible d'utiliser la fonction CLUSTER qui
"range" a un instant donné la table selon le champ indiqué. Si on
percoit la nécessité de classer cette table
(démontrée par des tests de performance significatifs), il serait
possible de déclencher de manière régulière (par
exemple par l'utilisation de Cron) l'utiisation de la fonction CLUSTER. Le
choix d'utiliser ou non CLUSTER devra être fait en fonction des
performences et non de l'existence de CLUSTERED sous Sybase (leur
présence n'est pas/plus forcément judicieuse);
J.3 Les vues
J.3.1 Problèmes rencontrés
1. Les vues de la bases ne sont pas crées avec la
même syntaxe (=> difficile de faire une règle unique de
traitement):
- Utilisation de ", de ' ou rien pour les noms de colonne
- Utilisation ponctuelle de syntaxe du type "cci.." pour les
noms de table
2. Utiisation de caractères spéciaux (accents, ,
majuscules)
3. Les colonnes ne sont pas systématiquement
renommées
4. L'utiisation de " dans la clause WHERE n'est pas
interprétée par PostgreSQL comme un champ de texte.
5. Les jointures externes ne sont pas représentées
de la même facon sous Sybase et sous PostgeSQL.
6. Certaines fonction internes a Sybase (convert, isnull,
datepart, right, suser_id) n'existent pas sous PostgreSQL.
7. Certaines conversions de types existent sous Sybase mais pas
sous PostgreSQL (transformation de varchar en int et transformation de smallint
vers bit)
J.3.2 Solutions possibles
1. L'utiisation des ' ou " ainsi que l'utilisation du nom de
la base pour les tables (puisqu'on ne peut pas gérer de vue "interbase"
sous PostgreSQL) n'étant pas indispensable, ils peuvent être
supprimés.
16
17
18
19
20
21
22
23
24
25
26
27 28
Problèmes spécifiques à chaque type
d'information à migrer
2. Les caractères spéciaux doivent, comme pour les
tables, être remplacés par leur équivalent "simple".
3. il faut détecter le renomage (utilisation d'un
alias) grâce à la structure alias = nom_champ afin de le remplacer
par la structure nom_champ AS alias valide sous PostgreSQL.
Il faut cependant prendre garde au fonctions qui peuvent
être utilisées à la place du nom de champ et qui sont
parfois répartis sur plusieurs lignes (elles rendent la détection
de la fin de "nom_champ" plus difficile).
4. Remplacement des "par des'
5. Sous postgreSQL, la fonction de jointure ne s'utilise pas
totalement de la même façon que sous Sybase. Alors que sous Sybase
l'utiisation de "*=" ou de "=*" entre deux champs dans la clause "where" est
suffisante, sous PostgreSQL, il est nécessaire d'utiliser fonction
"left" ou "right outer join" entre les deux tables à joindre et de
préciser les champs dans une clause "on".
Certaines informations (comme la correspondance entre un champ
et la table à laquelle il appartient) n'étant pas disponibles
pour le programme Perl, il n'est pas possible d'automatiser cette
transformation: elle devra donc être réalisée
manuellement.
6. Il est souvent possible d'utiiser les fonctions
correspondantes sous PostgreSQL:
- "convert" est remplacé par "cast"
- "isnull" est remplacé par "coalesce"
- "datepart" est emplacé par "date_part"
- pour "right", il n'y a pas de fonction correspondante sous
PostgreSQL. Cependant, comme cette fonction est ici utilisée uniquement
pour compléter à gauche une chaine de caractère de '0'
pour qu'elle ait une taille fixe, il est possible de la remplacer la la
fonction lpad.
Les fonctions suser_id n'existent pas sous Sybase (et aucune
fonction correspondante n'existe). Il a donc faullu créer ces fonctions
de toute pièce grâce à pl/pgsql:
1
2
3
4
5
6
7
8
9
10
11
12
13
14 15
Source J.1 - Création des fonctions suser_id() et
suser_id(username)
CREATE OR REPLACE FUNCTION s user_id (text)
RETURNS integer
AS'
DECLARE
nom alias for $1;

uid integer;

BEGIN
SELECT INTO uid

usesysid

from pg_catalog .pg_shadow
where usename=nom;
RETURN uid;

END;
' language 'plpgsql';
/*---------------------------------------*/
|
Problèmes spécifiques à chaque type
d'information à migrer
|
|
|
CREATE OR REPLACE FUNCTION s user_id () RETURNS
integer AS ' DECLARE
uid integer;
BEGIN
SELECT INTO uid
usesysid
from pg_catalog .pg_shadow
where usename=SESSION_USER;
RETURN uid;
END;
' language 'plpgsql';
|
|
7. En ce qui concerne la conversion de varchar en int, il est
possible de passer par un text (les conversions "varchar vers text" et "text
vers int" exitent toutes les deux. Il est alors possible, soit de modifier le
code source de la vue (mais cette solution n'est pas très "propre" car
elle nécessite une intervention manuelle), soit de créer un
nouveau type de conversion (CAST) dans PostgreSQL.
1
2
3
4
5
6
7
8
1
2
3
4
5
6
7
8
Source J.2 - Création d'une fonction de conversion de type
(varchar vers int)
CREATE OR REPLACE FUNCTION
varchar_to_int(character varying) RETURNS
int2 AS '
DECLARE
input alias for $1;
BEGIN
return (input:: text :: int2);
END;
' language 'plpgsql';
CREATE CAST (varchar AS int2)
WITH FUNCTION varchar_to_int (varchar);


Les smallint (aussi appelés int2) ne possédent
pas de conversion vers les bit alors que les autres types d'entiers
possèdent cette conversion. Tout comme pour la transformation à
partir du varchar, on peut donc créer une conversion passant par un type
intermédiaire (ici le int4).
Source J.3 - Création d'une fonction de conversion de type
(smallint vers bit)
CREATE OR REPLACE FUNCTION small in t _ to_bit
(in t 2) RETURNS bit AS '
DECLARE
input alias for $1;

BEGIN

return (input::int4 ::bit);
END;
' language 'plpgsql';
CREATE CAST (int2 AS bit) WITH
FUNCTION smallint_to_bit( int2);
|
Problèmes spécifiques à chaque type
d'information à migrer
|
|
J.4 Les données
J.4.1 Problèmes rencontrés
1. Le format d'export des dates par BCP n'est pas compatible avec
l'import dans PostgreSQL
J.4.2 Solutions possibles
1. Pour les dates, il n'y a pas moyen de modifier par une option
le format d'export de BCP.
Plusieurs solutions sont alors possibles:
- Utiliser une vue où la date serait convertie au bon
format et stockée au format texte (mais il faut alors également
utiliser une version récente de BCP qui supporte l'export de vues).
Cette solution est assez lourde et implique la création d'autant de vue
qu'il y a de tables contenant des dates avant de pouvoir effectuer la moindre
extraction (qui sera ralentie par la "surcouche" qu'amène la vue et les
fonctions utilisées).
- Utiliser un fichier format (formatfile) donné en
paramètre à BCP (option -f) et qui contient la description de
tous les champs de la table. Cette solution permet une modification "invisible"
pour l'export mais nécessite de créer les fichiers de format (et
également de décrire les colonnes qui ne sont pas de format date)
ce qui est fastidieux.
- Créer un script Perl qui modifiera les
données de type date (elles ont un "aspect" facilement repérable
dans un fichier (Mmm JJ AAAA HH :MM :SS :sss{ AM ou PM} ). Après
quelques tests, cette solution parait la plus facile à mettre en place
et à utiliser.
J.5 Les procédures et les triggers
Ces éléments n'ayant pas été
traités durant le stage (pas de migration effective), il n'est pas
possible de lister de manière exhaustive les problèmes
rencontrés et les solutions apportées.
Cependant, lors de la phase d'évaluation du temps
restant, il a fallu déterminer quels problèmes pourraient se
poser lors de la migration et l'impact qu'ils pourraient avoir sur la
difficulté de "traduction".
1. La déclaration des variables sous Sybase est
réalisées aussi bien avant que après le BEGIN alors que
sous PostgreSQL, elle doit être réalisée dans le
DECLARE.
2. La structure des procédure n'est pas toujours
clairement établie avec l'utilisation de DECLARE, BEGIN et END.
3. Dans les structures de boucles ou de choix, l'utilisation du
BEGIN et du END est courrante mais n'est pas
généralisée.
4. Sous Sybase, la fin d'une instruction n'est pas
forcément indiquée de manière réellement explicite
(par exemple avec un;) ce qui rend la détection plus complexe.
5.
|
Problèmes spécifiques a chaque type d'information
a migrer
|
|
|
|
La nature du résultat envoyé par une
procédure n'est pas explicite et peut poser des problèmes dans le
cas d'un résultats composé de plusieurs "colonnes" et plusieurs
"lignes" en comparaison d'une seule valeur.
6. Certaines fonctions internes a Sybase n'existent pas sous
PostgreSQL. Mais cet aspet peut être traité de la même facon
que lors qu traitement des vues.
7. L'utiisation de raiserror pour traiter les erreurs sous Sybase
ne peut pas être identique sous PostgreSQL.
Annexe K
Mesures pour les indicateurs de
complexité des procédures
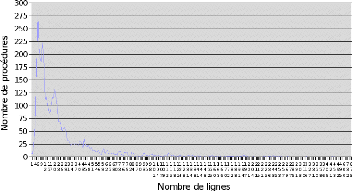
FIG. K.1 - Nombre de lignes par procédure
|
Mesures pour les indicateurs de complexité des
procédures
|
|
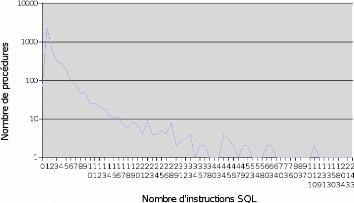
FIG. K.2 - Nombre d'instructions SQL par procédure
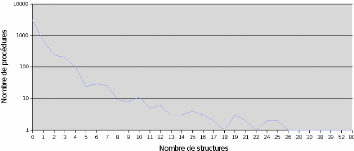
FIG. K.3 - Nombre de structures if ou while par
procédure
|
Mesures pour les indicateurs de complexité des
procédures
|
|
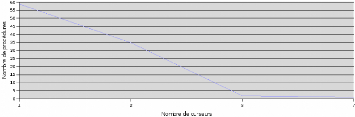
FIG. K.4 - Nombre de curseurs par procédure
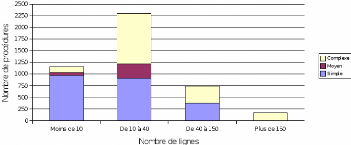
FIG. K.5 - Répartition des procédures par type
Installation de modules
supplémentaires pour Perl
Lors de mes développements, il m'a été
nécessaire d'installer de nouveaux modules pour Perl.
Ceux-ci peuvent être installés de deux
manières différentes : en récupérant et en
compilant le module manuellement, ou en utillisant le module MCPAN.
L'utilisation du module MCPAN facilite de facon très
importante l'installation de modules mais elle nécessite une phase de
configuration qui peut être grandement simplifiée en créant
directement le fichier de configuration: /root/.cpan/CPAN/
MyConfig.pm
|
Source L.1 - Fichier de configuration du module MCPAN
|
|
1
|
$CPAN::Config = {
|
|
2
|
'build_cache' => q[10],
|
|
3
|
'build_dir' => q[/ root / .cpan/build],
|
|
4
|
'cache_metadata' => q[1],
|
|
5
|
'cpan_home' => q[/root/.cpan],
|
|
6
|
'dontload_hash' => { },
|
|
7
|
'ftp ' => q[/usr/kerberos/bin/ftp],
|
|
8
|
'ftp_proxy' => q[
proxy.cci.net:8080],
|
|
9
|
'getcwd' => q[cwd],
|
|
10
|
'gzip' => q[/usr/bin/gzip],
|
|
11
|
'http_proxy' => q[
proxy.cci.net:8080],
|
|
12
|
'inactivity_timeout' => q[0] ,
|
|
13
|
'index_expire' => q[1],
|
|
14
|
'inhibit_startup_message' => q[0] ,
|
|
15
|
'keep_source_where' =>
q[/root/.cpan/sources],
|
|
16
|
'links' => q[/usr/bin/links],
|
|
17
|
'make' => q[/usr/bin/make],
|
|
18
|
'make_arg' => q [],
|
|
19
|
'make_install_arg' => q[],
|
|
20
|
'makepl_arg' => q[],
|
|
21
|
'ncftp' => q[],
|
|
22
|
'ncftpget' => q[],
|
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
Installation de modules supplémentaires pour Perl
|
|
|
'no_proxy' => q[],
'pager' => q[/usr/bin/less],
'prerequisites_policy' => q[ask], 'proxy_pass' =>
q[<mot de passe >],
'proxy_user' => q[<utilisateur >],
'scan_cache' => q[atstart], 'shell' =>
q[/bin/bash], 'tar' => q[/bin/tar],
'term_is_latin' => q[1] , 'unzip' =>
q[/usr/bin/unzip],
'urllist' => [q[
ftp://ftp.lip6.fr/pub/perl/cPAN/]],
'wait_list' => [q[wait://ls6--www.
informatik . uni--dortmund . de
:1404]],
'wget' => q[/usr/bin/wget],
I;
1;
__END__
|
Ensuite, pour installer un nouveau module, il suffit de se loguer
en administrateur et de lancer la commande:
$perl --MrPAN --e shell
Puis sous le prompt qui apparait, utiliser la commande:
$install Appconfig
Enregistrement d'un fichier en
UTF-8 sous Emacs
Lorsque certains fichiers ont été crées
sous Windows, une partie des caractères ne sont pas compatibles avec
l'UTF-8, il faut alors les transformer pour qu'ils soient utilisables par les
scripts Perl sous Linux.
Pour cela, Emacs possède un certain nombre de fonctions
permettant de réaliser assez simplement cette opération.
Il faut tout d'abord ouvrir le ficher sous Emacs
Il faut ensuite remplacer tous les retour chariot (saut de ligne)
typiques de Windows (visibles avec Emacs sous la forme àM) par leur
équivalent Unix. Pour cela:
|
Alt Shift %
^M
"Entree" "Entree" !
"Entree"
|
Remarque : le "!" sert à effectuer tous les remplacement
sans poser de question. Il faut ensuite enregister le fichier en forçant
l'encodage UTF-8 Unix:
|
Ctrl x "Entree"
c
utf --8--unix
"Entree"
Ctrl x Ctrl s
|
Convention d'écriture:
"Entree" représente la touche de retour à la ligne
du clavier.
Lorsque plusieurs touches sont indiquées sur la même
ligne, cela signifie qu'elles doivent être appuyées en même
temps.
Webographie
N.1 CCI
CCI de la Haute-Savoie:
http://www.haute-savoie.cci.fr/
CRCI Rhône-Alpes:
http://www.rhone-alpes.cci.fr/
Portail fraçais des chambres de commerce et
d'industrie:
http://www.cci.fr/HomePage_CCIFR
AFCCI:
http://www.acfci.cci.fr/
N.2 PostgreSQL
http://www.postgresql.org/
Site français des utilisateurs de PostgreSQL:
http://postgresqlfr.org/drupal/
Installation de PostgreSQL - Club d'entraide des
développeurs francophones:
http://stessy.developpez.com/postgresql/installation/
Newsgroup des utilisateurs et développeurs de
PostgreSQL:
comp.databases.postgresql .*
Outil d'administration PGAdmin:
http://www.pgadmin.org/pgadmin3/index.php?locale=fr_FR
N.3 Sybase
http://www.sybase.com/home
Manuels Sybase:
http://www.sybase.com/support/manuals
Newsgroup des utilisateurs de Sybase:
com p.databases.sybase
N.4 Perl
http://www.perl.com/
Les mongueurs de Perl :
http://paris.mongueurs.net/indexfr.html
Foire aux questions Perl :
http://www.bribes.org/perl/docfr/perlfaq.html
Introduction à Perl :
http://lea-linux.org/dev/perl.php3
Newsgroup français des utilisateurs de Perl :
fr.comp.lang .perl
N.5 RedHat DataBase
http://sources.redhat.com/rhdb/
Manuels RHDB:
http://www.redhat.com/docs/manuals/database/
RedHat Network:
https://rhn.redhat.com/index.pxt
N.6 Sources d'informations generalistes
Forums de discution axés programmation et/ou base de
données:
http://www.developpez.
net/foru ms/index. php
http://forum.hardware.fr/hardwarefr/Programmation/SGBD/liste_sujet.htm
http://www.dbforums.com/index.php
Wikipédia:
http://fr.wikipedia.org/wiki/Accueil
Glossaire du jargon informatique:
http://www.linux-france.org/prj/jargonf/general/bgfrm.html
Bibliographie
[1] Guy Achard-Bayle. <<Éléments pour une
description linguistique du mémoire professionnel universitaire
>>. Texte rédigé dans le cadre du groupe de travail sur le
mémoire professionnel, février 2002.
[2] Françoise Demaizière et Jean Uebersfeld.
<<Approche du mémoire professionnel universitaire >>. Texte
rédigé dans le cadre du groupe de travail sur le mémoire
professionnel, 2002-2003.
[3] Michel Goossens, Frank Mittelbach, et Alexander Samarin,
Latex Companion. Campus Press, juin 2001.
[4] Vincent Seguin, Aide-Mémoire Latex,
septembre 2000.
[5] C. Willems et F. Geraerds, Aide Mémoire pour
Latex, juillet 1996.
[6] Eddie Saudrais, Le petit typographe rationnel, mars
2000.
[7] Sybase, Utility Guide.
[8] Sybase, Sybase Adaptive Server Enterprise - Manuel de
référence - Volume 1 : Eléments syntaxiques.
[9] Microsoft, Manuel de Référence Transact -
SQL. pour Miscrosoft SQL Server version 6.0.
[10] Sybase, Transact-SQL User's Guide.
[11] Noam Chomsky.
http://web.mit.edu/linguistics/www/bibliography/noam.html.
[12] Luc Maranget, Cours de compilation. École
Polytechnique.
[13] Jean-Philippe Dalbera, <<Le corpus entre
données, analyse et théorie >>, Corpus et recherches
linguistiques, novembre 2002.
[14] Peter D. Turney, Michael L. Littman, Jeffrey Bigham, et
Victor Shnayder, << Combining independent modules to solve
multiple-choice synonym and analogy problems (combinaison de modules
indépendants pour la résolution de problèmes de synonymie
et d'analogie à choix multiples) >>, dans Proceedings of the
International Conference on Recent Advances in Natural Language Processing
(RANLP-03), p. 482-389. Conseil National de Recherches Canada &
Institut de Technologie de l'Information, septembre 2003. Numéro de
publication du CNRC : NRC 46506.
[15] Pankaj Jalote, Gestion de projet informatique en
pratique. Campus Press, 2002.
[16] Cyrille Chartier-Kastler, Précis de conduite de
projet informatique. Les Éditions d'organisation, 1995.
[17] Project Management Institute, éditeur, A guide
to the Project Management Body of Knowledge. Project Management Institute,
2000.
[18] Rational Unified Process, éditeur, Rational
Unified Process Best Practices for Software Development Teams. Rational
Software Corporation, 1998.
[19] Pierre-Yves Cloux, RUP, XP Architectures et outils.
Dunod, 2003.
[20]
<<Extreme programming - méthodes agiles :
L'état des lieux >>, 2001.
[21] Stève Sfartz, Processus de développement
Objet: Best Practices. Improve, 2001.
[22] John C. Worsley et Joshua D. Drake, PostGreSQL par la
pratique. O'Reilly, 1re édition, octobre 2002.
[23] Bruce Momjian, PostgreSQL Introduction and Concepts.
Addison & Wesley, 2001.
[24] Alavoor Vasudevan et Albert-Paul Bouillot,
Database-SQL-RDBMS HOW-TO pour Linux (PostgreSQL Object Relational Database
System), v13.0 édition, octobre 1999. version française.
[25] Red Hat, Red Hat Database, janvier 2002.
Whitepaper.
[26] Red Hat, PostgreSQL - Red Hat Edition Graphical
Tools Guide, 2003.
[27] Randal L. Schwartz et Tom Phoenix, Introduction
à Perl. O'Reilly, 3e édition, janvier 2002.
[28] Larry Wall, Tom Christiansen, et Jon Orwant,
Programmation en Perl. O'Reilly, 3e édition,
décembre 2001.
[29] Sylvain Lhullier, Introduction à la
programmation en Perl, mars 2004. Version 1.0.1.
[30] Paul Gaborit, Documentation Perl, mai 2004.
[31] François Dagorn et Olivier Salaun,
Débuter en Perl, mai 2002.
[32] Laboratoire d'Informatique Médicale de la
faculté de médecine de Rennes, Introduction au langage Perl,
novembre 2003.
[33] <<Hors-série login n°22 - spécial
perl >>, janvier - mars 2004.
[34] Jeffrey E.F. Friedl, Mastering Regular Expressions.
O'Reilly, décembre 1998. Powerful Techniques for Perl and Other
Tools.
[35] K. El-Emam, <<A methodology for validating
software product metrics (méthodologie de validation de systèmes
de mesure de logiciels) >>. Rapport technique, Conseil National de
Recherches Canada & Institut de Technologie de l'Information, Juin 2000.
Numéro de publication du CNRC : NRC 44142.
[36] MySQL, Database Server Feature Comparisons.
Comparaison dynamique disponible sur
http://dev.mysql.com/tech-resources/crash-me.php.
[37] Oracle, Migrating Applications from Microsoft SQL
Server to Oracle9i Database, novembre 2003.
[38] Oracle, Reference Guide for Microsoft SQL Server and
Sybase Adaptive Server Migrations, mars 2002. Release 9.2.0 for Microsoft
Windows 98/2000 and Microsoft Windows NT.
[39] Marina Marina Greenstein, Sybase and Oracle Migration
Sybase and Oracle Migration to DB2 11DB to DB2 11DB. IBM, 2001.
[40] IBM, Migration Success Factors.
Glossaire
A
ACFCI: Assemblée des Chambres Françaises de
Commerce et d'Industrie. AG: Assemblée Générale.
APCCI: Assemblée Permanente des Chambres de Commerce et
d'Industrie.
Application métier: Progiciel qui intègre les
règles de gestion du métier pour lequel elle a été
conçue, sans imposer de fonctions superflues.
Approche descendante: (en anglais, top-down). Le fait de
concevoir un système en allant du général au particulier,
en passant par des étapes d'affinage.
Approche montante: (en anglais, bottom-up). Approche inverse
de l'approche descendante. On conçoit donc le système en allant
du détail vers le général, en passant par des
étapes d'agrégation.
ASCII: (American Standard Code for Information Interchange).
Ensemble de carac-
tères non accentués (les 128
premières valeurs des codages ISO-8859-X).
ATA-VISA: Documents nécessaires aux procédures
douanières d'exportation temporaire.
B
C
Back-porter: Le fait de porter de nouveaux
développements d'une application depuis une version récente vers
une version plus ancienne. L'idée est de faire profiter des corrections
de bug (principalement) les utilisateurs qui ne veulent pas faire de mise
à jour.
BCP: (BulkCoPy). Logiciel permettant l'extraction de
données d'une base Sybase.
BEE: (Base Economique Evènementielle). Application
métier de CRM, développée sous 4D.
Benchmark: Banc d'essai, permettant de mesurer les performances
d'un système pour le comparer à d'autres.
BSD: (Berkeley Software Distribution). L'université de
Berkeley est connue dans le monde Unix pour les nombreux logiciels qu'elle a
développé puis mis dans le domaine public.
CCIFE: Chambres de Commerce et d'Industrie Françaises
à l'Étranger. CCI: Chambre de Commerce et d'industrie.
CFE: Centre de Formalité des Entreprises.
CODIR: (COmité de DIRection). Il est composé de la
Direction Générale et de tous les responsables de service de la
CCI.
Copyleft: Le copyleft est la possibilité donnée
par l'auteur d'utiliser, copier, étudier, modifier et distribuer son
oeuvre à l'utiisateur, avec la restriction que celui-ci devra laisser
l'oeuvre sous les mêmes conditions d'utilisation, y compris dans les
versions modifiées ou étendues.
Le copyleft (traduit humoristiquement par gauche d'auteur) a
été inventé par Richard Stallman de la Free Software
Foundation en 1984.
Le fondement juridique du copyleft est le copyright (ou le
droit d'auteur, selon la juridiction où il est exprimé) avec un
contrat d'utilisation qui prend la forme d'une licence.
Corpus: En linguistique, ce terme désigne un recueil de
pièces ou de documents qui concernent une certaine unité de genre
ou bien d'époque.
CRCI: Chambre Régionale de Commerce et d'Industrie.
CRM: (Customer Relationship Management). Gestion de la relation
avec la clientèle.
D
DBMS: (Data Base Management System - Système de Gestion
de Base de Données). voir SGBD
E
F
EAI: (Enterprise Application Integration). Intégration
des applications dans l'entreprise. Le but d'un EAI est de faire fonctionner
ensemble (en particulier en matière d'échange transparent de
données) les programmes existant dans une entreprise, en
vérifiant leur interopérabiité, et gérer
l'hétérogénéité générale.
Encodage: Le codage des caractères par
l'intermédiaire de tables de correspondance permet d'associer à
chaque caractère (visible ou de contrôle), un code
numérique.
eXtreme Programing: voir XP.
FSF: (Free Software Foundation). Créé par Richard
Stallman, la FSF a pour but de promouvoir et développer l'utilisation
des logiciels et documentations libres.
G
Gauche d'auteur: voir Copyleft.
GNU: GNU est un acronyme récursif pour GNU's Not UNIX
GPL: (General Public License). Aussi appelée, licence
publique générale GNU. Le statut juridique d'une partie des
logiciels distribués librement, à l'origine utiisé pour le
projet GNU de la FSF.
Grammaire formelle: Formalisme permettant de définir une
syntaxe et donc un lan-
gage formel, c'est-à-dire un ensemble de mots
sur un alphabet donné.
Grammaire: Étude des règles qui régissent
une langue. Elle comporte plusieurs disciplines dont la phonétique, la
phonologie, la morphologie, la syntaxe et la sémantique.
I
L
IATP: Impôt Additionnel à la Taxe
Professionnelle.
Interlangue: Dans le domaine de la traduction automatique, une
interlangue est une langue artificielle qui sert d'intermédaire entre la
langue source et la langue cible
Langage naturel: Le langage que vont utiliser deux êtres
humains pour se parler.
Langage pivot: Terme généralement utilisé en
informatique pour désigner une interlangue.
LaTeX: Lamport TeX. Système de composition
générique de texte qui utilise TeX comme moteur de formatage.
Après avoir écrit un texte et l'avoir structuré à
l'aide de balises, une compilation permet d'obtenir le rendu final du texte.
Latin1: Norme ISO correspondant à une sorte d'ASCII
étendu sur 8 bits et permettant de coder la plupart des
caractères accentués de l'alphabet latin (notre alphabet). voir
encodage.
Lemme: (ou encore lexie) Est l'unité autonome constituante
du lexique d'une langue. Dans le langage courant, on utilise souvent le terme
mot.
Lexique: En linguistique, le lexique d'une langue constitue
l'ensemble de ses lemmes ou, d'une manière plus courante mais moins
précise, l'ensemble de ses mots. Dans les usages courants, on utiise
plus facilement le terme de vocabulaire.
Logiciel libre: Le logiciel libre rassemble les applications
livrées avec leurs sources, que l'on peut donc modifier à
volonté pour l'adapter à ses besoins, par opposition aux
programmes fermés et copyrightés. Cependant, il faut bien noter
que libre ne signifie pas forcément gratuit.
O
ODBC: (Open DataBase Connectivity). Spécification
reconnue pour l'échange d'informations entre applications et base de
données relationnelles, mettant en oeuvre le langage SQL.
Open Source: Principe selon lequel le code source du logiciel
est libre d'accès, autorisant ainsi la création de
communautés qui développeront de nouvelles
fonctionnalités. C'est une notion proche de celle de logiciel libre.
OS: (Operating System - Système d'Exploitation). Un
système d'exploitation est un ensemble cohérent de logiciels
permettant d'utiiser un ordinateur et tous ses éléments (ou
périphériques). Il assure le démarrage de celui-ci et
fournit aux programmes applicatifs les interfaces pour contrôler les
éléments de l'ordinateur.
P
Perl : (Practical Extraction and Report Language). Langage de
programmation de haut niveau avec un héritage éclectique
écrit par Larry Wall et un bon millier de développeurs. Il
dérive du langage C et, dans une moindre mesure, de Sed, Awk, du shell
Unix et d'au moins une douzaine d'autres langages et outils.
Phonologie: Branche de la linguistique qui étudie les
phonèmes, c'est-à-dire comment s'organisent les sons d'une langue
afin de former des énoncés.
Phonétique: Branche de la linguistique qui
étudie les sons des langues.
POD: (Plain Old Documentation - bonne vieille documentation).
Langage qui permet d'insérer la documentation dans du code sans qu'elle
soit lue par l'interpréteur Perl mais qui peut être extraite sous
différents formats grâce à des outils comme pod2html ou
pod2man.
Pragmatique: En tant que partie de la linguistique, elle
s'intéresse aux unités linguistiques dont la signification ne
peut être comprise qu'en contexte. C'est un des aspect de la
sémantique.
R
RAD: (Rapid Application Development). Méthode de
développement de logiciels par itérations où l'on
réalise, teste et fournit des morceaux de l'application à
intervalles réguliers sans attendre que l'ensemble soit achevé.La
méthode repose sur l'utilisation d'outils de programmation à
interface graphique, qui permettent d'obtenir rapidement des prototypes.
RCS: Registre du Commerce et de Sociétés.
RHDB: (RedHat Database). Projet de RedHat regroupant
PostgreSQL et des outils d'installation et d'administration
supplémentaires.
RHEL: (RedHat Entreprise Linux). Distribution de Linux
proposée par RedHat destinée aux entreprises et
accompagnée de différents niveaux de support et de
maintenance.
RHN: (Red Hat Network). Site Internet réservé
aux personnes bénéficiant du support RedHat. L'inscription y est
gratuite mais version complète nécessite la cotisation aux
services de support.
RH: Ressources Humaines.
S
RUP: (Rational Unified Process). Processus de
développement logiciel itératif et incrémental
proposé par Rational.
Scalabiité: (de l'anglais scalabiity :
extensibilité). Capacité d'un système à faire face
à des charges d'utilisation variables, la consommation de ressources
étant la plus linéaire possible (donc la plus
prévisible).
Sel syntaxique: Par opposition au sucre syntaxique, est une
fonctionnalité conçue pour rendre plus difficile d'écrire
du mauvais code. En pratique, le sel syntaxique est comme un passage
obligé par lequel le programmeur doit passer pour prouver qu'il sait ce
qu'il fait, sans que le code écrit pour cela n'exprime une action
particulière du logiciel.
SE: (Système d'Exploitation). voir OS.
SGBDR: (Système de Gestion de Base de Données
Relationnel). Les données sont enregistrées dans des tableaux
à deux dimensions (lignes et colonnes). La manipulation de ces
données se fait selon la théorie mathématique des
relations.
SGBD: (Système de Gestion de Base de Données).
Système permettant de contrôler les données ainsi que les
utilisateurs d'une base de données.
SI: (Système d'Information). Ensemble des moyens
techniques et humains permettant à une organisation de traiter son
information.
SQL: (Structured Query Language). Langage relationel de
requêtes permettant d'interragir avec des bases de données.
Sucre syntaxique: (en anglais, syntactic sugar). Terme
imaginé par Peter J. Landin pour des ajouts à la syntaxe d'un
langage de programmation qui ne modifient pas son expressivité mais le
rendent plus agréable à utiliser pour les humains.
Syntaxe: Notion désignant l'étude de la
façon dont sont formées les propositions qui elles-même
forment ensuite des phrases. C'est un des aspects de la grammaire.
Sémantique: Notion désignant l'étude des
signifiés. C'est un des aspects de la grammaire.
T
T-SQL: Le T-SQL (abréviation de Transaction-SQL), est
une extension de SQL qui permet entre autres la déclaration de
variables, le contrôle des transactions, des erreurs et l'utilisation de
fonctions SQL existantes. Les bases de données MSSQL et Sybase utilisent
des procédures en T-SQL.
TIC: (Technologies de l'Information et de la Communication).
Acronyme désignant l'ensemble des technologies modernes permettant de
gérer l'information et la communication au sein d'une organisation.
Trigger: Dans une base de données, un trigger est une
procédure SQL qui déclenche une action lorsqu'un
événement (INSERT, DELETE ou UPDATE) se produit.
U
UCS: (Universal Character Set). Jeu de caractères
universel, défini par la norme ISO 10646, aussi connue sous le nom
d'Unicode.
UML (Unified Modeling Language). Langage normalisé par
l'OMG début 1997, permettant de décrire une application en
fonction des méthodes objet avec lesquelles elle a été
construite.
Unicode: voir UCS.
UTF8: (UCS Transformation Format sur 8 bits). UTF utilisant 8
bits pour coder les caractères. voir UTF et encodage.
X
UTF: (UCS Transformation Format). Codage de l'UCS (ISO 10646)
défini pour permettre son utiisation sur les réseaux.
XP: (eXtreme Programing). Méthode de gestion de projets
proposant un ensemble de Bests Practices de développement.
GNU Free Documentation License Version 1.2 November
2002
Copyright (C) 2000,2001,2002 Free Software Foundation, Inc.
59 Temple Place, Suite 330, Boston, MA 02111-1307 USA Everyone is
permitted to copy and distribute verbatim copies of this license document, but
changing it is not allowed.
0. PREAMBLE
The purpose of this License is to make a manual, textbook, or
other functional and useful document "free" in the sense of freedom: to assure
everyone the effective freedom to copy and redistribute it, with or without
modifying it, either commercially or noncommercially. Secondarily, this License
preserves for the author and publisher a way to get credit for their work,
while not being considered responsible for modifications made by others.
This License is a kind of "copyleft", which means that
derivative
works of the document must themselves be free in the same sense.
It complements the GNU General Public License, which is a copyleft license
designed for free software.
We have designed this License in order to use it for manuals for
free software, because free software needs free documentation: a free program
should come with manuals providing the same freedoms that the software does.
But this License is not limited to software manuals; it can be used for any
textual work, regardless of subject matter or whether it is published as a
printed book. We recommend this License principally for works whose purpose is
instruction or reference.
1. APPLICABILITY AND DEFINITIONS
This License applies to any manual or other work, in any medium,
that contains a notice placed by the copyright holder saying it can be
distributed under the terms of this License. Such a notice grants a world-wide,
royalty-free license, unlimited in duration, to use that work under the
conditions stated herein. The "Document", below, refers to any such manual or
work. Any member of the public is a licensee, and is addressed as "you". You
accept the license if you copy, modify or distribute the work in a way
requiring permission under copyright law.
A "Modified Version" of the Document means any work containing
the Document or a portion of it, either copied verbatim, or with
modifications and/or translated into another language.
A "Secondary Section" is a named appendix or a front-matter
section of the Document that deals exclusively with the relationship of the
publishers or authors of the Document to the Document's overall subject (or to
related matters) and contains nothing that could fall directly within that
overall subject. (Thus, if the Document is in part a textbook of mathematics, a
Secondary Section may not explain any mathematics.) The relationship could be a
matter of historical connection with the subject or with related matters, or of
legal, commercial, philosophical, ethical or political position regarding
them.
The "Invariant Sections" are certain Secondary Sections whose
titles are designated, as being those of Invariant Sections, in the notice that
says that the Document is released under this License. If a section does not
fit the above definition of Secondary then it is not allowed to be designated
as Invariant. The Document may contain zero Invariant Sections. If the Document
does not identify any Invariant Sections then there are none.
The "Cover Texts" are certain short passages of text that are
listed,
as Front-Cover Texts or Back-Cover Texts, in the notice that
says that the Document is released under this License. A Front-Cover Text may
be at most 5 words, and a Back-Cover Text may be at most 25 words.
A "Transparent" copy of the Document means a machine-readable
copy, represented in a format whose specification is available to the general
public, that is suitable for revising the document
straightforwardly with generic text editors or (for images
composed of pixels) generic paint programs or (for drawings) some widely
available drawing editor, and that is suitable for input to text formatters or
for automatic translation to a variety of formats suitable for input to text
formatters. A copy made in an otherwise Transparent file
format whose markup, or absence of markup, has been arranged to
thwart or discourage subsequent modification by readers is not Transparent. An
image format is not Transparent if used for any substantial amount of text. A
copy that is not "Transparent" is called "Opaque".
Examples of suitable formats for Transparent copies include plain
ASCII without markup, Texinfo input format, LaTeX input format, SGML or XML
using a publicly available DTD, and standard-conforming simple HTML, PostScript
or PDF designed for human modification. Examples of transparent image formats
include PNG, XCF and JPG. Opaque formats
include proprietary formats that can be read and edited only by
proprietary word processors, SGML or XML for which the DTD and/or processing
tools are not generally available, and the
machine-generated HTML, PostScript or PDF produced by some word
processors for output purposes only.
The "Title Page" means, for a printed book, the title page
itself,
plus such following pages as are needed to hold, legibly, the
material this License requires to appear in the title page. For works in
formats which do not have any title page as such, "Title Page"
means the text near the most prominent appearance of the work's title,
preceding the beginning of the body of the text.
A section "Entitled XYZ" means a named subunit of the Document
whose title either is precisely XYZ or contains XYZ in parentheses following
text that translates XYZ in another language. (Here XYZ stands for a specific
section name mentioned below, such as "Acknowledgements", "Dedications",
"Endorsements", or "History".) To "Preserve the Title"
of such a section when you modify the Document means that it
remains a section "Entitled XYZ" according to this definition.
The Document may include Warranty Disclaimers next to the notice
which states that this License applies to the Document. These Warranty
Disclaimers are considered to be included by reference in this License, but
only as regards disclaiming warranties: any other implication that these
Warranty Disclaimers may have is void and has no effect on the meaning of this
License.
2. VERBATIM COPYING
You may copy and distribute the Document in any medium, either
commercially or noncommercially, provided that this License, the copyright
notices, and the license notice saying this License applies
to the Document are reproduced in all copies, and that you add no
other conditions whatsoever to those of this License. You may not use technical
measures to obstruct or control the reading or further copying of the copies
you make or distribute. However, you may accept compensation in exchange for
copies. If you distribute a large enough number of copies you must also follow
the conditions in section 3.
You may also lend copies, under the same conditions stated above,
and you may publicly display copies.
If you publish printed copies (or copies in media that commonly
have printed covers) of the Document, numbering more than 100, and the
Document's license notice requires Cover Texts, you must enclose the copies in
covers that carry, clearly and legibly, all these Cover Texts: Front-Cover
Texts on the front cover, and Back-Cover Texts on the back cover. Both covers
must also clearly and legibly identify you as the publisher of these copies.
The front cover must present the full title with all words of the title equally
prominent and visible. You may add other material on the covers in addition.
Copying with changes limited to the covers, as long as they preserve the title
of the Document and satisfy these conditions, can be treated as verbatim
copying in other respects.
If the required texts for either cover are too voluminous to fit
legibly, you should put the first ones listed (as many as fit reasonably) on
the actual cover, and continue the rest onto adjacent pages.
If you publish or distribute Opaque copies of the Document
numbering more than 100, you must either include a machine-readable Transparent
copy along with each Opaque copy, or state in or with each Opaque copy a
computer-network location from which the general network-using public has
access to download using public-standard network protocols a complete
Transparent copy of the Document, free of added material. If you use the latter
option, you must take reasonably prudent steps, when you begin distribution of
Opaque copies in quantity, to ensure that this Transparent copy will remain
thus accessible at the stated location until at least one year after the last
time you distribute an Opaque copy (directly or through your agents or
retailers) of that edition to the public.
It is requested, but not required, that you contact the authors
of the Document well before redistributing any large number of copies, to give
them a chance to provide you with an updated version of the Document.
4. MODIFICATIONS
You may copy and distribute a Modified Version of the Document
under the conditions of sections 2 and 3 above, provided that you release the
Modified Version under precisely this License, with the Modified Version
filling the role of the Document, thus licensing distribution and modification
of the Modified Version to whoever possesses a copy of it. In addition, you
must do these things in the Modified Version:
A. Use in the Title Page (and on the covers, if any) a title
distinct from that of the Document, and from those of previous versions (which
should, if there were any, be listed in the History section of the Document).
You may use the same title as a previous version if the original publisher of
that version gives permission.
B. List on the Title Page, as authors, one or more persons or
entities responsible for authorship of the modifications in the Modified
Version, together with at least five of the principal authors of the Document
(all of its principal authors, if it has fewer than five), unless they release
you from this requirement.
C. State on the Title page the name of the publisher of the
Modified Version, as the publisher.
D. Preserve all the copyright notices of the Document.
E. Add an appropriate copyright notice for your modifications
adjacent to the other copyright notices.
F. Include, immediately after the copyright notices, a license
notice giving the public permission to use the Modified Version under the terms
of this License, in the form shown in the Addendum below.
G. Preserve in that license notice the full lists of Invariant
Sections and required Cover Texts given in the Document's license notice.
H. Include an unaltered copy of this License.
I. Preserve the section Entitled "History", Preserve its Title,
and add to it an item stating at least the title, year, new authors, and
publisher of the Modified Version as given on the Title Page. If there is no
section Entitled "History" in the Document, create one stating the title, year,
authors, and publisher of the Document as given on its Title Page, then add an
item describing the Modified Version as stated in the previous sentence.
J. Preserve the network location, if any, given in the Document
for public access to a Transparent copy of the Document, and likewise the
network locations given in the Document for previous versions it was based on.
These may be placed in the "History" section. You may omit a network location
for a work that was published at least four years before the Document itself,
or if the original publisher of the version it refers to gives permission.
K. For any section Entitled "Acknowledgements" or "Dedications",
Preserve the Title of the section, and preserve in the section all the
substance and tone of each of the contributor acknowledgements and/or
dedications given therein.
L. Preserve all the Invariant Sections of the Document,
unaltered in their text and in their titles. Section numbers or the equivalent
are not considered part of the section titles.
M. Delete any section Entitled "Endorsements". Such a section
may not be included in the Modified Version.
N. Do not retitle any existing section to be Entitled
"Endorsements" or to conflict in title with any Invariant Section.
O. Preserve any Warranty Disclaimers.
If the Modified Version includes new front-matter sections or
appendices that qualify as Secondary Sections and contain no
material copied from the Document, you may at your option designate some or all
of these sections as invariant. To do this, add their titles to the list of
Invariant Sections in the Modified Version's license notice. These titles must
be distinct from any other section titles.
You may add a section Entitled "Endorsements", provided it
contains nothing but endorsements of your Modified Version by various
parties--for example, statements of peer review or that the text has been
approved by an organization as the authoritative definition of a standard.
You may add a passage of up to five words as a Front-Cover Text,
and a passage of up to 25 words as a Back-Cover Text, to the end of the list of
Cover Texts in the Modified Version. Only one passage of Front-Cover Text and
one of Back-Cover Text may be added by (or through arrangements made by) any
one entity. If the Document already includes a cover text for the same cover,
previously added by you or by arrangement made by the same entity you are
acting on behalf of, you may not add another; but you may replace the old one,
on explicit permission from the previous publisher that added the old one.
The author(s) and publisher(s) of the Document do not by this
License give permission to use their names for publicity for or to assert or
imply endorsement of any Modified Version.
5. COMBINING DOCUMENTS
You may combine the Document with other documents released under
this License, under the terms defined in section 4 above for modified versions,
provided that you include in the combination all of the Invariant Sections of
all of the original documents, unmodified, and list them all as Invariant
Sections of your combined work in its license notice, and that you preserve all
their Warranty Disclaimers.
The combined work need only contain one copy of this License, and
multiple identical Invariant Sections may be replaced with a single copy. If
there are multiple Invariant Sections with the same name but different
contents, make the title of each such section unique by adding at the end of
it, in parentheses, the name of the original author or publisher of that
section if known, or else a unique number. Make the same adjustment to the
section titles in the list of
Invariant Sections in the license notice of the combined work.
In the combination, you must combine any sections Entitled
"History" in the various original documents, forming one section Entitled
"History"; likewise combine any sections Entitled "Acknowledgements", and any
sections Entitled "Dedications". You must delete all sections Entitled
"Endorsements".
6. COLLECTIONS OF DOCUMENTS
You may make a collection consisting of the Document and other
documents released under this License, and replace the individual copies of
this License in the various documents with a single copy that is included in
the collection, provided that you follow the rules of this License for verbatim
copying of each of the documents in all other respects.
You may extract a single document from such a collection, and
distribute it individually under this License, provided you insert a copy of
this License into the extracted document, and follow this License in all other
respects regarding verbatim copying of that document.
7. AGGREGATION WITH INDEPENDENT WORKS
A compilation of the Document or its derivatives with other
separate and independent documents or works, in or on a volume of a storage or
distribution medium, is called an "aggregate" if the copyright resulting from
the compilation is not used to limit the legal rights of the compilation's
users beyond what the individual works permit. When the Document is included in
an aggregate, this License does not apply to the other works in the aggregate
which are not themselves derivative works of the Document.
If the Cover Text requirement of section 3 is applicable to these
copies of the Document, then if the Document is less than one half of the
entire aggregate, the Document's Cover Texts may be placed on covers that
bracket the Document within the aggregate, or the electronic equivalent of
covers if the Document is in electronic form. Otherwise they must appear on
printed covers that bracket the whole aggregate.
8. TRANSLATION
Translation is considered a kind of modification, so you may
distribute translations of the Document under the terms of
section 4. Replacing Invariant Sections with translations requires special
permission from their copyright holders, but you may include translations of
some or all Invariant Sections in addition to the original versions of these
Invariant Sections. You may include a translation of this License, and all the
license notices in the
Document, and any Warranty Disclaimers, provided that you also
include the original English version of this License and the original versions
of those notices and disclaimers. In case of a disagreement between the
translation and the original version of this License or a notice or disclaimer,
the original version will prevail.
If a section in the Document is Entitled "Acknowledgements",
"Dedications", or "History", the requirement (section 4) to Preserve its Title
(section 1) will typically require changing the actual title.
9. TERMINATION
You may not copy, modify, sublicense, or distribute the Document
except as expressly provided for under this License. Any other attempt to copy,
modify, sublicense or distribute the Document is void, and will automatically
terminate your rights under this License. However, parties who have received
copies, or rights, from you under this License will not have their licenses
terminated so long as such parties remain in full compliance.
10. FUTURE REVISIONS OF THIS LICENSE
The Free Software Foundation may publish new, revised versions
of the GNU Free Documentation License from time to time. Such new
versions will be similar in spirit to the present version, but may differ in
detail to address new problems or concerns. See
http://www.gnu.org/copyleft/.
Each version of the License is given a distinguishing version
number. If the Document specifies that a particular numbered version of this
License "or any later version" applies to it, you have the option of following
the terms and conditions either of that specified version or of any later
version that has been published (not as a draft) by the Free Software
Foundation. If the Document does not specify a version number of this License,
you may choose any version ever published (not as a draft) by the Free Software
Foundation.
| 

